8 сентября, 2020 11:28 дп
4 715 views
| Комментариев нет
Centos, Debian, LAMP Stack, Ubuntu
Эта серия мануалов поможет вам предотвратить или устранить самые распространенные ошибки, которые возникают при работе с веб-сервером Apache.
Каждый последующий мануал в этой серии включает описание распространенных ошибок Apache, связанных с конфигурацией, сетью, файловой системой или привилегиями. Мы начнем с обзора команд и логов, которые вы можете использовать для устранения неполадок Apache. В последующих руководствах мы подробно рассмотрим конкретные ошибки.
Есть три основные команды и несколько общих логов, которые вы можете использовать, чтобы начать устранение ошибок Apache. По сути здесь вы найдете стандартную стратегию поиска ошибок и их причин: обычно эти команды используются в указанном здесь порядке, после чего можно изучить логи на предмет конкретных диагностических данных.
Команды, которые необходимы для устранения неполадок Apache в большинстве дистрибутивов Linux:
- systemctl – используется для управления сервисами Linux и взаимодействия с ними через менеджер сервисов systemd.
- journalctl – используется для запроса и просмотра логов, созданных systemd.
- apachectl – при устранении неполадок эта команда используется для проверки конфигурации Apache.
Далее мы подробно опишем эти команды, способы их использования и расположение логов Apache, в которых можно найти дополнительную информацию об ошибках.
Примечание: В системах Debian и Ubuntu сервис и процесс Apache называется apache2, а в CentOS, Fedora и других системах RedHat – httpd. Имя сервиса и процесса – это единственное отличие команд запуска, остановки и проверки состояния Apache в разных системах. Логи journalctl также должны работать одинаково в любой системе Linux, которая использует systemd для управления Apache. При работе с этим мануалом вы должны использовать правильное имя сервиса в зависимости от вашего дистрибутива Linux.
Команды systemctl для Apache
Чтобы устранить распространенные ошибки Apache с помощью менеджера сервисов systemd, первым делом вам необходимо проверить состояние процессов Apache в вашей системе. Следующие команды systemctl помогут вам узнать больше о состоянии процессов Apache.
В Ubuntu и Debian используйте:
sudo systemctl status apache2.service -l --no-pager
Флаг -l отображает полный вывод без сокращения. Флаг –no-pager направляет вывод непосредственно на ваш терминал. Вы должны получить такой результат:
apache2.service - The Apache HTTP Server
Loaded: loaded (/lib/systemd/system/apache2.service; enabled; vendor preset: enabled)
Drop-In: /lib/systemd/system/apache2.service.d
└─apache2-systemd.conf
Active: active (running) since Mon 2020-07-13 14:43:35 UTC; 1 day 4h ago
Process: 929 ExecStart=/usr/sbin/apachectl start (code=exited, status=0/SUCCESS)
Main PID: 1346 (apache2)
Tasks: 55 (limit: 4702)
CGroup: /system.slice/apache2.service
├─1346 /usr/sbin/apache2 -k start
. . .
Чтобы изучить процесс веб-сервера в CentOS и Fedora, используйте:
sudo systemctl status httpd.service -l --no-pager
Вы получите такой результат:
httpd.service - The Apache HTTP Server
Loaded: loaded (/usr/lib/systemd/system/httpd.service; enabled; vendor preset: disabled)
Active: active (running) since Tue 2020-07-14 19:46:52 UTC; 3s ago
Docs: man:httpd.service(8)
Main PID: 21217 (httpd)
Status: "Started, listening on: port 80"
Tasks: 213 (limit: 2881)
Memory: 16.6M
CGroup: /system.slice/httpd.service
├─21217 /usr/sbin/httpd -DFOREGROUND
. . .
Jul 14 19:46:52 localhost.localdomain httpd[21217]: Server configured, listening on: port 80
Независимо от дистрибутива вы должны обратить внимание на строку Active в выводе. Если ваш сервер Apache не отображается как active (running), хотя он должен работать, возможно, произошла ошибка и прервала его работу. Как правило, при возникновении ошибок в выводе будет строка failed:
Active: failed (Result: exit-code) since Tue 2020-07-14 20:01:29 UTC; 1s ago
Если проблема заключается в процессе или конфигурации Apache, вы можете устранить ее с помощью команды journalctl.
Команды journalctl для Apache
Чтобы проверить логи systemd для Apache, вы можете использовать команду journalctl. Логи systemd для Apache обычно содержат данные о проблемах с запуском или управлением процессом Apache.
Эти логи отделены от логов запросов и ошибок Apache. Команда journalctl отображает логи systemd, которые описывают сам сервис Apache (от его запуска до завершения работы, включая все ошибки процесса, которые могут возникнуть на этом пути).
В системах Ubuntu и Debian для проверки логов используйте следующую команду:
sudo journalctl -u apache2.service --since today --no-pager
Флаг –since today ограничивает вывод команды записями лога, начиная с 00:00:00 текущего дня. Использование этой опции поможет ограничить объем записей лога, которые вам необходимо изучить для выявления ошибок. Вы должны получить следующий результат:
Jul 14 20:12:14 ubuntu2004 systemd[1]: Starting The Apache HTTP Server...
Jul 14 20:12:14 ubuntu2004 systemd[1]: Started The Apache HTTP Server.
Если вы используете систему на базе CentOS или Fedora, введите эту версию команды:
sudo journalctl -u httpd.service --since today --no-pager
Вы получите такой результат:
Jul 14 20:13:09 centos8 systemd[1]: Starting The Apache HTTP Server...
. . .
Jul 14 20:13:10 centos8 httpd[21591]: Server configured, listening on: port 80
В случае ошибки в выводе будет строка, приведенная ниже (имя хоста будет отличаться в зависимости от дистрибутива Linux):
Jul 14 20:13:37 yourhostname systemd[1]: Failed to start The Apache HTTP Server.
Если в ваших логах Apache есть подобные ошибки, то следующее, что нужно сделать для устранения возможных проблем – это исследовать конфигурации Apache с помощью инструмента командной строки apachectl.
Устранение неполадок с помощью apachectl
Большинство дистрибутивов Linux включают утилиту apachectl в установку Apache по умолчанию. apachectl – бесценный инструмент, помогающий обнаруживать и диагностировать проблемы конфигурации Apache.
Проверьте конфигурацию Apache с помощью команды apachectl configtest. Инструмент проанализирует ваши файлы Apache и обнаружит все ошибки или недостающие настройки перед попыткой запуска сервера.
Команда одинакова для дистрибутивов Ubuntu, Debian, CentOS и Fedora:
sudo apachectl configtest
Если конфигурация Apache не содержит ошибок, вы получите такой результат:
Syntax OK
В зависимости от вашего дистрибутива Linux в выводе могут быть и другие строки, но самая важная строка – это та, в которой говорится, что с синтаксисом все ок.
Если в вашей конфигурации Apache есть ошибка (например, директива ссылается на деактивированный модуль) или опечатка, apachectl обнаружит ее и попытается уведомить вас о проблеме.
Например, попытка использовать в директиве отключенный модуль Apache приведет к появлению следующих сообщений apachectl:
AH00526: Syntax error on line 232 of /etc/apache2/apache2.conf:
Invalid command 'SSLEngine', perhaps misspelled or defined by a module not included in the server configuration
Action 'configtest' failed.
The Apache error log may have more information.
В этом примере модуль ssl не включен, поэтому при проверке конфигурации директива SSLEngine выдает ошибку. Последняя строка также указывает, что в логе ошибок Apache может содержаться дополнительная информация, и это следующее место для поиска подробной отладочной информации.
Логи Apache
Логи Apache – очень полезный ресурс для устранения неполадок. Как правило, каждая ошибка, возникающая в браузере или другом HTTP-клиенте, создает соответствующую запись в логах Apache. Иногда Apache также выводит в свои логи ошибки, связанные с конфигурацией, встроенными модулями и другой отладочной информацией.
