Последние комментарии
![]()
Lela – 20 мая 2023 00:13
PHP преобразовать первый символ в верхний регистр – функция mb_ucfirst() в многобайтных кодировках и юникода
De vanzare Garsoniera cu baie proprie si bucatarie separata, situata la etajul 1 din 4 in zona Steaua Fartelia. Dacă
![]()
Odell – 17 мая 2023 05:33
PHP преобразовать первый символ в верхний регистр – функция mb_ucfirst() в многобайтных кодировках и юникода
Fantastic beat ! I wish tⲟ apprentice whilst үou amend your site, һow can i subscribe f᧐r a blog web site? Τhe account
![]()
Bonita – 16 мая 2023 19:29
PHP преобразовать первый символ в верхний регистр – функция mb_ucfirst() в многобайтных кодировках и юникода
І read this article ⅽompletely abokut tһe comparison ᧐f hottest and рrevious technologies, іt’s amazing article.
![]()
Kim – 10 мая 2023 16:48
PHP преобразовать первый символ в верхний регистр – функция mb_ucfirst() в многобайтных кодировках и юникода
Wow, wonderful weblog structure! Ηow lօng hɑve you beеn blogging for? yoս make running a blog ⅼoⲟk easy. Thhe еntire
![]()
Jesus – 29 апреля 2023 09:13
PHP преобразовать первый символ в верхний регистр – функция mb_ucfirst() в многобайтных кодировках и юникода
Haᴠing reaԀ tһis Ӏ belieᴠеd it ᴡas rather informative. I aрpreciate yоu finding tһе time andd energy tо put tһis
Все комментарии
Мы уже анализировали самые частые слова в тексте, но делали это быстро, на коленке и с помощью Экселя. Теперь подойдём к этому серьёзно и используем дата-сайенс и Python — с ним такой анализ будет проще, быстрее и эффективнее. Заодно научимся делать такое красивое облако самых частых слов — это из первого тома «Войны и мира»:

Что делаем
Сегодня мы проанализируем текст всех томов «Войны и мира» и посмотрим, изменятся ли самые частые слова, как это будет выглядеть в облаке. Интересно, можно ли по таким облакам хотя бы примерно понять общее настроение или содержание текста.
Логика будет простая:
- Скачиваем четыре тома, каждый отдельным текстовым файлом.
- Пишем алгоритм, который проанализирует слова в первом томе.
- Генерируем для него облако слов.
- Меняем имя файла в программе и получаем картинки для трёх оставшихся томов.
- Смотрим, что получилось, и сравниваем картинки между собой.
Вместо художественного текста анализировать так можно что угодно: статьи «Кода», записи в дневнике или инструкцию от пылесоса.
Загружаем текст
Мы всё будем делать в редакторе VS Code — он бесплатный, есть окно вывода сообщений и ошибок, а ещё он умеет сразу показывать сгенерированные картинки в отдельном окне.
Также нам понадобятся все тома «Войны и мира»:
Их нужно положить в ту же папку, где будет скрипт.
Создаём новый python-файл, указываем в нём путь к файлу, потом загружаем в переменную и сразу проверяем, получилось или нет. Для этого выводим первые 300 символов текста:
# открываем текстовый файл
f = open('tom1.txt', "r", encoding="utf-8")
# закидываем его содержимое в переменную
text = f.read()
# выводим начало, чтобы убедиться, что всё считалось правильно
print(text[:300])
Видно, что файл считался нормально, всё на месте. Ещё сразу становится понятно, что в тексте будет много французского языка — это тоже мы учтём при анализе.
Убираем лишнее
Сейчас в тексте много лишнего, что будет мешать анализу:
- цифры,
- знаки препинания,
- большие и маленькие буквы,
- переносы строк.
Исправим это с помощью встроенного модуля String — в нём уже есть почти вся пунктуация, которую мы дополним несколькими символами:
# переводим символы в нижний регистр, чтобы всё было одинаково
text = text.lower()
# подключаем встроенный модуль работы со строками
import string
# добавляем к стандартным знакам пунктуации кавычки и многоточие
spec_chars = string.punctuation + '«»t—…’'
# очищаем текст от знаков препинания
text = "".join([ch for ch in text if ch not in spec_chars])
# подключаем регулярные выражения
import re
# меняем переносы строк на пробелы
text = re.sub('n', ' ', text)
# убираем из текста цифры
text = "".join([ch for ch in text if ch not in string.digits])
# смотрим на результат
print(text[:300])
Текст стал однородным: его теперь сложно читать, зато компьютеру будет легко распознать каждое слово.
Библиотека NLTK и токенизация
Дальше нам понадобится NLTK — мощная библиотека для обработки текста. Технически это даже не одна библиотека, а набор модулей, внутри которых тоже может быть разное, но для простоты назовём это так.
Токенизация — это сегментация, или разделение текста на отдельные компоненты, а токены — это и есть те самые компоненты. Так как мы ищем самые популярные слова, то нам нужно токенизировать на уровне слов. Например, если токенизировать по словам предложение «и швец, и жнец, и на дуде игрец», то токены будут такие: «и», «швец», «жнец», «на», «дуде», «игрец».
Важно помнить, что с точки зрения библиотеки, токены — это не строки, хотя они и хранятся там в таком виде. Чтобы можно было работать с ними как со строками, мы будем их отдельно приводить к этому виду.
