Готовая программа не всегда работает как надо. Бывает, возникают баги, предупреждения, исключения. В итоге программа зависает, дает сбой или вылетает. Но это не конец света. Любую ошибку в коде можно исправить, если знать, почему она возникла.
Программная ошибка: что это и почему возникает
Программная ошибка — это дефект в коде. Из-за него программа сбоит или выдает неверные результаты. Некоторые ошибки серьезные — например, блокируют логин и пароль, из-за чего пользователь не может попасть в личный кабинет. А другие незаметны. Некоторое время программа работает как будто бы исправно — и только потом начинает глючить.
Ошибка в программировании — это зачастую ошибки разработчиков, которые находят тестировщики. Запускают разные тесты и отладку, чтобы определить источники проблемы.
Научитесь находить ошибки в приложениях и на сайтах до того, как ими начнут пользоваться клиенты. Для этого освойте профессию «Инженер по тестированию». Изучать язык программирования необязательно. Тестировщик работает с готовыми сайтами, приложениями, сервисами, а не с кодом. В программе от Skypro: четыре проекта для портфолио, практика с обратной связью, все основные инструменты тестировщика.
Ошибки часто называют багами, но подразумевают под ними разное, например:
❗ Ворнинги, или предупреждения. Возникают, когда программа начинает вести себя не так, как задумывалось. Не являются критичными ошибками. Программа с ворнингами работает, но с аномалиями.
❗ Исключения. Это не ошибки, а особые ситуации, которые нужно обработать.
❗ Синтаксические ошибки. Это ошибка в программе, связанная с написанием кода. Пример: программист забыл поставить точку или неверно написал название оператора. Если не исправить, код программы не запустится, а останется просто текстом.
Классификация багов
У багов есть два атрибута — серьезности (Severity) и приоритета (Priority). Серьезность касается технической стороны, а приоритет — организационной.
🚨 По серьезности. Атрибут показывает, как сильно ошибка влияет на общую функциональность программы. Чем выше значение атрибута, тем хуже.
По серьезности баги классифицируют так:
- Blocker — блокирующий баг. Программа запускается, но спустя время баг останавливает ее выполнение. Чтобы снова пользоваться программой, блокирующую ошибку в коде устраняют.
- Critical — критический баг. Нарушает функциональность программы. Появляется в разных частях кода, из-за этого основные функции не выполняются.
- Major — существенный баг. Не нарушает, но затрудняет работу основного функционала программы либо не дает функциям выполняться так, как задумано.
- Minor — незначительный баг. Слабо влияет на функционал программы, но может нарушать работу некоторых дополнительных функций.
- Trivial — тривиальный баг. На работу программы не влияет, но ухудшает общее впечатление. Например, на экране появляются посторонние символы или всё рябит.
🚦 По приоритету. Атрибут показывает, как быстро баг необходимо исправить, пока он не нанес программе приличный ущерб. Бывает таким:
- Top — наивысший. Такой баг — суперсерьезный, потому что может обвалить всю программу. Его устраняют в первую очередь.
- High — высокий. Может затруднить работу программы или ее функций, устраняют как можно скорее.
- Normal — обычный. Баг программу не ломает, просто где-то что-то будет работать не совсем верно. Устраняют в штатном порядке.
- Low — низкий. Баг не влияет на программу. Исправляют, только если у команды есть на это время.
Типы ошибок в программе
🧨 Логические. Приводят к тому, что программа зависает, работает не так, как надо, или выдает неожиданные результаты — например, не записывает файл, а стирает.
Логические ошибки коварны: их трудно обнаружить. Программа выглядит так, будто в ней всё правильно, но при этом работает некорректно. Чтобы победить логические ошибки, специалист должен хорошо ориентироваться в коде программы.
🧨 Синтаксические. Это опечатки в названиях операторов, пропущенные запятые или кавычки. Безобидные ошибки: их обнаруживают и подсвечивают в коде компиляторы, а программисту остается исправить.
🧨 Взаимодействия. Это ошибка в участке кода, который отвечает за взаимодействие с аппаратным или программным окружением. Такая ошибка возникает, например, если неправильно использовать веб-протоколы. Исправляется элементарно: разработчик переписывает нужный кусок кода.
🧨 Компиляционные. Любая программа — это текст. Чтобы он заработал как программа, используют компилятор. Он преобразует программный код в машинный, но одновременно может вызывать ошибки.
Компиляционные баги появляются, если что-то не так с компилятором или в коде есть синтаксические ошибки. Компилятор будто ругается: «Не понимаю, что тут написано. Не знаю, как обработать».
🧨 Ошибки среды выполнения. Возникают, когда программа скомпилирована и уже выглядит как файл — жми и работай. Юзер запускает файл, а программа тормозит и виснет. Причина — нехватка ресурсов, например памяти или буфера.
Такой баг — ошибка разработчика. Он не предвидел реальные условия развертывания программы. Теперь ему надо вернуться в исходный код и поправить фрагмент.
🧨 Арифметические. Бывает, в коде есть числовые переменные и математические формулы. Если где-то проблема — не указаны константы или округление сработало не так, возникает баг. Надо лезть в код и проверять математику.
