![]() Одна из возможных проблем, с которыми можно столкнуться после установки Windows 10 — кракозябры вместо русских букв в интерфейсе программ, а также в документах. Чаще неправильное отображение кириллицы встречается в изначально англоязычных и не совсем лицензионных версиях системы, но бывают и исключения.
Одна из возможных проблем, с которыми можно столкнуться после установки Windows 10 — кракозябры вместо русских букв в интерфейсе программ, а также в документах. Чаще неправильное отображение кириллицы встречается в изначально англоязычных и не совсем лицензионных версиях системы, но бывают и исключения.
В этой инструкции — о том, как исправить «кракозябры» (или иероглифы), а точнее — отображение кириллицы в Windows 10 несколькими способами. Возможно, также будет полезным: Как установить и включить русский язык интерфейса в Windows 10 (для систем на английском и других языках).
Исправление отображения кириллицы с помощью настроек языка и региональных стандартов Windows 10
Самый простой и чаще всего работающий способ убрать кракозябры и вернуть русские буквы в Windows 10 — исправить некоторые неправильные настройки в параметрах системы.
Для этого потребуется выполнить следующие шаги (примечание: привожу также названия нужных пунктов на английском, так как иногда необходимость исправить кириллицу возникает в англоязычных версиях системы без нужды менять язык интерфейса).
- Откройте панель управления (для этого можно начать набирать «Панель управления» или «Control Panel» в поиске на панели задач.
- Убедитесь, что в поле «Просмотр» (View by) установлено «Значки» (Icons) и выберите пункт «Региональные стандарты» (Region).
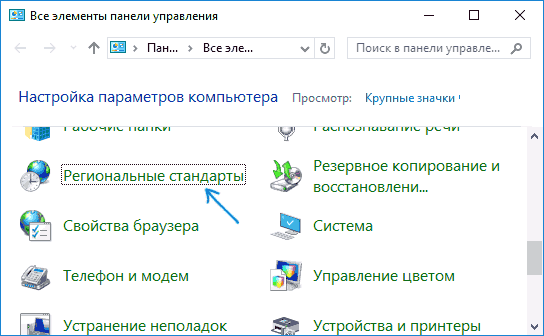
- На вкладке «Дополнительно» (Administrative) в разделе «Язык программ, не поддерживающих Юникод» (Language for non-Unicode programs) нажмите по кнопке «Изменить язык системы» (Change system locale).
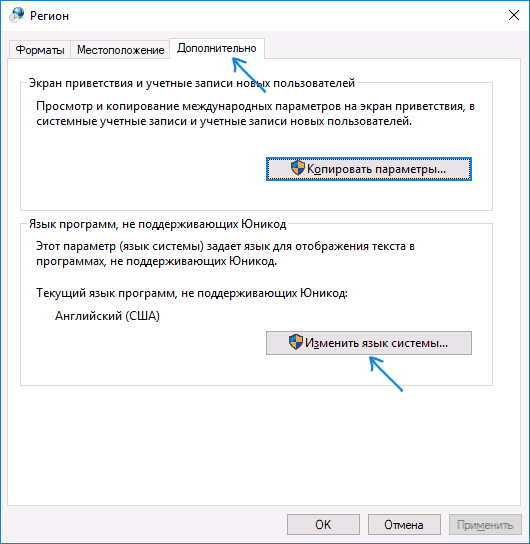
- Выберите русский язык, нажмите «Ок» и подтвердите перезагрузку компьютера.
После перезагрузки проверьте, была ли решена проблема с отображением русских букв в интерфейсе программ и (или) документах — обычно, кракозябры бывают исправлены после этих простых действий.
Как исправить иероглифы Windows 10 путем изменения кодовых страниц
Кодовые страницы представляют собой таблицы, в которых определенным байтам сопоставляются определенные символы, а отображение кириллицы в виде иероглифов в Windows 10 связано обычно с тем, что по умолчанию задана не та кодовая страница и это можно исправить несколькими способами, которые могут быть полезны, когда требуется не изменять язык системы в параметрах.
С помощью редактора реестра
Первый способ — использовать редактор реестра. На мой взгляд, это самый щадящий для системы метод, тем не менее, рекомендую создать точку восстановления прежде чем начинать. Совет про точки восстановления относится и ко всем последующим способам в этом руководстве.
- Нажмите клавиши Win+R на клавиатуре, введите regedit и нажмите Enter, откроется редактор реестра.
- Перейдите к разделу реестра
HKEY_LOCAL_MACHINESYSTEMCurrentControlSetControlNlsCodePage
и в правой части пролистайте значения этого раздела до конца.
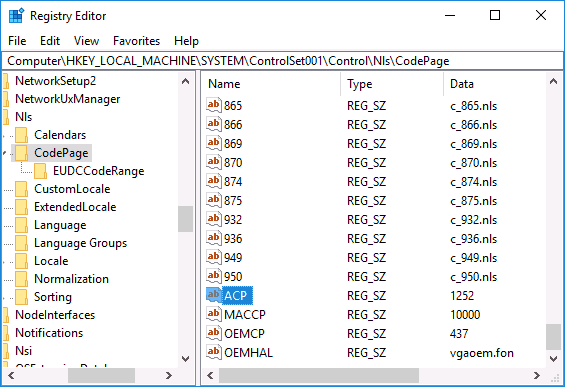
- Дважды нажмите по параметру ACP, установите значение 1251 (кодовая страница для кириллицы), нажмите Ок и закройте редактор реестра.
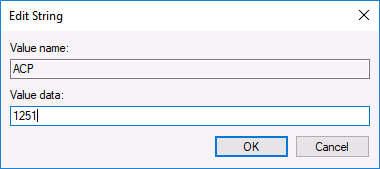
- Перезагрузите компьютер (именно перезагрузка, а не завершение работы и включение, в Windows 10 это может иметь значение).
Обычно, это исправляет проблему с отображением русских букв. Вариация способа с помощью редактора реестра (но менее предпочтительная) — посмотреть на текущее значение параметра ACP (обычно — 1252 для изначально англоязычных систем), затем в том же разделе реестра найти параметр с именем 1252 и изменить его значение с c_1252.nls на c_1251.nls.
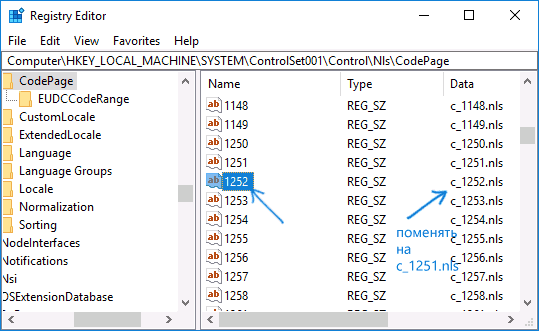
Путем подмена файла кодовой страницы на c_1251.nls
Второй, не рекомендуемый мной способ, но иногда выбираемый теми, кто считает, что правка реестра — это слишком сложно или опасно: подмена файла кодовой страницы в C: Windows System32 (предполагается, что у вас установлена западно-европейская кодовая страница — 1252, обычно это так. Посмотреть текущую кодовую страницу можно в параметре ACP в реестре, как было описано в предыдущем способе).
- Зайдите в папку C: Windows System32 и найдите файл c_1252.NLS, нажмите по нему правой кнопкой мыши, выберите пункт «Свойства» и откройте вкладку «Безопасность». На ней нажмите кнопку «Дополнительно».
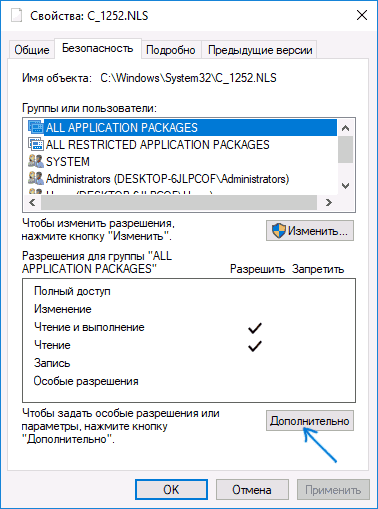
- В поле «Владелец» нажмите «Изменить».
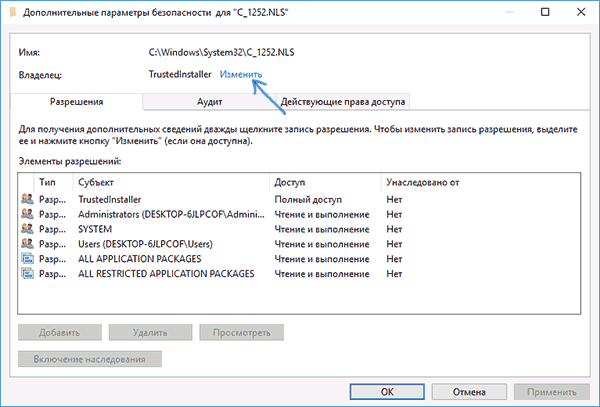
- В поле «Введите имена выбираемых объектов» укажите ваше имя пользователя (с правами администратора). Если в Windows 10 используется учетная запись Майкрософт, вместо имени пользователя укажите адрес электронной почты. Нажмите «Ок» в окне, где указывали пользователя и в следующем (Дополнительные параметры безопасности) окне.
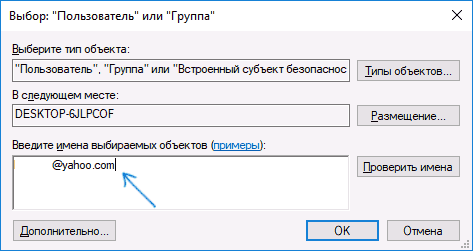
- Вы снова окажетесь на вкладке «Безопасность» в свойствах файла. Нажмите кнопку «Изменить».
- Выберите пункт «Администраторы» (Administrators) и включите полный доступ для них. Нажмите «Ок» и подтвердите изменение разрешений. Нажмите «Ок» в окне свойств файла.
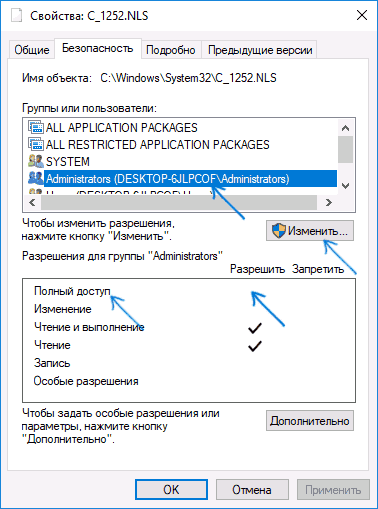
- Переименуйте файл c_1252.NLS (например, измените расширение на .bak, чтобы не потерять этот файл).
- Удерживая клавишу Ctrl, перетащите находящийся там же в C:WindowsSystem32 файл c_1251.NLS (кодовая страница для кириллицы) в другое место этого же окна проводника, чтобы создать копию файла.
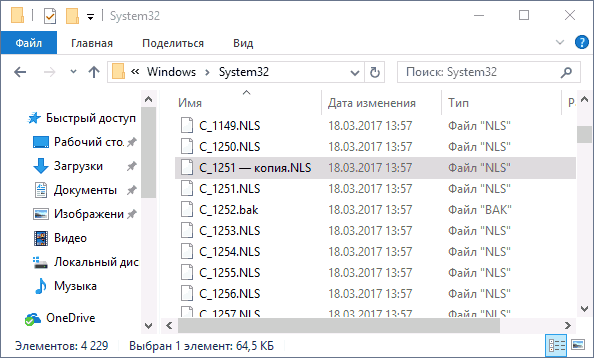
- Переименуйте копию файла c_1251.NLS в c_1252.NLS.
- Перезагрузите компьютер.
После перезагрузки Windows 10 кириллица должна будет отображаться не в виде иероглифов, а как обычные русские буквы.
Здравствуйте, уважаемые читатели блога KtoNaNovenkogo.ru. Сегодня мы поговорим с вами про то, откуда берутся кракозябры на сайте и в программах, какие кодировки текста существуют и какие из них следует использовать. Подробно рассмотрим историю их развития, начиная от базовой ASCII, а также ее расширенных версий CP866, KOI8-R, Windows 1251 и заканчивая современными кодировками консорциума Юникод UTF 16 и 8.