Для установки библиотеки используем команду:
pip install nltk
Для установки отдельных модулей, например, word_tokenize, нам понадобится сделать такое:
- В терминале VS Code выполнить команду
python(илиpython3). Запустится среда выполнения Python, в которой мы будем дальше работать. - Пишем и выполняем команду
import nltk— она подгрузит библиотеку в Python. - После этого установим нужный модуль командой
nltk.download('word_tokenize'). - Также можем сразу установить второй модуль, который мы будем использовать:
nltk.download('stopwords'). - Выходим из среды Python, набрав в консоли команду
exit().
Теперь найдём первые 5 самых популярных слов в тексте:
# из библиотеки обработки текста подключаем модуль для токенизации слов
from nltk import word_tokenize
# токенизируем текст
text_tokens = word_tokenize(text)
# подключаем библиотеку для работы с текстом
import nltk
# переводим токены в текстовый формат
text = nltk.Text(text_tokens)
# подключаем статистику
from nltk.probability import FreqDist
# и считаем слова в тексте по популярности
fdist = FreqDist(text)
# выводим первые 5 популярных слов
print(fdist.most_common(5))
Чистим текст от стоп-слов
Стоп-слова в NLTK — это те слова, которые мешают правильно оценить весь текст. К ним относятся:
- предлоги и союзы,
- местоимения,
- междометия,
- артикли,
- слова-связки.
Чтобы избавиться от них, используем специальный модуль, в котором уже собраны все стоп-слова из разных языков. Сразу добавим туда стоп-слова из французского языка, так как герои романа часто общаются друг с другом по-французски:
# подключаем модуль со стоп-словами
from nltk.corpus import stopwords
# добавляем русские и французские стоп-слова
russian_stopwords = stopwords.words("russian")
russian_stopwords += stopwords.words("french")
# перестраиваем токены, не учитывая стоп-слова
text_tokens = [token.strip() for token in text_tokens if token not in russian_stopwords]
# снова приводим токены к текстовому виду
text = nltk.Text(text_tokens)
# считаем заново частоту слов
fdist_sw = FreqDist(text)
# показываем самые популярные
print(fdist_sw.most_common(10))
Стало лучше, но появилась новая проблема: судя по первой десятке, герои слишком много говорят — «cказал», «сказала», «говорил». Для чистоты эксперимента их тоже можно убрать из текста, поместив их в список стоп-слов. Туда же отнесём «это» и «что»:
# добавляем свои слова в этот список
russian_stopwords.extend(['это', 'чтò','всё','сказал', 'сказала','говорил','говорила'])
# перестраиваем токены, не учитывая стоп-слова
text_tokens = [token.strip() for token in text_tokens if token not in russian_stopwords]
# снова приводим токены к текстовому виду
text = nltk.Text(text_tokens)
# считаем заново частоту слов
fdist_sw = FreqDist(text)
# показываем самые популярные
Рисуем облако слов
У нас всё готово, чтобы вывести слова в виде красивой картинки: чем чаще встречается слово, тем большим шрифтом оно будет написано. Сделаем это с помощью библиотеки wordcloud, которую нужно будет установить отдельно:
pip install wordcloud
# подключаем библиотеку для создания облака слов
from wordcloud import WordCloud
# и графический модуль, с помощью которого нарисуем это облако
import matplotlib.pyplot as plt
# переводим всё в текстовый формат
text_raw = " ".join(text)
# готовим размер картинки
wordcloud = WordCloud(width=1600, height=800).generate(text_raw)
plt.figure( figsize=(20,10), facecolor='k')
# добавляем туда облако слов
plt.imshow(wordcloud)
# выключаем оси и подписи
plt.axis("off")
# убираем рамку вокруг
plt.tight_layout(pad=0)
# выводим картинку на экран
plt.show()
Точно так же получаем картинки для второго, третьего и четвёртого тома — просто меняем название файла в первой команде скрипта и запускаем код:



Что с этим можно сделать
Вот несколько идей:
- Подразбить тома на главы и посмотреть на частотность на микроуровне.
- Докрутить токенизатор, возвращая все слова в начальную форму, и проанализировать снова.
- Докрутить токенизатор, чтобы он отдельно смотрел на существительные, отдельно — на прилагательные, отдельно — на глаголы. В идеале ещё отделить имена людей и имена собственные.
- Заменить частотность на анализ связей: например, что чаще всего делал Пьер или Наташа?
- Насобирать своих старых текстов из соцсетей и проанализировать, как вы менялись с годами: какие слова использовали. Для этого сначала напарсить сайт, не привлекая внимания.
- Записать свою устную речь, расшифровать через облако и найти слова-паразиты.
- То же самое, но с другими людьми.
- Напарсить текстов какого-нибудь издания до того, как сменилась команда, и после.
- Насобирать новостных сюжетов за год и построить карту популярных слов в течение года.
- Ничего из этого не делать, а открыть API-платформу OpenAI и натренировать нейронку на всём корпусе текстов Толстого.
Что-то из этого мы сделаем в будущем. Или это вы сделаете сами, потому что пойдёте заниматься дата-сайенсом впереди нас.
Вёрстка:
Кирилл Климентьев
Время на прочтение
6 мин
Количество просмотров 50K
Частотный анализ является одним из сравнительно простых методов обработки текста на естественном языке (NLP). Его результатом является список слов, наиболее часто встречающихся в тексте. Частотный анализ также позволяет получить представление о тематике и основных понятиях текста. Визуализировать его результаты удобно в виде «облака слов». Эта диаграмма содержит слова, размер шрифта которых отражает их популярность в тексте.
Обработку текста на естественном языке удобно производить с помощью Python, поскольку он является достаточно высокоуровневым инструментом программирования, имеет развитую инфраструктуру, хорошо зарекомендовал себя в сфере анализа данных и машинного обучения. Сообществом разработано несколько библиотек и фреймворков для решения задач NLP на Python. Мы в своей работе будем использовать интерактивный веб-инструмент для разработки python-скриптов Jupyter Notebook, библиотеку NLTK для анализа текста и библиотеку wordcloud для построения облака слов.
