На чтение 2 мин Опубликовано 20.07.2016
![]() Сегодня вы узнаете как очень просто и быстро можно узнать расположение CSS стилей любого элемента вашего сайта. Наверняка с вами случалось такое, что вы хотели изменить какой-либо элемент на сайте (к примеру цвет кнопки) но не могли найти расположение CSS стилей данного элемента. Особенно это часто случается на CMS системах, типа WordPress, где множество файлов и не понятно где там CSS. Но вам и необязательно рыться в файлах (в дебрях) в поисках CSS стилей. Вам достаточно одно нажатие на кнопку и вы узнаете точное расположение CSS стиля любого элемента вашего сайта.
Сегодня вы узнаете как очень просто и быстро можно узнать расположение CSS стилей любого элемента вашего сайта. Наверняка с вами случалось такое, что вы хотели изменить какой-либо элемент на сайте (к примеру цвет кнопки) но не могли найти расположение CSS стилей данного элемента. Особенно это часто случается на CMS системах, типа WordPress, где множество файлов и не понятно где там CSS. Но вам и необязательно рыться в файлах (в дебрях) в поисках CSS стилей. Вам достаточно одно нажатие на кнопку и вы узнаете точное расположение CSS стиля любого элемента вашего сайта.
![]() Всё очень просто, зайдите на свой сайт, нажмите правой кнопкой мыши по элементу, CSS стили которого вы хотите узнать. В появившемся окне нажмите на вкладку — Просмотреть код.
Всё очень просто, зайдите на свой сайт, нажмите правой кнопкой мыши по элементу, CSS стили которого вы хотите узнать. В появившемся окне нажмите на вкладку — Просмотреть код.

![]() Далее, с правой стороны сайта у вас откроется окно с исходным кодом выбранного вами элемента. В окне Styles будут указаны CSS стили данного элемента. Рядом с CSS стилями, с правой стороны будет отображаться ссылка, URL адрес, по которому находятся данные CSS стили. Наведите курсор мыши на данную ссылку и у вас появится подсказка с полным URL адресом CSS стилей.
Далее, с правой стороны сайта у вас откроется окно с исходным кодом выбранного вами элемента. В окне Styles будут указаны CSS стили данного элемента. Рядом с CSS стилями, с правой стороны будет отображаться ссылка, URL адрес, по которому находятся данные CSS стили. Наведите курсор мыши на данную ссылку и у вас появится подсказка с полным URL адресом CSS стилей.

![]() Вот в принципе и всё, теперь вы можете зайти в свою корневую директорию сайта на хостинге и быстро найти нужный вам CSS стиль, но и конечно же быстро изменить его.
Вот в принципе и всё, теперь вы можете зайти в свою корневую директорию сайта на хостинге и быстро найти нужный вам CSS стиль, но и конечно же быстро изменить его.
![]() А есть вариант ещё проще, вам даже не надо заходить в корень сайта и менять там стили. Если ваш сайт на WordPress, то установите себе один очень классный плагин — Simple Custom CSS.
А есть вариант ещё проще, вам даже не надо заходить в корень сайта и менять там стили. Если ваш сайт на WordPress, то установите себе один очень классный плагин — Simple Custom CSS.

![]() Скопируйте CSS стили из окна просмотра кода и вставьте их на страницу плагина, измените стили так как вам надо и сохраните настройки.
Скопируйте CSS стили из окна просмотра кода и вставьте их на страницу плагина, измените стили так как вам надо и сохраните настройки.

![]() Зайдите на сайт, элемент стили которого вы меняли, автоматически изменится.
Зайдите на сайт, элемент стили которого вы меняли, автоматически изменится.

![]() Вот и всё, всё очень просто, удачи вам !
Вот и всё, всё очень просто, удачи вам !
По сути каскадная таблица стилей (CSS) находится в отдельной директории на сервере, где лежит скрипт самого сайта.
Для того чтобы увидеть путь к файлу CSS нужно правой кнопкой мыши нажать на странице сайта и выбрать из выпадающего меню пункт “Просмотр кода страницы” или “Посмотреть исходный код страницы” (в зависимости от браузера), после чего откроется новая вкладка с исходным кодом.
В коде страницы ищем путь между тегами <head> и </head>, который оканчивается на .css (например http://сайт.ru/style/style.css), это и есть путь к файлу каскадной таблицы стилей.
Вам придется идти на хостинг в админ панель и искать нужную директорию.
Если Вы храните сайт на ПК, то нужную папку ищем на локальном сервере, где правим стиль и заливаем на сервер по FTP.
Если все же для Вас эта задача сложна, то скиньте адрес своего сайта мне в личные сообщения и я подскажу адрес CSS стиля.
Здесь написана серия статей о том, как изменить шрифт, размер, цвет некоторых важных элементов блога — таких, как заголовок блога или поста, тег more и тому подобное. Нужный код искал вручную, экспериментируя с тестовым доменом, на основе чего позже писалась статья.
И вот недавно понадобилось изменить цвет ссылок. Перелопатив кучу литературы по этому вопросу, понял простую вещь: все приводят примеры из собственных шаблонов, но шаблоны-то у нас у всех разные и хорошо, если код из примера хоть чуть-чуть похож: не нытьем, так катаньем все равно найду — методом тыка.

С кодом ссылки номер не прошел. Все указывали совершенно разные пути. Задумался, нет ли простого и точного инструмента, как найти нужный код html на любом сайте. Многие блоггеры даже с опытом испытывают трудности в незначительной доработке шаблона. В этом нет ничего страшного, ведь у каждого свои интересы и цели создания сайта.
Если вы хотите внести небольшие изменения в шаблон, например изменить любой заголовок, название статей и рубрик, цвет и размер шрифтов и ссылок, обычно вполне достаточно научиться простому принципу, который рассмотрен в этой статье. Но бывают и сложные случаи, требуюущие либо более глубокого изучения html и css, либо помощи специалиста.
Однажды обратился знакомый с просьбой найти, где изменить цвет панели рубрик в его шаблоне. Закачал тему на тестовый поддомен. Настройки этого элемента хранились не в style.css, а в другом файле, поэтому человек не мог найти.
Как найти и изменить html и css код сайта
Если не любите длинные статьи, для вас в конце статьи видеоурок, в котором рассказывается, как можно увидеть код html сайта с помощью Notepad++ и внести изменения в дизайн любого шаблона на примере, как поменять цвет шрифта. В видео найдутся и другие тонкости обращения с блогом. А для тех, кому ближе и понятнее текст, внизу подробный разбор темы со скриншотами.
httpv://youtu.be/uIlVvwCt2ho
Термины и понятия
Было бы точнее называть статью «Как найти код css«, но я решил остановиться на «неправильном» названии, потому что в основном ответ на этот вопрос ищут в html. CSS и HTML — очень разные вещи, хоть и являются двумя частями одной системы. В интернете много технических статей, нам здесь достаточно будет понять, что:
- HTML — отвечает за структуру сайта (что за чем следует, в каком порядке и т. д.). Это основа, на которой создан сайт. Если сравнить с домом, то это это его планировка, расположение комнат.
- CSS — отвечает за дизайн (какие шрифты, размеры, цвета и подобное). Это общий стиль дома и стиль его отдельных комнат: какие обои будут, светильники, занавески, мебель. Поэтому документ, в котором прописываются коды css, называется «таблица стилей»
И если вы задались вопросом, как изменить, например, цвет заголовка сайта, размер шрифта в текстах или цвет заголовков в сайдбаре, то искать все это нужно в таблице стилей CSS. Вот это единственное, что стоит понять для начала, чтобы вносить изменения в код самостоятельно.
Мне нравится превращать сложное в простое. Помню, давно, когда у меня была первая машина, очень старая, проводка гнилая, часто перегорали предохранители, и я тянул ее каждый раз на СТО на буксире. Представьте, сколько денег было выкинуто, при том что самостоятельная замена, как оказалось, стоит копейки.
Однажды я посмотрел, что именно делает мастер. До сих пор не знаю, как устроен предохранитель. Но знаю, где его менять). Мотор я чинить сам бы не стал, а уж предохранитель заменить не сложно. Так же и с сайтами.
Если вы не хотите стать программистом, то нет необходимости глубоко разбираться в программинге. Достаточно ясно понимать, что для чего предназначено, где это искать и как изменить. То, что можно, лучше изменить самим, а все остальное оставить специалистам. В статье о дизайне блога есть полезная ссылка на эту тему.
Нужно ли быть специалистом во всем
В seo-блогах часто ведутся дискуссии, нужно ли новичку глубоко разбираться в html, а еще лучше — научиться самим писать сайты, чтобы было все уникальное.. Ну, не знаю — каждому свое и тут уж кому что ближе. Мне интересно чуть больше, поэтому я сейчас дополнительно учусь у Владимира. В ноябре этого года Владимир открыл свой авторский блог. Его блог сделан на самом простом, бесплатном шаблоне, он его лишь чуть изменил под себя.
Через 10 дней существования блог занял 104-е место в рейтинге всех сайтов Рунета с посещаемостью около 1,5 тысяч человек в сутки. За 10 дней. Так в чем же дело? Владимир прекрасно разбирается в html, может заказать и купить себе уникальный шаблон. Вот и вы должны понять, что секрет кроется не в шаблонах, а в полезности информации.
Где прячется код html
Простите за отступление, вернемся к нашим кодам). Допустим, вы хотите изменить цвет шрифта заголовка блога. Будем рассматривать на примере моего тестового сайта.
- Открываем сайт в браузере Google Chrome (если еще не пользуетесь им, установите — он хорошо заточен для работы с сайтами, в нем много встроенных инструментов).
- Наводим курсор мышки на элемент, который собираемся изменить. В данном случае — на название блога. Щелкаем по нему «правой» мышкой и в появившемся окне выбираем ПРОСМОТР КОДА ЭЛЕМЕНТА.
ВАЖНО: не перепутайте с ПРОСМОТРОМ КОДА СТРАНИЦЫ! Вся страница нам сейчас не нужна, только отдельный элемент.