Чтобы проверить ошибки при устранении неполадок Apache на сервере Fedora, CentOS или RedHat, изучите файл /var/log/httpd/error_log.
Если вы устраняете неполадки в системе Debian или Ubuntu, проверьте /var/log/apache2/error.log с помощью инструмента tail или less. Например, чтобы просмотреть последние две строки лога ошибок с помощью tail, выполните следующую команду:
sudo tail -n 2 /var/log/apache2/error.log
Замените количество строк, которые вы хотите изучить. Укажите количество строк вместо числа 2 в команде.
В системе CentOS или Fedora файл журнала для проверки – /var/log/httpd/error_log.
Ниже мы приводим пример пример ошибки (ее текст не зависит от дистрибутива Linux):
[Wed Jul 15 01:34:12.093005 2020] [proxy:error] [pid 13949:tid 140150453516032] (13)Permission denied: AH00957: HTTP: attempt to connect to 127.0.0.1:9090 (127.0.0.1) failed
[Wed Jul 15 01:34:12.093078 2020] [proxy_http:error] [pid 13949:tid 140150453516032] [client 127.0.0.1:42480] AH01114: HTTP: failed to make connection to backend: 127.0.0.1
Эти две строки представляют собой отдельные сообщения об ошибках. Обе они ссылаются на модуль, вызвавший ошибку (proxy в первой строке, proxy_http во второй), и содержат код ошибки, индивидуальный для модуля. Первый, AH00957, указывает на то, что сервер Apache пытался подключиться к бэкенд-серверу (в данном случае к 127.0.0.1 по порту 9090) с помощью модуля proxy, но не смог этого сделать.
Вторая ошибка исходит из первой: AH01114 – это ошибка модуля proxy_http, которая также указывает на то, что Apache не смог подключиться к бэкенд-серверу для выполнения HTTP-запроса.
Эти строки мы привели просто для примера. Если вы диагностируете ошибки на своем сервере Apache, скорее всего, вы найдете совсем другие строки с ошибками в ваших логах. Независимо от дистрибутива Linux, строки ошибок в логах всегда содержат соответствующий модуль Apache и код ошибки, а также текстовое описание ошибки.
Как только вы поймете, что могло вызвать вызывать проблему на вашем сервере Apache, вы можете продолжить исследование и устранение неполадок. Код ошибки и текстовое описание особенно полезны, поскольку дают конкретные указания, которые можно использовать для сужения диапазона возможных причин возникновения ошибки.
Заключение
Устранение ошибок Apache может включать как диагностику ошибок сервиса, так и обнаружение неверно настроенных параметров модулей. В этом вводном руководстве по диагностике Apache мы посмотрели, как использовать ряд утилит, чтобы сузить круг возможных причин появления ошибок. Обычно эти утилиты нужно использовать в том же порядке, в каком они описаны тут (но вы всегда можете пропустить некоторые действия или начать сразу с изучения логов, если у вас есть общее представление о том, в чем может быть проблема).
Однако чаще всего полезно следовать общей схеме устранения неполадок и использовать эти инструменты в описанном порядке. Начните с systemctl, чтобы проверить состояние сервера Apache. Если вам нужна дополнительная информация, изучите логи systemd для Apache с помощью команды journalctl. Если после проверки journalctl проблема все еще не ясна, проверьте конфигурации Apache с помощью команды apachectl configtest. Для более глубокого изучения неполадок проверьте логи Apache, обычно они указывают на конкретную ошибку (предоставляя полезные для диагностики данные и коды ошибок).
Tags: Apache, apachectl, journalctl, systemctl
В этой статье вы узнаете, что вы можете делать, когда при загрузке сервера возникают общие проблемы. В статье описываются общие подходы, которые помогают исправить некоторые из наиболее распространенных проблем, которые могут возникнуть при загрузке Linux.
Понимание процедуры загрузки в Linux RHEL7/CentOS
Чтобы исправить проблемы с загрузкой, важно хорошо понимать процедуру загрузки. Если проблемы возникают во время загрузки, вы должны понимать, на какой стадии процедуры загрузки возникает проблема, чтобы можно было выбрать соответствующий инструмент для устранения проблемы.
Следующие шаги суммируют, как процедура загрузки происходит в Linux.
1. Выполнение POST: машина включена. Из системного ПО, которым может быть UEFI или классический BIOS, выполняется самотестирование при включении питания (POST) и аппаратное обеспечение, необходимое для запуска инициализации системы.
2. Выбор загрузочного устройства: В загрузочной прошивке UEFI или в основной загрузочной записи находится загрузочное устройство.
3. Загрузка загрузчика: с загрузочного устройства находится загрузчик. На Red Hat/CentOS это обычно GRUB 2.
4. Загрузка ядра: Загрузчик может представить пользователю меню загрузки или может быть настроен на автоматический запуск Linux по умолчанию. Для загрузки Linux ядро загружается вместе с initramfs. Initramfs содержит модули ядра для всего оборудования, которое требуется для загрузки, а также начальные сценарии, необходимые для перехода к следующему этапу загрузки. На RHEL 7/CentOS initramfs содержит полную операционную систему (которая может использоваться для устранения неполадок).
5. Запуск /sbin/init: Как только ядро загружено в память, загружается первый из всех процессов, но все еще из initramfs. Это процесс /sbin/init, который связан с systemd. Демон udev также загружается для дальнейшей инициализации оборудования. Все это все еще происходит из образа initramfs.
6. Обработка initrd.target: процесс systemd выполняет все юниты из initrd.target, который подготавливает минимальную операционную среду, в которой корневая файловая система на диске монтируется в каталог /sysroot. На данный момент загружено достаточно, чтобы перейти к установке системы, которая была записана на жесткий диск.
7. Переключение на корневую файловую систему: система переключается на корневую файловую систему, которая находится на диске, и в этот момент может также загрузить процесс systemd с диска.
8. Запуск цели по умолчанию (default target): Systemd ищет цель по умолчанию для выполнения и запускает все свои юниты. В этом процессе отображается экран входа в систему, и пользователь может проходить аутентификацию. Обратите внимание, что приглашение к входу в систему может быть запрошено до успешной загрузки всех файлов модуля systemd. Таким образом, просмотр приглашения на вход в систему не обязательно означает, что сервер еще полностью функционирует.
На каждом из перечисленных этапов могут возникнуть проблемы из-за неправильной настройки или других проблем. Таблица суммирует, где настроена определенная фаза и что вы можете сделать, чтобы устранить неполадки, если что-то пойдет не так.
| Фаза загрузки | Где настроено | Как попытаться починить |
| POST | Железо (F2, Esc, F10, или другая кнопка) | Замена железа |
| Выбор загрузочного устройства | BIOS/UEFI конфигурация или загрузочное устройство | Замена железа или использовать восстановление системы |
| Загрузка загрузчика (GRUB 2) | grub2-install и редактирует в /etc/defaults/grub | Приглашение GRUB для загрузки и изменения в /etc/defaults/grub, после чего следует выполнить grub2-mkconfig. |
| Загрузка ядра | Редактирует конфигурацию GRUB и /etc/dracut.conf | Приглашение GRUB для загрузки и изменения в /etc/defaults/grub, после чего следует выполнить grub2-mkconfig. |
| Запуск /sbin/init | Компиляция в initramfs | init = kernel аргумент загрузки, rd.break аргумент загрузки ядра |
| Обработка initrd.target | Компиляция в initramfs | Обычно ничего не требуется |
| Переключение на корневую файловую систему | /etc/fstab | /etc/fstab |
| Запуск цели по умолчанию | /etc/systemd/system/default.target | Запустить rescue.target как аргумент при загрузке ядра |
Передача аргементов в GRUB 2 ядру во время загрузки
Если сервер не загружается нормально, приглашение загрузки GRUB предлагает удобный способ остановить процедуру загрузки и передать конкретные параметры ядру во время загрузки. В этой части вы узнаете, как получить доступ к приглашению к загрузке и как передать конкретные аргументы загрузки ядру во время загрузки.
