Is there any function that would be the equivalent of a combination of df.isin() and df[col].str.contains()?
For example, say I have the series
s = pd.Series(['cat','hat','dog','fog','pet']), and I want to find all places where s contains any of ['og', 'at'], I would want to get everything but ‘pet’.
I have a solution, but it’s rather inelegant:
searchfor = ['og', 'at']
found = [s.str.contains(x) for x in searchfor]
result = pd.DataFrame[found]
result.any()
Is there a better way to do this?
smci
32k19 gold badges113 silver badges146 bronze badges
asked Oct 26, 2014 at 20:23
3
One option is just to use the regex | character to try to match each of the substrings in the words in your Series s (still using str.contains).
You can construct the regex by joining the words in searchfor with |:
>>> searchfor = ['og', 'at']
>>> s[s.str.contains('|'.join(searchfor))]
0 cat
1 hat
2 dog
3 fog
dtype: object
As @AndyHayden noted in the comments below, take care if your substrings have special characters such as $ and ^ which you want to match literally. These characters have specific meanings in the context of regular expressions and will affect the matching.
You can make your list of substrings safer by escaping non-alphanumeric characters with re.escape:
>>> import re
>>> matches = ['$money', 'x^y']
>>> safe_matches = [re.escape(m) for m in matches]
>>> safe_matches
['\$money', 'x\^y']
The strings with in this new list will match each character literally when used with str.contains.
answered Oct 26, 2014 at 20:40
![]()
Alex RileyAlex Riley
166k45 gold badges259 silver badges236 bronze badges
4
You can use str.contains alone with a regex pattern using OR (|):
s[s.str.contains('og|at')]
Or you could add the series to a dataframe then use str.contains:
df = pd.DataFrame(s)
df[s.str.contains('og|at')]
Output:
0 cat
1 hat
2 dog
3 fog
answered Oct 26, 2014 at 21:33
l’L’ll’L’l
44.4k9 gold badges93 silver badges144 bronze badges
3
Here is a one line lambda that also works:
df["TrueFalse"] = df['col1'].apply(lambda x: 1 if any(i in x for i in searchfor) else 0)
Input:
searchfor = ['og', 'at']
df = pd.DataFrame([('cat', 1000.0), ('hat', 2000000.0), ('dog', 1000.0), ('fog', 330000.0),('pet', 330000.0)], columns=['col1', 'col2'])
col1 col2
0 cat 1000.0
1 hat 2000000.0
2 dog 1000.0
3 fog 330000.0
4 pet 330000.0
Apply Lambda:
df["TrueFalse"] = df['col1'].apply(lambda x: 1 if any(i in x for i in searchfor) else 0)
Output:
col1 col2 TrueFalse
0 cat 1000.0 1
1 hat 2000000.0 1
2 dog 1000.0 1
3 fog 330000.0 1
4 pet 330000.0 0
answered Apr 1, 2020 at 21:30
Grant ShannonGrant Shannon
4,5901 gold badge45 silver badges36 bronze badges
1
Had the same issue. Without making it too complex, you can add | in between each entry, like fieldname.str.contains("cat|dog") works
![]()
Suraj Rao
29.3k11 gold badges94 silver badges103 bronze badges
answered Dec 16, 2022 at 4:26
1
In this tutorial, we will look at how to search for a string (or a substring) in a pandas dataframe column with the help of some examples.
How to check if a pandas series contains a string?
You can use the pandas.series.str.contains() function to search for the presence of a string in a pandas series (or column of a dataframe). You can also pass a regex to check for more custom patterns in the series values. The following is the syntax:
# usnig pd.Series.str.contains() function with default parameters
df['Col'].str.contains("string_or_pattern", case=True, flags=0, na=None, regex=True)
It returns a boolean Series or Index based on whether a given pattern or regex is contained within a string of a Series or Index.
The case parameter tells whether to match the string in a case-sensitive manner or not.
The regex parameter tells the function that you want to match for a specific regex pattern.
The flags parameter can be used to pass additional flags for the regex match through to the re module (for example re.IGNORECASE)
Let’s look at some examples to see the above syntax in action
Pass the string you want to check for as an argument.
import pandas as pd
# create a pandas series
players = pd.Series(['Rahul Dravid', 'Yuvraj Singh', 'Sachin Tendulkar', 'Mahendra Singh Dhoni', 'Virat Kohli'])
# names with 'Singh'
print(players.str.contains('Singh', regex=False))
Output:
0 False 1 True 2 False 3 True 4 False dtype: bool
Here, we created a pandas series containing names of some India’s top cricketers. We then find the names containing the word “Singh” using the str.contains() function. We also pass regex=False to indicate not to assume the passed value as a regex pattern. In this case, you can also go with the default regex=True as it would not make any difference.
Also note that we get the result as a pandas series of boolean values representing which of the values contained the given string. You can use this series to filter values in the original series.
For example, let’s only print out the names containing the word “Singh”
# display the type
type(players.str.contains('Singh'))
# filter for names containing 'Singh'
print(players[players.str.contains('Singh')])
Output:
1 Yuvraj Singh 3 Mahendra Singh Dhoni dtype: object
Here we applied the .str.contains() function on a pandas series. Note that you can also apply it on individual columns of a pandas dataframe.
# create a dataframe
df = pd.DataFrame({
'Name': ['Rahul Dravid', 'Yuvraj Singh', 'Sachin Tendulkar', 'Mahendra Singh Dhoni', 'Virat Kohli'],
'IPL Team': ['RR', 'KXIP', 'MI', 'CSK', 'RCB']
})
# filter for names that have "Singh"
print(df[df['Name'].str.contains('Singh', regex=False)])
Output:
Name IPL Team 1 Yuvraj Singh KXIP 3 Mahendra Singh Dhoni CSK
Search for string irrespective of case
By default, the pd.series.str.contains() function’s string searches are case sensitive.
# create a pandas series
players = pd.Series(['Rahul Dravid', 'yuvraj singh', 'Sachin Tendulkar', 'Mahendra Singh Dhoni', 'Virat Kohli'])
# names with 'Singh' irrespective of case
print(players.str.contains('Singh', regex=False))
Output:
0 False 1 False 2 False 3 True 4 False dtype: bool
We get False for “yuvraj singh” because it does not contain the word “Singh” in the same case.
You can, however make the function search for strings irrespective of the case by passing False to the case parameter.
# create a pandas series
players = pd.Series(['Rahul Dravid', 'yuvraj singh', 'Sachin Tendulkar', 'Mahendra Singh Dhoni', 'Virat Kohli'])
# names with 'Singh' irrespective of case
print(players.str.contains('Singh', regex=False, case=False))
Output:
0 False 1 True 2 False 3 True 4 False dtype: bool
Search for a matching regex pattern in column
You can also pass regex patterns to the above function for searching more complex values/patterns in the series.
# create a pandas series
balls = pd.Series(['wide', 'no ball', 'wicket', 'dot ball', 'runs'])
# check for wickets or dot balls
good_balls = balls.str.contains('wicket|dot ball', regex=True)
# display good balls
print(good_balls)
Output:
0 False 1 False 2 True 3 True 4 False dtype: bool
Here we created a pandas series with values representing different outcomes when a blower bowls a ball in cricket. Let’s say we want to find all the good balls which can be defined as either a wicket or a dot ball. We used the regex pattern 'wicket|dot ball' to match with either “wicket” or “dot ball”.
You can similarly write more complex regex patterns depending on your use-case to match values in a pandas series.
For more the pd.Series.str.contains() function, refer to its documentation.
With this, we come to the end of this tutorial. The code examples and results presented in this tutorial have been implemented in a Jupyter Notebook with a python (version 3.8.3) kernel having pandas version 1.0.5
Subscribe to our newsletter for more informative guides and tutorials.
We do not spam and you can opt out any time.
-

Piyush is a data professional passionate about using data to understand things better and make informed decisions. He has experience working as a Data Scientist in the consulting domain and holds an engineering degree from IIT Roorkee. His hobbies include watching cricket, reading, and working on side projects.
View all posts
Python is a great language for doing data analysis, primarily because of the fantastic ecosystem of data-centric python packages. Pandas is one of those packages and makes importing and analyzing data much easier.
Pandas str.find() method is used to search a substring in each string present in a series. If the string is found, it returns the lowest index of its occurrence. If string is not found, it will return -1.
Start and end points can also be passed to search a specific part of string for the passed character or substring.
Syntax: Series.str.find(sub, start=0, end=None)
Parameters:
sub: String or character to be searched in the text value in series
start: int value, start point of searching. Default is 0 which means from the beginning of string
end: int value, end point where the search needs to be stopped. Default is None.
Return type: Series with index position of substring occurrence
To download the CSV used in code, click here.
In the following examples, the data frame used contains data of some NBA players. The image of data frame before any operations is attached below.
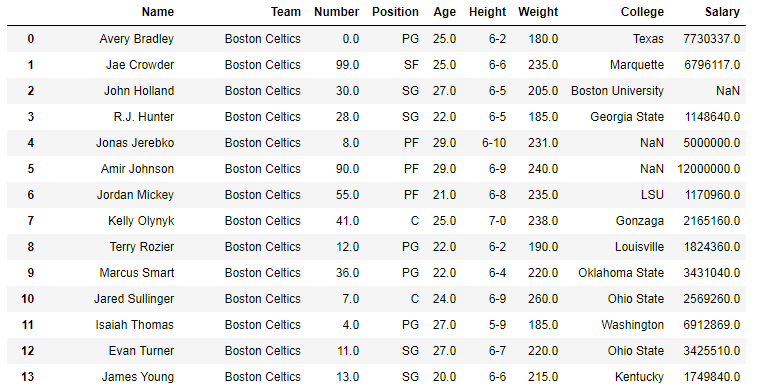
Example #1: Finding single character
In this example, a single character ‘a’ is searched in each string of Name column using str.find() method. Start and end parameters are kept default. The returned series is stored in a new column so that the indexes can be compared by looking directly. Before applying this method, null rows are dropped using .dropna() to avoid errors.
Python3
Output:
As shown in the output image, the occurrence of index in the Indexes column is equal to the position first occurrence of character in the string. If the substring doesn’t exist in the text, -1 is returned. It can also be seen by looking at the first row itself that ‘A’ wasn’t considered which proves this method is case sensitive.

