Для
характеристики рассеяния значений
количественного признака X
генеральной
совокупности вокруг своего среднего
значения служат понятия генеральной
дисперсии и генерального среднего
квадратического отклонения.
Генеральной
дисперсией
DT
называется
среднее арифметическое квадратов
отклонения значений признака X
генеральной
совокупности от их среднего значения![]()
Если все значения ![]()
признака
генеральной совокупности объема N
являются
различными, то
![]()
(9.23)
Если
значения x1,
x2,
…, xk
имеют соответственно частоты
N1,
N2,..,Nk
причем
N1+
N2+…+,Nk=N
,
то
![]()
(9.24)
Генеральным
средним квадратическим отклонением
![]()
называется
корень квадратный из генеральной
дисперсии, т.е.
![]()
(9.25)
Для
характеристики рассеяния значений
количественного признака выборки вокруг
среднего значения ![]()
вводят
понятия выборочной дисперсии и выборочного
среднего квадратического отклонения
Выборочной
дисперсией
DB
называют среднее арифметическое
квадратов отклонения наблюдаемых
значений выборки от их среднего
значения![]()
.
Если
все значения![]()
,
признака выборки объема n
различны,
то
![]()
(9.26)
Если
значения x1,
x2,
…, xk
имеют соответственно частоты n1,
n2, …,
nk,
причем
n1+n2+…+nk=n,
то
![]()
(9.27)
Выборочное
среднее квадратическое отклонение
![]()
определяется
формулой
![]()
(9.28)
Для
вычисления выборочной дисперсии можно
пользоваться формуло
DB=![]()
,
(9.29)
где
![]()
![]()
(9.30)
Докажем
формулу (9.29). Преобразуя формулу (9.27),
получаем
DВ=![]()
Из
формулы (9.24) аналогично находим
![]()
.
Следовательно,
для обоих случаев
![]()
(9.31)
где
x2
–
среднее квадратов значение; (x2)
– квадрат общей средней.
Можно
доказать, что
![]()
(9.32)
Так
как
![]()
,
то выборочная дисперсия DВ
является смещенной оценкой генеральной
дисперсии DГ
.
Чтобы получить несмещенную оценку
генеральной дисперсии
DГ,
вводят понятие так называемой эмпирической
(или исправленной) дисперсии s2.
Эмпирическая,
или исправленная,
дисперсия
s2
определяется
формулой
![]()
![]()
![]()
![]()
(9.33)
Исправленная
дисперсия (9.33) является несмешанной
оценкой генеральной дисперсии, так как
M(
)=M(![]()
![]()
![]()
Для
оценки среднего квадратического
отклонения генеральной совокупности
служит «исправленное» среднее
квадратическое отклонение, или
эмпирический стандарт
s=![]()
(9.34)
В
случае, когда все значения x1,
x2,
…, xn
различны,
т.е. все ni=1
и k
= n,
формулы
(9.33)
и (9.34) принимают вид
![]()
(9.35)
![]()
(9.36)
Соседние файлы в предмете [НЕСОРТИРОВАННОЕ]
- #
- #
- #
- #
- #
- #
- #
- #
- #
30.04.2022143.36 Кб0Учебное пособие 40024.doc
- #
- #
Как найти дисперсию?
Спасибо за ваши закладки и рекомендации
Дисперсия – это мера разброса значений случайной величины $X$ относительно ее математического ожидания $M(X)$ (см. как найти математическое ожидание случайной величины). Дисперсия показывает, насколько в среднем значения сосредоточены, сгруппированы около $M(X)$: если дисперсия маленькая – значения сравнительно близки друг к другу, если большая – далеки друг от друга (см. примеры нахождения дисперсии ниже).
Если случайная величина описывает физические объекты с некоторой размерностью (метры, секунды, килограммы и т.п.), то дисперсия будет выражаться в квадратных единицах (метры в квадрате, секунды в квадрате и т.п.). Ясно, что это не совсем удобно для анализа, поэтому часто вычисляют также корень из дисперсии – среднеквадратическое отклонение $sigma(X)=sqrt{D(X)}$, которое имеет ту же размерность, что и исходная величина и также описывает разброс.
Еще одно формальное определение дисперсии звучит так: “Дисперсия – это второй центральный момент случайной величины” (напомним, что первый начальный момент – это как раз математическое ожидание).
Нужна помощь? Решаем теорию вероятностей на отлично
Формула дисперсии случайной величины
Дисперсия случайной величины Х вычисляется по следующей формуле:
$$
D(X)=M(X-M(X))^2,
$$
которую также часто записывают в более удобном для расчетов виде:
$$
D(X)=M(X^2)-(M(X))^2.
$$
Эта универсальная формула для дисперсии может быть расписана более подробно для двух случаев.
Если мы имеем дело с дискретной случайной величиной (которая задана перечнем значений $x_i$ и соответствующих вероятностей $p_i$), то формула принимает вид:
$$
D(X)=sum_{i=1}^{n}{x_i^2 cdot p_i}-left(sum_{i=1}^{n}{x_i cdot p_i} right)^2.
$$
Если же речь идет о непрерывной случайной величине (заданной плотностью вероятностей $f(x)$ в общем случае), формула дисперсии Х выглядит следующим образом:
$$
D(X)=int_{-infty}^{+infty} f(x) cdot x^2 dx – left( int_{-infty}^{+infty} f(x) cdot x dx right)^2.
$$
Пример нахождения дисперсии
Рассмотрим простые примеры, показывающие как найти дисперсию по формулам, введеным выше.
Пример 1. Вычислить и сравнить дисперсию двух законов распределения:
$$
x_i quad 1 quad 2 \
p_i quad 0.5 quad 0.5
$$
и
$$
y_i quad -10 quad 10 \
p_i quad 0.5 quad 0.5
$$
Для убедительности и наглядности расчетов мы взяли простые распределения с двумя значениями и одинаковыми вероятностями. Но в первом случае значения случайной величины расположены рядом (1 и 2), а во втором – дальше друг от друга (-10 и 10). А теперь посмотрим, насколько различаются дисперсии:
$$
D(X)=sum_{i=1}^{n}{x_i^2 cdot p_i}-left(sum_{i=1}^{n}{x_i cdot p_i} right)^2 =\
= 1^2cdot 0.5 + 2^2 cdot 0.5 – (1cdot 0.5 + 2cdot 0.5)^2=2.5-1.5^2=0.25.
$$
$$
