
Богдан Василенко
SEO-специалист SE Ranking
По каждому запросу поисковая система подбирает релевантные результаты — страницы, подходящие по тематике, и ранжирует их, отображая в виде списка. Согласно исследованиям, 99 % пользователей находят информацию, отвечающую запросу, уже на первой странице выдачи и не пролистывают дальше. И чем выше позиция сайта в топ-10, тем больше посетителей она привлекает.
Перед тем, как распределить ресурсы в определенном порядке, поисковики оценивают их по ряду параметров. Это позволяет улучшить выдачу для пользователя, предоставляя наиболее полезные, удобные и авторитетные варианты.
В чём заключается оптимизация сайта?
Оптимизация сайта или SEO (Search Engine Optimization) представляет собой комплекс действий, цель которых — улучшить качество ресурса и адаптировать его с учётом рекомендаций поисковых систем.
SEO помогает попасть содержимому сайта в индекс, улучшить позиции его страниц при ранжировании и увеличить органический, то есть бесплатный трафик. Техническая оптимизация сайта — это важный этап SEO, направленный на работу с его внутренней частью, которая обычно скрыта от пользователей, но доступна для поисковых роботов.
Страницы представляют собой HTML-документы, и их отображение на экране — это результат воспроизведения браузером HTML-кода, от которого зависит не только внешний вид сайта, но и его производительность. Серверные файлы и внутренние настройки ресурса могут влиять на его сканирование и индексацию поисковиком.
SEO включает анализ технических параметров сайта, выявление проблем и их устранение. Это помогает повысить позиции при ранжировании, обойти конкурентов, увеличить посещаемость и прибыль.
Как обнаружить проблемы SEO на сайте?
Процесс оптимизации стоит начать с SEO-аудита — анализа сайта по самым разным критериям. Есть инструменты, выполняющие оценку определенных показателей, например, статус страниц, скорость загрузки, адаптивность для мобильных устройств и так далее. Альтернативный вариант — аудит сайта на платформе для SEO-специалистов.
Один из примеров — сервис SE Ranking, объединяющий в себе разные аналитические инструменты. Результатом SEO-анализа будет комплексный отчёт. Для запуска анализа сайта онлайн нужно создать проект, указать в настройках домен своего ресурса, и перейти в раздел «Анализ сайта». Одна из вкладок — «Отчёт об ошибках», где отображаются выявленные проблемы оптимизации.
Все параметры сайта разделены на блоки: «Безопасность», «Дублирование контента», «Скорость загрузки» и другие. При нажатии на любую из проблем появится её описание и рекомендации по исправлению. После технической SEO оптимизации и внесения корректировок следует повторно запустить аудит сайта. Увидеть, были ли устранены ошибки, можно колонке «Исправленные».
Ошибки технической оптимизации и способы их устранения
Фрагменты кода страниц, внутренние файлы и настройки сайта могут негативно влиять на его эффективность. Давайте разберём частые проблемы SEO и узнаем, как их исправить.
Отсутствие протокола HTTPS
Расширение HTTPS (HyperText Transfer Protocol Secure), которое является частью доменного имени, — это более надежная альтернатива протоколу соединения HTTP. Оно обеспечивает шифрование и сохранность данных пользователей. Сегодня многие браузеры блокируют переход по ссылке, начинающейся на HTTP, и отображают предупреждение на экране.
Поисковые системы учитывают безопасность соединения при ранжировании, и если сайт использует версию HTTP, это будет минусом не только для посетителей, но и для его позиций в выдаче.
Как исправить
Чтобы перевести ресурс на HTTPS, необходимо приобрести специальный сертификат и затем своевременно продлевать срок его действия. Настроить автоматическое перенаправление с HTTP-версии (редирект) можно в файле конфигурации .htaccess.
После перехода на безопасный протокол будет полезно выполнить аудит сайта и убедиться, что всё сделано правильно, а также при необходимости заменить неактуальные URL с HTTP среди внутренних ссылок (смешанный контент).
У сайта нет файла robots.txt
Документ robots размещают в корневой папке сайта. Его содержимое доступно по ссылке website.com/robots.txt. Этот файл представляет собой инструкцию для поисковых систем, какое содержимое ресурса следует сканировать, а какое нет. К нему роботы обращаются в первую очередь и затем начинают обход сайта.
Ограничение сканирования файлов и папок особенно актуально для экономии краулингового бюджета — общего количества URL, которое может просканировать робот на данном сайте. Если инструкция для краулеров отсутствует или составлена неправильно, это может привести к проблемам с отображением страниц в выдаче.
Как исправить
Создайте текстовый документ с названием robots в корневой папке сайта и с помощью директив пропишите внутри рекомендации по сканированию содержимого страниц и каталогов. В файле могут быть указаны виды роботов (user-agent), для которых действуют правила; ограничивающие и разрешающие команды (disallow, allow), а также ссылка на карту сайта (sitemap).
Проблемы с файлом Sitemap.xml
Карта сайта — это файл, содержащий список всех URL ресурса, которые должен обойти поисковый робот. Наличие sitemap.xml не является обязательным условием, для попадания страниц в индекс, но во многих случаях файл помогает поисковику их обнаружить.
Обработка XML Sitemap может быть затруднительна, если ее размер превышает 50 МБ или 50000 URL. Другая проблема — присутствие в карте страниц, закрытых для индексации метатегом noindex. При использовании канонических ссылок на сайте, выделяющих их похожих страниц основную, в файле sitemap должны быть указаны только приоритетные для индексации URL.
Как исправить
Если в карте сайта очень много URL и её объем превышает лимит, разделите файл на несколько меньших по размеру. XML Sitemap можно создавать не только для страниц, но и для изображений или видео. В файле robots.txt укажите ссылки на все карты сайта.
В случае, когда SEO-аудит выявил противоречия, — страницы в карте сайта, имеющие запрет индексации noindex в коде, их необходимо устранить. Также проследите, чтобы в Sitemap были указаны только канонические URL.
Дубли контента
Один из важных факторов, влияющих на ранжирование, — уникальность контента. Недопустимо не только копирование текстов у конкурентов, но и дублирование их внутри своего сайта. Это проблема особенно актуальна для больших ресурсов, например, интернет-магазинов, где описания к товарам имеют минимальные отличия.
Причиной, почему дубли страниц попадают в индекс, может быть отсутствие или неправильная настройка «зеркала» — редиректа между именем сайта с www и без. В этом случае поисковая система индексирует две идентичные страницы, например, www.website.com и website.com.
Также к проблеме дублей приводит копирование контента внутри сайта без настройки канонических ссылок, определяющих приоритетную для индексации страницу из похожих.
Как исправить
Настройте www-редиректы и проверьте с помощью SEO-аудита, не осталось ли на сайте дублей. При создании страниц с минимальными отличиями используйте канонические ссылки, чтобы указать роботу, какие из них индексировать. Чтобы не ввести в заблуждение поисковые системы, неканоническая страница должна содержать тег rel=”canonical” только для одного URL.
Страницы, отдающие код ошибки
Перед тем, как отобразить страницу на экране, браузер отправляет запрос серверу. Если URL доступен, у него будет успешный статус HTTP-состояния — 200 ОК. При возникновении проблем, когда сервер не может выполнить задачу, страница возвращает код ошибки 4ХХ или 5ХХ. Это приводит к таким негативным последствиям для сайта, как:
- Ухудшение поведенческих факторов. Если вместо запрошенной страницы пользователь видит сообщение об ошибке, например, «Page Not Found» или «Internal Server Error», он не может получить нужную информацию или завершить целевое действие.
- Исключение контента из индекса. Когда роботу долго не удается просканировать страницу, она может быть удалена из индекса поисковой системы.
- Расход краулингового бюджета. Роботы делают попытку просканировать URL, независимо от его статуса. Если на сайте много страниц с ошибками, происходит бессмысленный расход краулингового лимита.
Как исправить
После анализа сайта найдите страницы в статусе 4ХХ и 5ХХ и установите, в чём причина ошибки. Если страница была удалена, поисковая система через время исключит её из индекса. Ускорить этот процесс поможет инструмент удаления URL. Чтобы своевременно находить проблемные страницы, периодически повторяйте поиск проблем на сайте.
Некорректная настройка редиректов
Редирект — это переадресация в браузере с запрошенного URL на другой. Обычно его настраивают при смене адреса страницы и её удалении, перенаправляя пользователя на актуальную версию.
Преимущества редиректов в том, что они происходят автоматически и быстро. Их использование может быть полезно для SEO, когда нужно передать наработанный авторитет от исходной страницы к новой.
Но при настройке переадресаций нередко возникают такие проблемы, как:
- слишком длинная цепочка редиректов — чем больше в ней URL, тем позже отображается конечная страница;
- зацикленная (циклическая) переадресация, когда страница ссылается на себя или конечный URL содержит редирект на одно из предыдущих звеньев цепочки;
- в цепочке переадресаций есть неработающий, отдающий код ошибки URL;
- страниц с редиректами слишком много — это уменьшает краулинговый бюджет.
Как исправить
Проведите SEO-аудит сайта и найдите страницы со статусом 3ХХ. Если среди них есть цепочки редиректов, состоящие из трех и более URL, их нужно сократить до двух адресов — исходного и актуального. При выявлении зацикленных переадресаций необходимо откорректировать их последовательность. Страницы, имеющие статус ошибки 4ХХ или 5ХХ, нужно сделать доступными или удалить из цепочки.
Низкая скорость загрузки
Скорость отображения страниц — важный критерий удобства сайта, который поисковые системы учитывают при ранжировании. Если контент загружается слишком долго, пользователь может не дождаться и покинуть ресурс.
Google использует специальные показатели Core Web Vitals для оценки сайта, где о скорости говорят значения LCP (Largest Contentful Paint) и FID (First Input Delay). Рекомендуемая скорость загрузки основного контента (LCP) — до 2,5 секунд. Время отклика на взаимодействие с элементами страницы (FID) не должно превышать 0,1.
К распространённым факторам, негативно влияющим на скорость загрузки, относятся:
- объёмные по весу и размеру изображения;
- несжатый текстовый контент;
- большой вес HTML-кода и файлов, которые добавлены в него в виде ссылок.
Как исправить
Стремитесь к тому, чтобы вес HTML-страниц не превышал 2 МБ. Особое внимание стоит уделить изображениям сайта: выбирать правильное расширение файлов, сжимать их вес без потери качества с помощью специальных инструментов, уменьшать слишком крупные по размеру фотографии в графическом редакторе или через панель управления сайтом.
Также будет полезно настроить сжатие текстов. Благодаря заголовку Content-Encoding, сервер будет уменьшать размер передаваемых данных, и контент будет загружаться в браузере быстрее. Также полезно оптимизировать объем страницы, используя архивирование GZIP.
Не оптимизированы элементы JavaScript и CSS
Код JavaScript и CSS отвечает за внешний сайта. С помощью стилей CSS (Cascading Style Sheets) задают фон, размер и цвета блоков страницы, шрифты текста. Сценарии на языке JavaScript делают дизайн сайта динамичным.
Элементы CSS/JS важны для ресурса, но в то же время они увеличивают общий объём страниц. Файлы CSS, превышающие по размеру 150 KB, а JavaScript — 2 MB, могут негативно влиять на скорость загрузки.
