Запросы «DNA» и «ДНК» перенаправляются сюда; см. также другие значения терминов DNA и ДНК.
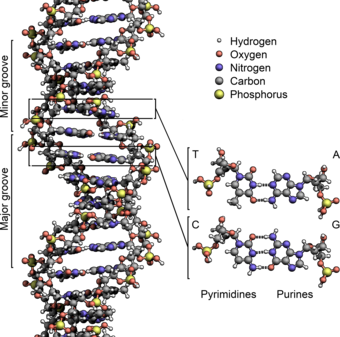
Структура ДНК (двойная спираль). Различные атомы в структуре показаны в разных цветах; детальная структура двух пар оснований показана снизу справа

Дезоксирибонуклеи́новая кислота́ (ДНК) — макромолекула (одна из трёх основных, две другие — РНК и белки), обеспечивающая хранение, передачу из поколения в поколение и реализацию генетической программы развития и функционирования живых организмов.
Молекула ДНК хранит биологическую информацию в виде генетического кода, состоящего из последовательности нуклеотидов[1]. ДНК содержит информацию о структуре различных видов РНК и белков.
В клетках эукариот (животных, растений и грибов) ДНК находится в ядре клетки в составе хромосом, а также в некоторых клеточных органеллах (митохондриях и пластидах). В клетках прокариотических организмов (бактерий и архей) кольцевая или линейная молекула ДНК, так называемый нуклеоид, прикреплена изнутри к клеточной мембране. У прокариот и у низших эукариот (например дрожжей) встречаются также небольшие автономные, преимущественно кольцевые молекулы ДНК, называемые плазмидами. Кроме того, одно- или двухцепочечные молекулы ДНК могут образовывать геном ДНК-содержащих вирусов.
С химической точки зрения ДНК — длинная полимерная молекула, состоящая из повторяющихся блоков — нуклеотидов. Каждый нуклеотид состоит из азотистого основания, сахара (дезоксирибозы) и фосфатной группы. Связи между нуклеотидами в полимерной цепи образуются за счёт дезоксирибозы и фосфатной группы (фосфодиэфирные связи).
В подавляющем большинстве случаев (кроме некоторых вирусов, содержащих одноцепочечную ДНК) макромолекула ДНК состоит из двух нуклеотидных цепей. В нуклеотидах, входящих в состав ДНК, встречаются четыре азотистых основания: аденин (A), гуанин (G), тимин (T) и цитозин (C). Азотистые основания одной цепи соединены с азотистыми основаниями другой цепи водородными связями, обеспечивая таким образом связь двух цепей макромолекулы ДНК друг с другом. Азотистые основания образуют связи поппарно согласно принципу комплементарности: аденин (A) соединяется только с тимином (T), гуанин (G) — только с цитозином (C) [⇨].
Двухцепочечная молекула ДНК закручена по винтовой линии. Структура молекулы ДНК в целом получила традиционное, но ошибочное название «двойной спирали»: на самом деле, она является «двойным винтом». Винтовая линия может быть правой (A- и B-формы ДНК) или левой (Z-форма ДНК)[2].
Последовательность нуклеотидов позволяет «кодировать» информацию о различных типах РНК, наиболее важными из которых являются информационные, или матричные (мРНК), рибосомальные (рРНК) и транспортные (тРНК). Все эти типы РНК синтезируются на матрице ДНК за счёт копирования последовательности ДНК в последовательность РНК, синтезируемой в процессе транскрипции, и далее принимают участие в биосинтезе белков (процессе трансляции). Помимо кодирующих последовательностей, ДНК содержит последовательности, выполняющие в клетках регуляторные и структурные функции. Кроме того, в геноме эукариот часто встречаются участки, принадлежащие «генетическим паразитам», например транспозонам.
Расшифровка структуры ДНК (1953 год) стала одним из поворотных моментов в истории биологии. За выдающийся вклад в это открытие Фрэнсису Крику, Джеймсу Уотсону и Морису Уилкинсу была присуждена Нобелевская премия по физиологии или медицине 1962 года. Розалинд Франклин, получившая рентгенограммы, без которых Уотсон и Крик не имели бы возможность сделать выводы о структуре ДНК, умерла в 1958 году от рака (Нобелевскую премию не дают посмертно)[3].
История изучения[править | править код]



ДНК как химическое вещество была выделена Иоганном Фридрихом Мишером в 1869 году из остатков клеток, содержащихся в гное. Он выделил вещество, в состав которого входят азот и фосфор. Вначале новое вещество получило название нуклеин, а позже, когда Мишер определил, что это вещество обладает кислотными свойствами, вещество получило название нуклеиновая кислота[4]. Биологическая функция новооткрытого вещества была неясна, и долгое время ДНК считалась запасником фосфора в организме. Более того, даже в начале XX века многие биологи считали, что ДНК не имеет никакого отношения к передаче информации, поскольку строение молекулы, по их мнению, было слишком однообразным и не могло содержать закодированную информацию.
До 1930-х годов считалось, что ДНК содержится только в животных клетках, а в растительных — РНК. В 1934 году в журнале «Hoppe-Seyler’s Zeitschrift fur physiologishe Chemie»[5], затем в 1935 году в «Ученых записках МГУ»[6] вышли статьи советских биохимиков А. Н. Белозерского и А. Р. Кизеля, в которых доказывалось присутствие ДНК в растительных клетках. В 1936 году группой Белозерского ДНК была выделена из семян и тканей бобовых, злаковых и других растений[7]. Результатом исследований этой же группы советских учёных в 1939 — 1947 годах стала первая в мировой научной литературе информация о содержании нуклеиновых кислот у различных видов бактерий.
Постепенно было доказано, что именно ДНК, а не белки, как считалось раньше, является носителем генетической информации. Одно из первых решающих доказательств принесли эксперименты Освальда Эвери, Колина Маклауда и Маклина Маккарти (1944 г.) по трансформации бактерий. Им удалось показать, что за так называемую трансформацию (приобретение болезнетворных свойств безвредной культурой в результате добавления в неё мёртвых болезнетворных бактерий) отвечает выделенная из пневмококков ДНК. Эксперимент американских учёных Алфреда Херши и Марты Чейз (эксперимент Херши — Чейз, 1952 г.) с помеченными радиоактивными изотопами белками и ДНК бактериофагов показали, что в заражённую клетку передаётся только нуклеиновая кислота фага, а новое поколение фага содержит такие же белки и нуклеиновую кислоту, как исходный фаг[8].
Вплоть до 50-х годов XX века точное строение ДНК, как и способ передачи наследственной информации, оставалось неизвестным. Хотя и было доподлинно известно, что ДНК состоит из нескольких цепочек, состоящих из нуклеотидов, никто не знал точно, сколько этих цепочек и как они соединены.
В результате работы группы биохимика Эрвина Чаргаффа в 1949—1951 гг. были сформулированы так называемые правила Чаргаффа. Чаргаффу и сотрудникам удалось разделить нуклеотиды ДНК при помощи бумажной хроматографии и определить точные количественные соотношения нуклеотидов разных типов. Соотношение, выявленное для аденина (А), тимина (Т), гуанина (Г) и цитозина (Ц), оказалось следующим: количество аденина равно количеству тимина, а гуанина — цитозину: А=Т, Г=Ц[9][10]. Эти правила, наряду с данными рентгеноструктурного анализа, сыграли решающую роль в расшифровке структуры ДНК.
Структура двойной спирали ДНК была предложена Френсисом Криком и Джеймсом Уотсоном в 1953 году на основании рентгеноструктурных данных, полученных Морисом Уилкинсом и Розалинд Франклин, и правил Чаргаффа[11]. Позже предложенная Уотсоном и Криком модель строения ДНК была доказана, а их работа отмечена Нобелевской премией по физиологии или медицине 1962 г. Среди лауреатов не было скончавшейся к тому времени от рака Розалинд Франклин, так как премия не присуждается посмертно[12].
Интересно, что в 1957 году американцы Александер Рич, Гэри Фелзенфелд и Дэйвид Дэйвис описали нуклеиновую кислоту, составленную тремя спиралями[13]. А в 1985—1986 годах Максим Давидович Франк-Каменецкий в Москве показал, как двухспиральная ДНК складывается в так называемую H-форму, составленную уже не двумя, а тремя нитями ДНК[14][15].
Структура молекулы[править | править код]
Нуклеотиды[править | править код]
Структуры оснований в составе ДНК
Дезоксирибонуклеиновая кислота (ДНК) представляет собой биополимер (полианион), мономером которого является нуклеотид[16][17].
Каждый нуклеотид состоит из остатка фосфорной кислоты, присоединённого по 5′-положению к сахару дезоксирибозе, к которому также через гликозидную связь (C—N) по 1′-положению присоединено одно из четырёх азотистых оснований.
Именно наличие характерного сахара и составляет одно из главных различий между ДНК и РНК, зафиксированное в названиях этих нуклеиновых кислот (в состав РНК входит сахар рибоза)[18]. Пример нуклеотида — аденозинмонофосфат, у которого основанием, присоединённым к фосфату и рибозе, является аденин (A) (показан на рисунке).
Исходя из структуры молекул, основания, входящие в состав нуклеотидов, разделяют на две группы: пурины (аденин [A] и гуанин [G]) образованы соединёнными пяти- и шестичленным гетероциклами; пиримидины (цитозин [C] и тимин [T]) — шестичленным гетероциклом[19].
В виде исключения, например, у бактериофага PBS1, в ДНК встречается пятый тип оснований — урацил ([U]), пиримидиновое основание, отличающееся от тимина отсутствием метильной группы на кольце, обычно заменяющее тимин в РНК[20].
Тимин (T) и урацил (U) не так строго приурочены к ДНК и РНК соответственно, как это считалось ранее. Так, после синтеза некоторых молекул РНК значительное число урацилов в этих молекулах метилируется с помощью специальных ферментов, превращаясь в тимин. Это происходит в транспортных и рибосомальных РНК[21].
Двойная спираль[править | править код]

В зависимости от концентрации ионов и нуклеотидного состава молекулы двойная спираль ДНК в живых организмах существует в разных формах. На рисунке представлены формы A, B и Z (слева направо)
Полимер ДНК обладает довольно сложной структурой. Нуклеотиды соединены между собой ковалентно в длинные полинуклеотидные цепи. Эти цепи в подавляющем большинстве случаев (кроме некоторых вирусов, обладающих одноцепочечными ДНК-геномами) попарно объединяются при помощи водородных связей во вторичную структуру, получившую название двойной спирали[11][18].
Остов каждой из цепей состоит из чередующихся фосфатов и сахаров[22]. Внутри одной цепи ДНК соседние нуклеотиды соединены фосфодиэфирными связями, которые формируются в результате взаимодействия между 3′-гидроксильной (3’—ОН) группой молекулы дезоксирибозы одного нуклеотида и 5′-фосфатной группой (5’—РО3) другого. Асимметричные концы цепи ДНК называются 3′ (три прайм) и 5′ (пять прайм). Полярность цепи играет важную роль при синтезе ДНК (удлинение цепи возможно только путём присоединения новых нуклеотидов к свободному 3′-концу).
Как уже было сказано выше, у подавляющего большинства живых организмов ДНК состоит не из одной, а из двух полинуклеотидных цепей. Эти две длинные цепи закручены одна вокруг другой в виде двойной спирали, стабилизированной водородными связями, образующимися между обращёнными друг к другу азотистыми основаниями входящих в неё цепей. В природе эта спираль, чаще всего, правозакрученная. Направления от 3′-конца к 5′-концу в двух цепях, из которых состоит молекула ДНК, противоположны (цепи «антипараллельны» друг другу).
Ширина двойной спирали составляет от 22 до 24 Å, или 2,2—2,4 нм, длина каждого нуклеотида — 3,3 Å (0,33 нм)[23]. Подобно тому, как в винтовой лестнице сбоку можно увидеть ступеньки, на двойной спирали ДНК в промежутках между фосфатным остовом молекулы можно видеть рёбра оснований, кольца которых расположены в плоскости, перпендикулярной по отношению к продольной оси макромолекулы.
В двойной спирали различают малую (12 Å) и большую (22 Å) бороздки[24]. Белки, например, факторы транскрипции, которые присоединяются к определённым последовательностям в двухцепочечной ДНК, обычно взаимодействуют с краями оснований в большой бороздке, где те более доступны[25].
Образование связей между основаниями[править | править код]
Каждое основание на одной из цепей связывается с одним определённым основанием на второй цепи. Такое специфическое связывание называется комплементарным. Пурины комплементарны пиримидинам (то есть способны к образованию водородных связей с ними): аденин образует связи только с тимином, а цитозин — с гуанином. В двойной спирали цепочки также связаны с помощью гидрофобных взаимодействий и стэкинга, которые не зависят от последовательности оснований ДНК[26].
Комплементарность двойной спирали означает, что информация, содержащаяся в одной цепи, содержится и в другой цепи. Обратимость и специфичность взаимодействий между комплементарными парами оснований важна для репликации ДНК и всех остальных функций ДНК в живых организмах.
Так как водородные связи нековалентны, они легко разрываются и восстанавливаются. Цепочки двойной спирали могут расходиться как замок-молния под действием ферментов (хеликазы) или при высокой температуре[27]. Разные пары оснований образуют разное количество водородных связей. АТ связаны двумя, ГЦ — тремя водородными связями, поэтому на разрыв ГЦ требуется больше энергии. Процент ГЦ-пар и длина молекулы ДНК определяют количество энергии, необходимой для диссоциации цепей: длинные молекулы ДНК с большим содержанием ГЦ более тугоплавки[28]. Температура плавления нуклеиновых кислот зависит от ионного окружения, рост ионной силы стабилизирует ДНК по отношению к денатурированию. При добавлении к ДНК хлорида натрия существует линейная зависимость между температурой плавления и логарифмом ионной силы раствора. Предполагается, что добавление электролита ведет к экранированию зарядов в цепях ДНК и этим уменьшает силы электростатического отталкивания между заряженными фосфатными группами, способствуя жёсткости структуры. Аналогично температуру плавления ДНК повышают ионы марганца, кобальта, цинка и никеля, но ионы меди, кадмия и свинца, напротив, понижают её[29].
Части молекул ДНК, которые из-за их функций должны быть легко разделяемы, например, ТАТА последовательность в бактериальных промоторах, обычно содержат большое количество А и Т.
Химические модификации азотистых оснований[править | править код]
Структура цитозина, 5-метилцитозина и тимина. Тимин может возникать путём деаминирования 5-метилцитозина
Азотистые основания в составе ДНК могут быть ковалентно модифицированы, что используется при регуляции экспрессии генов. Например, в клетках позвоночных метилирование цитозина с образованием 5-метилцитозина используется соматическими клетками для передачи профиля генной экспрессии дочерним клеткам. Метилирование цитозина не влияет на спаривание оснований в двойной спирали ДНК. У позвоночных метилирование ДНК в соматических клетках ограничивается метилированием цитозина в последовательности ЦГ[30]. Средний уровень метилирования отличается у разных организмов, так, у нематоды Caenorhabditis elegans метилирование цитозина не наблюдается, а у позвоночных обнаружен высокий уровень метилирования — до 1 %[31]. Другие модификации оснований включают метилирование аденина у бактерий и гликозилирование урацила с образованием «J-основания» в кинетопластах[32].
Метилирование цитозина с образованием 5-метилцитозина в промоторной части гена коррелирует с его неактивным состоянием[33]. Метилирование цитозина важно также для инактивации Х-хромосомы у млекопитающих[34]. Метилирование ДНК используется в геномном импринтинге[35]. Значительные нарушения профиля метилирования ДНК происходят при канцерогенезе[36].
Несмотря на биологическую роль, 5-метилцитозин может спонтанно утрачивать аминную группу (деаминироваться), превращаясь в тимин, поэтому метилированные цитозины являются источником повышенного числа мутаций[37].
Повреждения ДНК[править | править код]

Интеркалированное химическое соединение, которое находится в середине спирали — бензопирен, основной мутаген табачного дыма[38]
ДНК может повреждаться разнообразными мутагенами, к которым относятся окисляющие и алкилирующие вещества, а также высокоэнергетическая электромагнитная радиация — ультрафиолетовое и рентгеновское излучение. Тип повреждения ДНК зависит от типа мутагена. Например, ультрафиолет повреждает ДНК путём образования в ней димеров тимина, которые возникают при образовании ковалентных связей между соседними основаниями[39].
Оксиданты, такие как свободные радикалы или пероксид водорода, приводят к нескольким типам повреждения ДНК, включая модификации оснований, в особенности гуанозина, а также двухцепочечные разрывы в ДНК[40]. По некоторым оценкам, в каждой клетке человека окисляющими соединениями ежедневно повреждается порядка 500 оснований[41][42]. Среди разных типов повреждений наиболее опасные — это двухцепочечные разрывы, потому что они трудно репарируются и могут привести к потерям участков хромосом (делециям) и транслокациям.
Многие молекулы мутагенов вставляются (интеркалируют) между двумя соседними парами оснований. Большинство этих соединений, например: бромистый этидий, даунорубицин, доксорубицин и талидомид, имеет ароматическую структуру. Для того чтобы интеркалирующее соединение могло поместиться между основаниями, они должны разойтись, расплетая и нарушая структуру двойной спирали. Эти изменения в структуре ДНК мешают репликации, вызывая мутации, и транскрипции. Поэтому интеркалирующие соединения часто являются канцерогенами, наиболее известные из которых — бензопирен, акридины, афлатоксин и бромистый этидий[43][44][45]. Несмотря на эти негативные свойства, в силу их способности подавлять транскрипцию и репликацию ДНК, интеркалирующие соединения используются в химиотерапии для подавления быстро растущих клеток рака[46].
Некоторые вещества (цисплатин[47], митомицин C[48], псорален[49]) образуют поперечные сшивки между нитями ДНК и подавляют синтез ДНК, благодаря чему используются в химиотерапии некоторых видов рака (см. Химиотерапия злокачественных новообразований).
Суперскрученность[править | править код]
Если взяться за концы верёвки и начать скручивать их в разные стороны, она становится короче и на верёвке образуются «супервитки». Так же может быть суперскручена и ДНК. В обычном состоянии цепочка ДНК делает один оборот на каждые 10,4 пар оснований, но в суперскрученном состоянии спираль может быть свёрнута туже или расплетена[50]. Выделяют два типа суперскручивания: положительное — в направлении нормальных витков, при котором основания расположены ближе друг к другу; и отрицательное — в противоположном направлении. В природе молекулы ДНК обычно находятся в отрицательном суперскручивании, которое вносится ферментами — топоизомеразами[51]. Эти ферменты удаляют дополнительное скручивание, возникающее в ДНК в результате транскрипции и репликации[52].

Структура теломер. Зелёным цветом показан ион металла, хелатированный в центре структуры[53]
Структуры на концах хромосом[править | править код]
На концах линейных хромосом находятся специализированные структуры ДНК, называемые теломерами. Основная функция этих участков — поддержание целостности концов хромосом[54]. Теломеры также защищают концы ДНК от деградации экзонуклеазами и предотвращают активацию системы репарации[55]. Поскольку обычные ДНК-полимеразы не могут реплицировать 3′ концы хромосом, это делает специальный фермент — теломераза.
В клетках человека теломеры часто представлены одноцепочечной ДНК и состоят из нескольких тысяч повторяющихся единиц последовательности ТТАГГГ[56]. Эти последовательности с высоким содержанием гуанина стабилизируют концы хромосом, формируя очень необычные структуры, называемые G-квадруплексами и состоящие из четырёх, а не двух взаимодействующих оснований. Четыре гуаниновых основания, все атомы которых находятся в одной плоскости, образуют пластинку, стабилизированную водородными связями между основаниями и хелатированием в центре неё иона металла (чаще всего калия). Эти пластинки располагаются стопкой друг над другом[57].
На концах хромосом могут образовываться и другие структуры: основания могут быть расположены в одной цепочке или в разных параллельных цепочках. Кроме этих «стопочных» структур теломеры формируют большие петлеобразные структуры, называемые Т-петли или теломерные петли. В них одноцепочечная ДНК располагается в виде широкого кольца, стабилизированного теломерными белками[58]. В конце Т-петли одноцепочечная теломерная ДНК присоединяется к двухцепочечной ДНК, нарушая спаривание цепочек в этой молекуле и образуя связи с одной из цепей. Это трёхцепочечное образование называется Д-петля (от англ. displacement loop)[57].
Биологические функции[править | править код]
ДНК является носителем генетической информации, записанной в виде последовательности нуклеотидов с помощью генетического кода. С молекулами ДНК связаны два основополагающих свойства живых организмов — наследственность и изменчивость. В ходе процесса, называемого репликацией ДНК, образуются две копии исходной цепочки, наследуемые дочерними клетками при делении, отсюда следует, что образовавшиеся клетки оказываются генетически идентичны исходной.
Генетическая информация реализуется при экспрессии генов в процессах транскрипции (синтеза молекул РНК на матрице ДНК) и трансляции (синтеза белков на матрице РНК).
Последовательность нуклеотидов «кодирует» информацию о различных типах РНК: информационных, или матричных (мРНК), рибосомальных (рРНК) и транспортных (тРНК). Все эти типы РНК синтезируются на основе ДНК в процессе транскрипции. Роль их в биосинтезе белков (процессе трансляции) различна. Информационная РНК содержит информацию о последовательности аминокислот в белке, рибосомальные РНК служат основой для рибосом (сложных нуклеопротеиновых комплексов, основная функция которых — сборка белка из отдельных аминокислот на основе иРНК), транспортные РНК доставляют аминокислоты к месту сборки белков — в активный центр рибосомы, «ползущей» по иРНК.
Структура генома[править | править код]

