17 авг. 2022 г.
читать 2 мин
Одно из ключевых допущений линейной регрессии состоит в том, что между остатками нет корреляции, т. е. остатки независимы.
Один из способов определить, выполняется ли это предположение, — выполнить тест Дарбина-Ватсона , который используется для обнаружения наличия автокорреляции в остатках регрессии. В этом тесте используются следующие гипотезы:
H 0 (нулевая гипотеза): между остатками нет корреляции.
H A (альтернативная гипотеза): остатки автокоррелированы.
В этом руководстве представлен пошаговый пример выполнения теста Дурбина-Ватсона в Excel.
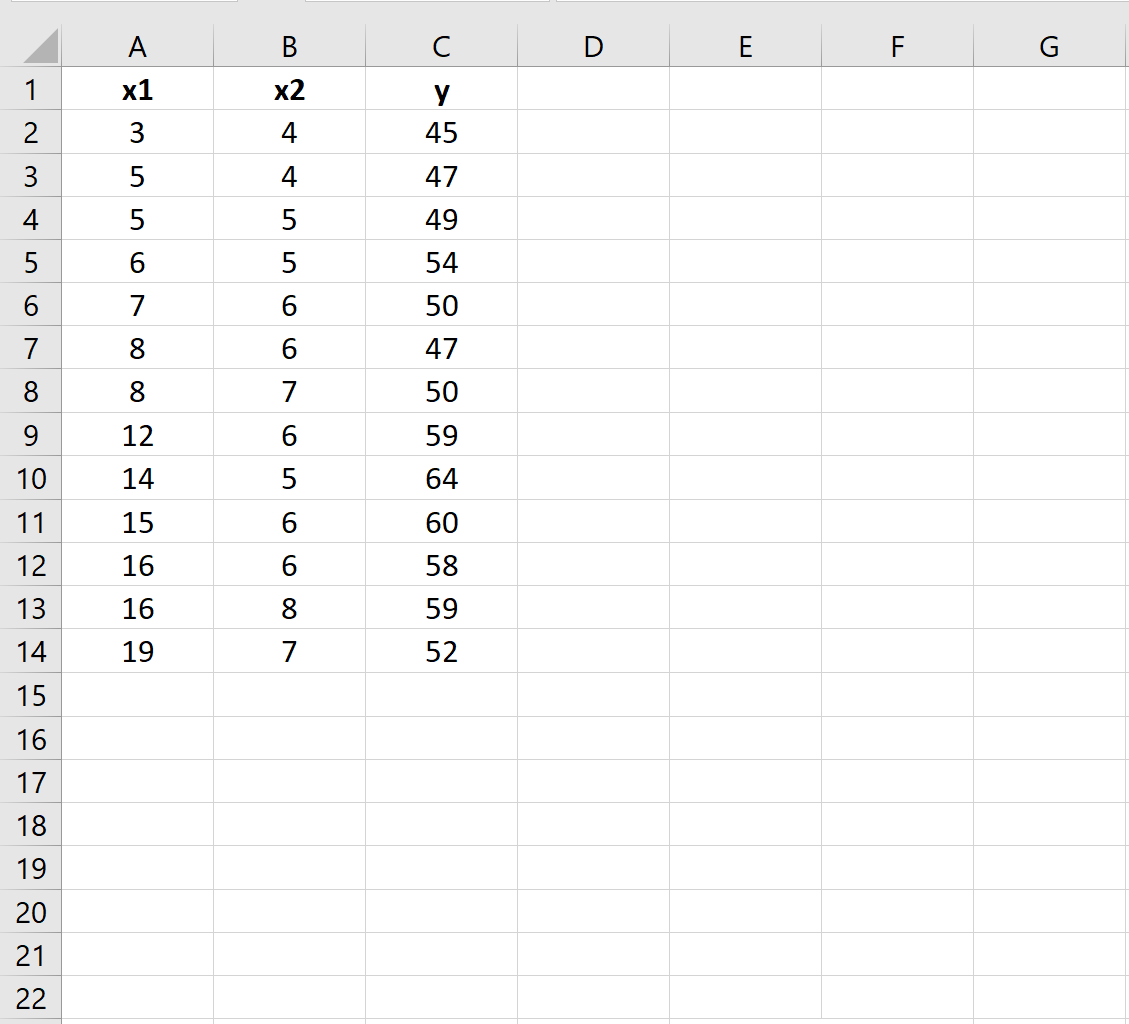
Шаг 1: введите данные
Во-первых, мы введем значения для набора данных, для которого мы хотели бы построить модель множественной линейной регрессии :
Шаг 2: Подберите модель множественной линейной регрессии
Далее мы подгоним модель множественной линейной регрессии, используя y в качестве переменной отклика и x1 и x2 в качестве переменных-предикторов.
Для этого щелкните вкладку « Данные » на верхней ленте. Затем нажмите « Анализ данных» в группе « Анализ ».

