Ошибки SQL являются неотъемлемой частью работы с базами данных. Важно понимать их причины и способы решения, чтобы успешно разрабатывать и поддерживать приложения. В этой статье мы рассмотрим различные виды ошибок SQL, их возможные причины, а также методы решения таких проблем. Мы также предоставим ответы на часто задаваемые вопросы ошибках SQL и предложим полезные советы для профессионалов в области баз данных.
Основные виды ошибок SQL:
- Синтаксические ошибки
- Ошибки времени выполнения
- Логические ошибки
Оглавление
- 0.1 Синтаксические ошибки
- 0.2 Ошибки времени выполнения
- 0.3 Логические ошибки
- 1 Как исправить ошибки SQL: шаг за шагом
- 1.1 Определение типа ошибки
- 1.2 Анализ причин ошибки
- 1.3 Применение соответствующего решения
- 2 Часто задаваемые вопросы
- 2.1 Как наиболее эффективно найти и исправить ошибки SQL?
- 2.2 Влияет ли версия базы данных на возникновение ошибок SQL?
- 2.3 Как предотвратить ошибки SQL при разработке приложений?
Синтаксические ошибки
a. Неправильное использование ключевых слов (H4 Heading) b. Ошибки в структуре запроса (H4 Heading) c. Проблемы с кавычками и скобками (H4 Heading)
Ошибки времени выполнения
a. Ошибки доступа к данным (H4 Heading) b. Ошибки ограничений целостности (H4 Heading) c. Проблемы с производительностью (H4 Heading)
Логические ошибки
a. Неправильный выбор операторов (H4 Heading) b. Ошибки в вычислениях (H4 Heading) c. Проблемы с агрегацией данных (H4 Heading)
Чтобы разобраться подробнее – приходите на бесплатный курс
- Определение типа ошибки (H3 Heading)
- Анализ причин ошибки (H3 Heading)
- Применение соответствующего решения (H3 Heading)
Определение типа ошибки
- Используйте сообщения об ошибках
- Отслеживайте контекст запроса
Анализ причин ошибки
- Проверьте синтаксис
- Проверьте права доступа
- Убедитесь, что данные корректны
Применение соответствующего решения
- Исправьте синтаксические ошибки
- Решите проблемы с данными
- Оптимизируйте запросы
Часто задаваемые вопросы
- Как наиболее эффективно найти и исправить ошибки SQL?
- Какие инструменты могут помочь в диагностике и исправлении ошибок SQL?
- Влияет ли версия базы данных на возникновение ошибок SQL?
- Как предотвратить ошибки SQL при разработке приложений?
Чтобы разобраться подробнее – приходите на бесплатный курс
Как наиболее эффективно найти и исправить ошибки SQL?
- Используйте подходящие инструменты и ресурсы для отладки
- Разбивайте сложные запросы на простые
- Протестируйте запросы с разными наборами данных
Какие инструменты могут помочь в диагностике и исправлении ошибок SQL?
- Редакторы кода с поддержкой SQL, такие как Visual Studio Code или Sublime Text
- Среды разработки баз данных, такие как SQL Server Management Studio или MySQL Workbench
- Специализированные инструменты для анализа и оптимизации запросов, такие как SQL Sentry Plan Explorer или EverSQL
Влияет ли версия базы данных на возникновение ошибок SQL?
Да, версия базы данных может влиять на возникновение ошибок SQL из-за различий в поддерживаемых функциях, синтаксисе и стандартах. Важно использовать актуальную версию базы данных и знать о возможных ограничениях или различиях между версиями.
Как предотвратить ошибки SQL при разработке приложений?
- Используйте хорошие практики проектирования баз данных и написания запросов
- Тестируйте ваш код на разных этапах разработки
- Внедряйте контроль версий и процессы код-ревью для обеспечения качества кода
- Обучайте разработчиков основам SQL и принципам работы с базами данных
Заключение:
Ошибки SQL являются неизбежным аспектом работы с базами данных, но с правильными знаниями и инструментами их можно успешно диагностировать и исправлять. Надеемся, что эта статья помогла вам лучше понять различные типы ошибок SQL, их причины и способы решения. Следуйте нашим рекомендациям и советам, чтобы свести к минимуму вероятность возникновения ошибок SQL и обеспечить надежную и эффективную работу ваших приложений с базами данных.
Время на прочтение
6 мин
Количество просмотров 63K
Сегодня SQL используют уже буквально все на свете: и аналитики, и программисты, и тестировщики, и т.д. Отчасти это связано с тем, что базовые возможности этого языка легко освоить.
Однако работая с большим количеством junior-ов, мы раз от раза находим в их решениях одни и те же ошибки. Реально — иногда просто создается ощущение, что они копируют друг у друга код.
Кстати, иногда такая же участь постигает и специалистов более высокого полета.
Сегодня мы решили собрать 7 таких ошибок в одном месте, чтобы как можно меньше людей их совершали.
Примечание: Ошибки будут 2 видов — реальные ошибки и своего рода best practices, которым часто не следуют.
Но, обо всем по порядку 🙂

Кстати, будем рады видеть вас в своих социальных сетях — ВКонтакте Телеграм Инстаграм
1. Преобразование типов
Мы привыкли, что в математике мы всегда можем разделить одно число на другое и получить ответ. Если нацело не получается, то в виде дроби.
В SQL это не всегда так работает. Например, в PostgreSQL деление двух целых чисел друг на друга даст целочисленный ответ. Это можно проверить как для целочисленных столбцов, так и для чисел.
SELECT a/b FROM demo
# столбец целых чисел
SELECT 1 / 2
# 0Аналогичные запросы, например, в MySQL дадут дробное число, как и положено.
Если Вы точно не уверены или хотите подстраховаться, то лучше всегда явно делать преобразование типов. Например:
SELECT a::NUMERIC/b FROM demo
SELECT a*1.0/b FROM demo
SELECT CAST(1 AS FLOAT)/2 FROM demoВсе перечисленные примеры дадут нужный ответ.
