К вашим услугам кеш поисковиков, интернет-архивы и не только.

Если, открыв нужную страницу, вы видите ошибку или сообщение о том, что её больше нет, ещё не всё потеряно. Мы собрали сервисы, которые сохраняют копии общедоступных страниц и даже целых сайтов. Возможно, в одном из них вы найдёте весь пропавший контент.
Поисковые системы
Поисковики автоматически помещают копии найденных веб‑страниц в специальный облачный резервуар — кеш. Система часто обновляет данные: каждая новая копия перезаписывает предыдущую. Поэтому в кеше отображаются хоть и не актуальные, но, как правило, довольно свежие версии страниц.
1. Кеш Google
Чтобы открыть копию страницы в кеше Google, сначала найдите ссылку на эту страницу в поисковике с помощью ключевых слов. Затем кликните на стрелку рядом с результатом поиска и выберите «Сохранённая копия».
Есть и альтернативный способ. Введите в браузерную строку следующий URL: http://webcache.googleusercontent.com/search?q=cache:lifehacker.ru. Замените lifehacker.ru на адрес нужной страницы и нажмите Enter.
Сайт Google →
2. Кеш «Яндекса»
Введите в поисковую строку адрес страницы или соответствующие ей ключевые слова. После этого кликните по стрелке рядом с результатом поиска и выберите «Сохранённая копия».
Сайт «Яндекса» →
3. Кеш Bing
В поисковике Microsoft тоже можно просматривать резервные копии. Наберите в строке поиска адрес нужной страницы или соответствующие ей ключевые слова. Нажмите на стрелку рядом с результатом поиска и выберите «Кешировано».
Сайт Bing →
4. Кеш Yahoo
Если вышеупомянутые поисковики вам не помогут, проверьте кеш Yahoo. Хоть эта система не очень известна в Рунете, она тоже сохраняет копии русскоязычных страниц. Процесс почти такой же, как в других поисковиках. Введите в строке Yahoo адрес страницы или ключевые слова. Затем кликните по стрелке рядом с найденным ресурсом и выберите Cached.
Сайт Yahoo →
Специальные архивные сервисы
Указав адрес нужной веб‑страницы в любом из этих сервисов, вы можете увидеть одну или даже несколько её архивных копий, сохранённых в разное время. Таким образом вы можете просмотреть, как менялось содержимое той или иной страницы. В то же время архивные сервисы создают новые копии гораздо реже, чем поисковики, из‑за чего зачастую содержат устаревшие данные.
Чтобы проверить наличие копий в одном из этих архивов, перейдите на его сайт. Введите URL нужной страницы в текстовое поле и нажмите на кнопку поиска.
1. Wayback Machine (Web Archive)
Сервис Wayback Machine, также известный как Web Archive, является частью проекта Internet Archive. Здесь хранятся копии веб‑страниц, книг, изображений, видеофайлов и другого контента, опубликованного на открытых интернет‑ресурсах. Таким образом основатели проекта хотят сберечь культурное наследие цифровой среды.
Сайт Wayback Machine →
2. Arhive.Today
Arhive.Today — аналог предыдущего сервиса. Но в его базе явно меньше ресурсов, чем у Wayback Machine. Да и отображаются сохранённые версии не всегда корректно. Зато Arhive.Today может выручить, если вдруг в Wayback Machine не окажется копий необходимой вам страницы.
Сайт Arhive.Today →
3. WebCite
Ещё один архивный сервис, но довольно нишевый. В базе WebCite преобладают научные и публицистические статьи. Если вдруг вы процитируете чей‑нибудь текст, а потом обнаружите, что первоисточник исчез, можете поискать его резервные копии на этом ресурсе.
Сайт WebCite →
Другие полезные инструменты
Каждый из этих плагинов и сервисов позволяет искать старые копии страниц в нескольких источниках.
1. CachedView
Сервис CachedView ищет копии в базе данных Wayback Machine или кеше Google — на выбор пользователя.
Сайт CachedView →
2. CachedPage
Альтернатива CachedView. Выполняет поиск резервных копий по хранилищам Wayback Machine, Google и WebCite.
Сайт CachedPage →
3. Web Archives
Это расширение для браузеров Chrome и Firefox ищет копии открытой в данный момент страницы в Wayback Machine, Google, Arhive.Today и других сервисах. Причём вы можете выполнять поиск как в одном из них, так и во всех сразу.

