Алгоритмы для поиска палиндромов
Время на прочтение
13 мин
Количество просмотров 144K

Сегодня я хочу вам рассказать об алгоритмах подсчёта количества палиндромов в строке: для чего это нужно, где применяется, как это быстро сделать, какие подводные камни нас ожидают и многое другое. Рассмотрим различные способы для решения данной задачи, выясним плюсы и минусы каждого способа. Эта статья будет обзорной: если я что-то не описываю здесь, то постараюсь всегда дать вам набор ссылок, где всё подробно описано и расписано. Надеюсь, что материал будет интересен как новичкам в сфере алгоритмов, так и матёрым программистам. Что же, если я смог заинтересовать вас, то прошу под кат!
Для начала стоит вспомнить, что же такое палиндром.
Палиндро́м — число (например, 404), буквосочетание, слово или текст, одинаково читающееся в обоих направлениях. Иногда палиндромом называют любой симметричный относительно своей середины набор символов.(выдержка из Википедии)
Определение очень лёгкое и понятное. Мы в данном посте будем рассматривать палиндромы-слова(поп, кок и т.д.). Но это не значит, что алгоритмы неприменимы для иных ситуаций. Просто чуть сузим область.
Для чего может потребоваться искать палиндромы?
На самом деле, не очень то и часто приходится искать палиндромы в повседневной жизни. Уж больно специфичная это задача. Если говорить о строковых алгоритмах, то мы намного чаще встречаем тот же поиск подстроки в строке, чем нахождение количества палиндромов. Поэтому и освещение в литературе намного слабее.
Одно из основных применений — спортивное/олимпиадное программирование. Там задач на такое хватает. Задач понаписывают, а участникам уже думай, каким способом это решить. Из личного опыта скажу, что мне такие задачи встречались всего пару раз, но все они были из разряда «вот тебе задача, ты не думай, а просто напиши алгоритм». То есть не интересные задачи, которые развивают просто механическую память по набиванию алгоритмов.
А более практическое применение нахождения палиндромов — это биологические алгоритмы. Согласно всё той же Википедии и ссылкам снизу Вики, палиндромность биологических соединений играет важную роль на свойствах различных биологических соединений. Я в биологии слаб, поэтому если вам интересно, то вы можете найти более подробную информацию сами.
Отлично, мы выяснили, что мы будем заниматься не совсем бесполезными делами. Давайте же уже перейдем к рассмотрению алгоритмов!
Замечание: во всех нижеприведённых алгоритмах одиночный символ не считается за палиндром. Как вы понимаете, это легко поправить, если одиночные символы тоже нужно будет учесть.
0) Самый банальный алгоритм с асимптотикой O(N^3)
bool SlowN3::isPalindrom(int leftBorder, int rightBorder)
{
while(leftBorder <= rightBorder)
{
if(str[leftBorder] != str[rightBorder])
{
return false;
}
++leftBorder;
--rightBorder;
}
return true;
}
long long SlowN3::operator ()()
{
for(int leftBorder = 0;leftBorder < str.length(); ++leftBorder)
{
for(int rightBorder = leftBorder + 1; rightBorder < str.length(); ++rightBorder)
{
if( isPalindrom(leftBorder, rightBorder) )
{
++cntPalindromes;
}
}
}
return cntPalindromes;
}
Хочу предупредить сразу, что все исходники будут на C++, и это будут значимые части классов, которые нам могут быть интересны.
Алгоритм самый что ни на есть «лоб»: имеется строка, есть указатель на начало подстроки данной строки, есть указатель на конец данной подстроки. В двух вложенных циклах перебираем границы подстрок и банально проверяем, является ли наша подстрока палиндромом. Ничего сложного.
Но это всё ужасно медленно работает. Почему? Да потому что мы квадрат от N раз (N у нас будет всегда длина строки) перебираем границы текущей подстроки, а потом ещё и за O(N) в худшем случае выполняем проверку для каждой подстроки на палиндромность.
Плюсов у данного способа немного:
+ Легко реализуется. Действительно, оставить багу здесь ну очень сложно.
+ Легко читается. Вы только взглянули, и уже поняли, что да как здесь работает.
+ Малая скрытая константа. Как известно, на время работы алгоритма влияет не только асимптотическая оценка (здесь мы работаем только с худшими случаями), но и скрытая константа. У этого алгоритма скрытая константа крайне мала.
Минусы:
— Крайне малая скорость работы. Как вы можете видеть, что при строке из тысячи букв ‘a’ данный алгоритм сделает порядка 10^9 итераций, что есть очень плохо. А что если строка длиной 100000?
