Алгоритмизируем музыку
Время на прочтение
10 мин
Количество просмотров 5.2K

Считается, что сочинение музыки это творческое занятие, где алгоритмы применять невозможно. И действительно, от композиторов чаще всего можно услышать про музу, озарение и золотое сечение, но не про сухие правила. Поэтому в данной статье дается попытка описать простые алгоритмы, которым следует музыка. В итоге можно будет оценить, сколько творчества и сколько профессиональных знаний в данной деятельности. Описание будет на примере популярной музыки, но базовые принципы применимы ко всем жанрам.
Творчество – это создание нового, такого, чего в природе раньше не было. Для лучшего понимания, рассмотрим пример. Имеется два новобранца-дворника, первый окончил профессиональные курсы, а второй даже метлы никогда не видел. Первый сразу же пойдет мести двор, используя стандартные движения, хват метлы и алгоритм обхода двора. Второму же сначала придется проявить творчество, чтобы просто взять метлу в руки. И если он после этого заявит, что он творческая личность, изобрел хват метлы и достоин премии, повышения и известности, вряд ли его кто-то воспримет серьезно. Но если дело относится к музыке, то почему-то воспринимают.
К счастью для данной статьи, российская поп музыка полностью игнорирует даже элементарную теорию музыки, поэтому данные песни будут приводиться в качестве примера творчества. Западная же музыка, а именно мировые поп-звезды, наоборот, пример хорошего применения профессиональных знаний. На контрасте будет легко найти преимущества и недостатки каждого из подходов.
Основы
Цель музыки – вызвать эмоциональный отклик у слушателя. Для этого на макроуровне композитор контролирует энергию, напряжение и предсказуемость. А для того, чтобы слушатель не потерял интерес и дослушал песню до конца, используется обычное для искусства средство — контраст.
Предсказуемость
Предсказуемостью это то, насколько легко можно предсказать, что будет дальше в песне. Детские песни для взрослого полностью предсказуемы, поэтому их интересно слушать только детям. Если же наоборот, песня полностью непредсказуема, то её будет очень тяжело воспринимать.
Песня звучит предсказуемо, если она состоит из элементов (мелодия, аккорды и т.п.), которые все уже много раз слышали. Поэтому задача композитора к стандартному шаблону придумать что-то новое, чтобы в песне появились элементы непредсказуемости. Для этого можно проявить творчество, а можно профессионально украсть. В песнях Dua Lipa – New Rules и Sabrina Carpenter – Why используется странный звук в начале припева именно для непредсказуемости. Если еще вспомнить песню Rita Ora – Anywhere, то получится два новых элемента (странный звук и вокализ) на три песни.
В качестве примера абсолютно предсказуемой песни можно привести Натали – У меня есть только ты. Данную песню слушать приятно, но только один раз. Возвращаться к ней нет желания именно потому, что здесь нет ни одного нового элемента.
Поэтому для песни нужен баланс между предсказуемостью и непредсказуемостью. Сколько нужно последнего, точно оценить сложно, но для популярной музыки эта величина вряд ли превышает единицы процента.
Напряжение и энергия
Напряжение работает следующим образом. Сначала нагнетается уровень напряжения, а потом он разрешается. Куплет нагнетает напряжение, а припев его разрешает.
В течение песни энергия меняется закономерным образом: куплет – низкая энергия, припев – высокая. В одну из последних частей песни помещается максимум энергии, эта точка называется кульминацией.
Энергию песни легко оценить (подробнее ниже), в отличие от напряжения – это сугубо субъективное впечатление, некое чувство, которое возникает при прослушивании музыки. Но общий тренд достаточно прост: растет энергия – растет напряжение, энергия снижается – напряжение разрешается.
Согласованность напряжения и энергии
Если с энергией всё достаточно просто, то с напряжением дело чуть запутаннее. Напряжение растет вместе с энергией, а чтобы его разрешить, нужно понизить энергию. То есть, получается противоречие: припев одновременно должен повысить энергию, и в то же самое время понизить энергию, для того чтобы разрешить напряжение.
Это противоречие можно решить следующим образом. Суммарная энергия припева повышается, но один или несколько элементов снижают свою энергию. В итоге получается, максимальная энергия с одновременным разрешением!
Кульминация
В какое же место песни поместить максимум энергии (кульминацию)? Если в самое начало – то слушать песню дальше будет неинтересно. Если же в самый конец, то песня завершиться очень резко и неожиданно, будет некое чувство потерянности и незавершенности. Остается единственный вариант, максимально близко к концу.
В популярных песнях максимум энергии может находиться в двух местах, либо в бридже, либо в третьем припеве. Если в бридже, то после третьего припева песня сразу же заканчивается. Если же максимум в третьем припеве, то прибавляется какая-либо концовка.
Но это теоретически, на практике же, найти кульминацию может быть затруднительно. Так как считается, что если «сильной» кульминации нет, то слушатель будет слушать песню снова и снова, она станет хитом и принесет много денег звукозаписывающим компаниям.
Контраст
Одним из главных средств выразительности в искусстве является контраст. В музыке чаще всего он проявляется в громкости, высоте мелодии, интонации пения и количестве одновременно играющих инструментов.
Основные функции контраста это сохранять внимание слушателя и определять границы частей песни. Между основными частями песни (куплет, припев, бридж), как правило, присутствует большой контраст, изменения затрагивают практически все элементы песни. Если же основные части песни состоят из двух подчастей, то во второй обычно добавляется какой-либо новый инструмент, то есть контраст получается совсем небольшим.
Если в песне проблемы с контрастом, то понять какая часть песни сейчас играет становится затруднительно, не говоря уже о потере внимания и интереса.
Техники, правила и алгоритмы
Для того, чтобы увидеть техники, правила и алгоритмы, которые доступны композитору для управления энергией и напряжением, музыкальное произведение нужно разбить на более простые составляющие (разделяй и властвуй). Для популярной песни это будут слова, мелодия и аккомпанемент.
Слова
В словах для песни должен быть дизайн, а именно связь между всеми частями песни. Например, функция куплета заинтриговать, задать вопросы, или просто рассказать историю. И в полном соответствии с принципом контраста, функция припева разрешить интригу, ответить на вопросы, или дать эмоциональный отклик на историю.
Обобщая вышесказанное, в куплетах нужно нарастить напряжение, а в припеве его разрешить, чтобы слушатель, услышав ключевую фразу (как правило, название песни) воскликнул: «Ах вот оно как!».
Из этого следует вывод, что лучший способ разрушить дизайн слов песни – это поместить название песни и в куплет, и в припев.
Какие есть еще требования для слов? Так как песня воспринимается слухом, поэтому нужно, чтобы использовались разговорные фразы и выражения. Казалось бы, очевидное требование, но оно далеко не всегда соблюдается. Например, фильмы Гайдая часто используют сложные фразы, переполненные смыслом, которые в разговорной речи не встречаются. Поэтому данные фильмы принесли столько известных крылатых фраз и выражений. Особенно заметна разница в сравнении с американскими фильмами и сериалами, где это требование соблюдается на 200% и даже намёка на крылатые фразы нет.
Что будет, если не соблюдать это требование легко узнать на примере типичной российской поп-песни. Такое ощущение, что авторы специально пишут так, чтобы никто не смог их понять. Первая строчка песни понятна, вторая тоже, но не ясно, как эти две строчки между собой согласуются. А так как третья строчка ни с одной из предыдущих не связана каким-либо смыслом, то дальше наступает жуткий когнитивный диссонанс и пение превращается в бессмысленный набор звуков.
Мелодия
При написании мелодии для слов песни контролируется её скорость (т.е. темп речи), высота и длина фразы (фразу, как правило, легко определить, она ограничена паузами).
Если увеличить скорость, повысить высоту, сократить длину фразы, то энергия увеличится. Если наоборот, понизить скорость и высоту, увеличить длину фраз, то энергия понизится. Достаточно изменить один элемент из трех.
