
Содержание
- Формулы
- Другие частоты
- Как получить абсолютную частоту?
- Табулирование
- Расширенная частотная таблица
- Распределение частоты
- Распределение частот для сгруппированных данных
- пример
- Упражнение решено
- Решение
- Ссылки
В Абсолютная частота Он определяется как количество раз, когда одни и те же данные повторяются в наборе наблюдений числовой переменной. Сумма всех абсолютных частот эквивалентна суммированию данных.
Когда у вас есть много значений статистической переменной, их удобно организовать соответствующим образом, чтобы извлечь информацию о ее поведении. Такую информацию дают меры центральной тенденции и меры рассеивания.
В расчетах этих показателей данные представлены через частоту, с которой они появляются во всех наблюдениях.
В следующем примере показано, насколько раскрывается абсолютная частота каждой части данных. В первой половине мая это были самые продаваемые размеры коктейльных платьев из известного магазина женской одежды:
8; 10; 8; 4; 6; 10; 12; 14; 12; 16; 8; 10; 10; 12; 6; 6; 4; 8; 12; 12; 14; 16; 18; 12; 14; 6; 4; 10; 10; 18
Сколько платьев продается определенного размера, например размера 10? Владельцам интересно знать его на заказ.
Сортировка данных упрощает подсчет, всего имеется ровно 30 наблюдений, которые отсортированы от наименьшего размера к наибольшему следующим образом:
4;4; 4; 6; 6; 6; 6; 8; 8; 8; 8; 10; 10; 10; 10; 10; 10; 12; 12; 12; 12; 12; 12;14; 14; 14;16;16; 18; 18
И теперь видно, что размер 10 повторяется 6 раз, поэтому его абсолютная частота равна 6. Такая же процедура проводится для определения абсолютной частоты остальных размеров.
Формулы
Абсолютная частота, обозначаемая как fя, равно тому, сколько раз определенное значение Xя находится в группе наблюдений.
Предполагая, что общее количество наблюдений равно N значениям, сумма всех абсолютных частот должна быть равна этому числу:
∑fя = f1 + f2 + f3 +… Fп = N
Другие частоты
Если каждое значение fя деленное на общее количество данных N, мы имеем относительная частота Fр значения Xя:
Fр = fя / N
Относительные частоты – это значения от 0 до 1, потому что N всегда больше любого fя, но сумма должна быть равна 1.
Умножение каждого значения f на 100р у тебя есть относительная частота в процентах, сумма которых составляет 100%:
Относительная частота в процентах = (fя / N) x 100%
Также важно накопленная частота Fя с точностью до определенного наблюдения, это сумма всех абсолютных частот до этого наблюдения включительно:
Fя = f1 + f2 + f3 +… Fя
Если накопленную частоту разделить на общее количество данных N, мы получим совокупная относительная частота, который умножается на 100 дает кумулятивная относительная частота в процентах.
Как получить абсолютную частоту?
Чтобы найти абсолютную частоту определенного значения, которое принадлежит набору данных, все они упорядочены от наименьшего к наибольшему, и подсчитывается, сколько раз появляется это значение.
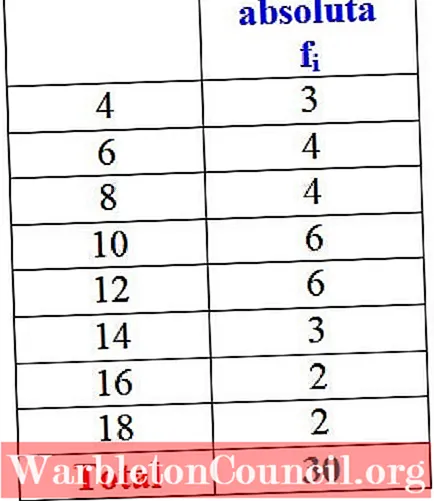
В примере с размерами платьев абсолютная частота размера 4 составляет 3 платья, то есть f.1 = 3. Для размера 6 было продано 4 платья: f2 = 4. В размере 8 также было продано 4 платья, f3 = 4 и так далее.
Табулирование
Общие результаты могут быть представлены в таблице, в которой указаны абсолютные частоты каждого из них:
Очевидно, что лучше упорядочить информацию и иметь возможность получить к ней быстрый доступ, вместо того, чтобы работать с отдельными данными.
Важный: обратите внимание, что при сложении всех значений столбца fявы всегда получаете общее количество данных. Если нет, вам необходимо проверить бухгалтерию, так как есть ошибка.
Расширенная частотная таблица
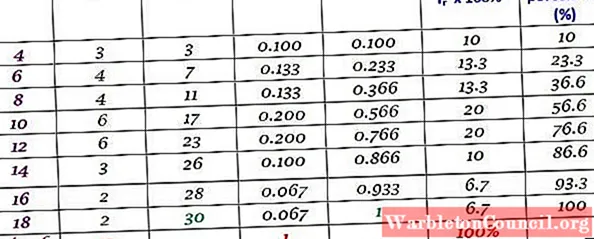
Приведенную выше таблицу можно расширить, добавив другие типы частот в последовательные столбцы справа:
Распределение частоты
Частотное распределение является результатом организации данных с точки зрения их частот. При работе с большим количеством данных их удобно сгруппировать по категориям, интервалам или классам, каждая со своей соответствующей частотой: абсолютная, относительная, накопленная и процентная.
Их цель – облегчить доступ к информации, содержащейся в данных, а также правильно ее интерпретировать, что невозможно, если она представлена в произвольном порядке.