ДНК генома бактериофага: фотография под просвечивающим электронным микроскопом
Большинство природных ДНК имеет двухцепочечную структуру, линейную (эукариоты, некоторые вирусы и отдельные роды бактерий) или кольцевую (прокариоты, хлоропласты и митохондрии). Линейную одноцепочечную ДНК содержат некоторые вирусы и бактериофаги.
Молекулы ДНК находятся in vivo в плотно упакованном, конденсированном состоянии[59]. В клетках эукариот ДНК располагается главным образом в ядре и на стадии профазы, метафазы или анафазы митоза доступны для наблюдения с помощью светового микроскопа в виде набора хромосом. Бактериальная (прокариоты) ДНК обычно представлена одной кольцевой молекулой ДНК, расположенной в неправильной формы образовании в цитоплазме, называемым нуклеоидом[60]. Генетическая информация генома состоит из генов. Ген — единица передачи наследственной информации и участок ДНК, который влияет на определённую характеристику организма. Ген содержит открытую рамку считывания, которая транскрибируется, а также регуляторные последовательности (англ.) (рус., например промотор и энхансер, которые контролируют экспрессию открытых рамок считывания.
У многих видов только малая часть общей последовательности генома кодирует белки. Так, только около 1,5 % генома человека состоит из кодирующих белок экзонов, а больше 50 % ДНК человека состоит из некодирующих повторяющихся последовательностей ДНК[61]. Причины наличия такого большого количества некодирующей ДНК в эукариотических геномах и огромная разница в размерах геномов (С-значение) — одна из неразрешённых научных загадок[62]; исследования в этой области также указывают на большое количество фрагментов реликтовых вирусов в этой части ДНК.
Последовательности генома, не кодирующие белок[править | править код]
В настоящее время накапливается всё больше данных, противоречащих идее о некодирующих последовательностях как «мусорной ДНК» (англ. junk DNA).
Теломеры и центромеры содержат малое число генов, но они важны для функционирования и стабильности хромосом[55][63]. Часто встречающаяся форма некодирующих последовательностей человека — псевдогены, копии генов, инактивированные в результате мутаций[64]. Эти последовательности нечто вроде молекулярных ископаемых, хотя иногда они могут служить исходным материалом для дупликации и последующей дивергенции генов[65].
Другой источник разнообразия белков в организме — это использование интронов в качестве «линий разреза и склеивания» в альтернативном сплайсинге[66].
Наконец, не кодирующие белок последовательности могут кодировать вспомогательные клеточные РНК, например мяРНК[67]. Недавнее исследование транскрипции генома человека показало, что 10 % генома даёт начало полиаденилированным РНК[68], а исследование генома мыши показало, что 62 % его транскрибируется[69].
Транскрипция и трансляция[править | править код]
Генетическая информация, закодированная в ДНК, должна быть прочитана и в конечном итоге выражена в синтезе различных биополимеров, из которых состоят клетки. Последовательность оснований в цепочке ДНК напрямую определяет последовательность оснований в РНК, на которую она «переписывается» в процессе, называемом транскрипцией. В случае мРНК эта последовательность определяет аминокислоты белка. Соотношение между нуклеотидной последовательностью мРНК и аминокислотной последовательностью определяется правилами трансляции, которые называются генетическим кодом. Генетический код состоит из трёхбуквенных «слов», называемых кодонами, состоящих из трёх нуклеотидов (то есть ACT, CAG, TTT и т. п.).
Во время транскрипции нуклеотиды гена копируются на синтезируемую РНК РНК-полимеразой. Эта копия в случае мРНК декодируется рибосомой, которая «читает» последовательность мРНК, осуществляя спаривание матричной РНК с транспортными РНК, которые присоединены к аминокислотам. Поскольку в трёхбуквенных комбинациях используются 4 основания, всего возможны 64 кодона (4³ комбинации). Кодоны кодируют 20 стандартных аминокислот, каждой из которых соответствует в большинстве случаев более одного кодона. Один из трёх кодонов, которые располагаются в конце мРНК, не означает аминокислоту и определяет конец белка, это «стоп» или «нонсенс» кодоны — TAA, TGA, TAG.
Репликация[править | править код]
Деление клеток необходимо для размножения одноклеточного и роста многоклеточного организма, но до деления клетка должна удвоить геном, чтобы дочерние клетки содержали ту же генетическую информацию, что и исходная клетка. Из нескольких теоретически возможных механизмов удвоения (репликации) ДНК реализуется полуконсервативный. Две цепочки разделяются, а затем каждая недостающая комплементарная последовательность ДНК воспроизводится ферментом ДНК-полимеразой. Этот фермент синтезирует полинуклеотидную цепь, находя правильный нуклеотид через комплементарное спаривание оснований и присоединяя его к растущей цепочке. ДНК-полимераза не может начинать новую цепь, а может лишь наращивать уже существующую, поэтому она нуждается в короткой цепочке нуклеотидов — (праймере), синтезируемом праймазой. Так как ДНК-полимеразы могут синтезировать цепочку только в направлении 5′ –> 3′, антипараллельные цепи ДНК копируются по-разному: одна цепь синтезируется непрерывно, а вторая прерывчато[70].
Взаимодействие с белками[править | править код]
Все функции ДНК зависят от её взаимодействия с белками. Взаимодействия могут быть неспецифическими, когда белок присоединяется к любой молекуле ДНК, или зависеть от наличия особой последовательности. Ферменты также могут взаимодействовать с ДНК, из них наиболее важные — это РНК-полимеразы, которые копируют последовательность оснований ДНК на РНК в транскрипции или при синтезе новой цепи ДНК — репликации.
Структурные и регуляторные белки[править | править код]
Хорошо изученными примерами взаимодействия белков и ДНК, не зависящего от нуклеотидной последовательности ДНК, является взаимодействие со структурными белками. В клетке ДНК связана с этими белками, образуя компактную структуру, которая называется хроматин. У эукариот хроматин образован при присоединении к ДНК небольших щелочных белков — гистонов, менее упорядоченный хроматин прокариот содержит гистон-подобные белки[71][72]. Гистоны формируют дискообразную белковую структуру — нуклеосому, вокруг каждой из которых вмещается два оборота спирали ДНК. Неспецифические связи между гистонами и ДНК образуются за счёт ионных связей щелочных аминокислот гистонов и кислотных остатков сахарофосфатного остова ДНК[73]. Химические модификации этих аминокислот включают метилирование, фосфорилирование и ацетилирование[74]. Эти химические модификации изменяют силу взаимодействия между ДНК и гистонами, влияя на доступность специфических последовательностей для факторов транскрипции и изменяя скорость транскрипции[75]. Другие белки в составе хроматина, которые присоединяются к неспецифическим последовательностям — белки с высокой подвижностью в гелях, которые ассоциируют большей частью с согнутой ДНК[76]. Эти белки важны для образования в хроматине структур более высокого порядка[77].
Особая группа белков, присоединяющихся к ДНК — это белки, которые ассоциируют с одноцепочечной ДНК. Наиболее хорошо охарактеризованный белок этой группы у человека — репликационный белок А, без которого невозможно протекание большинства процессов, где расплетается двойная спираль, включая репликацию, рекомбинацию и репарацию. Белки этой группы стабилизируют одноцепочечную ДНК и предотвращают формирование стеблей-петель или деградации нуклеазами[78].
В то же время другие белки узнают и присоединяются к специфическим последовательностям. Наиболее изученная группа таких белков — различные классы факторов транскрипции, то есть белки, регулирующие транскрипцию. Каждый из этих белков узнаёт свою последовательность, часто в промоторе, и активирует или подавляет транскрипцию гена. Это происходит при ассоциации факторов транскрипции с РНК-полимеразой либо напрямую, либо через белки-посредники. Полимераза ассоциирует сначала с белками, а потом начинает транскрипцию[79]. В других случаях факторы транскрипции могут присоединяться к ферментам, которые модифицируют находящиеся на промоторах гистоны, что изменяет доступность ДНК для полимераз[80].
Так как специфические последовательности встречаются во многих местах генома, изменения в активности одного типа фактора транскрипции могут изменить активность тысяч генов[81]. Соответственно, эти белки часто регулируются в процессах ответа на изменения в окружающей среде, развития организма и дифференцировки клеток. Специфичность взаимодействия факторов транскрипции с ДНК обеспечивается многочисленными контактами между аминокислотами и основаниями ДНК, что позволяет им «читать» последовательность ДНК. Большинство контактов с основаниями происходит в главной бороздке, где основания более доступны[25].
Ферменты, модифицирующие ДНК[править | править код]
Топоизомеразы и хеликазы[править | править код]
В клетке ДНК находится в компактном, т. н. суперскрученном состоянии, иначе она не смогла бы в ней уместиться. Для протекания жизненно важных процессов ДНК должна быть раскручена, что производится двумя группами белков — топоизомеразами и хеликазами.
Топоизомеразы — ферменты, которые имеют и нуклеазную, и лигазную активности. Они изменяют степень суперскрученности в ДНК. Некоторые из этих ферментов разрезают спираль ДНК и позволяют вращаться одной из цепей, тем самым уменьшая уровень суперскрученности, после чего фермент заделывает разрыв[51]. Другие ферменты могут разрезать одну из цепей и проводить вторую цепь через разрыв, а потом лигировать разрыв в первой цепи[82]. Топоизомеразы необходимы во многих процессах, связанных с ДНК, таких как репликация и транскрипция[52].
Хеликазы — белки, которые являются одним из молекулярных моторов. Они используют химическую энергию нуклеозидтрифосфатов, чаще всего АТФ, для разрыва водородных связей между основаниями, раскручивая двойную спираль на отдельные цепочки[83]. Эти ферменты важны для большинства процессов, где белкам необходим доступ к основаниям ДНК.
Нуклеазы и лигазы[править | править код]
В различных процессах, происходящих в клетке, например рекомбинации и репарации, участвуют ферменты, способные разрезать и восстанавливать целостность нитей ДНК. Ферменты, разрезающие ДНК, носят название нуклеаз. Нуклеазы, которые гидролизуют нуклеотиды на концах молекулы ДНК, называются экзонуклеазами, а эндонуклеазы разрезают ДНК внутри цепи. Наиболее часто используемые в молекулярной биологии и генетической инженерии нуклеазы — это эндонуклеазы рестрикции (рестриктазы), которые разрезают ДНК около специфических последовательностей. Например, фермент EcoRV (рестрикционный фермент № 5 из ‘E. coli’) узнаёт шестинуклеотидную последовательность 5′-GAT|ATC-3′ и разрезает ДНК в месте, указанном вертикальной линией. В природе эти ферменты защищают бактерии от заражения бактериофагами, разрезая ДНК фага, когда она вводится в бактериальную клетку. В этом случае нуклеазы — часть системы модификации-рестрикции[84]. ДНК-лигазы «сшивают» концы фрагментов ДНК между собой, катализируя формирование фосфодиэфирной связи с использованием энергии АТФ.
Рестрикционные нуклеазы и лигазы используются в клонировании и фингерпринтинге.