В действительности, средств выразительности, влияющих на энергию мелодии, больше, поэтому были описаны самые основные, причем именно их и легче всего услышать.
Аккомпанемент
Аккомпанемент (минус, instrumental) устроен нетривиально и состоит из трех функциональных частей (основа, ритм и заполнение). Но для общего понимания того, как он влияет на энергию песни, достаточно учесть количество одновременно играющих инструментов. Всё интуитивно просто: увеличилось количество инструментов – увеличилась энергия, уменьшилось – энергия понизилась.
Halsey – Without me
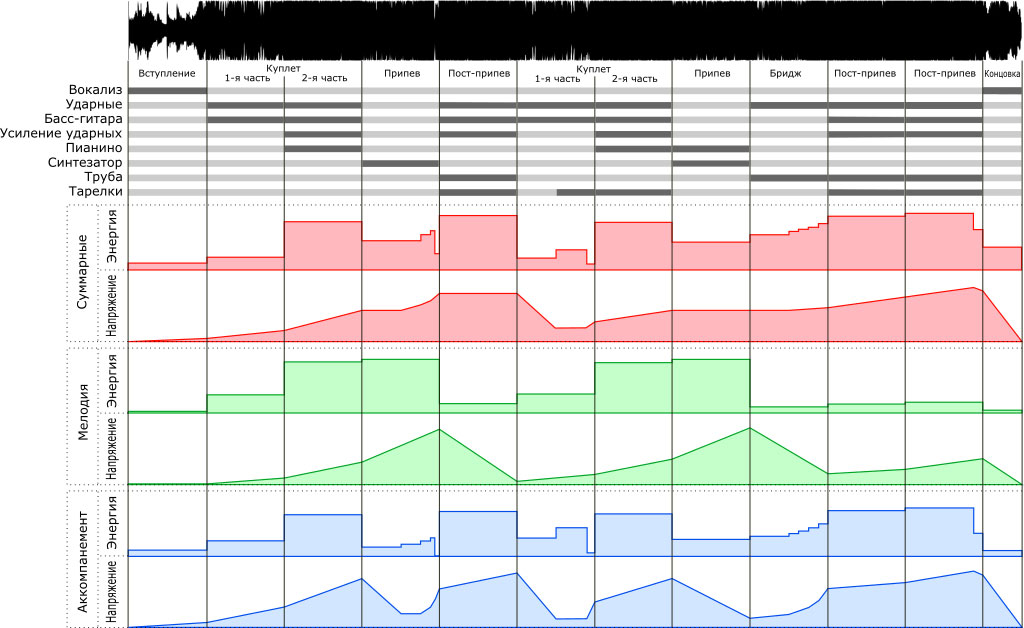
Как это работает, рассмотрим на примере песни Halsey – Without me, которая имела значительный коммерческий успех.

На рисунке представлены сверху вниз:
- Звуковая дорожка;
- Диаграмма звучания основных инструментов (светлый – не играет, темный – играет);
- Графики энергии и напряжения: суммарный всей песни, мелодии и аккомпанемента (построены исключительно по субъективным ощущениям). Диаграмма звучания инструментов напрямую коррелирует с энергией аккомпанемента.
Слова песни соответствуют стандартному шаблону – история в куплетах, эмоции в припеве. Причем, последняя наиболее важная деталь истории раскрывается только в бридже, поэтому до этого момента слушателя должна мучить загадка, почему же такая трогательная история любви в итоге закончилась.
В данной песне энергия мелодии в первую очередь зависит от высоты тона, с которым Halsey «в среднем» поёт каждую часть. От первой части первого куплета и до первой части припева высота повышается, далее плавно снижается. Со второго куплета и до бриджа всё повторяется и далее в бридже имеем самую низкую энергию мелодии.
Аккомпанемент идеально согласован с мелодией вокала. В первой части припева имеем максимальную энергию мелодии и разрешение аккомпанемента. Далее наоборот, мелодия разрешается, а аккомпанемент достигает своей максимальной энергии. В итоге получается, что припев суммарно имеет практически постоянную высокую энергию и напряжение.
Из суммарных графиков видна «конструкция» песни, а именно закономерное изменение энергии и напряжения. Выделяется третий припев, который короче первых двух, что сделано для снижения предсказуемости.
Также в третьем припеве отсутствует участок с постоянным уровнем напряжения. Это не недостаток, а стандартное решение для популярных песен – после бриджа с низкой энергией сразу вступает припев.
Максимальный уровень энергии приходится на 13 часть песни (всего 14 частей). Следовательно, кульминация помещена максимально близко к концу. Поэтому песня заканчивается неожиданно быстро. Именно поэтому графики напряжения не снижаются до нуля. Это оставляет у слушателя чувство незавершенности, которое должно заставлять слушать песню снова и снова. И как видно из коммерческого успеха данной песни, данное решение сработало идеально.
Вывод
Таким образом, алгоритм для сочинения популярной музыки достаточно прост. Для этого песня разбивается на более простые элементы, такие как слова, мелодия и аккомпанемент. И далее эти элементы комбинируются так, чтобы получилась хорошая структура песни. Иначе говоря, чтобы графики суммарной энергии и напряжения отражали какую-либо закономерность. Какие средства выразительности использовать, как развивать мелодию вокала, когда и какие добавлять инструменты, можно решить самому (т.е. проявить творчество), а можно подсмотреть у какой-нибудь успешной песни. В итоге, применив простую комбинаторику можно получить хорошую популярную песню.
Как выглядит творчество (не для впечатлительных)
Как выглядит творчество, рассмотрим на примере песен из топа Русского радио Полина Гагарина – Ангелы в танце и Zivert – Credo.
Полина Гагарина – Ангелы в танце
Слова песни Полины Гагариной – Ангелы в танце типичны для русской популярной песни – смысл на слух не воспринимается. Главная строчка песни – «наши ангелы в танце», соответственно возникают следующие вопросы. Почему ангелы и откуда они взялись? Почему они танцуют? Почему наши? Логично прояснить эти моменты в куплетах, но авторы этого не сделали.
Слова всей песни повествовательные, нет ни одной эмоциональной строчки. Причем, первый куплет рассказывает (очень метафорично) о сумасшедшей влюбленности (после тебя, танцы на углях). Далее тема песни резко меняется, и Полина приглашает послушать groove. А в припеве оказывается, что песня посвящена всем, у кого депрессия (и выгорание).
В словах отсутствует какая-либо история, вместо нее малосвязанный набор предложений и общих философских фраз, которые вряд ли смогут вызвать эмоциональный отклик у слушателя.
Энергия мелодии во второй части куплета резко повышается, далее, в припеве, она остается почти такой же, и во второй части припева она значительно падает. Со второго куплета всё повторяется примерно так же. Так как нет значительно контраста между куплетом и припевом, то возникает неопределенность, мы всё еще в куплете или это уже припев.
Аккомпанемент ведет себя не менее странно. Во второй части куплета, вместе с резким повышением энергии мелодии, энергия аккомпанемента тоже резко повышается, причем до уровня припева (так как вступают типичные для припева инструменты: тарелка и длинные ноты пианино). Неопределенность, не припев ли это, значительно усиливается.
Также непонятно, почему в середине первой части второго куплета начинают играть тарелки. Получается, что данная часть песни разбита на две подчасти, но такое решение в структуру песни не вписывается.
В итоге суммарные графики энергии и напряжения песни никакой закономерности не отражают. В действительности, со второй части куплета, происходит «потеря координат» и понимать, где мы сейчас находимся (в куплете или припеве) становится крайне затруднительно.
Данная песня красочно демонстрирует важность предсказуемости в музыке. Так как энергия аккомпанемента и мелодии вокала меняются без всякой логики и закономерности, песня становится абсолютно непредсказуемой.
Zivert – Credo

Песня Zivert – Credo пример 100% творчества, даже возникает такое ощущение, что авторы других песен никогда не слышали. Это отчетливо проявляется на структурном уровне, а именно в длительности частей песни.
