Автор оригинала: Marcos Lopez Gonzalez.
1. введение
Конечно, мы никогда бы не предположили, что мы можем привести String к массиву String в Java:
java.lang.String cannot be cast to [Ljava.lang.String;
Но, оказывается, это распространенная ошибка JPA.
В этом кратком уроке мы покажем, как это происходит и как это решить.
В JPA нередко возникает эта ошибка , когда мы работаем с собственными запросами и используем метод createNativeQuery в EntityManager .
Его Javadoc фактически предупреждает нас , что этот метод вернет список Object [] или просто Object , если запрос возвращает только один столбец.
Давайте рассмотрим пример. Во-первых, давайте создадим исполнителя запросов, который мы хотим повторно использовать для выполнения всех наших запросов:
public class QueryExecutor {
public static List executeNativeQueryNoCastCheck(String statement, EntityManager em) {
Query query = em.createNativeQuery(statement);
return query.getResultList();
}
}
Как было показано выше, мы используем метод createNativeQuery() и всегда ожидаем результирующий набор, содержащий массив String .
После этого давайте создадим простую сущность для использования в наших примерах:
@Entity
public class Message {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Long id;
private String text;
// getters and setters
}
И, наконец, давайте создадим тестовый класс, который вставляет Сообщение перед запуском тестов:
public class SpringCastUnitTest {
private static EntityManager em;
private static EntityManagerFactory emFactory;
@BeforeClass
public static void setup() {
emFactory = Persistence.createEntityManagerFactory("jpa-h2");
em = emFactory.createEntityManager();
// insert an object into the db
Message message = new Message();
message.setText("text");
EntityTransaction tr = em.getTransaction();
tr.begin();
em.persist(message);
tr.commit();
}
}
Теперь мы можем использовать наш Исполнитель запросов для выполнения запроса, который извлекает текстовое поле нашей сущности:
@Test(expected = ClassCastException.class)
public void givenExecutorNoCastCheck_whenQueryReturnsOneColumn_thenClassCastThrown() {
List results = QueryExecutor.executeNativeQueryNoCastCheck("select text from message", em);
// fails
for (String[] row : results) {
// do nothing
}
}
Как мы видим, поскольку в запросе есть только один столбец, JPA фактически вернет список строк, а не список строковых массивов. Мы получаем ClassCastException , потому что запрос возвращает один столбец, и мы ожидали массив.
3. Ручная Фиксация Литья
Самый простой способ исправить эту ошибку-проверить тип объектов результирующего набора , чтобы избежать исключения ClassCastException. Давайте реализуем метод для этого в нашем Исполнителе запросов :
public static List executeNativeQueryWithCastCheck(String statement, EntityManager em) {
Query query = em.createNativeQuery(statement);
List results = query.getResultList();
if (results.isEmpty()) {
return new ArrayList<>();
}
if (results.get(0) instanceof String) {
return ((List) results)
.stream()
.map(s -> new String[] { s })
.collect(Collectors.toList());
} else {
return (List) results;
}
}
Затем мы можем использовать этот метод для выполнения нашего запроса без получения исключения:
@Test
public void givenExecutorWithCastCheck_whenQueryReturnsOneColumn_thenNoClassCastThrown() {
List results = QueryExecutor.executeNativeQueryWithCastCheck("select text from message", em);
assertEquals("text", results.get(0)[0]);
}
Это не идеальное решение, так как мы должны преобразовать результат в массив, если запрос возвращает только один столбец.
4. Исправление сопоставления сущностей JPA
Другой способ исправить эту ошибку-сопоставить результирующий набор с сущностью. Таким образом, мы можем заранее решить, как сопоставить результаты наших запросов и избежать ненужных отливок.
Давайте добавим еще один метод к нашему исполнителю для поддержки использования пользовательских сопоставлений сущностей:
public static List executeNativeQueryGeneric(String statement, String mapping, EntityManager em) {
Query query = em.createNativeQuery(statement, mapping);
return query.getResultList();
}
После этого давайте создадим пользовательское SqlResultSetMapping для сопоставления результирующего набора нашего предыдущего запроса с Сообщением сущностью:
@SqlResultSetMapping(
name="textQueryMapping",
classes={
@ConstructorResult(
targetClass=Message.class,
columns={
@ColumnResult(name="text")
}
)
}
)
@Entity
public class Message {
// ...
}
В этом случае мы также должны добавить конструктор, соответствующий нашему недавно созданному SqlResultSetMapping :
public class Message {
// ... fields and default constructor
public Message(String text) {
this.text = text;
}
// ... getters and setters
}
Наконец, мы можем использовать наш новый метод исполнителя для выполнения тестового запроса и получения списка Сообщений :
@Test
public void givenExecutorGeneric_whenQueryReturnsOneColumn_thenNoClassCastThrown() {
List results = QueryExecutor.executeNativeQueryGeneric(
"select text from message", "textQueryMapping", em);
assertEquals("text", results.get(0).getText());
}
Это решение намного чище, так как мы делегируем отображение результирующего набора в JPA.
5. Заключение
В этой статье мы показали, что собственные запросы являются общим местом для получения этого ClassCastException . Мы также рассмотрели возможность выполнения проверки типа самостоятельно, а также ее решения путем сопоставления результатов запроса с транспортным объектом.
Как всегда, полный исходный код примеров доступен на GitHub .
Если вы используете Hibernate в течение длительного времени, есть большая вероятность, что вы столкнулись с MultipleBagFetchException:
org.hibernate.loader.MultipleBagFetchException: cannot simultaneously fetch multiple bagsВ этой статье мы рассмотрим причины, по которым Hibernate выбрасывает MultipleBagFetchException, а также лучший способ решения этой проблемы.
