В этой статье мы приступим к изучению показателей вариации: размах вариации, межквартильный размах, среднее линейное отклонение.
В математической статистике вариация занимает одно из центральных мест. Что же такое вариация? Это изменчивость. Вариация показателя – изменчивость показателя.
Показатели вариации дают очень важную характеристику процессам и явлениям. Они отражают устойчивость процессов и однородность явлений. Чем меньше показатель вариации, тем более процесс устойчивый, а значит, и более предсказуемый.
Показатели вариации отражают не отдельно взятые значения, а дают характеристику некоторому явлению или процессу в целом. Имея в наличии показатели среднего значения и вариации, можно получить первичное представление о характере данных. Средняя – это обобщающий уровень, а вариация характеризует, насколько среднее значение (или другой показатель) хорошо обобщает значения некоторой совокупности данных. Если показатель вариации незначительный, то значения совокупности находятся близко к среднему, следовательно, среднее значение хорошо обобщает совокупность. Если вариация большая, то среднее значение плохо обобщает данные (значения разбросаны далеко друг от друга), и получается «средняя температура по больнице».
Размах вариации
Размах вариации – разница между максимальным и минимальным значением:
![]()
Ниже приведена графическая интерпретация размаха вариации.

Видно максимальное и минимальное значение, а также расстояние между ними, которое и соответствует размаху вариации.
С одной стороны, показатель размаха может быть вполне информативным и полезным. К примеру, максимальная и минимальная стоимость квартиры в городе N, максимальная и минимальная зарплата по профессии в регионе и проч. С другой стороны, размах может быть очень широким и не иметь практического смысла, т.к. зависит лишь от двух наблюдений. Таким образом, размах вариации очень неустойчивая величина.
Межквартильный размах
В статистике для анализа выборки часто прибегают к другому показателю вариации – межквартильному размаху. Квартиль – это то значение, которые делит ранжированные (отсортированные) данные на части, кратные одной четверти, или 25%. Так, 1-й квартиль – это значение, ниже которого находится 25% совокупности. 2-й квартиль делит совокупность данных пополам (то бишь медиана), ну и 3-й квартиль отделяет 25% наибольших значений. Так вот межквартильный размах – это разница между 3-м и 1-м квартилями. У данного показателя есть одно неоспоримое преимущество: он является робастным, т.е. не зависит от аномальных отклонений.
Наглядное отображение размаха вариации и межкварительного расстояния производят с помощью диаграммы «ящик с усами».
Среднее линейное отклонение
Есть показатели вариации, которые учитывают сразу все значения, а не только отдельные наблюдения (типа максимума или минимума). Одним из таких является среднее линейное отклонение. Этот показатель характеризует меру разброса значений вокруг их среднего. В чем суть? Для того, чтобы показать меру разброса данных, нужно вначале определиться, относительно чего этот самый разброс будет считаться. Обычно это среднее арифметическое. Далее нужно посчитать, насколько каждое значение отклоняется от средней. Нас интересует среднее из таких отклонений. Однако напрямую складывать положительные и отрицательные отклонения нельзя, т.к. они взаимоуничтожатся и их сумма будет равна нулю. Поэтому все отклонения берутся по модулю. Средне линейное отклонение рассчитывается по формуле:
![]()
где
a – среднее линейное отклонение,
X – анализируемый показатель,
X̅ – среднее значение показателя,
n – количество значений в анализируемой совокупности данных.
Рассчитанное по этой формуле значение показывает среднее абсолютное отклонение от средней арифметической. Наглядная картинка в помощь.

Отклонения каждого наблюдения от среднего указаны маленькими стрелочками. Именно они берутся по модулю и суммируются. Потом все делится на количество значений.
Для полноты картины нужно привести еще и пример. Допустим, имеется фирма по производству черенков для лопат. Каждый черенок должен быть 1,5 метра длиной, но, что еще важней, все должны быть одинаковыми или, по крайней мере, плюс-минус 5 см. Однако нерадивые работники то 1,2 м отпилят, то 1,8 м. Дачники недовольны. Решил директор провести статистический анализ длины черенков. Отобрал 10 штук и замерил их длину, нашел среднюю и рассчитал среднее линейное отклонение. Средняя получилась как раз, что надо – 1,5 м. А вот среднее линейное отклонение вышло 0,16 м. Вот и получается, что каждый черенок длиннее или короче, чем нужно, в среднем на 16 см. Есть, о чем поговорить с работниками.
На этом сегодняшнюю заметку закончим. В следующей статье будут рассмотрены такие показатели вариации, как дисперсия, среднеквадратичное отклонение и коэффициент вариации.
Поделиться в социальных сетях:
3) Коэффициент вариации
33. Правило сложения дисперсий
Дисперсия
–
средний квадрат отклонений значений
признака от их средней величины.
Она
может быть разложена на 2 сост.части,
позволяющие оценить влияние различ.факторов
обуславливающих вариацию признака.
Согласно
правилу сложения дисперсий общая
дисперсия признака может быть представлена:

,
где

–
общая дисперсия;

–
средняя из внутригрупповых дисперсий;

–
межгрупповая дисперсия.
Общая
дисперсия измеряет
вариацию признака по всей совокупности
под влиянием всех факторов, обусловивших
эту вариацию.

Межгрупповая
дисперсия
отражает ту часть вариации результативного
признака, которая обусловлена воздействием
факторного признака. Это воздействие
проявляется в отклонении групповых
средних от общей средней:


–
среднее значение результативного
признака по i-ой группе;

–
общая средняя по совокупности в целом;

–
объем (численность) i-ой
группы.
Если
факторный признак, по которому производится
группировка, не оказывает никакого
влияния на результативный признак, то
групповые средние будут равны между
собой и совпадут с общей средней. В этом
случае межгрупповая средняя будет равна
нулю.
Внутригрупповая
дисперсия отражает
случайную вариацию, т.е. часть вариации,
происходящую под влиянием неучтенных
факторов и независящую от признака
фактора, положенного в основание
группировки.

Средняя
из внутригрупповых дисперсий
отражает ту часть вариации результативного
признака, которая обусловлена действием
всех прочих неучтенных факторов, кроме
фактора, по которому осуществлялась
группировка:
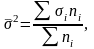

–
дисперсия результативного признака в
i-ой группе;
–
объем (численность) i-ой группы;
34. Показатель симметричности распределения
Показатель
симметричности распределения –
коэффициент асимметрии.
Симметричным является
распределение, в котором частоты любых
двух вариантов, равноотстоящих в обе
стороны от центра распределения, равны
между собой. Для симметричных одновершинных
распределений средняя арифметическая,
мода и медиана равны между собой.
Положительная величина показателя
асимметрии указывает на наличие
правосторонней
асимметрии, отрицательная – на наличие
левосторонней
асимметрии.
Существуют
различные способы расчета коэффициента
асимметрии:
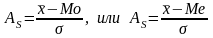
Величина As может
изменяться от –1 до +1 (для одновершинных
распределений). Чем ближе по модулю As к
1, тем асимметрия существеннее.
Наиб.точным
и распространенным явл.пок,основ.на
определен.центральн.момента
третьего порядка
(в симметрич.распред.его велич.равна
0):

Для
оценки существенности такого коэффициента
асимметрии вычисляется показатель
средней квадратической ошибки
коэффициента асимметрии:

В
случае, если
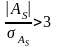
,
асимметрия считается существенной.
35. Показатель островершиности распределения
Эксцесс (Ex)
представляет собой выпад вершины
эмпирического распределения вверх или
вниз от вершины кривой нормального
распределения. Он рассчитывается для
симметричных распределений.
Наиболее
точным является показатель, использующий
центральный момент четвертого порядка
(М4):
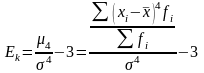
Если
показатель эксцесса больше нуля, то
распределение островершинное и скачок
считается значительным, если коэффициент
эксцесса меньше нуля, то распределение
считается плосковершинным и скачок
считается незначительным. Среднеквадратическая
ошибка эксцесса показывает, насколько
существенен скачок в явлении и
рассчитывается по формуле:
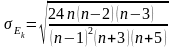
Соседние файлы в предмете [НЕСОРТИРОВАННОЕ]
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
Стандартное отклонение (англ. Standard Deviation) — простыми словами это мера того, насколько разбросан набор данных.
Вычисляя его, можно узнать, являются ли числа близкими к среднему значению или далеки от него. Если точки данных находятся далеко от среднего значения, то в наборе данных имеется большое отклонение; таким образом, чем больше разброс данных, тем выше стандартное отклонение.
Стандартное отклонение обозначается буквой σ (греческая буква сигма).
Стандартное отклонение также называется:
- среднеквадратическое отклонение,
- среднее квадратическое отклонение,
- среднеквадратичное отклонение,
- квадратичное отклонение,
- стандартный разброс.
Использование и интерпретация величины среднеквадратического отклонения
Стандартное отклонение используется:
- в финансах в качестве меры волатильности,
- в социологии в опросах общественного мнения — оно помогает в расчёте погрешности.
Пример:
Рассмотрим два малых предприятия, у нас есть данные о запасе какого-то товара на их складах.
| День 1 | День 2 | День 3 | День 4 | |
|---|---|---|---|---|
| Пред.А | 19 | 21 | 19 | 21 |
| Пред.Б | 15 | 26 | 15 | 24 |
В обеих компаниях среднее количество товара составляет 20 единиц:
- А -> (19 + 21 + 19+ 21) / 4 = 20
- Б -> (15 + 26 + 15+ 24) / 4 = 20
Однако, глядя на цифры, можно заметить:
- в компании A количество товара всех четырёх дней очень близко находится к этому среднему значению 20 (колеблется лишь между 19 ед. и 21 ед.),
- в компании Б существует большая разница со средним количеством товара (колеблется между 15 ед. и 26 ед.).
Если рассчитать стандартное отклонение каждой компании, оно покажет, что
- стандартное отклонение компании A = 1,
- стандартное отклонение компании Б ≈ 5.
Стандартное отклонение показывает эту волатильность данных — то, с каким размахом они меняются; т.е. как сильно этот запас товара на складах компаний колеблется (поднимается и опускается).
Расчет среднеквадратичного (стандартного) отклонения
Формулы вычисления стандартного отклонения