D(Y)=sum_{i=1}^{n}{y_i^2 cdot p_i}-left(sum_{i=1}^{n}{y_i cdot p_i} right)^2 =\
= (-10)^2cdot 0.5 + 10^2 cdot 0.5 – (-10cdot 0.5 + 10cdot 0.5)^2=100-0^2=100.
$$
Итак, значения случайных величин различались на 1 и 20 единиц, тогда как дисперсия показывает меру разброса в 0.25 и 100. Если перейти к среднеквадратическому отклонению, получим $sigma(X)=0.5$, $sigma(Y)=10$, то есть вполне ожидаемые величины: в первом случае значения отстоят в обе стороны на 0.5 от среднего 1.5, а во втором – на 10 единиц от среднего 0.
Ясно, что для более сложных распределений, где число значений больше и вероятности не одинаковы, картина будет более сложной, прямой зависимости от значений уже не будет (но будет как раз оценка разброса).
Пример 2. Найти дисперсию случайной величины Х, заданной дискретным рядом распределения:
$$
x_i quad -1 quad 2 quad 5 quad 10 quad 20 \
p_i quad 0.1 quad 0.2 quad 0.3 quad 0.3 quad 0.1
$$
Снова используем формулу для дисперсии дискретной случайной величины:
$$
D(X)=M(X^2)-(M(X))^2.
$$
В случае, когда значений много, удобно разбить вычисления по шагам. Сначала найдем математическое ожидание:
$$
M(X)=sum_{i=1}^{n}{x_i cdot p_i} =-1cdot 0.1 + 2 cdot 0.2 +5cdot 0.3 +10cdot 0.3+20cdot 0.1=6.8.
$$
Потом математическое ожидание квадрата случайной величины:
$$
M(X^2)=sum_{i=1}^{n}{x_i^2 cdot p_i}
= (-1)^2cdot 0.1 + 2^2 cdot 0.2 +5^2cdot 0.3 +10^2cdot 0.3+20^2cdot 0.1=78.4.
$$
А потом подставим все в формулу для дисперсии:
$$
D(X)=M(X^2)-(M(X))^2=78.4-6.8^2=32.16.
$$
Дисперсия равна 32.16 квадратных единиц.
Пример 3. Найти дисперсию по заданному непрерывному закону распределения случайной величины Х, заданному плотностью $f(x)=x/18$ при $x in(0,6)$ и $f(x)=0$ в остальных точках.
Используем для расчета формулу дисперсии непрерывной случайной величины:
$$
D(X)=int_{-infty}^{+infty} f(x) cdot x^2 dx – left( int_{-infty}^{+infty} f(x) cdot x dx right)^2.
$$
Вычислим сначала математическое ожидание:
$$
M(X)=int_{-infty}^{+infty} f(x) cdot x dx = int_{0}^{6} frac{x}{18} cdot x dx = int_{0}^{6} frac{x^2}{18} dx =
left.frac{x^3}{54} right|_0^6=frac{6^3}{54} = 4.
$$
Теперь вычислим
$$
M(X^2)=int_{-infty}^{+infty} f(x) cdot x^2 dx = int_{0}^{6} frac{x}{18} cdot x^2 dx = int_{0}^{6} frac{x^3}{18} dx = left.frac{x^4}{72} right|_0^6=frac{6^4}{72} = 18.
$$
Подставляем:
$$
D(X)=M(X^2)-(M(X))^2=18-4^2=2.
$$
Дисперсия равна 2.
Другие задачи с решениями по ТВ
Подробно решим ваши задачи на вычисление дисперсии
Вычисление дисперсии онлайн
Как найти дисперсию онлайн для дискретной случайной величины? Используйте калькулятор ниже.
- Введите число значений случайной величины К.
- Появится форма ввода для значений $x_i$ и соответствующих вероятностей $p_i$ (десятичные дроби вводятся с разделителем точкой, например: -10.3 или 0.5). Введите нужные значения (проверьте, что сумма вероятностей равна 1, то есть закон распределения корректный).
- Нажмите на кнопку “Вычислить”.
- Калькулятор покажет вычисленное математическое ожидание $M(X)$ и затем искомое значение дисперсии $D(X)$.
Видео. Полезные ссылки
Видеоролики: что такое дисперсия и как найти дисперсию
Если вам нужно более подробное объяснение того, что такое дисперсия, как она вычисляется и какими свойствами обладает, рекомендую два видео (для дискретной и непрерывной случайной величины соответственно).
Спасибо за ваши закладки и рекомендации
Полезные ссылки
Не забывайте сначала прочитать том, как найти математическое ожидание. А тут можно вычислить также СКО: Калькулятор математического ожидания, дисперсии и среднего квадратического отклонения.
Что еще может пригодиться? Например, для изучения основ теории вероятностей – онлайн учебник по ТВ. Для закрепления материала – еще примеры решений задач по теории вероятностей.
А если у вас есть задачи, которые надо срочно сделать, а времени нет? Можете поискать готовые решения в решебнике или заказать в МатБюро:
Эмпирическая дисперсия и выборочная дисперсия (устаревшее: эмпирическое квадрат рассеяния ) или чуть меньше дисперсии ( латинский variantia = «разнообразия» или variare под названием = «(веры) изменение, быть разными»), А статистический показатель разброса значений образец и, в описательной статистике, ключевая фигура образца. Это одна из мер дисперсии, описывающая среднеквадратическое отклонение отдельных измеренных значений от среднего эмпирического значения . Таким образом, он представляет собой своего рода среднеквадратичное отклонение . Положительный корень эмпирической дисперсии – это эмпирическое стандартное отклонение . Эмпирическое стандартное отклонение является наиболее распространенной мерой дисперсии.
Термины «дисперсия», «выборочная дисперсия» и «эмпирическая дисперсия» не используются последовательно в литературе. В общем, следует различать
- Дисперсия (в смысле теории вероятностей) как ключевая фигура распределения вероятностей или распределения случайной величины
- Выборочная дисперсия (с точки зрения индуктивной статистики) как функция оценки дисперсии (с точки зрения теории вероятностей)
- эмпирическая дисперсия, обсуждаемая здесь как показатель конкретной выборки, то есть несколько чисел.
Точное разграничение и связи можно найти в разделе « Взаимосвязь условий отклонения» .
определение
мотивация
Дисперсия конечной совокупности по размеру является мерой разброса индивидуальных значений вокруг среднего значения совокупности и определяется как



