У меня есть фрейм данных по фильмам: название, актёрский состав, жанры, бюджет и т.д. Нужно найти фильм с максимальным бюджетом. Я нашел максимальный бюджет.
Но как мне сопоставить с его с названием фильма?
Текущий код:
data = pd.read_csv('movie_bd_v5.csv')
top_budget = data['budget'].max()
![]()
0xdb
51.4k194 золотых знака56 серебряных знаков232 бронзовых знака
задан 10 фев 2021 в 11:09
![]()
1
Воспользуйтесь методом DataFrame.nlargest():
top_budget_movie = data.nlargest(1, columns=["budget"])["name"]
UPD:
можно сделать менее эффективно (в два шага) – сначала находим максимум и после этого выбираем строки в которых бюджет максимальный:
max_budget = data['budget'].max()
res = df.query("budget == @max_budget")["name"]
PS в этом случае если существует более одного фильма с максимальным (одинаковым) бюджетом, то вам придется самому позаботиться о дубликатах…
ответ дан 10 фев 2021 в 11:22
![]()
2
Находит максимальное значение элемента в последовательности.
Синтаксис:
max(iterable, *[, key, default]) max(arg1, arg2, *args[, key])
Параметры:
iterable– итерируемый объект,key– должна быть функцией (принимает один аргумент), используется для порядка сравнения элементов итерируемого объекта. Функция вычисляется один раз,default– значение по умолчанию, если итерируемый объект окажется пустым,arg1...argN– позиционный аргумент,*args– список позиционных аргументов.
Возвращаемое значение:
- наибольшее значение объекта.
Описание:
Функция max() возвращает наибольшее значение элемента итерируемого объекта или самое большое из двух или более переданных позиционных аргументов.
- Если указан один позиционный аргумент, он должен быть итерируемым объектом (список, кортеж, словарь и т.д.).
- Если в функцию передается два или более позиционных аргумента, возвращается самый большой из них.
- В случае, когда максимальное значение имеют сразу несколько аргументов. Возвращает первый по порядку элемент с максимальным значением. Это согласуется с другими инструментами сохранения стабильности сортировки, такими как
sorted(iterable, key=keyfunc, reverse=True)[0]иheapq.nlargest(1, iterable, key=keyfunc)
Аргумент key – функция подобная той, которая используется в дополнительном методе списков list.sort(). Функция принимает один аргумент и используется для упорядочивания элементов.
>>> x = ['4', '11', '6', '31'] # функция `max` сравнивает # числа как строки >>> max(x) '6' # функция 'key=lambda i: int(i)' применяется # к каждому элементу списка 'x', преобразуя # строки в тип 'int' и теперь функция `max` # сравнивает элементы списка как числа. >>> max(x, key=lambda i: int(i)) '31' # или другое применение функции 'key' # выбор списка с наибольшей суммой элементов >>> max([1,2,3,4], [3,4,5], key=sum) [3, 4, 5]
Аргумент default по умолчанию указывает объект, который нужно вернуть, если предоставленный итерируемый объект пуст. Если итерация пуста и значение по умолчанию не указано, то возникает ошибка ValueError.
# Значение по умолчанию >>> max([], default=10) 10
Функция max() сравнивает элементы, используя оператор <. Поэтому, все передаваемые в них значения должны быть сопоставимы друг с другом и одного типа, иначе бросается исключение TypeError
При передаче в качестве аргумента текстовых строк, байтовых строк или байтовых массивов, а так же списка символов, максимальное значение будет выбираться исходя из порядка следования символов, в таблице соответствующей кодировки.
>>> x = list('abcdifgh') >>> max(x) # 'i'
Изменено в Python 3.8: Аргумент key может быть None.
Примеры поиска максимального значения в последовательности.
- Нахождение самой длинной строки в списке строк;
- Нахождение максимального значения в списке строк, записанных как целые числа;
- Нахождения максимального значения в строке, которая состоит из чисел и строк;
- Определение индекса у максимального значения в списке;
- Выбор максимального значения для ключа или значения в словаре;
- Нахождение списка с наибольшей суммой элементов в списке списков;
- Нахождение списка с наибольшим количеством элементов в списке списков.
# использование позиционных аргументов >>> max(5, 3, 6, 5, 6) # 6 # использование в качестве аргумента - список >>> max([1.2, 1.3, 1.5, 2, 5.52]) # 5.52 # комбинирование позиционных аргументов и списка # при передаче списка 'x' происходит его распаковка >>> x = (1.2, 1.3, 1.5, 2, 5.52) >>> max(5, 3, 5, *x) # 5,52
Нахождение самой длинной строки в списке строк.
