Наверное, любой сервис, на котором вообще есть поиск, рано или поздно приходит к потребности научиться исправлять ошибки в пользовательских запросах. Errare humanum est; пользователи постоянно опечатываются и ошибаются, и качество поиска от этого неизбежно страдает — а с ним и пользовательский опыт.
При этом каждый сервис обладает своей спецификой, своим лексиконом, которым должен уметь оперировать исправитель опечаток, что в значительной мере затрудняет применение уже существующих решений. Например, такие запросы пришлось научиться править нашему опечаточнику:
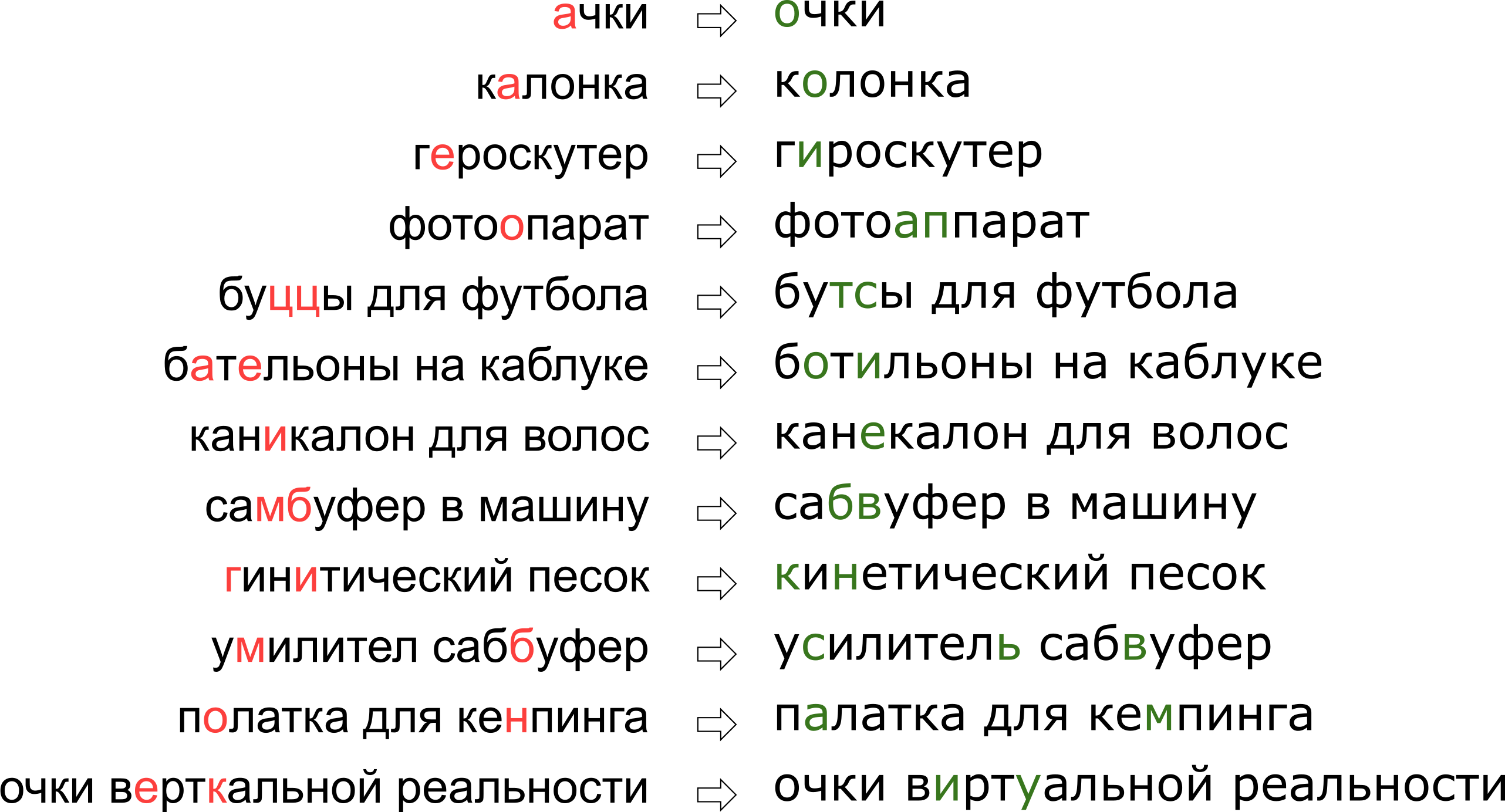
Может показаться, что мы отказали пользователю в его мечте о вертикальной реальности, но на самом деле буква К просто стоит на клавиатуре рядом с буквой У.
В этой статье мы разберём один из классических подходов к исправлению опечаток, от построения модели до написания кода на Python и Go. И в качестве бонуса — видео с моего доклада «”Очки верткальной реальности”: исправляем опечатки в поисковых запросах» на Highload++.
Постановка задачи
Итак, нам пришёл опечатанный запрос и его надо исправить. Обычно математически задача ставится таким образом:
Эта постановка — самая элементарная — предполагает, что если нам пришёл запрос из нескольких слов, то мы исправляем каждое слово по отдельности. В реальности, конечно, мы захотим исправлять всю фразу целиком, учитывая сочетаемость соседних слов; об этом я расскажу ниже, в разделе “Как исправлять фразы”.
Неясных моментов здесь два — где взять словарь и как посчитать
 . Первый вопрос считается простым. В 1990 году [1] словарь собирали из базы утилиты spell и доступных в электронном виде словарей; в 2009 году в Google [4] поступили проще и просто взяли топ самых популярных слов в Интернете (вместе с популярными ошибочными написаниями). Этот подход взял и я для построения своего опечаточника.
. Первый вопрос считается простым. В 1990 году [1] словарь собирали из базы утилиты spell и доступных в электронном виде словарей; в 2009 году в Google [4] поступили проще и просто взяли топ самых популярных слов в Интернете (вместе с популярными ошибочными написаниями). Этот подход взял и я для построения своего опечаточника.
Второй вопрос сложнее. Хотя бы потому, что его решение обычно начинается с применения формулы Байеса!

Теперь вместо исходной непонятной вероятности нам нужно оценить две новые, чуть более понятные:
 — вероятность того, что при наборе слова
— вероятность того, что при наборе слова
 можно опечататься и получить
можно опечататься и получить
 , и
, и
 — в принципе вероятность использования пользователем слова
— в принципе вероятность использования пользователем слова
.
Как оценить
? Очевидно, что пользователь с большей вероятностью путает А с О, чем Ъ с Ы. А если мы исправляем текст, распознанный с отсканированного документа, то велика вероятность путаницы между rn и m. Так или иначе, нам нужна какая-то модель, описывающая ошибки и их вероятности.
Такая модель называется noisy channel model (модель зашумлённого канала; в нашем случае зашумлённый канал начинается где-то в центре Брока пользователя и заканчивается по другую сторону его клавиатуры) или более коротко error model — модель ошибок. Эта модель, которой ниже посвящен отдельный раздел, будет ответственна за учёт как орфографических ошибок, так и, собственно, опечаток.
Оценить вероятность использования слова —
— можно по-разному. Самый простой вариант — взять за неё частоту, с которой слово встречается в некотором большом корпусе текстов. Для нашего опечаточника, учитывающего контекст фразы, потребуется, конечно, что-то более сложное — ещё одна модель. Эта модель называется language model, модель языка.
Модель ошибок
Первые модели ошибок считали
, подсчитывая вероятности элементарных замен в обучающей выборке: сколько раз вместо Е писали И, сколько раз вместо ТЬ писали Т, вместо Т — ТЬ и так далее [1]. Получалась модель с небольшим числом параметров, способная выучить какие-то локальные эффекты (например, что люди часто путают Е и И).
В наших изысканиях мы остановились на более развитой модели ошибок, предложенной в 2000 году Бриллом и Муром [2] и многократно использованной впоследствии (например, специалистами Google [4]). Представим, что пользователи мыслят не отдельными символами (спутать Е и И, нажать К вместо У, пропустить мягкий знак), а могут изменять произвольные куски слова на любые другие — например, заменять ТСЯ на ТЬСЯ, У на К, ЩА на ЩЯ, СС на С и так далее. Вероятность того, что пользователь опечатался и вместо ТСЯ написал ТЬСЯ, обозначим
 — это параметр нашей модели. Если для всех возможных фрагментов
— это параметр нашей модели. Если для всех возможных фрагментов
 мы можем посчитать
мы можем посчитать
 , то искомую вероятность
, то искомую вероятность
набора слова s при попытке набрать слово w в модели Брилла и Мура можно получить следующим образом: разобьем всеми возможными способами слова w и s на более короткие фрагменты так, чтобы фрагментов в двух словах было одинаковое количество. Для каждого разбиения посчитаем произведение вероятностей всех фрагментов w превратиться в соответствующие фрагменты s. Максимум по всем таким разбиениям и примем за значение величины
:

Давайте посмотрим на пример разбиения, возникающего при вычислении вероятности напечатать «аксесуар» вместо «аксессуар»:

Как вы наверняка заметили, это пример не очень удачного разбиения: видно, что части слов легли друг под другом не так удачно, как могли бы. Если величины
 и
и
 ещё не так плохи, то
ещё не так плохи, то
 и
и
 , скорее всего, сделают итоговый «счёт» этого разбиения совсем печальным. Более удачное разбиение выглядит как-то так:
, скорее всего, сделают итоговый «счёт» этого разбиения совсем печальным. Более удачное разбиение выглядит как-то так:

Здесь всё сразу стало на свои места, и видно, что итоговая вероятность будет определяться преимущественно величиной
 .
.
Как вычислить 
Несмотря на то, что возможных разбиений для двух слов имеется порядка
 , с помощью динамического программирования алгоритм вычисления
, с помощью динамического программирования алгоритм вычисления
можно сделать довольно быстрым — за
 . Сам алгоритм при этом будет очень сильно напоминать алгоритм Вагнера-Фишера для вычисления расстояния Левенштейна.
. Сам алгоритм при этом будет очень сильно напоминать алгоритм Вагнера-Фишера для вычисления расстояния Левенштейна.
Мы заведём прямоугольную таблицу, строки которой будут соответствовать буквам правильного слова, а столбцы — опечатанного. В ячейке на пересечении строки i и столбца j к концу алгоритма будет лежать в точности вероятность получить s[:j] при попытке напечатать w[:i]. Для того, чтобы её вычислить, достаточно вычислить значения всех ячеек в предыдущих строках и столбцах и пробежаться по ним, домножая на соответствующие
. Например, если у нас заполнена таблица
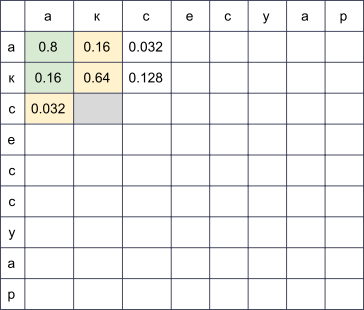
, то для заполнения ячейки в четвёртой строке и третьем столбце (серая) нужно взять максимум из величин
 и
и
 . При этом мы пробежались по всем ячейкам, подсвеченным на картинке зелёным. Если также рассматривать модификации вида
. При этом мы пробежались по всем ячейкам, подсвеченным на картинке зелёным. Если также рассматривать модификации вида
 и
и
 , то придётся пробежаться и по ячейкам, подсвеченным жёлтым.
, то придётся пробежаться и по ячейкам, подсвеченным жёлтым.
Сложность этого алгоритма, как я уже упомянул выше, составляет
: мы заполняем таблицу
 , и для заполнения ячейки (i, j) нужно
, и для заполнения ячейки (i, j) нужно
 операций. Впрочем, если мы ограничим рассмотрение фрагментами не больше какой-то ограниченной длины
операций. Впрочем, если мы ограничим рассмотрение фрагментами не больше какой-то ограниченной длины
 (например, не больше двух букв, как в [4]), сложность уменьшится до
(например, не больше двух букв, как в [4]), сложность уменьшится до
 . Для русского языка в своих экспериментах я брал
. Для русского языка в своих экспериментах я брал
 .
.
Как максимизировать
Мы научились находить
за полиномиальное время — это хорошо. Но нам нужно научиться быстро находить наилучшие слова во всём словаре. Причём наилучшие не по
, а по
! На деле нам достаточно получить какой-то разумный топ (например, лучшие 20) слов по
, который мы потом отправим в модель языка для выбора наиболее подходящих исправлений (об этом ниже).
Чтобы научиться быстро проходить по всему словарю, заметим, что таблица, представленная выше, будет иметь много общего для двух слов с общими префиксами. Действительно, если мы, исправляя слово «аксесуар», попробуем заполнить её для двух словарных слов «аксессуар» и «аксессуары», мы заметим, что первые девять строк в них вообще не отличаются! Если мы сможем организовать проход по словарю так, что у двух последующих слов будут достаточно длинные общие префиксы, мы сможем круто сэкономить вычисления.
И мы сможем. Давайте возьмём словарные слова и составим из них trie. Идя по нему поиском в глубину, мы получим желаемое свойство: большинство шагов — это шаги от узла к его потомку, когда у таблицы достаточно дозаполнить несколько последних строк.
Этот алгоритм, при некоторых дополнительных оптимизациях, позволяет нам перебирать словарь типичного европейского языка в 50-100 тысяч слов в пределах сотни миллисекунд [2]. А кэширование результатов сделает процесс ещё быстрее.
Как получить
Вычисление
для всех рассматриваемых фрагментов — самая интересная и нетривиальная часть построения модели ошибок. Именно от этих величин будет зависеть её качество.
Подход, использованный в [2, 4], сравнительно прост. Давайте найдём много пар
 , где
, где
 — правильное слово из словаря, а
— правильное слово из словаря, а
 — его опечатанный вариант. (Как именно их находить — чуть ниже.) Теперь нужно извлечь из этих пар вероятности конкретных опечаток (замен одних фрагментов на другие).
— его опечатанный вариант. (Как именно их находить — чуть ниже.) Теперь нужно извлечь из этих пар вероятности конкретных опечаток (замен одних фрагментов на другие).
Для каждой пары возьмём составляющие её
и
и построим соответствие между их буквами, минимизирующее расстояние Левенштейна:

Теперь мы сразу видим замены: а → а, е → и, с → с, с → пустая строка и так далее. Также мы видим замены двух и более символов: ак → ак, се → си, ес → ис, сс → с, сес → сис, есс → ис и прочая, и прочая. Все эти замены необходимо посчитать, причём каждую столько раз, сколько слово s встречается в корпусе (если мы брали слова из корпуса, что очень вероятно).
После прохода по всем парам
за вероятность
принимается количество замен α → β, встретившихся в наших парах (с учётом встречаемости соответствующих слов), делённое на количество повторений фрагмента α.
Как найти пары
? В [4] предлагается такой подход. Возьмём большой корпус сгенерированного пользователями контента (UGC). В случае Google это были просто тексты сотен миллионов веб-страниц; в нашем — миллионы пользовательских поисковых запросов и отзывов. Предполагается, что обычно правильное слово встречается в корпусе чаще, чем любой из ошибочных вариантов. Так вот, давайте для каждого слова находить близкие к нему по Левенштейну слова из корпуса, которые значительно менее популярны (например, в десять раз). Популярное возьмём за
, менее популярное — за
. Так мы получим пусть и шумный, но зато достаточно большой набор пар, на котором можно будет провести обучение.
Этот алгоритм подбора пар оставляет большое пространство для улучшений. В [4] предлагается только фильтр по встречаемости (
в десять раз популярнее, чем
), но авторы этой статьи пытаются делать опечаточник, не используя какие-либо априорные знания о языке. Если мы рассматриваем только русский язык, мы можем, например, взять набор словарей русских словоформ и оставлять только пары со словом
, найденном в словаре (не лучшая идея, потому что в словаре, скорее всего, не будет специфичной для сервиса лексики) или, наоборот, отбрасывать пары со словом s, найденном в словаре (то есть почти гарантированно не являющимся опечатанным).
Чтобы повысить качество получаемых пар, я написал несложную функцию, определяющую, используют ли пользователи два слова как синонимы. Логика простая: если слова w и s часто встречаются в окружении одних и тех же слов, то они, вероятно, синонимы — что в свете их близости по Левенштейну значит, что менее популярное слово с большой вероятностью является ошибочной версией более популярного. Для этих расчётов я использовал построенную для модели языка ниже статистику встречаемости триграмм (фраз из трёх слов).
Модель языка
Итак, теперь для заданного словарного слова w нам нужно вычислить
— вероятность его использования пользователем. Простейшее решение — взять встречаемость слова в каком-то большом корпусе. Вообще, наверное, любая модель языка начинается с собирания большого корпуса текстов и подсчёта встречаемости слов в нём. Но ограничиваться этим не стоит: на самом деле при вычислении P(w) мы можем учесть также и фразу, слово в которой мы пытаемся исправить, и любой другой внешний контекст. Задача превращается в задачу вычисления
 , где одно из
, где одно из
— слово, в котором мы исправили опечатку и для которого мы теперь рассчитываем
, а остальные
— слова, окружающие исправляемое слово в пользовательском запросе.
Чтобы научиться учитывать их, стоит пройтись по корпусу ещё раз и составить статистику n-грамм, последовательностей слов. Обычно берут последовательности ограниченной длины; я ограничился триграммами, чтобы не раздувать индекс, но тут всё зависит от вашей силы духа (и размера корпуса — на маленьком корпусе даже статистика по триграммам будет слишком шумной).
Традиционная модель языка на основе n-грамм выглядит так. Для фразы
 её вероятность вычисляется по формуле
её вероятность вычисляется по формуле