В примере с размерами данные не сгруппированы, так как это не слишком много размеров, и ими можно легко управлять и учитывать. Таким же образом можно обрабатывать и качественные переменные, но когда данных очень много, лучше всего сгруппировать их по классам.
Распределение частот для сгруппированных данных
Чтобы сгруппировать данные в классы равного размера, примите во внимание следующее:
-Размер, ширина или широта класса: разница между самым высоким значением в классе и самым низким.
Размер класса определяется путем деления ранга R на количество рассматриваемых классов. Диапазон – это разница между максимальным значением данных и самым маленьким, например:
Размер класса = Ранг / Количество классов.
-Предел класса: диапазон от нижней границы до верхней границы класса.
-Классовый знак: это середина интервала, который считается представителем класса. Он рассчитывается на основе полусуммы верхнего и нижнего пределов класса.
–Кол-во классов: Формула Стерджеса может быть использована:
Количество классов = 1 + 3,322 log N
Где N – количество классов. Поскольку это обычно десятичное число, оно округляется до следующего целого числа.
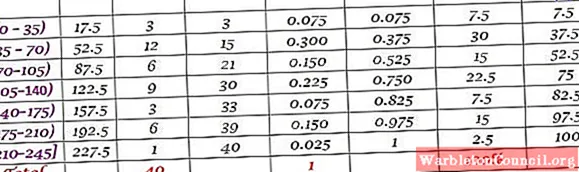
пример
Машина на большом заводе вышла из строя из-за повторяющихся сбоев. Последовательные периоды простоя в минутах указанной машины записаны ниже, всего 100 данных:

Сначала определяется количество классов:
Количество классов = 1 + 3,322 log N = 1 + 3,32 log 100 = 7,64 ≈ 8
Размер класса = Диапазон / Количество классов = (88-21) / 8 = 8,375
Это также десятичное число, поэтому за размер класса принимается 9.
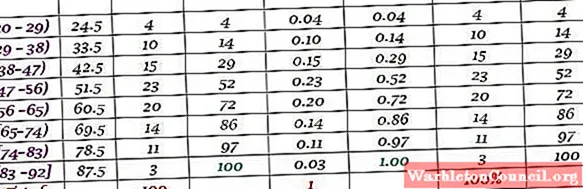
Оценка класса – это среднее значение между верхней и нижней границей класса, например, для класса [20-29) есть оценка:
Оценка класса = (29 + 20) / 2 = 24,5
Таким же образом мы ищем метки классов оставшихся интервалов.
Упражнение решено
40 молодых людей указали, что время в минутах, которое они провели в Интернете в прошлое воскресенье, было следующим, в порядке возрастания:
0; 12; 20; 35; 35; 38; 40; 45; 45, 45; 59; 55; 58; 65; 65; 70; 72; 90; 95; 100; 100; 110; 110; 110; 120; 125; 125; 130; 130; 130; 150; 160; 170; 175; 180; 185; 190; 195; 200; 220.
Предлагается построить частотное распределение этих данных.
Решение
Диапазон R набора N = 40 данных:
R = 220 – 0 = 220
Применение формулы Стерджеса для определения количества классов дает следующий результат:
Количество классов = 1 + 3 322 журнала N = 1 + 3,32 журнала 40 = 6,3
Поскольку это десятичное число, непосредственное целое число равно 7, поэтому данные сгруппированы в 7 классов. Каждый класс имеет ширину:
Размер класса = Ранг / Количество классов = 220/7 = 31,4
Близкое и округленное значение – 35, поэтому выбрана ширина класса 35.
Оценки за класс рассчитываются путем усреднения верхнего и нижнего пределов каждого интервала, например, для интервала [0,35):
Оценка класса = (0 + 35) / 2 = 17,5
Таким же образом поступаем и с другими классами.
Наконец, частоты вычисляются в соответствии с процедурой, описанной выше, в результате получается следующее распределение:
Ссылки
- Беренсон, М. 1985. Статистика для управления и экономики. Interamericana S.A.
- Деворе, Дж. 2012. Вероятность и статистика для техники и науки. 8-е. Издание. Cengage.
- Левин, Р. 1988. Статистика для администраторов. 2-й. Издание. Прентис Холл.
- Шпигель, М. 2009. Статистика. Серия Шаум. 4-й Издание. Макгроу Хилл.
- Уолпол, Р. 2007. Вероятность и статистика для инженерии и науки. Пирсон.
Абсолютная и относительная частота
Абсолютная частота
Абсолютная частота определяет как часто определенное событие происходит в ходе эксперимента. Это всегда натуральное число между нулем и общим числом попыток.
i
Подсказка
Абсолютная частота относится только к количеству частоты определенного события.
Относительная частота
Относительная частота описывает насколько велика пропорция абсолютной частоты в общем количестве экспериментов. Она вычисляется следующим образом:
$text{Относительная частота} n_i$ $=frac{text{Абсолютная частота} f_i}{text{Количество попыток} N}$
Пример
Монету подбрасывают 10 раз. 6 раз выпадает орел и 4 раза решка. Определите абсолютную и относительную частоту.
Aбсолютная частота:
$f_{10}(орел)=6$
$f_{10}(решка)=4$
Относительная частота:
$N=10$
$n_{10}(орел)=frac{6}{10}=frac{3}{5}$
$n_{10}(решка)=frac{4}{10}=frac{2}{5}$
Абсолютная частота – всего одна статистическая мера используется в области изучение, – это количество раз, когда данные повторяются в наборе из них, значение, которое наблюдается в случайный эксперимент для каждой характеристики, время, в течение которого фазы или явления, которые наблюдая.