Example #2: Searching substring (More than one character)
In this example, ‘er’ substring will be searched in the Name column of data frame. The start parameter is kept 2 to start search from 3rd(index position 2) element.
Python3
Output:
As shown in the output image, the last index of occurrence of substring is returned. But it can be seen, in case of Terry Rozier(Row 9 in data frame), instead of first occurrence of ‘er’, 10 was returned. This is because the start parameter was kept 2 and the first ‘er’ occurs before that.

Last Updated :
18 Jan, 2023
Like Article
Save Article
Improve Article
Save Article
Like Article
Improve Article
Save Article
Like Article
Series.str can be used to access the values of the series as strings and apply several methods to it. Pandas Series.str.contains() function is used to test if pattern or regex is contained within a string of a Series or Index. The function returns boolean Series or Index based on whether a given pattern or regex is contained within a string of a Series or Index.
Syntax: Series.str.contains(pat, case=True, flags=0, na=nan, regex=True)
Parameter :
pat : Character sequence or regular expression.
case : If True, case sensitive.
flags : Flags to pass through to the re module, e.g. re.IGNORECASE.
na : Fill value for missing values.
regex : If True, assumes the pat is a regular expression.
Returns : Series or Index of boolean values
Example #1: Use Series.str.contains a () function to find if a pattern is present in the strings of the underlying data in the given series object.
Python3
import pandas as pd
import re
sr = pd.Series(['New_York', 'Lisbon', 'Tokyo', 'Paris', 'Munich'])
idx = ['City 1', 'City 2', 'City 3', 'City 4', 'City 5']
sr.index = idx
print(sr)
Output :

Now we will use Series.str.contains a () function to find if a pattern is contained in the string present in the underlying data of the given series object.
Python3
result = sr.str.contains(pat = 'is')
print(result)
Output :
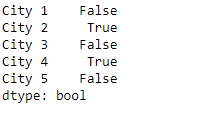
As we can see in the output, the Series.str.contains() function has returned a series object of boolean values. It is true if the passed pattern is present in the string else False is returned.
Example #2: Use Series.str.contains a () function to find if a pattern is present in the strings of the underlying data in the given series object. Use regular expressions to find patterns in the strings.
Python3
import pandas as pd
import re
sr = pd.Series(['Mike', 'Alessa', 'Nick', 'Kim', 'Britney'])
idx = ['Name 1', 'Name 2', 'Name 3', 'Name 4', 'Name 5']
sr.index = idx
print(sr)
Output :

Now we will use Series.str.contains a () function to find if a pattern is contained in the string present in the underlying data of the given series object.
Python3
result = sr.str.contains(pat = 'i[a-z]', regex = True)
print(result)
Output :
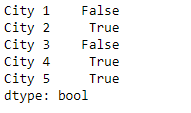
As we can see in the output, the Series.str.contains() function has returned a series object of boolean values. It is true if the passed pattern is present in the string else False is returned.
Last Updated :
22 Oct, 2021
Like Article
Save Article
Example
str.contains() method can be used to check if a pattern occurs in each string of a Series. str.startswith() and str.endswith() methods can also be used as more specialized versions.
In [1]: animals = pd.Series(['cat', 'dog', 'bear', 'cow', 'bird', 'owl', 'rabbit', 'snake'])
Check if strings contain the letter ‘a’:
In [2]: animals.str.contains('a')
Out[2]:
0 True
1 False
2 True
3 False
4 False
5 False
6 True
7 True
8 True
dtype: bool
This can be used as a boolean index to return only the animals containing the letter ‘a’:
In [3]: animals[animals.str.contains('a')]
Out[3]:
0 cat
2 bear
6 rabbit
7 snake
dtype: object
str.startswith and str.endswith methods work similarly, but they also accept tuples as inputs.
In [4]: animals[animals.str.startswith(('b', 'c'))]
# Returns animals starting with 'b' or 'c'
Out[4]:
0 cat
2 bear
3 cow
4 bird
dtype: object
