Нашли ошибку на странице?
Выделите её мышкой и нажмите
Ctrl + Enter

Задать вопрос
| Раздел: CronosPRO | Дата редакции: 27.03.2013 | id статьи: 1316 |
В файл Errlog.txt записывается справочная информация и коды ошибок Windows (http://msdn.microsoft.com/), если они возникают при работе системы «CronosPRO».
Информация в файле Errlog.txt может быть полезна не только для разработчиков ПО, но и для администраторов системы «CronosPRO». Многие ошибки администратор системы может устранить самостоятельно, без обращения в службу технической поддержки.
12.09 11:26:34 CronosUserName D:CronosPlusBDBankNameCroBank.tad error=3 cause=3 offset=0 len=ffffffff readOnly=0 01.10 21:00:01 CronosUserName D:CronosPlusBDBankNameCroBank.tad BdCopySL.cpy error=2 cause=2 offset=0 len=ffffffff readOnly=0 12.02 17:49:35 CronosUserName D:CronosPlusBDBankNameCroBank.tad offset=43f00 len=4000 err=6 13.02 10:30:00 CronosUserName D:CronosPlusBDBankNameCroBank.tad offset=10 len=12f00 err=33 22.05 10:10:57 CronosUserName D:CronosPlusBDBankNameCroBank.tad offset=c47d len=44b err=59 22.07 10:03:48 CronosUserName D:CronosPlusBDBankNameCroBank.tad offset=9280 len=10 err=64 13.08 16:14:43 CronosUserName D:CronosPlusBDBankNameCroBank.tad offset=10 len=36761a0 err=1450
-
Операционная система не может открыть файл (к примеру, файл банка данных), так как файл отсутствует по указанному адресу.
Скорее всего, файлы были перенесены или удалены. При обращении к несуществующим файлам возникает данная ошибка.
-
Операционная система не может открыть очередной файл (к примеру, файл банка данных), для того чтобы дать пользователю доступ к нему.
Обычно причиной данной ошибки является использование на сервере ИСУБД «CronosPRO» «настольной» операционной системы, например, Windows XP. Подобные операционные системы, в отличие от серверных ОС, имеют существенное ограничение на число одновременно открытых по сети файлов. Например, Windows XP в рамках одной сетевой сессии позволяет открыть не более 16384 файлов. Это ограничение может приводить к проблемам в случае одновременного подключения большого числа банков данных (как правило, это происходит при выполнении глобального поиска).
Для устранения проблемы рекомендуется установить на компьютере, используемом в качестве сервера ИСУБД «CronosPRO», серверную операционную систему (например, Windows Server 2003 или 2008).
Если это невозможно, проблему можно попробовать решить уменьшением максимально допустимого количества одновременно подключаемых банков данных. Для этого в главном меню ИСУБД «CronosPRO» следует выполнить команду Параметры -> Глобальные параметры и в открывшемся окне «Общие параметры» изменить значение параметра «Максимальное число банков в кэше» (оптимальное значение следует подобрать экспериментально).
-
Операционная система не может открыть файл банка данных, для того чтобы дать пользователю доступ к нему.
У пользователя работающего с системой недостаточно прав для чтения/записи информации в файлы банка. Необходимо дать доступ на чтение (если по банкам проводится только поиск) или полный доступ (если по банкам проводится поиск и изменяется информация). Для устранения этой ошибки обратитесь к Вашему системному администратору.
-
Блокировка файла другим процессом (программой)
Чаще всего эта ошибка возникает из-за работы антивирусных программ на сервере или на клиенте. Для устранения ошибки добасьте папку с банком(-ами) в список доверенный в настройках антивируса.
Второй причиной может быть процесс резерсного копирования.
Данная ошибка возникает, если ИСУБД «CronosPRO» по какой-либо причине не может получить доступ к файлам банка, находящимся в локальной сети. Основными причинами ошибки являются:
-
Разрывы сетевого соединения
Для устранения данной проблемы следует обратиться к системному администратору.
-
Комбинация ОС Windows 7 (Vista) + Windows Server 2008
-
Ошибка возникает при многократном подключении и отключении банков данных. Чаще всего это происходит при работе с банками типа «Глобальный поиск».
Для устранения проблемы выполните следующие шаги. Выберите в главном меню ИСУБД «CronosPRO» команду Параметры → Глобальные параметры. В открывшемся окне «Общие параметры» измените значение параметра «Максимальное число банков в кэше», установив его равным количеству банков в общем списке банков ИСУБД. Для сохранения изменений нажмите кнопку «Сохранить».
Последнее обновление: 07/22/2022
[Среднее время чтения статьи: 4,7 мин.]
Файлы TXT, такие как SQLServer_ERRORLOG_2020-01-24T04.16.06.txt, классифицируются как файлы Текст (Plain Text). Как файл Plain Text он был создан для использования в Microsoft SQL Server 2008 Express (64-bit) 10.00.1600.22 от компании Microsoft.
Впервые SQLServer_ERRORLOG_2020-01-24T04.16.06.txt был представлен 02/08/2009 в составе Microsoft SQL Server 2008 Express (64-bit) 10.00.1600.22 для Windows 10.
По нашим данным, этот файл является последним обновлением от компании Microsoft.
В этой короткой статье приводятся подробные сведения о файле, шаги по устранению проблем TXT с SQLServer_ERRORLOG_2020-01-24T04.16.06.txt и список бесплатных загрузок для каждой версии, содержащейся в нашем полном каталоге файлов.
Что такое сообщения об ошибках SQLServer_ERRORLOG_2020-01-24T04.16.06.txt?
Общие ошибки выполнения SQLServer_ERRORLOG_2020-01-24T04.16.06.txt
Ошибки файла SQLServer_ERRORLOG_2020-01-24T04.16.06.txt часто возникают на этапе запуска Microsoft SQL Server 2008 Express (64-bit), но также могут возникать во время работы программы.
Эти типы ошибок TXT также известны как «ошибки выполнения», поскольку они возникают во время выполнения Microsoft SQL Server 2008 Express (64-bit). К числу наиболее распространенных ошибок выполнения SQLServer_ERRORLOG_2020-01-24T04.16.06.txt относятся:
- Не удается найти SQLServer_ERRORLOG_2020-01-24T04.16.06.txt.
- SQLServer_ERRORLOG_2020-01-24T04.16.06.txt — ошибка.
- Не удалось загрузить SQLServer_ERRORLOG_2020-01-24T04.16.06.txt.
- Ошибка при загрузке SQLServer_ERRORLOG_2020-01-24T04.16.06.txt.
- Не удалось зарегистрировать SQLServer_ERRORLOG_2020-01-24T04.16.06.txt / Не удается зарегистрировать SQLServer_ERRORLOG_2020-01-24T04.16.06.txt.
- Ошибка выполнения — SQLServer_ERRORLOG_2020-01-24T04.16.06.txt.
- Файл SQLServer_ERRORLOG_2020-01-24T04.16.06.txt отсутствует или поврежден.
Библиотека времени выполнения Microsoft Visual C++
![]()
Ошибка выполнения!
Программа: C:Program FilesMicrosoft SQL Server100Setup BootstrapLog20200124_040544SQLServer_ERRORLOG_2020-01-24T04.16.06.txt
Среда выполнения получила запрос от этого приложения, чтобы прекратить его необычным способом.
Для получения дополнительной информации обратитесь в службу поддержки приложения.
В большинстве случаев причинами ошибок в TXT являются отсутствующие или поврежденные файлы. Файл SQLServer_ERRORLOG_2020-01-24T04.16.06.txt может отсутствовать из-за случайного удаления, быть удаленным другой программой как общий файл (общий с Microsoft SQL Server 2008 Express (64-bit)) или быть удаленным в результате заражения вредоносным программным обеспечением. Кроме того, повреждение файла SQLServer_ERRORLOG_2020-01-24T04.16.06.txt может быть вызвано отключением питания при загрузке Microsoft SQL Server 2008 Express (64-bit), сбоем системы при загрузке или сохранении SQLServer_ERRORLOG_2020-01-24T04.16.06.txt, наличием плохих секторов на запоминающем устройстве (обычно это основной жесткий диск) или заражением вредоносным программным обеспечением. Таким образом, крайне важно, чтобы антивирус постоянно поддерживался в актуальном состоянии и регулярно проводил сканирование системы.
Как исправить ошибки SQLServer_ERRORLOG_2020-01-24T04.16.06.txt — 3-шаговое руководство (время выполнения: ~5-15 мин.)
Если вы столкнулись с одним из вышеуказанных сообщений об ошибке, выполните следующие действия по устранению неполадок, чтобы решить проблему SQLServer_ERRORLOG_2020-01-24T04.16.06.txt. Эти шаги по устранению неполадок перечислены в рекомендуемом порядке выполнения.
Шаг 1. Восстановите компьютер до последней точки восстановления, «моментального снимка» или образа резервной копии, которые предшествуют появлению ошибки.
Чтобы начать восстановление системы (Windows XP, Vista, 7, 8 и 10):
- Нажмите кнопку «Пуск» в Windows
- В поле поиска введите «Восстановление системы» и нажмите ENTER.
- В результатах поиска найдите и нажмите «Восстановление системы»
- Введите пароль администратора (при необходимости).
- Следуйте инструкциям мастера восстановления системы, чтобы выбрать соответствующую точку восстановления.
- Восстановите компьютер к этому образу резервной копии.
Если на этапе 1 не удается устранить ошибку SQLServer_ERRORLOG_2020-01-24T04.16.06.txt, перейдите к шагу 2 ниже.
Шаг 2. Если вы недавно установили приложение Microsoft SQL Server 2008 Express (64-bit) (или схожее программное обеспечение), удалите его, затем попробуйте переустановить Microsoft SQL Server 2008 Express (64-bit).
Чтобы удалить программное обеспечение Microsoft SQL Server 2008 Express (64-bit), выполните следующие инструкции (Windows XP, Vista, 7, 8 и 10):
- Нажмите кнопку «Пуск» в Windows
- В поле поиска введите «Удалить» и нажмите ENTER.
- В результатах поиска найдите и нажмите «Установка и удаление программ»
- Найдите запись для Microsoft SQL Server 2008 Express (64-bit) 10.00.1600.22 и нажмите «Удалить»
- Следуйте указаниям по удалению.
После полного удаления приложения следует перезагрузить ПК и заново установить Microsoft SQL Server 2008 Express (64-bit).
Если на этапе 2 также не удается устранить ошибку SQLServer_ERRORLOG_2020-01-24T04.16.06.txt, перейдите к шагу 3 ниже.
![]()
Microsoft SQL Server 2008 Express (64-bit) 10.00.1600.22
Microsoft Corporation
Шаг 3. Выполните обновление Windows.
Когда первые два шага не устранили проблему, целесообразно запустить Центр обновления Windows. Во многих случаях возникновение сообщений об ошибках SQLServer_ERRORLOG_2020-01-24T04.16.06.txt может быть вызвано устаревшей операционной системой Windows. Чтобы запустить Центр обновления Windows, выполните следующие простые шаги:
- Нажмите кнопку «Пуск» в Windows
- В поле поиска введите «Обновить» и нажмите ENTER.
- В диалоговом окне Центра обновления Windows нажмите «Проверить наличие обновлений» (или аналогичную кнопку в зависимости от версии Windows)
- Если обновления доступны для загрузки, нажмите «Установить обновления».
- После завершения обновления следует перезагрузить ПК.
Если Центр обновления Windows не смог устранить сообщение об ошибке SQLServer_ERRORLOG_2020-01-24T04.16.06.txt, перейдите к следующему шагу. Обратите внимание, что этот последний шаг рекомендуется только для продвинутых пользователей ПК.
Если эти шаги не принесут результата: скачайте и замените файл SQLServer_ERRORLOG_2020-01-24T04.16.06.txt (внимание: для опытных пользователей)
Если ни один из предыдущих трех шагов по устранению неполадок не разрешил проблему, можно попробовать более агрессивный подход (примечание: не рекомендуется пользователям ПК начального уровня), загрузив и заменив соответствующую версию файла SQLServer_ERRORLOG_2020-01-24T04.16.06.txt. Мы храним полную базу данных файлов SQLServer_ERRORLOG_2020-01-24T04.16.06.txt со 100%-ной гарантией отсутствия вредоносного программного обеспечения для любой применимой версии Microsoft SQL Server 2008 Express (64-bit) . Чтобы загрузить и правильно заменить файл, выполните следующие действия:
- Найдите версию операционной системы Windows в нижеприведенном списке «Загрузить файлы SQLServer_ERRORLOG_2020-01-24T04.16.06.txt».
- Нажмите соответствующую кнопку «Скачать», чтобы скачать версию файла Windows.
- Скопируйте этот файл в соответствующее расположение папки Microsoft SQL Server 2008 Express (64-bit):
Windows 10: C:Program FilesMicrosoft SQL Server100Setup BootstrapLog20200124_040544
- Перезагрузите компьютер.
Если этот последний шаг оказался безрезультативным и ошибка по-прежнему не устранена, единственно возможным вариантом остается выполнение чистой установки Windows 10.
СОВЕТ ОТ СПЕЦИАЛИСТА: Мы должны подчеркнуть, что переустановка Windows является достаточно длительной и сложной задачей для решения проблем, связанных с SQLServer_ERRORLOG_2020-01-24T04.16.06.txt. Во избежание потери данных следует убедиться, что перед началом процесса вы создали резервные копии всех важных документов, изображений, установщиков программного обеспечения и других персональных данных. Если вы в настоящее время не создаете резервных копий своих данных, вам необходимо сделать это немедленно.
Скачать файлы SQLServer_ERRORLOG_2020-01-24T04.16.06.txt (проверено на наличие вредоносного ПО — отсутствие 100 %)
ВНИМАНИЕ! Мы настоятельно не рекомендуем загружать и копировать SQLServer_ERRORLOG_2020-01-24T04.16.06.txt в соответствующий системный каталог Windows. Microsoft, как правило, не выпускает файлы Microsoft SQL Server 2008 Express (64-bit) TXT для загрузки, поскольку они входят в состав установщика программного обеспечения. Задача установщика заключается в том, чтобы обеспечить выполнение всех надлежащих проверок перед установкой и размещением SQLServer_ERRORLOG_2020-01-24T04.16.06.txt и всех других файлов TXT для Microsoft SQL Server 2008 Express (64-bit). Неправильно установленный файл TXT может нарушить стабильность работы системы и привести к тому, что программа или операционная система полностью перестанут работать. Действовать с осторожностью.
Файлы, относящиеся к SQLServer_ERRORLOG_2020-01-24T04.16.06.txt
Файлы TXT, относящиеся к SQLServer_ERRORLOG_2020-01-24T04.16.06.txt
| Имя файла | Описание | Программа (версия) | Размер файла (байты) | Расположение файла |
|---|---|---|---|---|
| Detail_GlobalRules.txt | Plain Text | Microsoft SQL Server 2008 Express (64-bit) 10.00.1600.22 | 58775 | C:Program FilesMicrosoft SQL Server100Setup… |
| SQLServer_ERRORLOG_202… | Plain Text | Microsoft SQL Server 2008 Express (64-bit) 10.00.1600.22 | 15966 | C:Program FilesMicrosoft SQL Server100Setup… |
| SQLServer_ERRORLOG_202… | Plain Text | Microsoft SQL Server 2008 Express (64-bit) 10.00.1600.22 | 16202 | C:Program FilesMicrosoft SQL Server100Setup… |
| SQLServer_ERRORLOG_202… | Plain Text | Microsoft SQL Server 2008 Express (64-bit) 10.00.1600.22 | 9866 | C:Program FilesMicrosoft SQL Server100Setup… |
| Summary_DESKTOP-QSDHE5… | Plain Text | Microsoft SQL Server 2008 Express (64-bit) 10.00.1600.22 | 1929 | C:Program FilesMicrosoft SQL Server100Setup… |
Вы скачиваете пробное программное обеспечение. Для разблокировки всех функций программного обеспечения требуется покупка годичной подписки, стоимость которой оставляет 39,95 долл. США. Подписка автоматически возобновляется в конце срока (Подробнее). Нажимая кнопку «Начать загрузку» и устанавливая «Программное обеспечение», я подтверждаю, что я прочитал (-а) и принимаю Лицензионное соглашение и Политику конфиденциальности компании Solvusoft.
Один,Базовые знания
По умолчанию журнал ошибок находится по адресу:
C:Program FilesMicrosoft SQL ServerMSSQL.1MSSQLLOGERRORLOG
И файл ERRORLOG.n. По умолчанию зарезервировано 7 файлов журнала ошибок SQL Server, а именно: ErrorLog, Errorlog.1 ~ Errorlog.6 Текущий журнал ошибок (файл ErrorLog) не имеет расширения. При каждом запуске экземпляра SQL Server будет создан новый журнал ошибок ErrorLog, предыдущий ErrorLog будет переименован в ErrorLog.1, предыдущий ErrorLog.1 будет переименован в ErrorLog.2 и так далее, исходный ErroLog.6 будет переименован. удалено.
два,Сжать файл журнала ошибок
В файле ErrorLog на производственном сервере иногда возникает ситуация, когда файл очень большой, особенно когда ситуация аутентификации при входе записывается в журнал ошибок. В это время скорость просмотра журнала ошибок с помощью SQL Server Management Studio или текста редактор будет работать медленно Это проблема.В этом случае вы можете сгенерировать новый файл журнала с помощью хранимой процедуры sp_cycle_errorlog без перезапуска сервера и циклически изменить номер расширения журнала ошибок, как при перезапуске службы. В дополнение к Execute sp_cycle_errorlog вы также можете использовать DBCC ERRORLOG для достижения той же функции. На практике вы также можете регулярно выполнять хранимую процедуру, создав задание, так что размер файла журнала контролируется в разумных пределах.
Меры предосторожности: Данные в старом файле ErrorLog будут перезаписаны! Если вам необходимо сохранить данные в старых файлах ErrorLog, вы можете скопировать эти старые файлы ErrorLog на внешний носитель.
Exec (‘DBCC ErrorLog’) или exec sp_cycle_errorlog, либо вы можете использовать следующую команду, чтобы поместить sp в задание для регулярного выполнения.
три,ErrorlogДругая конфигурация
(1) SQL Server по умолчанию сохраняет 7 файлов журнала ошибок. Когда создается новый журнал ошибок, самый старый журнал также удаляется. Если вы хотите сохранить больше журналов ошибок, вы можете установить его следующим способом (SQL Server 2005) :
- Откройте SQL Server Management Studio
- В каталоге «Управление» щелкните правой кнопкой мыши журнал SQL Server и выберите «Настроить».
- Во всплывающем окне «Настроить журнал ошибок SQL Server» установите флажок «Ограничить количество файлов журнала ошибок перед повторной обработкой» и установите «Максимальное количество файлов журнала ошибок» на желаемое значение. Это значение от 6 до 99.

(Рисунок 1: Количество файлов журнала ошибок 0 ~ 99)
В дополнение к вышеуказанным методам его также можно изменить, изменив реестр.
Создайте новый раздел реестра (измените, если он есть):
HKEY_LOCAL_MACHINE/SOFTWARE/Microsoft/MSSQLServer/MSSQLServer/NumErrorLogs, По умолчанию такой раздел реестра отсутствует. Выберите REG_DWORD в качестве типа и установите значение, равное количеству журналов, которые вы хотите сохранить. Метод изменения раздела реестра также может быть реализован с помощью следующей хранимой процедуры:
exec xp_instance_regwrite N’HKEY_LOCAL_MACHINE’, N’Software/Microsoft/MSSQLServer/MSSQLServer’,N’NumErrorLogs’, REG_DWORD, 20
(2) По умолчанию журнал ошибок SQL Server находится в файлах: Program Files / Microsoft SQL Server / MSSQL.n / MSSQL / LOG / ERRORLOG и ERRORLOG.n. Путь можно изменить следующими способами:
- В диспетчере конфигурации SQL Server щелкните Служба SQL Server.
- На правой панели щелкните правой кнопкой мыши SQL Server (<имя экземпляра>), а затем щелкните Свойства.
- В поле «Параметры запуска» вкладки «Дополнительно» есть параметры, разделенные точкой с запятой (;). Среди них есть параметр, начинающийся с -e. Измените путь после параметра, чтобы сохранить журнал ошибок по указанному пути. После завершения изменения службу необходимо перезапустить, чтобы она вступила в силу.

(Рисунок 2: Путь к файлу ErrorLog)
(3) Если вы хотите отфильтровать и запросить файл журнала ошибок, вы можете обратиться к:Фильтрация журнала ошибок SQL Server (ERRORLOG)
четыре,Рекомендации
О журнале ошибок SQL ServerЖурнал ошибок
SQL Server ErrorLog Журнал ошибок(Если пространство, занимаемое базой данных, становится больше)
Диагностика SQLSERVERОбщие журналы проблем
SQLSERVER errorlogобъяснять
Для эффективного управления веб-сервером необходимо получить обратную связь об активности и производительности сервера, а также о всех проблемах, которые могли случиться. Apache HTTP Server обеспечивает очень полную и гибкую возможность ведения журнала. В этой статье мы разберём, как настроить логи Apache и как понимать, что они содержат.
HTTP-сервер Apache предоставляет множество различных механизмов для регистрации всего, что происходит на вашем сервере, от первоначального запроса до процесса сопоставления URL-адресов, до окончательного разрешения соединения, включая любые ошибки, которые могли возникнуть в процессе. В дополнение к этому сторонние модули могут предоставлять возможности ведения журналов или вставлять записи в существующие файлы журналов, а приложения, такие как программы CGI, сценарии PHP или другие обработчики, могут отправлять сообщения в журнал ошибок сервера.
В этой статье мы рассмотрим модули журналирования, которые являются стандартной частью http сервера.
Логи Apache в Windows
В Windows имеются особенности настройки имени файла журнала — точнее говоря, пути до файла журнала. Если имена файлов указываются с начальной буквы диска, например “C:/“, то сервер будет использовать явно указанный путь. Если имена файлов НЕ начинаются с буквы диска, то к указанному значению добавляется значение ServerRoot — то есть «logs/access.log» с ServerRoot установленной на “c:/Server/bin/Apache24″, будет интерпретироваться как “c:/Server/bin/Apache24/logs/access.log“, в то время как “c:/logs/access.log” будет интерпретироваться как “c:/logs/access.log“.
Также особенностью указания пути до логов в Windows является то, что нужно использовать слэши, а не обратные слэши, то есть “c:/apache” вместо “c:apache“. Если пропущена буква диска, то по умолчанию будет использоваться диск, на котором размещён httpd.exe. Рекомендуется явно указывать букву диска при абсолютных путях, чтобы избежать недоразумений.
Apache error: ошибки сервера и сайтов
Путь до файла журнала с ошибками указывается с помощью ErrorLog, например, для сохранения ошибок в папке “logs/error.log” относительно корневой папки веб-сервера:
ErrorLog "logs/error.log"
Если не указать директиву ErrorLog внутри контейнера <VirtualHost>, сообщения об ошибках, относящиеся к этому виртуальному хосту, будут записаны в этот общий файл. Если в контейнере <VirtualHost> вы указали путь до файла журнала с ошибками, то сообщения об ошибках этого хоста будут записываться там, а не в этот файл.
С помощью директивы LogLevel можно установить уровень важности сообщений, которые должны попадать в журнал ошибок. Доступные варианты:
- debug
- info
- notice
- warn
- error
- crit
- alert
- emerg
Журнал ошибок сервера, имя и местоположение которого задаётся директивой ErrorLog, является наиболее важным файлом журнала. Это место, куда Apache httpd будет отправлять диагностическую информацию и записывать любые ошибки, с которыми он сталкивается при обработке запросов. Это первое место, где нужно посмотреть, когда возникает проблема с запуском сервера или работой сервера, поскольку он часто содержит подробности о том, что пошло не так и как это исправить.
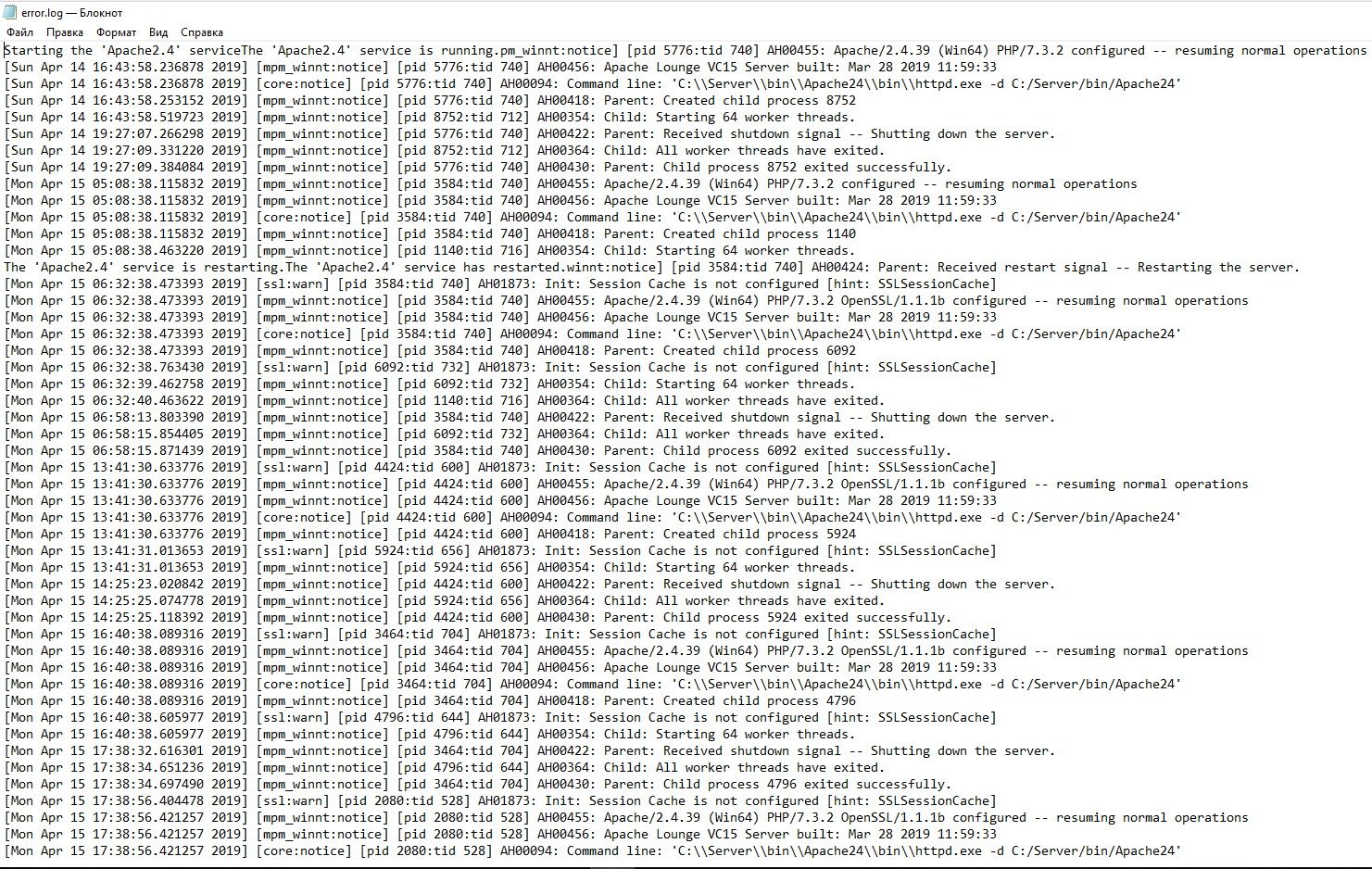
Журнал ошибок обычно записывается в файл (обычно это error_log в системах Unix и error.log в Windows и OS/2). В системах Unix также возможно, чтобы сервер отправлял ошибки в системный журнал или передавал их программе.
Формат журнала ошибок определяется директивой ErrorLogFormat, с помощью которой вы можете настроить, какие значения записываются в журнал. По умолчанию задан формат, если вы его не указали. Типичное сообщение журнала следующее:
[Fri Sep 09 10:42:29.902022 2011] [core:error] [pid 35708:tid 4328636416] [client 72.15.99.187] File does not exist: /usr/local/apache2/htdocs/favicon.ico
Первый элемент в записи журнала — это дата и время сообщения. Следующим является модуль, создающий сообщение (в данном случае ядро) и уровень серьёзности этого сообщения. За этим следует идентификатор процесса и, если необходимо, идентификатор потока процесса, в котором возникло условие. Далее у нас есть адрес клиента, который сделал запрос. И, наконец, подробное сообщение об ошибке, которое в этом случае указывает на запрос о несуществующем файле.
В журнале ошибок может появиться очень большое количество различных сообщений. Большинство выглядит похожим на пример выше. Журнал ошибок также будет содержать отладочную информацию из сценариев CGI. Любая информация, записанная в stderr (стандартный вывод ошибок) сценарием CGI, будет скопирована непосредственно в журнал ошибок.
Если поместить токен %L в журнал ошибок и журнал доступа, будет создан идентификатор записи журнала, с которым вы можете сопоставить запись в журнале ошибок с записью в журнале доступа. Если загружен mod_unique_id, его уникальный идентификатор запроса также будет использоваться в качестве идентификатора записи журнала.
Во время тестирования часто бывает полезно постоянно отслеживать журнал ошибок на наличие проблем. В системах Unix вы можете сделать это, используя:
tail -f error_log
Apache access: логи доступа к серверу
Журнал доступа к серверу записывает все запросы, обработанные сервером. Расположение и содержимое журнала доступа контролируются директивой CustomLog. Директива LogFormat может быть использована для упрощения выбора содержимого журналов. В этом разделе описывается, как настроить сервер для записи информации в журнал доступа.
Различные версии Apache httpd использовали разные модули и директивы для управления журналом доступа, включая mod_log_referer, mod_log_agent и директиву TransferLog. Директива CustomLog теперь включает в себя функциональность всех старых директив.
Формат журнала доступа легко настраивается. Формат указывается с использованием строки формата, которая очень похожа на строку формата printf в стиле C. Некоторые примеры представлены в следующих разделах. Полный список возможного содержимого строки формата смотрите здесь: https://httpd.apache.org/docs/current/mod/mod_log_config.html
Общий формат журнала (Common Log)
Типичная конфигурация для журнала доступа может выглядеть следующим образом.
LogFormat "%h %l %u %t "%r" %>s %b" common CustomLog logs/access_log common
В первой строке задано имя (псевдоним) common, которому присвоено в качестве значения строка “%h %l %u %t “%r” %>s %b“.
Строка формата состоит из директив, начинающихся с символа процента, каждая из которых указывает серверу регистрировать определённый фрагмент информации. Литеральные (буквальные) символы также могут быть помещены в строку формата и будут скопированы непосредственно в вывод журнала. Символ кавычки (“) должен быть экранирован путём размещения обратной косой черты перед ним, чтобы он не интерпретировался как конец строки формата. Строка формата также может содержать специальные управляющие символы “n“для новой строки и “t” для обозначения таба (табуляции).
В данной строке значение директив следующее:
- %h — имя удалённого хоста. Будет записан IP адрес, если HostnameLookups установлен на Off, что является значением по умолчанию.
- %l — длинное имя удалённого хоста (от identd, если предоставит). Это вернёт прочерк если не присутствует mod_ident и IdentityCheck не установлен на On.
- %u — удалённый пользователь, если запрос был сделан аутентифицированным пользователем. Может быть фальшивым, если возвращён статус (%s) 401 (unauthorized).
- %t — время получения запроса в формате [18/Sep/2011:19:18:28 -0400]. Последнее показывает сдвиг временной зоны от GMT
- “%r” – первая строка запроса, помещённая в буквальные кавычки
- %>s — финальный статус. Если бы было обозначение %s, то означало бы просто статус — для запросов, которые были внутренне перенаправлены это обозначало бы исходный статус.
- %b — размер ответа в байтах, исключая HTTP заголовки. В формате CLF, то есть ‘–‘ вместо 0, когда байты не отправлены.
Директива CustomLog устанавливает новый файл журнала, используя определённый псевдоним. Имя файла для журнала доступа относительно ServerRoot, если оно не начинается с косой черты (буквы диска).
Приведённая выше конфигурация будет сохранять записи журнала в формате, известном как Common Log Format (CLF). Этот стандартный формат может создаваться многими различными веб-серверами и считываться многими программами анализа журналов. Записи файла журнала, созданные в CLF, будут выглядеть примерно так:
127.0.0.1 - frank [10/Oct/2000:13:55:36 -0700] "GET /apache_pb.gif HTTP/1.0" 200 2326
Каждая часть этой записи журнала описана ниже.
127.0.0.1 (%h)
Это IP-адрес клиента (удалённого хоста), который сделал запрос к серверу. Если для HostnameLookups установлено значение On, сервер попытается определить имя хоста и зарегистрировать его вместо IP-адреса. Однако такая конфигурация не рекомендуется, поскольку она может значительно замедлить работу сервера. Вместо этого лучше всего использовать постпроцессор журнала, такой как logresolve, для определения имён хостов. Указанный здесь IP-адрес не обязательно является адресом машины, на которой сидит пользователь. Если между пользователем и сервером существует прокси-сервер, этот адрес будет адресом прокси, а не исходной машины.
– (%l)
«Дефис» в выходных данных указывает на то, что запрошенная часть информации недоступна. В этом случае информация, которая недоступна, является идентификационной информацией клиента RFC 1413, определённой с помощью id на клиентском компьютере. Эта информация крайне ненадёжна и почти никогда не должна использоваться, кроме как в жёстко контролируемых внутренних сетях. Apache httpd даже не будет пытаться определить эту информацию, если для IdentityCheck не установлено значение On.
frank (%u)
Это идентификатор пользователя, запрашивающего документ, как определено HTTP-аутентификацией. Такое же значение обычно предоставляется сценариям CGI в переменной среды REMOTE_USER. Если код состояния для запроса равен 401, то этому значению не следует доверять, поскольку пользователь ещё не аутентифицирован. Если документ не защищён паролем, эта часть будет “–“, как и предыдущая.
[10/Oct/2000:13:55:36 -0700] (%t)
Время получения запроса. Формат такой:
[день/месяц/год:час:минута:секунда зона]
день = 2*цифры
месяц = 3*цифры
год = 4*цифры
час = 2*цифры
минута = 2*цифры
секунда = 2*цифры
зона = (`+’ | `-‘) 4*цифры
Можно отобразить время в другом формате, указав %{format}t в строке формата журнала, где формат такой же, как в strftime(3) из стандартной библиотеки C, или один из поддерживаемых специальных токенов. Подробности смотрите в строках формате строки mod_log_config.
“GET /apache_pb.gif HTTP/1.0” (“%r”)
Строка запроса от клиента указана в двойных кавычках. Строка запроса содержит много полезной информации. Во-первых, клиент использует метод GET. Во-вторых, клиент запросил ресурс /apache_pb.gif, и в-третьих, клиент использовал протокол HTTP/1.0. Также возможно зарегистрировать одну или несколько частей строки запроса независимо. Например, строка формата “%m %U%q %H” будет регистрировать метод, путь, строку запроса и протокол, что приведёт к тому же результату, что и “%r“.
200 (%>s)
Это код состояния, который сервер отправляет обратно клиенту. Эта информация очень ценна, потому что она показывает, привёл ли запрос к успешному ответу (коды начинаются с 2), к перенаправлению (коды начинаются с 3), к ошибке, вызванной клиентом (коды начинаются с 4), или к ошибкам в сервер (коды начинаются с 5). Полный список возможных кодов состояния можно найти в спецификации HTTP (RFC2616 раздел 10).
2326 (%b)
Последняя часть указывает размер объекта, возвращаемого клиенту, не включая заголовки ответа. Если контент не был возвращён клиенту, это значение будет “–“. Чтобы записать «0» без содержимого, вместо %b используйте %B.
Логи комбинированного формата (Combined Log)
Другая часто используемая строка формата называется Combined Log Format. Может использоваться следующим образом.
LogFormat "%h %l %u %t "%r" %>s %b "%{Referer}i" "%{User-agent}i"" combined
CustomLog log/access_log combined
Этот формат точно такой же, как Common Log Format, с добавлением ещё двух полей. Каждое из дополнительных полей использует директиву начинающуюся с символа процента %{заголовок}i, где заголовок может быть любым заголовком HTTP-запроса. Журнал доступа в этом формате будет выглядеть так:
127.0.0.1 - frank [10/Oct/2000:13:55:36 -0700] "GET /apache_pb.gif HTTP/1.0" 200 2326 "http://www.example.com/start.html" "Mozilla/4.08 [en] (Win98; I ;Nav)"
Дополнительными полями являются:
“http://www.example.com/start.html” (“%{Referer}i”)
Referer — это часть заголовок HTTP-запроса, которая называется также Referer. В этой строке содержится информация о странице, с которой клиент был прислан на данный сайт. (Это должна быть страница, которая ссылается или включает /apache_pb.gif).
“Mozilla/4.08 [en] (Win98; I ;Nav)” (“%{User-agent}i”)
Заголовок HTTP-запроса User-Agent. Это идентифицирующая информация, которую клиентский браузер сообщает о себе.

По умолчанию в главном конфигурационном файле Apache прописаны следующие настройки логов:
<IfModule log_config_module>
LogFormat "%h %l %u %t "%r" %>s %b "%{Referer}i" "%{User-Agent}i"" combined
LogFormat "%h %l %u %t "%r" %>s %b" common
<IfModule logio_module>
LogFormat "%h %l %u %t "%r" %>s %b "%{Referer}i" "%{User-Agent}i" %I %O" combinedio
</IfModule>
CustomLog "logs/access.log" common
</IfModule>
Как можно увидеть, установлены три псевдонима: combined, common и combinedio. При этом по умолчанию используется common. При желании вы без труда сможете переключиться на combined или настроить формат строки лога под свой вкус.
Например, если вы предпочитаете, чтобы в файле лога доступа также присутствовала информация о пользовательском агенте и реферере, то есть Combined Logfile Format, то вы можете использовать следующую директиву:
CustomLog "logs/access.log" combined
Связанные статьи:
- Почему в логах ошибок Apache не сохраняются записи об ошибке 404 (100%)
- Как в Apache под Windows настроить автоматическую ротацию и очистку логов (100%)
- Удалённый просмотр и поиск по логам Apache в Windows (модуль mod_view) (100%)
- Apache для Windows (54.5%)
- Как запустить Apache на Windows (54.5%)
- Настройка веб-сервера Apache для запуска программ Ruby на Windows (RANDOM – 54.5%)
Скажите честно, в своей практике вам чаще приходилось сталкиваться с логами, напоминающими чей-то поток сознания, или всё же это были красивые структурированные файлы, на которые любо-дорого смотреть? Надеюсь, что второе. В наших продуктах, само собой, мы тоже стремимся идти по второму пути, однако необходимость зафиксировать большое количество процессов накладывает свой отпечаток. Так что сегодня мы научимся не “читать книгу и видеть фигу”, а бесстрашно открывать любой лог Veeam Backup & Replication и видеть его внутреннюю красоту.
Перед прочтением этой статьи настоятельно рекомендую предварительно ознакомиться со статьёй-глоссарием, дабы понимать используемую терминологию. Затем прочитать эту статью про источники данных для логов. А затем ещё и эту, дабы понимать, в какой лог ради чего следует залезать.

Когда читаешь логи, очень важно держать в голове и применять шесть простых правил.
Правило первое: В логах тьма ошибок с ворнингами и это нормально. Не надо бросаться на первую попавшуюся ошибку и пытаться с ней что-то сделать. Как мы помним из прочитанных ранее статей, в логах фиксируется вся информация, которая приходит от разнородных систем, включая внешние. Ошибка может обозначать переход между режимами или быть банальной проверкой. Вот пример:
// Виму надо отключиться от vCenter:
[19.10.2020 05:02:53] <01> Info [Soap] Logout from "https://vcenter.test.local:443/sdk"
// Убеждаемся, что мы действительно отключились, попробовав выполнить любое действие. Получить ошибку здесь — ожидаемый результат.
[19.10.2020 05:02:53] <01> Error The session is not authenticated. (System.Web.Services.Protocols.SoapException)
[19.10.2020 05:02:53] <01> Error at System.Web.Services.Protocols.SoapHttpClientProtocol.ReadResponse(SoapClientMessage message, WebResponse response, Stream responseStream, Boolean asyncCall)Правило второе: Когда читаете лог, не надо смотреть только на последнюю в списке ошибку. Даже если она подсвечена в репорте, упавшем на почту. Причина её появления запросто может быть на пару экранов (и десяток других ошибок) выше. Например, в упавшем на почту HTML репорте видим ошибку «Microsoft SQL server hosting the configuration database is currently unavailable». Открываем лог джобы и видим, что последняя ошибка в логе прямо нам говорит “Не могу подключиться к SQL серверу, потому что <причины>”.
[12.11.2019 23:24:00] <18> Error Microsoft SQL server hosting the configuration database is currently unavailable. Possible reasons are heavy load, networking issue, server reboot, or hot backup.
[12.11.2019 23:24:00] <18> Error Please wait, and try again later.Сразу хочется победно прокричать “Ага!” и побежать чинить связь до SQL сервера, перезагружать его, трясти за бампер и пинать по колесу. Однако если попробовать разобраться и отмотать лог ближе к началу, там обнаруживаются строки:
12.11.2019 23:22:00] <18> Error Violation of PRIMARY KEY constraint 'PK_Storages'. Cannot insert duplicate key in object 'dbo.Backup.Model.Storages'. The duplicate key value is (af4d30aa-9605-4fe6-8229-f362eb848f19).
[12.11.2019 23:22:00] <18> Error Violation of PRIMARY KEY constraint 'PK_Storages'. Cannot insert duplicate key in object 'dbo.Backup.Model.Storages'. The duplicate key value is (af4d30aa-9605-4fe6-8229-f362eb848f19).Из чего сразу становится понятно, что со связью до базы всё хорошо — а вот что плохо, так это то, что VBR не может выполнить какую-то кверю, и копать надо в эту сторону.
Правило третье: Редкая ошибка локализуется внутри одного конкретного лога. Изучение соседних логов на тот же момент времени позволяет собрать намного больше информации. Хрестоматийный пример — это лог джобы, где нам просто говорят, что возникала такая-то ошибка в такой-то таске. Какие-то выводы, конечно, мы сделать уже можем, но лучше открыть лог таски и получить более подробное описание случившегося бедствия. И если уж совсем ничего не понятно, то нам на помощь приходят логи агентов, в которых вся ситуация будет разобрана крайне подробно. Но тут действует правило “Чем дальше в лес, тем более узким и специфичным становится лог”. А ещё часть инфы может всплыть в сервисных логах, часть в виндовых ивентах и так далее.
Вот, например, берём типичный лог упавшей джобы:
[13.06.2019 11:06:07] <52> Error Failed to call RPC function 'CreateSessionTicket': Agent with the specified identifier '{c8fdc9b9-0d60-486c-80de-9fc4218d276f}' does not existТипичный никчёмный Failed to call RPC function, из которого максимум, что можно понять — что не удалось провзаимодействовать с транспортным агентом. Однако если вспомнить, что транспортный агент управляется транспортным сервисом (известен в документации как Datamover) и заглянуть в его лог (Svc.VeeamTransport.log) на хосте, где он запускался, то можно обнаружить:
[13.06.2019 09:05:07] < 10648> tpl| Agent '{c8fdc9b9-0d60-486c-80de-9fc4218d276f}' will be terminated due to reason: some I/O operation has hanged.
[13.06.2019 09:06:07] < 10648> tpl| WARN|AGENT [{c8fdc9b9-0d60-486c-80de-9fc4218d276f}] HAS HANGED UNEXPECTEDLY AND WAS TERMINATED.То есть агент был принудительно выключен сервисом после неудачной попытки записать что-то на таргет, но к VBR эта информация по какой-то причине не пришла. Теперь мы хотя бы знаем, в какую сторону копать.
Правило четвёртое: Если в логах видим, что ошибка происходит где-то за границами компонентов VBR, значит, искать их причину надо тоже за границами компонентов VBR. Veeam хоть и старательно логирует все приходящие к нему события, однако ещё больше их(событий) остаётся на целевой системе. Типичным примером здесь будет создание VSS снапшота. По большому счёту, Windows отдаёт информацию на уровне “получилось или нет что-то сделать”, из чего крайне редко получается вычленить причину, почему же не получилось. Однако внутри виндовых ивентов можно найти множество событий, прямо указывающих на проблему. Главное — всегда тщательно сопоставлять время в логах от разных систем. Помним, что у VBR своё время, у vSphere всегда UTC+0, а виндовые ивенты показываются в локальном времени машины, на которой их смотрят. Типичные примеры экспорта внешних логов — для Windows и для Microsoft SQL.
Правило пятое: Следи за тредами (они обозначаются как <XX>) и распутывай клубок последовательно! Многие вещи могут происходить параллельно, и если просто читать логи линия за линией, то можно прийти к неправильному выводу. Особенно это важно, если джоба кажется зависшей и надо понять, что именно в ней зависло.
Вот типичный лог для этой ситуации:
[18.06.2020 03:44:03] <36> Info [AP] Waiting for completion. Id: [0xf48cca], Time: 00:30:00.0333386
[18.06.2020 03:45:18] <53> Info [AP] (6ff9) output: --asyncNtf:Pipeline timeout: it seems that pipeline hanged.Если читать это лог, не обращая внимания на номера тредов <36> и <53>, то кажется, что у нас какие-то проблемы с агентом 6ff9, и надо срочно разбираться, что с ним случилось. Однако если продолжить чтение лога с оглядкой на тред <36>, то обнаруживается, что:
[18.06.2020 03:14:03] <36> Info [AP] (bf19) command: 'Invoke: DataTransfer.SyncDisk…То есть этот тред посвящён совершенно другому агенту с id bf19! Открываем лог этого агента и видим:
[17.06.2020 12:41:23] < 2160> ERR |Data error (cyclic redundancy check).
[17.06.2020 12:41:23] < 2160> >> |Failed to read data from the file [E:Hyper-VVHDsSRV-DCFS02SRV-DCFS02-C.vhdx].Значит, проблема в битом VHDX и надо искать методы его лечения.
Правило шестое: Не получается, непонятно, кажется, что вот-вот, но идёт третий день без сна и всё никак — звони в сапорт! Veeam — огромный продукт, где есть тысячи нюансов, нюансы для нюансов и прочих сокровенных знаний, которые никогда не понадобятся 99,99% населения этой планеты. Однако именно этих знаний в большинстве случаев и не хватает, чтобы успешно найти причину неисправности самому. Сапорт Вима совсем не просто так получает свою зарплату и считается одним из лучших в IT-индустрии. А ещё он русскоязычный и доступен по телефону
Смело открываем лог
И вот настал тот прекрасный момент, когда мы наконец-то готовы открыть свой первый лог. А любой уважающий себя файл начинается с некоего заголовка, где собрана вся основная информация. Чаще всего нас, конечно же, будут интересовать логи джоб и тасок, так что рассмотрим пример с ними.
===================================================================
Starting new log
Log has been started by 'VEEAMSYSTEM' user (Non-interactive)
Logging level: [4 (AboveNormal)]
MachineName: [VEEAM], OS: [Microsoft Windows Server 2019 Standard (10.0.17763)], CPU: [2]
Process: [64 bit], PID: [10816], SessionId: [0]
UTC Time: [22.10.2020 2:03:53], DaylightSavingTime: [False]
Culture: [ru-RU], UI culture: [en-US]
Module: [C:Program FilesVeeamBackup and ReplicationBackupVeeam.Backup.Manager.exe]. File version: [10.0.1.4854], Assembly version: [10.0.0.0], Edition: [standard]
Process start time: [22.10.2020 0:01:19], Garbage collector mode: [Workstation]
CmdLineParams: [startbackupjob owner=[vbsvc] Normal bed49ecd-54a4-4f53-b337-e71fabe92988 44c3f481-66ec-475f-bd04-a321e69274a0]
Network Interface, Name: Ethernet0, Description: Intel(R) 82574L Gigabit Network Connection, Interface Type: Ethernet, Operational Status: Up;
Unicast IPAddresses: fe80::b99c:9c8a:6179:295b%6; 172.17.32.51;
Gateway IPAddresses: 172.17.32.1;
Network Interface, Name: Loopback Pseudo-Interface 1, Description: Software Loopback Interface 1, Interface Type: Loopback, Operational Status: Up;
Unicast IPAddresses: ::1; 127.0.0.1;
UTC offset: 3,00 hoursНачало не вызывает никаких особых вопросов. Мы видим, как называется машина, на которой установлен VBR, и под каким пользователем запускается Veeam Backup Service.
Log has been started by 'VEEAMSYSTEM' user (Non-interactive)
MachineName: [VEEAM], OS: [Microsoft Windows Server 2019 Standard (10.0.17763)],Важный пункт — это версия запускающегося модуля.
Module: [C:Program FilesVeeamBackup and ReplicationBackupVeeam.Backup.Manager.exe]. File version: [10.0.1.4854], Assembly version: [10.0.0.0], Edition: [standard]Если ранее были установлены какие-то хотфиксы или приватные патчи, это сразу будет видно по номеру версии. В описании каждого патча, каждого релиза всегда обязательно указывается, на какую версию его следует устанавливать. Если вы словили какую-то багу, для которой вам выдали приватный фикс, то не надо затем сверху накатывать новый общий патч или свежий релиз. Никаких гарантий работоспособности в данном случае вы не получите.
Затем идёт перечисление всех сетевых интерфейсов и их IP-адреса. Также по названию карты зачастую можно понять, стоит ли Veeam на виртуальной машине или на физической. Хотя вы и сами наверняка это знаете, но может пригодиться.
Network Interface, Name: Ethernet0, Description: Intel(R) 82574L Gigabit Network Connection, Interface Type: Ethernet, Operational Status: Up;
Unicast IPAddresses: fe80::b99c:9c8a:6179:295b%6; 172.17.32.51;
Gateway IPAddresses: 172.17.32.1;
Network Interface, Name: Loopback Pseudo-Interface 1, Description: Software Loopback Interface 1, Interface Type: Loopback, Operational Status: Up;
Unicast IPAddresses: ::1; 127.0.0.1;И завершается всё информацией о времени и зоне, относительно которой указываются все цифры. Для географически разнесённых инфраструктур это критически важная часть. Автор сам несколько раз напарывался на ситуацию, когда старательно ищешь суть проблемы, а потом понимаешь, что искал на несколько часов позже или раньше.
UTC Time: [22.10.2020 2:03:53], DaylightSavingTime: [False]
UTC offset: 3,00 hoursТеперь, когда заголовок прочитан, давайте на примере бекапа и реплики посмотрим, что нас ожидает в логе любой джобы. Я не буду объяснять каждую строчку, иначе мы отсюда через месяц только разойдёмся. Просто легкая пробежка по общему принципу.
-
Первым делом джоба должна перечитать свои собственные настройки, дабы вообще знать, что ей требуется сделать.
-
Затем формируется список объектов, участвующих в бекапе.
-
Для всех объектов надо заблокировать необходимые ресурсы (файлы с бекапами, например) и убедиться, что никто другой не пытается с ними работать в этот момент времени.
-
Потом выясняем, где какая машина находится, что с ней можно сделать, какой транспортный режим использовать и на какую прокси назначить.
-
После чего можно запускать отдельные таски и ждать отчёта об их успешном (хочется верить, что да) выполнении.
-
И в конце, когда все таски отчитались, наступает тяжелая пора проверки ретеншенов. Удаляются старые точки, запускаются синтетические трансформы и прочий страшный сон для ваших СХД.
-
Когда всё закончилось успехом, надо везде рапортовать про это, записать в базу новую информацию и счастливо заснуть до следующего запуска. Конечно, строго говоря, на фоне будет происходить масса разнообразных и увлекательных сервисных вещей, но сегодня не об этом.
Теперь давайте обратим внимание на таски. Каждая таска запускается с чётко поставленной целью забекапить конкретную машину. Значит, после запуска её дело — это суметь подключиться к хосту, запустить агентов (в документации известны как data movers), проверить, что есть связь между компонентами, и совершить процесс передачи информации от хранилища вашего хоста до бекапного репозитория с необходимыми трансформациями по пути. Сжатие, разжатие, дедупликация, шифрование и так далее.
Соответственно, начинаем поиски проблемы широкими мазками, а именно — выясняем, на каком моменте всё сломалось. В этом нам помогает волшебное словосочетание has been completed. В общем случае таски рапортуют таким образом:
[19.10.2020 05:02:44] <29> Info Task session [3af0e723-b2a3-4054-b4e3-eea364041402] has been completed, status: Success, 107,374,182,400 of 107,374,182,400 bytes, 55,326,015,488 of 55,326,015,488 used bytes, 14 of 14 objects, details:14 объектов — это так называемые OiB, Object in Backup. Эта информация дублируется в логе джобы после завершения каждой таски с пометкой о том, сколько тасок уже завершилось. А в самом конце джоба должна заканчиваться полным отчётом.
[19.10.2020 05:02:53] <01> Info Job session '0f8ad58b-4183-4500-9e49-cc94f0674d87' has been completed, status: 'Success', '100 GB' of '100 GB' bytes, '1' of '1' tasks, '1' successful, '0' failed, details: '', PointId: [d3e21f72-9a52-4dc9-bcbe-98d38498a3e8]Другая полезная фраза — это Preparing point. Позволяет нам понять, какой тип бекапа сейчас будет создаваться.
В случае создания полного бекапа, в народе именуемого фульник (Full или Active full), создаётся следующая запись:
[17.11.2019 22:01:28] <01> Info Preparing point in full mode Инкрементальный проход выглядит вот так:
[17.11.2019 22:01:28] <01> Info Preparing point in incremental mode И реверс инкремент:
[17.11.2019 22:01:28] <01> Info Preparing point in synthetic mode Для Synthetic full своей особой записи не существует! Она начинает с создания обычного инкремента, поэтому надо искать ниже в логе запись «Creating synthetic full backup». Или пройтись по «Preparing oib» в логе таски.
vSphere
Теперь переходим к специфике гипервизоров, ибо, как можно легко догадаться, VMware и Hyper-V под капотом устроены даже приблизительно не одинаково, так что и работать с ними надо по-разному.
И начнём мы именно с VMware. Для начала просто посмотрим версию хоста по слову Build- в логе джобы. Так мы сможем узнать версию и номер билда хоста с машиной. Если хост был добавлен как часть Vcenter, бонусом получаем поле source host type.
[01.11.2020 05:00:26] <01> Info VM task VM name: 'vudc01', VM host name: 'https://esxi.test.local', VM host info: 'VMware ESXi 6.5.0 build-16207673', VM host apiVersion: '6.5', source host name: 'vcenter.test.local', source host id: '3de6c11c-ad7e-4ec0-ba12-d99a0b30b493', source host type: 'VC', size: '107374182400', display name: 'vudc01'.Эта же информация дублируется в момент проверки доступных режимов работы прокси.
[01.11.2020 05:00:24] <01> Info [ProxyDetector] Proxy [dsg.test.local] lies in different subnet with host [VMware ESXi 6.5.0 build-16207673]В логе соответствующей таски это всё тоже имеется, только там это часть здоровенной XML, так что копипастить я её не буду. Зато там есть даже более интересная строка Host content info:
[01.11.2020 05:01:37] <37> Info [Soap] Host content info: host "vcenter.test.local", type "vpx", version "6.5.0", build "15259038", apiVersion "6.5", hostTime "01.11.2020 2:01:26", sessionKey: "52c2dbf9-1835-2eb3-bb0e-396166a8101f"Там же, в логе таски, можно получить информацию о дисках и датасторах по строке Disk: label
[07.08.2019 06:55:41] <82> Info Disk: label "Hard disk 1", path "[ALLIN_PURE_GDI] LXRP-IT-GPILDB1/LXRP-IT-GPILDB1_21.vmdk", capacity 25,0 GB, backing "CFlatVirtualDiskV2", mode "persistent", thinProvisioned "False"Как мы видим, нас интересует ALLIN_PURE_GDI, поэтому переключаемся на лог джобы и видим:
[12.08.2019 05:40:12] <01> Info [ProxyDetector] Datastore 'ALLIN_PURE_GDI' lun was found, it uses vmfsили
[12.08.2019 05:40:12] <01> Info [ProxyDetector] Datastore 'ALLIN_PURE_GDI' lun was found, it uses nasЕщё бывает «Backup VM ‘VMname’ is DirectNFS compatible», но это не значит, что наша машина точно на NFS шаре.
Жизненный цикл vSpehere снапшотов
…и места, где они обитают.
Часто (а на самом деле практически всегда) понимать, в какой момент создавался снапшот, в какой был удалён и что с ним происходило, весьма важно для получения целостной картины мира реплик и бекапов. Поэтому открываем лог таски и ищем в нём API вызовы для создания и консолидации (удаления) снапшотов. Создание снапшота отлично ищется по Create snapshot
[02.11.2020 05:01:09] <29> Info [VimApi] Create snapshot, ref "vm-26", name "VEEAM BACKUP TEMPORARY SNAPSHOT", description "Please do not delete this snapshot. It is being used by Veeam Backup.", memory "False", quiesce "False"
[02.11.2020 05:01:11] <29> Info [Soap] Snapshot VM 'vm-26' was created. Ref: 'snapshot-540'Удаление снапшота ищется по Removing snapshot.
[01.11.2020 05:02:30] <26> Info [Soap] Removing snapshot 'snapshot-536'
[01.11.2020 05:02:30] <26> Info [VimApi] RemoveSnapshot, type "VirtualMachineSnapshot", ref "snapshot-536", removeChildren "False"
[01.11.2020 05:02:32] <26> Info [VmSnapshotTracker] Snapshot id: 'snapshot-536' closed
[01.11.2020 05:02:32] <26> Info [Soap] Loaded 2 elements
[01.11.2020 05:02:32] <26> Info [ViSnapshot] Checking if disks consolidation is needed for vm 'vm-26'
[01.11.2020 05:02:32] <26> Info [ViSnapshot] Consolidation is not neededЗдесь что хочется отметить: по загадочной причине в логе VMware.log зачастую нет никакой информации об ошибках произошедших во время создания/удаления снапшота. Поэтому полную картину мира надо восстанавливать по всем логам vSphere, включая логи VPXD и HOSTD.
С точки зрения vSphere, в VMware.log обычно есть только события на создание снапшота:
2019-05-24T13:58:57.921Z| vmx| I125: SnapshotVMX_TakeSnapshot start: 'VEEAM BACKUP TEMPORARY SNAPSHOT', deviceState=0, lazy=0, quiesced=0, forceNative=0, tryNative=1, saveAllocMaps=0 cb=35DE089A0, cbData=35F700420
....
2019-05-24T13:59:01.111Z| vcpu-0| I125: VigorTransport_ServerSendResponse opID=a9e2725d-8d3e-41c3-bea7-40d55d4d13fe-3088830-h5c:70160745-a8-af-3321 seq=187319: Completed Snapshot request. И на удаление:
2019-05-24T13:59:31.878Z| vmx| I125: SNAPSHOT: SnapshotDeleteWork '/vmfs/volumes/5b0c32e4-3bc067bb-614b-f4e9d4a8b220/test_build/test_build.vmx' : 29
....
2019-05-24T13:59:35.411Z| vcpu-0| I125: ConsolidateEnd: Snapshot consolidate complete: The operation completed successfully (0).Причём снапшоты, сделанные вручную, логируются несколько иначе, но это детали.
Зато как только мы заводим разговор о репликах, всё становится ещё веселее. VMware.log ведётся только когда виртуалка работает. А для реплицированных машин нормальное состояние — быть выключенными. Так что этот лог вам никак помочь не может. Поэтому здесь нам понадобятся логи vCenter или хоста. Самый простой способ их добыть — это ПКМ на vCenter > Export System Logs. В открывшемся визарде обязательно выбираем «Include vCenter server logs» и дожидаемся скачивания результата. Логи влёгкую могут весить несколько гигабайт, а скачиваться будут через браузер. Так что советую делать это на машине максимально близкой к VC. Самое интересное для нас внутри, это:
-
ESXi: В архиве проходим по /var/run/log/ и находим hotsd.log. Рядом будут лежать упакованные более ранние версии.
-
VC: ищем файлы vpxd-xxx.log по пути /var/log/vmware/vpxd.
Теперь давайте сравним, как будут выглядеть записи об одних и тех же операция в логе VBR, логе vpxd, и логе hostd. Здесь мы опустим моменты создания снапшота на исходной машине, так как нас интересует только реплика.
Итак, поскольку последний дельта-файл реплики доступен для записи и мы не можем гарантировать, что там никто ничего не натворил (горячий привет всем любящим включать реплицированные машины прямо с хоста), первым делом мы должны откатить все эти изменения:
//Veeam Task log:
[19.05.2020 18:41:04] <20> Info [SnapReplicaVm] Find working snapshots for replica vm '[name 'TinyLinux2_replica', ref 'vm-3411']'
[19.05.2020 18:41:04] <20> Info [SnapReplicaVm] Reverting vm '[name 'TinyLinux2_replica', ref 'vm-3411']' to restore point '5/19/2020 15:37:13'
[19.05.2020 18:41:04] <20> Info [Soap] Reverting snapshot snapshot-3415
[19.05.2020 18:41:04] <20> Info [VimApi] RevertSnapshot, type "VirtualMachineSnapshot", ref "snapshot-3415"//VPXD:
2020-05-19T15:41:00.508Z info vpxd[04767] [Originator@6876 sub=vpxLro opID=7717265a] [VpxLRO] -- BEGIN task-32169 -- snapshot-3415 -- vim.vm.Snapshot.revert -- 52e02fc8-9bbb-74da-63ac-74879274c5a3(52e50ab9-39d5-0996-21ce-3877ead7a6e9)//Hostd:
2020-05-19T15:41:00.492Z info hostd[2099911] [Originator@6876 sub=Vimsvc.TaskManager opID=7717265a-a1-62d8 user=vpxuser:VSPHERE.LOCALAdministrator] Task Created : haTask-676-vim.vm.Snapshot.revert-5370407
2020-05-19T15:41:00.652Z info hostd[2099895] [Originator@6876 sub=Vimsvc.TaskManager opID=7717265a-a1-62d8 user=vpxuser:VSPHERE.LOCALAdministrator] Task Completed : haTask-676-vim.vm.Snapshot.revert-5370407 Status successПосле успешного отката (двусмысленные фразы, что вы делаете, аха-ха-ха, прекратите) нам надо зафиксировать успех, т.е. сделать текущую дельту доступной только для чтения. Для этого создаём ещё один снапшот сверху:
//Veeam Task log:
[19.05.2020 18:41:17] <20> Info [SnapReplicaVmTarget] Creating working snapshot
[19.05.2020 18:41:17] <20> Info [SnapReplicaVm] Creating working snapshot for replica vm '[name 'TinyLinux2_replica', ref 'vm-3411']'
[19.05.2020 18:41:19] <20> Info [VimApi] Create snapshot, ref "vm-3411", name "Veeam Replica Working Snapshot", description "<RPData PointTime="5249033617402408751" WorkingSnapshotTime="5249033617402408751" PointSize="0" PointType="EWorkingSnapshot" DescriptorType="Default" />", memory "False", quiesce "False"
[19.05.2020 18:41:21] <20> Info [Soap] Snapshot VM 'vm-3411' was created. Ref: 'snapshot-3416'//VPXD:
2020-05-19T15:41:15.469Z info vpxd[00941] [Originator@6876 sub=vpxLro opID=32de210d] [VpxLRO] -- BEGIN task-32174 -- vm-3411 -- vim.VirtualMachine.createSnapshot -- 52e02fc8-9bbb-74da-63ac-74879274c5a3(52e50ab9-39d5-0996-21ce-3877ead7a6e9)//Hostd:
2020-05-19T15:41:15.453Z info hostd[2099906] [Originator@6876 sub=Vimsvc.TaskManager opID=32de210d-b7-635b user=vpxuser:VSPHERE.LOCALAdministrator] Task Created : haTask-676-vim.VirtualMachine.createSnapshot-5370436
2020-05-19T15:41:15.664Z info hostd[2099914] [Originator@6876 sub=Vimsvc.TaskManager] Task Completed : haTask-676-vim.VirtualMachine.createSnapshot-5370436 Status successТеперь можно и данные передавать. Когда этот процесс закончится, наступает пора откатиться на “защитный” снапшот, дабы удалить всё, что могло попасть в его дельту (снова горячий привет любителям включать машины невовремя, ага) и удалить его. Благо больше он нам не нужен.
//Veeam Task log:
[19.05.2020 18:41:44] <20> Info [Soap] Reverting snapshot snapshot-3416
[19.05.2020 18:41:44] <20> Info [VimApi] RevertSnapshot, type "VirtualMachineSnapshot", ref "snapshot-3416"
[19.05.2020 18:41:46] <20> Info [Soap] Removing snapshot 'snapshot-3416'
[19.05.2020 18:41:46] <20> Info [VimApi] RemoveSnapshot, type "VirtualMachineSnapshot", ref "snapshot-3416", removeChildren "False//VPXD:
2020-05-19T15:41:40.571Z info vpxd[22153] [Originator@6876 sub=vpxLro opID=15fb90d9] [VpxLRO] -- BEGIN task-32176 -- snapshot-3416 -- vim.vm.Snapshot.revert -- 52e02fc8-9bbb-74da-63ac-74879274c5a3(52e50ab9-39d5-0996-21ce-3877ead7a6e9)
2020-05-19T15:41:42.758Z info vpxd[17341] [Originator@6876 sub=vpxLro opID=1b7624e9] [VpxLRO] -- BEGIN task-32177 -- snapshot-3416 -- vim.vm.Snapshot.remove -- 52e02fc8-9bbb-74da-63ac-74879274c5a3(52e50ab9-39d5-0996-21ce-3877ead7a6e9)//Hostd:
2020-05-19T15:41:40.966Z info hostd[2099914] [Originator@6876 sub=Vimsvc.TaskManager opID=15fb90d9-ad-6417 user=vpxuser:VSPHERE.LOCALAdministrator] Task Completed : haTask-676-vim.vm.Snapshot.revert-5370516 Status success
2020-05-19T15:41:42.764Z info hostd[6710321] [Originator@6876 sub=Vimsvc.TaskManager opID=1b7624e9-89-6435 user=vpxuser:VSPHERE.LOCALAdministrator] Task Created : haTask-676-vim.vm.Snapshot.remove-5370522
2020-05-19T15:41:42.995Z info hostd[2099912] [Originator@6876 sub=Vimsvc.TaskManager] Task Completed : haTask-676-vim.vm.Snapshot.remove-5370522 Status successНо поскольку свято место пусто не бывает, сразу после удаления этого снапшота надо создать новый, который возьмёт на себя ответственность называться “Restore Point”. Хотя фактически он служит той же цели — запрещает изменять предыдущую дельту, где лежат данные с боевой машины.
//Veeam Task log:
[19.05.2020 18:41:51] <20> Info [VimApi] Create snapshot, ref "vm-3411", name "Restore Point 5-19-2020 18:40:53", description "<RPData PointTime="5248941014961933064" WorkingSnapshotTime="5249033617402408751" PointSize="64" PointType="ECompleteRestorePoint" DescriptorType="Default" />", memory "False", quiesce "False"
[19.05.2020 18:41:53] <20> Info [Soap] Snapshot VM 'vm-3411' was created. Ref: 'snapshot-3417'//VPXD:
2020-05-19T15:41:47.170Z info vpxd[48063] [Originator@6876 sub=vpxLro opID=5cc1af26] [VpxLRO] -- BEGIN task-32179 -- vm-3411 -- vim.VirtualMachine.createSnapshot -- 52e02fc8-9bbb-74da-63ac-74879274c5a3(52e50ab9-39d5-0996-21ce-3877ead7a6e9)//Hostd:
2020-05-19T15:41:47.155Z info hostd[2099311] [Originator@6876 sub=Vimsvc.TaskManager opID=5cc1af26-f3-646c user=vpxuser:VSPHERE.LOCALAdministrator] Task Created : haTask-676-vim.VirtualMachine.createSnapshot-5370539
2020-05-19T15:41:47.303Z info hostd[2099419] [Originator@6876 sub=Vimsvc.TaskManager] Task Completed : haTask-676-vim.VirtualMachine.createSnapshot-5370539 Status successИ обязательный десерт — применение ретеншн политики. В общем случае это слияние базового диска и самой старой дельты. Только учтите, что эта информация отображается уже в логе джобы, а не таски.
//Veeam Job Log:
[19.05.2020 18:42:21] <49> Info [SnapReplicaVm] DeleteRestorePoint 'PointTime: 5/19/2020 15:33:10, DigestStorageTimeStamp: 9/3/2020 19:51:05, SnapshotRef: snapshot-3413, Type: Default'
[19.05.2020 18:42:21] <49> Info [Soap] Removing snapshot 'snapshot-3413'
[19.05.2020 18:42:21] <49> Info [VimApi] RemoveSnapshot, type "VirtualMachineSnapshot", ref "snapshot-3413", removeChildren "False"//VPXD:
2020-05-19T15:42:17.312Z info vpxd[49540] [Originator@6876 sub=vpxLro opID=7e40daff] [VpxLRO] -- BEGIN task-32181 -- snapshot-3413 -- vim.vm.Snapshot.remove -- 528b44cf-9794-1f2d-e3ff-e3e78efc8f76(52b14d11-1813-4647-353f-cfdcfbc6c149)//Hostd:
2020-05-19T15:42:17.535Z info hostd[2099313] [Originator@6876 sub=Vimsvc.TaskManager] Task Completed : haTask-676-vim.vm.Snapshot.remove-5370588 Status success
2020-05-19T15:42:17.302Z info hostd[6710322] [Originator@6876 sub=Vimsvc.TaskManager opID=7e40daff-e0-6513 user=vpxuser:VSPHERE.LOCALAdministrator] Task Created : haTask-676-vim.vm.Snapshot.remove-5370588Ищем компоненты
Снапшоты — это, конечно, очень хорошо, однако неплохо бы было понимать, что же именно в нашей инфраструктуре принимало участие в создании реплики или бекапа. А поскольку процесс репликации имеет более сложную структуру, то и разбираться будем на его примере.
На самом деле с ходу найти все участвовавшие компоненты может быть сложно, так как в логе нет единого места с их перечислением. Банальный пример: прокси выбираются в момент прохода джобы, исходя из возможностей инфраструктуры. Однако если знать, как искать, то всё находится довольно легко.
И да, это будет опять vSphere. Получить общую информацию проще всего в логе таски по строке Processing object
[02.11.2020 05:00:38] <29> Info Processing object 'vudc01' ('vm-26') from host 'vcenter.test.local' ('3de6c11c-ad7e-4ec0-ba12-d99a0b30b493')Чуть ниже уже будет более подробная информация в строке VM information. Как видим, для машин, добавленных через VC, указывается, в том числе, и хост.