2. HAVING вместо WHERE
Часто встречается ошибка — оператор HAVING используется вместо WHERE в запросах с агрегацией. Это неверно!
WHERE производит фильтрацию строк в исходном наборе данных, отсеивая неподходящие. После этого GROUP BY формирует группы и оператор HAVING производит фильтрацию уже целых групп (будто группа — одно запись).
Например:
SELECT date, COUNT(*)
FROM transactions t
WHERE date >= '2019-01-01'
GROUP BY date
HAVING COUNT(*) = 2 Здесь мы сначала отсеиваем строки, в которых хранятся записи до 2019 года. После этого формируем группы и оставляем только те, в которых ровно две записи.
Некоторые же пишут так:
SELECT date, COUNT(*)
FROM transactions t
GROUP BY date
HAVING COUNT(*) = 2 AND date >= '2019-01-01'Так делать не нужно 🙂
Кстати, для закрепления этой темы мы специально делали задачку «Отфильтрованные продажи» у себя на платформе. Если интересно порешать и другие задачки по SQL – welcome 🙂
3. Алиасы и план запроса
Если «проговаривать SQL-запрос» словами, то получится что-то такое:
В таблице есть старая цена, а есть новая цена. Их разность я назову diff. Я хочу отобрать только те строки, где значение diff больше 100.
Звучит вполне логично. Но в SQL прям так реализовать не получится – и многие попадаются в эту ловушку.
Вот неправильный запрос:
SELECT old_price - new_price AS diff
FROM goods
WHERE diff > 100Ошибка его заключается в том, что мы используем алиас столбца diff внутри оператора WHERE.
Да, это выглядит вполне логичным, но мы не можем так сделать из-за порядка выполнения операторов в SQL-запросе. Дело в том, что фильтр WHERE выполняется сильно раньше оператора SELECT (а значит и AS). Соответственно, в момент выполнения столбца diff просто не существует. Об этом, кстати, и говорит ошибка:
ERROR: column "diff" does not existПравильно будет использовать подзапрос или переписать запрос следующим образом:
SELECT old_price - new_price AS diff
FROM goods
WHERE old_price - new_price > 100Важно: Внутри ORDER BY вы можете указывать алиас – этот оператор выполняется уже после SELECT.
Кстати, мы тут делали карточку, где наглядно показывается последовательность выполнения операторов. Возможно, это вам пригодится.
4. Не использовать COALESCE
Пришло время неочевидных пунктов. Но сейчас мы поясним свои чаяния.
COALESCE – это оператор, который принимает N значений и возвращает первое, которое не NULL. Если все NULL, то вернется NULL.
Нужен этот оператор для того, чтобы в расчеты случайно не попадали пропуски. Такие пропуски всегда сложно заметить, потому что при расчете среднего на основании ста тысяч строк вы вряд ли заметите подвох, даже если 1000 просто будет отсутствовать. Обычно такие численные пропуски заполняют средними значениями/минимальными/максимальными/медианными/средними или с помощью какой-то интерполяции — зависит от задачи.
Мы же рассмотрим нечисловой пример, а вполне себе бизнесовый. Например, есть таблица клиентов Clients. В поле name заносится имя пользователя.
Отдел маркетинга решил сделать email-рассылку, которая начинается с фразы:
Приветствуем, имя_пользователя!
Очевидно, что если name is NULL, то это превратится в тыкву:
Приветствуем, !
Вот в таких случаях и помогает COALESCE:
SELECT COALESCE(name, 'Дорогой друг') FROM ClientsСовет: Лучше всегда перестраховываться. Особенно это касается вычислений и агрегирований – там вы не найдете ошибку примерно никогда, так что лучше подложить соломку.
5. Игнорирование CASE
Если вы используете CASE, то иногда вы можете сократить свои запросы в несколько раз.
Вот, например, была задача — вывести поле sum со знаком «-», если type=1 и со знаком «+», если type=0.
Пользователь предложил такое решение:
SELECT id, sum FROM transactions t WHERE type = 0
UNION ALL
SELECT id, -sum FROM transactions t WHERE type = 1В целом, не так плохо. Но это всего лишь промежуточный запрос, задача была намного масштабней и таких конструкций в итоге было наворочено очень много.
А вот то же самое с CASE:
SELECT id, CASE WHEN type = 0 THEN sum ELSE -sum END FROM transactions t Согласитесь, получше?
Так более того, CASE можно использовать еще много для чего. Например, чтобы сделать из «длинной» таблицы «широкую».
А еще, кстати, COALESCE, который мы обсуждали выше — это просто «синтаксический сахар» и обертка вокруг CASE. Если интересно — мы подробно это описали в статье.
6. Лишние подзапросы
Из-за того, что многие пишут SQL-запросы также, как это «звучит» в их голове, получается нагромождение подзапросов.
Это проходит с опытом — начинаешь буквально «мыслить на SQL» и все становится ок. Но первое время появляются такие штуки:
SELECT id, LAG(neg) OVER(ORDER BY id) AS lg
FROM (
SELECT id, sm, -sm AS neg
FROM (
SELECT id, sum AS sm FROM transactions t
) t
) t1И это еще не все — можно и побольше накрутить. Но зачем так, если можно так:
SELECT id, LAG(-sum) OVER(ORDER BY id) FROM transactions t Совет: Если пока сложно, не надо сразу бросаться писать оптимизированными конструкциями. Напишите сначала, как сможете, а потом пытайтесь сократить.
