Как найти похожую картинку, фотографию, изображение в интернет
12.07.2019
Допустим у Вас есть какое-то изображение (рисунок, картинка, фотография), и Вы хотите найти такое же (дубликат) или похожее в интернет. Это можно сделать при помощи специальных инструментов поисковиков Google и Яндекс, сервиса TinEye, а также потрясающего браузерного расширения PhotoTracker Lite, который объединяет все эти способы. Рассмотрим каждый из них.
Поиск по фото в Гугл
Тут всё очень просто. Переходим по ссылке https://www.google.ru/imghp и кликаем по иконке фотоаппарата:

Дальше выбираем один из вариантов поиска:
- Указываем ссылку на изображение в интернете
- Загружаем файл с компьютера
На открывшейся страничке кликаем по ссылке «Все размеры»:

В итоге получаем полный список похожих картинок по изображению, которое было выбрано в качестве образца:

Есть еще один хороший способ, работающий в браузере Chrome. Находясь на страничке с интересующей Вас картинкой, подведите к ней курсор мыши, кликните правой клавишей и в открывшейся подсказке выберите пункт «Найти картинку (Google)»:

Вы сразу переместитесь на страницу с результатами поиска!
Статья по теме: Поисковые сервисы Google, о которых Вы не знали!
Поиск по картинкам в Яндекс
У Яндекса всё не менее просто чем у Гугла 🙂 Переходите по ссылке https://yandex.by/images/ и нажимайте значок фотоаппарата в верхнем правом углу:

Укажите адрес картинки в сети интернет либо загрузите её с компьютера (можно простым перетаскиванием в специальную области в верхней части окна браузера):
![]()
Результат поиска выглядит таким образом:
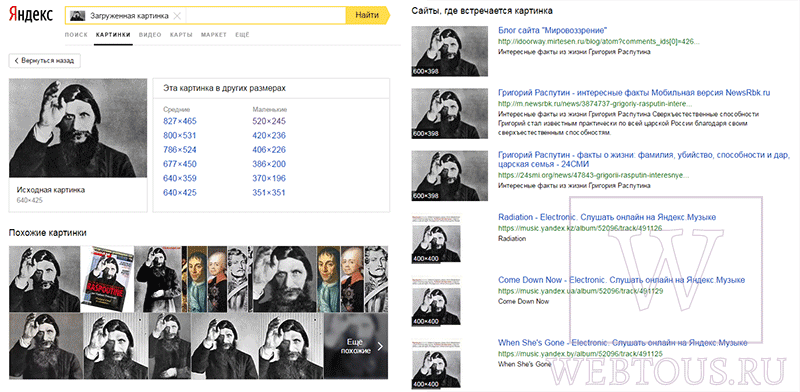
Вы мгновенно получаете доступ к следующей информации:
- Какие в сети есть размеры изображения, которое Вы загрузили в качестве образца для поиска
- Список сайтов, на которых оно встречается
- Похожие картинки (модифицированы на основе исходной либо по которым алгоритм принял решение об их смысловом сходстве)
Поиск похожих картинок в тинай
Многие наверняка уже слышали об онлайн сервисе TinEye, который русскоязычные пользователи часто называют Тинай. Он разработан экспертами в сфере машинного обучения и распознавания объектов. Как следствие всего этого, тинай отлично подходит не только для поиска похожих картинок и фотографий, но их составляющих.
Проиндексированная база изображений TinEye составляет более 10 миллиардов позиций, и является крупнейших во всем Интернет. «Здесь найдется всё» — это фраза как нельзя лучше характеризует сервис.

Переходите по ссылке https://www.tineye.com/, и, как и в случае Яндекс и Google, загрузите файл-образец для поиска либо ссылку на него в интернет.