Его использование очень распространено в Описательная статистика, поскольку с помощью этой меры можно узнать, как наблюдения одной и той же характеристики распределены в выборке.
Следовательно, его расчет очень прост, так как он требует только подсчета того, сколько раз наблюдается характеристика или сколько раз она появляется в группе данных.
Его представление можно выразить через следующие номенклатуры: Fя, Иксяили же пя, где буквы f, x, n соответствуют частоте, а буква i обозначает i-ю итерацию проводимого эксперимента.
В этой статье вы найдете:
Расчет абсолютной частоты
Существует очень простой способ проверить точность ваших вычислений, то есть всех абсолютных частот выборочной совокупности, и это получить сумму всех из них.
Это означает, что сумма каждой из абсолютных частот выборки точно соответствует общему количеству данных того же самого, эти данные представлены как N.
В этом случае формула для расчета абсолютной частоты:
я = п
Ʃ fя = f1+ f2+ f3 +… + Fп = N
я = п
Полезность абсолютной частоты
Абсолютная частота позволяет:
- Графически изобразить частота появления каждого из выборочных данных с помощью частотных гистограмм, гистограмм, круговых диаграмм и других элементов, специально разработанных для каждого исследования.
- Узнайте больше о характеристиках выборки, совокупности и вселенной.
- Создай таблица частот как для количественных, так и для качественных переменных, которые можно расположить по порядку.
- Создавайте частотные таблицы с дискретными переменными, те, которые упорядочены от наивысшего к наименьшему, и таблицы частоты с непрерывными переменными, которые позволяют упорядочить их от низшего к высшему и сгруппировать в классы или интервалы.
- Рассчитать Накопленная абсолютная частота и Относительная частота, все важно заполнить таблицу частот, расчет других измерений статистика и разработка соответствующей графики
Примеры абсолютной частоты
Чтобы проиллюстрировать абсолютную частоту, будут рассмотрены две формы, рассматривая значения в дискретных переменных и непрерывных переменных.
Пример абсолютной частоты для дискретных переменных
Компания хочет развлечь детей своих 20 сотрудников (таким образом, N = 20) и сделать им подарок, после консультации были получены следующие данные:
2, 1, 0, 2, 4, 3, 4, 3, 2, 0, 1, 3, 2, 1, 1, 3, 0, 2, 2, 0
Табулирование данных дает следующую таблицу:
| Количество детей | Fя |
| 0 | 4 |
| 1 | 4 |
| 2 | 6 |
| 3 | 4 |
| 4 | 2 |
| Общее | 20 |
Затем можно проверить, что все данные были подсчитаны, поскольку сумма всех абсолютных частот полностью совпадает с размером выборки: Всего = 20 равно N = 20.
Таким же образом можно определить частоту количества детей каждого работника: 4 работника не имеют детей, 4 имеют только 1 ребенка, 6 рабочих имеют 2 детей, 4 имеют 3 детей и, наконец, 2 из них имеют 4 дети.
Пример абсолютной частоты для непрерывных переменных
Та же компания из предыдущего примера также должна знать рост каждого из своих сотрудников (N по-прежнему = 20), в этом случае данные будут десятичными числами, учитывая эту характеристику, удобнее работать с интервалами данных, так как иначе работа табулирование.
После выполнения соответствующих измерений были получены следующие 20 измерений:
1.67, 1.72, 1.90, 1.76, 1.72, 1.96, 1.78, 1.68, 1.87, 1.84, 1.92, 1.72, 1.71, 1.88, 1.77, 1.66, 1.73, 1.82, 1.90, 1.79
Табулирование данных дает следующую таблицу:
| Рост сотрудника | фи |
| [1.60 – 1.70) | 3 |
| [1.70 – 1.80) | 9 |
| [1.80 – 1.90) | 4 |
| [1.90 – 2.00) | 4 |
| Общее | 20 |
Символ «[» указывает, что номер, следующий за ним, включен в категорию, а символ «)» указывает, что номер, предшествующий ему, не включен в категорию.
Тогда можно проверить, что все данные, поскольку сумма всех абсолютных частот полностью совпадает с размером выборки: Total = 20 равно N = 20.
Таким же образом можно определить частоту роста рабочих: 3 сотрудника имеют рост от 1,60 до 1,70, Рост 9 сотрудников от 1,70 до 1,80, рост 4 сотрудников от 1,80 до 1,90 и, наконец, 4 сотрудника ростом от 1,90 до 2.00.
Графическое представление абсолютной частоты
Есть разные способы построить абсолютную частоту, некоторые из них:
- Диаграммы секторов: Этот график состоит из круга, разделенного на секторы, пропорциональные относительной частоте, которую он представляет.
- Гистограмма абсолютной частоты: представляет каждый Переменная в виде столбиков, его основание пропорционально соответствующей абсолютной частоте.
- Диаграммы многоугольника или прямоугольника: выполняется путем рисования линий, соединяющих самые высокие точки столбцов гистограммы абсолютной частоты.
Определение частотного распределения.
Частотное распределение или плотность распределения (англ. ‘frequency distribution’) представляет собой табличное отображение данных, обобщенных в относительно небольшое количество интервалов.
Распределения частот помогают в анализе больших объемов статистических данных и работают со всеми типами измерительных шкал.
Ставки доходности являются основными фундаментальными единицами, которые финансовые аналитики и портфельные менеджеры используют для принятия инвестиционных решений, и мы можем использовать распределение частот для обобщения ставок доходности.