Щелкаем по нему — в нижней части браузера появляется окно просмотра кода:

Красным выделена строка кода, которую мы меняем.
А вот в области, выделенной синим, содержится то, что мы ищем. Именно здесь вы можете найти точную (а не приблизительную) строчку кода, отвечающую за шрифты, цвет, размер, выделение и прочее. Таким образом вы можете узнать ЛЮБОЙ код любого элемента любого шаблона.
Находим нужную строчку в блоке, выделенным синим. Справа там есть ползунок, можно пролистать и найти нужную строчку.
Общий принцип, где что ищется:
Название шрифта — в строке FONT FAMILY
Размер шрифта — в строке FONT SIZE
Цвет шрифта — в строке COLOR
Вот три основные строчки, в которых меняется название, размер и цвет шрифта любого элемента. Справа в строке style css дается позиция строчки в документе. Если вам нужно изменить какой-то другой элемент (например, нужно узнать, где находится строчка. в которой можно изменить цвет панели меню или цвет ссылок), все делается абсолютно так же.
ВНИМАНИЕ:
красным на рисунке выделена строчка, которую мы будем копировать,
чтобы потом найти ее в таблице стилей.
4. Копируем строчку. Поскольку в этом примере мы хотим изменить цвет названия сайта, то копирую строчку, во второй картинке выделенную красным прямоугольником. В моем шаблоне она отвечает за изменение цвета названия сайта:
#header h1 a, #header h1 a:visited {
Находим нужную строчку в файле «таблица стилей (style.css)». Это делается уже в админке. Настоятельно прошу, пока нет уверенности и полного понимания, все эксперименты проводить на тестовом поддомене, чтобы исключить поломку сайта.
Итак, заходим в админпанель: КОНСОЛЬ — ВНЕШНИЙ ВИД — РЕДАКТОР. В правом сайдбаре находим файл ТАБЛИЦА СТИЛЕЙ (STYLE.CSS), открываем его.
Теперь открываем строку поиска клавишами CTRL + F: в верхнем окне появится пустая строчка-окошко. Вставляем в него ту строку, что скопировали в пункте 4.
И вы увидите, как в таблице стилей эта строчка выделится (на рисунке — оранжевым цветом):
Вносим изменение в элемент. В нашем случае мы меняем цвет шрифта, поэтому в строке COLOR подставляем другое значение — того цвета, который хотим. В примере черный цвет, его значение:
#282828
Выбрать цвет можно в любом сервисе палитр веб-цветов: наберите в поисковике «Палитра веб-цветов» и подберите тот, что хотите. Выбираем цвет, копируем его цифровое значение и аккуратно подставляем взамен старого. после чего нажимаем ОБНОВИТЬ ФАЙЛ и переходим смотреть, что получилось.
Если изменения не отобразились, очистите кэш за прошедший час и снова зайдите на страницу — на этот раз все должно отобразиться.
Описывается это долго, но на практике все делается быстро, особенно когда появляется начальный навык.
Более подробно, как изменить те или иные элементы:
Как изменить шрифт в заголовке блога
Как изменить шрифт в заголовке поста
Как изменить Home на Главную
Как изменить «читать далее»
На сегодня все, больше не буду мучить вас кодами. Надеюсь, что теперь вы сами сможете легко находить и менять любой элемент кода html, или, вернее, код css — да простят меня специалисты за упрощение. А если не разберетесь, посетите все же страницу Полезные сайты. Не тратьте время на ерунду.
Предлагаю посмотреть видео Артема Абрамовича, как искать и находить в любой теме/шаблоне, для любого движка (wordpress, joomla и т.п.) любое слово или элемент и заменить на то, что вам надо:

Для большинства людей общий аудит сайта – задача достаточно сложная и трудоемкая, однако с такими инструментами, как Screaming Frog SEO Spider (СЕО Паук) задача может стать значительно более простой как для профессионалов, так и для новичков. Удобный интерфейс Screaming Frog обеспечивает легкую и быструю работу, однако многообразие вариантов конфигурации и функциональности может затруднить знакомство с программой, первые шаги в общении с ней.
Нижеследующая инструкция призвана продемонстрировать различные способы использования Screaming Frog в первую очередь для аудита сайтов, но также и других задач.
Базовые принципы сканирования сайта
-
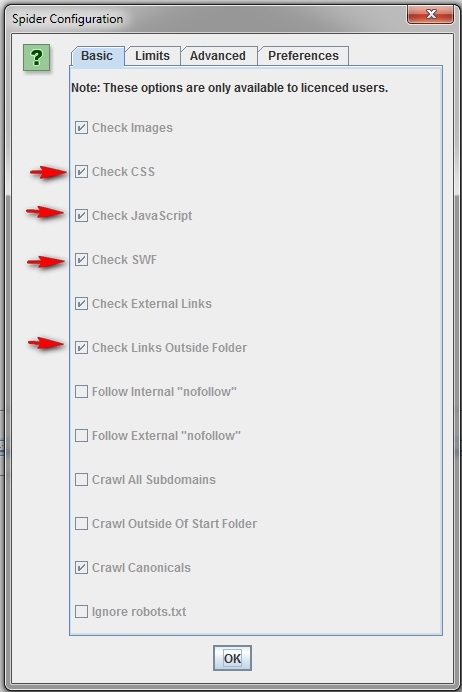
Как сканировать весь сайт.
По умолчанию Screaming Frog сканирует только поддомен, на который вы заходите. Любой дополнительный поддомен, с которым сталкивается Spider, рассматривается как внешняя ссылка. Для того чтобы сканировать дополнительные поддомены, необходимо внести корректировки в меню конфигурации Spider. Выбрав опцию «Crawl All Subdomains», вы можете быть уверены в том, что Паук проанализирует любые ссылки, которые встречаются на поддоменах вашего сайта.