На открывшейся страничке Вы получите точные данные о том, сколько раз картинка встречается в интернет, и ссылки на странички, где она была найдена.
PhotoTracker Lite – поиск 4в1
Расширение для браузера PhotoTracker Lite (работает в Google Chrome, Opera с версии 36, Яндекс.Браузере, Vivaldi) позволяет в один клик искать похожие фото не только в указанных выше источниках, но и по базе поисковика Bing (Bing Images)!
Скриншот интерфейса расширения:
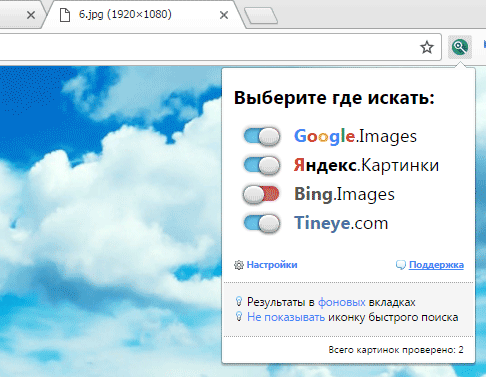
В настройках приложения укажите источники поиска, после чего кликайте правой кнопкой мыши на любое изображение в браузере и выбирайте опцию «Искать это изображение» PhotoTracker Lite:
![]()
Есть еще один способ поиска в один клик. По умолчанию в настройках приложения активирован пункт «Показывать иконку быстрого поиска». Когда Вы наводите на какое-то фото или картинку, всплывает круглая зеленая иконка, нажатие на которую запускает поиск похожих изображений – в новых вкладках автоматически откроются результаты поиска по Гугл, Яндекс, Тинай и Бинг.

Расширение создано нашим соотечественником, который по роду увлечений тесно связан с фотографией. Первоначально он создал этот инструмент, чтобы быстро находить свои фото на чужих сайтах.
Когда это может понадобиться
- Вы являетесь фотографом, выкладываете свои фото в интернет и хотите посмотреть на каких сайтах они используются и где возможно нарушаются Ваши авторские права.
- Вы являетесь блогером или копирайтером, пишите статьи и хотите подобрать к своему материалу «незаезженное» изображение.
- А вдруг кто-то использует Ваше фото из профиля Вконтакте или Фейсбук в качестве аватарки на форуме или фальшивой учетной записи в какой-либо социальной сети? А ведь такое более чем возможно!
- Вы нашли фотографию знакомого актера и хотите вспомнить как его зовут.
На самом деле, случаев, когда может пригодиться поиск по фотографии, огромное множество. Можно еще привести и такой пример…
Как найти оригинал заданного изображения
Например, у Вас есть какая-то фотография, возможно кадрированная, пожатая, либо отфотошопленная, а Вы хотите найти её оригинал, или вариант в лучшем качестве. Как это сделать? Проводите поиск в Яндекс и Гугл, как описано выше, либо средствами PhotoTracker Lite и получаете список всех найденных изображений. Далее руководствуетесь следующим:
- Оригинальное изображение, как правило имеет больший размер и лучшее качество по сравнению с измененной копией, полученной в результате кадрирования. Конечно можно в фотошопе выставить картинке любой размер, но при его увеличении относительно оригинала, всегда будут наблюдаться артефакты. Их можно легко заметить даже при беглом визуальном осмотре.
Статья в тему: Как изменить размер картинки без потери в качестве.
- Оригинальные фотографии часто имеют водяные знаки, обозначающие авторство снимка (фамилия, адрес сайта, название компании и пр.). Конечно водяной знак может добавить кто угодно на абсолютно на любое изображение, но в этом случае можно поискать образец фото на сайте или по фамилии автора, наверняка он где-то выкладывает своё портфолио онлайн.
- И наконец, совсем простой признак. Если Ваш образец фото черно-белый (сепия и пр.), а Вы нашли такую же, но полноцветную фотографию, то у Вас явно не оригинал. Добавить цветность ч/б фотографии гораздо более сложнее, чем перевести цветную фотографию в черно-белую 🙂
Уважаемые читатели, порекомендуйте данный материал своим друзьям в социальных сетях, а также задавайте свои вопросы в комментариях и делитесь своим мнением!
Похожие публикации:
- 15 рекламных роликов из 90-х годов, которые никого не оставят равнодушными
- Как отключить автоматическое создание групп вкладок в Chrome
- Истории друзей ВК — как легко убрать из ленты новостей
- Как оцифровать и восстановить старые фото своими руками
- Wi-Fi 7: полное описание нового стандарта
Понравилось? Поделитесь с друзьями!