Что такое исключения в программах
Это механизм, который помогает программе обрабатывать нестандартную ситуацию и при этом не вылетать. Идеально, если программист предусмотрел все возможные ситуации. Но так бывает редко, поэтому лучше использовать специальный обработчик. Он обработает исключения так, что программа продолжит работать.
Как это происходит:
- Когда программист кодит, то продумывает, в какой части программы может вылезти ошибка.
- В этой части пишет специальный фрагмент, который предупредит компьютер, что ошибка — вполне ожидаемое явление и резко обрывать программу не нужно.
- Когда юзер запустит программу и появится ошибка, компьютер увидит заранее подготовленное предупреждение программиста. Продолжит выполнять алгоритм так, словно никакого бага и не было.
Исключения бывают программными и аппаратными:
- Аппаратные создает процессор. К ним относят деление на ноль, выход за границы массива, обращение к невыделенной памяти.
- Программные создает операционка и приложения. Возникают, когда программа их инициирует: аномальная ситуация возникла — программа создала исключение.
Как контролировать баги в программе
🔧 Следите за компилятором. Когда компилятор преобразует текст программы в машинный код, то подсвечивает в нём сомнительные участки, которые способны вызывать баги. Некоторые предупреждения не обозначают баг как таковой, а только говорят: «Тут что-то подозрительное». Всё подозрительное надо изучать и прорабатывать, чтобы не было проблемы в будущем.
🔧 Используйте отладчик. Это программа, которая без участия айтишника проверяет, исправно ли работает алгоритм. В случае чего сообщает об ошибках. Например, отладчик используют для построчного выполнения программы. Вместе с тем проверяют значения переменных: фактические сравнивают с ожидаемыми. Если что-то не сходится, ищут баги и исправляют.
🔧 Проводите юнит-тесты. Это когда разработчик или тестировщик описывает ситуации для каждого компонента и указывает, к какому результату должна привести программа. Потом запускает проверку. Если результат не совпадает с ожидаемым, появляется предупреждение. Дальше программисты находят и устраняют проблему.
Ключевое: что такое ошибки в программировании
- Ошибка в программировании — это дефект кода, баг, который может вызывать в программе сбои и неожиданное поведение.
- По серьезности баги делятся на блокирующие, критические, существенные, незначительные, тривиальные. По приоритету — на наивысший, высокий, обычный, низкий.
- Ошибки в коде могут быть разными, например связанные с логикой программы. Или с математическими вычислениями — логические. Еще бывают синтаксические, ошибки взаимодействия, компиляционные и ошибки среды выполнения.
- Некоторые ошибки помогают ловить обработчики исключений.
- Чтобы находить ошибки в коде, тестировщики используют компиляторы, отладчики и пишут юнит-тесты.
Баг (bug) – это ошибка в коде или в работе программы. Разработчики описывают этим сленговым словом ситуацию, когда что-то работает неправильно, выдает неверный или непредсказуемый результат.
Не любую ошибку можно назвать багом. Этот термин обычно применяют, когда код работает, но некорректно. При этом программа запускается и даже что-то делает, в отличие от, например, синтаксической ошибки, из-за которой код попросту не запустится.
Программу с багами называют забагованной. А отладку кода – дебаггингом, то есть избавлением от багов.
Слово bug в переводе с английского означает «жук». Оно пришло в программирование из сленга инженеров, которые называли багами ошибки при работе электронных схем. А в 1947 году создательница первого компилятора Грейс Хоппер обнаружила в компьютере Mark II бабочку, закоротившую контакты. В журнале происшествий написали: «Первый случай, когда был найден настоящий баг». Так термин закрепился в компьютерной сфере.

Где встречаются баги
В разработке и тестировании. Разработчики регулярно сталкиваются с багами: современные программные продукты – сложные, а в языках программирования много неочевидных вещей. Поэтому столкнуться с багами легко. Чаще всего они становятся следствием неверного употребления команд, неправильно реализованных алгоритмов или ошибок в дизайне программы. Часть багов находят еще при разработке, другие – на этапе тестирования или даже после выпуска продукта.
В готовом программном обеспечении. Даже уже выпущенные программы часто бывают не лишены багов. Некоторые из них очень известные, возникают у многих, даже имеют собственные имена. Есть и уникальные ошибки, которые встречаются однократно. Часто баги зависят от внешних параметров: например, в одной версии операционной системы программа работает корректно, а в другой – нет.
В играх. Отдельной категорией можно назвать баги в видеоиграх: ситуации, когда игровые сцены или персонажи работают не как надо. Примеров множество: двери, которые не могут открыться, внезапные вылеты игры при достижении определенного момента, персонажи, застрявшие в текстурах или зависшие на одном месте. Даже некоторые игры, которые считаются культовыми, на этапе выхода были очень забагованными.

На сайтах. Современные сайты такие гибкие и функциональные благодаря скриптам, написанным на языках программирования. В браузере работает JavaScript, на сервере языки могут быть разными: PHP, Python, Ruby и другие. Баг может возникнуть и на стороне сервера, и в клиентской части сайта – иногда его замечают только после выпуска в продакшн. Есть даже понятие bug bounty: вознаграждение, которое компания выплачивает пользователю, нашедшему критичный баг в информационной безопасности.
Кто сталкивается с багами
В широком смысле встретить баг может любой человек, который пользуется компьютером или смартфоном. Ведь и в готовом ПО ошибки не исключены. В более узком – баги находят разработчики, они же занимаются их исправлением.