Если вы не видите эту опцию, вам нужно сначала загрузить пакет инструментов анализа .
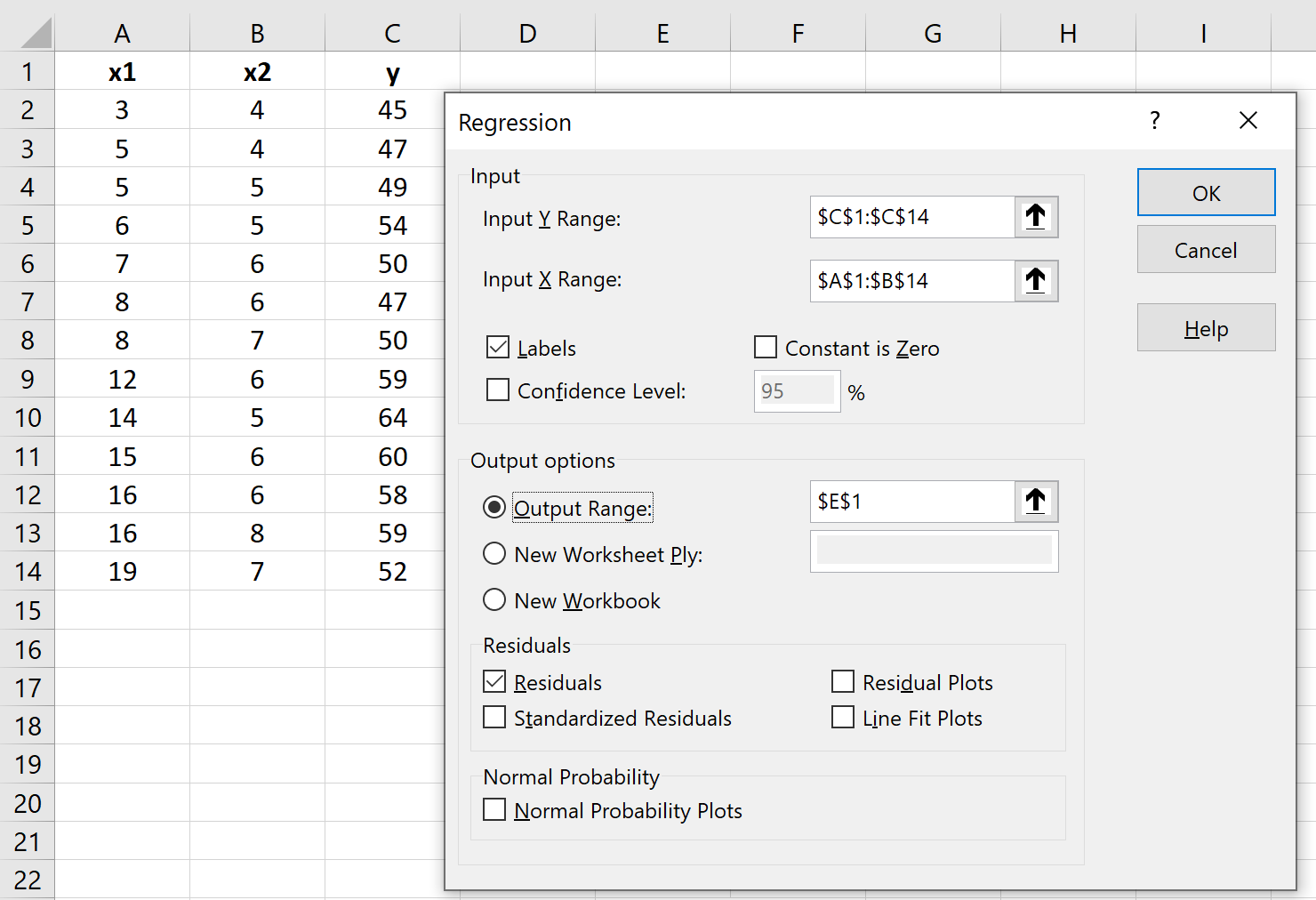
В появившемся окне нажмите « Регрессия », а затем нажмите « ОК ». В появившемся новом окне заполните следующую информацию:
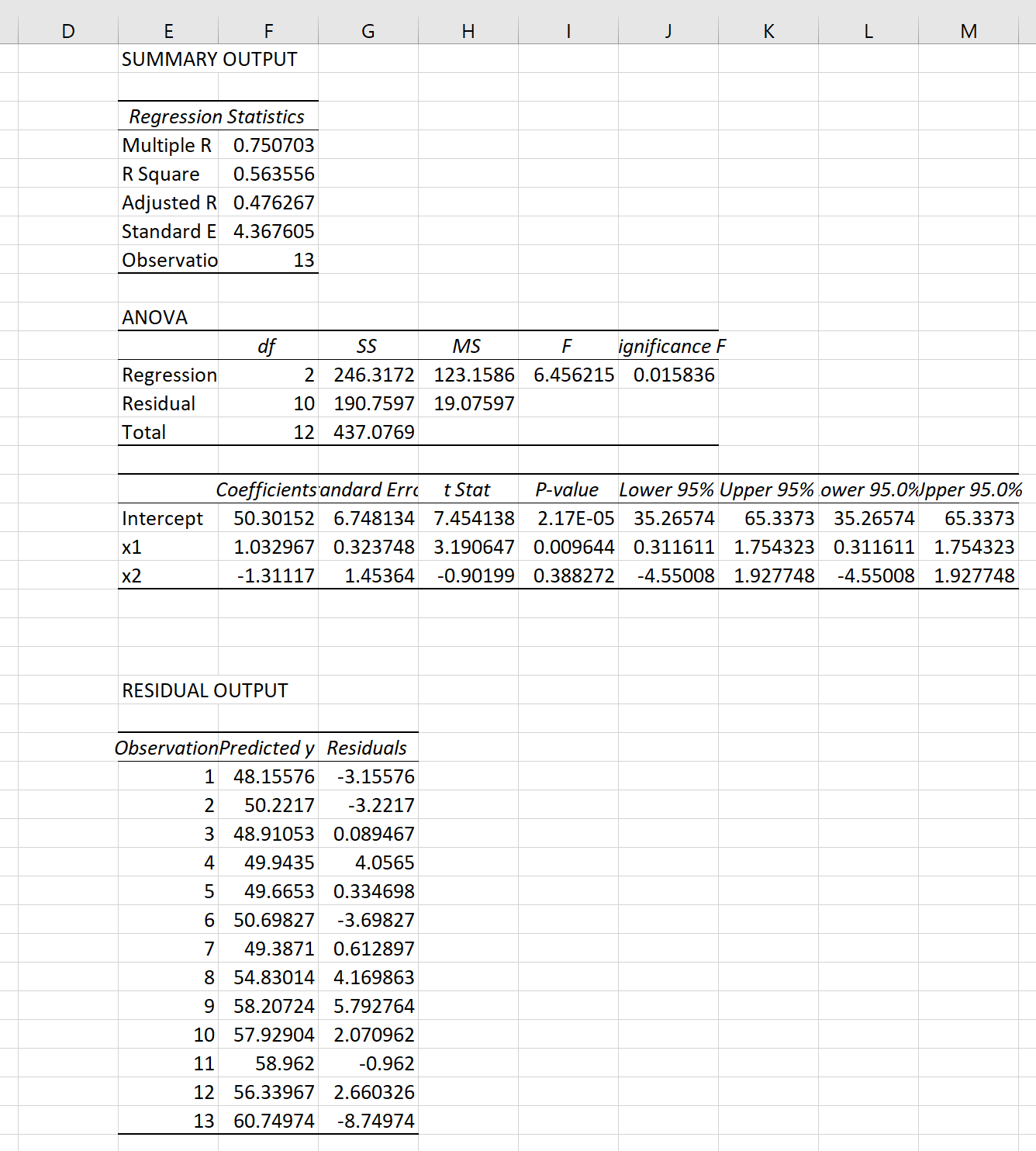
Как только вы нажмете OK , появится вывод регрессии:
Шаг 3. Выполните тест Дарбина-Ватсона.
Статистика теста для теста Дарбина-Ватсона, обозначенная d , рассчитывается следующим образом:
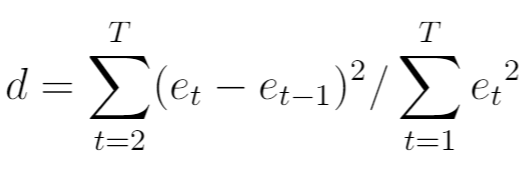
куда:
- T: общее количество наблюдений
- e t : t -й остаток регрессионной модели.
Чтобы рассчитать эту тестовую статистику в Excel, мы можем использовать следующую формулу:
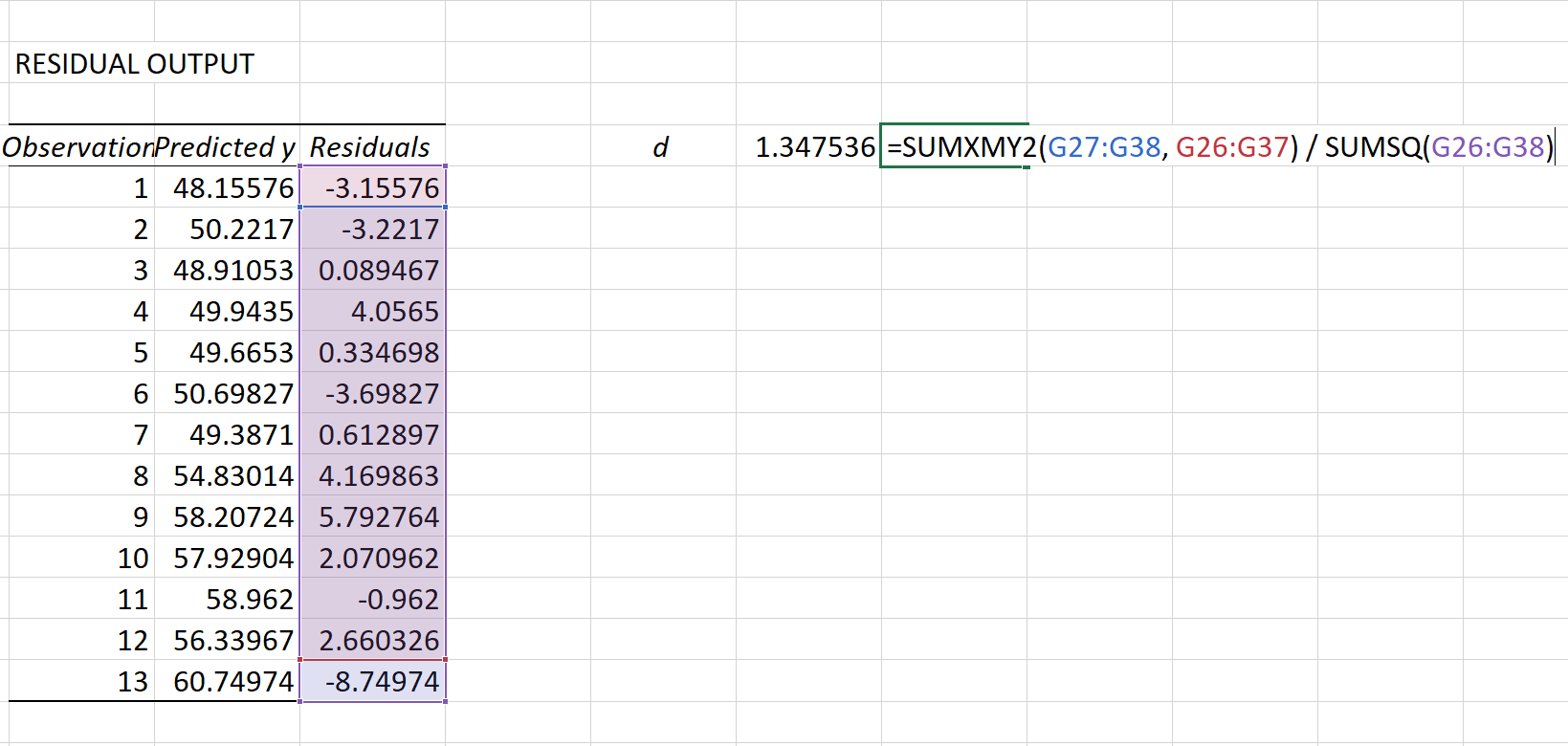
Тестовая статистика оказывается 1,3475 .
Чтобы определить, является ли статистика теста Дарбина-Ватсона значимой на определенном альфа-уровне, мы можем обратиться к этой таблице критических значений.
Для α = 0,05, n = 13 наблюдений и k = 2 независимых переменных в регрессионной модели таблица Дарбина-Ватсона показывает следующие верхние и нижние критические значения:
- Нижнее критическое значение: 0,86
- Верхнее критическое значение: 1,56
Поскольку наша тестовая статистика 1,3475 не лежит за пределами этого диапазона, у нас нет достаточных доказательств, чтобы отвергнуть нулевую гипотезу теста Дарбина-Уотсона.
Другими словами, между остатками нет корреляции.
Что делать, если обнаружена автокорреляция
Если вы отвергаете нулевую гипотезу и заключаете, что в остатках присутствует автокорреляция, то у вас есть несколько различных вариантов исправления этой проблемы, если она достаточно серьезна:
- Для положительной последовательной корреляции рассмотрите возможность добавления в модель лагов зависимой и/или независимой переменной.
- Для отрицательной последовательной корреляции убедитесь, что ни одна из ваших переменных не является сверхдифференциальной .
- Для сезонной корреляции рассмотрите возможность добавления в модель сезонных фиктивных переменных .
Дополнительные ресурсы
Как создать остаточный график в Excel
Как рассчитать стандартизированные остатки в Excel
Как рассчитать остаточную сумму квадратов в Excel
Постановка задачи
Критерий Дарбина-Уотсона (Durbin–Watson statistic) – один из самых распространенных критериев для проверки автокорреляции.
Данный критерий входит в стандартный инструментарий python:
-
присутствует в таблице выдачи результатов регрессионного анализа модуля линейной регрессии Linear Regression;
-
может быть рассчитан с помощью функции statsmodels.stats.stattools.durbin_watson.
К сожалению, стандартные инструменты python не позволяют получить табличные значения статистики критерия Дарбина-Уотсона, нам предлагается воспользоваться методом грубой оценки: считается, что при расчетном значении статистики критерия в интервале [1; 2] автокорреляция отсутствует (см. Durbin–Watson statistic). Однако, для качественного статистического анализа такой подход неприемлем.
Представляет интерес реализовать в полной мере критерий Дарбина-Уотсона средствами python, добавив этот важный критерий в инструментарий специалиста DataScience.
В данном обзоре мы коснемся только собственно критерия Дарбина-Уотсона и его применения для выявления автокорреляции. Особенности построения регрессионных моделей и прогнозирования в условиях автокорреляции (двухшаговый метод наименьших квадратов и пр.) мы рассматривать не будем.
Применение пользовательских функций
Как и в предыдущем обзоре, здесь будут использованы несколько пользовательских функций для решения разнообразных задач. Все эти функции созданы для облегчения работы и уменьшения размера программного кода. Данные функции загружается из пользовательского модуля my_module__stat.py, который доступен в моем репозитории на GitHub.
Вот перечень данных функций:
-
graph_plot_sns_np – функция строит линейный график средствами seaborn;
-
graph_regression_plot_sns – функция строит график регрессионной модели и график остатков средствами seaborn;
-
regression_error_metrics – функция возвращает ошибки аппроксимации регрессионной модели;
-
graph_hist_boxplot_probplot_sns – функция позволяет визуализировать исходные данные для одной переменной путем одновременного построения гистограммы, коробчатой диаграммы и вероятностного графика средствами seaborn; имеется возможность выбирать, какие графики строить (h – hist, b – boxplot, p – probplot);
-
norm_distr_check – проверка нормальности распределения исходных данных с использованием набора из нескольких статистических тестов.
-
Goldfeld_Quandt_test, Breush_Pagan_test, White_test – проверка гетероскедастичности с использование тестов Голдфелда-Квандта, Бриша-Пэгана и Уайта соответственно;
-
graph_regression_pair_predict_plot_sns – прогнозирование: построение графика регрессионной модели (с доверительными интервалами) и вывод расчетной таблицы с данными для заданной области значений X.
В процессе данного обзора мы создаем пользовательскую функцию Durbin_Watson_test, которая проверяет гипотезу о наличии автокорреляции (она тоже включена в пользовательский модуль my_module__stat.py).
Основы теории
Информацию о критерии Дарбина-Уотсона можно почерпнуть в [1, с.659], [2, с.117], [3, с.239], [4, с.188], а также:
-
Durbin–Watson statistic
-
Критерий Дарбина — Уотсона
Итак, предположим, мы рассматриваем регрессионную модель:


или в матричном виде:
![]()
![]()
Критерий Дарбина-Уотсона применяется в ситуации, когда регрессионные остатки связаны автокорреляционной зависимостью 1-го порядка [2, с.111]:
![]()
где ![]() – некоторое число (
– некоторое число (![]() ), а случайные величины
), а случайные величины ![]() удовлетворяют требованиям, предъявляемым к регрессионным остаткам классической модели (т.е. равенство нулю среднего значения, постоянство дисперсии и некоррелированность между собой):
удовлетворяют требованиям, предъявляемым к регрессионным остаткам классической модели (т.е. равенство нулю среднего значения, постоянство дисперсии и некоррелированность между собой):
![]()
![]()
Проверяется нулевая гипотеза об отсутствии автокорреляции:
![]()
Альтернативной гипотезой может быть:
-
существование отрицательной автокорреляции (левосторонняя критическая область):
![]()
-
существование положительной автокорреляции (правосторонняя критическая область):
![]()
-
существование автокорреляции вообще (двусторонняя критическая область):
![]()
Расчетное значение статистики критерия Дарбина-Уотсона имеет вид:

где ![]() – остатки (невязки) регрессионной модели.
– остатки (невязки) регрессионной модели.
По таблицам (см. [1, с.659], [2, с.402], [3, с.291]) в зависимости от уровня значимости ![]() (5%, 2.5%, 1%), числа параметров регрессионной модели
(5%, 2.5%, 1%), числа параметров регрессионной модели ![]() (кроме свободного члена
(кроме свободного члена ![]() ) (от 1 до 5) и объема выборки
) (от 1 до 5) и объема выборки ![]() (от 15 до 100) определяются критические значения статистики Дарбина-Уотсона: нижний
(от 15 до 100) определяются критические значения статистики Дарбина-Уотсона: нижний ![]() и верхний
и верхний ![]() предел.
предел.
Правила принятия гипотез по критерию Дарбина-Уотсона выглядят довольно своеобразно – критические значения образуют пять областей различных статистических решений (причем критические границы принятия ![]() и непринятия
и непринятия ![]() не совпадают):
не совпадают):
|
Значение |
Принимается гипотеза |
Вывод |
|---|---|---|
|
|
отвергается |
есть положительная автокорреляция |
|
|
неопределенность |
|
|
|
принимается |
автокорреляция отсутствует |
|
|
неопределенность |
|
|
|
отвергается |
есть отрицательная автокорреляция |
Есть очень удачная мнемоническая схема, приведенная в [3, с.240]:

Особенности критерия Дарбина-Уотсона:
-
Критические значения критерия табулированы для объема выборки от 15 до 100, аппроксимаций мне обнаружить не удалось. При меньших значениях критерий применять нельзя, при больших – очевидно, приходиться пользоваться грубым оценочным правилом: при расчетном значении статистики критерия в интервале [1; 2] автокорреляция отсутствует (см. https://en.wikipedia.org/wiki/Durbin–Watson_statistic).
-
Критерий позволяет выявить только автокорреляцию 1-го порядка. Отклонение нулевой гипотезы не означает, что автокорреляции нет вообще – возможно наличие автокорреляции более высоких порядков.
-
Критерий построен в предположении, что регрессоры
 и ошибки
и ошибки  не коррелированы, поэтому его нельзя применять, в частности, для моделей авторегрессии [4, с.191].
не коррелированы, поэтому его нельзя применять, в частности, для моделей авторегрессии [4, с.191]. -
Критерий не подходит для моделей без свободного члена
 .
. -
Критерий имеет зону неопределенности, когда нет оснований ни принимать, ни отвергать нулевую гипотезу.
-
Между статистикой критерия и коэффициентом автокорреляции существует приближенное соотношение:
![]()
Существуют и другие критерии для проверки автокорреляции (тест Бройша-Годфри, Льюнга-Бокса и пр.).
Как было указано выше, большой проблемой является отсутствие табличных значений статистики критерия Дарбина-Уостона в стандартном инструментарии python. Для реализации возможностей данного критерия в полном объеме нам потребуется оцифровка весьма объемных таблиц критических значений.
Оцифровка табличных значений статистики критерия Дарбина – Уотсона
Я решил добавить в обзор этот раздел, хотя, строго говоря, можно было обойтись и без него, а сразу воспользоваться оцифрованными таблицами статистики критерия Дарбина-Уотсона.
Однако, если мы хотим выполнять качественный статистический анализ, неизбежно придется работать с большим количеством статистических критериев и далеко не все из них реализованы в python. Критерий Дарбина-Уотсона – это только один из многих. Количество критериев, рассматриваемых в литературе по прикладной статистике в последние годы постоянно увеличивается. Специалисту придется реализовывать многие критерии самостоятельно и одна из проблем, с которой придется столкнуться – это таблицы критических значений. Далеко не все табличные значения имеют аппроксимации, а значит придется каким-то образом оцифровывать эти таблицы. Небольшие таблицы можно сохранить в файлах вручную, а вот такой подход с объемными таблицами (как в нашем случае) – это слишком непроизводительно и нерационально.
В общем, на мой взгляд, представляет интерес разобрать пример оцифровки статистических таблиц на примере нашего критерия Дарбина-Уотсона – это позволит специалистам сэкономить человеко-часы работы и облегчить совершенствование инструментов статистического анализа.
Замечу сразу, что я не являюсь глубоким специалистом в области анализа и обработки изображений и текстов на python – это не совсем мой профиль. Профессионалы в этой области, возможно, раскритикуют то, как решается поставленная задача и предложат более удачное решение. Если будет так – то заранее спасибо. Я же эту задачу старался решить наиболее простым и рациональным способом, доступным для широкого круга специалистов. На всякий случай могу процитировать Давоса Сиворта из “Игры престолов”: “Простите за то, что увидите”.
Алгоритм действий:
Для оцифровки я использовал таблицы, приведенные в [3, с.290-292].
-
Сканируем таблицы, сохраняем в виде jpg-файлов (Durbin_Watson_test_1.jpg, Durbin_Watson_test_2.jpg, Durbin_Watson_test_3.jpg) в папке text_processing, расположенной внутри папки с рабочим .ipynb-файлом:


-
Распознаем текст (я воспользовался онлайн-сервисом https://convertio.co/), полученные текстовые файлы Durbin-Watson-test-1.ocr.txt, Durbin-Watson-test-2.ocr.txt, Durbin-Watson-test-3.ocr.txt также помещаем в папке text_processing.
-
Откроем файлы, запишем содержимое файлов в переменные, каждая из которых соответствует одной странице:
with open('text_processingDurbin-Watson-test-1.ocr.txt') as f1:
Durbin_Watson_test_1 = f1.readlines()
display(Durbin_Watson_test_1, type(Durbin_Watson_test_1), len(Durbin_Watson_test_1))
С остальными файлами – действуем аналогично:
with open('text_processingDurbin-Watson-test-2.ocr.txt') as f2:
Durbin_Watson_test_2 = f2.readlines()
display(Durbin_Watson_test_2, type(Durbin_Watson_test_2), len(Durbin_Watson_test_2))
with open('text_processingDurbin-Watson-test-3.ocr.txt') as f3:
Durbin_Watson_test_3 = f3.readlines()
display(Durbin_Watson_test_3, type(Durbin_Watson_test_3), len(Durbin_Watson_test_3))Видим, что переменные представляют собой списки, элементами которых является строки.
Для облегчения дальнейшей обработки данных создадим список, элементами которого являются переменные-страницы:
Durbin_Watson_test = [Durbin_Watson_test_1, Durbin_Watson_test_2, Durbin_Watson_test_3]Далее я не стал публиковать здесь скриншоты с обработкой страниц – из-за экономии места. В ipyng-файле, который доступен в моем репозитории, весь процесс обработки представлен достаточно подробно.
-
Исключаем все строки, которые начинаются не с цифр; при этом воспользуемся алгоритмом перезаписи списка:
# создаем новый список
Durbin_Watson_test_new = list()
# удаляем строки
for page in Durbin_Watson_test:
page_temp = list() # временная страница
for line in page:
if line[0].isdigit():
page_temp.append(line) # перезаписываем список
Durbin_Watson_test_new.append(page_temp)-
Исключаем из текста управляющие символы (t, n) – с помощью регулярных выражений (regex) (модуль re):
# задаем шаблон для удаления символов
pattern = r'[t+n+]'
# выполняем обработку
Durbin_Watson_test_new = [
[re.sub(pattern, ' ', elem) for elem in page]
for page in Durbin_Watson_test_new]-
Удаляем все символы, кроме цифр, точек, запятых и пробелов:
# задаем шаблон для удаления символов
pattern = r'[^0-9,. ]'
# выполняем обработку
Durbin_Watson_test_new = [
[re.sub(pattern, '', elem) for elem in page]
for page in Durbin_Watson_test_new]-
Заменяем запятые на точки:
# задаем шаблон для удаления символов
pattern = r'[,]'
# выполняем обработку
Durbin_Watson_test_new = [
[re.sub(pattern, '.', elem) for elem in page]
for page in Durbin_Watson_test_new]-
Разделяем строки:
# задаем шаблон
pattern = r'[ ]+'
# выполняем обработку
Durbin_Watson_test_new = [[re.split(pattern, elem) for elem in page]
for page in Durbin_Watson_test_new]-
Сохраняем данные в DataFrame – для этого создадим список Durbin_Watson_list_df, элементами которого являются отдельные DataFrame, каждый из которых соответствует отдельной странице:
# создаем новый список
Durbin_Watson_list_df = list()
for page in Durbin_Watson_test_new:
Durbin_Watson_list_df.append(pd.DataFrame(page))-
Исправляем вручную отдельные аномалии, возникшие при распознавании отсканированных данных – к сожалению, работы вручную совсем избежать не удается.
-
Корректируем DataFrame, соответствующий 1-й странице:
# создаем временный DataFrame
temp_df = Durbin_Watson_list_df[0]
# удаляем последние столбцы
temp_df = temp_df.drop(columns=[11, 12])
# корректируем вручную отдельные ошибки
temp_df.loc[[4],] = [19, 1.18, 1.40, 1.08, 1.53, 0.97, 1.68, 0.86, 1.85, 0.75, 2.02]
temp_df.loc[[8],[3]] = 1.17
temp_df.loc[[10],[3]] = 1.21
temp_df.loc[[17],[9]] = 1.11
temp_df.loc[[21],[4]] = 1.59
temp_df.loc[[25],[5]] = 1.34
temp_df.loc[[31],[10]] = 1.77
# записываем изменения
Durbin_Watson_list_df[0] = temp_df-
Корректируем DataFrame, соответствующий 2-й странице:
# создаем временный DataFrame
temp_df = Durbin_Watson_list_df[1]
# удаляем последние столбцы
temp_df = temp_df.drop(columns=[11, 12])
# корректируем вручную отдельные ошибки
temp_df.loc[[2],[8]] = 1.77
temp_df.loc[[10],[9]] = 0.86
temp_df.loc[[10],[10]] = 1.77
temp_df.loc[[14],[9]] = 0.96
temp_df.loc[[17],[10]] = 1.71
temp_df.loc[[34],[10]] = 1.71
# записываем изменения
Durbin_Watson_list_df[1] = temp_df-
Корректируем DataFrame, соответствующий 3-й странице:
# создаем временный DataFrame
temp_df = Durbin_Watson_list_df[2]
# удаляем последние столбцы
temp_df = temp_df.drop(columns=[11, 12])
# корректируем вручную отдельные ошибки
temp_df.loc[[2],[9]] = 0.48
temp_df.loc[[13],] = [28, 1.10, 1.24, 1.04, 1.32, 0.97, 1.41, 0.90, 1.51, 0.83, 1.62]
temp_df.loc[[20],[3]] = 1.14
temp_df.iloc[21:26, 7] = [1.04, 1.06, 1.07, 1.09, 1.10]
temp_df.loc[[26],[9]] = 1.11
temp_df.loc[[35],] = [90, 1.50, 1.54, 1.47, 1.56, 1.45, 1.59, 1.43, 1.61, 1.41, 1.64]
# записываем изменения
Durbin_Watson_list_df[2] = temp_dfОбращаем внимание, что откорректированные вручную значения являются числовыми, а все остальные значения – еще имеют строковый тип.
11. Преобразуем значения из строкового в числовой тип:
for elem_df in Durbin_Watson_list_df:
for col in elem_df.columns:
elem_df[col] = pd.to_numeric(elem_df[col], errors='ignore')-
Корректируем структуру DataFrame:
-
меняем индекс – индексом теперь будет объем выборки n
-
каждый DataFrame снабжаем мультииндексом по столбцам (подробнее см. [7, с.169])
# меняем индекс
Durbin_Watson_list_df = [
elem_df.set_index([0])
for elem_df in Durbin_Watson_list_df]
# добавляем мультииндекс по столбцам
multi_index_list = ['p=0.95', 'p=0.975', 'p=0.99'] # список, содержащий значения для верхней строки мульииндекса
for i, elem_df in enumerate(Durbin_Watson_list_df):
elem_df.index.name = 'n'
elem_df.columns = pd.MultiIndex.from_product(
[[multi_index_list[i]],
['m=1', 'm=2', 'm=3', 'm=4', 'm=5'],
['dL','dU']])-
Объединяем отдельные DataFrame в один:
Durbin_Watson_test_df = Durbin_Watson_list_df[0].copy()
for i, elem_df in enumerate(Durbin_Watson_list_df):
if i > 0:
Durbin_Watson_test_df = Durbin_Watson_test_df.join(elem_df)
display(Durbin_Watson_test_df) 
Durbin_Watson_test_df.info()
Итак, мы сформировали DataFrame с оцифрованными данными таблиц критических значений статистики Дарбина-Уотсона. Получить доступ к данным теперь очень просто – например, нам требуется вывести табличные значения статистики критерия при объеме выборки ![]() , доверительной вероятности
, доверительной вероятности ![]() и числе параметров регрессионной модели
и числе параметров регрессионной модели ![]() :
:
n = 40
p = 0.95
m=2
Durbin_Watson_test_df.loc[[n], (f'p={p}', f'm={m}')]
-
Построим график табличных значений.
График получился весьма объемным – 3х5 элементов – однако он необходим: на графике можно увидеть те ошибки (пики и впадины), которые мы могли пропустить при ручной обработке ранее (некорректно отсканированные и распознанные цифры), тогда придется вернуться к этапу 10.
# меняем настройки Mathplotlib
plt.rcParams['axes.titlesize'] = 10 # шрифт заголовка
plt.rcParams['legend.fontsize'] = 9 # шрифт легенды
plt.rcParams['xtick.labelsize'] = 8 # шрифт подписей меток
plt.rcParams['ytick.labelsize'] = 8
fig = plt.figure(figsize=(297/INCH, 420/INCH))
ax_1_1 = plt.subplot(5,3,1)
ax_2_1 = plt.subplot(5,3,2)
ax_3_1 = plt.subplot(5,3,3)
ax_1_2 = plt.subplot(5,3,4)
ax_2_2 = plt.subplot(5,3,5)
ax_3_2 = plt.subplot(5,3,6)
ax_1_3 = plt.subplot(5,3,7)
ax_2_3 = plt.subplot(5,3,8)
ax_3_3 = plt.subplot(5,3,9)
ax_1_4 = plt.subplot(5,3,10)
ax_2_4 = plt.subplot(5,3,11)
ax_3_4 = plt.subplot(5,3,12)
ax_1_5 = plt.subplot(5,3,13)
ax_2_5 = plt.subplot(5,3,14)
ax_3_5 = plt.subplot(5,3,15)
fig.suptitle('Табличные значения статистики критерия Дарбина-Уотсона', fontsize = 16)
(Ymin, Ymax) = (0.3, 2.2)
x = Durbin_Watson_test_df.index
title_fontsize = 10
name_1_1 = ['p=0.95', 'm=1']
ax_1_1.set_title(name_1_1[0] + ' ' + name_1_1[1])
ax_1_1.plot(x, Durbin_Watson_test_df[tuple(name_1_1 + ['dL'])],
x, Durbin_Watson_test_df[tuple(name_1_1 + ['dU'])])
name_1_2 = ['p=0.95', 'm=2']
ax_1_2.set_title(name_1_2[0] + ' ' + name_1_2[1])
ax_1_2.plot(x, Durbin_Watson_test_df[tuple(name_1_2 + ['dL'])],
x, Durbin_Watson_test_df[tuple(name_1_2 + ['dU'])])
name_1_3 = ['p=0.95', 'm=3']
ax_1_3.set_title(name_1_3[0] + ' ' + name_1_3[1])
ax_1_3.plot(x, Durbin_Watson_test_df[tuple(name_1_3 + ['dL'])],
x, Durbin_Watson_test_df[tuple(name_1_3 + ['dU'])])
name_1_4 = ['p=0.95', 'm=4']
ax_1_4.set_title(name_1_4[0] + ' ' + name_1_4[1])
ax_1_4.plot(x, Durbin_Watson_test_df[tuple(name_1_4 + ['dL'])],
x, Durbin_Watson_test_df[tuple(name_1_4 + ['dU'])])
name_1_5 = ['p=0.95', 'm=5']
ax_1_5.set_title(name_1_5[0] + ' ' + name_1_5[1])
ax_1_5.plot(x, Durbin_Watson_test_df[tuple(name_1_5 + ['dL'])],
x, Durbin_Watson_test_df[tuple(name_1_5 + ['dU'])])
name_2_1 = ['p=0.975', 'm=1']
ax_2_1.set_title(name_2_1[0] + ' ' + name_2_1[1])
ax_2_1.plot(x, Durbin_Watson_test_df[tuple(name_2_1 + ['dL'])],
x, Durbin_Watson_test_df[tuple(name_2_1 + ['dU'])])
name_2_2 = ['p=0.975', 'm=2']
ax_2_2.set_title(name_2_2[0] + ' ' + name_2_2[1])
ax_2_2.plot(x, Durbin_Watson_test_df[tuple(name_2_2 + ['dL'])],
x, Durbin_Watson_test_df[tuple(name_2_2 + ['dU'])])
name_2_3 = ['p=0.975', 'm=3']
ax_2_3.set_title(name_2_3[0] + ' ' + name_2_3[1])
ax_2_3.plot(x, Durbin_Watson_test_df[tuple(name_2_3 + ['dL'])],
x, Durbin_Watson_test_df[tuple(name_2_3 + ['dU'])])
name_2_4 = ['p=0.975', 'm=4']
ax_2_4.set_title(name_2_4[0] + ' ' + name_2_4[1])
ax_2_4.plot(x, Durbin_Watson_test_df[tuple(name_2_4 + ['dL'])],
x, Durbin_Watson_test_df[tuple(name_2_4 + ['dU'])])
name_2_5 = ['p=0.975', 'm=5']
ax_2_5.set_title(name_2_5[0] + ' ' + name_2_5[1])
ax_2_5.plot(x, Durbin_Watson_test_df[tuple(name_2_5 + ['dL'])],
x, Durbin_Watson_test_df[tuple(name_2_5 + ['dU'])])
name_3_1 = ['p=0.99', 'm=1']
ax_3_1.set_title(name_3_1[0] + ' ' + name_3_1[1])
ax_3_1.plot(x, Durbin_Watson_test_df[tuple(name_3_1 + ['dL'])],
x, Durbin_Watson_test_df[tuple(name_3_1 + ['dU'])])
name_3_2 = ['p=0.99', 'm=2']
ax_3_2.set_title(name_3_2[0] + ' ' + name_3_2[1])
ax_3_2.plot(x, Durbin_Watson_test_df[tuple(name_3_2 + ['dL'])],
x, Durbin_Watson_test_df[tuple(name_3_2 + ['dU'])])
name_3_3 = ['p=0.99', 'm=3']
ax_3_3.set_title(name_3_3[0] + ' ' + name_3_3[1])
ax_3_3.plot(x, Durbin_Watson_test_df[tuple(name_3_3 + ['dL'])],
x, Durbin_Watson_test_df[tuple(name_3_3 + ['dU'])])
name_3_4 = ['p=0.99', 'm=4']
ax_3_4.set_title(name_3_4[0] + ' ' + name_3_4[1])
ax_3_4.plot(x, Durbin_Watson_test_df[tuple(name_3_4 + ['dL'])],
x, Durbin_Watson_test_df[tuple(name_3_4 + ['dU'])])
name_3_5 = ['p=0.99', 'm=5']
ax_3_5.set_title(name_3_5[0] + ' ' + name_3_5[1])
ax_3_5.plot(x, Durbin_Watson_test_df[tuple(name_3_5 + ['dL'])],
x, Durbin_Watson_test_df[tuple(name_3_5 + ['dU'])])
ax_1_1.set_ylim(Ymin, Ymax)
ax_2_1.set_ylim(Ymin, Ymax)
ax_3_1.set_ylim(Ymin, Ymax)
ax_1_2.set_ylim(Ymin, Ymax)
ax_2_2.set_ylim(Ymin, Ymax)
ax_3_2.set_ylim(Ymin, Ymax)
ax_1_3.set_ylim(Ymin, Ymax)
ax_2_3.set_ylim(Ymin, Ymax)
ax_3_3.set_ylim(Ymin, Ymax)
ax_1_4.set_ylim(Ymin, Ymax)
ax_2_4.set_ylim(Ymin, Ymax)
ax_3_4.set_ylim(Ymin, Ymax)
ax_1_5.set_ylim(Ymin, Ymax)
ax_2_5.set_ylim(Ymin, Ymax)
ax_3_5.set_ylim(Ymin, Ymax)
legend = (r'$d_L$', r'$d_U$')
ax_1_1.legend(legend)
ax_2_1.legend(legend)
ax_3_1.legend(legend)
ax_1_2.legend(legend)
ax_2_2.legend(legend)
ax_3_2.legend(legend)
ax_1_3.legend(legend)
ax_2_3.legend(legend)
ax_3_3.legend(legend)
ax_1_4.legend(legend)
ax_2_4.legend(legend)
ax_3_4.legend(legend)
ax_1_5.legend(legend)
ax_2_5.legend(legend)
ax_3_5.legend(legend)
plt.show()
# возвращаем настройки Mathplotlib
plt.rcParams['axes.titlesize'] = f_size + 10 # шрифт заголовка
plt.rcParams['legend.fontsize'] = f_size + 6 # шрифт легенды
plt.rcParams['xtick.labelsize'] = f_size + 4 # шрифт подписей меток
plt.rcParams['ytick.labelsize'] = f_size + 4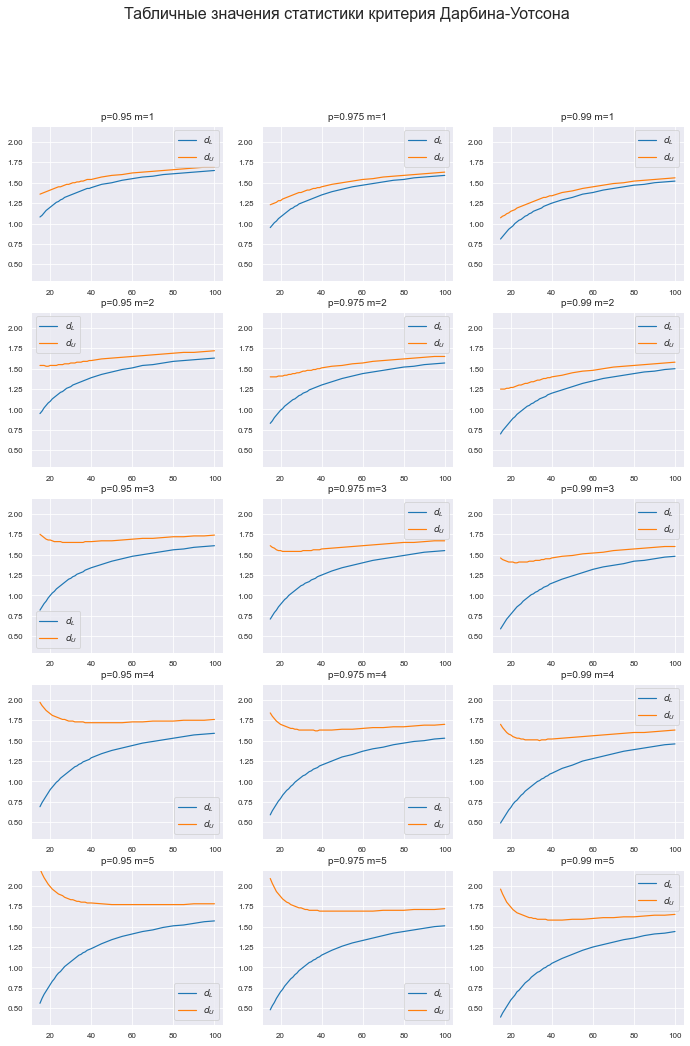
-
Сохраняем полученный DataFrame в csv-файл, помещаем его в папку table, расположенную внутри папки с рабочим .ipynb-файлом (в которой папку table у нас хранятся файлы с данными из статистических таблиц):
Durbin_Watson_test_df.to_csv(
path_or_buf='tableDurbin_Watson_test_table.csv',
mode='w+',
sep=';',
index_label='n')Табличные значения статистики критерия Дарбина-Уотсона у нас теперь имеются, можем приступать к созданию пользовательской функции.
Создание пользовательской функции для реализации критерия Дарбина – Уотсона
Рассчитать статистику критерия Дарбина-Уотсона мы можем с помощью функции statsmodels.stats.stattools.durbin_watson.
Создадим пользовательскую функцию Durbin_Watson_test для проверки гипотезы об автокорреляции:
def Durbin_Watson_test(
data,
m = None,
p_level: float=0.95):
a_level = 1 - p_level
data = np.array(data)
n = len(data)
# расчетное значение статистики критерия
DW_calc = sms.stattools.durbin_watson(data)
# табличное значение статистики критерия
if (n >= 15) and (n <= 100):
# восстанавливаем структуру DataFrame из csv-файла
DW_table_df = pd.read_csv(
filepath_or_buffer='table/Durbin_Watson_test_table.csv',
sep=';',
#index_col='n'
)
DW_table_df = DW_table_df.rename(columns={'Unnamed: 0': 'n'})
DW_table_df = DW_table_df.drop([0, 1, 2])
for col in DW_table_df.columns:
DW_table_df[col] = pd.to_numeric(DW_table_df[col], errors='ignore')
DW_table_df = DW_table_df.set_index('n')
DW_table_df.columns = pd.MultiIndex.from_product(
[['p=0.95', 'p=0.975', 'p=0.99'],
['m=1', 'm=2', 'm=3', 'm=4', 'm=5'],
['dL','dU']])
# интерполяция табличных значений
key = [f'p={p_level}', f'm={m}']
f_lin_L = sci.interpolate.interp1d(DW_table_df.index, DW_table_df[tuple(key + ['dL'])])
f_lin_U = sci.interpolate.interp1d(DW_table_df.index, DW_table_df[tuple(key + ['dU'])])
DW_table_L = float(f_lin_L(n))
DW_table_U = float(f_lin_U(n))
# проверка гипотезы
Durbin_Watson_scale = {
1: DW_table_L,
2: DW_table_U,
3: 4 - DW_table_U,
4: 4 - DW_table_L,
5: 4}
Durbin_Watson_comparison = {
1: ['0 ≤ DW_calc < DW_table_L', 'H1: r > 0'],
2: ['DW_table_L ≤ DW_calc ≤ DW_table_U', 'uncertainty'],
3: ['DW_table_U < DW_calc < 4 - DW_table_U', 'H0: r = 0'],
4: ['4 - DW_table_U ≤ DW_calc ≤ 4 - DW_table_L', 'uncertainty'],
5: ['4 - DW_table_L < DW_calc ≤ 4', 'H1: r < 0']}
r_scale = list(Durbin_Watson_scale.values())
for i, elem in enumerate(r_scale):
if DW_calc <= elem:
key_scale = list(Durbin_Watson_scale.keys())[i]
comparison = Durbin_Watson_comparison[key_scale][0]
conclusion = Durbin_Watson_comparison[key_scale][1]
break
elif n < 15:
comparison = '-'
conclusion = 'count less than 15'
else:
comparison = '-'
conclusion = 'count more than 100'
# формируем результат
result = pd.DataFrame({
'n': (n),
'm': (m),
'p_level': (p_level),
'a_level': (a_level),
'DW_calc': (DW_calc),
'ρ': (1 - DW_calc/2),
'DW_table_L': (DW_table_L if (n >= 15) and (n <= 100) else '-'),
'DW_table_U': (DW_table_U if (n >= 15) and (n <= 100) else '-'),
'comparison of calculated and critical values': (comparison),
'conclusion': (conclusion)
},
index=['Durbin-Watson_test'])
return resultПротестируем созданную функцию – будем моделировать временные ряды с различными свойствами и выполнять проверку автокорреляции:
y_func = lambda x, b0, b1: b0 + b1*x
N = 30 # число наблюдений
(mu, sigma) = (0, 25) # параметры моделируемой случайной компоненты (среднее и станд.отклонение)-
Смоделируем временной ряд с трендом, без автокорреляции остатков:
# моделирование
T_model = np.linspace(1, N, N) # независимая переменная - номер наблюдения
(b0, b1) = (100, 5) # параметры моделируемого временного ряда
Y_model = np.array(y_func(T_model, b0, b1)) + np.random.normal(mu, sigma, N)
# визуализация
axes = sns.jointplot(
x=T_model, y=Y_model,
kind='reg')
plt.show()
# проверка автокорреляции
display(Durbin_Watson_test(Y_model, m=1, p_level=0.95))