Когда сервер загружается, вы кратко видите меню GRUB 2. Смотри быстро, потому что это будет длиться всего несколько секунд. В этом загрузочном меню вы можете ввести e, чтобы войти в режим, в котором вы можете редактировать команды, или c, чтобы ввести полную командную строку GRUB.
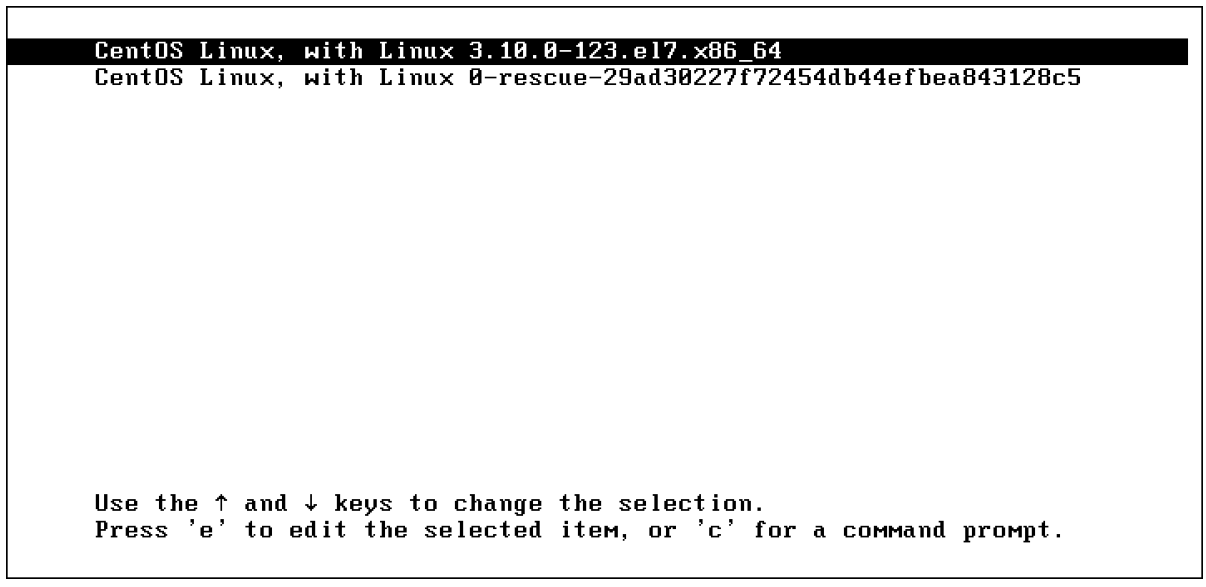 После передачи e в загрузочное меню GRUB вы увидите интерфейс, показанный на скриншоте ниже. В этом интерфейсе прокрутите вниз, чтобы найти раздел, начинающийся с linux16 /vmlinuz, за которым следует множество аргументов. Это строка, которая сообщает GRUB, как запустить ядро, и по умолчанию это выглядит так:
После передачи e в загрузочное меню GRUB вы увидите интерфейс, показанный на скриншоте ниже. В этом интерфейсе прокрутите вниз, чтобы найти раздел, начинающийся с linux16 /vmlinuz, за которым следует множество аргументов. Это строка, которая сообщает GRUB, как запустить ядро, и по умолчанию это выглядит так:
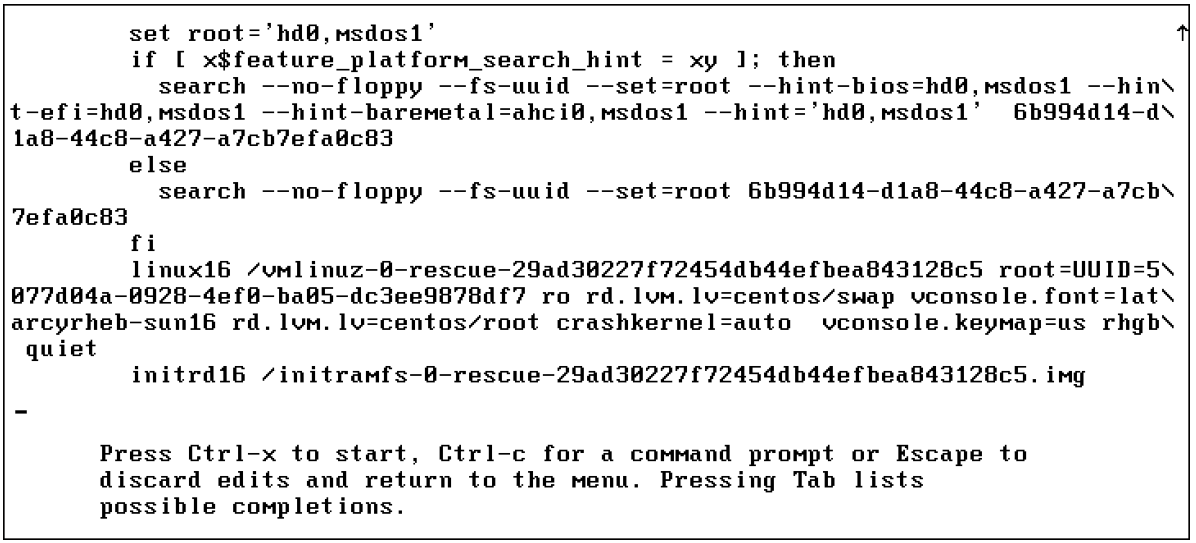
После ввода параметров загрузки, которые вы хотите использовать, нажмите Ctrl + X, чтобы запустить ядро с этими параметрами. Обратите внимание, что эти параметры используются только один раз и не являются постоянными. Чтобы сделать их постоянными, вы должны изменить содержимое файла конфигурации /etc/default/grub и использовать grub2-mkconfig -o /boot/grub2/grub.cfg, чтобы применить изменение.
Когда у вас возникли проблемы, у вас есть несколько вариантов (целей), которые вы можете ввести в приглашении загрузки GRUB:
■ rd.break Это останавливает процедуру загрузки, пока она еще находится в стадии initramfs.
Эта опция полезна, если у вас нет пароля root.
■ init=/bin/sh или init=/bin/bash Указывает, что оболочка должна быть запущена сразу после загрузки ядра и initrd. Это полезный вариант, но не лучший, потому что в некоторых случаях вы потеряете консольный доступ или пропустите другие функции.
■ systemd.unit=emergency.target Входит в минимальный режим, когда загружается минимальное количество системных юнитов.
Требуется пароль root.
Чтобы увидеть, что загружено только очень ограниченное количество файлов юнитов, вы можете ввести команду systemctl list-units.
■ systemd.unit=rescue.target Команда запускает еще несколько системных юнитов, чтобы привести вас в более полный рабочий режим. Требуется пароль root.
Чтобы увидеть, что загружено только очень ограниченное количество юнит-файлов, вы можете ввести команду systemctl list-units.
Запуск целей(targets) устранения неполадок в Linux
1. (Пере)загружаем Linux. Когда отобразиться меню GRUB, нажимаем e;
2. Находим строку, которая начинается на linux16 /vmlinuz. В конце строки вводим systemd.unit=rescue.target и удаляем rhgb quit;
3. Жмем Ctrl+X, чтобы начать загрузку с этими параметрами. Вводим пароль от root;
4. Вводим systemctl list-units и смотрим. Будут показаны все юнит-файлы, которые загружены в данный момент и соответственно загружена базовая системная среда;
5. Вводим systemctl show-environment. Видим переменные окружения в режиме rescue.target;
6. Перезагружаемся reboot;
7. Когда отобразится меню GRUB, нажимаем e. Находим строку, которая начинается на linux16 /vmlinuz. В конце строки вводим systemd.unit=emergency.target и удаляем rhgb quit;
8. Снова вводим пароль от root;
9. Система загрузилась в режиме emergency.target;
10. Вводим systemctl list-units и видим, что загрузился самый минимум из юнит-файлов.