Чтобы ускорить сканирование не используйте картинки, CSS, JavaScript, SWF или внешние ссылки.
-
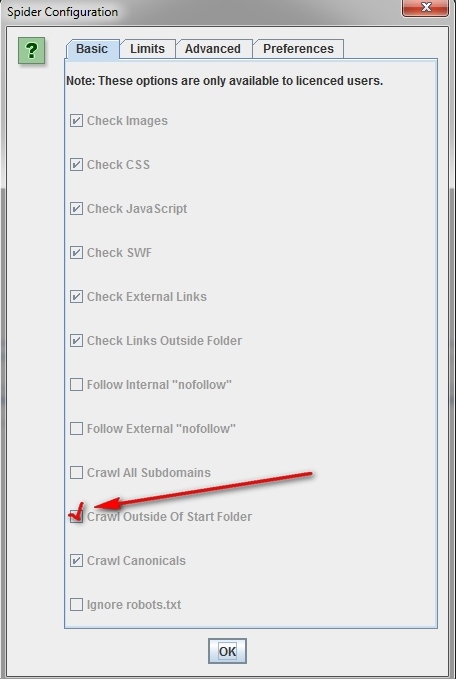
Как сканировать один каталог.
Если вы хотите ограничить сканирование конкретной папкой, то просто введите URL и нажмите на кнопку «старт», не меняя параметры, установленные по умолчанию. Если вы внесли изменения в предустановленные настройки, то можно сбросить их при помощи меню «File».

Если вы хотите начать сканирование с конкретной папки, а после перейти к анализу оставшейся части поддомена, то перед тем, как начать работу с нужным вам URL, перейдите сначала в раздел Spider под названием «Configuration» и выберите в нем опцию «Crawl Outside Of Start Folder».
-
Как сканировать набор определеных поддоменов или подкатологов.
Чтобы взять в работу конкретный список поддоменов или подкатологов вы можете использовать RegEx, чтобы задать правила включения (Include settings) или исключения (Exclude settings) определенных элементов в меню «Configuration».
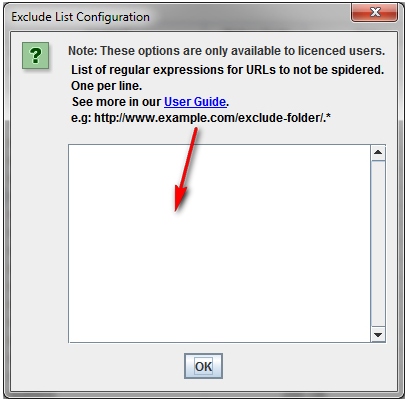
На показанном ниже примере были выбраны для сканирования все страницы сайта havaianas.com, кроме страниц «About» в каждом отдельном поддомене (исключение). Следующий пример показывает как можно просканировать именно англоязычные страницы поддоменов этого же сайта (включение).
-
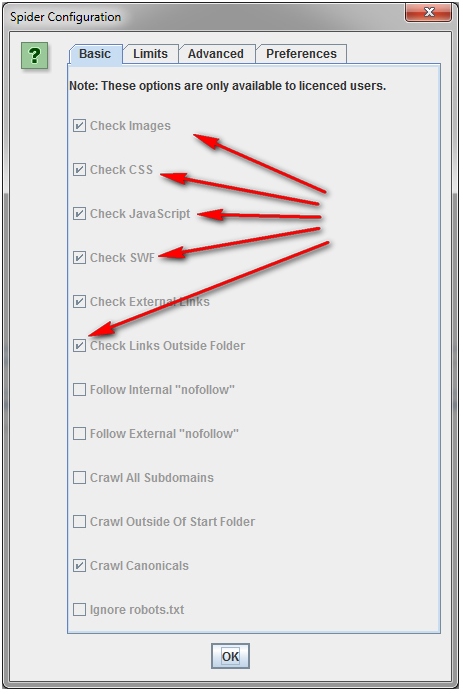
Если требуется просканировать список всех страниц моего сайта.
По умолчанию, Screaming Frog сканирует все изображения JavaScript, CSS и флеш-файлы, с которыми сталкивается Паук. Чтобы анализировать исключительно HTML, вам нужно снять галочку с опций «Check Images», «Check CSS», «Check JavaScript» и «Check SWF» в меню «Configuration» Spider. Запуск Паука будет совершаться без учета указанных позиций, что позволит вам получить список всех страниц сайта, на которые имеются внутренние ссылки. После завершения сканирования перейдите во вкладку «Internal» и отфильтруйте результаты по стандарту HTML. Кликните по кнопке «Export», чтобы получить полный список в формате CSV.

