Карта слов и выражений русского языка
Онлайн-тезаурус с возможностью поиска ассоциаций, синонимов, контекстных связей
и
примеров
предложений к словам и выражениям русского языка.
Справочная информация по склонению имён существительных и прилагательных,
спряжению
глаголов, а также
морфемному строению слов.
Сайт оснащён мощной системой поиска с
поддержкой русской морфологии.
Разбор слова
по составу ОНЛАЙН
Подобрать синонимы
ОНЛАЙН
Найти предложения со словом
или
выражением ОНЛАЙН
Поиск по произведениям русской классики
ОНЛАЙН
Словарь афоризмов русских писателей
Бесплатный сервис поиска слов Адвего покажет онлайн все вхождения ключевых слов, стоп-слов и слов по заданному образцу. Поиск фраз и наборов символов на любом языке.
Как работает поиск слов и фраз в тексте
Скопируйте в первое поле проверяемый текст, а во втором поле укажите все слова и фразы по одной на строку, после чего нажмите кнопку “Найти”. Чтобы найти слова в документе или на странице сайта, скопируйте весь текст в поле для проверки.
По умолчанию система ищет только точные совпадения с указанной строкой (с учетом знаков препинания).
Например, по строке “номер” будет найдено слово “номер”, но не будут найдены слова “номерной” или “госномер”. Аналогично, при поиске по фразе “легкий завтрак” будет найдена только фраза “легкий завтрак”, но не будут найдены фразы “легким завтраком” или “легкий, завтрак”.
Чтобы задать поиск по маске, используйте символ звездочки * в начале, в конце или с обеих сторон каждого слова:
ра*— будут найдены все слова, начинающиеся на “ра”, в том числе слово “ра”: работа, разный, рад.*ет— будут найдены все слова, заканчивающиеся на “ет”, в том числе слово “ет”: работает, полет, нет.*ой*— будут найдены все слова, содержащие буквосочетание “ой” в любом месте: ойкнул, водопой, спокойствие.
Маску можно указать для одного или нескольких слов во фразе, правила будут применяться последовательно:
ра* *ет— будут найдены фразы только из двух рядом стоящих слов, первое из которых начинается на “ра”, а второе заканчивается на “ет”: рабочий совет, но не будут найдены фразы “свет комет” или “равная опора”.
Также можно найти все вхождения любой заданной последовательности символов в тексте — для этого необходимо добавить символ ! в начале и конце строки.
Например, по запросу !дом! будут найдены вхождения этого буквосочетания в словах “дом”, “домашний”, “одомашненный” и т. д., но выделены будут именно вхождения, а не слова целиком, в отличие от режима поиска по маске с символом *.
Чтобы выделить все вхождения конкретного слова или фразы в тексте, нажмите на строку с ними в таблице совпадений. Чтобы выделить все совпадения, нажмите на строку с общим количеством совпадений.
Проверять текст можно неограниченное количество раз — после его редактирования или изменения списка слов нажмите повторно кнопку “Найти” и система покажет результаты новой проверки.
Возможности сервиса:
- поиск заданных слов и фраз (ключевых, стоп-слов);
- поиск по фразе целиком или по ее части;
- поиск необходимого слова или фразы в документе;
- поиск одинаковых и повторяющихся слов;
- поиск однокоренных слов по маске;
- поиск любых последовательностей символов;
- поиск в английском тексте и на любом языке.
Привлечь дополнительный трафик на сайт можно путем расширения семантического ядра страницы похожими ключевыми фразами.
Такие фразы можно найти легко, быстро и бесплатно. Как? Разберемся далее.
Как расширить семантическое ядро?
Итак, если расширить список ключевых фраз, то можно привлечь дополнительный трафик на сайт из органической выдачи.
Для любого значимого запроса у поисковых систем Google и Yandex есть ТОП-10 результатов поиска.
В ТОП-10 поисковой выдачи находятся лидеры поиска, то есть наиболее релевантные сайты исходя из данных алгоритма ранжирования. Такие сайты, как правило, обладают оптимальными поведенческими факторами, оптимальным контентом и не спамным внешним ссылочным профилем. Как следствие, обычно такие страницы ранжируются не только по одному запросу, а по группе поисковых запросов.
Итак, страницы из ТОП-10 результатов поисковой выдачи ранжируются по разным ключевым фразам.

По оценкам поисковых алгоритмов, ключевые фразы из видимости документа относятся к теме документа, а значит такие фразы могут продвигаться в рамках одной страницы и их следует использовать для расширения семантического ядра страницы.