где
 — непосредственно частота слова, а
— непосредственно частота слова, а
 — вероятность слова
— вероятность слова
 при условии, что перед ним идут
при условии, что перед ним идут
 — не что иное, как отношение частоты триграммы
— не что иное, как отношение частоты триграммы
 к частоте биграммы
к частоте биграммы
. (Заметьте, что эта формула — просто результат многократного применения формулы Байеса.)
Иными словами, если мы захотим вычислить
 , обозначив частоту произвольной n-граммы за
, обозначив частоту произвольной n-граммы за
 , мы получим формулу
, мы получим формулу

Логично? Логично. Однако трудности начинаются, когда фразы становятся длиннее. Что, если пользователь ввёл впечатляющий своей подробностью поисковый запрос в десять слов? Мы не хотим держать статистику по всем 10-граммам — это дорого, а данные, скорее всего, будут шумными и не показательными. Мы хотим обойтись n-граммами какой-то ограниченной длины — например, уже предложенной выше длины 3.
Здесь-то и пригождается формула выше. Давайте предположим, что на вероятность слова появиться в конце фразы значительно влияют только несколько слов непосредственно перед ним, то есть что

Положив
, для более длинной фразы получим формулу

Обратите внимание: фраза состоит из пяти слов, но в формуле фигурируют n-граммы не длиннее трёх. Это как раз то, чего мы добивались.
Остался один тонкий момент. Что, если пользователь ввёл совсем странную фразу и соответствующих n-грамм у нас в статистике и нет вовсе? Было бы легко для незнакомых n-грамм положить
 , если бы на эту величину не надо было делить. Здесь на помощь приходит сглаживание (smoothing), которое можно делать разными способами; однако подробное обсуждение серьёзных подходов к сглаживанию вроде Kneser-Ney smoothing выходит далеко за рамки этой статьи.
, если бы на эту величину не надо было делить. Здесь на помощь приходит сглаживание (smoothing), которое можно делать разными способами; однако подробное обсуждение серьёзных подходов к сглаживанию вроде Kneser-Ney smoothing выходит далеко за рамки этой статьи.
Как исправлять фразы
Обговорим последний тонкий момент перед тем, как перейти к реализации. Постановка задачи, которую я описал выше, подразумевала, что есть одно слово и его надо исправить. Потом мы уточнили, что это одно слово может быть в середине фразы среди каких-то других слов и их тоже нужно учесть, выбирая наилучшее исправление. Но в реальности пользователи просто присылают нам фразы, не уточняя, какое слово написано с ошибкой; нередко в исправлении нуждается несколько слов или даже все.
Подходов здесь может быть много. Можно, например, учитывать только левый контекст слова в фразе. Тогда, идя по словам слева направо и по мере необходимости исправляя их, мы получим новую фразу какого-то качества. Качество будет низким, если, например, первое слово оказалось похоже на несколько популярных слов и мы выберем неправильный вариант. Вся оставшаяся фраза (возможно, изначально вообще безошибочная) будет подстраиваться нами под неправильное первое слово и мы можем получить на выходе полностью нерелевантный оригиналу текст.
Можно рассматривать слова по отдельности и применять некий классификатор, чтобы понимать, опечатано данное слово или нет, как это предложено в [4]. Классификатор обучается на вероятностях, которые мы уже умеем считать, и ряде других фичей. Если классификатор говорит, что нужно исправлять — исправляем, учитывая имеющийся контекст. Опять-таки, если несколько слов написаны с ошибкой, принимать решение насчёт первого из них придётся, опираясь на контекст с ошибками, что может приводить к проблемам с качеством.
В реализации нашего опечаточника мы использовали такой подход. Давайте для каждого слова
в нашей фразе найдём с помощью модели ошибок топ-N словарных слов, которые могли иметься в виду, сконкатенируем их во фразы всевозможными способами и для каждой из
 получившихся фраз, где
получившихся фраз, где
 — количество слов в исходной фразе, посчитаем честно величину
— количество слов в исходной фразе, посчитаем честно величину

Здесь
— слова, введённые пользователем,
— подобранные для них исправления (которые мы сейчас перебираем), а
 — коэффициент, определяемый сравнительным качеством модели ошибок и модели языка (большой коэффициент — больше доверяем модели языка, маленький коэффициент — больше доверяем модели ошибок), предложенный в [4]. Итого для каждой фразы мы перемножаем вероятности отдельных слов исправиться в соответствующие словарные варианты и ещё домножаем это на вероятность всей фразы в нашем языке. Результат работы алгоритма — фраза из словарных слов, максимизирующая эту величину.
— коэффициент, определяемый сравнительным качеством модели ошибок и модели языка (большой коэффициент — больше доверяем модели языка, маленький коэффициент — больше доверяем модели ошибок), предложенный в [4]. Итого для каждой фразы мы перемножаем вероятности отдельных слов исправиться в соответствующие словарные варианты и ещё домножаем это на вероятность всей фразы в нашем языке. Результат работы алгоритма — фраза из словарных слов, максимизирующая эту величину.
Так, стоп, что? Перебор
фраз?
К счастью, за счёт того, что мы ограничили длину n-грамм, найти максимум по всем фразам можно гораздо быстрее. Вспомните: выше мы упростили формулу для
 так, что она стала зависеть только от частот n-грамм длины не выше трёх:
так, что она стала зависеть только от частот n-грамм длины не выше трёх:

Если мы домножим эту величину на
 и попытаемся максимизировать по
и попытаемся максимизировать по
 , мы увидим, что достаточно перебрать всевозможные
, мы увидим, что достаточно перебрать всевозможные
 и
и
 и решить задачу для них — то есть для фраз
и решить задачу для них — то есть для фраз
 . Итого задача решается динамическим программированием за
. Итого задача решается динамическим программированием за
 .
.
Реализация
Собираем корпус и считаем n-граммы
Сразу оговорюсь: данных в моём распоряжении было не так много, чтобы заводить какой-то сложный MapReduce. Так что я просто собрал все тексты отзывов, комментариев и поисковых запросов на русском языке (описания товаров, увы, приходят на английском, а использование результатов автоперевода скорее ухудшило, чем улучшило результаты) с нашего сервиса в один текстовый файл и поставил сервер на ночь считать триграммы простым скриптом на Python.
В качестве словарных я брал топ слов по частотности так, чтобы получалось порядка ста тысяч слов. Исключались слишком длинные слова (больше 20 символов) и слишком короткие (меньше трёх символов, кроме захардкоженных известных русских слов). Отдельно пощадил слова по регулярке r"^[a-z0-9]{2}$" — чтобы уцелели версии айфонов и другие интересные идентификаторы длины 2.
При подсчёте биграмм и триграмм во фразе может встретиться несловарное слово. В этом случае это слово я выбрасывал и бил всю фразу на две части (до и после этого слова), с которыми работал отдельно. Так, для фразы «А вы знаете, что такое «абырвалг»? Это… ГЛАВРЫБА, коллега» учтутся триграммы “а вы знаете”, “вы знаете что”, “знаете что такое” и “это главрыба коллега” (если, конечно, слово “главрыба” попадёт в словарь…).
Обучаем модель ошибок
Дальше всю обработку данных я проводил в Jupyter. Статистика по n-граммам грузится из JSON, производится постобработка, чтобы быстро находить близкие друг к другу по Левенштейну слова, и для пар в цикле вызывается (довольно громоздкая) функция, выстраивающая слова и извлекающая короткие правки вида сс → с (под спойлером).
Код на Python
def generate_modifications(intended_word, misspelled_word, max_l=2):
# Выстраиваем буквы слов оптимальным по Левенштейну образом и
# извлекаем модификации ограниченной длины. Чтобы после подсчёта
# расстояния восстановить оптимальное расположение букв, будем
# хранить в таблице помимо расстояний указатели на предыдущие
# ячейки: memo будет хранить соответствие
# i -> j -> (distance, prev i, prev j).
# Дальше немного непривычно страшного Python кода - вот что
# бывает, когда язык используется не по назначению!
m, n = len(intended_word), len(misspelled_word)
memo = [[None] * (n+1) for _ in range(m+1)]
memo[0] = [(j, (0 if j > 0 else -1), j-1) for j in range(n+1)]
for i in range(m + 1):
memo[i][0] = i, i-1, (0 if i > 0 else -1)
for j in range(1, n + 1):
for i in range(1, m + 1):
if intended_word[i-1] == misspelled_word[j-1]:
memo[i][j] = memo[i-1][j-1][0], i-1, j-1
else:
best = min(
(memo[i-1][j][0], i-1, j),
(memo[i][j-1][0], i, j-1),
(memo[i-1][j-1][0], i-1, j-1),
)
# Отдельная обработка для перепутанных местами
# соседних букв (распространённая ошибка при
# печати).
if (i > 1
and j > 1
and intended_word[i-1] == misspelled_word[j-2]
and intended_word[i-2] == misspelled_word[j-1]
):
best = min(best, (memo[i-2][j-2][0], i-2, j-2))
memo[i][j] = 1 + best[0], best[1], best[2]
# К концу цикла расстояние по Левенштейну между исходными словами # хранится в memo[m][n][0].
# Теперь восстанавливаем оптимальное расположение букв.
s, t = [], []
i, j = m, n
while i >= 1 or j >= 1:
_, pi, pj = memo[i][j]
di, dj = i - pi, j - pj
if di == dj == 1:
s.append(intended_word[i-1])
t.append(misspelled_word[j-1])
if di == dj == 2:
s.append(intended_word[i-1])
s.append(intended_word[i-2])
t.append(misspelled_word[j-1])
t.append(misspelled_word[j-2])
if 1 == di > dj == 0:
s.append(intended_word[i-1])
t.append("")
if 1 == dj > di == 0:
s.append("")
t.append(misspelled_word[j-1])
i, j = pi, pj
s.reverse()
t.reverse()
# Генерируем модификации длины не выше заданной.
for i, _ in enumerate(s):
ss = ts = ""
while len(ss) < max_l and i < len(s):
ss += s[i]
ts += t[i]
yield ss, ts
i += 1
Сам подсчёт правок выглядит элементарно, хотя длиться может долго.
Применяем модель ошибок
Эта часть реализована в виде микросервиса на Go, связанного с основным бэкендом через gRPC. Реализован алгоритм, описанный самими Бриллом и Муром [2], с небольшими оптимизациями. Работает он у меня в итоге примерно вдвое медленнее, чем заявляли авторы; не берусь судить, дело в Go или во мне. Но по ходу профилировки я узнал о Go немного нового.
- Не используйте
math.Max, чтобы считать максимум. Это примерно в три раза медленнее, чемif a > b { b = a }! Только взгляните на реализацию этой функции:// Max returns the larger of x or y. // // Special cases are: // Max(x, +Inf) = Max(+Inf, x) = +Inf // Max(x, NaN) = Max(NaN, x) = NaN // Max(+0, ±0) = Max(±0, +0) = +0 // Max(-0, -0) = -0 func Max(x, y float64) float64 func max(x, y float64) float64 { // special cases switch { case IsInf(x, 1) || IsInf(y, 1): return Inf(1) case IsNaN(x) || IsNaN(y): return NaN() case x == 0 && x == y: if Signbit(x) { return y } return x } if x > y { return x } return y }Если только вам ВДРУГ не нужно, чтобы +0 обязательно был больше -0, не используйте
math.Max. - Не используйте хэш-таблицу, если можете использовать массив. Это, конечно, довольно очевидный совет. Мне пришлось перенумеровывать символы юникода в числа в начале программы так, чтобы использовать их как индексы в массиве потомков узла trie (такой lookup был очень частой операцией).
- Коллбеки в Go недёшевы. В ходе рефакторинга во время код ревью некоторые мои потуги сделать decoupling ощутимо замедлили программу при том, что формально алгоритм не изменился. С тех пор я остаюсь при мнении, что оптимизирующему компилятору Go есть, куда расти.
Применяем модель языка
Здесь без особых сюрпризов был реализован алгоритм динамического программирования, описанный в разделе выше. На этот компонент пришлось меньше всего работы — самой медленной частью остаётся применение модели ошибок. Поэтому между этими двумя слоями было дополнительно прикручено кэширование результатов модели ошибок в Redis.
Результаты
По итогам этой работы (занявшей примерно человекомесяц) мы провели A/B тест опечаточника на наших пользователях. Вместо 10% пустых выдач среди всех поисковых запросов, которые мы имели до внедрения опечаточника, их стало 5%; в основном оставшиеся запросы приходятся на товары, которых просто нет у нас на платформе. Также увеличилось количество сессий без второго поискового запроса (и ещё несколько метрик такого рода, связанных с UX). Метрики, связанные с деньгами, впрочем, значимо не изменились — это было неожиданно и сподвигло нас к тщательному анализу и перепроверке других метрик.
Заключение
Стивену Хокингу как-то сказали, что каждая включенная им в книгу формула вдвое уменьшит число читателей. Что ж, в этой статье их порядка полусотни — поздравляю тебя, один из примерно
 читателей, добравшихся до этого места!
читателей, добравшихся до этого места!
Бонус
Ссылки
[1] M. D. Kernighan, K. W. Church, W. A. Gale. A Spelling Correction Program Based on a Noisy Channel Model. Proceedings of the 13th conference on Computational linguistics — Volume 2, 1990.
[2] E.Brill, R. C. Moore. An Improved Error Model for Noisy Channel Spelling Correction. Proceedings of the 38th Annual Meeting on Association for Computational Linguistics, 2000.
[3] T. Brants, A. C. Popat, P. Xu, F. J. Och, J. Dean. Large Language Models in Machine Translation. Proceedings of the 2007 Conference on Empirical Methods in Natural Language Processing.
[4] C. Whitelaw, B. Hutchinson, G. Y. Chung, G. Ellis. Using the Web for Language Independent Spellchecking and Autocorrection. Proceedings of the 2009 Conference on Empirical Methods in Natural Language Processing: Volume 2.
#статьи
- 21 ноя 2019
-
15
В данном руководстве я расскажу, где искать причину возникновения ошибки сканирования сайта и как вернуть страницы в индекс Google.
vlada_maestro / shutterstock