1) Самый банальный алгоритм с асимптотикой O(N^2)
Код:
void SlowN2::oddCount()
{
for(int indMiddle = 0; indMiddle < str.length(); ++indMiddle)
{
int leftBorder = indMiddle - 1, rightBorder = indMiddle + 1;
while(leftBorder >= 0 && rightBorder < str.length() && str[leftBorder] == str[rightBorder])
{
++cntPalindromes;
--leftBorder;
++rightBorder;
}
}
}
void SlowN2::evenCount()
{
for(int indMiddle = 0; indMiddle < str.length(); ++indMiddle)
{
int leftBorder = indMiddle, rightBorder = indMiddle + 1;
while(leftBorder >= 0 && rightBorder < str.length() && str[leftBorder] == str[rightBorder])
{
++cntPalindromes;
--leftBorder;
++rightBorder;
}
}
}
Здесь уже чуточку интереснее. У нас имеется строка, и два временных массива для палиндромов чётной и нечётной длины. А число в ячейке i массива будет хранить количество палиндромов в строке s(исходная строка) с центром в точке i. Для нечётной длины палиндрома центр находится легко, ну а для чётной мы просто чуть поиграемся с индексами и сместим чуточку центр(что видно в коде). Наш результат это есть сумма чисел из двух массивов.
Как видите, снова ничего сложного. Но работает это заметно быстрее предыдущего алгоритма. Почему? Давайте рассмотрим, как же оно всё работает.
Мы бежим по строке, перебирая центральный символ нашего потенциального палиндрома. А потом просто бежим влево и вправо от центрального элемента до тех пор, пока символы одинаковы. Как только они стали разными, это значит, что дальше не будет палиндромов с центром в нашем выбранном элементе, и переходим к следующему.
А работает это быстро на обычных строках очень быстро потому, что наш второй, вложенный цикл, который бежит до тех пор, пока крайние символы равны, обрывается крайне быстро(если предположить, что палиндромов в строке много меньше общего числа подстрок).
Рассмотрим плюсы и минусы способа.
Плюсы:
+ Всё также легко кодится. Ошибиться очень сложно.
+ Малая скрытая константа
+ Хорошо ведёт себя на случайных строках
Минусы:
— Всё ещё долгое время работы
После этого способа уже голова начинает думать-думать-думать. И тут идея! А что если мы модифицируем этот способ, только будем от центрального элемента прыгать не на 1 символ с каждой итерацией, а на чуточку больше? И тут нам на помощь приходят…
2) Используем хеши!
Этот способ чуточку сложнее, поэтому сразу приведу код, а потом постараюсь обьяснить, что за магия там творится(хотя магии нет, как вы сами прекрасно знаете):
inline long long Hash::getHash(int indLeft, int indRight) const
{
return prefixHash[indRight] - (indLeft > 0 ? prefixHash[indLeft - 1] : 0);
}
inline long long Hash::getRevHash(int indLeft, int indRight) const
{
return suffixHash[indLeft] - (indRight < suffixHash.size() - 1 ? suffixHash[indRight + 1] : 0);
}
void Hash::PrepareSimpleNumbers()
{
if(str.length() > simpleNumbers.size())
{
size_t oldSize = simpleNumbers.size();
simpleNumbers.resize(str.length());
simpleNumbers[0] = 1LL;
for(int i = oldSize; i < simpleNumbers.size(); ++i)
simpleNumbers[i] = simpleNumbers[i - 1] * SimpleBase;
}
}
void Hash::CountingPrefixHash()
{
prefixHash[0] = str[0];
for(int i = 1; i < prefixHash.size(); ++i)
{
prefixHash[i] = prefixHash[i - 1] + str[i] * simpleNumbers[i];
}
}
void Hash::CountingSuffixHash()
{
suffixHash[suffixHash.size() - 1] = str[str.length() - 1];
for(int i = (int) str.length() - 2, j = 1; i >= 0; --i, ++j)
{
suffixHash[i] = suffixHash[i + 1] + str[i] * simpleNumbers[j];
}
}
bool Hash::isPalindrome(int indLeft, int indRight) const
{
return getHash(indLeft, indRight) * simpleNumbers[prefixHash.size() - indRight - 1] ==
getRevHash(indLeft, indRight) * simpleNumbers[indLeft];
}
void Hash::CountingOdd()
{
for (int i = 0; i < oddCount.size(); i++)
{
int indLeft = 1, indRight = min(i + 1, static_cast<int> (oddCount.size() - i));
while (indLeft <= indRight)
{
int middle = (indLeft + indRight) / 2;
if (isPalindrome(i - middle + 1, i + middle - 1))
{
oddCount[i] = middle - 1;
indLeft = middle + 1;
}
else
{
indRight = middle - 1;
}
}
}
}
void Hash::CountingEven()
{
for (int i = 0; i < evenCount.size(); i++)
{
int indLeft = 1, indRight = min(i, static_cast<int> (evenCount.size() - i));
while (indLeft <= indRight)
{
int middle = (indLeft + indRight) / 2;
if (isPalindrome(i - middle, i + middle - 1))
{
evenCount[i] = middle;
indLeft = middle + 1;
}
else
{
indRight = middle - 1;
}
}
}
}
long long Hash::operator()()
{
PrepareSimpleNumbers();
CountingPrefixHash();
CountingSuffixHash();
CountingOdd();
CountingEven();
for(int i = 0; i < str.length(); ++i)
{
cntPalindromes += oddCount[i] + evenCount[i];
}
return cntPalindromes;
}
Краткая суть данного способа: мы перебираем центральный элемент нашего палиндрома, и потом дихотомией стараемся найти наибольший радиус нашего палиндрома (под радиусом здесь понимается расстояние от центрального элемента до крайнего, если у нас палиндром чётной длины, то просто добавим чуточку игры с индексами, чтобы всё работало). Во время подбора мы должны как-то быстро сравнивать подстроки на идентичность. делаем это с помощью хешей. Асимптотика, как легко догадаться: N тратим на перебор центрального элемента, logN в худшем случае тратим на подбор радиуса палиндрома, за единицу сравниваем подстроки с помощью хешей. Итого имеем O(NlogN), что очень даже неплохо на самом деле.
