Skip to content
В этой статье мы рассмотрим разные подходы к одной из самых распространенных и, по моему мнению, важных задач в Excel – как найти в ячейках и в столбцах таблицы повторяющиеся значения.
Работая с большими наборами данных в Excel или объединяя несколько небольших электронных таблиц в более крупные, вы можете столкнуться с большим числом одинаковых строк.
И сегодня я хотел бы поделиться несколькими быстрыми и эффективными методами выявления дубликатов в одном списке. Эти решения работают во всех версиях Excel 2016, Excel 2013, 2010 и ниже. Вот о чём мы поговорим:
- Поиск повторяющихся значений включая первые вхождения
- Поиск дубликатов без первых вхождений
- Определяем дубликаты с учетом регистра
- Как извлечь дубликаты из диапазона ячеек
- Как обнаружить одинаковые строки в таблице данных
- Использование встроенных фильтров Excel
- Применение условного форматирования
- Поиск совпадений при помощи встроенной команды “Найти”
- Определяем дубликаты при помощи сводной таблицы
- Duplicate Remover – быстрый и эффективный способ найти дубликаты
Самой простой в использовании и вместе с тем эффективной в данном случае будет функция СЧЁТЕСЛИ (COUNTIF). С помощью одной только неё можно определить не только неуникальные позиции, но и их первые появления в столбце. Рассмотрим разницу на примерах.
Поиск повторяющихся значений включая первые вхождения.
Предположим, что у вас в колонке А находится набор каких-то показателей, среди которых, вероятно, есть одинаковые. Это могут быть номера заказов, названия товаров, имена клиентов и прочие данные. Если ваша задача – найти их, то следующая формула для вас:
=СЧЁТЕСЛИ(A:A; A2)>1
Где А2 – первая ячейка из области для поиска.
Просто введите это выражение в любую ячейку и протяните вниз вдоль всей колонки, которую нужно проверить на дубликаты.

Как вы могли заметить на скриншоте выше, формула возвращает ИСТИНА, если имеются совпадения. А для встречающихся только 1 раз значений она показывает ЛОЖЬ.
Подсказка! Если вы ищите повторы в определенной области, а не во всей колонке, обозначьте нужный диапазон и “зафиксируйте” его знаками $. Это значительно ускорит вычисления. Например, если вы ищете в A2:A8, используйте
=СЧЕТЕСЛИ($A$2:$A$8, A2)>1
Если вас путает ИСТИНА и ЛОЖЬ в статусной колонке и вы не хотите держать в уме, что из них означает повторяющееся, а что – уникальное, заверните свою СЧЕТЕСЛИ в функцию ЕСЛИ и укажите любое слово, которое должно соответствовать дубликатам и уникальным:
=ЕСЛИ(СЧЁТЕСЛИ($A$2:$A$17; A2)>1;”Дубликат”;”Уникальное”)
Если же вам нужно, чтобы формула указывала только на дубли, замените “Уникальное” на пустоту (“”):

=ЕСЛИ(СЧЁТЕСЛИ($A$2:$A$17; A2)>1;”Дубликат”;””)

В этом случае Эксель отметит только неуникальные записи, оставляя пустую ячейку напротив уникальных.
Поиск неуникальных значений без учета первых вхождений
Вы наверняка обратили внимание, что в примерах выше дубликатами обозначаются абсолютно все найденные совпадения. Но зачастую задача заключается в поиске только повторов, оставляя первые вхождения нетронутыми. То есть, когда что-то встречается в первый раз, оно однозначно еще не может быть дубликатом.
Если вам нужно указать только совпадения, давайте немного изменим:
=ЕСЛИ(СЧЁТЕСЛИ($A$2:$A2; A2)>1;”Дубликат”;””)
На скриншоте ниже вы видите эту формулу в деле.

Нетрудно заметить, что она не обозначает первое появление слова, а начинает отсчет со второго.
Чувствительный к регистру поиск дубликатов
Хочу обратить ваше внимание на то, что хоть формулы выше и находят 100%-дубликаты, есть один тонкий момент – они не чувствительны к регистру. Быть может, для вас это не принципиально. Но если в ваших данных абв, Абв и АБВ – это три разных параметра – то этот пример для вас.
Как вы могли уже догадаться, выражения, использованные нами ранее, с такой задачей не справятся. Здесь нужно выполнить более тонкий поиск, с чем нам поможет следующая функция массива:
{=ЕСЛИ(СУММ((–СОВПАД($A$2:$A$17;A2)))<=1;””;”Дубликат”)}
Не забывайте, что формулы массива вводятся комбиинацией Ctrl + Shift + Enter.
Если вернуться к содержанию, то здесь используется функция СОВПАД для сравнения целевой ячейки со всеми остальными ячейками с выбранной области. Результат возвращается в виде ИСТИНА (совпадение) или ЛОЖЬ (не совпадение), которые затем преобразуются в массив из 1 и 0 при помощи оператора (–).
После этого, функция СУММ складывает эти числа. И если полученный результат больше 1, функция ЕСЛИ сообщает о найденном дубликате.
Если вы взглянете на следующий скриншот, вы убедитесь, что поиск действительно учитывает регистр при обнаружении дубликатов:

Смородина и арбуз, которые встречаются дважды, не отмечены в нашем поиске, так как регистр первых букв у них отличается.
Как извлечь дубликаты из диапазона.
Формулы, которые мы описывали выше, позволяют находить дубликаты в определенном столбце. Но часто речь идет о нескольких столбцах, то есть о диапазоне данных.
Рассмотрим это на примере числовой матрицы. К сожалению, с символьными значениями этот метод не работает.

При помощи формулы массива
{=ИНДЕКС(НАИМЕНЬШИЙ(ЕСЛИ(СЧЁТЕСЛИ($A$2:$E$11;$A$2:$E$11)>1;$A$2:$E$11);СТРОКА($1:$100)); НАИМЕНЬШИЙ(ЕСЛИОШИБКА(ЕСЛИ(ПОИСКПОЗ(НАИМЕНЬШИЙ(ЕСЛИ( СЧЁТЕСЛИ($A$2:$E$11;$A$2:$E$11)>1;$A$2:$E$11);СТРОКА($1:$100)); НАИМЕНЬШИЙ(ЕСЛИ(СЧЁТЕСЛИ($A$2:$E$11;$A$2:$E$11)>1;$A$2:$E$11); СТРОКА($1:$100));0)=СТРОКА($1:$100);СТРОКА($1:$100));””);СТРОКА()-1))}
вы можете получить упорядоченный по возрастанию список дубликатов. Для этого введите это выражение в нужную ячейку и нажмите Ctrl+Alt+Enter.
Затем протащите маркер заполнения вниз на сколько это необходимо.
Чтобы убрать сообщения об ошибке, когда дублирующиеся значения закончатся, можно использовать функцию ЕСЛИОШИБКА:
=ЕСЛИОШИБКА(ИНДЕКС(НАИМЕНЬШИЙ(ЕСЛИ(СЧЁТЕСЛИ($A$2:$E$11;$A$2:$E$11)>1;$A$2:$E$11); СТРОКА($1:$100));НАИМЕНЬШИЙ(ЕСЛИОШИБКА(ЕСЛИ(ПОИСКПОЗ( НАИМЕНЬШИЙ(ЕСЛИ(СЧЁТЕСЛИ($A$2:$E$11;$A$2:$E$11)>1;$A$2:$E$11); СТРОКА($1:$100));НАИМЕНЬШИЙ(ЕСЛИ(СЧЁТЕСЛИ($A$2:$E$11;$A$2:$E$11)>1;$A$2:$E$11); СТРОКА($1:$100));0)=СТРОКА($1:$100);СТРОКА($1:$100));””);СТРОКА()-1));””)
Также обратите внимание, что приведенное выше выражение рассчитано на то, что оно будет записано во второй строке. Соответственно выше него будет одна пустая строка.
Поэтому если вам нужно разместить его, к примеру, в ячейке K4, то выражение СТРОКА()-1 в конце замените на СТРОКА()-3.
Обнаружение повторяющихся строк
Мы рассмотрели, как обнаружить одинаковые данные в отдельных ячейках. А если нужно искать дубликаты-строки?
Есть один метод, которым можно воспользоваться, если вам нужно просто выделить одинаковые строки, но не удалять их.
Итак, имеются данные о товарах и заказчиках.
Создадим справа от наших данных формулу, объединяющую содержание всех расположенных слева от нее ячеек.
Предположим, что данные хранятся в столбцах А:C. Запишем в ячейку D2:
=A2&B2&C2
Добавим следующую формулу в ячейку E2. Она отобразит, сколько раз встречается значение, полученное нами в столбце D:
=СЧЁТЕСЛИ(D:D;D2)
Скопируем вниз для всех строк данных.
В столбце E отображается количество появлений этой строки в столбце D. Неповторяющимся строкам будет соответствовать значение 1. Повторам строкам соответствует значение больше 1, указывающее на то, сколько раз такая строка была найдена.
Если вас не интересует определенный столбец, просто не включайте его в выражение, находящееся в D. Например, если вам хочется обнаружить совпадающие строки, не учитывая при этом значение Заказчик, уберите из объединяющей формулы упоминание о ячейке С2.
Обнаруживаем одинаковые ячейки при помощи встроенных фильтров Excel.
Теперь рассмотрим, как можно обойтись без формул при поиске дубликатов в таблице. Быть может, кому-то этот метод покажется более удобным, нежели написание выражений Excel.
Организовав свои данные в виде таблицы, вы можете применять к ним различные фильтры. Фильтр в таблице вы можете установить по одному либо по нескольким столбцам. Давайте рассмотрим на примере.
В первую очередь советую отформатировать наши данные как «умную» таблицу. Напомню: Меню Главная – Форматировать как таблицу.
После этого в строке заголовка появляются значки фильтра. Если нажать один из них, откроется выпадающее меню фильтра, которое содержит всю информацию по данному столбцу. Выберите любой элемент из этого списка, и Excel отобразит данные в соответствии с этим выбором.
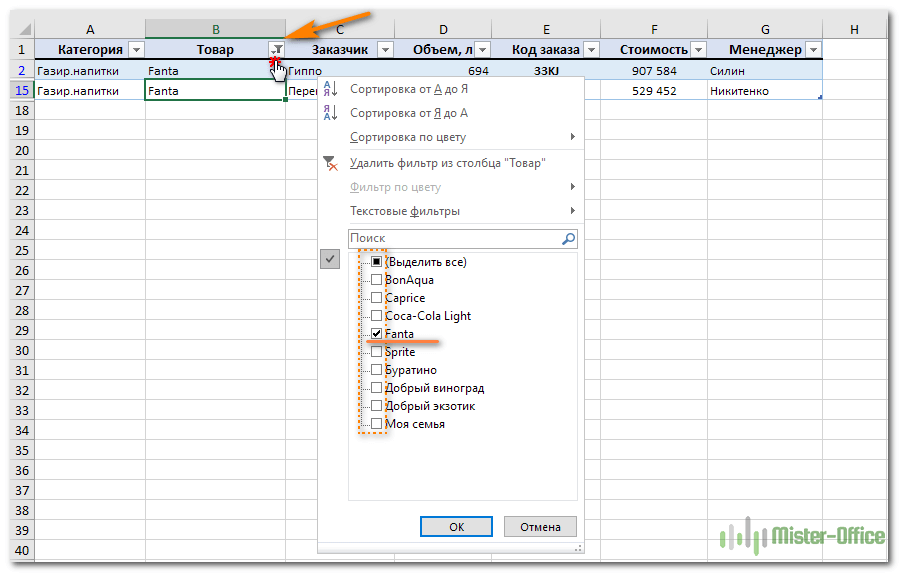
Вы можете убрать галочку с пункта «Выделить все», а затем отметить один или несколько нужных элементов. Excel покажет только те строки, которые содержат выбранные значения. Так можно обнаружить дубликаты, если они есть. И все готово для их быстрого удаления.
Но при этом вы видите дубли только по отфильтрованному. Если данных много, то искать таким способом последовательного перебора будет несколько утомительно. Ведь слишком много раз нужно будет устанавливать и менять фильтр.
Используем условное форматирование.
Выделение цветом по условию – весьма важный инструмент Excel, о котором достаточно подробно мы рассказывали.
Сейчас я покажу, как можно в Экселе найти дубли ячеек, просто их выделив цветом.
Как показано на рисунке ниже, выбираем Правила выделения ячеек – Повторяющиеся. Неуникальные данные будут подсвечены цветом.
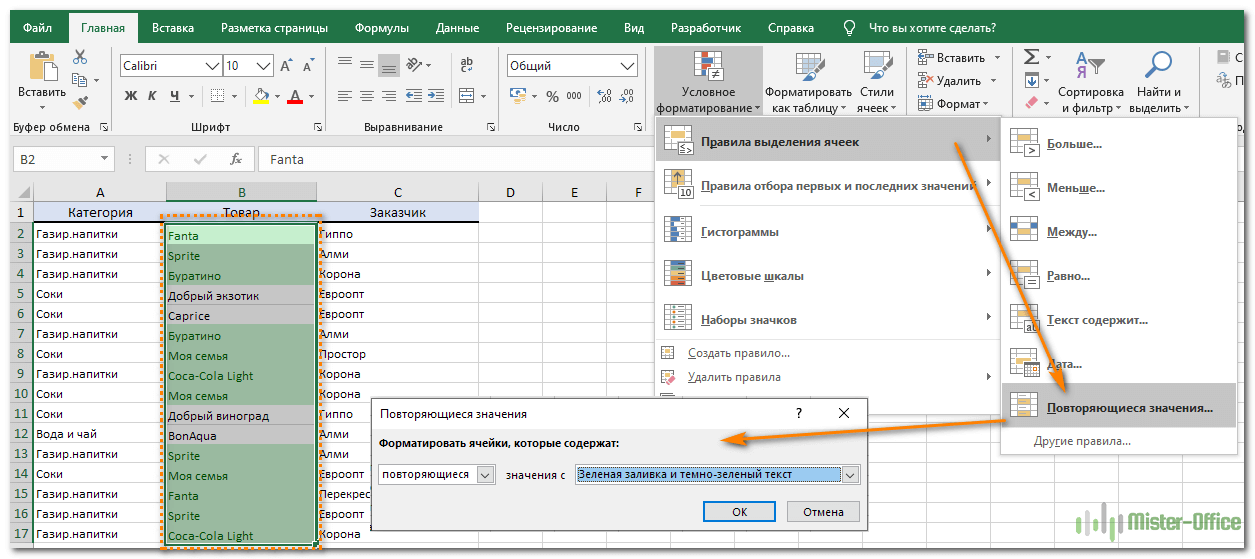
Но здесь мы не можем исключить первые появления – подсвечивается всё.
Но эту проблему можно решить, использовав формулу условного форматирования.
=СЧЁТЕСЛИ($B$2:$B2; B2)>1