Кому-то эти сведения могут показаться излишними, но знали бы вы, сколько мне приходит вопросов именно касаемо вылезших кракозябров (не читаемого набора символов). Теперь у меня будет возможность отсылать всех к тексту этой статьи и самостоятельно отыскивать свои косяки. Ну что же, приготовьтесь впитывать информацию и постарайтесь следить за ходом повествования.
ASCII — базовая кодировка текста для латиницы
Развитие кодировок текстов происходило одновременно с формированием отрасли IT, и они за это время успели претерпеть достаточно много изменений. Исторически все начиналось с довольно-таки не благозвучной в русском произношении EBCDIC, которая позволяла кодировать буквы латинского алфавита, арабские цифры и знаки пунктуации с управляющими символами.
Но все же отправной точкой для развития современных кодировок текстов стоит считать знаменитую ASCII (American Standard Code for Information Interchange, которая по-русски обычно произносится как «аски»). Она описывает первые 128 символов из наиболее часто используемых англоязычными пользователями — латинские буквы, арабские цифры и знаки препинания.
Еще в эти 128 знаков, описанных в ASCII, попадали некоторые служебные символы навроде скобок, решеток, звездочек и т.п. Собственно, вы сами можете увидеть их:
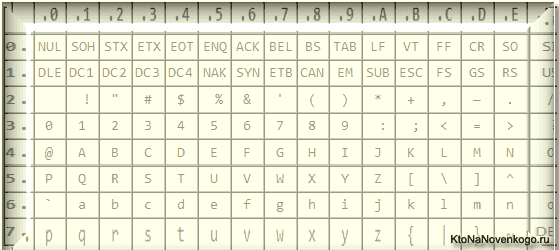
Именно эти 128 символов из первоначального вариант ASCII стали стандартом, и в любой другой кодировке вы их обязательно встретите и стоять они будут именно в таком порядке.
Но дело в том, что с помощью одного байта информации можно закодировать не 128, а целых 256 различных значений (двойка в степени восемь равняется 256), поэтому вслед за базовой версией Аски появился целый ряд расширенных кодировок ASCII, в которых можно было кроме 128 основных знаков закодировать еще и символы национальной кодировки (например, русской).
Тут, наверное, стоит еще немного сказать про системы счисления, которые используются при описании. Во-первых, как вы все знаете, компьютер работает только с числами в двоичной системе, а именно с нулями и единицами («булева алгебра», если кто проходил в институте или в школе). Один байт состоит из восьми бит, каждый из которых представляет из себя двойку в степени, начиная с нулевой, и до двойки в седьмой:
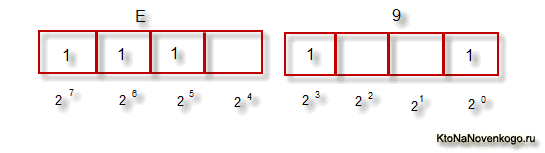
Не трудно понять, что всех возможных комбинаций нулей и единиц в такой конструкции может быть только 256. Переводить число из двоичной системы в десятичную довольно просто. Нужно просто сложить все степени двойки, над которыми стоят единички.
В нашем примере это получается 1 (2 в степени ноль) плюс 8 (два в степени 3), плюс 32 (двойка в пятой степени), плюс 64 (в шестой), плюс 128 (в седьмой). Итого получает 233 в десятичной системе счисления. Как видите, все очень просто.
Но если вы присмотритесь к таблице с символами ASCII, то увидите, что они представлены в шестнадцатеричной кодировке. Например, «звездочка» соответствует в Аски шестнадцатеричному числу 2A. Наверное, вам известно, что в шестнадцатеричной системе счисления используются кроме арабских цифр еще и латинские буквы от A (означает десять) до F (означает пятнадцать).
Ну так вот, для перевода двоичного числа в шестнадцатеричное прибегают к следующему простому и наглядному способу. Каждый байт информации разбивают на две части по четыре бита, как показано на приведенном выше скриншоте. Т.о. в каждой половинке байта двоичным кодом можно закодировать только шестнадцать значений (два в четвертой степени), что можно легко представить шестнадцатеричным числом.
Причем, в левой половине байта считать степени нужно будет опять начиная с нулевой, а не так, как показано на скриншоте. В результате, путем нехитрых вычислений, мы получим, что на скриншоте закодировано число E9. Надеюсь, что ход моих рассуждений и разгадка данного ребуса вам оказались понятны. Ну, а теперь продолжим, собственно, говорить про кодировки текста.
Расширенные версии Аски — кодировки CP866 и KOI8-R с псевдографикой
Итак, мы с вами начали говорить про ASCII, которая являлась как бы отправной точкой для развития всех современных кодировок (Windows 1251, юникод, UTF 8).
Изначально в нее было заложено только 128 знаков латинского алфавита, арабских цифр и еще чего-то там, но в расширенной версии появилась возможность использовать все 256 значений, которые можно закодировать в одном байте информации. Т.е. появилась возможность добавить в Аски символы букв своего языка.
Тут нужно будет еще раз отвлечься, чтобы пояснить — зачем вообще нужны кодировки текстов и почему это так важно. Символы на экране вашего компьютера формируются на основе двух вещей — наборов векторных форм (представлений) всевозможных знаков (они находятся в файлах со шрифтами, которые установлены на вашем компьютере) и кода, который позволяет выдернуть из этого набора векторных форм (файла шрифта) именно тот символ, который нужно будет вставить в нужное место.
Понятно, что за сами векторные формы отвечают шрифты, а вот за кодирование отвечает операционная система и используемые в ней программы. Т.е. любой текст на вашем компьютере будет представлять собой набор байтов, в каждом из которых закодирован один единственный символ этого самого текста.
Программа, отображающая этот текст на экране (текстовый редактор, браузер и т.п.), при разборе кода считывает кодировку очередного знака и ищет соответствующую ему векторную форму в нужном файле шрифта, который подключен для отображения данного текстового документа. Все просто и банально.
Значит, чтобы закодировать любой нужный нам символ (например, из национального алфавита), должно быть выполнено два условия — векторная форма этого знака должна быть в используемом шрифте и этот символ можно было бы закодировать в расширенных кодировках ASCII в один байт. Поэтому таких вариантов существует целая куча. Только лишь для кодирования символов русского языка существует несколько разновидностей расширенной Аски.
Например, изначально появилась CP866, в которой была возможность использовать символы русского алфавита и она являлась расширенной версией ASCII.
Т.е. ее верхняя часть полностью совпадала с базовой версией Аски (128 символов латиницы, цифр и еще всякой лабуды), которая представлена на приведенном чуть выше скриншоте, а вот уже нижняя часть таблицы с кодировкой CP866 имела указанный на скриншоте чуть ниже вид и позволяла закодировать еще 128 знаков (русские буквы и всякая там псевдографика):