Найдем самую длинную строку. В качестве ключевой функции используем len(). Она посчитает количество символов в строке каждого элемента списка строк, а функция max() выберет максимальное число. Строки можно передать например как позиционные аргументы, так и списком ['Jul', 'John', 'Vicky'], результат будет тот же.
>>> line = ['Jul', 'John', 'Vicky'] >>> max(line, key=len) # 'Vicky'
Нахождение max() в списке строк, записанных как целые числа.
Есть список строк чисел и необходимо найти максимум, как если бы они были целыми числами? Если применить функцию max() к исходному списку “как есть”, то она выберет наибольшее значение списка исходя из лексикографической сортировки. Для нахождения максимума, как числа, применим функцию lambda i: int(i) в качестве ключа key, которая “на лету” преобразует элементы списка в целые числа, тогда функция max() выберет то что нам нужно.
>>> x = ['4', '11', '6', '31'] >>> max(x) # '6' >>> max(x, key = lambda i: int(i)) # '31'
Нахождения max() в строке, которая состоит из чисел и строк.
Что бы найти максимум в строке, которая состоит из чисел и строк, необходимо сначала разделить исходную строку на список подстрок. Используем приемы, описанные в примерах функции sum():
- по разделителю, например пробелу
' 'или';'методом строкиstr.split(), - вытащить все цифры из исходной строки при помощи функцией
re.findall().
Затем в цикле перебрать полученный список и все строки с цифрами преобразовать в соответствующие числовые типы и уже потом применить функцию
# исходная строка >>> line = '12; 12,5; 14; один; 15.6; два' # способы преобразования строки в список строк # 1 способ по разделителю ';' >>> line.split(';') # ['12', ' 12,5', ' 14', ' один', ' 15.6', ' два'] # 2 способ по регулярному выражению >>> import re >>> match = re.findall(r'[d.?,?]+', line) >>> list(match) # ['12', '12,5', '14', '15.6']
Далее будем работать с более сложным списком, полученным 1 способом, где встречаются слова. И так, имеем список строк с цифрами и другими строками. Стоит задача: преобразовать строки с цифрами в соответствующие числовые типы и отбросить строки со словами, что бы потом найти максимум.
Задача усложняется тем, что вещественные числа в строках записаны как через запятую, так и через точку. Для необходимых проверок и преобразований определим функцию str_to_num().
>>> def str_to_num(str, chars=['.', ',']): ... # убираем начальные и конечные пробелы ... str = str.strip() ... if (any(char in str for char in chars) and ... str.replace('.', '').replace(',', '').isdigit()): ... # если в строке есть точка или запятая и при их замене на '' ... # строка состоит только из цифр то это тип float ... return float(str.replace(',', '.')) ... elif str.isdigit(): ... # если строка состоит только из цифр то это тип int ... return int(str) # полученный список строк 1-м способом >>> str_list = ['12', ' 12,5', ' 14', ' один', ' 15.6', ' два'] # новый список чисел, где будем искать максимум >>> num_list = [] >>> for i in str_list: ... # применим функцию преобразования строки в число ... n = str_to_num(i) ... if n is not None: ... # если функция возвращает число, ... # то добавляем в новый список ... num_list.append(str_to_num(i)) >>> num_list # [12, 12.5, 14, 15.6] >>> max(num_list) # 15.6
Определение индекса у максимального значения в списке.
Допустим есть список чисел и стоит задача, определить индекс максимального значения в этом списке. Для решения этой задачи необходимо пронумеровать список, т.е. создать кортеж – индекс/число, а затем найти максимум, используя в качестве ключа key=lambda i : i[1].
>>> lst = [1, 5, 3, 6, 9, 7] # пронумеруем список >>> lst_num = list(enumerate(lst, 0)) >>> lst_num # [(0, 1), (1, 5), (2, 3), (3, 6), (4, 9), (5, 7)] # найдем максимум (из второго значения кортежей) >>> t_max = max(lst_num, key=lambda i : i[1]) >>> t_max # (4, 9) # индекс максимального значения >>> t_max[0] # 4
Нахождение max() для ключа или значения в словаре dict.
Допустим есть словарь, задача: найти максимальное значение ключа или самого значения ключа и вывести эту пару.