σ — стандартное отклонение,
xi — величина отдельного значения выборки,
μ — среднее арифметическое выборки,
n — размер выборки.
Эта формула применяется, когда анализируются все значения выборки.

S — стандартное отклонение,
n — размер выборки,
xi — величина отдельного значения выборки,
xср — среднее арифметическое выборки.
Эта формула применяется, когда присутствует очень большой размер выборки, поэтому на анализ обычно берётся только её часть.
Единственная разница с предыдущей формулой: “n — 1” вместо “n”, и обозначение “xср” вместо “μ”.
Разница между формулами S и σ (“n” и “n–1”)
Состоит в том, что мы анализируем — всю выборку или только её часть:
- только её часть – используется формула S (с “n–1”),
- полностью все данные – используется формула σ (с “n”).
Как рассчитать стандартное отклонение?
Пример 1 (с σ)
Рассмотрим данные о запасе какого-то товара на складах Предприятия Б.
| День 1 | День 2 | День 3 | День 4 | |
| Пред.Б | 15 | 26 | 15 | 24 |
Если значений выборки немного (небольшое n, здесь он равен 4) и анализируются все значения, то применяется эта формула:

Применяем эти шаги:
1. Найти среднее арифметическое выборки:
μ = (15 + 26 + 15+ 24) / 4 = 20
2. От каждого значения выборки отнять среднее арифметическое:
x1 – μ = 15 – 20 = -5
x2 – μ = 26 – 20 = 6
x3 – μ = 15 – 20 = -5
x4 – μ = 24 – 20 = 4
3. Каждую полученную разницу возвести в квадрат:
(x1 – μ)² = (-5)² = 25
(x2 – μ)² = 6² = 36
(x3 – μ)² = (-5)² = 25
(x4 – μ)² = 4² = 16
4. Сделать сумму полученных значений:
Σ (xi – μ)² = 25 + 36+ 25+ 16 = 102
5. Поделить на размер выборки (т.е. на n):
(Σ (xi – μ)²)/n = 102 / 4 = 25,5
6. Найти квадратный корень:
√((Σ (xi – μ)²)/n) = √ 25,5 ≈ 5,0498
Пример 2 (с S)
Задача усложняется, когда существуют сотни, тысячи или даже миллионы данных. В этом случае берётся только часть этих данных и анализируется методом выборки.
У Андрея 20 яблонь, но он посчитал яблоки только на 6 из них.
Популяция — это все 20 яблонь, а выборка — 6 яблонь, это деревья, которые Андрей посчитал.
| Яблоня 1 | Яблоня 2 | Яблоня 3 | Яблоня 4 | Яблоня 5 | Яблоня 6 |
| 9 | 2 | 5 | 4 | 12 | 7 |
Так как мы используем только выборку в качестве оценки всей популяции, то нужно применить эту формулу:

Математически она отличается от предыдущей формулы только тем, что от n нужно будет вычесть 1. Формально нужно будет также вместо μ (среднее арифметическое) написать X ср.
Применяем практически те же шаги:
1. Найти среднее арифметическое выборки:
Xср = (9 + 2 + 5 + 4 + 12 + 7) / 6 = 39 / 6 = 6,5
2. От каждого значения выборки отнять среднее арифметическое:
X1 – Xср = 9 – 6,5 = 2,5
X2 – Xср = 2 – 6,5 = –4,5
X3 – Xср = 5 – 6,5 = –1,5
X4 – Xср = 4 – 6,5 = –2,5
X5 – Xср = 12 – 6,5 = 5,5
X6 – Xср = 7 – 6,5 = 0,5
3. Каждую полученную разницу возвести в квадрат:
(X1 – Xср)² = (2,5)² = 6,25
(X2 – Xср)² = (–4,5)² = 20,25
(X3 – Xср)² = (–1,5)² = 2,25
(X4 – Xср)² = (–2,5)² = 6,25
(X5 – Xср)² = 5,5² = 30,25
(X6 – Xср)² = 0,5² = 0,25
4. Сделать сумму полученных значений:
Σ (Xi – Xср)² = 6,25 + 20,25+ 2,25+ 6,25 + 30,25 + 0,25 = 65,5
5. Поделить на размер выборки, вычитав перед этим 1 (т.е. на n–1):
(Σ (Xi – Xср)²)/(n-1) = 65,5 / (6 – 1) = 13,1
6. Найти квадратный корень:
S = √((Σ (Xi – Xср)²)/(n–1)) = √ 13,1 ≈ 3,6193
Дисперсия и стандартное отклонение
Стандартное отклонение равно квадратному корню из дисперсии (S = √D). То есть, если у вас уже есть стандартное отклонение и нужно рассчитать дисперсию, нужно лишь возвести стандартное отклонение в квадрат (S² = D).
Дисперсия — в статистике это “среднее квадратов отклонений от среднего”. Чтобы её вычислить нужно:
- Вычесть среднее значение из каждого числа
- Возвести каждый результат в квадрат (так получатся квадраты разностей)
- Найти среднее значение квадратов разностей.
Ещё расчёт дисперсии можно сделать по этой формуле:

S² — выборочная дисперсия,
Xi — величина отдельного значения выборки,
Xср (может появляться как X̅) — среднее арифметическое выборки,
n — размер выборки.
Правило трёх сигм
Это правило гласит: вероятность того, что случайная величина отклонится от своего математического ожидания более чем на три стандартных отклонения (на три сигмы), почти равна нулю.

Глядя на рисунок нормального распределения случайной величины, можно понять, что в пределах:
- одного среднеквадратического отклонения заключаются 68,26% значений (Xср ± 1σ или μ ± 1σ),
- двух стандартных отклонений — 95,44% (Xср ± 2σ или μ ± 2σ),
- трёх стандартных отклонений — 99,72% (Xср ± 3σ или μ ± 3σ).
Это означает, что за пределами остаются лишь 0,28% — это вероятность того, что случайная величина примет значение, которое отклоняется от среднего более чем на 3 сигмы.
Стандартное отклонение в excel
Вычисление стандартного отклонения с “n – 1” в знаменателе (случай выборки из генеральной совокупности):
1. Занесите все данные в документ Excel.

2. Выберите поле, в котором вы хотите отобразить результат.
3. Введите в этом поле “=СТАНДОТКЛОНА(“
4. Выделите поля, где находятся данные, потом закройте скобки.

5. Нажмите Ввод (Enter).

В случае если данные представляют всю генеральную совокупность (n в знаменателе), то нужно использовать функцию СТАНДОТКЛОНПА.