Музыкальное произведение состоит из частей одинаковой длины (возможны отклонения, но это делается очень аккуратно). Здесь же первое вступление длится около 16 секунд, а второе уже 8, куплет снова 16, а припев целых 32. Далее следует пост-припев, состоящий из двух подчастей по 8 секунд. Хотя обычно, либо все части песни делятся на подчасти, либо ни одной. После такого «творческого» подхода, ожидания слушателя полностью разрушены и не понятно, что дальше ожидать от песни.
Кроме того, в середине припева ничего нового не происходит, хотя ожидания, что должно что-то измениться, есть. А во второй подчасти пост-припева внезапно добавляется хлопок. Имеем гениальный садистский ход: где слушатель ожидает – ничего не добавляем, а где не ожидает – добавляем по максимуму!
В данной песне присутствует два творческих решения, которые невозможно прокомментировать. Первое, в песне два вступления, причем одно — это предприпев. Второе, энергия песни со второго куплета и до второго припева понижается.
После описанных недостатков, остальные кажутся сущими мелочами. В действительности, только их достаточно чтобы полностью испортить песню. К ним относятся неправильное произношение слов: «пЕшим», «прЕчесался», «неовИчно» и бросающееся на слух неверное ударение в слове «чЕловек».
К тому же, все слова песни повествовательны. Фраза «каждому по факту» по интонации ближе к бюрократии, чем даже к нормальному разговору, не говоря уже о пении.
К сомнительно положительному моменту песни можно отнести то, что есть дизайн в словах песни. В куплетах и предприпеве смысл на слух не воспринимается, но припев понять легко (контраст: понятно – не понятно).
Из краткого разбора песни Zivert – Credo, напрашивается вывод, для того чтобы занять первую строчку хит парада Русского Радио достаточно в припеве спеть о чем-нибудь наболевшем. А что творится в оставшихся элементах песни, значения не имеет.
Как алгоритмы рекомендуют песни и определяют, что нам нравится, и могут ли машины писать музыку? Ответ на эти вопросы ищет Николай Дубинин, ведущий YouTube-канала «Индустрия 4.0»
Нейросети хорошо научились работать с изображениями, видео и текстами — они распознают лица, эмоции, создают правдоподобные дипфейки, переводят онлайн, генерируют человеческую речь. Но есть область в которой глобально они бессильны — это музыка. Конечно, все пишут о магии Spotify — когда сервис советует какие-то новые неизвестные треки, которые удивительным образом нам нравятся. Как на самом деле работают алгоритмы Spotify, «Яндекс.Музыки» и Apple Music? Могут ли они создавать новую великую музыку или даже воскрешать умерших музыкантов и продолжить писать за них?
Коллаборативная фильтрация
Первое и основное, что делают все, — коллаборативная фильтрация. Что это такое? Алгоритм видит, что нравится вам, и видит, и что нравится другим. Он находит похожих пользователей и предлагает им как бы обменяться треками, которые они не слышали.
Представьте, что происходит когда алгоритму известны предпочтения сотен миллионов пользователей. К тому же, как отчитываются Spotify, они каждый день получают до 5 млрд цифровых взаимодействий. Точность попадания становится практически идеальной.
Но с коллаборативной фильтрацией есть две проблемы:
- Холодные пользователи. Это те, кто только что зарегистрировался в сервисе, и система о них ничего не знает;
- Холодные треки. Это те, которые только появились, и о них ничего неизвестно, либо какие-то редкие песни.
Проблема с холодными пользователями решается просто — новичками после регистрации предлагают рассказать, кого они слушают. После этого система понимает, что можно предложить конкретному пользователю. А если пользователь не хочет отвечать на вопросы, ему накидывается средняя популярная музыка, и система смотрит на реакцию. Если пользователь переключает трек, алгоритм понимает — не зашло, и подбрасывает что-то из другого жанра. Своими действиями холодный пользователь обучает систему, и она уже понимает, что ему предложить, чтобы он не ушел с сервиса.
Главный принцип коллаборативной фильтрации — explore and exploit — исследовать и использовать. Использовать — пользовательскую историю, его плейлисты, поведение — прослушали ли вы песню полностью, пропустили или лайкнули. А исследуют алгоритмы информацию о других пользователях: их плейлисты и любимых исполнителей.
А что насчет холодных треков? Как алгоритмы работают с ними?
- Алгоритмы в буквальном смысле гуляют по сети, анализируют тексты и таким образом видят, что пишут об исполнителях и об их треках. Нейросети следят за трендами.
- А еще сервисы анализируют каждый загруженный в систему аудиофайл. Трек нарезается на фрагменты — по ним делаются спектрограммы, понятные машинам. Так нейросети обучают на «внутренностях» популярных треков, по которым много отзывов. После этого алгоритм подбирает что-то похожее по звучанию из тех холодных треков, которые мало кто слышал.
Но разложить песню на ДНК у машины до конца пока не получается — так же, как из мельчайших частей написать что-то новое.
По словам руководителя лаборатории машинного обучения «Яндекса» Александра Крайнова, генерировать текст для машины гораздо легче, чем музыку: «В тексте есть символы, есть некоторая закономерность. Символы — это уже закодированная, сжатая информация. С изображением тоже просто, просто потому что там объем данных меньше. А звук — он большой, сложный, у него очень длинные и большие временные зависимости. В звуке очень много чего может объединяться: кто-то петь начинает на заднем плане, то есть это не просто звук голоса, а слова».
Могут ли машины самостоятельно писать музыку?
Например, год назад вышла песня, созданная алгоритмом, который обучали на хитах “Евровидения”. Называется «Синие джинсы и кровавые слезы».
Но, конечно, финальный вариант все равно докручивали люди.
«Нейронные сети замечательно умеют генерировать картины, например. Нейронные сети хорошо генерируют человеческую речь: то, как Алиса говорит, — это целиком и полностью сгенерированная нейронной сетью речь», — говорит Александр Крайнов. Но в написании музыки «от и до» заметного прорыва пока нет. В основном все заметные проекты генерируют потоковую музыку из семплов: собирается готовая библиотека звуков, а программисты придумывают алгоритмы — то есть по каким законам эти семплы будут складываться в музыку. И математические формулы создают бесконечный поток музыки. Например, российский сервис по генерации музыки Mubert работает именно по такому принципу.
Может ли нейросеть проанализировать творчество уже ушедших из жизни музыкантов, понять, какие законы они использовали у себя в музыке, и попробовать написать что-то новое под них? Способна ли нейросеть написать новую песню за «Кино», за Queen, за «Сектор Газа»? По мнению основателя Mubert Алексея Кочеткова, теоретически да, но для этого нужно несколько нейросетей: одна будет петь, другая — играть на гитаре, например. Но человек в этом процессе все равно необходим.
Многие наверняка видели ролик музыканта Кирилла Нечаева. Он взял исследование «Яндекс.Музыки», в котором они проанализировали тексты исполнителей русского рэпа.
Например, у Элджея, по мнению нейросети, самые характерные слова это: тусовка, детка, видеться, травка, таблетка, кроссовки, тряпки, сиять, фотка, д***я. Программа написала новые тексты под Элджея, Макса Коржа, Гуфа и других, а Нечаев все это спел.
Но одно дело — написать текст, совсем другое — музыку. И пока нейросеть не в состоянии сотворить шедевр.
Что еще почитать по теме:
- «Трек недоступен в вашем регионе»: как стриминг определяет доступ и цены
- Как работают искусственный интеллект, машинное и глубокое обучение
- Где слушать генеративную музыку
- Разборка Spotify: как главный музыкальный стриминг-сервис стал коварной медиа-империей
- Введение в генеративную музыку (ENG)
Подписывайтесь на Telegram-канал РБК Тренды и будьте в курсе актуальных тенденций и прогнозов о будущем технологий, эко-номики, образования и инноваций.