-
 со средним населением .
со средним населением .


Поскольку она неизвестна в практических ситуациях и все еще требует расчета, часто используется эмпирическая дисперсия. Это особенно необходимо, когда в больших популяциях невозможно подсчитать каждого отдельного субъекта в популяции.
определение
Учитывая образец из элементов . Это означает



эмпирическое среднее образца. Это эмпирическое среднее значение является оценкой среднего значения для населения . Эмпирическую дисперсию можно определить двумя способами. Либо эмпирическая дисперсия выборки определяется как сумма квадратов отклонений, деленная на количество измеренных значений:



-
,

или он определяется как слегка измененная форма как сумма квадратов отклонений, деленная на количество степеней свободы
-
.

Объяснение
Таким образом, эмпирическая дисперсия представляет собой своего рода «среднеквадратическое отклонение» и является оценкой дисперсии генеральной совокупности . Представления следуют непосредственно из определения

-
соответственно .


Эта слегка измененная форма часто называется выборочной дисперсией и используется такими программными пакетами, как Б. Предпочтительны SPSS , R и т. Д. Если образец не показывает изменчивости, т.е. ЧАС. , то есть дисперсия . Усреднение можно интуитивно объяснить не с помощью модифицированной формы эмпирической дисперсии, а следующим образом: из-за свойства фокусировки эмпирического среднего последнее отклонение уже определяется первым . Следовательно, свободно изменяются только отклонения, и поэтому можно усреднить путем деления на количество степеней свободы .






Если говорится только об «эмпирической дисперсии», следует обратить внимание на то, какое соглашение или определение применимо в соответствующем контексте. Ни наименования определений, ни соответствующие обозначения не являются единообразными в литературе, но термин эмпирическая дисперсия часто используется для немодифицированной формы, а термин выборочная дисперсия – для измененной формы . Также есть обозначения , но их еще называют или . Некоторые авторы называют в среднеквадратичное отклонение от среднего эмпирической и к теоретической дисперсии или индуктивной дисперсии , в отличии от эмпирической дисперсии.




как объективная и образец дисперсия (и как искаженный образец дисперсия называется) , потому что несмещенная оценка для дисперсии является.
Эмпирическая дисперсия частотных данных
Эмпирическое стандартное отклонение также является мерой того, насколько далеко выборка в среднем разбросана вокруг эмпирического среднего. Будьте абсолютная частота появлений и число значений для истинно, то есть . Пусть , далее будет относительная частота от , т.е.. ЧАС. пропорция значений, для которых применяется. Абсолютное частотное распределение и относительное частотное распределение часто сводятся в таблице частот . Характеристики вместе с частотами или также называются частотными данными . Для частотных данных с характеристиками и относительными частотами эмпирическая дисперсия рассчитывается следующим образом








-
,

с .