В MegaIndex есть специальный инструмент для поиска таких похожих запросов.
Как это работает:
- Периодически роботы сканируют выдачу поисковой системы Yandex по всей базе запросов. В базе находятся десятки миллионов ключевых фраз;
- Полученные данные о поисковой выдаче сохраняются в базу. Как результат, по каждой странице есть список ключевых фраз, по которым страница выводится в поисковой системе;
- Используя специальный инструмент можно отправить запрос к базе данных, и выгрузить ключевые фразы для расширения семантического ядра.
Ссылка на инструмент — Поиск запросов у конкурентов по ТОП-10.
Инструмент бесплатный.
Итак, у пользователя есть возможность выгрузить все ключевые фразы, по которым ранжируются страницы из ТОП-10.
Например, если сайт wixfy продвигается по ключевой фразе продвижение сайтов, то расширить семантическое ядро страницы можно за счет следующих фраз:
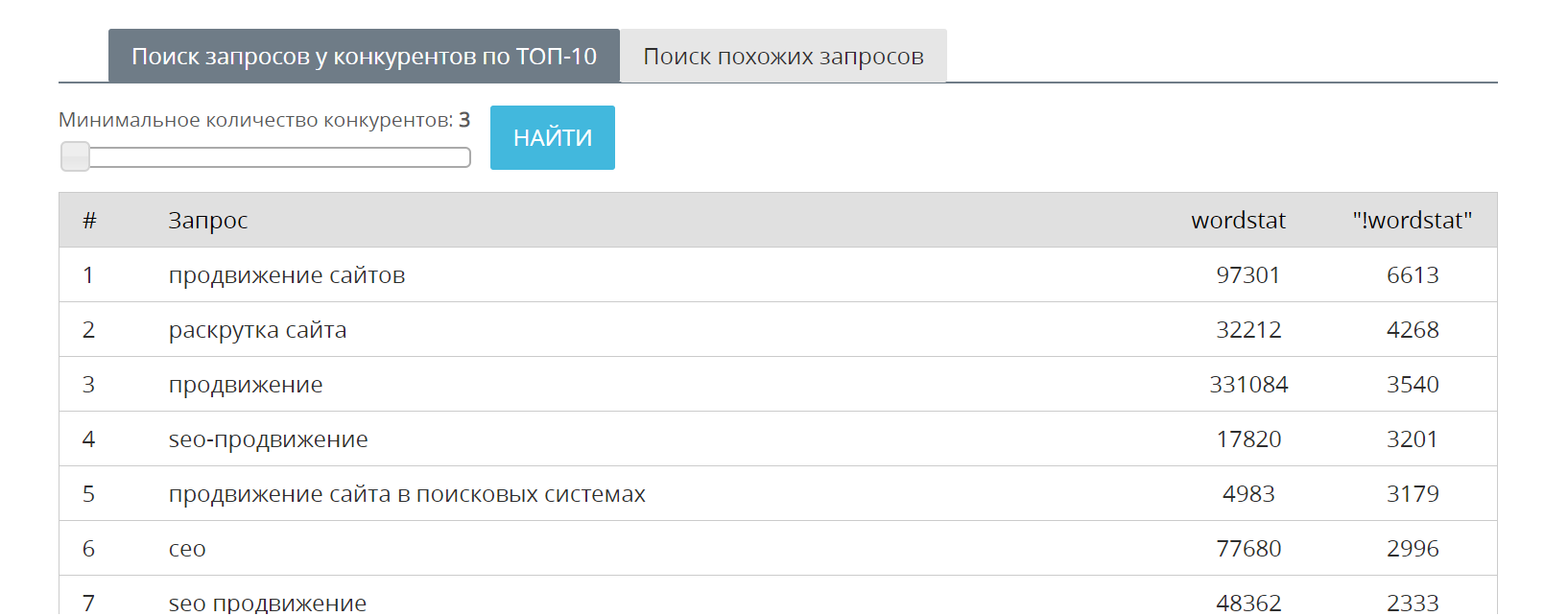
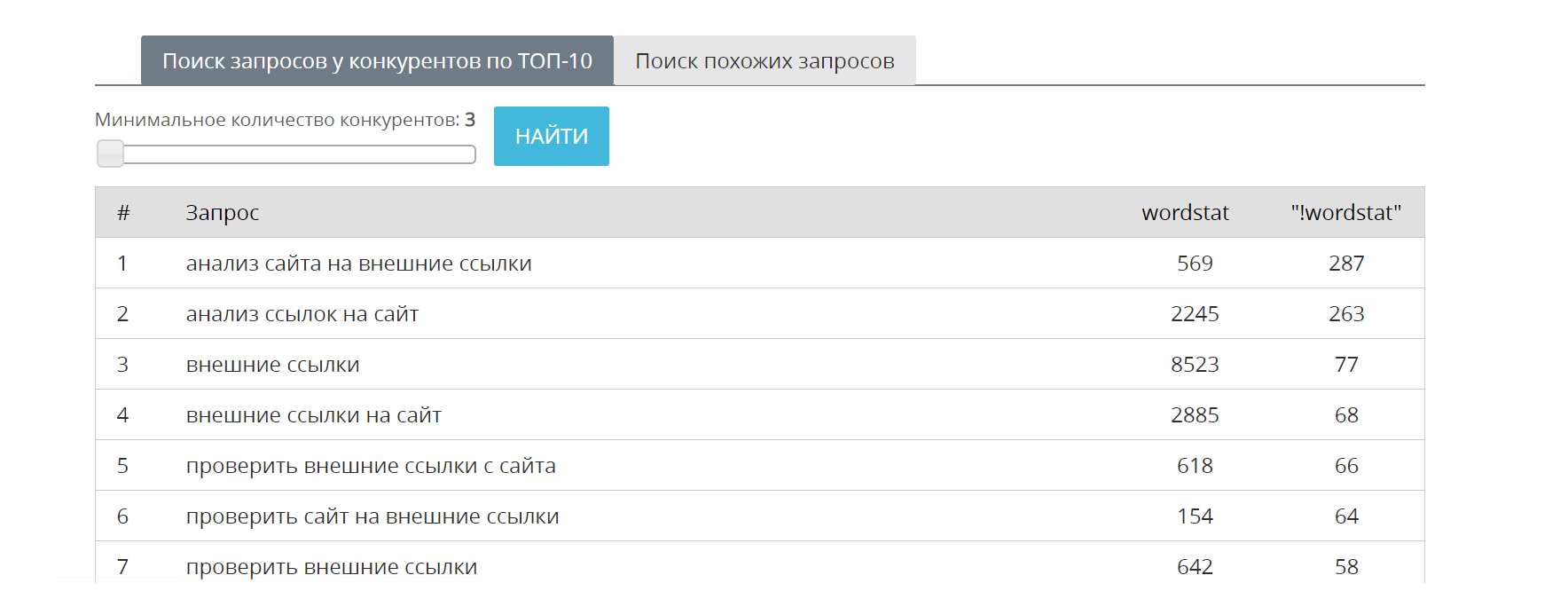
Если сайт indexoid продвигается по ключевой фразе внешние ссылки, то расширить семантическое ядро страницы можно за счет следующих фраз:
Бесплатно расширить список запросов в целях SEO просто, вот как:
- На вход достаточно подать основной запрос, по которому страница продвигается;
- Выгрузить список похожих запросов, созданный на основе данных из видимости;
- Обновить продвигаемую страницу с учетом новых ключевых фраз.
Альтернативные способы
Есть два альтернативных способа, используя которые можно расширить семантическое ядро страницы. Способы следующие:
- Поиск в базах ключевых фраз по вхождениям;
- Парсинг поисковых подсказок.
Собрать ключевые фразы по вхождениям путем выгрузки из базы просто, вот как:
- На вход достаточно подать одну ключевую фразу;
- Система сформирует список ключевых фраз из поисковых запросов, где упоминается фраза;
- Выгрузить список ключевых фраз.
На практике для поиска ключевых фраз по вхождениям можно использовать сервис от MegaIndex.
Ссылка на сервис — Поиск похожих фраз.
Сервис бесплатный.