Видите, в правом столбце цифры начинаются с 8, т.к. числа с 0 до 7 относятся к базовой части ASCII (см. первый скриншот). Т.о. русская буква «М» в CP866 будет иметь код 9С (она находится на пересечении соответствующих строки с 9 и столбца с цифрой С в шестнадцатеричной системе счисления), который можно записать в одном байте информации, и при наличии подходящего шрифта с русскими символами эта буква без проблем отобразится в тексте.
Откуда взялось такое количество псевдографики в CP866? Тут все дело в том, что эта кодировка для русского текста разрабатывалась еще в те мохнатые года, когда не было такого распространения графических операционных систем как сейчас. А в Досе, и подобных ей текстовых операционках, псевдографика позволяла хоть как-то разнообразить оформление текстов и поэтому ею изобилует CP866 и все другие ее ровесницы из разряда расширенных версий Аски.
CP866 распространяла компания IBM, но кроме этого для символов русского языка были разработаны еще ряд кодировок, например, к этому же типу (расширенных ASCII) можно отнести KOI8-R:

Принцип ее работы остался тот же самый, что и у описанной чуть ранее CP866 — каждый символ текста кодируется одним единственным байтом. На скриншоте показана вторая половина таблицы KOI8-R, т.к. первая половина полностью соответствует базовой Аски, которая показана на первом скриншоте в этой статье.
Среди особенностей кодировки KOI8-R можно отметить то, что русские буквы в ее таблице идут не в алфавитном порядке, как это, например, сделали в CP866.
Если посмотрите на самый первый скриншот (базовой части, которая входит во все расширенные кодировки), то заметите, что в KOI8-R русские буквы расположены в тех же ячейках таблицы, что и созвучные им буквы латинского алфавита из первой части таблицы. Это было сделано для удобства перехода с русских символов на латинские путем отбрасывания всего одного бита (два в седьмой степени или 128).
Windows 1251 — современная версия ASCII и почему вылезают кракозябры
Дальнейшее развитие кодировок текста было связано с тем, что набирали популярность графические операционные системы и необходимость использования псевдографики в них со временем пропала. В результате возникла целая группа, которая по своей сути по-прежнему являлись расширенными версиями Аски (один символ текста кодируется всего одним байтом информации), но уже без использования символов псевдографики.
Они относились к так называемым ANSI кодировкам, которые были разработаны американским институтом стандартизации. В просторечии еще использовалось название кириллица для варианта с поддержкой русского языка. Примером такой может служить Windows 1251.
Она выгодно отличалась от используемых ранее CP866 и KOI8-R тем, что место символов псевдографики в ней заняли недостающие символы русской типографики (окромя знака ударения), а также символы, используемые в близких к русскому славянских языках (украинскому, белорусскому и т.д.):
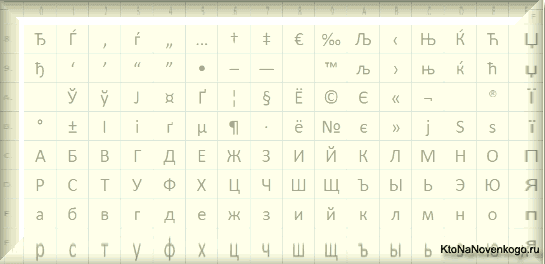
Из-за такого обилия кодировок русского языка, у производителей шрифтов и производителей программного обеспечения постоянно возникала головная боль, а у нас с вам, уважаемые читатели, зачастую вылезали те самые пресловутые кракозябры, когда происходила путаница с используемой в тексте версией.
Очень часто они вылезали при отправке и получении сообщений по электронной почте, что повлекло за собой создание очень сложных перекодировочных таблиц, которые, собственно, решить эту проблему в корне не смогли, и зачастую пользователи для переписки использовали транслит латинских букв, чтобы избежать пресловутых кракозябров при использовании русских кодировок подобных CP866, KOI8-R или Windows 1251.
По сути, кракозябры, вылазящие вместо русского текста, были результатом некорректного использования кодировки данного языка, которая не соответствовала той, в которой было закодировано текстовое сообщение изначально.
Допустим, если символы, закодированные с помощью CP866, попробовать отобразить, используя кодовую таблицу Windows 1251, то эти самые кракозябры (бессмысленный набор знаков) и вылезут, полностью заменив собой текст сообщения.