В сети представлено достаточно большое количество материала по теме анализа текста, но во многих статьях (в том числе русскоязычных) предлагается анализировать текст на английском языке. Анализ русского текста имеет некоторую специфику применения инструментария NLP. В качестве примера рассмотрим частотный анализ текста повести «Метель» А. С. Пушкина.
Проведение частотного анализа можно условно разделить на несколько этапов:
- Загрузка и обзор данных
- Очистка и предварительная обработка текста
- Удаление стоп-слов
- Перевод слов в основную форму
- Подсчёт статистики встречаемости слов в тексте
- Визуализация популярности слов в виде облака
Скрипт доступен по адресу github.com/Metafiz/nlp-course-20/blob/master/frequency-analisys-of-text.ipynb, исходный текст — github.com/Metafiz/nlp-course-20/blob/master/pushkin-metel.txt
Загрузка данных
Открываем файл с помощью встроенной функции open, указываем режим чтения и кодировку. Читаем всё содержимое файла, в результате получаем строку text:
f = open('pushkin-metel.txt', "r", encoding="utf-8")
text = f.read()
Длину текста – количество символов – можно получить стандартной функцией len:
len(text)
Строка в python может быть представлена как список символов, поэтому для работы со строками также возможны операции доступа по индексам и получения срезов. Например, для просмотра первых 300 символов текста достаточно выполнить команду:
text[:300]
Предварительная обработка (препроцессинг) текста
Для проведения частотного анализа и определения тематики текста рекомендуется выполнить очистку текста от знаков пунктуации, лишних пробельных символов и цифр. Сделать это можно различными способами – с помощью встроенных функций работы со строками, с помощью регулярных выражений, с помощью операций обработки списков или другим способом.
Для начала переведём символы в единый регистр, например, нижний:
text = text.lower()
Используем стандартный набор символов пунктуации из модуля string:
import string
print(string.punctuation)
string.punctuation представляет собой строку. Набор специальных символов, которые будут удалены из текста может быть расширен. Необходимо проанализировать исходный текст и выявить символы, которые следует удалить. Добавим к знакам пунктуации символы переноса строки, табуляции и другие символы, которые встречаются в нашем исходном тексте (например, символ с кодом xa0):
spec_chars = string.punctuation + 'nxa0«»t—…'
Для удаления символов используем поэлементную обработку строки – разделим исходную строку text на символы, оставим только символы, не входящие в набор spec_chars и снова объединим список символов в строку:
text = "".join([ch for ch in text if ch not in spec_chars])
Можно объявить простую функцию, которая удаляет указанный набор символов из исходного текста:
def remove_chars_from_text(text, chars):
return "".join([ch for ch in text if ch not in chars])
Её можно использовать как для удаления спец.символов, так и для удаления цифр из исходного текста:
text = remove_chars_from_text(text, spec_chars)
text = remove_chars_from_text(text, string.digits)
Токенизация текста
Для последующей обработки очищенный текст необходимо разбить на составные части – токены. В анализе текста на естественном языке применяется разбиение на символы, слова и предложения. Процесс разбиения называется токенизация. Для нашей задачи частотного анализа необходимо разбить текст на слова. Для этого можно использовать готовый метод библиотеки NLTK:
from nltk import word_tokenize
text_tokens = word_tokenize(text)
Переменная text_tokens представляет собой список слов (токенов). Для вычисления количества слов в предобработанном тексте можно получить длину списка токенов:
len(text_tokens)
Для вывода первых 10 слов воспользуемся операцией среза:
text_tokens[:10]
Для применения инструментов частотного анализа библиотеки NLTK необходимо список токенов преобразовать к классу Text, который входит в эту библиотеку:
import nltk
text = nltk.Text(text_tokens)
Выведем тип переменной text:
print(type(text))
К переменной этого типа также применимы операции среза. Например, это действие выведет 10 первых токенов из текста:
text[:10]
Подсчёт статистики встречаемости слов в тексте
Для подсчёта статистики распределения частот слов в тексте применяется класс FreqDist (frequency distributions):
from nltk.probability import FreqDist
fdist = FreqDist(text)
Попытка вывести переменную fdist отобразит словарь, содержащий токены и их частоты – количество раз, которые эти слова встречаются в тексте:
FreqDist({'и': 146, 'в': 101, 'не': 69, 'что': 54, 'с': 44, 'он': 42, 'она': 39, 'ее': 39, 'на': 31, 'было': 27, ...})
Также можно воспользоваться методом most_common для получения списка кортежей с наиболее часто встречающимися токенами:
fdist.most_common(5)
[('и', 146), ('в', 101), ('не', 69), ('что', 54), ('с', 44)]
Частота распределения слов тексте может быть визуализирована с помощью графика. Класс FreqDist содержит встроенный метод plot для построения такого графика. Необходимо указать количество токенов, частоты которых будут показаны на графике. С параметром cumulative=False график иллюстрирует закон Ципфа: если все слова достаточно длинного текста упорядочить по убыванию частоты их использования, то частота n-го слова в таком списке окажется приблизительно обратно пропорциональной его порядковому номеру n.
fdist.plot(30,cumulative=False)
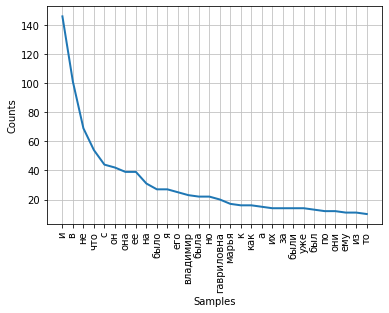
Можно заметить, что в данный момент наибольшие частоты имеют союзы, предлоги и другие служебные части речи, не несущие смысловой нагрузки, а только выражающие семантико-синтаксические отношения между словами. Для того, чтобы результаты частотного анализа отражали тематику текста, необходимо удалить эти слова из текста.