Если команда разработки пропустила ошибку, ее ищут на следующем этапе – тестировании. Тестировщики пытаются неочевидными способами воспользоваться программой, чтобы отыскать скрытые ошибки. Найденные баги описываются в специальном отчете – он называется баг-репорт. Отчет тестировщики отправляют разработчикам, чтобы те исправили ошибки.
Из-за чего возникают баги
Мы выяснили, что такое баг. Теперь поговорим о причинах, из-за которых они появляются.
- Первая и наиболее распространенная причина – ошибка разработчика. В IT-среде есть шутка: «Кто же победит: человек, венец природы… или крохотная забытая скобочка?». Маленькие недочеты могут быть очень критичными. Если поставить плюс вместо минуса в простейшем математическом вычислении, то получится совершенно другой результат.
- Иногда причиной багов становится незнание. Например, разработчик был не в курсе специфического поведения какой-нибудь конструкции в языке, поэтому воспользовался ею не совсем корректно.
- Часто баги возникают, если в команде программистов нет слаженности. Один не понимает, что написал другой, правит код по своему усмотрению и получает некорректное поведение программы.
- Наконец, дизайн программы и архитектурные ошибки тоже могут быть причиной багов. Использование неоптимальных алгоритмов, ведущих к сбоям, неверный выбор инструментов – все это может привести к забагованности.

Ворнинги, вылеты, исключения: чем отличаются от багов
Ошибки бывают разными, и это не только баги. Вот с чем еще может столкнуться программист.
Предупреждение. Это не совсем ошибка. Это скорее сообщение о риске некорректной работы. Не все предупреждения действительно указывают на что-то опасное. Например, линтеры – программы для написания чистого кода – выдают предупреждения, если человек пишет в «неправильном» стиле. На сленге предупреждения называют ворнингами от английского warning.
Исключение. Exception, или исключение, – это встроенный механизм защиты от ошибок в языках программирования. Программа выдает сообщение, что что-то пошло не так. Условия для исключений пишут сами программисты. Например, ставят защиту на ввод: если пользователь введет строку вместо числа, выбросится исключение.
Преимущество этого механизма в том, что он помогает обрабатывать проблемные ситуации еще до их появления и не допускать появления багов. Разработчик пишет, как должна вести себя программа, если столкнется с исключением. К примеру, в случае со строкой вместо числа можно прописать, чтобы программа сообщила пользователю об ошибке и попросила ввести данные в корректной форме.
Вылет. Так называют ситуацию, когда программа экстренно завершает работу из-за ошибки. Вылет может сопровождаться сообщением о сбое. Причины разные: начиная от ошибок в коде и заканчивая недостаточной мощностью компьютера, который не справляется с «тяжелой» программой.
Синтаксическая ошибка. Самый простой вариант: разработчик допустил опечатку в синтаксисе и неправильно написал какую-то конструкцию, поэтому программа не собралась. Запись оказалась неизвестна компилятору или интерпретатору. В таком случае среда программирования говорит разработчику о синтаксической ошибке и указывает, где ее искать.
Какими бывают баги
Разработчики классифицируют баги по нескольким категориям. Некоторые – скорее шуточные, другие обсуждаются всерьез. А у некоторых распространенных багов даже есть свои названия.
- Опечатка – простейший вариант. Разработчик случайно пишет не то, и вся программа работает неправильно.
- Бесконечный цикл – ситуация, когда условие для выхода из цикла никогда не наступает, и программа виснет.
- Переполнение буфера – явление, когда программе перестает хватать памяти, и она начинает пользоваться памятью за пределами выделенного ей количества.
- Состояние гонки – баг многопоточных приложений, когда несколько потоков одновременно обращаются к одному и тому же элементу и как бы «соревнуются» за доступ. Результат непредсказуем.
- Количественный баг – ошибка при работе с большим количеством действий, когда при многократных повторениях появляются баги. Например, большое количество данных распределяется неравномерно.
- Демонстрационный эффект – явление, когда программа работала нормально на этапе написания, но сломалась при демонстрации. Зачастую возникает из-за недостаточного тестирования и невнимательности: разработчик не учел какой-то сценарий.
Баги – это очень плохо?
Баги бывают забавными, не приносящими серьезного вреда. Некоторые из них, особенно игровые, порождают мемы и шутки. Но бывают и очень опасные баги, чреватые потерей денег или даже риском для жизни.
Например, баг в медицинском оборудовании может привести к трагедии. Баг в коде сайта – к утечке огромного бюджета: так было, когда блокчейн-компания Compound случайно отправила своим пользователям почти 90 миллионов долларов. А самый дорогой баг в истории – арифметическое переполнение в программной начинке ракеты-носителя «Арион-5», из-за которого ракета взорвалась в полете.
Конечно, критичность багов зависит от сферы. Если отрасль разработки связана с большими финансами или жизненно важным оборудованием, проверка качества кода в этой отрасли очень жесткая. Ведь цена ошибки очень велика.