Совет: Если вы намерены использовать заданные настройки для последующих сканирований, то Screaming Frog предоставит вам возможность сохранить заданные опции.
-
Если требуется просканировать список всех страниц в определенном подкаталоге.
В дополнение к «Check Images», «Check CSS», «Check JavaScript» и «Check SWF» в меню «Configuration» Spider вам нужно будет выбрать «Check Links Outside Folder». То есть вы исключите данные опции из Паука, что предоставит вам список всех страниц выбранной папки.
-
Если требуется просканировать список доменов, которые ваш клиент только что перенаправил на свой коммерческий сайт.
В ReverseInter.net добавьте URL этого сайта, после нажмите ссылку в верхней таблице, чтобы найти сайты, использующие те же IP-адрес, DNS-сервер, или код GA.
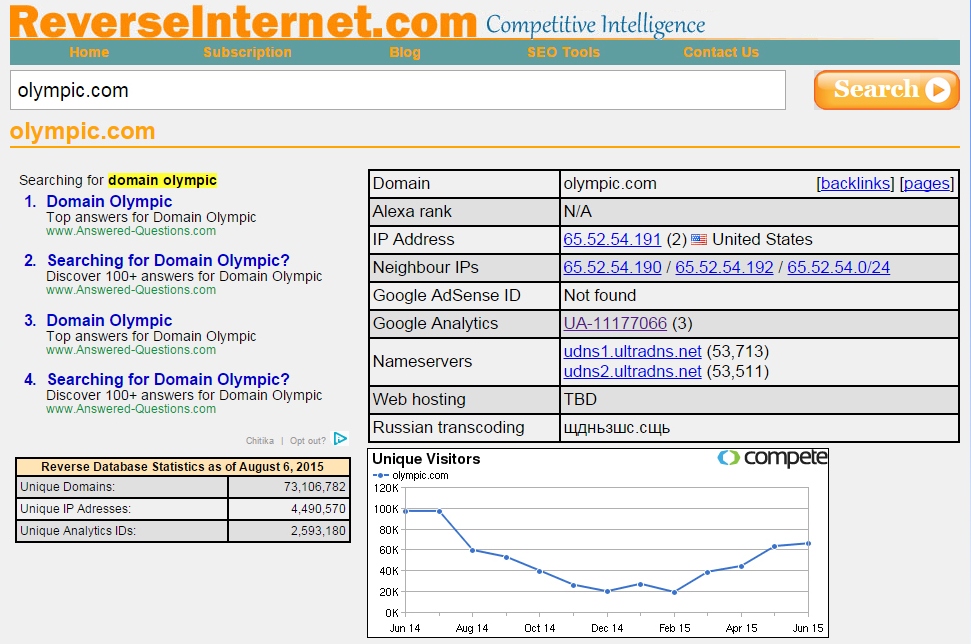
Далее используя расширение для Google Chrome под названием Scraper, вы сможете найти список всех ссылок с анкором «посетить сайт». Если Scraper уже установлен, то вы можете запустить его, кликнув кнопкой мыши в любом месте страницы и выбрав пункт «Scrape similar». Во всплывающем окне вам нужно будет изменить XPath-запрос на следующее:
//a[text()=’visit site’]/@href.
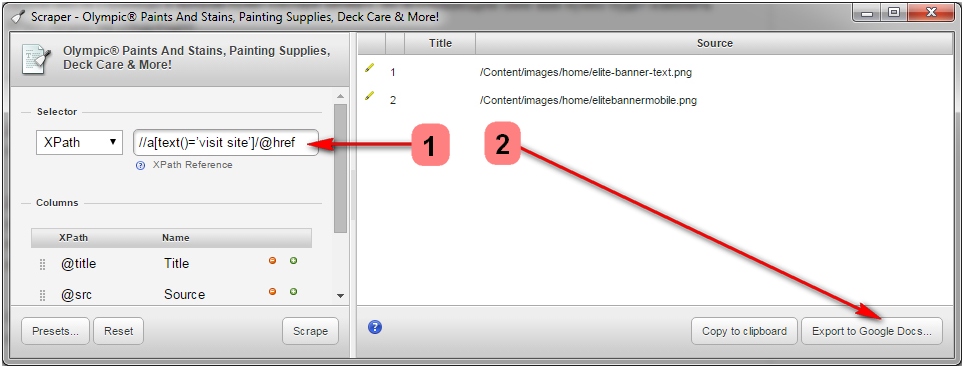
Далее кликните «Scrape» и после «Export to Google Docs». Из вордовского документа вы после сможете сохранить список в качестве файла .csv.
Далее этот список вы сможете загрузить в Spider и запустить сканирование. Когда Spider закончит работу, вы увидите соответствующий статус во вкладке «Internal». Либо же вы можете зайти в «Response Codes» и при помощи позиции «Redirection» отфильтровать результаты, чтобы увидеть все домены, которые были перенаправлены на коммерческий сайт или куда-либо еще.
Обратите внимание на то, что загружая файлы формата .csv в Screaming Frog вы должны выбрать соответственно тип формата «CSV», иначе программа даст сбой.
Совет: Данный метод вы также можете использовать для того, чтобы идентифицировать домены ссылающиеся на конкурентов и выявить, каким образом они были использованы.
-
Как найти все поддомены сайта и проверить внутренние ссылки.
Внесите в ReverseInternet корневой URL-адрес домена, после кликните по вкладке «Subdomains», чтобы увидеть список поддоменов.
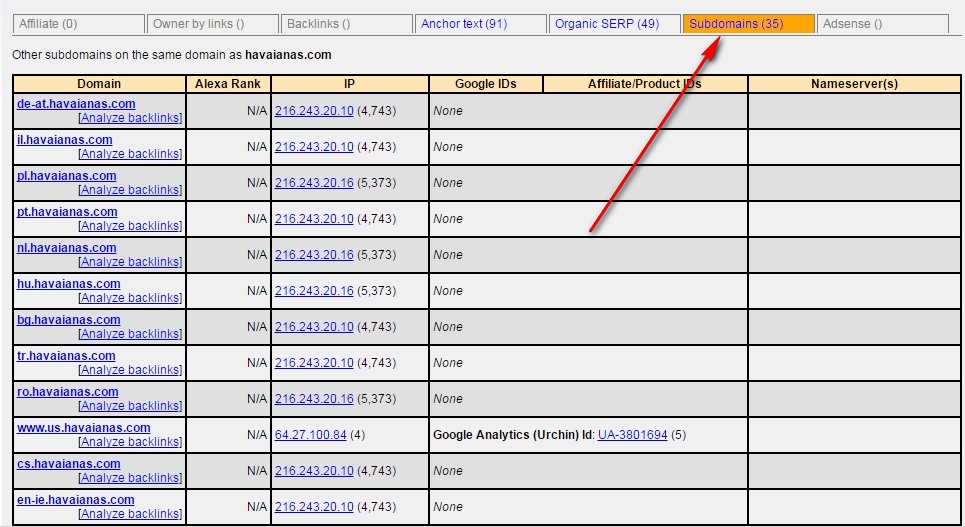
После этого задействуйте Scrape Similar, чтобы собрать список URL, используя запрос XPath:
//a[text()=’visit site’]/@href.
Экспортируйте полученные результаты в формате .csv, после загрузите файл CSV в Screaming Frog, используя режим «List». Когда Spider закончит работу, вы сможете просмотреть коды состояния, равно как и любые ссылки на страницах поддоменов, анкорные вхождения и даже повторяющиеся заголовки страниц.
-
Как сканировать коммерческий или любой другой большой сайт.
Screaming Frog не предназначена для того, чтобы сканировать сотни тысяч страниц, однако имеется несколько мер, позволяющих предотвратить сбои в программе при сканировании больших сайтов. Во-первых, вы можете увеличить объем памяти, используемой Пауком. Во-вторых, вы можете отключить сканирование подкаталога и работать лишь с определенными фрагментами сайта, задействуя инструменты включения и исключения. В-третьих, вы можете отключить сканирование изображений, JavaScript, CSS и флеш-файлов, сделав акцент на HTML. Это сбережет ресурсы памяти.
Совет: Если раньше при сканировании больших сайтов требовалось ждать весьма долго окончания выполнения операции, то Screaming Frog позволяет ставить паузу на процедуру использования больших объемов памяти. Эта ценнейшая опция позволяет вам сохранить уже полученные результаты до того момента, когда программа предположительно готова дать сбой, и увеличить размеры памяти.
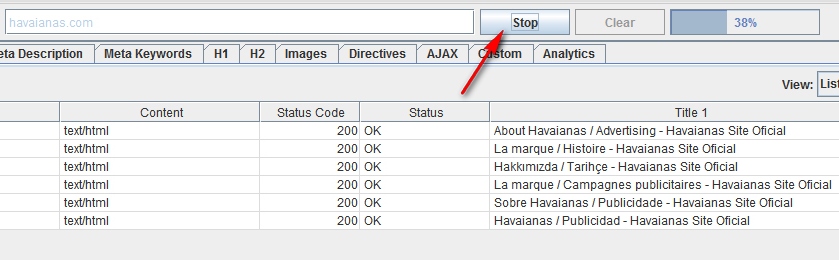
На данный момент такая опция подключена по умолчанию, но если вы планируете сканировать большой сайт, то лучше все же убедиться, что в меню конфигурации Паука, во вкладке «Advanced» стоит галочка в поле «Pause On High Memory Usage».
-
Как сканировать сайт, размещенный на старом сервере.
В некоторых случаях старые серверы могут оказаться неспособны обрабатывать заданное количество URL-запросов в секунду. Чтобы изменить скорость сканирования в меню «Configuration» откройте раздел «Speed» и во всплывающем окне выберите максимальное число потоков, которые должны быть задействованы одновременно. В этом меню вы также можете выбрать максимальное количество URL-адресов, запрашиваемых в секунду.
Совет: Если в результатах сканирования вы обнаружите большое количество ошибок сервера, перейдите во вкладку «Advanced» в меню конфигурации Паука и увеличите значение времени ожидания ответа (Response Timeout) и число новых попыток запросов (5xx Response Retries). Это позволит получать лучшие результаты.
-
Как сканировать сайт, который требует cookies.
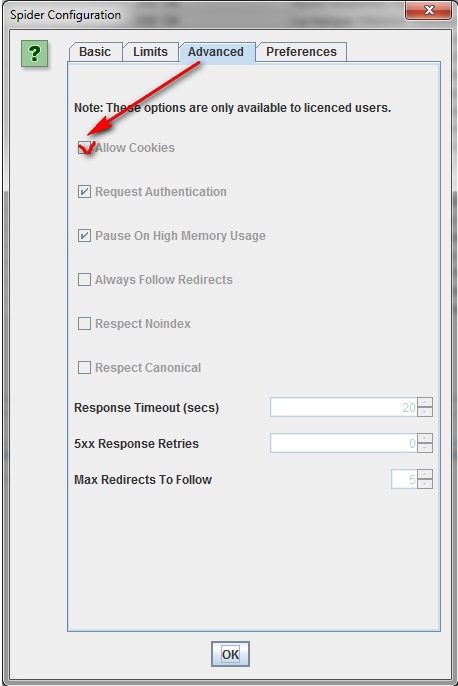
Хотя поисковые роботы не принимают cookies, если при сканировании сайта вам требуется разрешить cookies, то просто выберите «Allow Cookies» во вкладке «Advanced» меню «Configuration».
-
Как сканировать сайт, используя прокси или другой пользовательский агент.
В меню конфигурации выберите «Proxy» и внесите соответствующую информацию. Чтобы сканировать, задействуя иной агент, выберите в меню конфигурации «User Agent», после из выпадающего меню выберите поисковый бот или введите его название.
-
Как сканировать сайты, требующие авторизации.
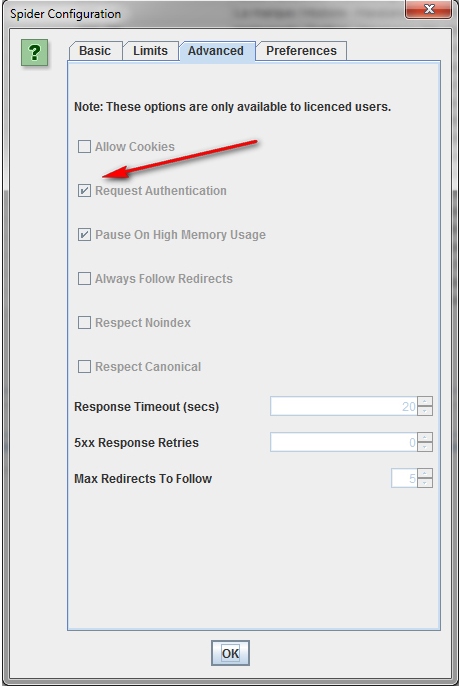
Когда Паук Screaming Frog заходит на страницу, запрашивающую идентификацию, всплывает окно, в котором требуется ввести логин и пароль.
Для того чтобы впредь обходиться без данной процедуры, в меню конфигурации, во вкладке «Advanced» снимите флажок с опции «Request Authentication».
Внутренние ссылки
-