Когда мы анализируем норму прибыли, нашей отправной точкой является доходность за период владения (HPR, от англ. ‘holding period return’), также называемая общей доходностью (англ. ‘total reutrn’).
Формула доходности за период владения.
Доходность за период владения (R_t) за период времени (t), равна:
( large R_t = (P_t – P_{t-1} + D_t) big/ P_{t-1} ) (Формула 1)
где
- (P_t) = цена за акцию в конце периода (t).
- (P_{t-1}) = цена за акцию в конце периода (t – 1). Это период времени, непосредственно предшествующий периоду (t).
- (D_t)= денежные поступления от распределений, полученные за период времени (t). (Для обыкновенных акций распределение – это дивиденды; для облигаций – купонная выплата).
Таким образом, доходность (R_t) за период времени (t) представляет собой прирост стоимости капитала (или убыток) плюс поступления от распределений, деленные на цену акций начального периода.
Формулу 1 можно использовать для определения доходности за период владения любым активом – за день, неделю, месяц или год, просто изменив интерпретацию временного интервала между последовательными значениями временного индекса (t).
Доходность за период владения, как определено в Формуле 1, имеет две важные характеристики.
- Во-первых, она характеризуется временным периодом. Например, если между последовательными наблюдениями за ценой используется месячный интервал времени, то ставка доходности является месячной цифрой.
- Во-вторых, ставка доходности не имеет связанной с ней денежной единицы. Например, предположим, что цены указаны в евро. Числитель и знаменатель Формулы 1 будут выражаться в евро, но полученное соотношение не будет выражать денежную единицу, поскольку денежные единицы в числителе и знаменателе будут взаимно аннулироваться.
Результат сохраняется независимо от валюты, в которой указаны цены на акции.
Тем не менее, обратите внимание на то, что если бы цены и денежные поступления от распределений были выражены в разных валютах, вам следовало бы конвертировать их в одну общую валюту перед расчетом доходности за период владения.
Из-за колебаний обменного курса в течение периода владения, доходность за период владения активом, рассчитанная в разных валютах, как правило, будет отличаться.
С учетом этих проблем мы переходим к частотному распределению доходности за период владения по индексу S&P 500.
- Во-первых, мы изучаем годовые ставки доходности;
- Затем мы смотрим на ежемесячные ставки доходности.
Годовые ставки доходности S&P 500, рассчитанные по Формуле 1, охватывают период с января 1926 г. по декабрь 2012 г., что составляет в общей сложности 87 ежегодных наблюдений. Ежемесячные данные о доходности охватывают период с января 1926 года по декабрь 2012 года, в общей сложности 1044 ежемесячных наблюдений.
Мы можем сформулировать основную процедуру построения частотного распределения следующим образом.
Построение частотного распределения.
- Отсортируйте данные в порядке возрастания.
- Рассчитайте размах данных Range, который определяется как
Размах (англ. ‘range’) = Максимальное значение – Минимальное значение. - Определите количество интервалов в частотном распределении, (k).
- Определите ширину интервала как ( mathrm{Range} / k ).
- Определите интервалы, последовательно добавляя ширину интервала к минимальному значению, чтобы определить конечные точки интервалов. Последним будет интервал, включающий максимальное значение.
- Подсчитайте количество наблюдений, попадающих в каждый интервал.
- Составьте таблицу полученных интервалов от наименьшего до наибольшего, в которой показано количество наблюдений, попадающих в каждый интервал.
На шаге 4 при округлении ширины интервала округляйте скорее вверх, чем вниз, чтобы убедиться, что последний интервал включает в себя максимальное значение данных.
Как видно из вышеописанной процедуры, распределение частот группирует данные в набор интервалов. Интервалы также иногда называют классами, диапазонами или ячейками (англ. class, range, bin).
Интервал (англ. ‘interval’) – это набор значений, в который попадает наблюдение. Каждое наблюдение попадает только в один интервал, и общее количество интервалов охватывает все значения, представленные в выборке данных.
Фактическое количество наблюдений в данном интервале называется абсолютной частотой (англ. ‘absolute frequency’) или просто частотой.
Частотное распределение или распределение частот (англ. ‘frequency distribution’) – это перечень интервалов вместе с соответствующими показателями частоты.
Пример построения частотного распределения.
Чтобы проиллюстрировать основную процедуру, предположим, что у нас есть 12 наблюдений, отсортированных в порядке возрастания:
-4,57, -4,04, -1,64, 0,28, 1,34, 2,35, 2,38, 4,28, 4,42, 4,68, 7,16 и 11,43
Минимальное наблюдение составляет -4,57, а максимальное наблюдение составляет +11,43, поэтому размах составляет +11,43 – (-4,57) = 16. Если мы установим (k = 4), ширина интервала составит 16/4 = 4.
Таблица 1 показывает последовательное добавление ширины интервала 4 для определения конечных точек для интервалов (шаг 5).
|
-4.57 |
+ |
4.00 = |
-0.57 |
|
-0.57 |
+ |
4.00 = |
3.43 |
|
3.43 |
+ |
4.00 = |
7.43 |
|
7.4 |
+ |
4.00 = |
11.43 |
Таким образом, интервалы составляют:
[-4,57 до -0,57),
[-0,57 до 3,43),
[3,43 до 7,43) и
[7,43 до 11,43]
Обозначения вроде [-4,57 -0,57) означают -4,57 (leq) наблюдение (<) -0,57. В этом контексте квадратная скобка указывает, что конечная точка включена в интервал.
|
Интервал |
Абсолютная |
|||
|---|---|---|---|---|
|
A |
-4.57 |
≤ наблюдение < |
-0.57 |
3 |
|
B |
-0.57 |
≤ наблюдение < |
3.43 |
4 |
|
C |
3.43 |
≤ наблюдение < |
7.43 |
4 |
|
D |
7.43 |
≤ наблюдение ≤ |
11.43 |
1 |
Обратите внимание, что интервалы не перекрываются, поэтому каждое наблюдение может быть однозначно помещено в один интервал.