Как исправить
Чтобы уменьшить размер и вес кода CSS и JavaScript, используют такие технологии, как сжатие, кэширование, минификация. SEO-аудит помогает определить, влияют ли CSS/JS-файлы на скорость сайта и какие методы оптимизации использованы.
Кэширование CSS/JS-элементов снижает нагрузку на сервер, поскольку в этом случае браузер загружает сохранённые в кэше копии контента и не воспроизводит страницы с нуля. Минификация кода, то есть удаление из него ненужных символов и комментариев, уменьшает исходный размер. Ещё один способ оптимизации таблиц стилей и скриптов — объединение нескольких файлов CSS и JavaScript в один.
Отсутствие мобильной оптимизации
Когда сайт подходит только для больших экранов и не оптимизирован для смартфонов, у посетителей возникают проблемы с его использованием. Это негативно отражается на поведенческих факторах и, как следствие, позициях при ранжировании.
Шрифт может оказаться слишком мелким для чтения. Если элементы интерфейса размещены слишком близко друг к другу, нажать на кнопку и ссылку проще только после увеличения фрагмента экрана. Нередко загруженная на смартфоне страница выходит за пределы экрана, и для просмотра контента приходится использовать нижнюю прокрутку.
О проблемах с настройками мобильной версии говорит отсутствие метатега viewport, отвечающего за адаптивность страницы под экраны разного формата, или его неправильное заполнение. Также о нестабильности элементов страницы во время загрузки информирует еще показатель производительности сайта Core Web Vitals — CLS (Cumulative Layout Shift). Его норма: 0,1.
Как исправить
В качестве альтернативы отдельной версии для мобильных устройств можно создать сайт с адаптивным дизайном. В этом случае его внешний вид, компоновка и величина блоков будет зависеть от размера экрана конкретного пользователя.
Обратите внимание, чтобы в HTML-коде страниц были метатеги viewport. При этом значение device-width не должно быть фиксированным, чтобы ширина страницы адаптировалась под размер ПК, планшета, смартфона.
Отсутствие alt-текста к изображениям
В HTML-коде страницы за визуальный контент отвечают теги <img>. Кроме ссылки на сам файл, тег может содержать альтернативный текст с описанием изображения и ключевыми словами.
Если атрибут alt — пустой, поисковику сложнее определить тематику фото. В итоге сайт не сможет привлекать дополнительный трафик из раздела «Картинки», где поисковая система отображает релевантные запросу изображения. Также текст alt отображается вместо фото, когда браузер не может его загрузить. Это особенно актуально для пользователей голосовыми помощниками и программами для чтения экрана.
Как исправить
Пропишите альтернативный текст к изображениям сайта. Это можно сделать после установки SEO-плагина к CMS, после чего в настройках к изображениям появятся специальные поля. Рекомендуем заполнить атрибут alt, используя несколько слов. Добавление ключевых фраз допустимо, но не стоит перегружать описание ими.
Заключение
Технические ошибки негативно влияют как на восприятие сайта пользователями, так и на позиции его страниц при ранжировании. Чтобы оптимизировать ресурс с учётом рекомендаций поисковых систем, нужно сначала провести SEO-аудит и определить внутренние проблемы. С этой задачей справляются платформы, выполняющие комплексный анализ сайта.
К частым проблемам оптимизации можно отнести:
- имя сайта с HTTP вместо безопасного расширения HTTPS;
- отсутствие или неправильное содержимое файлов robots.txt и sitemap.xml;
- медленная загрузка страниц;
- некорректное отображение сайта на смартфонах;
- большой вес файлов HTML, CSS, JS;
- дублированный контент;
- страницы с кодом ошибки 4ХХ, 5ХХ;
- неправильно настроенные редиректы;
- изображения без alt-текста.
Если вовремя находить и исправлять проблемы технической оптимизации сайта, это поможет в продвижении — его страницы будут занимать и сохранять высокие позиции при ранжировании.
Рассказываю, как бесплатно проверить свой сайт на технические ошибки и получить подробные инструкции по их устранению.
Технические ошибки на сайте, слабая внутренняя оптимизация, плохое юзабилити, медленная загрузка могут сильно влиять на его позиции в поисковой выдаче. Это часто приводит к тому, что сайт никак не может подняться по целевым запросам и застревает где-то на последних страницах выдачи. Или, наоборот, висит на какой-нибудь одиннадцатой строчке и ему не хватает минимальной оптимизации, чтобы выйти на первую страницу.
Провести самостоятельно аудит и исправить ошибки, которые препятствуют продвижению, под силу далеко не каждому. Для этого приходится обращаться к сторонним специалистам или пользоваться специализированными сервисами. Об одном из таких сервисов онлайн проверки сайтов и пойдёт сегодня речь.
Сервис называется Sitechecker.pro. Добавьте сразу в закладки, чтобы не потерять.
Содержание
- Что такое Sitechecker, Sitechecker Crawler и в чем их отличие
- Sitechecker
- Sitechecker Crawler
- В заключение
Что такое Sitechecker, Sitechecker Crawler и в чем их отличие
Инструмент состоит из 2 частей.
- Sitechecker
Бесплатный SEO анализ сайта онлайн. - Sitechecker Crawler
Краулер сайтов для поиска и устранения технических SEO ошибок.
Такая комбинация помогает быстро выявлять проблемные страницы на сайтах, и точечно доводить их до идеала с технической точки зрения.
Sitechecker проверяет на технические ошибки одну конкретную страницу, а Sitechecker Crawler проверяет все страницы сайта. Данные по сайту внутри краулера дают возможность изучить значение конкретной страницы в масштабе всего сайта, оценить их связь между собой и увидеть ошибки.
Остановимся на каждом из них подробнее.
Sitechecker
Удобный анализ и мониторинг SEO параметров сайта.
Основные возможности Sitechecker
- Подробный аудит
Оценка 156-ти параметров сайта на одной странице - Подсказки «Как устранить»
Детальные пояснения по решению всех выявленных ошибок на сайте - Высокая скорость
Среднее время проверки сайта составляет 7 секунд - Абсолютно бесплатный
Бесплатное использование вне зависимости от количества проверок
Параметры проверки
Оптимизация контента
- Основные параметры (статус-код HTTP, размер)
- Title проверка
- Description проверка
- Google сниппет
- H1-H6 проверка (количество, длина, соответствие title, количество всех тегов)
- Проверка контента (длина контента, соотношение контента к коду)
Изображения
- Favicon
- Изображения
Поисковая оптимизация
- Проверка канонических ссылок
- Проверка альтернативных ссылок
- Пагинация (теги пагинаций)
- Индексирование поисковыми системами (мeta-теги, x-robots теги, robots.txt, noindex тег)
- Уязвимость URL (регистр символов, длина URL, произвольные параметры, переадресация протокола, скрытые ссылки, редирект c www, веб-страница 404, редирект c index)
- Проверка маскировки (Google, Yandex)
Внешние и внутренние ссылки
- Внешние ссылки
- Внутренняя перелинковка сайта
- Внутренние страницы
Скорость веб-страницы
- Мобильный предпросмотр
- Удобство работы (mobile)
- Удобство работы (desktop)
Результаты проверки выглядят примерно таким образом.

Как видно из отчета, оценка главной страницы моего сайта составила всего 47 из 100. Мне ещё есть над чем работать. И начать видимо придётся с двух критических ошибок: уменьшить длину заголовка H1 до рекомендованных 70 символов и оптимизировать изображения на десктопной версии сайта.
Для пользователей браузера Google Chrome есть приятный бонус в виде простого и эффективного расширения Sitechecker, которое в один клик запускает проверку любой страницы.
Установить расширение
Sitechecker Crawler
Проверка всех страниц сайта на технические SEO ошибки.
Основные возможности Sitechecker Crawler
- Удобная фильтрация и сортировка
Фильтрация страниц по отдельным техническим ошибкам - Все ошибки в одном месте
Проверяйте на ошибки все страницы сайта в одном месте - 7 минут на 1 сайт
Получите сообщение об окончании краулинга сайта всего через 7 минут - 1 000 URL для краулинга бесплатно
Проверьте 1 домен и 1 000 URL абсолютно бесплатно
Как пользоваться краулером
- Добавьте домен сайта в Sitechecker Crawler.
- По завершению краулинга на вашу электронную почту придёт уведомление.
- Проверьте полученные результаты. Определите самые опасные ошибки и исправьте их первыми.
- Уделите особое внимание ключевым страницам сайта.
Страница отчета работы краулера выглядит таким образом.

Как видим, краулер обошел ровно 1 000 страниц, доступных на бесплатном тарифе. Кликнув по All crawled URLs попадём в список этих страниц.

Можно посмотреть все страницы, которые отдают статус, отличный от 200.

Очень удобно, что основные мета теги всех страниц видны прямо в списке.

Можно проверить правильность заполнения анкоров с внутренних ссылок на ключевые страницы сайта, а также провести аудит исходящих ссылок.

Можно проверить распределение веса каждой страницы сайта по формуле Google PageRank, удалить из индекса ненужные страницы и оптимизировать внутреннюю перелинковку.
![]()
В общем, мне есть над чем поработать. Уверен, у вас тоже появится пища для размышлений.
В заключение
Безусловно, сервис будет полезен владельцам сайтов, вебмастерам, интернет-маркетологам и другим специалистам, чья деятельность так или иначе связана с настройкой, оптимизацией и продвижением интернет-ресурсов.
Огромным плюсом сервиса является наличие бесплатного тарифа, которого будет вполне достаточно для частного использования. Для коммерческого использования лучше подписаться на платные тарифы, разумеется. Они поддерживают до 100 активных сайтов со 100 000 страницами, возможностью экспорта в CSV и генерации отчетов в PDF. В скором времени должны появиться брендированные PDF отчеты.
- Когда проводить технический аудит сайта
- Какие инструменты использовать
- Что нужно проверять
Когда нужно проводить технический аудит, с какой периодичностью
Технический аудит сайта обязательно проводится перед запуском проекта, после редизайна, переезда, изменения структуры, а также не реже одного раза в один-два месяца (зависит от размера ресурса).
Какие инструменты использовать
Для проведения технического аудита вам понадобятся:
- Яндекс.Вебмастер
C помощью сервиса Яндекс.Вебмастер можно узнать:
— какие страницы проиндексированы и участвуют в поиске, а какие – отдают ошибки;
— информацию о добавленных или удалённых страницах;
— о вирусах и вредоносном коде, наложенных фильтрах;
— скорость загрузки страниц;
— настройки региональности сайта;
— файл robots.txt;
— файлы Sitemap и т. д.
Подробная инструкция по работе с Яндекс.Вебмастером.
- Search Console от Google
C помощью сервиса Google Search Console можно проверить:
— нет ли на сайте внутренних дублей или дублирования заголовков и метаописаний;
— применённые к сайту фильтры;
— ошибки внутри сайта, связанные с недоступностью страниц;
— информацию о поисковой видимости и посещаемости сайта;
— внешние ссылки: общее количество ссылок, какие сайты и страницы ссылаются на вас, на какие страницы вашего сайта ведут ссылки, какие анкоры (тексты) у ссылок;
— как распределяются внутренние ссылки сайта;
— удобство просмотра на мобильных устройствах;
— заблокированные ресурсы;
— ошибки сканирования;
— файл robots.txt;
— файлы Sitemap.