Сергей Сандаков, 42 года.
С 2011 г. пишу обзоры полезных онлайн сервисов и сайтов, программ для ПК.
Интересуюсь всем, что происходит в Интернет, и с удовольствием рассказываю об этом своим читателям.
Россия
Всё о GoogleРекламаДля бизнеса Как работает Google Поиск
КонфиденциальностьУсловия
Настройки
Перевод публикуется с сокращениями, автор оригинальной
статьи Anusha Saive.
Вы можете легко вывести свой проект или маркетинговую кампанию на новый уровень с помощью правильных изображений. Если знать, как использовать правильные фильтры для сортировки и ключевые слова, нетрудно получить изображение для любой цели.
Далеко не каждая
поисковая система предоставит вам лучшие изображения. Приступим к
рассмотрению.
1. TinEye
TinEye – инструмент для поиска похожих на
оригинал изображений, требующий, чтобы вы либо ввели URL, либо загрузили картинку, чтобы узнать, откуда она появилась. Эта поисковая система проста в
использовании и отличается дружественным интерфейсом.
Можно также использовать расширение браузера TinEye для быстрого поиска: нажмите правой кнопкой мыши на любое изображение и найдите его.
2. Google Images
Никто не опережает Google Images,
когда дело доходит до поиска изображений. Все, что вам нужно сделать – ввести ключевое слово и нажать «Enter». Для более
детального поиска предлагаются определенные фильтры, предоставляющие широкий
выбор связанных изображений. Этот удобный инструмент дает именно то, что вам
необходимо.
Вы можете выбрать из
большого списка фильтров, представляющих изображения в виде клипарта,
мультфильма, иллюстраций и т. д. Фильтрация позволяет выбрать цвет,
размер, тематику и другую подобную информацию. Чтобы воспользоваться этим
инструментом, найдите значок камеры в поле поиска и нажмите на него.
3. Yahoo Image Search
Yahoo Image Search – еще один удобный вариант для поиска изображений. Он похож на Google Images и дает отличные результаты. В этом продукте
фильтры менее сложны, но удобно расположены и находятся на виду.
4. Picsearch
Если хотите получить более разнообразные результаты по введенному ключевому слову, попробуйте Picsearch.
Эта поисковая система не показывает массу конкретных
результатов, как некоторые другие поисковики, но демонстрирует связанные
изображения по ключевому слову.
Расширенные опции поиска позволяют фильтровать
результаты по размеру, разрешению картинки, заднему фону и т. д.

5. Bing Image Search
Bing IS является лучшей альтернативой Google Images,
поскольку выдает довольно похожие результаты. С точки зрения макета он также
довольно близок к сервису Google и обладает невероятными функциями для поиска людей,
используя параметры лица, головы и плеч.
Доступны многочисленные опции поиска и фильтры.
6. Flickr
Flickr работает несколько
иначе. Это своего рода платформа, где фотографы-любители и профессионалы делятся изображениями. В случае, если вы
находитесь на Flickr для поиска картинок на маркетинговую, брендовую или
коммерческую тематику, обязательно изучите лицензию.
7. Pinterest Visual Search Tool
Pinterest давно всем знаком и многие жить без него не
могут из-за некоторых особенностей инструмента. Одна из них – встроенный
визуальный поиск. Чтобы получить доступ к этой платформе, вам нужно войти в
свою учетку, нажать на любой появившийся в ленте пин,
а затем щелкнуть по значку в правом нижнем углу, связанному с закрепленными в
системе изображениями.
Эта поисковая машина
имеет обширную базу данных и дает лучшие результаты,
соответствующие искомому изображению.
8. Getty Images
Getty
Images выполняет поиск по ключевым словам и по
изображению. Для поиска по ключевым словам существует
несколько вариантов с функциями автоматического предложения. Ресурс предлагает набор фильтров, гарантирующих, что вы получите именно то, что
ищете.
Сервис предоставляет
изображения в двух вариантах: творческие и редакционные, а также видео. Вам
придется заплатить за лицензию, чтобы использовать любую фотографию (ее можно купить в пакетах или поштучно с фиксированной ценой).