Как говорил дядюшка Кнут:
Преждевременная оптимизация — корень всех зол
7. Неправильное использование оконных функций
Вообще говоря, оконные функции — довольно продвинутый инструмент. Считается, что им владеют специалисты уровня Middle и выше. Но по факту, их нужно знать всем — сейчас без них уже сложно жить (это чистое имхо).
И если базовые вещи по оконным функциям можно освоить довольно быстро, то всякая экзотика и нестандартное поведение осваивается, как правило, только на собственных шишках.
Одна из таких вещей — поведение оконной функции LAST_VALUE и прочих.
Например, когда мы пишем запрос:
WITH cte AS (
SELECT 'Marketing' AS department, 50 AS employees, 2018 AS year
UNION
SELECT 'Marketing' AS department, 10 AS employees, 2019 AS year
union
SELECT 'Sales' AS department, 35 AS employees, 2018 AS year
UNION
SELECT 'Sales' AS department, 25 AS employees, 2019 AS year
)
SELECT c.*,
LAST_VALUE(employees) OVER (PARTITION BY department ORDER BY year) AS emp
FROM cte cМы ожидаем увидеть 2 раза по 10 для департамента Маркетинг и 2 раза по 25 для Продаж. Однако такой запрос дает иную картину:

Получается, что запрос тупо продублировал значения из столбца employees. Как так?
Лезем в документацию PostgreSQL и видим:
Заметьте, что функции first_value, last_value и nth_value рассматривают только строки в «рамке окна», которая по умолчанию содержит строки от начала раздела до последней родственной строки для текущей.
Ага, вот и ответ. То есть каждый раз у нас окно — это не весь набор строк, а только до текущей строки.
Получается, есть два способа вылечить такое поведение:
-
Убрать ORDER BY
-
Добавить определение рамки
Вот, например, второй вариант:
WITH cte AS (
SELECT 'Marketing' AS department, 50 AS employees, 2018 AS year
UNION
SELECT 'Marketing' AS department, 10 AS employees, 2019 AS year
union
SELECT 'Sales' AS department, 35 AS employees, 2018 AS year
UNION
SELECT 'Sales' AS department, 25 AS employees, 2019 AS year
)
SELECT c.*,
LAST_VALUE(employees) OVER (
PARTITION BY department
ORDER BY year ROWS BETWEEN CURRENT ROW AND UNBOUNDED FOLLOWING
) AS emp
FROM cte cКстати, такую тему подняла наша подписчица в Телеграме под постом «7 самых важных оконных функций». Спасибо ей!
А вас рады будем видеть в числе подписчиков 🙂
Эпилог
Эти 7 ошибок — не единственные, которые часто встречаются среди новичков и даже профессионалов. У нас есть еще одна пачка тезисов по этому поводу — но это уже тема другой статьи.
Если вам есть что добавить — будем рады продолжить обсуждение в комментариях. Возможно, чей-то код станет лучше и чище в результате нашей беседы 🙂
SQL-запрос – это то, что либо работает хорошо, либо не работает вообще, частично он никак работать не может, в отличие, например, от того же PHP. Как следствие, найти ошибку в SQL-запросе, просто рассматривая его – трудно, особенно если этот запрос снабжён целой кучей JOIN и UNION. Однако, в этой статье я расскажу о методе поиска ошибок в SQL-запросе.
Поскольку обычно в SQL-запрос подставляются какие-то переменные в PHP, то необходимо его сначала вывести. Сделать это можно, например, так:
<?php
$a = 5;
$query = "SELECT FROM `table` WHERE `id` = '$a'";
$result_set = $mysqli->query($query); // Не работает
echo $query; // Выводим запрос, который отправляется
?>
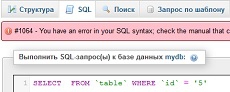
В результате, скрипт выведет такой запрос: SELECT FROM `table` WHERE `id` = ‘5’. Теперь чтобы найти ошибку в нём, надо зайти в phpMyAdmin, открыть базу данных, с которой происходит работа, открыть вкладку “SQL” и попытаться выполнить запрос.
И вот здесь уже ошибка будет показана, не в самой понятной форме (иногда прямо точно описывает ошибку), но она будет. Вот что написал phpMyAdmin: “#1064 – You have an error in your SQL syntax; check the manual that corresponds to your MySQL server version for the right syntax to use near ‘FROM `table` WHERE `id` = ‘5’ ORDER BY `table`.`id` ASC LIMIT 0, 30′ at line 1“. Это означает, что ошибка рядом с FROM. Присматриваемся к этому выделенному нами небольшому участку и обнаруживаем, что мы забыли поставить “*“. Исправляем сразу в phpMyAdmin эту ошибку, убеждаемся, что запрос сработал и после этого идём исправлять ошибку уже в коде.
С помощью этого метода я нахожу абсолютно все ошибки в SQL-запросе, которые мне не удаётся обнаружить непосредственно при осмотре в PHP-коде.
Надеюсь, теперь и Вы сможете найти ошибку в любом SQL-запросе.
-

Создано 01.05.2013 10:54:01
-
Михаил Русаков

Копирование материалов разрешается только с указанием автора (Михаил Русаков) и индексируемой прямой ссылкой на сайт (http://myrusakov.ru)!
Добавляйтесь ко мне в друзья ВКонтакте: http://vk.com/myrusakov.
Если Вы хотите дать оценку мне и моей работе, то напишите её в моей группе: http://vk.com/rusakovmy.
Если Вы не хотите пропустить новые материалы на сайте,
то Вы можете подписаться на обновления: Подписаться на обновления
Если у Вас остались какие-либо вопросы, либо у Вас есть желание высказаться по поводу этой статьи, то Вы можете оставить свой комментарий внизу страницы.