Подробная инструкция по работе с Search Console от Google.
- Парсер
С помощью парсера можно проанализировать техническую составляющую сайта. Программа позволяет выявить множество технических ошибок: битые ссылки, дубли Title, Description и заголовков H, неисправные редиректы, уровень вложенности и т. д.
Есть платные (ComparseR, Netpeak Spider, Screaming Frog и др.) и бесплатные (WildShark SEO Spider, Xenu, Majento SiteAnalayzer 1.4.4.91 и т. д.) программы. Они помогут выявить и устранить технические ошибки, которые мешают продвижению.
Подробный обзор наиболее популярных парсеров в нашем блоге – «Обзор ТОП-6 парсеров сайтов».
Что нужно проверять
Код ответа сервера
При проверке кода ответа сервера убедитесь, что:
— Для склеивания страниц на сайте используется 301 редирект вместо 302.
— Все несуществующие страницы отдают 404 код ответа сервера. Также проверьте, настроена ли страница 404 ошибки. Для этого введите любую несуществующую страницу на сайте и посмотрите, что будет видеть пользователь: понятно ли, что это страница ошибки, есть ли ссылки на другие разделы сайта, логотип и т. д. О том, как оформить страницу 404, подробно описано в статье «Error 404 — что значит, как найти и исправить ошибку».
— Все существующие и нужные страницы отдают 200 ОК.
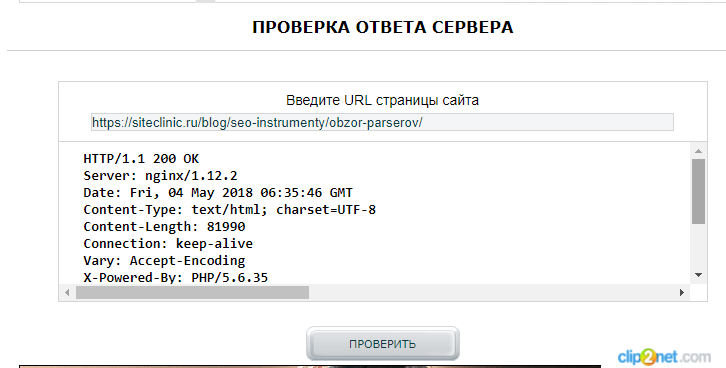
Код ответа сервера можно проверить с помощью онлайн-сервиса Mainspy.ru.
Для проверки нужно ввести URL страницы и нажать на кнопку «Проверить».
Рисунок 1
Также можно использовать Яндекс.Вебмастер или расширения для браузеров:
Live HTTP Headers – для Firefox;
HTTP Headers – для Chrome.
С их помощью можно в один клик получить информацию по отдельным страницам.
Битые ссылки
Чаще всего причиной появления битых ссылок становится удаление старых ненужных страниц и файлов или изменения в структуре сайта.
Для проверки сайта на наличие внутренних и внешних битых ссылок можно использовать:
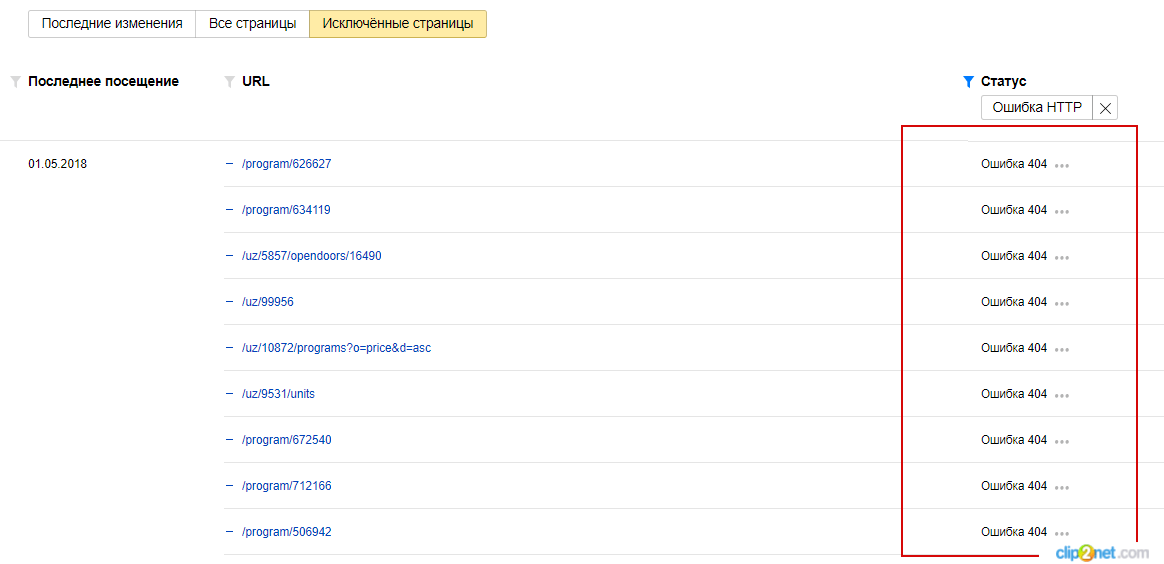
— Яндекс.Вебмастер;
Для этого перейдите в «Индексирование» → «Страницы в поиске» → «Исключенные страницы» → «Ошибка 404»:
Рисунок 2
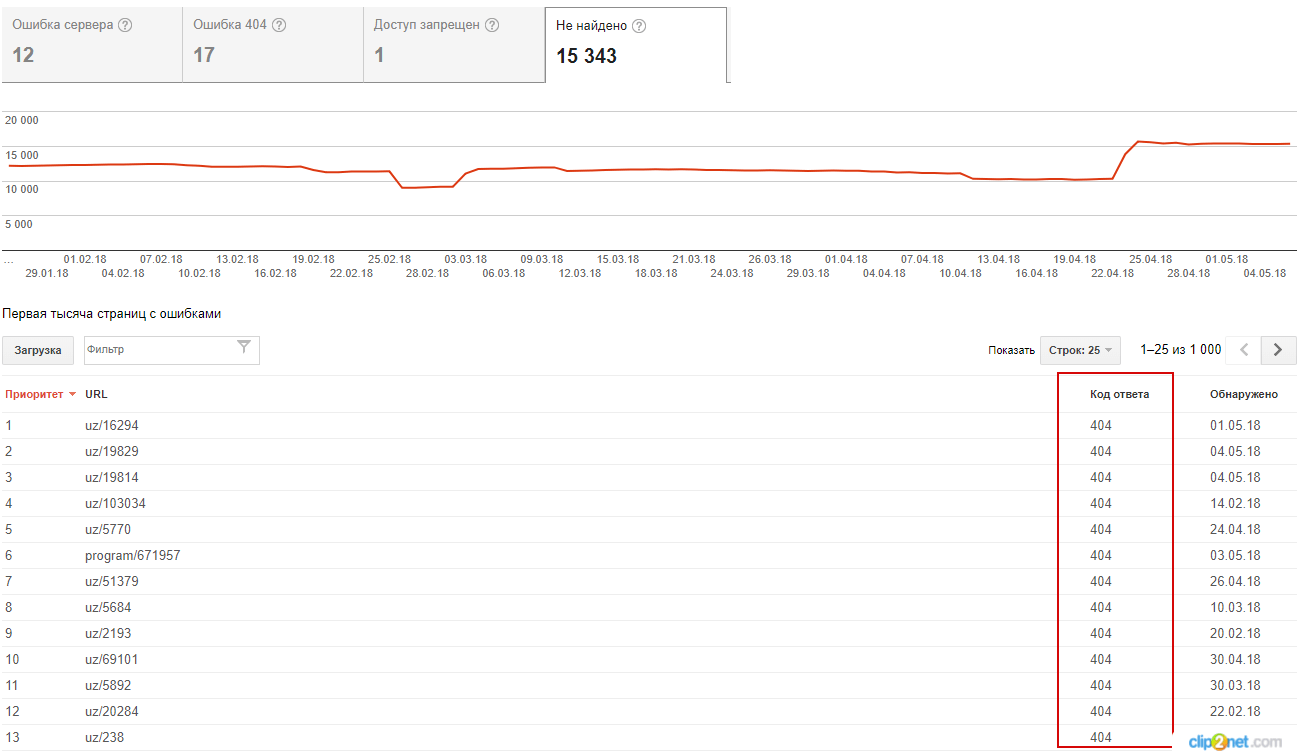
— Search Console;
Зайдите в Search Console → «Сканирование» → «Ошибки сканирования» → «Ошибка 404»:
Рисунок 3
— бесплатные программы WildShark SEO Spider, Xenu, Majento SiteAnalayzer 1.4.4.
Подробная инструкция о том, как найти битые ссылки с помощью инструментов.
После того как будут найдены битые ссылки, определите, что делать с каждой из них:
- Если страница по ссылке была перемещена, настройте 301 редирект.
- Если целевая страница внутренней ссылки удалена, удалите ссылку или заполните несуществующую страницу контентом и т. д.
Корректная настройка зеркал сайта
Чаще всего зеркало сайта возникает из-за www-префикса. Также бывают случаи, когда при переезде на другой домен забывают настроить 301-й редирект.
Убедитесь, что у сайта одно главное зеркало. Для этого надо проверить:
— настроен ли 301-й редирект с дубликатов на основной сайт;
— правильно ли указан основной домен в панелях Google Search Console, Яндекс.Вебмастере и файле robots.txt.
Внутренние дубли
Проверьте, нет ли на сайте дублей. Внутренние дубли могут привести к ухудшению индексации сайта, смене релевантной страницы в выдаче и понижению позиций.
Часто встречаются внутренние дубли, когда:
- страница доступна с www и без, со слешем и без (site.ru/ и site.ru), с index.html и без;
- страницы генерируются с результатов выбора фильтров, сравнения и сортировки товаров;
- CMS автоматически создаёт дубликаты;
- индексируется корзина товаров;
- один и тот же товар размещён в нескольких категориях и доступен по разным URL и т. д.
Основные методы поиска дублей на сайте
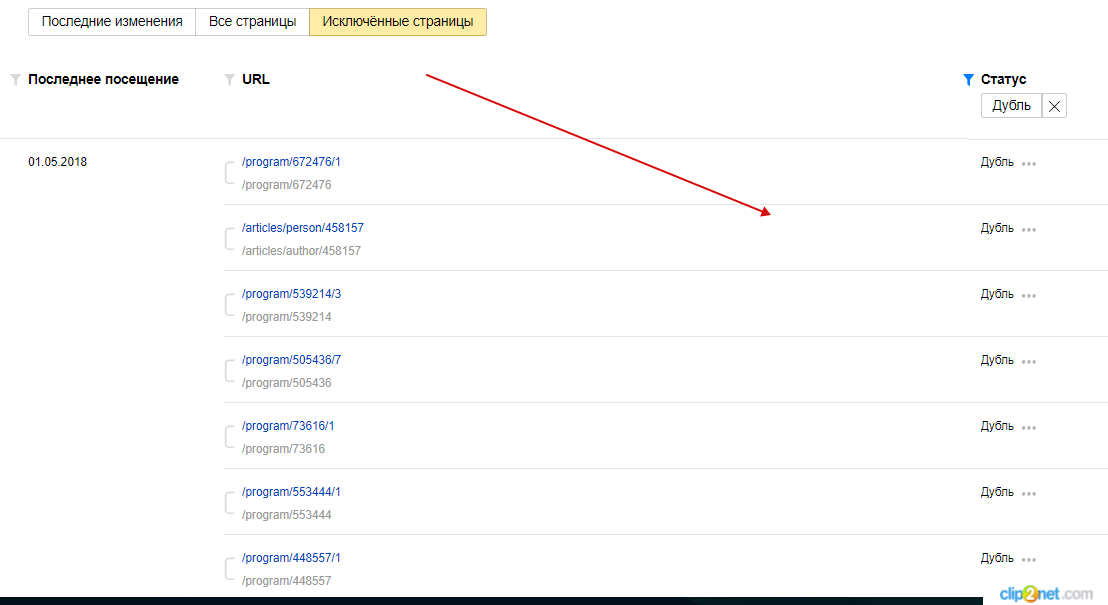
1. Яндекс.Вебмастер
Зайдите в Яндекс.Вебмастер → «Индексирование» → «Страницы в поиске» → «Исключенные страницы», выберите статус «Дубль».