9. Яндекс
Яндекс позволяет искать изображения с помощью широкого
спектра фильтров и параметров сортировки по формату, ориентации,
размеру и т. д. Также доступен еще один
инструмент поиска, называемый «Похожие изображения».
10. Shutterstock
Ищете бюджетный вариант с хорошим ассортиментом? Shutterstock – то что нужно. Он отобрал пальму первенства у Getty Images с помощью огромной
библиотеки изображений.
Ресурс позволяет
выполнять поиск изображений любым удобным для вас способом. Ежемесячные и
годовые тарифные планы предполагают варианты с предоплатой или с оплатой после покупки.
11. The New York Public Library Digital Collections
Последний, но не худший
источник. Если вам нужны изображения с высоким разрешением, относящиеся к
исторической эпохе, картам, книгам, бухгалтерской тематике, фотографии и т. д.,
не забудьте поискать в The New York Public Library! Огромный архив изображений – общественное достояние.
Этот инструмент поиска
исторических изображений позволяет уточнить условия, выбрав
результат в зависимости от жанра, коллекции, места, темы, издателя и т.д.
Дополнительные материалы:
- 10 лучших альтернатив YouTube, которые стоит попробовать в 2021 году
Источники
- https://www.fossmint.com/image-search-engines/
Как искать похожие изображения: лучшие сервисы
1 звезда
2 звезды
3 звезды
4 звезды
5 звезд
Если вы хотите найти похожие изображения с помощью какой-то картинки, то вы можете сделать это только на нескольких веб-сайтах. Рассказываем, как работают подобные сервисы.



Проще и удобнее всего это работает с Google.
- Откройте веб-страницу Google и выберите категорию «Картинки» в правом верхнем углу.
- Теперь перетащите изображение в строку поиска или щелкните значок камеры справа.
- Сюда вы можете загрузить изображение со своего компьютера или ввести его URL-адрес, если нашли картинку где-то в Сети. Затем Google будет искать похожие изображения и отображать связанные с ними веб-страницы.
TinEye
TinEye — это поисковая система, специализирующаяся исключительно на изображениях. Подобно Google, она ведет поиск картинок во всему интернету.
- Откройте сайт TinEye и загрузите слева изображение с вашего компьютера или введите справа ссылку на фото. Вы также можете перетащить сюда картинку.
- Затем вы увидите похожие изображения и связанные с ними веб-страницы.
- Если вы нажмете под изображением на ссылку «Compare», вы сможете сравнить две картинки друг с другом.
Reverse Image Search
Сервис Reverse Image Search использует сразу несколько поисковых систем при поиске изображений и объединяет результаты.
- Откройте веб-страницу Reverse Image Search.
- Выберите изображение с вашего компьютера или облачного хранилища, например, с Google Диск, или введите URL-адрес картинки.
- Затем вы можете выбрать, хотите ли вы искать изображение во всех доступных или только через определенные поисковые системы. Для этого уберите галочки напротив иконок поисковиков или выберите «All Search Engines».
- После нажатия на кнопку «Search Images» («Искать изображения»), вы увидите результаты поиска.
Яндекс
Отечественный поисковик также поддерживает поиск по картинкам.
- Перейдите на главную страницу Яндекса и откройте вкладку «Картинки».
- Перетащите изображение в окно с браузером или кликните на иконку с камерой в поисковой строке.
- Здесь вы можете выбрать файл на компьютере или вставить ссылку на фото из интернета. Если вы используете поиск по ссылке, то нажмите кнопку «Найти» для отображения результатов. При загрузке картинки на сервис страница с похожими изображениями откроется автоматически.
Читайте также:
- Законно ли скачивать видео с YouTube?
- Как перенести данные с Андроида на Айфон: пошаговая инструкция
Была ли статья интересна?
Как найти похожие картинки
Уровень сложности
Простой
Время на прочтение
9 мин
Количество просмотров 3.3K

Веб 2.0 — отличная штука. Сайты на самообслуживании. Пользователи наполняют их собственноручно («постят контент», как сейчас выражаются). Сами напостили, сами посмеялись. А владелец сайта только платит за хостинг и стрижет купоны на рекламе. Удобно же.
Но жизнь наша так странно устроена, что плюсов без минусов не бывает, а нередко недостатки вообще являются продолжением достоинств. Есть проблемы и у самонаполняемых сайтов — баяны. В смысле, дубли.
Дубли многие посетители не любят, особенно старожилы, на зубок помнящие мемасики, появившиеся во времена превед‑медведа и олбанского йазыгга. Каждое очередное их появление они встречают фырканьем и угрозами немедленно отписаться.
Что же делать? Конечно, призвать на помощью железную машину — пусть она сама ищет баяны.
С текстом процедура более‑менее освоена. Простенькую машину для полнотекстового поиска можно найти чуть ли не в любой СУБД. Если кому‑то надо посложнее, например, учитывающую морфологию языка, — к вашим услугам Sphinx, Solr и так далее. Даже если ваши запросы простираются настолько далеко, что вы желаете искать не просто дубли, а переделки бородатых анекдотов, в которых Василий Иванович и Петька в духе времени заменены на Дарта Вейдера и Гарри Поттера, к вашим услугам td/idf, косинусы угла между векторами и прочие методы поиска плагиата.
С текстом разобрались. Но что делать с картинками? Ведь это же наверное как‑то можно? Гугл‑то ищет похожие, хоть и паршиво. Яндекс ищет, и даже получше, чем Гугл. Да что там Яндекс — на некоторых развлекательных сайтах вроде Пикабу тоже есть средства дебаянизации.
Да, можно. И не очень сложно, как ни странно, — потому что умные люди уже выполнили за нас самую сложную часть работы, придумав и испытав красивые и остроумные алгоритмы.
Как же искать дубли картинок? Очень просто.
Шаг 1. Для каждой картинки в базе составить ее цифровой отпечаток (fingerprinting) — какую‑то последовательность битов, отражающую ее содержание.
Шаг 2. Создать отпечаток для искомой картинки и сравнить его с теми, что уже лежат в нашей базе.
Вуаля! А дьявол, как водится, обитает уже в деталях.
Делай раз: создаем отпечаток
Здравый смысл подсказывает, что отпечаток не должен быть слишком длинным — чем короче, тем лучше. Его надо ведь хранить в самой базе, а потом еще и сравнивать с остальными. Если он будет размером с само изображение, и то, и другое станет делать затруднительно.
Значим, нам нужна какая‑то хэш‑функция, которая свернет содержимое рисунка в короткую строку битов.
Традиционные хэш‑функции вроде cемейства sha разумеется, отпадают. Они слишком чувствительны — даже если двоичное содержимое двух картинок различается всего на один бит, посчитанные хэши вообще не будут иметь ничего общего (хотя, как ни странно, именно sha1 используется в движке Википедии. Могли бы выдумать и получше).
О криптографических хэшах речи тем более нет. Они точно так же нервно реагируют на лишний бит, только при этом и считать их еще гораздо напряжнее.
Нам же нужно нечто, что для похожих картинок давало бы похожие хэши, да чтобы при этом еще похожесть была с точки зрения человека, а не машины. Не битовые карты были друг на друга похожи, а сама картинка. Тут стул — и там стул, тут солнце — и там оно.
И такие хэши действительно придуманы. Можно, например, с помощью методов машинного обучения распознать, что у нас нарисовано, — допустим, собачка, распознать, какой именно породы, какой расцветки и в какой позе она стоит, и потом закодировать в хэше эти признаки.
Но нам такие изыски точно ни к чему, мы обойдемся кое‑чем попроще. Нам ведь не надо классифицировать нарисованное, нам надо просто найти дубликаты.
Поэтому у нас методика будет такая: изображение обесцвечивается, то есть переводится в 50 64 оттенка серого и сильно уменьшается. Первая операция делает похожими картинки, различающиеся лишь цветами, вторая сильно сокращает объем информации для обработки и убирает второстепенные детали. Затем по получившейся картинке считается хэш.
Можно, например, посчитать средний цвет по всему изображению и выставить для каждого пиксела значение 0 или 1 — темнее или светлее он среднего. Это быстро и легко, но результаты получаются довольно посредственные.
Гораздо лучше использовать дискретное косинусное преобразование, получив в результате так называемый перцептивный хэш (perceptual hash, phash). Можно даже не писать алгоритм самому, phash уже включен в самую популярную библиотеку обработки изображений — ImageMagick.
Другой вариант — разностный хэш (difference hash, dhash). Он дает результаты чуть хуже, чем перцептивный, однако же вполне приемлемые, а считается при этом проще и быстрее. Идея та же самая, но при этом в битах кодируется разница соседних пикселей — положительная она или отрицательная.
Можно, разумеется, выдумать что‑нибудь еще в том же духе, но надо ли?
Делай два: сравниваем хэши
Это совсем легко. Говоря умными словами, используем расстояние Хэмминга, а выражаясь по-простому, считаем, сколько битов в двух хэшах различаются.
Если, к примеру, вы используете MySQL или ее младшую сестру Марию, то это можно сделать с помощью встроенной функции:
SELECT * FROM images WHERE BIT_COUNT(newMem ^ hash) <= 6
newMem тут – dhash (или phash) новой картинки, дубли которой мы хотим найти, hash – соответственно хэш картинки, уже лежащей в базе. Крышка символизирует побитовый XOR, а число 6 получено опытным путем.
Вот для наглядности пример исходной картинки.