На практике мы можем захотеть усовершенствовать вышеуказанную базовую процедуру. Например, мы можем захотеть, чтобы интервалы начинались и заканчивались целыми числами для простоты интерпретации.
Нам также нужно объяснить выбор количества интервалов (k). Мы обратимся к этим вопросам далее, при обсуждении построения частотных распределений для S&P 500.
Пример построения частотного распределения для ставок доходности S&P 500.
Сначала рассмотрим пример построения частотного распределения для годовых ставок доходность по S&P 500 за период с 1926 по 2012 год.
В течение этого периода доходность по S&P 500 имела минимальное значение -43,34 процента (в 1931 году) и максимальное значение +53,99 процента (в 1933 году).
Таким образом, размах данных составлял + 54% – (-43%) = 97%, приблизительно.
Теперь нужно определить количество интервалов k, в которые мы должны сгруппировать наблюдения.
Хотя учебники по статистике содержат некоторые базовые рекомендации для определения (k), на практике определение полезного значения для (k) часто включает проверку данных и вынесение оценочного суждения.
Насколько детальными должны быть интервалы?
Если мы используем слишком мало интервалов, мы обобщаем слишком много наблюдений и теряем соответствующие характеристики. Если мы используем слишком много интервалов, мы можем не получить достаточный уровень обобщения.
Мы можем установить подходящее значение для (k), оценив полезность полученной ширины интервала. Большое количество пустых интервалов может указывать на то, что мы пытаемся представить слишком много деталей.
Начав с относительно небольшой ширины интервала, мы можем видеть, являются ли интервалы в основном пустыми и не является ли слишком большим значение (k), связанное с этой шириной интервала.
Если интервалы в основном пустые или (k) очень велико, мы можем рассмотреть большие интервалы (меньшие значения (k)), пока не получим распределение частот, которое эффективно обобщает распределение.
Для годовых ставок S&P 500 интервалы доходности шириной в 1 процент привели бы к 97 интервалам, и многие из них были бы пустыми, потому что у нас есть только 87 ежегодных наблюдений.
Нам всегда нужно помнить, что целью распределения частот является обобщение данных. Предположим, что для простоты интерпретации мы хотим использовать ширину интервала, целых, а не в дробных значениях процентов.
Ширина 2-процентного интервала имеет намного меньше пустых интервалов, чем ширина 1-процентного интервала, и эффективно обобщает данные. 2-процентная ширина интервала будет связана с 97/2 = 48,5 интервалами, которые мы можем округлить до 49 интервалов.
Это количество интервалов будет покрывать 2% (times) 49 = 98%. Мы можем подтвердить, что, если мы начнем наименьший 2-процентный интервал с целого числа -44,0%, последний интервал заканчивается на -44,0% + 98% = 54% и включает максимальную доходность в выборке: 53,99%.
При построении распределения частот у нас также будут интервалы, которые заканчиваются и начинаются со значения 0 процентов, что позволяет нам подсчитывать отрицательные и положительные значения доходности. Без лишней работы мы нашли эффективный способ обобщения данных.
Мы будем использовать интервалы доходности 2%, начиная с ( -44% leq R_t < -42%) (в таблице указано «-44% до -42%») и заканчивая (52% leq R_t leq 54%).
В Таблице 3 показано распределение частот для годовых ставок доходности по S&P 500.
Таблица 3 включает три других полезных способа представления данных, которые мы можем вычислить, как только мы установили распределение частот:
- относительная частота,
- накопленная частота (также называемая накопленной абсолютной частотой) и
- накопленная относительная частота.
Определение относительной частоты.
Относительная частота (англ. ‘relative frequency’) – это абсолютная частота каждого интервала, деленная на общее количество наблюдений.
Накопленная относительная частота (англ. ‘cumulative relative frequency’) накапливает (складывает) относительные частоты, когда мы движемся от первого до последнего интервала. Она говорит нам о доле наблюдений, которые меньше верхнего предела каждого интервала.