Спонсор поста
Используемые версии
Java 17
Hibernate 6.1.0.Final
H2 Database 2.1.214
Доменная модель
В нашем приложении определены три сущности: Post, PostComment и Tag, которые связаны следующим образом:
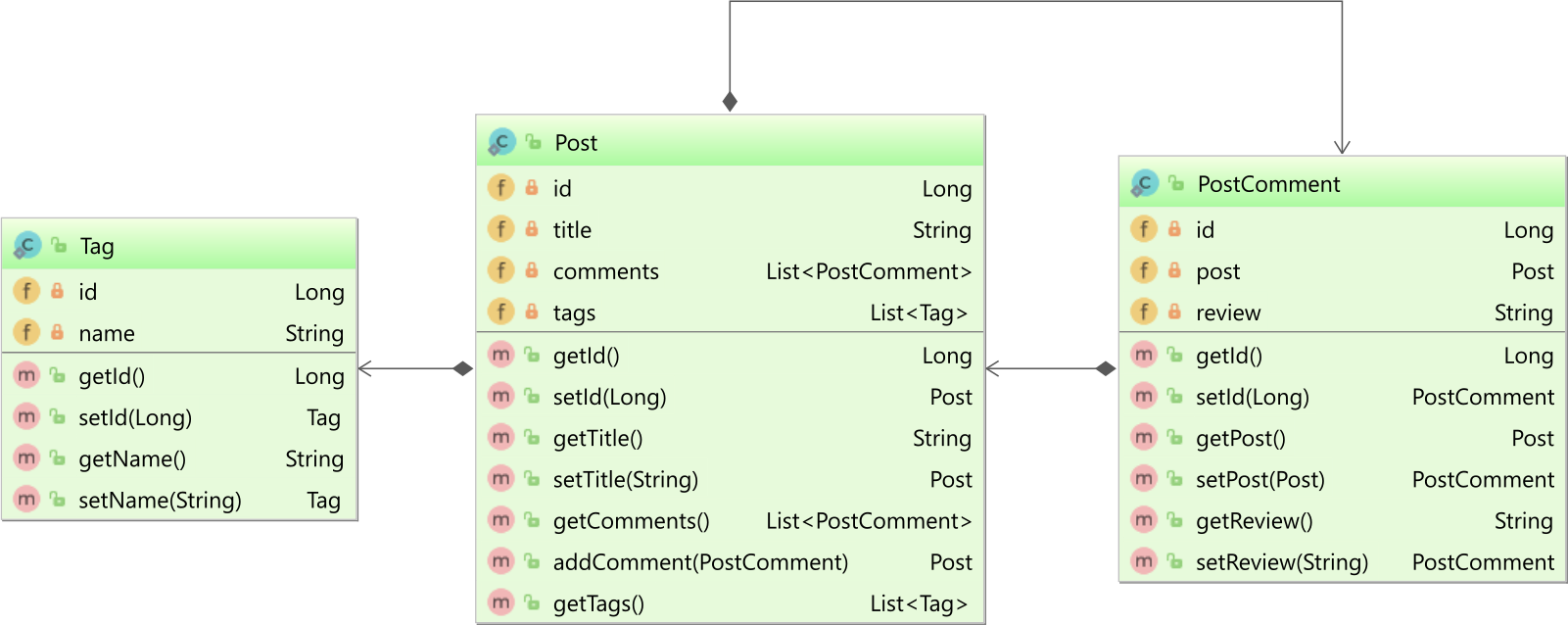
Нас в основном интересует то, что сущность Post определяет двунаправленную связь @OneToMany с дочерней сущностью PostComment, а также однонаправленную связь @ManyToMany с сущностью Tag.
@OneToMany(
mappedBy = "post",
cascade = CascadeType.ALL,
orphanRemoval = true
)
private List<PostComment> comments = new ArrayList<>();
@ManyToMany(
cascade = {
CascadeType.PERSIST,
CascadeType.MERGE
}
)
@JoinTable(
name = "post_tag",
joinColumns = @JoinColumn(name = "post_id"),
inverseJoinColumns = @JoinColumn(name = "tag_id")
)
private List<Tag> tags = new ArrayList<>();Причина, по которой для связи @ManyToMany установлены только PERSIST и MERGE, заключается в том, что Tag не является дочерней сущностью.
Поскольку жизненный цикл Tag не связан с сущностью Post, каскадная операция REMOVE или включение механизма orphanRemoval было бы ошибкой.
Исправление для Hibernate
Для начала рассмотрим причины появления исключения в Hibernate, а также вариант исправления, который вредит производительности приложения, но который часто упоминают на различных форумах. Далее мы рассмотрим вариант, как исправить эту проблему в Spring JPA.
Если мы хотим получить объекты Post со значениями идентификатора от 1 до 50, а также все связанные с ними объекты PostComment и Tag, мы напишем запрос, подобный следующему:
List<Post> posts = entityManager.createQuery("""
select p
from Post p
left join fetch p.comments
left join fetch p.tags
where p.id between :minId and :maxId
""", Post.class)
.setParameter("minId", 1L)
.setParameter("maxId", 50L)
.getResultList();Однако при выполнении приведенного выше запроса сущности Hibernate выбрасывает ошибку MultipleBagFetchException при компиляции запроса JPQL:
org.hibernate.loader.MultipleBagFetchException: cannot simultaneously fetch multiple bags: [
dev.struchkov.example.hibernate.nbfe.problem.domain.Post.comments,
dev.struchkov.example.hibernate.nbfe.problem.domain.Post.tags
]Таким образом, Hibernate не выполняет SQL-запрос. Причина, по которой Hibernate выбрасывает исключение, заключается в том, что могут возникать дубликаты.
Как НЕ “исправить” проблему
Если вы погуглите MultipleBagFetchException, вы увидите множество неправильных ответов, например, этот ответ на StackOverflow, который, что удивительно, имеет более 300 голосов.

Так просто, но так неправильно!
Использование Set вместо List
Итак, давайте изменим тип коллекции связи с List на Set:
@OneToMany(
mappedBy = "post",
cascade = CascadeType.ALL,
orphanRemoval = true
)
private Set<PostComment> comments = new HashSet<>();
@ManyToMany(
cascade = {
CascadeType.PERSIST,
CascadeType.MERGE
}
)
@JoinTable(
name = "post_tag",
joinColumns = @JoinColumn(name = "post_id"),
inverseJoinColumns = @JoinColumn(name = "tag_id")
)
private Set<Tag> tags = new HashSet<>();При повторном выполнении предыдущего запроса, исключение не возникнет. Однако вот SQL-запрос, который Hibernate выполнил:
select p1_0.id,
c1_0.post_id,
c1_0.id,
c1_0.review,
t1_0.post_id,
t1_1.id,
t1_1.name,
p1_0.title
from Post p1_0
left join PostComment c1_0
on p1_0.id = c1_0.post_id
left join (post_tag t1_0 join Tag t1_1 on t1_1.id = t1_0.tag_id)
on p1_0.id = t1_0.post_id
where p1_0.id between 1 and 50;Таблицы post и post_comment связаны через столбец внешнего ключа post_id, поэтому объединение дает набор результатов, содержащий все строки таблицы post со значениями первичного ключа от 1 до 50 вместе со связанными с ними строками таблицы post_comment.
Таблицы post и tag также связаны через столбцы post_id и tag_id в связующей таблице post_tag, поэтому эти два объединения дают набор результатов, содержащий все строки таблицы post со значениями от 1 до 50, а также связанные с ними строки таблицы tag.
Теперь, чтобы объединить эти два набора результатов, база данных может использовать только декартово произведение, поэтому конечный набор результатов содержит 50 строк post, умноженных на соответствующие строки таблицы post_comment и tag.