Теперь чуть подробнее остановимся на данном методе.
На чём основывается наш метод? Так как мы перебираем центральный элемент, а потом дихотомией подбираем радиус наибольшего палиндрома с центром в данном элементе, то мы должны быстро брать хеш левой части нашего потенциального палиндрома и сравнивать его с хешем правой части нашего потенциального палиндрома.
Как это сделать? Давайте предварительно рассчитаем хеш для каждого префикса и суффикса исходной строки. В коде это у нас делают методы CountingPrefixHash() и CountingSuffixHash() соответственно.
С помощью методов getHash() и getRevHash() мы можем быстро получить хеши левой и правой частей рассматриваемого на данном этапе потенциального палиндрома. Тут может возникнуть вопрос, почему нельзя воспользоваться одной и той же функцией подсчёта хеша для левой и правой частей. А всё потому, что мы при проверке на палиндромность левую часть мы читаем слева направо, а вторую справа налево. И нам необходимо поддерживать хеш слева направо и справа налево.
Осталась единственная сложность: как сравнить этих 2 хеша? И эту проблему мы решаем с помощью метода isPalindrome(), который приводит хеши к одному основанию и сравнивает их.
Результатом каждой итерации у нас будет количество палиндромов с центром i. Пробегаемся 2 раза для палиндромов чётной и нечётной длины, ответ на нашу задачу есть сумма всех значений массивов oddCount и evenCount
Более подробно про данный метод вы можете почитать в этой статье.
Плюсы:
+ Асимптотически мы снизили до NlogN, что не может не радовать. Если брать только худшие случаи, то в теории когда-нибудь мы выиграем
Минусы:
— Довольно тяжело пишется. Легко посеять багу. Нужна немного теоретическая подготовка в области хешей.
— Медленно работает на случайных тестах. Вы можете сами в этом убедиться. А всё из-за большой скрытой константы и из-за того, что даже если у нас нет ни одного палиндрома с центром в данном элементе, то алгоритм сделает logN прыжков, а это всё занимает время.
— Коллизии. Как вы видите, в моём исходнике используется хеш, который обычно пишут на олимпиадах по программированию(да-да, я немного этим когда-то занимался). Так вот, на соревнованиях данный способ показывает себя хорошо. Лично у меня коллизии не случались. Но я знаю про способы спокойно данный хеш завалить(в частности способ с использованием строк Туэ-Морса). Я когда-то слышал, что есть какой-то фиббоначиевый хеш, который вроде бы не ломается на данном тесте, но информация недостоверная. Так что будьте осторожны с коллизиями.
А если мы хотим 100% решение без всякой там коллизийной поправки и ввода хеша по другому основанию и так далее?