Среди всех музыкальных сервисов Spotify стал первой компанией, объединившей несколько моделей анализа песен. Разработчица София Чиокка рассказала, какие именно механизмы позволяют Spotify находить песни, которые понравятся именно вам.
В этот понедельник, как и в каждый понедельник, более 100 миллионов пользователей Spotify открыли ожидающий их новый плейлист. Это индивидуальный микс из тридцати песен, которые они никогда не слышали, но которые им, вероятно, понравятся. Это называется Discover Weekly, и это похоже на магию.
Я огромная фанатка Spotify, а особенно Discover Weekly. Почему? Я чувствую, что меня видят. Spotify знает мои музыкальные вкусы лучше, чем любой человек в моей жизни, и я восхищаюсь тем, что каждую неделю я слышу в подборке отличные треки, которые сама бы никогда не нашла.
Те, кто незнаком с сервисом, познакомьтесь с моим виртуальным лучшим другом:
Оказалось, что я не одна одержима Discover Weekly. Пользователи сходят от него с ума, что привело к тому, что Spotify смещает свой фокус, инвестируя больше ресурсов в плейлисты, основанные на алгоритмах.
It’s scary how well @Spotify Discover Weekly playlists know me. Like former-lover-who-lived-through-a-near-death experience-with-me well.
— dave horwitz (@Dave_Horwitz) October 27, 2015
At this point @Spotify’s discover weekly knows me so well that if it proposed I’d say yes
— Amanda Whitbred (@amandawhitbred) August 18, 2016
С тех пор, как Discover Weekly появился в 2015 году, мне не терпелось узнать, как он работает. После трех недель поиска информации, мне удалось заглянуть за занавес.
Итак, как Spotify так хорошо подбирает 30 песен для каждого человека каждую неделю? Давайте сделаем шаг назад и посмотрим на то, как делают рекомендации другие музыкальные сервисы и как Spotify справляется с этой задачей лучше.
Краткая история отбора музыки
В 2000-х рекомендации музыки начались с Songza, в котором использовали ручной отбор, чтобы создавать плейлисты для пользователей. “Ручное курирование” означало, что команда “музыкальных экспертов” или других кураторов вручную составляла плейлисты, которые хорошо звучали, а пользователи просто слушали их. (Позже эту же стратегию применили Beats Music). Ручной отбор хорошо работал, он был простым, но он не принимал во внимание индивидуальный музыкальный вкус каждого слушателя.
Как и Songza, Pandora была одним из первопроходцев в области отбора музыки. Они применили более сложный подход, вручную проставив теги с атрибутами песен. Это означало, что люди слушали музыку и выбирали несколько тегов для каждой песни. Затем алгоритм Pandora фильтровал песни по определенным тегам, чтобы создавать плейлисты с похожей музыкой.
Примерно в то же время в MIT Media Lab на свет появилось агентство The Echo Nest, которое предложило более радикальный подход к персонализированной музыке. The Echo Nest использовали алгоритмы, чтобы анализировать текстовое и музыкальное содержание песен для идентификации музыки и создания персональных рекомендаций и плейлистов.
И, наконец, ещё один подход использует Last.fm. Это процесс под названием коллаборативная фильтрация, о котором я расскажу чуть позже.
Как же в Spotify создали волшебный алгоритм, который отслеживает вкусы каждого пользователя гораздо точнее, чем другие сервисы?
Три типа моделей рекомендаций Spotify
Spotify использует не одну революционную модель. Вместо этого они совмещают несколько лучших стратегий, чтобы создать собственный мощный рекомендательный движок.
Чтобы создать Discover Weekly, Spotify применяет три главных типа моделей:
- Модели совместной фильтрации (их применяет Last.fm), которые анализирует ваше поведение и поведение других пользователей.
- Модели обработки естественного языка (NLP), которые работают на основе анализа текста.
- Аудио-модели, которые анализируют необработанное аудио.
Давайте посмотрим на каждую из этих моделей.
Совместная фильтрация
Для начала немного информации: когда люди слышат о совместной фильтрации, они вспоминают Netflix, так как именно эта компания одной из первых применила совместную фильтрацию для создания рекомендательной модели, которая использовала оценки пользователей, чтобы понять, какие фильмы рекомендовать другим “аналогичным” пользователям.
После того, как Netflix это удалось, эту модель стали использовать все чаще, и теперь она является стартовой точкой для всех желающих создать рекомендательный движок.
Однако в Spotify нет пользовательских оценок для музыки. Вместо этого данные Spotify основаны на неявной обратной связи, то есть, на песнях, которые мы послушали, а также на дополнительных данных, например, сохранили ли пользователи трек в своей плейлист или посетили ли они страницу исполнителя после прослушивания.
Но что такое совместная фильтрация, и как она работает? Вот краткое описание в виде небольшого диалога:
Что здесь происходит? У каждого из них есть свои предпочтения: человеку слева нравятся песни P, Q, R и S, а человеку справа — Q, R, S и T. Совместная фильтрация использует эти данные, чтобы предложить человеку справа послушать P, а человеку слева — трек T. Все просто, да?
Но как Spotify использует эту концепцию, чтобы создать рекомендации для миллионов пользователей, основываясь на миллионах предпочтений других людей? Матричные вычисления при помощи библиотек Python.
Эта матрица на самом деле огромна. Каждый ряд представляет одного из 140 миллионов пользователей Spotify, а каждая колонка представляет одну из 30 миллионов песен в базе Spotify. Затем библиотека Python запускает эту длинную и сложную формулу факторизации матрицы:
Когда вычисления закончены, мы получаем два типа векторов, обозначенных здесь как X и Y. X — это вектор пользователя, представляющий вкус одного пользователя, а Y — вектор песни, представляющий профиль отдельно взятой песни.
Теперь у нас есть 140 миллионов векторов пользователей и 30 миллионов векторов песен. Содержимое этих векторов — это числа, бессмысленные по отдельности, но крайне важные для сравнения.
Чтобы обнаружить пользователей со схожим с моим вкусом, совместная фильтрация сравнивает мой вектор с векторами других пользователей. То же относится и к вектору Y — вы можете сравнить вектор данной песни с векторами других песен, чтобы найти наиболее похожие на конкретный трек.
Совместная фильтрация работает достаточно хорошо, но Spotify добавляет и другие механизмы. Перейдем к NLP.
Обработка естественного языка
Второй тип рекомендательных моделей — модели обработки естественного языка (NLP). Источник данных этих моделей — слова. Это метаданные песен, новостные статьи, блоги и другие тексты в интернете.

Обработка естественного языка, то есть, способность компьютера понимать человеческую речь как она есть, это обширное поле, которое часто предшествует анализу смысла.
Мы не будем рассматривать механизмы NLP, поэтому вот поверхностное объяснение того, что происходит. Spotify постоянно ищет тексты о музыке и вычисляет, что люди говорят о конкретных исполнителях и песнях: какие прилагательные они используют и какие другие песни и исполнители часто упоминаются рядом.
Хотя я не знаю, как именно Spotify обрабатывает собранные данные, я могу сказать, как с ними работали The Echo Nest. Они распределяли данные на “культурные векторы” или “основные термины”. У каждого исполнителя и у каждой песни были тысячи меняющихся ежедневно основных терминов. К каждому термину было привязано свое значение, которое показывало, насколько важно это описание (то есть, вероятность, с которой кто-то опишет эту музыку этим термином).
Затем, как и в совместной фильтрации, NLP-модель использует эти термины и значения, чтобы создать векторное представление, которое используется для сравнения песен.
Модели необработанного аудио
Вы можете подумать: “У нас уже есть так много данных”. Зачем нам анализировать само аудио?”
Во-первых, третья модель улучшает точность этого рекомендательного сервиса. Но у этой модели есть и более важная цель: в отличие от двух предыдущих типов, она принимает во внимание новые песни.