SEO-специалист компании Adindex.ua

Googlebot не всегда должным образом обрабатывает директивы в тегах <meta name=”robots”>. Одной из причин может быть неверное расположение этих элементов в структуре кода страницы. Из-за этого нужные страницы выпадают из поиска, а нежелательные, наоборот, попадают.
На сайте нашего клиента были реализованы метатеги noindex (для закрытия страниц от индексации поисковым роботом) и canonical (для указания основной версии страницы для Googlebot). Эти теги размещались в секции <head> и были действительны, однако поисковый робот не мог их распознать.
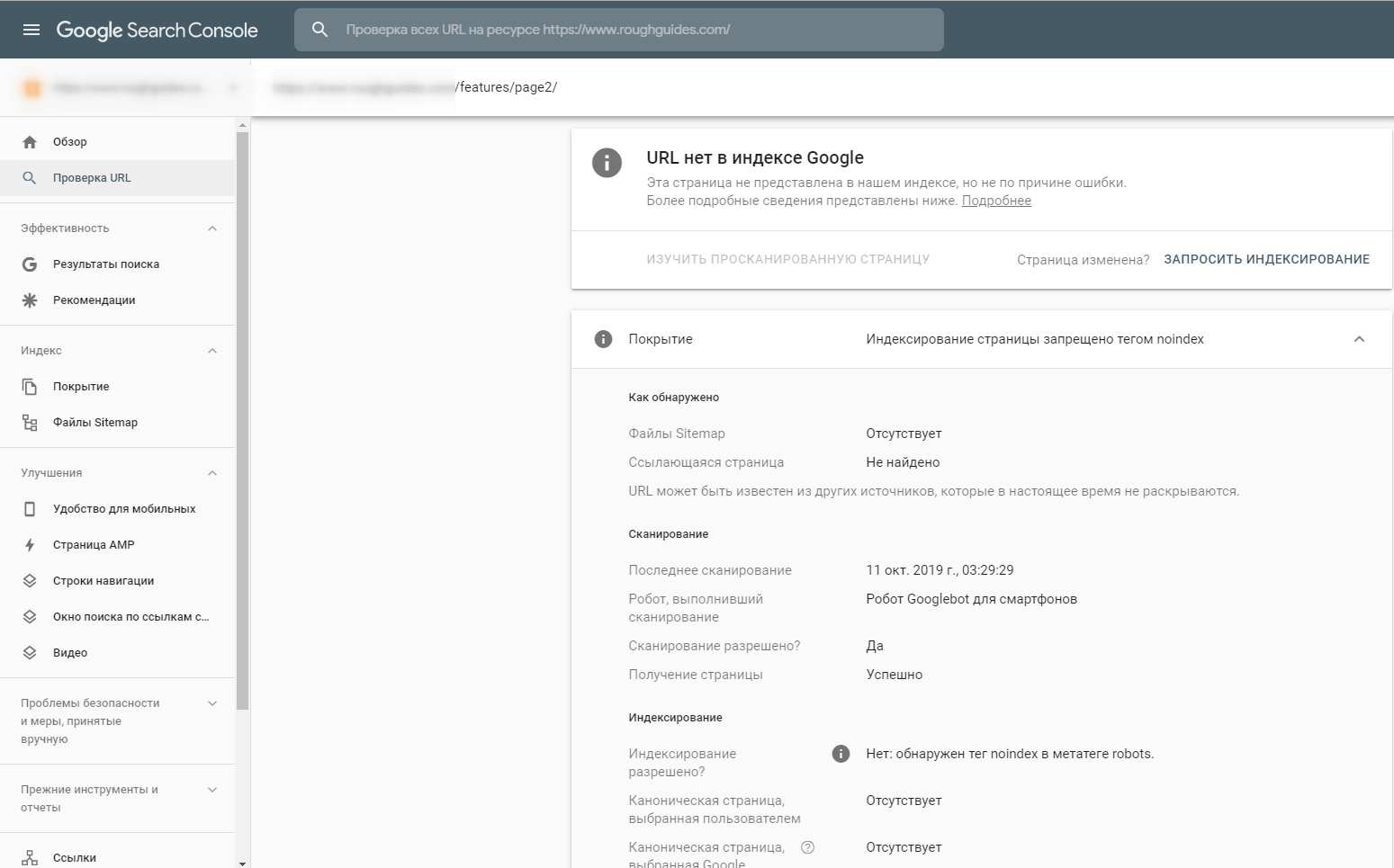
Как следствие, в индекс Google попадали страницы, ненужные с точки зрения поискового продвижения. Проверка страниц в консоли поиска показала, что Googlebot не видит установленные директивы <meta name=”robots”>:
Для поиска решения проблемы сравнили исходный HTML-код страницы с готовым DOM. Первое — это код, который браузер выдаёт в режиме просмотра кода страницы, а второе — то, что браузер использует для показа страницы конечным пользователям, когда весь код выполнен на стороне клиента (например, JavaScript-сценарии).
В результате заметили интересную особенность: в необработанном HTML-коде стоял блок JavaScript, он находился над метатегами robots. Когда страница была полностью обработана и весь код на стороне клиента выполнен, JavaScript вставлял на страницу дополнительный блок <iframe>, который размещался над метатегами.
Этот блок кода оказался проблематичным в связи с двухэтапным процессом индексации Google:
- Первый этап индексации основан на исходном коде HTML веб-страницы, когда никакие клиентские скриптовые сценарии не выполняются как часть процесса индексации.
- На втором этапе Google выполняет индексацию той же страницы, но с загрузкой клиентских сценариев, и страница отображается в том виде, как это сделал бы веб-браузер.
Проблема была как раз на втором этапе индексации. JavaScript-сценарий вставлял блок скриптов над метатегами robots в финальном коде страницы. Но по официальному стандарту W3C блок не принадлежит разделу <head> кода страницы и должен находиться в <body>.
Когда Google видит данный блок в разделе <head>, он предполагает, что <head> завершился и начался раздел <body> страницы. Судя по всему, Google обрабатывает метатеги как часть второго этапа индексации. Это и стало причиной ошибки, так как Google преждевременно обработал остальной код скриптового блока как часть <body> и проигнорировал наличие тегов robots.
Решение проблемы оказалось довольно простым — переместить метатеги robots над блоком скриптов в разделе <head>. В течение нескольких дней бот распознал изменения и начал сообщать о них в Google Search Console:
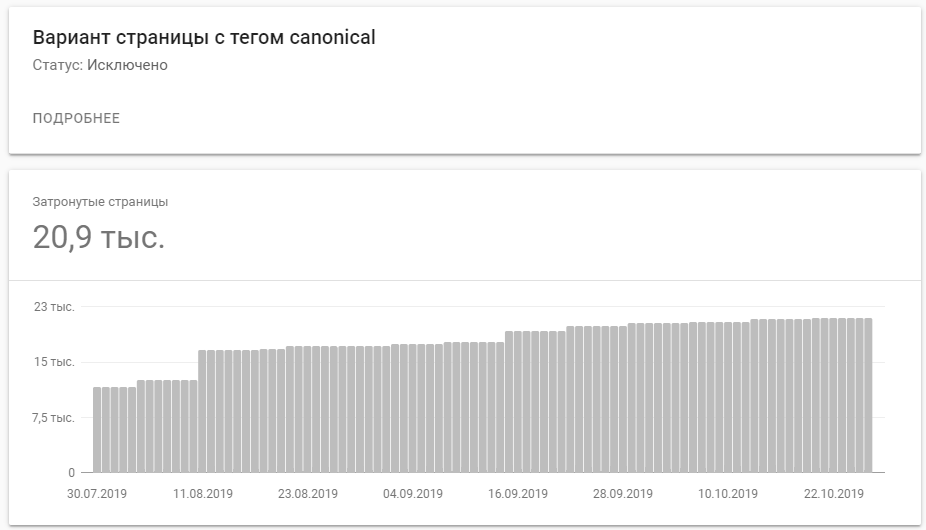
Количество проиндексированных страниц с тегом canonical заметно увеличилось. Вот такую динамику показывает Google Search Console:

Научитесь: Интернет-маркетолог с нуля
Узнать больше
Всем доброго времени суток! Совсем недавно столкнулся с ошибкой 404 именно в поисковике «Яндекс». Как понимаю многих тяготит данная проблема, поэтому я решил написать более подробную статью по данной теме. Начнем с того, что ошибка 404 может возникнуть и появится не только в поисковике.
Также она не зависит от установленной операционной системы: Windows XP, 7, 8.1, 10 или даже Android и iOS. На других сайтах может быть также надпись: «Not Found», «Страницы не существует» или «Нет такой страницы». Как вы уже поняли данная ошибка может возникнуть на любом сайте и странице.
Содержание
- Причины появления ошибки 404
- Как убрать ошибку
- Задать вопрос автору статьи
Чаще всего такая ошибка возникает, если при запросе к серверу он не может найти такую страницу. Например, вам скинули какую-то ссылку, вы на неё пытаетесь зайти, но зайти не можете и вылезает подобное сообщение – именно потому, что данной страницы просто нет. Чаще всего это происходит, когда ссылку нечаянно меняют при отправке добавляя в неё некоторые символы.
Давайте расскажу на примере. Вот у нас есть ссылка:
https://wifigid.ru/besprovodnye-tehnologii/wi-fi
Если скопировать эту ссылку или вставить куда-то, то вы без проблем попадете на установленную страницу. Но если в строку ссылки добавить какой-нибудь символ или удалить что-то, то вы увидите вот такое окошко.
Как видите я добавил в конец ссылки два символа и теперь страница не открывается. Как видите у нас нет надписи 404 ошибки, но сам смысл и посыл подобного предупреждения – одинаковый. На других сайтах данные статьи могут иметь разный дизайн.
В первую очередь нужно проверить правильность ссылки, потому что чаще всего люди отправляя адрес страницы могут нечаянно его изменить. Очень часто бывает, когда администраторы сайтов уделают или переносят страницы в другое место. Поэтому тут вашей вины нет, как вариант можно поискать на сайте в строке поиска нужную страницу по данному запросу или теме.
Как убрать ошибку
На самом деле точно решить данную проблему нельзя, так как проблема не у вас. Если вам ссылку скинул друг или знакомый, то попросите его продублировать её. Возможно, при отправке он как я и говорил ранее, нечаянно прописал лишний символ или поставил пробел.
![]()
Второй вариант — это ещё раз попробовать прогрузить этот сайт. Найдите кнопку перезагрузки страницы и нажмите её (имеет значок закругленной стрелочки).
![]()
Очень часто пользователь сам дописывает некоторые символы – посмотрите в ссылку и удалите лишнее, если найдете. Есть ещё один действенный способ найти нужный адрес вот по такой битой ссылке. Откройте любой поисковик «Яндекс» или «Google» и вставьте данный адрес в поиск.
Я в качестве эксперимента вставил ту самую битую ссылку, куда я добавил в конец два символа и Яндекс мне быстро нашел нужный адрес. Далее просто переходим на страницу. Второй вариант — это перейти на главную страницу сайта. После этого нужно найти поисковую строчку и вписать туда название темы, которую вы искали.
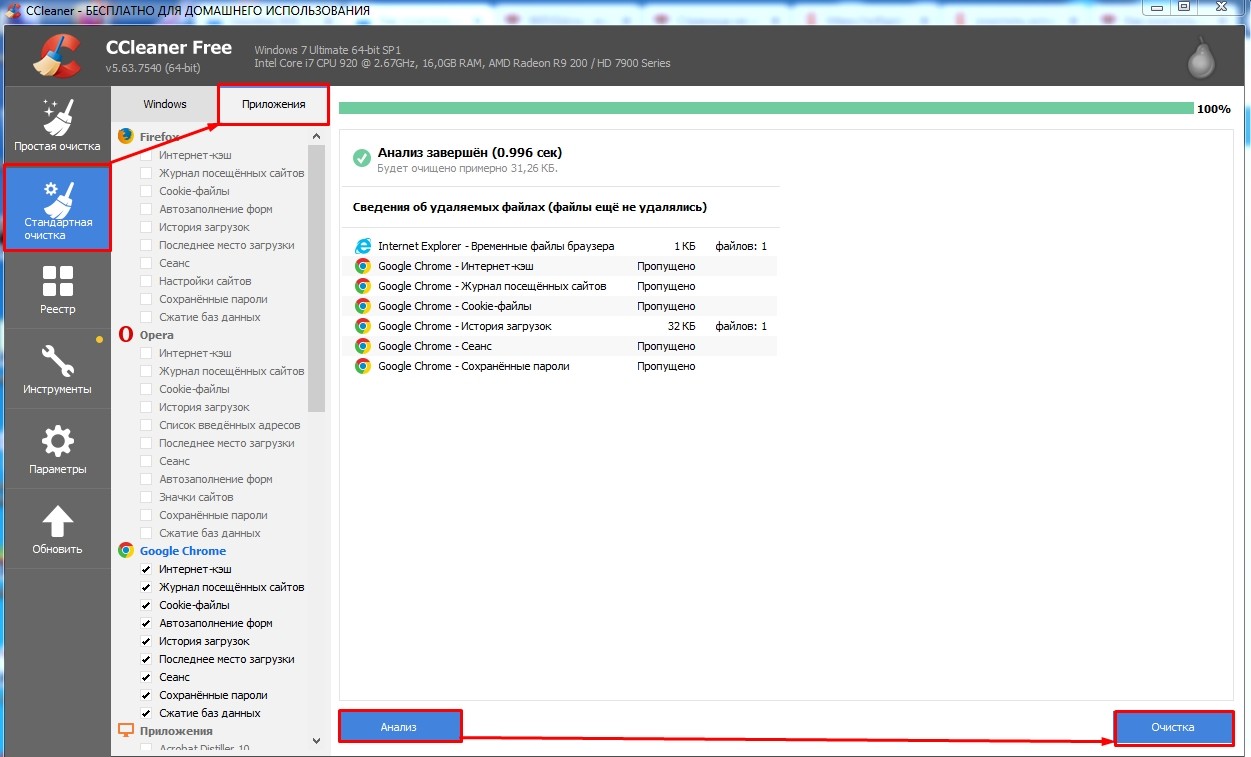
Попробуйте открыть ссылку в другом браузере: Google Chrome, Yandex, Opera и т.д. Если у вас получится открыть данную страницу, то вам нужно очистить кэш вашего браузера. Это можно сделать через «Историю браузера» в настройках. Или сделать с помощью программы CCleaner. Запускаем приложением заходим: «Стандартная очистка» – «Приложения». Установите галочки только возле своего браузера (для этого достаточно нажать на иконку). После этого нажимаем «Анализ» и «Очистка».
Если вы не можете зайти даже на главную страницу, то возможно на сервере ведутся какие-то технические работы и он пока не доступен. Поэтому можно попробовать зайти на него через какое-то время. Иногда бывает, что страница удалена с сайта самим администратором – поэтому поводу можно узнать у них, отправив свой вопрос на почту.
Бывают случаи, когда проблема появляется из-за кривых DNS адресов, которые используется у вашего провайдера. Но можно прописать их вручную.
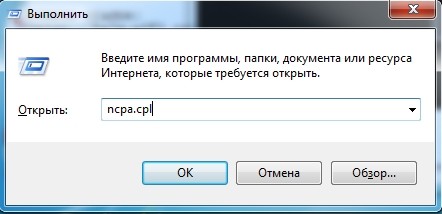
- Нажмите одновременно на клавиши и R.

- Прописываем: «ncpa.cpl».
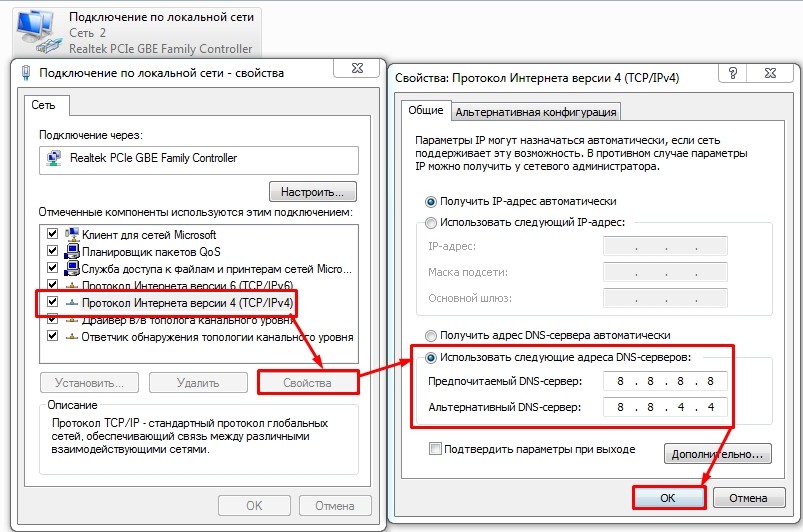
- Выберите именно то подключение, через которое у вас идет интернет. Нажимаем правой кнопкой по нему и заходим в «Свойства». После этого выберите четвертый протокол и зайдите в его свойство. Укажите DNS адреса (8.8.8.8 и 8.8.4.4) как на картинке ниже. В конце два раза нажмите «ОК».
Если вам ничего не помогло, то напишите об этом в комментариях и опишите именно свой случай. Также вы можете писать свои решения там же. Помните – вы всегда можете обратиться ко мне или любому из наших специалистов там же в комментариях.
Каждому сайту нужны внимание и забота. Гораздо эффективнее, когда над ним работает много заботливых рук профессионалов. Но в реальности у разработчиков и оптимизаторов часто не хватает времени для исправления досадных ошибок, которые могут сильно повлиять на поведение пользователей и дать существенную пробоину в получении трафика.

Когда я открываю какую-то страницу из поиска и вижу “404 Not Found”, то очень сильно раздражаюсь и негодую.
Ведь я потратила на это время, предвкушая, что вот-вот найду полезный и интересный контент, но….. Зайду ли я на этот сайт еще раз? В 99% – нет. Так поступает большинство пользователей. Но не будем впадать в панику и пессимизм.
Что же это за ошибка, откуда она берется и как это исправить – поговорим в этой статье.
Почему пишет страница не найдена?
И на этот вопрос есть несколько ответов.
- Во-первых, пользователь неверно ввел адрес в строку браузера: забыл символ, букву, цифру итд. Сервер запрос получил, но вот найти такую страницу не смог.
- Во-вторых, сбои с правильным отображением могут происходить из-за нарушений сеансов связи.
- В-третьих, ошибка not found может появиться в случае некорректного функционирования самого сервера, который выдает такой месседж даже при нормально работающем сайте. Такое встречается крайне редко и связано с вирусными атаками.
- В-четвертых, код ошибки 404 означает, что на сайте есть физически несуществующая страница.
Раскладываем на слагаемые
Мало кто знает о том, что каждая цифра в 404 имеет свою символику. Первая четверка повествует о том, что поисковый запрос занял очень много времени или сам пользователь допустил ошибку и неверно ввел url. Ноль говорит о синтаксической ошибке, а оставшаяся четверка указывает на то, что запрошенный источник не был найден.
В большинстве случаев это пугает пользователей, поэтому важно по максимуму сделать ее привлекательной, чтобы посетитель не ушел сразу, а продолжил свое путешествие по вашему сайту в поисках нужной информации. Но многие разработчики не уделяют должного внимания этой ошибке и поэтому теряют пользователей.
Что такое идеальная страница 404 Not Found?
Большинство страниц имеет однотипное и безликое оформление ошибки. Но привлекательная картинка или текст могут существенно сгладить негативное впечатление и стать своеобразным извинением перед пользователем за досадную ошибку. Если подойти к этому вопросу серьезно, то страница с ошибкой может решать такие задачи как:
- привлекать внимание посетителей
- Объяснять причину ошибку
- давать инструкцию для исправления
Почему бы не прибегнуть к юмору и креативу? Посмотрите удачные примеры оформления страниц с 404 ошибкой:
Любое препятствие или ошибку можно превратить в возможность. Именно в возможность выделиться среди конкурентов. Ошибка 404 для этого подходит как нельзя лучше. Укажите там контакты. Если это интернет – магазин, то устройте грандиозную распродажу. А знаете ли вы, что в глобальной сети интернет ходит легенда о том, что самый первый сервер находился именно в комнате № 404 Европейской Ассоциации по ядерным исследованиям. Поверили?:) Представляете, если обыграть так всю страницу в виде засекреченной лаборатории, в комнате с роковым номером, заваленной сложнейшим оборудованием работают и живут фанатики своего дела. Мигание разноцветных индикаторов отражается на их белых халатах. Они обмениваются фразами, непонятными непосвященным, общаются на языке цифр, как будто и сами превратились в детали своих удивительных машин. Поиграйте с анимацией, видео, гифками.
Согласитесь, что такие картинки могут зацепить внимание посетителей и продлить время их пребывания на сайте. Помимо забавной картинки можно разместить полезную информацию, касающуюся тематики вашего бизнеса или просто развлекательный контент.
Как удалить ошибку 404
Самый действенный способ исправить подобный опус – правильно ввести страницу в строку браузера и обновить ее при помощи клавиши F5, она работает одинаково во всех браузерах.
Второй способ – проверить уровень соединения с интернетом. Ошибка 404 может показываться, если отсутствует подключение.
Третий способ – ошибка также вылезает, когда пользователь сам неправильно ввел адрес ресурса. Для ее исправления достаточно внимательно проверить адрес и скорректировть его.
Четвертый способ – бывает так, что иногда нужно просто перейти на один уровень вверх в случае связанного ресурса.
Пятый способ – проверить, правда ли существует нужная страница, можно в поисковике или на мобильном гаджете. Для инициализации существуют и более продвинутые сервисы, например, WhoIs.
В нужную строку просто введите адрес и система сама выдаст всю информацию по объекту: подтверждение физического существования, провайдер, сайт итд.
Иногда случается и так, что пользователь не может ничего сделать – страница не обновляется и ошибка не исчезает. Причина кроется в том, что владелец сайта перенес информацию на новый ресурс, но не привязал старый адрес к новому. Если информация нужна срочно и вы уверены, что она там раньше была, можно отправить сообщение владельцу сайта по электронной почте и уточнить причину ошибки.
Рекомендации специалистам: как найти все 404 ссылки на сайте
Чтобы качественно проверить все страницы, лучше воспользоваться сразу несколькими специализированными сервисами: плагин Broken Link Checker для WordPress, инструменты Google Web Masters Tool и аналогичные сервисы в Яндексе. Есть еще специальный файл htaccess, который помогает настроить редиректы, права доступа для разных админов, авторизацию и позволяет настраивать собственные общие страницы ошибок, в том числе 404. Проверить ссылки можно и через специализированные сервисы, которыми пользоваться очень просто: достаточно ввести в строку поиска ссылку и система выдаст результат уже через пару минут.
Влияет ли ошибка на ранжирование в поисковиках?
Дело в том, что подобные ошибки сокращают время пребывание пользователей на сайте, а в 2018 году этот показатель стал учитываться поисковиками при ранжировании сайта. Яндекс и Гугл видят в этом угрозу снижения качества сайта и низкое соответствие запросам пользователей. И даже могут понизить сайт в результатах поиска.
404 ошибка – это не критично, но все-таки поможет повлиять на поведение пользователей. Уделите время на то, чтобы сделать эту страницу по максимуму полезной и интересной.

Богдан Василенко
SEO-специалист SE Ranking
По каждому запросу поисковая система подбирает релевантные результаты — страницы, подходящие по тематике, и ранжирует их, отображая в виде списка. Согласно исследованиям, 99 % пользователей находят информацию, отвечающую запросу, уже на первой странице выдачи и не пролистывают дальше. И чем выше позиция сайта в топ-10, тем больше посетителей она привлекает.
Перед тем, как распределить ресурсы в определенном порядке, поисковики оценивают их по ряду параметров. Это позволяет улучшить выдачу для пользователя, предоставляя наиболее полезные, удобные и авторитетные варианты.
В чём заключается оптимизация сайта?
Оптимизация сайта или SEO (Search Engine Optimization) представляет собой комплекс действий, цель которых — улучшить качество ресурса и адаптировать его с учётом рекомендаций поисковых систем.
SEO помогает попасть содержимому сайта в индекс, улучшить позиции его страниц при ранжировании и увеличить органический, то есть бесплатный трафик. Техническая оптимизация сайта — это важный этап SEO, направленный на работу с его внутренней частью, которая обычно скрыта от пользователей, но доступна для поисковых роботов.
Страницы представляют собой HTML-документы, и их отображение на экране — это результат воспроизведения браузером HTML-кода, от которого зависит не только внешний вид сайта, но и его производительность. Серверные файлы и внутренние настройки ресурса могут влиять на его сканирование и индексацию поисковиком.
SEO включает анализ технических параметров сайта, выявление проблем и их устранение. Это помогает повысить позиции при ранжировании, обойти конкурентов, увеличить посещаемость и прибыль.
Как обнаружить проблемы SEO на сайте?
Процесс оптимизации стоит начать с SEO-аудита — анализа сайта по самым разным критериям. Есть инструменты, выполняющие оценку определенных показателей, например, статус страниц, скорость загрузки, адаптивность для мобильных устройств и так далее. Альтернативный вариант — аудит сайта на платформе для SEO-специалистов.
Один из примеров — сервис SE Ranking, объединяющий в себе разные аналитические инструменты. Результатом SEO-анализа будет комплексный отчёт. Для запуска анализа сайта онлайн нужно создать проект, указать в настройках домен своего ресурса, и перейти в раздел «Анализ сайта». Одна из вкладок — «Отчёт об ошибках», где отображаются выявленные проблемы оптимизации.
Все параметры сайта разделены на блоки: «Безопасность», «Дублирование контента», «Скорость загрузки» и другие. При нажатии на любую из проблем появится её описание и рекомендации по исправлению. После технической SEO оптимизации и внесения корректировок следует повторно запустить аудит сайта. Увидеть, были ли устранены ошибки, можно колонке «Исправленные».
Ошибки технической оптимизации и способы их устранения
Фрагменты кода страниц, внутренние файлы и настройки сайта могут негативно влиять на его эффективность. Давайте разберём частые проблемы SEO и узнаем, как их исправить.
Отсутствие протокола HTTPS
Расширение HTTPS (HyperText Transfer Protocol Secure), которое является частью доменного имени, — это более надежная альтернатива протоколу соединения HTTP. Оно обеспечивает шифрование и сохранность данных пользователей. Сегодня многие браузеры блокируют переход по ссылке, начинающейся на HTTP, и отображают предупреждение на экране.
Поисковые системы учитывают безопасность соединения при ранжировании, и если сайт использует версию HTTP, это будет минусом не только для посетителей, но и для его позиций в выдаче.
Как исправить
Чтобы перевести ресурс на HTTPS, необходимо приобрести специальный сертификат и затем своевременно продлевать срок его действия. Настроить автоматическое перенаправление с HTTP-версии (редирект) можно в файле конфигурации .htaccess.
После перехода на безопасный протокол будет полезно выполнить аудит сайта и убедиться, что всё сделано правильно, а также при необходимости заменить неактуальные URL с HTTP среди внутренних ссылок (смешанный контент).
У сайта нет файла robots.txt
Документ robots размещают в корневой папке сайта. Его содержимое доступно по ссылке website.com/robots.txt. Этот файл представляет собой инструкцию для поисковых систем, какое содержимое ресурса следует сканировать, а какое нет. К нему роботы обращаются в первую очередь и затем начинают обход сайта.
Ограничение сканирования файлов и папок особенно актуально для экономии краулингового бюджета — общего количества URL, которое может просканировать робот на данном сайте. Если инструкция для краулеров отсутствует или составлена неправильно, это может привести к проблемам с отображением страниц в выдаче.
Как исправить
Создайте текстовый документ с названием robots в корневой папке сайта и с помощью директив пропишите внутри рекомендации по сканированию содержимого страниц и каталогов. В файле могут быть указаны виды роботов (user-agent), для которых действуют правила; ограничивающие и разрешающие команды (disallow, allow), а также ссылка на карту сайта (sitemap).
Проблемы с файлом Sitemap.xml
Карта сайта — это файл, содержащий список всех URL ресурса, которые должен обойти поисковый робот. Наличие sitemap.xml не является обязательным условием, для попадания страниц в индекс, но во многих случаях файл помогает поисковику их обнаружить.
Обработка XML Sitemap может быть затруднительна, если ее размер превышает 50 МБ или 50000 URL. Другая проблема — присутствие в карте страниц, закрытых для индексации метатегом noindex. При использовании канонических ссылок на сайте, выделяющих их похожих страниц основную, в файле sitemap должны быть указаны только приоритетные для индексации URL.
Как исправить
Если в карте сайта очень много URL и её объем превышает лимит, разделите файл на несколько меньших по размеру. XML Sitemap можно создавать не только для страниц, но и для изображений или видео. В файле robots.txt укажите ссылки на все карты сайта.
В случае, когда SEO-аудит выявил противоречия, — страницы в карте сайта, имеющие запрет индексации noindex в коде, их необходимо устранить. Также проследите, чтобы в Sitemap были указаны только канонические URL.
Дубли контента
Один из важных факторов, влияющих на ранжирование, — уникальность контента. Недопустимо не только копирование текстов у конкурентов, но и дублирование их внутри своего сайта. Это проблема особенно актуальна для больших ресурсов, например, интернет-магазинов, где описания к товарам имеют минимальные отличия.
Причиной, почему дубли страниц попадают в индекс, может быть отсутствие или неправильная настройка «зеркала» — редиректа между именем сайта с www и без. В этом случае поисковая система индексирует две идентичные страницы, например, www.website.com и website.com.
Также к проблеме дублей приводит копирование контента внутри сайта без настройки канонических ссылок, определяющих приоритетную для индексации страницу из похожих.
Как исправить
Настройте www-редиректы и проверьте с помощью SEO-аудита, не осталось ли на сайте дублей. При создании страниц с минимальными отличиями используйте канонические ссылки, чтобы указать роботу, какие из них индексировать. Чтобы не ввести в заблуждение поисковые системы, неканоническая страница должна содержать тег rel=”canonical” только для одного URL.
Страницы, отдающие код ошибки
Перед тем, как отобразить страницу на экране, браузер отправляет запрос серверу. Если URL доступен, у него будет успешный статус HTTP-состояния — 200 ОК. При возникновении проблем, когда сервер не может выполнить задачу, страница возвращает код ошибки 4ХХ или 5ХХ. Это приводит к таким негативным последствиям для сайта, как:
- Ухудшение поведенческих факторов. Если вместо запрошенной страницы пользователь видит сообщение об ошибке, например, «Page Not Found» или «Internal Server Error», он не может получить нужную информацию или завершить целевое действие.
- Исключение контента из индекса. Когда роботу долго не удается просканировать страницу, она может быть удалена из индекса поисковой системы.
- Расход краулингового бюджета. Роботы делают попытку просканировать URL, независимо от его статуса. Если на сайте много страниц с ошибками, происходит бессмысленный расход краулингового лимита.
Как исправить
После анализа сайта найдите страницы в статусе 4ХХ и 5ХХ и установите, в чём причина ошибки. Если страница была удалена, поисковая система через время исключит её из индекса. Ускорить этот процесс поможет инструмент удаления URL. Чтобы своевременно находить проблемные страницы, периодически повторяйте поиск проблем на сайте.
Некорректная настройка редиректов
Редирект — это переадресация в браузере с запрошенного URL на другой. Обычно его настраивают при смене адреса страницы и её удалении, перенаправляя пользователя на актуальную версию.
Преимущества редиректов в том, что они происходят автоматически и быстро. Их использование может быть полезно для SEO, когда нужно передать наработанный авторитет от исходной страницы к новой.
Но при настройке переадресаций нередко возникают такие проблемы, как:
- слишком длинная цепочка редиректов — чем больше в ней URL, тем позже отображается конечная страница;
- зацикленная (циклическая) переадресация, когда страница ссылается на себя или конечный URL содержит редирект на одно из предыдущих звеньев цепочки;
- в цепочке переадресаций есть неработающий, отдающий код ошибки URL;
- страниц с редиректами слишком много — это уменьшает краулинговый бюджет.
Как исправить
Проведите SEO-аудит сайта и найдите страницы со статусом 3ХХ. Если среди них есть цепочки редиректов, состоящие из трех и более URL, их нужно сократить до двух адресов — исходного и актуального. При выявлении зацикленных переадресаций необходимо откорректировать их последовательность. Страницы, имеющие статус ошибки 4ХХ или 5ХХ, нужно сделать доступными или удалить из цепочки.
Низкая скорость загрузки
Скорость отображения страниц — важный критерий удобства сайта, который поисковые системы учитывают при ранжировании. Если контент загружается слишком долго, пользователь может не дождаться и покинуть ресурс.
Google использует специальные показатели Core Web Vitals для оценки сайта, где о скорости говорят значения LCP (Largest Contentful Paint) и FID (First Input Delay). Рекомендуемая скорость загрузки основного контента (LCP) — до 2,5 секунд. Время отклика на взаимодействие с элементами страницы (FID) не должно превышать 0,1.
К распространённым факторам, негативно влияющим на скорость загрузки, относятся:
- объёмные по весу и размеру изображения;
- несжатый текстовый контент;
- большой вес HTML-кода и файлов, которые добавлены в него в виде ссылок.
Как исправить
Стремитесь к тому, чтобы вес HTML-страниц не превышал 2 МБ. Особое внимание стоит уделить изображениям сайта: выбирать правильное расширение файлов, сжимать их вес без потери качества с помощью специальных инструментов, уменьшать слишком крупные по размеру фотографии в графическом редакторе или через панель управления сайтом.
Также будет полезно настроить сжатие текстов. Благодаря заголовку Content-Encoding, сервер будет уменьшать размер передаваемых данных, и контент будет загружаться в браузере быстрее. Также полезно оптимизировать объем страницы, используя архивирование GZIP.
Не оптимизированы элементы JavaScript и CSS
Код JavaScript и CSS отвечает за внешний сайта. С помощью стилей CSS (Cascading Style Sheets) задают фон, размер и цвета блоков страницы, шрифты текста. Сценарии на языке JavaScript делают дизайн сайта динамичным.
Элементы CSS/JS важны для ресурса, но в то же время они увеличивают общий объём страниц. Файлы CSS, превышающие по размеру 150 KB, а JavaScript — 2 MB, могут негативно влиять на скорость загрузки.
Как исправить
Чтобы уменьшить размер и вес кода CSS и JavaScript, используют такие технологии, как сжатие, кэширование, минификация. SEO-аудит помогает определить, влияют ли CSS/JS-файлы на скорость сайта и какие методы оптимизации использованы.
Кэширование CSS/JS-элементов снижает нагрузку на сервер, поскольку в этом случае браузер загружает сохранённые в кэше копии контента и не воспроизводит страницы с нуля. Минификация кода, то есть удаление из него ненужных символов и комментариев, уменьшает исходный размер. Ещё один способ оптимизации таблиц стилей и скриптов — объединение нескольких файлов CSS и JavaScript в один.
Отсутствие мобильной оптимизации
Когда сайт подходит только для больших экранов и не оптимизирован для смартфонов, у посетителей возникают проблемы с его использованием. Это негативно отражается на поведенческих факторах и, как следствие, позициях при ранжировании.
Шрифт может оказаться слишком мелким для чтения. Если элементы интерфейса размещены слишком близко друг к другу, нажать на кнопку и ссылку проще только после увеличения фрагмента экрана. Нередко загруженная на смартфоне страница выходит за пределы экрана, и для просмотра контента приходится использовать нижнюю прокрутку.
О проблемах с настройками мобильной версии говорит отсутствие метатега viewport, отвечающего за адаптивность страницы под экраны разного формата, или его неправильное заполнение. Также о нестабильности элементов страницы во время загрузки информирует еще показатель производительности сайта Core Web Vitals — CLS (Cumulative Layout Shift). Его норма: 0,1.
Как исправить
В качестве альтернативы отдельной версии для мобильных устройств можно создать сайт с адаптивным дизайном. В этом случае его внешний вид, компоновка и величина блоков будет зависеть от размера экрана конкретного пользователя.
Обратите внимание, чтобы в HTML-коде страниц были метатеги viewport. При этом значение device-width не должно быть фиксированным, чтобы ширина страницы адаптировалась под размер ПК, планшета, смартфона.
Отсутствие alt-текста к изображениям
В HTML-коде страницы за визуальный контент отвечают теги <img>. Кроме ссылки на сам файл, тег может содержать альтернативный текст с описанием изображения и ключевыми словами.
Если атрибут alt — пустой, поисковику сложнее определить тематику фото. В итоге сайт не сможет привлекать дополнительный трафик из раздела «Картинки», где поисковая система отображает релевантные запросу изображения. Также текст alt отображается вместо фото, когда браузер не может его загрузить. Это особенно актуально для пользователей голосовыми помощниками и программами для чтения экрана.
Как исправить
Пропишите альтернативный текст к изображениям сайта. Это можно сделать после установки SEO-плагина к CMS, после чего в настройках к изображениям появятся специальные поля. Рекомендуем заполнить атрибут alt, используя несколько слов. Добавление ключевых фраз допустимо, но не стоит перегружать описание ими.
Заключение
Технические ошибки негативно влияют как на восприятие сайта пользователями, так и на позиции его страниц при ранжировании. Чтобы оптимизировать ресурс с учётом рекомендаций поисковых систем, нужно сначала провести SEO-аудит и определить внутренние проблемы. С этой задачей справляются платформы, выполняющие комплексный анализ сайта.
К частым проблемам оптимизации можно отнести:
- имя сайта с HTTP вместо безопасного расширения HTTPS;
- отсутствие или неправильное содержимое файлов robots.txt и sitemap.xml;
- медленная загрузка страниц;
- некорректное отображение сайта на смартфонах;
- большой вес файлов HTML, CSS, JS;
- дублированный контент;
- страницы с кодом ошибки 4ХХ, 5ХХ;
- неправильно настроенные редиректы;
- изображения без alt-текста.
Если вовремя находить и исправлять проблемы технической оптимизации сайта, это поможет в продвижении — его страницы будут занимать и сохранять высокие позиции при ранжировании.