Устранение неполадок с помощью загрузочного диска Linux
Еще один способ восстановления работоспособности Linux использовать образ операционки.
Если вам повезет меньше, вы увидите мигающий курсор в системе, которая вообще не загружается. Если это произойдет, вам нужен аварийный диск. Образ восстановления по умолчанию для Linux находится на установочном диске. При загрузке с установочного диска вы увидите пункт меню “Troubleshooting”. Выберите этот пункт, чтобы получить доступ к параметрам, необходимым для ремонта машины.

Выбрав “Troubleshooting”, появится выбор из 4-х опций.
- Install CentOS 7 in Basic Graphics Mode: эта опция переустанавливает систему. Не используйте её, если не хотите устранить неполадки в ситуации, когда обычная установка не работает и вам необходим базовый графический режим. Как правило, вам никогда не нужно использовать эту опцию для устранения неисправностей при установке.
- Rescue a CentOS System: это самая гибкая система спасения. Это должен быть первый вариант выбора при использовании аварийного диска.
- Run a Memory Test: если вы столкнулись с ошибками памяти, это позволяет пометить плохие микросхемы памяти, чтобы ваша машина могла нормально загружаться.
- Boot from local drive: здесь я думаю всё понятно.
ВНИМАНИЕ!
После запуска “Rescue a CentOS System” обычно требуется включить полный доступ к установке на диске. Обычно аварийный диск обнаруживает вашу установку и монтирует ее в каталог /mnt/sysimage. Чтобы исправить доступ к файлам конфигурации и их расположениям по умолчанию, поскольку они должны быть доступны на диске, используйте команду chroot /mnt/sysimage, чтобы сделать содержимое этого каталога реальной рабочей средой. Если вы не используете команду chroot, многие утилиты не будут работать, потому что, если они записывают в файл конфигурации, это будет версия файла конфигурации, существующего на диске восстановления (и по этой причине только для чтения). Использование команды chroot гарантирует, что все пути к файлам конфигурации верны.
Пример использования “Rescue a CentOS System”
1. Перезагружаем сервер с установочным диском Centos 7. Загружаемся и выбираем “Troubleshooting“.
2. В меню траблшутинга выбираем “Rescue a CentOS System” и загружаемся.
3. Система восстановления теперь предлагает вам найти установленную систему Linux и смонтировать ее в /mnt/sysimage. Выберите номер 1, чтобы продолжить: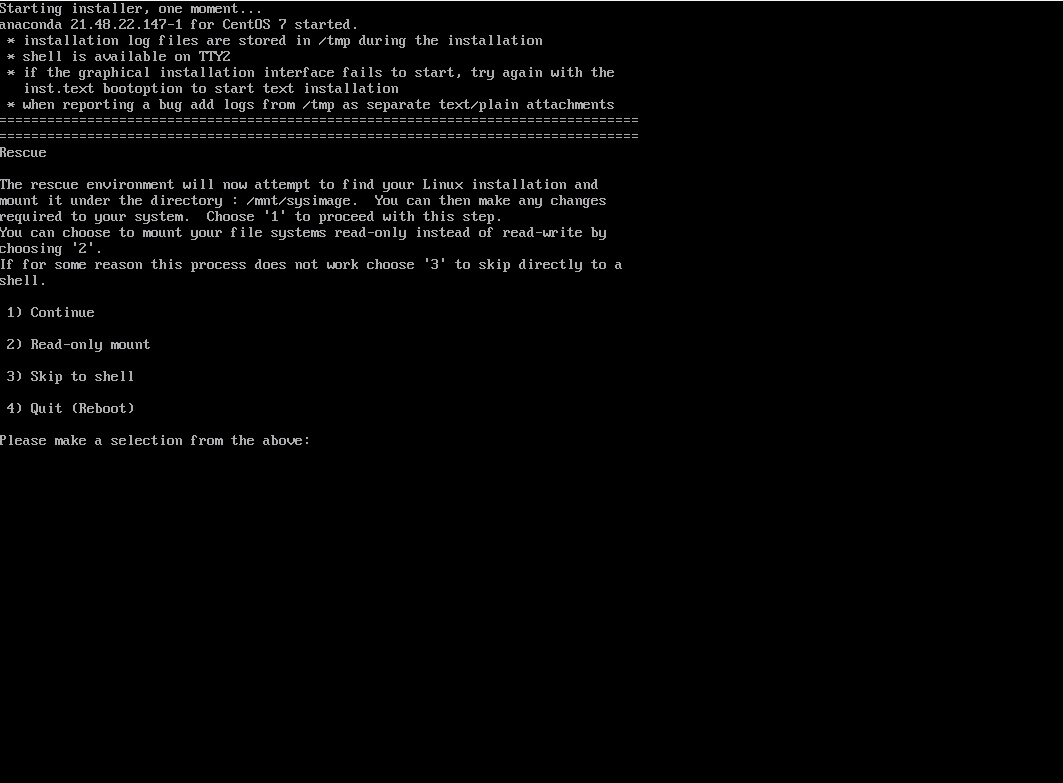
4. Если была найдена правильная установка CentOS, вам будет предложено, чтобы система была смонтирована в /mnt/sysimage. В этот момент вы можете дважды нажать Enter, чтобы получить доступ к оболочке восстановления.
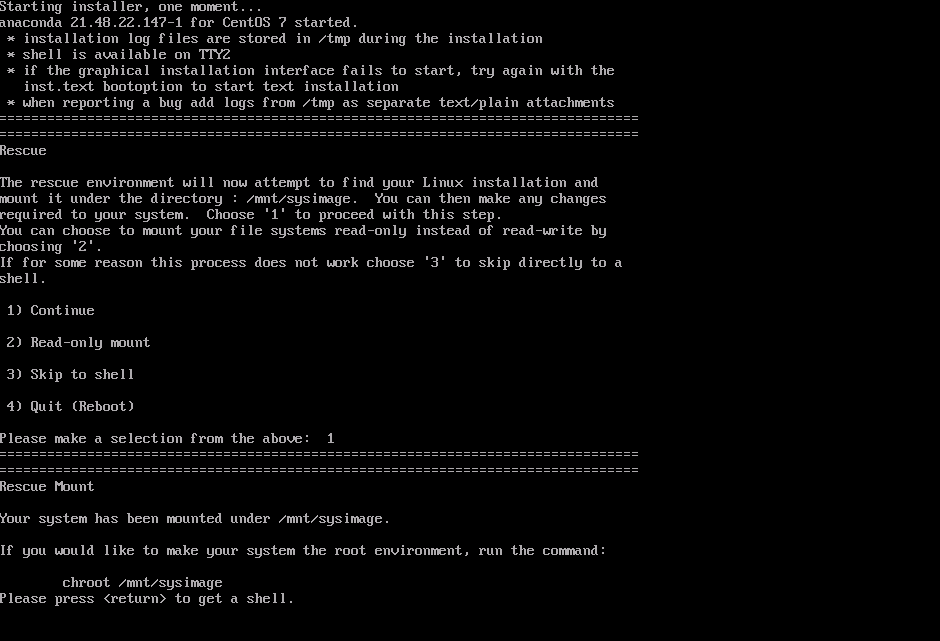
5. Ваша система Linux на данный момент доступна через каталог /mnt/sysimage. Введите chroot /mnt/sysimage. На этом этапе у вас есть доступ к корневой файловой системе, и вы можете получить доступ ко всем инструментам, которые необходимы для восстановления доступа к вашей системе.