Аналогичная ситуация очень часто возникает при создании сайтов на WordPress и Joomla, форумов или блогов, когда текст с русскими символами по ошибке сохраняется не в той кодировке, которая используется на сайте по умолчанию, или же не в том текстовом редакторе, который добавляет в код отсебятину не видимую невооруженным глазом.
В конце концов такая ситуация с множеством кодировок и постоянно вылезающими кракозябрами многим надоела, появились предпосылки к созданию новой универсальной вариации, которая бы заменила собой все существующие и решила бы, наконец, на корню проблему с появлением не читаемых текстов. Кроме этого существовала проблема языков подобных китайскому, где символов языка было гораздо больше, чем 256.
Юникод (Unicode) — универсальные кодировки UTF 8, 16 и 32
Эти тысячи знаков языковой группы юго-восточной Азии никак невозможно было описать в одном байте информации, который выделялся для кодирования символов в расширенных версиях ASCII. В результате был создан консорциум под названием Юникод (Unicode — Unicode Consortium) при сотрудничестве многих лидеров IT индустрии (те, кто производит софт, кто кодирует железо, кто создает шрифты), которые были заинтересованы в появлении универсальной кодировки текста.
Первой вариацией, вышедшей под эгидой консорциума Юникод, была UTF 32. Цифра в названии кодировки означает количество бит, которое используется для кодирования одного символа. 32 бита составляют 4 байта информации, которые понадобятся для кодирования одного единственного знака в новой универсальной кодировке UTF.
В результате чего, один и тот же файл с текстом, закодированный в расширенной версии ASCII и в UTF-32, в последнем случае будет иметь размер (весить) в четыре раза больше. Это плохо, но зато теперь у нас появилась возможность закодировать с помощью ЮТФ число знаков, равное двум в тридцать второй степени (миллиарды символов, которые покроют любое реально необходимое значение с колоссальным запасом).
Но многим странам с языками европейской группы такое огромное количество знаков использовать в кодировке вовсе и не было необходимости, однако при задействовании UTF-32 они ни за что ни про что получали четырехкратное увеличение веса текстовых документов, а в результате и увеличение объема интернет трафика и объема хранимых данных. Это много, и такое расточительство себе никто не мог позволить.
В результате развития Юникода появилась UTF-16, которая получилась настолько удачной, что была принята по умолчанию как базовое пространство для всех символов, которые у нас используются. Она использует два байта для кодирования одного знака. Давайте посмотрим, как это дело выглядит.
В операционной системе Windows вы можете пройти по пути «Пуск» — «Программы» — «Стандартные» — «Служебные» — «Таблица символов». В результате откроется таблица с векторными формами всех установленных у вас в системе шрифтов. Если вы выберете в «Дополнительных параметрах» набор знаков Юникод, то сможете увидеть для каждого шрифта в отдельности весь ассортимент входящих в него символов.
Кстати, щелкнув по любому из них, вы сможете увидеть его двухбайтовый код в формате UTF-16, состоящий из четырех шестнадцатеричных цифр:
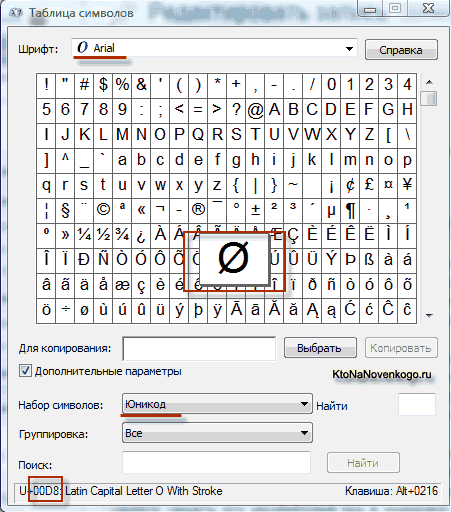
Сколько символов можно закодировать в UTF-16 с помощью 16 бит? 65 536 (два в степени шестнадцать), и именно это число было принято за базовое пространство в Юникоде. Помимо этого существуют способы закодировать с помощью нее и около двух миллионов знаков, но ограничились расширенным пространством в миллион символов текста.
Но даже эта удачная версия кодировки Юникода не принесла особого удовлетворения тем, кто писал, допустим, программы только на английском языке, ибо у них, после перехода от расширенной версии ASCII к UTF-16, вес документов увеличивался в два раза (один байт на один символ в Аски и два байта на тот же самый символ в ЮТФ-16).
Вот именно для удовлетворения всех и вся в консорциуме Unicode было решено придумать кодировку переменной длины. Ее назвали UTF-8. Несмотря на восьмерку в названии, она действительно имеет переменную длину, т.е. каждый символ текста может быть закодирован в последовательность длиной от одного до шести байт.
На практике же в UTF-8 используется только диапазон от одного до четырех байт, потому что за четырьмя байтами кода ничего уже даже теоретически не возможно представить. Все латинские знаки в ней кодируются в один байт, так же как и в старой доброй ASCII.
Что примечательно, в случае кодирования только латиницы, даже те программы, которые не понимают Юникод, все равно прочитают то, что закодировано в ЮТФ-8. Т.е. базовая часть Аски просто перешла в это детище консорциума Unicode.
Кириллические же знаки в UTF-8 кодируются в два байта, а, например, грузинские — в три байта. Консорциум Юникод после создания UTF 16 и 8 решил основную проблему — теперь у нас в шрифтах существует единое кодовое пространство. И теперь их производителям остается только исходя из своих сил и возможностей заполнять его векторными формами символов текста. Сейчас в наборы даже эмодзи смайлики добавляют.
В приведенной чуть выше «Таблице символов» видно, что разные шрифты поддерживают разное количество знаков. Некоторые насыщенные символами Юникода шрифты могут весить очень прилично. Но зато теперь они отличаются не тем, что они созданы для разных кодировок, а тем, что производитель шрифта заполнил или не заполнил единое кодовое пространство теми или иными векторными формами до конца.
Кракозябры вместо русских букв — как исправить
Давайте теперь посмотрим, как появляются вместо текста кракозябры или, другими словами, как выбирается правильная кодировка для русского текста. Собственно, она задается в той программе, в которой вы создаете или редактируете этот самый текст, или же код с использованием текстовых фрагментов.
Для редактирования и создания текстовых файлов лично я использую очень хороший, на мой взгляд, Html и PHP редактор Notepad++. Впрочем, он может подсвечивать синтаксис еще доброй сотни языков программирования и разметки, а также имеет возможность расширения с помощью плагинов. Читайте подробный обзор этой замечательной программы по приведенной ссылке.
В верхнем меню Notepad++ есть пункт «Кодировки», где у вас будет возможность преобразовать уже имеющийся вариант в тот, который используется на вашем сайте по умолчанию:
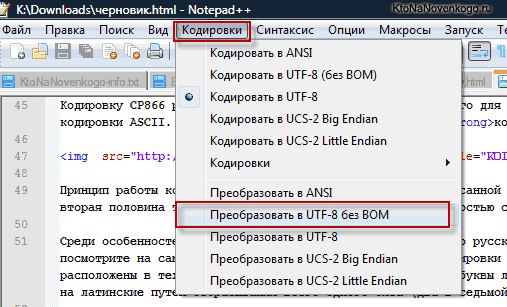
В случае сайта на Joomla 1.5 и выше, а также в случае блога на WordPress следует во избежании появления кракозябров выбирать вариант UTF 8 без BOM. А что такое приставка BOM?
Дело в том, что когда разрабатывали кодировку ЮТФ-16, зачем-то решили прикрутить к ней такую вещь, как возможность записывать код символа, как в прямой последовательности (например, 0A15), так и в обратной (150A). А для того, чтобы программы понимали, в какой именно последовательности читать коды, и был придуман BOM (Byte Order Mark или, другими словами, сигнатура), которая выражалась в добавлении трех дополнительных байтов в самое начало документов.
В кодировке UTF-8 никаких BOM предусмотрено в консорциуме Юникод не было и поэтому добавление сигнатуры (этих самых пресловутых дополнительных трех байтов в начало документа) некоторым программам просто-напросто мешает читать код. Поэтому мы всегда при сохранении файлов в ЮТФ должны выбирать вариант без BOM (без сигнатуры). Таким образом, вы заранее обезопасите себя от вылезания кракозябров.
Что примечательно, некоторые программы в Windows не умеют этого делать (не умеют сохранять текст в ЮТФ-8 без BOM), например, все тот же пресловутый Блокнот Windows. Он сохраняет документ в UTF-8, но все равно добавляет в его начало сигнатуру (три дополнительных байта). Причем эти байты будут всегда одни и те же — читать код в прямой последовательности. Но на серверах из-за этой мелочи может возникнуть проблема — вылезут кракозябры.
Поэтому ни в коем случае не пользуйтесь обычным блокнотом Windows для редактирования документов вашего сайта, если не хотите появления кракозябров. Лучшим и наиболее простым вариантом я считаю уже упомянутый редактор Notepad++, который практически не имеет недостатков и состоит из одних лишь достоинств.
В Notepad ++ при выборе кодировки у вас будет возможность преобразовать текст в кодировку UCS-2, которая по своей сути очень близка к стандарту Юникод. Также в Нотепаде можно будет закодировать текст в ANSI, т.е. применительно к русскому языку это будет уже описанная нами чуть выше Windows 1251. Откуда берется эта информация?
Она прописана в реестре вашей операционной системы Windows — какую кодировку выбирать в случае ANSI, какую выбирать в случае OEM (для русского языка это будет CP866). Если вы установите на своем компьютере другой язык по умолчанию, то и эти кодировки будут заменены на аналогичные из разряда ANSI или OEM для того самого языка.
После того, как вы в Notepad++ сохраните документ в нужной вам кодировке или же откроете документ с сайта для редактирования, то в правом нижнем углу редактора сможете увидеть ее название:
![]()
Чтобы избежать кракозябров, кроме описанных выше действий, будет полезным прописать в его шапке исходного кода всех страниц сайта информацию об этой самой кодировке, чтобы на сервере или локальном хосте не возникло путаницы.
Вообще, во всех языках гипертекстовой разметки кроме Html используется специальное объявление xml, в котором указывается кодировка текста.
<?xml version="1.0" encoding="windows-1251"?>
Прежде, чем начать разбирать код, браузер узнает, какая версия используется и как именно нужно интерпретировать коды символов этого языка. Но что примечательно, в случае, если вы сохраняете документ в принятом по умолчанию юникоде, то это объявление xml можно будет опустить (кодировка будет считаться UTF-8, если нет BOM или ЮТФ-16, если BOM есть).
В случае же документа языка Html для указания кодировки используется элемент Meta, который прописывается между открывающим и закрывающим тегом Head:
<head> ... <meta charset="utf-8"> ... </head>
Эта запись довольно сильно отличается от принятой в стандарте в Html 4.01, но полностью соответствует новому внедряемому потихоньку стандарту Html 5, и она будет стопроцентно правильно понята любыми используемыми на текущий момент браузерами.
По идее, элемент Meta с указание кодировки Html документа лучше будет ставить как можно выше в шапке документа, чтобы на момент встречи в тексте первого знака не из базовой ANSI (которые правильно прочитаются всегда и в любой вариации) браузер уже должен иметь информацию о том, как интерпретировать коды этих символов.
Windows 10 русские буквы кракозябры, как можно исправить? По большей части другие символы, вместе кириллицы в ОС могут появиться после того, как вы переустановили ОС Виндовс 10, или иную программу на ПК. В основном сбой происходит из-за неправильных параметров или когда происходит некорректная работа страницы кодов. Итак, мы с вами рассмотрим 3 способа, позволяющих заменить кракозябры русскими буквами.
Исправляем кракозябры вместо русских букв в Windows 10