# моделирование
T_model = np.linspace(1, N, N) # независимая переменная - номер наблюдения
(b0, b1) = (100, -5) # параметры моделируемого временного ряда
Y_model = np.array(y_func(T_model, b0, b1)) + np.random.normal(mu, sigma, N)
# визуализация
axes = sns.jointplot(
x=T_model, y=Y_model,
kind='reg')
plt.show()
# проверка автокорреляции
display(Durbin_Watson_test(Y_model, m=1, p_level=0.95))

-
Смоделируем временной ряд без тренда:
# моделирование
T_model = np.linspace(1, N, N) # независимая переменная - номер наблюдения
(b0, b1) = (100, 0) # параметры моделируемого временного ряда
Y_model = np.array(y_func(T_model, b0, b1)) + np.random.normal(mu, sigma, N)
# визуализация
axes = sns.jointplot(
x=T_model, y=Y_model,
kind='reg')
plt.show()
# проверка автокорреляции
display(Durbin_Watson_test(Y_model, m=1, p_level=0.95))

# моделирование
T_model = np.linspace(1, N, N) # независимая переменная - номер наблюдения
(b0, b1) = (0, 0) # параметры моделируемого временного ряда
Y_model = np.array(y_func(T_model, b0, b1)) + np.random.normal(mu, sigma, N)
# визуализация
axes = sns.jointplot(
x=T_model, y=Y_model,
kind='reg')
plt.show()
# проверка автокорреляции
display(Durbin_Watson_test(Y_model, m=1, p_level=0.95))

-
Смоделируем временной ряд с трендом, с положительной автокорреляцией:
# моделирование
T_model = np.linspace(1, N, N) # независимая переменная - номер наблюдения
(b0, b1) = (100, 5) # параметры моделируемого временного ряда
E = np.array([np.random.normal(mu, sigma, 1)])
r = 0.9
for i in range(1, N):
elem = r*E[i-1] + np.random.normal(mu, sigma, 1)
E = np.append(E, elem)
Y_model = np.array(y_func(T_model, b0, b1)) + E
# визуализация
axes = sns.jointplot(
x=T_model, y=Y_model,
kind='reg')
plt.show()
# проверка автокорреляции
display(Durbin_Watson_test(Y_model, m=1, p_level=0.95))

-
Смоделируем временной ряд с трендом, с отрицательной автокорреляцией:
# моделирование
T_model = np.linspace(1, N, N) # независимая переменная - номер наблюдения
(b0, b1) = (100, 5) # параметры моделируемого временного ряда
E = np.array([np.random.normal(mu, sigma, 1)])
r = -0.9
for i in range(1, N):
elem = r*E[i-1] + np.random.normal(mu, sigma, 1)
E = np.append(E, elem)
Y_model = np.array(y_func(T_model, b0, b1)) + E
# визуализация
axes = sns.jointplot(
x=T_model, y=Y_model,
kind='reg')
plt.show()
# проверка автокорреляции
display(Durbin_Watson_test(Y_model, m=1, p_level=0.95))

-
Смоделируем временной ряд без тренда, с положительной автокорреляцией:
# моделирование
T_model = np.linspace(1, N, N) # независимая переменная - номер наблюдения
(b0, b1) = (100, 0) # параметры моделируемого временного ряда
E = np.array([np.random.normal(mu, sigma, 1)])
r = 0.9
for i in range(1, N):
elem = r*E[i-1] + np.random.normal(mu, sigma, 1)
E = np.append(E, elem)
Y_model = np.array(y_func(T_model, b0, b1)) + E
# визуализация
axes = sns.jointplot(
x=T_model, y=Y_model,
kind='reg')
plt.show()
# проверка автокорреляции
display(Durbin_Watson_test(Y_model, m=1, p_level=0.95))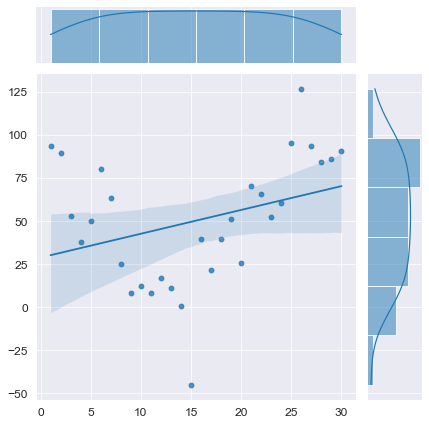

# моделирование
T_model = np.linspace(1, N, N) # независимая переменная - номер наблюдения
(b0, b1) = (0, 0) # параметры моделируемого временного ряда
E = np.array([np.random.normal(mu, sigma, 1)])
r = 0.9
for i in range(1, N):
elem = r*E[i-1] + np.random.normal(mu, sigma, 1)
E = np.append(E, elem)
Y_model = np.array(y_func(T_model, b0, b1)) + E
# визуализация
axes = sns.jointplot(
x=T_model, y=Y_model,
kind='reg')
plt.show()
# проверка автокорреляции
display(Durbin_Watson_test(Y_model, m=1, p_level=0.95))

-
Смоделируем временной ряд без тренда, с отрицательной автокорреляцией:
# моделирование
T_model = np.linspace(1, N, N) # независимая переменная - номер наблюдения
(b0, b1) = (100, 0) # параметры моделируемого временного ряда
E = np.array([np.random.normal(mu, sigma, 1)])
r = -0.9
for i in range(1, N):
elem = r*E[i-1] + np.random.normal(mu, sigma, 1)
E = np.append(E, elem)
Y_model = np.array(y_func(T_model, b0, b1)) + E
# визуализация
axes = sns.jointplot(
x=T_model, y=Y_model,
kind='reg')
plt.show()
# проверка автокорреляции
display(Durbin_Watson_test(Y_model, m=1, p_level=0.95))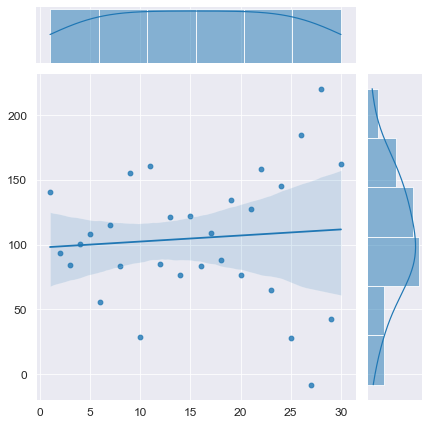

# моделирование
T_model = np.linspace(1, N, N) # независимая переменная - номер наблюдения
(b0, b1) = (0, 0) # параметры моделируемого временного ряда
E = np.array([np.random.normal(mu, sigma, 1)])
r = -0.9
for i in range(1, N):
elem = r*E[i-1] + np.random.normal(mu, sigma, 1)
E = np.append(E, elem)
Y_model = np.array(y_func(T_model, b0, b1)) + E
# визуализация
axes = sns.jointplot(
x=T_model, y=Y_model,
kind='reg')
plt.show()
# проверка автокорреляции
display(Durbin_Watson_test(Y_model, m=1, p_level=0.95))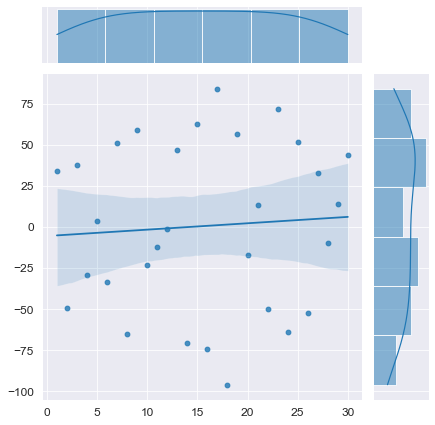