Если Вам понравился сайт, то разместите ссылку на него (у себя на сайте, на форуме, в контакте):
-
Кнопка:
Она выглядит вот так:
-
Текстовая ссылка:
Она выглядит вот так: Как создать свой сайт
- BB-код ссылки для форумов (например, можете поставить её в подписи):

“Что случилось с моим приложением? Я установил новую версию MySQL. Запросы, что выполнялись на старой версии теперь падают с кучей ошибок.”
Многие программисты сталкиваются с этим вопросом при обновлении до версий 5.7 или 8.
В этой статье мы рассмотрим один из самых частых кейсов и его решение.
Мы говорим об этой ошибке
ERROR 1055 (42000): Expression #2 of SELECT list is not in GROUP BY clause
and contains nonaggregated column 'test.web_log.user_id' which is not functionally
dependent on columns in GROUP BY clause; this is incompatible
with sql_mode=only_full_group_by
Видели ли вы когда-либо её?
SQL_MODE
Для начала разрешите мне представить концепцию SQL_MODE.
MySQL может работать используя разные SQL режимы, которые влияют
на синтаксис запросов и валидацию.
В зависимости от установленного значения переменной sql_mode
запрос может быть валидным и выполняться или может получить
ошибку валидации и не может быть выполнен.
Старейшие версии MySQL научили пользователей писать запросы, которые
семантически корректны, потому что разработаны для работы в “прощающем режиме”.
Пользователи могли писать любой синтаксически правильный запрос независимо от
соответствия SQL стандарту или сематических правил.
Это была плохая привычка, которая была исправлена введением sql_mode, чтобы настроить MySQL
работать более строгим способом для проверки запросов.
Некоторые пользователи не знают об этой функции, потому что значение по умолчанию не было таким строгим. Начиная с версии 5.7, значение по умолчанию является более строгим, и по этой причине у некоторых пользователей возникают проблемы с неожиданными ошибками запросов после перехода на 5.7 или 8.0.
Переменная sql_mode может быть установлена в файле конфигурации (/etc/my.cnf) или
может быть изменена во время выполнения.
Область действия переменной может быть GLOBAL или SESSION, поэтому может измениться
в соответствии с целью для любого отдельного соединения.
Переменная sql_mode может иметь несколько значений, разделённых запятой, для настройки различных поведений.
Например, вы можете проинструктировать MySQL как обращаться с датами с нулями, как 0000-00-00,
чтобы дата считалась действительной или нет.
В “прощающем режиме” (или если переменная sql_mode пуста), вы можете вставить такое значение без проблем.
# установка sql в "прощающий режим"
mysql> set session sql_mode='';
Query OK, 0 rows affected (0.00 sec)
mysql> create table t1( mydate date );
Query OK, 0 rows affected (0.05 sec)
mysql> insert into t1 values('0000-00-00');
Query OK, 1 row affected (0.00 sec)
mysql> select * from t1;
+------------+
| mydate |
+------------+
| 0000-00-00 |
+------------+
1 row in set (0.00 sec)
Но это не правильное поведение, как заявлено в режиме TRADITIONAL.
Как хорошие программисты знают, что нужно проверять даты
в коде приложения, чтобы избежать некорректных данных или некорректных результатов.
Далее мы показываем, как динамически проинструктировать MySQL вести себя в traditional режиме,
чтобы выбросить исключений вместо замалчивания ошибки:
mysql> set session sql_mode='TRADITIONAL';
Query OK, 0 rows affected (0.00 sec)
mysql> insert into t1 values('0000-00-00');
ERROR 1292 (22007): Incorrect date value: '0000-00-00' for column 'mydate' at row 1
Существует множество режимов, которые вы можете использовать.
Покрытие всех режимов – не цель данной статьи, поэтому обратитесь
к официальной документации
за подробностями и примерами.
Проблема ONLY_FULL_GROUP_BY
Давайте сосредоточимся на самом частом кейсе ошибок миграции с 5.7 на 8.0.
Как уже было сказано, в 5.7 более строгий режим, чем в 5.6, в 8.0 более строгий, чем в 5.7.
Это работает, если вы обновляете MySQL, копируя старый файл my.cnf,
который не имеет специфичных настроек для переменной sql_mode. Итак, имейте в виду.
Давайте создадим простую таблицу для хранения кликов на вебстраницах нашего сайта.
Мы будем записывать название страницы и ID зарегистрированного пользователя.
mysql> create table web_log ( id int auto_increment primary key, page_url varchar(100), user_id int, ts timestamp);
Query OK, 0 rows affected (0.03 sec)
mysql> insert into web_log(page_url,user_id,ts) values('/index.html',1,'2019-04-17 12:21:32'),
-> ('/index.html',2,'2019-04-17 12:21:35'),('/news.php',1,'2019-04-17 12:22:11'),('/store_offers.php',3,'2019-04-17 12:22:41'),
-> ('/store_offers.php',2,'2019-04-17 12:23:04'),('/faq.html',1,'2019-04-17 12:23:22'),('/index.html',3,'2019-04-17 12:32:25'),
-> ('/news.php',2,'2019-04-17 12:32:38');
Query OK, 7 rows affected (0.01 sec)
Records: 7 Duplicates: 0 Warnings: 0
mysql> select * from web_log;
+----+--------------------+---------+---------------------+
| id | page_url | user_id | ts |
+----+--------------------+---------+---------------------+
| 1 | /index.html | 1 | 2019-04-17 12:21:32 |
| 2 | /index.html | 2 | 2019-04-17 12:21:35 |
| 3 | /news.php | 1 | 2019-04-17 12:22:11 |
| 4 | /store_offers.php | 3 | 2019-04-17 12:22:41 |
| 5 | /store_offers.html | 2 | 2019-04-17 12:23:04 |
| 6 | /faq.html | 1 | 2019-04-17 12:23:22 |
| 7 | /index.html | 3 | 2019-04-17 12:32:25 |
| 8 | /news.php | 2 | 2019-04-17 12:32:38 |
+----+--------------------+---------+---------------------+
Теперь мы хотим написать запрос для подсчёта наиболее посещаемых страниц сайта
mysql> set session sql_mode='';
Query OK, 0 rows affected (0.00 sec)
mysql> SELECT page_url, user_id, COUNT(*) AS visits
-> FROM web_log
-> GROUP BY page_url ORDER BY COUNT(*) DESC;
+-------------------+---------+--------+
| page_url | user_id | visits |
+-------------------+---------+--------+
| /index.html | 1 | 3 |
| /news.php | 1 | 2 |
| /store_offers.php | 3 | 2 |
| /faq.html | 1 | 1 |
+-------------------+---------+--------+
4 rows in set (0.00 sec)
Этот запрос работает, но на самом деле не корректен.