Например, ваш друг написал песню и выложил её на Spotify. Может быть, её прослушали 50 раз, поэтому совместная фильтрация не сработает должным образом. Если её не упомянули нигде в интернете, то NLP-модели её не увидят. К счастью, аудио-модели не выделяют популярные песни и новые песни, поэтому с их помощью, песня вашего друга может попасть в Discover Weekly вместе с более известными песнями.
Как мы можем анализировать данные необработанного аудио, которые кажутся такими абстрактными? При помощи сверточных нейронных сетей!
Сверточные нейронные сети — это технология, которая используется и в распознавании лиц. Spotify модифицировали её для обработки аудиоданных вместо пикселей. Вот пример архитектуры нейронной сети:
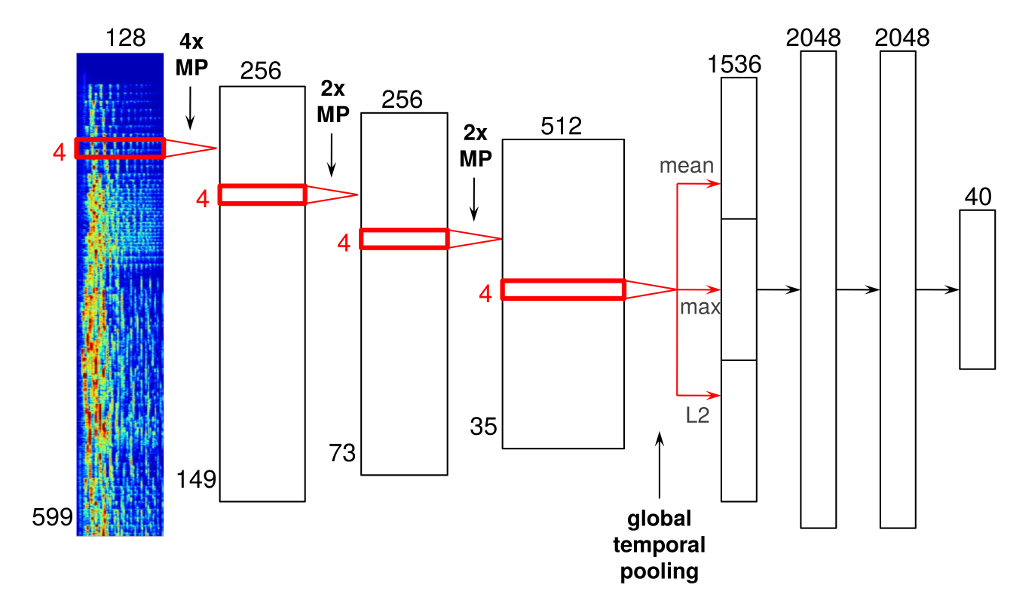
Эта нейронная сеть имеет четыре сверточных слоя (толстые полосы слева) и три плотных слоя (более узкие полосы справа). Входные данные представляют собой представления звуковых кадров со временем и частотой, которые затем конкатенируются для формирования спектрограммы.
Звуковые кадры проходят через сверточные слои, и результатом этого становится слой “глобального временного объединения”, который объединяет всю ось времени, эффективно вычисляя статистику изученных функций на протяжении песни. После обработки нейросеть выдает характеристики песни: время, тональность, лад, темп и громкость. Ниже вы можете видеть эти данные для 30-секундного отрывка песни Daft Punk “Around the World”.
В конце концов, эти ключевые характеристики песни позволяют Spotify понимать фундаментальные сходства песен и находить пользователей, которым эти песни должны понравиться.
В этом и заключаются основы трех основных типов рекомендательных моделей, на которых основан механизм Spotify и создание плейлиста Discover Weekly.
Конечно, все эти модели связаны в большую экосистему Spotify, которая включает огромное количество данных для рекомендательных моделей и использует множество кластеров Hadoop для обработки гигантских матриц бесконечного количества музыкальных статей и колоссального количества аудиофайлов.
Если вы нашли опечатку – выделите ее и нажмите Ctrl + Enter! Для связи с нами вы можете использовать info@apptractor.ru.
Оценка этой статьи по мнению читателей:
Последний альбом группы Queen с участием легендарного Фредди Меркьюри был записан уже после смерти вокалиста. И в этом альбоме есть одна интереcная песня, собранная буквально по кусочкам из обрывков записей Меркьюри, сделанных незадолго до смерти.
Эта композиция не должна была появиться и никто в Queen даже не думал, что из этих обрывков что-то можно сделать. Но продюсер группы практически самолично собрал всё воедино и создал знаменитую… как же ее… Простите, но название совершенно вылетело из головы.
И что же делать в подобных ситуациях?
Раньше, услышав красивую песню где-нибудь в кафе или на улице, вы могли достать смартфон, запустить приложение Shazam или SoundHound и тут же получить всю подробную информацию. Но сегодня бурный рост технологий позволил нечто большее!
Возвращаясь к забытой песне Фредди Меркьюри, мне достаточно запустить на смартфоне Google Ассистент, сказать фразу «Что сейчас играет?», а затем просто напеть мелодию, которая крутится в голове — «та-да-та-тааааа та-та-та-таааа та-да-та-таааа»:
И буквально через несколько секунд смартфон выдает правильный результат — You Don’t Fool Me группы Queen:
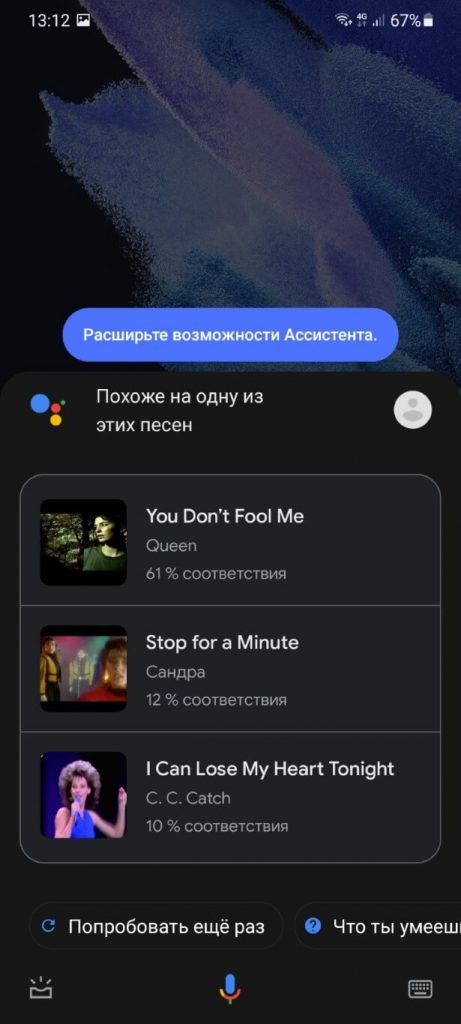
Как это вообще возможно!? Обычно в таких ситуациях отвечают — искусственный интеллект. Но если вам хочется получить настоящий ответ, тогда предлагаю вместе со мной погрузиться в увлекательный мир музыки!
После прочтения этой статьи вы поймете, как именно бездушный процессор смартфона стал еще на один шаг ближе к человеческому разуму. Или, по крайней мере, научился еще лучше его имитировать.
Часть 1. Природа звука
Бессмысленно говорить о том, как работает Shazam или распознавание музыки в целом, если не понимать, что такое музыка и звуки вообще. Поэтому вначале я уделю немного внимания этому вопросу.
Если же вы хорошо в этом разбираетесь, тогда переходите к следующему разделу. Но помните — понять работу Shazam без понимания этих основ будет тяжело.
Итак, звук возникает у нас в голове, когда воздух стучит по барабанной перепонке в наших ушах. Очень подробно этот процесс я описывал в статье о шумоподавлении или вреде громкой музыки. Так что здесь не будем повторяться.
Сам по себе воздух не может ни ударить по барабанной перепонке, ни сдвинуть с места даже пылинку. Это делают миллиарды молекул, хаотично летающих в пространстве.