ДНК-лигаза I (кольцеобразная структура, состоящая из нескольких одинаковых молекул белка, показанных разными цветами), лигирующая повреждённую цепь ДНК
Полимеразы[править | править код]
Существует также важная для метаболизма ДНК группа ферментов, которые синтезируют цепи полинуклеотидов из нуклеозидтрифосфатов — ДНК-полимеразы. Они добавляют нуклеотиды к 3′-гидроксильной группе предыдущего нуклеотида в цепи ДНК, поэтому все полимеразы работают в направлении 5′–> 3′[85]. В активном центре этих ферментов субстрат — нуклеозидтрифосфат — спаривается с комплементарным основанием в составе одноцепочечной полинуклеотидной цепочки — матрицы.
В процессе репликации ДНК ДНК-зависимая ДНК-полимераза синтезирует копию исходной последовательности ДНК. Точность очень важна в этом процессе, так как ошибки в полимеризации приведут к мутациям, поэтому многие полимеразы обладают способностью к «редактированию» — исправлению ошибок. Полимераза узнаёт ошибки в синтезе по отсутствию спаривания между неправильными нуклеотидами. После определения отсутствия спаривания активируется 3′–> 5′ экзонуклеазная активность полимеразы, и неправильное основание удаляется[86]. В большинстве организмов ДНК-полимеразы работают в виде большого комплекса, называемого реплисомой, которая содержит многочисленные дополнительные субъединицы, например хеликазы[87].
РНК-зависимые ДНК-полимеразы — специализированный тип полимераз, которые копируют последовательность РНК на ДНК. К этому типу относятся обратная транскриптаза, которая содержится в ретровирусах и используется при инфекции клеток, а также теломераза, необходимая для репликации теломер[88]. Теломераза — необычный фермент, потому что она содержит собственную матричную РНК[55].
Транскрипция осуществляется ДНК-зависимой РНК-полимеразой, которая копирует последовательность ДНК одной цепочки на мРНК. В начале транскрипции гена РНК-полимераза присоединяется к последовательности в начале гена, называемой промотором, и расплетает спираль ДНК. Потом она копирует последовательность гена на матричную РНК до тех пор, пока не дойдёт до участка ДНК в конце гена — терминатора, где она останавливается и отсоединяется от ДНК. Также как ДНК-зависимая ДНК-полимераза человека, РНК-полимераза II, которая транскрибирует большую часть генов в геноме человека, работает в составе большого белкового комплекса, содержащего регуляторные и дополнительные единицы[89].
Генетическая рекомбинация[править | править код]
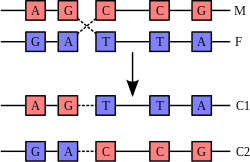
Рекомбинация происходит в результате физического разрыва в хромосомах (М) и (F) и их последующего соединения с образованием двух новых хромосом (C1 и C2)
Двойная спираль ДНК обычно не взаимодействует с другими сегментами ДНК, и в человеческих клетках разные хромосомы пространственно разделены в ядре[90]. Это расстояние между разными хромосомами важно для способности ДНК действовать в качестве стабильного носителя информации. В процессе рекомбинации с помощью ферментов две спирали ДНК разрываются, обмениваются участками, после чего непрерывность спиралей восстанавливается, поэтому обмен участками негомологичных хромосом может привести к повреждению целостности генетического материала.
Рекомбинация позволяет хромосомам обмениваться генетической информацией, в результате этого образуются новые комбинации генов, что увеличивает эффективность естественного отбора и важно для быстрой эволюции новых белков[91]. Генетическая рекомбинация также играет роль в репарации, особенно в ответе клетки на разрыв обеих цепей ДНК[92].
Самая распространённая форма кроссинговера — это гомологичная рекомбинация, когда принимающие участие в рекомбинации хромосомы имеют очень похожие последовательности. Иногда в качестве участков гомологии выступают транспозоны. Негомологичная рекомбинация может привести к повреждению клетки, поскольку в результате такой рекомбинации возникают транслокации. Реакция рекомбинации катализируется ферментами, которые называются рекомбиназы, например, Cre. На первом этапе реакции рекомбиназа делает разрыв в одной из цепей ДНК, позволяя этой цепи отделиться от комплементарной цепи и присоединиться к одной из цепей второй хроматиды. Второй разрыв в цепи второй хроматиды позволяет ей также отделиться и присоединиться к оставшейся без пары цепи из первой хроматиды, формируя структуру Холлидея. Структура Холлидея может передвигаться вдоль соединённой пары хромосом, меняя цепи местами. Реакция рекомбинации завершается, когда фермент разрезает соединение, а две цепи лигируются[93].
Эволюция метаболизма, основанного на ДНК[править | править код]
ДНК содержит генетическую информацию, которая делает возможной жизнедеятельность, рост, развитие и размножение всех современных организмов. Однако как долго в течение четырёх миллиардов лет истории жизни на Земле ДНК была главным носителем генетической информации, неизвестно. Существуют гипотезы, что РНК играла центральную роль в обмене веществ, поскольку она может и переносить генетическую информацию, и осуществлять катализ с помощью рибозимов[94][95][96]. Кроме того, РНК — один из основных компонентов «фабрик белка» — рибосом. Древний РНК-мир, где нуклеиновая кислота была использована и для катализа, и для переноса информации, мог послужить источником современного генетического кода, состоящего из четырёх оснований. Это могло произойти в результате того, что число оснований в организме было компромиссом между небольшим числом оснований, увеличивавшим точность репликации, и большим числом оснований, увеличивающим каталитическую активность рибозимов[97].
К сожалению, древние генетические системы не дошли до наших дней. ДНК в окружающей среде в среднем сохраняется в течение 1 миллиона лет, постепенно деградируя до коротких фрагментов. Извлечение ДНК из бактериальных спор, заключённых в кристаллах соли 250 млн лет назад, и определение последовательности генов 16S рРНК[98], служит темой оживлённой дискуссии в научной среде[99][100].
См. также[править | править код]
- Вектор (биология)
- Геном человека
- Действие излучений на структуру и функции ДНК
- Методы секвенирования нового поколения
- Мобильные элементы генома
- Нуклеопротеиды
- Спиртовая преципитация
- Футпринтинг ДНК
- Центральная догма молекулярной биологии
- Цис-элемент
- ДНК-компьютер
- Трёхцепочечная ДНК
Примечания[править | править код]
- ↑ Александр Панчин. Сумма биотехнологии [1]. — АСТ, 2015. — С. 13. — 432 с. — ISBN 978-5-17-093602-1.
- ↑ Bustamante C., Bryant Z., Smith S. B. Ten years of tension: single-molecule DNA mechanics (англ.) // Nature. — 2003. — Vol. 421, no. 6921. — P. 423—427.
- ↑ Erica Westly. No Nobel for You: Top 10 Nobel Snubs. Rosalind Franklin–her work on the structure of DNA never received a Nobel (англ.). Scientific American (6 октября 2008). Дата обращения: 18 ноября 2013. Архивировано 8 января 2014 года.
- ↑ Dahm R. Friedrich Miescher and the discovery of DNA (англ.) // Dev Biol (англ.) (рус. : journal. — 2005. — Vol. 278, no. 2. — P. 274—288. — PMID 15680349.
- ↑ Kiesel A., Beloserskii A. Hoppe-Seyler’s Zeitschrift fur physiologishe Chemie, 229, 160—166. 1934.
- ↑ Белозерский А. Н. Ученые записки МГУ, вып.4, 209—215, 1935.
- ↑ Белозерский А. Н., Чигирев С. Д. Биохимия, 1, 136—146, 1936.
- ↑ Hershey A., Chase M. Independent functions of viral protein and nucleic acid in growth of bacteriophage (англ.) // The Journal of General Physiology (англ.) (рус. : journal. — Rockefeller University Press (англ.) (рус., 1952. — Vol. 36, no. 1. — P. 39—56. — PMID 12981234.
- ↑ Elson D., Chargaff E. On the deoxyribonucleic acid content of sea urchin gametes (англ.) // Experientia : journal. — 1952. — Vol. 8, no. 4. — P. 143—145. — doi:10.1007/BF02170221. — PMID 14945441.
- ↑ Chargaff E., Lipshitz R., Green C. Composition of the deoxypentose nucleic acids of four genera of sea-urchin (англ.) // J Biol Chem : journal. — 1952. — Vol. 195, no. 1. — P. 155—160. — PMID 14938364.
- ↑ 1 2 Watson J., Crick F. Molecular structure of nucleic acids; a structure for deoxyribose nucleic acid (рум.) // Nature. — 1953. — Т. 171, nr. 4356. — P. 737—8.
- ↑ The Nobel Prize in Physiology or Medicine 1962 Архивная копия от 4 января 2007 на Wayback Machine Nobelprize .org Accessed 22 Dec 06
- ↑ Н. Домрина В России есть кому делать науку — если будет на что // Журнал «Наука и жизнь», № 2, 2002. Дата обращения: 21 апреля 2013. Архивировано 3 октября 2013 года.
- ↑ Maxim Frank-Kamenetskii DNA structure: A simple solution to the stability of the double helix? // Журнал Nature № 324, 305 (27 November 1986). Дата обращения: 21 апреля 2013. Архивировано 16 ноября 2005 года.
- ↑ Maxim Frank-Kamenetskii H-form DNA and the hairpin-triplex model // Журнал Nature № 333, 214 (19 May 1988)
- ↑ Alberts, Bruce; Alexander Johnson, Julian Lewis, Martin Raff, Keith Roberts, and Peter Walters. Molecular Biology of the Cell; Fourth Edition (англ.). — New York and London: Garland Science (англ.) (рус., 2002.
- ↑ Butler, John M. (2001) Forensic DNA Typing «Elsevier». pp. 14 — 15. ISBN 978-0-12-147951-0
- ↑ 1 2 Berg J., Tymoczko J. and Stryer L. (2002) Biochemistry. W. H. Freeman and Company ISBN 0-7167-4955-6
- ↑ Abbreviations and Symbols for Nucleic Acids, Polynucleotides and their Constituents Архивная копия от 5 февраля 2007 на Wayback Machine IUPAC-IUB Commission on Biochemical Nomenclature (CBN) Accessed 03 Jan 2006
- ↑ Takahashi I., Marmur J. Replacement of thymidylic acid by deoxyuridylic acid in the deoxyribonucleic acid of a transducing phage for Bacillus subtilis (англ.) // Nature : journal. — 1963. — Vol. 197. — P. 794—5.
- ↑ Agris P. Decoding the genome: a modified view (англ.) // Nucleic Acids Res (англ.) (рус. : journal. — 2004. — Vol. 32, no. 1. — P. 223—38. — PMID 14715921.
- ↑ Ghosh A., Bansal M. A glossary of DNA structures from A to Z (англ.) // Acta Crystallogr D Biol Crystallogr (англ.) (рус. : journal. — International Union of Crystallography, 2003. — Vol. 59, no. Pt 4. — P. 620—6.
- ↑ Mandelkern M., Elias J., Eden D., Crothers D. The dimensions of DNA in solution (англ.) // J Mol Biol (англ.) (рус. : journal. — 1981. — Vol. 152, no. 1. — P. 153—61.
- ↑ Wing R., Drew H., Takano T., Broka C., Tanaka S., Itakura K., Dickerson R. Crystal structure analysis of a complete turn of B-DNA (англ.) // Nature : journal. — 1980. — Vol. 287, no. 5784. — P. 755—8.
- ↑ 1 2 Pabo C., Sauer R. Protein-DNA recognition (англ.) // Annu Rev Biochem (англ.) (рус. : journal. — Vol. 53. — P. 293—321.
- ↑ Ponnuswamy P., Gromiha M. On the conformational stability of oligonucleotide duplexes and tRNA molecules (англ.) // J Theor Biol (англ.) (рус. : journal. — 1994. — Vol. 169, no. 4. — P. 419—432. — PMID 7526075.
- ↑ Clausen-Schaumann H., Rief M., Tolksdorf C., Gaub H. Mechanical stability of single DNA molecules (англ.) // Biophys J (англ.) (рус. : journal. — 2000. — Vol. 78, no. 4. — P. 1997—2007. — PMID 10733978.
- ↑ Chalikian T., Völker J., Plum G., Breslauer K. A more unified picture for the thermodynamics of nucleic acid duplex melting: a characterization by calorimetric and volumetric techniques (англ.) // Proceedings of the National Academy of Sciences of the United States of America : journal. — 1999. — Vol. 96, no. 14. — P. 7853—7858. — PMID 10393911.
- ↑ Е.Е.Крисс, К.Б.Яцимирский. Взаимодействие нуклеиновых кислот с металлами..
- ↑ Молекулярная биология клетки: в 3-х томах / Б. Альбертс, А. Джонсон, Д. Льюис и др. — М.-Ижевск: НИЦ «Регулярная и хаотическая динамика», Институт компьютерных исследований, 2013. — Т. I. — С. 719—733. — 808 с. — ISBN 978-5-4344-0112-8.
- ↑ Bird A. DNA methylation patterns and epigenetic memory (англ.) // Genes Dev : journal. — 2002. — Vol. 16, no. 1. — P. 6—21.
- ↑ Gommers-Ampt J., Van Leeuwen F., de Beer A., Vliegenthart J., Dizdaroglu M., Kowalak J., Crain P., Borst P. beta-D-glucosyl-hydroxymethyluracil: a novel modified base present in the DNA of the parasitic protozoan T. brucei (англ.) // Cell : journal. — Cell Press, 1993. — Vol. 75, no. 6. — P. 1129—36.
- ↑ Jones P. A. Functions of DNA methylation: islands, start sites, gene bodies and beyond // Nature Reviews Genetics. — 2012. — Т. 13, № 7. — С. 484—492.
- ↑ Klose R., Bird A. Genomic DNA methylation: the mark and its mediators (англ.) // Trends Biochem Sci (англ.) (рус. : journal. — 2006. — Vol. 31, no. 2. — P. 89—97.
- ↑ Li E., Beard C., Jaenisch R. Role for DNA methylation in genomic imprinting //Nature. — 1993. — Т. 366. — №. 6453. — С. 362—365
- ↑ Ehrlich M. DNA methylation in cancer: too much, but also too little //Oncogene. — 2002. — Т. 21. — №. 35. — С. 5400-5413
- ↑ Walsh C., Xu G. Cytosine methylation and DNA repair (неопр.) // Curr Top Microbiol Immunol. — Т. 301. — С. 283—315.
- ↑ Created from PDB 1JDG Архивная копия от 22 сентября 2008 на Wayback Machine
- ↑ Douki T., Reynaud-Angelin A., Cadet J., Sage E. Bipyrimidine photoproducts rather than oxidative lesions are the main type of DNA damage involved in the genotoxic effect of solar UVA radiation (англ.) // Biochemistry : journal. — 2003. — Vol. 42, no. 30. — P. 9221—6.
- ↑ Cadet J., Delatour T., Douki T., Gasparutto D., Pouget J., Ravanat J., Sauvaigo S. Hydroxyl radicals and DNA base damage (неопр.) // Mutation Research (англ.) (рус.. — Elsevier, 1999. — Т. 424, № 1—2. — С. 9—21.
- ↑ Shigenaga M., Gimeno C., Ames B. Urinary 8-hydroxy-2′-deoxyguanosine as a biological marker of in vivo oxidative DNA damage (англ.) // Proceedings of the National Academy of Sciences of the United States of America : journal. — 1989. — Vol. 86, no. 24. — P. 9697—701.
- ↑ Cathcart R., Schwiers E., Saul R., Ames B. Thymine glycol and thymidine glycol in human and rat urine: a possible assay for oxidative DNA damage (англ.) // Proceedings of the National Academy of Sciences of the United States of America : journal. — 1984. — Vol. 81, no. 18. — P. 5633—7.
- ↑ Ferguson L., Denny W. The genetic toxicology of acridines (неопр.) // Mutation Research (англ.) (рус.. — Elsevier, 1991. — Т. 258, № 2. — С. 123—60.
- ↑ Jeffrey A. DNA modification by chemical carcinogens (англ.) // Pharmacol Ther : journal. — 1985. — Vol. 28, no. 2. — P. 237—72.
- ↑ Stephens T., Bunde C., Fillmore B. Mechanism of action in thalidomide teratogenesis (англ.) // Biochem Pharmacol (англ.) (рус. : journal. — 2000. — Vol. 59, no. 12. — P. 1489—99.
- ↑ Braña M., Cacho M., Gradillas A., de Pascual-Teresa B., Ramos A. Intercalators as anticancer drugs (англ.) // Curr Pharm Des (англ.) (рус. : journal. — 2001. — Vol. 7, no. 17. — P. 1745—80.
- ↑ Trzaska, Stephen. Cisplatin (англ.) // Chemical & Engineering News (англ.) (рус. : journal. — 2005. — 20 June (vol. 83, no. 25).
- ↑ Tomasz, Maria. Mitomycin C: small, fast and deadly (but very selective) (англ.) // Chemistry and Biology (англ.) (рус. : journal. — 1995. — September (vol. 2, no. 9). — P. 575—579. — doi:10.1016/1074-5521(95)90120-5. — PMID 9383461.
- ↑ Wu Q., Christensen L. A., Legerski R. J., Vasquez K. M. Mismatch repair participates in error-free processing of DNA interstrand crosslinks in human cells (англ.) // EMBO Rep. (англ.) (рус. : journal. — 2005. — June (vol. 6, no. 6). — P. 551—557. — doi:10.1038/sj.embor.7400418. — PMID 15891767. — PMC 1369090.
- ↑ Benham C., Mielke S. DNA mechanics (неопр.) // Annu Rev Biomed Eng (англ.) (рус.. — 2005. — Т. 7. — С. 21—53. — PMID 16004565.
- ↑ 1 2 Champoux J. DNA topoisomerases: structure, function, and mechanism (англ.) // Annu Rev Biochem (англ.) (рус. : journal. — 2001. — Vol. 70. — P. 369—413. — PMID 11395412.
- ↑ 1 2 Wang J. Cellular roles of DNA topoisomerases: a molecular perspective (англ.) // Nat Rev Mol Cell Biol : journal. — 2002. — Vol. 3, no. 6. — P. 430—440. — PMID 12042765.
- ↑ Created from NDB UD0017 Архивировано 7 июня 2013 года.
- ↑ Greider C., Blackburn E. Identification of a specific telomere terminal transferase activity in Tetrahymena extracts (англ.) // Cell : journal. — Cell Press, 1985. — Vol. 43, no. 2 Pt 1. — P. 405—413. — PMID 3907856.
- ↑ 1 2 3 Nugent C., Lundblad V. The telomerase reverse transcriptase: components and regulation (англ.) // Genes Dev : journal. — 1998. — Vol. 12, no. 8. — P. 1073—1085. — PMID 9553037.
- ↑ Wright W., Tesmer V., Huffman K., Levene S., Shay J. Normal human chromosomes have long G-rich telomeric overhangs at one end (англ.) // Genes Dev : journal. — 1997. — Vol. 11, no. 21. — P. 2801—2809. — PMID 9353250.
- ↑ 1 2 Burge S., Parkinson G., Hazel P., Todd A., Neidle S. Quadruplex DNA: sequence, topology and structure (англ.) // Nucleic Acids Res (англ.) (рус. : journal. — 2006. — Vol. 34, no. 19. — P. 5402—5415. — PMID 17012276.
- ↑ Griffith J., Comeau L., Rosenfield S., Stansel R., Bianchi A., Moss H., de Lange T. Mammalian telomeres end in a large duplex loop (англ.) // Cell. — Cell Press, 1999. — Vol. 97, no. 4. — P. 503—514. — PMID 10338214.
- ↑ Teif V.B. and Bohinc K. Condensed DNA: condensing the concepts (неопр.) // Progress in Biophysics and Molecular Biology. — 2010. — doi:10.1016/j.pbiomolbio.2010.07.002.
- ↑ Thanbichler M., Wang S., Shapiro L. The bacterial nucleoid: a highly organized and dynamic structure (англ.) // J Cell Biochem (англ.) (рус. : journal. — 2005. — Vol. 96, no. 3. — P. 506—21.
- ↑ Wolfsberg T., McEntyre J., Schuler G. Guide to the draft human genome (англ.) // Nature. — 2001. — Vol. 409, no. 6822. — P. 824—6.
- ↑ Gregory T. The C-value enigma in plants and animals: a review of parallels and an appeal for partnership (англ.) // Ann Bot (Lond) : journal. — 2005. — Vol. 95, no. 1. — P. 133—46.
- ↑ Pidoux A., Allshire R. The role of heterochromatin in centromere function (англ.) // Philos Trans R Soc Lond B Biol Sci : journal. — 2005. — Vol. 360, no. 1455. — P. 569—79. (недоступная ссылка)
- ↑ Harrison P., Hegyi H., Balasubramanian S., Luscombe N., Bertone P., Echols N., Johnson T., Gerstein M. Molecular fossils in the human genome: identification and analysis of the pseudogenes in chromosomes 21 and 22 (англ.) // Genome Res (англ.) (рус. : journal. — 2002. — Vol. 12, no. 2. — P. 272—80.
- ↑ Harrison P., Gerstein M. Studying genomes through the aeons: protein families, pseudogenes and proteome evolution (англ.) // J Mol Biol (англ.) (рус. : journal. — 2002. — Vol. 318, no. 5. — P. 1155—74.
- ↑ Soller M. Molecular fossils in the human genome: identification and analysis of the pseudogenes in chromosomes 21 and 22 (англ.) // Cell Mol Life Sci : journal. — 2006. — Vol. 63, no. 7—9. — P. 796—819. (недоступная ссылка)
- ↑ Michalak P. RNA world – the dark matter of evolutionary genomics (англ.) : journal. — 2006. — Vol. 19, no. 6. — P. 1768—74. [ Архивировано] 28 января 2019 года.
- ↑ Cheng J., Kapranov P., Drenkow J., Dike S., Brubaker S et al. RNA world – the dark matter of evolutionary genomics (англ.) : journal. — 2005. — Vol. 308. — P. 1149—54.
- ↑ Mattick J. S. RNA regulation: a new genetics? (англ.) // Nat Rev Genet : journal. — 2004. — Vol. 5. — P. 316—323.
- ↑ Albà M. Replicative DNA polymerases (англ.) // Genome Biol (англ.) (рус. : journal. — 2001. — Vol. 2, no. 1. — P. REVIEWS3002.
- ↑ Sandman K., Pereira S., Reeve J. Diversity of prokaryotic chromosomal proteins and the origin of the nucleosome (англ.) // Cell Mol Life Sci : journal. — 1998. — Vol. 54, no. 12. — P. 1350—64.
- ↑ Dame R. T. The role of nucleoid-associated proteins in the organization and compaction of bacterial chromatin (англ.) // Microbiology (англ.) (рус. : journal. — Microbiology Society (англ.) (рус., 2005. — Vol. 56, no. 4. — P. 858—870. — PMID 15853876.
- ↑ Luger K., Mäder A., Richmond R., Sargent D., Richmond T. Crystal structure of the nucleosome core particle at 2.8 A resolution (англ.) // Nature : journal. — 1997. — Vol. 389, no. 6648. — P. 251—60.
- ↑ Jenuwein T., Allis C. Translating the histone code (англ.) // Science. — 2001. — Vol. 293, no. 5532. — P. 1074—80.
- ↑ Ito T. Nucleosome assembly and remodelling (неопр.) // Curr Top Microbiol Immunol. — Т. 274. — С. 1—22.
- ↑ Thomas J. HMG1 and 2: architectural DNA-binding proteins (англ.) // Biochem Soc Trans (англ.) (рус. : journal. — 2001. — Vol. 29, no. Pt 4. — P. 395—401.
- ↑ Grosschedl R., Giese K., Pagel J. HMG domain proteins: architectural elements in the assembly of nucleoprotein structures (англ.) // Trends Genet (англ.) (рус. : journal. — 1994. — Vol. 10, no. 3. — P. 94—100.
- ↑ Iftode C., Daniely Y., Borowiec J. Replication protein A (RPA): the eukaryotic SSB (англ.) // Crit Rev Biochem Mol Biol (англ.) (рус. : journal. — 1999. — Vol. 34, no. 3. — P. 141—80.
- ↑ Myers L., Kornberg R. Mediator of transcriptional regulation (англ.) // Annu Rev Biochem (англ.) (рус. : journal. — Vol. 69. — P. 729—49.
- ↑ Spiegelman B., Heinrich R. Biological control through regulated transcriptional coactivators (англ.) // Cell : journal. — Cell Press, 2004. — Vol. 119, no. 2. — P. 157—167.
- ↑ Li Z., Van Calcar S., Qu C., Cavenee W., Zhang M., Ren B. A global transcriptional regulatory role for c-Myc in Burkitt’s lymphoma cells (англ.) // Proceedings of the National Academy of Sciences of the United States of America : journal. — 2003. — Vol. 100, no. 14. — P. 8164—9.
- ↑ Schoeffler A., Berger J. Recent advances in understanding structure-function relationships in the type II topoisomerase mechanism (англ.) // Biochem Soc Trans (англ.) (рус. : journal. — 2005. — Vol. 33, no. Pt 6. — P. 1465—70.
- ↑ Tuteja N., Tuteja R. Unraveling DNA helicases. Motif, structure, mechanism and function (англ.) // Eur J Biochem (англ.) (рус. : journal. — 2004. — Vol. 271, no. 10. — P. 1849—1863.
- ↑ Bickle T., Krüger D. Biology of DNA restriction (англ.) // Microbiology and Molecular Biology Reviews (англ.) (рус. : journal. — American Society for Microbiology (англ.) (рус., 1993. — Vol. 57, no. 2. — P. 434—50.
- ↑ Joyce C., Steitz T. Polymerase structures and function: variations on a theme? (англ.) // American Society for Microbiology (англ.) (рус. : journal. — 1995. — Vol. 177, no. 22. — P. 6321—9.
- ↑ Hubscher U., Maga G., Spadari S. Eukaryotic DNA polymerases (англ.) // Annu Rev Biochem (англ.) (рус. : journal. — Vol. 71. — P. 133—63.
- ↑ Johnson A., O’Donnell M. Cellular DNA replicases: components and dynamics at the replication fork (англ.) // Annu Rev Biochem (англ.) (рус. : journal. — Vol. 74. — P. 283—315.
- ↑ Tarrago-Litvak L., Andréola M., Nevinsky G., Sarih-Cottin L., Litvak S. The reverse transcriptase of HIV-1: from enzymology to therapeutic intervention (англ.) // The FASEB Journal (англ.) (рус. : journal. — Federation of American Societies for Experimental Biology (англ.) (рус., 1994. — Vol. 8, no. 8. — P. 497—503.
- ↑ Martinez E. Multi-protein complexes in eukaryotic gene transcription (неопр.) // Plant Mol Biol. — 2002. — Т. 50, № 6. — С. 925—47.
- ↑ Cremer T., Cremer C. Chromosome territories, nuclear architecture and gene regulation in mammalian cells (англ.) // Nat Rev Genet : journal. — 2001. — Vol. 2, no. 4. — P. 292—301.
- ↑ Pál C., Papp B., Lercher M. An integrated view of protein evolution (англ.) // Nat Rev Genet : journal. — 2006. — Vol. 7, no. 5. — P. 337—48.
- ↑ O’Driscoll M., Jeggo P. The role of double-strand break repair – insights from human genetics (англ.) // Nat Rev Genet : journal. — 2006. — Vol. 7, no. 1. — P. 45—54.
- ↑ Dickman M., Ingleston S., Sedelnikova S., Rafferty J., Lloyd R., Grasby J., Hornby D. The RuvABC resolvasome (англ.) // Eur J Biochem (англ.) (рус. : journal. — 2002. — Vol. 269, no. 22. — P. 5492—501.
- ↑ Joyce G. The antiquity of RNA-based evolution (англ.) // Nature. — 2002. — Vol. 418, no. 6894. — P. 214—21.
- ↑ Orgel L. Prebiotic chemistry and the origin of the RNA world (англ.) // Crit Rev Biochem Mol Biol (англ.) (рус. : journal. — Vol. 39, no. 2. — P. 99—123. Архивировано 28 июня 2007 года.
- ↑ Davenport R. Ribozymes. Making copies in the RNA world (англ.) // Science. — 2001. — Vol. 292, no. 5520. — P. 1278. — PMID 11360970.
- ↑ Szathmáry E. What is the optimum size for the genetic alphabet? (англ.) // Proceedings of the National Academy of Sciences of the United States of America : journal. — 1992. — Vol. 89, no. 7. — P. 2614—8. — PMID 1372984.
- ↑ Vreeland R., Rosenzweig W., Powers D. Isolation of a 250 million-year-old halotolerant bacterium from a primary salt crystal (англ.) // Nature : journal. — 2000. — Vol. 407, no. 6806. — P. 897—900.
- ↑ Hebsgaard M., Phillips M., Willerslev E. Geologically ancient DNA: fact or artefact? (англ.) // Trends Microbiol (англ.) (рус. : journal. — 2005. — Vol. 13, no. 5. — P. 212—20.
- ↑ Nickle D., Learn G., Rain M., Mullins J., Mittler J. Curiously modern DNA for a “250 million-year-old” bacterium (англ.) // J Mol Evol (англ.) (рус. : journal. — 2002. — Vol. 54, no. 1. — P. 134—7.
Литература[править | править код]
- Альбертс Б., Брей Д., Льюис Дж. и др. Молекулярная биология клетки в 3-х томах. — М.: Мир, 1994. — 1558 с. — ISBN 5-03-001986-3.
- Докинз Р. Эгоистичный ген. — М.: Мир, 1993. — 318 с. — ISBN 5-03-002531-6.
- История биологии с начала XX века до наших дней. — М.: Наука, 1975. — 660 с.
- Льюин Б. Гены. — М.: Мир, 1987. — 544 с.
- Пташне М. Переключение генов. Регуляция генной активности и фаг лямбда. — М.: Мир, 1989. — 160 с. Все форумы > Книга «переключение генов» М. Пташне Архивная копия от 30 октября 2007 на Wayback Machine.
- Уотсон Дж. Д. Двойная спираль: воспоминания об открытии структуры ДНК. Архивная копия от 18 января 2012 на Wayback Machine — М.: Мир, 1969. — 152 с.
- Франк-Каменецкий, М. Самая главная молекула: От структуры ДНК до биомедицины XXI века. — 2-е изд. — М.: Альпина нон-фикшн, 2018. — 336 с. — ISBN 978-5-00139-038-1.
Ссылки[править | править код]
- Методы Архивная копия от 8 июня 2007 на Wayback Machine выделения и исследования ДНК.
- Веб-адреса молекулярно-биологических журналов Архивная копия от 15 августа 2007 на Wayback Machine.
- Международная база данных Архивная копия от 21 марта 2010 на Wayback Machine — последовательности ДНК из разных организмов (англ.).
- Веб-сайт Сэнгеровского Института Архивная копия от 8 января 2021 на Wayback Machine одного из мировых лидеров в области определения последовательностей ДНК и их анализа (англ.).
ДНК и гены
ДНК ПРОКАРИОТ И ЭУКАРИОТ
 |
|
, вошедшая в книгу рекордов Гиннесса")
Справа крупнейшая спираль ДНК человека, выстроенная из людей на пляже в Варне (Болгария), вошедшая в книгу рекордов Гиннесса 23 апреля 2016 года
Дезоксирибонуклеиновая кислота. Общие сведения
 Содержание страницы:
Содержание страницы:
- Дезоксирибонуклеиновая кислота
- Строение нуклеиновых кислот
- Репликация
- Строение РНК
- Транскрипция
- Трансляция
- Генетический код
- Геном: гены и хромосомы
- Прокариоты
- Эукариоты
- Строение генов
- Строение генов прокариот
- Строение генов эукариот
- Сравнение строения генов
- Мутации и мутагенез
- Генные мутации
- Хромосомные мутации
- Геномные мутации
- Видео по теме ДНК
- Дополнительный материал
ДНК (дезоксирибонуклеиновая кислота) – своеобразный чертеж жизни, сложный код, в котором заключены данные о наследственной информации. Эта сложная макромолекула способна хранить и передавать наследственную генетическую информацию из поколения в поколение. ДНК определяет такие свойства любого живого организма как наследственность и изменчивость. Закодированная в ней информация задает всю программу развития любого живого организма. Генетически заложенные факторы предопределяют весь ход жизни как человека, так и любого др. организхма. Искусственное или естественное воздействие внешней среды способны лишь в незначительной степени повлиять на общую выраженность отдельных генетических признаков или сказаться на развитии запрограммированных процессов.
Дезоксирибонуклеи́новая кислота (ДНК) — макромолекула (одна из трёх основных, две другие — РНК и белки), обеспечивающая хранение, передачу из поколения в поколение и реализацию генетической программы развития и функционирования живых организмов. ДНК содержит информацию о структуре различных видов РНК и белков.
В клетках эукариот (животных, растений и грибов) ДНК находится в ядре клетки в составе хромосом, а также в некоторых клеточных органоидах (митохондриях и пластидах). В клетках прокариотических организмов (бактерий и архей) кольцевая или линейная молекула ДНК, так называемый нуклеоид, прикреплена изнутри к клеточной мембране. У них и у низших эукариот (например, дрожжей) встречаются также небольшие автономные, преимущественно кольцевые молекулы ДНК, называемые плазмидами.
С химической точки зрения ДНК — это длинная полимерная молекула, состоящая из повторяющихся блоков — нуклеотидов. Каждый нуклеотид состоит из азотистого основания, сахара (дезоксирибозы) и фосфатной группы. Связи между нуклеотидами в цепи образуются за счёт дезоксирибозы (С) и фосфатной (Ф) группы (фосфодиэфирные связи).
 и фосфатной группы.")
Рис. 2. Нуклертид состоит из азотистого основания, сахара (дезоксирибозы) и фосфатной группы
В подавляющем большинстве случаев (кроме некоторых вирусов, содержащих одноцепочечную ДНК) макромолекула ДНК состоит из двух цепей, ориентированных азотистыми основаниями друг к другу. Эта двухцепочечная молекула закручена по винтовой линии.
В ДНК встречается четыре вида азотистых оснований (аденин, гуанин, тимин и цитозин). Азотистые основания одной из цепей соединены с азотистыми основаниями другой цепи водородными связями согласно принципу комплементарности: аденин соединяется только с тимином (А-Т), гуанин — только с цитозином (Г-Ц). Именно эти пары и составляют «перекладины» винтовой “лестницы” ДНК (см.: рис. 2, 3 и 4).

Рис. 2. Азотистые основания
Последовательность нуклеотидов позволяет «кодировать» информацию о различных типах РНК, наиболее важными из которых являются информационные, или матричные (мРНК), рибосомальные (рРНК) и транспортные (тРНК). Все эти типы РНК синтезируются на матрице ДНК за счёт копирования последовательности ДНК в последовательность РНК, синтезируемой в процессе транскрипции, и принимают участие в биосинтезе белков (процессе трансляции). Помимо кодирующих последовательностей, ДНК клеток содержит последовательности, выполняющие регуляторные и структурные функции.

Рис. 3. Репликация ДНК
Расположение базовых комбинаций химических соединений ДНК и количественные соотношения между этими комбинациями обеспечивают кодирование наследственной информации.
Образование новой ДНК (репликация)
- Процесс репликации: раскручивание двойной спирали ДНК — синтез комплементарных цепей ДНК-полимеразой — образование двух молекул ДНК из одной.
- Двойная спираль «расстегивается» на две ветви, когда ферменты разрушают связь между базовыми парами химических соединений.
- Каждая ветвь является элементом новой ДНК. Новые базовые пары соединяются в той же последовательности, что и в родительской ветви.
По завершении дупликации образуются две самостоятельные спирали, созданные из химических соединений родительской ДНК и имеющие с ней одинаковый генетический код. Таким путем ДНК способна перерывать информацию от клетки к клетке.
Более подробная информация:
СТРОЕНИЕ НУКЛЕИНОВЫХ КИСЛОТ

Рис. 4 . Азотистые основания: аденин, гуанин, цитозин, тимин
Дезоксирибонуклеиновая кислота (ДНК) относится к нуклеиновым кислотам. Нуклеиновые кислоты – это класс нерегулярных биополимеров, мономерами которых являются нуклеотиды.
НУКЛЕОТИДЫ состоят из азотистого основания, соединенного с пятиуглеродным углеводом (пентозой) – дезоксирибозой (в случае ДНК) или рибозой (в случае РНК), который соединяется с остатком фосфорной кислоты (H2PO3–).
Азотистые основания бывают двух типов: пиримидиновые основания – урацил (только в РНК), цитозин и тимин, пуриновые основания – аденин и гуанин.

Рис. 5. Структура нуклеотидов (слева), расположение нуклеотида в ДНК (снизу) и типы азотистых оснований (справа): пиримидиновые и пуриновые

Атомы углерода в молекуле пентозы нумеруются числами от 1 до 5. Фосфат соединяется с третьим и пятым атомами углерода. Так нуклеинотиды соединяются в цепь нуклеиновой кислоты. Таким образом, мы можем выделить 3’ и 5’-концы цепи ДНК:

Рис. 6. Выделение 3’ и 5’-концов цепи ДНК
Две цепи ДНК образуют двойную спираль. Эти цепи в спирали сориентированы в противоположных направлениях. В разных цепях ДНК азотистые основания соединены между собой с помощью водородных связей. Аденин всегда соединяется с тимином, а цитозин – с гуанином. Это называется правилом комплементарности (см. принцип комплементарности).
Правило комплементарности:
Например, если нам дана цепь ДНК, имеющая последовательность
3’– ATGTCCTAGCTGCTCG – 5’,
то вторая ей цепь будет комплементарна и направлена в противоположном направлении – от 5’-конца к 3’-концу:
5’– TACAGGATCGACGAGC– 3’.

Рис. 7. Направленность цепей молекулы ДНК и соединение азотистых оснований с помощью водородных связей
РЕПЛИКАЦИЯ ДНК
Репликация ДНК – это процесс удвоения молекулы ДНК путем матричного синтеза. В большинстве случаев естественной репликации ДНК праймером для синтеза ДНК является короткий фрагмент РНК (создаваемый заново). Такой рибонуклеотидный праймер создается ферментом праймазой (ДНК-праймаза у прокариот, ДНК-полимераза у эукариот), и впоследствии заменяется дезоксирибонуклеотидами полимеразой, выполняющей в норме функции репарации (исправления химических повреждений и разрывов в молекле ДНК).
Репликация происходит по полуконсервативному механизму. Это значит, что двойная спираль ДНК расплетается и на каждой из ее цепей по принципу комплементарности достраивается новая цепь. Дочерняя молекула ДНК, таким образом, содержит в себе одну цепь от материнской молекулы и одну вновь синтезированную. Репликация происходит в направлении от 3’ к 5’ концу материнской цепи.

Рис. 8. Репликация (удвоение) молекулы ДНК
ДНК-синтез – это не такой сложный процесс, как может показаться на первый взгляд. Если подумать, то для начала нужно разобраться, что же такое синтез. Это процесс объединения чего-либо в одно целое. Образование новой молекулы ДНК проходит в несколько этапов:
1) ДНК-топоизомераза, располагаясь перед вилкой репликации, разрезает ДНК для того, чтобы облегчить ее расплетание и раскручивание.
2) ДНК-хеликаза вслед за топоизомеразой влияет на процесс «расплетения» спирали ДНК.
3) ДНК-связывающие белки осуществляют связывание нитей ДНК, а также проводят их стабилизацию, не допуская их прилипания друг к другу.
4) ДНК-полимераза δ (дельта), согласовано со скоростью движения репликативной вилки, осуществляет синтез ведущей цепи дочерней ДНК в направлении 5’→3′ на матрице материнской нити ДНК по направлению от ее 3′-конца к 5′-концу (скорость до 100 пар нуклеотидов в секунду). Этим события на данной материнской нити ДНК ограничиваются.