3) Алгоритм Манакера
Код:
//Find palindroms like 2*N+1
void Manacker::PalN2()
{
int leftBorder = 0, rightBorder = -1, tempMirror;//start digits for algortihm
for(int i = 0; i < str.length(); ++i)
{
tempMirror = (i > rightBorder ? 0 : std::min(ansPalN2[leftBorder + rightBorder - i],
rightBorder - i)) + 1;//find mirror of current index
while(i + tempMirror < str.length() && i - tempMirror >= 0 &&
str[i - tempMirror] == str[i + tempMirror])//increase our index
{
++tempMirror;
}
ansPalN2[i] = --tempMirror;
if(i + tempMirror > rightBorder)//try to increase our right border of palindrom
{
leftBorder = i - tempMirror;
rightBorder = i + tempMirror;
}
}
}
void Manacker::Pal2()
{
int leftBorder = 0, rightBorder = -1, tempMirror;
for(int i = 0; i < str.length(); ++i)
{
tempMirror = (i > rightBorder ? 0 : std::min(ansPal2[leftBorder + rightBorder - i + 1],
rightBorder - i + 1)) + 1;
while(i + tempMirror - 1 < str.length() &&
i - tempMirror >= 0 && str[i - tempMirror] == str[i + tempMirror - 1])
{
++tempMirror;
}
ansPal2[i] = --tempMirror;
if(i + tempMirror - 1 > rightBorder)
{
leftBorder = i - tempMirror;
rightBorder = i + tempMirror - 1;
}
}
}
Итак, мы получили с помощью хешей алгоритм за NlogN. Но хочется быстрее. Хочется чего-то линейного. И тут нам на помощь спешит Алгоритм Манакера (по ссылке вы также можете видеть реализацию алгоритма на Java), который мало того, что линеен, так ещё и обладает крайне малой скрытой константой, что положительно сказывается на его скорости работы. Подробно описывать способ я не буду, так как это получится пересказ этой замечательной ссылки (я сам учил алгоритм именно по этой ссылке). Здесь я приведу слегка пересказанное объяснение.
Алгоритм заключается в том, что мы обрабатываем строку символ за символом, поддерживая самый правый палиндром в нашей строке. И на каждой итерации смотрим, наш текущий элемент находится внутри границ самого правого палиндрома или нет. Если находится, то мы можем извлечь ответ из ранее посчитанных значений, путём нехитрых манипуляций с индексами. Если же не находится, то мы идём точно таким же алгоритмом, который описан в пункте 1) этого обзора: идём символ за символом и сравниваем зеркальные элементы относительно центра. Идём до тех пор, пока они равны. И не забываем обновить после этого границы самого правого найденного палиндрома. Это вкратце. Про некоторые подводные камни вы можете почитать в приведённой статье.
Что ещё интересного: во всех задачах, которые я решал на контестах (по олимпиадному программированию), хватало именно этого алгоритма. Очень просто пишется, если ты его писал N раз дома и уже знаешь наизусть.
Плюсы:
+ Довольно короткий код.
+ Очень быстро работает. Мало того, что асимптотика O(N), так ещё и малая скрытая константа.
Минусы:
— Идея не такая простая, чтобы самому сходу придумать данный алгоритм
— Можно запутаться во всяких индексах, если проявить невнимательность при написании кода
А есть ли другие способы решить данную задачу за линейное время?
4) Дерево палиндромов
Немного предыстории. Эту относительно новую структуру данных открыл Михаил Рубинчик rumi13 и представил её на Петрозаводских сборах. Структура крайне интересная своей с одной стороны простотой, а с другой тем, что позволяет быстро решать довольно широкий спектр задачи про палиндромы. И самое главное — позволяет довольно просто считать количество палиндромов в строке за O(N) (но само дерево палиндромов думаю придумывалось далеко не для этого, а для более серьёзных задач с палиндромами).
Код:
PalindromicTree::PalindromicTree(const std::string& s) : FindPalindrome(s)
{
initTree();
}
PalindromicTree::~PalindromicTree()
{
for(int i = 0;i < pullWorkNodes.size(); ++i)
{
delete pullWorkNodes[i];
}
}
void PalindromicTree::initTree()
{
root1 = new Node;
root1->len = -1;
root1->sufflink = root1;
root2 = new Node;
root2->len = 0;
root2->sufflink = root1;
suff = root2;
pullWorkNodes.push_back(root1);
pullWorkNodes.push_back(root2);
}
void PalindromicTree::findAddSuffix(Node* &cur, int pos, int& curlen)
{
while (true)
{
curlen = cur->len;
if (pos - 1 - curlen >= 0 && str[pos - 1 - curlen] == str[pos])
{
break;
}
cur = cur->sufflink;
}
}
void PalindromicTree::makeSuffixLink(Node* &cur, int pos, int& curlen,int let)
{
while (true)
{
cur = cur->sufflink;
curlen = cur->len;
if (pos - 1 - curlen >= 0 && str[pos - 1 - curlen] == str[pos])
{
suff->sufflink = cur->next[let];
break;
}
}
}
void PalindromicTree::addLetter(int pos)
{
Node* cur = suff;
int let = str[pos] - 'a', curlen = 0;
findAddSuffix(cur, pos, curlen);
if (cur->next[let] != nullptr)
{
suff = cur->next[let];
return;
}
suff = new Node;
pullWorkNodes.push_back(suff);
suff->len = cur->len + 2;
cur->next[let] = suff;
if (suff->len == 1)
{
suff->sufflink = root2;
suff->num = 1;
return;
}
makeSuffixLink(cur, pos, curlen, let);
suff->num = 1 + suff->sufflink->num;
}
long long PalindromicTree::operator ()()
{
for (int i = 0; i < str.length(); ++i)
{
addLetter(i);
cntPalindromes += suff->num - 1;
}
return cntPalindromes;
}
Опять же, перескажу вкратце суть данного алгоритма. С более подробным разъяснением вы можете ознакомиться в этой замечательной статье.