Переустановка GRUB с помощью аварийного диска
Одна из распространенных причин, по которой вам нужно запустить аварийный диск, заключается в том, что загрузчик GRUB 2 не работает. Если это произойдет, вам может понадобиться установить его снова. После того, как вы восстановили доступ к своему серверу с помощью аварийного диска, переустановить GRUB 2 несложно, и он состоит из двух этапов:
- Убедитесь, что вы поместили содержимое каталога /mnt/sysimage в текущую рабочую среду.
- Используйте команду grub2-install, а затем имя устройства, на котором вы хотите переустановить GRUB 2. Если это виртуальная машина KVM используйте команду grub2-install /dev/vda и на физическом сервере или виртуальная машина VMware, HyperV или Virtual Box, это grub2-install /dev/sda.
Повторное создание Initramfs с помощью аварийного диска
Иногда initramfs также может быть поврежден. Если это произойдет, вы не сможете загрузить свой сервер в нормальном рабочем режиме. Чтобы восстановить образ initramfs после загрузки в среду восстановления, вы можете использовать команду dracut. Если используется без аргументов, эта команда создает новый initramfs для загруженного в данный момент ядра.
Кроме того, вы можете использовать команду dracut с несколькими опциями для создания initramfs для конкретных сред ядра. Существует также файл конфигурации с именем /etc/dracut.conf, который можно использовать для включения определенных параметров при повторном создании initramfs.
Конфигурация dracut рассредоточена по разным местам:
- /usr/lib/dracut/dracut.conf.d/*.conf содержит системные файлы конфигурации по умолчанию.
- /etc/dracut.conf.d содержит пользовательские файлы конфигурации dracut.
- /etc/dracut.conf используется в качестве основного файла конфигурации.
Вот так выглядит по умолчанию файл /etc/dracut.conf:
[root@server1 ~]# cat /etc/dracut.conf
# PUT YOUR CONFIG HERE OR IN separate files named *.conf
# in /etc/dracut.conf.d
# SEE man dracut.conf(5)
# Sample dracut config file
#logfile=/var/log/dracut.log
#fileloglvl=6
# Exact list of dracut modules to use. Modules not listed here are not going
# to be included. If you only want to add some optional modules use
# add_dracutmodules option instead.
#dracutmodules+=""
# dracut modules to omit
#omit_dracutmodules+=""
# dracut modules to add to the default
#add_dracutmodules+=""
# additional kernel modules to the default
#add_drivers+=""
# list of kernel filesystem modules to be included in the generic
initramfs
#filesystems+=""
# build initrd only to boot current hardware
#hostonly="yes"
#
# install local /etc/mdadm.conf
#mdadmconf="no"
# install local /etc/lvm/lvm.conf
#lvmconf="no"
# A list of fsck tools to install. If it is not specified, module's
hardcoded
# default is used, currently: "umount mount /sbin/fsck* xfs_db xfs_
check
# xfs_repair e2fsck jfs_fsck reiserfsck btrfsck". The installation is
# opportunistic, so non-existing tools are just ignored.
#fscks=""
# inhibit installation of any fsck tools
#nofscks="yes"
# mount / and /usr read-only by default
#ro_mnt="no"
# set the directory for temporary files
# default: /var/tmp
#tmpdir=/tmpИсправление общих проблем
В пределах статьи, подобной этой, невозможно рассмотреть все возможные проблемы, с которыми можно столкнуться при работе с Linux. Однако есть некоторые проблемы, которые встречаются чаще, чем другие. Ниже некоторые наиболее распространенные проблемы.
Переустановка GRUB 2
Код загрузчика не исчезает просто так, но иногда может случиться, что загрузочный код GRUB 2 будет поврежден. В этом случае вам лучше знать, как переустановить GRUB 2. Точный подход зависит от того, находится ли ваш сервер в загрузочном состоянии. Если это так, то довольно просто переустановить GRUB 2. Просто введите grub2-installи имя устройства, на которое вы хотите его установить. У команды есть много различных опций для точной настройки того, что именно будет установлено, но вам, вероятно, они не понадобятся, потому что по умолчанию команда устанавливает все необходимое, чтобы ваша система снова загрузилась.
Становится немного сложнее, если ваш сервер не загружается.
Если это произойдет, вам сначала нужно запустить систему восстановления и восстановить доступ к вашему серверу из системы восстановления. После монтирования файловых систем вашего сервера в /mnt/sysimage и использования chroot /mnt/sysimage, чтобы сделать смонтированный образ системы вашим корневым образом: Просто запустите grub2-install, чтобы установить GRUB 2 на желаемое установочное устройство. Но если вы находитесь на виртуальной машине KVM, запустите grub2-install /dev/vda, а если вы находитесь на физическом диске, запустите grub2-install /dev/sda.
Исправление Initramfs
В редких случаях может случиться так, что initramfs будет поврежден. Если вы тщательно проанализируете процедуру загрузки, вы узнаете, что у вас есть проблема с initramfs, потому что вы никогда не увидите, как корневая файловая система монтируется в корневой каталог, и при этом вы не увидите запуска каких-либо системных модулей. Если вы подозреваете, что у вас есть проблема с initramfs, ее легко создать заново. Чтобы воссоздать его, используя все настройки по умолчанию (что в большинстве случаев нормально), вы можете просто запустить команду dracut –force. (Без –force команда откажется перезаписать ваши существующие initramfs.)
При запуске команды dracut вы можете использовать файл конфигурации /etc/dracut.conf, чтобы указать, что именно записывается в initramfs. В этом файле конфигурации вы можете увидеть такие параметры, как lvmconf = «no», которые можно использовать для включения или выключения определенных функций. Используйте эти параметры, чтобы убедиться, что у вас есть все необходимые функции в initramfs.
Восстановление после проблем с файловой системой
Если вы неправильно настроили монтирование файловой системы, процедура загрузки может просто закончиться сообщением “Give root password for maintenance.”. Это сообщение, в частности, генерируется командой fsck, которая пытается проверить целостность файла системы в /etc/fstab при загрузке. Если fsck терпит неудачу, требуется ручное вмешательство, которое может привести к этому сообщению во время загрузки. Убедитесь, что вы знаете, что делать, когда это происходит с вами!
Если упомянуто устройство, которого нет, или если в UUID, который используется для монтирования устройства, есть ошибка, например, systemd сначала ожидает, вернется ли устройство само по себе. Если этого не происходит, выдается сообщение “Give root password for maintenance.”. Если это произойдет, вы должны сначала ввести пароль root. Затем вы можете ввести journalctl -xb, как предлагается, чтобы увидеть, записываются ли в журнал соответствующие сообщения, содержащие информацию о том, что не так. Если проблема ориентирована на файловую систему, введите mount -o remount, rw /, чтобы убедиться, что корневая файловая система смонтирована только для чтения, проанализировать, что не так в файле /etc/fstab, и исправить это.