Рисунок 4
2. Панели вебмастеров Google
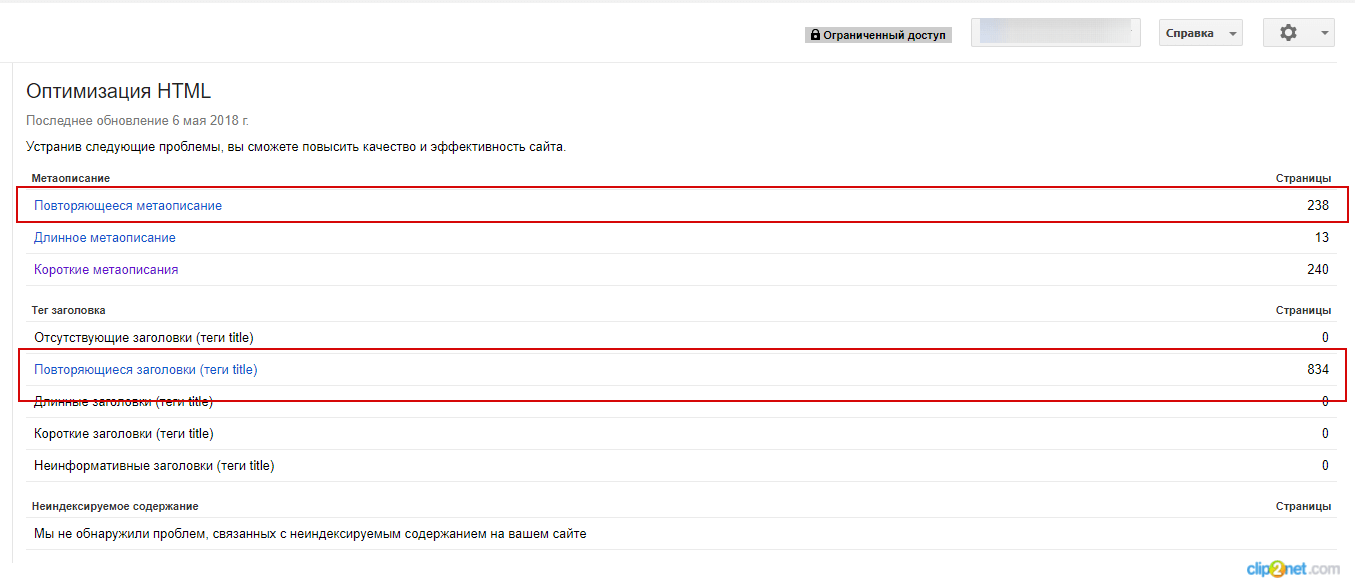
Зайдите в Search Console → «Оптимизация» → «Оптимизация HTML». На этой странице можно увидеть количество повторяющихся метатегов и заголовков Title.
Так можно найти полные дубли страниц:
Рисунок 5
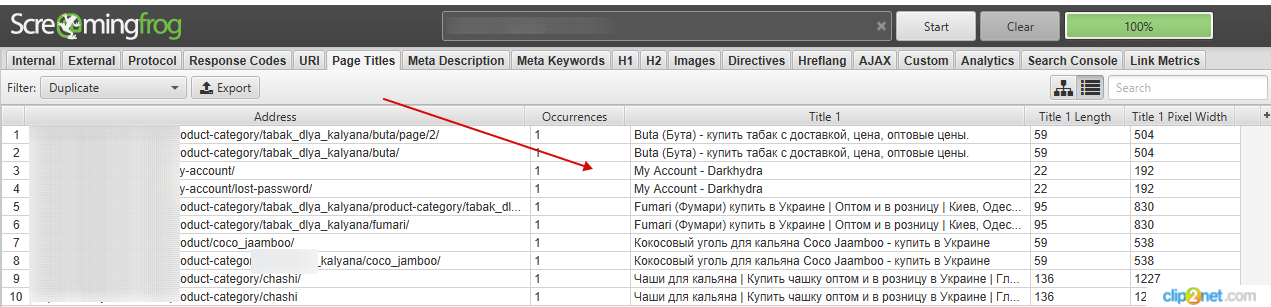
3. Парсер
Для поиска дублей можно воспользоваться одним из популярных парсеров. Например: WildShark SEO Spider, Xenu, Majento SiteAnalayzer 1.4.4.91, SEO Spider и т. д.
Для этого просканируйте сайт, отсортируйте результаты по заголовку и ищите визуальные совпадения заголовков.
Рисунок 6
Подробная инструкция по теме: «Дубли страниц. Чем опасны? Как найти и удалить?»
Скорость загрузки сайта
Проверьте скорость загрузки сайта. Исходя из собственной практики и рекомендаций поисковых систем, мы можем определить следующие требования:
— Время до первого байта (TTFB): до 300 мс. Google в своей справке рекомендует 200 мс, но на практике загрузка и 300 мс. не всегда возможна.
— Время загрузки страницы: 3–5 с.
— Время рендеринга: до 1,5 с.
Нужно отметить, что на ранжирование, прежде всего, влияет время ответа сервера (получение первого байта).
Если ваше значение выше, постарайтесь ускорить загрузку сайта.
Сервисы проверки скорости загрузки:
— WebPageTest;
— Pingdom Website Speed Test.
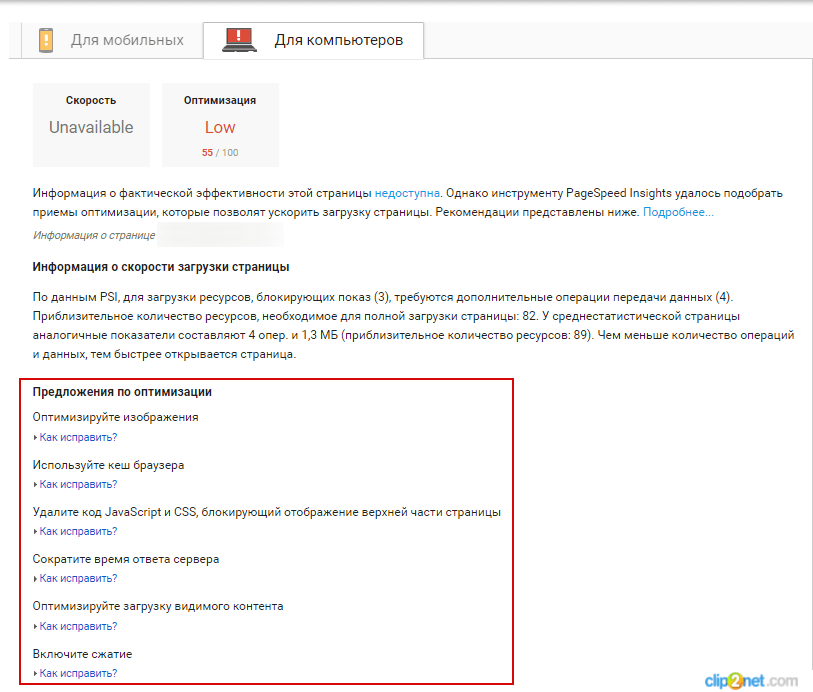
Увидеть, есть ли недочёты, можно с помощью сервиса Google PageSpeed
Рисунок 7
Подробнее узнать, как оптимизировать скорость загрузки сайта, можно здесь.
Наличие корректно настроенного файла robots.txt
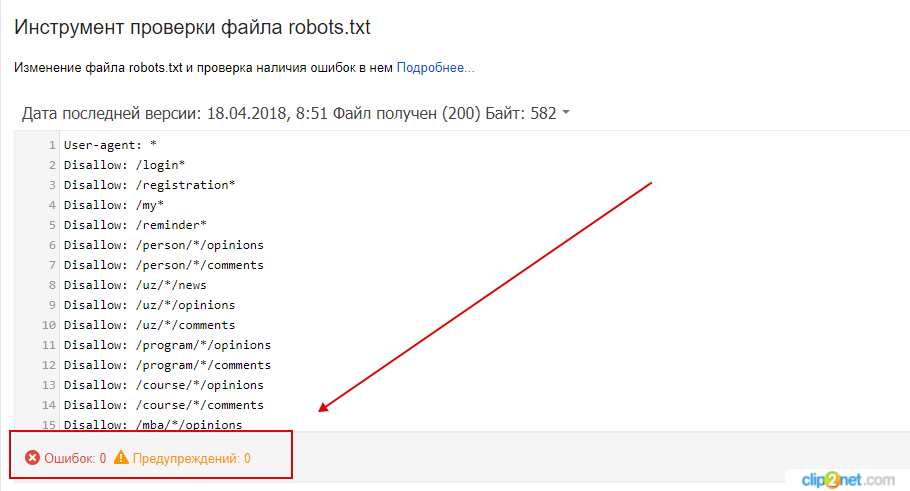
Проверьте, заполнен ли robots.txt в соответствии с правилами, не допущены ли при его создании ошибки.
Перечень ошибок, возникающих при анализе robots.txt, можно посмотреть в Яндекс.Помощь.
Проверить файл можно с помощью сервисов:
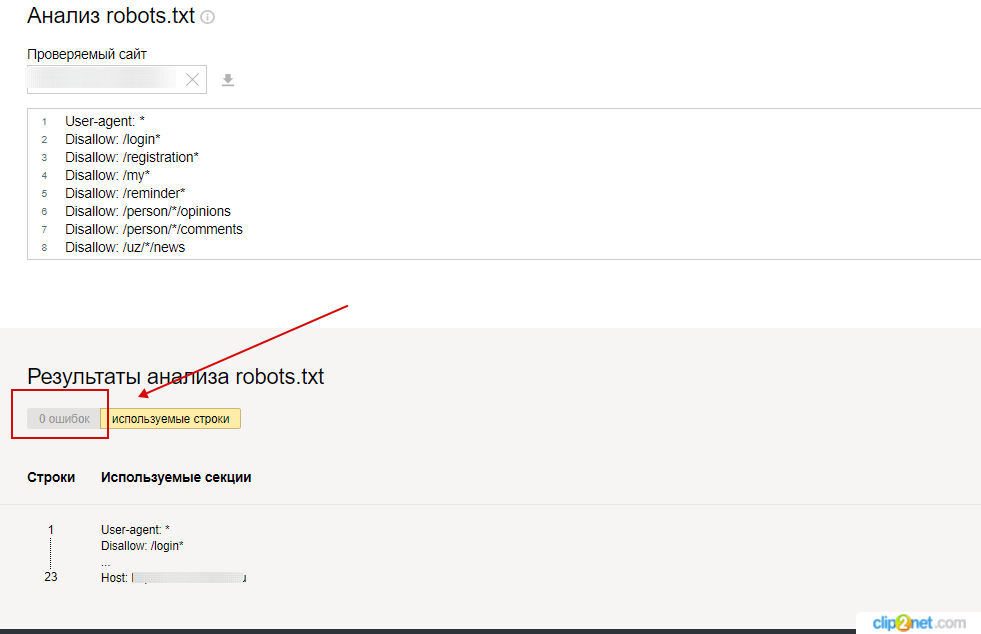
— Яндекс.Вебмастер
Яндекс.Вебмастер → «Анализ robots.txt».
Рисунок 8
— Google Search Console
Рисунок 9
Гайд по robots.txt: как создать, настроить и проверить.
Sitemap
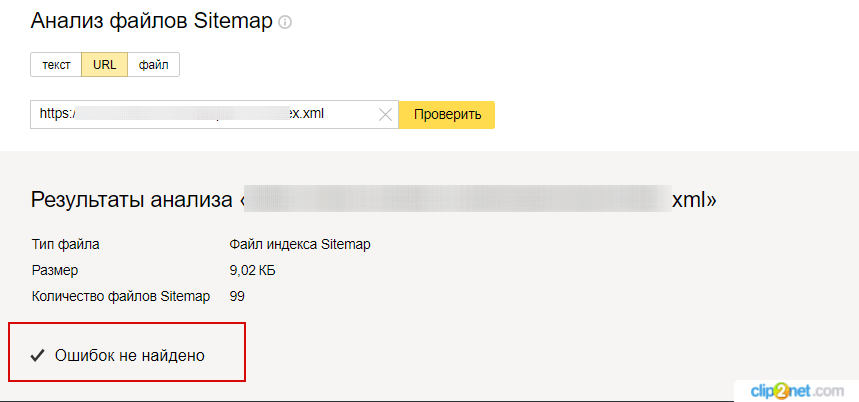
Убедитесь, что на сайте создана карта в формате XML (Sitemap) и добавлена в панель инструментов для вебмастеров Google и Яндекса.
Проверьте, не допущены ли в ней ошибки. Сделать это можно с помощью специальных инструментов поисковых систем Яндекс и Google.
Яндекс.Вебмастер → «Инструменты» → «Анализ файлов Sitemap»
Рисунок 10
Зайдите в Search Console → «Сканирование» → «Ошибки сканирования» → «файлы Sitemap»
Рисунок 11
Недостаточно качественные страницы
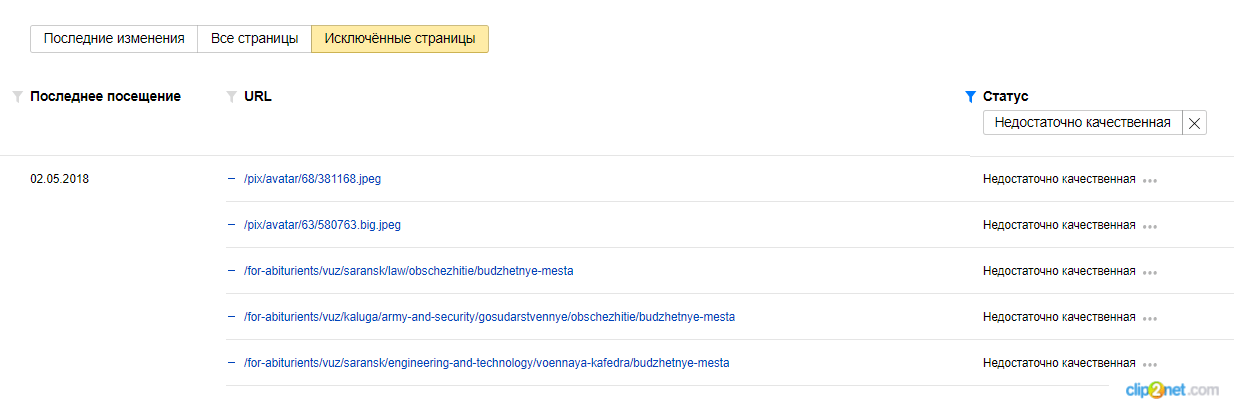
Убедитесь, что на сайте нет удалённых низкокачественных страниц. Найти исключённые страницы можно с помощью Яндекс.Вебмастера и Google Search Console.
Яндекс.Вебмастер
Переходим в раздел «Индексирование» → «Страницы в поиске» → «Исключенные страницы», выбираем фильтр «Недостаточно качественные».
Рисунок 12
Google Search Console
Сигналом от Google о том, какие страницы были удалены из поиска из-за качества, можно считать «Отправленный URL возвращает ложную ошибку 404». В таких случаях нужно проанализировать страницы, убедиться, что они существуют, а не удалены (и просто ответ сервера некорректен).
Подробнее о мягкой 404 можно прочитать в нашем блоге.
Подробнее о страницах низкого качества написано в этой статье «Страницы низкого качества или как понять, что твой сайт “не очень”»
Адаптивный дизайн сайта
Доля мобильного трафика постоянно растёт, поэтому важно проверить адаптивность сайта под мобильные устройства.
Для проверки можно использовать:
— PageSpeed Insights
Инструмент позволяет проверить скорость загрузки страниц и даёт рекомендации, как эту скорость повысить.
Рисунок 13
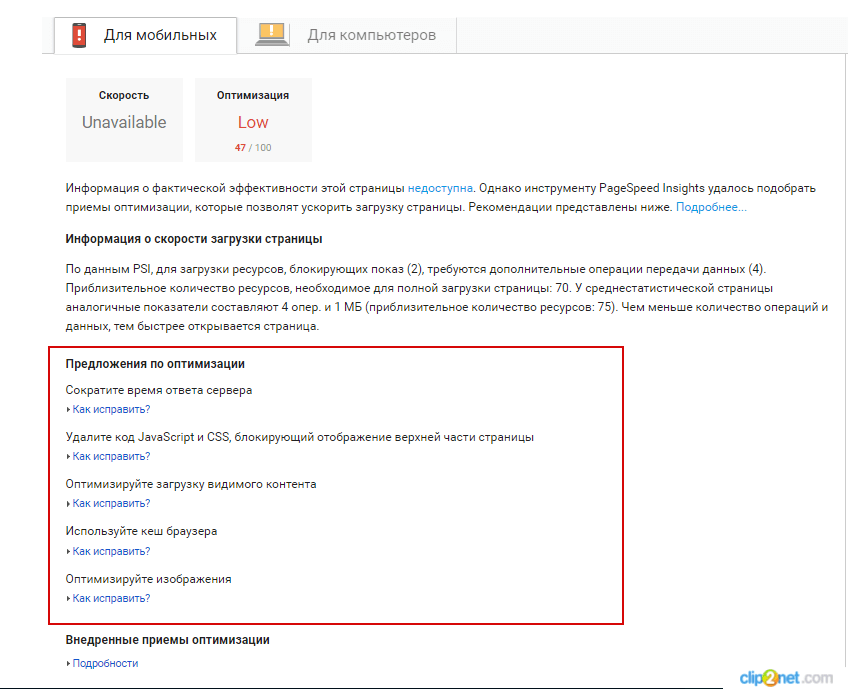
— Mobile-Friendly Test от Google.
Инструмент позволяет проанализировать, как выглядит сайт на смартфоне, скорость загрузки и отображения информации.
Рисунок 14
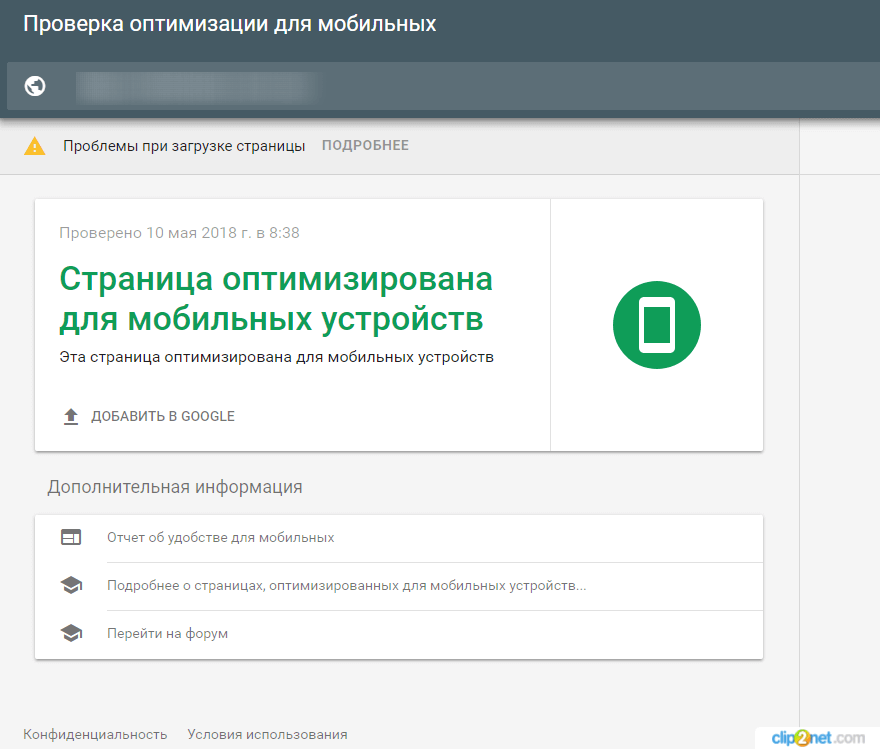
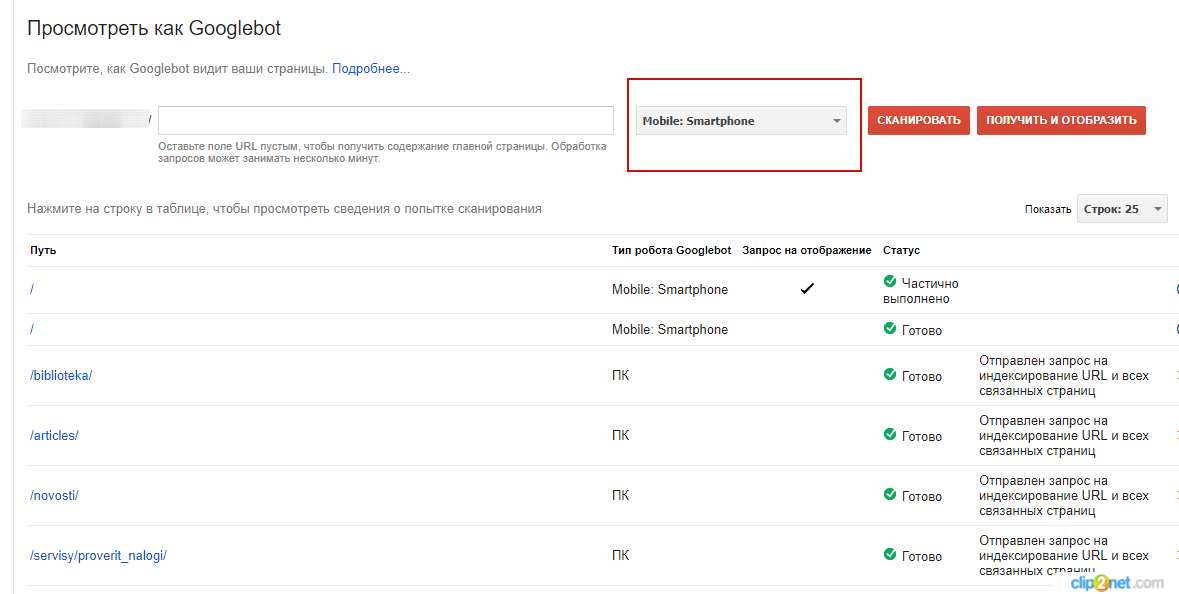
— Посмотреть как Googlebot (в панели Google Search Console).
Инструмент позволяет проанализировать отображение сайта на разных устройствах.
Рисунок 15
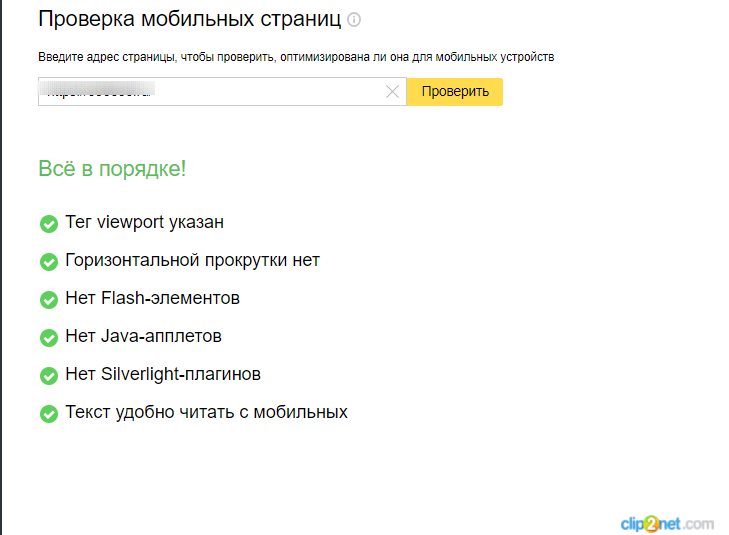
— Яндекс.Вебмастер → «Инструменты» → «Проверка мобильных страниц».
Инструмент позволяет проверить сайт на мобилопригодность.
Рисунок 16
О том, как влияет адаптивность сайта на ранжирование в ПС, как проверить и оптимизировать сайт под мобильные устройства, подробно описано в статье «Мобильная адаптация сайта – ответы на вопросы».
Заключение
В этой статье перечислены основные инструменты, которые понадобятся для проведения технического аудит сайта, и основные базовые параметры, которые нужно анализировать. Если вы не уверены в своих силах и знаниях, мы можем провести технический аудит вашего сайта и написать инструкции по решению проблемы.
Заказать технический аудит
Еще по теме:
- Вы не любите Joomla!? Вы просто не умеете ее готовить
- SEO чек-лист: что проверять перед запуском сайта?
- Как оптимизировать страницы пагинации на сайте
- Пример ТЗ на разработку сайта: универсальные пункты и образец составления
- Обзор CMS: PrestaShop – преимущества и недостатки
Продолжим серию обзоров популярных CMS и поговорим о Joomla: в чем её преимущества и с чем вам придется познакомиться, работая с этой CMS. Мы постарались…
1. Что проверить перед запуском сайта 1.1. Основные моменты 1.2. Технические аспекты 2. За чем следить после запуска сайта 2.1. Поведенческие факторы 2.2. Наличие фильтров…
Настройка SEO пагинации Рекомендации поисковиков Актуальные способы настройки пагинации Настройка каноникала на первую страницу Настройка каноникала каждой из страниц на себя Оптимизация каждой страницы пагинации…
Что такое тз для сайта и зачем оно нужно Кто составляет задание на создание сайта Как написать хорошее ТЗ Пример оформления технического задания для сайта…
Проводя внутреннюю оптимизацию для наших клиентов, мы сталкиваемся с различными CMS и в результате работы составляем свое мнение о достоинствах и недостатках той или иной…

SEO-аналитик
Оптимизирую сайты с 2009 года. Люблю сложные кейсы, которые оказались не по зубам специалистам с других компаний. Делаю очень подробные аудиты.
Пишу статьи-инструкции на блог SiteClinic по SEO-инструментам и аналитике.
Любимая цитата: Чтобы добиться успеха, надо искренне любить то, чем вы занимаетесь.
Есть вопросы?
Задайте их прямо сейчас, и мы ответим в течение 8 рабочих часов.
Визуальные проблемы сайта
Сейчас Chrome-браузеры безусловно доминируют у пользователей (включая даже браузер Opera, который использует движок Chrome), поэтому проверка работы сайта в Chrome — это первое, что нужно сделать. Для проверки отображения сайта (или страниц сайта) в других браузерах можно воспользоваться Browser Shots — и задать самые последние версии популярных (пока еще) браузеров — Mozilla Firefox, Internet Explorer или Safari.
Для проверки отображения сайта на мобильных устройствах можно воспользоваться либо проверкой WebPageTest — нужно выбрать мобильный браузер для проверки скорости, будет снят скриншот сайта по итогам проверки. Для более детальной проверки можно воспользоваться Cross Browser Testing.
По скриншотам сайта практически всегда видно, есть ли какие-то проблемы с отображением или версткой. И что нужно поправить (где что «разъехалось»).
Другим подходом по исправлению ошибок сайта является приведение страниц сайта к стандартам. Основных стандартов, отвечающих за визуальную составляющую сайтов, три — HTML, CSS, WCAG (последний отвечает за удобство использования сайта). К сожалению, кроссбраузерная верстка на текущий момент, практически, исключает соответствие стандарту CSS. Но соответствие стандартам HTML и WCAG полезно как для текущей работы сайта (исправляет ряд пользовательских и технических проблем).
Стандарт HTML проверяется известным образом: через сервис validator.w3.org. Стандарт WCAG — через менее известные сервисы (например, AChecker). Все эти сервисы выдают конкретный набор технических ошибок сайта, которые нужно исправлять.
Проблемы скорости сайта
Медленная работа сайта напрямую к техническим ошибкам не относится, но для качественного и эффективного сайта его быстрая работа — неотъемлемая часть. Для получения конкретного списка ошибок и их исправления (на начальном этапе) отлично подойдет сервис Google PageSpeed Insights(исправление ошибок до оценки 90, после этого ошибки перестают быть релевантными реальным проблемам скорости).
Если «тормоза» сайта связаны с сервером, то при исправлении ошибок серверной части (о них дальше) вы автоматически решите значительную часть проблем скорости на стороне сервера.
Более глубокая диагностика скорости сайта может быть выполнена с помощью сервиса Айри.рф или WebPageTest.
Ненайденные ресурсы
Это значительный блок технических ошибок сайта, влияющий на все показатели: удобство использования, поисковое продвижение, конверсия. Ненайденные ресурсы сайта разделяются на три большие группы: «битые» ссылки (которые находятся поисковыми роботами или пользователями), ошибки разработки (когда отсутствуют какие-либо необходимые для просмотра сайта ресурсы) и структурные ошибки (которые могут быть не найдены поисковиками и пользователями, но рано или поздно «всплывут» на сайте, потому что заложены в структуру — например, «битая» ссылка в динамическом меню или внутренние редиректы).
Для сбора проблем первой группы — «битых» ссылок — отлично подойдут отчеты Google Webmasters или Яндекс.Вебмастер. Конечно, желательно устранить все ошибки сайта до того, как их нашли поисковые роботы (чтобы не терять в эффективности продвижения), но если проблемы нашли, то их нужно срочно устранять. Вторая группа получается из анализа логов посещаемости сайта (access.log), для этого нужно получить логи сайта в хостинга и воспользоваться любым анализатором (например, AWStats), либо доступна из панели хостинг-провайдера или облачного сервиса. Третья группа достоверно может быть получена только ручной проверкой сайта, но также хорошо подходят программы или сервисы для сканирования сайта (например, Xenu): в этом случае будут обнаружены и некоторые проблемы из первой и второй групп.
Работа с ненайденными ресурсами для каждого сайта индивидуальна, но ее тоже можно разбить на несколько больших групп:
- Работа с ошибками разработки. Часть таких ошибок может быть связано с отсутствием иконок сайта (apple-touch-icon.png, apple-touch-icon-precomposed.png, browserconfig.xml и др), для их исправления есть подробное руководство (нужно подготовить все необходимые файлы для сайта и залить на хостинг). Другая часть ошибок — с реальными «косяками» при сборке сайта (отсутствие фоновых изображений для элементов управления, отсутствие JavaScript-библиотек или файлов стилей, которые используются сторонними модулями).Нужно тщательно посмотреть, откуда вызывается «битый» ресурс — и либо положить его на хостинг в нужное место, либо удалить его вызов из требуемого файла. Также возможны ошибки с неверным автоматическим наименованием изображений или ресурсных файлов. Естественно, это все технические ошибки сайта, и все их нужно устранять.
- Работа с «битыми» ссылками. Если устранить ошибки, связанные с «битыми» ресурсами, то останутся ошибки, относящиеся к страницам сайта. Самые очевидные из них — проблемы, найденные поисковыми роботами или реальными пользователями при посещении сайта. Все такие «битые» ссылки (404 ошибки из панели Google, Яндекс или обнаруженные при проверке сайта или по логам) нужно просмотреть, а затем поставить каждой «битой» ссылке в соответствие правильную страницу. Для поисковиков это позволит учесть вес «битой» страницы, а для пользователей — получить правильную страницу вместо ненайденной.Далее нужно взять весь список страниц «неправильная — правильная» и сформировать правила редиректов (через .htaccess, конфигурацию nginx или инструментами системы управления сайтом).Полное руководство, как настроить редиректы, можно найти здесь.
- Структурные ошибки. Более редкие проблемы, — например, ошибки пагинации или разделов меню — исправляются уже за счет доработок шаблонов сайта, внутренних модулей или настроек. Сюда же можно отнести проблемы с внутренними редиректами (раздел сайта «переехал», но остались в структуре сайта ссылки на старый раздел, и используются они вместо новых ссылок) и протоколами (ресурсы вызываются по
http://, но идет редирект наhttps://— правильнее вызывать сразу по https).
Уменьшение количества 404 ошибок на сайте положительно и скажется на нагрузке на хостинг: такие страницы обычно не кэшируются, и иногда система управления сайтом пытается найти подходящую страницу взамен ненайденной, чем существенно использует вычислительные ресурсы.
Серверные проблемы
Серверные ошибки встречаются на порядок реже 404 ошибок, и исправляются обычно очень оперативно. Но работа по качеству сайта обязательно должна включать анализ и исправление серверных ошибок независимо от их количества. Серверные ошибки также можно разделить на несколько групп, каждая из которых подразумевает свою методику исправления. Сбор серверных ошибок затруднен (обычно поисковые роботы их не видят, а ручная проверка сайта затруднена, или характер ошибок случайный), для этой цели хорошо подойдет только анализ серверных логов (AWStats) или специальные функции хостинга или облака.
Ошибки размещения
Сейчас почти не встречаются, но при некорректной настройке хостинга (или смене настроек) некоторые адреса на сайте (или сайт целиком) могут выдавать ошибки 403 или 500. 403 ошибка — ошибка доступа — возникает при неправильных правах доступа к сайту, и права эти нужно исправить (с деталями может помочь техническая поддержка хостинга). 500 ошибка часто возникает при неверном формате файла .htaccess на хостинге (после его модификации).
Серверные ошибки
Более серьезными являются серверные ошибки (HTTP коды 502, 503, 504, подробнее о HTTP кодах), они напрямую влияют на качество веб-сайта и возможность его исправной работы. Код 502 говорит, чаще всего, об ошибке в веб-приложении (скрипте), 503 — о слишком большой нагрузке на хостинг (он не справляется с входящим потоком запросов), а 504 — о превышении времени обработки скриптов (может быть связана как с ошибкой в скриптах, так и большой нагрузкой на хостинг или недостаточными ресурсами вашего хостинга).
Каждая серверная ошибка — это «потерянный» пользователь. Если 404 ошибки, в большинстве случаев, не ведут к обнулению конверсии, то указанные серверные ошибки ведут. Исправление серверных ошибок находится полностью в зоне ведения вашей команды веб-разработки. Количество серверных ошибок (и детальную информацию по ним) можно узнать только из логов хостинга (error.log), в анализе и исправлении помогут специальные инструменты (и отладочная информация).
Серверные отказы
Достаточно новый тип ошибок (ранее они не фиксировались) появился с широким распространением nginx (который записывает их в логи). Серверный отказ (код ошибки 499) возникает при обрыве соединения на стороне пользователя (браузера) при получении какого-либо ресурса сайта. Существует два источника таких ошибок: большое время ожидания на стороне хостинга (хостинг не отвечает на запросы, и пользователь закрыл страницу) и медленная передача данных пользователю (плохая связность интернет-каналов хостинга или плохая связь у конечного пользователя).
В первом случае необходимо проверить, чтобы запросы на стороне хостинга обрабатывались достаточно быстро (рекомендуемое время обработки запроса не более 500 мс). Во втором случае при большом количестве отказов имеет смысл задуматься о смене хостинга или применении CDN для сайта (чтобы «приблизить» сайт к посетителям).
JavaScript-ошибки
И финальная часть — ошибки клиентских скриптов. Обычно о них вспоминают в последнюю очередь при работе по качеству сайта (считая, что если сайт работает, то никаких критичных на нем нет). К сожалению, достаточно часто JavaScript-ошибки блокируют нормальное поведение сайта для пользователя (а иногда — даже ключевые функции типа оформления заказа). И оперативное устранение таких ошибок, в прямом смысле, спасает конверсию.
Как отследить JavaScript-ошибки? Существует некоторое количество интернет-сервисов по сбору JavaScript-ошибок с сайта (например, Track.js или Айри.рф), а также возможность сбора информации из браузеров прямо на сайт (в базу данных) — JSNLog. Каждый инструмент позволяет получить полный список ошибок и максимальное описание окружения для их воспроизведения. Дальше — дело за малым: передать список разработчикам сайта (или ответственным за клиентскую часть) с обязательным исправлением.
Список перечисленных технических проблем сайта охватывает все основные области — внешний вид, функционал, структура, серверную часть, а сбор и анализ проблем может быть существенно автоматизирован (в отличие от ручного тестирования). Это руководство поможет сделать ваши сайты еще лучше, еще качественнее и еще надежнее.
Автор: Мария Питерская, Айри.рф (Коммерческий директор)
Стандартные методики технического аудита могут давать искаженные и неполные данные. Чтобы получить полную картину, нужно пройти путями робота. На что смотреть в процессе – рассмотрим в этой статье.
Подавляющая часть статьи основана на информации о функционировании гуглобота: его действия намного лучше документированы и описаны в справочных материалах. Гуглобот более последователен, зависим от правил и спецификаций, и технические проблемы влияют на его поведение намного сильнее, чем на яндексбота. Кроме того, его проще эмулировать – для этого есть полноценные средства в большинстве специализированных парсеров и даже в браузерах.
Каждый первый кейс по SEO утверждает: «Мы исправили технические ошибки сайта, и получили рост в 29 раз…». А дальше перечисляются «попугаи» Google Speed Insight и ещё какая-то ерунда, не способная повлиять ровным счётом ни на что.
А что может?
Практика последнего года показывает, что подход к техническим аудитам надо корректировать с учетом следующих фактов:
- Обе ПС практически избавились от проблем с обработкой JS в общем смысле. Но в результате растёт количество проблем с ошибками этой обработки;
- Сайты стали сложнее: когда сайт фактически раскидан по нескольким хостам, это осложняет процессы и способно подкинуть нетривиальные задачки, которые нельзя выловить стандартными средствами;
- Проблемы с поведенческими ботами привели к тому, что вебмастера стали интенсивно внедрять способы защиты от роботов. Не каждый способ разумен, и почти каждый сам по себе может создавать проблемы;
- Интеграция сторонних сервисов и систем аналитики также может стать причиной появления странных багов.
Технические ошибки, возникающие как следствие описанных выше явления, можно разделить на несколько базовых категорий:
- То, что не даёт роботу полноценно просканировать странички
- То, что мешает выстроить общую структуру сайта
- Возросшие требования к ресурсам, необходимым для полноценного функционирования сайта
- Расход лимитов на обход сайта поисковыми роботами впустую
Все эти ошибки могут стать причиной того, что в поисковую выдачу не попадёт важный контент. Кроме того, поисковая система может решить, что у вас слишком проблемный сайт, на который не стоит приводить посетителей. Представители Гугл примерно в таком духе и выражались: если на сайте есть пяток качественных страниц, а всё остальное – невнятный мусор, то как-то странно вести туда посетителя. Ткнёт он по ссылке на хорошей странице и попадёт на некачественную. Всем будет неловко.
А теперь рассмотрим последовательность действий при аудитах.
Инструментарий
Вам в любом случае понадобится хороший парсер, предназначенный для решения задач SEO. Классика – это Screaming Frog SEO Spider (платный) или SiteAnalyzer (всё ещё бесплатный). Есть и другие решения, выбирайте на свой вкус. Главное – чтобы парсер мог полноценно сканировать сайт по правилам выбранного поискового бота в максимально полном объёме. Без предварительного парсинга всего сайта целиком можно пропустить множество неявных ошибок, приводящим к выпадению из доступа целых разделов сайта, оценке связей между отдельными страницами и разделами и т.п.
Если нет времени на серьёзное сканирование (или нет инструментария), можно обойтись использованием браузера Chrome, браузерного расширения View Rendered Source, сторонними сервисами типа bertal.ru, плюс специализированные редакторы типа WinMerge или Diff Checker, с помощью которых можно обнаружить разницу между двумя текстами.
База: проблемы сканирования
Заряжаем парсер, настраивая его так, чтобы он последовательно обошёл и сохранил всё, что имеет прямое отношение к полноценному функционированию сайта. Вам это понадобится для сравнения версий, выявления дублированного контента, оценке внутренней перелинковки, но главное – некоторой статистики по доступности страниц. Обязательное условие: выбрать правила обхода поискового робота.
Это достаточно тонкий момент: если вы пробежались по сайту, получив код 200 от основных посадочных страниц – это вовсе не значит, что при следующем сканировании вы получите такой же результат. Если какая-то часть объёма сайта стабильно отдаёт нечто невнятное, а то и вовсе не отвечает – это проблема, и вы должны иметь хоть какое-то представление о её динамике за период.
Кроме того, парсер – это всего лишь эмуляция реальных поисковых роботов, обращающаяся с вашего IP, с вашими настройками. То, что вы получили 200, вовсе не означает, что такой же ответ получит поисковый робот, обходящий сайт по своим правилам и со своими ограничениями.
На этом этапе мы проверяем доступность основных ресурсов сайта в общем, вне зависимости от случайностей. Не очень важно, кто именно не может добраться до контента целевой странички: робот, посетитель сайта или оба. Результат будет одинаковым: вместо посещаемой и конвертирующей посадочной страницы вы получите мёртвый узел сайта. «Суслика видишь? – А он есть». Вот как этот суслик.
Проблемы здесь практически всегда упираются в одно и то же:
- Ошибки перелинковки на уровне CMS. Например, категория у вас есть, а входных ссылок на неё – нет
- Ошибки настроек сканирования
- Общие ошибки структурирования сайта
Банально: вот у вас создана товарная категория, но на неё не предусмотрены внутренние ссылки, они есть разве что в карте сайта sitemap.xml. В таком случае есть шанс, что страничка получит видимость в поиске, и даже получит трафик оттуда. Рассчитывать на такое можно, но не нужно. Убедитесь, что раздел доступен из меню или листингов, и человек может туда зайти. Люди не смотрят sitemap.xml, туда заходят только роботы – а сайт вы делали для людей.
На эту тему есть множество подробных материалов, рассказывающих в подробностях о настройках robots.txt, канонических адресах и т.п., поэтому углубляться в эти вопросы не будем.
Проверяем доступность URL
Оцениваем ответы сервера. Собственно, общую картину по ответам мы уже получили при общем парсинге сайта. Однако оценить ответы можно и без скачивания сайта, выборочно. Для этого достаточно использовать сторонние сервисы или браузер.
Ответ сервера можно проверить любым удобным инструментом. Я использую bertal.ru или redbot.org. Для обоих сервисов на сайте Арсенкина можно найти удобные букмарклеты. Можно обойтись возможностями браузера, в консоли разработчика, но в этом случае вы получите данные только со своего IP.
Для нашей задачи важны два нюанса:
- Использовать правила реального поискового робота
- Понять, доступен ли URL c IP, реально используемого поисковой системой
С эмуляцией гуглобота всё достаточно просто: открываем «Инструменты разработчика» в браузере Chrome, открываем консоль, выбираем интересующий User-Agent. К сожалению, эмуляции яндекс-бота там нет. Впрочем, он в этом смысле не очень и интересен.
Однако надо понимать, что речь опять-таки идёт об эмуляции. А хорошо бы проверить, доступен ли URL с реального IP, которым пользуется гуглобот. И тут нам на помощь придёт инструмент проверки Mobile-friendly.
В этом случае обращение к сайту будет с одного из реальных IP, с которых ходит гуглобот.
И теперь вы можете воочию оценить, что получает гуглобот при обращении к заданной странице – с подробностями.
Однако такая проверка означает только возможность найти страницу, но ничего не говорит о возможности её просканировать и внести в индекс. А эти возможности определяются:
- метатегом noindex
- директивами в robots.txt
- наличием канонического адреса
- наличием тегов альтернативной мобильной версии
Бывает, что робот получает совсем противоречивые директивы. При выборочном сканировании вы об этом не узнаете. К примеру, в качестве канонической страницы указана страница, запрещенная к индексированию. Получая смешанные указания, гуглобот начинает нервничать и вести себя непредсказуемо – как и все нормальные служаки, действующие строго по инструкции. И тут ваша задача – убедиться, что никаких противоречий в настройках нет. Для этого проверяем:
- Карту сайта в формате sitemap.xml. Там не должно быть ничего, чего не должно быть в индексе: закрытых в robots.txt URL, запрещенных для индексирования страниц, отдающих что-то кроме 200, альтернативных ссылок на мобильную версию, неканонических и т.п.
- Проверяем HTTP-заголовок. Да, canonical и мета robots могут быть заданы и там – через X-Robots-Tag. И их значения могут противоречить метатегам в области HEAD
- Область HEAD в HTML. Она вторична по отношению к тегам в заголовке.
- Если сайт использует JS – убедитесь, что ничего не меняется в настройках сканирования и индексации его средствами.
- Проверяйте настройки консолей вебмастеров: что-то может быть загружено в настройки непосредственно туда (например, карты сайта). Кроме того, есть настройки, отвечающие за обработку параметров и локальных настроек. Важно убедиться, что там ничего не конфликтует с настройками сайта и сервера.
Итак, мы поняли, способен ли гуглобот получить доступ к странице. Теперь надо понять, насколько это системно, и может ли робот получать страницу регулярно.
Оценка доступности в динамике
В этом нам помогут всё те же серверные логи. С их помощью можно понять, куда, когда, как часто заходит робот, и есть ли разница в ответах сервера, размерах страницы, доступности ресурсов, возможности подгружать все служебные файлы, важные для отрисовки страницы. Если вы видите отличия в размерах страницы за период или невозможность загрузки css или js — это тревожный звоночек. Робот не смог полностью загрузить важный контент, и это может напрямую сказываться на ранжировании.
А в чем, собственно, разница между роботом и человеком с точки зрения сервера?
- Робот может разово за считанные минуты обойти тысячи страниц
- Краулинг отличается от просмотра страницы человеком
- Роботы не спят ночью, у них нет человеческого распорядка
- Порядочный поисковый робот вежливо представляется. Непорядочный – может и наврать
Если за минувшие год-два вы предпринимали какие-то усилия по защите от зловредных ботов, или ваш хостер имеет соответствующие сервисы — это может быть проблемой.
- Под блокировку поведенческих и сервисных ботов могут попадать и поисковые роботы
- Сервер может искусственно сдерживать активность роботов, ограничивая скорость или предоставляя оптимизированные варианты страниц
- Производительность сервера также меняется в зависимости от времени суток: например, у вас на CRON могут висеть какие-то периодически выполняемые задачи, сброс кэша, выгрузки из CRM и т.п. Всё это способно повлиять на производительность сайта и доступность его контента.
Вручную тут разбираться будет сложно, в этом случае есть смысл привлечь техподдержку сайта или системного администратора. Как минимум, вы должны понимать, как ведет себя сервер при пиковой нагрузке, а также когда выполняются важные системные задачи. Не далее как сегодня сервисы мониторинга доступности нескольких моих сайтов на одной площадке дружно прокричали, что сайты лежат – спасибо, «Таймвеб», что всего 5 минут. Но уже понятно, что речь – о системности на стороне хостера.
Попробуйте ткнуться на сайт с эмуляцией бота в то же время, когда проходят сервисные работы. Если вы знаете, какие параметры использует гуглобот для визитов – попробуйте воспроизвести их.
Задачка непростая, но иногда без неё никак не понять, каковы реальные технические проблемы могут быть у поисковых роботов, обращающихся к вашему сайту. Если сайт регулярно недоступен, не надо ждать высоких позиций в поиске.
Выясняем, как робот отрисовывает страницу
Итак, мы поняли, как гуглобот сканирует страницу. Теперь надо понять, что он там видит.
В этом случае нужно сопоставлять только исходный HTML с отрисованным JS. Обязательная часть теста – использование мобильного UA. Использовать можно как Screaming Frog SEO Spider, так и специализированные инструменты типа браузерного расширения View Rendered Source или текстовые редакторы типа WinMerge или Diff Checker, которые могут сопоставлять два текстовых файла для обнаружения разницы.
Основные проблемы здесь связаны либо с JS, либо с файлами-куки:
-
Гуглобот сканирует страницы очищая куки между запросами
-
Для рендеринга гуглобот использует Chromium версии 74, который не в полной мере понимает современные версии JS
Здесь на помощь приходит загрузка страниц без файлов куки, например, в режиме “Инкогнито” – с последующим сравнением двух DOM.
Использование инструмента мобильного тестирования с последующим сравнением данных в пользовательском браузере.
Если ошибки на этой стадии не обнаружены – переходим к следующему пункту.
Оцениваем кэш поисковой системы
Всё, что мы делаем – пытаемся посмотреть на сайт с точки зрения поискового робота. Но реальное поведение бота может сильно отличаться от нашего.
- Перегруженный сервер может банально глючить, отдавая самые неожиданные ответы или страницы. Типичный пример – soft 404. Вы получаете страничку 404, или пустую страницу, при этом ответ сервера – 200.
- JS обрабатывается отдельным процессом, в отличие от инструментов для тестирования
- Есть ещё проблема кэшей: серверных, на уровне CMS, браузерных. Притом эти кэши могут сильно отличаться в зависимости от пользователя и его прав.
Когда вы запрашиваете страницу, к серверу отправляется пачка запросов и происходит много вычислений, в том числе – и на стороне клиента. “Хром” не зря так любит кушать оперативную память. Сервер может отдавать вам сохраненные данные без повторных вычислений — это и есть кэширование. И если на уровне кэшей есть какие-то проблемы, то пользователи получают искаженную информацию.
Ещё один вполне обычный вариант – когда при достаточно сложной структуре и архитектуре сайта робот или посетитель не получает правильного ответа от каких-то ресурсов. Примеры:
- Медленная или плохо настроенная CDN, где лежат картинки, css, js
- Часть сайта размещена на другом сервере (скажем, на субдомене, который перенаправляет на основной сайт)
- Проблемы на стороне базы данных
Итог один: контент, который должен быть подгружен, не подгружается – частично или целиком. Чтобы понять, в чём могут быть проблемы, нужно оценить данные в кэше поисковой системы.
Выбор средств тут небогат, но кое-что есть.
- Оценка исходного кода. Проблема: нужно отключать JS, иначе браузер при открытии кэшированной версии запустит все JS, и вы будете оценивать искаженную информацию.
- Поиск определенного контента: вам нужно оценить отдельные шинглы. В этом случае надо искать контент, выводимый средствами JS. Для этого используется запрос типа inurl:сайт.ру/url вместе с цитатным запросом в кавычках вида “тут у нас проблемный фрагмент”.
- Оценка визуализированного DOM из Search Console. В общем, нельзя сказать, что это точный инструмент: это уже не тот скриншотер, что был раньше, но не факт, что сделан по тем же принципам, что реальный гуглобот.
И Google, и Яндекс в настоящий момент предоставляют несколько вариантов кэшированных данных (текст, код, рендер). Это удобно.
Проблемы дублирования
Если раньше мы оценивали проблемы дублирования в рамках одного сайта, то сейчас надо оценить, насколько уникален контент вашего сайта в рамках интернет. Вы могли разместить чужое; кто-то мог стырить контент у вас. Поисковой системе незачем держать в индексе явные дубли, и надо понимать, насколько уникален ваш контент.
Google, в отличие от Яндекса, поддерживает междоменные канонические адреса. Что это значит и чем это чревато?
Например, тем, что контент, размещенный у вас, может быть склеен с совсем другим сайтом: ваша страничка будет считаться дублем и в выдачу не попадёт. И для этого вам даже не надо ничего прописывать, Google сам определит, где тут каноническая страничка.
Помимо кражи контента, такая ситуация может быть следствием взлома с внедренным редиректом или междоменным тегом link с атрибутом rel=”canonical”. Даже необязательно взлома: «нулленные» шаблоны того же WordPress уже частенько содержат такие редиректы. Подробнее об этом можно почитать в справке Google.
В этом случае помогает как цитатный поиск по вашему выбору, так и специализированные внешние сервисы.
Если вы обнаружите точные копии, нужно оценить: насколько авторитетным и ценным для поисковой системы выглядит ваш сайт в сравнении с сайтом-конкурентом, разместившим точно такой же контент. И дальше – думать, что делать:
- Уникализировать свой контент
- Жаловаться кому-то
- Отправлять людей с битами по адресу негодяя
и т.п.
Копии контента, собственно, могут быть и вне поисковой выдачи – они могут транслироваться в “Новости” или какие-то сервисы поисковых систем. Не надо думать, что «это всё равно мои учетки». Сайт может не ранжироваться, если есть другой источник этих же данных, публикующий их и предоставляющий поиску раньше, а конверсии с сайта и внешнего источника могут очень сильно отличаться.
Если существенные проблемы на этой стадии не найдены – двигаемся дальше.
Проблемный и невалидный HTML
В глубокой древности сервисы аудита любили прогонять заданные странички через HTML-валидатор, и несоответствие спецификациям сразу же становилось причиной вердикта: сайт не оптимизирован. Валидность кода интересна только концерну W3C, мы же можем рассматривать результаты валидатора как косвенный признак – тут могут скрываться более серьёзные ошибки. Для примера:
- В область head воткнуты теги, которых там быть не должно. Робот-краулер встречает такое и не понимает, что тут ещё не про область основного контента. Ошибка не слишком часто встречается, но достаточно, чтобы её упомянуть. Буквально пару дней назад мне попалось даже задваивание тегов head и body, а «сломанная» область head попадается куда чаще.
- Страничка сильно изменяется средствами JS, и стоит внимательно изучить, насколько именно и правильно ли формируется структура и оформление. Да, основные поисковые системы сейчас без особых проблем отрисовывают JS-контент, притом в реальном времени. Но убедиться, что тут всё в порядке – просто необходимо.
Используйте валидатор https://validator.w3.org/: он вывалит на вас тонну ненужной информации с кучей мелких блох. Игнорируйте: вам сейчас нужны явные ошибки. Проблемы с атрибутами пока можно отбросить, смотрите на ошибки с тегами и DOM.
Основные ошибки такого рода вам покажет и Screaming Frog при полном парсинге, как минимум – самые грубые.
Заключение
Благодаря полноценной технической проверке можно получить ответы на вопросы, никак иначе не решаемые.
- Кривой редирект на уровне сервера (со слешем и без слеша) в сочетании с 301 редиректом на главную вместо честной 404 создавал бесконечное кольцо редиректов. По итогам треть большого каталога была просто недоступна гуглоботу (бот Яндекса с проблемой не столкнулся – но там другие правила сканирования).
-
Левые теги (div, iframe) в области head приводили к преждевременному завершению заголовка, и метатеги попадали в область body, где их никто не станет читать и учитывать. Таким образом, в выдачу залетали технические дубли, создавая проблему каннибализации по запросам.
- Плохая реализация кэширования приводит к тому, что поисковый робот начинает увлеченно читать файлы шаблона, и на сканирование контента у него не остаётся ресурсов. А вам потом – думать, почему сайт так плохо идёт в поиске.
- Часть сайта размещена на субдомене, перенаправляющем на основной домен, и контент с субдомена либо недоступен, либо сервер отвечает слишком медленно. По итогам пользователь получает то, что должен, а поисковый робот – нет.
Невозможно в одной статье описать все возможные проблемы технического характера, из-за которых ваш сайт может плохо индексироваться, оцениваться слишком низко или вообще выпадать из поиска. Однако задачей статьи было показать логику проведения технического аудита с примерами базового инструментария.
В качестве ставшего традиционным на vc завершения статьи: подписывайтесь на мой телеграм-канал: вести я его собираюсь хаотично, без рекламы курсов, заводил ради первоапрельской шутки.