Но чтобы они могли что-то или кого-то ударить, вначале нужно хорошенько их толкнуть — в точности как шары в бильярде. Именно это и делает любой динамик. Он движется вперед и назад, толкая молекулы воздуха то в одну, то в обратную сторону.
Мы даже можем отобразить это движение динамика на графике в виде волны:
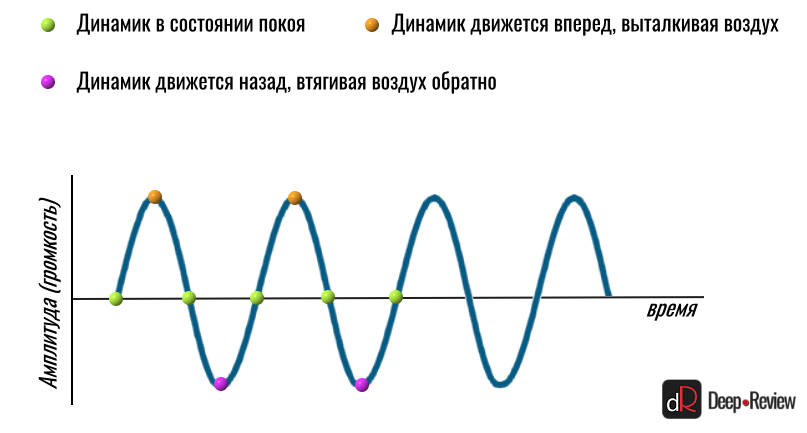
Чем сильнее динамик отклонится в сторону (или вверх/вниз на графике), тем выше будет волна, а значит звук — громче. То, какую ноту или звук мы услышим, зависит только от того, сколько движений вперед-назад за одну секунду сделает наш динамик.
Если за 1 секунду произойдет 440 движений вперед-назад, мы услышим ноту ля. И не важно, что будет вибрировать 440 раз в секунду — струна гитары, фортепиано или школьная линейка, прижатая одной стороной к столу — мы будем слышать ноту ля.
Вот только если это будет делать динамик, вместо приятного звука мы услышим не очень приятный монотонный гул:
Почему так происходит? Почему, когда мы нажимаем клавишу ля на пианино, она звучит приятно, а не так «искусственно», будто сгенерирована на компьютере?
Всё дело в том, что в реальном мире практически не существует идеальных движений. То есть, если бы струна гитары или скрипки вибрировала или двигалась вперед-назад только так:

Тогда бы мы услышали точно такой же монотонный неприятный гул, как в примере выше. Что более интересно, совершенно неважно, на каком инструменте мы пытались бы воспроизвести ноту ля (на фортепиано, скрипке, гитаре) — во всех случаях мы бы услышали один и тот же монотонный звук.
А теперь посмотрите в замедленном движении, что происходит со струной в реальности (на примере скрипки):

Такое движение скорее можно схематически изобразить вот так:

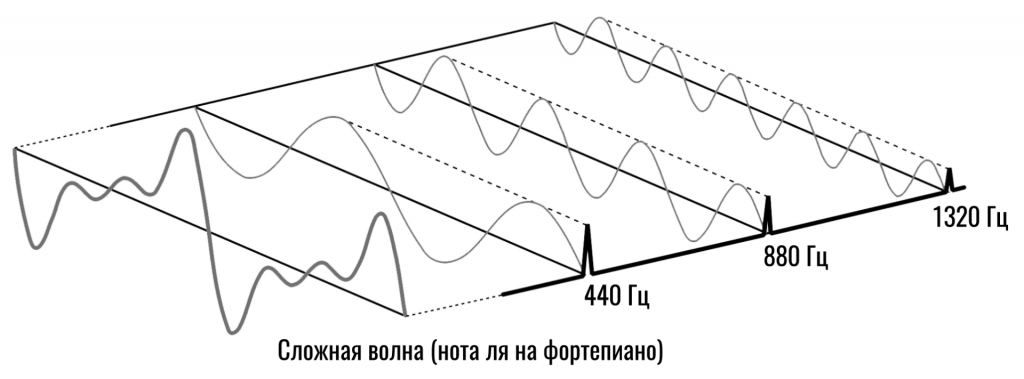
И это еще очень упрощенный пример. На самом деле, движение струны гораздо сложнее! Струна вибрирует вся целиком (как показано на первой анимации) и создает звук на частоте 440 Гц (монотонная нота ля). Но также вибрирует и каждая половинка струны, создавая звуки на частотах 880 Гц (половинка в два раза короче целой струны, а значит и вибрирует в 2 раза быстрее, т.е. 880 раз в секунду).
Кроме того, струна вибрирует третями, четвертями и т.д. И каждый участок струны, вибрируя, запускает еще отдельные звуковые волны на частотах в 3, 4, 5 (и так до бесконечности) раз выше основного тона (в нашем примере — нота ля или 440 Гц). Каждая такая вибрация создает свой собственный монотонный звук на более высоких частотах.
Мы называем такие звуки гармониками. То есть, основная гармоника — это частота 440 Гц (если мы говорим о ноте ля), вторая гармоника — это когда струна будет вибрировать половинами, т.е. звук на частоте 880 Гц, третья гармоника — 1320 Гц (440*3) и так далее.
А теперь добавьте к этому еще и вибрацию корпуса инструмента, например, скрипки. Ведь струна жестко закреплена на корпусе и ее вибрация также приводит к вибрации всего инструмента. Эти вибрации в свою очередь зависят от породы дерева, толщины корпуса и его формы.
Каждая такая вибрация добавляет к нашему ансамблю звуков еще и свои монотонные писки на разных частотах.
Именно эти дополнительные частоты/ноты/звуки, вызванные особенностями колебания струны/корпуса и создают уникальный тембр каждого музыкального инструмента.
Мы можем даже самостоятельно создать звук похожий на пианино или гитару, просто взяв монотонный гул, который я приводил выше, и добавить к нему еще различные монотонные пищалки, только на более высоких частотах и с разной громкостью.
От того, насколько громко (и как долго) будет звучать каждая дополнительная частота и зависит тембр инструмента.
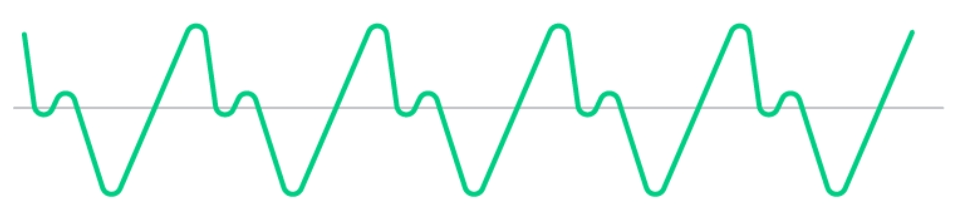
Реальная звуковая волна
Вы наверняка не раз видели звуковую волну какого-то реального звука и она совершенно не похожа на все эти красивые графики волн, которые встречаются в статьях, например, такую:

В реальности звук «выглядит» скорее так:

Но как это понимать? Где здесь красивые привычные волны? Как хотя бы понять частоту этой звуковой волны? Напомню, частота — это количество волн за секунду. К примеру, на синем графике чуть выше мы видим частоту 8 Гц или 8 волн за секунду. А на втором графике вообще отсутствуют какие-то повторяющиеся узоры. Почему?
Ответ на этот вопрос уже дан чуть выше. Ни один инструмент не создает только одну звуковую волну на одной частоте. В этом случае мы бы слышали монотонный гул. Но так как на основной тон накладывается еще десяток-другой частот, график полностью искажается.
Вот, к примеру, у нас есть основная частота 440 Гц (нота ля):

Струна будет создавать другие частоты, первой из которых станет 880 Гц (это вторая гармоника или 440*2). Такая частота будет получаться, когда две половинки струны будут вибрировать отдельно. И выглядеть вторая волна (880 Гц) будет уже так:

То есть, мы видим, что количество волн увеличилось вдвое (440 Гц и 880 Гц). Но две волны не будут путешествовать по воздуху отдельно, они сольются в одну. И какой же она будет?