Правила расчета
Поведение в трансформациях
Дисперсия не меняется, когда данные сдвигаются на постоянное значение c, поэтому и , поэтому


-
а также .


Если они масштабируются с коэффициентом , применяется следующее:


-
а также .


Альтернативные представления
Поскольку средний квадрат отклонения
Дисперсия в дисперсионном анализе часто обозначается как «среднее» или «среднее» отклонение в квадрате.
-
.

Средние квадраты отклонений соответствующих переменных суммированы в так называемой таблице дисперсионного анализа.
Представление с помощью блока смещения
Другое представление можно получить из теоремы смещения , согласно которой

применяется. Умножение на дает вам
-
,

из чего

следует.
Представление без эмпирических средств
Другое представление, которое обходится без использования среднего эмпирического, –

или же.
-
.

Если вы поместите среднее арифметическое наблюдаемых значений в слагаемые двойной суммы

складывает и вычитает (т.е. вставляет ноль), затем применяет
-
.

Это эквивалентно
-
.
Производные термины
Эмпирическое стандартное отклонение
Эмпирическое стандартное отклонение, также известное как образец дисперсия или образец стандартного отклонения , является положительным корнем квадратным из эмпирической дисперсии, т.е.

или же
-
.

В отличие от эмпирической дисперсии, эмпирическое стандартное отклонение имеет те же единицы, что и эмпирическое среднее или сама выборка. Как и в случае с эмпирической дисперсией, наименование и обозначение эмпирического стандартного отклонения не единообразны. Эмпирическое стандартное отклонение следует отличать от стандартного отклонения с точки зрения теории вероятностей . Это индикатор распределения вероятностей или распределения случайной величины , тогда как эмпирическое стандартное отклонение является индикатором выборки.
Эмпирический коэффициент вариации
Эмпирический коэффициент вариации является безразмерной мерой дисперсии и определяется как эмпирического стандартного отклонения , деленная на эмпирическое среднее, т.е.

В отличие от стандартного отклонения, существует безразмерная дисперсия и, следовательно, не зависит от единиц измерения. Его преимущество в том, что он выражается в процентах от среднего эмпирического значения .

пример
Образец дан
-
,

так оно и есть . Для результатов среднего эмпирического значения

-
.

В случае кусочного расчета результат
-
.

Первое определение дает вам

тогда как второе определение
-
,

запасы. Стандартное отклонение также можно рассчитать, используя приведенный выше пример дисперсии. Это делается простым выдергиванием корней. Если определить нескорректированную дисперсию выборки, то (согласно первому определению)
-
.

Однако, если эмпирическое стандартное отклонение определяется через скорректированную дисперсию выборки, то (согласно 2-му определению)
-
.

Происхождение различных определений
Определение соответствует определению эмпирической дисперсии как среднеквадратичного отклонения от эмпирического среднего. Это основано на идее определения степени разброса среднего эмпирического значения. Да будет так . Первый подход заключается в суммировании разницы между измеренными значениями и эмпирическим средним. это ведет к


Однако это всегда приводит к 0, потому что положительные и отрицательные слагаемые компенсируют друг друга ( свойство центра тяжести ), поэтому это не подходит для количественной оценки дисперсии. Чтобы получить значение дисперсии, большее или равное 0, можно, например, вычислить суммы разностей, то есть сумму абсолютных отклонений.

считать, или квадрат, т.е. сумма квадратов

форма. Однако это имеет побочный эффект, заключающийся в том, что большие отклонения от эмпирического среднего значения имеют больший вес. В результате отдельные выбросы также имеют более сильное влияние. Чтобы степень дисперсии не зависела от количества измеренных значений в образце, она делится на это число. Результатом этой прагматической меры дисперсии является среднеквадратическое отклонение от эмпирического среднего значения или дисперсии, определенной выше .
Определение слова уходит корнями в теорию оценивания . Там будет

используется в качестве несмещенной оценки для неизвестной дисперсии с распределением вероятностей . Это верно из-за следующей теоремы: если существуют независимые и одинаково распределенные случайные величины с и , то применяется . Следовательно, существует оценка неизвестной дисперсии совокупности .






Если теперь перейти от случайных величин к реализациям , оценочное значение будет получено из абстрактной функции оценки . Таким образом, отношение к соответствует отношению функции к ее значению в одной точке .





Таким образом, это можно рассматривать как практически мотивированную меру дисперсии в описательной статистике, тогда как оценка неизвестной дисперсии находится в индуктивной статистике. Это различное происхождение оправдывает вышеупомянутую манеру говорить в качестве эмпирической дисперсии, а также в качестве индуктивной дисперсии или теоретической дисперсии. Следует отметить, что это также можно интерпретировать как оценку оценочной функции. При использовании метода моментов в качестве оценочной функции дисперсии
-
.