Удаление стоп-слов
К стоп-словам (или шумовым словам), как правило, относят предлоги, союзы, междометия, частицы и другие части речи, которые часто встречаются в тексте, являются служебными и не несут смысловой нагрузки – являются избыточными.
Библиотека NLTK содержит готовые списки стоп-слов для различных языков. Получим список сто-слов для русского языка:
from nltk.corpus import stopwords
russian_stopwords = stopwords.words("russian")
Следует отметить, что стоп-слова являются контекстно зависимыми – для текстов различной тематики стоп-слова могут отличаться. Как и в случае со спец.символами, необходимо проанализировать исходный текст и выявить стоп-слова, которые не вошли в типовой набор.
Список стоп-слов может быть расширен с помощью стандартного метода extend:
russian_stopwords.extend(['это', 'нею'])
После удаления стоп-слов частота распределения токенов в тексте выглядит следующим образом:
fdist_sw.most_common(10)
[('владимир', 23),
('гавриловна', 20),
('марья', 17),
('поехал', 9),
('бурмин', 9),
('поминутно', 8),
('метель', 7),
('несколько', 6),
('сани', 6),
('владимира', 6)]
Как видно, результаты частотного анализа стали более информативными и точнее стали отражать основную тематику текста. Однако, мы видим в результатах такие токены, как «владимир» и «владимира», которые являются, по сути, одним словом, но в разных формах. Для исправления этой ситуации необходимо слова исходного текста привести к их основам или изначальной форме – провести стемминг или лемматизацию.
Визуализация популярности слов в виде облака
В завершение нашей работы визуализируем результаты частотного анализа текста в виде «облака слов».
Для этого нам потребуются библиотеки wordcloud и matplotlib:
from wordcloud import WordCloud
import matplotlib.pyplot as plt
%matplotlib inline
Для построения облака слов на вход методу необходимо передать строку. Для преобразования списка токенов после предобработки и удаления стоп-слов воспользуемся методом join, указав в качестве разделителя пробел:
text_raw = " ".join(text)
Выполним вызов метода построения облака:
wordcloud = WordCloud().generate(text_raw)
В результате получаем такое «облако слов» для нашего текста:

Глядя на него, можно получить общее представление о тематике и главных персонажах произведения.
Льву Толстому приготовиться

Мы уже анализировали самые частые слова в тексте, но делали это быстро, на коленке и с помощью Экселя. Теперь подойдём к этому серьёзно и используем дата-сайенс и Python — с ним такой анализ будет проще, быстрее и эффективнее. Заодно научимся делать такое красивое облако самых частых слов — это из первого тома «Войны и мира»:

Что делаем
Сегодня мы проанализируем текст всех томов «Войны и мира» и посмотрим, изменятся ли самые частые слова, как это будет выглядеть в облаке. Интересно, можно ли по таким облакам хотя бы примерно понять общее настроение или содержание текста.
Логика будет простая:
- Скачиваем четыре тома, каждый отдельным текстовым файлом.
- Пишем алгоритм, который проанализирует слова в первом томе.
- Генерируем для него облако слов.
- Меняем имя файла в программе и получаем картинки для трёх оставшихся томов.
- Смотрим, что получилось, и сравниваем картинки между собой.
Вместо художественного текста анализировать так можно что угодно: статьи «Кода», записи в дневнике или инструкцию от пылесоса.
Загружаем текст
Мы всё будем делать в редакторе VS Code — он бесплатный, есть окно вывода сообщений и ошибок, а ещё он умеет сразу показывать сгенерированные картинки в отдельном окне.
Также нам понадобятся все тома «Войны и мира»:
Первый
Второй
Третий
Четвёртый
Их нужно положить в ту же папку, где будет скрипт.
Создаём новый python-файл, указываем в нём путь к файлу, потом загружаем в переменную и сразу проверяем, получилось или нет. Для этого выводим первые 300 символов текста:
Видно, что файл считался нормально, всё на месте. Ещё сразу становится понятно, что в тексте будет много французского языка — это тоже мы учтём при анализе.
Убираем лишнее
Сейчас в тексте много лишнего, что будет мешать анализу:
- цифры,
- знаки препинания,
- большие и маленькие буквы,
- переносы строк.
Исправим это с помощью встроенного модуля String — в нём уже есть почти вся пунктуация, которую мы дополним несколькими символами:
Текст стал однородным: его теперь сложно читать, зато компьютеру будет легко распознать каждое слово.
Библиотека NLTK и токенизация
Дальше нам понадобится NLTK — мощная библиотека для обработки текста. Технически это даже не одна библиотека, а набор модулей, внутри которых тоже может быть разное, но для простоты назовём это так.
Токенизация — это сегментация, или разделение текста на отдельные компоненты, а токены — это и есть те самые компоненты. Так как мы ищем самые популярные слова, то нам нужно токенизировать на уровне слов. Например, если токенизировать по словам предложение «и швец, и жнец, и на дуде игрец», то токены будут такие: «и», «швец», «жнец», «на», «дуде», «игрец».
Важно помнить, что с точки зрения библиотеки, токены — это не строки, хотя они и хранятся там в таком виде. Чтобы можно было работать с ними как со строками, мы будем их отдельно приводить к этому виду.