# имеем словарь >>> d = {1: 3, 2: 4, 1: 9, 4: 1} # преобразуем его в список отображение >>> key_val = d.items() # преобразуем отображение в список # кортежей (ключ, значение) >>> key_val_list = list(key_val) # [(1, 9), (2, 4), (4, 1)]
По умолчанию, при нахождении максимального элемента из списка кортежей будет выбираться кортеж, у которого наибольшее значение имеет ключ исходного словаря (первый элемент в кортеже).
Но если необходимо получить пару (key, value), у которого наибольшее значение имеет значение ключа (второй элемент), то для этого нужно применить лямбда-функцию lambda i : i[1] в качестве аргумента key функции max(), которая укажет, из какого элемента кортежа выбирать наибольшее значение.
# происходит сравнение по # первым элементам кортежа >>> kv = max(key_val_list) >>> kv # (4, 1) # максимальное значение ключа в словаре >>> kv[0] # 4 # меняем порядок сравнения >>> kv = max(key_val_list, key=lambda i : i[1]) >>> kv # (1, 9) # максимальное значение в словаре >>> kv[1] # 9 # ключ этого значения в словаре >>> kv[0] # 1 # получаем максимальное значение из словаря >>> d[kv[0]] # 9
Нахождение списка с наибольшей суммой элементов в списке списков.
Для выполнения данной задачи, используем функцию max(), а в качестве ключевой функции применим встроенную функцию sum().
# исходный список >>> lst = [[1, 2, 3], [4, 5], [1, 3, 4, 5], [10, 20]] # выбираем список с наибольшей суммой элементов >>> max(lst, key=sum) # [10, 20]
Выбор списка с наибольшим количеством элементов из списка списков.
Для выполнения данной задачи, используем функцию max(), а в качестве ключевой функции применим встроенную функцию len().
# исходный список >>> lst = [[1, 2, 3], [4, 5], [1, 3, 4, 5], [10, 20]] # выбираем список с наибольшим количеством элементов >>> max(lst, key=len) # [1, 3, 4, 5]
In this article, we are going to discuss how to find the maximum value and its index position in columns and rows of a Dataframe.
Create Dataframe to Find max values & position of columns or rows
Python3
import numpy as np
import pandas as pd
matrix = [(10, 56, 17),
(np.NaN, 23, 11),
(49, 36, 55),
(75, np.NaN, 34),
(89, 21, 44)
]
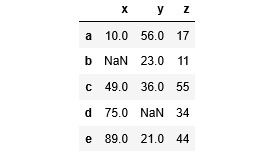
abc = pd.DataFrame(matrix, index=list('abcde'), columns=list('xyz'))
abc
Output:
Time complexity: O(n) where n is the number of elements in the matrix.
Auxiliary space: O(n) where n is the number of elements in the matrix.
Find maximum values in columns and rows in Pandas
Pandas dataframe.max() method finds the maximum of the values in the object and returns it. If the input is a series, the method will return a scalar which will be the maximum of the values in the series. If the input is a Dataframe, then the method will return a series with a maximum of values over the specified axis in the Dataframe. The index axis is the default axis taken by this method.
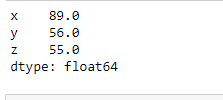
Get the maximum values of every column in Python
To find the maximum value of each column, call the max() method on the Dataframe object without taking any argument. In the output, We can see that it returned a series of maximum values where the index is the column name and values are the maxima from each column.
Python3
maxValues = abc.max()
print(maxValues)
Output:
Get max value from a row of a Dataframe in Python
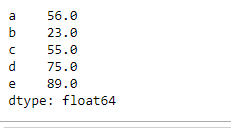
For the maximum value of each row, call the max() method on the Dataframe object with an argument axis=1. In the output, we can see that it returned a series of maximum values where the index is the row name and values are the maxima from each row.
Python3
maxValues = abc.max(axis=1)
print(maxValues)
Output:
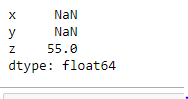
Get the maximum values of every column without skipping NaN in Python
From the above examples, NaN values are skipped while finding the maximum values on any axis. By putting skipna=False we can include NaN values also. If any NaN value exists it will be considered as the maximum value.