|
Интервал доходности (%) |
Частота |
Относительная частота (%) |
Накоп- |
Накопленная относительная частота (%) |
|---|---|---|---|---|
|
-44.0 до -42.0 |
1 |
1.15 |
1 |
1.15 |
|
-42.0 до -40.0 |
0 |
0.00 |
1 |
1.15 |
|
-40.0 до -38.0 |
0 |
0.00 |
1 |
1.15 |
|
-38.0 до -36.0 |
1 |
1.15 |
2 |
2.30 |
|
-36.0 до -34.0 |
1 |
1.15 |
3 |
3.45 |
|
-34.0 до -32.0 |
0 |
0.00 |
3 |
3.45 |
|
-32.0 до -30.0 |
0 |
0.00 |
3 |
3.45 |
|
-30.0 до -28.0 |
0 |
0.00 |
3 |
3.45 |
|
-28.0 до -26.0 |
1 |
1.15 |
4 |
4.60 |
|
-26.0 to -24.0 |
1 |
1.15 |
5 |
5.75 |
|
-24.0 до -22.0 |
1 |
1.15 |
6 |
6.90 |
|
-22.0 до -20.0 |
0 |
0.00 |
6 |
6.90 |
|
-20.0 до -18.0 |
0 |
0.00 |
6 |
6.90 |
|
-18.0 до -16.0 |
0 |
0.00 |
6 |
6.90 |
|
-16.0 до -14.0 |
1 |
1.15 |
7 |
8.05 |
|
-14.0 до -12.0 |
0 |
0.00 |
7 |
8.05 |
|
-12.0 до -10.0 |
4 |
4.60 |
11 |
12.64 |
|
-10.0 до -8.0 |
7 |
8.05 |
18 |
20.69 |
|
-8.0 до -6.0 |
1 |
1.15 |
19 |
21.84 |
|
-6.0 до -4.0 |
1 |
1.15 |
20 |
22.99 |
|
-4.0 до -2.0 |
1 |
1.15 |
21 |
24.14 |
|
-2.0 до 0.0 |
3 |
3.45 |
24 |
27.59 |
|
0.0 до 2.0 |
2 |
2.30 |
26 |
29.89 |
|
2.0 до 4.0 |
1 |
1.15 |
27 |
31.03 |
|
4.0 до 6.0 |
6 |
6.90 |
33 |
37.93 |
|
6.0 до 8.0 |
4 |
4.60 |
37 |
42.53 |
|
8.0 до 10.0 |
1 |
1.15 |
38 |
43.68 |
|
10.0 до 12.0 |
4 |
4.60 |
42 |
48.28 |
|
12.0 до 14.0 |
1 |
1.15 |
43 |
49.43 |
|
14.0 до 16.0 |
4 |
4.60 |
47 |
54.02 |
|
16.0 до 18.0 |
2 |
2.30 |
49 |
56.32 |
|
18.0 до 20.0 |
6 |
6.90 |
55 |
63.22 |
|
20.0 до 22.0 |
3 |
3.45 |
58 |
66.67 |
|
22.0 до 24.0 |
5 |
5.75 |
63 |
72.41 |
|
24.0 до 26.0 |
2 |
2.30 |
65 |
74.71 |
|
26.0 до 28.0 |
2 |
2.30 |
67 |
77.01 |
|
28.0 до 30.0 |
2 |
2.30 |
69 |
79.31 |
|
30.0 до 32.0 |
5 |
5.75 |
74 |
85.06 |
|
32.0 до 34.0 |
4 |
4.60 |
78 |
89.66 |
|
34.0 до 36.0 |
0 |
0.00 |
78 |
89.66 |
|
36.0 до 38.0 |
4 |
4.60 |
82 |
94.25 |
|
38.0 до 40.0 |
0 |
0.00 |
82 |
94.25 |
|
40.0 до 42.0 |
0 |
0.00 |
82 |
94.25 |
|
42.0 до 44.0 |
2 |
2.30 |
84 |
96.55 |
|
44.0 до 46.0 |
0 |
0.00 |
84 |
96.55 |
|
46.0 до 48.0 |
1 |
1.15 |
85 |
97.70 |
|
48.0 до 50.0 |
0 |
0.00 |
85 |
97.70 |
|
50.0 до 52.0 |
0 |
0.00 |
85 |
97.70 |
|
52.0 до 54.0 |
2 |
2.30 |
87 |
100.00 |
Источник: Ibbotson Associates.
Примечание: нижний предел интервала – это нестрогое неравенство ((leq)), а верхний предел – строгое неравенство ((<)). Итоги накопленных относительных частот отражают вычисления полной точности, с округлением до двух десятичных разрядов.
Изучив частотное распределение, приведенное в Таблице 3, мы видим, что первый интервал доходности, от -44 до -42%, содержит одно наблюдение; его относительная частота составляет 1/87 или 1,15 процента.
Накопленная частота для этого интервала равна 1, поскольку только одно наблюдение составляет менее -42%. Таким образом, накопленная относительная частота составляет 1/87 или 1,15 процента.
Следующий интервал доходности включает 0 наблюдений; следовательно, его накопленная частота равна 0 + 1, а его накопленная относительная частота равна 1,15% (накопленная относительная частота от предыдущего интервала).
Мы можем найти другие накопленные частоты, добавив (абсолютную) частоту к предыдущей накопленной частоте. Таким образом, накопленная частота показывает нам число наблюдений, которые меньше верхнего предела каждого интервала доходности.
Как видно из Таблицы 3, интервалы доходности в этой выборке имеют частоты от 0 до 7. Интервал, охватывающий доходность от -10% до -8% (-10% leq R_t < -8%) имеет больше всего наблюдений: 7.
Следующей по частоте является доходность от 4 до 6% (4% leq R_t < 6%) и от 18 до 20% (18% leq R_t < 20%), с 6 наблюдениями в каждом интервале.
Из столбца накопленной частоты мы видим, что количество отрицательных значений отрицательной доходности равно 24. Число положительных значений доходности должно быть равно 87-24 или 63. Мы можем выразить количество положительных и отрицательных значений доходности в процентах от общего числа, чтобы получить представление о риске, присущем инвестициям на фондовом рынке.
В течение 87-летнего периода S&P 500 имел отрицательную годовую доходность в 27,6% случаев (то есть 24/87). Этот результат отражен в пятом столбце Таблицы 3, где указывается накопленная относительная частота.