Что делать, когда требуется получить информацию о внешних и внутренних ссылках сайта (анкорах, директивах, перелинковке и пр.).
Если вам не нужно проверять на сайте изображения, JavaScript, Flash или CSS, то исключите эти опции из режима сканирования, чтобы сберечь ресурсы памяти.
После завершения Пауком сканирования, используйте меню «Advanced Export», чтобы из базы «All Links» экспортировать CSV. Это предоставит вам все ссылочные локации и соответствующие им анкорные вхождения, директивы и пр.
Для быстрого подсчета количества ссылок на каждой странице перейдите во вкладку «Internal» и отсортируйте информацию через опцию «Outlinks». Все, чтобы будет выше 100-ой позиции, возможно, потребует дополнительного внимания.
-
Как найти неработающие внутренние ссылки на страницу или сайт.
Как и всегда, не забудьте исключить изображения, JavaScript, Flash или CSS из объектов сканирования, дабы оптимизировать процесс.
После окончания сканировния Пауком, отфильтруйте результаты панели «Internal» через функцию «Status Code». Каждый 404-ый, 301-ый и прочие коды состояния будут хорошо просматриваться.
При нажатии на каждый отдельный URL в результатах сканирования в нижней части окна программы вы увидите информацию. Нажав в нижнем окне на «In Links», вы найдете список страниц, ссылающихся на выбранный URL-адрес, а также анкорные вхождения и директивы, используемые на этих страницах. Используйте данную функцию для выявления внутренних ссылок, требующих обновления.
Чтобы экспортировать в CSV формате список страниц, содержащих битые ссылки или перенаправления, используйте в меню «Advanced Export» опцию «Redirection (3xx) In Links» или «Client Error (4xx) In Links», либо «Server Error (5xx) In Links».
-
Как выявить неработающие исходящие ссылки на странице или сайте (или все битые ссылки одновременно).
Аналогично делаем сначала акцент на сканировании HTML-содержимого, не забыв при этом оставить галочку в пункте «Check External Links».
По завершении сканирования выберите в верхнем окне вкладку «External» и при помощи «Status Code» отфильтруйте содержимое, чтобы определить URL с кодами состояния, отличными от 200. Нажмите на любой отдельный URL-адрес в результатах сканирования и после выберите вкладку «In Links» в нижнем окне – вы найдете список страниц, которые указывают на выбранный URL. Используйте эту информацию для выявления ссылок, требующих обновления.
Чтобы экспортировать полный список исходящих ссылок, нажмите на «Export» во вкладке «Internal». Вы также можете установить фильтр, чтобы экспортировать ссылки на внешние изображения, JavaScript, CSS, Flash и PDF. Чтобы ограничить экспорт только страницами, сортируйте посредством опции «HTML».
Чтобы получить полный список всех локаций и анкорных вхождений исходящих ссылок, выберите в меню «Advanced Export» позицию «All Out Links», а после отфильтруйте столбец «Destination» в экспортируемом CSV, чтобы исключить ваш домен.
-
Как найти перенаправляющие ссылки.
По завершении сканирования выберите в верхнем окне панель «Response Codes» и после отсортируйте результаты при помощи опции «Redirection (3xx)». Это позволит получить список всех внутренних и исходящих ссылок, которые будут перенаправлять. Применив фильтр «Status Code», вы сможете разбить результаты по типам. При нажатии «In Links» в нижнем окне, вы сможете увидеть все страницы, на которых используются перенаправляющие ссылки.
Если экспортировать информацию прямо из этой вкладки, то вы увидите только те данные, которые отображаются в верхнем окне (оригинальный URL, код состояния и то место, в которое происходит перенаправление).
Чтобы экспортировать полный список страниц, содержащих перенаправляющие ссылки, вам следует выбрать «Redirection (3xx) In Links» в меню «Advanced Export». Это вернет CSV-файл, который включает в себя расположение всех перенаправляющих ссылок. Чтобы показать только внутренние редиректы, отфильтруйте содержимое в CSV-файле с данными о вашем домене при помощи колонки «Destination».
Совет: Поверх двух экспортированных файлов используйте VLOOKUP, чтобы сопоставить столбцы «Source» и «Destination» с расположением конечного URL-адреса.
Пример формулы выглядит следующим образом:
=VLOOKUP([@Destination],’response_codes_redirection_(3xx).csv’!$A$3:$F$50,6,FALSE). Где «response_codes_redirection_(3xx).csv» — это CSV-файл, содержащий перенаправляющие URL-адреса и «50» — это количество строк в этом файле.
Контент сайта
-
Как идентифицировать страницы с неинформативным содержанием (т.н. «thin content» − «токний контент»).
После завершения работы Spider перейдите в панель «Internal», задав фильтрацию по HTML, а после прокрутите вправо к столбцу «Word Count». Отсортируйте содержимое страниц по принципу количества слов, чтобы выявить те, на которых текста меньше всего. Можете перетащить столбец «Word Count» влево, поместив его рядом с соответствующими URL-адресами, сделав информацию более показательной. Нажмите на кнопку «Export» во вкладке «Internal», если вам удобнее работать с данными в формате CSV.
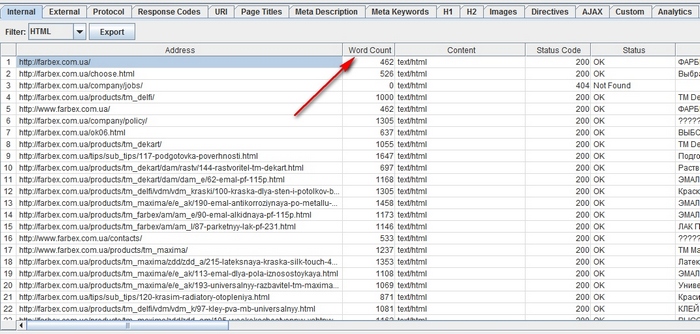
Помните, что Word Count позволяет оценить объем размещенного текста, однако не дает решительно никаких сведений о том, является ли этот текст просто названиями товаров/услуг или оптимизированным под ключевые слова блоком.
-
Если требуется выделить с конкретных страниц список ссылок на изображения.
Если вы уже просканировали весь сайт или отдельную папку, то просто выберите страницу в верхнем окне, после нажмите «Image Info» в нижнем окне, чтобы просмотреть изображения, которые были найдены на этой странице. Картинки будут перечисляться в столбце «To».
Совет: Щелкните правой кнопкой мыши на любую запись в нижнем окне, чтобы скопировать или открыть URL-адрес.