Результат работы формулы выденения повторяющихся значений вы видите выше. Они выделены зелёным цветом.
Чтобы освежить память, можете руководствоваться нашим материалом «Как изменить цвет ячейки в зависимости от значения».
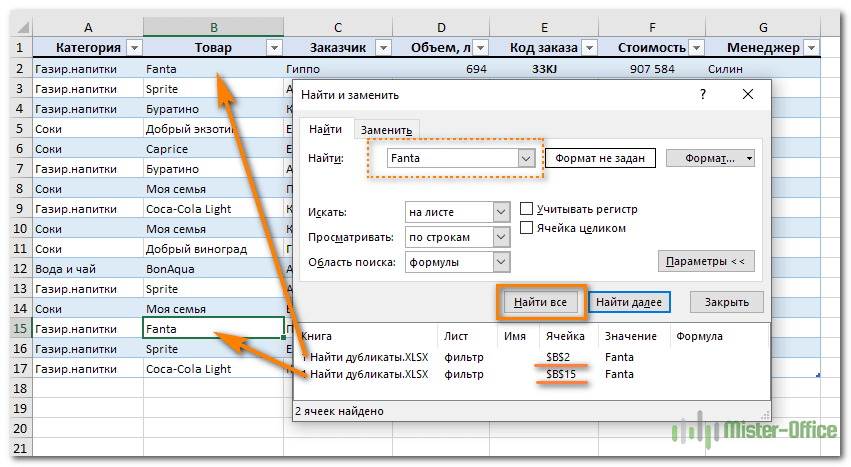
Поиск совпадений при помощи команды «Найти».
Еще один простой, но не слишком технологичный способ – использование встроенного поиска.
Зайдите на вкладку Главная и кликните «Найти и выделить». Откроется диалоговое окно, в котором можно ввести что угодно для поиска в таблице. Чтобы избежать опечаток, можете скопировать искомое прямо из списка данных.
Затем нажимаем «Найти все», и видим все найденные дубликаты и места их расположения, как на рисунке чуть ниже.

В случае, когда объём информации очень велик и требуется ускорить работу поиска, предварительно выделите столбец или диапазон, в котором нужно искать, и только после этого начинайте работу. Если этого не сделать, Excel будет искать по всем имеющимся данным, что, конечно, медленнее.
Этот метод еще более трудоемкий, нежели использование фильтра. Поэтому применяют его выборочно, только для отдельных значений.
Как применить сводную таблицу для поиска дубликатов.
Многие считают сводные таблицы слишком сложным инструментом, чтобы постоянно им пользоваться. На самом деле, не все так запутано, как кажется. Для новичков рекомендую к ознакомлению наше руководство по созданию и работе со сводными таблицами.
Для более опытных – сразу переходим к сути вопроса.
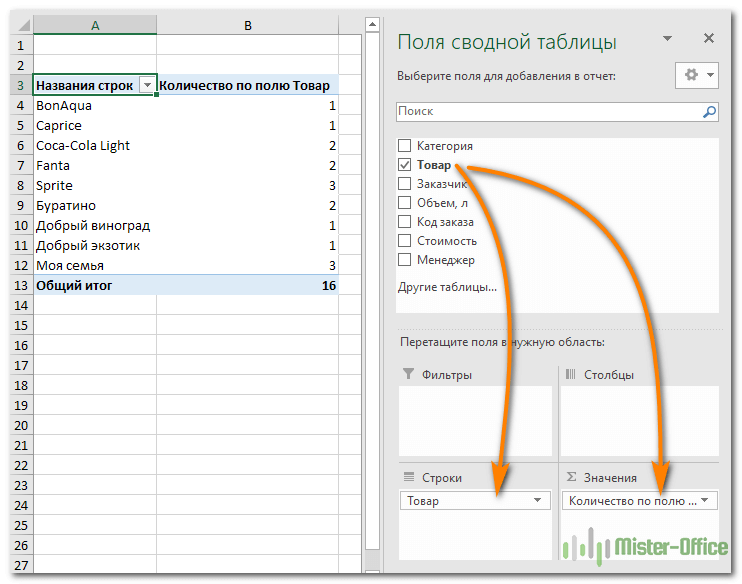
Создаем новый макет сводной таблицы. А затем в качестве строк и значений используем одно и то же поле. В нашем случае – «Товар». Поскольку название товара – это текст, то для подсчета таких значений Excel по умолчанию использует функцию СЧЕТ, то есть подсчитывает количество. А нам это и нужно. Если будет больше 1, значит, имеются дубликаты.

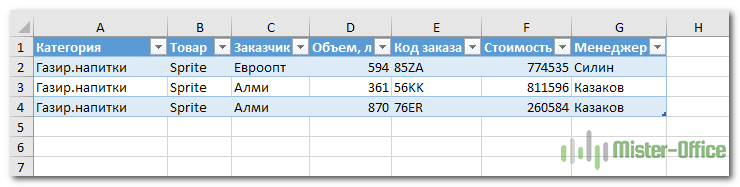
Вы наблюдаете на скриншоте выше, что несколько товаров дублируются. И что нам это дает? А далее мы просто можем щелкнуть мышкой на любой из цифр, и на новом листе Excel покажет нам, как получилась эта цифра.
К примеру, откуда взялись 3 дубликата Sprite? Щелкаем на цифре 3, и видим такую картину:

Думаю, этот метод вполне можно использовать. Что приятно – никаких формул не требуется.
Duplicate Remover – быстрый и эффективный способ найти дубликаты в Excel
Теперь, когда вы знаете, как использовать формулы для поиска повторяющихся значений в Excel, позвольте мне продемонстрировать вам еще один быстрый, эффективный и без всяких формул способ: инструмент Duplicate Remover для Excel.
Этот универсальный инструмент может искать повторяющиеся или уникальные значения в одном столбце или же сравнивать два столбца. Он может находить, выбирать и выделять повторяющиеся записи или целые повторяющиеся строки, удалять найденные дубли, копировать или перемещать их на другой лист. Я думаю, что пример практического использования может заменить очень много слов, так что давайте перейдем к нему.
Как найти повторяющиеся строки в Excel за 2 быстрых шага
Сначала посмотрим в работе наиболее простой инструмент — быстрый поиск дубликатов Quick Dedupe. Используем уже знакомую нам таблицу, в которой мы выше искали дубликаты при помощи формул:

Как видите, в таблице несколько столбцов. Чтобы найти повторяющиеся записи в этих трех столбцах, просто выполните следующие действия:
- Выберите любую ячейку в таблице и нажмите кнопку Quick Dedupe на ленте Excel. После установки пакета Ultimate Suite для Excel вы найдете её на вкладке Ablebits Data в группе Dedupe. Это наиболее простой инструмент для поиска дубликатов.
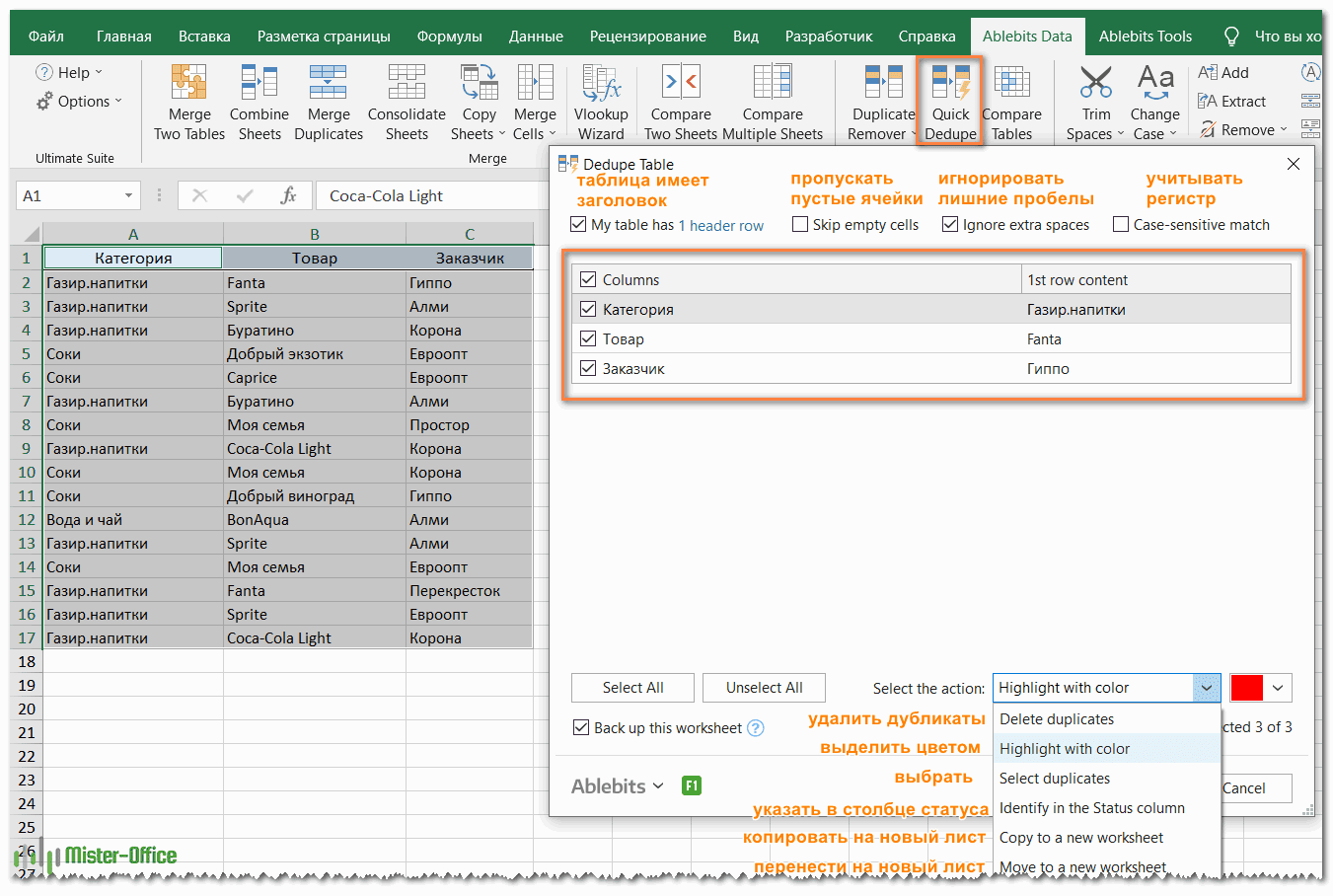
- Интеллектуальная надстройка возьмет всю таблицу и попросит вас указать следующие две вещи:
- Выберите столбцы для проверки дубликатов (в данном примере это все 3 столбца – категория, товар и заказчик).
- Выберите действие, которое нужно выполнить с дубликатами. Поскольку наша цель – выявить повторяющиеся строки, я выбрал «Выделить цветом».
Помимо выделения цветом, вам доступен ряд других опций:
- Удалить дубликаты
- Выбрать дубликаты
- Указать их в столбце статуса
- Копировать дубликаты на новый лист
- Переместить на новый лист
Нажмите кнопку ОК и подождите несколько секунд. Готово! И никаких формул 😊.
Как вы можете видеть на скриншоте ниже, все строки с одинаковыми значениями в первых 3 столбцах были обнаружены (первые вхождения не идентифицируются как дубликаты).