Например, если сайт wixfy продвигается по ключевой фразе wix seo, то расширить семантическое ядро страницы можно за счет следующих фраз:
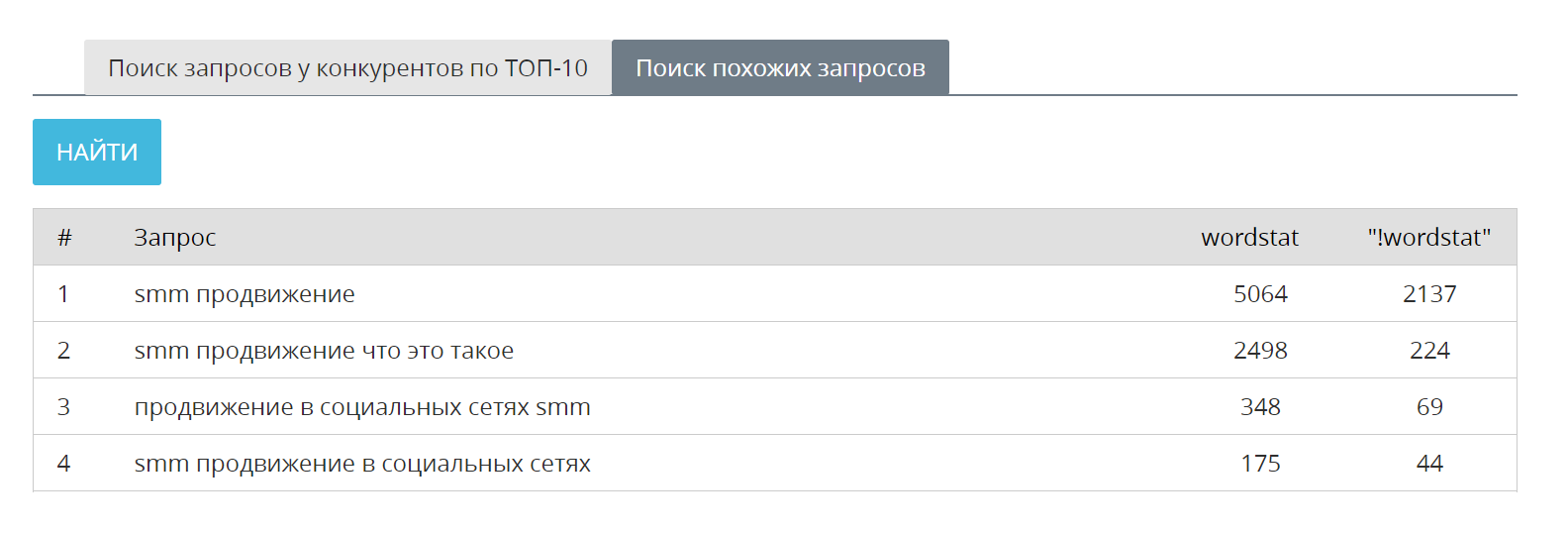
С полученным списком следует провести комплекс мер по кластеризации ключевых фраз, чтобы составить семантическое ядро правильно для каждой страницы сайта.
Парсинг поисковых подсказок можно провести используя специальный сервис — Kparser.
Используйте бесплатные инструменты, чтобы увеличить поток трафика из органической выдачи поисковой системы на сайт.
Вопросы и ответы
Зачем использовать ключевые фразы из поисковой видимости?
Большое семантическое ядро не имеет смысла, если собрано не правильно.
Если составлять список похожих запросов не на основе данных о видимости, то нет гарантий что страница будет ранжироваться по таким запросам.
В семантике, собираемой под поисковое продвижение, есть важный нюанс — не все похожие запросы следует размещать на одной странице.
Если запрос А и запрос Б похожи с точки зрения логики, то не факт что такие запросы могут продвигаться на одной странице.
Интенты таких запросов считаются разными, поэтому выдача поисковой системы разная. Такие запросы нельзя продвигать на одной странице. Для подобных запросов при продвижении под Yandex нужно создавать две отдельные страницы.
Про термин интент подробнее в материале по ссылке далее — Что такое интент.
Если использовать ключевые фразы из поисковой видимости, то такие фразы можно продвигать на одной странице.
Для большинства страниц в интернете можно найти дополнительные ключевые фразы, используя данные о видимости страниц из ТОП-10.
Зачем расширять семантическое ядро страницы?
Большое семантическое ядро позволяет одной странице ранжироваться в поисковой выдаче по разным запросам.
Также размещение дополнительной информации на странице означает улучшение ответа на поисковый запрос.
Выводы
Задача поискового оптимизатора заключается в том, чтобы собрать полный список запросов, по которым может ранжироваться продвигаемая страница.
С большими объемами семантики работать сложно, но есть специальные инструменты, которые облегчают выполнение работы.
Используя специальные сервисы оптимизировать семантику страницы проще, легче и быстрее.
К примеру, можно использовать сервис от MegaIndex.
Ссылка на сервис — Расширение семантики похожими запросами.
Сервис бесплатный.
Далее видео о том, как используя онлайн сервис MegaIndex можно расширить семантическое ядро страниц сайта.
- Большинство страниц можно расширить дополнительными ключевыми фразами;
- Расширение семантического ядра страницы проводится для привлечения дополнительного трафика из поисковой выдачи;
- Бывают похожие запросы, по которым одна и та же страница не может ранжироваться. Поэтому для расширения списка запросов лучше использовать данные из поисковой видимости;
- Для поисковой системы дата обновления контента имеет значение. Размещение новой информации на странице означает обновление страницы и улучшение ответа на поисковый запрос.
А какие вы используете способы для расширения и актуализации семантического ядра?
Остались ли у вас вопросы, мнения, комментарии по теме расширения списка ключевых фраз?
Инструмент позволяет из списка фраз оставить только максимально непохожие фразы, и отсеять дубли и
похожие по смыслу фразы.
Например, это полезно при составлении ТЗ копирайтеру на основании анализа заголовков конкурентов.
Сначала вы собираете все
заголовки, потом этим инструментом отсеиваете дубли и похожие строки. У вас остаются лишь уникальные
пункты, из которых вы уже
соберете план.
Что такое максимальный % похожести и каким его выбрать?
Максимальный процент похожести – это насколько максимально могут быть похожи фразы, чтобы считаться
разными.
Чем меньший процент вы ставите, тем жестче отрабатывает алгоритм, и больше фраз удаляет. И наоборот –
повышая процент, алгоритм оставляет больше фраз.
Чем длиннее фразы в вашем списке, тем алгоритму легче отработать. Поэтому на длинных фразах вы можете
понижать это число до 10-30%, а на коротких –
поднимать до 40-80%. Точных значений нет – экспериментируйте на своих данных.
Как определяется похожесть фраз?
Сначала из фразы удаляются предлоги, союзы и прочие малозначающие части речи – это первичная очистка.
Потом используется алгоритм стеммизации слов. Каждое слово в фразах приводится к некой первоначальной
форме (например, слова дерево и дерева
приведутся к форме дерев. Таким образом каждая фраза представляется в виде множества стемм. Эти
множества и сравниваются между собой на похожесть.
Алгоритм работает не идеально, и в сложных случаях может глючить. Но в 90% случаев он неплохо
отрабатывает, и показывает хорошие результаты.
Ограничения
Поиск похожести – ресурсоемкая задача. Поэтому для незарегистрированных пользователей максимальное
количество строк, которое можно проверить за один раз – 100 фраз.
Как найти похожие тексты и отсортировать
Время на прочтение
2 мин
Количество просмотров 4.6K
Есть простой метод отсортировать набор текстов по похожести на заданный текст: по Эвклидову расстоянию между частотами слов в анализируемых текстах. В принципе, на этом алгоритм должен быть понятен, простую реализацию можно найти здесь.
Как ни удивительно, простой метод даёт хорошие результаты. Например, если ищем следующую книгу чтоб почитать, можно ввести текст прочтённой книги или нескольких прочтённых книг как образец для поиска, и тогда для этого репозитория из 10 книг получаем следующие результаты для книги «FAIRY TALES By The Brothers Grimm»:
0.0320757 RepoTHE ADVENTURES OF TOM SAWYER.txt
0.0363329 RepoA TALE OF TWO CITIES - A STORY OF THE FRENCH REVOLUTION.txt
0.0388528 RepoALICEТS ADVENTURES IN WONDERLAND.txt
0.0440605 RepoMOBY-DICK or, THE WHALE.txt
0.046679 RepoTHE ADVENTURES OF SHERLOCK HOLMES.txt
0.0472574 RepoThe Iliad of Homer.txt
0.0511793 RepoThe Romance of Lust.txt
0.053746 RepoPRIDE AND PREJUDICE.txt
0.0543531 RepoBEOWULF - AN ANGLO-SAXON EPIC POEM.txt
0.0557194 RepoFrankenstein; or, the Modern Prometheus.txt
Как видно из результатов, наиболее похожими обнаружены сказкоподобные книги, а наименее похожей — книга ужасов.
В коммерческих целях такую программу возможно использовать для того чтобы для заданной веб-страницы найти наиболее подходящую рекламу, сравнивая текст читаемой пользователем страницы с текстами страниц, куда ведут имеющиеся рекламные объявления.
Другое применение — в нахождении резюме из базы по примеру резюме кандидата, который подходит на данную позицию, но не желает присоединиться или уходит из компании. Поиск замены работнику — не такой уж и редкий бизнес-случай. Также можно отсортировать базу резюме по похожести на описание вакансии.
P.S. Кстати, Хабр в списке похожих статей выдаёт что-то не сильно похожее. Может Хабру тоже применить данный метод?