Ваша реализация соответствует . Однако обычно он не используется, поскольку не соответствует общепринятым критериям качества . Эта оценка не оправдывает ожиданий , поскольку

-
.

Взаимосвязь понятий дисперсии
Как уже упоминалось во введении, существуют разные термины дисперсии, некоторые из которых имеют одно и то же название. Их отношение друг к другу становится ясным, если рассмотреть их роль в моделировании индуктивной статистики:
- Дисперсии (в смысле теории вероятностей) является мерой дисперсии абстрактного распределения вероятностей или распределений случайной величины в стохастиках.
- Выборочная дисперсия (в смысле индуктивных статистики) является функцией оценки для оценки дисперсии (в смысле теории вероятностей) неизвестного распределения вероятности. Следовательно, это не показатель, а метод оценки, позволяющий максимально точно угадать дисперсию неизвестного распределения вероятностей.
- Обсуждаемая здесь эмпирическая дисперсия, помимо своей роли в описательной статистике, является конкретной оценкой лежащей в основе дисперсии в соответствии с методом оценки, которая дается выборочной дисперсией (в смысле индуктивной статистики).
Ключевым моментом является разница между методом оценки (выборочная дисперсия в смысле индуктивной статистики) и его конкретной оценкой (эмпирическая дисперсия). Он соответствует разнице между функцией и ее значением функции.
Годовая дисперсия
В теории финансового рынка , дисперсии или летучесть из возвратов часто рассчитывается. Эти отклонения, если они основаны на ежедневных данных, необходимо пересчитать в год; ЧАС. можно экстраполировать на один год. Это делается с использованием коэффициента годовой (в году около торговых дней). Таким образом, волатильность можно оценить как корень годовой дисперсии.


-
.

Индивидуальные доказательства
- ↑ Норберт Хенце: Стохастик для начинающих . Знакомство с увлекательным миром случайностей. 10-е издание. Springer Spectrum, Висбаден 2013, ISBN 978-3-658-03076-6 , стр. 31 , DOI : 10.1007 / 978-3-658-03077-3 .
- ↑ а б Эрхард Берендс: Элементарный стохастик . Учебное пособие, совместно разработанное студентами. Springer Spectrum, Висбаден 2013, ISBN 978-3-8348-1939-0 , стр. 274 , DOI : 10.1007 / 978-3-8348-2331-1 .
- ↑ Томас Клефф: Описательная статистика и исследовательский анализ данных . Компьютеризированный вводный курс с Excel, SPSS и STATA. 3-е, переработанное и дополненное издание. Springer Gabler, Wiesbaden 2015, ISBN 978-3-8349-4747-5 , стр. 56 , DOI : 10.1007 / 978-3-8349-4748-2 .
- ^ Людвиг Фармейр, художник Риты, Ирис Пигеот, Герхард Тутц: Статистика. Путь к анализу данных. 8., перераб. и дополнительное издание. Springer Spectrum, Берлин / Гейдельберг, 2016 г., ISBN 978-3-662-50371-3 , стр. 65
- ↑ a b Helge Toutenburg, Christian Heumann: Описательная статистика . 6-е издание. Springer-Verlag, Берлин / Гейдельберг 2008, ISBN 978-3-540-77787-8 , стр. 75 , DOI : 10.1007 / 978-3-540-77788-5 .
- ↑ Томас Клефф: Описательная статистика и исследовательский анализ данных . Компьютеризированный вводный курс с Excel, SPSS и STATA. 3-е, переработанное и дополненное издание. Springer Gabler, Wiesbaden 2015, ISBN 978-3-8349-4747-5 , стр. 255 , DOI : 10.1007 / 978-3-8349-4748-2 .
- ↑ Глава 10: Неожиданные оценки (файл PDF), www.alt.mathematik.uni-mainz.de, по состоянию на 31 декабря 2018 г.
- ^ Людвиг Фармейр , художник Риты, Ирис Пигеот , Герхард Тутц : Статистика. Путь к анализу данных. 8., перераб. и дополнительное издание. Springer Spectrum, Берлин / Гейдельберг, 2016 г., ISBN 978-3-662-50371-3 , стр. 65.
-
↑ Это и , таким образом
,
-
из чего следует утверждение.
-
- ↑ Это следует, как указано выше, путем прямого пересчета.
- ↑ Вернер Тимишль : Прикладная статистика. Введение для биологов и медицинских работников. 2013, 3-е издание, с. 109.
- ↑ Лотар Сакс : Методы статистической оценки , с. 400.
- ^ Рейнхольд Косфельд, Ганс Фридрих Экей, Маттиас Тюрк: Описательная статистика . Основы – методы – примеры – задачи. 6-е издание. Springer Gabler, Wiesbaden 2016, ISBN 978-3-658-13639-0 , стр. 122 , DOI : 10.1007 / 978-3-658-13640-6 .
- ↑ а б Норберт Хенце: Стохастик для начинающих . Знакомство с увлекательным миром случайностей. 10-е издание. Springer Spectrum, Висбаден 2013, ISBN 978-3-658-03076-6 , стр. 31-32 , DOI : 10.1007 / 978-3-658-03077-3 .
- ↑ а б Эрхард Берендс: Элементарный стохастик . Учебное пособие, совместно разработанное студентами. Springer Spectrum, Висбаден 2013, ISBN 978-3-8348-1939-0 , стр. 274-275 , DOI : 10.1007 / 978-3-8348-2331-1 .
- ↑ Вернер Тимишль: Прикладная статистика. Введение для биологов и медицинских работников. 2013, 3-е издание, с. 109.
- ↑ Норберт Хенце: Стохастик для начинающих . Знакомство с увлекательным миром случайностей. 10-е издание. Springer Spectrum, Висбаден 2013, ISBN 978-3-658-03076-6 , стр. 33 , DOI : 10.1007 / 978-3-658-03077-3 .
- ^ Отфрид Бейер, Хорст Хакель: Расчет вероятности и математическая статистика. 1976, стр.123.