Итак, идея дерева. В вершинах нашего дерева будут находиться только сами палиндромы: ‘a’, ‘b’, ‘aba’ и так далее. Понятно, что сам палиндромы мы не будем хранить, а просто будем хранить из какой вершины мы пришли сюда, и какой символ с двух сторон добавили. Также у нас существуют две фиктивные вершины для удобной реализации алгоритма.
Но как и в любом интересном дереве, у нас также существуют суффиксные ссылки. Суффиксная ссылка будет вести в вершину, которая также является палиндромом (ну потому что у нас в вершинах хранятся только палиндромы) и которая является наибольшим собственным суффиксом данной вершины. То есть из вершины ‘aba’ ссылка будет вести в вершину ‘a’.
Далее, мы по очереди добавляем символы в дерево по одному. И благодаря хитрому устройству дерева и рекурсивной операции добавления (а также суффиксным ссылкам, по которым осуществляется переход), мы обновляем всё дерево.
Это вкратце, подробнее почитайте информацию по ссылке выше (если не боитесь английского)
Плюсы:
+ Если Вы ранее работали с деревьями, то вам будет очень просто понять данную идею.
+ Позволяет решать большой спектр задач на палиндромы
Минусы:
— Работает медленнее, чем алгоритм Манакера.
— Можно поставить багу. Но, чисто субъективно, тут это сделать сложнее, чем в том же алгоритме Манакера.
Также стоит упомянуть, что с помощью деревьев существует ещё одно решение данной задачи. Оно заключается в использовании суффиксного дерева и быстрого алгоритма LCA(который работает за препроцессинг O(N) и ответ на запрос O(1). Алгоритм Фарах-Колтон-Бендера). Но он на практике не применяется, так как довольно сложен и у него крайне большая скрытая константа. Представляет скорее академический интерес.
Что может быть ещё интересно про алгоритмы? Правильно, потребление памяти и время работы.
На гитхабе Вы можете скачать также код для тестирования, который генерирует случайные строки и ищет в них палиндромы.
Моё тестирование показало, что ожидаемо алгоритм номер 0 работает крайне медленно. Лидером, как Вы можете догадаться, является алгоритм Манакера. Но что самое интересное: алгоритм с O(N^2) выигрывает с примерно двукратным отрывом у алгоритма с использованием хешей с O(NlogN), что ещё раз доказывает, что не асимптотикой единой меряются алгоритмы. Так происходит из-за особенностей отсечения алгоритма номер 1, и отсутствия оной в способе с хешами. Что касается дерева палиндромов, то оно проигрывает Манакеру в основном из-за операций с памятью, так как приходится выделять память под каждую новую вершину. Но если использовать, например, new с размещением, то разрыв сократится.
Память все алгоритмы потребляют линейно от размера входных данных.
На этом мы завершим наш обзор. Надеюсь, что вы почерпнули для себя хоть что-то новое и вам было хоть чуточку интересно! Все исходники вы можете найти в моём публичном репозитории на Github.
P.S.: Если вы заметили какие-то опечатки, неточности или у вас есть дополнения — прошу отписываться в комментариях и писать в ЛС.
P.P.S.: Смело задавайте вопросы в комментариях — постараюсь ответить, если хватит моей компетенции.