[01.11.2020 05:00:46] <26> Info VM information: name "vudc01", ref "vm-26", uuid "564d7c38-f4ae-5702-c3c9-6f42ef95535c", host "esx02.test.local", resourcePool "resgroup-22", connectionState "Connected", powerState "PoweredOn", template "False", changeTracking "True", configVersion "vmx-08"Далее следует масса информации про выбор прокси и доступных режимов работы. Всё это происходит под тегом [ProxyDetector]. Общий алгоритм таков: берём и проверяем возможность скачать диски поочередно в режимах SAN > HotAdd > NBD. Каким способом получилось, так и качаем. Начинается всё веселье в этом моменте:
[01.11.2020 05:00:24] <01> Info [ProxyDetector] Trying to detect source proxy modes for VM [vudc01], has snapshots:False, disk types:[Scsi: True, Sata: False, Ide: False, Nvme: False]
[01.11.2020 05:00:24] <01> Info [ProxyDetector] Host storage 'VMware ESXi 6.5.0 build-16207673' has 1 lunsИ дальше полная вакханалия проверок, так как проверяются все возможные прокси на все возможные режимы. Да ещё и два раза — как таргет и как сорс. Единственное исключение возможно только в том случае, если в настройках джобы указан конкретный прокси и запрещены все режимы кроме одного.
[16.09.2020 00:08:01] <01> Info [ProxyDetector] Trying to detect source proxy modes for VM [TinyLinux2], has snapshots:False, disk types:[Scsi: True, Sata: False, Ide: False, Nvme: False]
[16.09.2020 00:08:11] <01> Info [ProxyDetector] Detecting storage access level for proxy [VMware Backup Proxy]
[16.09.2020 00:08:11] <01> Info Proxy [VMware Backup Proxy] - is in the same subnet as host [VMware ESXi 6.7.0 build-16
[16.09.2020 00:08:11] <01> Info [ProxyDetector] Detected mode [nbd] for proxy [VMware Backup Proxy]
...
[16.09.2020 00:08:13] <01> Info [ProxyDetector] Trying to detect target proxy modes, sanAllowed:False, vmHasSnapshots:True, diskTypes:[Scsi: True, Sata: False, Ide: False, Nvme: False], vmHasDisksWithoutUuid:False
[16.09.2020 00:08:24] <01> Info [ProxyDetector] Detecting storage access level for proxy [10.1.10.6]
[16.09.2020 00:08:24] <01> Info [ProxyDetector] Detected mode [nbd] for proxy [10.1.10.6]Какой прокси, в каком режиме и куда был назначен — надо смотреть в логе каждой таски по фразе Preparing for processing of disk
[16.09.2020 01:03:28] <20> Info Preparing for processing of disk [shared-spbsupstg02-ds04] TinyLinux2/TinyLinux2.vmdk, resources: source proxy 'VMware Backup Proxy' and target proxy '10.1.10.6'
[16.09.2020 01:03:28] <34> Info Processing disk '[shared-spbsupstg02-ds04] TinyLinux2/TinyLinux2.vmdk'
[16.09.2020 01:03:28] <34> Info Using source proxy 'VMware Backup Proxy' and target proxy '10.1.10.6' for disk processingТакже полезное можно найти в логе /Utils/VMC.log. С ним только одна сложность: вся информация внутри представлена в виде ID. Никаких имён и человекочитаемых названий. Слава роботам!
[16.09.2020 04:05:40] <56> Info [ViProxyEnvironment] Initialization of ViProxyEnvironment for the proxy 10.1.10.6 (5c7f925e-999b-473e-9a99-9230f51d5ebb).Если мы говорим про Direct SAN режим, то самое важное — это корректность сопоставления LUN’ов с их номерами. В данном примере виден общий смысл происходящего: сначала получаем номера лунов, проверяем все подключённые к прокси луны на предмет нахождения идентичного и в случае успеха работаем с ним.
[04.06.2019 17:54:05] <01> Info [ProxyDetector] Searching for VMFS LUN and volumes of the following datastores: ['test_datastore']
[04.06.2019 17:54:05] <01> Info [ProxyDetector] Datastore 'test_datastore' lun was found, it uses vmfs
[04.06.2019 17:54:05] <01> Info [ProxyDetector] VMFS LUNs: ['NETAPP iSCSI Disk (naa.60a980004270457730244a48594b304f)'], NAS volumes: <no>
...
[04.06.2019 17:54:16] <01> Info [ProxyDetector] Proxy [VMware Backup Proxy]: Detecting san access level
[04.06.2019 17:54:16] <01> Info [ProxyDetector] Proxy [VMware Backup Proxy]: disks ['6000C29C75E76E488EC846599CAF8D94566972747561','6000C29EA317A4903AFE2B7B038D3AD6566972747561','6000C29274D8E07AAE27F7DB20F38964566972747561','60A980004270457730244A48594B304F4C554E202020','6000C29EE0D83222ED7BFCB185D91117566972747561','6000C292083A3095167186895AD288DB566972747561','6000C2950C4F2CB5D9186595DC6B4953566972747561','6000C29BF52BB6F46A0E6996DA6C9729566972747561']
...
[04.06.2019 17:54:16] <01> Info [ProxyDetector] Proxy VMware Backup Proxy disk: , disk inquiry:
SCSI Unique ID 60A980004270457730244A48594B304F4C554E202020 is accessible through san for ESXi with vmfs lun: NETAPP iSCSI Disk (naa.60a980004270457730244a48594b304f)Эти же номера можно проверить самим. В vSphere клиенте — в разделе Host > Configure > Storage devices, а в Windows посмотреть в стандартный Disk Manager. Все номера должны совпадать.
Репозиторий
В отличие от бекапа, реплика хранится непосредственно на сторадже хоста. Репозиторию Veeam отводится роль хранителя метаданных. Под каждое задание создаётся своя папка, где хранятся .vbk файлы, содержащие так называемые дайджесты. Чтобы найти конкретный, открываем лог таски и ищем [DigestsRepositoryAccessor]. Получаем путь, название репозитория и ID.
[15.09.2020 05:44:54] <19> Info [DigestsRepositoryAccessor] Creating new digests storage at [E:ReplicasReplication_Job_4_7b409570-c4e1-424f-a0c5-b0b6e6e47272_vm-344122020-09-15T024444.vbk].
[15.09.2020 05:33:54] <21> Info Setting repository 'Backup Repository 1' ('adf7fbb6-0337-4805-8068-77960414f406') credentials for backup client.Если репозиторием выступает сетевая шара, то будет написан её путь:
[15.09.2020 06:50:53] <41> Info [DigestsRepositoryAccessor] Creating new digests storage at [2.17.12.57testReplicasReplication_Job_4_7b409570-c4e1-424f-a0c5-b0b6e6e47272_vm-344322020-09-15T035033.vbk]Если углубиться в поисках, то по Setting repository можно найти не только ID и название, но и под какой учёткой мы туда ходим. Если вы используете не одну учётку для всего на свете, то запросто можно промахнуться в визарде и долго искать причину, почему не удаётся подключиться к серверу.
[15.09.2020 06:50:02] <20> Info Setting repository 'DD share' ('36a89698-2433-4c1a-b8d3-901d9c07d03a') credentials for backup client.
[15.09.2020 06:50:02] <20> Info Creds user name: ddvesysadmin
[15.09.2020 06:50:02] <20> Info Setting share creds to [2.17.12.57test]. CredsId: [66de1ea7-7e89-48f6-bc73-61a4d1a7621e]
[15.09.2020 06:50:02] <20> Info Setting share creds to [2.17.12.57test]. Domain: [ddve], User: [sysadmin]WAN акселераторы
Получившая недавно второе рождение функция, которая бывает особенно актуальна для реплик. Проверить, работают акселераторы или нет, можно, найдя в логе джобы флаг <UseWan>. А по строке Request: SourceWanAccelerator можно получить информацию об ID используемых акселераторах.
[15.09.2020 05:32:59] <01> Info - - Request: SourceWanAccelerator: [WanAccelerator '8f0767e1-99ab-4050-a414-40edc5bebc39'], TargetWanAccelerator: [WanAccelerator '22fa299c-8855-4cf8-a6c7-6e8587250750']
[15.09.2020 05:32:59] <01> Info - - - - Response: Subresponses: [Wan accelerator],[Wan accelerator]В таск логе имена будут указаны уже в явном виде
[15.09.2020 05:33:54] <21> Info Using source WAN Accelerator KK-BB2
[15.09.2020 05:33:54] <21> Info Using target WAN Accelerator 10.1.10.6Что за второе рождение упоминалось в начале? Это так называемый High Bandwidth режим. Если раньше смысл от акселераторов был только на действительно медленных линках (очень медленных линках), то в v10 был введён новый режим, обеспечивающий прирост в производительности на скоростях до 100 Мб/с. Включается он отдельной галочкой, а в логах таски это видно вот по этим строкам:
[15.09.2020 05:33:54] <21> Info Selecting WaTransport algorithm, input arguments: performance mode preferred: False, perf mode available on target WAN: False
[15.09.2020 05:33:54] <21> Info Selecting WaTransport algorithm: selected classic modeВ первой строке указаны результаты проверки, включён ли необходимый режим на обоих WA — мы видим, что нет, и выбираем классическую версию.
Просто полезные слова для поиска
Но хватит уже упражняться в копипасте логов, давайте в конце перечислю некоторые места в логах, на которые может быть полезно обратить внимание.
Backup/Replication Job log
«> Error» или «> Warning» — здесь что-то произошло, на что точно надо обратить внимание. Не обязательно всё сломалось именно тут, но что-то здесь точно произошло. Возможно даже пошло не так, как планировалось.
Job Options: — здоровенная XML, где перечислены все настройки задания. После неё обычно идёт раздел VSS Settings, где перечислены настройки VSS.
[RetentionAlgorithm] — момент отрабатывания ретеншн алгоритма. Тут удаляются ставшие ненужными точки или синтезируются новые.
[JobSession] Load: — ботлнеки, про которые в нашем блоге есть отдельная статья.
Preparing point — узнаём, в каком режиме создаётся бекап (инкремент, реверс инкремент или фул).
Starting agent — узнаём, какой агент когда был запущен, и по его ID идём читать соответствующий ему лог.
VMware Job
[ProxyDetector] — весь процесс выбора рабочих прокси и режима транспорта. Технически, в Hyper-V будет всё то же самое, только с гораздо меньшим количеством деталей.
[SanSnapshots] — блок создания и работы с SAN-снапшотами.
VM task — детальная информация о каждой конкретной машине в задании.
Hyper-V Job
VM tasks — в отличие от VMware тут не будет исчерпывающей информации, однако как отправная точка для поиска истины — самое то.
VM guest info — много информации о гостевой машине и самом хосте. Однако имя машины надо предварительно посмотреть в секции Creating task, которая немного выше.
Task log
Starting Disk — можно узнать, когда началась обработка конкретного диска. Очень полезно, если у машины их много, включён parallel processing и всё несколько запутано.
Operation was canceled by user — где-то рядом ещё должно быть “Stop signal has been received”. Указывает на реальное время остановки бекапа и может означать всё что угодно. Если время подозрительно красивое, вроде 06:00:00, а юзер мамой клянётся, что ничего не трогал, то 99,99% — установлено Backup Window и ваше время истекло.
Starting agent — опять же, получаем ID нужного агента и далее смотрим прицельно.
Preparing oib — указывает, готовится ли бекап машины в инкрементальном виде или фул.
.source. shows — показывает, на каком сервере будет запущен передающий агент (Source Proxy).
.target. — показывает, на каком сервере будет запущен принимающий агент (Repository/Target proxy).
VMware Task
VM information: Практически вся информация, которую можно узнать про целевую машину.
[VimApi] Create или [VimApi] Remove — создание и удаление снапшотов. Через [VimApi] делается ещё несколько действий, так что не удивляйтесь.
Hyper-V Task
Files to process — краткий список того, что будет забекаплено.
[RTS] — весь процесс создания снапшотов и их удаления.
Agent log
Err | или WARN| — то же самое, что и > Error > Warning. В Err действительно есть пробел перед палочкой, это не опечатка.
Traffic size — размер всей переданной информации.
stat – размер файла бекапа.
Backup service log
== Name — показывает абсолютно все джобы и их текущее состояние (работает или остановлена). Между == и названием два пробела.
[Scheduler] Ready to start jobs: — список джоб, которые будут запущены в соответствии с расписанием.
by user — эта пометка делается, если юзер что-то сделал сам.
Backup copy job log
[OibFinder] — покажет вам, какие репозитории и точки восстановления были исключены из обработки. Иногда даже может сказать, почему.
[CryptoKeyRecryptor] — позволит понять, менялся ли на этом проходе юзер-пароль или энтерпрайз-ключ.
Surebackup
Backup point или Replica point — время, когда была создана проверяемая точка.
[<vm name>] [PowerOnVm] [StableIp] — моменты включения и выключения машин в лаборатории.
И на этом пока предлагаю остановиться. Так как список этот можно продолжать долго и никогда не закончить. Инженер техподдержки учится премудростям логочтения и устройства Veeam примерно три месяца, так что охватить всю широту наших глубин в рамках серии статей задача утопическая. Да и новая версия не за горами и часть информации может стать более невалидной.
Поэтому, если есть вопросы, то добро пожаловать в комментарии. Если есть предложение по написанию подобной статьи на какую-то конкретную тему — адрес тот же, комментарии.
Засим позвольте откланяться и до новых встреч.

В работе системного администратора, нередко возникает необходимость посмотреть логи сервера (Server Logs), с какими задачами работал сервер в конкретное время, какие действия совершали пользователи. Причины возникновения этой необходимости могут быть разные:
- Сбой в работе сервера;
- Выявление неблагонамеренных действий;
- Анализ рабочих процессов.
Всю необходимую информацию можно получить в логи сервера (Server Logs), то есть файлах, в которые вносятся записи о различных процессах, действиях пользователей, и т.п. Но, для этого необходимо понимать, где хранятся эти данные, а главное, как с ними работать.
- 1 Что такое логи сервера?
- 2 Как правильно читать логи сервера?