Python3
maxValues = abc.max(skipna=False)
print(maxValues)
Output:
Get maximum values from multiple columns in Python
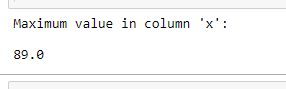
To get the maximum value of a single column see the following example
Python3
maxClm = df['x'].max()
print("Maximum value in column 'x': ")
print(maxClm)
Output:
Get max value in one or more columns
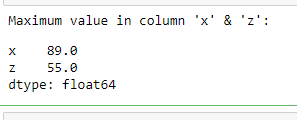
A list of columns can also be passed instead of a single column to find the maximum values of specified columns
Python3
maxValues = df[['x', 'z']].max()
print("Maximum value in column 'x' & 'z': ")
print(maxValues)
Output:
Find the maximum position in columns and rows in Pandas
Pandas dataframe.idxmax() method returns the index of the first occurrence of maximum over the requested axis. While finding the index of the maximum value across any index, all NA/null values are excluded.
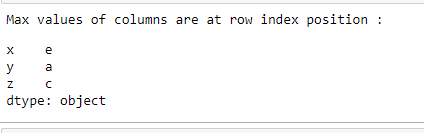
Find the row index which has the maximum value
It returns a series containing the column names as index and row as index labels where the maximum value exists in that column.
Python3
maxValueIndex = df.idxmax()
print("Maximum values of columns are at row index position :")
print(maxValueIndex)
Output:
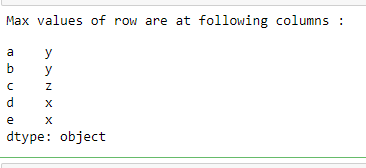
Find the column name which has the maximum value
It returns a series containing the rows index labels as index and column names as values where the maximum value exists in that row.
Python3
maxValueIndex = df.idxmax(axis=1)
print("Max values of row are at following columns :")
print(maxValueIndex)
Output:
Last Updated :
03 Feb, 2023
Like Article
Save Article
В этом руководстве мы собираемся понять использование методов min и max в Python. По сути, метод Python max() возвращает максимальное значение среди набора переданных значений или элементов переданного итеративного объекта.
Ниже приведен синтаксис использования метода Python max() для поиска наибольшего значения в итерируемом объекте.
max(iterable, *[, key, default])
- iterable — это объект, содержащий значения, для которых необходимо найти наибольшее,
- key определяет функцию упорядочивания с одним аргументом,
- И значение по умолчанию — это значение по умолчанию, возвращаемое методом, если переданная итерация пуста.
Чтобы найти наибольшее среди двух или более значений, переданных в качестве аргументов,
max(arg1, arg2, *args[, key])
Где,
- arg1, arg2,…. argn — это n значений, среди которых метод
max()вернет наибольшее значение.
Мы можем использовать метод max() по-разному, чтобы найти максимум или наибольшее значение данной итерации или для двух или более аргументов.
Давайте посмотрим, как метод работает с итерируемым объектом, двумя или более значениями, с указанной ключевой функцией и с несколькими итерационными объектами, переданными в качестве аргументов.
С итерируемым объектом
В приведенном ниже примере мы рассматриваем список с некоторыми значениями, для которого мы должны найти самый большой элемент. Внимательно посмотрите на приведенный ниже код.
#initialisation of list
list1 = [ 1,3,4,7,0,4,8,2 ]
#finding max element
print("max value is : ", max(list1,default=0))
Выход:
max value is : 8
Как мы видим, для приведенного выше кода мы инициализируем список list1 и напрямую передаем его методу max() со значением по умолчанию, равным 0. Функция возвращает 8, поскольку это наибольшее значение.
Если бы список был пуст, функция передала бы значение по умолчанию, равное 0.
Передача двух или более значений методу max()
Когда два или более значений передаются методу max() , он возвращает максимальное или самое большое из них всех. Эти аргументы могут быть целыми числами, значениями с плавающей запятой, символами или даже строками.
Возьмем пример,
print("max value is : ", max(6,1,73,6,38))
Выход:
max value is : 73
Получаем максимальное значение, 73.
С ключевой функцией
Как мы упоминали ранее, ключ — это однострочная функция упорядочивания, на основе которой должно быть найдено максимальное значение среди набора значений.
Например, если мы хотим найти кортеж из списка кортежей, который имеет наибольшее значение 2-го элемента. Давайте посмотрим, как мы можем это сделать.
#initialisation of variables
list1 = [(9,2,7), (6,8,4), (3,5,1)]
def f(tuple_1):
return tuple_1[1]
print("max : ", max(list1, key=f))
Выход:
max : (6, 8, 4)
Здесь f() — это определяемая пользователем функция, которая возвращает второй элемент переданного кортежа. Передача этой функции в качестве ключа методу max() гарантирует, что кортеж будет возвращен с самым большим 2-м элементом. В нашем примере это (6, 8, 4).