Распределение частот дает нам представление не только о том, где находится большинство наблюдений, но также о том, является ли распределение нормальным, ассиметричным (со скосом влево или вправо) или островершинным.
(см. также: CFA – Симметрия и асимметрия в распределениях доходности)
В случае с S&P 500 мы видим, что более половины наблюдений являются положительными, а большая часть этих ставок годовой доходности превышает 10% (только 14 из 63 ставок – около 22% – составляли от 0 до 10%).
Таблица 3 позволяет нам сделать еще один важный вывод относительно выбора количества интервалов, связанного, в частности, с доходностью капитала. Из распределения частот в Таблице 3 мы видим, что только 6 наблюдений попадают в промежуток между -44% и -16%, и только 5 – между 38% и 54%.
Рыночные данные о доходности часто характеризуются несколькими очень большими или маленькими результатами.
Мы могли бы исключить интервалы доходности по краям частотного распределения, выбрав меньшее значение (k), но тогда мы потеряли бы информацию о том, насколько плохо или хорошо работала фондовая биржа.
Риск-менеджеру может потребоваться информация о наихудших возможных результатах и, следовательно, может потребоваться подробная информация о крайних значениях распределения (или хвостах распределения, от англ. ‘tail’). Для этого ему может быть полезно распределение частоты с относительно большим значением (k).
Портфельный менеджер или финансовый аналитик могут быть в равной степени заинтересованы в подробной информации о хвостах распределений. Однако, если менеджер или аналитик хочет получить картину только того, где находится большинство наблюдений, он может предпочесть использовать ширину интервала 4% (например, 25 интервалов, начинающихся с -44%).
Распределение частот для ежемесячной доходности S&P 500 выглядит совсем не так, как для годовой доходности. Серия ежемесячных ставок доходности с января 1926 года по декабрь 2012 года насчитывает 1044 наблюдения.
Доходность варьируется от минимума -30% до максимума +43%. При таком большом количестве ежемесячных данных мы должны сделать обобщение, чтобы получить представление о распределении, и поэтому мы группируем данные в 37 равных интервалов доходности, шириной в 2 процента.
Выгода от обобщения таким образом является существенной.
В Таблице 4 представлено полученное распределение частот. Абсолютные частоты находятся во втором столбце, за которым следуют относительные частоты. Относительные частоты округлены до двух десятичных знаков. Накопленные абсолютные частоты и накопленные относительные частоты находятся в четвертом и пятом столбцах соответственно.
|
Интервал доходности (%) |
Абсолютная частота |
Отно- |
Накоп- |
Накопленная относительная частота (%) |
|---|---|---|---|---|
|
-30.0 до -28.0 |
1 |
0.10 |
1 |
0.10 |
|
-28.0 до -26.0 |
0 |
0.00 |
1 |
0.10 |
|
-26.0 до -24.0 |
1 |
0.10 |
2 |
0.19 |
|
-24.0 до -22.0 |
1 |
0.10 |
3 |
0.29 |
|
-22.0 до -20.0 |
2 |
0.19 |
5 |
0.48 |
|
-20.0 до -18.0 |
2 |
0.19 |
7 |
0.67 |
|
-18.0 до -16.0 |
3 |
0.29 |
10 |
0.96 |
|
-16.0 до -14.0 |
2 |
0.19 |
12 |
1.15 |
|
-14.0 до -12.0 |
6 |
0.57 |
18 |
1.72 |
|
-12.0 до -10.0 |
7 |
0.67 |
25 |
2.39 |
|
-10.0 до -8.0 |
23 |
2.20 |
48 |
4.60 |
|
-8.0 до -6.0 |
34 |
3.26 |
82 |
7.85 |
|
-6.0 до -4.0 |
59 |
5.65 |
141 |
13.51 |
|
-4.0 до -2.0 |
98 |
9.39 |
239 |
22.89 |
|
-2.0 до 0.0 |
157 |
15.04 |
396 |
37.93 |
|
0.0 до 2.0 |
220 |
21.07 |
616 |
59.00 |
|
2.0 до 4.0 |
173 |
16.57 |
789 |
75.57 |
|
4.0 до 6.0 |
137 |
13.12 |
926 |
88.70 |
|
6.0 до 8.0 |
63 |
6.03 |
989 |
94.73 |
|
8.0 до 10.0 |
25 |
2.39 |
1,014 |
97.13 |
|
10.0 до 12.0 |
15 |
1.44 |
1,029 |
98.56 |
|
12.0 до 14.0 |
6 |
0.57 |
1,035 |
99.14 |
|
14.0 до 16.0 |
2 |
0.19 |
1,037 |
99.33 |
|
16.0 до 18.0 |
3 |
0.29 |
1,040 |
99.62 |
|
18.0 до 20.0 |
0 |
0.00 |
1,040 |
99.62 |
|
20.0 до 22.0 |
0 |
0.00 |
1,040 |
99.62 |
|
22.0 до 24.0 |
0 |
0.00 |
1,040 |
99.62 |
|
24.0 до 26.0 |
1 |
0.10 |
1,041 |
99.71 |
|
26.0 до 28.0 |
0 |
0.00 |
1,041 |
99.71 |
|
28.0 до 30.0 |
0 |
0.00 |
1,041 |
99.71 |
|
30.0 до 32.0 |
0 |
0.00 |
1,041 |
99.71 |
|
32.0 до 34.0 |
0 |
0.00 |
1,041 |
99.71 |
|
34.0 до 36.0 |
0 |
0.00 |
1,041 |
99.71 |
|
36.0 до 38.0 |
0 |
0.00 |
1,041 |
99.71 |
|
38.0 до 40.0 |
2 |
0.19 |
1,043 |
99.90 |
|
40.0 до 42.0 |
0 |
0.00 |
1,043 |
99.90 |
|
42.0 до 44.0 |
1 |
0.10 |
1,044 |
100.00 |
Источник: Ibbotson Associates.