Как избежать багов
Мы уже выяснили, что критичные баги несут опасность. Поэтому разработчики стараются не допускать их в готовом продукте:
- отлаживают программу еще на этапе создания. Хороший разработчик еще при написании кода учитывает возможные нештатные ситуации в его работе, проверяет его и пишет исключения;
- тестируют для любых ситуаций, в том числе нетривиальных. В свою очередь тестировщики находят неочевидные ситуации, в которых программа может сломаться, и сообщают о них;
- проводят юнит-тестирование для каждого компонента. Это отдельное тестирование разных частей кода – юнитов. Оно помогает понять, корректно ли работают эти компоненты – это более глубокий уровень. Ведь ошибка в одном компоненте может вызвать баги во всей программе.
Для начинающего разработчика главное – внимательность, потому что частая причина багов – опечатки. А они вероятнее, если человек еще не привык писать код. Скрупулезность и внимание к деталям помогут если не избежать багов, то серьезно сократить их количество и быстро исправить те, что остались.
Уровень сложности
Простой
Время на прочтение
9 мин
Количество просмотров 2.7K

Кадр из фильма «Космический десант». Начало войны с багами.
Принцип такой: если баг обнаружен, то мы его либо исправляем в рамках SLA, либо сразу решаем, что фиксить не будем — когда это особенность продукта, тривиальная ошибка или стоимость фикса выше, чем последствия бага. Если исправление занимает больше нескольких часов или откладывается на конец спринта, должен быть точный запланированный срок, чтобы поддержка могла ответить клиенту не «мы в курсе, работы идут», а «мы в курсе, завтра в 17:30 починим».
Мы решили раскатить это на всю компанию.
К последнему времени мы накопили достаточно багов и техдолга, чтобы это стали замечать пользователи. Понизились метрики удовлетворённости продуктом, и мы все вместе решили бороться с багами. Остановили на неделю работу части команд разработки и устроили багатон, исправили штук двести с лишним багов за этот единый порыв.
Стало приятно и весело, но ненадолго. Эффект надо было сохранить.
Спойлер: у нас не вышло. Но прогресс есть.
С чего начиналось
Сначала мы осознали проблему, решили внедрять ZBP и провели багатон: вот пост про то, как это делалось, там же есть про оценку и приоритизацию багов.
После багатона стало понятно, что рутина никуда не девается, эффект от багатона быстро развеивается, и надо было менять подход к самому процессу обработки багов. В целом нам виделось, что это цепочка из трёх больших вещей:
- Багатона.
- Новой политики работы с багами и новых процессов качества.
- Работы с самим производством, чтобы снижать уровень возможных багов или хотя бы правильно регистрировать ошибки, чтобы их было легче обрабатывать.
Багатон провели, багбэклоги перестали напрягать 18 из 50 команд (тех самых, что участвовали в багатоне), а дальше мы решили, что будет простой принцип: если появляется баг, его надо лечить сразу. Либо не лечить, потому что мы готовы с этим жить.
«Готовы с этим жить» — это, например, если кнопка нежно-светло-зелёная, а нужна была оливково-зелёная — можно не тратить ресурсы, а просто принять, что чёрт с ней, кнопки имеют право на самоопределение. Что интересно, на этих тикетах чаще бывает сложнее и дороже объяснить, что нужно в задаче, чем исправить.
Второй тип «готовы с этим жить» — это когда баг проявляется на малом проценте пользователей, а чтобы его поправить, нужно переписать всю архитектуру. В такой ситуации проще ходить через поддержку вручную, а не делать как правильно. В этом плане вспоминается прекрасный анекдот про то, как в хостинге клиент жалуется на то, что процесс в личном кабинете работает то быстро, то медленно. Решение там такое: он создаёт задачу в интерфейсе, вместо бэкенда она отправляется тикетом в поддержку, а клиенту показывается прогресс-бар на время SLA. Дальше поддержка может сделать сразу, а может по верхней границе SLA. После закрытия тикета клиент видит, что операция в личном кабинете выполнена. Кратко — бывают баги, которые дешевле закрывать примерно так.
Третий тип «готовы жить» — это когда баг есть, но мы знаем, что либо продукт с ним будет закрыт через 2 месяца, либо случится что-то ещё, что сделает неактуальным всю ветку кода с ним. Задачу не ставим, описываем, чтобы при повторном обращении поддержка могла увидеть, с какой резолюцией баг был закрыт, и могла сразу дать ответ клиенту.
В итоге багбэклог должен стремиться к нулю. В теории.
А теперь практика
Естественно, не все команды были готовы к тому, чтобы принять такую политику. Идея как таковая понравилась всем. Собственно, у нас было несколько команд, которые сами дошли до такого подхода и уже давно его использовали. Кто-то видел такой подход в других компаниях. Мы организовали митап для всех разработчиков, позвали туда QA-лидов и всех сочувствующих. Рассказали про Zero Bug Policy как о явлении, её типах, плане внедрения и ДОДах, послушали тех, кто уже имел подобный опыт. И пришли к выводу, что это всё хорошо бы внедрить в компании.
Чего не ожидали, так это огромного количества вопросов от команд по деталям. Заинтересовались все, но почти у каждого была куча особенностей, не дающих реализовать ZBP в полной мере. Плюс просто многое было непонятно. В итоге если сначала казалось, что встреча будет одна большая, а после неё наступит счастье, то нет.
Вторая встреча была про ответы на вопросы, разбор сомнений и возражений. СТО и рабочая группа проекта разложили всё по полочкам.
Примеры:
— Должна ли быть разница в политиках для внутренней разработки и внешних продуктов? И какая?