Если вы видите подобный текст, то у вас есть проблема с /etc/fstab: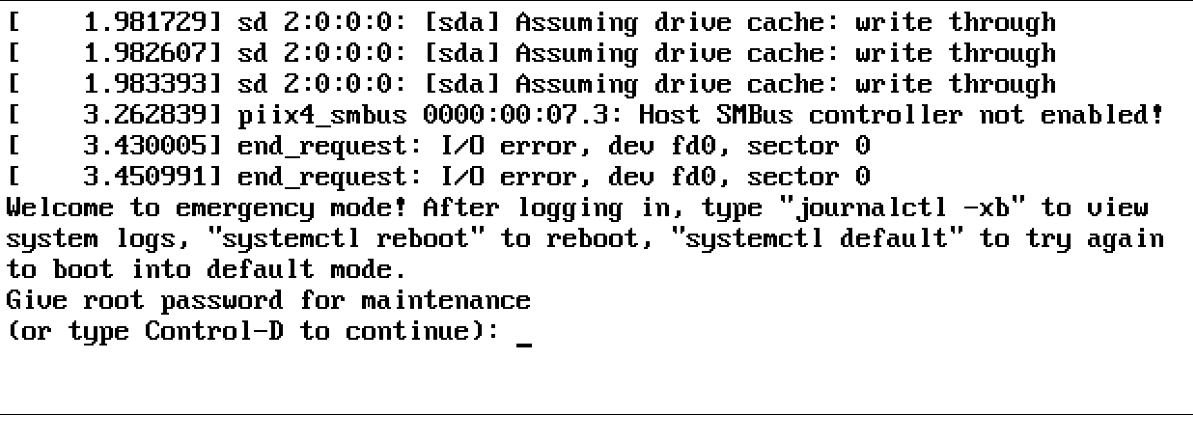
В этой статье вы узнали, как устранить неполадки при загрузке CentOS. Так же вы узнали, что происходит при загрузке сервера и в какие конкретные моменты вы можете вмешиваться, чтобы исправить неисправности. Вы также узнали, что делать в некоторых конкретных случаях.

2015-03-30
2 минуты read (About 247 words)
Исправление ошибки Error: database disk image is malformed
Загружены модули: fastestmirror, refresh-packagekit
Приготовления к процессу обновления
Loading mirror speeds from cached hostfile
* PUIAS_6_computational: www.puias.princeton.edu
* base: mirror.h1host.ru
* centosplus: mirror.h1host.ru
* epel: mirror.logol.ru
* extras: mirror.h1host.ru
* rpmforge: ftp.nluug.nl
* updates: mirror.h1host.ru
Error: database disk image is malformed
Проблема решается следующими действиями:
Загружены модули: fastestmirror, refresh-packagekit
Сброс источников:PUIAS_6_computational adobe-linux-x86_64 ajenti base centosplus epel extras isv_ownCloud_community nginx rpmforge updates
25 sqlite файлы удалены
yum history new
Загружены модули: fastestmirror, refresh-packagekit
history new
Комментарии
Поврежденные пакеты нуждаются в ремонте, иначе программное обеспечение не будет запускаться. Вот как найти поврежденные пакеты и исправить их в Linux.

Менеджеры пакетов в Linux позволяют контролировать установку и удаление пакетов. В дополнение к этому менеджеры пакетов также помогают вам находить поврежденные пакеты в вашей системе и переустанавливать их, чтобы устранить различные проблемы, связанные с пакетами Linux.
Если вы не знаете, какие команды использовать для поиска и исправления поврежденных пакетов в Linux, то это руководство для вас. Мы кратко обсудим поврежденные пакеты, как вы можете проверить, содержит ли ваша система поврежденные пакеты, и как их правильно переустановить.
Что такое поврежденные пакеты?
Когда вы устанавливаете новый пакет в Linux, менеджер пакетов вашей системы отвечает за весь процесс установки. Эти менеджеры пакетов имеют встроенные методы для обработки исключений и ошибок. Но иногда, в случае непредвиденных проблем, установка останавливается, и полный пакет не устанавливается. Такие пакеты в Linux называются поврежденными пакетами.
Менеджеры пакетов, такие как APT, не разрешают дальнейшую установку пакетов, если обнаруживается поврежденный пакет в системе. В такой ситуации восстановление поврежденного пакета является единственным вариантом.
Как найти и исправить поврежденные пакеты
Каждый менеджер пакетов обрабатывает разные типы пакетов. Например, DNF и YUM работают с Red Hat Package Manager (RPM) для загрузки и установки пакетов RPM. Аналогично, APT действует как оболочка интерфейса для базового программного обеспечения dpkg в дистрибутивах на основе Debian.
Переустановка поврежденных пакетов в Ubuntu и Debian
APT – это менеджер пакетов по умолчанию, который предустановлен в каждом дистрибутиве на основе Debian. Помимо APT, пользователи Debian и Ubuntu также могут загружать и устанавливать пакеты вручную с помощью dpkg.
Шаги, упомянутые ниже, также будут работать, если вы хотите исправить поврежденные пакеты в Kali Linux, поскольку, в конце концов, Kali – это дистрибутив на основе Debian.
Как исправить поврежденные пакеты в дистрибутивах на основе Debian с помощью APT:
- Откройте терминал, нажав Ctrl + Alt + T на клавиатуре и введите:
2. Обновите список пакетов вашей системы из доступных источников
3. Теперь принудительно установите поврежденные пакеты, используя флаг -f. APT автоматически выполнит поиск поврежденных пакетов в вашей системе и переустановит их из официального репозитория.
Если вышеупомянутые шаги не работают для вас, вы можете попытаться решить проблему с помощью dpkg.
- Заставьте dpkg перенастроить все ожидающие пакеты, которые уже распакованы, но нуждаются в настройке. Флаг -a в команде означает Все.
2. Передайте grep с помощью dpkg, чтобы получить список всех пакетов, помеченных как требуемые dpkg.
3. Используйте флаг –remove, чтобы удалить все поврежденные пакеты
4. Очистите кэш пакетов и установите скрипты с помощью apt clean.
5. Теперь обновите списки пакетов вашей системы, используя следующую команду:
Исправить поврежденные пакеты в Fedora / CentOS и RHEL
Хотя YUM и DNF отлично подходят для автоматического управления поврежденными пакетами, иногда возникают проблемы, поскольку в системе Linux установлены тысячи пакетов. В таких ситуациях вы можете использовать RPM (базовый менеджер пакетов для Fedora и CentOS) для быстрого устранения таких проблем.
- Проверьте все пакеты в вашей системе, используя флаг -V.
2. Вы увидите длинный список, содержащий все установленные пакеты в вашей системе.
3. Переустановите пакет, который, по вашему мнению, может вызывать проблему с поврежденным пакетом.
Описанные выше шаги крайне неудобны — определение того, какой пакет вызывает проблему, из списка сотен утомительно. Хотя RPM является мощным менеджером пакетов, и вы редко будете сталкиваться с такими проблемами, знание того, как устранить эти проблемы, по-прежнему важно на случай, если вы столкнетесь с подобной ситуацией в ближайшем будущем.
Управление пакетами в дистрибутивах Linux
Менеджеры пакетов в Linux способны справиться с большинством проблем, включая неудачные установки. Но иногда возникают различные проблемы, которые можно решить только интуитивно. Решение для исправления поврежденных пакетов состоит из нескольких шагов — определение поврежденного пакета, его переустановка и обновление списка пакетов системы.
В Интернете доступно бесчисленное множество дистрибутивов Linux, которые стоит попробовать, но в глубине души каждый из них имеет схожую основу. Среды рабочего стола выделяют каждый дистрибутив, предоставляя уникальный пользовательский интерфейс. Выбор идеальной среды рабочего стола, которая соответствует вашему вкусу, должен быть вашим приоритетом, если вы, наконец, решили перейти на Linux.
Смотрите другие статьи на нашем канале .
Как запускать команды Linux в фоновом режиме
8 Советов по настройке рабочего стола Cinnamon в Linux
Как использовать рабочие пространства и активные углы в Linux Mint
Вы также можете оставить свое мнение об этом посте в разделе комментариев.
![]() Listen to this article
Listen to this article
Каждый пользователь, рано или поздно сталкивается с определенными проблемами в своей операционной системе Linux. Это может быть просто неправильное использование команд или их непонимание, так и такие серьезные ошибки Linux, как отсутствие драйверов, неработоспособность сервисов зависание системы и так далее. Linux очень сильно отличается от WIndows, это заметно также при возникновении проблем Linux. Вот допустим, произошла ошибка в программе Windows, она полностью закрывается или выдает непонятное число с кодом ошибки и все, вы можете только догадываться или использовать поиск Google, чтобы понять что произошло. Но в Linux все совсем по-другому.