Какие-то пики одной волны совпадут с впадинами другой и немного погасятся, в каком-то месте пики двух волн наложатся и она станет еще выше (громче). В общем, вместо двух волн разной частоты мы получим одну волну такого вида:
Глядя на эту волну, мы даже можем легко себе представить, как именно будет двигаться динамик, чтобы воспроизвести этот звук.
Вначале он максимально отклонится вперед, толкая молекулы на нас, затем назад до состояния покоя (прямая серая линия или 0 по оси Y — это состояние покоя), затем немножко вперед (маленький зеленый горбик на графике), после чего резко назад, втягивая воздух обратно (зеленая линия идет вниз, ниже серой полоски). Затем динамик снова вытолкнет весь воздух вперед (максимальная горка на графике) и так далее.
Естественно, чем больше разных частот будет создавать струна своим колебанием, тем сложнее окажется финальный «рисунок».
Таким образом, реальная звуковая волна — это результат наложения сотен волн различной частоты. Оттого она и выглядит так сложно.
На этом мы, пожалуй, и остановимся. Этих знаний должно хватить для понимания основной темы.
Часть 2. Как работает Shazam и любая другая технология распознавания музыки
Если я попрошу вас напеть какую-то музыкальную композицию, что именно вы споете? Будете ли вы учитывать басовую партию или партию ударных инструментов? А если речь идет об оркестровой музыке, в которой одновременно могут звучать десятки музыкальных инструментов?
Конечно же, вы просто напоете основную мелодию, игнорируя всё остальное. И что самое удивительное, я без проблем пойму, о чем идет речь. Даже если до вашего исполнения слушал эту композицию только на хорошей акустике в высоком качестве.
То есть, мы интуитивно можем сократить очень сложную и красивую музыку до нескольких простых нот. Точно так же работает и технология распознавания музыки. Вот только у смартфона нет интуиции и в этом его проблема.
Для бездушной железки даже самая прекрасная мелодия ничем не отличается от рёва мотора или простого шума ветра. Поэтому мы должны создать алгоритм, который бы привил смартфону чувство прекрасного. Этим и займемся!
Шаг 1. Анализируем частоты
Чтобы Shazam или любой другой сервис мог хоть что-то сделать с музыкой, он должен для начала ее «понять». То есть, вместо сложного и бессмысленного графика, вроде этого:
Наш смартфон должен увидеть, какие конкретно частоты звучат в каждый момент времени. Другими словами, он должен получить музыку в том виде, в котором она была до того, как все частоты смешались в один поток и направились к звукозаписывающей аппаратуре на студии.
К примеру, вместо сложной волны от нажатия клавиши фортепиано, в которой смешались монотонные звуки на частотах 440 Гц, 880 Гц и 1320 Гц, нам нужно получить эти частоты отдельно и узнать громкость каждой из них:
Это как если бы я показал вам цветное пятно и сказал, чтобы вы назвали, какие основные цвета и в какой пропорции я смешивал, чтобы получить этот уникальный цвет.
К счастью, нам не нужно ломать голову над этой задачей, так как ее успешно решил французский математик еще в 1807 году! Так появилась функция под названием преобразование Фурье.
При помощи этого математического метода мы получаем из сложной волны набор всех частот, из которых она состоит, а также амплитуду (громкость) каждой из них.
После этого у смартфона появляется спектрограмма. Это такой график, который по оси Y показывает конкретную частоту, а по оси X — время. То есть, мы можем видеть, какие частоты и насколько громко звучат в каждый момент времени:
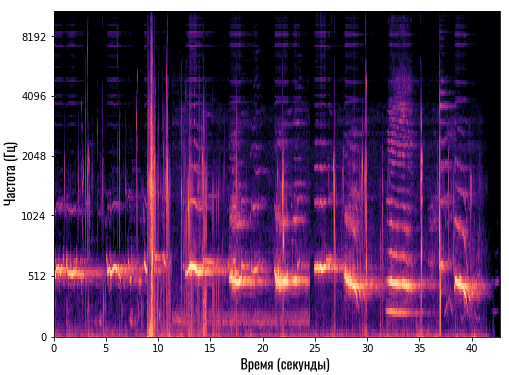
Так как у нас только две оси (X и Y), то громкость мы отображаем цветом. Чем ярче цвет — тем громче звучит эта частота.
К примеру, на спектрограмме выше мы видим, как где-то на 9-й секунде (по оси X) очень громко заиграли все инструменты или все частоты (красная вертикальная линия). А где-то на 31-й секунде частоты свыше 1500 Гц вообще пропали, то есть, в этот момент они не звучат в нашей композиции:
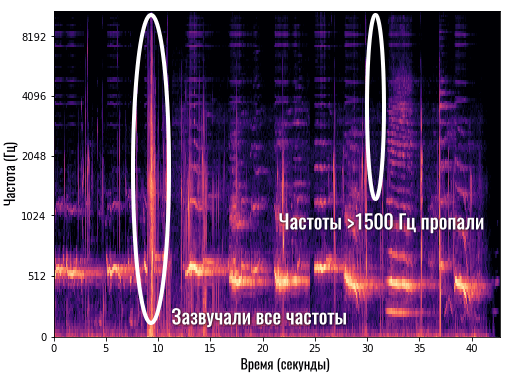
Согласитесь, в таком виде работать с музыкой гораздо проще и понятнее, чем смотреть на бессмысленный график ломаной линии. Здесь мы можем, к примеру, убрать какой-то дефект на частоте 10 000 Гц (какой-то лишний звонкий писк). Ведь мы увидим яркую полоску сверху, которую можно удалить, а затем снова сложить все частоты в один звук, но уже без удаленной частоты.
Теперь давайте подытожим. На первом шаге смартфон переводит записанный фрагмент мелодии в спектрограмму. Но пользоваться ею не получится. Ведь помимо мелодии, здесь присутствуют и посторонние звуки (шум улицы, кафе или разговоров, низкое качество микрофона и пр.).
Кроме того, в этой спектрограмме очень много информации. Смартфону она не нужна, как и нам не нужно знать все партии каждого инструмента, чтобы напеть фрагмент мелодии. И это приводит нас ко второму шагу.
Шаг 2. Создаем карту созвездий
Первое, что мы сделали для облегчения спектрограммы, это записали звук в режиме моно (стерео нам ни к чему), а также обрезали все частоты свыше 5000 Гц (или 4000 Гц — в зависимости от сервиса или алгоритма).
Естественно, качество звука сильно упало, так как мы слышим частоты до 15-20 тысяч герц (в зависимости от возраста) и эта информация есть в каждом музыкальном произведении. Но для распознавания музыки эти частоты совершенно не нужны. Основная мелодия находится гораздо ниже (в пределах 100-2000 Гц):

На этой картинке мы видим, что основной диапазон голосов и музыкальных инструментов (насыщенная темная часть каждой полоски) легко помещается до 1000 Гц, а уже гармоники уходят до предела слышимости.
А теперь начинается самое интересное! Алгоритм начинает анализировать полученную спектрограмму и искать на ней самые яркие области в каждый момент времени. Другими словами, он определяет, какие частоты (можем для простоты называть их нотами) звучат наиболее громко в конкретный момент времени.