“>
Как уже говорлось, исправить непонятные символы на кириллицу можно тремя методами. Для этого нам нужно будет отредактировать некие системные настройки и определённые элементы. Один метод более лёгкий, другой сложнее, но эффективнее. Третий немного запутанный. Итак, займёмся более лёгким методом.
Метод 1 Меняем язык Windows 10
Итак, вначале давайте настроим параметр «Региональные стандарты». Исходя из его правильной настройки происходит показ текстовых данных в большинстве приложений системы и со стороны. Проводить его редактирование мы будем следующим путём:
- В страницу поиска вписываем слово «Панель…» и переходим по появившемуся элементу «Панель управления»;

- Затем, нам нужно просмотреть появившиеся вкладки. Нам нужна вкладка «Региональные стандарты»;

- У нас открывается новое окошко. Нам нужно выбрать меню «Дополнительно». После этого, кликнем по кнопочке «Изменить язык…»;

- Затем, нужно удостовериться, что у вас отмечен раздел «Русский (Россия)». Если у вас стоит другая страна, из ниспадающего меню нужно выбрать Россию. Кроме этого, можно поставить галочку над командой: использовать Юникод UTF-8. Многим пользователям данная команда также помогает. Затем, нужно кликнуть по ОК (Хотя, Юникод UTF-8 можно и не ставить. Когда он был поставлен, появились кракозябры в одной из программ для создания скриншотов и пришлось его убрать. После этого, кракозябры из этой программы пропали.);

- Проделанные действия изменятся, как только вы перезагрузите компьютер, о чём мы видим из этого окна:

После этого, нам нужно подождать, когда компьютер перезагрузится. Затем необходимо проверить, исчезли проблемы с кракозябрами, или нет? Если не исчезли, в этом случае переходим к следующему методу.
Метод 2 Применяем системный реестр
Страницы кодовые осуществляют действие сравнения знаков и байтов. Есть довольно много видов подобных таблиц. Все они взаимодействуют с конкретным языком. Поэтому, частенько кракозябры появляются именно из-за того, что такая страница у вас выбрана неверно. Давайте рассмотрим, как исправить эту величину используя реестр.
До начала действий в системном реестре, я бы порекомендовал создать точку восстановления системы. Затем:
- Кликнем по клавишам Win+R для запуска утилиты «Выполнить». В ней нам нужно вписать выражение: regedit и нажимаем ОК;

- В реестре нужно пройти по адресу: HKEY_LOCAL_MACHINESYSTEMCurrentControlSetControlNls CodePage
- В правом окошке нам нужно прокрутить страницу до самого низа. Нам нужен файл «ACP». В столбике «Значение» над данным файлом должны быть 4 цифры: 1251;
- Как видим, у меня стоят цифры: 65001. Именно из-за этого и могут появляться кракозябры. А кракозябры у меня были в одном из файлов Word. Поэтому, в этом случае нужно кликнуть ЛКМ по слову ACP 2 раза.

- У нас открывается окошко изменений строкового параметра. Цифру нужно поменять на 1251 и нажать ОК. Затем, нам нужно перезагрузить компьютер и проверить, исчезла ошибка, или нет.

Но, если данная цифра 1251, итак, у вас стоит на месте, то нужно применить чуть-чуть иные действия:
Проделав данные действия, нужно перезагрузить компьютер, чтобы изменения начали действовать.
Видео кракозябры вместо русских букв в Windows 10
Метод 3 Изменяем кодовую страницу
Часть пользователей не желают что-то менять в реестре по своим соображениям, или просто боятся в нём что-то сделать неверно. Этому методу есть альтернатива, можно кодовую страницу изменить через «Проводник»:
- Входим в «Проводник» через ярлык «Компьютер» и на диске С проходим по адресу: C:WindowsSystem32
- В данной папочке нам нужно найти элемент С_1252.NLS
- После этого, нужно кликнуть по нему ПКМ и в открывшемся ниспадающем меню выбрать вкладку «Свойства»;

- В открывшемся окошке нам нужно выбрать меню «Безопасность» и нажать по кнопочке «Дополнительно»;

- Итак, нам необходимо узнать, кто является владельцем этой учётной записи. После этого, кликнем по кнопочке «Изменить»;

- В пустое поле нужно вписать имя учётной записи, у которой права администратора. Затем, нужно нажать ОК;

- Мы вновь попадаем в окошко «Безопасности». Тут нам нужно отредактировать настройку доступа администраторов;

- Выбираем строчку, где есть слово «Администраторы». Затем, предоставляем Администраторам полный доступ, поставив флажок над нужной командой. Далее, нажимаем «Применить» и ОК;

- Возвращаемся в проводник и теперь нам нужно переименовать тот элемент, который мы отредактировали. А именно, поменять его расширение с NLS на TXT. После этого, зажимаем CTRL и потянем данный файл вверх, чтобы создать его копию;