- 3 Логи серверов на Windows
- 4 Логи SQL сервера
- 5 Как включить или выключить запись логов сервера?
- 6 Где находятся логи сервера?
- 7 Пример работы с логами сервера
- 8 Вывод
Что такое логи сервера?
Собственно говоря, само слово «логи сервера», является банальной транслитерацией, от словосочетания «server log», которое переводится как «журнал сервера».
Существуют следующие типы логов:
- Ошибки – записи, фиксирующие различные сбои в работе сервера, или при обращении к конкретным функциям или задачам. С их помощью можно быстро ликвидировать разные баги и сбои;
- Доступ – записи, которые фиксируют точные дату и время подключения конкретного пользователя, каким образом он попал на сайт, и т.д. Позволяют проводить аналитическую работу, а также находить уязвимые места, в тех случаях, когда ресурс пытались взломать;
- Прочее – записи с данными о работе разных компонентов сервера, например, почты.
Разумеется, если вы не наблюдаете никаких проблем, или подозрительных моментов, связанных с работой сервера, то нет никакой необходимости в частом просмотре логов. Тем не менее, специалисты рекомендуют выборочно изучать их, хотя бы раз в год.
С другой стороны, если уже произошло какое-то ЧП, например, сайт резко начал выдавать большое количество ошибок, подвергся спам-атаке, или стремительно возросла нагрузка на сервер, то изучение логов, позволит быстро понять в чем проблема и устранить её.
Тем не менее, для большинства рядовых пользователей записи в log-файлах, представляют собой просто странный набор символов. А значит, нужно понять, как правильно их читать.
Как правильно читать логи сервера?

В данном примере, мы разберем два типа записей, касающихся логов доступа и ошибок, поскольку именно к ним чаще всего обращаются, при возникновении каких-то проблем.
Итак, запись лога доступа, из файла access.log:
mysite.biz 25.34.94.132 — — [21/Nov/2017:03:21:08 +0200] «GET /blog/2/ HTTP/1.0» 200 18432 «-» «Unknow Bot (http://www.unknow.com/bot; [email protected])»
Что она обозначает:
- mysite.biz – домен сайта, которым вы интересуетесь;
- 34.94.132 – IP-адрес, который использовал пользователь при заходе на сайт;
- [21/Nov/2017:03:21:08 +0200] – дата, точное время и часовой пояс пользователя;
- GET – запрос, который отправляется для получения данных. В том случае, если пользователь передает данные, запрос будет «POST»;
- /blog/2/ — относительный адрес страницы, к которой был обращен запрос;
- HTTP/1.0 – используемый протокол;
- 200 – код ответа на запрос;
- 18432 – количество данных, переданных по запросу, в байтах;
- Unknow Bot (http://www.unknow.com/bot; [email protected]) – данные о роботе, или реальном человеке, который зашел на сайт. В том случае, если это человек, будет отображена ОС, тип устройства и т.д. В конкретном примере на сайт зашел робот-парсер, принадлежащий ресурсу unknow.com.
Таким образом, мы узнали, что с IP-адреса 25.34.94.132, двадцать первого ноября, 2017-го года, в три часа, двадцать одну минуту и восемь секунд, на наш сайт заходил бот, принадлежащий другому веб-ресурсу. Он отправил запрос на получение данных, и получил 18432 байт информации.
Теперь можно заблокировать доступ для ботов от этого сайта, либо от всех, кто пользуется этим IP, разумеется, если в этом есть необходимость.
Логи ошибок, можно посмотреть в файле с говорящим именем – error.log. Они выглядят следующим образом:
[Sat Oct 1 18:23:28.719615 2019] [:error] [pid 10706] [client 44.248.44.22:35877]
PHP Notice: Undefined variable: moduleclass_sfx in
/var/data/www/mysite.biz/modules/contacts/default.php on line 13
Что здесь написано?
- Дата, время и тип ошибки, а также IP-адрес, который использовал посетитель;
- Тип события, в данном случае – «PHP Notice» (уведомление), а также уточнение, что в данном случае, мы имеем дело с неизвестной переменной;
- Местоположение файла с уведомлением, а также строка, на которой оно находится.
Если говорить просто, то в данном случае мы имеем сообщение о том, что первого октября, в 18:23, 2019-го года, произошла ошибка, связанная с модулем контактов.
Разумеется, даже после расшифровки, полученные данные не так просто проанализировать. Именно поэтому, для удобной обработки данных из логов сервера, используется различное программное обеспечение. К таким программам относятся: Awstats, Webtrends, WebAlyzer, и многие другие.
Сегодня существует множество платных и бесплатных вариантов программ, для обработки и анализа лог-файлов.
Логи серверов на Windows
У логов серверов на Windows, изначально более удобный и структурированный вывод информации, в виде простой и понятной таблицы.
Существует несколько уровней событий:
- Подробности;
- Сведения;
- Предупреждение;
- Ошибка;
- Критический.
Также есть возможность быстрой фильтрации и сортировки записей, в зависимости от того, какие данные вы хотите получить.
Логи SQL сервера
На сегодняшний день, базы данных SQL, являются наиболее распространенным способом работы с большими объемами информации. В первую очередь, логи sql сервера, стоит изучить, если вы не уверены в том, что какие-то процессы были успешно завершены. Этими процессами могут быть:
- Резервное копирование;
- Восстановление данных;
- Массовые изменения;
- Различные скрипты, и программы для обработки данных.
Для того, чтобы просмотреть записи в логах, можно использовать SQL Server Management Studio, либо другой, удобный вам редактор текстов. Записи распределены по журналам следующих типов:
- Сбор данных;
- Database Mail;
- SQL Сервер;
- События Windows;
- Журнал заданий;
- Коллекция аудита;
- SQL Сервер, агент.
Для того, чтобы получить доступ к журналам, необходимо иметь права «securityadmin».
Как включить или выключить запись логов сервера?
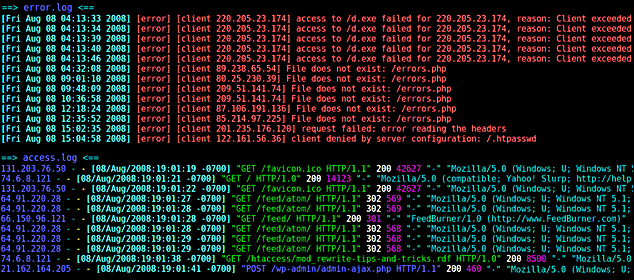
Для того, чтобы осуществить эту операцию, нужно зайти в административную панель вашего хостера. Как правило, в основном меню есть раздел «Журнал», или «Логи», в котором можно включить или выключить запись данных о предоставленном доступе, ошибках, и т.п.
Где находятся логи сервера?
Расположение журналов, зависит в первую очередь от используемой вами операционной системы.
Логи серверов с CentOS, или Fedora, хранятся в дирректории «/var/log/».
Названия файлов:
- Журнал ошибок – «error.log»;
- Журнал nginx – «nginx»;
- Журнал доступов – «log»;
- Основной журнал – «syslog»;
- Журнал загрузки системы – «dmesg».
Логи ошибок, связанных с работой MySQL, находятся в директории «/var/lib/mysql/», в файле «$hostname.err».
Для операционных систем Debian и Ubuntu, логи сервера располагаются в папке «/var/log/», в файлах:
- Nginx — журнал nginx;
- /mysql/error.log – журнал ошибок для баз данных MySQL;
- Syslog – основной журнал;
- Dmesg – загрузка системы, драйвера;
- Apache2 – журнал веб-сервера Apache.
Как видите, у всех ОС, основанных на Linux, логи сервера, как правило имеют одинаковые названия, и директории.
С логами для Windows server, дело обстоит несколько иначе. Если нужно просмотреть журналы, необходимо войти в систему, нажать клавиши «Win» и «R», после чего откроется окно просмотра событий, где есть возможность подобрать интересующие нас логи.
Если вы хотите посмотреть логи PowerShell, то необходимо открыть программу и ввести команду: «Get-EventLog -Logname ‘System’».
Все данные будут выведены в виде удобной таблицы.
Пример работы с логами сервера
Представьте себе, что вы внезапно обнаружили существенное увеличение нагрузки на ваш сервер, связанное с внешними воздействиями. Сервисы аналитики начинают регистрировать рекорды посещаемости, и можно было бы радоваться, но видно, что эти «пользователи» не совершают действий, которых от них ждут, неважно что это – изучение контента, или покупки на сайте.
Можно потратить много времени на выяснения причины, а можно просто посмотреть логи доступа и проверить, с каких IP, и кто заходил на ваш сайт, в выбранные промежуток времени. Вполне вероятно, что вы обнаружите большое количество переходов с нескольких IP-адресов, которые делались автоматически, то есть ваш сайт попал под DDoS-атаку.
В этом случае, можно заблокировать доступ к сайту с выбранных IP, и в дальнейшем расширять этот список, при необходимости.
Вывод
На сегодняшний день, log-файлы сервера, являются крайне удобным инструментом, который позволяет отслеживать работу сайта, выявлять баги и ошибки, злонамеренных пользователей, противодействовать DDoS-атакам.
Для того, чтобы правильно работать с логами сервера, необходимо знать их расположение, иметь возможность изучить нужные файлы, а также понимать разные типы записей. В большинстве панелей управления, пользователю сразу предоставляется возможность включать и выключать запись логов. К тому же есть возможность скачивать или просматривать журналы.
Кроме того, сегодня можно найти ряд программного обеспечения, и они позволяют взаимодействовать с информацией из журналов через удобный графический интерфейс, с большой скоростью расшифровывать её и выводить в простом виде.
У систем, основанных на Linux, как правило примерно одинаковое расположение файлов с логами, что существенно упрощает работу с ними.
У Windows Server, есть свой собственный графический интерфейс для чтения логов, который весьма удобен, и позволяет быстро получить необходимую информацию.
![]() Загрузка…
Загрузка…

Содержание:
- Важные логи сайта
- Расположение логов
- Чтение записей в логах
- Просмотр с помощью команды tail
- Просмотр с помощью ISPManager
- Программы для анализа логов
- Ведение логов медленных запросов сервера
- Ведение логов с помощью Logrotate
Логи сайта — это системные журналы, позволяющие получить информацию о посещении сайта ботами и пользователями, а также выявить скрытые проблемы на сервере — ошибки, битые ссылки, медленные запросы от сервера и многое другое.
Важные логи сайта
- Access.log — логи посещений пользователей и ботов. Позволяет составить более точную и подробную статистику, нежели сторонние ресурсы, выполняющие внешнее сканирование сайта и отправляющие ряд ненужных запросов серверу. Благодаря данному логу можно получить информацию об используемом браузере и IP-адрес посетителя, данные о местонахождении клиента (страна и город) и многое другое. Стоит обратить внимание, если сайт имеет высокую посещаемость, то анализ логов сервера потребует больше времени. Поэтому для составления статистики стоит использовать специализированные программы (анализаторы).
- Error.log — программные ошибки сервера. Стоит внимательно отнестись к анализу данного лога, ведь боты поисковиков, сканируя, получают все данные о работе сайта. При обнаружении большого количества ошибок, сайт может попасть под санкции поисковых систем. В свою очередь из записей данного журнала можно узнать точную дату и время ошибки, IP-адрес получателя, тип и описание ошибки.
- Slow.log (название зависит от используемой оболочки сервера) — в данный журнал записываются медленные запросы сервера. Так принято обозначать запросы с повышенным порогом задержки, выданные пользователю. Этот журнал позволяет выявить слабые места сервера и исправить проблему. Ниже будет рассмотрен способ включить ведение данного лога на разных типах серверов, а также настройка задержки, с которой записи будут заноситься в файл.
Расположение логов
Важно обратить внимание, что местоположение логов сайта по умолчанию зависит от используемого типа оболочки и может быть изменено администратором.
Стандартные пути до Error.log
Nginx
/var/log/nginx/error.log
Php-Fpm
/var/log/php-fpm/error.log
Apache (CentOS)
/var/log/httpd/error_log
Apache (Ubuntu, Debian)
/var/log/apache2/error_log
Стандартные пути до Access.log
Nginx
/var/log/nginx/access.log
Php-Fpm
/var/log/php-fpm/access.log
Apache (CentOS)
/var/log/httpd/access_log
Apache (Ubuntu, Debian)
/var/log/apache2/access_log
Чтение записей в логах
Записи в логах имеют структуру: одно событие – одна строка.
Записи в разных логах имеют общие черты, но количество подробностей отличается. Далее будут приведены примеры строк из разных системных журналов.
Примеры записей
Error.log
[Sat Sep 1 15:33:40.719615 2019] [:error] [pid 10706] [client 66.249.66.61:60699] PHP Notice: Undefined variable: moduleclass_sfx in /var/data/www/site.ru/modules/contacts/default.php on line 14
В приведенном примере:
- [Sat Sep 1 15:33:40.719615 2019] — дата и время события.
- [:error] [pid 10706] — ошибка и её тип.
- [client 66.249.66.61:60699] — IP-адрес подключившегося клиента.
- PHP Notice: Undefined variable: moduleclass_sfx in — событие PHP Notice. В данной ситуации — обнаружена неизвестная переменная.
- /var/data/www/site.ru/modules/contacts/default.php on line 14 — путь и номер строки в проблемном файле.
Access.log
194.61.0.6 – alex [10/Oct/2019:15:32:22 -0700] "GET /apache_pb.gif HTTP/1.0" 200 5396 "http://www.mysite/myserver.html" "Mozilla/4.08 [en] (Win98; I ;Nav)"
В приведенном примере:
- 194.61.0.6 — IP-адрес пользователя.
- alex — если пользователь зарегистрирован в системе, то в логах будет указан идентификатор.
- [10/Oct/2019:15:32:22 -0700]— дата и время записи.
- «GET /apache_pb.gif HTTP/1.0» — «GET» означает, что определённый документ со страницы сайта был отправлен пользователю. Существует команда «POST», наоборот отправляет конкретные данные (комментарий или любое другое сообщение) на сервер . Далее указан извлечённый документ «Apache_pb.gif», а также использованный протокол «HTTP/1.0».
- 200 5396 — код и количество байтов документа, которые были возвращены сервером.
- «http://www. www.mysite/myserver.html»— страница, с которой был произведён запрос на извлечение документа «Apache_pb.gif».
- «Mozilla/4.08 [en] (Win98; I ;Nav)» — данные о пользователе, которой произвёл запрос (используемый браузер и операционная система).