Если вам нужны дополнительные возможности для работы с дубликатами и уникальными значениями, используйте мастер удаления дубликатов Duplicate Remover, который может найти дубликаты с первыми вхождениями или без них, а также уникальные значения. Подробные инструкции приведены ниже.
Мастер удаления дубликатов – больше возможностей для поиска дубликатов в Excel.
В зависимости от данных, с которыми вы работаете, вы можете не захотеть рассматривать первые экземпляры идентичных записей как дубликаты. Одно из возможных решений – использовать разные формулы для каждого сценария, как мы обсуждали в этой статье выше. Если же вы ищете быстрый, точный метод без формул, попробуйте мастер удаления дубликатов — Duplicate Remover. Несмотря на свое название, он не только умеет удалять дубликаты, но и производит с ними другие полезные действия, о чём мы далее поговорим подробнее. Также умеет находить уникальные значения.
- Выберите любую ячейку в таблице и нажмите кнопку Duplicate Remover на вкладке Ablebits Data.
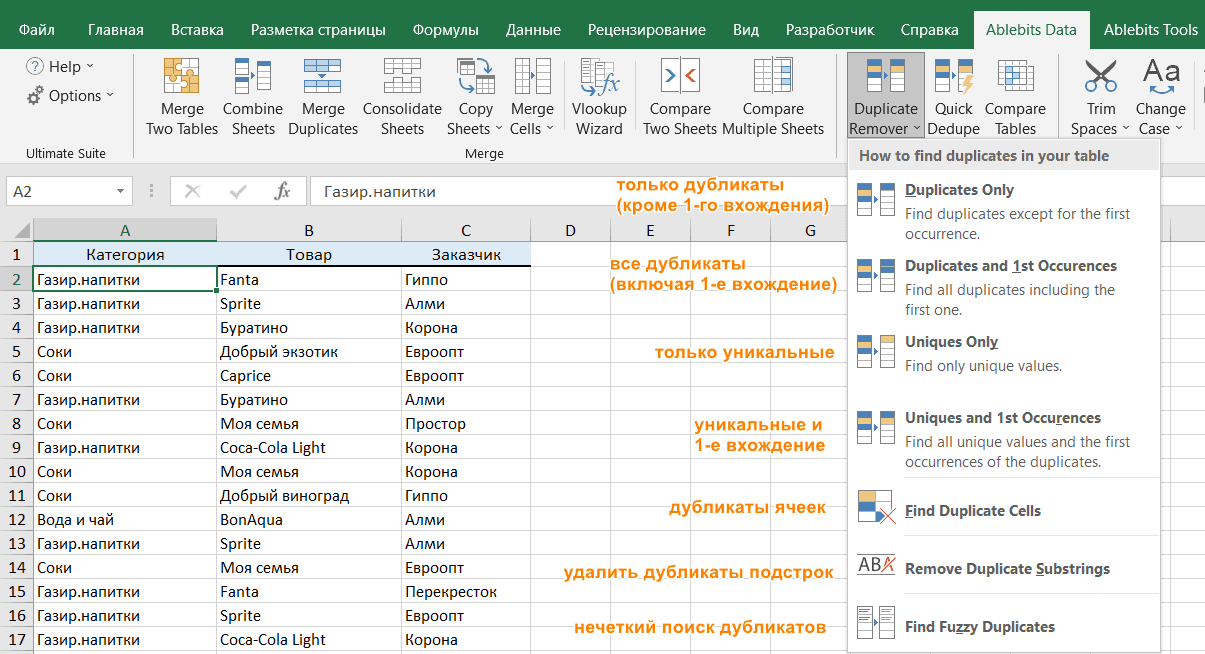
- Вам предложены 4 варианта проверки дубликатов в вашем листе Excel:
- Дубликаты без первых вхождений повторяющихся записей.
- Дубликаты с 1-м вхождением.
- Уникальные записи.
- Уникальные значения и 1-е повторяющиеся вхождения.
В этом примере выберем второй вариант, т.е. Дубликаты + 1-е вхождения:

- Теперь выберите столбцы, в которых вы хотите проверить дубликаты. Как и в предыдущем примере, мы возьмём первые 3 столбца:
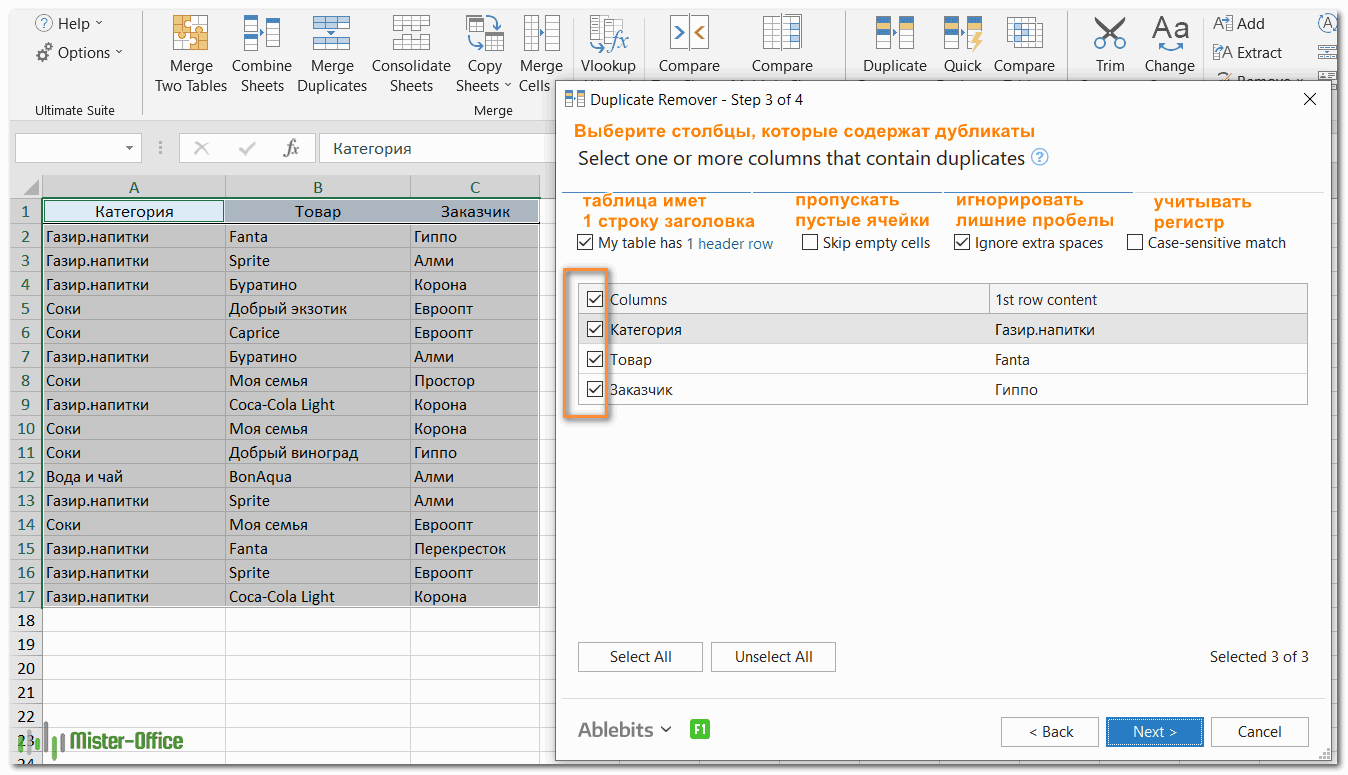
- Наконец, выберите действие, которое вы хотите выполнить с дубликатами. Как и в случае с инструментом быстрого поиска дубликатов, мастер Duplicate Remover может идентифицировать, выбирать, выделять, удалять, копировать или перемещать повторяющиеся данные.

Поскольку цель этого примера – продемонстрировать различные способы определения дубликатов в Excel, давайте отметим параметр «Выделить цветом» (Highlight with color) и нажмите Готово.
Мастеру Duplicate Remover требуется всего лишь несколько секунд, чтобы проверить вашу таблицу и показать результат:

Как видите, результат аналогичен предыдущему. Но здесь мы выделили дубликаты, включая и первое появление повторяющихся записей.
Никаких формул, никакого стресса, никаких ошибок – всегда быстрые и безупречные результаты 🙂
Итак, мы с вам научились различными способами обнаруживать повторяющиеся записи в таблице Excel. В следующих статьях разберем, что мы с этим можем полезного сделать.
Если вы хотите попробовать эти инструменты для поиска дубликатов в таблицах Excel, вы можете загрузить полнофункциональную ознакомительную версию программы. Будем очень признательны за ваши отзывы в комментариях!
- Найти и выделить цветом дубликаты в Excel
- Формула проверки наличия дублей в диапазонах
- Внутри диапазона
- !SEMTools, поиск дублей внутри диапазона
- Найти дубли ячеек в столбце, кроме первого
- Найти в столбце дубли ячеек, включая первый
- Найти дубли в столбце без учета лишних пробелов
Найти повторяющиеся значения в столбцах Excel — на поверку не такая уж и простая задача. Есть пара встроенных инструментов, таких как условное форматирование и инструмент удаления дубликатов, но они не всегда подходят для решения реальных задач.
Поиск дублей в Excel может быть очень разным, и, в зависимости от вводных, производиться тоже будет по-разному.
Ключевых моментов несколько:
- Какие конкретно повторяющиеся значения — повторы слов в ячейках, сами повторяющиеся ячейки или повторяющиеся строки?
- Если ячейки, то:
- Какие ячейки мы готовы считать дубликатами — все кроме первой или включая ее?
- Считаем ли дублями строки, отличающиеся только пробелами до/после слов или лишними пробелами между словами?
- Где мы будем искать дубли — в одном столбце, в двух столбцах или в нескольких?
- А может, нам нужно найти неявные дубли?
Сначала рассмотрим простые примеры.
Для выделения дубликатов ячеек подходит инструмент условное форматирование. В процедуре есть ряд готовых правил, в том числе и для повторяющихся значений.
Найти инструмент можно на вкладке программы “Главная”:
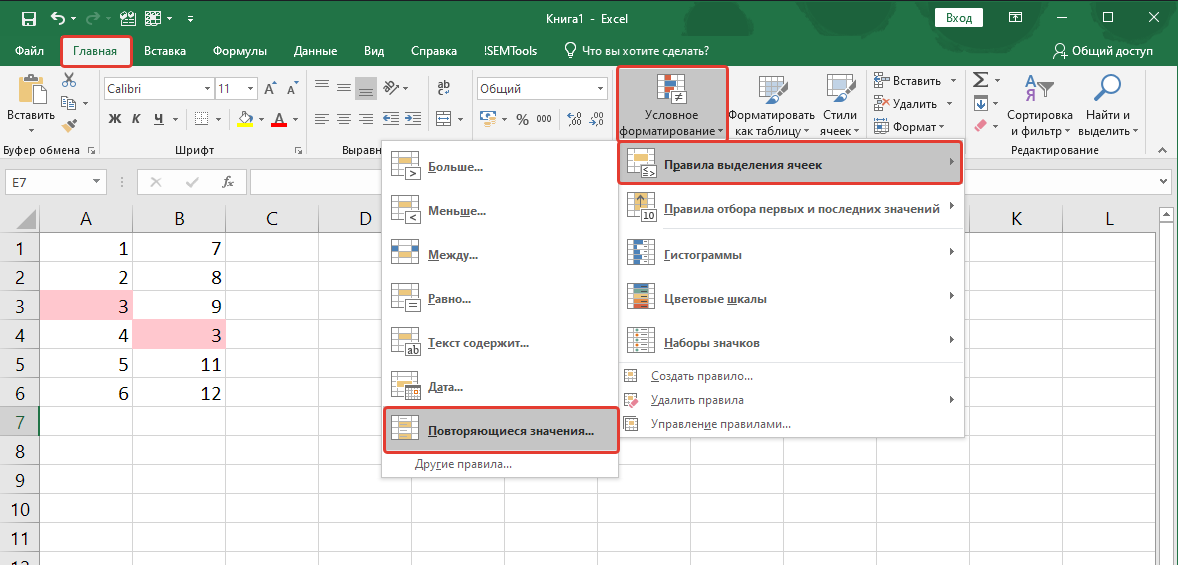
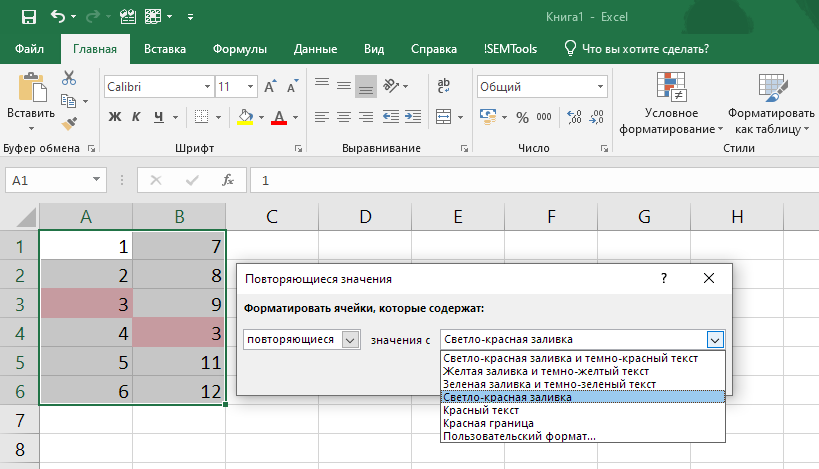
Процедура интуитивно понятна:
- Выделяем диапазон, в котором хотим найти дубликаты.
- Вызываем процедуру.
- Выбираем форматирование для отобранных ячеек (есть предустановленные форматы или же можно задать свой вариант).
Важно понимать, что процедура находит дубликаты внутри всего диапазона и поэтому может не быть применима для сравнения двух столбцов. Достаточно иметь дубликаты внутри одного столбца — и процедура подсветит их оба, хотя во втором их не будет:
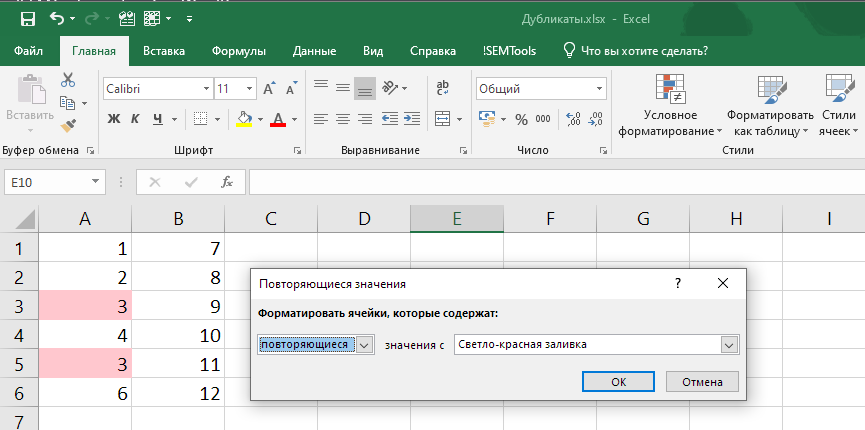
Данное поведение является неочевидным, и об этом факте часто забывают. Если дальше вы планируете удалять повторы, можете потерять оба варианта в одном столбце.
Как избежать подобной ситуации, если хочется найти именно дубли в другом столбце? Простейшее решение: удалить дубли внутри каждого столбца перед применением условного форматирования.
Но есть и другие решения. О них дальше.
Формула проверки наличия дублей в диапазонах
Использование собственной формулы для проверки дубликатов в списке или диапазоне имеет ряд преимуществ, единственная задача — составление такой формулы. Но её я возьму на себя.
Внутри диапазона
Чтобы проверить, есть ли в диапазоне повторяющиеся значения, можно использовать такую формулу массива:
=СУММПРОИЗВ(СЧЁТЕСЛИ(диапазон;тот-же-диапазон)-1)>0
Так выглядит на практике применение формулы:

В чем же преимущество такой формулы, ведь она полностью дублирует опцию условного форматирования, спросите вы.
А дело все в том, что формулу несложно видоизменить и улучшить.
Например, можно улучшить эффективность формулы, добавив в нее функцию СЖПРОБЕЛЫ .Это позволит находить дубликаты, отличающиеся незаметными лишними пробелами:
=СУММПРОИЗВ(--(СЖПРОБЕЛЫ(ячейка)=СЖПРОБЕЛЫ(диапазон)))>1
Эта формула слегка отличается, так как проверяет встречаемость в диапазоне значения одной ячейки.
Если внести ее как правило отбора условного форматирования, она позволит выявлять неявные дубли. Ниже демонстрация того, как работает формула:
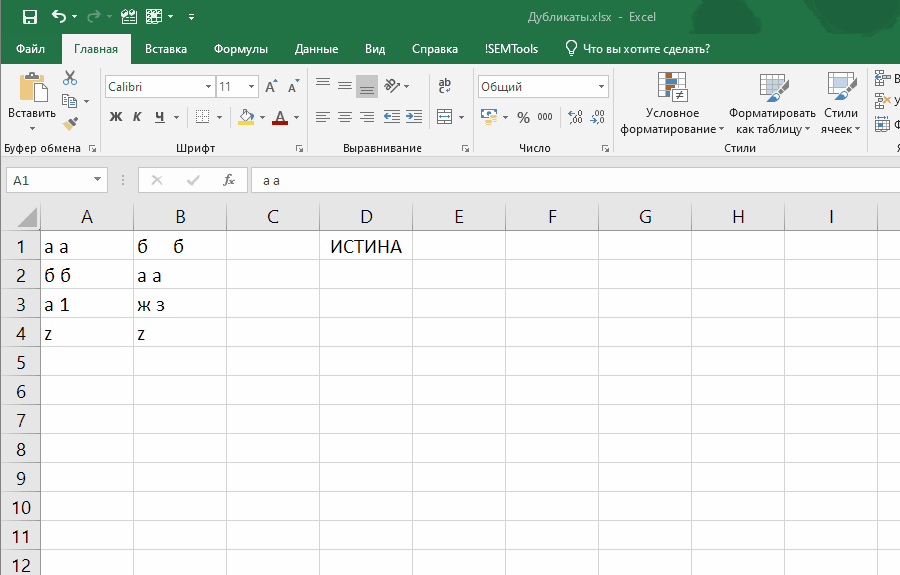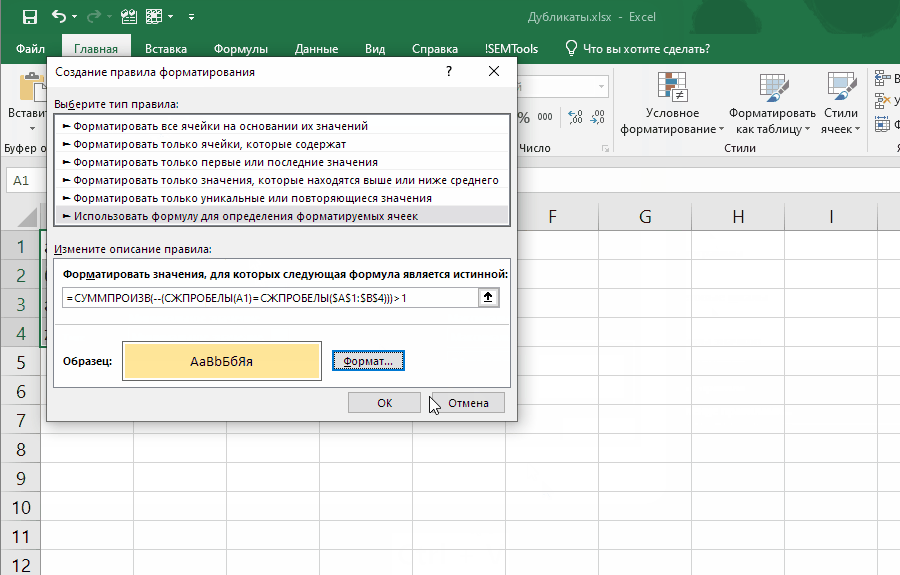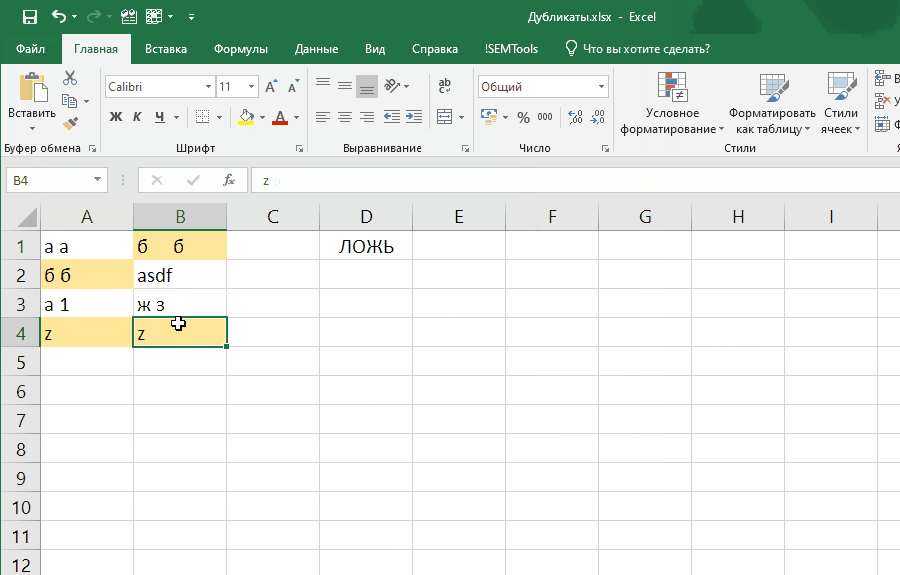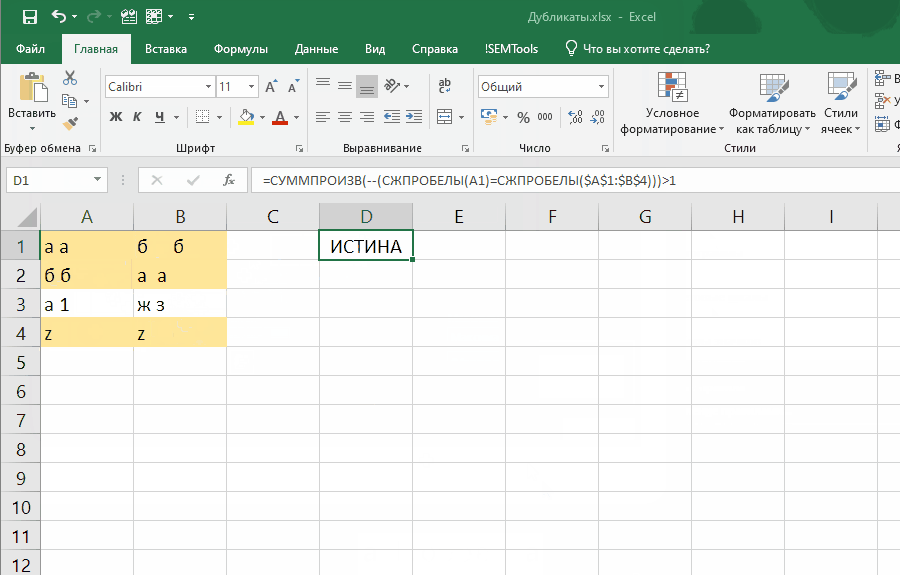
Обратите внимание на один момент в этой демонстрации: диапазон закреплен ($A$1:$B$4), а искомая ячейка (A1) нет. Именно это позволяет условному форматированию находить все дубликаты в диапазоне.
!SEMTools, поиск дублей внутри диапазона
Когда-то я потратил немало времени, пользуясь перечисленными выше методами поиска повторяющихся значений. Все они мне не нравились. Причина была одна: это попросту медленно. Поэтому я решил сделать отдельные процедуры для поиска и удаления дубликатов в Excel в своей надстройке.
Давайте покажу, как они работают.
Найти дубли ячеек в столбце, кроме первого
Процедура позволяет выделить все вторые, третьи и т.д. повторяющиеся значения в столбце.

Найти в столбце дубли ячеек, включая первый
Зачастую нужно найти в столбце все повторяющиеся ячейки, включая первую, для того, чтобы далее отфильтровать их все.