Выборочная дисперсия, описание
Выборочная дисперсия является сводной характеристикой для наблюдения рассеяния количественного признака выборки вокруг среднего значения.
Определение
Выборочная дисперсия – это среднее арифметическое значений вариантов части отобранных объектов генеральной совокупности (выборки).
Связь выборочной и генеральной дисперсии
Генеральная дисперсия представляет собой среднее арифметическое квадратов отступлений значений признаков генеральной совокупности от их среднего значения.
Осторожно! Если преподаватель обнаружит плагиат в работе, не избежать крупных проблем (вплоть до отчисления). Если нет возможности написать самому, закажите тут.
Определение
Генеральная совокупность – это комплекс всех возможных объектов, относительно которых планируется вести наблюдение и формулировать выводы.
Выборочная совокупность или выборка является частью генеральной совокупности, выбранной для изучения и составления заключения касательной всей генеральной совокупности.
Как вычислить выборочную дисперсию
Выборочная дисперсия при различии всех значений варианта выборки находится по формуле:
({widehat D}_В=frac{displaystylesum_{i-1}^n{(x_i-{overline x}_В)}^2}n)
Для значений признаков выборочной совокупности с частотами n1, n2,…,nk формула выглядит следующим образом:
({widehat D}_В=frac{displaystylesum_{i-1}^kn_i{(x_i-{overline x}_В)}^2}n)
Квадратный корень из выборочной дисперсии характеризует рассеивание значений вариантов выборки вокруг своего среднего значения. Данная характеристика называется выборочным средним квадратическим отклонением и имеет вид:
({widehatsigma}_В=sqrt{{widehat D}_В})
Упрощенный способ вычисления выборочной или генеральной дисперсии производят по формуле:
(D=overline{x^2}-left[overline xright]^2)
Если вариационный ряд выборочной совокупности интервальный, то за xi принимается центр частичных интервалов.
Пример
Найти выборочную дисперсию выборки со значениями:
- xi: 1, 2, 3, 4;
- ni: 20, 15, 10, 5.
Решение
Для начала необходимо определить выборочную среднюю:
({overline x}_В=frac1{50}(1cdot20+2cdot15+3cdot10+4cdot5)=frac1{50}cdot100=2)
Затем найдем выборочную дисперсию:
(D_В=frac1{50}({(1-2)}^2cdot20+{(2-2)}^2cdot15+{(3-2)}^2cdot10+{(4-2)}^2cdot5)=1)
Исправленная дисперсия
Математически выборочная дисперсия не соответствует генеральной, поскольку выборочная используется для смещенного оценивания генеральной дисперсии. По этой причине математическое ожидание выборочной дисперсии вычисляется так:
(Mleft[D_Bright]=frac{n-1}nD_Г)
В данной формуле DГ – это истинное значение дисперсии генеральной совокупности.
Исправить выборочную дисперсию можно путем умножения ее на дробь:
(frac n{n-1})
Получим формулу следующего вида:
(S^2=frac n{n-1}cdot D_В=frac{displaystylesum_{i=1}^kn_i{(x_i-{overline x}_В)}^2}{n-1})
Исправленная дисперсия используется для несмещенной оценки генеральной дисперсии и обозначается S2.
Среднеквадратическая генеральная совокупность оценивается при помощи исправленного среднеквадратического отклонения, которое вычисляется по формуле:
(S=sqrt{S^2})
При нахождении выборочной и исправленной дисперсии разнятся лишь знаменатели в формулах. Различия в этих характеристиках при больших n незначительны. Применение исправленной дисперсии целесообразно при объеме выборки меньше 30.
Для чего применяют исправленную выборочную дисперсию
Исправленную выборочную используют для точечной оценки генеральной дисперсии.
Пример
Длину стержня измерили одним и тем же прибором пять раз. В результате получили следующие величины: 92 мм, 94 мм, 103 мм, 105 мм, 106 мм. Задача найти выборочную среднюю длину предмета и выборочную исправленную дисперсию ошибок измерительного прибора.
Решение
Сначала вычислим выборочную среднюю:
({overline x}_В=frac{92+94+103+105+106}5=100)
Затем найдем выборочную дисперсию:
(D_В=frac{displaystylesum_{i=1}^k{(x_i-{overline x}_В)}^2}n=frac{{(92-100)}^2+{(94-100)}^2+{(103-100)}^2+{(105-100)}^2+{(106-100)}^2}5=34)
Теперь рассчитаем исправленную дисперсию:
(S^2=frac5{5-1}cdot34=42,5)
From Wikipedia, the free encyclopedia