- Кликнем по созданному клону файла ПКМ и изменим его имя на NLS.
 Мы проделали нужные действия в проводнике, чтобы подменить кодовые страницы. Теперь нам нужна перезагрузка компьютера. После неё, нужно проверить, что наш способ сработал!
Мы проделали нужные действия в проводнике, чтобы подменить кодовые страницы. Теперь нам нужна перезагрузка компьютера. После неё, нужно проверить, что наш способ сработал!
Вывод: проблема — Windows 10 русские буквы кракозябры теперь нами решена тремя способами. При этом, первый самый лёгкий, а второй самый надёжный. Третий получился немного запутанным. Если вы его плохо поняли, совет: всё же применить 2 метод. Он проще. Успехов!
Всех приветствую на портале WiFiGiD.RU. Сегодня мы рассмотрим еще одну достаточно популярную проблему, когда в Windows вместо букв отображаются кракозябры, иероглифы, знаки вопроса и какие-то непонятные символы. Проблема встречается на всех версиях Windows 10, 11, 7 и 8, и решается она одинаково. Причем кракозябры могут быть как в отдельных программах (например, в блокноте или Word) или системных окнах (в проводнике, компьютере или панели управления). В статье я расскажу вам, как можно исправить кодировку и вернуть все на свои места.
Содержание
- Способ 1: Изменение системного языка
- Способ 2: Изменение кодовой таблицы
- Способ 3: Подмена файлов
- Способ 4: Дополнительные советы
- Задать вопрос автору статьи
Способ 1: Изменение системного языка
Итак, у нас вместо русских букв отображаются знаки вопроса или другие непонятные символы в Windows – давайте разбираться вместе. После установки английской или любой другой версии, есть вероятность, что язык, который установлен в системе, установился неправильно. Второй вариант – когда региональные стандарты языка были сбиты или установлены не так как нужно. Давайте это исправим.
- Зажимаем на клавиатуре две клавиши:
+ R
- Теперь используем команду:
control
- В панели управления найдите пункт «Региональные стандарты» – ориентируйтесь на значок. Если вы видите, что пунктов не так много как у меня, измените режим «Просмотра».
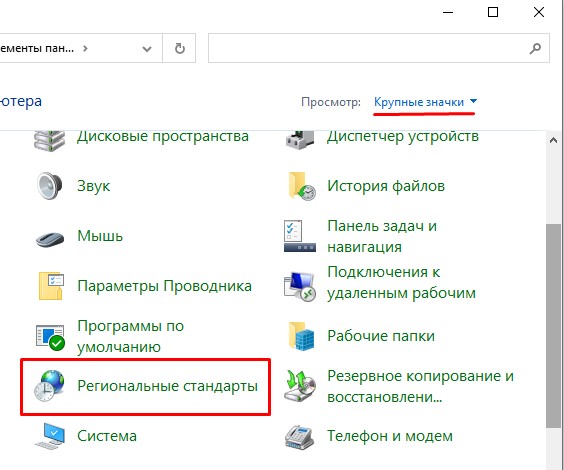
- На второй вкладке нажмите по кнопке «Изменить язык…».
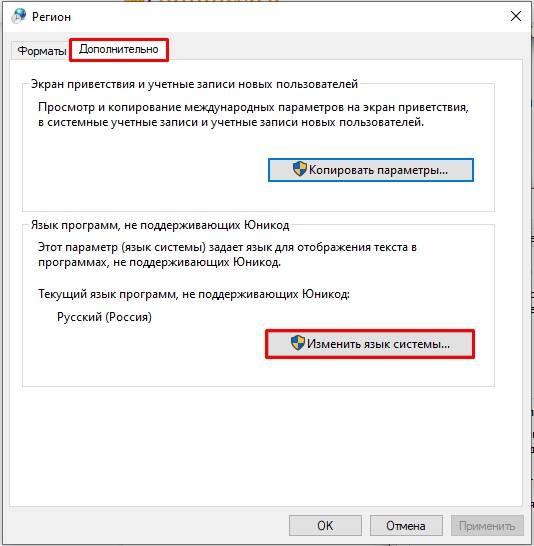
- Сначала в первом пункте установите «Русский» язык. Ниже есть настройка использования Юникода (UTF-8). Если эта галочка стоит, значит попробуйте её убрать. Если эта конфигурация, наоборот, выключена – активируйте. Нажмите «ОК».
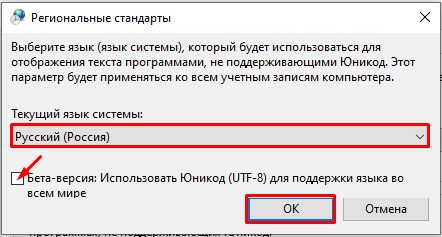
- Вас попросят перезагрузиться – сделайте это.
Способ 2: Изменение кодовой таблицы
Смотрите, каждому символу кириллицы соответствует свое отображение. Также у каждого такого символа есть специальный байтовый код. Чтобы все это работало нормально, для каждого символа и байта есть таблица соответствия. Если таблица выбрана неправильно, код байта будет показывать иероглифы – вопросительные знаки или еще какие кракозябры.
Мы просто подставим для нашей кириллицы правильную таблицу отображения символов, и после этого проблема должна решиться. Мы будем использовать редактор реестра. Сам способ не должен поломать систему, но перед этим я настоятельно рекомендую создать точку восстановления (на всякий случай!).
Читаем – как создать точку восстановления.
После этого переходим к описанным ниже шагам:
- Используем наши любимые волшебные кнопки:
+ R
- Вводим команду:
regedit
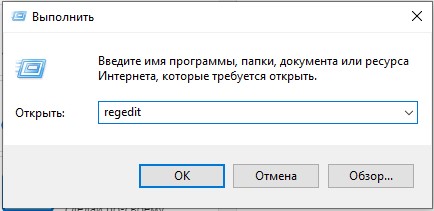
- Можете скопировать путь, который я укажу ниже, и вставить в адресную строку. Или просто пройтись по папкам и разделам вручную.
HKEY_LOCAL_MACHINESYSTEMCurrentControlSetControlNlsCodePage
- В правом блоке, где находится список файлов с конфигурациями, в самом низу найдите:
ACP
- Именно этот файл отвечает за настройку соответствия таблицы символов. Два раза кликните левой кнопкой мыши и установите значение:
1251
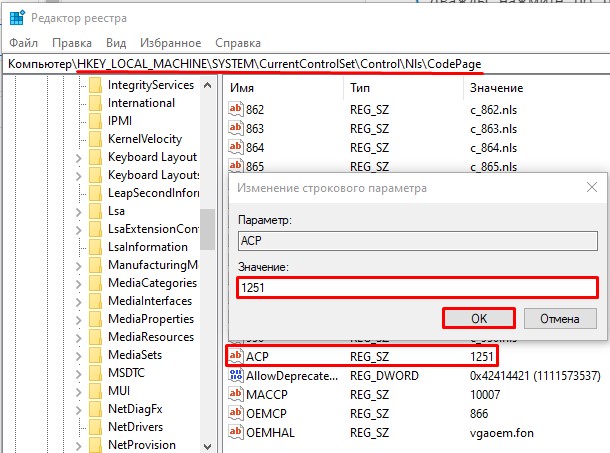
- Нажмите «ОК», закройте окно редактора реестра и перезагрузите компьютер.
Способ 3: Подмена файлов