— Нет, разницы быть не должно.
— Хочется конкретики в том, что считаем багом, чтобы потом не особо спорить, баг это или фича, или это вообще баг в требованиях, а не в коде или ещё где-то.
— Тут мы прописали в политике определение бага, проанализировали оферту и статистику, на основании чего зафиксировали рекомендации.
— Какие метрики ещё можно отслеживать?
— Помимо SLA и суммарного веса багов рекомендуем отслеживать в продуктовых командах оценки в сторах и отзывы, количество обращений в каналы с багами, плотность багов (количество открытых багов / количество закрытых фич), количество редевов по задачам.
После этой встречи вопросы стали специфичнее, но ящик Пандоры не закрылся.
Дальше мы решили, что все вопросы достаточно узкие, и разбирали их уже с конкретными командами, чтобы не отвлекать вообще всю разработку компании.
Итогом всех этих итераций стало то, что у нас появилось целых 4 вариации Zero Bug Policy:
- Классическая строгая. «Это наш баг, и мы его фиксим». Тривиал по выбору команды закрывается сразу после регистрации или закрывается автоматически через 2 недели. Если это минор — мы можем запланировать на конкретную дату, но мы должны понимать когда, чтобы те, кто на саппорте, говорили нашим ученикам и учителям: «Да, мы в курсе, планируем тогда-то». Если мейджор, то это должно пройти в текущий спринт. Если это критикал или блокер — по их стандартным SLA, блокер — за 1 день. Очень важно, что баги в приоритете в спринтах, то есть их нельзя таскать из недели в неделю, потому что они не уместились. Дедлайны реальные.
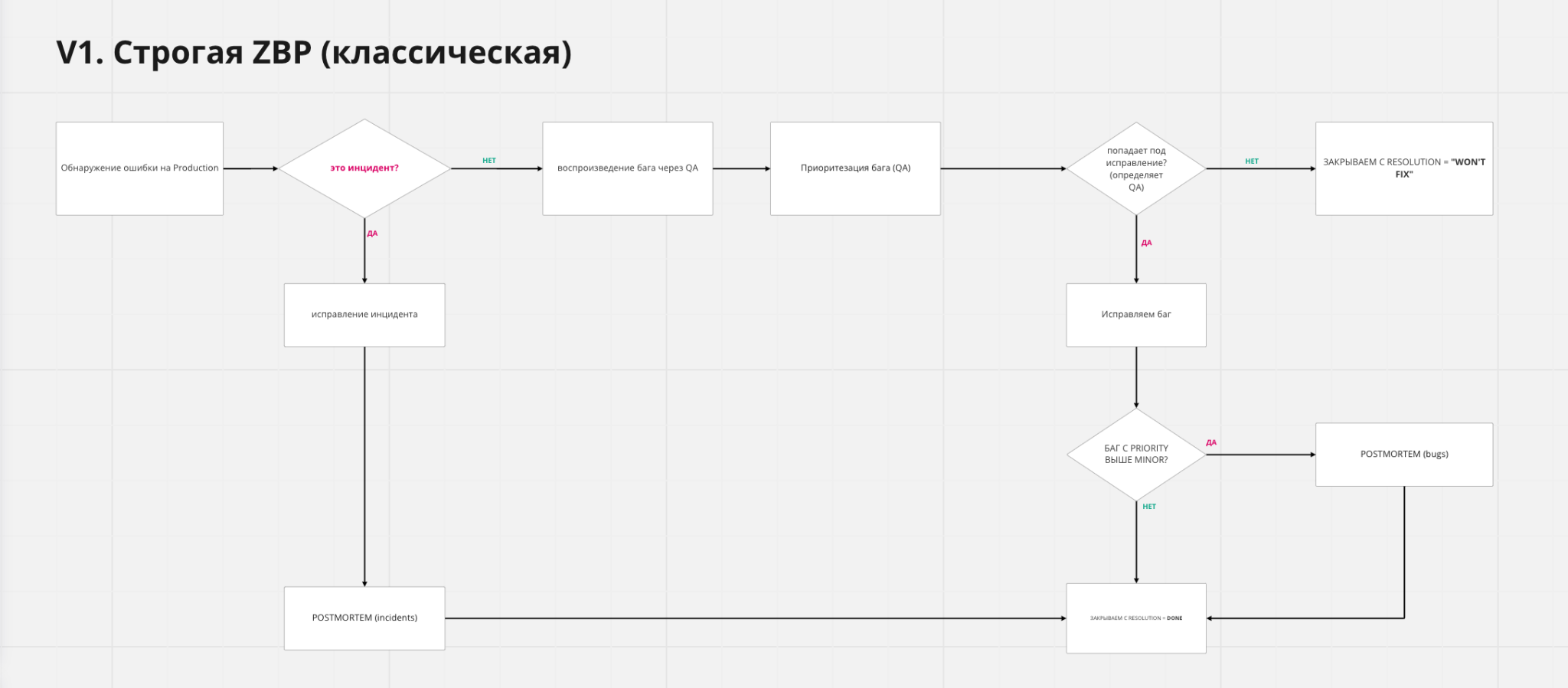
Рекомендуется для платформенных команд, в которых стабильность превыше всего и где есть сильный QA - Багоцид, или спринты любви, — это упрощённый вариант, когда баги можно откладывать, если они не блокер или критикал. Мейджоры и миноры можно не чинить сразу, а складывать в бэклог. Но дальше в течение пары спринтов нужно разобрать этот бэклог до нуля или близкого значения. Можно взять это в следующий продуктовый спринт как задачу, а можно выделить отдельный спринт. Например, 2 бизнесовых, потом один багоцидный. На практике в итоге у нас никто не делает чисто багоцидные спринты, просто берут некоторое количество багов как задачи в бизнесовые.