Конечно, данный вычислительный эксперимент не может претендовать на всеобъемлемость, однако определенный любопытный предварительный вывод можно сделать: при наличии любого тренда (даже если этот тренда представляет собой равенство постоянной величине ![]() ) критерий Дарбина-Уотсона выдает нам наличие положительной автокорреляции (даже если в модели автокорреляция не заложена нет или она отрицательная). Такой вывод нужно исследовать более глубоко, но это не входит в цель данного обзора. Специалист должен помнить об особенностях критерия Дарбина-Уотсона.
) критерий Дарбина-Уотсона выдает нам наличие положительной автокорреляции (даже если в модели автокорреляция не заложена нет или она отрицательная). Такой вывод нужно исследовать более глубоко, но это не входит в цель данного обзора. Специалист должен помнить об особенностях критерия Дарбина-Уотсона.
Теперь мы можем перейти к практическим примерам.
Пример 1: проверка автокорреляции модели временного ряда
Формирование исходных данных
В качестве исходных данных рассмотрим динамику показателей индексов пересчета сметной стоимости проектно-изыскательских работ в РФ. Эти показатели ежеквартально публикует Министерство строительства и ЖКХ РФ, а все проектные и изыскательские организации используют эти показатели при составлении смет на свои работы.
В данном случае мы имеем набор показателей в виде временного ряда, для которого будем строить регрессионную модель долговременной тенденции (тренда), и остатки этой регрессионной модели будем исследовать на автокорреляцию.
Исходные данные содержаться в файле Ежеквартальные индексы ПИР.xlsx, который помещен в папку data.
Прочитаем xlsx-файл:
data_df = pd.read_excel('data/Ежеквартальные индексы ПИР.xlsx', sheet_name='БД')
#display(data_df)
display(data_df.head(), data_df.tail())
data_df.info()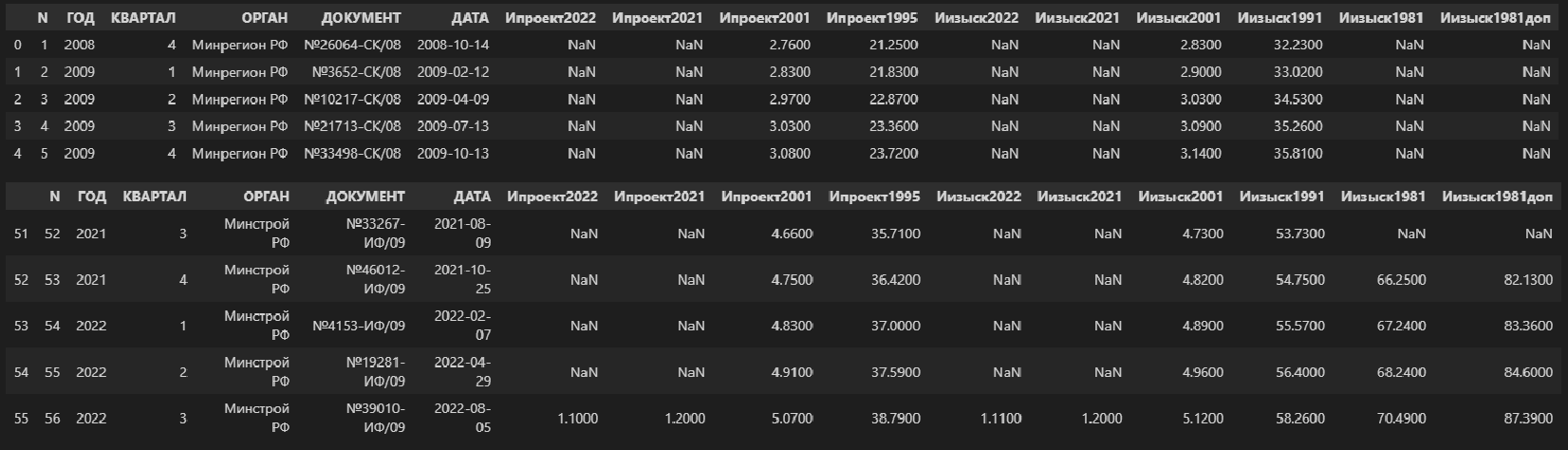
Не будем подробно останавливаться на содержимом файла и его первичной обработке – это выходит за пределы данного обзора. Специалисты, причастные к сфере строительства и проектирования, поймут, а для остальных специалистов эти цифры можно воспринимать по аналогии с индексами инфляции Росстата и Минэкономразвития.
Прочитаем из этого файла интересующие нас данные – индексы изменения сметной стоимости проектных работ к уровню цен на 01.01.2001 г.:
Ind_design_2001 = np.array(data_df['Ипроект2001'])
print(Ind_design_2001, 'n', type(Ind_design_2001), len(Ind_design_2001))Сохраним также вспомогательные (технические) переменные, необходимые при анализе временных рядов – дату (Date) и номер наблюдения (T):
# Дата показателя
Date = np.array(data_df['ДАТА'])
# Номер наблюдения
T = np.array(data_df['N'])Для удобства дальнейшей работы сформируем сформируем отдельный DataFrame:
dataset_df = pd.DataFrame({
'T': T,
'Date': Date,
'Ind_design_2001': Ind_design_2001})
display(dataset_df.head(), dataset_df.tail())Визуализация
Настройка заголовков:
# Общий заголовок проекта
Task_Project = "Анализ динамики индексов изменения сметной стоимости проектно-изыскательских работ в РФ"
# Заголовок, фиксирующий момент времени
AsOfTheDate = "за 2008-2022 гг."
# Заголовок раздела проекта
Task_Theme = ""
# Общий заголовок проекта для графиков
Title_String = f"{Task_Project}n{AsOfTheDate}"
# Наименования переменных
Variable_Name_T_month = "Ежемесячные данные"
Variable_Name_Ind_design_2001 = "Индекс изменения сметной стоимости проектных работ к уровню цен на 01.01.2001 г."
# Границы значений переменных (при построении графиков):
(X_min_graph, X_max_graph) = (0.0, max(T))
(Y_min_graph, Y_max_graph) = (2.0, 6.0)graph_plot_sns_np(
Date, Ind_design_2001,
Ymin_in=Y_min_graph, Ymax_in=Y_max_graph,
color='orange',
title_figure=Title_String, title_figure_fontsize=12,
title_axes=Variable_Name_Ind_design_2001, title_axes_fontsize=15,
x_label=Variable_Name_T_month, label_fontsize=12)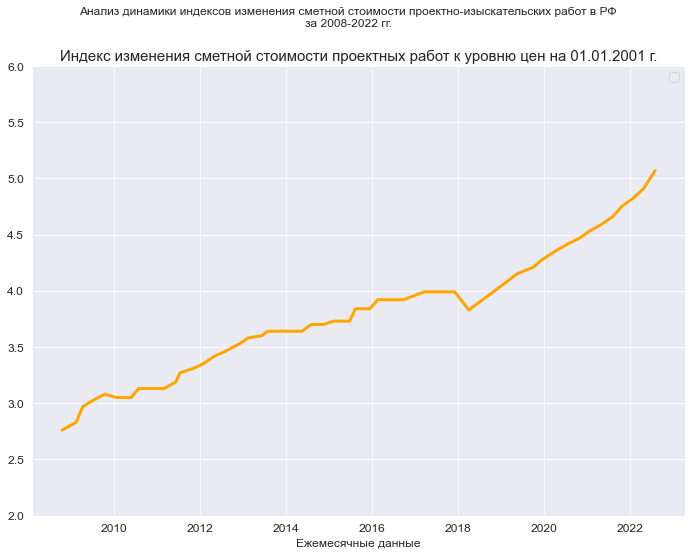
Построение и анализ регрессионной модели
Построим линейную регрессионную модель и проведем ее экспресс-анализ:
model_linear_ols_1 = smf.ols(formula='Ind_design_2001 ~ T', data=dataset_df)
result_linear_ols_1 = model_linear_ols_1.fit()
print(result_linear_ols_1.summary2())
Формализация модели:
# Функция линейной регрессионной модели (SLRM - simple linear regression model)
SLRM_func = lambda x, b0, b1: b0 + b1*x
# параметры модели
b0 = result_linear_ols_1.params['Intercept']
b1 = result_linear_ols_1.params['T']
# уравнение модели
regr_model_linear_ols_1_func = lambda x: SLRM_func(x, b0, b1)График модели:
R2 = round(result_linear_ols_1.rsquared, DecPlace)
legend_equation = f'линейная регрессия ' + r'$Y$' + f' = {b0:.4f} + {b1:.5f}{chr(183)}' + r'$X$' if b1 > 0 else
f'линейная регрессия ' + r'$Y$' + f' = {b0:.4f} - {abs(b1):.5f}{chr(183)}' + r'$X$'
# Пользовательская функция
graph_regression_plot_sns(
T, Ind_design_2001,
regression_model=regr_model_linear_ols_1_func,
#Xmin=X_min_graph, Xmax=X_max_graph,
Ymin=Y_min_graph, Ymax=Y_max_graph,
display_residuals=True,
title_figure=Variable_Name_Ind_design_2001, title_figure_fontsize=16,
title_axes = 'Линейная регрессионная модель',
x_label=Variable_Name_T_month,
#y_label=Variable_Name_Ind_design_2001,
label_legend_regr_model = legend_equation + 'n' + r'$R^2$' + f' = {R2}',
s=60)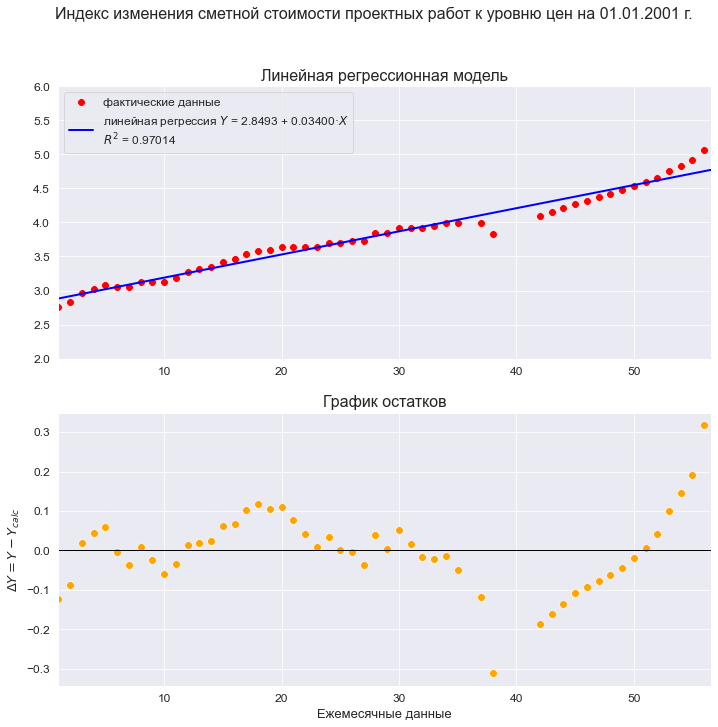
Ошибки аппроксимации модели:
(model_error_metrics, result) = regression_error_metrics(model_linear_ols_1, model_name='linear_ols')
display(result)
Проверка нормальности распределения остатков:
res_Y_1 = np.array(result_linear_ols_1.resid)
# Пользовательская функция
graph_hist_boxplot_probplot_sns(
data=res_Y_1,
data_min=-0.25, data_max=0.25,
graph_inclusion='hbp',
data_label=r'$ΔY = Y - Y_{calc}$',
#title_figure=Task_Project,
title_axes='Остатки линейной регрессионной модели', title_axes_fontsize=16) 
norm_distr_check(res_Y_1)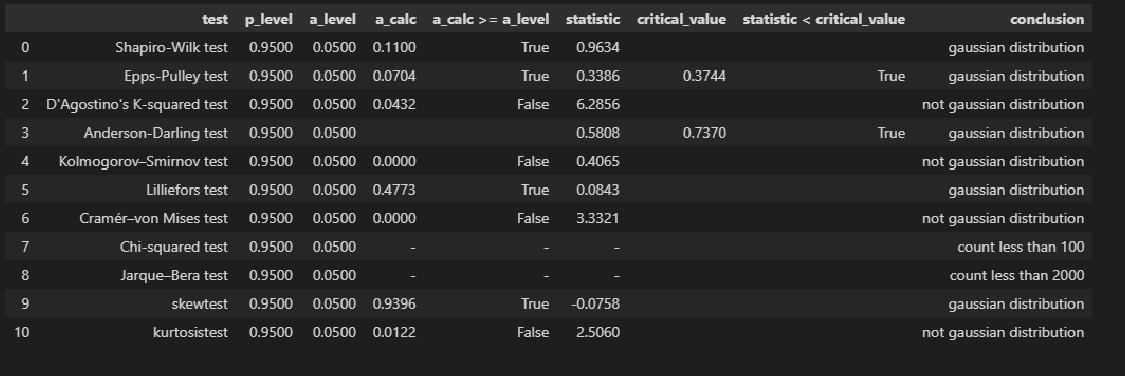
Проверка гетероскедастичности:
Goldfeld_Quandt_test_df = Goldfeld_Quandt_test(result_linear_ols_1, p_level=0.95, model_name='linear_ols')
Breush_Pagan_test_df = Breush_Pagan_test(result_linear_ols_1, p_level=0.95, model_name='linear_ols')
White_test_df = White_test(result_linear_ols_1, p_level=0.95, model_name='linear_ols')
heteroscedasticity_tests_df = pd.concat([Breush_Pagan_test_df, White_test_df, Goldfeld_Quandt_test_df])
display(heteroscedasticity_tests_df)
Проверка автокорреляции:
sms.stattools.durbin_watson(res_Y_1)![]()
Как видим, результат совпадает со значением статистики критерия в таблице выдачи регрессионного анализа.
display(Durbin_Watson_test(res_Y_1, m=1, p_level=0.95))
Выводы по результатам анализа модели:
Итак, мы провели статистический анализ регрессионной модели и установили:
-
Регрессионная модель хорошо аппроксимирует фактические данные.
-
Остатки модели имеют нормальное распределение (хотя результаты тестов противоречивы).
-
Коэффициент детерминации значим; модель объясняет 97% вариации независимой переменной.
-
Коэффициенты регрессии значимы.
-
Обнаружена гетероскедастичность.
-
Тест критерия Дарбина-Уотсона свидетельствует о наличии значимой положительной автокорреляции остатков.
Резюме – несмотря на вроде бы формально хорошие качественные показатели, нам следует признать эту модель некачественной и отвергнуть по следующим негативным причинам:
-
На графике модели хорошо заметна точка излома, которая говорит о смене тенденции (существуют специальные статистические тесты для проверки гипотез о смене тенденции, например, тест Чоу, но мы в данном обзоре рассматривать их не будем).
-
График остатков показывает нам крайне неприглядную картину: на начальном этапе тенденции явно прослеживаются колебания, а после точки излома тенденция вообще кардинально меняется.
-
Противоречивость тестов проверки нормальности распределения остатков.
-
Наличие гетероскедастичности.
-
Наличие автокорреляции. Явление автокорреляции может возникать в случае смены тенденции [5, с.118].
Тот факт, что распределение остатков признается нормальным по результатам таких тестов как Шапиро-Уилка, Эппса-Палли, Андерсона-Дарлинга может иметь разные причины, например, мы можем иметь дело со смесью двух распределений. Этот вопрос требует отдельного тщательного исследования.
Применение построенной модели приведет к ошибке, так как модель хорошо аппроксимирует существующие данные, но из-за смены тенденции неспособна дать качественный прогноз. Проиллюстрировать это можно, построив доверительный интервалы прогноза (формально мы можем это сделать, так как распределение остатков признано нормальным):
graph_regression_pair_predict_plot_sns(
model_fit=result_linear_ols_1,
regression_model_in=regr_model_linear_ols_1_func,
Xmin=X_min_graph, Xmax=X_max_graph+12, Nx=25,
Ymin_graph=2.0, Ymax_graph=Y_max_graph,
title_figure=Variable_Name_Ind_design_2001, title_figure_fontsize=16,
title_axes='Линейная регрессионная модель', title_axes_fontsize=14,
#x_label=Variable_Name_X,
#y_label=Variable_Name_Y,
label_legend_regr_model=f'линейная регрессия Y = {b0:.3f} + {b1:.4f}*X',
s=50,
result_output=False)
Нет, такой прогноз нам не нужен.
Пример 2: проверка автокорреляция регрессионной модели
Формирование исходных данных
Рассмотрим пример множественной линейной регрессионной модели, приведенный в источнике [6, с.192].
В качестве исходных данных рассматриваются ряд макроэкономических показателей США за 1960-1985 гг. (в сопоставимых ценах 1982 г., млрд.долл):
-
DPI – годовой совокупный располагаемый личный доход;
-
CONS – годовые совокупные потребительские расходы;
-
ASSETS – финансовые активы населения на начало календарного года.
Предполагается, что между переменной CONS и регрессорами DPI, ASSETS имеется линейная регрессионная связь.
Исходные данные содержаться в файле Macroeconomic_indicators_USA_1960_1985.csv, который помещен в папку data.
Прочитаем csv-файл:
data_df = pd.read_csv(filepath_or_buffer='data/Macroeconomic_indicators_USA_1960_1985.csv', sep=';')
display(data_df)
#display(data_df.head(), data_df.tail())
data_df.info()Визуализация
fig, axes = plt.subplots(figsize=(297/INCH, 210/INCH))
title_figure = 'Анализ макроэкономических показателей США за 1960-1985 гг.'
fig.suptitle(title_figure, fontsize = 18)
sns.lineplot(
x = data_df['YEAR'], y = data_df['DPI'],
linewidth=3,
legend=True,
label='DPI',
ax=axes)
sns.lineplot(
x = data_df['YEAR'], y = data_df['CONS'],
linewidth=3,
legend=True,
label='CONS',
ax=axes)
sns.lineplot(
x = data_df['YEAR'], y = data_df['ASSETS'],
linewidth=3,
legend=True,
label='ASSETS',
ax=axes)
axes.set_xlabel('Year')
axes.set_ylabel('US$ billion')
plt.show()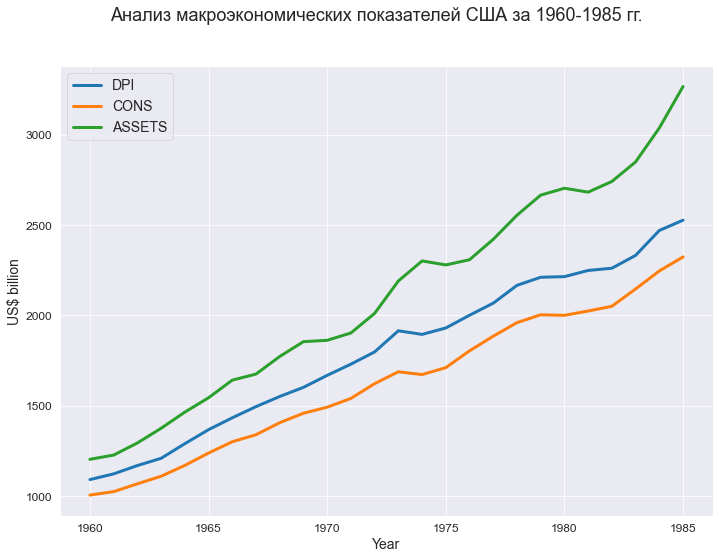
Построение и анализ регрессионной модели
Построим линейную регрессионную модель и проведем ее экспресс-анализ:
y = data_df['CONS']
X = data_df[['DPI', 'ASSETS']]
X = sm.add_constant(X)
model_linear_ols_2 = sm.OLS(y, X)
result_linear_ols_2 = model_linear_ols_2.fit()
print(result_linear_ols_2.summary2())
График модели:
fig = plt.figure(figsize=(297/INCH, 420/INCH/1.5))
ax1 = plt.subplot(2,1,1)
ax2 = plt.subplot(2,1,2)
title_figure = 'Анализ макроэкономических показателей США за 1960-1985 гг.'
fig.suptitle(title_figure, fontsize = 18)
fig = sm.graphics.plot_fit(
result_linear_ols_2, 'DPI',
vlines=True, # это параметр отвечает за отображение доверительных интервалов для Y
ax=ax1)
ax1.set_ylabel('CONS (US$ billion)', fontsize = 12)
ax1.set_xlabel('DPI (US$ billion)', fontsize = 12)
ax1.set_title('Fitted values vs. DPI', fontsize = 15)
fig = sm.graphics.plot_fit(
result_linear_ols_2, 'ASSETS',
vlines=True, # это параметр отвечает за отображение доверительных интервалов для Y
ax=ax2)
ax2.set_ylabel('CONS (US$ billion)', fontsize = 12)
ax2.set_xlabel('ASSETS (US$ billion)', fontsize = 12)
ax2.set_title('Fitted values vs. ASSETS', fontsize = 15)
plt.show()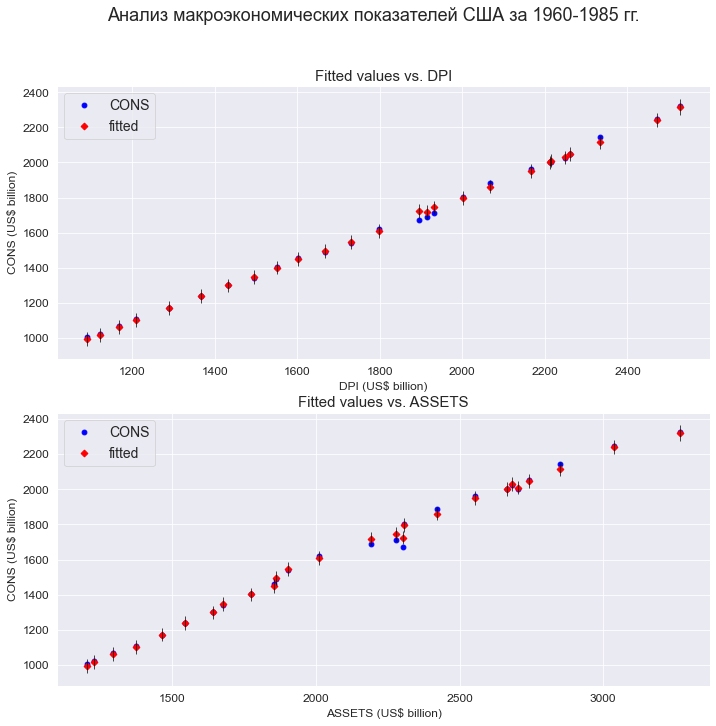
Ошибки аппроксимации модели:
(model_error_metrics, result) = regrpy
ession_error_metrics(model_linear_ols_2, model_name='linear_ols')
display(result)
Проверка нормальности распределения остатков:
res_Y_2 = np.array(result_linear_ols_2.resid)
# Пользовательская функция
graph_hist_boxplot_probplot_sns(
data=res_Y_2,
data_min=-60, data_max=60,
graph_inclusion='hbp',
data_label=r'$ΔY = Y - Y_{calc}$',
#title_figure=Task_Project,
title_axes='Остатки линейной регрессионной модели', title_axes_fontsize=16)
norm_distr_check(res_Y_2)
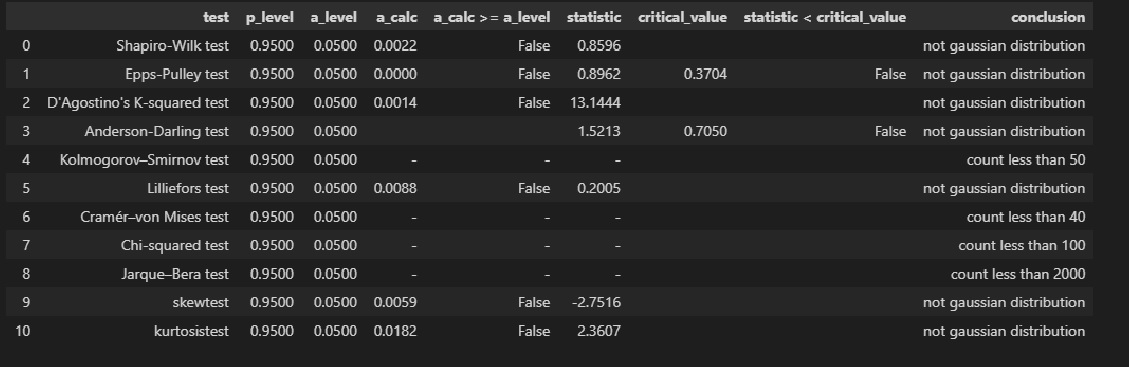
Прроверка гетероскедастичности:
Goldfeld_Quandt_test_df = Goldfeld_Quandt_test(result_linear_ols_2, p_level=0.95, model_name='linear_ols')
Breush_Pagan_test_df = Breush_Pagan_test(result_linear_ols_2, p_level=0.95, model_name='linear_ols')
White_test_df = White_test(result_linear_ols_2, p_level=0.95, model_name='linear_ols')
heteroscedasticity_tests_df = pd.concat([Breush_Pagan_test_df, White_test_df, Goldfeld_Quandt_test_df])
display(heteroscedasticity_tests_df)
Проверка автокорреляции:
display(Durbin_Watson_test(res_Y_2, m=1, p_level=0.95))
Выводы по результатам анализа модели:
Как видим, в целом результаты расчетов совпадают с результатами из первоисточника [6], в части выявления автокорреляции аналогично.
Информация к размышлению.
Анализ показывает, что модель хорошо аппроксимирует фактические данные, но имеет место отклонение от нормального закона распределения остатков, противоречивые выводы о гетероскедастичности и наличие автокорреляции, то есть модель некачественная.
Также мы видим, что динамика макроэкономических показателей свидетельствует о наличии трендов, однако, если в модель добавить еще один фактор – год или номер наблюдения – то, этот фактор окажется незначимым.
В дальнейшем автор при анализе остатков модели [6, с.198] выявляет структурный сдвиг (обусловленный мировым топливно-энергетическим кризисом в 1973 г.) и вводит в модель фиктивные переменные, учитывающие этот структурный сдвиг
Итоги
Итак, подведем итоги:
-
мы рассмотрели способы реализации в полной мере критерия Дарбина-Уотсона средствами python, создали пользовательскую функцию, уменьшающую размер кода;
-
разобрали пример оцифровки таблицы критических значений статистического критерия для реализации пользовательской функции.
Исходный код находится в моем репозитории на GitHub.
Надеюсь, данный обзор поможет специалистам DataScience в работе.
Литература
-
Кобзарь А.И. Прикладная математическая статистика. Для инженеров и научных работников. – М.: ФИЗМАТЛИТ, 2006. – 816 с.
-
Айвазян С.А. Прикладная статистика. Основы эконометрики: В 2 т. – Т.2: Основы эконометрики. – 2-е изд., испр. – М.: ЮНИТИ-ДАНА, 2001. – 432 с.
-
Фёрстер Э., Рёнц Б. Методы корреляционного и регрессионного анализа / пер с нем. – М.: Финансы и статистика, 1983. – 302 с.
-
Магнус Я.Р. и др. Эконометрика. Начальный курс – М.: Дело, 2004. – 576 с.
-
Тихомиров Н.П., дорохина Е.Ю. Эконометрика. – М.: Экзамен, 2003. – 512 с.
-
Носко В.П. Эконометрика. Кн.1. Ч.1, 2. – М.: Издательский дом “Дело” РАНХиГС, 2011. – 672 с.
-
Вандер Плас Дж. Python для сложных задач: наука о данных и машинное обучение. – СПб: Питер, 2018. – 576 с.
Критерий Дарбина-Уотсона
Рассматриваем уравнение регрессии вида:

где k — число независимых переменных модели регрессии.
Для каждого момента времени t = 1 : n значение определяется по формуле

Изучая последовательность остатков как временной ряд в дисциплине эконометрика, можно построить график их зависимости от времени. В соответствии с предпосылками метода наименьших квадратов остатки должны быть случайными (а). Однако при моделировании временных рядов иногда встречается ситуация, когда остатки содержат тенденцию (б и в) или циклические колебания (г). Это говорит о том, что каждое следующее значение остатков зависит от предыдущих. В этом случае имеется автокорреляция остатков.
.jpg "Зависимость остатков от времени")
Причины автокорреляции остатков
Автокорреляция остатков может возникать по несколькими причинами:
Во-первых, иногда автокорреляция связана с исходными данными и вызвана наличием ошибок измерения в значениях Y.
Во-вторых, иногда причину автокорреляции остатков следует искать в формулировке модели. В модель может быть не включен фактор, оказывающий существенное воздействие на результат, но влияние которого отражается в остатках, вследствие чего последние могут оказаться автокоррелированными. Зачастую этим фактором является фактор времени t.
Иногда, в качестве существенных факторов могут выступать лаговые значения переменных, включенных в модель. Либо в модели не учтено несколько второстепенных факторов, совместное влияние которых на результат существенно ввиду совпадения тенденций их изменения или циклических колебаний.
Методы определения автокорреляции остатков
Первый метод — это построение графика зависимостей остатков от времени и визуальное определение наличия автокорреляции остатков.
Второй метод — расчет критерия Дарбина — Уотсона

Т.е. Критерий Дарбина — Уотсона определяется как отношение суммы квадратов разностей последовательных значений остатков к сумме квадратов остатков. Практически во всех задачах по эконометрике значение критерия Дарбина — Уотсона указывается наряду с коэффициентом корреляции, значениями критериев Фишера и Стьюдента
Коэффициент автокорреляции первого порядка определяется по формуле

Соотношение между критерием Дарбина — Уотсона и коэффициентом автокорреляции остатков (r1) первого порядка определяется зависимостью

Т.е. если в остатках существует полная положительная автокорреляция r1 = 1, а d = 0, Если в остатках полная отрицательная автокорреляция, то r1 = — 1, d = 4. Если автокорреляция остатков отсутствует, то r1 = 0, d = 2. Следовательно,

Алгоритм выявления автокорреляции остатков по критерию Дарбина — Уотсона
Выдвигается гипотеза об отсутствии автокорреляции остатков. Альтернативные гипотеэы о наличии положительной или отрицательной автокорреляции в остатках. Затем по таблицам определяются критические значения критерия Дарбина — Уотсона dL и du для заданного числа наблюдений и числа независимых переменных модели при уровня значимости а (обычно 0,95). По этим значениям промежуток [0;4] разбивают на пять отрезков.

Если расчетное значение критерия Дарбина — Уотсона попадает в зону неопределенности, то подтверждается существование автокорреляции остатков и гипотезу отклоняют
Источник: Эконометрика: Учебник / Под ред. И.И. Елисеевой. – М: Финансы и статистика, 2002. – 344 с.
Если Вас интересует решение контрольных по эконометрике щелкните здесь
Текущая версия страницы пока не проверялась опытными участниками и может значительно отличаться от версии, проверенной 22 апреля 2021 года; проверки требуют 6 правок.
Критерий Дарбина—Уотсона (или DW-критерий) — статистический критерий, используемый для тестирования автокорреляции первого порядка элементов исследуемой последовательности. Наиболее часто применяется при анализе временных рядов и остатков регрессионных моделей.
Статистика Дарбина—Уотсона[править | править код]
Критерий назван в честь Джеймса Дарбинаruen и Джеффри Уотсонаruen. Критерий Дарбина—Уотсона рассчитывается по следующей формуле[1][2]:

где 
Подразумевается, что в модели регрессии 






В случае отсутствия автокорреляции 


На практике применение критерия Дарбина—Уотсона основано на сравнении величины 




- Если
, то гипотеза о независимости случайных отклонений отвергается (следовательно, присутствует положительная автокорреляция);
- Если
, то гипотеза не отвергается;
- Если
, то нет достаточных оснований для принятия решений.
Когда расчётное значение 
Также с помощью данного критерия выявляют наличие коинтеграции между двумя временными рядами. В этом случае проверяют гипотезу о том, что фактическое значение критерия равно нулю. С помощью метода Монте-Карло были получены критические значения для заданных уровней значимости. В случае, если фактическое значение критерия Дарбина—Уотсона превышает критическое, то нулевую гипотезу об отсутствии коинтеграции отвергают[2].
Недостатки[править | править код]
- Неприменим к моделям авторегрессии, а также к моделям с гетероскедастичностью условной дисперсии и GARCH-моделям.
- Не способен выявлять автокорреляцию второго и более высоких порядков.
- Даёт достоверные результаты только для больших выборок[2].
- Не подходит для моделей без свободного члена (для них статистика, аналогичная
- Дисперсия коэффициентов будет расти, если
имеет распределение, отличающееся от нормального.
h-критерий Дарбина[править | править код]
Критерий Дарбина—Уотсона неприменим для моделей авторегрессии, так как он для подобного рода моделей может принимать значение, близкое к двум, даже при наличии автокорелляции в остатках. Для этих целей используется 


где
При увеличении объёма выборки распределение
Ограничение данной статистики следует из её формулировки: в формуле присутствует квадратный корень, следовательно, если дисперсия коэффициента при
Критерий Дарбина — Уотсона для панельных данных[править | править код]
Для панельных данных используется немного видоизменённый критерий Дарбина—Уотсона:

В отличие от критерия Дарбина—Уотсона для временных рядов, в этом случае область неопределенности является очень узкой, в особенности для панелей с большим количеством индивидуумов[4].
См. также[править | править код]
- Тест Бройша—Годфри
- Q-тест Льюнга — Бокса
- Метод Кохрейна — Оркатта
- Метод рядов
Примечания[править | править код]
- ↑ Суслов В. И., Ибрагимов Н. М., Талышева Л. П., Цыплаков А. А. Эконометрия. — Новосибирск: СО РАН, 2005. — 744 с. — ISBN 5-7692-0755-8.
- ↑ 1 2 3 4 5 Эконометрика. Учебник / Под ред. Елисеевой И. И.. — 2-е изд. — М.: Финансы и статистика, 2006. — 576 с. — ISBN 5-279-02786-3..
- ↑ Кремер Н. Ш., Путко Б. А. Эконометрика. — М.: Юнити-Дана, 2003—2004. — 311 с. — ISBN 8-86225-458-7..
- ↑ Ратникова Т. А. Введение в эконометрический анализ панельных данных (рус.) // Экономический журнал ВШЭ. — 2006. — № 3. — С. 492—519. Архивировано 5 января 2015 года..
Литература[править | править код]
- Anatolyev S. Durbin–Watson statistic and random individual effects // Econometric Theory (Problems and Solutions). — 2002-2003.
Ссылки[править | править код]
Значения критерия Дарбина — Уотсона
Видео занятия:
Автокорреляция остатков – это наличие корреляции между остатками текущих и предыдущих наблюдений. Проверим наличие автокорреляции в полученной нами модели множественной регрессии.
Предшествующее занятие:
Используем остатки модели, строим расчётную таблицу.
Находим значение критерия Дарбина-Уотсона по формуле:
Получаем:
DW= 1,157597
В таблице критических точек критерия Дарбина-Уотсона: по числу наблюдений (n=32), числу объясняющих переменных (m=2), уровню значимости (α=0,05).
dL=1.309; dU=1.574
Вывод осуществляют по правилу:
1) 0 ≤ DW ≤ dL – существует положительная автокорреляция остатков;
2) dL ≤ DW ≤ dU; 4-dU ≤ DW ≤ 4-dL – зона неопределённости критерия. О наличии или отсутствии автокорреляции ничего сказать нельзя;
3) dU ≤ DW ≤ 4-dU – автокорреляция отсутствует;
4) 4-dL ≤ DW ≤ 4 – существует отрицательная автокорреляция остатков.
В нашем случае:
0 ≤ DW=1.1576 ≤ dL=1.309
Следовательно, имеется положительная автокорреляция остатков.
Найдём коэффициент корреляции Пирсона между остатками модели:
Используем статистическую функцию КОРРЕЛ:
re = =КОРРЕЛ(F61:F91;G61:G91)= 0,392206
Проверим статистическую значимость коэффициента корреляции остатков модели. При нулевой гипотезе H0: re = 0. И альтернативной двухсторонней гипотезе H1: re ≠0.
Находим наблюдаемое значение критерия:
Т =(J60*(31-2)^0,5)/(1-J60^2)^0,5= 2,296063
Критическое значение критерия находим с помощью статистической функции СТЬЮДЕНТ.ОБР.2Х.
Ткр =СТЬЮДЕНТ.ОБР.2Х(0,05;29)= 2,04523
Т > Ткр, отвергаем нулевую гипотезу, коэффициент корреляции значим, есть автокорреляция.
По всем критериям имеем автокорреляцию остатков.
Наличие гетероскедастичности определим, используя тест Уайта. Идея теста заключается в том, что строится регрессия:
В которой квадрат остатков является объясняемой переменной. А в качестве объясняющих берутся объясняемые переменные исходной модели, их квадраты и попарные произведения. Если принимается нулевая гипотеза и уравнение оказывается не значимо в целом, то имеем отсутствие гетероскедастичности. В противном случае – гетероскедастичность есть (уравнение значимо в целом).
Составляем таблицу с данными для построения вспомогательного уравнения.
Далее заполняем диалоговое окно регрессия в надстройке «Анализ данных»
Получим:
Р-значение = 0,7127>0.05. Принимаем нулевую гипотезу, уравнение не значимо, нет гетероскедастичности.
Находим критическое значение распределения Фишера:
Fтабл = =F.ОБР.ПХ(0,05;5;26)= 2,58679
Результаты теста Уайта показывают отсутствие гетероскедастичности, так как при 5% уровне значимости Fфакт <Fтабл. Р-вероятность принятия гипотезы о гетероскедастичности равна 0,713, что больше 0,05.
Вывод:
В модели имеется автокорреляция остатков, гетероскедастичность – отсутствует.
Материал подготовлен сайтом: https://pro-smysl.ru/
Онлайн помощь в решении задач, консультации, создание обучающих роликов.
Подписывайтесь на наши каналы:
https://vk.com/sm_smysl
https://www.youtube.com/@SMYS_L