Представим, что у нас 50 постов, по 10_000 комментариев для каждого, также каждый пост имеет 10 тегов. Конечный набор результатов будет содержать 10_000_000 записей (50 x 10000 x 20), как показано в следующем тестовом примере:
List<Post> posts = entityManager.createQuery("""
select p
from Post p
left join fetch p.comments
left join fetch p.tags
where p.id between :minId and :maxId
""", Post.class)
.setParameter("minId", 1L)
.setParameter("maxId", 50L)
.getResultList();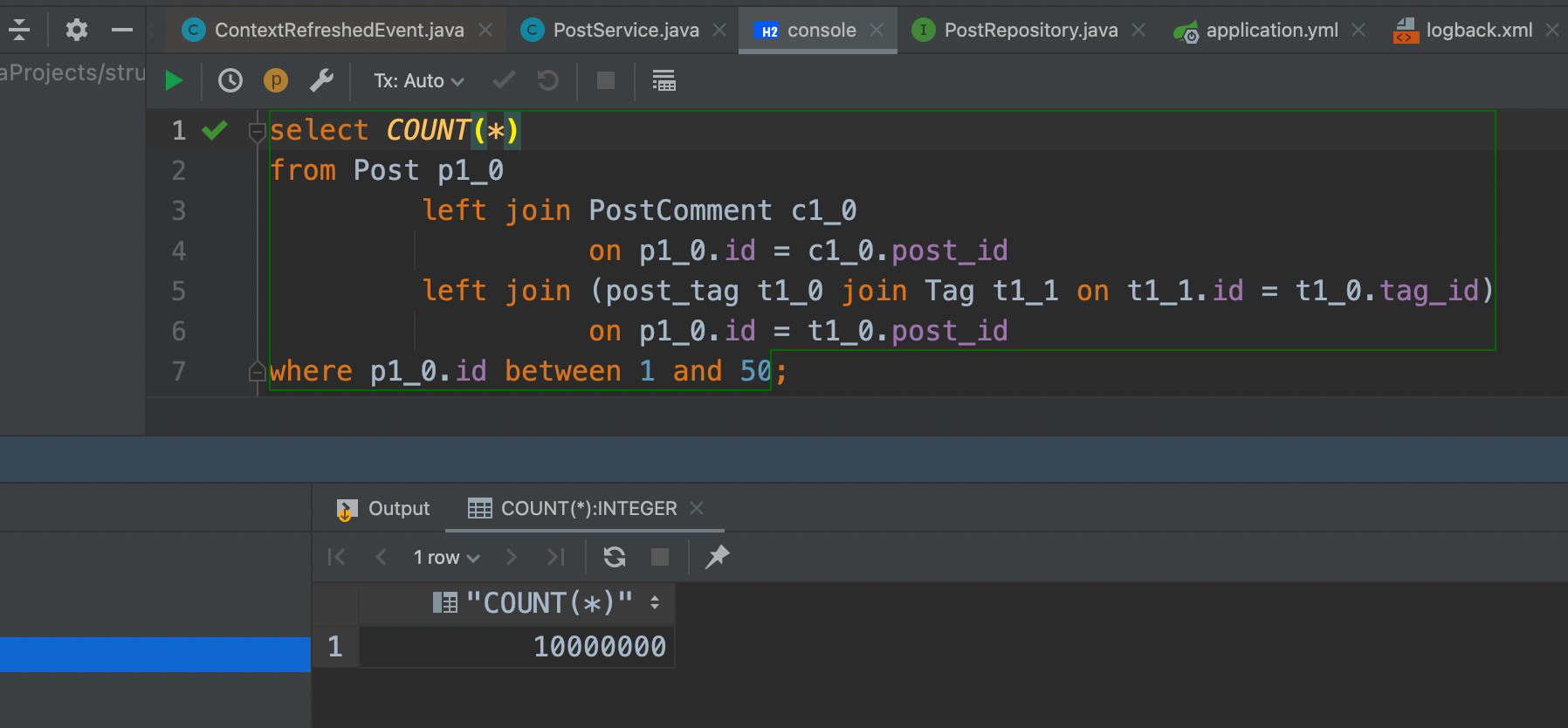
Этот вариант сработает правильно, но мы заплатим за это производительностью. Сделаем импровизированный бенчмарк: перед и после выполнения этого кода получим текщее время системы в миллисекундах, а далее вычтем из большего меньшее и так получим потраченное время на выполнение. Да это не самый удачный способ замера, но даже он подойдет.
Результат бенчмарка: 24192 миллисекунд. Запомните это значение, сравним его с правильным решением.
Чтобы избежать декартова произведения, за один раз можно получить не более одной связи. Таким образом, вместо выполнения одного JPQL-запроса, который извлекает две связи сразу, мы можем выполнить два JPQL-запроса:
List<Post> posts = entityManager.createQuery("""
select distinct p
from Post p
left join fetch p.comments
where p.id between :minId and :maxId""", Post.class)
.setParameter("minId", 1L)
.setParameter("maxId", 50L)
.getResultList();
posts = entityManager.createQuery("""
select distinct p
from Post p
left join fetch p.tags t
where p in :posts""", Post.class)
.setParameter("posts", posts)
.setHint(QueryHints.PASS_DISTINCT_THROUGH, false)
.getResultList();Первый запрос JPQL определяет основные критерии фильтрации и извлекает объекты Post вместе с соответствующими записями PostComment.
Теперь нам нужно получить сущности Post вместе с Tag. Благодаря Persistence Context, Hibernate установит коллекцию tags для ранее полученных сущностей Post.
Здесь применяем тот же бенчмарк, и получаем 3300 миллисекунд, что примерно в 7 раз быстрее.
Решение для Spring Jpa
Вряд ли вы где-нибудь увидите работу с чистым Hibernate, скорее всего это будет Spring JPA. Давайте посмотрим, как и для него решить эту проблему.
Для начала создаем проблему:
package dev.struchkov.example.spring.nbfe.repository;
import dev.struchkov.example.spring.nbfe.domain.Post;
import org.springframework.data.jpa.repository.JpaRepository;
import org.springframework.data.jpa.repository.Query;
import org.springframework.data.repository.query.Param;
import java.util.List;
public interface PostRepository extends JpaRepository<Post, Long> {
@Query("""
select distinct p
from Post p
left join fetch p.comments
left join fetch p.tags
where p.id between :minId and :maxId
""")
List<Post> findAllWithCommentsAndTags(
@Param("minId") long minId,
@Param("maxId") long maxId
);
}Ваше приложение Spring даже не запустится, выбросив исключение MultipleBagFetchException при попытке создать JPA TypedQuery из связанной аннотации @Query.