![]()
Читайте также 💻🔎🕸
- 3 специальных браузера для анонимного сёрфинга
- Что делать, если тормозит браузер
- Как включить режим инкогнито в разных браузерах
- 6 лучших браузеров для компьютера
- Как установить расширения в мобильный «Яндекс.Браузер» для Android
Как проверить базовые настройки сайта, если рядом нет веб-разработчика? Иногда бывает так, что сайт исчезает из поиска.
Совсем.
Резко, в один день!
То есть вы время от времени проверяли, все ли в порядке — и отслеживали, на каких позициях ваш сайт находится по конкретным ключевым словам.
И он был всегда в зоне видимости. И тут, бац, такое!
Причём по ссылке сайт доступен, то есть работает, все с ним вроде внешне в порядке.
Что делать?
📍 Вспомните, у кого логины-пароли от административной панели сайта и хостинга
📍 «Вспомнив всё», идёте в административную панель и хостинг и проверяете параметры работы сайта по чек-листу:
1. Проверьте, не включена ли специальная настройка, отключающая видимость сайта для поисковиков в административной панели
В административной панели всех сайтов в настройках есть пункт «Попросить поисковые системы не индексировать сайт». Вот здесь он находится, например, у сайтов на WordPress:

Понятно, что не надо ставить здесь галочку, если мы хотим, чтобы сайт нормально индексировался поисковиками. Этой настройкой пользуются, пока сайт находится в разработке, чтобы не показывать роботам поисковиков черновые страницы.
Кто нажал на галочку, если ранее её не было — выяснять Вам.
Как это можно сделать? — посмотреть журнал событий, но…
если он был настроен. А если нет, то, возможно, следов и не найти.
2. Проверьте, не закрыты ли страницы сайта для роботов поисковиков в файле Robots.txt
Найти его (если он есть у вашего сайта — а если у вас хороший веб-разработчик, то он должен быть, это Базовая seo-оптимизация сайта в момент его создания) — можно по адресу https://domen.ru/robots.txt — здесь вместо domen.ru вставьте домен (адрес) вашего сайта.
В файле robots.txt содержатся команды для роботов поисковика насчет конкретных страниц — на какие «смотреть» и анализировать, а на какие не надо. Например, роботу часто приказывают не «видеть» страницы с корзиной или другие, где нет ценного с точки зрения seo контента.
Разобраться не так уж сложно:
команда allow — позволить видеть;
команда disallow — не позволяем.
Да, это очень упрощенно.
На самом деле файл Robots.txt содержит ещё, как правило, массу информации, его нужно уметь правильно составлять — но на первоначальном этапе просто посмотрите, какие страницы роботу приказали «не видеть».
3. Проверьте в хостинге в Журнале событий (или напишите в поддержку хостинга с уточнением этой информации), кто за последние дни входил в личный кабинет, с какого IP (номер устройства), и какие изменения вносил в файлы сайта
Вот это, пожалуй, сложнее всего. Но здесь в зависимости от степени отзывчивости, чаще всего служба поддержки хостинга все нормально разъясняет. Далее можно сопоставить IP своих устройств с теми, с которых были входы и сделать выводы — кто, и какие изменения вносил в файлы сайта.
Ряд файлов имеют критически важное значение для работы сайта — например, файл config. Стоит досконально выяснить, что именно произошло, если изменения были внесены именно в этот файл.
4. Поменяйте пароли у всех пользователей от административной панели сайта и от хостинга. Делайте это регулярно
К административной панели сайта могут иметь доступ несколько пользователей — они будут отражены в специальном разделе. У сайтов на WordPress, например, этот раздел находится здесь:

В хостинге тоже есть несколько типов пользователей. Аккуратно погуляйте по вкладкам-разделам личного кабинета хостинга, ничего не удаляя и не изменяя.
Без особого труда обычно можно найти раздел с типами доступа к хостингу (FTP и другие) и логинами-паролями для разных пользователей.
Не правильно оставлять те же пароли, которые были в момент разработки сайта у разработчика или у наемного интернет-маркетолога.
Поскольку многие их не меняют, эта статья и была написана.
К сожалению, пока на рынке ещё есть не совсем принципиальные разработчики, которые спустя некоторое время вносят вредоносные коррективы в сайты своих клиентов, чтобы получить новые заказы на seo — продвижение.
К счастью с нами для вас, в целом компетентность рынка растёт — и эта статья написана в том числе, чтобы помочь вам разобраться ещё лучше, как управлять возможно основным каналом получения заявок в бизнесе — сайтом!
Если все же остались вопросы или нужна профессиональная помощь — обращайтесь, поможем с удовольствием, первая консультация по интернет-маркетингу — бесплатно 🙂
Сервисы и трюки, с которыми найдётся ВСЁ.
Зачем это нужно: с утра мельком прочитали статью, решили вечером ознакомиться внимательнее, а ее на сайте нет? Несколько лет назад ходили на полезный сайт, сегодня вспомнили, а на этом же домене ничего не осталось? Это бывало с каждым из нас. Но есть выход.
Всё, что попадает в интернет, сохраняется там навсегда. Если какая-то информация размещена в интернете хотя бы пару дней, велика вероятность, что она перешла в собственность коллективного разума. И вы сможете до неё достучаться.
Поговорим о простых и общедоступных способах найти сайты и страницы, которые по каким-то причинам были удалены.
1. Кэш Google, который всё помнит
Google специально сохраняет тексты всех веб-страниц, чтобы люди могли их просмотреть в случае недоступности сайта. Для просмотра версии страницы из кэша Google надо в адресной строке набрать:
http://webcache.googleusercontent.com/search?q=cache:https://www.iphones.ru/
Где https://www.iphones.ru/ надо заменить на адрес искомого сайта.
2. Web-archive, в котором вся история интернета

Во Всемирном архиве интернета хранятся старые версии очень многих сайтов за разные даты (с начала 90-ых по настоящее время). На данный момент в России этот сайт заблокирован.
3. Кэш Яндекса, почему бы и нет