Легко понять, что page_url – столбик для группировки, значение, которое нас больше всего интересует
и мы хотим, чтобы оно было уникальным для подсчёта.
Также столбик visits понятен, это счётчик. Но как насчёт user_id?
Что представляет эта колонка?
Мы сгруппировали по page_url, поэтому значение, возвращаемое для user_id – только одно из значений в группе.
Фактически не только пользователь номер 1 посетил index.html, но также пользователи 2 и 3 посетили эту страницу.
Как нам интерпретировать значение? Это первый посетитель? Или последний?
Мы не знаем правильного ответа!
Мы должны рассматривать значение колонки user_id как случайный элемент из группы.
В любом случае, правильный ответ – запрос семантически некорректен,
так как нет смысла для возвращаемого значения столбика, что не является частью функции группировки.
Запрос будет недействительным в традиционном SQL.
Давайте проверим это
mysql> SET SESSION sql_mode='ONLY_FULL_GROUP_BY';
Query OK, 0 rows affected (0.00 sec)
mysql> SELECT page_url, user_id, COUNT(*) AS visits
-> FROM web_log
-> GROUP BY page_url ORDER BY COUNT(*) DESC;
ERROR 1055 (42000): Expression #2 of SELECT list is not in GROUP BY clause
and contains nonaggregated column 'test.web_log.user_id' which is not functionally
dependent on columns in GROUP BY clause; this is incompatible with sql_mode=only_full_group_by
Как и ожидалось, у нас ошибка.
Режим SQL ONLY_FULL_GROUP_BY – это часть TRADITIONAL режима и включен по умолчанию
начиная с 5.7.
Множество программистов столкнулось с разновидностью этой ошибки после миграции на последнюю версию
MySQL.
Теперь мы знаем, что вызывает эту ошибку, но наше приложение всё ещё не работает.
Какие возможные решения у нас есть, чтобы вернуть приложение к работе?
Решение 1 – переписать запрос
Так как не корректно выбирать колонку, которая не является частью группировки,
мы можем переписать запрос без этой колонки. Очень просто.
mysql> SELECT page_url, COUNT(*) AS visits
-> FROM web_log
-> GROUP BY page_url ORDER BY COUNT(*) DESC;
+-------------------+--------+
| page_url | visits |
+-------------------+--------+
| /index.html | 3 |
| /news.php | 2 |
| /store_offers.php | 2 |
| /faq.html | 1 |
+-------------------+--------+
Если много ваших запросов затронуты проблемой, вы можете потенциально сделать много работы,
чтобы найти и переписать их.
Или, возможно, проблемные запросы – часть старого приложения, которое нет возможности изменить.
Но это решение заставляет вас писать правильные запросы и пусть конфигурация вашей базы данных
проверяет на такие ошибки в терминах SQL-валидации.
Решение 2 – вернуть “прощающий режим”
Вы можете поменять конфигурацию подключения или MySQL сервера и вернуть “прощающий” режим.
Или вы можете убрать только ONLY_FULL_GROUP_BY из настроек по умолчанию.
По умолчанию SQL режим в 5.7 включает режимы: ONLY_FULL_GROUP_BY, STRINCT_TRANS_TABLES, NO_ZERO_IN_DATE, NO_ZERO_DATE, ERROR_FOR_DIVISION_BY_ZERO, NO_AUTO_CREATE_USER.
#set the complete "forgiving" mode
mysql> SET GLOBAL sql_mode='';
# alternatively you can set sql mode to the following
mysql> SET GLOBAL sql_mode='STRICT_TRANS_TABLES,STRICT_ALL_TABLES,NO_ZERO_IN_DATE,NO_ZERO_DATE,ERROR_FOR_DIVISION_BY_ZERO,TRADITIONAL,NO_ENGINE_SUBSTITUTION';
Для yii2-приложения конфиг может выглядеть так:
<?php
return [
'class' => 'yiidbConnection',
'dsn' => 'mysql:host=' . getenv('MYSQL_HOST') . ';port=' . getenv('MYSQL_PORT') . ';dbname=' . getenv('MYSQL_DB'),
'username' => getenv('MYSQL_USER'),
'password' => getenv('MYSQL_PASSWORD'),
'charset' => 'utf8',
'attributes' => [
PDO::ATTR_PERSISTENT => true,
PDO::MYSQL_ATTR_INIT_COMMAND => 'SET sql_mode="STRICT_TRANS_TABLES,NO_ZERO_IN_DATE,NO_ZERO_DATE,ERROR_FOR_DIVISION_BY_ZERO,NO_ENGINE_SUBSTITUTION"'
],
];
Решение 3 – использование агрегирующих функций
Если ваше приложение точно нуждается в получении поля user_id для какой-то корректной причины,
или слишком сложно менять исходный код (например, для поддержки обратной совместимости с внешними приложениями),
вы можете положиться на агрегирующие функции, чтобы избежать изменения SQL-режима.
Тогда для всех новых запросов проверка уже будет выполняться.