Для установки библиотеки используем команду:
pip install nltk
Для установки отдельных модулей, например, word_tokenize, нам понадобится сделать такое:
- В терминале VS Code выполнить команду python (или python3). Запустится среда выполнения Python, в которой мы будем дальше работать.
- Пишем и выполняем команду import nltk — она подгрузит библиотеку в Python.
- После этого установим нужный модуль командой nltk.download(‘word_tokenize’).
- Также можем сразу установить второй модуль, который мы будем использовать: nltk.download(‘stopwords’).
- Выходим из среды Python, набрав в консоли команду exit().
Теперь найдём первые 5 самых популярных слов в тексте:
Чистим текст от стоп-слов
Стоп-слова в NLTK — это те слова, которые мешают правильно оценить весь текст. К ним относятся:
- предлоги и союзы,
- местоимения,
- междометия,
- артикли,
- слова-связки.
Чтобы избавиться от них, используем специальный модуль, в котором уже собраны все стоп-слова из разных языков. Сразу добавим туда стоп-слова из французского языка, так как герои романа часто общаются друг с другом по-французски:
Стало лучше, но появилась новая проблема: судя по первой десятке, герои слишком много говорят — «сказал», «сказала», «говорил». Для чистоты эксперимента их тоже можно убрать из текста, поместив их в список стоп-слов. Туда же отнесём «это» и «что»:
Рисуем облако слов
У нас всё готово, чтобы вывести слова в виде красивой картинки: чем чаще встречается слово, тем большим шрифтом оно будет написано. Сделаем это с помощью библиотеки wordcount, которую нужно будет установить отдельно:
pip install wordcount
Точно так же получаем картинки для второго, третьего и четвёртого тома — просто меняем название файла в первой команде скрипта и запускаем код:
Что с этим можно сделать
Вот несколько идей:
- Подразбить тома на главы и посмотреть на частотность на микроуровне.
- Докрутить токенизатор, возвращая все слова в начальную форму, и проанализировать снова.
- Докрутить токенизатор, чтобы он отдельно смотрел на существительные, отдельно — на прилагательные, отдельно — на глаголы. В идеале ещё отделить имена людей и имена собственные.
- Заменить частотность на анализ связей: например, что чаще всего делал Пьер или Наташа?
- Насобирать своих старых текстов из соцсетей и проанализировать, как вы менялись с годами: какие слова использовали. Для этого сначала напарсить сайт, не привлекая внимания.
- Записать свою устную речь, расшифровать через облако и найти слова-паразиты.
- То же самое, но с другими людьми.
- Напарсить текстов какого-нибудь издания до того, как сменилась команда, и после.
- Насобирать новостных сюжетов за год и построить карту популярных слов в течение года.
- Ничего из этого не делать, а открыть API-платформу OpenAI и натренировать нейронку на всём корпусе текстов Толстого.
Что-то из этого мы сделаем в будущем. Или это вы сделаете сами, потому что пойдёте заниматься дата-сайенсом впереди нас.
Input: A positive integer K and a big text. The text can actually be viewed as word sequence. So we don’t have to worry about how to break down it into word sequence.
Output: The most frequent K words in the text.
My thinking is like this.
-
use a Hash table to record all words’ frequency while traverse the whole word sequence. In this phase, the key is “word” and the value is “word-frequency”. This takes O(n) time.
-
sort the (word, word-frequency) pair; and the key is “word-frequency”. This takes O(n*lg(n)) time with normal sorting algorithm.
-
After sorting, we just take the first K words. This takes O(K) time.
To summarize, the total time is O(n+nlg(n)+K), Since K is surely smaller than N, so it is actually O(nlg(n)).
We can improve this. Actually, we just want top K words. Other words’ frequency is not concern for us. So, we can use “partial Heap sorting”. For step 2) and 3), we don’t just do sorting. Instead, we change it to be
2′) build a heap of (word, word-frequency) pair with “word-frequency” as key. It takes O(n) time to build a heap;
3′) extract top K words from the heap. Each extraction is O(lg(n)). So, total time is O(k*lg(n)).
To summarize, this solution cost time O(n+k*lg(n)).
This is just my thought. I haven’t find out way to improve step 1).
I Hope some Information Retrieval experts can shed more light on this question.
![]()
Deduplicator
44.4k7 gold badges65 silver badges115 bronze badges
asked Oct 9, 2008 at 2:24
![]()
Morgan ChengMorgan Cheng
73.4k66 gold badges170 silver badges229 bronze badges
7
This can be done in O(n) time
Solution 1:
Steps:
-
Count words and hash it, which will end up in the structure like this
var hash = { "I" : 13, "like" : 3, "meow" : 3, "geek" : 3, "burger" : 2, "cat" : 1, "foo" : 100, ... ... -
Traverse through the hash and find the most frequently used word (in this case “foo” 100), then create the array of that size
-
Then we can traverse the hash again and use the number of occurrences of words as array index, if there is nothing in the index, create an array else append it in the array. Then we end up with an array like:
0 1 2 3 100 [[ ],[cat],[burger],[like, meow, geek],[]...[foo]] -
Then just traverse the array from the end, and collect the k words.
Solution 2:
Steps:
- Same as above
- Use min heap and keep the size of min heap to k, and for each word in the hash we compare the occurrences of words with the min, 1) if it’s greater than the min value, remove the min (if the size of the min heap is equal to k) and insert the number in the min heap. 2) rest simple conditions.
- After traversing through the array, we just convert the min heap to array and return the array.