Рис. 9. Схематическое изображение процесса репликации ДНК: (1) Отстающая цепь (запаздывающая нить), (2) Ведущая цепь (лидирующая нить), (3) ДНК-полимераза α (Polα), (4) ДНК-лигаза, (5) РНК-праймер, (6) Праймаза, (7) Фрагмент Оказаки, (8) ДНК-полимераза δ (Polδ), (9) Хеликаза, (10) Однонитевые ДНК-связывающие белки, (11) Топоизомераза.
Далее описан синтез отстающей цепи дочерней ДНК (см. Схему репликативной вилки и функции ферментов репликации)
Нагляднее о репликации ДНК см. видео →
5) Непосредственно сразу после расплетания и стабилизации другой нити материнской молекулы к ней присоединяется ДНК-полимераза α (альфа) и в направлении 5’→3′ синтезирует праймер (РНК-затравку) – последовательность РНК на матрице ДНК длиной от 10 до 200 нуклеотидов. После этого фермент удаляется с нити ДНК.
Вместо ДНК-полимеразы α к 3′-концу праймера присоединяется ДНК-полимераза ε.
6) ДНК-полимераза ε (эпсилон) как бы продолжает удлинять праймер, но в качестве субстрата встраивает дезоксирибонуклеотиды (в количестве 150-200 нуклеотидов). В результате образуется цельная нить из двух частей – РНК (т.е. праймер) и ДНК. ДНК-полимераза ε работает до тех пор, пока не встретит праймер предыдущего фрагмента Оказаки (синтезированный чуть ранее). После этого данный фермент удаляется с цепи.
7) ДНК-полимераза β (бета) встает вместо ДНК-полимеразы ε, движется в том же направлении (5’→3′) и удаляет рибонуклеотиды праймера, одновременно встраивая дезоксирибонуклеотиды на их место. Фермент работает до полного удаления праймера, т.е. пока на его пути не встанет дезоксирибонуклеотид (еще более ранее синтезированный ДНК-полимеразой ε). Связать результат свой работы и впереди стоящую ДНК фермент не в состоянии, поэтому он сходит с цепи.
В результате на матрице материнской нити “лежит” фрагмент дочерней ДНК. Он называется фрагмент Оказаки.
8) ДНК-лигаза производит сшивку двух соседних фрагментов Оказаки, т.е. 5′-конца отрезка, синтезированного ДНК-полимеразой ε, и 3′-конца цепи, встроенного ДНК-полимеразой β.
СТРОЕНИЕ РНК
Рибонуклеиновая кислота (РНК) — одна из трёх основных макромолекул (две другие — ДНК и белки), которые содержатся в клетках всех живых организмов.
Так же, как ДНК, РНК состоит из длинной цепи, в которой каждое звено называется нуклеотидом. Каждый нуклеотид состоит из азотистого основания, сахара рибозы и фосфатной группы. Однако в отличие от ДНК, РНК обычно имеет не две цепи, а одну. Пентоза в РНК представлена рибозой, а не дезоксирибозой (у рибозы присутствует дополнительная гидроксильная группа на втором атоме углевода). Наконец, ДНК отличается от РНК по составу азотистых оснований: вместо тимина (Т) в РНК представлен урацил (U), который также комплементарен аденину.
Последовательность нуклеотидов позволяет РНК кодировать генетическую информацию. Все клеточные организмы используют РНК (мРНК) для программирования синтеза белков.
Клеточные РНК образуются в ходе процесса, называемого транскрипцией, то есть синтеза РНК на матрице ДНК, осуществляемого специальными ферментами – РНК-полимеразами.
Затем матричные РНК (мРНК) принимают участие в процессе, называемом трансляцией, т.е. синтеза белка на матрице мРНК при участии рибосом. Другие РНК после транскрипции подвергаются химическим модификациям, и после образования вторичной и третичной структур выполняют функции, зависящие от типа РНК.

Рис. 10. Отличие ДНК от РНК по азотистому основанию: вместо тимина (Т) в РНК представлен урацил (U), который также комплементарен аденину.
ТРАНСКРИПЦИЯ
Транскрипция – это процесс синтеза РНК на матрице ДНК. ДНК раскручивается на одном из участков. На одной из цепей содержится информация, которую необходимо скопировать на молекулу РНК – эта цепь называется кодирующей. Вторая цепь ДНК, комплементарная кодирующей, называется матричной. В процессе транскрипции на матричной цепи в направлении 3’ – 5’ (по цепи ДНК) синтезируется комплементарная ей цепь РНК. Таким образом, создается РНК-копия кодирующей цепи.

Рис. 11. Схематическое изображение транскрипции
Например, если нам дана последовательность кодирующей цепи
3’– ATGTCCTAGCTGCTCG – 5’,
то, по правилу комплементарности, матричная цепь будет нести последовательность
5’– TACAGGATCGACGAGC– 3’,
а синтезируемая с нее РНК – последовательность
3’– AUGUCCUAGCUGCUCG – 5’.
ТРАНСЛЯЦИЯ
Рассмотрим механизм синтеза белка на матрице РНК, а также генетический код и его свойства. Также для наглядности по ниже приведенной ссылке рекомендуем посмотреть небольшое видео о процессах транскрипции и трансляции, происходящих в живой клетке:
|
|
В представленном видоролике (кнопка-ссылка слева) показан процесс образования белка из аминокислот. Наглядно (в анимированном варианте) продемонстрированы процессы транскрипции и трансляции. Биосинтез белка на рибосоме также кратко описан в разделе Аминокислоты белков. Более подробное видео о геноме, ДНК и ее структуре, а также процессах кодировки представленно ниже на данной странице: Видео по теме ДНК |


Рис. 12. Процесс синтеза белка: ДНК кодирует РНК, РНК кодирует белок
Трансляция – это процесс, посредством которого генетическая информация преобразуется в белки, рабочие лошадки клетки. Небольшие молекулы, называемые переносными РНК («тРНК»), играют решающую роль в трансляции; они являются молекулами-адаптерами, которые соответствуют кодонам (строительным блокам генетической информации) с аминокислотами (строительными блоками белков). Организмы несут множество типов тРНК, каждая из которых кодируется одним или несколькими генами («набор генов тРНК»).
Вообще говоря, функция набора генов тРНК – переводить 61 тип кодонов в 20 различных типов аминокислот – сохраняется в разных организмах. Тем не менее, состав набора генов тРНК может значительно варьировать между организмами.
ГЕНЕТИЧЕСКИЙ КОД
Генетический код – способ кодирования аминокислотной последовательности белков с помощью последовательности нуклеотидов. Каждая аминокислота кодируется последовательностью из трех нуклеотидов – кодоном или триплетом.
Генетический код, общий для большинства про- и эукариот. В таблице приведены все 64 кодона и указаны соответствующие аминокислоты. Порядок оснований — от 5′ к 3′ концу мРНК.
Таблица 1. Стандартный генетический код
|
1-е ние |
2-е основание |
3-е ние |
|||||||
|
U |
C |
A |
G |
||||||
|
U |
UUU |
Фенилаланин (Phe/F) |
UCU |
Серин (Ser/S) |
UAU |
Тирозин (Tyr/Y) |
UGU |
Цистеин (Cys/C) |
U |
|
UUC |
UCC |
UAC |
UGC |
C |
|||||
|
UUA |
Лейцин (Leu/L) |
UCA |
UAA |
Стоп-кодон** |
UGA |
Стоп-кодон** |
A |
||
|
UUG |
UCG |
UAG |
Стоп-кодон** |
UGG |
Триптофан (Trp/W) |
G |
|||
|
C |
CUU |
CCU |
Пролин (Pro/P) |
CAU |
Гистидин (His/H) |
CGU |
Аргинин (Arg/R) |
U |
|
|
CUC |
CCC |
CAC |
CGC |
C |
|||||
|
CUA |
CCA |
CAA |
Глутамин (Gln/Q) |
CGA |
A |
||||
|
CUG |
CCG |
CAG |
CGG |
G |
|||||
|
A |
AUU |
Изолейцин (Ile/I) |
ACU |
Треонин (Thr/T) |
AAU |
Аспарагин (Asn/N) |
AGU |
Серин (Ser/S) |
U |
|
AUC |
ACC |
AAC |
AGC |
C |
|||||
|
AUA |
ACA |
AAA |
Лизин (Lys/K) |
AGA |
Аргинин (Arg/R) |
A |
|||
|
AUG |
Метионин* (Met/M) |
ACG |
AAG |
AGG |
G |
||||
|
G |
GUU |
Валин (Val/V) |
GCU |
Аланин (Ala/A) |
GAU |
Аспарагиновая кислота (Asp/D) |
GGU |
Глицин (Gly/G) |
U |
|
GUC |
GCC |
GAC |
GGC |
C |
|||||
|
GUA |
GCA |
GAA |
Глутаминовая кислота (Glu/E) |
GGA |
A |
||||
|
GUG |
GCG |
GAG |
GGG |
G |
Среди триплетов есть 4 специальных последовательности, выполняющих функции «знаков препинания»:
- *Триплет AUG, также кодирующий метионин, называется старт-кодоном. С этого кодона начинается синтез молекулы белка. Таким образом, во время синтеза белка, первой аминокислотой в последовательности всегда будет метионин.
- **Триплеты UAA, UAG и UGA называются стоп-кодонами и не кодируют ни одной аминокислоты. На этих последовательностях синтез белка прекращается.
Свойства генетического кода
1. Триплетность. Каждая аминокислота кодируется последовательностью из трех нуклеотидов – триплетом или кодоном.

2. Непрерывность. Между триплетами нет никаких дополнительных нуклеотидов, информация считывается непрерывно.

3. Неперекрываемость. Один нуклеотид не может входить одновременно в два триплета.

4. Однозначность. Один кодон может кодировать только одну аминокислоту.

5. Вырожденность. Одна аминокислота может кодироваться несколькими разными кодонами.

6. Универсальность. Генетический код одинаков для всех живых организмов.
Пример. Нам дана последовательность кодирующей цепи:
3’– CCGATTGCACGTCGATCGTATA– 5’.
Матричная цепь будет иметь последовательность:
5’– GGCTAACGTGCAGCTAGCATAT– 3’.
Теперь «синтезируем» с этой цепи информационную РНК:
3’– CCGAUUGCACGUCGAUCGUAUA– 5’.
Синтез белка идет в направлении 5’ → 3’, следовательно, нам нужно перевернуть последовательность, чтобы «прочитать» генетический код:
5’– AUAUGCUAGCUGCACGUUAGCC– 3’.
Теперь найдем старт-кодон AUG:
5’– AUAUGCUAGCUGCACGUUAGCC– 3’.
Разделим последовательность на триплеты:
![]()
Найдем стоп-кодон и согласно таблице генетического кода запишем последовательность аминокислот:

Центральная догма молекулярной биологии звучит следующим образом: информация с ДНК передается на РНК (транскрипция), с РНК – на белок (трансляция). ДНК также может удваиваться путем репликации, и также возможен процесс обратной транскрипции, когда по матрице РНК синтезируется ДНК, но такой процесс в основном характерен для вирусов.

Рис. 13. Центральная догма молекулярной биологии
ГЕНОМ: ГЕНЫ и ХРОМОСОМЫ
(общие понятия)
Геном – совокупность всех генов организма; его полный хромосомный набор.
Термин “геном” был предложен Г. Винклером в 1920 г. для описания совокупности генов, заключенных в гаплоидном наборе хромосом организмов одного биологического вида. Первоначальный смысл этого термина указывал на то, что понятие генома в отличие от генотипа является генетической характеристикой вида в целом, а не отдельной особи. С развитием молекулярной генетики значение данного термина изменилось. Известно, что ДНК, которая является носителем генетической информации у большинства организмов и, следовательно, составляет основу генома, включает в себя не только гены в современном смысле этого слова. Большая часть ДНК эукариотических клеток представлена некодирующими (“избыточными”) последовательностями нуклеотидов, которые не заключают в себе информации о белках и нуклеиновых кислотах. Таким образом, основную часть генома любого организма составляет вся ДНК его гаплоидного набора хромосом.
Гены — это участки молекул ДНК, кодирующие полипептиды и молекулы РНК
За последнее столетие наше представление о генах существенно изменилось. Ранее геном называли участок хромосомы, кодирующий или определяющий один признак или фенотипическое (видимое) свойство, например цвет глаз.
|
|
|
Рис. 14. Соответствие между кодирующими участками ДНК, мРНК и аминокислотной последовательностью полипептидной цепи. |

В 1940 г. Джордж Бидл и Эдвард Тейтем предложили молекулярное определение гена. Ученые обрабатывали споры гриба Neurospora crassa рентгеновским излучением и другими агентами, вызывающими изменения в последовательности ДНК (мутации), и обнаружили мутантные штаммы гриба, утратившие некоторые специфические ферменты, что в некоторых случаях приводило к нарушению целого метаболического пути. Бидл и Тейтем пришли к выводу, что ген — это участок генетического материала, который определяет или кодирует один фермент. Так появилась гипотеза «один ген — один фермент». Позднее эта концепция была расширена до определения «один ген — один полипептид», поскольку многие гены кодируют белки, не являющиеся ферментами, а полипептид может оказаться субъединицей сложного белкового комплекса.
На рис. 14 показана схема того, как триплеты нуклеотидов в ДНК определяют полипептид – аминокислотную последовательность белка при посредничестве мРНК. Одна из цепей ДНК играет роль матрицы для синтеза мРНК, нуклеотидные триплеты (кодоны) которой комплементарны триплетам ДНК. У некоторых бактерий и многих эукариот кодирующие последовательности прерываются некодирующими участками(так называемыми интронами).
Современное биохимическое определение гена еще более конкретно. Генами называются все участки ДНК, кодирующие первичную последовательность конечных продуктов, к которым относятся полипептиды или РНК, обладающие структурной или каталитической функцией.
Наряду с генами ДНК содержит и другие последовательности, выполняющие исключительно регуляторную функцию. Регуляторные последовательности могут обозначать начало или конец генов, влиять на транскрипцию или указывать место инициации репликации или рекомбинации. Некоторые гены могут экспрессироваться разными путями, при этом один и тот же участок ДНК служит матрицей для образования разных продуктов.
Мы можем приблизительно рассчитать минимальный размер гена, кодирующего средний белок. Каждая аминокислота в полипептидной цепи кодируется последовательностью из трех нуклеотидов; последовательности этих триплетов (кодонов) соответствуют цепочке аминокислот в полипептиде, который кодируется данным геном. Полипептидная цепь из 350 аминокислотных остатков (цепь средней длины) соответствует последовательности из 1050 п.н. (пар нуклеотидов). Однако многие гены эукариот и некоторые гены прокариот прерываются сегментами ДНК, не несущими информации о белке, и поэтому оказываются значительно длиннее, чем показывает простой расчет.
Сколько генов в одной хромосоме?
 Рис. 15. Вид хромосом в прокаритической (слева) и эукариотической клеках. Гистоны (Histones) — обширный класс ядерных белков, выполняющих две основные функции: они участвуют в упаковке нитей ДНК в ядре и в эпигенетической регуляции таких ядерных процессов, как транскрипция, репликация и репарация.
Рис. 15. Вид хромосом в прокаритической (слева) и эукариотической клеках. Гистоны (Histones) — обширный класс ядерных белков, выполняющих две основные функции: они участвуют в упаковке нитей ДНК в ядре и в эпигенетической регуляции таких ядерных процессов, как транскрипция, репликация и репарация.
ДНК прокариот устроена более просто: их клетки не имеют ядра, поэтому ДНК находится непосредственно в цитоплазме в форме нуклеоида.
 Как известно, бактериальные клетки имеют хромосому в виде нити ДНК, уложенной в компактную структуру – нуклеоид. Хромосома прокариота Escherichia coli, чей геном полностью расшифрован, представляет собой кольцевую молекулу ДНК (на самом деле, это не правильный круг, а скорее петля без начала и конца), состоящую из 4 639 675 п.н. В этой последовательности содержится примерно 4300 генов белков и еще 157 генов стабильных молекул РНК. В геноме человека примерно 3,1 млрд пар нуклеотидов, соответствующих почти 29 000 генам, расположенным на 24 разных хромосомах.
Как известно, бактериальные клетки имеют хромосому в виде нити ДНК, уложенной в компактную структуру – нуклеоид. Хромосома прокариота Escherichia coli, чей геном полностью расшифрован, представляет собой кольцевую молекулу ДНК (на самом деле, это не правильный круг, а скорее петля без начала и конца), состоящую из 4 639 675 п.н. В этой последовательности содержится примерно 4300 генов белков и еще 157 генов стабильных молекул РНК. В геноме человека примерно 3,1 млрд пар нуклеотидов, соответствующих почти 29 000 генам, расположенным на 24 разных хромосомах.
Прокариоты (Бактерии).
 Бактерия E. coli имеет одну двухцепочечную кольцевую молекулу ДНК. Она состоит из 4 639 675 п.н. и достигает в длину примерно 1,7 мм, что превышает длину самой клетки E. coli приблизительно в 850 раз. Помимо крупной кольцевой хромосомы в составе нуклеоида многие бактерии содержат одну или несколько маленьких кольцевых молекул ДНК, свободно располагающихся в цитозоле. Такие внехромосомные элементы называют плазмидами (рис. 16).
Бактерия E. coli имеет одну двухцепочечную кольцевую молекулу ДНК. Она состоит из 4 639 675 п.н. и достигает в длину примерно 1,7 мм, что превышает длину самой клетки E. coli приблизительно в 850 раз. Помимо крупной кольцевой хромосомы в составе нуклеоида многие бактерии содержат одну или несколько маленьких кольцевых молекул ДНК, свободно располагающихся в цитозоле. Такие внехромосомные элементы называют плазмидами (рис. 16).
Большинство плазмид состоит всего из нескольких тысяч пар нуклеотидов, некоторые содержат более 10000 п. н. Они несут генетическую информацию и реплицируются с образованием дочерних плазмид, которые попадают в дочерние клетки в процессе деления родительской клетки. Плазмиды обнаружены не только в бактериях, но также в дрожжах и других грибах. Во многих случаях плазмиды не дают никаких преимуществ клеткам-хозяевам, и их единственная задача — независимое воспроизведение. Однако некоторые плазмиды несут полезные для хозяина гены. Например, содержащиеся в плазмидах гены могут придавать клеткам бактерий устойчивость к антибактериальным агентам. Плазмиды, несущие ген β-лактамазы, обеспечивают устойчивость к β-лактамным антибиотикам, таким как пенициллин и амоксициллин. Плазмиды могут переходить от клеток, устойчивых к антибиотикам, к другим клеткам того же или другого вида бактерий, в результате чего эти клетки также становятся резистентными. Интенсивное применение антибиотиков является мощным селективным фактором, способствующим распространению плазмид, кодирующих устойчивость к антибиотикам (а также транспозонов, которые кодируют аналогичные гены) среди болезнетворных бактерий, и приводит к появлению бактериальных штаммов с устойчивостью к нескольким антибиотикам. Врачи начинают понимать опасность широкого использования антибиотиков и назначают их только в случае острой необходимости. По аналогичным причинам ограничивается широкое использование антибиотиков для лечения сельскохозяйственных животных.
См. также: Равин Н.В., Шестаков С.В. Геном прокариот // Вавиловский журнал генетики и селекции, 2013. Т. 17. № 4/2. С. 972–984.
Эукариоты.
Таблица 2. ДНК, гены и хромосомы некоторых организмов
|
Общая ДНК, п.н. |
Число хромосом* |
Примерное число генов |
|
|
Escherichia coli (бактерия) |
4 639 675 |
1 |
4 435 |
|
Saccharomyces cerevisiae (дрожжи) |
12 080 000 |
16** |
5 860 |
|
Caenorhabditis elegans (нематода) |
90 269 800 |
12*** |
23 000 |
|
Arabidopsis thaliana (растение) |
119 186 200 |
10 |
33 000 |
|
Drosophila melanogaster (плодовая мушка) |
120 367 260 |
18 |
20 000 |
|
Oryza sativa (рис) |
480 000 000 |
24 |
57 000 |
|
Mus musculus (мышь) |
2 634 266 500 |
40 |
27 000 |
|
Homo sapiens (человек) |
3 070 128 600 |
46 |
29 000 |
Примечание. Информация постоянно обновляется; для получения более свежей информации обратитесь к сайтам, посвященным отдельным геномным проектам
*Для всех эукариот, кроме дрожжей, приводится диплоидный набор хромосом. Диплоидный набор хромосом (от греч. diploos- двойной и eidos- вид) – двойной набор хромосом (2n), каждая из которых имеет себе гомологичную.
**Гаплоидный набор. Дикие штаммы дрожжей обычно имеют восемь (октаплоидный) или больше наборов таких хромосом.
***Для самок с двумя Х хромосомами. У самцов есть Х хромосома, но нет Y, т. е. всего 11 хромосом.
В клетке дрожжей, одних из самых маленьких эукариот, в 2,6 раза больше ДНК, чем в клетке E. coli (табл. 2). Клетки плодовой мушки Drosophila, классического объекта генетических исследований, содержат в 35 раз больше ДНК, а клетки человека — примерно в 700 раз больше ДНК, чем клетки E. coli. Многие растения и амфибии содержат еще больше ДНК. Генетический материал клеток эукариот организован в виде хромосом. Диплоидный набор хромосом (2n) зависит от вида организма (табл. 2).
Например, в соматической клетке человека 46 хромосом (рис. 17). Каждая хромосома эукариотической клетки, как показано на рис. 17, а, содержит одну очень крупную двухспиральную молекулу ДНК. Двадцать четыре хромосомы человека (22 парные хромосомы и две половые хромосомы X и Y) различаются по длине более чем в 25 раз. Каждая хромосома эукариот содержит определенный набор генов.

Рис. 17. Хромосомы эукариот. а — пара связанных и конденсированных сестринских хроматид из хромосомы человека. В такой форме эукариотические хромосомы пребывают после репликации и в метафазе в процессе митоза. б — полный набор хромосом из лейкоцита одного из авторов книги. В каждой нормальной соматической клетке человека содержится 46 хромосом.

Размер и функция ДНК как матрицы для хранения и передачи наследственного материала объясняют наличие особых структурных элементов в организации этой молекулы. У высших организмов ДНК распределена между хромосомами.
Совокупность ДНК (хромосом) организма называется геномом. Хромосомы находятся в клеточном ядре и формируют структуру, называемую хроматином. Хроматин представляет собой комплекс ДНК и основных белков (гистонов) в соотношении 1:1. Длину ДНК обычно измеряют числом пар комплементарных нуклеотидов (п.н.). Например, 3-я хромосома человека представляет собой молекулу ДНК размером 160 млн п.н.. Выделенная линеаризованная ДНК размером 3*106 п.н. имеет длину примерно 1 мм, следовательно, линеаризованная молекула 3-й хромосомы человека была бы 5 мм в длину, а ДНК всех 23 хромосом (~3*109 п.н., MR = 1,8*1012) гаплоидной клетки – яйцеклетки или сперматозоида – в линеаризованном виде составляла бы 1 м. За исключением половых клеток, все клетки организма человека (их около 1013) содержат двойной набор хромосом. При клеточном делении все 46 молекул ДНК реплицируются и снова организуются в 46 хромосом.
Если соединить между собой молекулы ДНК человеческого генома (22 хромосомы и хромосомы X и Y или Х и Х), получится последовательность длиной около одного метра. Прим.: У всех млекопитающих и других организмов с гетерогаметным мужским полом, у самок две X-хромосомы (XX), а у самцов — одна X-хромосома и одна Y-хромосома (XY).
Большинство клеток человека диплоидны, поэтому общая длина ДНК таких клеток около 2м. У взрослого человека примерно 1014 клеток, таким образом, общая длина всех молекул ДНК составляет 2・1011 км. Для сравнения, окружность Земли — 4・104 км, а расстояние от Земли до Солнца — 1,5・108 км. Вот как удивительно компактно упакована ДНК в наших клетках!
В клетках эукариот есть и другие органеллы, содержащие ДНК, — это митохондрии и хлоропласты. Выдвигалось множество гипотез относительно происхождения ДНК митохондрий и хлоропластов. Общепризнанная сегодня точка зрения заключается в том, что они представляют собой рудименты хромосом древних бактерий, которые проникли в цитоплазму хозяйских клеток и стали предшественниками этих органелл. Митохондриальная ДНК кодирует митохондриальные тРНК и рРНК, а также несколько митохондриальных белков. Более 95% митохондриальных белков кодируется ядерной ДНК.
СТРОЕНИЕ ГЕНОВ
Рассмотрим строение гена у прокариот и эукариот, их сходства и различия. Несмотря на то, что ген — это участок ДНК, кодирующий всего один белок или РНК, кроме непосредственно кодирующей части, он также включает в себя регуляторные и иные структурные элементы, имеющие разное строение у прокариот и эукариот.
Кодирующая последовательность – основная структурно-функциональная единица гена, именно в ней находятся триплеты нуклеотидов, кодирующие аминокислотную последовательность. Она начинается со старт-кодона и заканчивается стоп-кодоном.
До и после кодирующей последовательности находятся нетранслируемые 5’- и 3’-последовательности. Они выполняют регуляторные и вспомогательные функции, например, обеспечивают посадку рибосомы на и-РНК.
Нетранслируемые и кодирующая последовательности составлют единицу транскрипции – транскрибируемый участок ДНК, то есть участок ДНК, с которого происходит синтез и-РНК.
Терминатор – нетранскрибируемый участок ДНК в конце гена, на котором останавливается синтез РНК.
В начале гена находится регуляторная область, включающая в себя промотор и оператор.
Промотор – последовательность, с которой связывается полимераза в процессе инициации транскрипции. Оператор – это область, с которой могут связываться специальные белки – репрессоры, которые могут уменьшать активность синтеза РНК с этого гена – иначе говоря, уменьшать его экспрессию.
Строение генов у прокариот
Общий план строения генов у прокариот и эукариот не отличается – и те, и другие содержат регуляторную область с промотором и оператором, единицу транскрипции с кодирующей и нетранслируемыми последовательностями и терминатор. Однако организация генов у прокариот и эукариот отличается.