Например мы можем использовать агрегирующие функции MAX(), MIN() или даже GROUP_CONCAT().
mysql> SET SESSION sql_mode='ONLY_FULL_GROUP_BY';
mysql> SELECT page_url, MAX(user_id), COUNT(*) AS visits FROM web_log GROUP BY page_url ORDER BY COUNT(*) DESC;
+-------------------+--------------+--------+
| page_url | MAX(user_id) | visits |
+-------------------+--------------+--------+
| /index.html | 3 | 3 |
| /news.php | 2 | 2 |
| /store_offers.php | 3 | 2 |
| /faq.html | 1 | 1 |
+-------------------+--------------+--------+
mysql> SELECT page_url, GROUP_CONCAT(user_id), COUNT(*) AS visits FROM web_log GROUP BY page_url ORDER BY COUNT(*) DESC;
+-------------------+-----------------------+--------+
| page_url | GROUP_CONCAT(user_id) | visits |
+-------------------+-----------------------+--------+
| /index.html | 1,2,3 | 3 |
| /news.php | 1,2 | 2 |
| /store_offers.php | 3,2 | 2 |
| /faq.html | 1 | 1 |
+-------------------+-----------------------+--------+
MySQL даже предоставляет специальную функцию для решения этой проблемы: ANY_VALUE().
mysql> SELECT page_url, ANY_VALUE(user_id), COUNT(*) AS visits FROM web_log GROUP BY page_url ORDER BY COUNT(*) DESC;
+-------------------+--------------------+--------+
| page_url | ANY_VALUE(user_id) | visits |
+-------------------+--------------------+--------+
| /index.html | 1 | 3 |
| /news.php | 1 | 2 |
| /store_offers.php | 3 | 2 |
| /faq.html | 1 | 1 |
+-------------------+--------------------+--------+
Заключение
Лично я предпочитаю решение номер 1, так как оно заставляет вас писать запросы по стандарту SQL-92.
Следование стандартам часто считается лучшей практикой. Также хочу заметить, что это ловит часть ошибок,
аналогично статическому анализу кода.
Решение 2 подходит, если вы не можете поменять код приложения или переписывание всех запросов
действительно очень сложное. Отличное решение исправить проблему за несколько секунд, хотя я настоятельно рекомендую иметь план по переписыванию запросов, которые соответствуют стандарту SQL-92.
Больше деталей: https://dev.mysql.com/doc/refman/5.7/en/group-by-handling.html
По мотивам
https://www.percona.com/blog/2019/05/13/solve-query-failures-regarding-only_full_group_by-sql-mode/
Практически любой разработчик приложений баз данных сталкивается с необходимостью переделки ранее написанных SQL-запросов. При этом обычно преследуются две цели: во-первых – оптимизация времени выполнения запроса, во-вторых – улучшение дизайна запроса. Этот процесс подпадает под определение одной из основных практик экстремального программирования – рефакторинга (улучшения качества кода без изменения его функциональности). Основная масса литературы по рефакторингу посвящена переделке кодов программ, написанных на алгоритмических языках, и касается, как правило, объектно-ориентированных аспектов программирования. Целью данной статьи является попытка описания практики рефакторинга для SELECT-запросов языка SQL.
Признаки необходимости модификации запросов
Прежде чем заниматься переделкой кода, для начала надо четко определить, чем он плох, к чему надо стремиться, какими характеристиками должен обладать «совершенный запрос». Ниже предлагается ряд признаков «плохого» кода, при этом подразумевается, что по функциональности запрос уже нас устраивает и выдает в точнсти те данные, которые требуются.
1-ый признак
Код может быть «плохо оформлен», в этом случае его сложно понимать, соответственно – сложно переделывать. Для разработчика это должно означать несоответствие оформления запроса некоторым правилам, стандарту кодирования. Если не рассматривать правила именований объектов баз данных (считается, что схему данных изменить нельзя), то стандарт кодирования должен описывать, как должен быть отформатирован запрос (отступы, пробелы, длина строк…) и как должны именоваться объявляемые в его рамках переменные и алиасы (псевдонимы). Сюда же можно отнести требование использования только стандартных ключевых слов языка SQL и только в несокращенной форме.
Наглядно пользу форматирования кода можно продемонстрировать на следующем примере – листинг 1.
SELECT Suppliers.CompanyName, Products.ProductName, Products.QuantityPerUnit, Products.UnitPrice, OrderDetails.UnitPrice, OrderDetails.Quantity, OrderDetails.Discount, Orders.OrderDate, Orders.ShipName FROM Suppliers INNER JOIN Products ON Suppliers.SupplierID = Products.SupplierID INNER JOIN OrderDetails ON Products.ProductID = OrderDetails.ProductID INNER JOIN Orders ON OrderDetails.OrderID = Orders.OrderID WHERE (OrderDetails.Discount = 0) AND (Orders.OrderDate > '06/11/1996')
Листинг 1. Пример неформатированного запроса.
Тот же запрос после обработки может выглядеть так:
SELECT Suppliers.CompanyName, Products.ProductName, Products.QuantityPerUnit, Products.UnitPrice, OrderDetails.UnitPrice, OrderDetails.Quantity, OrderDetails.Discount, Orders.OrderDate, Orders.ShipName FROM Suppliers INNER JOIN Products ON Suppliers.SupplierID = Products.SupplierID INNER JOIN OrderDetails ON Products.ProductID = OrderDetails.ProductID INNER JOIN Orders ON OrderDetails.OrderID = Orders.OrderID WHERE (OrderDetails.Discount = 0) AND (Orders.OrderDate > '06/11/1996')
Листинг 2. Запрос после проведения форматирования.
2-ой признак
Точно так же, как и для алгоритмических языков, проблемой, с точки зрения дизайна и сопровождения, является наличие дублирующего кода.