А вот различные ее искажения и извращения, с посчитанными для них расстояниями Хэмминга (расстояния приведены для исходных картинок размером 3000х2000, для размещения на сайте я их ужал):








Как видите, хэш (в данном случае — dhash) отлично справляется с небольшими изменениями в исходном изображении — такими, которые берутся от легкого редактирования, конечно, а не от сознательных попыток обмануть алгоритм. Не потянул он только зеркальное переворачивание изображения, но ведь нам никто не мешает взять картинку, вызывающую сомнение, отзеркалить ее и прогнать по базе еще раз.
Если на вашем сайте собираются пользователи, размещающие на нем свои любовно собранные фотографии старых трамваев с бугелями, русских печек, спасательных лодок на пляже, выращенных собственноручно лимонных деревьев и тому подобные захватывающие вещи, — то есть, серьезные, солидные люди, а не подростки, из больного тщеславия возжелавшие сломать систему, то большего, чем dhash, вам и не требуется.
Делай два: сравниваем хэши по-настоящему
Очевидно, что запрос SQL, показанный выше, приведен тут чисто для блезиру. Если вам надо сравнить сто хэшей, он годится, но уже на тысяче, пожалуй, задумается. Почему — понятно: он сравнивает тестовый хэш со всеми остальными по очереди и из‑за вызова функции не может использовать индексы базы.
Положение усугубляется еще и тем, что алгоритм вычисления хэшей слегка недетерминированный и даже для одинаковых картинок может давать чуть различающиеся результаты — всего на один‑два бита, но и этого достаточно, чтобы даже поиск совершенно одинаковых картинок нельзя было провести с помощью простого запроса на равенство.
Да и с индексами тоже все непонятно — нам нужен такой, чтобы показывал расстояние Хэмминга от… От чего? То‑то и оно. Очевидно, тут нужно что‑то хитрое.
Такие индексы, вернее, деревья, в природе существуют. Например, есть такая экзотика, как vp‑tree (vantage point tree), что можно художественно перевести как «дерево с точками удобного наблюдения за другими точками». Понять его принцип несложно — это обычное двоичное дерево, только точки в нем группируются по удалению друг от друга. Не так радостно с построением дерева и поиском по нему — с первого раза врубиться в алгоритм нелегко, но это не самая большая проблема. Куда хуже, что такое дерево строится один раз и при добавлении новых точек или удалении старых его приходится перестраивать чуть ли не целиком. Это означает, что для использования на сайте, где постоянно добавляется новый материал и нередко удаляется старый, оно не очень подходит.
А как с этим справляется Гугл? О, Гугл, а вернее, работавший на него Мозес Чарикар (Moses Charikar), придумал весьма изящную вещь под названием Simhash, которая куда проще запутанных пространственных деревьев. Вот смотрите:
Допустим для конкретики, что наш хэш состоит из 64 битов. Разобьем их на 8 байтов.
Мы хотим найти хэши, отстоящие на расстояние не более 6 битов от проверяемого. Но это означает, что даже если все 6 отличающихся битов находятся в разных байтах хэша, то все равно, как ни крути, какие‑то два байта будут в обоих хэшах полностью совпадать.