Найти дубли в столбце без учета лишних пробелов
Если мы считаем дубликатами фразы, отличающиеся количеством пробелов между словами или после, наша задача — сначала избавиться от лишних пробелов, и далее произвести тот же поиск дубликатов.
Для первой операции есть отдельный инструмент «Удалить лишние пробелы»:

Найти повторяющиеся значения в Excel и решить сотни других задач поможет надстройка !SEMTools.
Скачайте прямо сейчас и убедитесь сами!
Смотрите также:
- Удалить дубли без смещения строк;
- Удалить неявные дубли;
- Найти повторяющиеся слова в Excel;
- Удалить повторяющиеся слова внутри ячеек.
Поиск и удаление повторений
Excel для Microsoft 365 Excel 2021 Excel 2019 Excel 2016 Excel 2013 Excel 2010 Excel 2007 Excel Starter 2010 Еще…Меньше
В некоторых случаях повторяющиеся данные могут быть полезны, но иногда они усложняют понимание данных. Используйте условное форматирование для поиска и выделения повторяющихся данных. Это позволит вам просматривать повторения и удалять их по мере необходимости.
-
Выберите ячейки, которые нужно проверить на наличие повторений.
Примечание: В Excel не поддерживается выделение повторяющихся значений в области “Значения” отчета сводной таблицы.
-
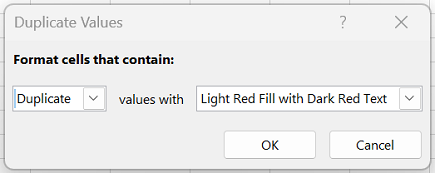
На вкладке Главная выберите Условное форматирование > Правила выделения ячеек > Повторяющиеся значения.

-
В поле рядом с оператором значения с выберите форматирование для применения к повторяющимся значениям и нажмите кнопку ОК.
Удаление повторяющихся значений
При использовании функции Удаление дубликатов повторяющиеся данные удаляются безвозвратно. Чтобы случайно не потерять необходимые сведения, перед удалением повторяющихся данных рекомендуется скопировать исходные данные на другой лист.
-
Выделите диапазон ячеек с повторяющимися значениями, который нужно удалить.
-
На вкладке Данные нажмите кнопку Удалить дубликаты и в разделе Столбцы установите или снимите флажки, соответствующие столбцам, в которых нужно удалить повторения.
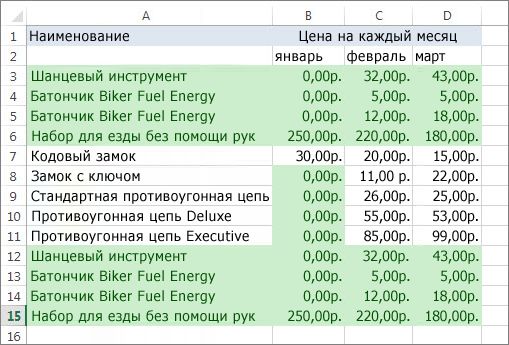
Например, на данном листе в столбце “Январь” содержатся сведения о ценах, которые нужно сохранить.
Поэтому флажок Январь в поле Удаление дубликатов нужно снять.
-
Нажмите кнопку ОК.
Примечание: Количество повторяющихся и уникальных значений, заданных после удаления, может включать пустые ячейки, пробелы и т. д.
Дополнительные сведения

Нужна дополнительная помощь?
Нужны дополнительные параметры?
Изучите преимущества подписки, просмотрите учебные курсы, узнайте, как защитить свое устройство и т. д.
В сообществах можно задавать вопросы и отвечать на них, отправлять отзывы и консультироваться с экспертами разных профилей.
Большие таблицы Эксель могут содержать повторяющиеся данные, что зачастую увеличивает объем информации и может привести к ошибкам в результате обработки данных при помощи формул и прочих инструментов. Это особенно критично, например, при работе с денежными и прочими финансовыми данными.
В данной статье мы рассмотрим методы поиска и удаления дублирующихся данных (дубликатов), в частности, строк в Excel.
Содержание
- Метод 1: удаление дублирующихся строк вручную
- Метод 2: удаление повторений при помощи “умной таблицы”
- Метод 3: использование фильтра
- Метод 4: условное форматирование
- Метод 5: формула для удаления повторяющихся строк
- Заключение
Метод 1: удаление дублирующихся строк вручную
Первый метод максимально прост и предполагает удаление дублированных строк при помощи специального инструмента на ленте вкладки “Данные”.
- Полностью выделяем все ячейки таблицы с данными, воспользовавшись, например, зажатой левой кнопкой мыши.
- Во вкладке “Данные” в разделе инструментов “Работа с данными” находим кнопку “Удалить дубликаты” и кликаем на нее.

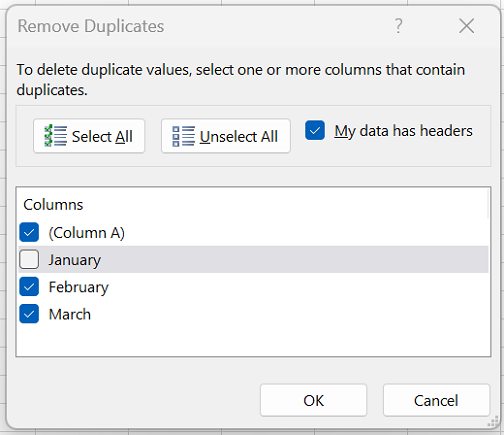
- Переходим к настройкам параметров удаления дубликатов:
- Если обрабатываемая таблица содержит шапку, то проверяем пункт “Мои данные содержат заголовки” – он должен быть отмечен галочкой.
- Ниже, в основном окне, перечислены названия столбцов, по которым будет осуществляться поиск дубликатов. Система считает совпадением ситуацию, в которой в строках повторяются значения всех выбранных в настройке столбцов. Если убрать часть столбцов из сравнения, повышается вероятность увеличения количества похожих строк.
- Тщательно все проверяем и нажимаем ОК.

- Далее программа Эксель в автоматическом режиме найдет и удалит все дублированные строки.
- По окончании процедуры на экране появится соответствующее сообщение с информацией о количестве найденных и удаленных дубликатов, а также о количестве оставшихся уникальных строк. Для закрытия окна и завершения работы данной функции нажимаем кнопку OK.




Метод 2: удаление повторений при помощи “умной таблицы”
Еще один способ удаления повторяющихся строк – использование “умной таблицы“. Давайте рассмотрим алгоритм пошагово.
- Для начала, нам нужно выделить всю таблицу, как в первом шаге предыдущего раздела.

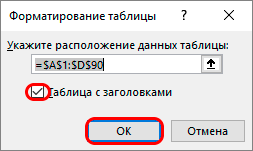
- Во вкладке “Главная” находим кнопку “Форматировать как таблицу” (раздел инструментов “Стили“). Кликаем на стрелку вниз справа от названия кнопки и выбираем понравившуюся цветовую схему таблицы.

- После выбора стиля откроется окно настроек, в котором указывается диапазон для создания “умной таблицы“. Так как ячейки были выделены заранее, то следует просто убедиться, что в окошке указаны верные данные. Если это не так, то вносим исправления, проверяем, чтобы пункт “Таблица с заголовками” был отмечен галочкой и нажимаем ОК. На этом процесс создания “умной таблицы” завершен.

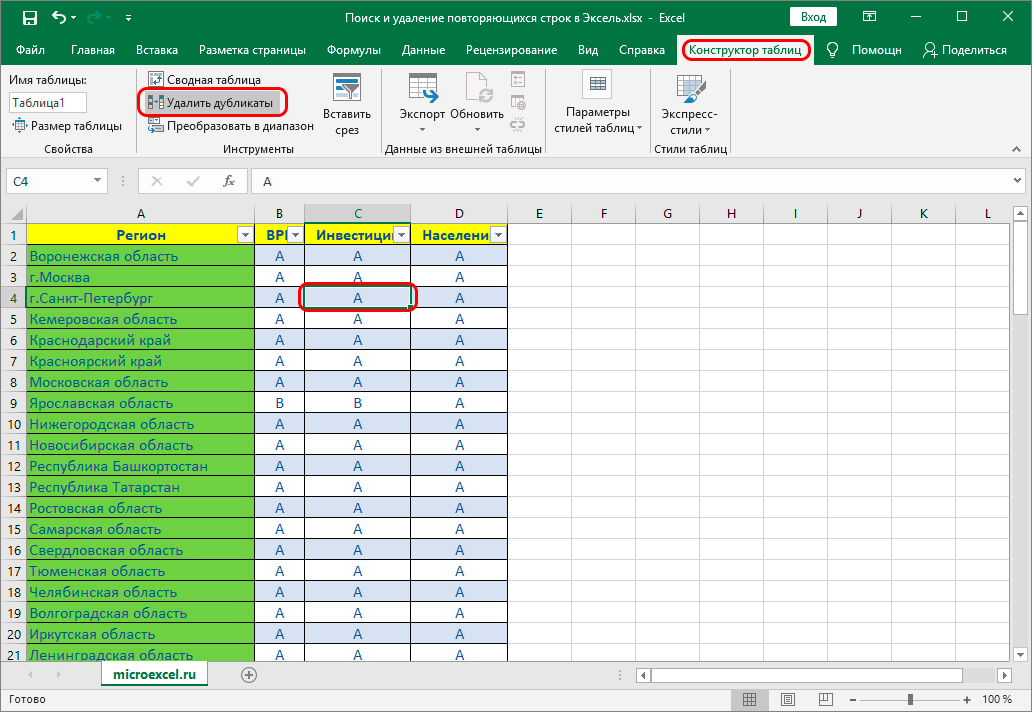
- Далее приступаем к основной задаче – нахождению задвоенных строк в таблице. Для этого:
- ставим курсор на произвольную ячейку таблицы;
- переключаемся во вкладку “Конструктор” (если после создания “умной таблицы” переход не был осуществлен автоматически);
- в разделе “Инструменты” жмем кнопку “Удалить дубликаты“.
- Следующие шаги полностью совпадают с описанными в методе выше действиями по удалению дублированных строк.



Примечание: Из всех описываемых в данной статье методов этот является наиболее гибким и универсальным, позволяя комфортно работать с таблицами различной структуры и объема.
Метод 3: использование фильтра
Следующий метод не удаляет повторяющиеся строки физически, но позволяет настроить режим отображения таблицы таким образом, чтобы при просмотре они скрывались.
- Как обычно, выделяем все ячейки таблицы.
- Во вкладке “Данные” в разделе инструментов “Сортировка и фильтр” ищем кнопку “Фильтр” (иконка напоминает воронку) и кликаем на нее.
- После этого в строке с названиями столбцов таблицы появятся значки перевернутых треугольников (это значит, что фильтр включен). Чтобы перейти к расширенным настройкам, жмем кнопку “Дополнительно“, расположенную справа от кнопки “Фильтр“.
- В появившемся окне с расширенными настройками:
- как и в предыдущем способе, проверяем адрес диапазон ячеек таблицы;
- отмечаем галочкой пункт “Только уникальные записи“;
- жмем ОК.

- После этого все задвоенные данные перестанут отображаться в таблицей. Чтобы вернуться в стандартный режим, достаточно снова нажать на кнопку “Фильтр” во вкладке “Данные”.




Метод 4: условное форматирование
Условное форматирование – гибкий и мощный инструмент, используемый для решения широкого спектра задач в Excel. В этом примере мы будем использовать его для выбора задвоенных строк, после чего их можно удалить любым удобным способом.
- Выделяем все ячейки нашей таблицы.
- Во вкладке “Главная” кликаем по кнопке “Условное форматирование“, которая находится в разделе инструментов “Стили“.
- Откроется перечень, в котором выбираем группу “Правила выделения ячеек“, а внутри нее – пункт “Повторяющиеся значения“.

- Окно настроек форматирования оставляем без изменений. Единственный его параметр, который можно поменять в соответствии с собственными цветовыми предпочтениями – это используемая для заливки выделяемых строк цветовая схема. По готовности нажимаем кнопку ОК.

- Теперь все повторяющиеся ячейки в таблице “подсвечены”, и с ними можно работать – редактировать содержимое или удалить строки целиком любым удобным способом.