Устранение этих двух недостатков (1-го и 2-го признака), скорее всего не изменит скорость выполнения запроса, но поможет лучшему пониманию его структуры и упростит внесение дальнейших изменений.
Следующие признаки «плохих» запросов будут связаны уже с их структурой. Поскольку все они определяются через наличие некоторых конструкций языка SQL, то воспринимать их нужно с оговоркой, что использование данных конструкций в запросе не является безальтернативным и от них можно избавиться.
3-ий признак
Невозможность визуального представления запроса. В качестве инструмента проверки на соответствие данному признаку можно предложить Query Designer из MS SQL Server. Наверное очевидно, что визуальное представление запроса помогает пониманию его структуры. Состав критичных конструкций языка SQL для этого признака можно взять из документации по SQL Server (Books Online, статья «Query Designer Considerations for SQL Server Databases»). В частности, таковой является конструкция UNION.
Рис.1. Визуальное представление запроса
4-ый признак
Наличие в запросе медленно работающих конструкций. В качестве примера можно привести использование связанных подзапросов. Избавление от подзапросов помимо увеличения скорости выполнения запроса, в большинстве случаев улучшит его читаемость. Предложения UNION также относятся к медленно работающим, т.к. в них требуется отбрасывать избыточные дубликаты [3].
5-ый признак
Невозможность построения на основе запроса индексированного представления. Если забежать вперед и предположить, что, несмотря на все ухищрения, запрос работает недостаточно быстро, то следующим способом его ускорить можно предложить получение требуемых данных на основе индексированного представления. Перечень ограничений можно опять же получить из документации SQL Server (Books Online, статья «Creating an Indexed View»). В «черный список» снова попали подзапросы и UNION, а также:
- предложение TOP;
- предложение ORDER BY
- внешние соединения
- использование ключевого слова DISTINCT
- …
Соответствие всем этим требованиям – конечно же, очень сильное ограничение. Естественно, что далеко не все запросы можно перестроить в соответствие с ними. Важно, чтобы программист понимал критичность использования некоторых конструкций с точки зрения производительности и дизайна кода. Во многих ситуациях реально из запроса выделить часть, удовлетворяющую ограничениям индексированного представления и построить индексированный view только для этой части.
Методы модификации запросов
Для минимизации риска Мартин Фаулер[2] рекомендует проводить рефакторинг «маленькими шажочками», осуществляя проверку результата после каждого из них. Часть его книги составляет каталог методов рефакторинга – попытка классифицировать и описать наиболее часто встречающиеся модификации кода (предназначенные, прежде всего, для объектно-ориентированного программирования). Подобный каталог можно составить и для SQL. Ниже, в качестве примера, приведены четыре метода рефакторинга для наиболее простых ситуаций.
1. Выделение пользовательской функции
Мотивом для проведения такого рефакторинга является частое использование некоторых стандартных вычислений, встречающееся в рамках одного запроса или группы запросов. Пример: расчет первого числа месяца для некоторой даты на языке SQL:
DATEADD(dd, 1-DAY(@date), @date)
Понятно, что запись не является особо сложной или громоздкой, но, тем не менее, ее многократное использование не способствует улучшению читаемости кода. Если поместить этот расчет в функцию, ее вызов будет выглядеть так:
FirstDayOfMonth(@date)
Такая запись уже не требует написания комментария (лучшая документация для исходного кода – это он сам).
2. Выделение представления
Это преобразование может быть оправдано как для повторяющегося участка кода, встречающегося в группе запросов, так и для отдельного запроса. Информативное имя представления также повысит читаемость кода. Особенностью данной модификации является то, что выделяемый участок кода не будет неразрывным в исходном запросе. В листинге 3 цветовым выделением обозначены фрагменты кода, которые необходимо перенести в представление, содержащее информацию таблиц Order и OrderDetails.
SELECT Suppliers.CompanyName, Products.ProductName, Products.QuantityPerUnit, Products.UnitPrice, OrderDetails.UnitPrice, OrderDetails.Quantity, OrderDetails.Discount, Orders.OrderDate, Orders.ShipName FROM Suppliers INNER JOIN Products ON Suppliers.SupplierID = Products.SupplierID INNER JOIN OrderDetails ON Products.ProductID = OrderDetails.ProductID INNER JOIN Orders ON OrderDetails.OrderID = Orders.OrderID WHERE (OrderDetails.Discount = 0) AND (Orders.OrderDate > '06/11/1996')
Листинг 3. Фрагменты кода, формирующие представление.
Эта особенность требует проведения значительного количества мелких действий при осуществлении подобного преобразования вручную.
3. Избавление от подзапросов
Часто причиной появления в коде подзапроса связано с переносом практики работы с циклами в алгоритмических языках и неумением думать в терминах теории множеств. Простейший случай может выглядеть следующим образом:
SELECT Products.ProductName, Products.QuantityPerUnit, Products.UnitPrice, (SELECT CompanyName FROM Suppliers WHERE Suppliers.SupplierID = Products.SupplierID) AS CompanyName FROM Products
Листинг 4. Простейший пример использования связанного подзапроса
Рис. 2. План выполнения запроса из листинга 4.
Того же результата можно добиться и без использования подзапроса:
SELECT Products.ProductName, Products.QuantityPerUnit, Products.UnitPrice, Suppliers.CompanyName FROM Products LEFT OUTER JOIN Suppliers ON Suppliers.SupplierID = Products.SupplierID
Листинг 5. Вариант модификации запроса из листинга 4.
Рис. 3. План выполнения модифицированного запроса из листинга 5
При рассмотрении планов выполнения запросов, видно, что планы выполнения обоих запросов практически одинаковые. План для исходного запроса на одно действие короче, но в процентном соотношении различие составляет менее 1%. Здесь нужно принимать во внимание, что оптимизаторы современных СУБД достаточно эффективно «разгоняют» простые запросы со связанными подзапросами. Для более сложных запросов разница может быть существеннее.