Оптимально для тех, кто чётко планирует спринты - По стоимости — команды выбирают метрику, по которой учитывают стоимость бага. Это могут быть трудозатраты на поддержку, количество обращений пользователей и так далее. Подходит любая метрика, близкая бизнесу. Дальше стоимость бага сравнивается со стоимостью продуктовой задачи (внедрения фичи). В силу сложности расчёта всего пара команд это использует. Такая схема рекомендуется для команд, которые умеют agile-testing и могут автоматизировать свои процессы. QA не должны стать прослойкой принятия решения, разработчики должны сами уметь брать баги в работу.
- Кастомная. Это когда берётся какая-то из политик выше, и в неё вносятся изменения, облегчающие жизнь с ней. Это либо команды с невероятно огромным багбэклогом, либо компромисс продакт-менеджера или тимлида — например, «сейчас примем лайтовую политику, а со следующего полугодия будем идти по строгой, дайте только сервис доделать». Отдельный кастомный вариант понадобился и для мобильной разработки: там завязка на внесении изменений, а не на релизе в силу особенностей release train.
В процессе внедрения оказалось, что баги передаются из команды в команду с разными оценками. В компании просто не было единой методологии определения уровня бага. Например, были команды, которые писали в критикалы вообще всё. Но ничего с этим не делали. Или были команды, которые считали, что половина пользователей — это ещё не критикал, до критикала надо, чтобы каждый это почувствовал.
Правила внедрения:
- При возникновении проблемы — определяем баг или доработка.
- Все баги заводятся и фиксируются. Тривиальные баги закрываются сами, если за 2 недели не перерастают во что-то посерьезнее.
- Блокирующий — вообще всё бросаем и делаем.
- Критический — дописываем строчку в коде, бросаем и делаем.
- Основной и ниже — отдаём первому освободившемуся или выбираем приоритет среди других задач.
- Если не успели пофиксить в этом спринте — баги встают на самый верх следующего спринта.
- Стараться делать работу над ошибками и не допускать похожие баги несколько раз.
- Не порождать известные баги.
- Каждый участник команды может и должен влиять на качество.
- Починка бага не должна создавать новые баги. Если при починке бага сломалось что-то другое — необходимо починить сразу же.
- Обязательные ретроспективы по каждому багу. После закрытия багов команда инициирует процесс проведения разбора причин возникновения бага + формирует план действий, в котором описано, что необходимо сделать, чтобы не повторить баг вновь. В процессе разбора багов, постмортема и приоритизации должна участвовать вся команда.
Некоторые баги с низкой оценкой постепенно могли повыситься в приоритете. Например, когда новый сервис, которым пользовались десятки человек, вдруг становился востребованным сотнями тысяч. Для этого у нас есть Support Tab вот такого типа в поддержке:


Каждый раз, когда приходит обращение по известному багу, первая линия нажимает кнопку счётчика. В какой-то момент баг получает повышение приоритета и с криком «хватит с этим жить» отправляется на исправление.
Но на самом деле ещё более волшебным было то, что мы на старте не знали весь скоуп команд. У нас ушла куча времени на актуализацию того, какой проект в Джире чей. Какие-то проекты учитывались в метриках, хотя не должны были. Какие-то не учитывались, хотя должны были. Мы прошли вторую большую уборку — как при оценке актуальности багов, когда почти половину получилось выкинуть как самозакрывшиеся (про это есть в посте про багатон).
В тот момент, когда суммарный вес багов (это доля пользователей, умноженная на серьёзность бага) превысил то, что у нас было до багатона — то есть мы потеряли результаты всей уборки, и поддерживать, по сути, было уже нечего — мы начали ходить по командам и закреплять QA-лидов за каждой, где закреплённого лида по какой-то причине не было. Где-то ушёл и не нашли замену, где-то исторически команда создавалась без связки с QA и так далее.
Дальше общие встречи, про которые вы уже знаете.
Потом мы ещё раз выстрелили себе в ногу тем, что поставили и объявили одни ожидания от внедрения, а потом пару раз их поменяли.
Следующим сюрпризом стало то, что команды очень не хотели подписываться на снижение суммарного веса багов. Причина простая: прямо в конце спринта перед измерением мог прилететь баг с большим весом. Получалось, что весь спринт команда работала, а итоговый результат хуже, чем до начала. Пришлось менять метрику с «багвес» на «багвес по багам, у которых уже кончился SLA». То есть мы хотели очиститься от старых багов почти полностью и не допускать протухания новых.
Вторая метрика была связана с закрытием багов в текущем месяце. Это процент от имеющихся горящих. Логично было закрывать 80% багов в срок их SLA, остальные уже как пойдёт. Ну, для нас логично. Но не учли, что команды доставали баги из бэклога и закрывали их, то есть если половина багов была старая, то метрика шла вниз, а если старые баги никто не трогал, то метрика шла вверх. А оценивался результат именно по дашбордам, и под это наметилась, скажем так, некоторая оптимизация работ в командах. Поправили, конечно, но это был интересный момент.