Третий способ чуть сложнее, мы просто возьмем файл, который используется для английского языка и подменим его на русский. Я все же рекомендую использовать прошлый вариант с реестром (он все же проще). Но, на всякий пожарный, опишу и этот способ.
- Откройте проводник и пройдите по пути:
C:/Windows/System32
- Найдите файл:
C_1252.NLS
- Он используется для английского языка. Через правую кнопку заходим в «Свойства».
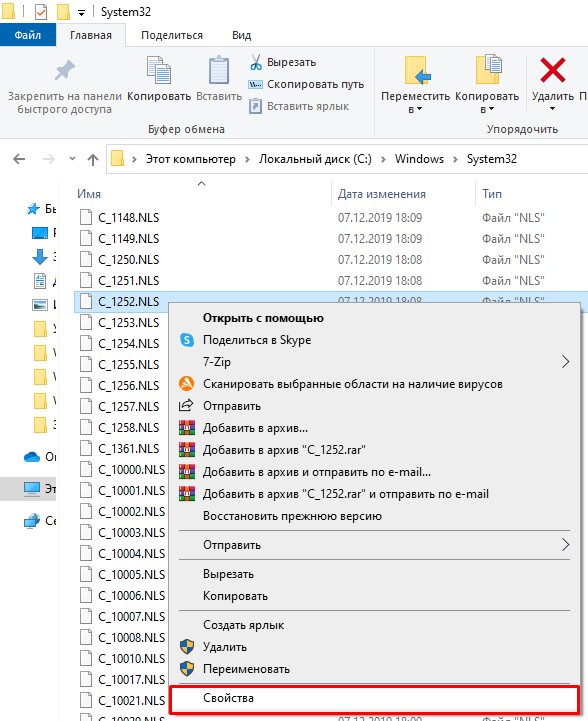
- Во вкладке «Безопасность» выбираем кнопку «Дополнительно». Нам нужно дать вам полные права. В противном случае вы ничего с этим файлом не сделаете.
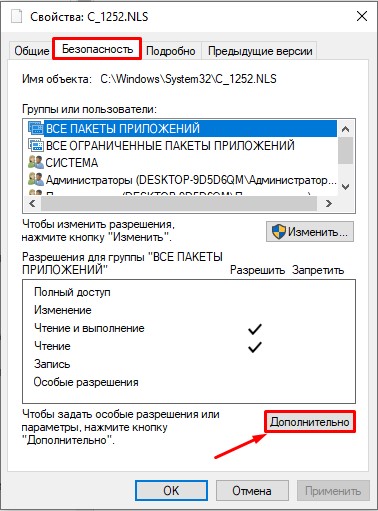
- В строке «Владелец» жмем по ссылке «Изменить».
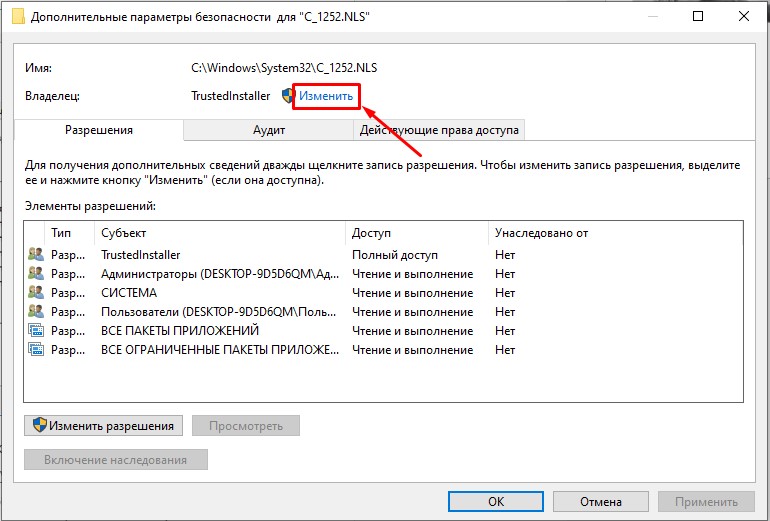
- «Дополнительно».
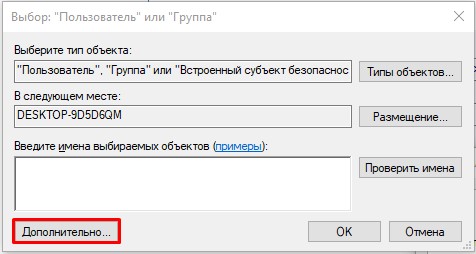
- Нажмите «Поиск». Ниже в списке кликните по той учетной записи, через которую вы сейчас сидите. Если у вас авторизация через учётку Microsoft, то указываем почту. Как только пользователь будет выбран, жмем «ОК».
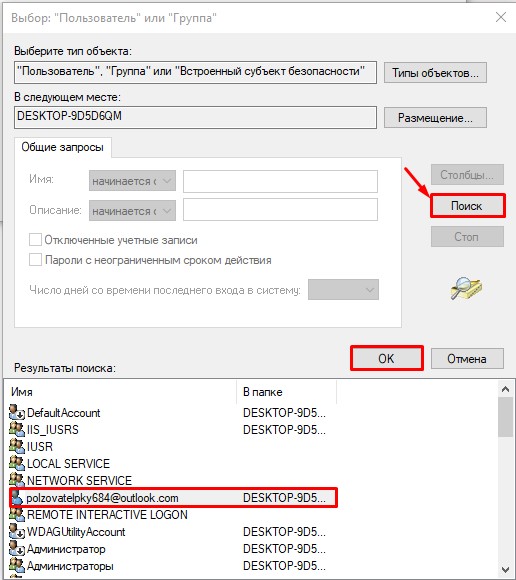
- В этом и следующем окне жмем на кнопку «ОК», чтобы применить параметры.
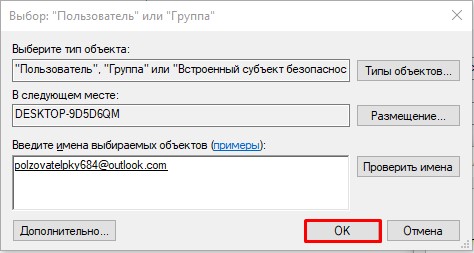
- В окне «Свойства» нажмите «Изменить».
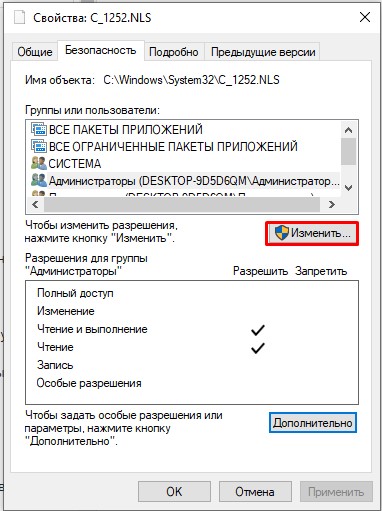
- Выберите «Администраторов» и установите «Полный доступ». Применяем настройки и закрываем оба окошка.
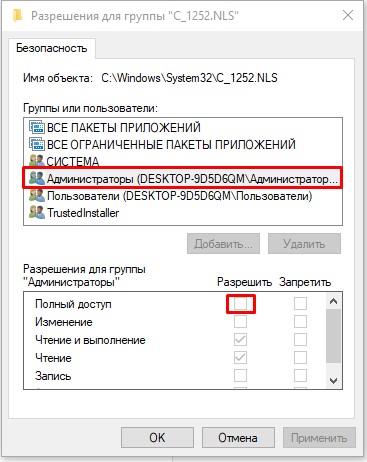
- Теперь установите другой формат для файла (через ПКМ и команду «Переименовать»):
c_1252.NLS
- Например:
c_1252.txt
- На клавиатуре, зажмите Ctrl и, не отпуская, перетащите в любое место в папке файл:
c_1251.NLS
- Мы создали копию файла. Теперь оригинал NLS переименуйте в:
c_1252.NLS
- Перезагрузите систему.
В случае чего у вас есть оригинал c_1251.NLS и сам файл c_1252, у которого мы изменили формат.
Способ 4: Дополнительные советы
Если вы видите иероглифы вместо русских букв в Windows 10, 11, 7 или 8, то есть вероятность, что произошла более серьезная поломка в системных файлах. Поэтому вот ряд советов:
- Если вы делали какие-то глобальные обновления в ОС, то попробуйте выполнить откат системы до самой ранней точки восстановления.
- Если вы устанавливали какую-то кривую и стороннюю сборку Windows, то советую выполнить установку оригинальной версии «Окон».
- Проверьте системные файлы на наличие ошибок.
- Можно попробовать выполнить чистку системы.
На этом все, дорогие друзья. Пишите свои вопросы в комментариях. Всем добра и берегите себя.
При работе с Windows 10 у пользователей иногда возникают проблемы с правильным отображением символов. Вместо привычных букв и цифр в тексте мы можем лицезреть какие-то замудрённые иероглифы или «кракозябры», которые не несут в себе никакого логического смысла. Чаще всего к этому приводят неправильно установленные значения в опциях региональных параметров.
Нередко такое случается, когда пользователь работает с русской раскладкой клавиатуры в ОС с английской локализацией. Проблема заключается в том, что в такой системе для программ, работающих с кириллицей, не предусмотрена обработка нужных символов. Также это справедливо и для других языков, в которых отсутствуют латинские символы, например, японского, китайского или греческого.
Сегодня мы поговорим о том, как избавиться от кракозябр в Windows 10 и настроить корректное отображение русских символов.
- Почему появляется эта проблема
- Решаем проблему через системные настройки
- Исправление проблемы через редактор реестра
- Исправляем страницу кода вручную
Суть проблемы
Как правило, мы можем наблюдать непонятные символы не в каждой программе. Например, символы, изображённые кириллицей в названии программ, отображены корректно. Но если запустить программу установки дистрибутивов, поддерживающих русский язык, мы получаем неведомую нам «китайскую грамоту».
И, пожалуй, основная проблема кроется в том, что в имеющейся ОС по дефолту отсутствует поддержка кириллических символов. На практике это может значить, что вы инсталлировали английский дистрибутив с установленным поверх него расширенным пакетом русификации. Однако последний не смог решить проблему корректно.