Просмотр логов сервера с помощью команды tail
Выполнить просмотр логов в Linux можно с помощью команды tail. Данный инструмент позволяет смотреть записи в логах, выводя последние строки из файла. По умолчанию tail выводит 10 строк.
Первый вариант использования Tail
tail -f /var/log/syslog
Аргумент «-f» позволяет команде делать просмотр событий в режиме реального времени, в ожидании новых записей в лог файлах. Для прерывания процесса следует нажать сочетание клавиш «Ctrl+C».
На место переменной «/var/log/syslog» в примере следует подставить актуальный адрес до нужных системных журналов.
Второй вариант использования Tail
tail -F /var/log/syslog
В Linux логи веб-сервера не ведутся до бесконечности, поскольку это усложняет их дальнейший анализ. При преодолении лимита записей, система переименует переполненный строками файл журнала и отправит в «архив». Вместо старого файла создастся новый, но с прежним названием.
Если будет использоваться аргумент «-f», команда продолжит отслеживание старого, переименованного журнала. Данный метод делает невозможным просмотр логов в реальном времени, поскольку файл более не актуален.
При использовании аргумента «-F», команда, после окончания записи старого журнала, перейдёт к чтению нового файла с логами. В таком случае просмотр логов в режиме реального времени продолжится.
Аналог команды Tail
tailf /var/log/syslog
Отличие команды tailf от предыдущей заключается в том, что она не обращается к файлу и файловой системе в период, когда запись логов не происходит. Это экономит ресурсы системы и заряд, если используется нестационарное устройство — ноутбук, смартфон или планшет.
Недостаток данного способа — проблема с чтением больших файлов. Если системный журнал достаточно большой, возникает вероятность отказа в работе программы.
Изменение стандартного количества строк для вывода
Как и отмечалось выше, по умолчанию выводится 10 строк. Если требуется увеличить или уменьшить их количество, в команду добавляется аргумент «-n» и необходимое число строк.
Пример:
tail -f -n 100 /var/log/syslog
При использовании данной команды будут показаны последние 100 строк журнала.
Просмотр логов с помощью ISPManager
Если на сервере установлен ISPManager, логи можно легко читать, используя приведенный ниже алгоритм.
- На главной странице, в панели инструментов «WWW» нужно нажать на вкладку «Журналы».
- ISPManager выдаст журналы посещений и серверных ошибок в виде:
- ru.access.log;
- ru.error.log.*
* Вместо «newdomen.ru» из примера в выдаче будет название актуального домена.
Открыть файл лога можно, нажав на «Посмотреть» в верхнем меню.
- Для просмотра всех записей журнала, необходимо нажать на «Скачать» и сохранить файл на локальный носитель.
- Более старые версии логов можно найти во вкладке «Архив».
Программы для анализа логов
Анализировать журналы с большим количеством данных вручную не только сложно, но и чревато ошибками. Для упрощения работы с лог файлами было создано большое количество сервисов и утилит.
Инструменты для анализа логов делятся на два основных типа — статические и работающие в режиме реального времени.
Статические программы
Данный тип выполняет работу только с извлеченными логами, но обеспечивает быструю сортировку данных.
WebLog Expert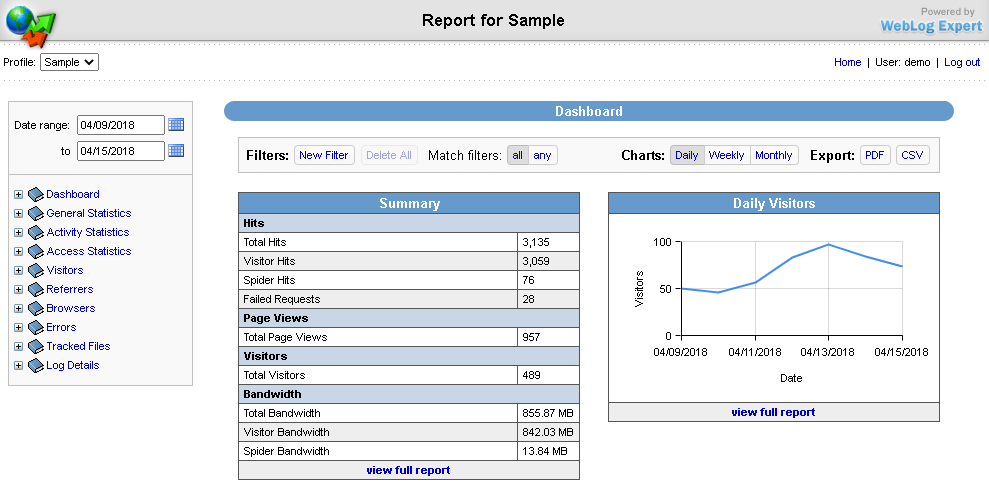
Возможности
- Предоставление информации об активность сайта, количестве посетителей, доступ к файлам, URL страницы, ссылающиеся страницы, информацию о пользователе (браузер и операционная система).
- Создание отчётов в формате HTML (.html), PDF (.pdf), CSV (.csv).
- Поддерживает анализ логов Nginx, Apache, ISS.
- Чтение файлов даже в архивах ZIP (.zip), GZ (.gz).
Web Log Explorer
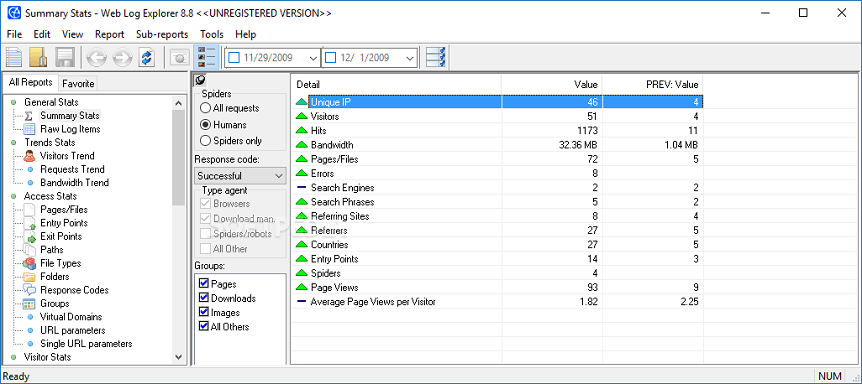
Возможности
- Создание многоуровневых отчётов, включающих количество посетителей, маршруты пользователей по сайту, местоположение хостов (страна и город), указанные в поисковике ключевые слова.
- Поддержка более 43 форматов логов.
- Возможность прямой загрузки логов с FTP, HTTP сервера.
- Чтение архивированных журналов.
Программы для анализа в режиме реального времени
Эти инструменты встраиваются в программную среду сервера, анализируют данные в реальном времени и записывают непрерывный отчёт.
GoAccess
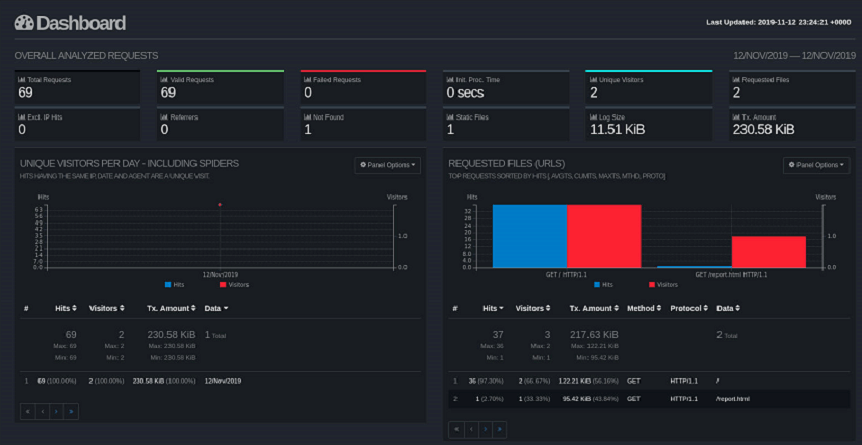
Возможности
- Автоматическая генерация отчёта в формате HTML (.html), JSON (.json), CSV (.csv).
- При подключении к серверу через SSH, возможен анализ в браузере и в терминале
- Поддержка почти всех форматов (Apache, Nginx, Amazon S3, Elastic Load Balancing, CloudFront и др.).
Logstash
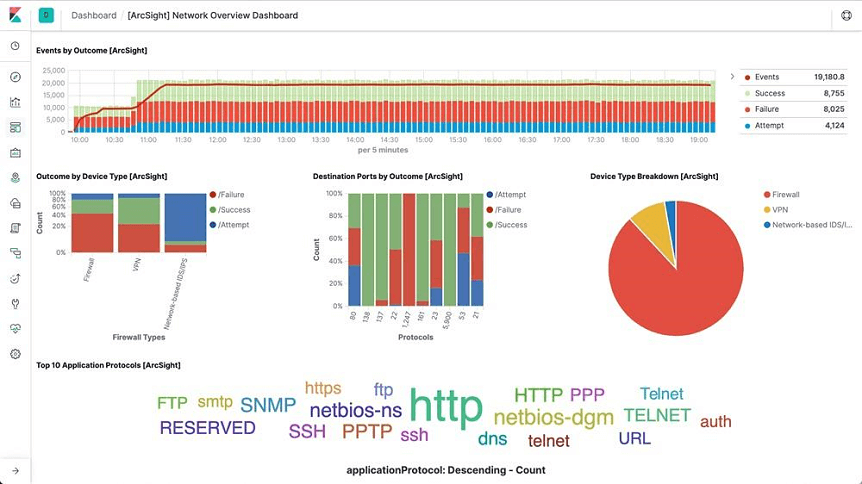
Возможности
- Постоянная генерация отчёта в файл JSON (.json).
- Получение и анализ информации из нескольких источников.
- Возможность пересылать журналы с помощью Filebeat.
- Поддержка анализа системных журналов.
- Поддерживается большое количество форматов: от Apache до Log4j (Java).
Ведения логов медленных запросов сервера
Анализ данного лога позволяет определить на какие типы запросов сервер отвечает долго. В идеале задержка должна составлять не более 1 секунды.
На некоторых типах оболочек (MySQL, PHP-FPM) ведение данного лога по умолчанию отключено. Процесс запуска и ведения зависит от сервера.
MySQL
Если сервер управляется с помощью MySQL, то необходимо создать каталог и сам файл для ведения журнала с помощью команд:
mkdir /var/log/mysql
touch /var/log/mysql/mysql-slow.log
Стоит изменить владельца файла, чтобы избежать дальнейших проблем с записью логов. Делается это командой:
chown mysql:mysql /var/log/mysql/mysql-slow.log
После выполнения предыдущих действий, нужно совершить вход в командную строку MySQL под учётной записью суперпользователя:
mysql -uroot -p
Для запуска и настройки ведения логов нужно последовательно ввести в терминале следующие команды:
> SET GLOBAL slow_query_log = 'ON'; > SET GLOBAL slow_launch_time = 2; > SET GLOBAL slow_query_log_file = '/var/log/mysql/mysql-slow.log'; > FLUSH LOGS;
В примере:
- slow_query_log — запускает ведение журналов медленных запросов.
- slow_launch_time — указывает максимальную задержку отклика, после которой статистика запроса попадёт в журнал. В данном случае запись в логи происходит при преодолении откликом порога 2 секунды.
- slow_query_log_file — задаёт путь до используемого журнала.
Проверить статус и параметры ведения лога медленных запросов можно командой:
> SHOW VARIABLES LIKE '%slow%';
Выход из консоли MySQL выполняется командой:
> exit
После выполнения всех предыдущих действий, можно просмотреть логи сервера. Для этого в терминале вводится:
tail -f /var/log/mysql/mysql-slow.log
PHP-FPM
Для ведения журнала на данной оболочке, необходимо отредактировать параметры в конфигурационном файле. Для этого в терминале вводится команда:
vi /etc/php-fpm.d/www.conf
Далее нужно найти строки:
- request_slowlog_timeout = 10s — параметр, позволяющий указать задержку, с которой запись о длительном запросе попадёт в журнал.
- slowlog = /var/log/php-fpm/www-slow.log — параметр, указывающий путь до актуального файла логирования (.log).
После применения изменений, необходимо перезагрузить сервер PHP-FPM. Для этого в консоль вводится команда:
systemctl restart php-fpm
Просмотр логов запускается командой:
tail -f /var/log/php-fpm/www-slow.log
Анализ логов медленных запросов
Логи медленных запросов могут за незначительное время вырасти до огромных размеров. Для сортировки и отображения повторяющихся запросов рекомендуется использовать программу MySQLDumpSlow.
Для запуска просмотра логов с помощью этой утилиты, нужно составить команду по приведенному ниже алгоритму:
mysqldumpslow местонахождение/файла
Ведение логов в Logrotate
На больших ресурсах журналы могут достигать огромных размеров, поэтому нужно своевременно архивировать или очищать логи. С помощью утилиты Logrotate можно управлять ведением журналов: настроить период ротации (архивирование старого журнала и создание нового), период и количество хранения журналов и многое другое.
Изначально программа отсутствует в системе. Ниже приведены команды для инсталляции Logrotate из официальных репозиториев.
Ubuntu, Debian:
sudo apt install logrotate
CentOS:
sudo yum install logrotate
После установки необходимо проверить путь для будущих конфигурационных файлов. Для правильной работы они должны находится в папке «logrotate.d». Проверить данный параметр можно открыв конфигурационный файл командой:
nano /etc/logrotate.conf
В директории «RPM packages drop log rotation information into this directory» должна присутствовать строка:
include /etc/logrotate.d
Теперь создаётся конфигурационный файл «rsyslog.conf». В нём будет находиться конфигурацию по работе с логами. Для создания файла в терминале вводится команда:
sudo nano /etc/logrotate.d/rsyslog.conf
В окне терминала откроется текстовой редактор. Теперь нужно внести конфигурацию, как указано в образце. В качестве примера будет использоваться журнал посещений «Access.log» (Nginx).
/var/log/nginx/access.log {
daily
rotate 3
size 500M
compress
delaycompress
}
Теперь остаётся только запустить Logrotate. Для этого вводится команда:
sudo logrotate -d /etc/logrotate.d/rsyslog.conf
Для проверки правильности работы программы в терминале можно ввести команду:
ls /var/cron.daily/