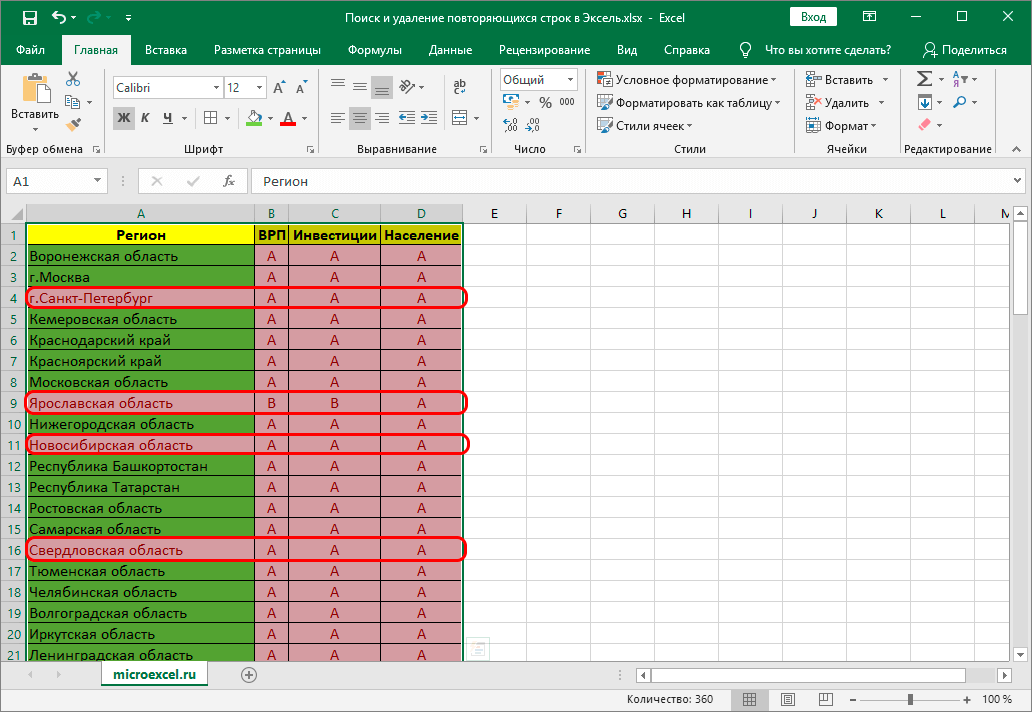
Важно! Этом метод не настолько универсален, как описанные выше, так как выделяет все ячейки с одинаковыми значениями, а не только те, для которых совпадает вся строка целиком. Это видно на предыдущем скриншоте, когда нужные задвоения по названиям регионов были выделены, но вместе с ними отмечены и все ячейки с категориями регионов, потому что значения этих категорий повторяются.
Метод 5: формула для удаления повторяющихся строк
Последний метод достаточно сложен, и им мало, кто пользуется, так как здесь предполагается использование сложной формулы, объединяющей в себе несколько простых функций. И чтобы настроить формулу для собственной таблицы с данными, нужен определенный опыт и навыки работы в Эксель.
Формула, позволяющая искать пересечения в пределах конкретного столбца в общем виде выглядит так:
=ЕСЛИОШИБКА(ИНДЕКС(адрес_столбца;ПОИСКПОЗ(0;СЧЁТЕСЛИ(адрес_шапки_столбца_дубликатов:адрес_шапки_столбца_дубликатов(абсолютный);адрес_столбца;)+ЕСЛИ(СЧЁТЕСЛИ(адрес_столбца;адрес_столбца;)>1;0;1);0));"")
Давайте посмотрим, как с ней работать на примере нашей таблицы:
- Добавляем в конце таблицы новый столбец, специально предназначенный для отображения повторяющихся значений (дубликаты).
- В верхнюю ячейку нового столбца (не считая шапки) вводим формулу, которая для данного конкретного примера будет иметь вид ниже, и жмем Enter:
=ЕСЛИОШИБКА(ИНДЕКС(A2:A90;ПОИСКПОЗ(0;СЧЁТЕСЛИ(E1:$E$1;A2:A90)+ЕСЛИ(СЧЁТЕСЛИ(A2:A90;A2:A90)>1;0;1);0));""). - Выделяем до конца новый столбец для задвоенных данных, шапку при этом не трогаем. Далее действуем строго по инструкции:
- ставим курсор в конец строки формул (нужно убедиться, что это, действительно, конец строки, так как в некоторых случаях длинная формула не помещается в пределах одной строки);
- жмем служебную клавишу F2 на клавиатуре;
- затем нажимаем сочетание клавиш Ctrl+SHIFT+Enter.
- Эти действия позволяют корректно заполнить формулой, содержащей ссылки на массивы, все ячейки столбца. Проверяем результат.