Рис. 18. Схема строения гена у прокариот (бактерий) – изображение увеличивается
В начале и в конце оперона есть единые регуляторные области для нескольких структурных генов. С транскрибируемого участка оперона считывается одна молекула и-РНК, которая содержит несколько кодирующих последовательностей, в каждой из которых есть свой старт- и стоп-кодон. С каждого из таких участков синтезируется один белок. Таким образом, с одной молекулы и-РНК синтезируется несколько молекул белка.
Для прокариот характерно объединение нескольких генов в единую функциональную единицу – оперон. Работу оперона могут регулировать другие гены, которые могут быть заметно удалены от самого оперона – регуляторы. Белок, транслируемый с этого гена называется репрессор. Он связывается с оператором оперона, регулируя экспрессию сразу всех генов, в нем содержащихся.
Для прокариот также характерно явление сопряжения транскрипции и трансляции.

Рис. 19 Явление сопряжения транскрипции и трансляции у прокариот – изображение увеличивается
Такое сопряжение не встречается у эукариот из-за наличия у них ядерной оболочки, отделяющей цитоплазму, где происходит трансляция, от генетического материала, на котором происходит транскрипция. У прокариот во время синтеза РНК на матрице ДНК с синтезируемой молекулой РНК может сразу связываться рибосома. Таким образом, трансляция начинается еще до завершения транскрипции. Более того, с одной молекулой РНК может одновременно связываться несколько рибосом, синтезируя сразу несколько молекул одного белка.
Строение генов у эукариот
Гены и хромосомы эукариот очень сложно организованы
У бактерий многих видов всего одна хромосома, и почти во всех случаях в каждой хромосоме присутствует по одной копии каждого гена. Лишь немногие гены, например гены рРНК, содержатся в нескольких копиях. Гены и регуляторные последовательности составляют практически весь геном прокариот. Более того, почти каждый ген строго соответствует аминокислотной последовательности (или последовательности РНК), которую он кодирует (рис. 14).
Структурная и функциональная организация генов эукариот гораздо сложнее. Исследование хромосом эукариот, а позднее секвенирование полных последовательностей геномов эукариот принесло много сюрпризов. Многие, если не большинство, генов эукариот обладают интересной особенностью: их нуклеотидные последовательности содержат один или несколько участков ДНК, в которых не кодируется аминокислотная последовательность полипептидного продукта. Такие нетранслируемые вставки нарушают прямое соответствие между нуклеотидной последовательностью гена и аминокислотной последовательностью кодируемого полипептида. Эти нетранслируемые сегменты в составе генов называют интронами, или встроенными последовательностями, а кодирующие сегменты — экзонами. У прокариот лишь немногие гены содержат интроны.
Итак, у эукариот практически не встречается объединение генов в опероны, и кодирующая последовательность гена эукариот чаще всего разделена на транслируемые участки – экзоны, и нетранслируемые участки – интроны.
В большинстве случаев функция интронов не установлена. В целом, лишь около 1,5% ДНК человека являются ≪кодирующими≫, т. е. несут информацию о белках или РНК. Однако с учетом крупных интронов получается, что ДНК человека на 30% состоит из генов. Поскольку гены составляют относительно небольшую долю в геноме человека, значительная часть ДНК остается неучтенной.

Рис. 16. Схема строение гена у эукариот – изображение увеличивается
С каждого гена сначала синтезируется незрелая, или пре-РНК, которая содержит в себе как интроны, так и экзоны.
После этого проходит процесс сплайсинга, в результате которого интронные участки вырезаются, и образуется зрелая иРНК, с которой может быть синтезирован белок.

Рис. 20. Процесс альтернативного сплайсинга – изображение увеличивается
Такая организация генов позволяет, например, осуществить процесс альтернативного сплайсинга, когда с одного гена могут быть синтезированы разные формы белка, за счет того, что в процессе сплайсинга экзоны могут сшиваться в разных последовательностях.
Сравнение строения генов прокариот и эукариот

Рис. 21. Отличия в строении генов прокариот и эукариот – изображение увеличивается
МУТАЦИИ И МУТАГЕНЕЗ
Мутацией называется стойкое изменение генотипа, то есть изменение нуклеотидной последовательности.
Процесс, который приводит к возникновению мутаций называется мутагенезом, а организм, все клетки которого несут одну и ту же мутацию — мутантом.
Мутационная теория была впервые сформулирована Гуго де Фризом в 1903 году. Современный ее вариант включает в себя следующие положения:
1. Мутации возникают внезапно, скачкообразно.
2. Мутации передаются из поколения в поколение.
3. Мутации могут быть полезными, вредными или нейтральными, доминантными или рецессивными.
4. Вероятность обнаружения мутаций зависит от числа исследованных особей.
5. Сходные мутации могут возникать повторно.
6. Мутации не направленны.
Мутации могут возникать под действием различных факторов. Различают мутации, возникшие под действием мутагенных воздействий: физических (например, ультрафиолета или радиации), химических (например, колхицина или активных форм кислорода) и биологических (например, вирусов). Также мутации могут быть вызваны ошибками репликации.
В зависимости от условий появления мутации подразделяют на спонтанные — то есть мутации, возникшие в нормальных условиях, и индуцированые — то есть мутации, которые возникли при особых условиях.
Мутации могут возникать не только в ядерной ДНК, но и, например, в ДНК митохондрий или пластид. Соответственно, мы можем выделять ядерные и цитоплазматические мутации.
В результате возникновения мутаций часто могут появляться новые аллели. Если мутантный аллель подавляет действие нормального, мутация называется доминантной. Если нормальный аллель подавляет мутантный, такая мутация называется рецессивной. Большинство мутаций, приводящих к возникновению новых аллелей являются рецессивными.
По эффекту выделяют мутации адаптивные, приводящие к повышению приспособленности организма к среде, нейтральные, не влияющие на выживаемость, вредные, понижающие приспособленность организмов к условиям среды и летальные, приводящие к смерти организма на ранних стадиях развития.
По последствиям выделяются мутации, приводящие к потери функции белка, мутации, приводящие к возникновению у белка новой функции, а также мутации, которые изменяют дозу гена, и, соответственно, дозу белка синтезируемого с него.
Мутация может возникнуть к любой клетке организма. Если мутация возникает в половой клетке, она называется герминативной (герминальной, или генеративной). Такие мутации не проявляются у того организма, у которого они появились, но приводят к появлению мутантов в потомстве и передаются по наследству, поэтому они важны для генетики и эволюции. Если мутация возникает в любой другой клетке, она называется соматической. Такая мутация может в той или иной степени проявляться у того организма, у которого она возникла, например, приводить к образованию раковых опухолей. Однако такая мутация не передается по наследству и не влияет на потомков.
Мутации могут затрагивать разные по размеру участки генома. Выделяют генные, хромосомные и геномные мутации.
Генные мутации
Мутации, которые возникают в масштабе меньшем, чем один ген, называются генными, или точечными (точковыми). Такие мутации приводят к изменению одного и нескольких нуклеотидов в последовательности. Среди генных мутаций выделяют замены, приводящие к замене одного нуклеотида на другой, делеции, приводящие к выпадению одного из нуклеотидов, инсерции, приводящие к добавлению лишнего нуклеотида в последовательность.

Рис. 23. Генные (точечные) мутации
По механизму воздействия на белок, генные мутации делят на: синонимичные, которые (в результате вырожденности генетического кода) не приводят к изменению аминокислотного состава белкового продукта, миссенс-мутации, которые приводят к замене одной аминокислоты на другую и могут влиять на структуру синтезируемого белка, хотя часто они оказываются незначительными, нонсенс-мутации, приводящие к замене кодирующего кодона на стоп-кодон, мутации, приводящие к нарушению сплайсинга:

Рис. 24. Схемы мутаций
Также по механизму воздействия на белок выделяют мутации, приводящие к сдвигу рамки считывания, например, инсерции и делеции. Такие мутации, как и нонсенс-мутации, хоть и возникают в одной точке гена, часто воздействуют на всю структуру белка, что может привести к полному изменению его структуры.
Рис. 25. Схема мутации, приводящей к сдвигу рамки считывания
Хромосомные мутации

Рис. 26. Хромосомные абберации
Хромосомными мутациями называются мутации, которые затрагивают отдельные гены в рамках одной хромосомы. Различают делеции, когда теряется один или несколько генов, дупликации, когда удваивается тот или иной ген или несколько генов, инверсии, когда участок хромосомы поворачивается на 180 градусов, транслокации, когда гены переходят с одной хромосомы на другую.

Рис. 27. Схемы хромосомных мутаций: делеции, дупликации, инверсии
|
|
|
|
Рис. 28. Транслокация |
Рис. 29. Хромосома до и после дупликации |


Геномные мутации
Наконец, геномные мутации затрагивают весь геном целиком, то есть меняется количество хромосом. Выделяют полиплоидии — увеличение плоидности клетки, и анеуплоидии, то есть изменение количества хромосом, например, трисомии (наличие у одной из хромосом дополнительного гомолога) и моносомии (отсутствие у хромосомы гомолога).
Видео по теме ДНК
РЕПЛИКАЦИЯ ДНК, КОДИРОВАНИЕ РНК, СИНТЕЗ БЕЛКА
(Если видео не отображается оно доступно по ссылке→)
См. дополнительно:
- Нуклеиновые кислоты (PDF)
- Общие сведения о секвенировании биополимеров
- Метагеномика и микробиом
- Бактериальный иммунитет и система CRISPR/Cas
- Трансляция белка на рисбосоме (общие сведения)
- Раскрыт секрет спиральной структуры ДНК (новое о ДНК)
- Антимутагенные свойства пробиотиков (в свете защиты ДНК)
- МикроРНК, микробиом кишечника и иммунитет
- Эпигенетика, короткоцепочечные жирные кислоты и врожденная иммунная память
- Замедление старения: роль питательных веществ и микробиоты в модуляции эпигенома (о метилировании ДНК)
Литература в помощь:
Будьте здоровы!
ССЫЛКИ К РАЗДЕЛУ О ПРЕПАРАТАХ ПРОБИОТИКАХ
- ПРОБИОТИКИ
- ПРОБИОТИКИ И ПРЕБИОТИКИ
- СИНБИОТИКИ
- ДОМАШНИЕ ЗАКВАСКИ
- КОНЦЕНТРАТ БИФИДОБАКТЕРИЙ ЖИДКИЙ
- ПРОПИОНИКС
- ЙОДПРОПИОНИКС
- СЕЛЕНПРОПИОНИКС
- ГЕМОПРОПИОВИТ
- БИФИКАРДИО
- ПРОБИОТИКИ С ПНЖК
- МИКРОЭЛЕМЕНТНЫЙ СОСТАВ
- БИФИДОБАКТЕРИИ
- ПРОПИОНОВОКИСЛЫЕ БАКТЕРИИ
- МИКРОБИОМ ЧЕЛОВЕКА
- МИКРОФЛОРА ЖКТ
- ДИСБИОЗ КИШЕЧНИКА
- МИКРОБИОМ и ВЗК
- МИКРОБИОМ И РАК
- МИКРОБИОМ, СЕРДЦЕ И СОСУДЫ
- МИКРОБИОМ И ПЕЧЕНЬ
- МИКРОБИОМ И ПОЧКИ
- МИКРОБИОМ И ЛЕГКИЕ
- МИКРОБИОМ И ПОДЖЕЛУДОЧНАЯ ЖЕЛЕЗА
- МИКРОБИОМ И ЩИТОВИДНАЯ ЖЕЛЕЗА
- МИКРОБИОМ И КОЖНЫЕ БОЛЕЗНИ
- МИКРОБИОМ И КОСТИ
- МИКРОБИОМ И ОЖИРЕНИЕ
- МИКРОБИОМ И САХАРНЫЙ ДИАБЕТ
- МИКРОБИОМ И ФУНКЦИИ МОЗГА
- АНТИОКСИДАНТНЫЕ СВОЙСТВА
- АНТИОКСИДАНТНЫЕ ФЕРМЕНТЫ
- АНТИМУТАГЕННАЯ АКТИВНОСТЬ
- МИКРОБИОМ и ИММУНИТЕТ
- МИКРОБИОМ И АУТОИММУННЫЕ БОЛЕЗНИ
- ПРОБИОТИКИ и ГРУДНЫЕ ДЕТИ
- ПРОБИОТИКИ, БЕРЕМЕННОСТЬ, РОДЫ
- ВИТАМИННЫЙ СИНТЕЗ
- АМИНОКИСЛОТНЫЙ СИНТЕЗ
- АНТИМИКРОБНЫЕ СВОЙСТВА
- КОРОТКОЦЕПОЧЕЧНЫЕ ЖИРНЫЕ КИСЛОТЫ
- СИНТЕЗ БАКТЕРИОЦИНОВ
- АЛИМЕНТАРНЫЕ ЗАБОЛЕВАНИЯ
- МИКРОБИОМ И ПРЕЦИЗИОННОЕ ПИТАНИЕ
- ФУНКЦИОНАЛЬНОЕ ПИТАНИЕ
- ПРОБИОТИКИ ДЛЯ СПОРТСМЕНОВ
- ПРОИЗВОДСТВО ПРОБИОТИКОВ
- ЗАКВАСКИ ДЛЯ ПИЩЕВОЙ ПРОМЫШЛЕННОСТИ
- НОВОСТИ
И транскрипция, и трансляция относятся к матричным биосинтезам. Матричным биосинтезом называется синтез
биополимеров (нуклеиновых кислот, белков) на матрице – нуклеиновой кислоте ДНК или РНК. Процессы матричного биосинтеза относятся к пластическому обмену: клетка расходует энергию АТФ.
Матричный синтез можно представить как создание копии исходной информации на несколько другом или новом
“генетическом языке”. Скоро вы все поймете – мы научимся достраивать по одной цепи ДНК другую, переводить РНК в ДНК
и наоборот, синтезировать белок с иРНК на рибосоме. В данной статье вас ждут подробные примеры решения задач, генетический словарик пригодится – перерисуйте его себе 🙂