А это значит, что мы можем заранее отобрать из базы те хэши, которые совпадают с нашим проверяемым в каких-то двух байтах, и высчитать расстояние только для них. Это прилично сокращает объем работ – раз в 200-300.
Как же это сделать?
Согласно оригинальной идее, нужно завести для хэшей дополнительные таблицы, число которых будет равно числу возможных сочетаний двух байтов из восьми, в нашем случае ![]() = 28. В каждой таблице хранятся одни и те же хэши, но с переставленными байтами. В основной в первом и втором байте – первый и второй байт хэша, в первой дополнительной – первый и третий, во второй – первый и четвертый, и так далее, пока мы не переберем все комбинации. Вот, на случай, если вам лень их считать самим.
= 28. В каждой таблице хранятся одни и те же хэши, но с переставленными байтами. В основной в первом и втором байте – первый и второй байт хэша, в первой дополнительной – первый и третий, во второй – первый и четвертый, и так далее, пока мы не переберем все комбинации. Вот, на случай, если вам лень их считать самим.
{1, 2}, {1, 3}, {1, 4}, {1, 5}, {1, 6}, {1, 7}, {1, 8}, {2, 3}, {2, 4}, {2, 5}, {2, 6}, {2, 7}, {2, 8}, {3, 4}, {3, 5}, {3, 6}, {3, 7}, {3, 8}, {4, 5}, {4, 6}, {4, 7}, {4, 8}, {5, 6}, {5, 7}, {5, 8}, {6, 7}, {6, 8}, {7, 8}
А теперь мы отсортируем эти таблицы по первым двум байтам и сможем воспользоваться двоичным поиском, отобрав с его помощью кандидатов на последующее сравнение!
Впрочем, в этом месте мы можем уклониться от совета уважаемого автора. У нас все-таки не Гугл, а сайт попроще, картинок мы храним гораздо меньше и поэтому нам не требуется изобретать собственные велосипеды с турбонаддувом. У нас ведь уже есть база – мы же где-то держим ссылки и атрибуты наших фотографий. Давайте воспользуемся ею и положим рядом с хэшем в виде двоичной строки этот же хэш, разбитый на байты.
CREATE TABLE images (
name VARCHAR(100) NOT NULL,
hash BIGINT UNSIGNED NOT NULL,
b1 TINYINT UNSIGNED NOT NULL,
...
b8 TINYINT UNSIGNED NOT NULL,
)К каждому байту, естественно, добавим отдельный индекс, а затем станем искать наш хэш вот таким запросом, перебирающим все возможные сочетания двух байтов из восьми:
SELECT name FROM images WHERE (
(b1=newMem_b1 AND b2=newMem_b2) OR
(b1=newMem_b1 AND b3=newMem_b3) OR
...
(b7=newMem_b7 AND b8=newMem_b8)
)
AND BIT_COUNT(newMem ^ hash) <= 6Запрос для человека, конечно, длинноват, но база смотрит на него по‑другому, и оптимизировать его ей не сложно, задействовав индексы по полям b1…b8.
Сочетания 2 по 8, разумеется, не написаны на скрижалях, это всего лишь один из вариантов, хотя и практически удобный. В зависимости от предполагаемого числа хранящихся изображений и расстояния Хэмминга, на котором мы хотим искать, можно разбить хэш на другое количество частей, не обязательно даже одинаковой длины.
Немного практических цифр. На моей старенькой, отпраздновавшей уже десятилетие машине, создание разностного хэша в nodejs занимает примерно полторы секунды, из которых секунда уходит на уменьшение изображения с помощью ImageMagick.
Поиск одного хэша по базе в 30.000 фотографий (больше котиков и фигуристых девушек у меня не нашлось) требует примерно двух секунд, из которых секунда уходит опять же на уменьшение исходного изображения. Это без индексов — я поленился для прототипа их создавать — так что задел для масштабирования поиска имеется. Хватит ли его на миллион‑другой фотографий — вопрос открытый. Если у вас есть столько разных фоточек, было бы интересно узнать ваши впечатления.
Ну и напоследок еще один вопрос. Что делать, если мы хотим найти более удаленные в смысле Хэмминга фотографии — различающиеся не на 6 битов, а на 20 или 30? Отвечаю: это уже совсем иная задача — если по‑английски, то не near‑duplicate search, а similarity detection, и совсем другая история, для которой описанные методы не подходят и надо придумывать что‑то еще.