Как уже было сказано выше, этот метод сложен и функционально ограничен, так как не предполагает удаления найденных столбцов. Поэтому, при прочих равных условиях, рекомендуется использовать один из ранее описанных методов, более логически понятных и, зачастую, более эффективных.
Заключение
Excel предлагает несколько инструментов для нахождения и удаления строк или ячеек с одинаковыми данными. Каждый из описанных методов специфичен и имеет свои ограничения. К универсальным варианту мы, пожалуй, отнесем использование “умной таблицы” и функции “Удалить дубликаты”. В целом, для выполнения поставленной задачи необходимо руководствоваться как особенностями структуры таблицы, так и преследуемыми целями и видением конечного результата.
Не секрет, что в Excel часто приходится работать с большими таблицами, которые содержат в себе огромное количество информации. При этом подобный объем информации при обработке может стать причиной сбоев или неправильных расчетов при использовании разнообразных формул или фильтрации. Особенно это ощущается, когда приходится работать с финансовой информацией.
Поэтому, чтобы упростить работу с таким массивом информации и исключить вероятность появления ошибок, мы разберем, как именно работать со строками в Excel и использовать их для удаления дубликатов. Возможно, звучит сложно, но разобраться в этом, на самом деле, довольно просто, особенно когда под рукой будет целых пять методов работы с поиском и удалением дубликатов.
Содержание
- Метод 1: удаление дублирующихся строк вручную
- Метод 2: удаление повторений при помощи «умной таблицы»
- Метод 3: использование фильтра
- Расширенный фильтр для поиска дубликатов в Excel
- Метод 4: условное форматирование
- Метод 5: формула для удаления повторяющихся строк
- Поиск совпадений при помощи команды «Найти»
- Как применить сводную таблицу для поиска дубликатов
- Заключение
Метод 1: удаление дублирующихся строк вручную
Первым делом следует рассмотреть возможность применения самого простого способа работы с дубликатами. Таковым является ручной метод, подразумевающий использование вкладки «Данные»:
- Для начала необходимо выделить все ячейки таблицы: зажимаем ЛКМ и выделяем всю область ячеек.
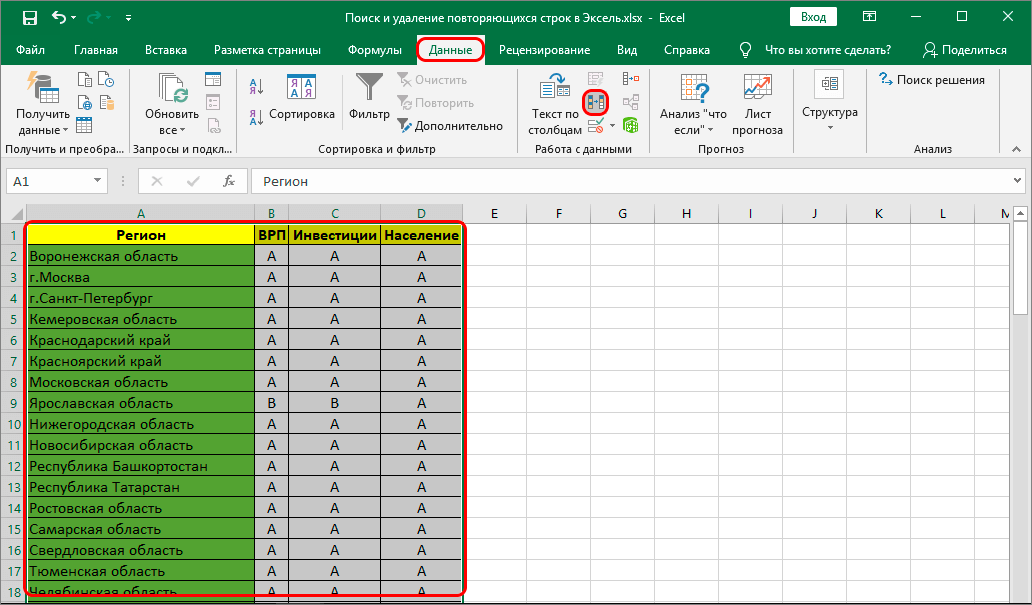
- Сверху в панели инструментов нужно выбрать раздел «Данные», чтобы получить доступ ко всем необходимым инструментам.
- Внимательно рассматриваем доступные значки и выбираем тот, который имеет два столбца ячеек, раскрашенных в разные цвета. Если навести на этот значок курсор, то высветится наименование «Удалить дубликаты».
- Чтобы эффективно использовать все параметры этого раздела, достаточно быть внимательным и не торопиться с установками. К примеру, если таблица имеет «Шапку», то обязательно обратите внимание на пункт «Мои данные содержат заголовки», в нем обязательно должна стоять галочка.
- Далее идет окно, в котором отображается информация по столбцам. Нужно выбрать те столбцы, которые вы хотите проверить на наличие дубликатов. Лучше выбирать все, чтобы минимизировать пропуск дублей.
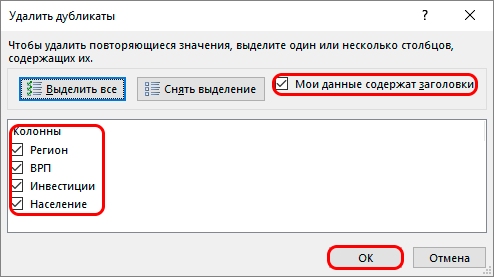
- Как только все будет готово, еще раз проверьте отмеченную информацию и нажимайте «ОК».
- Программа Excel начнет автоматически анализировать выбранные ячейки и удалит все совпадающие варианты.
- После полной проверки и удаления дубликатов из таблицы в программе появится окно, в котором будет сообщение о том, что процесс окончен и будет указана информация о том, сколько совпадающих строк было удалено.
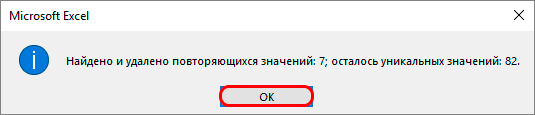
Вам остается только нажать на «ОК» и можно считать, что все готово. Внимательно выполняйте каждое действие, и результат вас наверняка не разочарует.
Метод 2: удаление повторений при помощи «умной таблицы»
Теперь внимательно разберем еще один полезный метод удаления дубликатов, который основывается на использовании «умной таблицы». Достаточно следовать указанным рекомендациям:
- Первым делом выделите всю таблицу, к которой необходимо применить умный алгоритм автоматической обработки информации.
- Теперь воспользуйтесь панелью с инструментами, где нужно выбрать раздел «Главная», а затем найти «Форматировать как таблицу». Обычно этот значок находится в подразделе «Стили». Остается воспользоваться специальной стрелкой вниз около значка и выбрать тот стиль оформления таблицы, который вам приглянулся больше всего.
- Как только все будет сделано правильно, появится дополнительное сообщение о форматировании таблицы. В нем указывается диапазон, для которого будет применена функция «Умной таблицы». И если вы заранее выделяли нужные ячейки, то диапазон будет указан автоматически и вам останется его всего лишь проверить.
- Осталось только приступить к поиску и дальнейшему удалению дублированных строк. Чтобы сделать это, необходимо выполнить дополнительные действия:
- поставьте курсор на произвольную ячейку таблицы;
- в верхней панели инструментов нужно выбрать раздел «Конструктор таблиц»;
- ищем значок в виде двух столбцов ячеек с разным цветом, при наведении на которые будет высвечиваться надпись «Удалить дубликаты»;
- выполните действия, которые мы указали в первом методе после использования данного значка.
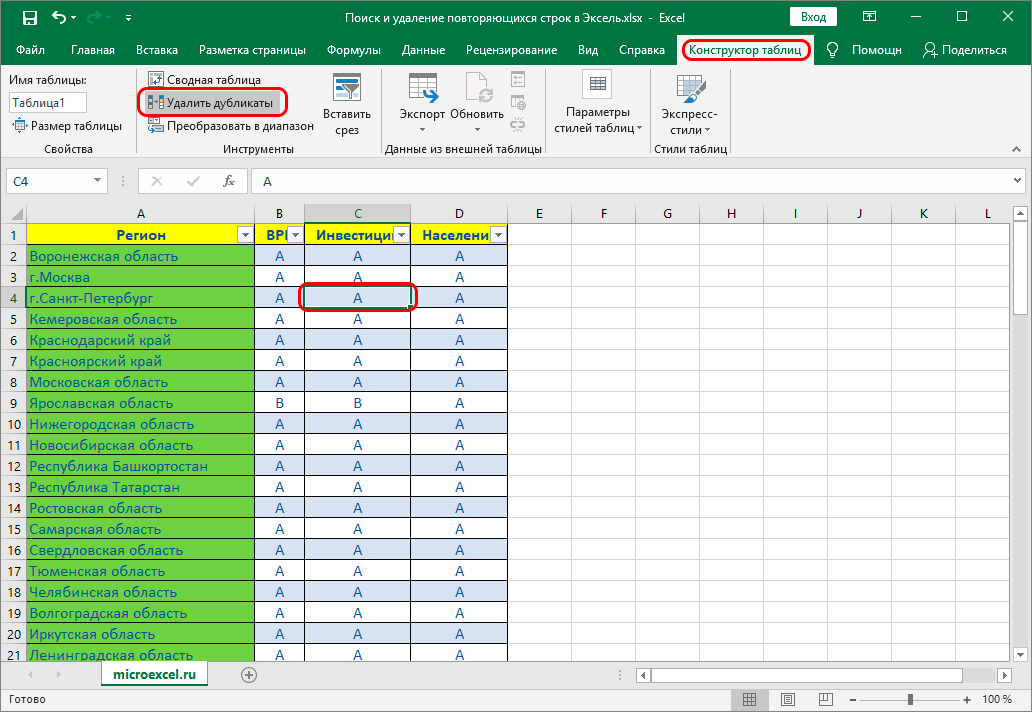
Обратите внимание! Данный метод обладает уникальным свойством – благодаря нему можно будет работать с таблицами разного диапазона без каких-либо ограничений. Любая выделенная область во время работы с Excel будет подвергаться тщательному анализу на дубликаты.
Метод 3: использование фильтра
Теперь обратим внимание на специальный метод, который позволяет не удалить дубликаты из таблицы, а просто скрыть их. По факту этот метод позволяет форматировать таблицу таким образом, чтобы при дальнейшей работе с таблицей вам ничто не мешало и была возможность визуально получить только актуальную и полезную информацию. Чтобы реализовать его, вам достаточно будет выполнить следующие действия:
- Первым делом следует выделить полностью таблицу, в которой вы собираетесь провести манипуляции по удалению дубликатов.
- Теперь перейдите в раздел «Данные» и сразу перейдите в подраздел «Фильтр».
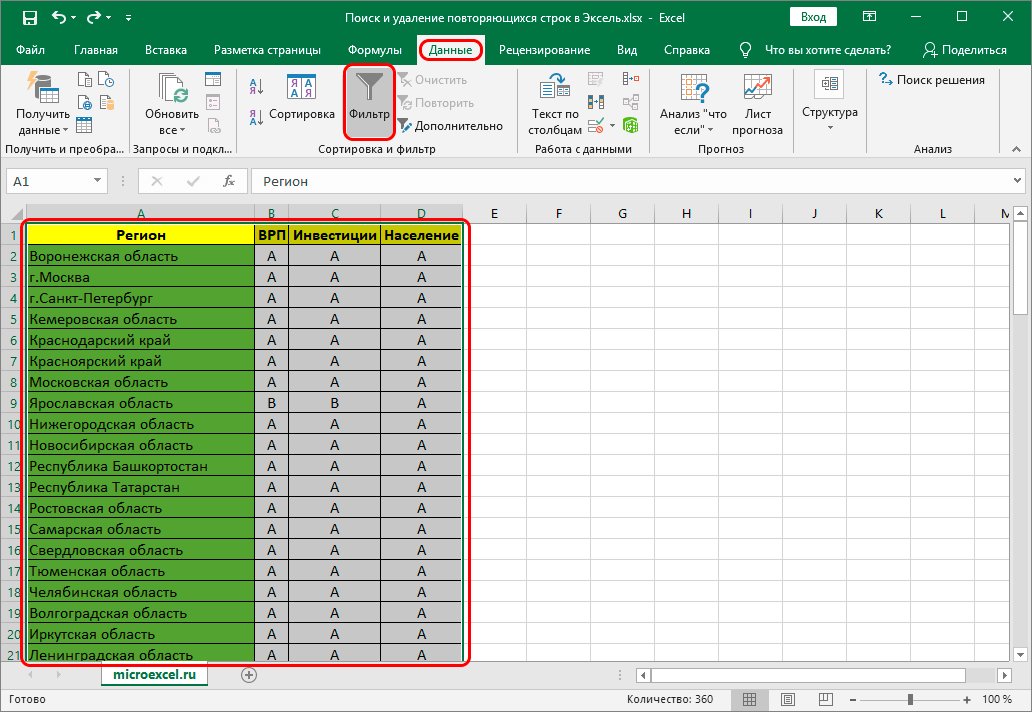
- Явным признаком того, что фильтр был активирован, является наличие в шапке таблицы специальных стрелок, после этого вам будет достаточно воспользоваться ими и указать информацию касательно дубликатов (к примеру, слово или обозначение в поиске).
Таким образом можно сразу отфильтровать все дубликаты и произвести дополнительные манипуляции с ними.
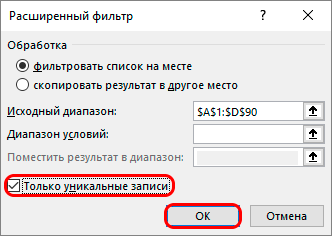
Расширенный фильтр для поиска дубликатов в Excel