Вы можете просматривать изображения на отдельно взятой странице, сканируя именно этот URL-адрес. Убедитесь, что глубина сканирования в настройках конфигурации сканирования Паука имеет значение «1». После того, как страница просканируется, перейдите во вкладку «Images», и вы увидите все изображения, которые удалось обнаружить Spider.
Наконец, если вы предпочитаете CSV, используйте меню «Advanced Export», опцию «All Image Alt Text», чтобы увидеть список всех изображений, их местоположение и любой связанный с ними замещающий текст.
-
Как найти изображения, у которых отсутствует замещающий текст или изображения, имеющие длинный Alt-текст.
Прежде всего, вам нужно убедиться, что в меню Паука «Configuration» выбрана позиция «Check Images». По завершении сканирования перейдите во вкладку «Images» и отфильтруйте содержимое при помощи опций «Missing Alt Text» или «Alt Text Over 100 Characters». Нажав на вкладку «Image Info» в нижнем окне, вы найдете все страницы, на которых размещаются хотя бы какие-нибудь изображения. Страницы будут перечислены в столбце «From».

Вместе с тем, в меню «Advanced Export» вы можете сэкономить время и экспортировать «All Image Alt Text» (Все картинки, весь текст) или «Images Missing Alt Text» (Картинки без Alt-тега) в формат CSV.
-
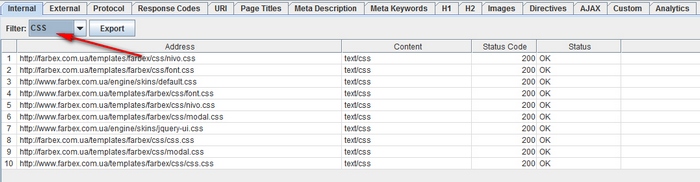
Как найти на сайте каждый CSS-файл.
В меню конфигурации Паука перед сканированием выберите «Check CSS». По окончании процесса отфильтруйте результаты анализа в панели «Internal» при помощи опции «CSS».
-
Как найти файлы JavaScript.
В меню конфигурации Паука перед сканированием выберите «Check JavaScript». По окончании процесса отфильтруйте результаты анализа в панели «Internal» при помощи опции «JavaScript».
-
Как выявить все плагины jQuery, использованные на сайте, и их местоположение.
Прежде всего, убедитесь, что в меню конфигурации выбрано «Check JavaScript». По завершении сканирования примените в панели «Internal» фильтр «JavaScript», а после сделайте поиск «jQuery». Это позволит вам получить список файлов с плагинами. Отсортируйте перечень по опции «Address» для более удобного просмотра. Затем просмотрите «InLinks» в нижнем окне или экспортируйте информацию в CSV. Чтобы найти страницы, на которых используются файлы, поработайте со столбиком «From».
Вместе с этим, вы можете использовать меню «Advanced Export», чтобы экспортировать «All Links» в CSV и отфильтровать столбец «Destination», дабы просматривать исключительно URL-адреса с «jquery».
Совет: Плохими для СЕО являются не только все плагины jQuery. Если вы видите сайт, использующий jQuery, то разумно будет убедиться, что контент, который вы собираетесь проиндексировать, включен в исходный код страницы и выдается при загрузке страницы, а не после этого. Если вы не уверены в данном аспекте, то почитайте о плагине в интернете, чтобы побольше узнать о том, как он работает.
-
Как определить, где на сайте размещается flash.
Перед сканированием в меню конфигурации выберите «Check SWF». А по завершении работы Паука отфильтруйте результаты в панели «Internal» по значению «Flash».

Помните, что этот метод позволяет лишь найти файлы формата .SWF, расположенные на странице. Если плагин вытаскивается через JavaScript, вам придется использовать пользовательский фильтр.
-
Как найти на сайте внутренние PDF-документы.
После завершения сканирования отфильтруйте результаты работы Spider при помощи опции «PDF» в панели «Internal».
-
Как выявить сегментацию контента в пределах сайта или группы страниц.
Если вы хотите найти на сайте страницы, содержащие необычный контент, установите пользовательский фильтр, выявляющий печати HTML, не свойственные данной странице. Сделано это должно быть до запуска Паука.
-
Как найти страницы, имеющие кнопки социального обмена.
Для этого перед запуском Паука нужно будет установить пользовательский фильтр. Для его установки перейдите в меню конфигурации и нажмите «Custom». После этого введите любой фрагмент кода из исходного кода страницы.
В приведенном примере задачей стояло найти страницы, содержащие кнопку «Like» социальной сети Facebook, соответственно для них был создан фильтр формата «http://www.facebook.com/plugins/like.php».
-
Как найти страницы, использующие iframe.
Для этого необходимо установить для тега <iframe соответствующий пользовательский фильтр.
-
Как найти страницы, содержащие встроенное видео или аудио контент.
Для этого установите пользовательский фильтр для фрагмента кода встраивания под Youtube или любой другой медиа плеер, используемый на сайте.
Мета данные и директивы
-
Как найти страницы с длинными, короткими или отсутсвующими заголовками, meta description или meta keywords
По завершении сканирования перейдите во вкладку «Page Titles» и отфильтруйте содержимое через «Over 70 Characters», чтобы увидеть чрезмерно длинные заголовки страниц. Аналогичное можно проделать в панелях «Meta Description» и «URL». Точно такой же алгоритм можно использовать для определения страниц, с отсутствующими или короткими заголовками и мета данными.