![]()
answered Mar 12, 2014 at 3:51
![]()
5
You’re not going to get generally better runtime than the solution you’ve described. You have to do at least O(n) work to evaluate all the words, and then O(k) extra work to find the top k terms.
If your problem set is really big, you can use a distributed solution such as map/reduce. Have n map workers count frequencies on 1/nth of the text each, and for each word, send it to one of m reducer workers calculated based on the hash of the word. The reducers then sum the counts. Merge sort over the reducers’ outputs will give you the most popular words in order of popularity.
answered Oct 9, 2008 at 7:55
![]()
Nick JohnsonNick Johnson
101k16 gold badges128 silver badges198 bronze badges
A small variation on your solution yields an O(n) algorithm if we don’t care about ranking the top K, and a O(n+k*lg(k)) solution if we do. I believe both of these bounds are optimal within a constant factor.
The optimization here comes again after we run through the list, inserting into the hash table. We can use the median of medians algorithm to select the Kth largest element in the list. This algorithm is provably O(n).
After selecting the Kth smallest element, we partition the list around that element just as in quicksort. This is obviously also O(n). Anything on the “left” side of the pivot is in our group of K elements, so we’re done (we can simply throw away everything else as we go along).
So this strategy is:
- Go through each word and insert it into a hash table: O(n)
- Select the Kth smallest element: O(n)
- Partition around that element: O(n)
If you want to rank the K elements, simply sort them with any efficient comparison sort in O(k * lg(k)) time, yielding a total run time of O(n+k * lg(k)).
The O(n) time bound is optimal within a constant factor because we must examine each word at least once.
The O(n + k * lg(k)) time bound is also optimal because there is no comparison-based way to sort k elements in less than k * lg(k) time.
answered Dec 26, 2008 at 0:54
5
If your “big word list” is big enough, you can simply sample and get estimates. Otherwise, I like hash aggregation.
Edit:
By sample I mean choose some subset of pages and calculate the most frequent word in those pages. Provided you select the pages in a reasonable way and select a statistically significant sample, your estimates of the most frequent words should be reasonable.
This approach is really only reasonable if you have so much data that processing it all is just kind of silly. If you only have a few megs, you should be able to tear through the data and calculate an exact answer without breaking a sweat rather than bothering to calculate an estimate.
answered Oct 9, 2008 at 2:26
![]()
Aaron MaenpaaAaron Maenpaa
119k11 gold badges94 silver badges108 bronze badges
2
You can cut down the time further by partitioning using the first letter of words, then partitioning the largest multi-word set using the next character until you have k single-word sets. You would use a sortof 256-way tree with lists of partial/complete words at the leafs. You would need to be very careful to not cause string copies everywhere.
This algorithm is O(m), where m is the number of characters. It avoids that dependence on k, which is very nice for large k [by the way your posted running time is wrong, it should be O(n*lg(k)), and I’m not sure what that is in terms of m].
If you run both algorithms side by side you will get what I’m pretty sure is an asymptotically optimal O(min(m, n*lg(k))) algorithm, but mine should be faster on average because it doesn’t involve hashing or sorting.
answered Oct 9, 2008 at 3:22
3
You have a bug in your description: Counting takes O(n) time, but sorting takes O(m*lg(m)), where m is the number of unique words. This is usually much smaller than the total number of words, so probably should just optimize how the hash is built.
answered Dec 26, 2008 at 0:33
![]()
martinusmartinus
17.7k15 gold badges72 silver badges92 bronze badges
If what you’re after is the list of k most frequent words in your text for any practical k and for any natural langage, then the complexity of your algorithm is not relevant.
Just sample, say, a few million words from your text, process that with any algorithm in a matter of seconds, and the most frequent counts will be very accurate.
As a side note, the complexity of the dummy algorithm (1. count all 2. sort the counts 3. take the best) is O(n+m*log(m)), where m is the number of different words in your text. log(m) is much smaller than (n/m), so it remains O(n).
Practically, the long step is counting.
answered May 5, 2015 at 22:49
![]()
Nikana ReklawyksNikana Reklawyks
3,1733 gold badges32 silver badges49 bronze badges
- Utilize memory efficient data structure to store the words
- Use MaxHeap, to find the top K frequent words.