Имеется еще дополнительный способ использования фильтров в программе Excel, для этого вам понадобится:
- Выполнить все действия прошлого метода.
- В окне инструментария воспользоваться значком «Дополнительно», который находится около того самого фильтра.
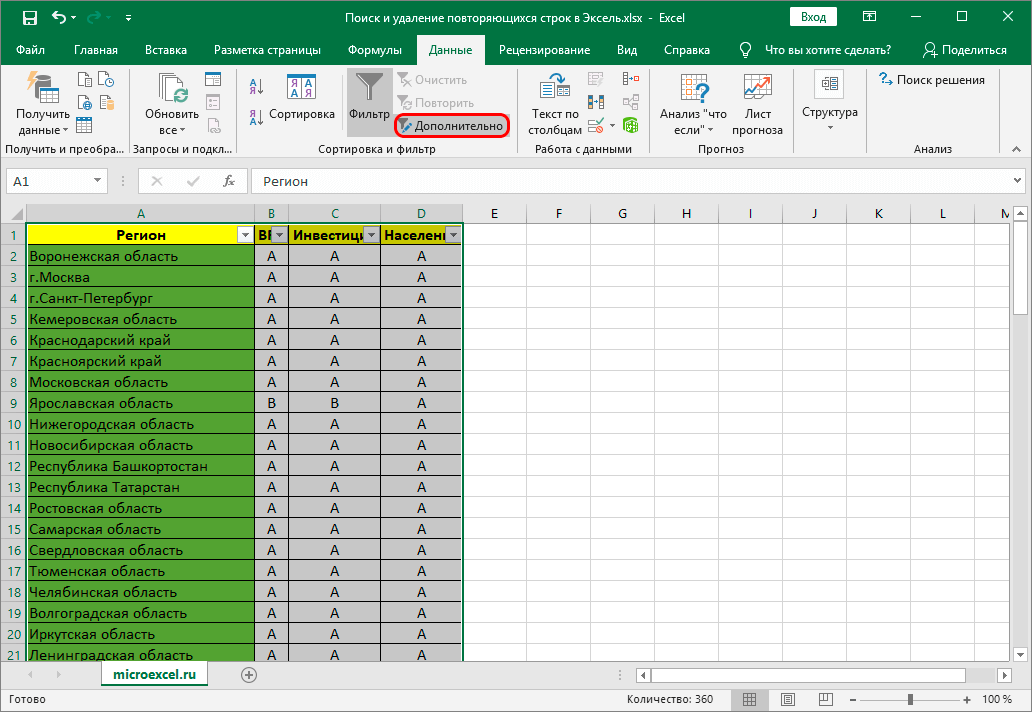
- После использования данного значка вам достаточно будет обратить внимание на окно дополнительных настроек. Этот расширенный инструментарий позволит ознакомиться с первоначальной информацией:
- поначалу следует проверить указанный диапазон таблицы, чтобы он совпадал с тем, что вы отмечали;
- обязательно отметьте пункт «Только уникальные записи»;
- как только все будет готово, остается лишь нажать на кнопку «ОК».
- Как только все рекомендации будут выполнены, вам останется лишь взглянуть на таблицу и убедиться в том, что дубликаты больше не отображаются. Это будет сразу видно, если взглянуть на информацию снизу слева, где отражается количество строк, отображаемое на экране.
Важно! Если вам необходимо будет вернуть все в изначальный вид, то сделать это максимально просто. Достаточно просто отменить фильтр, выполнив аналогичные действия, которые были указаны в инструкции метода.
Метод 4: условное форматирование
Условное форматирование – специальный инструментарий, который применяется в решении многих задач. Предусматривается возможность использования этого инструмента для поиска и удаления дубликатов в таблице. Для этого вам понадобится сделать следующее:
- Как и ранее, поначалу необходимо будет выделить ячейки таблицы, которую вы планируете форматировать.
- Теперь следует перейти во вкладку «Главная» и найти специальный значок «Уловное форматирование», который находится в подразделе «Стили».
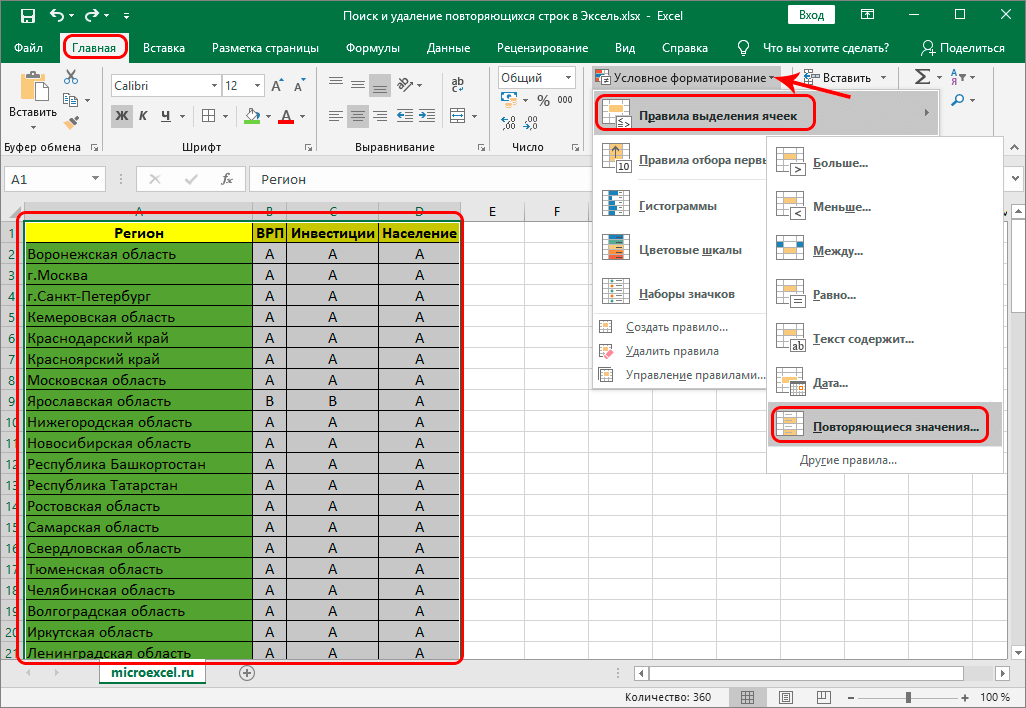
- После выполненных действий вы получите доступ к окну под названием «Правила выделения ячеек», далее нужно выбрать пункт «Повторяющиеся значения».
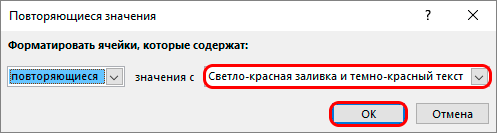
- Обязательно следует обратить внимание на настройки форматирования, их следует оставлять без изменения. Единственное, что можно изменить, так это цветовое обозначение в соответствии с вашими предпочтениями. Как только все будет готово, можно нажимать «ОК».
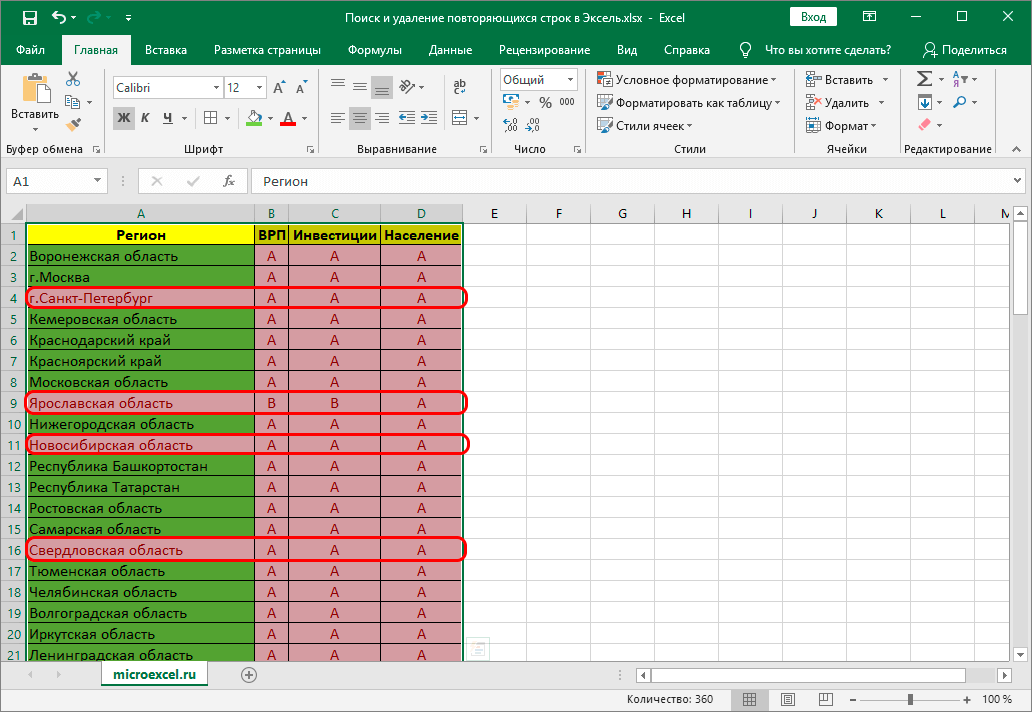
- Благодаря таким действиям можно подсветить все дубликаты другим цветом и в дальнейшем начинать с ними работать.
Внимание! Главным недостатком данного метода является то, что при использовании такой функции отмечаются абсолютно все одинаковые значения, а не только те варианты, где совпадает вся строка. Стоит помнить об этом нюансе, чтобы избежать проблем с визуальным восприятием и понять, как именно нужно действовать и на что обращать внимание.
Метод 5: формула для удаления повторяющихся строк
Данный метод является самым сложным из всех перечисленных, так как предназначается исключительно для тех пользователей, кто разбирается в функциях и особенностях этой программы. Ведь метод предполагает использование сложной формулы. Выглядит она следующим образом: =ЕСЛИОШИБКА(ИНДЕКС(адрес_столбца;ПОИСКПОЗ(0;СЧЁТЕСЛИ(адрес_шапки_столбца_дубликатов:адрес_шапки_столбца_дубликатов(абсолютный);адрес_столбца;)+ЕСЛИ(СЧЁТЕСЛИ(адрес_столбца;адрес_столбца;)>1;0;1);0));»»). Теперь необходимо определиться, как именно ей пользоваться и где применять:
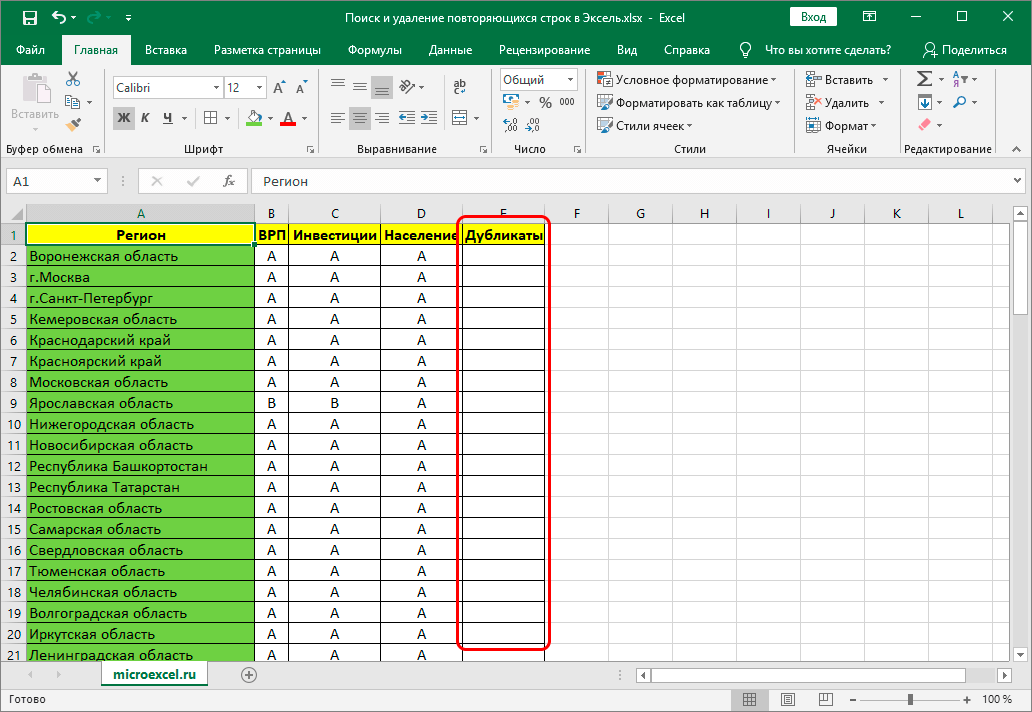
- Первым делом следует добавить новый столбец, который будет предназначен исключительно для дубликатов.
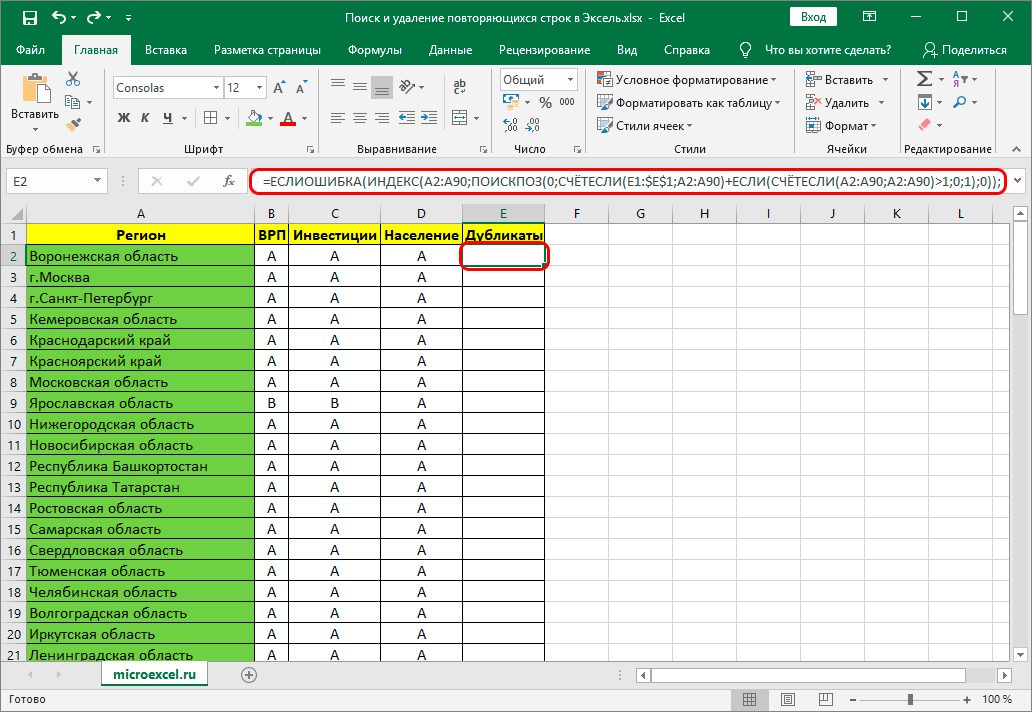
- Выделите верхнюю ячейку и введите в нее формулу: =ЕСЛИОШИБКА(ИНДЕКС(A2:A90;ПОИСКПОЗ(0;СЧЁТЕСЛИ(E1:$E$1;A2:A90)+ЕСЛИ(СЧЁТЕСЛИ(A2:A90;А2:А90)>1;0;1);0));»»).
- Теперь выделите полностью столбец для дубликатов, не трогая шапку.
- Поставьте курсор в конец формулы, только будьте внимательны с этим пунктом, так как далеко не всегда формулу хорошо видно в ячейке, лучше воспользоваться верхней строкой поиска и внимательно посмотреть правильное расположение курсора.
- После установки курсора необходимо нажать на кнопку F2 на клавиатуре.
- После этого нужно нажать сочетание клавиш «Ctrl+Shift+Enter».
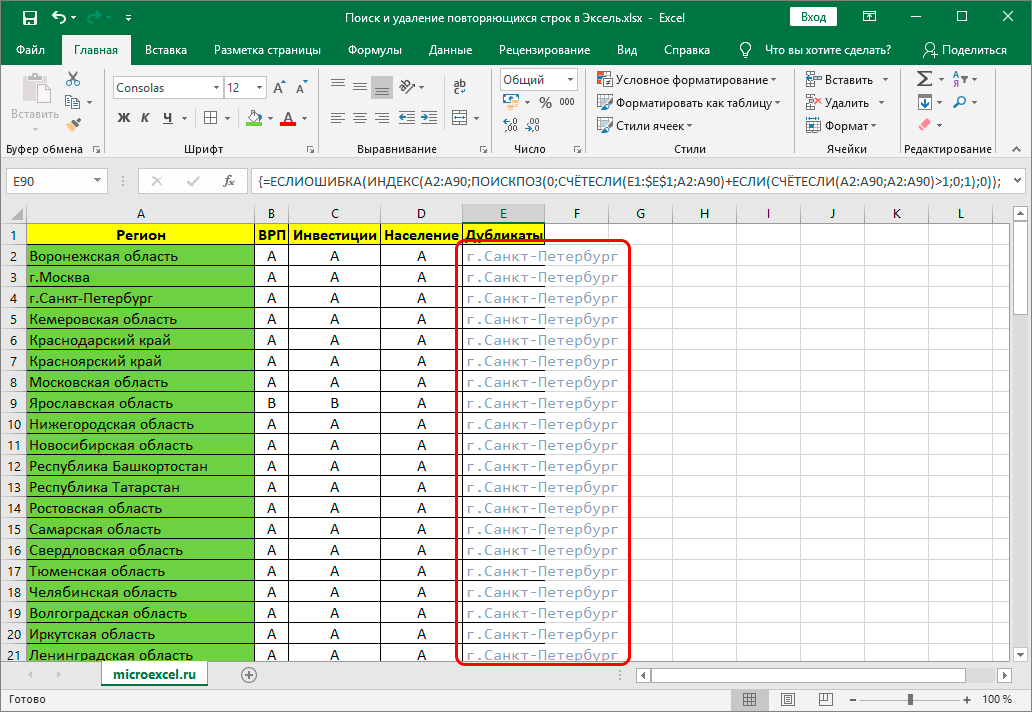
- Благодаря выполненным действиям можно будет корректно заполнить формулу необходимыми сведениями из таблицы.
Поиск совпадений при помощи команды «Найти»
Теперь стоит рассмотреть еще один интересный вариант поиска дубликатов. Специально для такого метода вам понадобится еще одна формула, которая выглядит следующим образом: =СЧЁТЕСЛИ(A:A; A2)>1.
Дополнительная информация! В данной формуле под А2 подразумеваются отметка первой ячейки из области, в которой вы планируете производить поиск. Как только формула будет введена в первую ячейку, можно протянуть значение и получить нужную информацию. Благодаря таким действиям можно будет распределить информацию на «ИСТИНА» и «ЛОЖЬ». А если вам требуется произвести поиск в ограниченной области, то отметьте диапазон поиска и обязательно закрепите эти обозначения значком $, который подтвердит фиксацию и сделает ее основой.
Если вас не устраивает информация в виде «ИСТИНА» или «ЛОЖЬ», то предлагаем воспользоваться следующей формулой, которая структурирует информацию: =ЕСЛИ(СЧЁТЕСЛИ($A$2:$A$17; A2)>1;»Дубликат»;»Уникальное»). Правильное выполнение всех действий позволит вам получить все необходимые действия и быстро разобраться с имеющимися дубликатами информации.
Как применить сводную таблицу для поиска дубликатов
Дополнительным методом использования функций Excel для поиска дубликатов является сводная таблица. Правда, чтобы ей воспользоваться, все же необходимо базовое понимание всех функций программы. А что касается основных действий, то они выглядят следующим образом:
- Первым делом необходимо создать макет таблицы.
- В качестве информации для строк и значений необходимо использовать одно и тоже поле.
- Выбранные слова совпадения станут основными для автоматического подсчета дубликатов. Только не забывайте, что основой функцией подсчета является команда «СЧЕТ». Для дальнейшего понимания учитывайте, что все значения, которые будут превышать значение в 1, будут являться дубликатами.
Обратите внимание на скриншот, где показан пример такого метода.
Главным отличительным пунктом этого способа является отсутствие каких-либо формул. Его смело можно брать на вооружение, но сначала следует изучить особенности и нюансы использования сводной таблицы.
Заключение
Теперь вы владеете всей необходимой информацией касательно методов использования поиска и удаления дубликатов, а также у вас есть рекомендации и подсказки, которые помогут оперативно решить поставленную задачу.
Оцените качество статьи. Нам важно ваше мнение:
