Можно ли спасти смазанное фото — вы точно вводили эту фразу в поисковик, если хоть раз держали в руках камеру. Смазы и ошибки по фокусу — одна из самых часто возникающих проблем, особенно у начинающих фотографов. Беда в том, что такие ошибки сложно исправить, если снимок уже сделан. Однако современные технологии способны на многое и могут исправить смаз даже когда кажется, что это невозможно. О том, как спасти смазанную, нерезкую или расфокусированную фотографию, читайте в этом материале.
 Слева то, как снято, справа — после того, как над фотографией немного поколдовали ретушёры / Фото: Алиса Смирнова, Фотосклад.Эксперт
Слева то, как снято, справа — после того, как над фотографией немного поколдовали ретушёры / Фото: Алиса Смирнова, Фотосклад.Эксперт
О том, можно ли спасти смазанный или расфокусированный снимок, нет единого мнения. Ответ на вопрос, можно ли спасти фото, как слева на иллюстрации выше, зависит от целей, способа дальнейшего использования снимка и общего перфекционизма. Если вам нужна картинка на растяжку поперёк главного проспекта вашего города, то конечно, все эти методы недостаточно совершенны, они не позволят сделать сильно размазанную фотографию звеняще резкой и настолько качественной, что её можно использовать для печати баннера. Проще переснять снимок без брака.
Но если вам нужно фото в соцсети или семейный альбом, тогда можно попробовать спасти его, и никто, скорее всего, даже не поймёт, что изначально лицо ребёнка на снимке выше уходило в нерезкость.
Усиление резкости при помощи High Pass
Как спасти размазанное фото при помощи фильтра Smart Sparpen
Как спасти сильно расфокусированное фото при помощи плагина Topaz Sharpen
Усиление резкости при помощи High Pass
Этот метод подходит для снимков с лёгкой степенью нерезкости. Такие, например, получаются, когда вы снимаете на светосильный объектив, и во время съёмки модель слегка отодвинулась и выскочила из глубины резкости. Или наоборот, когда вы, например, отклонились назад и в результате модель выпала из резкости.
Так происходит потому что у светосильных объективов очень небольшая глубина резкости. На типичном светосильном полтиннике при съёмке поясного портрета она может составлять 5-7 сантиметров. В этом промежутке объект будет резким, дальше — уходить в размытие. И из этого отрезка очень легко вывалиться.
 Сильного брака нет, но лицо чуть-чуть подмыто / Фото: Алиса Смирнова, Фотосклад.Эксперт
Сильного брака нет, но лицо чуть-чуть подмыто / Фото: Алиса Смирнова, Фотосклад.Эксперт
Чтобы исправить эту ошибку, мы будем использовать один из стандартных фильтров Photoshop — High Pass/Цветовой контраст. Его большой плюс в том, что он есть абсолютно во всех версиях фотошопа, ничего дополнительно искать и скачивать не придётся. Ещё одно преимущество — он быстрый и нересурсоёмкий по сравнению с другими методами, о которых речь пойдёт ниже.
Посмотрим, как это работает. Открываем проблемный снимок в Photoshop, делаем копию слоя при помощи команды Ctrl+J. Это нужно для того, чтобы потом при необходимости можно было нарисовать маску слоя.
 Выбираем фильтр в меню Filter/Other/High Pass // Фильтр/Другое/Цветовой контраст / Иллюстрация: Алиса Смирнова, Фотосклад.Эксперт
Выбираем фильтр в меню Filter/Other/High Pass // Фильтр/Другое/Цветовой контраст / Иллюстрация: Алиса Смирнова, Фотосклад.Эксперт
Далее изображение окрасится в серый цвет. Это нормально. На этом этапе нужно задать фильтру нужное значение. Покрутите ползунок, пока детали, которые вы хотите сделать резче, не станут хорошо заметными. Это должно выглядеть примерно так:
 Детали должны читаться, цвета ещё должны быть неразличимы / Иллюстрация: Алиса Смирнова, Фотосклад.Эксперт
Детали должны читаться, цвета ещё должны быть неразличимы / Иллюстрация: Алиса Смирнова, Фотосклад.Эксперт
Применяем фильтр, меняем режим наложения слоя с Normal на Overlay/Перекрытие.
 Слой становится прозрачным, картинка — реще / Иллюстрация: Алиса Смирнова, Фотосклад.Эксперт
Слой становится прозрачным, картинка — реще / Иллюстрация: Алиса Смирнова, Фотосклад.Эксперт
Снимок стал резче, но есть побочный эффект: фильтр усилил резкость, но он усилил и шум. Это неизбежно.
 Слева — до применения фильтра, справа — после / Иллюстрация: Алиса Смирнова, Фотосклад.Эксперт
Слева — до применения фильтра, справа — после / Иллюстрация: Алиса Смирнова, Фотосклад.Эксперт
И тут есть два пути решения проблемы: использовать High Pass в комплекте с шумодавом или пользоваться другими, более умными способами поднятия резкости. Подробнее о том, как бороться с шумами, читайте в этом материале.
Далее можно наложить на слой маску и стереть часть ненужной резкости. Например, в случае с портретами есть смысл оставлять фильтр только на глазах и губах модели и стирать на коже. Это позволит избежать лишних шумов и ненужных деталей: High Pass усиливает резкость всего, в том числе пор и других несовершенств кожи. Подробнее о том, как работать с масками, читайте здесь.
Минусы усиления резкости при помощи High Pass:
- он помогает в простых случаях, где нет сильного смаза;
- он усиливает шумы.
Как спасти размазанное фото при помощи фильтра Smart Sharpen
Smart Sharpen/Умная резкость в целом очень похож на High Pass, но разница в том, что у Smart Sharpen больше тонких настроек. Если научиться с ним работать, можно получить примерно тот же результат по резкости, что и у High Pass, но без усиления шумов.
Чтобы применить Smart Sharpen, открываем снимок в Photoshop, делаем копию слоя и в меню Filter/Фильтр находим команду Sharpen/Smart Sharpen // Резкость/Умная резкость. Открывается такое окно:
 Здесь нас будут интересовать ползунки Amount/Количество, Radius/Радиус, Reduce Noise/Шумоподавление / Иллюстрация: Алиса Смирнова, Фотосклад.Эксперт
Здесь нас будут интересовать ползунки Amount/Количество, Radius/Радиус, Reduce Noise/Шумоподавление / Иллюстрация: Алиса Смирнова, Фотосклад.Эксперт
Самый важный параметр — радиус. Он позволяет разделить информацию на фото на те детали, которые нужно сделать более резкими, и шум, которому более резким становиться не нужно. Самый простой способ подобрать правильное значение — поставить ползунок Amount/Количество примерно на середину и крутить радиус, пока изображение не станет выглядеть хорошо.
После этого можно доработать изображение до идеала, меняя количество и увеличивая значение шумодава.
Также среди базовых настроек Smart Sharpen можно поменять тип расфокуса. В графе Remove можно выбрать тип смаза, с которым фильтр будет бороться. Среди вариантов есть Lens Blur, Gaussian Blur, Motion Blur. Чаще всего лучше всех работает Gaussian Blur, но можно попробовать разные режимы.
Сравним результат работы High Pass и Smart Sharpen:
 Слева Smart Sharpen, справа High Pass. У High Pass картинка получается более шумной Иллюстрация: Алиса Смирнова, Фотосклад.Эксперт
Слева Smart Sharpen, справа High Pass. У High Pass картинка получается более шумной Иллюстрация: Алиса Смирнова, Фотосклад.Эксперт
Как спасти сильно расфокусированное фото при помощи плагина Topaz Sharpen
Если проблемы с резкостью более сильные, чем на примерах выше, чтобы спасти такой снимок, потребуется уже дополнительный софт. Один из удобных инструментов — плагин от Topaz Sharpen. Этот плагин в отличие от встроенных фильтров Photoshop работает не на усилении краевого контраста, а использует нейросеть, чтобы восстановить часть утраченной из-за смаза информации. Посмотрим на него в действии.
Возьмём, к примеру, вот такой снимок с типичной для парных и групповых портретов на светосильные объективы проблемой: ближний человек в резкости, второй уже сильно из неё выскочил.
 Таких ошибок лучше не совершать, но если они уже сделаны, их можно исправить / Фото: Алиса Смирнова, Фотосклад.Эксперт
Таких ошибок лучше не совершать, но если они уже сделаны, их можно исправить / Фото: Алиса Смирнова, Фотосклад.Эксперт
Открываем фото в Photoshop, делаем копию слоя, запускаем Topaz. По умолчанию он прячется в меню фильтров.
 Запуск плагина ничем не отличается от запуска встроенного фильтра Photoshop / Фото: Алиса Смирнова, Фотосклад.Эксперт
Запуск плагина ничем не отличается от запуска встроенного фильтра Photoshop / Фото: Алиса Смирнова, Фотосклад.Эксперт
Плагин достаточно умный и рассчитан на среднего пользователя, который не готов тратить много времени на настройку миллиона ползунков. Интерфейс интуитивно понятный: три основных настройки и несколько второстепенных.
 У фильтра три основных режима: Motion Blur, Out of focus, Too soft / Иллюстрация: Алиса Смирнова, Фотосклад.Эксперт
У фильтра три основных режима: Motion Blur, Out of focus, Too soft / Иллюстрация: Алиса Смирнова, Фотосклад.Эксперт
Каждый из режимов подходит для своего тип смаза. Motion Blur — для смазанного движения (и моделей, и рук фотографа), Out of focus — для объектов, выскочивших из фокуса, Too soft — для фото без ошибки по резкости, но и без выраженной резкости. Too soft — неплохой вариант для снимков на недорогие объективы, в которых нет ошибки по фокусу, просто нет красивой звенящей резкости.
 Результат работы фильтра в разных режимах, слева направо: Out of focus, Too soft, Motion Blur / Иллюстрация: Алиса Смирнова, Фотосклад.Эксперт
Результат работы фильтра в разных режимах, слева направо: Out of focus, Too soft, Motion Blur / Иллюстрация: Алиса Смирнова, Фотосклад.Эксперт
Также есть три кнопки: Normal, Very Noisy (очень шумно) и Very Blurry (очень размыто), с помощью которых вы можете подсказать фильтру суть проблемы на фото. Но выбор типа нерезкости можно полностью доверить автоматике, она неплохо справляется:
 Чтобы включить автоопределение нужно сдвинуть ползунки Auto. Здесь автоматика решила, что проблема снимка — объект вне фокуса и он очень размытый. И она права / Иллюстрация: Алиса Смирнова, Фотосклад.Эксперт
Чтобы включить автоопределение нужно сдвинуть ползунки Auto. Здесь автоматика решила, что проблема снимка — объект вне фокуса и он очень размытый. И она права / Иллюстрация: Алиса Смирнова, Фотосклад.Эксперт
Результат работы фильтра может показаться несколько преувеличенным и гротескным: например, волосы выглядят откровенно рисованными. Отрегулировать степень его воздействия можно при помощью ползунка Remove blur.
Также в конкретно этом случае после применения фильтра стоит нарисовать маску слоя. Это необходимо, чтобы убрать действие фильтра с лица матери, которое изначально было в фокусе, и фона, которому и положено быть в расфокусе.
 Такой снимок уже вполне можно печатать для семейного альбома / Иллюстрация: Алиса Смирнова, Фотосклад.Эксперт
Такой снимок уже вполне можно печатать для семейного альбома / Иллюстрация: Алиса Смирнова, Фотосклад.Эксперт
При работе с Topaz Sharpen стоит помнить, что фильтр умный, но иногда полезно быть умнее. По замыслу создателей плагина, каждый режим подходит для конкретной проблемы. На деле для каждого снимка стоит подбирать режим работы фильтра без оглядки на название этого режима. Бывают случаи, когда объект явно и точно вывалился из фокуса, и по идее нужно использовать Out of focus, но почему-то лучший результат даёт Motion Blur. Не всегда так, но и так бывает.
У плагина есть ряд минусов:
- он не распространяется бесплатно. Его стоимость составляет порядка 75 долларов, но есть бесплатная триал-версия;
- работает на нейросетях, достаточно ресурсоёмкий и на маломощных компьютерах и ноутбуках может работать очень медленно.
Это самая большая его проблема. Например, для просчёта снимка размером 3000 по длинной стороне требуется 10-15 минут на компьютере со следующими параметрами:
- процессор Intel Core i3 4170 3.70 Гц;
- видеокарта GeForce GTX 1050, 2 Гб;
- 16 Гб оперативной памяти.
Это, конечно совсем не быстро и не удобно. На маломощных машинах плагин стоит использовать только в случае, если снимок очень важен и при этом запорот. Для обработки больших объёмов фотографий нужна более совершенная техника.
Чем мощнее ваш компьютер (или ноутбук), тем быстрее будет работать фильтр. Для быстрой и беспроблемной работы хорошо подойдут компьютеры с современным процессором. Желательно, чтобы в компьютере был хотя бы Core i5 от Intel или AMD Ryzen 5.
Для полноценной работы нейросетевых фильтров также нужна видеокарта с объёмом видеопамяти не менее 4 Гб. В качестве бюджетного решения подойдёт GTX 1650 или 1660. Хорошим решением верхне-среднего уровня будет GeForce RTX 3060Ti. А если бюджет неограничен, и вы хотите, чтобы компьютер был актуален ещё несколько лет, берите самую топовую на сегодняшний день GeForce RTX 4090.
Для тех, кто любит готовые решения, есть системный блок в сборке. А чтобы рассмотреть все детали на снимках пригодится качественный монитор.
Если же вы предпочитаете ноутбуки, стоит обратить внимание на следующие модели: MSI Pulse GL76, MSI Bravo 15 B5DD-415XRU, Apple MacBook Pro A2485.
Восстановление расфокусированных и смазанных изображений. Практика
Время на прочтение
10 мин
Количество просмотров 333K
Не так давно я опубликовал на хабре первую часть статьи по восстановлению расфокусированных и смазанных изображений, где описывалась теоретическая часть. Эта тема, судя по комментариям, вызвала немало интереса и я решил продолжить это направление и показать вам какие же проблемы появляются при практической реализации казалось бы простых формул.
В дополнение к этому я написал демонстрационную программу, в которой реализованы основные алгоритмы по устранению расфокусировки и смаза. Программа выложена на GitHub вместе с исходниками и дистрибутивами.
Ниже показан результат обработки реального размытого изображения (не с синтетическим размытием). Исходное изображение было получено камерой Canon 500D с объективом EF 85mm/1.8. Фокусировка была выставлена вручную, чтобы получить размытие. Как видно, текст совершенно не читается, лишь угадывается диалоговое окно Windows 7.
И вот результат обработки:
Практически весь текст читается достаточно хорошо, хотя и появились некоторые характерные искажения.
Под катом подробное описание проблем деконволюции, способов их решения, а также множество примеров и сравнений. Осторожно, много картинок!
Вспомним теорию
Подробное описание теории было в первой части, но все же напомню вкратце основные моменты. В процессе искажения из каждого пикселя исходного изображения получается некоторое пятно в случае расфокусировки и отрезок для случая обычного смаза. Все это друг на друга накладывается и в результате мы получаем искаженное изображение — это называется сверткой изображения или конволюцией. То, по какому закону размазывается один пиксель и называется функцией искажения. Другие синонимы – PSF (Point spread function, т.е. функция распределения точки), ядро искажающего оператора, kernel и другие.
Чтобы восстановить исходное изображение нам необходимо каким-то образом обратить свертку, при этом не забывая про шум. Но это не так-то просто – если действовать, что называется, «в лоб», то получится огромная система уравнений, которую решить за приемлемое время невозможно.
Но на помощь к нам приходит преобразование Фурье и теорема о свертке, которая гласит, что операция свертки в пространственной области эквивалентна обычному умножению в частотной области (причем умножение поэлементное, а не матричное). Соответственно, операция обратная свертке эквивалентна делению в частотной области. Поэтому процесс искажения можно переписать следующим образом:
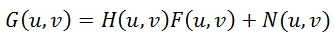 (1),
(1),
где все элементы — это фурье-образы соответствующих функций:
G(u,v) – результат искажения, т.е. то, что мы наблюдаем в результате (смазанное или расфокусированное изображение)
H(u,v) – искажающая функция, PSF
F(u,v) – исходное неискаженное изображение
N(u,v) – аддитивный шум
Итак, нам нужно восстановить максимальное приближение к исходному изображению F(u,v). Просто поделить правую и левую часть на H(u,v) не получится, т.к. при наличии даже совсем небольшого шума (а он всегда есть на реальных изображениях) слагаемое N(u,v)/H(u,v), будет доминировать, что приведет к тому, что исходное изображение будет целиком скрыто под шумом.
Чтобы решить эту проблему, были разработаны более устойчивые методы, одним из которых являтся фильтр Винера (Wiener). Он рассматривает изображение и шум как случайные процессы и находит такую оценку f’ для неискаженного изображения f, чтобы среднеквадратическое отклонение этих величин было минимальным:
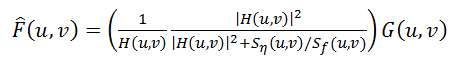 (2)
(2)
Функцией S здесь обозначаются энергетические спектры шума и исходного изображения соответственно – поскольку, эти величины редко бывают известны, то дробь Sn / Sf заменяют на некоторую константу K, которую можно приблизительно охарактеризовать как соотношение сигнал-шум.
Способы получения PSF
Итак, возьмем за отправную точки описанный фильтр Винера — вообще говоря, существует множество других подходов, но все они дают примерно одинаковые результаты. Так что все описанное ниже будет справедливо и для остальных методов деконволюции.
Основная задача — получить оценку функции распределения точки (PSF). Это можно сделать несколькими способами:
1. Моделирование. Очень непросто и трудоемко, т.к. современные объективы состоят из десятка, другого различных линз и оптических элементов, часть из которых имеет асферическую форму, каждый сорт стекла имеет свои уникальные характеристики преломления лучей с той или иной длиной волны. В итоге задача корректного расчета распространение света в такой сложнейшей оптической системе с учетом влияния диафрагмы, переотражений и т.п. становится практически невозможной. И решение ее, пожалуй, доступно только разработчикам современных объективов.
2. Непосредственное наблюдение. Вспомним, что PSF — это то, во что превращается каждая точка изображения. Т.е. если мы сформируем черный фон и одну белую точку на нем, а затем сфотографируем это с нужным значением расфокусировки, то мы получим непосредственно вид PSF. Кажется просто, но есть много нюансов и тонкостей.
3. Вычисление или косвенное наблюдение. Присмотримся к формуле (1) процесса искажение и подумаем, как можно получить H(u,v)? Решение приходит сразу — нужно иметь исходное F(u,v) и искаженное G(u,v) изображения. Тогда поделив фурье-образ искаженного изображения на фурье-образ исходного изображения мы получим искомую PSF.
Про боке
Перед тем как перейдем к деталям, расскажу немного теории расфокусировки применительно к оптике. Идеальный объектив имеет PSF в виде круга, соответственно каждая точка превращается в круг некоторого диаметра. Кстати, это для многих неожиданность, т.к. с первого взгляда кажется, что дефокус просто растушевывает все изображение. Это же объясняет и то, почему фотошоповское размытие Гаусса совсем не похоже на тот рисунок фона (его еще называют боке), который мы видим у объективов. На самом деле это два разных типа размытия — по Гауссу каждая точка превращается в нечеткое пятно (колокол Гаусса), а дефокус каждую точку превращает в круг. Соответственно и разные результаты.
Но идеальных объективов у нас нет и в реальности мы получаем то или иное отклонение от идеального круга. Именно это и формирует неповторимый рисунок боке каждого объектива, заставляя фотографов тратить кучу денег на объективы с красивым боке 🙂 Боке можно условно разделить на три типа:
— Нейтральное. Это максимальное приближение к кругу
— Мягкое. Когда края имеют меньшую яркость, чем центр
— Жесткое. Когда края имеют большую яркость, чем центр.
Рисунок ниже иллюстрирует это:

Более того, тип боке — мягкое или жесткое зависит еще и от того, передний это фокус или задний. Т.е. фотоаппарат сфокусирован перед объектом или же за ним. К примеру, если объектив имеет мягкий рисунок боке в переднем фокусе (когда, скажем, фокус на лице, а задний план размыт), то в заднем фокусе боке того же объектива будет жестким. И наоборот. Только нейтральное боке не меняется от вида фокуса.
Но и это еще не все — поскольку каждому объективу присущи те или иные геометрические искажения, то вид PSF зависит еще и от положения. В центре — близко к кругу, по краям — эллипсы и другие сплюснутые фигуры. Это хорошо видно на следующем фото — обратите внимание на правый нижний угол:

А теперь рассмотрим подробнее два последних метода получения PSF.
PSF — Непосредственное наблюдение
Как уже говорилось выше, необходимо сформировать черный фон и белую точку. Но просто напечатать на принтере одну точку недостаточно. Необходим намного большее отличие в яркости черного фона и белой точки, т.к. одна точка будет размываться по большому кругу — соответственно должна иметь большую яркость, чтобы быть видной после размытия.
Для этого я распечатал черный квадрат Малевича (да, тонера много ушло, но чего не сделаешь ради науки!), наложил с другой стороны фольгу, т.к. лист бумаги все же неплохо просвечивает и иголкой проколол маленькую дырочку. Затем соорудил нехитрую конструкцию из 200-ваттной лампы и сэндвича из черного листа и фольги. Выглядело это вот так:

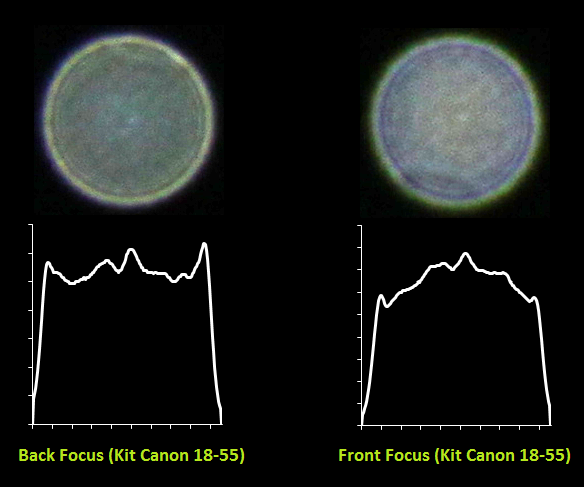
Далее включил лампу, закрыл ее листом, выключил общий свет и сделал несколько фоток используя два объектива — китовый Canon EF 18-55 и портретник Canon EF 85mm/1.8. Из получившихся фоток я вырезал PSF и затем построил графики профилей.
Вот что получилось для китового объектива:
И для портретника Canon EF 85mm/1.8:
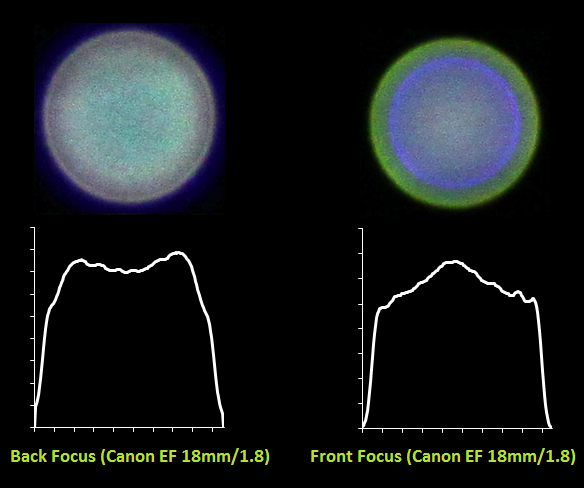
Хорошо видно как меняется характер боке с жествкого на мягкий для одного и того же объектива в случае переднего и заднего фокуса. Также видно, какую непростую форму имеет PSF — она весьма далека от идеального круга. Для портретника также видны большие хроматические аберрации из-за большой светосилы объектива и малой диафрагмы 1.8.
И вот еще пара снимков при диафрагме 14 — на нем видно, как поменялась форма с круга на правильный шестиугольник:

PSF — Вычисление или косвенное наблюдение
Следующий подход — косвенное наблюдение. Для этого, как писалось выше, нам нужно иметь исходное F(u,v) и искаженное G(u,v) изображения. Как их получить? Очень просто — необходимо поставить фотоаппарат на штатив и сделать один резкий и один размытый снимок одного и того изображения. Далее с помощью деления фурье-образа искаженного изображения на фурье-образ исходного изображения мы получим фурье-образ нашей искомой PSF. После чего применив обратное преобразование Фурье получим PSF в прямом виде.
Я сделал два снимка:


И в результате получил вот такую PSF:

На горизонтальную линию не обращайте внимания, это артефакт после преобразования Фурье в матлабе. Результат, скажем так, средненький — очень много шумов и детали PSF видны не так хорошо. Тем не менее, метод имеет право на существование.
Описанные методы можно и нужно использовать для построения PSF при восстановлении размытых изображений. Т.к. от того, насколько эта функция приближена к реальной напрямую зависит качество восстановления исходного изображения. При несовпадении предполагаемой и реальной PSF будут наблюдаться многочисленные артефакты в виде «звона», ореолов и снижения четкости. В большинстве случаев предполагается форма PSF в виде круга, тем не менее для достижения максимальной степени восстановления рекомендуется поиграться с формой этой функции, попробовав несколько вариантов от распространенных объективов — как мы видели, форма PSF может варьироваться в значительной степени в зависимости от диафрагмы, объектива и прочих условий.
Краевые эффекты
Следующая проблема заключается в том, что если напрямую применить фильтр Винера, то на краях изображения будет своеобразный «звон». Его причина, если объяснять на пальцах, заключается в следующем — когда делается деконволюция для тех точек, которые расположены на краях, то при сборке не хватает пикселей, которые находятся за краями изображения и они принимаются либо равным нулю, либо берутся с противоположной стороны (зависит от реализации фильтра Винера и преобразования Фурье). Выглядит это так:
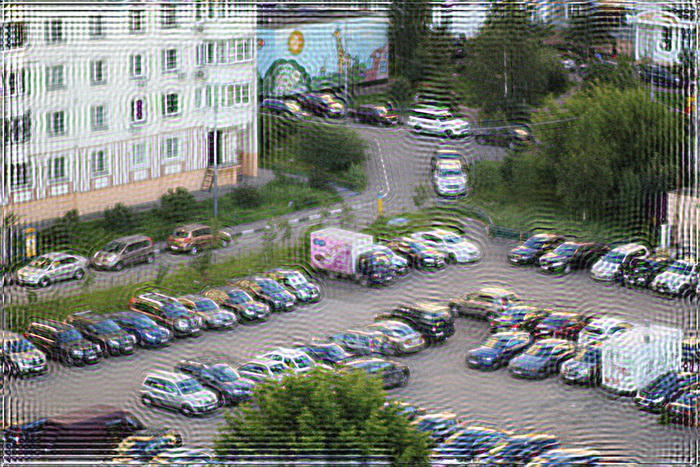
Одно из решений, чтобы избежать этого состоит предобработке краев изображения. Они размываются с помощью той же самой PSF. На практике это реализуется следующем образом — берется входное изображение F(x,y), размывается с помощью PSF и получается F'(x,y), затем итоговое входное изображение F”(x,y) формируется суммированием F(x,y) и F'(x,y) с использованием весовой функции, которая на краях принимает значение 1 (точка целиком берется из размытого F'(x,y)), а на расстоянии равном (или большем) радиусу PSF от края изображения принимает значение 0. Результат получается такой — звон на краях исчез:
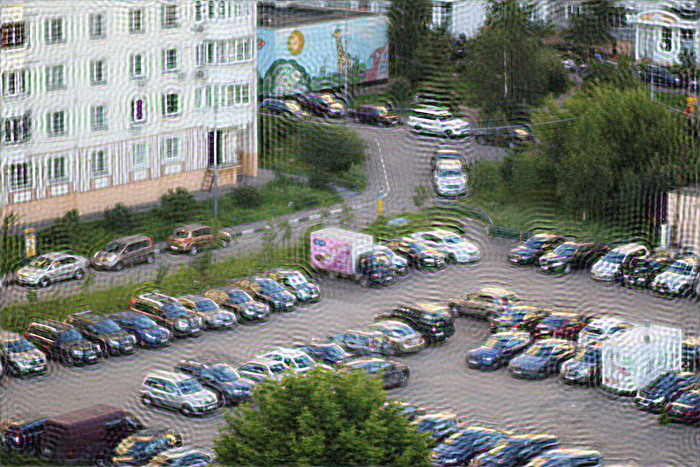
Практическая реализация
Я сделал программу, демонстрирующую восстановление смазанных и расфокусированных изображений. Написана она на C++ с использованием Qt. В качестве реализации преобразования Фурье я выбрал библиотеку FFTW, как самую быструю из опен-соурсных реализаций. Называется моя программа SmartDeblur, скачать ее можно на странице github.com/Y-Vladimir/SmartDeblur, все исходники открыты под лицензией GPL v3.
Скриншот главного окна:
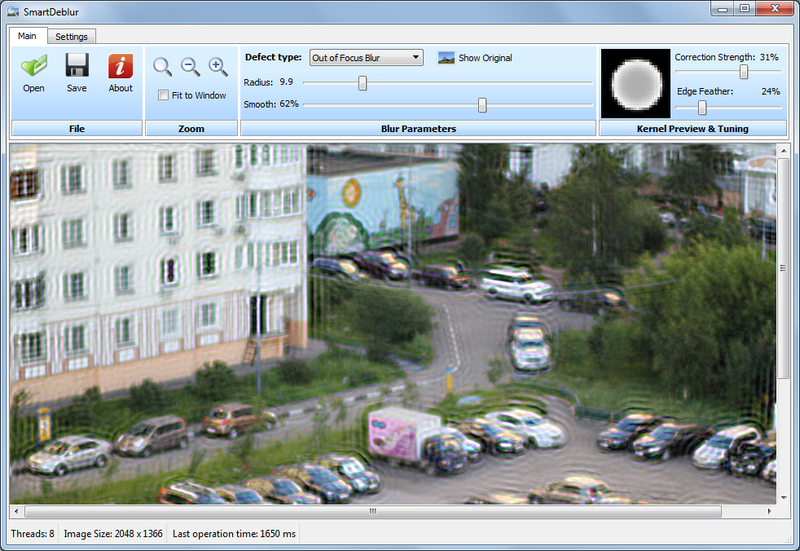
Основные функции:
— Высокая скорость. Обработка изображения размером 2048*1500 пикселей занимает около 300мс в режиме Preview (когда перемещаются ползунки настроек) и 1.5 секунды в чистовом режиме (когда отпустили ползунки настроек).
— Подбор параметров в Real-time режиме. Нет необходимости нажимать кнопки Preview, все делается автоматически, нужно лишь двигать ползунки настроек искажения
— Вся обработка идет для изображения в полном разрешении. Т.е. нет никакого маленького окошка предпросмотра и кнопок Apply.
— Поддержка восстановления смазанных и расфокусированных изображений
— Возможность подстройки вида PSF
Основной упор при разработке был сделан на скорость. В итоге она получилась такая, что превосходит коммерческие аналоги в десятки раз. Вся обработка сделана по-взрослому, в отдельном потоке. За 300 мс программа успевает сгенерить новую PSF, сделать 3 преобразования Фурье, сделать деконволюцию по Винеру и отобразить результат — и все это для изображения размером 2048*1500 пикселей. В чистовом режиме делается 12 преобразований Фурье (3 для каждого канала, плюс одно для каждого канала для подавления краевых эффектов) — это занимает около 1.5 секунд. Все времена указаны для процессора Core i7.
Пока в программе есть ряд багов и особенностей — скажем, при некоторых значениях настроек изображение покрывается рябью. Точно причину выяснить не удалось, но предположительно — особенности работы библиотеки FFTW.
Ну и в целом в процессе разработки пришлось обходить множество скрытых проблем как в FFTW (например не поддерживаются изображения с нечетным размером одной из сторон, типа 423*440.). Были проблемы и с Qt — выяснилось, что рендеринг линии со включенным Antialiasing работает не совсем точно. При некоторых значениях углов линия перескакивала на доли пикселя, что давало артефакты в виде сильной ряби. Для обхода этой проблемы добавил строчки:
// Workarround to have high accuracy, otherwise drawLine method has some micro-mistakes in the rendering
QPen pen = kernelPainter.pen();
pen.setWidthF(1.01);
kernelPainter.setPen(pen);
Сравнение
Осталось сравнить качество обработки с коммерческими аналогами.
Я выбрал 2 самые известные программы
1. Topaz InFocus — www.topazlabs.com/infocus
2. Focus Magic — www.focusmagic.com
Для чистоты эксперимента будем брать те рекламные изображения, которые приведены на официальных сайтах — так гарантируется, что параметры тех программ выбраны оптимальными (т.к. думаю, разработчики тщательно отбирали изображения и подбирали параметры перед публикацией в рекламе на сайте).
Итак, поехали — восстановление смаза:
Берем пример с сайта Topaz InFocus:
www.topazlabs.com/infocus/_images/licenseplate_compare.jpg

Обрабатываем с вот такими параметрами:
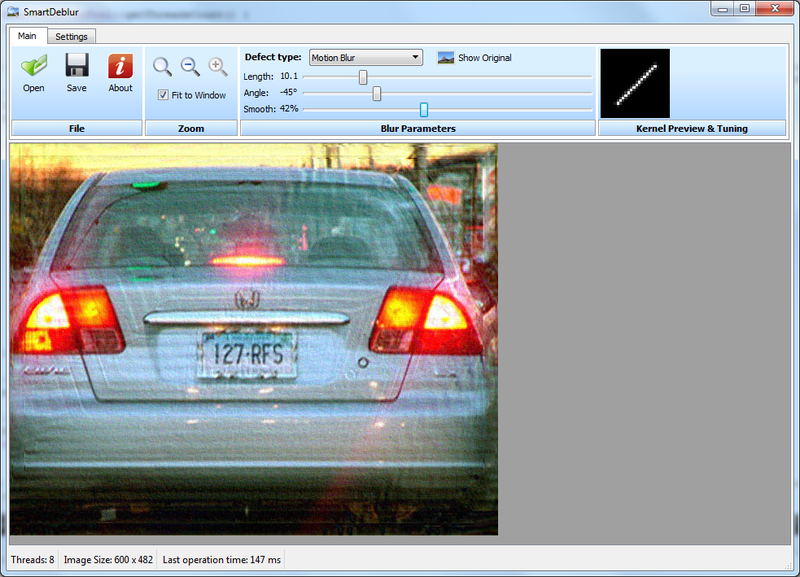
и получаем такой результат:

Результат с сайта Topaz InFocus:

Результат весьма схожий, это говорит о том, что в основе Topaz InFocus используется похожий алгоритм деконволюции плюс постобработка в виде заглаживания-удаления шумов и подчеркивания контуров.
Примеров сильно дефокусировки на сайте этой программы найти не удалось, да и она не предназначена для этого (максимальный радиус размытия составляет всего несколько пикселей).
Можно отметить еще один момент — угол наклона оказался ровно 45 градусов, а длина смаза 10 пикселей. Это наводит на мысль о том, что изображение смазано искусственно. В пользу этого факта говорит и то, что качество восстановления очень хорошее.
Пример номер два — восстановление дефокусировки. Для этого возьмем пример с сайта Focus Magic: www.focusmagic.com/focusing-examples.htm

Получили вот такой результат:
Тут уже не так очевидно, что лучше.
Заключение
На этом я хотел бы закончить эту статью. Хотя и много чего еще хотелось написать, но и так уже длинный текст получился. Буду очень признателен, если попробуете скачать SmartDeblur и потестировать на реальных изображениях — у меня, к сожалению, не так много расфокусированных и смазанных изображений, все поудалял.
И буду особо признателен, если пришлете мне (мыло есть в профиле) свой фидбек и примеры удачных/неудачных восстановлений. Ну и просьба сообщать о всех багах, замечаниях, предложениях — т.к. приложение еще пока местами сыроватое и немного нестабильное.
P.S. Исходники пока не очень чистые в плане стиля — там пока куча утечек памяти, еще не успел перевести на смарт-поинтеры, поэтому после нескольких изображений может перестать открывать файлы. Но в целом работает.
Ссылка на SmartDeblur: github.com/Y-Vladimir/SmartDeblur
UPD: Ссылка на продолжение
--
Vladimir Yuzhikov
Как сделать размытое фото четче
Размытие в кадре появляется по нескольким причинам: из-за естественного дрожания рук, которые держат камеру; неблагоприятных погодных условий; движения главного объекта съемки. Если после фотосъемки вы обнаружили, что некоторые снимки получились мутным, не спешите их удалять. Проблемные кадры вполне возможно восстановить – нужен только подходящий софт. В этом обзоре мы расскажем, как убрать размытие на фото несколькими простыми способами.
ФотоМАСТЕР
ФотоМАСТЕР – фоторедактор, включающий в себя «умные» функции искусственного интеллекта. Это означает, что софт сам анализирует фотографию и исправляет дефекты. В программе также есть ручные настройки для более детальной проработки фотографий. В редакторе можно исправить расфокусированное фото несколькими способами: обработать всю картинку или отдельные участки.
Помимо этой функции, среди возможностей ПО присутствует профессиональная цветокоррекция, исправление ошибок перспективы, работа с освещением, добавление визуальных эффектов.
Опробовать функционал редактора можно совершенно бесплатно, скачайте инсталлятор на ваш ПК.
Скачать
 Windows 11, 10, 8, 7 и XP
Windows 11, 10, 8, 7 и XP
Как убрать размытие на фото в ФотоМАСТЕРе
Рассмотрим, как убрать размытость на фото в программе несколькими способами.
Шаг 1. Установите программу
Для начала скачайте установщик программы и запустите распаковку двойным кликом. Когда редактор установится на компьютер, откройте его и импортируйте фото с дефектом.
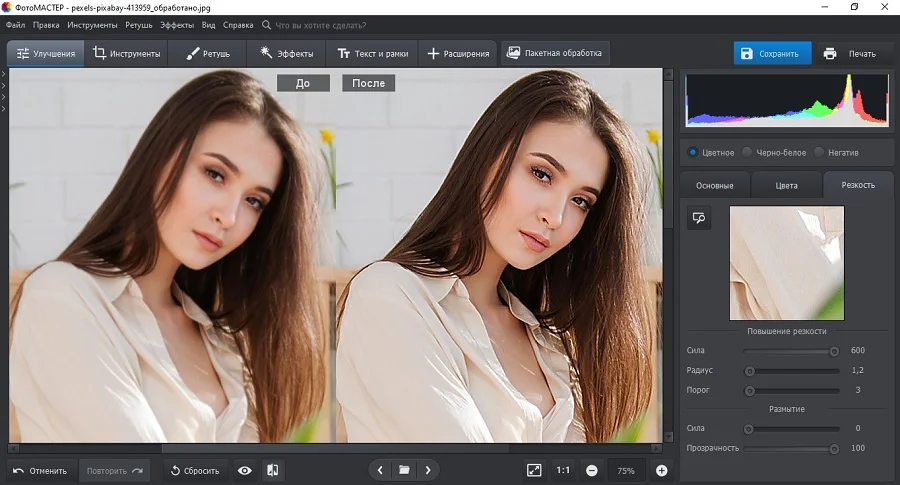
Шаг 2. Исправьте нечеткий кадр
Чтобы исправить некачественное изображение, в колонке справа откройте вкладку «Резкость». В разделе «повышение резкости» отредактируйте силу инструмента. Настройки можно подбирать наугад, т.к. все изменения сразу отображаются в окне предпросмотра.
Шаг 3. Обработайте отдельную область
Если требуется исправить нерезкость на определенном участке, например, сделать четким лицо, перейдите в раздел «Ретушь». В правой колонке отыщите инструмент «Корректор».
Отрегулируйте размер кисти и закрасьте курсором фрагмент, который нужно исправить. После этого раскройте вкладку «Резкость» и подберите подходящие параметры.
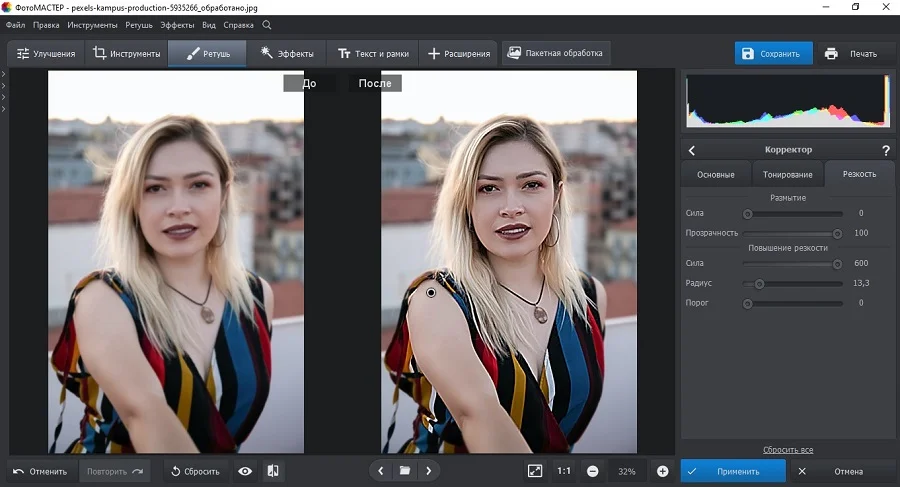
Шаг 4. Сохраните результат
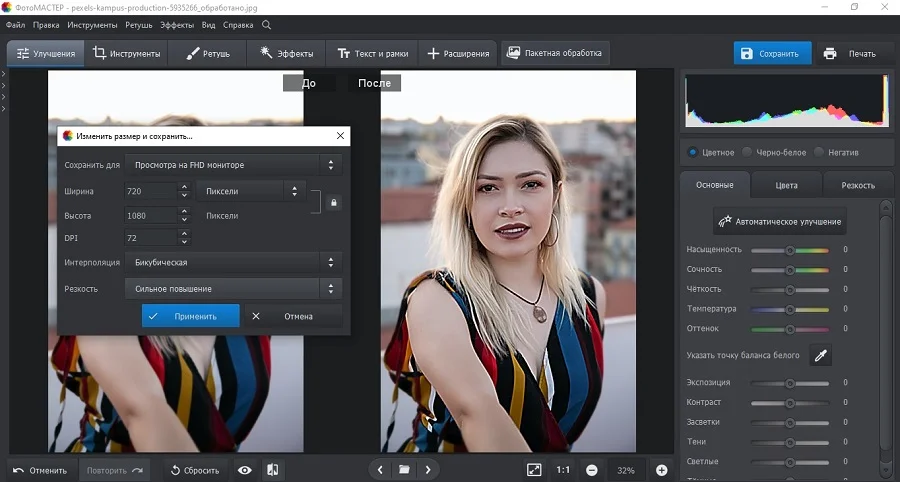
Вы можете повысить резкость во время экспорта, параллельно сжав размер медиафайла. Для этого раскройте пункт «Файл» и выберите «Изменить размер и сохранить».
В окне параметров отыщите пункт «Резкость» и выберите сильную умеренную или слабую степень.
ФотоМАСТЕР поддерживает все разрядности системы, можно устанавливать на любую сборку Windows. Благодаря тому, что софт почти не потребляет системных ресурсов вашего компьютера, он быстро работает даже на слабых устройствах.
![]() Умный фоторедактор для новичков и профи
Умный фоторедактор для новичков и профи
Скачать
Для Windows 11, 10, 8, 7, ХР
ФотоВИНТАЖ
ФотоВИНТАЖ разработан для реставрации старых фотокарточек. Данная программа включает в себя такие инструменты улучшения
качества снимков, как снижение шумов, колоризация, удаление отдельных предметов из кадра и другое. Присутствует коллекция фильтров и эффектов, можно накладывать
картинки друг на друга. Среди многочисленных опций редактора есть также возможность повысить резкость снимков. Чтобы в ФотоВИНТАЖе размытое фото сделать четким,
следуйте нашей инструкции.
Как убрать блюр с фото в ФотоВИНТАЖ
Как и в ФотоМАСТЕРе, в данной программе исправление можно провести несколькими способами.
Шаг 1. Запустите фоторедактор и загрузите изображение.
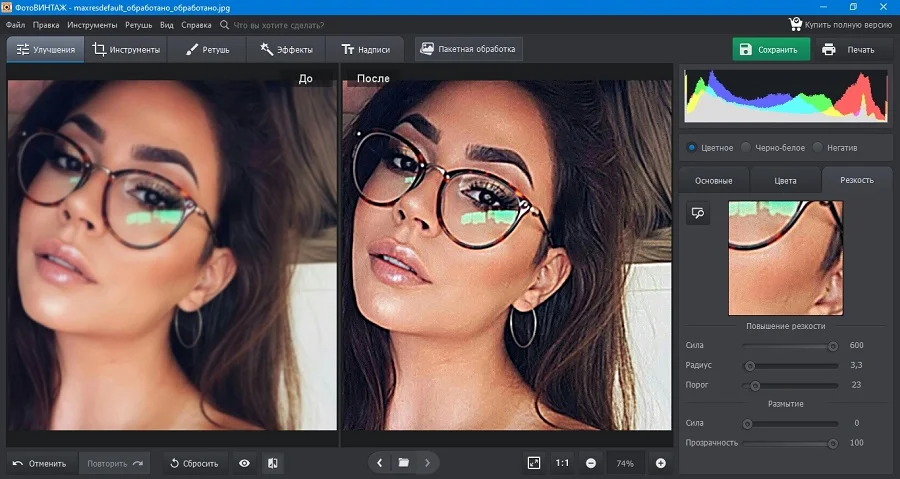
Шаг 2. Для более удобной работы включите режим просмотра До/После в нижней панели программы. После этого в боковой колонке раскройте вкладку «Резкость». Подберите подходящие параметры силы, радиуса и порога, отслеживая изменения.
Шаг 3. Вызовите меню экспорта через пункт меню «Файл». Вы можете сохранить картинку через опцию «Изменить размер и сохранить», параллельно сжав размер и увеличив резкость. Либо экспортируйте фотографию стандартным образом через функцию «Сохранить».
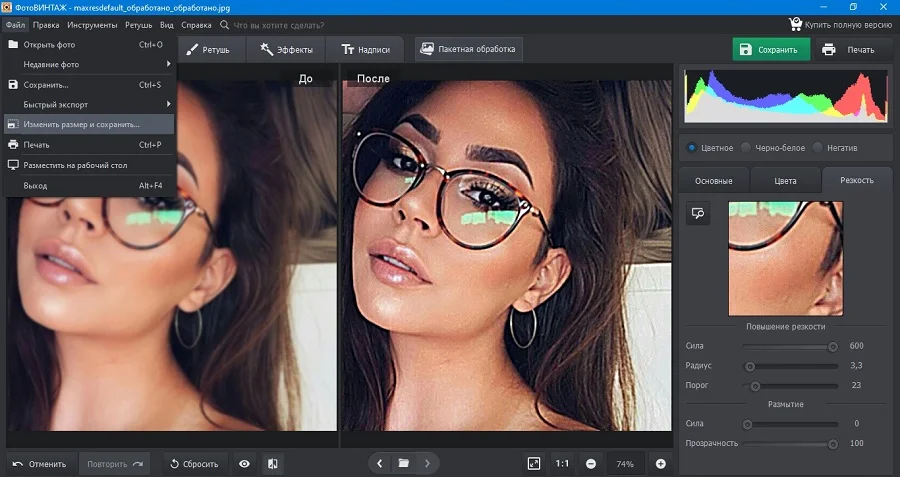
Как и ФотоМАСТЕР, данный софт почти не нагружает процессор, это хороший вариант для ноутбуков.
Topaz Sharpen AI
Как понятно из названия, Topaz Sharpen AI специализируется только на одной задаче – повышение резкости нечетких фотографий. Софт включает в себя функции искусственного интеллекта и позволяет исправить смазанное фото даже при работе со сложными дефектами. Несмотря на отсутствие русскоязычного интерфейса, работать в ней предельно просто, так как все действия совершаются в автоматическом режиме.
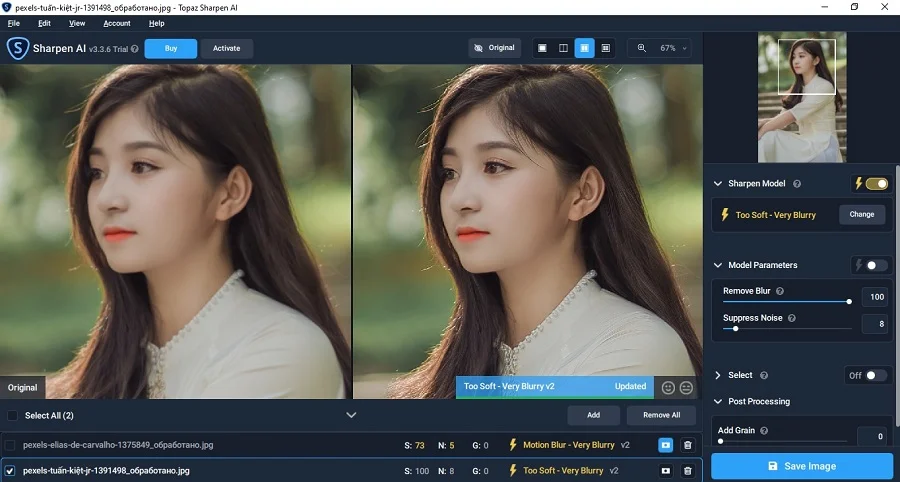
Плюсы:
- Качественный эффект даже при сильной «шевеленке».
- Поддерживается пакетная обработка.
- Можно использовать как плагин Photoshop.
Минусы:
- Сильная нагрузка на процессор.
- Медленная обработка.
- Отсутствует русский перевод.
Для повышения четкости в данной программе следуйте инструкции:
- Загрузите фотографию через кнопку Add files.
- Софт автоматически проанализирует снимок и выведет рекомендуемые настройки.
- Вы можете изменить параметры в колонке справа, настроить степень удаления блюра (Remove Blur) и снижение шума (Suppress Noise).
- Также можно изменить режим обработки Sharpen Mode, выбрав слабую, сильную или среднюю силу.
- Сохраните картинку кнопкой Save image.
Focus Magic
Focus Magic можно использовать как стандартную программу или плагин Photoshop. Софт помогает повысить четкость фото при помощи специальных фильтров. Во время обработки доступно подавление шумов, выбор режима анализа. Пользователи могут обрабатывать весь снимок или отдельные участки. Софт функционирует только на английском, но в целом разобраться с управлением не составит труда.
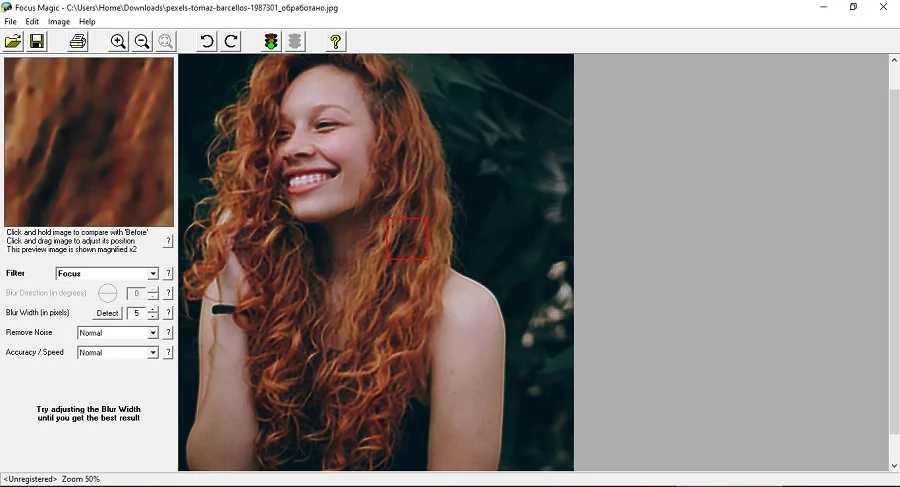
Плюсы:
- Автоматический анализ и обработка.
- Простой в управлении интерфейс.
- Почти отсутствует нагрузка на ЦПУ.
Минусы:
- Только на английском языке.
- Не очень реалистичный результат.
Чтобы сделать мутное изображение качественнее, проделайте следующее:
- Загрузите в приложение фотографию, кликнув по иконке в виде желтой папки.
- В пункте Filter выберите вариант Focus.
- Если вы хотите обработать участок снимка, наведите на него курсор с красным квадратиком и кликните по нужному месту.
- Чтобы отредактировать все изображение, в верхней панели кликните по значку в виде светофора.
- Для экспорта фотографии воспользуйтесь пунктом меню File.
SmartDeblur
Благодаря простому интерфейсу в SmartDeblur можно быстро научиться тому, как исправить размытое фото. Этой программой можно отредактировать естественный и творческий смаз и последствия расфокусировки. Софт умеет различать разные типы размытия и применяет настройки, исходя из силы дефекта. Возможностей приложения хватает даже на то, чтобы сделать различимым смазанные надписи.
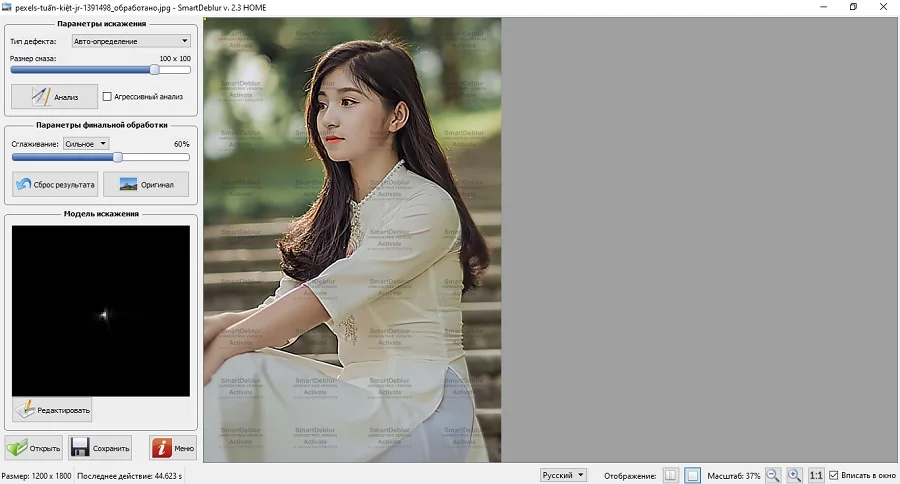
Плюсы:
- Способно восстанавливать размытый текст.
- Удобный русскоязычный интерфейс.
- Автоматический анализ и исправление.
Минусы:
- В пробной версии накладывается водяной знак.
- Некачественный результат при сильных размытиях.
Для исправления фотографии проделайте следующее:
- Загрузите снимок через кнопку «Открыть» в правом нижнем углу.
- Нажмите «Анализ», чтобы софт определил силу и метод размытия.
- Для более точных результатов отметьте пункт «Агрессивный анализ».
- Укажите степень сглаживания: сильное или слабое.
- Приложение автоматически исправит фото. При желании процесс можно повторить, если результат показался недостаточным.
- Для экспорта изображения воспользуйтесь кнопкой «Сохранить».
Приложения для Android и iOS
Многие мобильные фоторедакторы предлагают инструменты улучшения, которые позволяют увеличить резкость фото. Итоговый результат зависит от качества оригинального снимка и силы смаза.
Наиболее популярными фоторедакторами для Андроида и Айфона являются следующие:
- Pixlr;
- ToolWiz Photos;
- Facetune;
- Adobe Photoshop Lightroom;
- PicsArt;
- Adobe Photoshop Express;
- Snapseed.
Работа в подобных приложениях обычно схожа друг с другом, поэтому мы рассмотрим, как убрать смазанность на фото в редакторе Pixlr. Он поставляется с крупным набором инструментов повышения качества, в том числе автоматическими функциями улучшения.
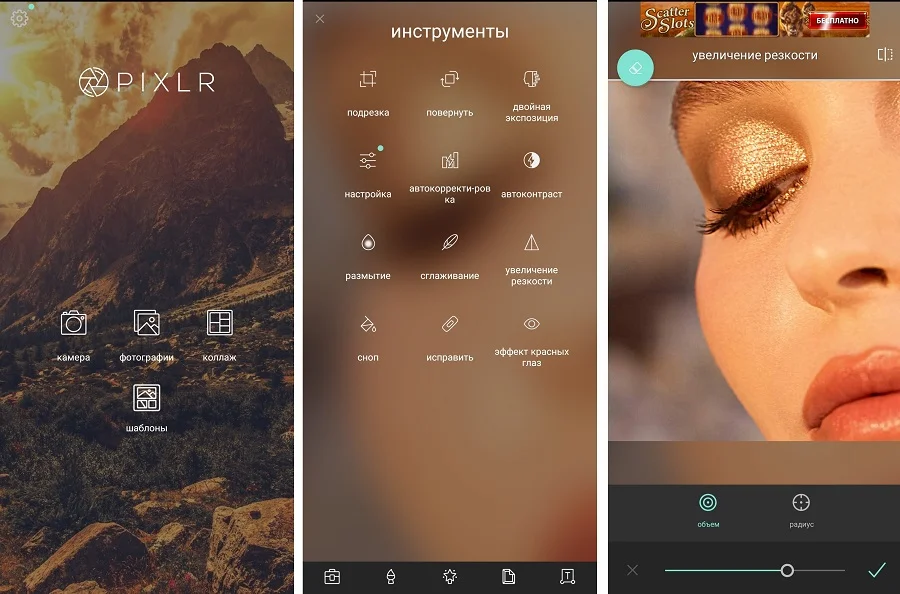
- Запустите редактор и в стартовом окне выберите «Фотографии».
- Добавьте изображение из галереи телефона.
- В нижней строке тапните по значку в виде чемоданчика.
- Среди списка инструментов отыщите «Увеличение резкости».
- Установите нужные параметры, двигая ползунки параметров «Объем» и «Радиус».
Помимо редакторов общего направления, для исправления проблемных фотографий можно использовать специализированные приложения. Чаще всего такой софт направлен только на одну цель – повышать качество снимков. К таким относятся следующие приложения:
- Enhance Photo Quality;
- Sharpen Image;
- Remini;
- AfterFocus;
- Fix Blur and Sharpen Images;
- EnhanceFox.
Так как подобный софт в основном направлен на одну-две задачи, они очень просты в работе. Давайте рассмотрим, как сделать фотографию четче в программе Enhance Photo Quality. В ее арсенале присутствует несколько опций: автоулучшение, колоризация, визуальные эффекты, фоторамки и компрессор.
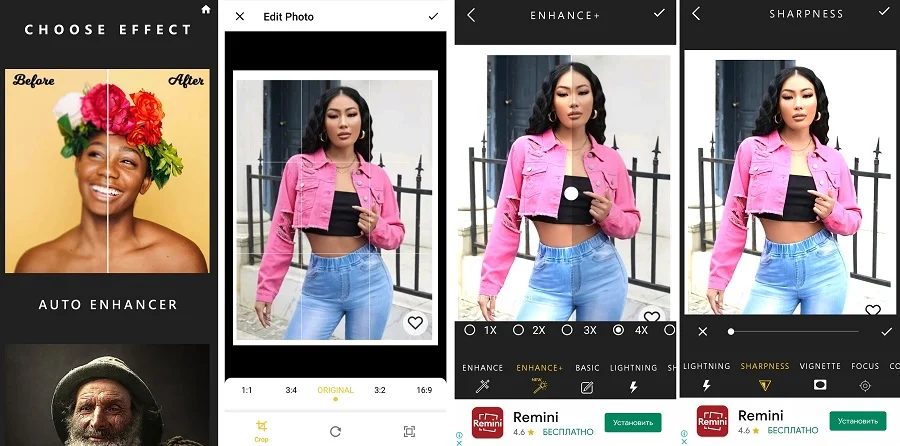
- В стартовом окне откройте вкладку Image и нажмите Start.
- В предложенных фильтрах выберите Auto Enhancer.
- Загрузите картинку из галереи.
- Укажите размер и примените правки галочкой.
- В открывшемся редакторе кликните по значку Sharpness и подберите параметр.
- Примените изменения и скачайте фото, кликнув на иконку в виде стрелки справа сверху.
К недостатку приложения стоит отнести не очень интуитивное управление. Использование бесплатное, но присутствует большое количество рекламы, которая часто перекрывает экран во время работы.
Как увеличить резкость фото в онлайн-сервисах
Онлайн-редакторы станут хорошим выходом, если у вас нет возможности установить сторонние программы. Улучшить резкость фото можно практически на любом сервисе. Среди них:
- Pixlr;
- Photopea;
- Fotor;
- Fotoramio;
- Polarr;
- Lunapic;
- Fotostars.
Так как все они действуют по схожему принципу, мы рассмотрим, как убрать блюр с фото на сайте Fotostars. Сервис поставляется с базовым набором функций: работа с яркостью и контрастом, цветокоррекция, обрезка, виньетка, текст. Сайт полностью бесплатный и не требует регистрации.
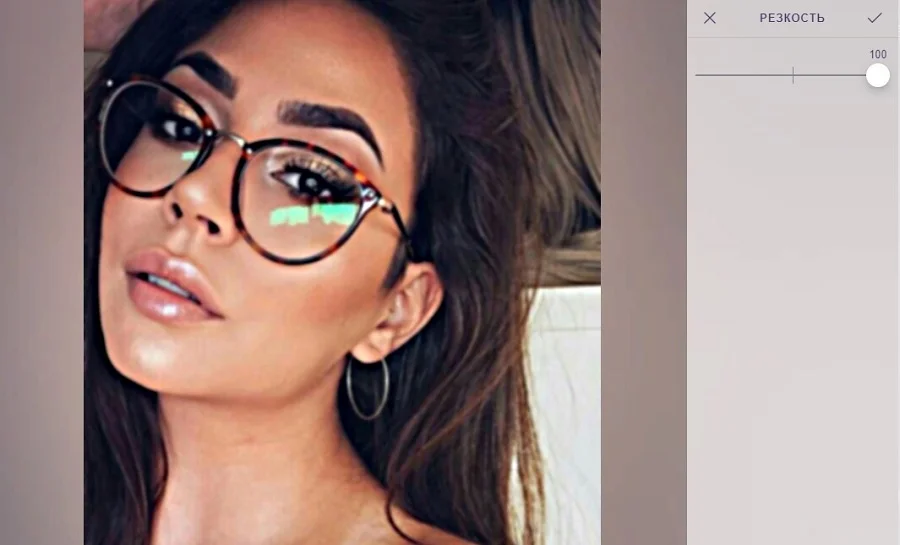
- На главной странице сервиса нажмите «Редактировать фото» и загрузите изображение.
- Среди списка инструментов выберите вариант «Резкость».
- Потяните ползунок до тех пор, пока кадр не станет более четким.
К небольшому недостатку сайта можно отнести сбои в работе: если вы перешли на другую вкладку браузера, редактор перестанет откликаться на щелчки мыши.
Выводы
Теперь вы знаете, как из размытой фотографии сделать четкую. Какой из рассмотренных способов выбрать, зависит от сложности цели и используемого вами устройства.
Однако наиболее удобным и надежным вариантом является ФотоМАСТЕР – он умеет справляться со сложными случаями и при этом не нагружает компьютер и не накладывает
ограничений. К тому же, в редакторе вы можете дополнительно улучшить снимок: провести ретушь, сделать пластику лица, применить фильтры и многое другое.
Аннотация
Восстановление смазанного (тусклого) лица обычно опирается на лицевые приоры – предшествующие ориентиры геометрии лица или ссылки, для восстановления достоверных его деталей. Однако входные данные низкого качества не могут обеспечить точную геометрическую точность, а ссылки высокого качества часто недоступны, что ограничивает применимость в реальных сценариях. В этой работе мы предлагаем метод GFP-GAN, который использует богатые и разнообразные приоры, предоставляемые предварительно подготовленными GAN приорами для восстановления тусклого лица. Этот генерирующий предшествующие приоры лица (GFP) уровень включается в процесс восстановления лица с помощью послойного преобразования пространственных объектов, позволяя нашему методу достичь хорошего баланса реалистичности и точности. Благодаря мощному генерированию изображения лица (лицевого дизайна) и тонких его деталей, наш метод GFP-GAN может совместно восстанавливать детали лица и улучшать цвета всего за один прямой проход, в то время как методы инверсии GAN требуют специальной оптимизации изображения при выводе. Обширные эксперименты показывают, что наш метод обеспечивает превосходную производительность по сравнению с предыдущим уровнем развития техники, как для синтетических, так и для реальных наборов данных.
![Рисунок 1. Сравнение с современными методами восстановления лица: HiFaceGAN [67], DFDnet [44], Wang и др. [61] и PULSE [52] на реальных изображениях низкого качества. В то время как предыдущие методы с трудом восстанавливали точные детали лица или сохраняли идентичность лица, наш предлагаемый GFP-GAN обеспечивает хороший баланс реалистичности и точности с гораздо меньшим количеством артефактов. Кроме того, мощная генеративная технология для лица позволяет нам совместно выполнять восстановление и улучшение цвета.](https://habrastorage.org/getpro/habr/upload_files/877/a14/1bb/877a141bbc280ce0543579b8c7bcee07.png "Рисунок 1. Сравнение с современными методами восстановления лица: HiFaceGAN [67], DFDnet [44], Wang и др. [61] и PULSE [52] на реальных изображениях низкого качества. В то время как предыдущие методы с трудом восстанавливали точные детали лица или сохраняли идентичность лица, наш предлагаемый GFP-GAN обеспечивает хороший баланс реалистичности и точности с гораздо меньшим количеством артефактов. Кроме того, мощная генеративная технология для лица позволяет нам совместно выполнять восстановление и улучшение цвета.")
1. Введение
Восстановление смазанных лиц направлено на восстановление высокого качества изображения лиц по сравнению с низкокачественными аналогами, страдающими низким разрешением [13, 48, 9], внесенным шумом [71], размытием [39, 58], артефактами сжатия [12] и т.д. Применительно к реальным сценариям это становится более сложным из-за более сложной деградации, разнообразных поз и выражений. В предыдущих работах [9, 69, 6] использованы приоры, относящиеся к восстанавливаемому лицу, такие, как ориентиры лица [9], карты анализа [6, 9], «тепловые карты» компонентов лица [69] и показано, что эти геометрические приоры лица имеют решающее значение для точного восстановления формы лица и его деталей. Однако эти приоры обычно оцениваются по входным изображениям и неизбежно ухудшаются при очень низком качестве входных данных из реального мира. Кроме того, несмотря на семантические связи, приведенные выше приоры содержат ограниченную информацию о текстуре для восстановления деталей лица (например, зрачка глаза).
Другая категория подходов исследует эталонные приоры, т.е. высококачественные для управления восстановлением лица детали [46, 45, 11] или словари компонентов [44], позволяющие получить реалистичные результаты и уменьшить зависимость от ухудшения входных данных. Однако недоступность ссылок с высоким разрешением ограничивает его практическую применимость, в то время как ограниченная емкость словарей ограничивает его разнообразие и богатство возможностей использования деталей лица.
В этом исследовании мы используем генеративный априорный анализ лица (GFP) для восстановления тусклого лица в реальном мире, т.е. приор, неявно инкапсулированный в предварительно обученную модель Генеративной Состязательной Сети (GAN) [18], такие как Style GUN [35, 36]. Эти лицевые GAN способны точно восстанавливать лица с высокой степенью вариабельности и, таким образом, обеспечивать богатые и разнообразные характеристики, такие как геометрия, текстура и цвет лица, что позволяет совместно восстанавливать детали лица и улучшать цвета (рис.1).
Тем не менее, сложно включить такие генеративные приоры в процесс восстановления. Предыдущие попытки обычно использовали инверсию GAN [19, 54, 52]. Сначала они “инвертируют” ухудшенное изображение обратно в скрытый код предварительно обученного GAN, а затем проводят дорогостоящую оптимизацию изображения для восстановления изображений. Несмотря на визуально реалистичные выходные данные, они обычно создают изображения с низкой точностью, поскольку скрытых кодов с низким размером недостаточно для точного восстановления.
Для решения этих проблем мы предлагаем метод GFP-GAN с тонкими конструкциями достижения хорошего баланса реалистичности и точности за один проход вперед. В частности, FPGA состоит из модуля удаления деградации и предварительно обученного GAN лица. Они соединены прямым отображением скрытого кода и несколькими слоями преобразования пространственных объектов с разделением каналов (CS-SFT) грубым и тонким способом. Предлагаемые слои CS-SFT выполняют пространственную модуляцию для разделения объектов и оставляют левые объекты при прямом прохождении для лучшего сохранения информации, что позволяет нашему методу эффективно включать генеративный приор при перепрохождении (новой итерации) с высокой точностью. Кроме того, мы учитываем потерю компонентов лица с локальными дискриминаторами для дальнейшего улучшения деталей восприятия лица, используя при этом потерю идентичности для дальнейшего повышения точности воспроизведения.
Мы суммируем вклады следующим образом. (1) Мы используем богатые и разнообразные генерации лицевых приор для восстановления смазанного лица. Эти приоры содержат достаточную информацию о текстуре лица и цвете, что позволяет нам совместно выполнять восстановление лица и улучшение цвета. (2) Мы предлагаем структуру GFP-GAN с тонкими конструкциями архитектур и потерями четкости, чтобы включить генерацию лицевого приора. Наш GFP-GAN со слоями CS-SFT обеспечивает хороший баланс точности и полноты текстуры за один проход вперед. (3) Обширные эксперименты показывают, что наш метод обеспечивает превосходную производительность по сравнению с предыдущим уровнем техники восстановления, как для синтезируемых, так и для реальных наборов данных.
 и предварительно обученной лицевой панели в качестве лицевой панели. Они соединены скрытым отображением кода и несколькими слоями преобразования пространственных объектов с разделением каналов (CS-SFT). Во время обучения мы используем 1) промежуточные потери при восстановлении для устранения сложной деградации, 2) Потерю компонентов лица с помощью дискриминаторов для улучшения деталей лица и 3) потерю при сохранении идентичности для сохранения идентичности лица.")
Похожие работы
Восстановление изображений обычно включает в себя сверхразрешение [13, 48, 60, 49, 74, 68, 22, 50], шумоподавление [71, 42, 26], удаление размытия [65, 39, 58] и удаление сжатия [12, 21]. Для достижения визуально приятных результатов генеративная состязательная сеть [18] обычно используется в качестве контроля потерь, чтобы приблизить решения к естественному многообразию [41, 57, 64, 7, 14], в то время как наша работа пытается использовать предварительно подготовленные эталоны лиц в качестве генеративных лицевых приоров (GFP).
Восстановление лица. Основываясь на общей галлюцинации лица [5, 30, 66, 70], для дальнейшего улучшения производительности были включены два типичных априорных анализа лица: геометрический априорный анализ и эталонный априорный анализ. Априорная геометрия включает ориентиры лица [9, 37, 77], карты разбора лица [58, 6, 9] и тепловые карты компонентов лица [69]. Однако 1) эти априоры требуют оценок на основе входных данных низкого качества и неизбежно ухудшается в реальных сценариях. 2) Они в основном сосредоточены на ограничениях геометрии и могут не содержать адекватных деталей для восстановления. Вместо этого используемый нами GFP не требует явной оценки геометрии из ухудшенных изображений и содержит адекватные текстуры внутри своей переобученной сети.
Эталонные приоры [46, 45, 11] обычно полагаются на эталонные изображения одной и той же идентичности. Чтобы преодолеть эту проблему, DFDNet [44] предлагает создать словарь (библиотеку) лиц каждого компонента (например, глаз, рта) с функциями CNN для управления восстановлением. Однако DFDNet в основном фокусируется на компонентах словаря и, таким образом, ухудшается в областях, выходящих за рамки словаря (например, волосы, уши и контур лица), вместо этого наш GFP-GAN может обрабатывать лица в целом для восстановления. Кроме того, ограниченный размер словаря снижает разнообразие и богатство деталей лиц, в то время как GFP может предоставлять богатые и разнообразные возможности, включая геометрические текстуры и цвета.
Генеративные приоры предварительно обученных GAN [34, 35, 36, 3] ранее использовались инверсией GAN [1, 76, 54, 19], чья основная цель состоит в том, чтобы найти наиболее близкие скрытые коды, заданные входным изображением. PULSE [52] итеративно оптимизирует скрытый код StyleGAN [35] до тех пор, пока расстояние между выходами и входами не станет ниже порогового значения. mGANprior [19] пытается оптимизировать несколько кодов для улучшения качества реконструкции. Однако эти методы обычно дают изображения с низкой точностью, так как скрытых кодов малой размерности недостаточно для управления восстановлением. В отличие от этого, предлагаемые нами слои CS-CFT модуляции позволяют предварительно включать пространственные объекты с несколькими разрешениями для достижения высокой точности воспроизведения. Кроме того, дорогостоящая итеративная оптимизация не требуется в нашем методе GFP-GAN во время вывода.
Операция разделения каналов обычно исследуется для разработки компактных моделей и улучшения возможностей представления моделей. Мобильная сеть [28] предлагает глубокие свертки, а GhostNet [23] разделяет сверточный слой на две части и использует меньше фильтров для создания собственных карт объектов. Архитектура двойного пути в DPN [8] позволяет повторно использовать функции и исследовать новые функции для каждого пути, тем самым улучшая его возможности представления. Аналогичная идея также используется в супер-разрешении [75]. Наши слои CS-SFT разделяют схожие идеи, но с различными операциями и целями. Мы применяем преобразование пространственных объектов [63, 55] для одного разделения и оставляем левое разделение в качестве идентичности, чтобы достичь хорошего баланса реальности и точности.
Дискриминаторы Локальных Компонентов. Локальный дискриминатор предлагается сосредоточить на локальных распределениях патчей [32, 47, 62]. Применительно к лицам эти дискриминационные потери накладываются на отдельные семантические области лица [43, 20]. Введенная нами потеря компонентов лица также использует такие конструкции, но с дальнейшим контролем стиля, основанным на изученных различительных особенностях.
3. Методология
3.1. Обзор GFP-GAN
В этом разделе мы опишем структуру GFP-GAN. Учитывая, что входное изображение лица x страдает от неизвестной деградации, цель восстановления замутненного лица состоит в том, чтобы оценить высококачественное изображение Y^, которое максимально похоже на изображение Y с точки зрения его реальности и точности.
Общая структура GFP-GAN показана на рис. 2. GFP-GAN состоит из модуля удаления деградации (U-Net) и предварительно обученного GAN лица (такого, как StyleGAN2 [36]), как и ранее. Они соединены скрытым отображением кода и несколькими слоями преобразования пространственных объектов с разделением каналов (CS-SFT). В частности, модуль удаления деградации предназначен для удаления неполной деградации и извлечения двух видов функций, т.е. 1) скрытые объекты Flatent для сопоставления входного изображения с ближайшим скрытым кодом в StyleGAN2 и 2) пространственные объекты с несколькими разрешениями Fspatial для модуляции объектов StyleGAN2.
После этого Flatent сопоставляется с промежуточными скрытыми кодами W несколькими линейными слоями. Учитывая близкий скрытый код к входному изображению, StyleGAN2 может генерировать промежуточные сверточные функции, обозначаемые FGAN. Эти особенности обеспечивают богатые детали лица, запечатленные в весах предварительно обученного GAN. Функции с несколькими разрешениями Fspatial используются для пространственной модуляции функций GAN лица FGAN с помощью предлагаемых слоев CS-SFT грубым и тонким способом, обеспечивая реалистичные результаты при сохранении высокой точности воспроизведения.
Во время обучения, за исключением глобальной потери распознавания, мы вводим потерю компонентов лица с помощью дискриминаторов, чтобы усилить перцептивно значимые компоненты лица, т.е. глаза и рот. Чтобы сохранить личность, мы также используем рекомендации по сохранению личности.
3.2. Модуль Удаления Деградации
Восстановление размытых лиц в реальном мире сталкивается со сложной и более серьезной деградацией, которая обычно представляет собой смесь воздействий низкого разрешения, размытия, шума и JPEG. Модуль фильтрации предназначен для явного удаления вышеупомянутой деградации и извлечения “чистых” функций, Flatent (скрытых) и Fspatial (пространственных), облегчающих нагрузку на последующие модули. Мы используем структуру U-Net [56] в качестве нашего модуля удаления деградации, поскольку это может: 1) увеличить поле восприятия для устранения большого размытия и 2) генерировать функции с несколькими вариантами разрешениями.
Формулировка выглядит следующим образом:

Сглаживание скрытых объектов Flatent используется для сопоставления входного изображения с ближайшим скрытым кодом в StyleGAN2 (раздел 3.3). Пространственные объекты Fspatial с несколькими разрешениями используются для модуляции функций StyleGAN2 (раздел 3.4).
Чтобы иметь промежуточный контроль по устранению деградации, мы используем потерю восстановления L1 в каждой шкале разрешения на ранней стадии обучения. В частности, мы также выводим изображения для каждой шкалы разрешения кодировщика UNet, а затем выполняем свертку выходных данных, чтобы результаты были близки к изображению истинного объекта.
3.3. Генеративный предварительный и скрытый код лица
Предварительно обученное лицо GAN фиксирует распределение по лицам в своих изученных весах сверток, а именно, генеративный приор [19, 54]. Мы используем такой предварительно подготовленный эталон лица и предоставляем разнообразные и богатые детали лица для вашей задачи. Типичный способ развертывания генеративных приоров состоит в том, чтобы сопоставить входное изображение с его ближайшими скрытыми кодами Z, а затем сгенерировать соответствующий вывод с помощью предварительно обученного GAN [1, 76, 54, 19]. Однако эти методы обычно требуют длительной итеративной оптимизации для сохранения точности. Вместо того, чтобы создавать конечное изображение напрямую, мы генерируем промежуточные сверточные функции FGAN ближайшего лица, поскольку оно содержит больше деталей и может быть дополнительно модулировано входными функциями для лучшей точности (см. Раздел 3.4).
В частности, учитывая закодированный Flatent векторное двумерное представление входного изображения (созданный U-Сетью, уравнение 1), мы сначала сопоставляем его с промежуточными скрытыми кодами W для лучшего сохранения семантических свойств, т.е. промежуточного пространства, преобразованного из Z несколькими многослойными слоями персептрона (MLP) [76]. Скрытые коды W затем проходят через каждый слой свертки в предварительно обученной GAN и генерируют функции GEN для каждого масштаба разрешения.
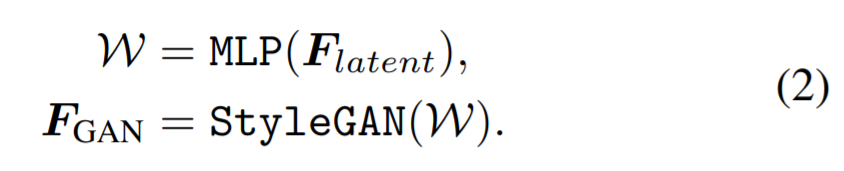
Обсуждение: Совместная реставрация и Улучшение цвета. Генеративные модели отражают разнообразные и богатые приоры, выходящие за рамки реалистичных деталей и ярких текстур. Например, они также содержат приоры цветов, которые могут быть использованы в нашей задаче для совместного восстановления лица и улучшения цвета. Изображения лиц из реального мира, например, старые фотографии, обычно имеют черно-белый цвет, винтажный желтый цвет или тусклый цвет. Живой цвет в генеративном лицевом приоре позволяет нам выполнять усиление цвета, включая окрашивание [72]. Мы считаем, что генеративные лицевые приоры также включают обычные геометрические приоры [9, 69], 3D-приоры [16] и т.д. для реставрации и манипуляций.
3.4. Преобразование пространственных объектов с разделением каналов
Чтобы лучше сохранить точность воспроизведения, мы дополнительно используем входные пространственные объекты Fspatial (созданные U-Net, уравнение 1) для модуляции функций FGAN из рисунка 2. Сохранение пространственной информации из входных данных имеет решающее значение для восстановления лица, так как обычно требуются локальные характеристики для сохранения точности и адаптивности восстановления в разных пространственных местоположениях лица. Поэтому мы используем преобразование пространственных объектов (SFT) [63], которое генерирует параметры аффинного преобразования для пространственной модуляции объектов. Оно показало свою эффективность при включении других условий в восстановление изображений [63, 44] и генерацию изображений [55].
В частности, в каждом масштабе разрешения мы генерируем пару параметров аффинного преобразования (α,β) из входных пространственных объектов несколькими сверточными слоями. После этого модуляция осуществляется путем масштабирования и сдвига функций GAN FGAN, сформулированных:

Для достижения лучшего баланса реалистичности и точности мы далее предлагаем слои преобразования пространственных объектов с разделением каналов (CSSFT), которые выполняют пространственную модуляцию части объектов GAN с помощью входных объектов Fspatial (способствующих точности) и оставляют левые объекты GAN (способствующие реалистичности) для прямого прохождения, как показано на рис. 2.:

где F split0GAN и F split1GAN это разделенные объекты из FGAN в канальном измерении, а Concat[·, ·] обозначает операцию объединения.
В результате CS-SFT пользуется преимуществами прямого включения предварительной информации и эффективной модуляции с помощью входных изображений, тем самым достигая хорошего баланса между точностью текстуры и точностью воспроизведения. Кроме того, CS-SFT также может снизить сложность, поскольку для модуляции требуется меньше каналов, аналогично GhostNet [23]. Мы свертываем слои SFT с разделением каналов в каждом масштабе разрешения и, наконец, генерируем восстановленную грань Y^.
3.5. Цели модели
Учебная цель обучения нашего GFP-GAN состоит из анализа: 1) потери при реконструкции, которая ограничивает результаты yˆ, близкие к истине y, 2) потери в состязательности для восстановления реалистичных текстур, 3) предполагаемой потери компонентов лица для дальнейшего улучшения деталей лица и 4) потери идентичности.
Потеря при реконструкции. Мы учитываем широко используемые потери L1 и потери восприятия [33, 41] для идентификации нашей потери при реконструкции Lrec, определяемой следующим образом:
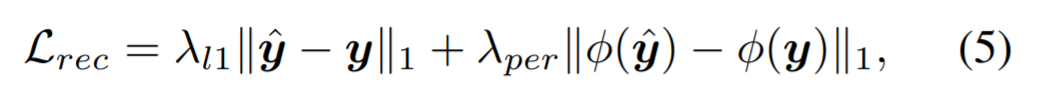
где φ — предварительно обученная сеть VGG-19 [59], и мы используем карты признаков {conv1, · · · , conv5} перед активацией [64]. λl1 и λper обозначают веса потерь L1 и потери восприятия соответственно.
Состязательный Проигрыш. Мы используем технологию состязательных потерь Ladv, чтобы GFP-GAN была ориентирована отдавать предпочтение решениям в области естественного изображения и создание реалистичных текстур. Аналогично StyleGAN2 [36], приняты логистические потери [18]:
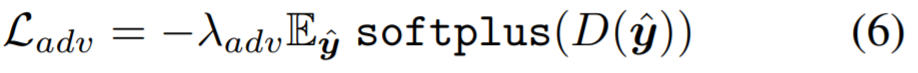
где D обозначает дискриминатор, а λadv представляет вес состязательных потерь.
Потеря Лицевого Компонента. Чтобы еще больше улучшить восприятие значимых компонентов лица, мы вводим потерю компонентов лица с помощью локальных дискриминаторов для глаз и рта. Как показано на рис. 2, мы сначала обрезаем интересующие области с выравниванием ROI [24]. Для каждого региона мы обучаем отдельные небольшие локальные дискриминаторы, чтобы различать, действительно ли восстанавливаются патчи, приближая патчи к естественному распределению компонентов лица.
Согласно [62], мы дополнительно включаем потерю чувствительности (стиля) и выбор типа функций на основе изученных дискриминаторов. В отличие от предыдущей потери соответствия объектов с пространственными ограничениями [62], наша потеря чувствительности к типу объектов пытается сопоставить статистику матрицы Грама [15] реальных и восстановленных исправлений. Матрица Грама вычисляет корреляции признаков и обычно эффективно фиксирует информацию о текстуре [17]. Мы извлекаем функции из нескольких слоев изученных (тестовых) локальных дискриминаторов и учимся сопоставлять эту статистику промежуточных представлений с реальными и восстановленными патчами. Эмпирически мы обнаружили, что потеря чувствительности функций работает лучше, чем предыдущая потеря соответствия функциям, с точки зрения создания реалистичных деталей лица и уменьшения неприятных артефактов.
Потеря лицевого компонента определяется следующим образом. Первый термин – это потеря различения [18], а второй термин – потеря стилевых признаков:

где ROI — область интереса из набора компонентов {левый глаз, правый глаз, рот}. DROI — это локальный дискриминатор для каждого региона. ψ обозначает функции с несколькими разрешениями из изученных дискриминаторов. λlocal и λfs представляют веса потерь локальных дискриминационных потерь и потерь стиля признаков соответственно.
Потеря Сохранения Идентичности. Мы оцениваем потерю идентичности, следуя [31] в нашей модели. Подобно потере восприятия [33], мы определяем потерю на основе встраивания в модель признаков входного лица. В частности, мы используем предварительно обученную модель распознавания лиц ArcFace [10], которая отражает наиболее характерные особенности при распознавании личности. Потеря, сохраняющая идентичность, приводит к тому, что восстановленный результат имеет небольшое отклонение от ожидаемого результата в компактном пространстве глубоких объектов (формально математически – всюду плотно):

где η представляет экстрактор признаков лица, то есть ArcFace [10] в нашей реализации. λid обозначает вес потери при сохранении идентичности.
Общая цель модели заключается в сочетании вышеуказанных потерь:
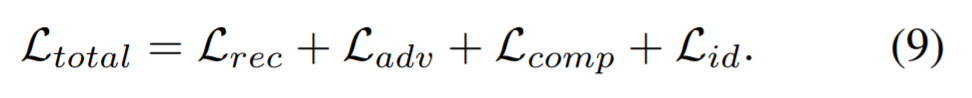
Гиперпараметры потерь устанавливаются следующим образом: λl1 = 0,1, λper = 1, λadv = 0,1, λlocal = 1, λfs = 200 и λid = 10.
4. Эксперименты
4.1. Наборы данных и внедрение
Обучающие наборы данных. Мы обучаем наш GFP-GAN на наборе данных FFHQ [35], который состоит из 70000 высококачественных изображений. Во время обучения мы изменяем размер всех изображений до 5122.
Модель GFP-GAN обучается на синтетических данных, которые приближаются к реальным изображениям низкого качества и переносятся затем на изображения реального мира при выводе. Мы следуем практике, описанной в [46, 44] и используем следующую модель разложения для синтеза обучающих данных:

Изображение высокого качества y сначала свертывается с ядром размытия по Гауссу kσ, после чего следует операция понижения дискретизации с коэффициентом масштабирования r. После этого к изображению добавляется аддитивный белый гауссовский шум nδ и, наконец, оно сжимается в формате JPEG с коэффициентом качества q. Как и в [44], для каждой обучающей пары мы случайным образом выбираем σ, r, δ и q из {0,2 : 10}, {1 : 8}, {0 : 15}, {60 : 100} соответственно. Мы также добавляем дрожание цвета во время обучения для улучшения цвета.
Тестирование наборов данных. Мы создаем один синтетический набор данных и три разных реальных набора данных с различными источниками. Все эти наборы данных не пересекаются с нашим учебным набором данных. Приводим его краткое описание:
· CelebA-Test – это синтетический набор данных с 3000 изображениями штаб-квартиры знаменитостей из его тестового раздела [51]. Способ генерации такой же, как и во время обучения.
· LFW-Test. LFW [29] содержит изображения низкого качества в дикой природе. Мы группируем все начальные изображения для каждой идентификации в разделе проверки, формируя 1711 тестовых изображений.
· CelebChild-Test содержит 180 детских лиц знаменитостей, собранных из Интернета. Они низкого качества, и многие из них представляют собой черно-белые старые фотографии.
· WebPhoto-Test. Мы просмотрели 188 фотографий низкого качества в реальной жизни из Интернета и извлекли 407 лиц для создания набора данных для тестирования веб-фотографий. Эти фотографии имеют разнообразную и сложную деградацию (искажения). Некоторые из них – старые фотографии с очень сильным ухудшением, как деталей, так и цвета.
Реализация. Мы используем предварительно обученный StyleGAN2 [36] с 5122 выходами в качестве нашего генеративного лицевого приора. Множитель канала StyleGAN2 установлен на единицу для компактного размера модели. UNET для удаления деградации состоит из семи понижающих выборок и семи повышающих выборок, каждая с остаточным блоком [25]. Для каждого слоя CS-SFT мы используем два сверточных слоя для генерации аффинных параметров α и β соответственно.
Размер обучающей мини-партии (теста) установлен равным 12. Мы дополняем обучающие данные горизонтальным переворотом и колебаниями цвета. Мы рассматриваем три компонента: левый глаз (left_eye), правый глаз(right_eye), рот (mount) для учета потери компонента лица, поскольку они являются значимыми для восприятия. Каждый компонент обрезается с помощью выравнивания ROI [24] по ориентирам лица, предоставленным в наборе исходных обучающих выборок. Мы обучаем нашу модель с помощью Adam optimizer [38] в общей сложности 800 тыс. итерациями. Скорость обучения была установлена на 2×10-3, а затем уменьшена в 2 раза на 700k-ой, 750k-ой итерациях. Мы реализуем наши модели с помощью платформы PyTorch и обучаем их с помощью четырех графических процессоров NVIDIA Tesla P40.


4.2. Сравнение с современными методами
Мы сравниваем GFP-GAN с несколькими современными методами восстановления лица: HiFaceGAN [67], DFDNET [44], PSFRGAN [6], Super-FAN [4] и Wan и др. [61]. Также рассматриваются для сравнения методы инверсии GAN для восстановления лица: PULSE [52] и mGANprior [19]. Мы также сравниваем GFP-GAN с методами восстановления изображений: CAN [74], ESRGAN [64] и DeblurGANv2 [40], точно настраивая их на нашем наборе для обучения лиц для релевантного сравнения. Мы принимаем их официальные коды, за исключением SuperFAN, для которого используем повторную реализацию.
Для оценки мы используем широко используемые показатели восприятия без ссылок: FID [27] и NIQE [53]. Мы также используем пиксельные метрики (PSNR и SSIM) и перцептивную метрику (метрику восприятия LPIPES [73]) для CelebA-Test c Ground-Truth (A-теста знаменитостей с достоверностью). Мы измеряем меру идентификации с помощью функции ArcFace [10], где меньшие значения указывают на более близкую идентификацию с GT.
Синтетический CelebA-Test. Сравнения проводятся при двух настройках: 1) восстановление замутненного лица, входы и выходы которого имеют одинаковое разрешение. 2) супер-разрешение 4×лица. Обратите внимание, что наш метод может использовать изображения с увеличенной дискретизацией в качестве входных данных для супер-разрешения лица.


Количественные результаты для каждой настройки приведены в таблице 1 и таблице 2. При обеих настройках GFP-GAN достигает самых низких уровней LPIPS, что указывает на то, что наши результаты по восприятию близки к истине.

GFP-GAN также может получить самую низкую FID и NIQE, показывающие, что выходы имеют близкое расстояние к реальному распределению лица и естественному распределению изображения, соответственно. Помимо перцептивной производительности (восприятия), наш метод также сохраняет лучшую идентичность по наименьшей степени встраивания функций (элементов) лица. Обратите внимание, что 1) малость FID и NIQE наш по сравнению с GT не свидетельствуют о том, что наши показатели лучше, чем в GT, а перцептивные метрики хорошо коррелируют с оценками экспертов (баллами по укрупненной шкале), но не всегда хорошо коррелируют на более мелкой шкале [2]; 2) пиксельные метрики PSNR и SSIM недостаточно коррелируют с субъективной оценкой человека, наблюдателя [2, 41] и наша модель несильна в этих двух метриках.
Качественные результаты представлены на рис. 3 и рис. 4.
1) Благодаря мощному генеративному распознаванию лица наша GFP-GAN восстанавливает точные детали глаз (зрачки и ресницы), зубов и т.д. 2) наш метод корректирует лица в целом при восстановлении, а также может создавать реалистичные волосы, в то время как предыдущие методы, основанные на словарях (библиотеках) компонентов (DFDNet) или извлечении карт (PSFRGAN), не позволяет получать точную текстуру волос (2-ой ряд, на фиг. 3). 3) GFP-GAN способен сохранять точность, например, естественного закрытого рта без принудительного дополнение зубов (2-й строке на фиг. 3). 4) на рис. 4, GFP-GAN также восстанавливает разумное направление взгляда.
Реальные LFW, CelebChild и WedPhoto-Test. Чтобы проверить способность к обобщению, мы оцениваем нашу модель на трех различных реальных наборах данных. Количественные результаты приведены в таблице. 3. Наш GFP-GAN обеспечивает превосходную производительность во всех трех реальных наборах данных, демонстрируя замечательную способность к обобщению. Хотя PULSE [52] также мог получить высокое качество восприятия (более низкие баллы FID), он не мог сохранить идентичность лица, как показано на рис. 5.


4.3. Абляционные исследования
Слои CS-SFT. Как показано в таблице. 4 (конфигурация a)) и рис. 6, когда мы удаляем слои пространственной модуляции, т.е. сохраняем только отображение скрытого кода без пространственной информации, восстановленные лица не могут сохранить идентичность лица даже с сохранением идентичности контура (высокий балл по губам и большой градус). Таким образом, пространственные объекты с несколькими разрешениями, используемые в слоях CS-SFT, жизненно важны для сохранения точности. Когда мы переключаем CS-SFT-слои на простые SFT-слои (конфигурация b) в таблице 4), мы наблюдаем, что 1) качество восприятия ухудшается по всем показателям и 2) оно сохраняет более сильную идентичность (меньший градус), поскольку функции входного изображения оказывают влияние на все модулированные функции, а выходные данные смещаются в сторону ухудшенных входных данных, что приводит к снижению качества восприятия. Напротив, SFT-слои обеспечивают хороший баланс реалистичности и точности, модулируя разделение функций.
Предварительно обученный GAN в качестве GFP. Предварительно обученный GAN предоставляет богатые и разнообразные возможности для восстановления. Снижение производительности наблюдается, если мы не используем генеративную функцию лица, как показано в таблице 4 [конфигурация c)] и рис. 6.
Потеря реставрации пирамиды. Потеря при восстановлении пирамиды используется в модуле удаления искажений (фильтрации) и усиливает способность к восстановлению при сложных искажениях в реальном мире. Без этого промежуточного контроля пространственные характеристики с несколькими разрешениями для последующих модуляций могут по-прежнему ухудшаться, что приведет к снижению производительности, как показано в таблице. 4 [конфигурация d)] и рис. 6.
Потеря Компонента Лица. Мы сравниваем результаты 1) удаления всех потерь компонентов (искажений) лица, 2) сохранения только дискриминаторов компонентов, 3) добавления дополнительных потерь при сопоставлении признаков, как в [62], и 4) принятия дополнительных потерь стиля признаков на основе статистики Грамм [15]. На рис. 7 показано, что дискриминаторы компонентов с потерей стиля объектов могут лучше улавливать распределение глаз и восстанавливать правдоподобные детали.



![Рисунок 9. Ограничения нашей модели. Также представлены результаты PSFRGAN [6].](https://habrastorage.org/getpro/habr/upload_files/0bb/146/fc7/0bb146fc7d8936f56005e68854788211.png "Рисунок 9. Ограничения нашей модели. Также представлены результаты PSFRGAN [6].")
4.4. Обсуждение и ограничения
Предвзятость в обучении. Наш метод хорошо работает на большинстве темнокожих лиц и различных групп населения (рис. 8), так как наш метод использует как предварительно обученное усиление, так и функции входного изображения для модуляции. Кроме того, мы используем потери при восстановлении и потери при сохранении идентичности, чтобы ограничить выходные данные и сохранить точность входных данных. Однако, когда входные изображения имеют оттенки серого, цвет лица может сильно отличаться (последний пример на рис. 8), так как входные данные не содержат достаточной информации о цвете. Таким образом, необходим разнообразный и сбалансированный набор данных.
Ограничения. Как показано на рис. 9, когда ухудшение реальных изображений является серьезным, восстановленные детали лица с помощью FPGA искажаются влияющими факторами. Наш метод также дает неестественные результаты для очень больших поз. Это связано с тем, что синтетическая деградация и распределение обучающих данных отличаются от таковых в реальном мире. Один из возможных способов – изучить эти распределения на основе реальных данных, а не просто использовать синтетические данные, которые оставлены в качестве будущей работы.
Заключение
Мы предложили структуру GFP-GAN, которая использует богатые и разнообразные генеративные функции лица для решения сложной задачи восстановления замутненного лица. Это включено в процесс восстановления с помощью слоев преобразования пространственных объектов с разделением каналов, что позволяет нам достичь хорошего баланса реалистичности и точности. Обширные сравнения демонстрируют превосходные возможности GFP-GAN в восстановлении суставных поверхностей и улучшении цвета для изображений реального мира, превосходящие предшествующие уровни техники.
Ссылки
[1] Rameen Abdal, Yipeng Qin, and Peter Wonka. Image2stylegan: How to embed images into the stylegan latent space? In ICCV, 2019. 2, 4
[2] Yochai Blau, Roey Mechrez, Radu Timofte, Tomer Michaeli,and Lihi Zelnik-Manor. The 2018 pirm challenge on perceptual image super-resolution. In ECCVW, 2018. 6
[3] Andrew Brock, Jeff Donahue, and Karen Simonyan. Large scale gan training for high fidelity natural image synthesis. arXiv preprint arXiv:1809.11096, 2018. 2
[4] Adrian Bulat and Georgios Tzimiropoulos. Super-fan: Integrated facial landmark localization and super-resolution of real-world low resolution faces in arbitrary poses with gans. In CVPR, 2018. 6, 7
[5] Qingxing Cao, Liang Lin, Yukai Shi, Xiaodan Liang, and Guanbin Li. Attention-aware face hallucination via deep reinforcement learning. In CVPR, 2017. 2
[6] Chaofeng Chen, Xiaoming Li, Lingbo Yang, Xianhui Lin, Lei Zhang, and Kwan-Yee K. Wong. Progressive semantic-aware style transformation for blind face restoration. arXiv:2009.08709, 2020. 1, 2, 6, 7, 8
[7] Jingwen Chen, Jiawei Chen, Hongyang Chao, and Ming Yang. Image blind denoising with generative adversarial network based noise modeling. In CVPR, 2018. 2
[8] Yunpeng Chen, Jianan Li, Huaxin Xiao, Xiaojie Jin, Shuicheng Yan, and Jiashi Feng. Dual path networks. In NeurIPS, 2017. 2
[9] Yu Chen, Ying Tai, Xiaoming Liu, Chunhua Shen, and Jian Yang. Fsrnet: End-to-end learning face super-resolution with facial priors. In CVPR, 2018. 1, 2, 4
[10] Jiankang Deng, Jia Guo, Niannan Xue, and Stefanos Zafeiriou. Arcface: Additive angular margin loss for deep face recognition. In CVPR, 2019. 5, 6
[11] Berk Dogan, Shuhang Gu, and Radu Timofte. Exemplar guided face image super-resolution without facial landmarks. In CVPRW, 2019. 1, 2
[12] Chao Dong, Yubin Deng, Chen Change Loy, and Xiaoou Tang. Compression artifacts reduction by a deep convolutional network. In ICCV, 2015. 1, 2
[13] Chao Dong, Chen Change Loy, Kaiming He, and Xiaoou Tang. Learning a deep convolutional network for image super-resolution. In ECCV, 2014. 1, 2
[14] Leonardo Galteri, Lorenzo Seidenari, Marco Bertini, and Alberto Del Bimbo. Deep generative adversarial compression artifact removal. In ICCV, 2017. 2
[15] Leon A Gatys, Alexander S Ecker, and Matthias Bethge. Image style transfer using convolutional neural networks. In CVPR, 2016. 5, 8
[16] Baris Gecer, Stylianos Ploumpis, Irene Kotsia, and Stefanos Zafeiriou. Ganfit: Generative adversarial network fitting for high fidelity 3d face reconstruction. In CVPR, 2019. 4
[17] Muhammad Waleed Gondal, Bernhard Scholkopf, and Michael Hirsch. The unreasonable effectiveness of texture transfer for single image super-resolution. In ECCV, 2018. 5
[18] Ian Goodfellow, Jean Pouget-Abadie, Mehdi Mirza, Bing Xu, David Warde-Farley, Sherjil Ozair, Aaron Courville, and Yoshua Bengio. Generative adversarial nets. In NeurIPS, 2014. 2, 4, 5
[19] Jinjin Gu, Yujun Shen, and Bolei Zhou. Image processing using multi-code gan prior. In CVPR, 2020. 2, 4, 6, 7
[20] Qiao Gu, Guanzhi Wang, Mang Tik Chiu, Yu-Wing Tai, and Chi-Keung Tang. Ladn: Local adversarial disentangling network for facial makeup and de-makeup. In ICCV, 2019. 3
[21] Jun Guo and Hongyang Chao. Building dual-domain representations for compression artifacts reduction. In ECCV, 2016. 2
[22] Yong Guo, Jian Chen, Jingdong Wang, Qi Chen, Jiezhang Cao, Zeshuai Deng, Yanwu Xu, and Mingkui Tan. Closedloop matters: Dual regression networks for single image super-resolution. In CVPR, 2020. 2
[23] Kai Han, Yunhe Wang, Qi Tian, Jianyuan Guo, Chunjing Xu, and Chang Xu. Ghostnet: More features from cheap operations. In CVPR, 2020. 2, 4
[24] Kaiming He, Georgia Gkioxari, Piotr Dollar, and Ross Gir-shick. Mask r-cnn. In ICCV, 2017. 5
[25] Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. Deep residual learning for image recognition. In CVPR, 2016. 5
[26] Majed El Helou, Ruofan Zhou, and Sabine Susstrunk. Stochastic frequency masking to improve super-resolution and denoising networks. In ECCV, 2020. 2
[27] Martin Heusel, Hubert Ramsauer, Thomas Unterthiner, Bernhard Nessler, and Sepp Hochreiter. Gans trained by a two time-scale update rule converge to a local nash equilibrium. In NeurIPS, 2017. 6
[28] Andrew G Howard, Menglong Zhu, Bo Chen, Dmitry Kalenichenko, Weijun Wang, Tobias Weyand, Marco Andreetto, and Hartwig Adam. Mobilenets: Efficient convolutional neural networks for mobile vision applications. arXiv:1704.04861, 2017. 2
[29] Gary B. Huang, Manu Ramesh, Tamara Berg, and Erik Learned-Miller. Labeled faces in the wild: A database for studying face recognition in unconstrained environments. Technical report, University of Massachusetts, Amherst, 2007. 5
[30] Huaibo Huang, Ran He, Zhenan Sun, and Tieniu Tan. Wavelet-srnet: A wavelet-based cnn for multi-scale face super resolution. In ICCV, 2017. 2
[31] Rui Huang, Shu Zhang, Tianyu Li, and Ran He. Beyond face rotation: Global and local perception gan for photorealistic and identity preserving frontal view synthesis. In CVPR, 2017. 5
[32] Satoshi Iizuka, Edgar Simo-Serra, and Hiroshi Ishikawa. Globally and locally consistent image completion. ACM Transactions on Graphics (ToG), 36(4):1–14, 2017. 3
[33] Justin Johnson, Alexandre Alahi, and Li Fei-Fei. Perceptual losses for real-time style transfer and super-resolution. In ECCV, 2016. 4, 5
[34] Tero Karras, Timo Aila, Samuli Laine, and Jaakko Lehtinen. Progressive growing of gans for improved quality, stability, and variation. In ICLR, 2018. 2
[35] Tero Karras, Samuli Laine, and Timo Aila. A style-based generator architecture for generative adversarial networks. In CVPR, 2018. 2, 5
[36] Tero Karras, Samuli Laine, Miika Aittala, Janne Hellsten, Jaakko Lehtinen, and Timo Aila. Analyzing and improving the image quality of stylegan. In CVPR, 2020. 2, 3, 4, 5
[37] Deokyun Kim, Minseon Kim, Gihyun Kwon, and Dae-Shik Kim. Progressive face super-resolution via attention to facial landmark. In BMVC, 2019. 2
[38] Diederik P Kingma and Jimmy Ba. Adam: A method for stochastic optimization. In ICLR, 2015. 6
[39] Orest Kupyn, Volodymyr Budzan, Mykola Mykhailych, Dmytro Mishkin, and Jiˇr´ı Matas. Deblurgan: Blind motion deblurring using conditional adversarial networks. In CVPR, 2018. 1, 2
[40] Orest Kupyn, Tetiana Martyniuk, Junru Wu, and Zhangyang Wang. Deblurgan-v2: Deblurring (orders-of-magnitude) faster and better. In ICCV, 2019. 6, 7
[41] Christian Ledig, Lucas Theis, Ferenc Huszar, Jose Caballero, Andrew Cunningham, Alejandro Acosta, Andrew Aitken, Alykhan Tejani, Johannes Totz, Zehan Wang, et al. Photorealistic single image super-resolution using a generative adversarial network. In CVPR, 2017. 2, 4, 6
[42] Stamatios Lefkimmiatis. Non-local color image denoising with convolutional neural networks. In CVPR, 2017. 2
[43] Tingting Li, Ruihe Qian, Chao Dong, Si Liu, Qiong Yan, Wenwu Zhu, and Liang Lin. Beautygan: Instance-level facial makeup transfer with deep generative adversarial network. In ACM MM, 2018. 3
[44] Xiaoming Li, Chaofeng Chen, Shangchen Zhou, Xianhui Lin, Wangmeng Zuo, and Lei Zhang. Blind face restoration via deep multi-scale component dictionaries. In ECCV, 2020. 1, 2, 4, 5, 6, 7
[45] Xiaoming Li, Wenyu Li, Dongwei Ren, Hongzhi Zhang, Meng Wang, and Wangmeng Zuo. Enhanced blind face restoration with multi-exemplar images and adaptive spatial feature fusion. In CVPR, 2020. 1, 2
[46] Xiaoming Li, Ming Liu, Yuting Ye, Wangmeng Zuo, Liang Lin, and Ruigang Yang. Learning warped guidance for blind face restoration. In ECCV, 2018. 1, 2, 5
[47] Yijun Li, Sifei Liu, Jimei Yang, and Ming-Hsuan Yang. Generative face completion. In CVPR, 2017. 3
[48] Bee Lim, Sanghyun Son, Heewon Kim, Seungjun Nah, and Kyoung Mu Lee. Enhanced deep residual networks for single image super-resolution. In CVPRW, 2017. 1, 2
[49] Ding Liu, Bihan Wen, Yuchen Fan, Chen Change Loy, and Thomas S Huang. Non-local recurrent network for image restoration. In NeurIPS, 2018. 2
[50] Jie Liu, Wenjie Zhang, Yuting Tang, Jie Tang, and Gangshan Wu. Residual feature aggregation network for image superresolution. In CVPR, 2020. 2
[51] Ziwei Liu, Ping Luo, Xiaogang Wang, and Xiaoou Tang. Deep learning face attributes in the wild. In ICCV, 2015. 5
[52] Sachit Menon, Alexandru Damian, Shijia Hu, Nikhil Ravi, and Cynthia Rudin. Pulse: Self-supervised photo upsampling via latent space exploration of generative models. In CVPR, 2020. 1, 2, 6, 7
[53] Anish Mittal, Rajiv Soundararajan, and Alan C Bovik. Making a “completely blind” image quality analyzer. IEEE Signal processing letters, 20(3):209–212, 2012. 6
[54] Xingang Pan, Xiaohang Zhan, Bo Dai, Dahua Lin, Chen Change Loy, and Ping Luo. Exploiting deep generative prior for versatile image restoration and manipulation. In ECCV, 2020. 2, 4
[55] Taesung Park, Ming-Yu Liu, Ting-Chun Wang, and Jun-Yan Zhu. Semantic image synthesis with spatially-adaptive normalization. In CVPR, 2019. 2, 4
[56] Olaf Ronneberger, Philipp Fischer, and Thomas Brox. U-net: Convolutional networks for biomedical image segmentation. In International Conference on Medical Image Computing and Computer-Assisted Intervention, 2015. 3
[57] Mehdi SM Sajjadi, Bernhard Scholkopf, and Michael Hirsch. Enhancenet: Single image super-resolution through automated texture synthesis. In ECCV, 2017. 2
[58] Ziyi Shen, Wei-Sheng Lai, Tingfa Xu, Jan Kautz, and MingHsuan Yang. Deep semantic face deblurring. In CVPR, 2018. 1, 2
[59] Karen Simonyan and Andrew Zisserman. Very deep convolutional networks for large-scale image recognition. In ICLR, 2015. 4
[60] Radu Timofte, Eirikur Agustsson, Luc Van Gool, MingHsuan Yang, and Lei Zhang. Ntire 2017 challenge on single image super-resolution: Methods and results. In CVPRW, 2017. 2
[61] Ziyu Wan, Bo Zhang, Dongdong Chen, Pan Zhang, Dong Chen, Jing Liao, and Fang Wen. Bringing old photos back to life. In CVPR, 2020. 1, 6, 7
[62] Ting-Chun Wang, Ming-Yu Liu, Jun-Yan Zhu, Andrew Tao, Jan Kautz, and Bryan Catanzaro. High-resolution image synthesis and semantic manipulation with conditional gans. In CVPR, 2018. 3, 5, 8
[63] Xintao Wang, Ke Yu, Chao Dong, and Chen Change Loy. Recovering realistic texture in image super-resolution by deep spatial feature transform. In CVPR, 2018. 2, 4
[64] Xintao Wang, Ke Yu, Shixiang Wu, Jinjin Gu, Yihao Liu, Chao Dong, Yu Qiao, and Chen Change Loy. Esrgan: Enhanced super-resolution generative adversarial networks. In ECCVW, 2018. 2, 4, 6, 7
[65] Li Xu, Jimmy S Ren, Ce Liu, and Jiaya Jia. Deep convolutional neural network for image deconvolution. In NeurIPS, 2014. 2
[66] Xiangyu Xu, Deqing Sun, Jinshan Pan, Yujin Zhang, Hanspeter Pfister, and Ming-Hsuan Yang. Learning to superresolve blurry face and text images. In ICCV, 2017. 2
[67] Lingbo Yang, Chang Liu, Pan Wang, Shanshe Wang, Peiran Ren, Siwei Ma, and Wen Gao. Hifacegan: Face renovation via collaborative suppression and replenishment. ACM Multimedia, 2020. 1, 6, 7
[68] Ke Yu, Xintao Wang, Chao Dong, Xiaoou Tang, and Chen Change Loy. Path-restore: Learning network path selection for image restoration. arXiv:1904.10343, 2019. 2
[69] Xin Yu, Basura Fernando, Bernard Ghanem, Fatih Porikli, and Richard Hartley. Face super-resolution guided by facial component heatmaps. In ECCV, pages 217–233, 2018. 1, 2, 4
[70] Xin Yu, Basura Fernando, Richard Hartley, and Fatih Porikli. Super-resolving very low-resolution face images with supplementary attributes. In CVPR, 2018. 2
[71] Kai Zhang, Wangmeng Zuo, Yunjin Chen, Deyu Meng, and Lei Zhang. Beyond a gaussian denoiser: Residual learning of deep cnn for image denoising. IEEE TIP, 26(7):3142–3155, 2017. 1, 2
[72] Richard Zhang, Phillip Isola, and Alexei A Efros. Colorful image colorization. In ECCV, 2016. 4
[73] Richard Zhang, Phillip Isola, Alexei A Efros, Eli Shechtman, and Oliver Wang. The unreasonable effectiveness of deep features as a perceptual metric. In CVPR, 2018. 6
[74] Yulun Zhang, Kunpeng Li, Kai Li, Lichen Wang, Bineng Zhong, and Yun Fu. Image super-resolution using very deep residual channel attention networks. In ECCV, 2018. 2, 6, 7
[75] Xiaole Zhao, Yulun Zhang, Tao Zhang, and Xueming Zou. Channel splitting network for single mr image super-resolution. IEEE Transactions on Image Processing, 28(11):5649–5662, 2019. 2
[76] Jiapeng Zhu, Yujun Shen, Deli Zhao, and Bolei Zhou. Indomain gan inversion for real image editing. In ECCV, 2020. 2, 4
[77] Shizhan Zhu, Sifei Liu, Chen Change Loy, and Xiaoou Tang. Deep cascaded bi-network for face hallucination. In ECCV, 2016. 2
Расфокусированные фотографии с эффектом боке становятся всё более популярными, но обычно они только раздражают. Допустим, вы постарались снять уникальное в своем роде семейное видео только лишь для того, чтобы обнаружить, что изображение размыто и дрожит.
Оказывается, существуют программы, которые могут улучшить резкость фотографий без возни в Photoshop. Хотя в большинстве случаев из размытого фото или видео никогда не сделать резкую и красивую копию, эти инструменты можно использовать для восстановления важных деталей и вернуть резкость, чтобы сделать материал чуть более качественным.
Естественно, не стоит ожидать, что, сделав ряд сильно расфокусированных фотографий, вы отредактируете их так, что они сгодятся на обложку журнала, однако вы можете изощряться в стиле сериала CSI, используя эти приложения, и получить удивительные результаты.
SmartDeblur
SmartDeblur — полностью бесплатное приложение, которым можно пользоваться сколько угодно раз, и во многих отношениях оно дружелюбнее, чем Focus Magic. С другой стороны, его работа не отличается стабильностью (программа зависала несколько, пока я ее тестировал, особенно при загрузке слишком тяжелых изображений), а результаты, которые выдает программа, могут быть разными.

Есть несколько полезных возможностей в SmartDeblur — наличие zoom-опции, а также опции Fit To Window (Подстроить под размер окна). Также можно сравнивать результаты с оригиналом, нажав на «Show Original». Предобзор доступен для всего изображения. Программа содержит образец на котором можно научиться увеличивать резкость, чтобы прочесть размытый текст.
Испытав инструмент на своих собственных фотографиях, я обнаружил, что он не работает так же хорошо как Focus Magic. Но мне удалось получить хорошие результаты с картинкой, содержащей текст.
- Плюсы: Абсолютно бесплатное, обладающее дружелюбным интерфейсом, очень полезное для прочтения на фотографии размытого текста.
- Минусы: Не очень стабильное, не так уж хорошо работает с реальными фотографиями (но испытайте приложение сами, чтобы вынести свой вердикт).
Пытаясь восстановить потерянные детали, вы почувствуете, будто работаете с CSI, но не ожидайте ничего выдающегося.
Focus Magic
Focus Magic — это нечто большее, чем просто программа увеличения резкости. Согласно заявлениям с их сайта, используются «продвинутые криминалистические деконволюционные технологии, которые буквально, как рукой, снимают размытие». В теории, приложение справляется с расфокусированными изображениями и размытыми видео, восстанавливая потерянные детали. Но действительно ли это работает?

Программа Focus Magic далеко не автоматический инструмент. И это огромный минус, поскольку бесплатная пробная версия позволяет выполнить только 10 операций. После этого нужно будет приобрести полную лицензию, которая стоит 45 долларов. После загрузки изображения вам сперва необходимо решить, будете ли фокусировать, убирать размытие при движении, дефокусировать или очищать изображение от мусора. Потом начинается долгий процесс подстройки параметров.
Поскольку возможно увидеть привью лишь для небольшой области изображения, уходит множество попыток, чтобы достичь хорошего эффекта для всей фотографии.
- Плюсы: Выглядит как профессиональный инструмент, с помощью которого действительно можно достичь хороших результатов.
- Минусы: Работа требует множества попыток, но их у пользователя бесплатной версией только 10. К тому же, отсутствует опция изменения масштаба (зума), что доставляет неудобства.
С помощью приложения можно вернуть резкость изображениям, если у вас есть терпение и деньги.
Blurity
Приложение Blurity в отличие от своих конкурентов обладает несколькими особенностями: очень подробным руководством и самодостаточностью. Под самодостаточностью я понимаю способность программы взять на себя тяжелую работу по настройке, если того пожелаете. Если знаете, что делаете, можете получить доступ к продвинутым настройкам, но это совсем необязательно.

После прохождения обучения, можно приступать к обработке. Для этого необходимо поместить красный квадрат на область с сильной размытостью и нажать на кнопку Process. В большинстве случаев на этом всё. Если результаты вас не удовлетворяют, можно переместить квадрат в другую область и попытаться снова. Приложение выполняет свою работу хорошо, ему удалось превратить некоторые размытые фотографии во вполне достойные.
Как видите, минусом являются водяные знаки, которые накладываются на все фотографии, которые вы обрабатываете, используя бесплатную версию приложения. Если вам действительно нравится программа и хотите избавиться от водяных знаков, лицензия будет стоить вам 39$.
- Плюсы: Легкость в использовании, хорошие результаты обработки, с текстом — хуже.
- Минусы: На все обработанные фото накладываются водяные знаки. Лицензия стоит 39$.
Выводы
Хотите – верьте, хотите – нет, но я потратил полдня, исследуя данную тему. Попытавшись повысить резкость у множества размытых фото и видео, я осознал одну вещь — лучше сразу снимать хороший материал. Но если по какой-то причине «план А» не сработал, то вышеперечисленные приложения способны выжать кое-что из вашего материала, но это на самом деле зависит от того, чего вы стремитесь достичь.