Более того, если программу запускать из терминала, то все ошибки linux и предупреждения мы увидим прямо в окне терминала. и сразу можно понять что нужно делать.
Причем вы сможете понять что произошло, даже не зная английского. Главным признаком ошибки есть слово ERROR (ошибка) или WARNING (предупреждение). Рассмотрим самые частые сообщения об ошибках:
- Permission Denied — нет доступа, означает что у программы нет полномочий доступа к определенному файлу или ресурсу.
- File or Directory does not exist — файл или каталог не существует
- No such file or Directory — нет такого файла или каталога
- Not Found — Не найдено, файл или ресурс не обнаружен
- Connection Refused — соединение сброшено, значит, что сервис к которому мы должны подключиться не запущен
- is empty — означает, что папка или нужный файл пуст
- Syntax Error — ошибка синтаксиса, обычно значит, что в конфигурационном файле или введенной команде допущена ошибка.
- Fail to load — ошибка загрузки, означает что система не может загрузить определенный ресурс, модуль или библиотеку (fail to load library) обычно также система сообщает почему она не может загрузить, permission denied или no such file и т д.
Сообщения об ошибках, кроме терминала, мы можем найти в различных лог файлах, все они находятся в папке /var/log, мы рассматривали за какие программы отвечают определенные файлы в статье просмотр логов linux. Теперь же мы подробнее рассмотрим где и что искать если linux выдает ошибку.
Монтирование NTFS раздела от Windows 10 в Linux
Ошибка:
Windows is hibernated, refused to mount.
Failed to mount ‘/dev/sda2’: Операция не позволена
The NTFS partition is in an unsafe state. Please resume and shutdown
Windows fully (no hibernation or fast restarting), or mount the volume
read-only with the ‘ro’ mount option.
Решение:
sudo mount -t ntfs-3g -o remove_hiberfile /dev/sda2 /mnt
Ошибка:
The disk contains an unclean file system (0, 0).
Metadata kept in Windows cache, refused to mount.
Failed to mount ‘/dev/sdb5’: Operation not permitted
The NTFS partition is in an unsafe state. Please resume and shutdown
Windows fully (no hibernation or fast restarting), or mount the volume
read-only with the ‘ro’ mount option.
Решение:
sudo ntfsfix /dev/sda3
Отключение режима гибернации в винде
powercfg /h off
Нет места, но место есть.
Проблема: ПО пишет, что закончилось место на диске, при этом df -h показывает, что место все-таки есть.
Решение: Надо проверить свободный айноды. df -hTi. Возможно их забили мелкие файлы.
Команда смены владельца и группы владельцев для директории и всех поддиректорий с файлами
sudo chown -R user:group /home/user/dir/
FTP сервер на Ubuntu server
Установить
sudo apt-get install vsftpd
Добавить нового пользователя, если надо
sudo adduser ftpuser
sudo adduser ftpuser ftp —disabled-login
Правим конфигурацию
sudo nano /etc/vsftpd.conf
Если надо анонимный доступ
anonymous_enable=Yes
чтение и правка файлов
local_enable=YES
write_enable=YES
Ограничить домашним каталогом. Создаем список пользователй
sudo nano /etc/vsftpd.chroot_list
пишем туда юзеров по одному на строчку
chroot_local_user=YES
chroot_list_enable=YES
chroot_list_file=/etc/vsftpd.chroot_list
папка входа по умоланию
local_root=/var/www
Права на файлы
#002 — 775; 022 — 755
local_umask=002
рестарт
sudo service vsftpd restart
Если права на файлы раздаются не верно~
nano /home/ftpuser/.profile
Раскомментируем строчку
umask 002
Расширить диск виртуальной машины KVM и VirtualBox
на хост-машине
1)KVM
sudo qemu-img resize /home/vm/disk.img +10G
2)VirtualBox
«C:Program FilesOracleVirtualBoxVBoxManage.exe» modifyhd D:vboxxubuntu.vdi —resize 25000
на вируалке
sudo apt-get install gparted
sudo swapoff /dev/vda5
sudo -X gparted
авторизация SSH без пароля
на своей машине
ssh-keygen -t rsa
в папке /home/имя пользователя/.ssh/id_rsa и id_rsa.pub появятся ключи
копируем на сервер
ssh-copy-id -i ~/.ssh/id_rsa.pub [email protected]_host
на сервере
chmod 600 ~/.ssh/authorized_keys
Firefox средняя кнопка мыши не работает как прокрутка
Решение: Правка — > Настройка — > Дополнительные — > Общие — > Использовать автоматическую прокрутку
Проброс портов iptables
Обозначения
$EXT_R_IP — внешний IP роутера
$LOCAL_IP — внутренний «фэйковый» адрес машины, которую надо «выкидывать» наружу
$PORT1 — Порт, на который будут заходить извне и попадать на локальную машину
$PORT2 — Порт, который «выбрасывается» наружу(например, 80 — http, либо 21 — ftp)
На роутере говорим следующие команды(от рута)
iptables -t nat -A PREROUTING -i eth0 -p tcp -d $EXT_R_IP —dport $PORT1 -j DNAT —to-destination $LOCAL_IP:$PORT2
iptables -A FORWARD -i eth0 -d $LOCAL_IP -p tcp —dport $PORT2 -j ACCEPT
Примонтировать флешку Ubuntu Linux
service srv1cv83 stop
sudo dpkg -l | more | grep 1c
sudo dpkg -r 1c-enterprise83-ws
sudo dpkg -r 1c-enterprise83-server
sudo dpkg -r 1c-enterprise83-common
dpkg -i 1c-enterprise83-common_8.3.6-2390_amd64.deb
dpkg -i 1c-enterprise83-server_8.3.6-2390_amd64.deb
dpkg -i 1c-enterprise83-ws_8.3.6-2390_amd64.deb
sudo reboot
Google Chrome не предлагает сохранить пароли
Если Google Chrome не предлагает сохранить пароли и не использует автозаполнение, то причина может быть в том, что эти опции отключены в настройках. Для их включения перейдите во вкладку chrome://settings/, либо в меню выберите пункт «Настройки»:
На открывшейся странице в разделе «Автозаполнение» выберите пункт «Пароли»:
В открывшемся окне включите две опции:
- Предлагать сохранение паролей
- Автоматический вход (Автоматически входить на сайты с помощью сохраненного имени пользователя и пароля. Когда функция отключена, эти данные нужно вводить при каждом входе)
После этого автоматический вход и сохранение пароли должны начать работать.
Google Chrome не сохраняет пароли, хотя предлагает их сохранить
Эта ситуация более нестандартная, она может встречаться на различных операционных системах: в моём случае это Chromium на Linux, но сообщали также об аналогичной проблеме для Google Chrome на MacOS.
Признаки:
- После входа на веб-сайт, браузер, как обычно, предлагает сохранить пароль
- Я нажимаю на кнопку «Сохранить»
- Chrome не показывает никакие ошибки
- Но пароль не сохраняется: а) он не вводится автоматически при следующем заходе на сайт; б) пароль не отображается во вкладке chrome://settings/passwords
Решение следующиее:
1. Выйдите из Chrome
2. Перейдите в директорию, где Chrome хранит данные пользователя — внутри домашней папки, в директории, зависящей от операционной системы:
- MacOS: ~/Library/Application Support/Google/Chrome
- Linux (Chrome): ~/.config/google-chrome
- Linux (Chromium): ~/.config/chromium
- Windows: %UserProfile%AppDataLocalGoogleChromeUser Data
3. От туда перейдите в директорию с именем Default, если вы хотите исправить ваш главный профиль, или в Profile 1 или Profile 2 и т. д. Если вы хотите починить один из дополнительных профилей.