К сожалению, нет способа добрать до кэша Яндекса по прямой ссылке. Поэтому приходиться набирать адрес страницы в поисковой строке и из контекстного меню ссылки на результат выбирать пункт Сохраненная копия. Если результат поиска в кэше Google вас не устроил, то этот вариант обязательно стоит попробовать, так как версии страниц в кэше Яндекса могут отличаться.
4. Кэш Baidu, пробуем азиатское
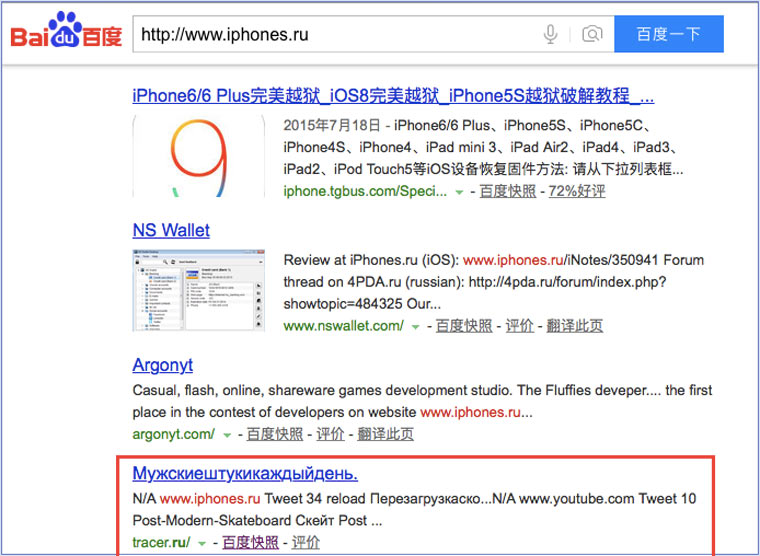
Когда ищешь в кэше Google статьи удаленные с habrahabr.ru, то часто бывает, что в сохраненную копию попадает версия с надписью «Доступ к публикации закрыт». Ведь Google ходит на этот сайт очень часто! А китайский поисковик Baidu значительно реже (раз в несколько дней), и в его кэше может быть сохранена другая версия.
Иногда срабатывает, иногда нет. P.S.: ссылка на кэш находится сразу справа от основной ссылки.
5. CachedView.com, специализированный поисковик
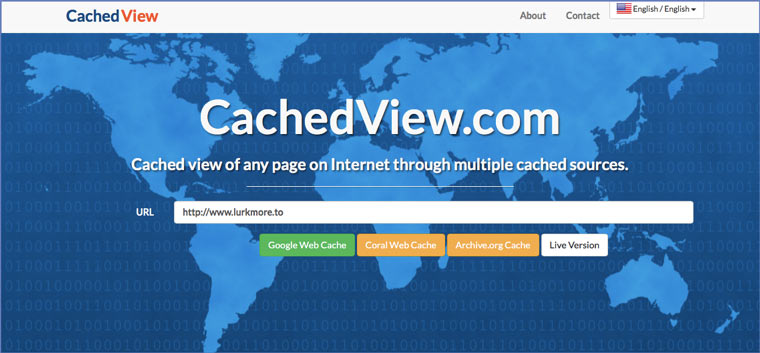
На этом сервисе можно сразу искать страницы в кэше Google, Coral Cache и Всемирном архиве интернета. У него также еcть аналог cachedpages.com.
6. Archive.is, для собственного кэша
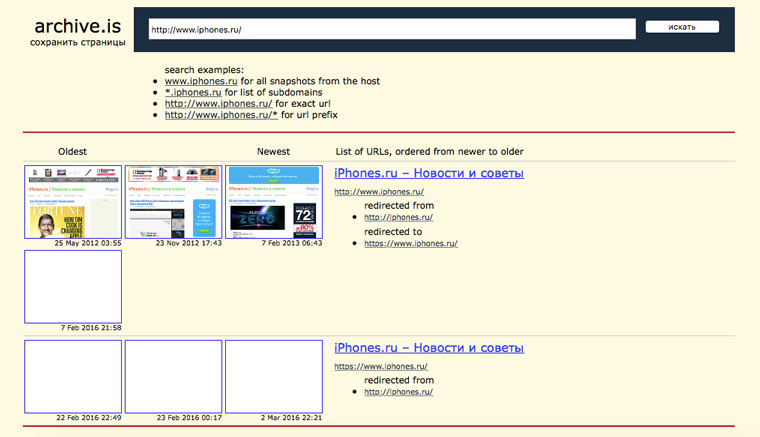
Если вам нужно сохранить какую-то веб-страницу, то это можно сделать на archive.is без регистрации и смс. Еще там есть глобальный поиск по всем версиям страниц, когда-либо сохраненных пользователями сервиса. Там есть даже несколько сохраненных копий iPhones.ru.
7. Кэши других поисковиков, мало ли
Если Google, Baidu и Yandeх не успели сохранить ничего толкового, но копия страницы очень нужна, то идем на seacrhenginelist.com, перебираем поисковики и надеемся на лучшее (чтобы какой-нибудь бот посетил сайт в нужное время).
8. Кэш браузера, когда ничего не помогает
Страницу целиком таким образом не посмотришь, но картинки и скрипты с некоторых сайтов определенное время хранятся на вашем компьютере. Их можно использовать для поиска информации. К примеру, по картинке из инструкции можно найти аналогичную на другом сайте. Кратко о подходе к просмотру файлов кэша в разных браузерах:
Safari
Ищем файлы в папке ~/Library/Caches/Safari.
Google Chrome
В адресной строке набираем chrome://cache
Opera
В адресной строке набираем opera://cache
Mozilla Firefox
Набираем в адресной строке about:cache и находим на ней путь к каталогу с файлами кеша.
9. Пробуем скачать файл страницы напрямую с сервера
Идем на whoishostingthis.com и узнаем адрес сервера, на котором располагается или располагался сайт:
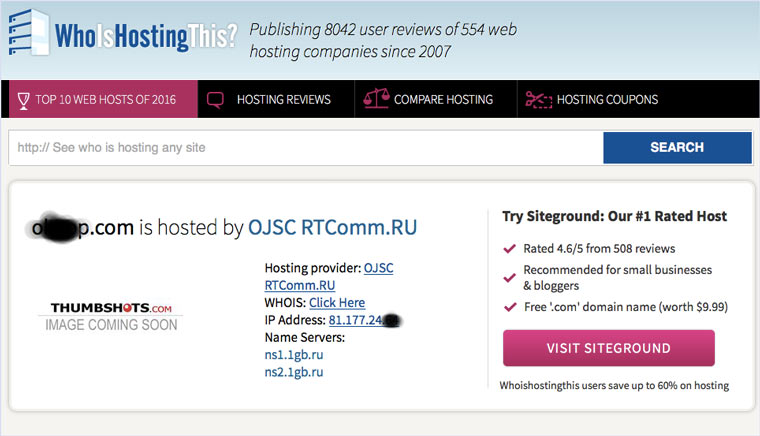
После этого открываем терминал и с помощью команды curl пытаемся скачать нужную страницу:

Что делать, если вообще ничего не помогло
Если ни один из способов не дал результатов, а найти удаленную страницу вам позарез как надо, то остается только выйти на владельца сайта и вытрясти из него заветную инфу. Для начала можно пробить контакты, связанные с сайтом на emailhunter.com:
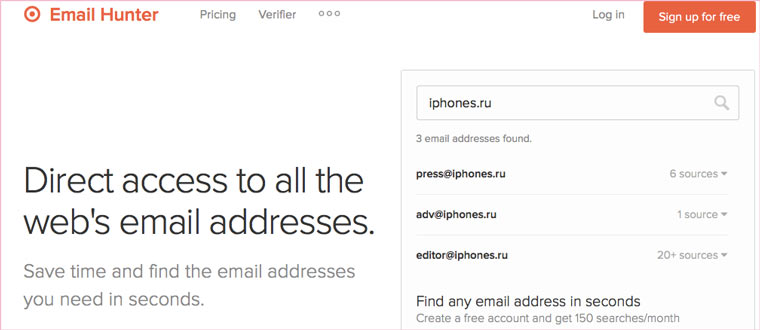
О других методах поиска читайте в статье 12 способов найти владельца сайта и узнать про него все.
А о сборе информации про людей читайте в статьях 9 сервисов для поиска информации в соцсетях и 15 фишек для сбора информации о человеке в интернете.

 (30 голосов, общий рейтинг: 4.80 из 5)
(30 голосов, общий рейтинг: 4.80 из 5)
🤓 Хочешь больше? Подпишись на наш Telegram.
![]()
iPhones.ru
Сервисы и трюки, с которыми найдётся ВСЁ. Зачем это нужно: с утра мельком прочитали статью, решили вечером ознакомиться внимательнее, а ее на сайте нет? Несколько лет назад ходили на полезный сайт, сегодня вспомнили, а на этом же домене ничего не осталось? Это бывало с каждым из нас. Но есть выход. Всё, что попадает в интернет,…
- Google,
- полезный в быту софт,
- хаки
![]()
Все течет — все меняется. В свое время я пользовался довольно интересным веб-сайтом. Потом необходимость в нем исчезла. А сейчас информация с сайта снова понадобилась. А сайта уже нет. Вместо него открывается рекламная страница. Можно ли как-то посмотреть искомый сайт, если вы сами не делали копии? Оказывается, можно. Нужно искать этот сайт в веб-архиве — web.archive.org.
Этот проект по сохранению интернет-сайтов под названием The Wayback Machine работает с середины 90-х годов. К настоящему времени накоплено около 500 млрд веб-страниц.
Запускаем сайт web.archive.org, вводим нужный вам адрес и нажимаем на кнопку Browse History. Через секунды вы увидите результаты: временную шкалу с календарем, где отмечены даты, когда сохранялись копии страниц. К примеру, страница http://na-svyazi.ru сохранялась 569 раз с 29 октября 2011 года до наших дней.
Вам остается выбрать дату и просмотреть сохраненную информацию. К сожалению, сервис не всегда сохраняет все страницы веб-сайта. Может слететь форматирование сайта, отсутствовать некоторые изображения. Но это все мелочи, если вы найдете необходимую вам информацию.
P.S. Вы можете сами отправить в архив любую интернет-страницу. Для этого на главной странице проекта The Wayback Machine нужно ввести адрес в блоке Save Page Now.
![]()
Download Article
![]()
Download Article
The internet has changed immensely over the years. For some, it can be hard to imagine what older websites even looked like. And yet, it is still possible to find old websites that no longer exist! Whether you are simply curious, or want to revisit a specific webpage from long ago, this wikiHow article will teach you how to use a variety of tools for surfing the internet of old.
-

