grep — это мощный инструмент командной строки, который позволяет вам искать в одном или нескольких входных файлах строки, соответствующие регулярному выражению, и записывать каждую совпадающую строку в стандартный вывод.
В этой статье мы покажем вам, как использовать GNU grep для поиска нескольких строк или шаблонов.
Grep несколько шаблонов
GNU grep поддерживает три синтаксиса регулярных выражений: базовый, расширенный и Perl-совместимый. Если тип регулярного выражения не указан, grep интерпретирует шаблоны поиска как базовые регулярные выражения.
Для поиска нескольких шаблонов используйте оператор OR (чередование).
Оператор чередования | (pipe) позволяет вам указать различные возможные совпадения, которые могут быть буквальными строками или наборами выражений. Этот оператор имеет самый низкий приоритет среди всех операторов регулярных выражений.
Синтаксис поиска нескольких шаблонов с использованием базовых регулярных выражений grep следующий:
grep 'pattern1|pattern2' file...Всегда заключайте регулярное выражение в одинарные кавычки, чтобы избежать интерпретации и расширения метасимволов оболочкой.
При использовании основных регулярных выражений метасимволы интерпретируются как буквальные символы. Чтобы сохранить особые значения метасимволов, они должны быть экранированы обратной косой чертой ( ). Вот почему мы избегаем оператора ИЛИ ( | ) косой чертой.
Чтобы интерпретировать шаблон как расширенное регулярное выражение, вызовите grep с параметром -E (или --extended-regexp ). При использовании расширенного регулярного выражения не избегайте символа | оператор:
grep -E 'pattern1|pattern2' file...Для получения дополнительной информации о том, как создавать регулярные выражения, ознакомьтесь с нашей статьей Grep regex .
Grep несколько строк
Буквальные строки — это самые простые шаблоны.
В следующем примере мы ищем все вхождения слов fatal , error и critical в файле ошибок журнала Nginx :
grep 'fatal|error|critical' /var/log/nginx/error.logЕсли искомая строка содержит пробелы, заключите ее в двойные кавычки.
Вот тот же пример с использованием расширенного регулярного выражения, которое избавляет от необходимости экранировать оператор |
grep -E 'fatal|error|critical' /var/log/nginx/error.logПо умолчанию grep чувствителен к регистру. Это означает, что символы верхнего и нижнего регистра рассматриваются как разные.
Чтобы игнорировать регистр при поиске, вызовите grep with параметром -i (или --ignore-case ):
grep -i 'fatal|error|critical' /var/log/nginx/error.logПри поиске строки grep отобразит все строки, в которых строка встроена в строки большего размера. Поэтому, если вы искали «error», grep также напечатает строки, где «error» встроено в слова большего размера, например, «errorless» или «antiterrorists».
Чтобы вернуть только те строки, в которых указанная строка представляет собой целое слово (заключенное в символы, отличные от слов), используйте параметр -w (или --word-regexp ):
grep -w 'fatal|error|critical' /var/log/nginx/error.logСимволы слова включают буквенно-цифровые символы (az, AZ и 0–9) и символы подчеркивания (_). Все остальные символы считаются несловесными символами.
Чтобы узнать больше о параметрах grep , посетите нашу статью Команда Grep .
Выводы
Мы показали вам, как использовать grep для поиска нескольких шаблонов, строк и слов.
Если у вас есть какие-либо вопросы или отзывы, не стесняйтесь оставлять комментарии.
Don’t try to use grep for this, use awk instead. To match 2 regexps R1 and R2 in grep you’d think it would be:
grep 'R1.*R2|R2.*R1'
while in awk it’d be:
awk '/R1/ && /R2/'
but what if R2 overlaps with or is a subset of R1? That grep command simply would not work while the awk command would. Lets say you want to find lines that contain the and heat:
$ echo 'theatre' | grep 'the.*heat|heat.*the'
$ echo 'theatre' | awk '/the/ && /heat/'
theatre
You’d have to use 2 greps and a pipe for that:
$ echo 'theatre' | grep 'the' | grep 'heat'
theatre
and of course if you had actually required them to be separate you can always write in awk the same regexp as you used in grep and there are alternative awk solutions that don’t involve repeating the regexps in every possible sequence.