Что получилось
На старте ожидали, что 80% команд перейдут на ZBP, то есть начнут применять методологию и покажут результаты. Сейчас уже 92% целевых команд применяют ZBP. 53% от целевых команд перешли на Zero Bug. 78% команд улучшили багвес. Хотели сократить багбэклог до 30% от изначального (сейчас 45%) и прокачать SLA с 85 до 95% (сейчас 91%).
График заведения багов к решению вот:

Еще мы отслеживали график багвеса. Он стал для нас как курс доллара: штука, на которую смотришь каждый день, попивая кофе. Здесь явно видны все переломные моменты и наши достижения:

Очень важно, что мы унифицировали очень много вещей, которые раньше складывались исторически по-разному в разных командах. Процессы были разные, лейблы были разные — в итоге образовался один процесс в Джире, общий для всех.
Можно сказать, что то, что получилось, — это наши попытки найти компромисс между качеством и хотелками бизнеса. Бизнес хочет быстрее и новые фичи, но при этом нужно не забывать про поддержку уже имеющегося продукта. Сейчас появился понятный инструмент удержания качества.
Плюсы внедрения:
- Снизили нагрузку на поддержку.
- Не тратим время на споры: есть баг — правим.
- QA не нужно приоритизировать баги.
- Не позволяет делать плохой продукт — кара настигнет неминуемо.
- Нет багов — нет неявного поведения. Не надо что-то разматывать и править данные.
- Чистая Sentry — чистая совесть. Легко детектить новые проблемы.
- Мотивирует писать тесты. Особенно, если договориться, что фикс бага выходит вместе с тестами на это поведение/место.
- Работающий продукт проще и приятнее разрабатывать.
- Не надо искать воркэраунды и транслировать их раз за разом.
- Растёт скорость решения проблем, с которыми сталкивается пользователь.
- Чистый бэклог, не нужно актуализировать старые проблемы.
- Прозрачные сроки решения по проблемам для поддержки.
Минусы:
- Сложно договориться, что такое баг и кто принимает это решение.
- Нужно договориться с бизнесом (убедить продакта). Нужно заручиться поддержкой сверху (но не на самом верху, именно в своей вертикали).
- Закладываем воздух в спринт на баги: как утилизировать свободное время — уж найдёте.
- Рано или поздно будет спринт, состоящий из целых багов: нужно быть готовыми отстоять, иначе эффект сойдёт на нет.
- Трудно доказать важность фикса на раннем этапе так как «мы это через Х дней будем переделывать».
- Трудно втянуть баг. Сразу после заведения — спринт уже забит, на планировании — спринт собираются забить. В самом спринте ошибки лежат внизу, поэтому мы их часто переносим в следующий.
- Если внедрено неполностью правильно, снижается ТТМ.
- Риски ретроспективы и постмортемов, т.к. команду может устраивать исправление, но не проработка причин.
- Могут появиться плохие хотфиксы и в погоне за скоростью создавать конвейер багов.
Мы смотрим, как это пойдёт дальше. Пока далеко не всё гладко и не всем нравится, баги нас ещё побеждают, но тенденцию мы переломили и готовы отыграть у них следующий квартал.
 Автор: Кристин Джеквони (Kristin Jackvony)
Автор: Кристин Джеквони (Kristin Jackvony)
Оригинал статьи
Перевод: Ольга Алифанова
Ранее я писала, как убедиться, что вы действительно нашли баг, прежде чем его заводить; как исследовать баг; и как написать баг-репорт, когда баг исследован. Но я никогда не писала о том, как добиться, чтобы баг исправили. Даже если вы зарепортили тщательно детализированный и внятно описанный баг, разработчик или команда все же могут решить, что он не достоин исправления. В этой статье мы разберем пять вещей, которые можно предпринять, чтобы помочь багу исчезнуть.
Первое: не распыляйтесь по пустякам
Возможно, это кажется алогичным, но если вы яростно боретесь за исправление каждого найденного вами бага, то можете вообще утратить внимание своей команды. Команды разработки всегда будут оставлять какие-то баги за бортом – или в качестве технического долга, чтобы исправить когда-нибудь потом, или как баги с пометкой “исправлен не будет”. Вместо того, чтобы биться за каждый баг, выбирайте наиболее важные из них.
Как определить, какие из них наиболее важные? Подумайте о двух факторах: во-первых, о влиянии бага на пользователя. Баг, где кнопка подтверждения съехала от центра на пару пикселей, не шибко повлияет на пользователя. Однако баг, при котором пользователь вообще не может отправить форму, повлияет на него куда сильнее. Во-вторых, подумайте о вероятности столкновения пользователя с багом. Если шаги воспроизведения бага включают нажатие кнопки “Назад” двадцать раз, двойное изменение масштаба окна браузера, а затем его обновление – вряд ли пользователь наткнется на этот баг. Однако баг, при котором клиент не может ввести данные банковской карты, с шансами заметят сразу. Баги, за исправление которых надо бороться – это баги, с которыми может столкнуться пользователь, и которые могут сильно на него повлиять.