Коэффициент вариации
Коэффициент вариации — отношение стандартного отклонения к среднему значению, т.е. Cv = (S/μ) × 100% или V = (σ/X̅) × 100%.
Стандартное отклонение делится на среднее и умножается на 100%.
Можно классифицировать вариабельность выборки по коэффициенту вариации:
- при <10% выборка слабо вариабельна,
- при 10% – 20 % — средне вариабельна,
- при >20 % — выборка сильно вариабельна.
Узнайте также про:
- Корреляции,
- Метод Крамера,
- Метод наименьших квадратов,
- Теорию вероятностей
- Интегралы.
Просмотров:
1 908
В статистике, да и в некоторых других расчетах используется среднее отклонение значения от всех значений диапазона. Для вычисления среднего отклонения в Excel используется функция СРОТКЛ.
Описание
Если открыть описание функции в справочнике по Excel, то можно увидеть что функция возвращает среднее абсолютных значений отклонений точек данных от среднего. Кроме того сказано что данная функция является мерой разброса множества данных. Сложно звучит, хотя на практике вычисление, производимое данной функцией не так трудно понять. Для начала рассмотрим синтаксис функции.
Синтаксис
СРОТКЛ(число1[;число2]…)
число1 – первое значение или ссылка
число2 – второе значение или ссылка
функция в качестве параметров может принимать как обычные
числа, которых может быть от 1 до 255, так и ссылки на массивы, как и сами
массивы. Необходимо отметить, что на результат функции влияют единицы измерения
входных данных.
Как и во многих других функциях при указании в качестве
аргумента диапазона значений или массива, функция производит вычисления избирательно
для значений набора. Так строки,
логические значения и пустые ячейки пропускаются, но при этом ячейка, содержащая
0 (ноль) учитывается. Связанно это с тем, что функция производит вычисления над
числовыми значениями.
Примеры
Пусть имеется рабочий лист со следующими значениями:
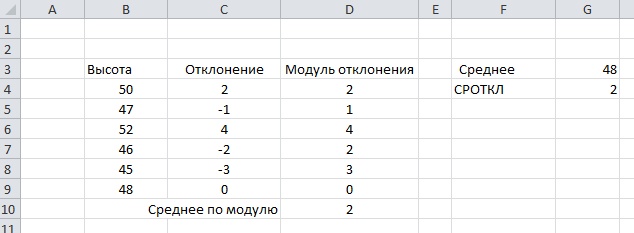
Анализировать мы будем диапазон от В4 до В9 содержащий
значения измеренных высот. В ячейку G4 введем функцию среднего отклонения
=СРОТКЛ(B4:B9)
Результатом выполнения функции будет значение 2. Так как же
вычисляется значение: введем в ячейку G3 функцию вычисляющую среднее значение для исходного набора
значений
=СРЗНАЧ(B4:B9)
Результатом будет значение 48. Теперь посчитаем в ячейках столбца
С для каждого исходного значения его отклонение от среднего. Так отклонение
числа 50 будет 2 (50-48), а отклонение значения 45 будет -3 (45-48). Но как мы
знаем из описания функция возвращает среднее от абсолютных значений, те
значений по модулю, поэтому в столбце D введем функцию возвращающую модуль
значений отклонения. Положительные числа и ноль останутся без изменений, а
отрицательные значения станут положительными. И теперь посчитаем среднее
значение по модулю отклонения:
=СРЗНАЧ(D4:D9)
Результат будет так же значение 2. То есть среднее значение
абсолютных значений отклонения числа от среднего значения по диапазону. То же
самое что возвращает функция СРОТКЛ.
В данной статье я расскажу о том, как найти среднеквадратическое отклонение. Этот материал крайне важен для полноценного понимания математики, поэтому репетитор по математике должен посвятить его изучению отдельный урок или даже несколько. В этой статье вы найдёте ссылку на подробный и понятный видеоурок, в котором рассказано о том, что такое среднеквадратическое отклонение и как его найти.
Среднеквадратическое отклонение дает возможность оценить разброс значений, полученных в результате измерения какого-то параметра. Обозначается символом  (греческая буква «сигма»).
(греческая буква «сигма»).
Формула для расчета довольно проста. Чтобы найти среднеквадратическое отклонение, нужно взять квадратный корень из дисперсии. Так что теперь вы должны спросить: “А что же такое дисперсия?”
Что такое дисперсия
Определение дисперсии звучит так. Дисперсия — это среднее арифметическое от квадратов отклонений значений от среднего.
Чтобы найти дисперсию последовательно проведите следующие вычисления:
- Определите среднее (простое среднее арифметическое ряда значений).
- Затем от каждого из значений отнимите среднее и возведите полученную разность в квадрат (получили квадрат разности).
- Следующим шагом будет вычисление среднего арифметического полученных квадратов разностей (Почему именно квадратов вы сможете узнать ниже).
Рассмотрим на примере. Допустим, вы с друзьями решили измерить рост ваших собак (в миллиметрах). В результате измерений вы получили следующие данные измерений роста (в холке): 600 мм, 470 мм, 170 мм, 430 мм и 300 мм.
| Порода собаки | Рост в миллиметрах |
| Ротвейлер | 600 |
| Бульдог | 470 |