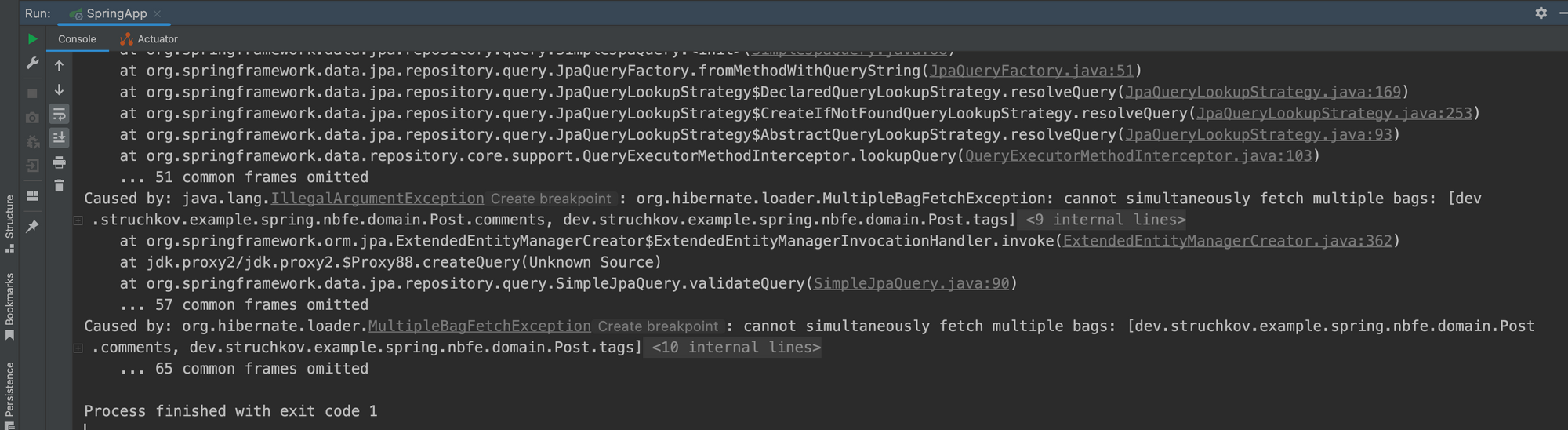
Таким образом, хотя мы не можем получить обе коллекции с помощью одного запроса JPA, мы точно также можем использовать два запроса для получения всех необходимых нам данных.
package dev.struchkov.example.spring.nbfe.repository;
import dev.struchkov.example.spring.nbfe.domain.Post;
import org.springframework.data.jpa.repository.JpaRepository;
import org.springframework.data.jpa.repository.Query;
import org.springframework.data.repository.query.Param;
import java.util.List;
public interface PostRepository extends JpaRepository<Post, Long> {
@Query("""
select distinct p
from Post p
left join fetch p.comments
where p.id between :minId and :maxId
""")
List<Post> findAllWithComments(
@Param("minId") long minId,
@Param("maxId") long maxId
);
@Query("""
select distinct p
from Post p
left join fetch p.tags
where p.id between :minId and :maxId
""")
List<Post> findAllWithTags(
@Param("minId") long minId,
@Param("maxId") long maxId
);
}Запрос findAllWithComments() будет собирать нужные сущности Post вместе со связью PostComment, а запрос findAllWithTags() будет собирать сущности Post вместе со связью Tag.
Выполнение двух запросов позволит нам избежать декартова произведения, но необходимо объединить результаты так, чтобы вернуть одну коллекцию записей Post, содержащую инициализированные коллекции комментариев и тегов.
И именно здесь нам снова поможет кэш первого уровня Hibernate. Создадим PostService и определим метод findAllWithCommentsAndTagsmethod(), который реализуется следующим образом:
package dev.struchkov.example.spring.nbfe.service;
import dev.struchkov.example.spring.nbfe.domain.Post;
import dev.struchkov.example.spring.nbfe.repository.PostRepository;
import lombok.RequiredArgsConstructor;
import org.springframework.stereotype.Service;
import org.springframework.transaction.annotation.Transactional;
import java.util.List;
@Service
@RequiredArgsConstructor
public class PostService {
private final PostRepository postRepository;
@Transactional(readOnly = true)
public List<Post> findAllWithCommentsAndTags(long minId, long maxId) {
final List<Post> posts = postRepository.findAllWithComments(
minId,
maxId
);
return !posts.isEmpty() ?
postRepository.findAllWithTags(
minId,
maxId
) :
posts;
}
}Из-за аннотации @Transactional метод будет выполняться в транзакционном контексте, что означает, что оба вызова метода PostRepository будут происходить в контексте одного и того же Persistence Context.
По этой причине методы репозитория вернут два объекта List, содержащие одинаковые ссылки на объекты Post, поскольку вы можете иметь не более одной ссылки на объект, управляемой данным Persistence Context.
В то время как первый метод будет извлекать объекты Post и хранить их в Persistence Context, второй метод, просто объединит существующие объекты со ссылками, извлеченными из БД, которые теперь содержат инициализированные коллекции тегов.
Таким образом, и комментарии, и коллекции тегов будут извлечены до возврата списка объектов Post обратно вызывающему метод сервису.
Заключение
Существует так много решений в блогах, видео, книгах и ответов на форумах, предлагающих неправильное решение проблемы MultipleBagFetchException Hibernate. Все эти ресурсы говорят вам, что использование Set вместо List является правильным способом избежать этого исключения.
Однако исключение MultipleBagFetchException говорит вам о том, что может быть получено декартово произведение, а это в большинстве случаев нежелательно при выборке сущностей, поскольку может привести к ужасным проблемам с производительностью.
Выполняя выборку не более одной коллекции на запрос, вы не только предотвратите эту проблему, но и избежите декартова произведения SQL, которое может возникнуть при выполнении одного SQL-запроса, объединяющего несколько несвязанных ассоциаций “один-ко-многим”.
Знание того, как бороться с исключением MultipleBagFetchException, очень важно при использовании Spring Data JPA, поскольку в конечном итоге вы столкнетесь с этой проблемой.
On the one hand, JPA and Hibernate provide an abstraction to do the CRUD operations against various databases, enable us to develop database applications quickly
On the other hand, JPA and Hibernate also create some performance issues that we need to be taken care of
This article will explore some common problems you may encounter when working with JPA and Hibernate in Spring Boot and Spring Data applications
Let’s get started!
Problem 1: EAGER FetchType
There are two types of fetching strategy in JPA and Hibernate to load data for the associated (child) entities, EAGER and LAZY. While LAZY only fetches data when they are needed (at the first time accessed of the associated entities), EAGER always fetches child entities along with its parent
While LAZY can cause LazyInitializationException, EAGER causes Hibernate to generate and execute unnecessary SELECT SQLs to the database and so increasing the memory consumption for unnecessary data
Let’s take a look at the following example
@Entity
class Company {
@OneToMany(fetch = FetchType.EAGER)
private Set<Employee> employees;
@OneToOne(fetch = FetchType.EAGER)
private Address address;
//...
}
interface CompanyRepository extends JpaRepository<Company, Integer> {
List<Company> findFirst10ByOrderByNameAsc();
}
@Service
class CompanyService {
//...
public List<String> findCompanyNames() {
List<Company> companies = companyRepository.findFirst10ByOrderByNameAsc();
return companies.stream()
.map(Company::getName)
.collect(Collectors.toList());
}
}
The above findCompanyNames() method only needs company names. However, besides fetching Company data, Hibernate also eagerly fetches data in the background for other EAGER FetchType associations including Set<Employee> and Address. The problem would become more significant when you have more EAGER associations or more entities in each
Apart from consuming memory for unnecessary data, EAGER FetchType can also cause the N+1 SQL problem which you can find more details in the latter part of this article
Approach 1: LAZY FetchType
-
Avoid using EAGER fetch in JPA and Hibernate. EAGER can fix the LazyInitializationException caused by the LAZY but it creates a performance pitfall especially when you have multiple EAGER associations in the entity
-
EAGER FetchType is the default in JPA ToOne mappings (@ManyToOne, @OneToOne), make sure you change them to LAZY explicitly
@ManyToOne(fetch = FetchType.LAZY)
private BookCategory bookCategory;
@OneToOne(fetch = FetchType.LAZY)
private BookDetail bookDetail;
LazyInitializationException is caused by uninitialized LAZY FetchType associations when they are accessed outside the transactional context
@Entity
public class Quote {
@ManyToOne(fetch = FetchType.LAZY)
private Author author;
//...
}
interface QuoteRepository extends JpaRepository<Quote, Integer>{
List<Quote> findFirst10ByOrderByName();
}
@Service
class QuoteService
//...
public List<QuoteWithAuthor> findQuotesWithAuthor() {
return of(quoteRepository.findFirst10ByOrderByName());
}
List<QuoteWithAuthor> of(List<Quote> quotes) {
return quotes.stream().map(q -> {
Author a = q.getAuthor();
AuthorIdName ain = new AuthorIdName(a.getId(), a.getName());
return new QuoteWithAuthor(q.getId(), q.getName(), ain);
}).collect(Collectors.toList());
}
}
In the above findQuotesWithAuthor() method, LazyInitializationException is thrown as the LAZY associated entity author is not initialized, the quoteRepository.findFirst10ByOrderByName() only fetchs the parent and EAGER associations then close the transaction
There are several ways to resolve the LazyInitializationException. However, some of them are pitfalls
Pitfall 2.1: EAGER FetchType
Use EAGER FetchType for the author association, so its data will be available along with its parent. However, this approach can create a performance pitfall as we learned in the previous section. It also can create the N+1 problem
Pitfall 2.2: @Transactional
Add @Transacional annotation to findQuotesWithAuthor() method can keep the associations fetching executed in database transactional context (so resolving the LazyInitializationException) but it can create the N+1 problem. You can learn more about this problem in the latter part of this tutorial
Pitfall 2.3: Hibernate.initialize(Object)
Hibernate.initialize(Object) forces initialization of a proxy or persistent collection. It helps initialize LAZY FetchType associations manually but also brings some drawbacks
-
It generates and executes an additional SQL against the database each time
-
It does not initialize child entities of the input object
Try to fix the symptoms and do outside the repository (data access layer) are the common theme of pitfall approaches
On the opposites, the right approaches will try to do inside the repository and fix the root cause by hinting JPA and Hibernate to generate and execute only 1 SQL to fetch the necessary association’s data as there are no throwing LazyInitializationException errors if all the necessary data are initialized before using
Approach 2.1: Projection
Spring Data can help retrieve partial view of a JPA @Entity with interface-based or class-based projection (DTO classes)
interface QuoteProjection {
Integer getId();
String getName();
AuthorProjection getAuthor();
}
interface AuthorProjection {
Integer getId();
String getName();
}
interface QuoteRepository extends JpaRepository<Quote, Integer> {
List<QuoteProjection> findFirst10ByOrderByNameDesc();
}
QuoteProjection and AuthorProjection are the partial views of 2 JPA entities, Quote and Author respectively
In findFirst10ByOrderByNameDesc() method of QuoteRepository, Spring Data JPA fetchs and converts the return data to List<QuoteProjection>
Approach 2.2: @EntityGraph
@EntityGraph annotation is used on the repository methods, providing a declarative way to fetch associations in a single query
interface QuoteRepository extends JpaRepository<Quote, Integer> {
@EntityGraph(attributePaths = "author")
List<Quote> findFirst10ByOrderByName();
}
Approach 2.3: JPQL JOIN FETCH
JPQL supports JOIN FETCH to fetch associations data in a single query
interface QuoteRepository extends JpaRepository<Quote, Integer> {
@Query(value="FROM Quote q LEFT JOIN FETCH q.author")
List<Quote> findWithAuthorAndJoinFetch(Pageable pageable);
}
Problem 3: N+1 SQL statements
The N+1 SQL problem occurs on the associated (child) entities when JPA and Hibernate have to execute N additional SQLs to do the operation
The issue can happen on both EAGER and LAZY FetchType and on reading or deleting operation against a database
Problem 3.1: N+1 on SELECT
Let’s take a look at the following example
@Entity
class Company {
@OneToMany(fetch = LAZY, mappedBy = "company", cascade = ALL)
private Set<Employee> employees;
@OneToMany(fetch = EAGER, mappedBy = "company", cascade = ALL)
private Set<Department> departments;
//...
}
interface CompanyRepository extends JpaRepository<Company, Integer> {
List<Company> findFirst10ByOrderByNameAsc();
}
@Service
class CompanyService {
//...
public List<String> findCompanyNames() {
List<Company> companies = companyRepository.findFirst10ByOrderByNameAsc();
return companies.stream()
.map(Company::getName)
.collect(Collectors.toList());
}
@Transactional
public List<CompanyIdName> findCompanyIdNames() {
return companyRepository.findFirst10ByOrderByNameAsc().stream()
.map(CompanyIdName::of)
.collect(Collectors.toList());
}
}
Suppose you have 10 Companies and each Company has some Employees in the database. With JPA show-sql and Hibernate generate_statistics settings are enabled in your Spring Boot application properties
spring.jpa.show-sql=true
spring.jpa.properties.hibernate.generate_statistics=true
When running the findCompanyNames() method, you may end up with the following output in the console
... nanoseconds spent preparing 11 JDBC statements;
... nanoseconds spent executing 11 JDBC statements;
-
The first SQL statement is executed to load the list of 10 companies
List<Company> -
The 10 consecutive SQLs, corresponding to the number of elements returned from the result of the first SQL statement, are executed to fetch the
Set<Department>EAGER associations
Separately, when running the findCompanyIdNames() method, you may end up with the following output in the console
... nanoseconds spent preparing 21 JDBC statements;
... nanoseconds spent executing 21 JDBC statements;
-
The first SQL statement is executed to load the list of 10 companies
List<Company> -
The 20 consecutive SQLs, corresponding to the number of elements returned from the result of the first SQL statement, are executed to fetch the EAGER
Set<Department>and LAZYSet<Employee>associations
Approach 3.1.1: @EntityGraph and Projection
@EntityGraph annotation is used on the repository methods, providing a declarative way to fetch associations in a single query
Spring Data can help to retrieve partial view of a JPA @Entity with interface-based or class-based projection (DTO classes)
interface CompanyProjection {
int getId();
String getName();
List<EmployeeProjection> getEmployees();
}
interface EmployeeProjection {
int getId();
String getName();
}
@EntityGraph(attributePaths = "employees")
List<CompanyProjection> findFirst10ByOrderByIdDesc();
CompanyProjection and EmployeeProjection are the partial views of 2 JPA entities, Company and Employee respectively
In findFirst10ByOrderByIdDesc() method, Spring Data JPA fetchs and converts the return data to List<CompanyProjection>
Approach 3.1.2: JOIN FETCH
JPQL supports JOIN FETCH to fetch associations data in a single query
@Query(value="FROM Company c LEFT JOIN FETCH c.employees")
List<Company> findWithEmployeesAndJoinFetch(Pageable pageable);
Try to hint JPA and Hibernate to generate and execute only 1 SQL is the common pattern of the above approaches. Now
when you trigger the findFirst10ByOrderByIdDesc() or findWithEmployeesAndJoinFetch() method, you would observe the expected output
... nanoseconds spent preparing 1 JDBC statements;
... nanoseconds spent executing 1 JDBC statements;
Problem 3.2: N+1 on DELETE
N+1 may also occur on Delete operations. Suppose you’d like to build a repository method to delete employees by a company id
interface EmployeeRepository extends JpaRepository<Employee, Integer> {
@Transactional
void deleteByCompanyId(int companyId);
}
When triggering deleteByCompanyId() method and looking into the output console, you would find out that Hibernate deletes one by one employee. It generates N+1 queries to do the operation
The first query selects a list of employees of companies with id as companyId
The second query selects company data with id as companyId
Then N consecutive queries are generated and executed to delete one by one employee, N is the size of the result list of the first query
Approach 3.2: Define the DELETE query explicitly
In the repository, define the DELETE query explicitly
interface EmployeeRepository extends JpaRepository<Employee, Integer> {
@Modifying
@Transactional
@Query("DELETE FROM Employee e WHERE e.company.id = ?1")
void deleteInBulkByCompanyId(int companyId);
@Transactional
void deleteByCompanyId(int categoryId);
}
With the deleteInBulkByCompanyId() method, only 1 DELETE query is executed to delete employes in bulk instead of one by one
Conclusion
In this article, we explored some of the common problems when using JPA and Hibernate in Spring Boot and Spring Data applications. We also learned about the pitfalls and the right approaches to resolving the issues
Время на прочтение
7 мин
Количество просмотров 73K
В преддверии курса “Highload Architect” приглашаем вас посетить открытый урок по теме “Паттерны горизонтального масштабирования хранилищ”.
А пока делимся традиционным переводом полезной статьи.
Введение
В этой статье я расскажу, в чем состоит проблема N + 1 запросов при использовании JPA и Hibernate, и как ее лучше всего исправить.
Проблема N + 1 не специфична для JPA и Hibernate, с ней вы можете столкнуться и при использовании других технологий доступа к данным.
Что такое проблема N + 1
Проблема N + 1 возникает, когда фреймворк доступа к данным выполняет N дополнительных SQL-запросов для получения тех же данных, которые можно получить при выполнении одного SQL-запроса.
Чем больше значение N, тем больше запросов будет выполнено и тем больше влияние на производительность. И хотя лог медленных запросов может вам помочь найти медленные запросы, но проблему N + 1 он не обнаружит, так как каждый отдельный дополнительный запрос выполняется достаточно быстро.
Проблема заключается в выполнении множества дополнительных запросов, которые в сумме выполняются уже существенное время, влияющее на быстродействие.
Рассмотрим следующие таблицы БД: post (посты) и post_comments (комментарии к постам), которые связаны отношением “один-ко-многим”:
Вставим в таблицу post четыре строки:
INSERT INTO post (title, id)
VALUES ('High-Performance Java Persistence - Part 1', 1)
INSERT INTO post (title, id)
VALUES ('High-Performance Java Persistence - Part 2', 2)
INSERT INTO post (title, id)
VALUES ('High-Performance Java Persistence - Part 3', 3)
INSERT INTO post (title, id)
VALUES ('High-Performance Java Persistence - Part 4', 4)А в таблицу post_comment четыре дочерние записи:
INSERT INTO post_comment (post_id, review, id)
VALUES (1, 'Excellent book to understand Java Persistence', 1)
INSERT INTO post_comment (post_id, review, id)
VALUES (2, 'Must-read for Java developers', 2)
INSERT INTO post_comment (post_id, review, id)
VALUES (3, 'Five Stars', 3)
INSERT INTO post_comment (post_id, review, id)
VALUES (4, 'A great reference book', 4)Проблема N+1 с простым SQL
Как уже говорилось, проблема N + 1 может возникнуть при использовании любой технологии доступа к данным, даже при прямом использовании SQL.
Если вы выберете post_comments с помощью следующего SQL-запроса:
List<Tuple> comments = entityManager.createNativeQuery("""
SELECT
pc.id AS id,
pc.review AS review,
pc.post_id AS postId
FROM post_comment pc
""", Tuple.class)
.getResultList();А позже решите получить заголовок (title) связанного поста (post) для каждого комментария (post_comment):
for (Tuple comment : comments) {
String review = (String) comment.get("review");
Long postId = ((Number) comment.get("postId")).longValue();
String postTitle = (String) entityManager.createNativeQuery("""
SELECT
p.title
FROM post p
WHERE p.id = :postId
""")
.setParameter("postId", postId)
.getSingleResult();
LOGGER.info(
"The Post '{}' got this review '{}'",
postTitle,
review
);
}Вы получите проблему N + 1, потому что вместо одного SQL-запроса вы выполнили пять (1 + 4):
SELECT
pc.id AS id,
pc.review AS review,
pc.post_id AS postId
FROM post_comment pc
SELECT p.title FROM post p WHERE p.id = 1
-- The Post 'High-Performance Java Persistence - Part 1' got this review
-- 'Excellent book to understand Java Persistence'
SELECT p.title FROM post p WHERE p.id = 2
-- The Post 'High-Performance Java Persistence - Part 2' got this review
-- 'Must-read for Java developers'
SELECT p.title FROM post p WHERE p.id = 3
-- The Post 'High-Performance Java Persistence - Part 3' got this review
-- 'Five Stars'
SELECT p.title FROM post p WHERE p.id = 4
-- The Post 'High-Performance Java Persistence - Part 4' got this review
-- 'A great reference book'Исправить эту проблему с N + 1 запросом очень просто. Все, что нужно сделать, это извлечь все необходимые данные одним SQL-запросом, например, так:
List<Tuple> comments = entityManager.createNativeQuery("""
SELECT
pc.id AS id,
pc.review AS review,
p.title AS postTitle
FROM post_comment pc
JOIN post p ON pc.post_id = p.id
""", Tuple.class)
.getResultList();
for (Tuple comment : comments) {
String review = (String) comment.get("review");
String postTitle = (String) comment.get("postTitle");
LOGGER.info(
"The Post '{}' got this review '{}'",
postTitle,
review
);
}На этот раз выполняется только один SQL-запрос и возвращаются все данные, которые мы хотим использовать в дальнейшем.
Проблема N + 1 с JPA и Hibernate
При использовании JPA и Hibernate есть несколько способов получить проблему N + 1, поэтому очень важно знать, как избежать таких ситуаций.
Рассмотрим следующие классы, которые мапятся на таблицы post и post_comments:
JPA-маппинг выглядят следующим образом:
@Entity(name = "Post")
@Table(name = "post")
public class Post {
@Id
private Long id;
private String title;
//Getters and setters omitted for brevity
}
@Entity(name = "PostComment")
@Table(name = "post_comment")
public class PostComment {
@Id
private Long id;
@ManyToOne
private Post post;
private String review;
//Getters and setters omitted for brevity
}FetchType.EAGER
Использование явного или неявного FetchType.EAGER для JPA-ассоциаций — плохая идея, потому что будет загружаться гораздо больше данных, чем вам нужно. Более того, стратегия FetchType.EAGER также подвержена проблемам N + 1.
К сожалению, ассоциации @ManyToOne и @OneToOne по умолчанию используют FetchType.EAGER, поэтому, если ваши маппинги выглядят следующим образом:
@ManyToOne
private Post post;У вас используется FetchType.EAGER и каждый раз, когда вы забываете указать JOIN FETCH при загрузке сущностей PostComment с помощью JPQL-запроса или Criteria API:
List<PostComment> comments = entityManager
.createQuery("""
select pc
from PostComment pc
""", PostComment.class)
.getResultList();Вы сталкиваетесь с проблемой N + 1:
SELECT
pc.id AS id1_1_,
pc.post_id AS post_id3_1_,
pc.review AS review2_1_
FROM
post_comment pc
SELECT p.id AS id1_0_0_, p.title AS title2_0_0_ FROM post p WHERE p.id = 1
SELECT p.id AS id1_0_0_, p.title AS title2_0_0_ FROM post p WHERE p.id = 2
SELECT p.id AS id1_0_0_, p.title AS title2_0_0_ FROM post p WHERE p.id = 3
SELECT p.id AS id1_0_0_, p.title AS title2_0_0_ FROM post p WHERE p.id = 4Обратите внимание на дополнительные запросы SELECT, которые появились, потому что перед возвращением списка сущностей PostComment необходимо извлечь ассоциацию с post.
В отличие от значений по умолчанию, используемых в методе find из EntityManager, в JPQL-запросах и Criteria API явно указывается план выборки (fetch plan), который Hibernate не может изменить, автоматически применив JOIN FETCH. Таким образом, вам это нужно делать вручную.
Если вам совсем не нужна ассоциация с post, то не повезло: с использованием FetchType.EAGER нет способа избежать ее получения. Поэтому по умолчанию лучше использовать FetchType.LAZY.
Но если вы хотите использовать ассоциацию с post, то можно использовать JOIN FETCH, чтобы избежать проблемы с N + 1:
List<PostComment> comments = entityManager.createQuery("""
select pc
from PostComment pc
join fetch pc.post p
""", PostComment.class)
.getResultList();
for(PostComment comment : comments) {
LOGGER.info(
"The Post '{}' got this review '{}'",
comment.getPost().getTitle(),
comment.getReview()
);
}На этот раз Hibernate выполнит один SQL-запрос:
SELECT
pc.id as id1_1_0_,
pc.post_id as post_id3_1_0_,
pc.review as review2_1_0_,
p.id as id1_0_1_,
p.title as title2_0_1_
FROM
post_comment pc
INNER JOIN
post p ON pc.post_id = p.id
-- The Post 'High-Performance Java Persistence - Part 1' got this review
-- 'Excellent book to understand Java Persistence'
-- The Post 'High-Performance Java Persistence - Part 2' got this review
-- 'Must-read for Java developers'
-- The Post 'High-Performance Java Persistence - Part 3' got this review
-- 'Five Stars'
-- The Post 'High-Performance Java Persistence - Part 4' got this review
-- 'A great reference book'Подробнее о том, почему следует избегать стратегии FetchType.EAGER, читайте в этой статье.
FetchType.LAZY
Даже если вы явно перейдете на использование FetchType.LAZY для всех ассоциаций, то вы все равно можете столкнуться с проблемой N + 1.
На этот раз ассоциация с post мапится следующим образом:
@ManyToOne(fetch = FetchType.LAZY)
private Post post;Теперь, когда вы запросите PostComment:
List<PostComment> comments = entityManager
.createQuery("""
select pc
from PostComment pc
""", PostComment.class)
.getResultList();Hibernate выполнит один SQL-запрос:
SELECT
pc.id AS id1_1_,
pc.post_id AS post_id3_1_,
pc.review AS review2_1_
FROM
post_comment pcНо если позже вы обратитесь к этой lazy-load ассоциации с post:
for(PostComment comment : comments) {
LOGGER.info(
"The Post '{}' got this review '{}'",
comment.getPost().getTitle(),
comment.getReview()
);
}Вы получите проблему с N + 1 запросом:
SELECT p.id AS id1_0_0_, p.title AS title2_0_0_ FROM post p WHERE p.id = 1
-- The Post 'High-Performance Java Persistence - Part 1' got this review
-- 'Excellent book to understand Java Persistence'
SELECT p.id AS id1_0_0_, p.title AS title2_0_0_ FROM post p WHERE p.id = 2
-- The Post 'High-Performance Java Persistence - Part 2' got this review
-- 'Must-read for Java developers'
SELECT p.id AS id1_0_0_, p.title AS title2_0_0_ FROM post p WHERE p.id = 3
-- The Post 'High-Performance Java Persistence - Part 3' got this review
-- 'Five Stars'
SELECT p.id AS id1_0_0_, p.title AS title2_0_0_ FROM post p WHERE p.id = 4
-- The Post 'High-Performance Java Persistence - Part 4' got this review
-- 'A great reference book'Поскольку ассоциация с post загружается лениво, при доступе к этой ассоциации будет выполняться дополнительный SQL-запрос для получения нужных данных.
Опять же, решение заключается в добавлении JOIN FETCH к запросу JPQL:
List<PostComment> comments = entityManager.createQuery("""
select pc
from PostComment pc
join fetch pc.post p
""", PostComment.class)
.getResultList();
for(PostComment comment : comments) {
LOGGER.info(
"The Post '{}' got this review '{}'",
comment.getPost().getTitle(),
comment.getReview()
);
}И как и в примере с FetchType.EAGER, этот JPQL-запрос будет генерировать один SQL-запрос.
Даже если вы используете FetchType.LAZY и не ссылаетесь на дочерние ассоциации двунаправленного отношения @OneToOne, вы все равно можете получить N + 1.
Подробнее о том, как преодолеть проблему N+1 c @OneToOne-ассоциациями, читайте в этой статье.
Кэш второго уровня
Проблема N + 1 также может возникать при использовании кэша второго уровня для обработки коллекций или результатов запроса.
Например, если выполните следующий JPQL-запрос, использующий кэш запросов:
List<PostComment> comments = entityManager.createQuery("""
select pc
from PostComment pc
order by pc.post.id desc
""", PostComment.class)
.setMaxResults(10)
.setHint(QueryHints.HINT_CACHEABLE, true)
.getResultList();Если PostComment не находится в кэше второго уровня, то будет выполнено N запросов для получения каждого отдельного PostComment:
-- Checking cached query results in region: org.hibernate.cache.internal.StandardQueryCache
-- Checking query spaces are up-to-date: [post_comment]
-- [post_comment] last update timestamp: 6244574473195524, result set timestamp: 6244574473207808
-- Returning cached query results
SELECT pc.id AS id1_1_0_,
pc.post_id AS post_id3_1_0_,
pc.review AS review2_1_0_
FROM post_comment pc
WHERE pc.id = 3
SELECT pc.id AS id1_1_0_,
pc.post_id AS post_id3_1_0_,
pc.review AS review2_1_0_
FROM post_comment pc
WHERE pc.id = 2
SELECT pc.id AS id1_1_0_,
pc.post_id AS post_id3_1_0_,
pc.review AS review2_1_0_
FROM post_comment pc
WHERE pc.id = 1В кэше запросов хранятся только идентификаторы сущностей PostComment. Таким образом, если сущности PostComment не находятся в кэше, они будут извлечены из базы данных и вы получите N дополнительных SQL-запросов.
Подробнее о курсе “Highload Architect”.
I’m experiencing some difficulties with generating tables in the database through JPA and Hibernate annotations.
When the below code is executed it generates the tables with the following EER diagram.

This is not how I want it to generate the tables.
First of all the relations between the tables are wrong, they need to be OneToOne and not OneToMany.
Secondly, i don’t want email to be the primary key in student and teacher.
In Student the ovNumber should be primary key and in Teacher the employeeNumber
I have tried doing it with the @Id annotation but that gives me the following error:
org.hibernate.mapping.JoinedSubclass cannot be cast to org.hibernate.mapping.RootClass
When i try to use @MappedSuperClass the table person does not generate, even when using @Inheritance(strategy=InheritanceType.TABLE_PER_CLASS).
Now my question,
How do I make another variable in subclasses the primary key for the corrosponding table whilst keeping the superclass primary key as foreign key?
How do I fix the relationship between the tables to be an OneToOne relation rather than a OneToMany relation?
Here is an EER diagram of how it should be.

Below are the model classes that are used to generate the tables.
Person.java
@Entity
@Polymorphism(type=PolymorphismType.IMPLICIT)
@Inheritance(strategy=InheritanceType.JOINED)
public class Person implements Comparable<Person>, Serializable {
private static final long serialVersionUID = 1L;
@Id
@Column(name="email", length=64, nullable=false)
private String email;
@Column(name="firstName", length=255)
private String firstName;
@Column(name="insertion", length=255)
private String insertion;
@Column(name="lastName", length=255)
private String lastName;
public Person() {}
/**
* constructor with only email.
*
* @param email
*/
public Person(String email) {
this.email = email;
}
/**
* @param email
* @param firstName
* @param insertion
* @param lastName
*/
public Person(String email, String firstName, String insertion, String lastName){
this.setEmail(email);
this.setFirstName(firstName);
this.setInsertion(insertion);
this.setLastName(lastName);
}
//getters and setters
public String getEmail() {
return email;
}
public void setEmail(String email) {
this.email = email;
}
public String getFirstName() {
return firstName;
}
public void setFirstName(String firstName) {
this.firstName = firstName;
}
public String getInsertion() {
return insertion;
}
public void setInsertion(String insertion) {
this.insertion = insertion;
}
public String getLastName() {
return lastName;
}
public void setLastName(String lastName) {
this.lastName = lastName;
}
@Override
public int compareTo(Person o) {
return email.compareTo(o.getEmail());
}
}
Teacher.java
@Entity
@Table(name="teacher")
@PrimaryKeyJoinColumn(name="email", referencedColumnName="email")
public class Teacher extends Person {
private static final long serialVersionUID = 1L;
//this needs to be the pk of teacher table
//@Id
@Column(name="employeeNumber", length=6, nullable=false)
private int employeeNumber;
@Column(name="abbreviation", length=6)
private String abbreviation;
public Teacher(){}
/**
* @param employeeNumber
* @param email
* @param firstName
* @param insertion
* @param lastName
*/
public Teacher(int employeeNumber, String email, String firstName, String insertion, String lastName){
super(email, firstName, insertion, lastName);
this.employeeNumber = employeeNumber;
setAbbreviation();
}
public String getAbbreviation() {
return abbreviation;
}
public void setAbbreviation() {
this.abbreviation = getLastName().substring(0, 4).toUpperCase() + getFirstName().substring(0, 2).toUpperCase();
}
public void setAbbreviation(String abbreviation){
this.abbreviation = abbreviation;
}
public int getEmployeeNumber() {
return employeeNumber;
}
public void setEmployeeNumber(int employeeNumber) {
this.employeeNumber = employeeNumber;
}
@Override
public String toString() {
return "Teacher [abbreviation=" + abbreviation + ", employeeNumber=" + employeeNumber + "]";
}
}
Student.java
@Entity
@Table(name="student")
@PrimaryKeyJoinColumn(name="email", referencedColumnName="email")
public class Student extends Person {
private static final long serialVersionUID = 1L;
@Column(name="cohort")
private int cohort;
//FIXME this needs to be the pk of student table
//@Id
@Column(name="ovNumber", nullable=false)
private int studentOV;
public Student(){}
public Student(int studentOV, int cohort, String email, String firstName,
String insertion, String lastName) {
super(email, firstName, insertion, lastName);
this.studentOV = studentOV;
this.cohort = cohort;
}
public int getCohort() {
return cohort;
}
public void setCohort(int cohort) {
this.cohort = cohort;
}
public int getStudentOV() {
return studentOV;
}
public void setStudentOV(int studentOV) {
this.studentOV = studentOV;
}
@Override
public int compareTo(Person o) {
return getEmail().compareTo(o.getEmail());
}
@Override
public String toString() {
return "Student [firstName=" + getFirstName() + ", insertion=" + getInsertion() + ", lastName=" + getLastName() + ", email="
+ getEmail() + ", cohort=" + getCohort() + ", studentOV=" + getStudentOV() + "]";
}
}