The green curve, which asymptotically approaches heights of 0 and 1 without reaching them, is the true cumulative distribution function of the standard normal distribution. The grey hash marks represent the observations in a particular sample drawn from that distribution, and the horizontal steps of the blue step function (including the leftmost point in each step but not including the rightmost point) form the empirical distribution function of that sample. (Click here to load a new graph.)
In statistics, an empirical distribution function (commonly also called an empirical Cumulative Distribution Function, eCDF) is the distribution function associated with the empirical measure of a sample.[1] This cumulative distribution function is a step function that jumps up by 1/n at each of the n data points. Its value at any specified value of the measured variable is the fraction of observations of the measured variable that are less than or equal to the specified value.
The empirical distribution function is an estimate of the cumulative distribution function that generated the points in the sample. It converges with probability 1 to that underlying distribution, according to the Glivenko–Cantelli theorem. A number of results exist to quantify the rate of convergence of the empirical distribution function to the underlying cumulative distribution function.
Definition[edit]
Let (X1, …, Xn) be independent, identically distributed real random variables with the common cumulative distribution function F(t). Then the empirical distribution function is defined as[2]

where  is the indicator of event A. For a fixed t, the indicator
is the indicator of event A. For a fixed t, the indicator  is a Bernoulli random variable with parameter p = F(t); hence
is a Bernoulli random variable with parameter p = F(t); hence  is a binomial random variable with mean nF(t) and variance nF(t)(1 − F(t)). This implies that
is a binomial random variable with mean nF(t) and variance nF(t)(1 − F(t)). This implies that  is an unbiased estimator for F(t).
is an unbiased estimator for F(t).
However, in some textbooks, the definition is given as
- [3][4]

Mean[edit]
The mean of the empirical distribution is an unbiased estimator of the mean of the population distribution.

which is more commonly denoted 
Variance[edit]
The variance of the empirical distribution times  is an unbiased estimator of the variance of the population distribution, for any distribution of X that has a finite variance.
is an unbiased estimator of the variance of the population distribution, for any distribution of X that has a finite variance.
![{displaystyle {begin{aligned}operatorname {Var} (X)&=operatorname {E} left[(X-operatorname {E} [X])^{2}right]\[4pt]&=operatorname {E} left[(X-{bar {x}})^{2}right]\[4pt]&={frac {1}{n}}left(sum _{i=1}^{n}{(x_{i}-{bar {x}})^{2}}right)end{aligned}}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/856a9443ed6145aee944520e94efa625bfadd3bd)
Mean squared error[edit]
The mean squared error for the empirical distribution is as follows.
![{displaystyle {begin{aligned}operatorname {MSE} &={frac {1}{n}}sum _{i=1}^{n}(Y_{i}-{hat {Y_{i}}})^{2}\[4pt]&=operatorname {Var} _{hat {theta }}({hat {theta }})+operatorname {Bias} ({hat {theta }},theta )^{2}end{aligned}}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/2928ea7b7ebfcad86439fae9b35ad4f576eaabfe)
Where  is an estimator and
is an estimator and  an unknown parameter
an unknown parameter
Quantiles[edit]
For any real number  the notation
the notation  (read “ceiling of a”) denotes the least integer greater than or equal to . For any real number a, the notation
(read “ceiling of a”) denotes the least integer greater than or equal to . For any real number a, the notation  (read “floor of a”) denotes the greatest integer less than or equal to .
(read “floor of a”) denotes the greatest integer less than or equal to .
If  is not an integer, then the
is not an integer, then the  -th quantile is unique and is equal to
-th quantile is unique and is equal to 
If is an integer, then the -th quantile is not unique and is any real number such that

Empirical median[edit]
If is odd, then the empirical median is the number

If is even, then the empirical median is the number

Asymptotic properties[edit]
Since the ratio (n + 1)/n approaches 1 as n goes to infinity, the asymptotic properties of the two definitions that are given above are the same.
By the strong law of large numbers, the estimator  converges to F(t) as n → ∞ almost surely, for every value of t:[2]
converges to F(t) as n → ∞ almost surely, for every value of t:[2]

thus the estimator is consistent. This expression asserts the pointwise convergence of the empirical distribution function to the true cumulative distribution function. There is a stronger result, called the Glivenko–Cantelli theorem, which states that the convergence in fact happens uniformly over t:[5]

The sup-norm in this expression is called the Kolmogorov–Smirnov statistic for testing the goodness-of-fit between the empirical distribution and the assumed true cumulative distribution function F. Other norm functions may be reasonably used here instead of the sup-norm. For example, the L2-norm gives rise to the Cramér–von Mises statistic.
The asymptotic distribution can be further characterized in several different ways. First, the central limit theorem states that pointwise, has asymptotically normal distribution with the standard  rate of convergence:[2]
rate of convergence:[2]