-
Как найти страницы с дублированными заголовками, meta description или meta keywords
По завершении сканирования перейдите во вкладку «Page Titles» и отфильтруйте содержимое через «Duplicate», чтобы увидеть дублирующиеся заголовки страниц. Аналогичное можно проделать в панелях «Meta Description» и «URL».
-
Как найти дублированный контент и/или URL, которые должны быть перенаправлены/переписаны/канонизированы.
По завершении работы Паука перейдите во вкладку «URL» и отфильтруйте результаты посредством «Underscores», «Uppercase» or «Non ASCII Characters», выявив URL, которые бы могли потенциально быть переписаны в более стандартную структуру. Отфильтруйте через инструмент «Duplicate», чтобы увидеть страницы, которые имеют несколько URL-версий. Примените фильтр «Dynamic», чтобы распознать URL-адреса, включающие параметры.
Кроме этого, если вы пройдете в панель «Internal» через фильтр «HTML» и прокрутите подальше вправо к колонке «Hash», то вы увидите уникальную последовательность букв и цифр на каждой странице. Если вы нажмете «Export», то сможете использовать условное форматирование в Excel, чтобы выделить повторяющиеся значения в этом столбце, в итоге показывая, что страницы идентичны и должны быть рассмотрены.
-
Как определить страницы, содержащие Мета-директивы.
После сканирования перейдите в панель «Directives». Чтобы увидеть тип директива просто прокрутите вправо и посмотрите, какие столбцы заполнены. Либо же используйте фильтр, чтобы найти любой из следующих тегов:
- Index;
- Noindex;
- Follow;
- Nofollow;
- Noarchive;
- Nosnippet;
- Noodp;
- Noydir;
- Noimageindex;
- Notranslate;
- Unavailable_after;
- Refresh;
- Canonical.
-
Как определить, что файл robots.txt работает так, как положено.
По умолчанию, Screaming Frog будет соответствовать robots.txt. В качестве приоритетных, программа будет следовать директивам, сделанным специально для пользовательского агента. Если таковых не имеется, то Spider будет следовать любым директивам для бота Google. Если же специальных директив для Googlebot нет, то Паук будет следовать глобальным директивам, принятым для всех пользовательских агентов. При этом Spider выберет лишь один какой-то набор директив, не затрагивая все последующие.
Если вам требуется заблокировать от Паука некоторые части сайта, то используйте для этих целей синтаксис обычного robots.txt с пользовательским агентом Screaming Frog SEO Spider. Если вы хотите игнорировать robots.txt, то просто выберите соответствующую опцию в меню конфигурации программы.
-
Как найти и проверить разметку Schema или другие микроданные.
Чтобы найти каждую страницу, содержащую разметку Schema или другие микроданные, вам нужно использовать пользовательские фильтры. В меню «Configuration» кликните по «Custom» и вбейте тот маркер, который вы ищите.
Чтобы найти каждую страницу, содержащую разметку Schema, просто добавьте следующий фрагмент кода в пользовательский фильтр: itemtype=http://schema.org.
Чтобы найти определенный тип разметки вам придется быть более конкретным. Например, использование пользовательского фильтра ‹span itemprop=”ratingValue”› позволит вам найти все страницы, содержащие разметку Schema для построения рейтингов.
Для сканирования вы можете использовать 5 различных фильтров. После вам останется лишь нажать «OK» и просветить программным сканером сайт или список страниц.
Когда Паук завершит работу, выберите в верхнем окне вкладку «Custom», чтобы увидеть все страницы с искомым вами маркером. Если вы задали более одного пользовательского фильтра, вы сможете поочередно просмотреть их, переключаясь в результатах сканирования между страничками фильтров.
Карта сайта
-
Как создать карту сайта (Sitemap) в XML.
После того, как паук закончил сканировать ваш сайт, нажмите на «Advanced Export» и выберите «XML Sitemap».
Сохранить вашу карту сайта, а после откройте ее в Excel. Выберите «Read Only» и откройте файл «As an XML table». При этом может выйти сообщение, что некоторые схемы не могут быть интегрированы. Просто нажмите на кнопку «Yes».
После того, как карта сайта предстанет перед вами в табличной форме, вы с легкостью сможете изменить частоту, приоритет и прочие настройки. Обязательно убедитесь в том, что Sitemap содержит только один предпочитаемый (канонический) вариант каждого URL, без параметров и прочих дублирующих факторов.
После внесения каких-либо изменений пересохраните файл в режиме XML.
-
Как узнать свой существующий XML-файл Sitemap.
В первую очередь, вам нужно будет создать копию Sitemap на своем ПК. Вы можете сохранить любую живую карту сайта, перейдя на URL и сохранив файл или импортировав его в Excel.
После этого перейдите в раздел меню Screaming Frog под названием «Mode» и выберите «List». После вверху страницы нажмите на «Select File», выберите свой файл и начните сканирование. По завершении работы Spider во вкладке «Internal», разделе «Sitemap dirt» вы сможете увидеть любые перенаправления, ошибки 404, дублированные URL-адреса и т.п.
Общие рекомендации по устранению неполадок
-
Как определить, почему некоторые разделы моего сайта не индексируются или не ранжируются.
Интересно, почему некоторые страницы не индексируются? Во-первых, убедитесь, что они не попали в robots.txt и не были помечены как noindex. Во-вторых, вам нужно удостовериться в том, что пауки могут добраться до страниц сайта, чтобы проверить внутренние ссылки. После того как паук просканирует ваш сайт, экспортируйте список внутренних ссылок как файл CSV, используя HTML-фильтр во вкладке «Internal».
Откройте документ CSV и во второй лист скопируйте список URL-адресов, которые не индексируются или не ранжируются. Используйте VLOOKUP, чтобы посмотреть, присутствуют ли подобные проблемные URL в результатах сканирования.
-
Как проверить, был ли перенос/редизайн сайта успешным.
Вы можете использовать Screaming Frog, чтобы выяснить, были ли старые URL-адреса перенаправлены. Поможет в этом режим «List», посредством которого можно проверить коды состояний. Если старые URL выдают ошибку 404, то вы будете точно знать, какие из них требуют переадресации.
-
Как найти медленно загружающиеся страницы сайта.
После завершения процесса сканирования перейдите во вкладку «Response Codes» и отсортируйте столбец «Response Time» по принципу «от большого к малому», чтобы найти страницы, которые могут страдать от медленной скорости загрузки.
-
Как найти вредоносные программы или спам на сайте.
В первую очередь, вам необходимо выявить следы, оставленные вредоносными программами или спамом. Далее в меню конфигурации нажмите на «Custom» и внесите название маркера, который вы ищите. За одно сканирование вы можете анализировать до 5 таких маркеров. Внесите все необходимые и после нажмите на «OK», чтобы изучить весь сайт или перечень страниц на нем.
По завершении процесса перейдите во вкладку «Custom», располагающуюся в верхнем окне, чтобы просмотреть все страницы, на которых были обнаружены указанные вами «следы» мошеннических и вирусных программ. Если вы задали более одного пользовательского фильтра, то результаты по каждому будут выведены в отдельное окно, и вы сможете ознакомиться с ними, переходя от одного фильтра к другому.
PPC и аналитика
-
Как одновременно проверить список всех URL, используемых для контекстной рекламы.
Сохраните список адресов в формате .txt или .csv и измените настройки режима с «Mode» на «List». После выберите свой файл для загрузки и нажмите на «Start». Просмотрите во вкладке «Internal» код состояния по каждой странице.
Scraping
-
Как собрать мета данные с ряда страниц.
У вас имеется куча URL-адресов, по которым важно получить как можно больше информации? Включите режим «Mode», затем загрузите список адресов формате .txt или .csv. После того как Spider завершит выполнение рабочей операции, вы сможете увидеть коды состояния, исходящие ссылки, количество слов и, конечно, мета данные по каждой странице в вашем списке.
-
Как сделать scraping сайта для всех страниц, содержащих определенный маркер.
Прежде всего, вам нужно будет разобраться с самим маркером – определить, что именно вам необходимо. После этого в меню «Configuration» нажмите на «Custom» и введите название искомого маркера. Помните, что вы можете ввести до 5 различных маркеров. Затем нажмите на «OK», чтобы запустить процесс сканирования и отфильтровать страницы сайта по наличию на них указанных «следов».
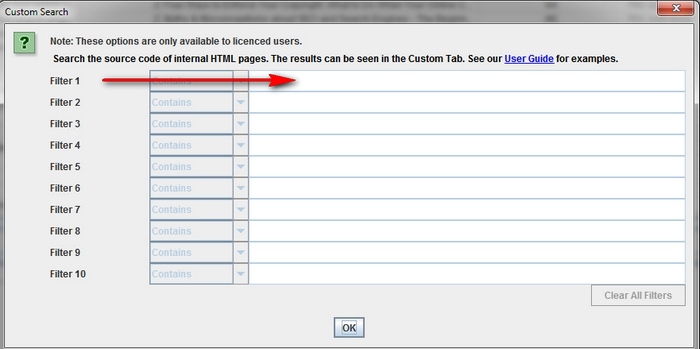
На примере показана ситуация, когда требуется найти все страницы, содержащие слова «Please Call» в разделах, касающихся стоимости товаров. Для этого был найден и скопирован HTML-код из исходного кода страницы.
После сканирования вам нужно перейти в раздел «Custom» в верхнем окне, чтобы просмотреть список всех страниц, содержащих заданный маркер. Если было введено более одного маркера, то информация по каждому из них будет подана в отдельном окне.
Совет: Данный метод хорош в том случае, если у вас нет прямого доступа к сайту. Если же вам требуется получить данные с сайта клиента, то значительно проще и быстрее будет попросить его взять нужную информацию непосредственно из базы данных и передать вам.
Переписывание URL
-
Как найти и удалить ID сессии или другие параметры из просканированных URL-адресов.
Чтобы идентифицировать URL с ID-сессиями или другими параметрами просто отсканируйте сайт с учетом настроек, заданных по умолчанию. По завершении работы Паука прейдите во вкладку «URL» и примените фильтр «Dynamic», чтобы увидеть все URL-адреса, содержащие требуемые параметры.
Чтобы на отсканированных страницах удалить параметры из показа выберите «URL Rewriting» в меню конфигурации. Затем в панели «Remove Parameters» нажмите «Add», чтобы добавить параметры, которые вы хотите убрать из URL и нажмите «OK». Чтобы активизировать внесенные изменения вам потребуется вновь запустить Паука.
-
Как переписать отсканированные URL (например, сменить .com на .co.uk или записать все URL в нижнем регистре).
Чтобы переписать любой из проработанных пауком адресов выберите в меню конфигурации «URL Rewriting», а после в панели «Regex Replace» нажмите на «Add» и добавить RegEx к тому, что вам требуется заменить.
После того, как вы внесете все требуемые корректировки, вы сможете проверить их в панели «Test» путем введения тестовых URL в окно «URL before rewriting». Строка «URL after rewriting» будет обновляться автоматически, следуя заданным вами параметрам.
Если вам требуется переписать все URL-адреса нижним регистром, то просто выберите «Lowercase discovered URLs» в панели «Options».
Не забудьте вновь запустить Spider после внесения изменений, чтобы те вступили в свои права.
Анализ ключевых слов
-
Как узнать, какие страницы сайтов конкурентов имеют наибольшую ценность.
В целом, конкуренты будут пытаться расширять ссылочную популярность и привлекать трафик на свои наиболее ценные страницы путем их внутренней перелинковки. Любой уделяющий внимание SEO конкурент также выстраивать прочную связь между корпоративным блогом и самыми важными страницами сайта.
Найдите наиболее значимые страницы сайта конкурента путем сканирования, а после перейдите в панель «Internal» и отсортируйте результаты в столбце «Inlinks» по принципу «от большого к малому», чтобы увидеть, какие страницы имеют более всего внутренних ссылок.
Чтобы просмотреть страницы, связанные с корпоративным блогом конкурента, уберите галочку из «Check links outside folder» в меню конфигурации Паука и просканируйте папку/поддомен блога. Затем в панели «External» отфильтруйте полученные результаты, используя поиск по URL главного домена. Прокрутите страницу до конца вправо и отсортируйте список в столбце «Inlinks», чтобы увидеть страницы, которые линкуются чаще всего.
Совет: Для удобства работы с таблицей программы перемещайте столбцы влево и вправо методом Drag and Drop.
-
Как узнать, какие анкоры конкуренты используют для внутренней перелинковки.
В меню «Advanced Export» выберите «All Anchor Text», чтобы экспортировать CSV, содержащие анкорные вхождения сайта и узнать их местоположение и привязки.
-
Как узнать, какие мета ключевики конкуренты используют на своем сайте.
После того как паук завершит сканирование, загляните в панель «Meta Keywords», чтобы просмотреть список мета ключевиков, найденных на каждой отдельной странице. Отсортируйте столбец «Meta Keyword 1» по алфавиту, чтобы сделать информацию более показательной.
Ссылочное построение
-
Как проанализировать потенциальные места расположения ссылок.
Собрав список URL-адресов, вы можете просканировать их в режиме «List», чтобы собрать как можно больше информации о страницах. После завершения сканирования проверьте коды состояния в панели «Response Codes» и в панели «Out Links» изучите исходящие ссылки, типы ссылок, анкорные вхождения и директивы. Это даст вам представление о том, какие сайты ссылаются эти страницы и как.
Для обзора панели «Out Links» убедитесь, что интересующий вас URL выбран в верхнем окне.
Вы наверняка захотите использовать пользовательские фильтры, чтобы определить, нет ли уже в данных местах ссылок.
Вы также можете экспортировать полный список ссылок, нажав на опцию «All Out Links» в панели «Advanced Export Menu». Это позволит получить не только ссылки, ведущие на сторонние сайты, но и показать внутренние ссылки по отдельным страницам вашего списка.
-
Как найти битые ссылки для внешней рекламы.
Итак, имеется сайт, с которого вы бы хотели получить ссылки на свой собственный ресурс. Используя Screaming Frog, вы можете найти битые ссылки на страницы сайта (или на весь сайт целиком) и после, связавшись с владельцем понравившегося вам ресурса, предложить ему заменить битые ссылки ссылками на ваш ресурс там, где это возможно.
-
Как проверить обратные ссылки и просмотреть анкоры.
Загрузите список своих обратных ссылок и запустите Паука в режиме «List». После экспортируйте полный список внешних ссылок, нажав на «All Out Links» в меню «Advanced Export Menu». Это предоставит вам URL и якорный текст/Alt-текст для всех ссылок на этих страницах. После этого вы можете отфильтровать столбец «Destination» в CSV-файле, чтобы определить, перелинкован ли ваш сайт и какой якорный текст/Alt-текст он включает.
-
Как убедиться в том, что обратные ссылки были успешно удалены.
Для этого требуется установить пользовательский фильтр, который содержит корневой домен URL, затем загрузить свой список обратных ссылок и запустить Паука в режиме «List». По окончании сканирования перейдите в панель «Custom», чтобы просмотреть список страниц, которые продолжают на вас ссылаться.
Совет: Помните о том, что нажав правой кнопкой мыши на любой URL-адрес в верхнем окне результатов сканирования, вы можете, в частности:
- Скопировать или открыть URL-адрес.
- Запустить повторное сканирование адреса или убрать его из списка.
- Экспортировать информацию о URL или изображении, имеющемся на этой странице, входящих и исходящих ссылках.
- Проверить индексацию страницы в Google, Bing и Yahoo.
- Проверить обратные ссылки страницы в Majestic, OSE, Ahrefs и Blekko.
- Просмотреть кэшированную версию.
- Просмотреть старые версии страницы.
- Открыть robots.txt для домена, в котором находится страница.
- Запустить поиск для других доменов на том же IP.
Заключение
Итак, мы детально рассмотрели все аспекты использования программы Screaming Frog. Надеемся, что наша подробная инструкция поможет Вам сделать аудит сайта более простым и в тоже время достаточно эффективным, при этом даст возможность сэкономить массу времени.