Первое, что пытаются делать пользователи в такой ситуации – переустановка операционки с чистого листа. Однако не все согласятся на такое, ведь кто-то, возможно, намеренно хочет работать с англоязычной средой. И в этой среде кириллические символы по идее могут и должны отображаться корректно.
Используем системные настройки для решения проблемы
Прежде всего, попробуем исправить ошибку через панель управления. Чтобы зайти в неё нажимаем ПКМ по кнопке-меню «Пуск» и в выпавшем списке выбираем соответствующий пункт.
В открывшемся новом окне находим раздел «Часы, язык, регион».
В новом разделе выбираем категорию региональных стандартов.
Здесь мы сможем настроить вариант даты и времени, а также числовой разделитель, количество дробных значений, формат отрицательных чисел, систему единиц измерения и пр.
Также здесь нам предлагается изменить формат денежных единиц и обозначение таковых. Здесь же мы можем настроить локальные параметры для разных регионов, включая отображаемые в системе текстовые символы. Именно эти опции нас и интересуют. Для их выбора переходим ко вкладке «Дополнительно» в верхней части окна.
Переходим в раздел выбора языка, не поддерживающего Юникод, и далее выбираем опцию изменение языка системы.
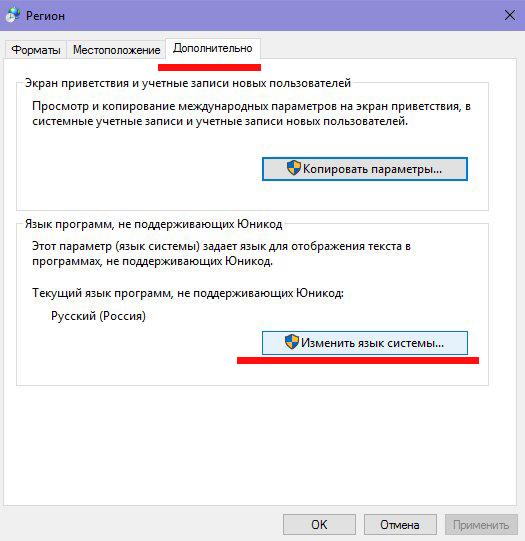
В списке выбираем нужный вариант (в нашем случае «Русский (Россия)» и нажимаем «ОК»)
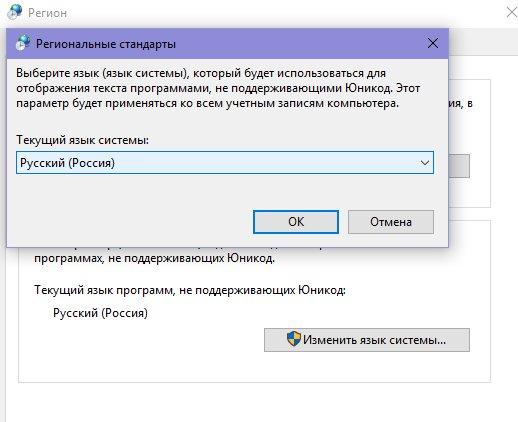
В появившемся окне уведомлений выбираем «Перезагрузить сейчас».
ПК уйдёт в перезагрузку, после чего проблема с кракозябрами должна исчезнуть. Однако не всегда этот способ срабатывает. Если он не помог решить проблему, рассмотрим ещё один вариант, в котором нам придётся поработать с реестром.
![]() Загрузка …
Загрузка …
Правим реестр для исправления непонятных букв
Для начала нам нужно создать обычный файл в текстовом редакторе. Сохранить его нужно будет с расширением .reg. Таким образом, мы сможем прописать нужные параметры в файле и применить изменения непосредственно к реестру. Вот что нам следует прописать в нашем файлике:
Windows Registry Editor Version 5.00
[HKEY_LOCAL_MACHINESOFTWAREMicrosoftWindows NTCurrentVersionFontMapper] «ARIAL»=dword:00000000
[HKEY_LOCAL_MACHINESOFTWAREMicrosoftWindows NTCurrentVersionFontSubstitutes]
«Arial,0″=»Arial,204»
«Comic Sans MS,0″=»Comic Sans MS,204»
«Courier,0″=»Courier New,204»
«Courier,204″=»Courier New,204»
«MS Sans Serif,0″=»MS Sans Serif,204»
«Tahoma,0″=»Tahoma,204»
«Times New Roman,0″=»Times New Roman,204»
«Verdana,0″=»Verdana,204»
Просто скопируйте это в свой текстовый документ и сохраните его. Теперь нужно запустить созданный и сохранённый файл, кликнув по нему дважды ЛКМ. Соглашаемся с системным уведомлением о внесении изменений в ОС. Далее перезагружаем ПК. Как правило, перед любыми изменениями в реестре нужно создавать резервную копию реестра, чтобы в любой момент можно было откатить его к первоначальной конфигурации.
![]() Загрузка …
Загрузка …
Редактируем страницу кода вручную
Страницы кода отвечают за сопоставление символов с байтами. Таких таблиц бывает много, и каждая из них работает с различными языками. Зачастую кракозябры появляются при неправильном выборе страницы и её сопоставлении. Чтобы исправить это, нам предстоит поработать с реестром. Для этого:
- Win+R запускаем системную службу «Выполнить». Прописываем в единственной строке regedit и жмём Ок.
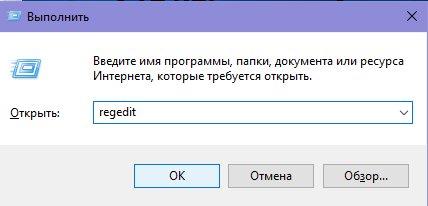
- В окне реестра нам нужно перейти по следующему пути: HKEY_LOCAL_MACHINESYSTEMCurrentControlSetControlNls
- Здесь выбираем папку CodePage и в правой части окна идём вниз, чтобы найти пункт ACP.
- Дважды кликаем ЛКМ по ACP, и перед нами открывается окно изменений строковых настроек. Здесь выставляем значение 1251. Если такое значение уже установлено для этого пункта, тогда нужно сделать по-другому.
![]() Загрузка …
Загрузка …
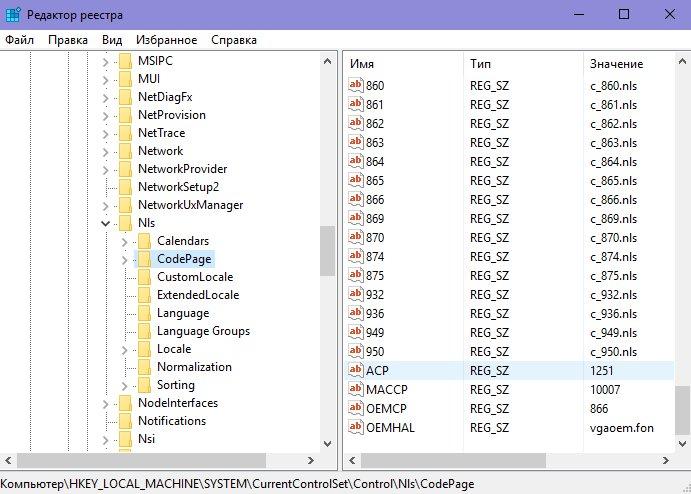
Находясь в том же разделе CodePage, в правой части окна ищем пункт 1252. Жмём по нему дважды ЛКМ и в появившемся окне меняем текущее значение 1252 на 1251.
После произведённых манипуляций отправляем компьютер в перезагрузку, чтобы применённые изменения вступили в силу.
![]() Загрузка …
Загрузка …
Post Views: 22 128