Возьмем 3 абстрактных нуклеотида ДНК (триплет) – АТЦ. На иРНК этим нуклеотидам будут соответствовать – УАГ (кодон иРНК).
тРНК, комплементарная иРНК, будет иметь запись – АУЦ (антикодон тРНК). Три нуклеотида в зависимости от своего расположения
будут называться по-разному: триплет, кодон и антикодон. Обратите на это особое внимание.
Репликация ДНК – удвоение, дупликация (лат. replicatio — возобновление, лат. duplicatio – удвоение)
Процесс синтеза дочерней молекулы ДНК по матрице родительской ДНК. Нуклеотиды достраивает фермент ДНК-полимераза по
принципу комплементарности. Переводя действия данного фермента на наш язык, он следует следующему правилу: А (аденин) переводит в Т (тимин), Г (гуанин) – в Ц (цитозин).
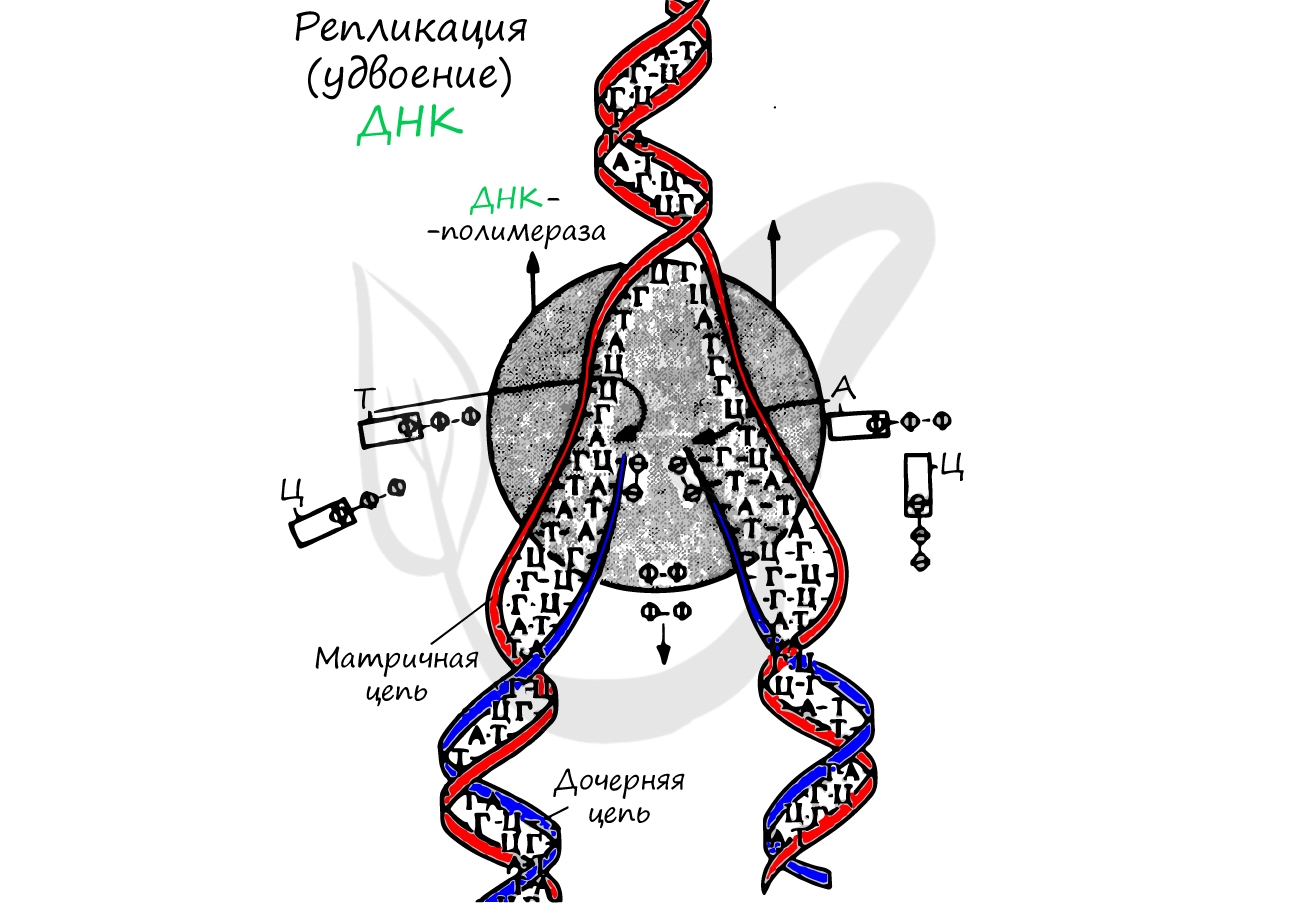
Удвоение ДНК происходит в синтетическом периоде интерфазы. При этом общее число хромосом не меняется, однако каждая из них
содержит к началу деления две молекулы ДНК: это необходимо для равномерного распределения генетического материала между
дочерними клетками.
Транскрипция (лат. transcriptio — переписывание)
Транскрипция представляет собой синтез информационной РНК (иРНК) по матрице ДНК. Несомненно, транскрипция происходит
в соответствии с принципом комплементарности азотистых оснований: А – У, Т – А, Г – Ц, Ц – Г (загляните в “генетический словарик”
выше).
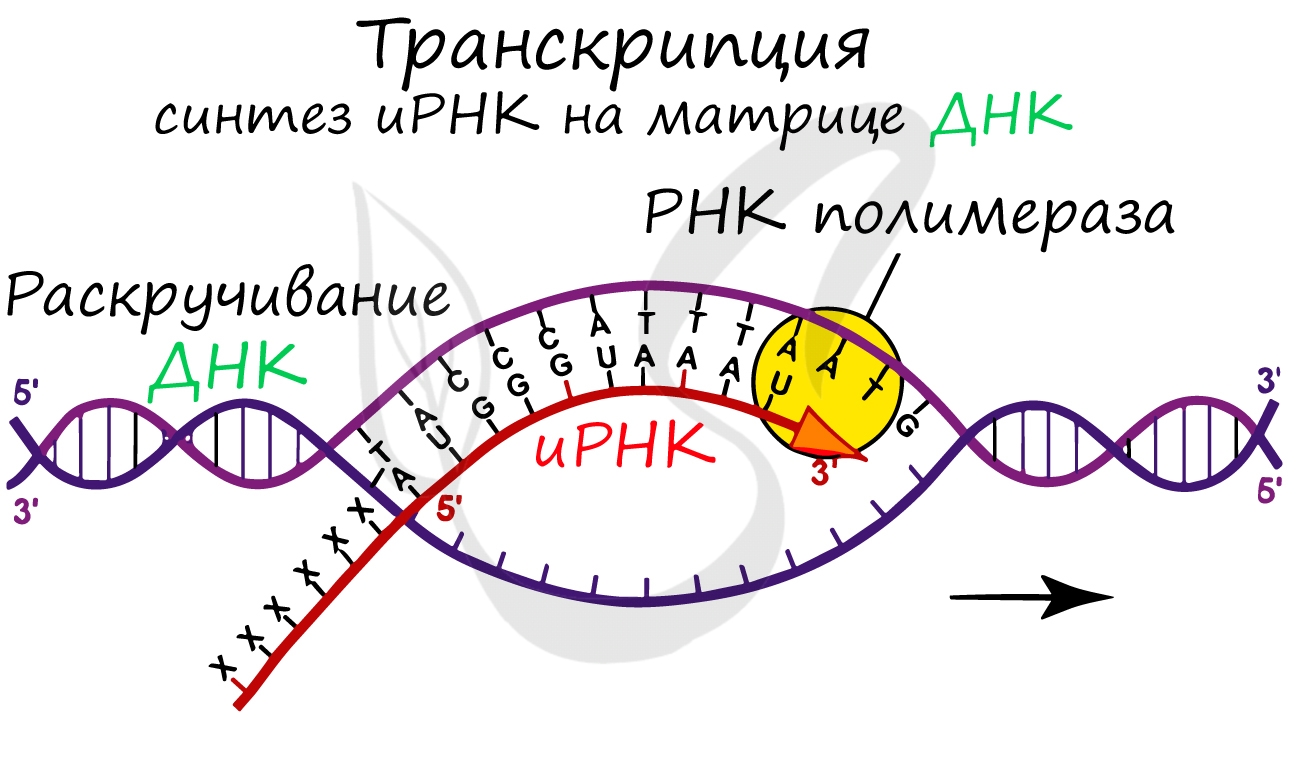
До начала непосредственно транскрипции происходит подготовительный этап: фермент РНК-полимераза узнает особый участок молекулы ДНК – промотор и связывается с ним. После связывания с промотором происходит раскручивание молекулы ДНК, состоящей из двух
цепей: транскрибируемой и смысловой. В процессе транскрипции принимает участие только транскрибируемая цепь ДНК.
Транскрипция осуществляется в несколько этапов:
- Инициация (лат. injicere — вызывать)
- Элонгация (лат. elongare — удлинять)
- Терминация (лат. terminalis — заключительный)
Образуется несколько начальных кодонов иРНК.
Нити ДНК последовательно расплетаются, освобождая место для передвигающейся РНК-полимеразы. Молекула иРНК
быстро растет.
Достигая особого участка цепи ДНК – терминатора, РНК-полимераза получает сигнал к прекращению синтеза иРНК. Транскрипция завершается. Синтезированная иРНК направляется из ядра в цитоплазму.
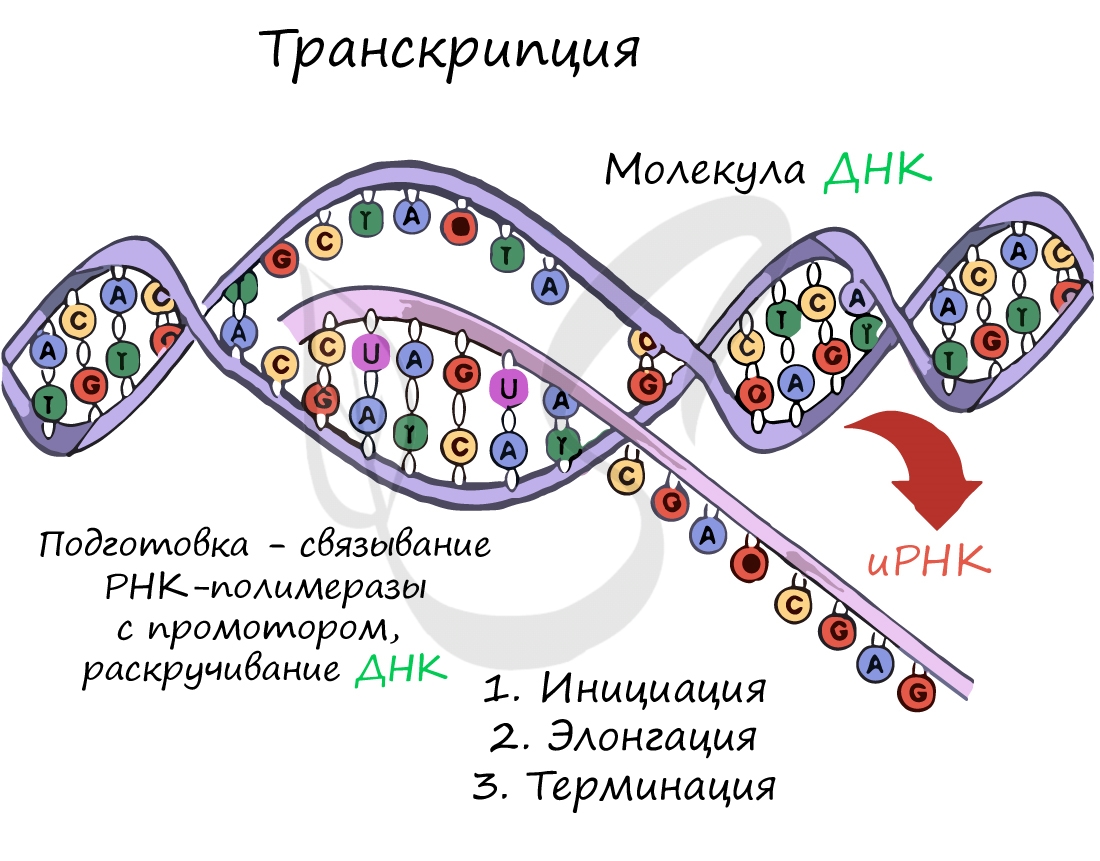
Трансляция (от лат. translatio — перенос, перемещение)
Куда же отправляется новосинтезированная иРНК в процессе транскрипции? На следующую ступень – в процесс трансляции.
Он заключается в синтезе белка на рибосоме по матрице иРНК. Последовательность кодонов иРНК переводится в последовательность
аминокислот.
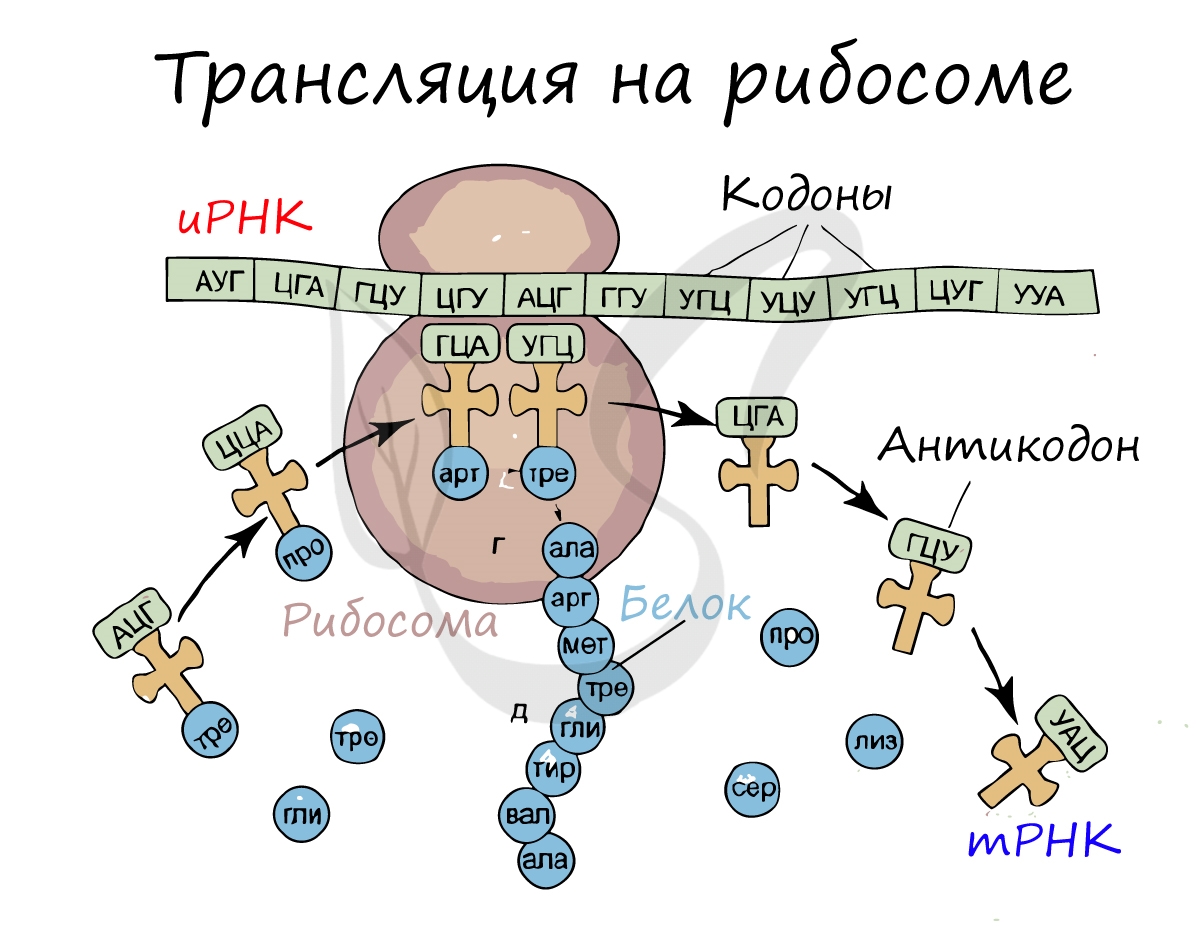
Перед процессом трансляции происходит подготовительный этап, на котором аминокислоты присоединяются к соответствующим молекулам тРНК. Трансляцию можно разделить на несколько стадий:
- Инициация
- Элонгация
- Терминация
Информационная РНК (иРНК, синоним – мРНК (матричная РНК)) присоединяется к рибосоме, состоящей из двух субъединиц.
Замечу, что вне процесса трансляции субъединицы рибосом находятся в разобранном состоянии.
Первый кодон иРНК, старт-кодон, АУГ оказывается в центре рибосомы, после чего тРНК приносит аминокислоту,
соответствующую кодону АУГ – метионин.
Рибосома делает шаг, и иРНК продвигается на один кодон: такое в фазу элонгации происходит десятки тысяч раз.
Молекулы тРНК приносят новые аминокислоты, соответствующие кодонам иРНК. Аминокислоты соединяются друг с другом: между ними образуются пептидные связи, молекула белка растет.
Доставка нужных аминокислот осуществляется благодаря точному соответствию 3 нуклеотидов (кодона) иРНК 3 нуклеотидам (антикодону) тРНК. Язык перевода между иРНК и тРНК выглядит как: А (аденин) – У (урацил), Г (гуанин) – Ц (цитозин).
В основе этого также лежит принцип комплементарности.
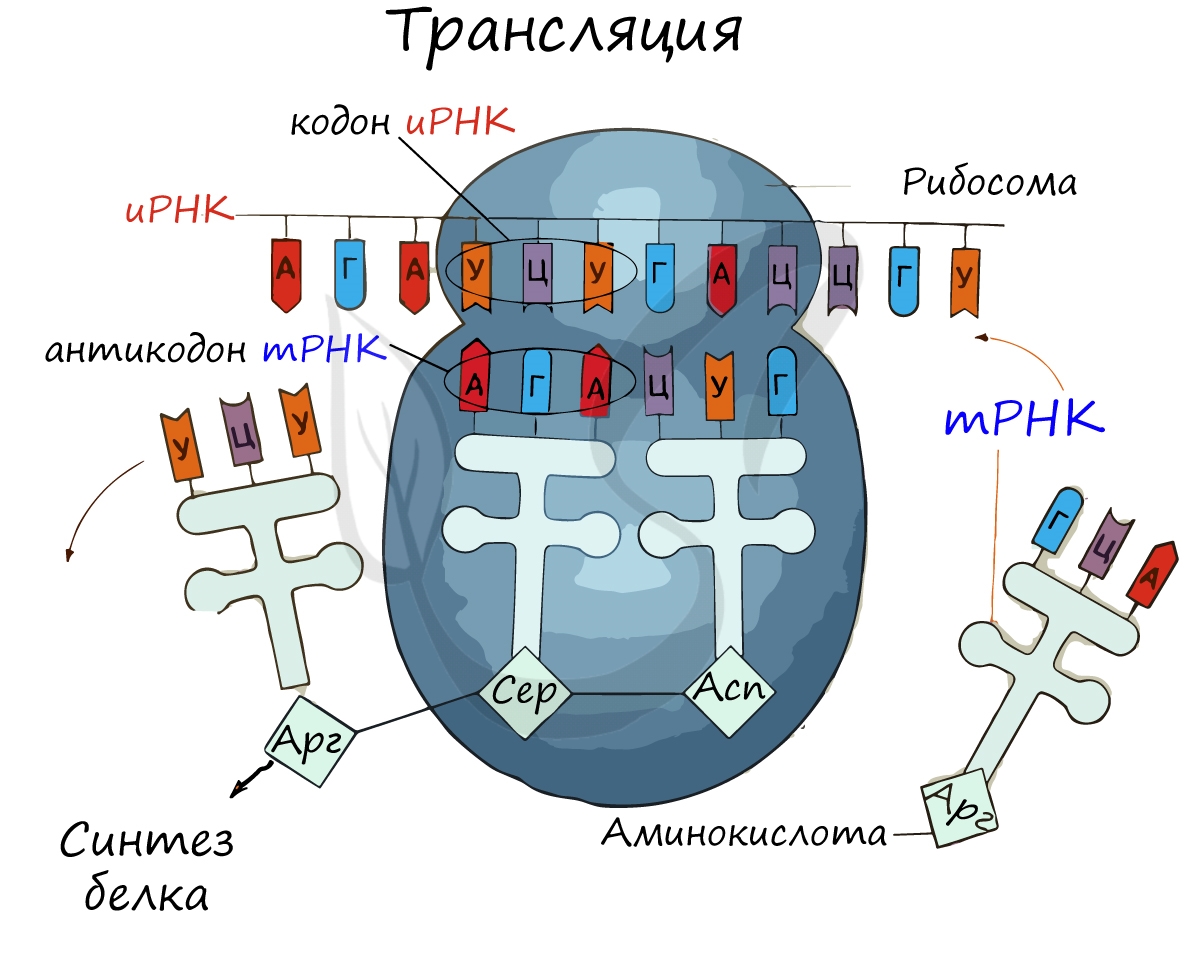
Движение рибосомы вдоль молекулы иРНК называется транслокация. Нередко в клетке множество рибосом садятся на одну молекулу
иРНК одновременно – образующаяся при этом структура называется полирибосома (полисома). В результате происходит одновременный синтез множества одинаковых белков.
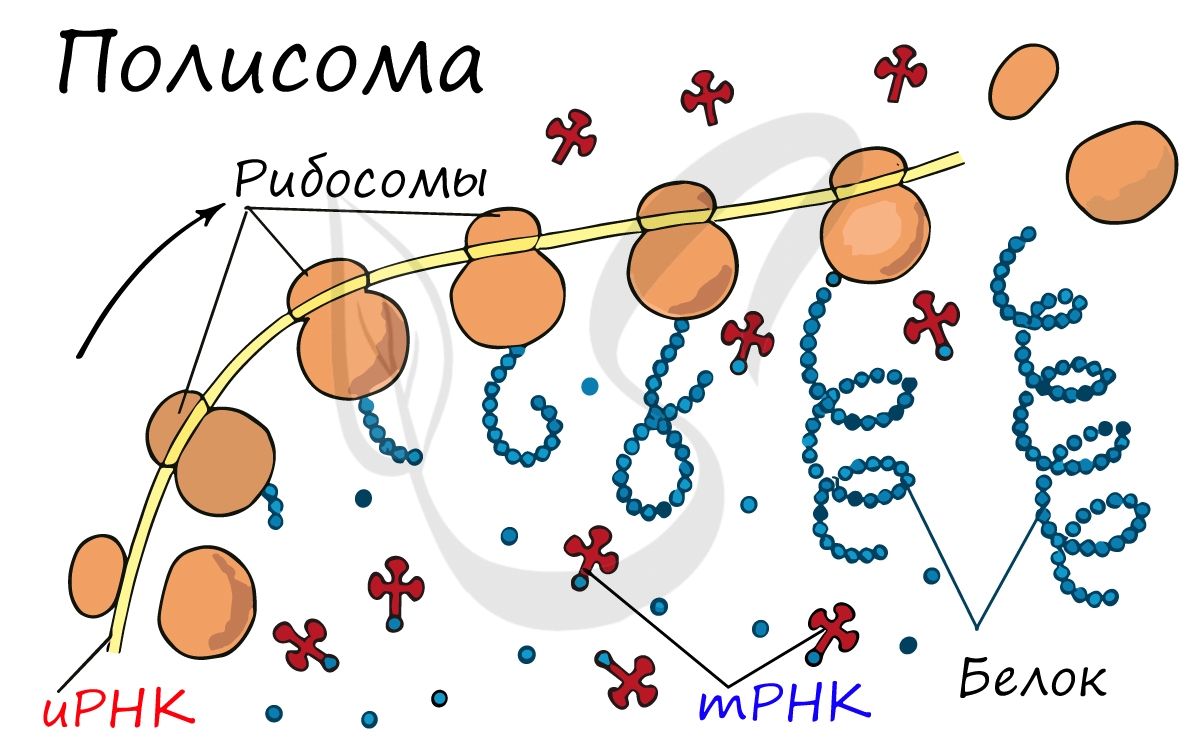
Синтез белка – полипептидной цепи из аминокислот – в определенный момент завершатся. Сигналом к этому служит попадание
в центр рибосомы одного из так называемых стоп-кодонов: УАГ, УГА, УАА. Они относятся к нонсенс-кодонам (бессмысленным), которые не кодируют ни одну аминокислоту. Их функция – завершить синтез белка.
Существует специальная таблица для перевода кодонов иРНК в аминокислоты. Пользоваться ей очень просто, если вы запомните, что
кодон состоит из 3 нуклеотидов. Первый нуклеотид берется из левого вертикального столбика, второй – из верхнего горизонтального,
третий – из правого вертикального столбика. На пересечении всех линий, идущих от них, и находится нужная вам аминокислота 🙂
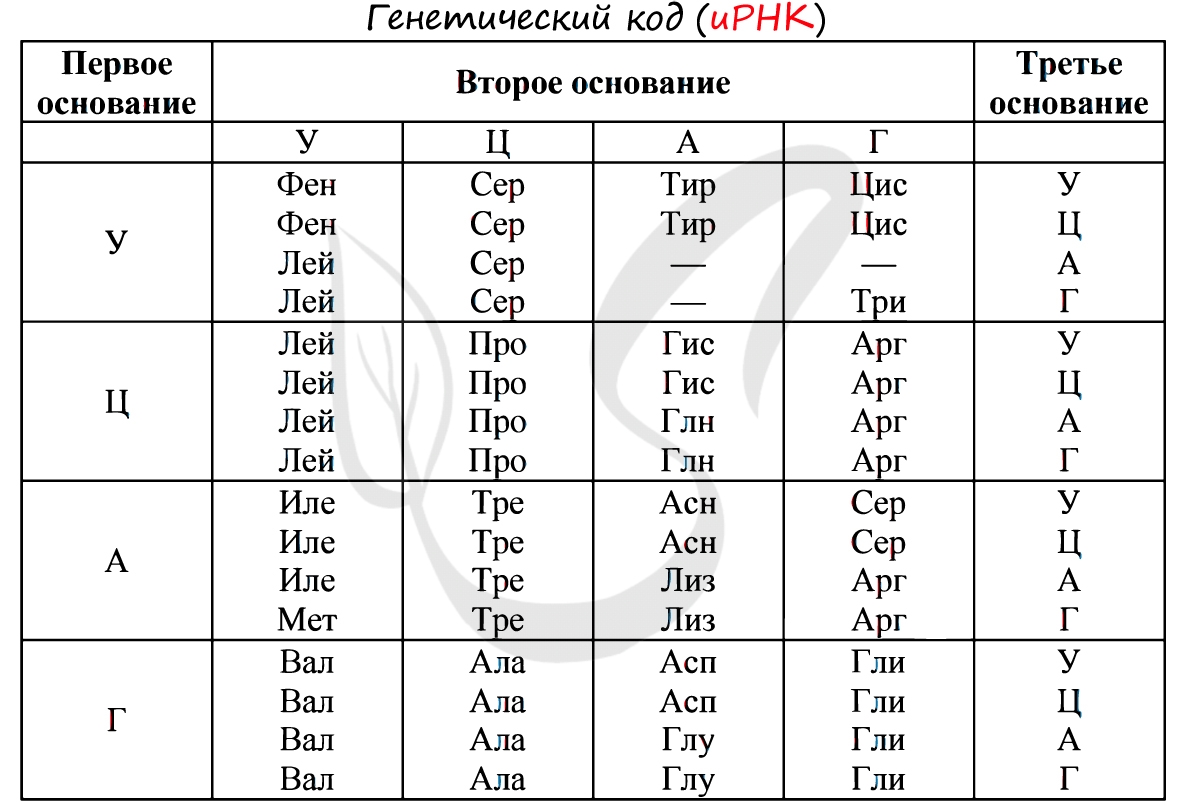
Давайте потренируемся: кодону ЦАЦ соответствует аминокислота Гис, кодону ЦАА – Глн. Попробуйте самостоятельно найти
аминокислоты, которые кодируют кодоны ГЦУ, ААА, УАА.
Кодону ГЦУ соответствует аминокислота – Ала, ААА – Лиз. Напротив кодона УАА в таблице вы должны были обнаружить прочерк:
это один из трех нонсенс-кодонов, завершающих синтез белка.
Примеры решения задачи №1
Без практики теория мертва, так что скорее решим задачи! В первых двух задачах будем пользоваться таблицей генетического кода (по иРНК),
приведенной вверху.
“Фрагмент цепи ДНК имеет следующую последовательность нуклеотидов: ЦГА-ТГГ-ТЦЦ-ГАЦ. Определите последовательность нуклеотидов
во второй цепочке ДНК, последовательность нуклеотидов на иРНК, антикодоны
соответствующих тРНК и аминокислотную последовательность соответствующего фрагмента молекулы белка, используя таблицу генетического кода”

Объяснение:
По принципу комплементарности мы нашли вторую цепочку ДНК: ГЦТ-АЦЦ-АГГ-ЦТГ. Мы использовали следующие правила при нахождении второй нити
ДНК: А-Т, Т-А, Г-Ц, Ц-Г.
Вернемся к первой цепочке, и именно от нее пойдем к иРНК: ГЦУ-АЦЦ-АГГ-ЦУГ. Мы использовали следующие правила при переводе ДНК в иРНК:
А-У, Т-А, Г-Ц, Ц-Г.
Зная последовательность нуклеотидов иРНК, легко найдем тРНК: ЦГА, УГГ, УЦЦ, ГАЦ. Мы использовали следующие правила перевода иРНК в тРНК:
А-У, У-А, Г-Ц, Ц-Г. Обратите внимание, что антикодоны тРНК мы разделяем запятыми, в отличие кодонов иРНК. Это связано с тем, что
тРНК представляют собой отдельные молекулы (в виде клеверного листа), а не линейную структуру (как ДНК, иРНК).
Пример решения задачи №2
“Известно, что все виды РНК синтезируются на ДНК-матрице. Фрагмент цепи ДНК, на которой синтезируется участок центральной петли тРНК, имеет
следующую последовательность нуклеотидов: ТАГ-ЦАА-АЦГ-ГЦТ-АЦЦ. Установите нуклеотидную последовательность участка тРНК, который синтезируется
на данном фрагменте, и аминокислоту, которую будет переносить эта тРНК в процессе биосинтеза белка, если третий триплет соответствует антикодону
тРНК”

Обратите свое пристальное внимание на слова “Известно, что все виды РНК синтезируются на ДНК-матрице. Фрагмент цепи ДНК, на которой
синтезируется участок центральной петли тРНК “. Эта фраза кардинально меняет ход решения задачи: мы получаем право напрямую и сразу
синтезировать с ДНК фрагмент тРНК – другой подход здесь будет считаться ошибкой.
Итак, синтезируем напрямую с ДНК фрагмент молекулы тРНК: АУЦ-ГУУ-УГЦ-ЦГА-УГГ. Это не отдельные молекулы тРНК (как было
в предыдущей задаче), поэтому не следует разделять их запятой – мы записываем их линейно через тире.
Третий триплет ДНК – АЦГ соответствует антикодону тРНК – УГЦ. Однако мы пользуемся таблицей генетического кода по иРНК,
так что переведем антикодон тРНК – УГЦ в кодон иРНК – АЦГ. Теперь очевидно, что аминокислота кодируемая АЦГ – Тре.
Пример решения задачи №3
Длина фрагмента молекулы ДНК составляет 150 нуклеотидов. Найдите число триплетов ДНК, кодонов иРНК, антикодонов тРНК и
аминокислот, соответствующих данному фрагменту. Известно, что аденин составляет 20% в данном фрагменте (двухцепочечной
молекуле ДНК), найдите содержание в процентах остальных нуклеотидов.

Один триплет ДНК состоит из 3 нуклеотидов, следовательно, 150 нуклеотидов составляют 50 триплетов ДНК (150 / 3). Каждый триплет ДНК
соответствует одному кодону иРНК, который в свою очередь соответствует одному антикодону тРНК – так что их тоже по 50.
По правилу Чаргаффа: количество аденина = количеству тимина, цитозина = гуанина. Аденина 20%, значит и тимина также 20%.
100% – (20%+20%) = 60% – столько приходится на оставшиеся цитозин и гуанин. Поскольку их процент содержания равен, то
на каждый приходится по 30%.
Теперь мы украсили теорию практикой. Что может быть лучше при изучении новой темы? 🙂
© Беллевич Юрий Сергеевич 2018-2023
Данная статья написана Беллевичем Юрием Сергеевичем и является его интеллектуальной собственностью. Копирование, распространение
(в том числе путем копирования на другие сайты и ресурсы в Интернете) или любое иное использование информации и объектов
без предварительного согласия правообладателя преследуется по закону. Для получения материалов статьи и разрешения их использования,
обратитесь, пожалуйста, к Беллевичу Юрию.
Статья на конкурс «био/мол/текст»: Биология — самая быстро развивающаяся наука во второй половине ХХ и ХХI веке. Связано это, в первую очередь, с появлением нового ее раздела — молекулярной биологии, подоплекой возникновения которой, в свою очередь, стало стремительное развитие физики, химии и физико-химических методов. Я расскажу о важнейших (на мой взгляд) методах молекулярной биологии, с помощью которых были сделаны многие открытия, известные не только в узких научных кругах, но и среди широкой публики. Они принесли множество Нобелевских премий как тем, кто их открыл, так и тем, кто их использовал. Многие из них применяются не только в биологии, но и в других областях: медицине, криминалистике, археологии.