Полезные ссылки, которые могут быть вам интересны после прочтения данной статьи (некоторые ссылки могут повторяться, так как могли проскакивать в самой статье):
0) Что такое палиндром
1) Алгоритм Манакера: Вики, Codeforces, e-maxx
2) Немного про хеши и их применение: e-maxx, Habrahabr
3) Обсуждение про завал хешей на Codeforces: тыц
4) Строки (слова) Туэ-Морса: раз, два
5) Статьи про дерево палиндромов: хорошее описание, codeforces
6) Вот ещё цикл статей про поиск чисел-палиндромов: Хабр
|
0 / 0 / 0 Регистрация: 30.11.2010 Сообщений: 3 |
|
|
1 |
|
Определить палиндром30.11.2010, 06:06. Показов 22743. Ответов 5
Задачка 1-го курса, простенькая, но почему-то мозги не выдают никаких идей… Звучит так: Определить, является ли заданное натуральное число палиндромом (т.е. число одинаковое слева направо и наоборот, например 12321). Конкретно меня интересует именно сам процесс нахождения, потому что я не знаю другого способа сравнения цифр числа, кроме как деления его на 10, а остаток сохраняя в новую переменную. Этот метод не канает, потому что число цифр заведомо неизвестно. Благодарю за внимание)
0 |

|
Programming Эксперт 94731 / 64177 / 26122 Регистрация: 12.04.2006 Сообщений: 116,782 |
30.11.2010, 06:06 |
|
Ответы с готовыми решениями: Определить строки в файле, содержащие максимальную по длине подстроку-палиндром
Определить минимальное количество символов, которые нужно добавить в строку, чтобы получить палиндром
Дан одномерный целочисленный массив…. 5 |
") Определить минимальное количество символов, которые нужно добавить в строку, чтобы получить палиндром
Определить минимальное количество символов, которые нужно добавить в строку, чтобы получить палиндром|
dihlofos Бродяга 314 / 268 / 56 Регистрация: 27.08.2010 Сообщений: 553 |
||||||||
|
30.11.2010, 06:32 |
2 |
|||||||
|
Можно, например, перевернуть число и сравнить с исходным.
Кстати если нужно найти количество цифр, можно делить число на 10, до тех пор, пока оно не станет равным нулю.
2 |
|
0 / 0 / 0 Регистрация: 30.11.2010 Сообщений: 3 |
|
|
30.11.2010, 06:47 [ТС] |
3 |
|
Ох, сколько пока неизвестных функций и манипуляций) Спасибо большое) Сейчас буду разбираться…
0 |
|
Erik1556 0 / 0 / 1 Регистрация: 19.07.2017 Сообщений: 5 |
||||
|
06.12.2017, 22:02 |
4 |
|||
0 |
|
повар1 783 / 590 / 317 Регистрация: 24.02.2017 Сообщений: 2,087 |
||||
|
06.12.2017, 22:14 |
5 |
|||
0 |
|
MusicManiac 5 / 5 / 6 Регистрация: 02.03.2016 Сообщений: 29 Записей в блоге: 3 |
||||
|
07.12.2017, 01:06 |
6 |
|||
|
Вот кусочек моего кода, по сути вырезанного из одной записи в блоге, но суть будет понятна: Проверяет являеться ли введеное число палиндромом в 5 строк
Взял тут – https://www.cyberforum.ru/blog… g5015.html Добавлено через 2 минуты Я даже как-то не посмотрел, что тема 2010 года
0 |


Палиндром
В данной статье решается задача по реализации программы(кода) на C++ для проверки, является ли слово, строка или число палиндромом. Программа должна просить ввести строку( не важно слово это или число), проверять, является ли она палиндромом и возвращать результат.
Что такое палиндром?
Палиндром — это строка(или число), которое можно прочитать одинаково справа налево, либо слева направо.
К примеру, слово «кот» не является палиндромом, а слово «потоп» является палиндромом. Также и с числами: число 12314 — не палиндром, число 345543 — палиндром.
Поняв это, можно начинать реализовывать алгоритм программы.
Для определения, является ли строка палиндромом, напишем функцию, которая примет на вход строку(объект string), а на выходе вернет логическое значение(тип данных bool). Строка будет содержать слово или число, которое функция проверит на палиндромность. Выходное значение true будет соответствовать тому, что строка является палиндромом, false будет соответствовать тому, что строка НЕ является палиндромом.
Обратите внимание, что строка — это, по сути своей, обычный одномерый массив.
Поэтому функция будет просто сравнивать первый и последний элемент массива, после сравнит второй и предпоследний элемент и так далее до середины. Если все они равны, значит строка является палиндромом. Ничего сложного.
Реализуем это в виде кода.
Для начала необходимо определить, сколько символов в строке, для этого воспользуемся методом length().
int len = word.length();
word — это строка, которую приняла функция. Теперь переменная len хранит значение длины строки.
После чего создадим цикл от 0 до len/2 и будем сравнивать элементы.
for(int i = 0; i < len/2; ++i)
{
if(word[i] != word[len-i-1])
{
return false;
}
}
Обратите внимание, в цикле есть условие. Если i-ый элемент не равен элементу len-i-1, то сразу возвращается false(То есть не палиндром).
Почему len-i-1?
Массивы в C++ нумеруются от 0, поэтому чтобы получить первый элемент строки, нам нужно достать 0-ой элемент из массива, а чтобы последний, то нам нужно достать len-1.
Как работает функция проверки на палиндром
Допустим, у нас слово «мотор», то len будет равна 5.
|м о т о р|
|0 1 2 3 4|
Чтобы получить значение последней буквы, необходимо обратиться к массиву строки с индексом len-1 = 4. А чтобы получить значение первой буквы — обращаемся к элементу 0.