Putting that aside, what if you wanted to extend your solution to match 3 regexps R1, R2, and R3. In grep that’d be one of these poor choices:
grep 'R1.*R2.*R3|R1.*R3.*R2|R2.*R1.*R3|R2.*R3.*R1|R3.*R1.*R2|R3.*R2.*R1' file
grep R1 file | grep R2 | grep R3
while in awk it’d be the concise, obvious, simple, efficient:
awk '/R1/ && /R2/ && /R3/'
Now, what if you actually wanted to match literal strings S1 and S2 instead of regexps R1 and R2? You simply can’t do that in one call to grep, you have to either write code to escape all RE metachars before calling grep:
S1=$(sed 's/[^^]/[&]/g; s/^/\^/g' <<< 'R1')
S2=$(sed 's/[^^]/[&]/g; s/^/\^/g' <<< 'R2')
grep 'S1.*S2|S2.*S1'
or again use 2 greps and a pipe:
grep -F 'S1' file | grep -F 'S2'
which again are poor choices whereas with awk you simply use a string operator instead of regexp operator:
awk 'index($0,S1) && index($0.S2)'
Now, what if you wanted to match 2 regexps in a paragraph rather than a line? Can’t be done in grep, trivial in awk:
awk -v RS='' '/R1/ && /R2/'
How about across a whole file? Again can’t be done in grep and trivial in awk (this time I’m using GNU awk for multi-char RS for conciseness but it’s not much more code in any awk or you can pick a control-char you know won’t be in the input for the RS to do the same):
awk -v RS='^$' '/R1/ && /R2/'
So – if you want to find multiple regexps or strings in a line or paragraph or file then don’t use grep, use awk.
Перевод публикуется с сокращениями, автор оригинальной статьи Abhishek
Nair.
Название утилиты расшифровывается как Globally search for a REgular expression and Print matching lines. Grep в основном ищет заданный шаблон или регулярное выражение из стандартного ввода или файла и печатает соответствующие заданным критериям строки. Он часто используется для фильтрации ненужных деталей при выводе только необходимой информации из больших файлов журналов.
Мощь регулярных выражений в сочетании с поддерживаемыми опциями в grep делает это возможным.
Начнем!
Синтаксис команды
Grep ожидает шаблон и
необязательные аргументы вместе со списком файлов, если они используются без
конвейера.
$ grep [options] pattern [files]
Пример:
$ grep my file.txt
my_file
$
1. Поиск в нескольких файлах
Grep позволяет искать
заданный шаблон не только в одном, но и в нескольких файлах с помощью масок (например, знака «*»):
$ sudo grep -i err /var/log/messages*
Вывод:
$ sudo grep err /var/log/messages*
/var/log/messages:Dec 28 10:36:52 centos7vm kernel: ACPI: Using IOAPIC for interrupt routing
/var/log/messages:Dec 28 10:36:52 centos7vm kernel: ACPI: PCI Interrupt Link [LNKA] (IRQs 5 9 10 *11)
/var/log/messages:Dec 28 10:36:52 centos7vm kernel: ACPI: PCI Interrupt Link [LNKB] (IRQs 5 9 *10 11)
/var/log/messages:Dec 28 10:36:52 centos7vm kernel: ACPI: PCI Interrupt Link [LNKC] (IRQs 5 *9 10 11)
/var/log/messages:Dec 28 10:36:52 centos7vm kernel: ACPI: PCI Interrupt Link [LNKD] (IRQs 5 9 10 *11)
/var/log/messages-20201225:Dec 23 23:01:00 centos7vm kernel: ACPI: Using IOAPIC for interrupt routing
/var/log/messages-20201225:Dec 23 23:01:00 centos7vm kernel: ACPI: PCI Interrupt Link [LNKA] (IRQs 5 9 10 *11)
/var/log/messages-20201225:Dec 23 23:01:00 centos7vm kernel: ACPI: PCI Interrupt Link [LNKB] (IRQs 5 9 *10 11)
/var/log/messages-20201225:Dec 23 23:01:00 centos7vm kernel: ACPI: PCI Interrupt Link [LNKC] (IRQs 5 *9 10 11)
/var/log/messages-20201225:Dec 23 23:01:00 centos7vm kernel: ACPI: PCI Interrupt Link [LNKD] (IRQs 5 9 10 *11)
/var/log/messages-20201225:Dec 23 23:01:00 centos7vm kernel: BERT: Boot Error Record Table support is disabled. Enable it by using bert_enable as kernel parameter.
/var/log/messages-20201227:Dec 27 19:11:18 centos7vm kernel: ACPI: PCI Interrupt Link [LNKA] (IRQs 5 9 10 *11)
/var/log/messages-20201227:Dec 27 19:11:18 centos7vm kernel: ACPI: PCI Interrupt Link [LNKB] (IRQs 5 9 *10 11)
/var/log/messages-20201227:Dec 27 19:11:18 centos7vm kernel: ACPI: PCI Interrupt Link [LNKC] (IRQs 5 *9 10 11)
/var/log/messages-20201227:Dec 27 19:11:18 centos7vm kernel: ACPI: PCI Interrupt Link [LNKD] (IRQs 5 9 10 *11)
/var/log/messages-20201227:Dec 27 19:11:18 centos7vm kernel: BERT: Boot Error Record Table support is disabled. Enable it by using bert_enable as kernel parameter.
/var/log/messages-20201227:Dec 27 19:11:21 centos7vm kernel: [drm:vmw_host_log [vmwgfx]] *ERROR* Failed to send host log message.
/var/log/messages-20201227:Dec 27 19:11:21 centos7vm kernel: [drm:vmw_host_log [vmwgfx]] *ERROR* Failed to send host log message.
$
Из приведенного вывода
можно заметить, что grep печатает имя файла перед соответствующей строкой, чтобы
указать местонахождение шаблона.
2. Поиск без учета регистра
Grep предлагает искать
паттерн, не глядя на его регистр. Используйте флаг -i, чтобы утилита игнорировала регистр:
$ grep -i [pattern] [file]
Вывод:
$ grep -i it text_file.txt
This is a sample text file. It contains
functionality. You can always use grep with any
kind of data but it works best with text data.
It supports numbers like 1, 2, 3 etc. as well as
This is a sample text file. It's repeated two times.
$
3. Поиск всего слова
Зачастую вместо
частичного совпадения необходимо полное соответствие поисковому слову. Это можно
сделать, используя флаг -w:
$ grep -w [pattern] [file]
Вывод:
$ grep -w is text_file.txt
This is a sample text file. It contains
This is a sample text file. It's repeated two times.
$
4. Проверка количества совпадений
Иногда вместо
фактического совпадения со строкой нам необходимо количество успешных
совпадений, найденных grep. Этот результат можно получить, используя опцию -c:
$ grep -c [pattern] [file]
Вывод:
$ grep -c is text_file.txt
2
$
5. Поиск в подкаталогах
Часто требуется выполнить
поиск файлов не только в текущем рабочем каталоге, но и в подкаталогах. Grep позволяет это сделать с помощью флага -r:
$ grep -r [pattern] *
Вывод:
$ grep -r Hello *
dir1/file1.txt:Hello One
dir1/file2.txt:Hello Two
dir1/file3.txt:Hello Three
$
Как можно заметить,
grep проходит через каждый подкаталог внутри текущего каталога и перечисляет
файлы и строки, в которых найдено совпадение.
6. Инверсивный поиск
Если вы хотите найти
что-то несоответствующее заданному шаблону, grep и это умеет при помощи флага -v:
$ grep -v [pattern] [file]
Вывод:
$ grep This text_file.txt
This is a sample text file. It contains
This is a sample text file. It's repeated two times.
$ grep -v This text_file.txt
several lines to be used as part of testing grep
functionality. You can always use grep with any
kind of data but it works best with text data.
It supports numbers like 1, 2, 3 etc. as well as
alphabets and special characters like - + * # etc.
$
Можно сравнить вывод
команды grep по одному и тому же шаблону и файлу с флагом -v или без него. С флагом печатается каждая строка, которая
не соответствует шаблону.
7. Печать номеров строк
Если хотите напечатать
номера найденных строк, чтобы узнать их позицию в файле, используйте
опцию -n:
$ grep -n [pattern] [file]
Вывод:
$ grep -n This text_file.txt
1:This is a sample text file. It contains
7:This is a sample text file. It's repeated two times.
$
8. Ограниченный вывод
Для больших файлов вывод может быть огромным и тогда вам понадобится
фиксированное количество строк вместо всей простыни. Можно использовать –m[num]:
$ grep -m[num] [pattern] [file]
Обратите внимание, как
использование флага влияет на вывод для того же набора условий:
$ grep It text_file.txt
This is a sample text file. It contains
It supports numbers like 1, 2, 3 etc. as well as
This is a sample text file. It's repeated two times.