Большинство ситуаций, встречающихся в реальных запросах, сложнее, тем не менее, в модифицированном запросе должен будет появиться JOIN с таблицей (таблицами) из подзапросов. При использовании агрегатных функций в подзапросе – они перейдут в основной запрос, к которому будет добавлено предложение GROUP BY (см. листинги 6,7).
SELECT OrderDate, ShipName, (SELECT SUM(UnitPrice*Quantity) FROM OrderDetails WHERE OrderDetails.OrderID = Orders.OrderID) AS OrderSum FROM Orders
Листинг 6. Пример SELECT-команды с агрегатной функцией в подзапросе
SELECT Orders.OrderDate, Orders.ShipName, SUM(OrderDetails.UnitPrice*OrderDetails.Quantity) AS OrderSum FROM Orders LEFT OUTER JOIN OrderDetails ON OrderDetails.OrderID = Orders.OrderID GROUP BY Orders.OrderID, Orders.OrderDate, Orders.ShipName
Листинг 7. Вариант модификации запроса из листинга 6.
4. Избавление от UNION
Наиболее простым примером использования UNION, от которого можно избавиться, является цепочка предложений UNION, основанных на одной и той же базовой таблице. Примеры исходного запроса и преобразованного приведены в листингах 8,9.
SELECT ProductID, ProductName, UnitPrice FROM Products WHERE ProductName LIKE 'A%' UNION SELECT ProductID, ProductName, UnitPrice FROM Products WHERE UnitPrice <= 40
Листинг 8. Запрос с UNION на основе одной базовой таблице
SELECT ProductID, ProductName, UnitPrice FROM Products WHERE ProductName LIKE 'A%' OR UnitPrice <= 40
Листинг 9. Модифицированный запрос (замена UNION на OR)
Очевидно, что модифицированный запрос имеет более простой дизайн. Для наглядной иллюстрации критичности использования UNION, ниже приведены планы выполнения этих запросов.
Рис. 4. План выполнения запроса с UNION (из листинга 8)

Рис. 5. План выполнения запроса после замены UNION на OR
В некоторых ситуациях в использовании UNION нет необходимости и достаточно более производительного предложения UNION ALL (при его выполнении не происходит объединения повторяющихся строк).
Программные средства рефакторинга SQL
Действия программиста, выполняемые при проведении рефакторинга, можно поделить на 3 группы: форматирование кода, непосредственное применение методов рефакторинга – преобразований кода и проверку того, что конечный запрос не отличается от исходного по набору возвращаемых данных. Частично эти действия могут быть автоматизированы, точно так же, как они автоматизируются для ряда объектно-ориентированных языков программирования. Ниже приведен краткий обзор средств, которые могут быть использованы для рефакторинга SQL-запросов. Обзор не претендует на полноту и ориентирован, в основном, на программные инструменты, входящие в состав средств разработки компании Microsoft или дополняющие их.
1. Форматирование кода и визуальное представление
Существует довольно большой набор средств форматирования SQL-кода. В их числе: Query Designer, входящий в состав SQL Server Management Studio – для форматирования достаточно скопировать запрос и активизировать панель визуального представления. Из средств сторонних разработчиков можно привести в качестве примера SQL Refactor компании Red Gate Software и QueryCommander – бесплатный инструмент с открытым кодом. Основные различия указанных средств – в разных стандартах форматирования, к которым они приводят исходные запросы и в возможности изменить это параметрами настроек.
2. Программы для рефакторинга запросов
Автору статьи не удалось найти средства, автоматизирующие непосредственно проведение рефакторинга SQL-кода. Единственный программный продукт, который претендует на эту роль (по крайней мере – по названию) – SQL Refactor, предлагает только возможности форматирования кода, выделение части SQL-кода в качестве хранимой процедуры и разбиение предложения CREATE TABLE на две части (с разделением уже существующих колонок между двумя таблицами). Никаких сервисов по модификации структуры запросов не предлагается.
3. Unit-тестирование для SQL-запросов
В экстремальном программировании практика проведения рефакторинга тесно связана с практикой написания тестов модулей, или unit-тестов. Основная аргументация связи этих практик – невозможность смело переделывать работающий код, если нет механизмов быстрой проверки того, что внесенные изменения его не испортили. В принципе, вполне возможно написание unit-тестов средствами, приспособленными для тестирования программ алгоритмических языков (jUnit, csUnit, встроенными механизмами написания unit-тестов в MS Visual Studio 2005). В случаях, если запросы пишутся для серверных компонентов, обеспечивающих доступ к базам данных, эти тесты могут вполне органично вписываться в общую систему тестирования этих компонентов. При этом необходимо учитывать особенность тестирования запросов: нужны механизмы сравнения наборов данных, а не отдельных значений. Удалось найти всего три средства построения unit-тестов, связанных с тестированием SQL-запросов: SQLUnit, DbUnit и TSQLUnit. Все три средства являются узкоспециализированными: DbUnit и SQLUnit исходно ориентированы на Java-разработчиков, TSQLUnit – требует написания unit-тестов на языке Python. Из них только в DbUnit есть функция сравнения наборов данных, в двух оставшихся – такая возможность отсутствует.
Заключение
Подход к проведению модификации существующего кода вполне оправдывает себя в применении к SQL-запросам. К сожалению, на сегодняшний день выбор средств автоматизации рефакторинга SQL весьма скуден, а имеющиеся средства недостаточно функциональны. Это скорее всего связано с тем фактом, что XP зародилось в среде разработчиков, программирующих преимущественно на объектно-ориентированных языках и специфичностью характера проведения рефакторинга для SQL-кода.
Просмотры: 629