«Био/мол/текст»-2011
Эта статья представлена на конкурс научно-популярных работ «био/мол/текст»-2011 в номинации «Лучшая обзорная статья».
Введение
Строение ДНК
Началом молекулярной биологии принято считать открытие структуры ДНК (рис. 1) в 1953 году Джеймсом Уотсоном и Френсисом Криком, за что они (совместно с Морисом Уилкинсом) в 1962 году получили Нобелевскую премию по физиологии и медицине [1], [2]. Они выяснили, что молекула ДНК представляет из себя две противоположно направленные цепочки полинуклеотидов, закрученных вокруг общей оси в двойную спираль, причем друг напротив друга в спирали всегда стоят определенные азотистые основания: напротив гуанина (Г или G) — цитозин (Ц или C), а напротив аденина (А) — тимин (Т) (рис. 1). Это называют правилом комплементарости: цепи удерживаются вместе за счет водородных связей, возникающих между нуклеотидами. Водородная связь гораздо слабее ковалентной, с помощью которой нуклеотидные остатки соединяются между собой в одной цепи ДНК, формируя так называемый сахаро-фосфатный остов. Его так называют, поскольку в нем остатки сахара (дезоксирибозы) в нуклеотидах связаны друг с другом через остатки ортофосфорной кислоты — фосфаты. Концы обеих цепей не равноценны: по порядковому номеру атома углерода в остатке сахара один из них называют 3´, а другой — 5´. Синтез ДНК (как и РНК) в природе, как правило, идет от 5´ к 3´-концу.
Возможно, следовало бы начать отсчет с экспериментов Бидла, Татума, Ледерберга, но это дело вкуса. — Ред.
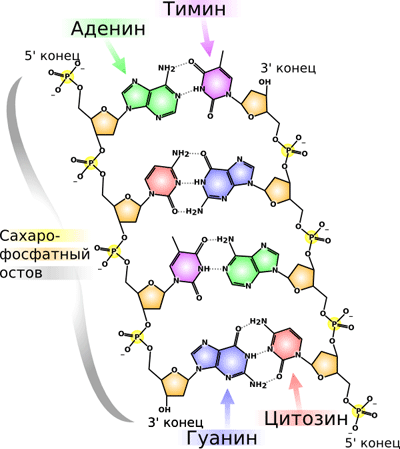
Рисунок 1. Схема строения двуцепочечной молекулы ДНК.
Однако ДНК не обязательно бывает двуцепочечной — иногда встречаются и одноцепочечные молекулы (например, в геномах некоторых вирусов). Это очень важно, поскольку, как будет рассказано ниже, двуцепочечные молекулы могут денатурировать на одноцепочечные, и, наоборот, одноцепочечные образовывать двуцепочечные.
Строение РНК аналогично (хотя обычно она состоит из одной цепи и часто образует комплементарные взаимодействия между участками одной молекулы), только вместо тимина в ее состав входит урацил, а вместо дезоксирибозы — рибоза. Подробнее обо всем этом написано в учебниках по молекулярной биологии [3].
Центральная догма молекулярной биологии
Я кратко напомню так называемую центральную догму молекулярной биологии, в первоначальном виде сформулированную Фрэнсисом Криком [4]. В общем случае она гласит, что генетическая информация при реализации передается от нуклеиновых кислот к белку, но не наоборот. А точнее, возможно передача ДНК → ДНК (репликация), ДНК → РНК (транскрипция) и РНК → белок (трансляция). Так же существуют значительно реже реализуемые пути, свойственные некоторым вирусам: РНК → ДНК (обратная транскрипция) и РНК → РНК (репликация РНК). Также напомню, что белки состоят из аминокислотных остатков, последовательность которых закодирована в генетическом коде организма: три нуклеотида (их называют кодон, или триплет) кодируют одну аминокислоту, причем одну и ту же аминокислоту может кодировать несколько кодонов.
Во второй половине XX века получили развитие технологии рекомбинантной ДНК (то есть, методы манипуляции ДНК, позволяющие различными способами изменять последовательность и состав нуклеотидов в молекуле). Именно на их основе происходит развитие всех молекулярно-биологических методов и поныне, хотя они стали значительно сложнее, как идейно, так и технологически. Именно молекулярная биология вызвала такой бурный рост количества биологической информации за последние полвека.
Я расскажу о методах манипуляции и изучения ДНК и РНК, совсем немного коснусь белков, поскольку в основном методы, связанные с ними, ближе к биохимии, чем к молекулярной биологии (хотя грань между ними в последнее время стала очень расплывчатой).
Разрезание и сшивание
Рестрикционные эндонуклеазы

Рисунок 2. Сайты рестрикции. Сверху — целевая последовательность рестриктазы SmaI, при работе которой образуются «тупые» концы. Снизу — целевая последовательность рестриктазы EcoRI, при работе которой образуются «липкие» концы.
Одним из первых и важнейших из шагов молекулярной биологии стала возможность разрезать молекулы ДНК, причем в строго определенных местах [3]. Этот метод был изобретен при изучении в 1950—1970-е годы такого феномена: некоторые виды бактерий при добавлении в среду чужеродной ДНК разрушали ее, в то время, как их собственная ДНК оставалась невредимой. Оказалось, что они для этого используют ферменты, позднее названные рестрикционными нуклеазами или рестриктазами. Существует множество видов рестриктаз: к 2007-му году их было известно более 3000 [5]. Важным свойством каждого подобного фермента является его способность разрезать строго определенную — целевую — последовательность нуклеотидов ДНК (рис. 2). Рестриктазы не воздействуют на собственную ДНК клетки, поскольку нуклеотиды в целевых последовательностях модифицированы так, что рестриктаза не может с ними работать. (Правда, иногда, наоборот, они могут разрезать только модифицированные последовательности — для борьбы с теми, кто модифицирует ДНК, защищаясь от вышеописанных рестриктаз.) Из-за того, что целевые последовательности бывают различной длины, частота встречаемости их в молекулах ДНК варьирует: чем длиннее необходимый фрагмент, тем меньше вероятность его появления. Соответственно, образующиеся при обработке различными рестриктазами фрагменты ДНК будут иметь различную длину.
Новые эндонуклеазы продолжают открывать и по сей день. Многие из них до сих пор не клонированы, то есть, не известны гены, которые их кодируют, и в качестве «фермента» используют некую очищенную фракцию белков, обладающую нужной каталитической активностью. Новосибирская компания СибЭнзим долгое время успешно соревновалась с компанией New England Biolabs — признанным во всем мире лидером по поставке рестритаз (то есть предлагала такое же или большее различных рестриктаз, некоторые из которых весьма экзотичны). — Ред.
За выделение первой рестриктазы, изучение ее свойств и первое применение для картирования хромосом Вернер Арбер (Werner Arber), Дэн Натанс (Dan Nathans) и Гамильтон Смит (Hamilton Smith) в 1978 году получили Нобелевскую премию по физиологии и медицине.
ДНК-лигазы
Для создания новых молекул ДНК, разумеется, кроме разрезания, необходима еще и возможность сшивания двух цепей. Это делают с помощью ферментов, называемых ДНК-лигазами, которые сшивают сахаро-фосфатный остов двух цепей ДНК. Поскольку по химическому строению ДНК не отличается у разных организмов, можно сшивать ДНК из любых источников, и клетка не сможет отличить полученную молекулу от своей собственной ДНК.
Разделение молекул ДНК: электрофорез в геле
Часто приходится иметь дело со смесью молекул ДНК разной длины. Например, при обработке химически выделенной из организма ДНК рестриктазами как раз получится смесь фрагментов ДНК, причем их длины будут различаться.
Поскольку любая молекула ДНК в водном растворе отрицательно заряжена, появляется возможность разделить смесь фрагментов ДНК различных размеров по их длине с помощью электрофореза [3], [6]. ДНК помещают в гель (обычно, агарозный для относительно длинных и сильно отличающихся молекул или полиакриламидный для электрофореза с высоким разрешением), который помещают в постоянное электрическое поле. Из-за этого молекулы ДНК будут двигаться к положительному электроду (аноду), причем их скорости будут зависеть от длины молекулы: чем она длиннее, тем сильнее ей мешает двигаться гель и, соответственно, тем ниже скорость. После электрофореза смеси фрагментов разных длин в геле образуют полосы, соответствующие фрагментам одной и той же длины. С помощью маркеров (смесей фрагментов ДНК известных длин) можно установить длину молекул в образце (рис. 3).

Рисунок 3. Схема проведения электрофореза ДНК в агарозном геле.
Визуализовать результаты фореза можно двумя способами. Первый, наиболее часто используемый в последнее время — добавление в гель веществ, флуоресцирующих в присутствии ДНК (традиционно использовался довольно токсичный бромистый этидий; в последнее время в обиход входят более безопасные вещества). Бромистый этидий светится оранжевым светом при облучении ультрафиолетом, причем при связывании с ДНК интенсивность свечения возрастает на несколько порядков (рис. 4). Другой метод заключается в использовании радиоактивных изотопов, которые необходимо предварительно включить в состав анализируемой ДНК. В этом случае на гель сверху кладут фотопластинку, которая засвечивается над полосами ДНК за счет радиоактивного излучения (этот метод визуализации называют авторадиографией).
Рисунок 4. Электрофорез в агарозном геле с использованием бромистого этидия для визуализации результатов в ультрафиолете (слева). Вторая слева дорожка — маркер с известными длинами фрагментов. Справа — Установка для проведения электрофореза в геле.
Кроме «обычного» электрофореза в пластине из геля, в некоторых случаях используют капиллярный электрофорез, который проводят в очень тонкой трубочке, наполненной гелем (обычно полиакриламидным). Разрешающая способность такого электрофореза значительно выше: с его помощью можно разделять молекулы ДНК, отличающиеся по длине всего на один нуклеотид. Об одном из важных приложений такого метода читайте ниже в описании метода секвенирования ДНК по Сэнгеру.
Выявление определенной последовательности ДНК в смеси. Саузерн блоттинг
С помощью электрофореза можно узнать размер молекул ДНК в растворе, однако он ничего не скажет о последовательности нуклеотидов в них. С помощью гибридизации ДНК можно понять, какая из полос содержит фрагмент со строго определенной последовательностью. Гибридизация ДНК основана на образовании водородных связей между двумя цепями ДНК, приводящем к их соединению [3], [7].
Сначала необходимо синтезировать ДНК-зонд, комплементарный той последовательности, которую мы ищем. Он обычно представляет собой одноцепочечную молекулу ДНК длиной 10–1000 нуклеотидов. Из-за комплементарности зонд свяжется с необходимой последовательностью, а за счет флуоресцентной метки или радиоизотопов, встроенных в зонд, результаты можно увидеть.
Для этого используют процедуру, называемую Саузерн-блоттинг или перенос по Саузерну, названную по имени ученого, ее изобретшего (Edwin Southern). Первоначально смесь фрагментов ДНК разделяют с помощью электрофореза. На гель сверху кладут лист нитроцеллюлозы или нейлона, и разделенные фрагменты ДНК переносятся на него за счет блоттинга: гель лежит на губке в ванночке с раствором щелочи, который просачивается через гель и нитроцеллюлозу за счет капиллярного эффекта от бумажных полотенец, сложенных сверху. Во время просачивания щелочь вызывает денатурацию ДНК, и на поверхность пластины нитроцеллюлозы переносятся и закрепляются там уже одноцепочечные фрагменты. Лист нитроцеллюлозы аккуратно снимают с геля и обрабатывают радиоактивно меченной ДНК-пробой, специфичной к необходимой последовательности ДНК. Лист нитроцеллюлозы тщательно отмывают, чтобы на нем остались только те молекулы пробы, которые гибридизовались с ДНК на нитроцеллюлозе. После авторадиографии ДНК, с которой гибридизовался зонд, будет видна как полосы на фотопластинке (рис. 5).
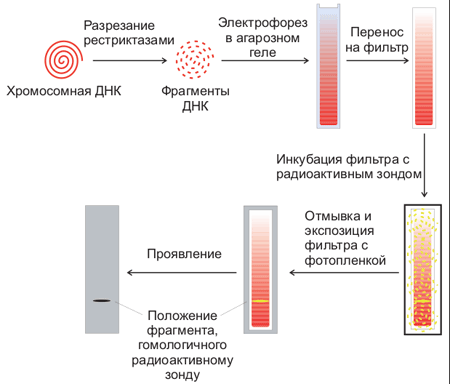
Рисунок 5. Схема проведения Саузерн-блоттинга.
Адаптация этой методики для определения специфических последовательностей РНК называется, в противоположность Саузерн-блоттингу, норзерн-блоттингом (northern blotting: southern по-английски означает «южный», а northern — «северный»). В этом случае проводят электрофорез в геле с молекулами мРНК, а в качестве зонда выбирают одноцепочечную молекулу ДНК или РНК.
Клонирование ДНК
Мы уже знаем, каким образом можно разрезать геном на части (а их сшивать с произвольными молекулами ДНК), разделять полученные фрагменты по длине и с помощью гибридизации выбрать необходимый. Теперь настало время узнать, как, скомбинировав эти методы, мы можем клонировать участок генома (например, определенный ген). В геноме любой ген занимает крайне маленькую длину (по сравнению со всей ДНК клетки). Клонирование ДНК буквально означает создание большого числа копий определенного ее фрагмента. Именно за счет этой амплификации мы получаем возможность выделить участок ДНК и получить его в достаточном для изучения количестве.
Каким образом разделить фрагменты ДНК по длине и идентифицировать нужный — было рассказано выше. Теперь надо понять, каким образом можно копировать необходимый нам фрагмент. Существует два основных метода: использование быстро делящихся организмов (обычно бактерий Escherichia coli — кишечной палочки — или дрожжей Saccharomyces serevisiae) или проделать аналогичный процесс, но in vitro с помощью полимеразной цепной реакции.
Репликация в бактериях
Поскольку при каждом клеточном делении бактерии (как и любые другие клетки, не считая предшественников половых клеток) удваивают свою ДНК, это можно использовать для умножения количества необходимой нам ДНК [3]. Для того, чтобы внедрить наш фрагмент ДНК в бактерию, необходимо «вшить» его в специальный вектор, в качестве которого обычно используют бактериальную плазмиду (небольшую — относительно бактериальной хромосомы — кольцевую молекулу ДНК, реплицирующуюся отдельно от хромосомы). У бактерий «дикого типа» часто встречаются подобные структуры: они часто переносятся «горизонтально» между разными штаммами или даже видами бактерий. Чаще всего в них содержатся гены устойчивости к антибиотикам (именно из-за этого свойства их и открыли) или бактериофагам, а также гены, позволяющие клетке использовать более разнообразный субстрат. (Иногда же они «эгоистичны» и не несут никаких функций.) Именно такие плазмиды обычно и используют в молекулярно-генетических исследованиях. В плазмидах обязательно содержится точка начала репликации (последовательность, с которой начинается репликация молекулы), целевая последовательность рестриктазы и ген, позволяющий отобрать те клетки, которые обладают этой плазмидой (обычно, это гены устойчивости к какому-нибудь антибиотику). В некоторых случаях (например, при изучении очень больших фрагментов ДНК) используют не плазмиду, а искусственную бактериальную хромосому.
В плазмиду с помощью рестриктаз и лигаз встраивают необходимый фрагмент ДНК, после чего добавляют ее в культуру бактерий при специальных условиях, обеспечивающих трансформацию — процесс активного захвата бактерией ДНК из внешней среды (рис. 6). После этого проводят отбор бактерий, трансформация которых прошла успешно, добавляя соответствующий гену в плазмиде антибиотик: в живых остаются только клетки, несущие ген устойчивости (а, следовательно, и плазмиду). Далее, после роста культуры клеток, из нее выделяют плазмиды, а из них с помощью рестриктаз выделяют «наш» фрагмент ДНК (или использую плазмиду целиком). Если же ген вставили в плазмиду для того, чтобы получить его белковый продукт, необходимо обеспечить культуре условия для роста, а потом просто выделить требуемый белок.
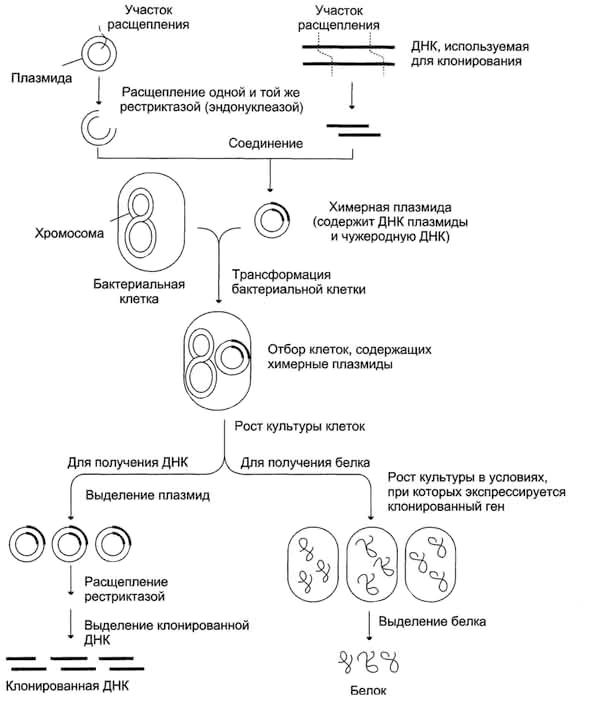
Рисунок 6. Схема клонирования участка ДНК (гена) в бактериях.
На этом месте сразу же должен возникать вопрос: как же все это возможно было использовать до того, когда были расшифрованы геномы, да и чтение последовательности ДНК было еще дорогим и малораспространенным? Положим, с помощью рестрикции и клонирования полученных фрагментов мы получим библиотеку ДНК, то есть набор бактерий, несущих различные плазмиды, содержащие суммарно весь геном (или заметную его часть). Но каким образом мы сможем понять, в каком из фрагментов содержится необходимый ген? Для этого использовали метод гибридизации. Сначала необходимо было выделить белок нужного гена. После чего отсеквенировать его фрагмент, обратить генетический код и получить последовательность нуклеотидов (конечно, из-за вырожденности генетического кода приходилось пробовать много различных вариантов). В соответствии с ней химически синтезировали короткую молекулу ДНК, которую и использовали в качестве зонда для гибридизации.
Но в некоторых случаях этот метод давал сбои — например, так произошло с фактором свертывания крови VIII. Этот белок участвует в свертывании крови , и нарушения в его функциональности являются причиной одного из самых распространенных генетических заболеваний — гемофилии А. Раньше для лечения приходилось выделять этот белок из большого числа организмов, потому что не удавалось клонировать его для производства бактериями. Связано это было с тем, что его длина составляет около 180000 пар нуклеотидов, и он содержит много интронов (некодирующих фрагментов между кодирующими) — неудивительно, что ни в одну плазмиду этот ген не попал целиком.
О механизмах свертывания крови см. «Как работает свертывание крови?». — Ред.
Полимеразная цепная реакция (ПЦР)
Полимеразная цепная реакция — молекулярно-биологический метод, позволяющий добиться колоссального (до 1012 раз) увеличения числа копий определенного фрагмента ДНК in vitro [3], [9]. Она была изобретена Кэри Муллисом (Kary Mullis) в 1983 году, за что в 1993 году он получил Нобелевскую премию по химии (совместно с М. Смитом). (См. также: «Кари Маллис, изобретатель ПЦР» [10].)
Метод основан на многократном избирательном копировании определенного участка ДНК при помощи ферментов в искусственных условиях. При этом происходит копирование только того участка ДНК, который удовлетворяет заданным условиям, и только в том случае, если он присутствует в исследуемом образце. В отличие от репликации ДНК в клетках живых организмов, с помощью ПЦР амплифицируют сравнительно короткие участки ДНК (обычно, не более 3000 пар нуклеотидов, однако есть методы позволяющие «поднимать» до 20 тысяч пар нуклеотидов — так называемый Long Range PCR).
Фактически, ПЦР является искусственной многократной репликацией фрагмента ДНК (рис. 7). ДНК-полимеразы так устроены, что не могут синтезировать новую ДНК, просто имея в наличии матрицу и мономеры. Для этого необходима еще и затравка (праймер), с которого они начинают синтез. Праймер — это короткий одноцепочечный фрагмент нуклеиновой кислоты, комплементарный ДНК-матрице. При репликации в клетке такие праймеры синтезируются специальным ферментом праймазой и являются молекулами РНК, которые позже заменяются на ДНК. Однако в ПЦР используют искусственно синтезированные молекулы ДНК, поскольку в этом случае не нужна стадия удаления РНК и синтеза на их месте ДНК. В ПЦР праймеры ограничивают амплифицируемый участок с обеих сторон.
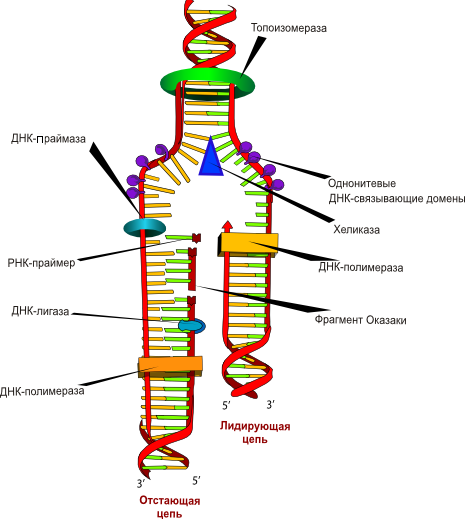
Рисунок 7. Репликация ДНК — важнейший для живых организмов процесс, основа множества молекулярно-биологических методов. Поскольку каждая из цепей ДНК содержит последовательность нуклеотидов, комплементарную другой цепи (их информационное содержание одинаково), при удвоении ДНК цепи расходятся, а затем каждая цепь служит матрицей, на которой выстраивается комплементарная ей новая цепь ДНК. В результате образуются два дуплекса ДНК, каждый из которых является точной (без учета ошибок синтеза) копией первоначальной молекулы.
Итак, пора объяснить, как же ПЦР работает. Изначально в реакционной смеси находятся: ДНК-матрица, праймеры, ДНК-полимераза, свободные нуклеозиды (будущие «буквы» в новосинтезированной ДНК), а также некоторые другие вещества, улучшающие работу полимеразы (их добавляют в специальные буферы, используемые в реакции).
Чтобы синтезировать ДНК, комплементарную матрице, необходимо, чтобы один из праймеров образовал с ней водородные связи (как говорят, «отжегся» на ней). Но ведь матрица уже образует их со второй цепью! Значит, сначала необходимо расплавить ДНК, — то есть разрушить водородные связи. Делают это с помощью простого нагревания (до ≈95 °С) — стадия, называемая денатурацией. Но теперь и праймеры из-за высокой температуры не могут отжечься на матрице! Тогда температуру понижают (50–65 °С), праймеры отжигаются, после чего температуру немного поднимают (до оптимума работы полимеразы, обычно, около 72 °С). И тогда полимераза начинает синтезировать комплементарные матрице цепи ДНК — это называют элонгацией (рис . 8). После одного такого цикла количество копий необходимых фрагментов удвоилось. Однако ничто не мешает повторить это еще раз. И не один, а несколько десятков раз! И с каждым повтором количество копий нашего фрагмента ДНК будет удваиваться, ведь новосинтезированные молекулы тоже будут служить матрицами (рис. 9)! (На самом деле эффективность ПЦР редко настолько высока, что количество копий именно удваивается, но в идеале это так, да и реальные числа часто бывают близки к этому.)
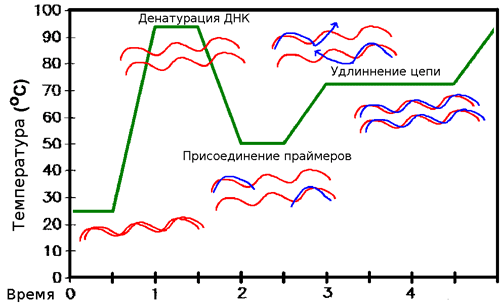
Рисунок 8. Схема ПЦР.
Рисунок 9. С каждым циклом ПЦР количество целевой ДНК удваивается.
Увидеть результаты ПЦР очень просто: достаточно провести электрофорез реакционной смеси после ПЦР, и будет видна яркая полоса с полученными копиями.
Раньше полимеразу, инактивирующуюся при нагревании с каждым циклом, приходилось все время добавлять, но вскоре было предложено использовать термостабильную полимеразу из термофильных бактерий, которая выдерживает такой нагрев, что сильно упростило проведение ПЦР (чаще всего используют Taq-полимеразу из бактерии Thermus aquaticus [11]).
Чтобы избежать сильного испарения воды из реакционной смеси, в нее добавляют масло, покрывающее ее сверху, и/или используют нагревающуюся крышку термоциклера — прибора, в котором проводят ПЦР. Он быстро меняет температуру пробирок, и их не приходится постоянно перекладывать из одного термостата в другой. Для предотвращения неспецифического синтеза еще до нагрева и собственно начала циклов, часто использую ПЦР с «горячим стартом»: вся ДНК и полимераза разделяются между собой парафиновой прослойкой, которая плавится при высокой температуре и дает им взаимодействовать уже в правильных условиях. Иногда же используют модифицированные полимеразы, которые не работают при низкой температуре.
Можно еще много говорить о различных тонкостях ПЦР, но важнее всего сказать об альтернативных классическому форезу методах определения результатов. Например, довольно очевидным вариантом является добавление в реакционную пробирку перед началом реакции веществ, флуоресцирующих в присутствии ДНК. Тогда, сравнив изначальную флуоресценцию с конечной, можно увидеть, синтезировалось ли значительное количество ДНК или нет. Но этот способ не специфичен: мы никак не сможем определить, синтезировался ли необходимый фрагмент, или это какие-то праймеры слиплись и достроились до непредсказуемых последовательностей.
Наиболее интересным вариантом является ПЦР «в реальном времени» («real-time PCR») . Существует несколько реализаций этого метода, но идея везде одна и та же: можно прямо в ходе реакции наблюдать за накоплением продуктов ПЦР (по флуоресценции). Соответственно, для проведения ПЦР «в реальном времени» нужен специальный прибор, способный возбуждать и считывать флуоресценцию в каждой пробирке. Самое простое решение — добавить в пробирку те же самые вещества, которые флуоресцируют в присутствии ДНК, однако минусы такого метода уже были описаны выше.
Строго это называется «ПЦР с регистрацией флуоресценции в режиме реального времени» или «количественная ПЦР». — Ред.
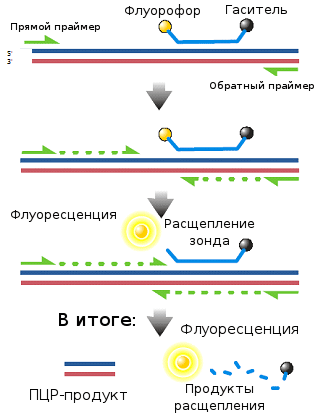
Рисунок 10. Схема работы ПЦР «в реальном времени»: Taq Man Assay.
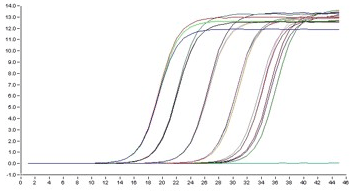
Рисунок 11. Пример кривых накопления флуоресценции в ПЦР «в реальном времени»: зависимость интенсивности флуоресценции (в нескольких пробирках — на каждую своя кривая) от номера цикла.
Самой популярной реализацией такого подхода является метод выщепления флуорофора за счет разрушения зонда (TaqMan Assay; рис. 10). В этом случае в реакционной смеси должен присутствовать еще один компонент — специальный одноцепочечный ДНК-зонд: молекула ДНК, комплементарная последовательности амплифицируемого фрагмента, расположенной между праймерами. При этом к одному его концу должен быть химически приделан флуорофор (флуоресцирующая молекула), а к другому — гаситель (молекула, поглощающая энергию флуорофора и «гасящая» флуоресценцию). Когда такой зонд находится в растворе или комплементарно связан с целевой последовательностью, флуорофор и гаситель находятся относительно недалеко друг от друга, и флуоресценции не наблюдается. Однако за счет 3´-экзонуклеазной активности, которой обладает Taq-полимераза (то есть она расщепляет ДНК, на которую «натыкается» в ходе синтеза, и на ее месте синтезирует новую), зонд при синтезе второй цепи разрушается, флуорофор и гаситель за счет диффузии удаляются друг от друга, и появляется флуоресценция.
Поскольку число копий в ходе ПЦР растет экспоненциально, так же растет и флуоресценция. Однако это продолжается недолго, поскольку в какой-то момент эффективность реакции начинает падать из-за постепенной инактивации полимеразы, нехватки каких-то компонентов и т. п. (рис. 11). Анализируя графики роста флуоресценции, можно много понять о протекании ПЦР, но, самое важное, можно узнать, сколько ДНК-матриц было изначально: это так называемая количественная ПЦР (quantitative PCR, qPCR).
Все варианты применения ПЦР в науке невозможно перечислить. Выделение фрагмента ДНК, секвенирование, мутагенез… ПЦР — один из самых востребованных для ненаучных целей метод (видео 1). Он широко применяется в медицине для ранней диагностики наследственных и инфекционных заболеваний, определения отцовства, в расследованиях для установления личности и для многого другого.
Видео 1. Восторг ученых по поводу изобретения ПЦР хорошо передает песня «Scientists for Better PCR» (хотя это и реклама фирмы BioRad, производящей, в том числе, оборудование и реагенты для ПЦР).
Естественные клеточные процессы in vitro
Все основные молекулярно-биологические процессы могут быть легко проведены in vitro (то есть, в пробирке). Пример приведен выше: ПЦР — это аналог репликации ДНК. Для этого достаточно просто смешать необходимые реагенты в подходящих условиях: для транскрипции нужны ДНК-матрица, РНК-полимераза и рибонуклеотиды, для трансляции — мРНК, субъединицы рибосом и аминокислоты, для обратной транскрипции — РНК-матрица, обратная транскриптаза ( она же ревертаза) и дезоксирибонуклеотиды. Эти методы широко применяются в различных областях биологии, когда необходимо, например, получить чистую РНК определенного гена. В этом случае нужно сначала провести обратную транскрипцию его (гена) мРНК, с помощью ПЦР амплифицировать ее, а затем с помощью in vitro-транскрипции получить много мРНК. Первая стадия необходима из-за того, что перед образованием зрелой мРНК в клетке проходит сплайсинг и процессинг РНК (у эукариот; у бактерий в этом смысле все проще) — подготовка к работе матрицей для синтеза белка. Иногда этого удается избежать, если вся кодирующая последовательность гена расположена в одном экзоне.
Секвенирование ДНК
Можно сказать, важнейшие методы манипуляции с ДНК уже описаны. Следующий этап — определение собственно нуклеотидной последовательности цепи в молекуле — секвенирование. Определение нуклеотидной последовательности ДНК крайне важно для множества фундаментальных и прикладных задач. Особое место оно занимает в науке: для анализа результатов секвенирования геномов была, фактически, создана новая наука — биоинформатика. Секвенированием сейчас пользуются молекулярные биологи, генетики, биохимики, микробиологи, ботаники и зоологи, и, конечно же, эволюционисты: практически вся современная систематика основана на его результатах. Секвенирование широко применяется в медицине как метод поиска наследственных заболеваний и изучения инфекций. (См., например, «Уточнение „родословной“ членистоногих» и «Скверный анекдот: негр, китаец и Крейг Вентер…». — Ред.)
На самом деле хронологически методы изобретались совсем в другом порядке. Например, секвенирование по Сэнгеру было разработано в 1977 году, а ПЦР, как говорилось выше, только в 1983-м.
Существует множество различных методик секвенирования, но все методы можно разделить на две категории: «классические» и нового поколения. Сейчас используется фактически только один «классический» метод — секвенирование по Сэнгеру , или метод терминаторов. По сравнению с новыми методами, у него есть важное преимущество: длина прочтения, то есть количество нуклеотидов в последовательности, которое можно получить за один раз, у него выше — до 1000 нуклеотидов [12]. В то же время у самого «хорошего» в этом плане «нового» метода секвенирования — 454-, или пиросеквенирования [13] — этот параметр не превышает 500 нуклеотидов . Именно длина прочтения ограничивает возможности новых методов: оказывается крайне сложно «собрать» целый геном из фрагментов размером в несколько десятков нуклеотидов. Как минимум, для этого требуются суперкомпьютеры, а некоторые места в геноме разрешить оказывается просто невозможно, если они содержат высокоповторяющиеся последовательности. В таком случае может помочь сравнение полученных фрагментов с уже имеющимся целым геномом, но таким образом невозможно прочесть геном организма впервые (de novo). (См. также: «Код жизни: прочесть не значит понять». — Ред.)
Английский биохимик и корифей молекулярной биологии, дважды лауреат Нобелевской премии по химии: за определение аминокислотной последовательности инсулина (1955 г.) и за разработку метода секвенирования ДНК (1980 г.). — Ред.
Есть метод нового поколения, позволяющий читать несколько тысяч пн, но с большими ошибками (Pacific Biosciences). 454/Roche сегодня могут читать и больше 500 пн; то же самое уже может и молодое «полупроводниковое секвенирование». — Ред.
Оба упомянутых выше метода секвенирования уже достаточно подробно описаны на «биомолекуле» [13]: очень советую ознакомиться. Я же для примера расскажу про другой распространенный быстрый и дешевый метод (в расчете на один прочитанный нуклеотид) — метод, реализованный в секвенаторах Illumina (видео 2). Основной его недостаток — чтение фрагментов очень короткой длины, не больше 100 нуклеотидов, и вытекающая отсюда сложность прочтения геном «с нуля» [14].
В этом методе можно выделить три стадии: подготовку библиотеки фрагментов (1), создание кластеров (2) и собственно секвенирование (3).
Видео 2. В интернете есть несколько хороших видео, на которых описан процесс секвенирования Illumina, например на официальном сайте компании (вкладка Technology). Правда, они все на английском языке.
- Сначала создается библиотека фрагментов ДНК из секвенируемого генома (или любого другого источника ДНК). ДНК с помощью ультразвука или специального фермента расщепляется на произвольные фрагменты длиной в несколько сотен нуклеотидов, из которых выбираются обладающие заданной длиной (выбирается экспериментатором). После этого к ним с двух концов ковалентно присоединяются различные адаптерные последовательности (рис. 12: 1);
- Этот раствор поступает на специальный микрочип с «пришитыми» к нему фрагментами ДНК, комплементарными адаптерным последовательностям, — праймерами. Там участки геномной ДНК прикрепляются с помощью адаптерных последовательностей к молекулам ДНК на чипе. С помощью ДНК-полимеразы у всех таких фрагментов достраивается вторая комплементарная цепь, которая будет уже ковалентно связана с праймером. Она случайно изгибается, и в какой-то момент попадет на праймер, комплементарный ее адаптерной последовательности. Они свяжутся, и снова достроится вторая цепь. Это повторяют несколько раз, после чего один из типов праймеров отрезают от молекулы ДНК, чтобы в образовавшемся кластере остались только одинаковые цепи (рис. 12: 2–6). Всего на чипе образуются сотни миллионов таких кластеров;
- Собственно секвенирование. К кластерам добавляют праймеры, комплементарные одной из адаптерных последовательностей, с которой они связываются. Затем добавляют ДНК-полимеразу и специально модифицированные нуклеотиды с прикрепленным к ним флуорофором (разным у разных типов нуклеотидов), синтез после которых заблокирован. Они присоединяются к молекулам ДНК в соответствии с правилом комплементарности. Затем камера сканирует, какой флуорофор появился в каждом кластере по цвету свечения в лазере, и компьютер запоминает расположение кластеров. По этому определяется, какой нуклеотид встроился в цепь. После этого отщепляются флуорофоры от всех нуклеотидов, и дальнейший синтез цепи разблокируется.
Все повторяется снова: добавляются нуклеотиды, чип сканируется, чтобы определить, какой нуклеотид присоединился к какому кластеру и т.п. (рис. 13). Таким образом секвенируют до 100 нуклеотидов в каждом кластере, а всего их сотни миллионов — в итоге это десятки миллиардов пар нуклеотидов.
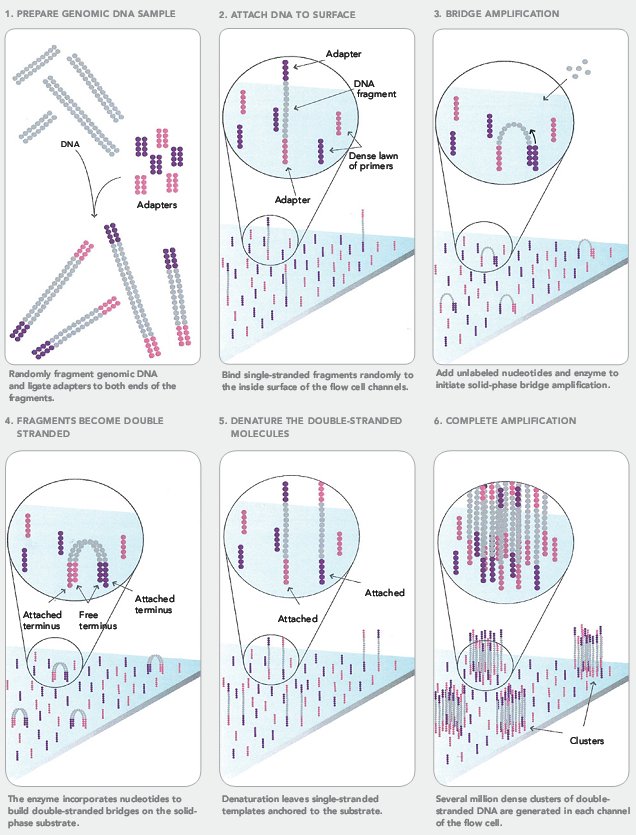
Рисунок 12. Подготовка к секвенированию Illumina.
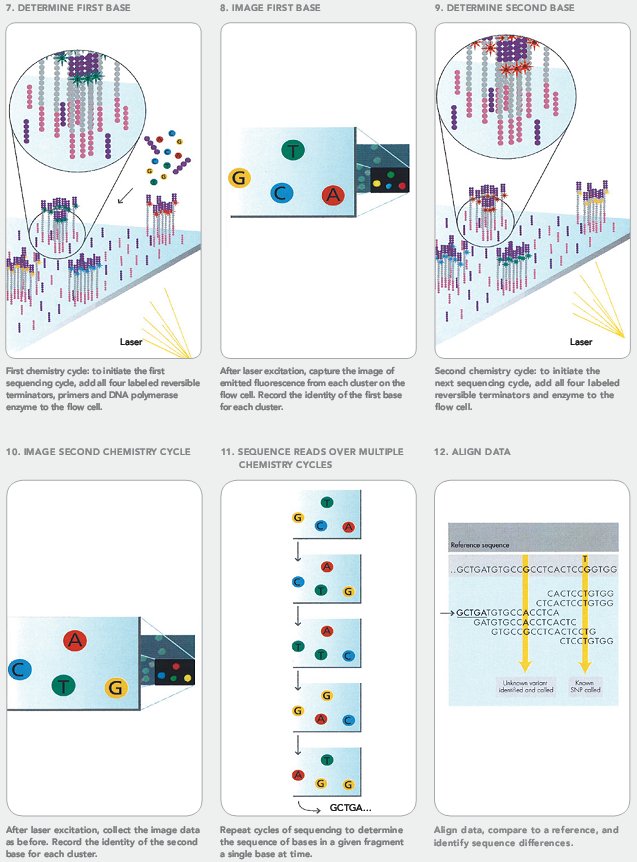
Рисунок 13. Собственно секвенирование Illumina.
Было уже довольно много сказано про методы работы с нуклеиновыми кислотами и их изучения. Пришло время узнать, каким образом можно выяснить, как же клетка работает — в частности, попытаться определить функцию гена и белка, который он кодирует.
In vitro-мутагенез
Для изучения функции белка очень важно научиться вносить в него мутации. Например, имея организм с неработающим ферментом, можно по биохимическим отличиям понять, что делает нормальный белок. Существуют разные способы создать полностью неработающий ген (как произвольный из всего генома, так и совершенно конкретный — тогда это называется нокаутом этого гена). Один из таких способов — вставка какого-то фрагмента ДНК в геном: если эта вставка придется на ген, то он (точнее, скорее всего, белок, который он кодирует) перестанет нормально функционировать.
Однако существуют способы очень точного изменения последовательности гена и, соответственно, белка. Про один из таких методов — сайт-специфичный мутагенез — я и расскажу. Суть его заключается в изменении конкретного (обычно одного) нуклеотида в последовательности. Для его использования сначала необходимо клонировать этот ген в плазмиде. После этого нужно провести как бы ПЦР с одним праймером. Причем этот праймер должен как раз включать в себя последовательность, которую мы хотим изменить — уже в нужном нам виде. Например, на рис. 14 вместо буквы А, которая должна была бы стоять напротив Т в родительской цепи, в праймере стоит Ц. После синтеза второй цепи ДНК плазмиды, содержащей праймер, в нее будет внесена мутация — А заменится на Ц. Такие плазмиды вводятся в клетки, в которых при делении две цепи окажутся в разных дочерних клетках. Таким образом, в половине клеток-потомков будет изначальный вариант плазмиды, а в половине — мутантный. Тогда, соответственно, половина клеток будет производить нормальный белок, кодируемый этим геном, а половина — мутантный. В случае, изображенном на рис. 14, в нем вместо одной аминокислоты (аспарагина) будет стоять другая (аланин). По аналогии можно вносить случайные мутации с помощью специальной ДНК-полимеразы, вносящей повышенное число ошибок.