$ grep -m2 It text_file.txt
This is a sample text file. It contains
It supports numbers like 1, 2, 3 etc. as well as
$
9. Отображение дополнительных строк
Иногда необходимо
вывести не только строки по некоторому шаблону, но и дополнительные строки выше
или ниже найденных для понимания контекста. Можно напечатать строку выше, ниже или оба варианта, используя флаги -A, -B или -C со значением num (количество дополнительных строк, которые будут напечатаны). Это применимо ко всем совпадениям, которые grep находит в указанном файле или в списке файлов.
$ grep -A[num] [pattern] [file]
или
$ grep -B[num] [pattern] [file]
или
$ grep -C[num] [pattern] [file]
Ниже показан обычный
вывод grep, а также вывод с флагами. Обратите внимание, как grep интерпретирует флаги и их значения, а также
изменения в соответствующих выходных данных:
- с флагом –A1 выведется 1 строка, следующая за основной;
- –B1 напечатает 1 строку перед основной;
- –C1 выведет по одной строке снизу и сверху.
$ grep numbers text_file.txt
It supports numbers like 1, 2, 3 etc. as well as
$ grep -A1 numbers text_file.txt
It supports numbers like 1, 2, 3 etc. as well as
alphabets and special characters like - + * # etc.
$ grep -B1 numbers text_file.txt
kind of data but it works best with text data.
It supports numbers like 1, 2, 3 etc. as well as
$ grep -C1 numbers text_file.txt
kind of data but it works best with text data.
It supports numbers like 1, 2, 3 etc. as well as
alphabets and special characters like - + * # etc.
$
10. Список имен файлов
Чтобы напечатать только
имя файлов, в которых найден шаблон, используйте флаг -l:
$ grep -l [pattern] [file]
Вывод:
$ grep -l su *.txt
file.txt
text_file.txt
$
11. Точный вывод строк
Если необходимо
напечатать строки, которые точно соответствуют заданному шаблону, а не какой-то
его части, применяйте в команде ключ -x:
$ grep -x [pattern] [file]
В приведенном ниже
примере file.txt содержится слово «support», а строки без точного совпадения
игнорируются.
$ grep -x support *.txt
file.txt:support
$
12. Совпадение по началу строки
Используя регулярные
выражения, можно найти начало строки:
$ grep [options] "^[string]" [file]
Пример:
$ grep It text_file.txt
This is a sample text file. It contains
It supports numbers like 1, 2, 3 etc. as well as
This is a sample text file. It's repeated two times.
$ grep ^It text_file.txt
It supports numbers like 1, 2, 3 etc. as well as
$
Обратите внимание, как
использование символа «^» изменяет выходные данные. Знак «^» указывает начало
строки, т.е. ^It соответствует любой
строке, начинающейся со слова It.
Заключение в кавычки может помочь, когда шаблон содержит пробелы и т. д.
13. Совпадение по концу строки
Эта полезная регулярка
способна помочь найти по шаблону конец строки:
$ grep [options] "[string]$" [file]
Пример:
$ grep "." text_file.txt
This is a sample text file. It contains
functionality. You can always use grep with any
kind of data but it works best with text data.
It supports numbers like 1, 2, 3 etc. as well as
alphabets and special characters like - + * # etc.
This is a sample text file. It's repeated two times.
$ grep ".$" text_file.txt
kind of data but it works best with text data.
alphabets and special characters like - + * # etc.
This is a sample text file. It's repeated two times.
$
Обратите внимание, как
меняется вывод, когда мы сопоставляем символ «.» и когда используем «$», чтобы сообщить утилите о строках, заканчивающихся на «.» (без тех, которые могут содержать
символ посередине).
14. Файл шаблонов
Если у вас есть некий
список часто используемых шаблонов, укажите его в файле и используйте флаг -f. Файл должен содержать по одному шаблону на строку.
$ grep -f [pattern_file] [file_to_match]
В примере мы создали файл
шаблонов pattern.txt с таким содержанием:
$ cat pattern.txt
This
It
$
Чтобы это использовать,
применяйте ключ -f:
$ grep -f pattern.txt text_file.txt
This is a sample text file. It contains
It supports numbers like 1, 2, 3 etc. as well as
This is a sample text file. It's repeated two times.