Небольшая шпаргалка для того, чтобы подключить CSS. Таблицы стилей делятся на внешние и внутренние. Внешние таблицы располагаются в отдельных файлах с расширением file.css, внутренние встраиваются в HTML-страницу.
Самый часто используемый способ подключения CSS, это подключение его на страницу при помощи тега <link>, который должен находиться в секции <head> HTML-страницы. В строке где написано название файла, нужно прописать абсолютный или относительный путь к файлу, до того места, где он лежит на сайте.
HTML
<html>
<head>
<meta charset="utf-8">
<meta name="viewport" content="width=device-width, initial-scale=1">
<title>Основы CSS</title>
<link type="text/css" rel="stylesheet" href="style.css">
<!--В этом месте: href="абсолютный или относительный путь к файлу, до того места, где он лежит на сайте." -->
</head>
<body>
<h1>Основы CSS</h1>
</body>
</html>
Внутренние таблицы стилей встраиваются в HTML-страницу, в секцию <head>, и находятся они внутри тегов <style></style>, как на примере.
HTML
<html>
<head>
<meta charset="utf-8">
<meta name="viewport" content="width=device-width, initial-scale=1">
<title>Основы CSS</title>
<style>
body{
background: #faebd7;
font-size: 16px;
}
h1{
color: #666666;
}
</style>
</head>
<body>
<h1>Основы CSS</h1>
</body>
</html>
Есть и другой способ, — это использование правила @import . Чтобы это правило работало оно должно находиться в таблице стилей (внутренней или внешней), в самом начале, перед остальными правилами. Обычно @import используется внутри CSS-файлов. Также эта директива используется для подключения шрифтов.
@import url (example.css); /* Путь к файлу */
@import url (https://fonts.googleapis.com/css2?family=Open+Sans:wght@300&display=swap); /* Ссылка или путь к шрифтам */
Существуют так же встроенные стили. Они пишутся непосредственно внутри HTML-тегов в атрибуте style. Такие стили будут влиять только на этот тег, и будут оказывать большее влияние, чем стили прописанные в css файле.
HTML
<html>
<head>
<meta charset="utf-8">
<meta name="viewport" content="width=device-width, initial-scale=1">
<title>Основы CSS</title>
</head>
<body>
<h1 style="font-size:20px;">Основы CSS</h1>
</body>
</html>