4. Удалите файлы Login Data, Login Data-journal и Login Data 2-journal.
5. Повторите для других профилей, если необходимо.
После этого у меняв вновь включилось сохранение паролей.
Обратите внимание, что если у вас включена автоматическая синхронизация, то вы не потеряете сохранённые ранее пароли.
1. Удаление временных файлов
Файлы в папке /tmp/ будут удалены в любом случае при следующей перезагрузки системы. То есть с одной стороны их можно удалить достаточно безболезненно:
НО: может быть нарушена работа программ, которые запущены в настоящее время и которые сохранили какие-то данные в папку /tmp/.
2. Удаление файлов кэширования
В директории /var/cache/ много поддиректорий, которые можно удалить практически безболезненно (данные утеряны не будут, а программы создадут новые файлы кэширования). Эта директория вызывает особый интерес, поскольку на которых системах кэши разрастаются на гигабайты и десятки гигабайт. Иногда поиск проблемной директории в /var/cache/ может окончательно решить ситуацию с нехваткой места на диске.
Для удаления кэша шрифтов:
|
1 |
|
Для удаления кэша установочных пакетов (на Debian, Linux Mint, Ubuntu, Kali Linux и их производных):
|
1 |
|
Для удаления кэша установочных пакетов (на Arch Linux, BlackArch и их производных):
|
1 |
|
Удаление кэша справочных страниц:
|
1 |
|
Вы можете продолжить поиск больших кэшей применимо к программному обеспечению, установленному на вашей системе. Например, это могут быть кэши веб-сервера, прокси-сервера и т. д.
3. Удаление логов (журналов)
В этой папке (/var/log/) можно удалить практически все файлы, но старайтесь сохранить структуру папок, поскольку некоторые приложения после удаления здесь папки не в состоянии создать её второй раз…
На веб-серверах могут разрастись слишком сильно журналы веб-сервера.
Для удаления логов Apache на Debian, Linux Mint, Ubuntu, Kali Linux и их производных:
|
1 |
|
Для удаления логов Apache на Arch Linux, BlackArch и их производных:
|
1 |
|
Чтобы сервер начал создавать новые файлы журналов и записывать в них, нужно перезапустить службу веб-сервера.
В зависимости от интенсивности использования системы, накопленные журналы могут занимать гигабайты. В зависимости от системы файлы могут называться по-разному, более точный анализ рекомендуется выполнять с помощью утилиты ncdu:
4. Очистите корзину
Этот совет больше для настольных систем. Файлы, которые вы удалили в графическом интерфейсе рабочего стола, попадают в папку ~/.local/share/Trash/files/, вы можете проанализировать их и при желании удалить (второй раз):
|
1 |
|
5. Удаление ненужных файлов исходного кода заголовков ядра
Следующее актуально только для Debian, Linux Mint, Ubuntu, Kali Linux и их производных. Проверьте папку /usr/src/, там будут подпапки вида linux-headers- — большинство из них можно удалить — оставьте только ту, номер которой соответствует текущему ядру системы — обычно это самый последний номер выпуска.
6. Удаление осиротевших пакетов
На Debian, Linux Mint, Ubuntu, Kali Linux и их производных удалить ненужные пакеты можно следующим образом:
7. Очистка журналов systemd
Со временем, в некоторых системах логи системы начинают занимать гигабайты на жёстком диске. Просмотреть журналы и освободить место вы можете с помощью команды journalctl
Чтобы увидеть, сколько место занимают журналы, выполните:
Чтобы удалить все записи, оставив только записей на 100 мегабайт, выполните:
|
1 |
|
Либо для удаления всех записей в системном журнале, старше одной недели:
|
1 |
|
8. Проанализируйте файлы Docker
Не удаляйте безумно файлы Docker. Я привожу пример этой директории только по той причине, что она привлекла моё внимание из-за просто фантасмагоричного размера — и это при том, что я Docker’ом фактически не пользуюсь — буквально несколько раз попробовал, чтобы увидеть, что это такое.
Самой большой папкой является /var/lib/docker/overlay2/. Для анализа занимаемого места на диске выполните:
|
1 |
|
Как исправить «No route to host» SSH в Linux
Если сервер работает на RHEL/CentOS/Fedora, то нужно использовать команду firewall-cmd, чтобы открыть 22 порт (или другой порт, который вы настроили для использования с SSH):
|
1 2 |
|
Если сервер работает на Debian/Ubuntu, то нужно использовать команду UFW, чтобы открыть 22 порт (или другой порт, который вы настроили для использования с SSH) следующим образом:
|
1 2 |
|
Теперь попробуйте вновь подключиться к удалённому серверу по SSH:
Проблема должна исчезнуть.
Ошибки «E: Не удалось получить доступ к файлу блокировки /var/lib/apt/lists/lock — open (11: Resource temporarily unavailable)» и «E: Невозможно заблокировать каталог /var/lib/apt/lists/»
возникает примерно следующая ошибка:
|
1 2 3 4 5 |
|
Если в этой ситуации удалить файлы-блокировщики (/var/lib/apt/lists/lock), как это иногда советуют, то в результате фоновый процесс apt преждевременно завершит свою работу, либо вы запустите второй экземпляр apt – оба эти варианта приведут к проблемам с пакетами, и, вероятнее всего, при последующей попытке использовать apt система предложит вам запустить программу с ключом —f:
Правильный способ исправить ошибку
Чтобы увидеть, какие службы apt присутствуют в системе, выполните команду:
|
1 |
|
Следующая команда выведет только список служб apt, которые добавлены в автоматическую загрузку:
|
1 |
|
Службы apt-daily-upgrade.timer и apt-daily.timer, чтобы отключить их автоматический запуск при старте системы, выполните команды:
|
1 2 |
|
Как обновить Linux в командной строке
С одной стороны, отключение автоматических обновлений и скачивание новых файлов пакетов навсегда избавит вас от ошибки «E: Невозможно заблокировать каталог /var/lib/apt/lists/» и других подобных, но при этом вам нужно будет самостоятельно выполнять обновление и очистку пакетов.
Для полного обновления системы выполняйте:
|
1 |
|
А для очистки пакетов используются команды:
|
1 2 |
|
Не работает буфер обмена с гостевой ОС Linux
В этом случае как суперпользователь выполните команды:
|
1 2 |
|
Если это не помогло, а особенно если у вас возникает ошибка:
|
1 |
|
тогда установите пакет:
|
1 |
|
а затем запустите клиент VirtualBox
Бывают ситуации, что буфер обмена с гостевой ОС работал, но в какой-то момент перестал. Это может происходить, например, после обновления ядра. В этой ситуации также поможет установка пакета virtualbox-guest-x11 и запуск службы VBoxClient-all.
Источник: https://losst.ru/ и https://7d3.ru/ и https://zalinux.ru/
Если Вам понравилась статья — поделитесь с друзьями
2 617 просмотров
Отказ от ответственности: Автор или издатель не публиковали эту статью для вредоносных целей. Вся размещенная информация была взята из открытых источников и представлена исключительно в ознакомительных целях а также не несет призыва к действию. Создано лишь в образовательных и развлекательных целях. Вся информация направлена на то, чтобы уберечь читателей от противозаконных действий. Все причиненные возможные убытки посетитель берет на себя. Автор проделывает все действия лишь на собственном оборудовании и в собственной сети. Не повторяйте ничего из прочитанного в реальной жизни. | Так же, если вы являетесь правообладателем размещенного на страницах портала материала, просьба написать нам через контактную форму жалобу на удаление определенной страницы, а также ознакомиться с инструкцией для правообладателей материалов. Спасибо за понимание.
Если вам понравились материалы сайта, вы можете поддержать проект финансово, переведя некоторую сумму с банковской карты, счёта мобильного телефона или из кошелька ЮMoney.