Для наглядности немного визуализируем работу функции:
1.Получаем слово «комок».
2.Запускаем цикл.
3. комок
Сравниваем к и к, они равны, идем дальше.
4. комок
Сравниваем о и о, они равны. Далее цикл останавливается, т.к. запущен до len/2, а это 5/2 = 2. В C++ результатом целочисленного деления является целое число с отброшенной дробной частью.
5. В конце функции возвращается true. Что означает, что слово палиндром.
Если бы во время сравнений букв получилось так, что они НЕ равны, то функция сразу бы завершила работу и вернула значение false. Что означает, что слово не палиндром.
Используем нашу функцию проверки на палиндром в программе на C++
Теперь нашу функцию можно вставить в программу на C++ и использовать. Напишем небольшое приложение, которое просит пользователя ввести слово(или число) в консоль, а после этого сообщает ему, является ли введенное слово палиндромом.
Код нашего приложения — это и есть решение задачи «Проверить, является ли слово палиндромом на C++»
Код программы на C++:
#include <iostream>
#include <cstring>
using namespace std;
bool check_polindrom(string word)
{
int len = word.length();
for(int i = 0; i < len/2; ++i)
{
if(word[i] != word[len-i-1])
{
return false;
}
}
return true;
}
int main()
{
string str;
cout << "Enter the word: ";
cin >> str;
if(check_polindrom(str))
{
cout << "Word is polindrom.";
}
else
{
cout << "Word is not polindrom";
}
return 0;
}
Теперь компилируем, запускаем и проверяем.
Проверим словом «palindrom»

palindrom — не палиндром
Программа сообщила, что слово не является палиндромом, а это так и есть на самом деле.
Проверим выдуманным словом палиндромом «potomotop»

potomotop — палиндром
Программа сообщила, что введенное слово палиндром. Всё верно.
Вот таким алгоритмом можно проверить является ли слово палиндромом. Данная программа работает не только со словами, но и с числами. Не требует сторонних библиотек. Решения других задач по программированию на языке C++ можно найти в этом разделе.
Создадим программу на Windows Forms которая поможет нам определить, является ли палиндромом введённый текст, слово или число.
Создадим простенький дизайн:
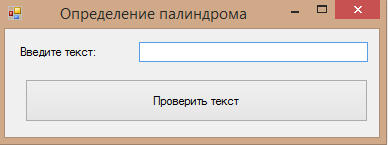
Здесь у нас TextBox, Label и Button. Вердикт о принадлежности или непринадлежности данных к палиндрому мы выведен в MessageBox’е.
Дважды щёлкаем на кнопку «Проверить текст» и переносимся в область кода, где будем творить.
|
string text = textBox1.Text; char[] obrtext = text.ToCharArray(); |
Для начала мы считываем строку, которую введёт пользователь и записываем её в переменную text. Затем мы создаём массив символов с типом char, чтобы по одному символу считать нашу строку. Благодаря этому мы в последствии перевернём введённый текст по символу в обратный порядок. Конвертируем текст из строкового формата в символьный массив благодаря .ToCharArray.
Теперь мы переворачиваем символы введённых данных в обратном порядке благодаря следующему методу:
Иначе говоря, если пользователь ввёл в TextBox строку «12345», то данный метод позволяет по символам перевернуть его до «54321».
Пока что наша переменная записана в виде массива символов. Но сравнивать мы будем не символы, а строки. Поэтому мы объявим строку с инициализацией символами из нашего массива.
|
string finaltext = new string(obrtext); |
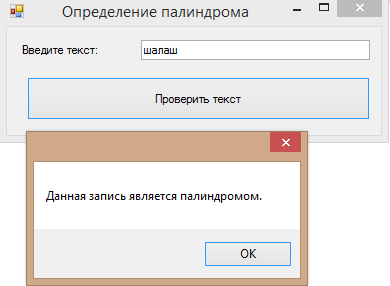
Теперь нам осталось лишь сравнить изначально введённую строку текста со строкой текста, которую мы перевернули. Если они равны, то введённые данные — палиндром.
|
if(text==finaltext) { MessageBox.Show(“Данная запись является палиндромом”); } if (text!=finaltext) { MessageBox.Show(“Данная запись не является палиндромом”); } |
Вот и всё, наша программа готова!
Скачать исходник
Продолжаем разбирать задачки с сайта Leetcode. В прошлый раз было про массив и сумму чисел, теперь тоже необычное.
Условия
В переменной X лежит какое-то целое число
Задача — проверить, является ли это число палиндромом.
Задача со звёздочкой — проверить на наличие палиндрома, не используя строки.