Второе: покажите баг в действии
Зачастую можно куда эффективнее сообщить о баге, если разработчики видят его своими глазами. Этого можно добиться разными способами. Во-первых, можно снять видео бага и прикрепить его к баг-репорту. Это особенно полезно, если у вас также есть видео правильной работы функциональности – разработчик сможет их сравнить. Во-вторых, можно пригласить разработчика к своему столу – реальному или виртуальному – и показать баг на месте преступления. В-третьих (что зачастую наиболее полезно), можно подойти к столу разработчика – реальному или виртуальному – и попросить пройти по шагам в приложении, которые приведут его к багу. Если разработчик самостоятельно познакомится с багом, он проявит больше эмпатии к конечному пользователю.
Третье: поделитесь пользовательским опытом
Эту технику можно использовать совместно с предыдущей или письменно. Демонстрируя или описывая баг, подчеркните, что будет думать пользователь, проходя по этим шагам. К примеру, “Пользователь хочет что-то удалить из корзины. Меняя количество на ноль и сохраняя, он ожидает, что предмет из корзины исчезнет. То, что предмет еще там, путает и раздражает его”.
Четвертое: поделитесь обратной связью от пользователей, столкнувшихся с похожей проблемой
Если у вас есть доступ к пользовательским жалобам, попробуйте поискать жалобы на похожие на ваш баг ситуации. К примеру, если вы разбираетесь с багом, при котором в календаре загружается неверный месяц, то, возможно, сможете найти жалобы на прошлогодний баг, при котором календарь был чересчур мал. Найдите самых возмущенных пользователей и зачитайте их прошлогодние жалобы команде. Это покажет коллегам, насколько эта функция важна пользователям.
Пятое: подчеркните потенциальное влияние бага на команду
Людей часто мотивирует то, что непосредственно на них влияет. Если ваши песни о пользовательских слезах не растопили сердца коллег, то, возможно, помогут эти предостережения:
- В результате бага в базу попадут плохие данные, и чистить их будет мучением.
- Если на эту проблему среди ночи пожалуется пользователь, кого-то из команды поднимут с кровати исправления ради.
- Если генеральный директор компании увидит баг, демонстрируя ваше приложение в своем кругу, он вряд ли будет рад, и непременно спросит у команды, почему она проигнорировала проблему.
Разработка ПО строго ограничена по времени, и всегда будет подвержена компромиссам между скоростью поставки и качеством. Но эти пять советов помогут вам добиться исправления наиболее важных багов.
Обсудить в форуме
Управление персоналом
Баги команды: опознать и обезвредить
Леонид Кроль
10 января 2023

Работая с командами, я часто вижу, что, собрав отличных специалистов, компания сталкивается с непредвиденными трудностями. Вроде бы все хорошо, но количество проблем заставляет в этом усомниться. Обсуждения длятся слишком долго, ведутся вяло и несогласованно; дедлайны кажутся реалистичными, но при этом срываются — а если не срываются, то люди сильно устают; все чувствуют, что работа пробуксовывает, застывает и выполняется из-под палки; у сотрудников, которые кажутся умными и инициативными, почти ничего не получается; люди трудятся без радости. И, главное, не понятно, чем все это вызвано.
В наше время не только айтишники знают слово «баг» — ошибка, вызывающая сбой в работе программы. Обычно баги не лежат на поверхности, но, если копнуть глубже, их можно обнаружить. Пообщавшись с командой некоторое время, я начинаю понимать, в чем дело. Систематизировав свои наблюдения, я составил список частых багов, которые, наслаиваясь друг на друга, постепенно ухудшают результативность команды.
1. Формальное согласие и игнорирование мелких споров. Вопрос до конца не прояснен, и небольшие расхождения вначале кажутся неважными. Однако представьте себе две прямые дороги, которые выходят из одной точки под небольшим углом: спустя некоторое время вы уйдете по ним в разные стороны.
Что делать? Учиться критически смотреть на общее согласие, выискивать возможные точки несоответствия и обсуждать их. Когда кажется, что все хорошо, не хочется затевать споры. Но лучше поспорить на берегу, чем потом, когда часть работы уже сделана «криво».
2. «Наш сукин сын». В команде есть люди, которые всех раздражают, но связываться с ними себе дороже, а объясняться — тем более. В результате часть времени уходит на их нейтрализацию и обдумывание того, как минимизировать их дестабилизирующее воздействие.
Что делать? Сфокусироваться на проблемном человеке и «решить вопрос» — с помощью обучения, перевода на другую работу или, если ничего не помогает, увольнения.
3. Плохая модерация собраний. Пятиминутка растягивается на полчаса: кто-то взял слово и упивается собственным монологом; кто-то не посмотрел материалы и задает вопросы о том, что мог прочитать заранее; кто-то опоздал, и его вводят в курс дела; кому-то скучно, и он тихо во что-то играет.
Что делать? Развивать у сотрудников навыки гибкой модерации, позволяющие каждому участнику команды отвечать не только за свою часть общего дела, но и за процесс, время, темп происходящего. В том числе на собрании.
Об авторе
Леонид Кроль — кандидат медицинских наук, профессор МП ВШЭ, эксперт в области психологии личности в бизнесе.
Войдите на сайт, чтобы читать полную версию статьи