1
Go to https://web.archive.org/ on your web browser. The Wayback Machine is a popular tool for archiving old websites, but anyone can search its archives as well. Head to the site’s URL to get started.
-

2
Conduct a search in the Machine’s search bar. The search bar is centered towards the top of the page. You can either type in a specific URL, or a few keywords relating to a site you are looking for.
- The Wayback Machine doesn’t quite support keyword searches the way Google or Bing do. In other words, you should only search for specific sites on the Wayback Machine’s search engine.
- To conduct a broader search of the Wayback Machine, try doing a Google search using site:https://web.archive.org/.
Advertisement
-

3
Choose a site. Depending on your search, the Wayback Machine will yield different sites to choose from. Pick one to continue.
-

4
Select a year on the bar graph. There should be a bar graph atop your screen, indicating the history of the website. Scrub along the bar graph with your cursor to see the different dates, and click one to discover what that site looked like in the past.
Advertisement
-

1
Run a standard Google search. To begin your journey into the internet’s past, search for something on Google as you usually would.
- If you are looking for an old page or article on a specific site, you might want to use site: followed by the URL to yield the proper results. (ex. site:wikihow.com). [1]
- If you are looking for an old page or article on a specific site, you might want to use site: followed by the URL to yield the proper results. (ex. site:wikihow.com). [1]
-

2
Click Tools. It should be located atop your results page, just under the right-hand side of the search bar.
-

3
Click Any time. Once you click Tools, Google will provide two options along the left-hand side of your screen: Any time and All results. Use the former to look into the internet’s past.
-

4
Click Custom range. Google offers several different filters for the timeframe of your search. If you need something fairly recent, the preset options are likely sufficient. But if you truly want to dip into the internet’s past, select Custom range to reach back even further.
-

5
Adjust the search’s date range. Your custom date range can be as wide or as narrow as you would like. Add a From and a To date to see what Google has to offer!
-

6
Click Go. Once you have chosen your date range, click the Go button to modify your search.
- Keep in mind that some sites may have been published a long time ago, but will automatically redirect to their most current version. Still, a wide variety of sites, including web forums and message boards, will offer a peek into their past.
- Sometimes, Google stores a “Cached” version of a webpage, although it may not be particularly old. Click the three dots next to a search result, then click “Cached” (if available) to see it. This could be helpful when looking for a recent edit or deletion.
- Also keep in mind Google’s results are for websites that do still exist, but may be hidden deep in Google’s search results due to their age.
Advertisement
-

1
Run a standard Bing search. Bing may not be as popular as Google, but it is likely to yield its own unique results.
-

2
Click Date. It is located atop the page, similar to where Google’s “Tools” icon is located. It will lead to a drop-down menu.
-

3
Create a Custom range. The drop-down menu offers a few different filters for specifying your search. To look really far back, create a Custom range of dates.
-

4
Click Apply. Your Bing search will automatically update to reflect your custom date range, and offer a glimpse into the internet’s past!
- Keep in mind Bing’s results are for websites that do still exist, but may be hidden deep in Bing’s search results due to their age.
Advertisement
Ask a Question
200 characters left
Include your email address to get a message when this question is answered.
Submit
Advertisement
About This Article
Article SummaryX
1. Go to web.archive.org.
2. Search for a website.
3. Select a website.
4. Select a date.
Did this summary help you?
Thanks to all authors for creating a page that has been read 67,043 times.