Передача нескольких итераций в качестве аргументов
Как мы заявляли ранее, метод Python max() может также возвращать в качестве аргументов наибольший из нескольких повторяемых элементов. Эти аргументы могут быть повторяемыми, например строка, символ, кортеж, список и т. д.
По умолчанию метод max() возвращает объект с максимальным нулевым элементом для списков, кортежей и т. д. А для строк он сравнивает первый символ каждой переданной строки.
Ниже мы взяли пример для кортежей. Внимательно посмотрите на код.
#initialisation of variables
tuple1 = (5,23,7)
tuple2 = (4,1,7)
tuple3 = (7,37,1)
print("max : ", max(tuple1,tuple2,tuple3))
Выход:
max : (7, 37, 1)
В этом примере три кортежа с некоторыми начальными значениями были напрямую переданы методу max() . Что возвращает кортеж с самым большим первым элементом, то есть (7, 37, 1).
Вывод
Помните, что если значение по умолчанию не установлено и в качестве аргументов функции max() передается пустая итерация, возникает ошибка ValueError.

По сути, метод Python min() возвращает минимальное значение среди набора переданных значений или элементов переданного итеративного объекта.
Общий синтаксис использования метода min() приведен ниже. Используя его, мы можем найти минимальное значение среди элементов итерации (список, кортеж, строка и т. д.).
min(iterable, *[, key, default])
А чтобы найти минимальное значение среди набора элементов, мы можем напрямую передать их все в функцию min() , разделив их запятыми («,»).
min(arg1, arg2, *args[, key])
где,
- iterable содержит значения, для которых необходимо найти наименьшее,
- key — это однострочная функция,
- default — это значение по умолчанию, возвращаемое функцией, если переданная итерация пуста,
- arg1, arg2,… argn — это набор значений, для которых функция min() вернет наименьшее значение.
1 С итерируемым объектом
Функция min() широко используется для поиска наименьшего значения, присутствующего в итерируемом объекте, таком как список, кортеж, список списков, список кортежей и т. д. В случае простых списков и кортежей она возвращает наименьшее значение, присутствующее в итерируемом объекте.
Посмотрите на пример, приведенный ниже.
# initialisation of list
list1 = [23,45,67,89]
# finding min element
print("Min value is : ", max(list1, default=0))
Выход:
Min value is : 23
Здесь передача списка list1 непосредственно методу min() дает нам минимум всех элементов, присутствующих в списке, то есть 23. Значение по default установлено на 0, так что, если переданный итерабельный объект был пустым, метод был бы вернули это значение по умолчанию (0).
Для списка символов метод min() возвращает элемент с минимальным значением ASCII.
2 С несколькими аргументами
Когда мы передаем несколько аргументов методу min() , он возвращает самый маленький из них.
Обратите внимание: мы можем передавать несколько значений, а также несколько итераций в метод min() . Для нескольких итераций метод возвращает элемент с наименьшим первым элементом (значение в 0-м индексе).
Пример ниже объясняет это легко:
# initialisation of lists
list1 = [23,45,67]
list2 = [89,65,34]
list3 = [19,90,31]
# finding min element
print("Min among set of values is : ", min(765,876,434))
print("Min list among the given lists is : ", min(list1,list2,list3))
Выход:
Min among set of values is : 434 Min list among the given lists is : [19, 90, 31]
В приведенном выше примере, когда мы передаем несколько значений в качестве аргументов методу min() , он просто возвращает нам наименьшее значение (434)
В то время как для list1, list2 и list3 он возвращает list3, поскольку он имеет минимальное 0-е значение индекса (19).
3 С ключевой функцией
Как мы упоминали ранее, ключевая функция — это однострочная функция упорядочивания, которая определяет, на основе какого параметра должен быть возвращен минимум.
Давайте рассмотрим пример, чтобы понять эту ключевую концепцию.
# initialisation of variables
list_of_tuples = [(9, 2, 7), (6, 8, 4), (3, 5, 1)]
list1 = [23,45]
list2 = [89,65,34]
list3 = [19,90,31,67]
def ret_2nd_ele(tuple_1):
return tuple_1[1]
#find Min from a list of tuples with key on the basis of the 2nd element
print("Min in list of tuples : ", min(list_of_tuples, key=ret_2nd_ele))
#find min from a bunch of lists on the basis of their length
print("List with min length : ", min(list1,list2,list3,key=len))
Выход:
Min in list of tuples : (9, 2, 7) List with min length : [23, 45]
- Сначала мы инициализируем список кортежей вместе с тремя другими целочисленными списками разной длины,
- Затем мы определяем функцию
ret_2nd_ele()которая возвращает 2-й элемент или 1-й элемент индекса переданного кортежа, - После этого мы передаем list_of_tuples методу
min()сret_2nd_ele()в качестве ключа, - Мы снова передаем три списка list1, list2 и list3 в качестве аргументов методу
min()с ключом, установленным как встроенный методlen().