Примечание: нижний предел интервала – это нестрогое неравенство ((leq)), а верхний предел – строгое неравенство ((<)). Относительная частота – это абсолютная частота или накопленная частота, деленная на общее количество наблюдений. Итоги накопленных относительных частот отражают вычисления полной точности, с округлением до двух десятичных разрядов.
Преимущество анализа распределения частот очевидно из Таблицы 4, которая говорит нам, что подавляющее большинство наблюдений (687/1044 = 66%) лежат в четырех интервалах, охватывающих доходность от -2% до +6%. Всего у нас 396 отрицательных и 648 положительных результатов. Почти 62% ежемесячных результатов являются положительными.
Глядя на накопленную относительную частоту в последнем столбце, мы видим, что интервал от -2 процентов до 0% показывает накопленную частоту 37,93% для верхнего предела доходности 0%. Это означает, что 37,93% наблюдений лежат ниже уровня 0%. Мы также видим, что не так много наблюдений больше +12% или меньше -12%.
Обратите внимание, что распределение частот годовой и месячной доходности не является напрямую сопоставимым. В среднем следует ожидать, что показатели доходности, измеренные с более короткими интервалами (например, месяцы), будут меньше, чем показатели доходности, измеренные с более длительными периодами (например, годами).
Далее мы построим частотное распределение средней доходности с поправкой на инфляцию за 1900-2010 гг. для 19 основных фондовых рынков.
Пример построения частотного распределения для доходности акций основных фондовых рынков.
Как в конечном итоге акции вознаграждали инвесторов в разных странах?
Чтобы ответить на этот вопрос, мы могли бы непосредственно изучить среднюю годовую доходность.
Среднее или среднее арифметическое (англ. ‘arithmetic mean’) для набора значений равно сумме значений, деленной на количество суммируемых значений. Например, чтобы найти среднее арифметическое значение 111 ставок годовой доходности, мы суммируем 111 ставок годовой доходности, а затем делим итоговое значение на 111.
Однако размер номинального уровня доходности зависит от изменений покупательной способности денег, и на международном уровне всегда присутствуют разнообразные уровни инфляции цен. Поэтому предпочтительнее сравнивать среднюю реальную доходность или доходность с учетом инфляции, полученную инвесторами в разных странах.
Димсон, Марш и Стонтон (2011) представили авторитетные доказательства доходности активов в 19 странах за 111 лет 1900-2010. В Таблице 5 приводятся их выводы для средней доходности с поправкой на инфляцию.
|
Страна |
Среднее арифметическое (%) |
|---|---|
|
Австралия |
9.1 |
|
Бельгия |
5.1 |
|
Канада |
7.3 |
|
Дания |
6.9 |
|
Финляндия |
9.3 |
|
Франция |
5.7 |
|
Германия |
8.1 |
|
Ирландия |
6.4 |
|
Италия |
6.1 |
|
Япония |
8.5 |
|
Нидерланды |
7.1 |
|
Новая Зеландия |
7.6 |
|
Норвегия |
7.2 |
|
Южная Африка |
9.5 |
|
Испания |
5.8 |
|
Швеция |
8.7 |
|
Швейцария |
6.1 |
|
Объединенное Королевство |
7.2 |
|
Соединенные Штаты |
8.3 |
Источник: Dimson, Marsh, and Staunton (2011).
Таблица 6 суммирует данные Таблицы 5 в пять интервалов, охватывающих доходность от 5 до 10%. На 19 рынках относительная частота интервала доходности от 5,0 до 6,0% рассчитывается, например, как 3/19 = 15,79%.
|
Интервал доходности (%) |
Абсолютная частота |
Относительная частота (%) |
Накопленная абсолютная частота |
Накопленная относительная частота (%) |
|---|---|---|---|---|
|
5.0 до 6.0 |
3 |
15.79 |
3 |
15.79 |
|
6.0 до 7.0 |
4 |
21.05 |
7 |
36.84 |
|
7.0 до 8.0 |
5 |
26.32 |
12 |
63.16 |
|
8.0 до 9.0 |
4 |
21.05 |
16 |
84.21 |
|
9.0 до 10 |
3 |
15.79 |
19 |
100.00 |
Как видно из Таблицы 6, в мире наблюдается значительный разброс средней реальной доходности. Более четверти наблюдений приходится на интервал от 7,0 до 8,0%, который имеет относительную частоту 26,32%. 3 или 4 наблюдения попадают в каждый из остальных 4-х интервалов.
СТАТИСТИЧЕСКАЯ ЧАСТОТА
Теория вероятностей имеет дело с экспериментами, исходы которых непредсказуемы: они зависят от случая.

Чтобы выяснить, насколько вероятно то или иное случайное событие, связанное с экспериментом, нужно подсчитать, как часто оно происходит. Для
этого используют две важные величины:
Абсолютная частота показывает, сколько раз в серии экспериментов
наблюдалось данное событие;
Относительная частота показывает, какая доля экспериментов
завершилась наступлением данного события. Относительную частоту можно найти, поделив абсолютную частоту на число экспериментов (и выразить в процентах).

За вероятность случайного события можно приближенно принять его относительную частоту, полученную в данной
серии экспериментов.