This result is extended by the Donsker’s theorem, which asserts that the empirical process  , viewed as a function indexed by
, viewed as a function indexed by  , converges in distribution in the Skorokhod space
, converges in distribution in the Skorokhod space ![scriptstyle D[-infty ,+infty ]](https://wikimedia.org/api/rest_v1/media/math/render/svg/3215d9f75e16a202f9c838f5664d27e250e93b9b) to the mean-zero Gaussian process
to the mean-zero Gaussian process  , where B is the standard Brownian bridge.[5] The covariance structure of this Gaussian process is
, where B is the standard Brownian bridge.[5] The covariance structure of this Gaussian process is
![{displaystyle operatorname {E} [,G_{F}(t_{1})G_{F}(t_{2}),]=F(t_{1}wedge t_{2})-F(t_{1})F(t_{2}).}](https://wikimedia.org/api/rest_v1/media/math/render/svg/b540ccd042666531c829625255e117fabd2d112e)
The uniform rate of convergence in Donsker’s theorem can be quantified by the result known as the Hungarian embedding:[6]

Alternatively, the rate of convergence of can also be quantified in terms of the asymptotic behavior of the sup-norm of this expression. Number of results exist in this venue, for example the Dvoretzky–Kiefer–Wolfowitz inequality provides bound on the tail probabilities of  :[6]
:[6]

In fact, Kolmogorov has shown that if the cumulative distribution function F is continuous, then the expression converges in distribution to  , which has the Kolmogorov distribution that does not depend on the form of F.
, which has the Kolmogorov distribution that does not depend on the form of F.
Another result, which follows from the law of the iterated logarithm, is that [6]

and

Confidence intervals[edit]

Empirical CDF, CDF and Confidence Interval plots for various sample sizes of Normal Distribution
As per Dvoretzky–Kiefer–Wolfowitz inequality the interval that contains the true CDF,  , with probability
, with probability  is specified as
is specified as

Empirical CDF, CDF and Confidence Interval plots for various sample sizes of Cauchy Distribution

As per the above bounds, we can plot the Empirical CDF, CDF and Confidence intervals for different distributions by using any one of the Statistical implementations. Following is the syntax from Statsmodel for plotting empirical distribution.
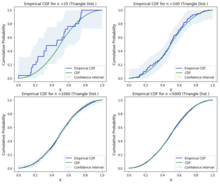
Empirical CDF, CDF and Confidence Interval plots for various sample sizes of Triangle Distribution
Statistical implementation[edit]
A non-exhaustive list of software implementations of Empirical Distribution function includes:
- In R software, we compute an empirical cumulative distribution function, with several methods for plotting, printing and computing with such an “ecdf” object.
- In MATLAB we can use Empirical cumulative distribution function (cdf) plot
- jmp from SAS, the CDF plot creates a plot of the empirical cumulative distribution function.
- Minitab, create an Empirical CDF
- Mathwave, we can fit probability distribution to our data
- Dataplot, we can plot Empirical CDF plot
- Scipy, we can use scipy.stats.ecdf
- Statsmodels, we can use statsmodels.distributions.empirical_distribution.ECDF
- Matplotlib, we can use histograms to plot a cumulative distribution
- Seaborn, using the seaborn.ecdfplot function
- Plotly, using the plotly.express.ecdf function
- Excel, we can plot Empirical CDF plot
See also[edit]
- Càdlàg functions
- Count data
- Distribution fitting
- Dvoretzky–Kiefer–Wolfowitz inequality
- Empirical probability
- Empirical process
- Estimating quantiles from a sample
- Frequency (statistics)
- Kaplan–Meier estimator for censored processes
- Survival function
- Q–Q plot
References[edit]
- ^ A modern introduction to probability and statistics : understanding why and how. Michel Dekking. London: Springer. 2005. p. 219. ISBN 978-1-85233-896-1. OCLC 262680588.
{{cite book}}: CS1 maint: others (link) - ^ a b c
van der Vaart, A.W. (1998). Asymptotic statistics. Cambridge University Press. p. 265. ISBN 0-521-78450-6. - ^ Coles, S. (2001) An Introduction to Statistical Modeling of Extreme Values. Springer, p. 36, Definition 2.4. ISBN 978-1-4471-3675-0.
- ^ Madsen, H.O., Krenk, S., Lind, S.C. (2006) Methods of Structural Safety. Dover Publications. p. 148-149. ISBN 0486445976
- ^ a b van der Vaart, A.W. (1998). Asymptotic statistics. Cambridge University Press. p. 266. ISBN 0-521-78450-6.
- ^ a b c van der Vaart, A.W. (1998). Asymptotic statistics. Cambridge University Press. p. 268. ISBN 0-521-78450-6.
Further reading[edit]
- Shorack, G.R.; Wellner, J.A. (1986). Empirical Processes with Applications to Statistics. New York: Wiley. ISBN 0-471-86725-X.
External links[edit]
 Media related to Empirical distribution functions at Wikimedia Commons
Media related to Empirical distribution functions at Wikimedia Commons