Таким образом, мы получаем кортеж с минимальным 2-м элементом (1-м элементом) для списка кортежей. И список с минимальной длиной (с использованием len() ) из трех списков, то есть list1 .
Всегда помните, что передача пустой итерации без значения по умолчанию, установленного для метода min() , вызывает ValueError .
DataFrame – это структура данных, представляющая особый вид двумерного массива, построенного поверх нескольких объектов Series. Это центральные структуры данных Pandas – чрезвычайно популярной и мощной платформы анализа данных для Python.
DataFram’ы имеют возможность присваивать имена строкам и/или столбцам и в некотором смысле представляют собой таблицы.
Давайте импортируем Pandas и создадим DataFrame из словаря:
import pandas as pd
df_data = {
"column1": [24, 9, 20, 24],
"column2": [17, 16, 201, 16]
}
df = pd.DataFrame(df_data)
print(df)У Pandas отличная интеграция с Python, и мы можем легко создавать DataFrame из словарей. df, который мы создали, теперь содержит столбцы и их соответствующие значения:
column1 column2
0 24 17
1 9 16
2 20 201
3 24 16В каждом столбце есть список элементов, и мы можем искать максимальный элемент каждого столбца, каждой строки или всего DataFrame.
Находим максимальный элемент в столбце DataFrame
Чтобы найти максимальный элемент каждого столбца, мы вызываем метод max() класса DataFrame, который возвращает Series имен столбцов и их наибольшие значения:
max_elements = df.max()
print(max_elements)Это даст нам максимальное значение для каждого столбца нашего df, как и ожидалось:
column1 24
column2 201
dtype: int64Однако, чтобы найти элемент max() одного столбца, вы сначала изолируете его и вызываете метод max() для этого конкретного Series:
max_element = df['column1'].max()
print(max_element)24Находим максимальный элемент в строке DataFrame
Поиск максимального элемента каждой строки DataFrame также зависит от метода max(), но мы устанавливаем аргумент axis равным 1.
Значение по умолчанию для аргумента axis равно 0. Если axis равно 0, метод max() найдет максимальный элемент каждого столбца. С другой стороны, если axis равно 1, функция max() найдет максимальный элемент каждой строки.
max_elements = df.max(axis=1)
print(max_elements)Это даст нам максимальное значение для каждой строки нашего df:
0 24
1 16
2 201
3 24
dtype: int64Если вы хотите выполнить поиск по определенной строке, вы можете получить к ней доступ через iloc[]:
print(df)
for row in df.index:
print(f'Max element of row {row} is:', max(df.iloc[row]))Мы напечатали df для справки, чтобы упростить проверку результатов, и получили элемент max() каждой строки, полученный с помощью iloc[]:
column1 column2
0 24 17
1 9 16
2 20 201
3 24 16
Max element of row 0 is: 24
Max element of row 1 is: 16
Max element of row 2 is: 201
Max element of row 3 is: 24Находим максимальный элемент во всем DataFrame
Наконец, узнаем, как найти максимальный элемент в DataFrame.
Основываясь на предыдущем опыте, это также должно быть просто. Мы просто используем встроенный метод max() и передадим ему один из двух ранее созданных списков элементов max: либо для всех строк, либо для всех столбцов. Это два аспекта одних и тех же данных, поэтому результат будет один и тот же.
Этот код должен дать нам единственное наивысшее значение во всем df:
max_by_columns = df.max()
max_by_rows = df.max(axis=1)
df_max = max(max_by_columns)
print("Max element based on the list of columns: ", df_max)
df_max2 = max(max_by_rows)
print("Max element based on the list of rows: ", df_max2)Получим это:
Max element based on the list of columns: 201
Max element based on the list of rows: 201Всё верно! Максимальный элемент списка максимальных элементов каждой строки должен совпадать с максимальным элементом списка максимальных элементов каждого столбца, и оба они должны совпадать с максимальным элементом всего DataFrame.
Заключение
В этом кратком руководстве мы рассмотрели, как найти максимальный элемент Pandas DataFrame для столбцов, строк и всего экземпляра DataFrame.
Просмотры: 3 851
