Текст должен быть в формате UTF-8. Не используйте двойное кодирование.
В Merchant Center поддерживаются такие стандарты кодировки, как UTF-8, UTF-16, Latin-1 и ASCII. Если вы не знаете, какой именно тип кодировки используется в вашем файле, выберите параметр Определять автоматически.
Если вы сохраняете файл в программе “Блокнот”, нажмите Сохранить как и выберите ANSI или UTF-8 в поле Кодировка. Если формат кодировки файла отличается от указанных выше, файл не будет обработан.
Важное примечание. Если в XML-файле используется кодировка Latin-1 или UTF-16, необходимо указать это в нем. Для этого в первой строке фида замените фрагмент <?xml version=" 1.0"?> на одно из следующих значений:
- для Latin-1:
<?xml version="1.0" encoding="ISO-8859-1"?>; - для UTF-16:
<?xml version="1.0" encoding="UTF-16"?>.
Инструкции
Шаг 1. Проверьте список товаров с ошибками
- Войдите в аккаунт Merchant Center.
- Перейдите на вкладку Товары в меню навигации и выберите Диагностика.
- Нажмите Проблемы с товарами. Откроется список затронутых позиций.
Как скачать список всех затронутых товаров (в формате .csv)
Как скачать список всех товаров с конкретной проблемой (в формате .csv)
- Найдите проблему в одноименном столбце и нажмите на значок скачивания
в конце строки.
Как посмотреть 50 самых популярных товаров с определенной проблемой
- Найдите проблему в одноименном столбце и нажмите Посмотреть примеры в столбце “Затронутые товары”.
Шаг 2. Задайте для текста формат UTF-8
- Отфильтруйте данные так, чтобы в столбце Issue title (Название проблемы) отображались только значения Invalid UTF-8 encoding (Недопустимая кодировка UTF-8).
- Проверьте сведения, указанные для товаров с этой проблемой. Исправьте данные в фиде так, чтобы для значений основных атрибутов был использован формат UTF-8.
Шаг 3. Повторно загрузите фид
- После изменения данных о товаре отправьте их повторно, выбрав один из перечисленных ниже способов.
- Добавить фид напрямую
- Как отправить данные с помощью Content API
- Как импортировать данные с платформы электронной торговли
- Перейдите на страницу “Диагностика” и убедитесь, что проблема решена.
Обратите внимание, что изменения на этой странице могут появиться не сразу.
Эта информация оказалась полезной?
Как можно улучшить эту статью?
#! /usr/bin/env python3
# -*- coding: utf-8 -*-
import codecs, sys, argparse
key = ":E9 EE E1 E0 ED FB E9 20 F5 F3 E9:"
help_text = '''
-e\-encode [файл або кілька файлів(через пробіл)] - запакувати
-o\-output_file файл - кінцевий файл(обов'яковий параметр для -e\-encode)
-r\--rat true\false - замаскувати файл\файли під інший файл(true - так,false - ні)(головний файл перший в списку -e, інші маскуються під нього)(в -o вказати файл з розширенням першого файлу)
-d\-decode [файл або кілька файлів(через пробіл)] - розпакувати
'''
def r_file(file,rat):
f = open(file,'rb')
temp = b""
if rat == "false":
temp += codecs.utf_8_encode(str(key+":"+file+":n"))[0]
for ff in f:
temp += ff
f.close()
return temp
def w_file(file,text):
f = open(file,'wb')
f.write(text)
f.close()
def f_decode(file):
f = open(file,"rb")
name = ""
text = b""
n = 0
for ff in f:
if key in codecs.utf_8_decode(ff)[0]: # строка 36
text = b""
name = codecs.utf_8_decode(ff)[0].split(":")[3]
n = 0
else:
f1 = open(name,"ab")
f1.write(ff)
f1.close()
f.close()
def createParser ():
parser = argparse.ArgumentParser()
parser.add_argument ('-e', '--encode', nargs='+')
parser.add_argument ('-d', '--decode', nargs='+')
parser.add_argument ('-o', '--output_file', nargs='?')
parser.add_argument ('-r', '--rat', nargs='?',default="false")
parser.add_argument ('-i', '--infa',default=None)
return parser
parser = createParser()
namespace = parser.parse_args(sys.argv[1:])
if namespace.encode != None:
if namespace.output_file == None:
print("Параметр -o\-output_file обов`язковий")
else:
files = namespace.encode
f = namespace.output_file
t = b''
rat = namespace.rat
for file in files:
if rat == "true":
t += r_file(file,"true")
rat = "false"
else:
t += r_file(file,"false")
w_file(f,t)
if namespace.decode != None:
files = namespace.decode
for file in files:
f_decode(file) #строка 78
if namespace.infa == None or namespace.infa != None:
print(help_text)
ыЙТПЛБС ØàÞÚÐï ╒┌тр╪ф╪┌ПрЎ.ТруНЬ_аЭШЩ ФРбв ЬЮ!…
Нет, мы не сошли с ума. Просто сегодня будем разбираться, как устранить ошибки кодировки и вернуть на сайт читаемый текст. Узнаем, как кодировка влияет на SEO-оптимизацию, и познакомимся с полезными сервисами, которые позволят вовремя идентифицировать ошибки.
Что такое кодировка, и когда возникают ошибки с отображением текста
Если вместо нормального текста на вашем сайте отображается странный набор символов, значит, есть проблемы с кодировкой. Впрочем, иногда кодировка на сайте является стандартизированной и выбрана корректно, но вместо текста все равно отображаются иероглифы.
Кодировка – это набор символов и система их передачи для последующего вывода на экран. Кроме алфавита при помощи кодировки передаются также специальные символы и цифры.
Сегодня массово используются 2 вида кодировки: Windows-1251 и UTF-8. Чаще всего «кракозябра» появляется, когда на одном сайте используется сразу несколько видов кодировки (да, такое бывает чаще, чем может показаться на первый взгляд).
Можно выделить и другие причины неполадок:
- Используется устаревший браузер.
- В браузере / программе установлена одна кодировка, на сайте – другая. В таком случае нужно поменять кодировку в программе.
- В БД и других файлах сайта указаны несовпадающие кодировки. В этом случае нужно выбрать одну кодировку для всего сайта.

Как поменять кодировку в браузере
Проблему с кодировкой на стороне браузера исправить легко.
Internet Explorer
- Открываем проблемную веб-страницу.
- Вызываем контекстное меню, кликнув правой кнопкой мыши по любому месту на странице.
- Выбираем «Кодировка».
- Кликаем Unicode (UTF-8).
Chrome
Chrome современный и модный браузер, но вот кодировку стандартными средствами поменять в нем нельзя (сюрприз!). Будем делать это через расширение.
- Открываем магазин Chrome.
- Кликаем «Расширения» в левой части экрана.
- Указываем слово «кодировка».
- Устанавливаем любое подходящее расширение.
Safari
- Выбираем пункт «Вид».
- Кликаем по разделу «Кодировка текста».
- Выбраем вариант Unicode (UTF-8).
Firefox
- Выбираем пункт «Вид».
- Кликаем по раздел «Кодировка текста».
- Нужно выбрать вариант Unicode (UTF-8).
Как выбрать кодировку
Если в качестве CMS вы используете WordPress, Joomla, Drupal, OpenCart или TYPO3, то дополнительно настраивать ничего не нужно. Эти движки по умолчанию работает именно с UTF-8. Все должно работать из коробки. Просто убедитесь, что везде прописана UTF-8.
В самых сложных случаях придется отдельно скачивать шаблоны под конкретную кодировку, предварительно создав MySQL. Последнее актуально, например, для DLE. Если же ваш cайт полностью самописный, просто проследите за тем, чтобы везде была установлена идентичная кодировка, желательно – UTF-8.
Какую кодировку выбрать
Сегодня большинство экспертов солидарны в том, что наиболее удобной кодировкой является UTF-8. Этот стандарт поддерживает большинство браузеров, баз данных, серверов и языков. Еще одно преимущество – она изначально была кроссплатформенной.
UTF-8 может закодировать любой unicode-символ. Пожалуй, именно это достоинство позволило кодировке стать одной из самых популярных в мире.
Windows-1251 известна в меньшей степени, но Windows-1251 и не отличается такой универсальностью и распространенностью как UTF-8. Проблемы с кодировкой могут встречаться на всех сайтах, даже на отлаженных площадках, которые работают в течение многих лет. Чтобы предотвратить проблемы с «кракозябрами» на своем сайте в будущем, необходимо с самого начала выбирать единую кодировку. Как вы уже догадались, лучший кандидат на эту роль – UTF-8.
Как узнать, какая кодировка используется на моем сайте
Узнать, какая кодировка используется на всем сайте или на конкретной странице, можно за несколько секунд. Для этого нужно просмотреть исходник HTML-страницы. Чтобы увидеть его, используем одновременное нажатие горячих клавиш Сtrl + U (на «Маке» активируем шорткатом Option/Alt + Command + U). Появится такое окно:

Теперь используем сочетание горячих клавиш Ctrl + F (Command + F) – откроется окно поиска. Вводим в поисковую строку атрибут charset (он же character set, кодировка документа). После этого атрибута мы увидим знак равенства. За ним и будет указана кодировка страницы.

Если атрибут charset не задан, его придется задать. Предварительно нужно проверить сайт при помощи сторонних сервисов. Один из них – Browserstack. Платформа платная, но, чтобы проверить кодировку, платить необязательно. Достаточно открыть сайт и выбрать пункт Get started free, создать аккаунт (можно просто залогиниться при помощи «Google-аккаунта»). После авторизации появится такое окно:

Выбираем интересующую нас операционную систему / устройство и вводим сайт, который нужно протестировать:

Если с кодировкой на сайте что-то не так, все ошибки будут представлены в результатах теста.
Для проверки и определения ошибок кодировки можно использовать не только Browserstack. Альтернатива – бесплатный сервис Validator. Он позволит идентифицировать кодировку сразу по нескольким данным, включая заголовки. Пример ошибки кодировки в результатах анализа Validator:

Также неплохие возможности для проверки технических ошибок сайта дает pr-cy.ru. Не забудьте выбрать пункт «Аудит страниц»:

Хорошие инструменты для проверки кодировки предоставляют сервисы NetPeak и SeoFrog. Последний удобен еще тем, что позволяет проверить кодировку сразу по всем страницам сайта, а не только по одной.
Кодировка и оптимизация
Даже если кодировка на сайте не совсем обычная или отличается на разных страницах, Google и «Яндекс» все равно проиндексируют такой сайт, но при условии, что контент уникален и не переспамлен ключами. Одна из самых неприятных ошибок здесь – несовместимость кодировки веб-ресурса с той, которая используется на сервере. Даже в таком случае Google, например, способен корректно идентифицировать ошибку. Сайт будет в выдаче, если соответствующие условия были соблюдены.
Ошибки кодировки сами по себе не влияют на оптимизацию сайта прямым образом. Они сказываются на отказах и времени, проведенном на сайте, а также на иных поведенческих показателях аудитории.
Если на вашем сайте возникают ошибки кодировки, и контент отображается некорректно, то посетитель ни при каких обстоятельствах не будет тратить свое время, пытаясь настроить правильную кодировку и, тем более, пытаться ее преобразовать в читаемую. Большинство посетителей просто не знают, как это сделать, но даже если знают, не будут тратить время и точно уйдут к конкурентам на тот сайт, где содержимое изначально отображается корректно.
Устранить проблемы кодировки сложно: мало поменять ее на одной или нескольких страницах. Обычно приходится исправлять ее также в мете (одноименных тегах), БД MySQL, файле htaccess и других системных файлах сайта.
Как исправить ошибки кодировки на своем сайте
Инструкция предназначена только для опытных пользователей и не является призывом к действию. Код и настройки я привожу исключительно в качестве примера. Если вы решитесь вносить изменения в БД и системные файлы, особенно в root, обязательно сделайте резервную копию всех данных сайта!
Документы / HTML-файлы
Если возникают проблемы с документами, необходимо удостовериться в том, что они имеют одинаковую кодировку, и в том, что она вообще задана. Для этого открываем HTML-файл при помощи любого редактора, который позволяет работать с кодом. Например, через Notepad++. Открываем проблемный документ и выполняем следующую последовательность действий:

Htaccess
«Кракозябра» может появляться даже в тех случаях, когда ошибки в документах уже исправлены. В таком случае нужно проверить файл htaccess. Открываем его при помощи редактора кода, затем, используя одновременное сочетание горячих клавиш Ctrl + F, открываем окно «Поиск по странице» и вводим уже знакомый нам атрибут Charset. Если атрибут найден, его необходимо исправить на тот, который является стандартным для вашего сайта. Если его нет вообще, добавляем атрибут AddDefaultCharset UTF-8 в любом месте в самом начале документа.
Теги типа meta
Именно мета-тег используется для установки требуемой кодировки. Кроме этого, в нем прописываются и другие мета-теги, которые задействованы для хранения информации, используемой браузерами. Прописываются теги типа meta в head-разделе. Выглядит следующим образом:
<!DOCTYPE HTML>
<html>
<head>
<title>Тег META</title>
<meta charset="utf-8">
</head>
<body>
<p>...</p>
</body>
</html>
Этот код приводится в качестве примера. Не исключено появление ошибок.
Базы данных
Если «кракозябры» при открытии страниц так и не исчезают, придется проверять MySQL. Нас интересуют значения, прописанные в таблицах баз данных. Чтобы устранить эту проблему, необходимо подключиться к серверу через mysql root. Для этого выполняем следующие шаги:

Так мы приведем кодировку БД к единому стандарту UTF-8.
Онлайн-декодеры
Онлайн-декодеры и другие инструменты с аналогичным функционалом позволяют преобразовать «кракозябру» в читаемый текст. Foxtools – приятный и удобный декодер, который работает в автоматическом режиме. У Foxtools вообще много полезных инструментов:

2cyr – еще более функциональный инструмент, который не только преобразует «кракозябры» в читаемый текст, но и выводит множество возможных вариантов. Бывает и такое, что все варианты «расшифровки» являются некорректными:

Итоги
Чтобы вовремя идентифицировать проблемы с кодировкой на своем сайте, используйте перечисленные выше инструменты. Не забывайте и об онлайн-декодерах: они эффективно расшифровывают нечитаемый текст в случаях, когда необходимо быстро преобразовать «кракозябру». Помните, что иероглифы на сайте недопустимы, и устранять такие ошибки нужно как можно скорее. В противном случае ухудшатся поведенческие факторы, и сайт может навсегда выпасть из поисковой выдачи.
Добрый день!
На сайте при тестировании конфигурации, были проблемы с кодировкой, ругался на latin1.
Я исправил ошибку стандартными средствами, как было указано в рекомендации и вроде еще выполнил пару команд (точно не помню, было давно):
Получил запросы на все таблицы
SEL ECT CONCAT(‘ALT ER TABLE `’, t.`TABLE_SCHEMA`, ‘`.`’, t.`TABLE_NAME`, ‘` CONVERT TO CHARACTER SET utf8 COLLATE utf8_unicode_ci;’) as sqlcode
FR OM `information_schema`.`TABLES` t
WHERE 1
AND t.`TABLE_SCHEMA` = ‘`DB_NAME`’
ORDER BY 1
и выполнил для каждой таблицы:
ALT ER TABLE `DB_NAME`.`TABLE_NAME` CONVERT TO CHARACTER SET utf8 COLLATE utf8_unicode_ci;
При проверке сайта стало все ок:
Кодировка соединения (check_mysql_connection_charset): Ok
character_set_connection=utf8, collation_connection=utf8_unicode_ci, character_set_results=utf8
Кодировка базы данных (check_mysql_db_charset): Ok
CHARSET=utf8, COLLATION=utf8_unicode_ci
НО! Выползла куча багов при работе со строковыми функциями. Похоже, где то я не до правил) Я заглянул в базу и увидел в кодировках полный бардак:
character_set_client utf8mb4
character_set_connection utf8mb4
character_set_database latin1
character_set_results utf8mb4
character_set_server latin1
character_set_system utf8
collation_connection utf8mb4_unicode_ci
collation_database latin1_swedish_ci
collation_server latin1_swedish_ci
Подскажите, как лучше всего исправить и привести базу и сайт к единой кодировке (UTF8utf8_unicode_ci наверно????) и самое главное что бы базу не загубить)

7 сентября 2020
Как исправить ошибку на платформе 1С битрикс :
Ошибка! Кодировки таблиц имеют ошибки, общее число ошибок: , из них автоматически могут быть исправлены: 0. А также ошибку отсутствия русского языка в highload-блоках

Структура базы данных
Замечание. Не проверено из-за ошибок кодировки таблиц
Показываю на примере хостинга reg.ru.
Нажимаем на знак вопроса, справа от текста ошибки, и смотрим журнал проверки системы:
……………………………………………………………………………..
Кодировка поля «UF_FULL_DESCRIPTION» таблицы «b_emarketcolor» (latin1) отличается от кодировки базы (utf8)
Кодировка поля «UF_XML_ID» таблицы «b_emarketcolor» (latin1) отличается от кодировки базы (utf8)
Кодировка поля «UF_LINK» таблицы «b_emarketcolor» (latin1) отличается от кодировки базы (utf8)
Кодировка таблицы «b_emarketcomments» (latin1) отличается от кодировки базы (utf8)
…………………………………………..
Заходим в панель управления хостинга ispmanager, выбираем базу, нажимаем перейти.

Заходим в панель управления phpMyAdmin, выбираем базу, находим нужную таблицу с неправильной кодировкой.

Нажимаем кнопку структура и исправляем. Нажимаем кнопку сохранить справа.

Входим в меню Операции сверху.

Также изменяем на нужную кодировку. Нажимаем на кнопку вперед справа.
Таким же образом поправляется ошибка в highload-блоках при отсутствии русского языка. Вместо него видим только знаки вопроса ???????.
Возврат к списку
- 1. Проверка кодировки
- 2. Исправление кодировки для template1
В процессе настройки сервера для сайта, пришлось столкнуться с некоторыми проблемами. В частности с проблемой кодировки базы данных PostgreSQL. Дело в том, что при установке PostgreSQL, шаблоны баз данных создавались с кодировкой LATIN1, а сайт работает на Django, с использованием кодировки UTF8. В результате, при попытке вставки данных выпадала следующая ошибка:
ERROR: encoding UTF8 does not match locale en_US Detail: The chosen LC_CTYPE setting requires encoding LATIN1.Поискав информацию, удалось найти несколько решений, среди которых было решение, которое позволяет пересоздать шаблон базы данных с кодировкой UTF8. Но пройдёмся внимательно по симптомам задачи.
Проверка кодировки
Для проверки кодировки, применяемой на сервере и в базе данных, необходимо выполнить следующие команды.
Заходим в режим работы с PoctgreSQL:
sudo -u postgres psqlpsql — это утилита для работы с базами данных, а postgres — это супер пользователь PostgreSQL.
И выполняем следующие команды:
postgres=# SHOW SERVER_ENCODING; server_encoding ----------------- LATIN1 (1 row) postgres=# l List of databases Name | Owner | Encoding | Collate | Ctype | Access privileges -----------+----------+----------+---------+-------+----------------------- postgres | postgres | LATIN1 | en_US | en_US | template0 | postgres | LATIN1 | en_US | en_US | =c/postgres + | | | | | postgres=CTc/postgres template1 | postgres | LATIN1 | en_US | en_US | =c/postgres + | | | | | postgres=CTc/postgres (3 rows)В выводе будет показана кодировка LATIN1, как для сервера, так и для баз данных.
Исправление кодировки для template1
А теперь исправим кодировку template1, который используется для создания баз данных.
postgres=# UPDATE pg_database SET datistemplate = FALSE WHERE datname = 'template1'; postgres=# DROP DATABASE Template1; postgres=# CREATE DATABASE template1 WITH owner=postgres ENCODING = 'UTF-8' lc_collate = 'en_US.utf8' lc_ctype = 'en_US.utf8' template template0; postgres=# UPDATE pg_database SET datistemplate = TRUE WHERE datname = 'template1';В данном случае сначала мы указываем, что template1 не является шаблоном для баз данных. Удаляем данный шаблон. Потом создаём новый шаблон с кодировкой UTF8 и устанавливаем данную базу данных в качестве шаблона для новых баз данных. Дальше новые базы данных будут создаваться с кодировкой UTF8.
И проверим, в какой кодировке у нас находиться шаблон template1, сам сервер, кстати, будет по-прежнему в кодировке LATIN1
postgres=# l List of databases Name | Owner | Encoding | Collate | Ctype | Access privileges -----------+----------+----------+------------+------------+----------------------- postgres | postgres | LATIN1 | en_US | en_US | template0 | postgres | LATIN1 | en_US | en_US | =c/postgres + | | | | | postgres=CTc/postgres template1 | postgres | UTF8 | en_US.utf8 | en_US.utf8 | (3 rows)
![]() Официальный сертифицированный
Официальный сертифицированный
хостинг для продуктов 1С Битрикс
Битрикс-стандарт INFO Оптимизированные тарифы для быстрой работы корпоративных и информационных сайтов на 1С Битрикс.
14.02.2020
При тестировании конфигурации в 1С Битрикс может возникать ошибка:
Ошибка! Сравнение для базы (utf8_general_ci) отличается от сравнения для соединения (utf8_unicode_ci).
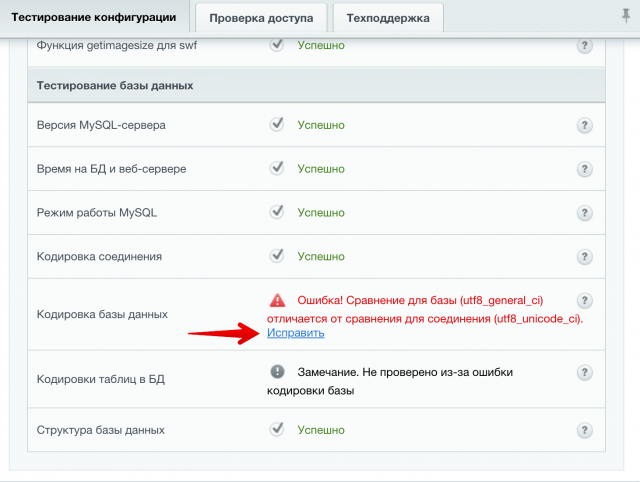
Данная ошибка не является критично, но рекомендуется исправить ее. В системе есть возможность автоматического исправления. Нажмите на ссылку «Исправить» и продолжите операцию.
После автоматического исправления снова запустите тестирование конфигурации. Ошибка должна исчезнуть.
Обратите внимание:
Ошибки связанные с кодировкой таблиц и структуры базы данных должны исправляться ПОСЛЕ исправления текущей, в противном случае база данных может повредиться. Строго следуйте порядку исправления ошибок по списку.
Концепция и все материалы с сайта btrxboost.com включающие в себя текстовую, графическую, видео, аудио и маркетинговую информацию, защищены российским и международным законодательством. В соответствии с соглашением об охране авторских прав и интеллектуальной собственности (ст. №1259, №1260, гл. 70 “Авторское право” ГК РФ от 18.12.2006 № 230-ФЗ) и согласно сертификату собственности авторских прав на информационные материалы RID 07N-4M-48 от 12.08.2012, а также сертификата DMCA id: f25cb914-aba8-4988-a116-13afb399bba2 от 21.06.2019.
В случае нарушений данных правил, применяются следующие меры: подача официального заявления в судебные органы в т.ч. с эскалацией запроса хостинг-провайдеру на котором расположен сайт-нарушитель, а также подача запроса на исключение сайта-нарушителя из поисковых систем согласно “Online Copyright Infringement Liability Limitation Act” по ч. II, раздел 512 к закону об авторском праве по DMCA.
Mysql поддерживает много кодировок и это нередко является головной болью для программистов. Самая частая проблема — кракозяблы вместо русского текста. Это происходит из за того, что текст либо лежит на сервере, либо отдается клиенту в неверной кодировке. Последнее(а иногда и первое) решается проще всего. Устанавливаем кодировку соединения (в utf8 в примере) сразу после установления соединения
|
mysql_set_charset(‘utf8’); // или mysql_query(‘SET NAMES «utf8″‘); |
Хуже, когда скрипт отдает в базу, данные в верной кодировке, а в ответ получаем кракозяблы или вопросики. Или когда часть таблиц в верной кодировке, часть нет.. В таких случаях придется разбираться детально.
|
mysql_query(«SHOW VARIABLES LIKE ‘char%’» ); /* character_set_client: latin1 character_set_connection: latin1 character_set_database: utf8 character_set_filesystem: binary character_set_results: latin1 character_set_server: cp1251 character_set_system: utf8 character_sets_dir: usrlocalmysql-5.1sharecharsets */ |
Этот запрос обязательно проверять в самом скрипте, а не в phpmyadmin, где могут быть установлены другие параметры
character_set_client— кодировка, в которой данные будут поступать от клиентаcharacter_set_connection— по умолчанию для всего, что в рамках соединения не имеет кодировкиcharacter_set_database— кодировка по умолчанию для базcharacter_set_filesystem— кодировка для работы с файловой системой (LOAD DATA INFILE, SELECT … INTO OUTFILE, и т.д.)character_set_results— кодировка, в которой будет выбран результатcharacter_set_server— кодировка, в которой работает серверcharacter_set_system— идентификаторы MySQL, всегда UTF8character_sets_dir— папка с кодировками
По умолчанию после установки mysql сервер, который устанавливается ленивым хостеромадмином имеет кодировку latin1. Соответственно указанные выше глобальные переменные будут в latin1. Базы соответственно по умолчанию и таблицы так же. И именно на это стоит обратить в самом начале обратить внимание, чтобы проблемы не всплывали позднее.
В идеальном варианте, нам следуетпривести все отмеченные цветом кодировки к единому значению. Тогда мы просто будем избавлены от мелких ошибок с кодировкой. Фактически, если мы работаем с хостингом, то на (3) и (6) мы повлиять не сможем. Но и это не страшно если настроены остальные три параметра. Mysql умет перекодировать на лету если правильно настроена кодировка соединения.
Ну и наконец, основной вопрос, что делать если одна из mysql таблиц(или несколько) в неверной кодировке и на сайте видны кракозяблывопросики?
1. Выяснить кодировку таблицы.
|
mysql > SHOW CREATE TABLE `files` ————————————————————————— CREATE TABLE `files` ( `id` int(10) unsigned NOT NULL AUTO_INCREMENT, `iNode` int(10) unsigned NOT NULL, `pid` int(10) unsigned NOT NULL, `sName` varchar(128) CHARACTER SET latin1 COLLATE latin1_general_ci NOT NULL, `sTitle` varchar(128) CHARACTER SET utf8 COLLATE utf8_general_ci NOT NULL, PRIMARY KEY (`id`), KEY `iNode` (`iNode`) ) ENGINE=MyISAM DEFAULT CHARSET=utf8 |
В этой таблице поле sName в кодировке latin1, если у нас соединение в другой кодировке, то мы увидим кракозябры.
2. Поэтому дальше проверим кодировку соединения, sql запросом SHOW VARIABLES LIKE ‘character_set_client’. Замечу, что php функция mysqli_client_encoding(), нам не подойдет, так как она отображает кодировку только на момент соединения.
3. Если кодировка соединения не совпала с кодировкой одного из полей таблицы, то 2 очевидных варианта.
Если у нас все таблицы в одной кодировке, то проще поменять кодировку соединения .
А как исправить неверную кодировку поля таблицы?
Для этого выполним 2 запроса
|
ALTER TABLE files CHANGE sName sName BLOB; ALTER TABLE files CHANGE sName sName VARCHAR(128) CHARACTER SET utf8; |
Нельзя обойтись только вторым запросом. Важно выполнить оба. Первый преобразовывает данные в двоичные, второй запрос, преобразовывает данные в строковые сменив кодировку.. Т.е. по сути мы не измениили двоичные данные, мы изменили правило формирования символов. Если бы мы попробовали обойтись только вторым запросом, то получили бы ошибочный набор.
Развернут apache и MySQL на Ubuntu 14.04LTS.
Вывод SHOW VARIABLES LIKE'character%'
Variable_name — Value
character_set_client — utf8
character_set_connection — utf8
character_set_database — utf8
character_set_filesystem — binary
character_set_results — utf8
character_set_server — utf8
character_set_system — utf8
character_sets_dir — /usr/share/mysql/charsets/
Вывод SHOW VARIABLES LIKE 'collation%';
Variable_name — Value
collation_connection — utf8_general_ci
collation_database — utf8_general_ci
collation_server — utf8_general_ci
php подключение к базе и вывод кодировки:
<?php
header('Content-Type: text/html; charset=utf-8');
require_once ('../config.php');
// Create connection
$conn = new mysqli(DB_URL, DB_USER, DB_PASS, DB_NAME);
printf("Изначальная кодировка: %sn", $conn->character_set_name());
mysqli_query($conn, "SET NAMES 'UTF-8'");
printf("А теперь: %sn", $conn->character_set_name());
$conn->set_charset("utf8");
// Check connection
if ($conn->connect_error) {
die("Connection failed: " . $conn->connect_error);
}
Вывод браузера
Изначальная кодировка: latin1 А теперь: latin1
Думаю, это главная причина проблемы, связанной с незаписывающимися кириллическими данными в БД из формы. Числа пишутся, кириллица — нет.
09.11.2021
После установки Битрикса на новый сервер возникла проблема, при «самопроверке» CMS, сообщение:
Ошибка! Кодировка соединения с базой данных должна быть utf8, текущее значение: utf8mb3

Сам Битрикс рекомендовал:

но в конфигурационных файлах все был прописано верно.
Проверка Битрикса выполняется через Настройки — Инструменты — Проверка системы (/bitrix/admin/site_checker.php)
.
В итоге пришлось решать вопрос исправлением файла bitrix/modules/main/classes/general/site_checker.php, в блоке ниже, заменил
utf8 на utf8mb3 и
utf8_unicode_ci на utf8mb3_unicode_ci
if (defined('BX_UTF') && BX_UTF === true)
{
if ($character_set_connection != 'utf8mb3')
$strError = GetMessage("SC_CONNECTION_CHARSET_WRONG", array('#VAL#' => 'utf8', '#VAL1#' => $character_set_connection));
elseif ($collation_connection != 'utf8mb3_unicode_ci')
$strError = GetMessage("SC_CONNECTION_COLLATION_WRONG_UTF", array('#VAL#' => $collation_connection));
}
Ошибка! Сравнение для базы (utf8_general_ci) отличается от сравнения для соединения (utf8_unicode_ci)
If I am sending utf-8 data to a mysql db which has a charset of utf-8 but a collation of latin1 would that be a problem? and why?
what does the collation do in this case?
I am getting mangled up data when I extract it from the db, will a collation change fix that?
Update
The mangled data in the DB is for example like this:
Töst
It should be like:
Täst
correct?
asked Dec 17, 2010 at 15:28
mahatmanichmahatmanich
10.6k5 gold badges59 silver badges81 bronze badges
About your error: make sure you send SET NAMES utf8 to your SQL server before INSERTing the data.
answered Dec 17, 2010 at 15:47
PellePelle
6,3804 gold badges33 silver badges50 bronze badges
1
It wouldn’t be a problem, per-se. The collation controls things like sort order & how comparisons are accomplished.
It is likely that the mangled data is being caused by something else.
answered Dec 17, 2010 at 15:37
ClarusClarus
2,24116 silver badges27 bronze badges
Collation relates to how different characters will be compared. This could cause issues if you are comparing utf-8 data with a latin1 collation since you may get different results than what you expect. Changing the collation will not stop the data from being mangled.
answered Dec 17, 2010 at 15:38
![]()
JimJim
22.2k6 gold badges52 silver badges80 bronze badges
If I am sending utf-8 data to a mysql db which has a charset of utf-8 but a collation of latin1 would that be a problem? and why?
what does the collation do in this case?
I am getting mangled up data when I extract it from the db, will a collation change fix that?
Update
The mangled data in the DB is for example like this:
Töst
It should be like:
Täst
correct?
asked Dec 17, 2010 at 15:28
mahatmanichmahatmanich
10.6k5 gold badges59 silver badges81 bronze badges
About your error: make sure you send SET NAMES utf8 to your SQL server before INSERTing the data.
answered Dec 17, 2010 at 15:47
PellePelle
6,3804 gold badges33 silver badges50 bronze badges
1
It wouldn’t be a problem, per-se. The collation controls things like sort order & how comparisons are accomplished.
It is likely that the mangled data is being caused by something else.
answered Dec 17, 2010 at 15:37
ClarusClarus
2,24116 silver badges27 bronze badges
Collation relates to how different characters will be compared. This could cause issues if you are comparing utf-8 data with a latin1 collation since you may get different results than what you expect. Changing the collation will not stop the data from being mangled.
answered Dec 17, 2010 at 15:38
![]()
JimJim
22.2k6 gold badges52 silver badges80 bronze badges
Здравствуйте, уважаемые читатели блога KtoNaNovenkogo.ru. Сегодня мы поговорим с вами про то, откуда берутся кракозябры на сайте и в программах, какие кодировки текста существуют и какие из них следует использовать. Подробно рассмотрим историю их развития, начиная от базовой ASCII, а также ее расширенных версий CP866, KOI8-R, Windows 1251 и заканчивая современными кодировками консорциума Юникод UTF 16 и 8.

Кому-то эти сведения могут показаться излишними, но знали бы вы, сколько мне приходит вопросов именно касаемо вылезших кракозябров (не читаемого набора символов). Теперь у меня будет возможность отсылать всех к тексту этой статьи и самостоятельно отыскивать свои косяки. Ну что же, приготовьтесь впитывать информацию и постарайтесь следить за ходом повествования.
ASCII — базовая кодировка текста для латиницы
Развитие кодировок текстов происходило одновременно с формированием отрасли IT, и они за это время успели претерпеть достаточно много изменений. Исторически все начиналось с довольно-таки не благозвучной в русском произношении EBCDIC, которая позволяла кодировать буквы латинского алфавита, арабские цифры и знаки пунктуации с управляющими символами.
Но все же отправной точкой для развития современных кодировок текстов стоит считать знаменитую ASCII (American Standard Code for Information Interchange, которая по-русски обычно произносится как «аски»). Она описывает первые 128 символов из наиболее часто используемых англоязычными пользователями — латинские буквы, арабские цифры и знаки препинания.
Еще в эти 128 знаков, описанных в ASCII, попадали некоторые служебные символы навроде скобок, решеток, звездочек и т.п. Собственно, вы сами можете увидеть их:
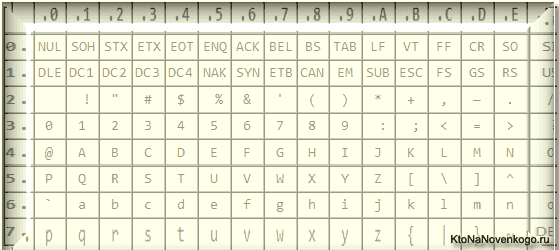
Именно эти 128 символов из первоначального вариант ASCII стали стандартом, и в любой другой кодировке вы их обязательно встретите и стоять они будут именно в таком порядке.
Но дело в том, что с помощью одного байта информации можно закодировать не 128, а целых 256 различных значений (двойка в степени восемь равняется 256), поэтому вслед за базовой версией Аски появился целый ряд расширенных кодировок ASCII, в которых можно было кроме 128 основных знаков закодировать еще и символы национальной кодировки (например, русской).
Тут, наверное, стоит еще немного сказать про системы счисления, которые используются при описании. Во-первых, как вы все знаете, компьютер работает только с числами в двоичной системе, а именно с нулями и единицами («булева алгебра», если кто проходил в институте или в школе). Один байт состоит из восьми бит, каждый из которых представляет из себя двойку в степени, начиная с нулевой, и до двойки в седьмой:
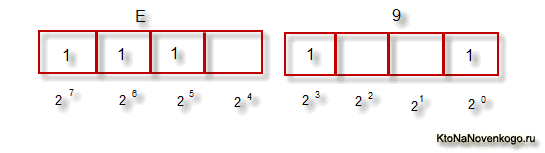
Не трудно понять, что всех возможных комбинаций нулей и единиц в такой конструкции может быть только 256. Переводить число из двоичной системы в десятичную довольно просто. Нужно просто сложить все степени двойки, над которыми стоят единички.
В нашем примере это получается 1 (2 в степени ноль) плюс 8 (два в степени 3), плюс 32 (двойка в пятой степени), плюс 64 (в шестой), плюс 128 (в седьмой). Итого получает 233 в десятичной системе счисления. Как видите, все очень просто.
Но если вы присмотритесь к таблице с символами ASCII, то увидите, что они представлены в шестнадцатеричной кодировке. Например, «звездочка» соответствует в Аски шестнадцатеричному числу 2A. Наверное, вам известно, что в шестнадцатеричной системе счисления используются кроме арабских цифр еще и латинские буквы от A (означает десять) до F (означает пятнадцать).
Ну так вот, для перевода двоичного числа в шестнадцатеричное прибегают к следующему простому и наглядному способу. Каждый байт информации разбивают на две части по четыре бита, как показано на приведенном выше скриншоте. Т.о. в каждой половинке байта двоичным кодом можно закодировать только шестнадцать значений (два в четвертой степени), что можно легко представить шестнадцатеричным числом.
Причем, в левой половине байта считать степени нужно будет опять начиная с нулевой, а не так, как показано на скриншоте. В результате, путем нехитрых вычислений, мы получим, что на скриншоте закодировано число E9. Надеюсь, что ход моих рассуждений и разгадка данного ребуса вам оказались понятны. Ну, а теперь продолжим, собственно, говорить про кодировки текста.
Расширенные версии Аски — кодировки CP866 и KOI8-R с псевдографикой
Итак, мы с вами начали говорить про ASCII, которая являлась как бы отправной точкой для развития всех современных кодировок (Windows 1251, юникод, UTF 8).
Изначально в нее было заложено только 128 знаков латинского алфавита, арабских цифр и еще чего-то там, но в расширенной версии появилась возможность использовать все 256 значений, которые можно закодировать в одном байте информации. Т.е. появилась возможность добавить в Аски символы букв своего языка.
Тут нужно будет еще раз отвлечься, чтобы пояснить — зачем вообще нужны кодировки текстов и почему это так важно. Символы на экране вашего компьютера формируются на основе двух вещей — наборов векторных форм (представлений) всевозможных знаков (они находятся в файлах со шрифтами, которые установлены на вашем компьютере) и кода, который позволяет выдернуть из этого набора векторных форм (файла шрифта) именно тот символ, который нужно будет вставить в нужное место.
Понятно, что за сами векторные формы отвечают шрифты, а вот за кодирование отвечает операционная система и используемые в ней программы. Т.е. любой текст на вашем компьютере будет представлять собой набор байтов, в каждом из которых закодирован один единственный символ этого самого текста.
Программа, отображающая этот текст на экране (текстовый редактор, браузер и т.п.), при разборе кода считывает кодировку очередного знака и ищет соответствующую ему векторную форму в нужном файле шрифта, который подключен для отображения данного текстового документа. Все просто и банально.
Значит, чтобы закодировать любой нужный нам символ (например, из национального алфавита), должно быть выполнено два условия — векторная форма этого знака должна быть в используемом шрифте и этот символ можно было бы закодировать в расширенных кодировках ASCII в один байт. Поэтому таких вариантов существует целая куча. Только лишь для кодирования символов русского языка существует несколько разновидностей расширенной Аски.
Например, изначально появилась CP866, в которой была возможность использовать символы русского алфавита и она являлась расширенной версией ASCII.
Т.е. ее верхняя часть полностью совпадала с базовой версией Аски (128 символов латиницы, цифр и еще всякой лабуды), которая представлена на приведенном чуть выше скриншоте, а вот уже нижняя часть таблицы с кодировкой CP866 имела указанный на скриншоте чуть ниже вид и позволяла закодировать еще 128 знаков (русские буквы и всякая там псевдографика):

Видите, в правом столбце цифры начинаются с 8, т.к. числа с 0 до 7 относятся к базовой части ASCII (см. первый скриншот). Т.о. русская буква «М» в CP866 будет иметь код 9С (она находится на пересечении соответствующих строки с 9 и столбца с цифрой С в шестнадцатеричной системе счисления), который можно записать в одном байте информации, и при наличии подходящего шрифта с русскими символами эта буква без проблем отобразится в тексте.
Откуда взялось такое количество псевдографики в CP866? Тут все дело в том, что эта кодировка для русского текста разрабатывалась еще в те мохнатые года, когда не было такого распространения графических операционных систем как сейчас. А в Досе, и подобных ей текстовых операционках, псевдографика позволяла хоть как-то разнообразить оформление текстов и поэтому ею изобилует CP866 и все другие ее ровесницы из разряда расширенных версий Аски.
CP866 распространяла компания IBM, но кроме этого для символов русского языка были разработаны еще ряд кодировок, например, к этому же типу (расширенных ASCII) можно отнести KOI8-R:

Принцип ее работы остался тот же самый, что и у описанной чуть ранее CP866 — каждый символ текста кодируется одним единственным байтом. На скриншоте показана вторая половина таблицы KOI8-R, т.к. первая половина полностью соответствует базовой Аски, которая показана на первом скриншоте в этой статье.
Среди особенностей кодировки KOI8-R можно отметить то, что русские буквы в ее таблице идут не в алфавитном порядке, как это, например, сделали в CP866.
Если посмотрите на самый первый скриншот (базовой части, которая входит во все расширенные кодировки), то заметите, что в KOI8-R русские буквы расположены в тех же ячейках таблицы, что и созвучные им буквы латинского алфавита из первой части таблицы. Это было сделано для удобства перехода с русских символов на латинские путем отбрасывания всего одного бита (два в седьмой степени или 128).
Windows 1251 — современная версия ASCII и почему вылезают кракозябры
Дальнейшее развитие кодировок текста было связано с тем, что набирали популярность графические операционные системы и необходимость использования псевдографики в них со временем пропала. В результате возникла целая группа, которая по своей сути по-прежнему являлись расширенными версиями Аски (один символ текста кодируется всего одним байтом информации), но уже без использования символов псевдографики.
Они относились к так называемым ANSI кодировкам, которые были разработаны американским институтом стандартизации. В просторечии еще использовалось название кириллица для варианта с поддержкой русского языка. Примером такой может служить Windows 1251.
Она выгодно отличалась от используемых ранее CP866 и KOI8-R тем, что место символов псевдографики в ней заняли недостающие символы русской типографики (окромя знака ударения), а также символы, используемые в близких к русскому славянских языках (украинскому, белорусскому и т.д.):
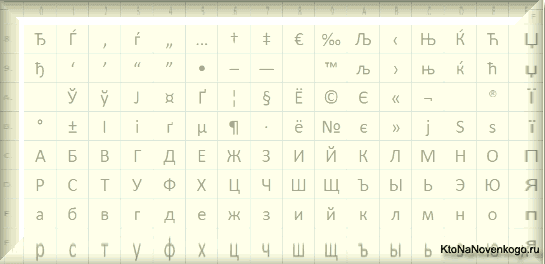
Из-за такого обилия кодировок русского языка, у производителей шрифтов и производителей программного обеспечения постоянно возникала головная боль, а у нас с вам, уважаемые читатели, зачастую вылезали те самые пресловутые кракозябры, когда происходила путаница с используемой в тексте версией.
Очень часто они вылезали при отправке и получении сообщений по электронной почте, что повлекло за собой создание очень сложных перекодировочных таблиц, которые, собственно, решить эту проблему в корне не смогли, и зачастую пользователи для переписки использовали транслит латинских букв, чтобы избежать пресловутых кракозябров при использовании русских кодировок подобных CP866, KOI8-R или Windows 1251.
По сути, кракозябры, вылазящие вместо русского текста, были результатом некорректного использования кодировки данного языка, которая не соответствовала той, в которой было закодировано текстовое сообщение изначально.
Допустим, если символы, закодированные с помощью CP866, попробовать отобразить, используя кодовую таблицу Windows 1251, то эти самые кракозябры (бессмысленный набор знаков) и вылезут, полностью заменив собой текст сообщения.

Аналогичная ситуация очень часто возникает при создании сайтов на WordPress и Joomla, форумов или блогов, когда текст с русскими символами по ошибке сохраняется не в той кодировке, которая используется на сайте по умолчанию, или же не в том текстовом редакторе, который добавляет в код отсебятину не видимую невооруженным глазом.
В конце концов такая ситуация с множеством кодировок и постоянно вылезающими кракозябрами многим надоела, появились предпосылки к созданию новой универсальной вариации, которая бы заменила собой все существующие и решила бы, наконец, на корню проблему с появлением не читаемых текстов. Кроме этого существовала проблема языков подобных китайскому, где символов языка было гораздо больше, чем 256.
Юникод (Unicode) — универсальные кодировки UTF 8, 16 и 32
Эти тысячи знаков языковой группы юго-восточной Азии никак невозможно было описать в одном байте информации, который выделялся для кодирования символов в расширенных версиях ASCII. В результате был создан консорциум под названием Юникод (Unicode — Unicode Consortium) при сотрудничестве многих лидеров IT индустрии (те, кто производит софт, кто кодирует железо, кто создает шрифты), которые были заинтересованы в появлении универсальной кодировки текста.
Первой вариацией, вышедшей под эгидой консорциума Юникод, была UTF 32. Цифра в названии кодировки означает количество бит, которое используется для кодирования одного символа. 32 бита составляют 4 байта информации, которые понадобятся для кодирования одного единственного знака в новой универсальной кодировке UTF.
В результате чего, один и тот же файл с текстом, закодированный в расширенной версии ASCII и в UTF-32, в последнем случае будет иметь размер (весить) в четыре раза больше. Это плохо, но зато теперь у нас появилась возможность закодировать с помощью ЮТФ число знаков, равное двум в тридцать второй степени (миллиарды символов, которые покроют любое реально необходимое значение с колоссальным запасом).
Но многим странам с языками европейской группы такое огромное количество знаков использовать в кодировке вовсе и не было необходимости, однако при задействовании UTF-32 они ни за что ни про что получали четырехкратное увеличение веса текстовых документов, а в результате и увеличение объема интернет трафика и объема хранимых данных. Это много, и такое расточительство себе никто не мог позволить.
В результате развития Юникода появилась UTF-16, которая получилась настолько удачной, что была принята по умолчанию как базовое пространство для всех символов, которые у нас используются. Она использует два байта для кодирования одного знака. Давайте посмотрим, как это дело выглядит.
В операционной системе Windows вы можете пройти по пути «Пуск» — «Программы» — «Стандартные» — «Служебные» — «Таблица символов». В результате откроется таблица с векторными формами всех установленных у вас в системе шрифтов. Если вы выберете в «Дополнительных параметрах» набор знаков Юникод, то сможете увидеть для каждого шрифта в отдельности весь ассортимент входящих в него символов.
Кстати, щелкнув по любому из них, вы сможете увидеть его двухбайтовый код в формате UTF-16, состоящий из четырех шестнадцатеричных цифр:
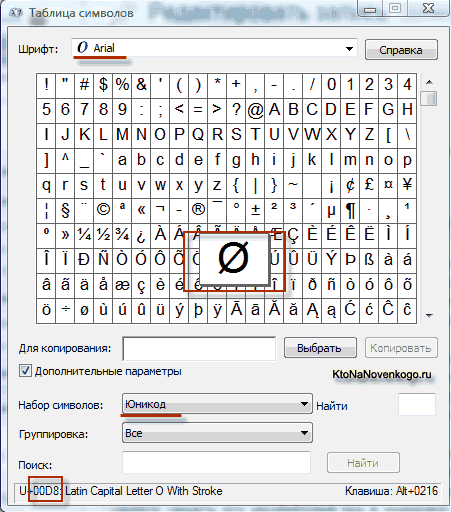
Сколько символов можно закодировать в UTF-16 с помощью 16 бит? 65 536 (два в степени шестнадцать), и именно это число было принято за базовое пространство в Юникоде. Помимо этого существуют способы закодировать с помощью нее и около двух миллионов знаков, но ограничились расширенным пространством в миллион символов текста.
Но даже эта удачная версия кодировки Юникода не принесла особого удовлетворения тем, кто писал, допустим, программы только на английском языке, ибо у них, после перехода от расширенной версии ASCII к UTF-16, вес документов увеличивался в два раза (один байт на один символ в Аски и два байта на тот же самый символ в ЮТФ-16).
Вот именно для удовлетворения всех и вся в консорциуме Unicode было решено придумать кодировку переменной длины. Ее назвали UTF-8. Несмотря на восьмерку в названии, она действительно имеет переменную длину, т.е. каждый символ текста может быть закодирован в последовательность длиной от одного до шести байт.
На практике же в UTF-8 используется только диапазон от одного до четырех байт, потому что за четырьмя байтами кода ничего уже даже теоретически не возможно представить. Все латинские знаки в ней кодируются в один байт, так же как и в старой доброй ASCII.
Что примечательно, в случае кодирования только латиницы, даже те программы, которые не понимают Юникод, все равно прочитают то, что закодировано в ЮТФ-8. Т.е. базовая часть Аски просто перешла в это детище консорциума Unicode.
Кириллические же знаки в UTF-8 кодируются в два байта, а, например, грузинские — в три байта. Консорциум Юникод после создания UTF 16 и 8 решил основную проблему — теперь у нас в шрифтах существует единое кодовое пространство. И теперь их производителям остается только исходя из своих сил и возможностей заполнять его векторными формами символов текста. Сейчас в наборы даже эмодзи смайлики добавляют.
В приведенной чуть выше «Таблице символов» видно, что разные шрифты поддерживают разное количество знаков. Некоторые насыщенные символами Юникода шрифты могут весить очень прилично. Но зато теперь они отличаются не тем, что они созданы для разных кодировок, а тем, что производитель шрифта заполнил или не заполнил единое кодовое пространство теми или иными векторными формами до конца.
Кракозябры вместо русских букв — как исправить
Давайте теперь посмотрим, как появляются вместо текста кракозябры или, другими словами, как выбирается правильная кодировка для русского текста. Собственно, она задается в той программе, в которой вы создаете или редактируете этот самый текст, или же код с использованием текстовых фрагментов.
Для редактирования и создания текстовых файлов лично я использую очень хороший, на мой взгляд, Html и PHP редактор Notepad++. Впрочем, он может подсвечивать синтаксис еще доброй сотни языков программирования и разметки, а также имеет возможность расширения с помощью плагинов. Читайте подробный обзор этой замечательной программы по приведенной ссылке.
В верхнем меню Notepad++ есть пункт «Кодировки», где у вас будет возможность преобразовать уже имеющийся вариант в тот, который используется на вашем сайте по умолчанию:
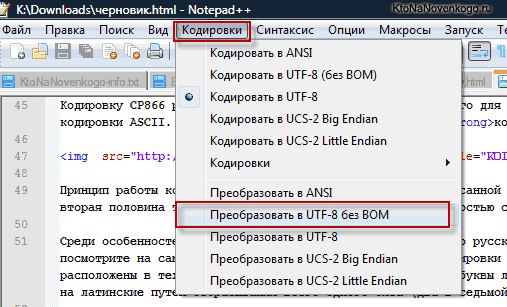
В случае сайта на Joomla 1.5 и выше, а также в случае блога на WordPress следует во избежании появления кракозябров выбирать вариант UTF 8 без BOM. А что такое приставка BOM?
Дело в том, что когда разрабатывали кодировку ЮТФ-16, зачем-то решили прикрутить к ней такую вещь, как возможность записывать код символа, как в прямой последовательности (например, 0A15), так и в обратной (150A). А для того, чтобы программы понимали, в какой именно последовательности читать коды, и был придуман BOM (Byte Order Mark или, другими словами, сигнатура), которая выражалась в добавлении трех дополнительных байтов в самое начало документов.
В кодировке UTF-8 никаких BOM предусмотрено в консорциуме Юникод не было и поэтому добавление сигнатуры (этих самых пресловутых дополнительных трех байтов в начало документа) некоторым программам просто-напросто мешает читать код. Поэтому мы всегда при сохранении файлов в ЮТФ должны выбирать вариант без BOM (без сигнатуры). Таким образом, вы заранее обезопасите себя от вылезания кракозябров.
Что примечательно, некоторые программы в Windows не умеют этого делать (не умеют сохранять текст в ЮТФ-8 без BOM), например, все тот же пресловутый Блокнот Windows. Он сохраняет документ в UTF-8, но все равно добавляет в его начало сигнатуру (три дополнительных байта). Причем эти байты будут всегда одни и те же — читать код в прямой последовательности. Но на серверах из-за этой мелочи может возникнуть проблема — вылезут кракозябры.
Поэтому ни в коем случае не пользуйтесь обычным блокнотом Windows для редактирования документов вашего сайта, если не хотите появления кракозябров. Лучшим и наиболее простым вариантом я считаю уже упомянутый редактор Notepad++, который практически не имеет недостатков и состоит из одних лишь достоинств.
В Notepad ++ при выборе кодировки у вас будет возможность преобразовать текст в кодировку UCS-2, которая по своей сути очень близка к стандарту Юникод. Также в Нотепаде можно будет закодировать текст в ANSI, т.е. применительно к русскому языку это будет уже описанная нами чуть выше Windows 1251. Откуда берется эта информация?
Она прописана в реестре вашей операционной системы Windows — какую кодировку выбирать в случае ANSI, какую выбирать в случае OEM (для русского языка это будет CP866). Если вы установите на своем компьютере другой язык по умолчанию, то и эти кодировки будут заменены на аналогичные из разряда ANSI или OEM для того самого языка.
После того, как вы в Notepad++ сохраните документ в нужной вам кодировке или же откроете документ с сайта для редактирования, то в правом нижнем углу редактора сможете увидеть ее название:
![]()
Чтобы избежать кракозябров, кроме описанных выше действий, будет полезным прописать в его шапке исходного кода всех страниц сайта информацию об этой самой кодировке, чтобы на сервере или локальном хосте не возникло путаницы.
Вообще, во всех языках гипертекстовой разметки кроме Html используется специальное объявление xml, в котором указывается кодировка текста.
<?xml version="1.0" encoding="windows-1251"?>
Прежде, чем начать разбирать код, браузер узнает, какая версия используется и как именно нужно интерпретировать коды символов этого языка. Но что примечательно, в случае, если вы сохраняете документ в принятом по умолчанию юникоде, то это объявление xml можно будет опустить (кодировка будет считаться UTF-8, если нет BOM или ЮТФ-16, если BOM есть).
В случае же документа языка Html для указания кодировки используется элемент Meta, который прописывается между открывающим и закрывающим тегом Head:
<head> ... <meta charset="utf-8"> ... </head>
Эта запись довольно сильно отличается от принятой в стандарте в Html 4.01, но полностью соответствует новому внедряемому потихоньку стандарту Html 5, и она будет стопроцентно правильно понята любыми используемыми на текущий момент браузерами.
По идее, элемент Meta с указание кодировки Html документа лучше будет ставить как можно выше в шапке документа, чтобы на момент встречи в тексте первого знака не из базовой ANSI (которые правильно прочитаются всегда и в любой вариации) браузер уже должен иметь информацию о том, как интерпретировать коды этих символов.