$
15. Указание нескольких шаблонов
Grep позволяет указать
несколько шаблонов с помощью -e:
$ grep -e [pattern1] -e [pattern2] -e [pattern3]...[file]
Пример:
$ grep -e is -e It -e to text_file.txt
This is a sample text file. It contains
several lines to be used as part of testing grep
It supports numbers like 1, 2, 3 etc. as well as
This is a sample text file. It's repeated two times.
$
Grep поддерживает
расширенные регулярные выражения или ERE (похожие на egrep) с использованием флага -E.
Использование ERE имеет
преимущество, когда вы хотите рассматривать мета-символы как есть и не хотите
заменять их строками. Использование -E
с grep эквивалентно команде egrep.
$ grep -E '[Extended RegEx]' [file]
Вот одно из применений
ERE, когда необходимо вывести строки, например, из больших конфигурационных
файлов. Здесь использовался флаг -v,
чтобы не печатать строки, соответствующие шаблону ^(#|$).
$ sudo grep -vE '^(#|$)' /etc/ssh/sshd_config
HostKey /etc/ssh/ssh_host_rsa_key
HostKey /etc/ssh/ssh_host_ecdsa_key
HostKey /etc/ssh/ssh_host_ed25519_key
SyslogFacility AUTHPRIV
AuthorizedKeysFile .ssh/authorized_keys
PasswordAuthentication yes
ChallengeResponseAuthentication no
GSSAPIAuthentication yes
GSSAPICleanupCredentials no
UsePAM yes
X11Forwarding yes
AcceptEnv LANG LC_CTYPE LC_NUMERIC LC_TIME LC_COLLATE LC_MONETARY LC_MESSAGES
AcceptEnv LC_PAPER LC_NAME LC_ADDRESS LC_TELEPHONE LC_MEASUREMENT
AcceptEnv LC_IDENTIFICATION LC_ALL LANGUAGE
AcceptEnv XMODIFIERS
Subsystem sftp /usr/libexec/openssh/sftp-server
$
Заключение
Приведенные выше
примеры – лишь верхушка айсберга. Grep поддерживает
целый ряд опций и может оказаться полезным инструментом в руках специалиста,
который способен эффективно его использовать. Мы можем не только взять на вооружение приведенные выше примеры, но и комбинировать их, чтобы получить требуемый
результат в различных условиях.
Для дальнейшего
изучения утилиты и расширения кругозора стоит почитать мануал, выполнив в
терминале команду man grep, или
посетить страницу с официальной документацией.
Дополнительные материалы:
- Настольные книги по Linux на русском языке
- 20 лучших инструментов для хакинга на Kali Linux
- 6 команд терминала и пара комбинаций, полезных для начинающих разработчиков
- 10 лучших видеокурсов для изучения Linux
- 7 книг по UNIX/Linux
Introduction
Grep is a powerful utility available by default on UNIX-based systems. The name stands for Global Regular Expression Print.
By using the grep command, you can customize how the tool searches for a pattern or multiple patterns in this case. You can grep multiple strings in different files and directories. The tool prints all lines that contain the words you specify as a search pattern.
In this guide, we will show you how to use grep to search multiple words or string patterns. Follow the examples in this tutorial to learn how to utilize grep most effectively.

Prerequisites
- Linux or UNIX-like system
- Access to a terminal or command line
- A user with permissions to access the necessary files and directories
The basic grep syntax when searching multiple patterns in a file includes using the grep command followed by strings and the name of the file or its path.
The patterns need to be enclosed using single quotes and separated by the pipe symbol. Use the backslash before pipe | for regular expressions.
grep 'pattern1|pattern2' fileName_or_filePathThe latest way to use grep is with the -E option. This option treats the pattern you used as an extended regular expression.
grep -E 'pattern1|pattern2' fileName_or_filePathThe deprecated version of extended grep is egrep.
egrep 'pattern1|pattern2' fileName_or_filePathAnother option is to add multiple separate patterns to the grep command.
To do so, use the -e flag and keep adding the desired number of search patterns:
grep -e pattern1 -e pattern2 fileName_or_filePathWhat is the Difference Between grep, grep -E, and egrep?
The egrep command is an outdated version of extended grep. It does the same function as grep -E.
The difference between grep and extended grep is that extended grep includes meta characters that were added later.
These characters are the parenthesis (), curly brackets {}, and question mark. The pipe character | is also treated as a meta character in extended grep.
Examples of Using Grep for Multiple Strings, Patterns and Words
To make sure you understand how to use grep to search multiple strings, we suggest creating a file with some text on which we are going to try out a couple of different use cases.
In our case, we named the file sample.txt and added a few paragraphs of text. We stored the file in the directory of the test user, that is, in /home/test/sample.txt
How to Grep Multiple Patterns in a File
In the examples below, we will use grep instead of extended grep. Do not forget to use the backslash before the pipe character.
Since grep does not support the pipe symbol as the alternation operator, you need to use the escape character (backslash ) to tell the grep command to treat the pipe differently.
For example, to search for the words extra and value in the sample.txt file use this command:
grep 'extra|value' sample.txtThe output highlights the string you wanted to grep.
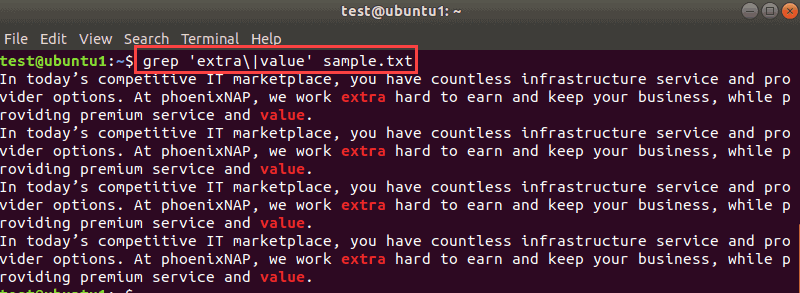
If the same file is in another directory, you need to navigate to that directory or use the full path of the file:
grep 'extra|value' /home/test/Desktop/sample.txtTo search for more than two words, keep adding them in the same manner.
For example, to search for three words, add the desired string of characters followed by a backslash and pipe:
grep 'extra|value|service' sample.txt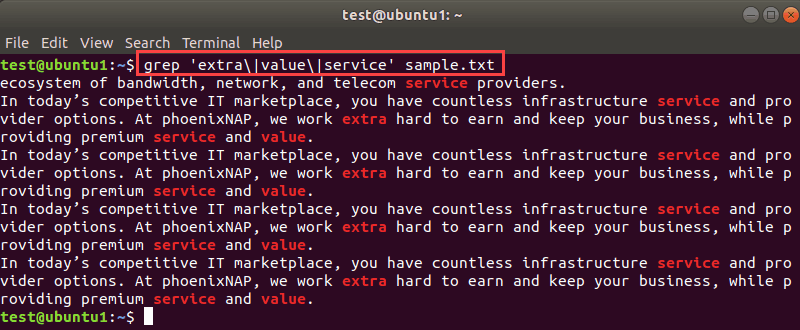
Let’s see how the above grep command looks when using grep -E, egrep, and grep -e:
grep -E ‘extra|value|service’ sample.txtegrep ‘extra|value|service’ sample.txtgrep -e extra -e value -e service sample.txtWe will use grep in further examples, but you can use whichever syntax you prefer.
Search for Multiple Exact Matches in a File
If you want to find exact matches for multiple patterns, pass the -w flag to the grep command.
grep -w 'provide|count' sample.txtFor example, the output below shows the difference between searching without -w and with it:
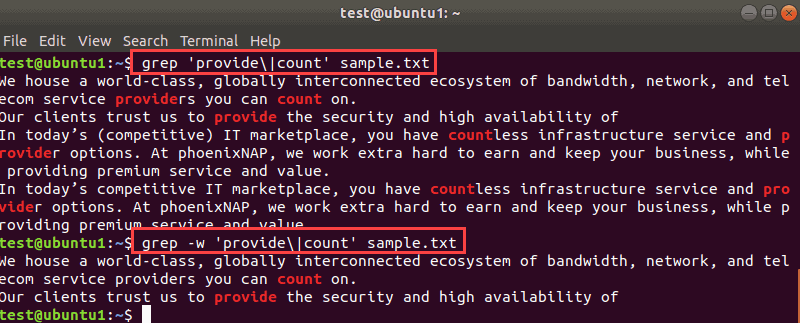
As you can see, the results are different. The first command shows all lines with the strings you used.
The second command shows how to grep exact matches for multiple strings. The output prints only the lines that contain the exact words.
Note: Grep offers many functionalities. Learn how to use grep for additional use cases.
Ignore Case when Using Grep for Multiple Strings
To avoid missing something when you search for multiple patterns, use the -i flag to ignore letter case.
For example, we will ignore case with this command:
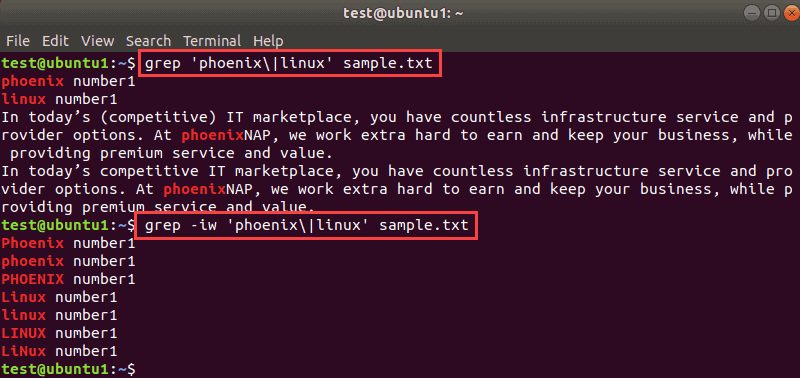
grep -i 'phoenix|linux' sample.txt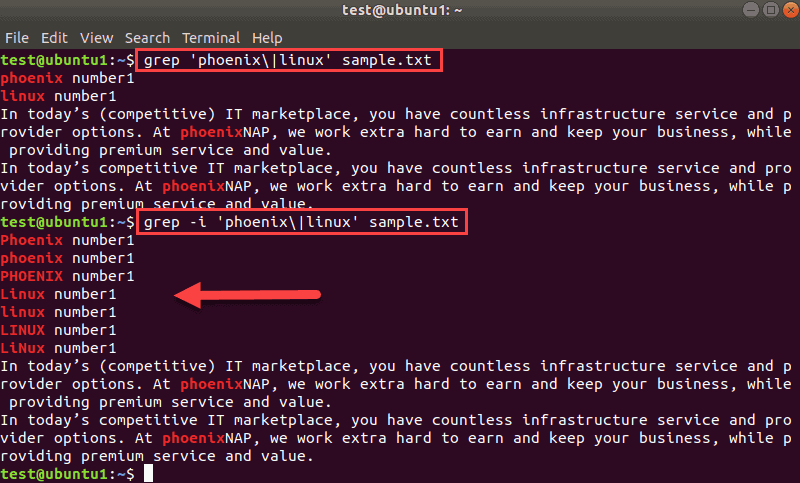
The output shows how the two commands differ. If you include the -i flag and ignore letter case, the result for multiple matches includes all matches.
This way, you get additional results. If you also add the -w flag to this command, you can narrow down the results even further:
Show the Count of Multiple Matches in a File
Let’s say you are monitoring a log file, and you want to see if the number of warnings or messages increases. You don’t want to see detailed results when a large number of matches return.
For example, to show the count of multiple matches in the bootstrap.log file, enter:
grep -c 'warning|error' /var/log/bootstrap.log
The output prints the number of matches. This way, you can quickly determine if the number of warnings and errors increased.
Grep for Multiple Patterns in a Specific File Type
You can use grep to search multiple strings in a certain type of file only. If you want to monitor log files in one directory or if you want to search through all text files, use an asterisk and the file extension instead of a file name.
For example, to search for warnings and errors through all .log files in the /var/log/ directory, enter:
grep 'warning|error' /var/log/*.logTo better demonstrate how this option works, we will only show the count of matches.
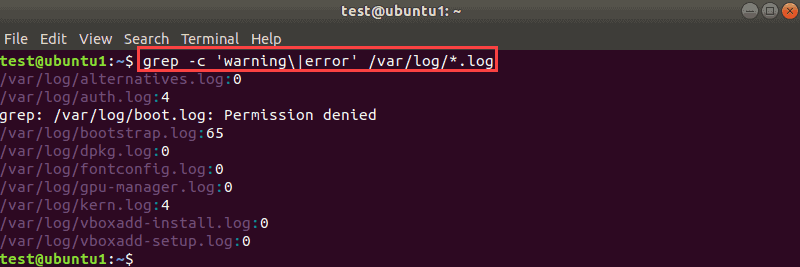
The output shows all the files that grep searched through for the strings you used.
Note: If you get a “Permission denied” message, as we did in the example above, you need sudo privileges. To include all files, use sudo with the grep command. Enter the sudo password, and grep will search through all files.
Search Recursively for Multiple Patterns in a File
The grep command searches only in the current directory when you use the asterisk wildcard.
To include all subdirectories when searching for multiple patterns, add the -R operator to grep:
grep -R 'warning|error' /var/log/*.logThe output will return results from all files the grep command found in the /var/log/ directory and its subdirectories.
Conclusion
In this tutorial, you learned how to use grep to search multiple words or string patterns in a file. The guide also showed you how to use extended grep.
The examples in this article help you practice how to refine your grep search. Also, check out our grep regex guide to learn more.
Grep это мощный инструмент командной строки, который позволяет вам искать в одном или нескольких входных файлах строки, соответствующие регулярному выражению, и записывать каждую соответствующую строку в стандартный вывод.
В этой статье мы покажем вам, как использовать grep в GNU для поиска нескольких строк или шаблонов.
Grep. Несколько шаблонов
grep в GNU поддерживает три синтаксиса регулярных выражений: Basic, Extended и Perl-совместимый. Если тип регулярного выражения не указан, grep интерпретирует шаблоны поиска как базовые регулярные выражения.
Для поиска нескольких шаблонов используйте оператор or (чередование).
Оператор чередования |(конвейер) позволяет указывать различные возможные совпадения, которые могут быть литеральными строками или наборами выражений. Этот оператор имеет самый низкий приоритет среди всех операторов регулярных выражений.
Синтаксис для поиска нескольких шаблонов с использованием grep основных регулярных выражений выглядит следующим образом:
grep 'pattern1|pattern2' file...
Всегда заключайте регулярное выражение в одинарные кавычки, чтобы избежать интерпретации и расширения метасимволов оболочкой.
При использовании основных регулярных выражений метасимволы интерпретируются как буквенные символы. Чтобы сохранить специальные значения метасимволов, их необходимо экранировать обратной косой чертой (). Вот почему мы избегаем оператора or (|) с косой чертой.
Чтобы интерпретировать шаблон как расширенное регулярное выражение, вызовите команду grep с параметром -E (или —extended-regexp). При использовании расширенного регулярного выражения не экранируйте оператор |:
grep -E 'pattern1|pattern2' file...
Grep. Несколько строк
Литеральные строки — самые основные образцы.
В следующем примере мы ищем все вхождения слов fatal, error и critical в журнале файла ошибки Nginx:
grep 'fatal|error|critical' /var/log/nginx/error.log
Если искомая строка содержит пробелы, заключите ее в двойные кавычки.
Вот тот же пример, использующий расширенное регулярное выражение, которое устраняет необходимость экранирования оператора |
grep -E 'fatal|error|critical' /var/log/nginx/error.log
По умолчанию учитывается регистр grep. Это означает, что прописные и строчные символы рассматриваются как разные.
Для того, чтобы игнорировать регистр при поиске, призовите grep with с параметром -i (или —ignore-case):
grep -i 'fatal|error|critical' /var/log/nginx/error.log
При поиске строки grep будет отображаться все строки, в которых строка встроена в более крупные строки. Так что, если вы искали «error», grep также напечатает строки, в которых «error» встроена в более крупные слова, такие как «errorless» или «antiterrorists».
Чтобы вернуть только те строки, в которых указанная строка представляет собой целое слово (заключенное не в словах), используйте параметр -w (или —word-regexp):
grep -w 'fatal|error|critical' /var/log/nginx/error.log
Символы в слове включают буквенно-цифровые символы (az, AZ и 0-9) и подчеркивания (_). Все остальные символы рассматриваются как несловесные символы.
Для более подробной информации о параметрах grep, посетите нашу статью Команда Grep.
Вывод
Мы показали вам, как grep ищет несколько шаблонов, строк и слов.
Если у вас есть какие-либо вопросы или отзывы, не стесняйтесь оставлять комментарии.
Если вы нашли ошибку, пожалуйста, выделите фрагмент текста и нажмите Ctrl+Enter.