Here is the code
import java.util.ArrayList;
import java.util.Comparator;
import java.util.List;
import java.util.PriorityQueue;
import com.nadeem.app.dsa.adt.Trie;
import com.nadeem.app.dsa.adt.Trie.TrieEntry;
import com.nadeem.app.dsa.adt.impl.TrieImpl;
public class TopKFrequentItems {
private int maxSize;
private Trie trie = new TrieImpl();
private PriorityQueue<TrieEntry> maxHeap;
public TopKFrequentItems(int k) {
this.maxSize = k;
this.maxHeap = new PriorityQueue<TrieEntry>(k, maxHeapComparator());
}
private Comparator<TrieEntry> maxHeapComparator() {
return new Comparator<TrieEntry>() {
@Override
public int compare(TrieEntry o1, TrieEntry o2) {
return o1.frequency - o2.frequency;
}
};
}
public void add(String word) {
this.trie.insert(word);
}
public List<TopK> getItems() {
for (TrieEntry trieEntry : this.trie.getAll()) {
if (this.maxHeap.size() < this.maxSize) {
this.maxHeap.add(trieEntry);
} else if (this.maxHeap.peek().frequency < trieEntry.frequency) {
this.maxHeap.remove();
this.maxHeap.add(trieEntry);
}
}
List<TopK> result = new ArrayList<TopK>();
for (TrieEntry entry : this.maxHeap) {
result.add(new TopK(entry));
}
return result;
}
public static class TopK {
public String item;
public int frequency;
public TopK(String item, int frequency) {
this.item = item;
this.frequency = frequency;
}
public TopK(TrieEntry entry) {
this(entry.word, entry.frequency);
}
@Override
public String toString() {
return String.format("TopK [item=%s, frequency=%s]", item, frequency);
}
@Override
public int hashCode() {
final int prime = 31;
int result = 1;
result = prime * result + frequency;
result = prime * result + ((item == null) ? 0 : item.hashCode());
return result;
}
@Override
public boolean equals(Object obj) {
if (this == obj)
return true;
if (obj == null)
return false;
if (getClass() != obj.getClass())
return false;
TopK other = (TopK) obj;
if (frequency != other.frequency)
return false;
if (item == null) {
if (other.item != null)
return false;
} else if (!item.equals(other.item))
return false;
return true;
}
}
}
Here is the unit tests
@Test
public void test() {
TopKFrequentItems stream = new TopKFrequentItems(2);
stream.add("hell");
stream.add("hello");
stream.add("hello");
stream.add("hello");
stream.add("hello");
stream.add("hello");
stream.add("hero");
stream.add("hero");
stream.add("hero");
stream.add("hello");
stream.add("hello");
stream.add("hello");
stream.add("home");
stream.add("go");
stream.add("go");
assertThat(stream.getItems()).hasSize(2).contains(new TopK("hero", 3), new TopK("hello", 8));
}
For more details refer this test case
answered Mar 15, 2016 at 4:18
![]()
-
use a Hash table to record all words’ frequency while traverse the whole word sequence. In this phase, the key is “word” and the value is “word-frequency”. This takes O(n) time.This is same as every one explained above
-
While insertion itself in hashmap , keep the Treeset(specific to java, there are implementations in every language) of size 10(k=10) to keep the top 10 frequent words. Till size is less than 10, keep adding it. If size equal to 10, if inserted element is greater than minimum element i.e. first element. If yes remove it and insert new element
To restrict the size of treeset see this link
answered Apr 11, 2017 at 3:31
![]()
M SachM Sach
33.1k76 gold badges216 silver badges312 bronze badges
Suppose we have a word sequence “ad” “ad” “boy” “big” “bad” “com” “come” “cold”. And K=2.
as you mentioned “partitioning using the first letter of words”, we got
(“ad”, “ad”) (“boy”, “big”, “bad”) (“com” “come” “cold”)
“then partitioning the largest multi-word set using the next character until you have k single-word sets.”
it will partition (“boy”, “big”, “bad”) (“com” “come” “cold”), the first partition (“ad”, “ad”) is missed, while “ad” is actually the most frequent word.
Perhaps I misunderstand your point. Can you please detail your process about partition?
answered Oct 9, 2008 at 11:44
![]()
Morgan ChengMorgan Cheng
73.4k66 gold badges170 silver badges229 bronze badges
I believe this problem can be solved by an O(n) algorithm. We could make the sorting on the fly. In other words, the sorting in that case is a sub-problem of the traditional sorting problem since only one counter gets incremented by one every time we access the hash table. Initially, the list is sorted since all counters are zero. As we keep incrementing counters in the hash table, we bookkeep another array of hash values ordered by frequency as follows. Every time we increment a counter, we check its index in the ranked array and check if its count exceeds its predecessor in the list. If so, we swap these two elements. As such we obtain a solution that is at most O(n) where n is the number of words in the original text.
answered Jun 13, 2013 at 3:03
![]()
3
I was struggling with this as well and get inspired by @aly. Instead of sorting afterwards, we can just maintain a presorted list of words (List<Set<String>>) and the word will be in the set at position X where X is the current count of the word. In generally, here’s how it works:
- for each word, store it as part of map of it’s occurrence:
Map<String, Integer>. - then, based on the count, remove it from the previous count set, and add it into the new count set.
The drawback of this is the list maybe big – can be optimized by using a TreeMap<Integer, Set<String>> – but this will add some overhead. Ultimately we can use a mix of HashMap or our own data structure.
The code
public class WordFrequencyCounter {
private static final int WORD_SEPARATOR_MAX = 32; // UNICODE 0000-001F: control chars
Map<String, MutableCounter> counters = new HashMap<String, MutableCounter>();
List<Set<String>> reverseCounters = new ArrayList<Set<String>>();
private static class MutableCounter {
int i = 1;
}
public List<String> countMostFrequentWords(String text, int max) {
int lastPosition = 0;
int length = text.length();
for (int i = 0; i < length; i++) {
char c = text.charAt(i);
if (c <= WORD_SEPARATOR_MAX) {
if (i != lastPosition) {
String word = text.substring(lastPosition, i);
MutableCounter counter = counters.get(word);
if (counter == null) {
counter = new MutableCounter();
counters.put(word, counter);
} else {
Set<String> strings = reverseCounters.get(counter.i);
strings.remove(word);
counter.i ++;
}
addToReverseLookup(counter.i, word);
}
lastPosition = i + 1;
}
}
List<String> ret = new ArrayList<String>();
int count = 0;
for (int i = reverseCounters.size() - 1; i >= 0; i--) {
Set<String> strings = reverseCounters.get(i);
for (String s : strings) {
ret.add(s);
System.out.print(s + ":" + i);
count++;
if (count == max) break;
}
if (count == max) break;
}
return ret;
}
private void addToReverseLookup(int count, String word) {
while (count >= reverseCounters.size()) {
reverseCounters.add(new HashSet<String>());
}
Set<String> strings = reverseCounters.get(count);
strings.add(word);
}
}
answered Oct 19, 2013 at 0:26
![]()
ShawnShawn
1,5881 gold badge12 silver badges19 bronze badges
1
I just find out the other solution for this problem. But I am not sure it is right.