Палиндром — это когда строка или число одинаково читается в прямом и обратном направлении:
121 — это палиндром.
А роза упала на лапу Азора — тоже палиндром (если не считать заглавных букв).
12321 — и это палиндром.
Решение, где используем строки
Самый простой способ проверить, число в переменной палиндром или нет, — преобразовать его в строку, выставить знаки задом наперёд и сравнить с оригиналом. Этим мы сразу решаем проблему отрицательных чисел, когда «−121»превращается в «121−» и сразу становится ясно, что это не палиндром.
Сначала решим это на Python. Тут вообще суть в одной строке:
X = 121
if str(X) == str(X)[::-1]:
print("Это палиндром")
else:
print("Это не палиндром")Здесь мы использовали трюк с переворачиванием строки без её изменения — применили конструкцию [::-1]. Работает это так:
- Первым параметром указывают начало, откуда начинать обработку строки. Раз ничего не указано, то начинаем с первого символа.
- Второй параметр — на каком по счёту символе надо остановиться. Здесь тоже ничего нет, поэтому алгоритм пройдёт до конца строки.
- Последний параметр — шаг и направление обработки. У нас указана минус единица, значит, алгоритм обработает строку справа налево, на каждом шаге считывая по символу.
- В итоге этот код вернёт нам строку, собранную в обратном порядке, при этом с оригинальной строкой ничего не случится — она останется неизменной.
Мы уже делали похожие штуки, когда писали свой генератор новых слов, но там было одно двоеточие, а здесь два.
Теперь решим это же, но на JavaScript:
var X = 121;
if (X.toString().split("").reverse().join("") == X.toString()) {
console.log("Это палиндром")
} else {
console.log("Это не палиндром")
}Здесь мы использовали другой метод пересборки:
- X.toString() — переводит число в строку.
- split(“”) — разбивает строку на массив из символов. В кавычках принцип разделения — если бы там была точка, то разделили бы на местах точек. А так как там пустота, то делится вообще по каждому из символов.
- reverse() — меняет элементы в массиве в обратном порядке.
- join(“”) — добавляет результат к пустой строке, чтобы на выходе получить строку в обратном порядке.
Решение без строк
Тем, кто справился с первой частью, предлагают задачу со звёздочкой — сделать то же самое, но не используя строки, а работая только с числами. Попробуем и мы.
Сделаем в JavaScript функцию, которая будет возвращать true, если в переменной лежит палиндром, и false — если нет. Всё остальное будем писать внутри этой функции:
function palindrome(x) {
}
Теперь обработаем три стандартные ситуации:
- Если в переменной лежит ноль, то это палиндром.
- Если переменная меньше ноля, то это не палиндром.
- Если переменная делится на 10 без остатка — это тоже не палиндром.
Запишем это на JavaScript:
function palindrome(x) {
// если перед нами ноль — это палиндром
if(x == 0) {
return true;
}
// если число меньше нуля или делится на 10 без остатка — это не палиндром
if(x < 0 || x%10 == 0){
return false;
}
}Чтобы проверить, является ли число палиндромом или нет, можно сделать так: отрезаем от числа цифры справа по одной, добавляем их в начало нового числа и постоянно сравниваем новое и старое значение. Если они станут равны — перед нами палиндром. Читайте комментарии, чтобы вникнуть в то, что происходит в коде:
function palindrome(x) {
// если перед нами ноль — это палиндром
if(x == 0) {
return true;
}
// если число меньше нуля или делится на 10 без остатка — это не палиндром
if(x < 0 || x%10 == 0){
return false;
}
// сюда будем собирать число в обратном порядке
temp = 0;
// а тут будем хранить промежуточные значения икса
preX = x;
// пока не дойдём до середины числа — повторяем цикл
while (x > temp) {
// берём самую правую цифру в числе — это остаток от деления на 10
pop = x%10;
// запоминаем старое значение переменной X
preX = x;
// и отрезаем от переменной последнюю цифру — делаем это через целую часть деления на 10
x /= 10;
// добавляем отрезанную цифру к обратной переменной
temp = temp*10 + pop;
}
// если обратная переменная совпала с оставшейся половиной исходной переменной — это палиндром
// мы добавляем сравнение с предыдущей версией исходной половины (которая на 1 цифру больше) на тот случай, если исходное число состояло из нечётного количества символов и его нельзя было бы разбить строго пополам
if(x == temp || preX == temp)
return true;
//
else
return false;
};Для запуска кода просто вызываем функцию и передаём её нашу переменную:
// запускаем код
var X = 121;
console.log(palindrome(X));
Чтобы попрактиковаться, попробуйте сделать такое же, но на Python и не подглядывая в наш код.
Вёрстка:
Кирилл Климентьев
Интервью
Катерина Маковеева