| Такса | 170 |
| Пудель | 430 |
| Мопс | 300 |
Вычислим среднее значение, дисперсию и среднеквадратическое отклонение.
Сперва найдём среднее значение. Как вы уже знаете, для этого нужно сложить все измеренные значения и поделить на количество измерений. Ход вычислений:
Среднее  мм.
мм.
Итак, среднее (среднеарифметическое) составляет 394 мм.
Теперь нужно определить отклонение роста каждой из собак от среднего:
![[ begin{array}{l} 1: 600-394 = 206 \ 2: 470-394 = 76 \ 3: 170-394 = -224\ 4: 430-394 = 36\ 5: 300-394 = -94 end{array} ]](https://yourtutor.info/wp-content/ql-cache/quicklatex.com-3916a3ccd97d909589dfe1dabb970af0_l3.png "Rendered by QuickLaTeX.com")
Наконец, чтобы вычислить дисперсию, каждую из полученных разностей возводим в квадрат, а затем находим среднее арифметическое от полученных результатов:
Дисперсия  мм2.
мм2.
Таким образом, дисперсия составляет 21704 мм2.
Как найти среднеквадратическое отклонение
Так как же теперь вычислить среднеквадратическое отклонение, зная дисперсию? Как мы помним, взять из нее квадратный корень. То есть среднеквадратическое отклонение равно:
 мм (округлено до ближайшего целого значения в мм).
мм (округлено до ближайшего целого значения в мм).
Применив данный метод, мы выяснили, что некоторые собаки (например, ротвейлеры) – очень большие собаки. Но есть и очень маленькие собаки (например, таксы, только говорить им этого не стоит).
Самое интересное, что среднеквадратическое отклонение несет в себе полезную информацию. Теперь мы можем показать, какие из полученных результатов измерения роста находятся в пределах интервала, который мы получим, если отложим от среднего (в обе стороны от него) среднеквадратическое отклонение.
То есть с помощью среднеквадратического отклонения мы получаем “стандартный” метод, который позволяет узнать, какое из значений является нормальным (среднестатистическим), а какое экстраординарно большим или, наоборот, малым.
Что такое стандартное отклонение
Но… все будет немного иначе, если мы будем анализировать выборку данных. В нашем примере мы рассматривали генеральную совокупность. То есть наши 5 собак были единственными в мире собаками, которые нас интересовали.
Но если данные являются выборкой (значениями, которые выбрали из большой генеральной совокупности), тогда вычисления нужно вести иначе.
Если есть  значений, то:
значений, то:
Все остальные расчеты производятся аналогично, в том числе и определение среднего.
Например, если наших пять собак – только выборка из генеральной совокупности собак (всех собак на планете), мы должны делить на 4, а не на 5, а именно:
Дисперсия выборки =  мм2.
мм2.
При этом стандартное отклонение по выборке равно  мм (округлено до ближайшего целого значения).
мм (округлено до ближайшего целого значения).
Можно сказать, что мы произвели некоторую “коррекцию” в случае, когда наши значения являются всего лишь небольшой выборкой.
Примечание. Почему именно квадраты разностей?
Но почему при вычислении дисперсии мы берём именно квадраты разностей? Допустим при измерении какого-то параметра, вы получили следующий набор значений: 4; 4; -4; -4. Если мы просто сложим абсолютные отклонения от среднего (разности) между собой … отрицательные значения взаимно уничтожатся с положительными:
 .
.
Получается, этот вариант бесполезен. Тогда, может, стоит попробовать абсолютные значения отклонений (то есть модули этих значений)?
 .
.
На первый взгляд получается неплохо (полученная величина, кстати, называется средним абсолютным отклонением), но не во всех случаях. Попробуем другой пример. Пусть в результате измерения получился следующий набор значений: 7; 1; -6; -2. Тогда среднее абсолютное отклонение равно:
 .
.
Вот это да! Снова получили результат 4, хотя разности имеют гораздо больший разброс.
А теперь посмотрим, что получится, если возвести разности в квадрат (и взять потом квадратный корень из их суммы).
Для первого примера получится:
 .
.
Для второго примера получится:
 .
.
Теперь – совсем другое дело! Среднеквадратическое отклонение получается тем большим, чем больший разброс имеют разности … к чему мы и стремились.
Фактически в данном методе использована та же идея, что и при вычислении расстояния между точками, только примененная иным способом.
И с математической точки зрения использование квадратов и квадратных корней дает больше пользы, чем мы могли бы получить на основании абсолютных значений отклонений, благодаря чему среднеквадратическое отклонение применимо и для других математических задач.
О том, как найти среднеквадратическое отклонение, вам рассказал репетитор по математике в Москве, Сергей Валерьевич