Рисунок 14. Схема проведения сайт-специфичного мутагенеза.
Bruce Alberts et al. Molecular biology of the cell. 5th edition.
Системная РНК-интерференция
РНК-интерференция — недавно (менее 20 лет назад) открытый феномен подавления экспрессии генов в присутствии определенных коротких фрагментов РНК. За открытие и изучение этого явления Эндрю Файер (Andrew Fire) и Крейг Мелло (Craig Mello) получили Нобелевскую премию по физиологии и медицине в 2006 году. Биомолекула уже достаточно писала про РНК-интерференцию: «Обо всех РНК на свете, больших и малых» [15], я же расскажу о так называемой системной РНК-интерференции у «модельной» нематоды C. elegans, — то есть, об отключении гена во всех (почти) клетках этого червя.
Такой поразительный эффект достигается с помощью введения в клетку двуцепочечных молекул РНК (дцРНК), одна из цепей в каждой из которых комплементарна участку мРНК «выключаемого» гена. Это открывает поразительные возможности для изучения функций генов. Раньше для отключения генов приходилось создавать «нокаутных» животных (что ученые все равно вынуждены делать, например, с мышами — см. «Нобелевскую премию по физиологии и медицине вручили за технологию нокаутирования мышей». — Ред.), у которых изучаемый ген в принципе отсутствует в геноме. Однако создание нокаутов достаточно сложно, а обратно включить ген у таких организмов уже невозможно. С помощью РНК-интерференции отключить ген очень легко, — так же, как и включить, перестав водить в организм соответствующие дцРНК [16].
Существует три основных способа введения дцРНК в организм. Самый очевидный — впрыскивание в животное их раствора. Пользуются также «вымачиванием» нематод в растворе РНК. Однако оказалось, что можно делать все гораздо проще: скармливать нематодам эти молекулы! Причем особенно удобно то, что это так же замечательно работает, если нематод кормить бактериями (E. coli), синтезирующими эти дцРНК (рис. 15) [17].
Рисунок 15. Системная РНК-интерференция. Червь C. elegans экспрессирует зеленый флуоресцентный (светящийся) белок в клетках глотки (ph) и мышцах стенки тела (bm). Слева — изначальный внешний вид. Справа — при РНК-интерференции с помощью «подкормки» бактериями ген инактивируется.
В принципе то, что молекулы РНК из кишечника распространяются практически по всем тканям, довольно удивительно. Известно, что за попадание молекул РНК в клетки кишечника отвечает белковый канал sid-1 [18], [19]. Однако каким образом РНК распространяются по организму червя, достоверно не известно, — скорее всего, с участием белка rsd-8 [16] Интересно, что все известные белки, принимающие участие в системной РНК-интерференции у C. elegans, имеются и у человека, однако такую эффективную систему искусственного подавления активности генов на системном уровне у человека наблюдать не удается. Если бы была возможность использовать системную РНК-интерференцию у человека, это могло бы стать методом борьбы с огромным набором заболеваний, от простуды до рака .
К слову, использование РНК-интерференции именно на культуре клеток человека позволило выявить, что многие гены человека способствуют развитию вируса гриппа: «Молекулярное двурушничество: гены человека работают на вирус гриппа». — Ред.
Изучение экспрессии генов: ДНК-микрочипы
При изучении функции гена очень важно узнать, когда и в каких тканях организма он работает (экспрессируется), а также вместе с какими другими генами. Если требуется узнать это про небольшое число генов и тканей, то можно это сделать очень просто: выделить РНК из ткани, провести обратную транскрипцию (то есть, синтезировать кДНК — комплементарную ДНК) и затем, провести количественную ПЦР. В зависимости от того, прошла ли ПЦР, мы узнаем, имеется ли мРНК исследуемого гена в ткани.
Однако если необходимо проделать то же самое для множества тканей и многих генов, то эта методика становится очень долгой и затратной. В таком случае используют ДНК-микрочипы [3]. Это небольшие пластинки, на которые нанесены и прикреплены молекулы ДНК, комплементарные РНК изучаемых генов, причем заранее известно, где на них (пластинках) какая молекула расположена. Одним из способов создания чипа является синтез молекул ДНК прямо на нем с помощью робота.
Чтобы изучать экспрессию генов с помощью чипов, необходимо также синтезировать их кДНК и пометить ее флуоресцентным красителем (не разделяя кДНК разных генов). Такую смесь наносят на микрочип, добиваясь, чтобы кДНК гибридизовалась с молекулами ДНК на чипе. После этого смотрят, где наблюдается флуоресценция и сравнивают это с расположением молекул ДНК на чипе. Если место флуоресценции совпадает с положением молекулы ДНК, то в данной ткани этот ген экспрессирован. Кроме того, пометив кДНК из разных тканей разными красителями, можно изучать экспрессию сразу нескольких (обычно все-таки не больше 2) тканей на одном чипе: по цвету флуоресценции можно определить, в какой из тканей он экспрессирован (если сразу в нескольких — получится смешанный цвет) (рис. 16).
Рисунок 16. Флуоресценция на ДНК-микрочипе после обработки раствором кДНК. Всего тут примерно 37500 прикрепленных молекул ДНК.
Однако в последнее время все чаще вместо чипов используют массовое секвенирование всей кДНК из ткани (создание так называемых транскриптомов), что сильно упростилось из-за развития методов секвенирования. Это оказывается дешевле и эффективнее, поскольку знание полных последовательностей всех мРНК дает больше информации, чем просто сам факт их наличия или отсутствия.
Мы рассмотрели основные методы молекулярной биологии. Надеюсь, что вам стало немного понятнее, каким образом делаются молекулярно-биологические исследования, за что дают Нобелевские премии, и как они могут помочь в некоторых прикладных задачах. Но, более всего, я надеюсь, что вы тоже увидели красоту идей, лежащих в их основе, и, возможно, вам захотелось узнать о каких-то из этих методик подробнее.
- Нобелевские лауреаты: Дж. Уотсон, Ф. Крик, М. Уилкинс;
- Уотсон Дж.Д. Двойная спираль. Воспоминания об открытии структуры ДНК. М.: Мир, 1969;
- Bruce Alberts et al. Essential cell biology (3rd ed.). 2009;
- Википедия: «Центральная догма молекулярной биологии»;
- Roberts RJ., Vincze T., Posfai J., Macelis D. (2007). REBASE — enzymes and genes for DNA restriction and modification. Nucleic Acids Res. 38, D234–D236;
- Википедия: Gel electrophoresis of nucleic acids (англ.);
- Википедия: Southern blot (англ.);
- Жимулев И.Ф. Лекции для студентов 3-го курса по общей и молекулярной генетике (гл. 7);
- Ребриков Д.В. ПЦР «в реальном времени». М.: БИНОМ. Лаборатория знаний, 2009;
- Телков М.В. (2006). Кари Маллис, изобретатель ПЦР. Химия и Жизнь. 8;
- R. Saiki, D. Gelfand, S Stoffel, S. Scharf, R Higuchi, et. al.. (1988). Primer-directed enzymatic amplification of DNA with a thermostable DNA polymerase. Science. 239, 487-491;
- C. Ledergerber, C. Dessimoz. (2011). Base-calling for next-generation sequencing platforms. Briefings in Bioinformatics. 12, 489-497;
- 454-секвенирование (высокопроизводительное пиросеквенирование ДНК);
- Wellcome Trust: «DNA Sequencing — The Illumina Method»;
- Обо всех РНК на свете, больших и малых;
- Grishok A. (2005). RNAi mechanisms in Caenorhabditis elegans. FEBS Lett. 579, 5932–5939;
- Angelo Fortunato, Andrew G. Fraser. (2005). Uncover Genetic Interactions in Caenorhabditis elegans by RNA Interference. Biosci Rep. 25, 299-307;
- Winston W.M., Molodowitch C., Hunter C.P. (2002). Systemic RNAi in C. elegans requires the putative transmembrane protein SID-1. Science. 295, 2456–2459;
- C.P. HUNTER, W.M. WINSTON, C. MOLODOWITCH, E.H. FEINBERG, J. SHIH, et. al.. (2006). Systemic RNAi in Caenorhabditis elegans. Cold Spring Harbor Symposia on Quantitative Biology. 71, 95-100.