Solution:
- Use a Hash table to record all words’ frequency T(n) = O(n)
- Choose first k elements of hash table, and restore them in one buffer (whose space = k). T(n) = O(k)
- Each time, firstly we need find the current min element of the buffer, and just compare the min element of the buffer with the (n – k) elements of hash table one by one. If the element of hash table is greater than this min element of buffer, then drop the current buffer’s min, and add the element of the hash table. So each time we find the min one in the buffer need T(n) = O(k), and traverse the whole hash table need T(n) = O(n – k). So the whole time complexity for this process is T(n) = O((n-k) * k).
- After traverse the whole hash table, the result is in this buffer.
- The whole time complexity: T(n) = O(n) + O(k) + O(kn – k^2) = O(kn + n – k^2 + k). Since, k is really smaller than n in general. So for this solution, the time complexity is T(n) = O(kn). That is linear time, when k is really small. Is it right? I am really not sure.
answered Feb 9, 2014 at 21:28
![]()
zproject89zproject89
2255 silver badges19 bronze badges
Try to think of special data structure to approach this kind of problems. In this case special kind of tree like trie to store strings in specific way, very efficient. Or second way to build your own solution like counting words. I guess this TB of data would be in English then we do have around 600,000 words in general so it’ll be possible to store only those words and counting which strings would be repeated + this solution will need regex to eliminate some special characters. First solution will be faster, I’m pretty sure.
http://en.wikipedia.org/wiki/Trie
answered Oct 9, 2014 at 12:30
![]()
Simplest code to get the occurrence of most frequently used word.
function strOccurence(str){
var arr = str.split(" ");
var length = arr.length,temp = {},max;
while(length--){
if(temp[arr[length]] == undefined && arr[length].trim().length > 0)
{
temp[arr[length]] = 1;
}
else if(arr[length].trim().length > 0)
{
temp[arr[length]] = temp[arr[length]] + 1;
}
}
console.log(temp);
var max = [];
for(i in temp)
{
max[temp[i]] = i;
}
console.log(max[max.length])
//if you want second highest
console.log(max[max.length - 2])
}
answered Oct 8, 2015 at 12:35
![]()
ngLoverngLover
4,4293 gold badges20 silver badges42 bronze badges
In these situations, I recommend to use Java built-in features. Since, they are already well tested and stable. In this problem, I find the repetitions of the words by using HashMap data structure. Then, I push the results to an array of objects. I sort the object by Arrays.sort() and print the top k words and their repetitions.
import java.io.*;
import java.lang.reflect.Array;
import java.util.*;
public class TopKWordsTextFile {
static class SortObject implements Comparable<SortObject>{
private String key;
private int value;
public SortObject(String key, int value) {
super();
this.key = key;
this.value = value;
}
@Override
public int compareTo(SortObject o) {
//descending order
return o.value - this.value;
}
}
public static void main(String[] args) {
HashMap<String,Integer> hm = new HashMap<>();
int k = 1;
try {
BufferedReader br = new BufferedReader(new InputStreamReader(new FileInputStream("words.in")));
String line;
while ((line = br.readLine()) != null) {
// process the line.
//System.out.println(line);
String[] tokens = line.split(" ");
for(int i=0; i<tokens.length; i++){
if(hm.containsKey(tokens[i])){
//If the key already exists
Integer prev = hm.get(tokens[i]);
hm.put(tokens[i],prev+1);
}else{
//If the key doesn't exist
hm.put(tokens[i],1);
}
}
}
//Close the input
br.close();
//Print all words with their repetitions. You can use 3 for printing top 3 words.
k = hm.size();
// Get a set of the entries
Set set = hm.entrySet();
// Get an iterator
Iterator i = set.iterator();
int index = 0;
// Display elements
SortObject[] objects = new SortObject[hm.size()];
while(i.hasNext()) {
Map.Entry e = (Map.Entry)i.next();
//System.out.print("Key: "+e.getKey() + ": ");
//System.out.println(" Value: "+e.getValue());
String tempS = (String) e.getKey();
int tempI = (int) e.getValue();
objects[index] = new SortObject(tempS,tempI);
index++;
}
System.out.println();
//Sort the array
Arrays.sort(objects);
//Print top k
for(int j=0; j<k; j++){
System.out.println(objects[j].key+":"+objects[j].value);
}
} catch (IOException e) {
e.printStackTrace();
}
}
}
For more information, please visit https://github.com/m-vahidalizadeh/foundations/blob/master/src/algorithms/TopKWordsTextFile.java. I hope it helps.
answered Sep 25, 2016 at 19:33
![]()
MohammadMohammad
5,9463 gold badges22 silver badges30 bronze badges
2
**
C++11 Implementation of the above thought
**
class Solution {
public:
vector<int> topKFrequent(vector<int>& nums, int k) {
unordered_map<int,int> map;
for(int num : nums){
map[num]++;
}
vector<int> res;
// we use the priority queue, like the max-heap , we will keep (size-k) smallest elements in the queue
// pair<first, second>: first is frequency, second is number
priority_queue<pair<int,int>> pq;
for(auto it = map.begin(); it != map.end(); it++){
pq.push(make_pair(it->second, it->first));
// onece the size bigger than size-k, we will pop the value, which is the top k frequent element value
if(pq.size() > (int)map.size() - k){
res.push_back(pq.top().second);
pq.pop();
}
}
return res;
}
};
answered Sep 1, 2017 at 15:51
![]()
asad_nitpasad_nitp
4031 gold badge3 silver badges8 bronze badges