Давайте возьмем нашу спектрограмму и отметим белыми точками такие «основные» частоты или ноты:
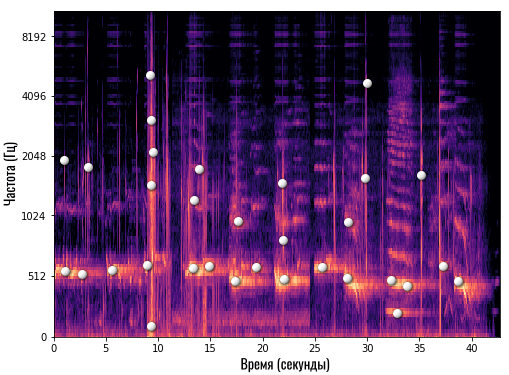
Сколько конкретно точек отмечает Shazam — сказать сложно, но это точно небольшое число (сравнительно). После такой обработки вместо массивной спектрограммы с большим количеством данных мы получаем очень компактную и аккуратную картину:
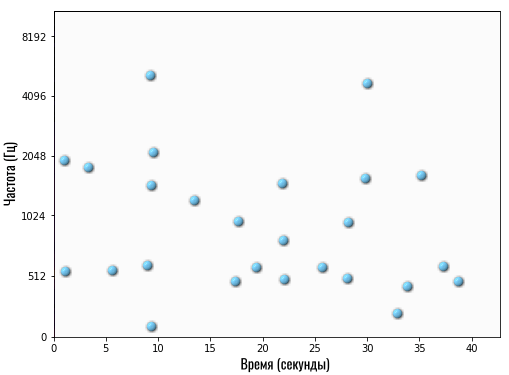
Теперь это своего рода уникальный отпечаток конкретной композиции. В Shazam его называют картой созвездий. Это примерно то, что делает наш мозг, когда мы хотим напеть сложную композицию — выделяет самые главные ноты.
Эта карта созвездий буквально показывает следующее:
- На 1-й секунде самые громкие частоты — это 512 и 2048 Гц
- На 5-й секунде самая ярко выраженная частота — 512 Гц
- На 30-й секунде композиции наиболее выражены частоты 1800 Гц и 4100 Гц
- И так далее
Помимо того, что мы колоссально сократили размер композиции, этот процесс естественным образом удалил все лишние звуки, так как на записи именно основная мелодия будет наиболее ярко выражена. Также мы удалили все гармоники, так как они практически всегда звучат тише основного тона.
Такую карту приложение создает на смартфоне еще до отправки данных на сервер Shazam. То есть, смартфон не передает звук.
В свою очередь компания также не хранит миллионы музыкальных композиций на своих серверах для сверки данных. Она пропустила каждую песню через этот алгоритм, чтобы получить ее «отпечатки». Они-то и хранятся на серверах.
Точнее, не совсем они…
Шаг 3. Убиваем главного врага — время
На данном этапе мы столкнулись с довольно серьезной проблемой. Предположим, вот это карта созвездий полноценной композиции на сервере Shazam:
Но человек даже теоретически не сможет каждый раз начинать записывать фрагмент интересующей его музыки с самого начала. Он может записать маленький кусочек где-то в середине композиции или за несколько секунд до конца песни.
В итоге, на смартфоне появится вот такая карта:
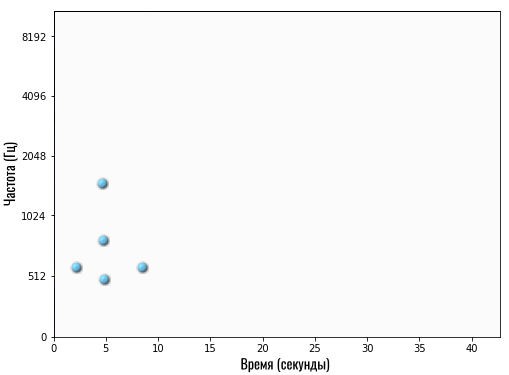
Если вы внимательно посмотрите, то увидите, что это фрагмент той же песни, что показана на карте чуть выше. Только в оригинале эти частоты (ноты) встречаются примерно с 19-й по 26-ю секунды, а здесь — примерно со 2-й по 9-ю.
Получается, смартфон передает серверу, что он услышал композицию, у которой на 5-й секунде ярко выражены 3 частоты: 510 Гц, 800 Гц и 1600 Гц (на графике по оси Y указаны только несколько частот, поэтому я называю частоты примерно).
Если сервер начнет искать у себя в базе данных композицию, у которой на 5-й секунде встречаются такие же основные частоты, то он может выдать любой результат, но только не правильный. Так как в оригинале эти частоты встречаются примерно на 22-й секунде.
А если не искать частоты с привязкой ко времени, то среди нескольких миллионов композиций может найтись сотня таких, в которых просто где-то встречаются 3 указанные частоты.
Что же делать?
Нужно избавиться от привязки ко времени, сохранив при этом привязку ко времени! Хотя это и кажется нелогичным на первый взгляд, решение получилось весьма элегантным.
Вместо списка частот (нот) с привязкой к конкретной секунде, мы берем одну любую точку на карте и связываем ее с несколькими другими точками. Например:
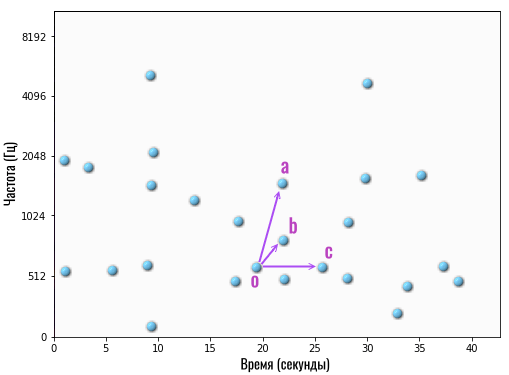
То есть, мы взяли опорную (главную) точку O (на 19-й секунде) и связали ее с несколькими другими точками (частотами/нотами) — a, b и c.
Под словом «связали» я лишь подразумеваю следующее. Мы берем две частоты и разницу во времени между ними. То есть, если мы говорим о связи O->A, тогда это две частоты: 515 Гц (точка O) и 1600 Гц (точка A), а разница во времени между ними составляет 3 секунды (точка A на 22 секунде минус точка O на 19 секунде).
Вот и всё! То есть, вместо конкретных частот с привязкой к определенному времени, мы храним информацию о том, как связаны конкретные частоты между собой. Например, сохраняем информацию о том, что в определенной композиции звук на частоте 1600 Гц начинается спустя 3 секунды после звука на частоте 515 Гц.
Теперь мы можем передать эту информацию на сервер и он поищет, есть ли у него в базе такая мелодия, в которой прозвучала частота 515 Гц, а затем ровно через 3 секунды был звук на частоте 1600 Гц.
Конечно, мы передаем не одну «связку частот», а множество. И какие-то пары будут встречаться в разных композициях, особенно если это ремикс популярной песни. Но Shazam или любой другой сервис выдаст в качестве результата ту песню, в которой таких совпадений было больше всего.
Размышления вместо выводов
Только что мы рассмотрели базовый принцип работы любого сервиса по распознаванию музыки. Конечно, у вас могло остаться множество вопросов, так как я хотел раскрыть тему в общих чертах, чтобы она была понятной самому широкому кругу читателей.
Например, не совсем понятно, по какому принципу алгоритм выбирает опорные точки, от которых затем строит связи с другими частотами.
Ответа на этот вопрос у меня нет, так как Shazam не раскрывает свои алгоритмы в таких деталях. Возможно, компания выбирает для каждого момента времени первую по счету точку (счет ведется снизу вверх слева направо) и связывает ее с несколькими рядом стоящими точками.
Кроме того, я не рассказал о том, как именно передаются и хранятся такие записи. Для этого используются хеши. Но само понятие хеш-функции настолько интересное и важное, что мне не хотелось использовать его без подробного и понятного объяснения. А это бы заняло еще больше места в статье и усложнило восприятие информации.
Также мы коснулись только алгоритмов, без упоминания нейросетей. А именно последние используются Google Ассистентом для определения мелодии, когда человек просто напевает или насвистывает мотив песни.
В этом случае также создаются уникальные «отпечатки» каждой песни, только затем добавляется еще один важный этап. Когда Google создала базу «отпечатков», для каждой такой песни были собраны «отпечатки» простых мелодий, напетых обычными людьми.
Затем нейросеть обучили находить оригинал по плохому неточному отпечатку, полученному с напетой человеком мелодии. Когда нейросеть прошла обучение на тысячах примеров, теперь она способна самостоятельно сопоставлять отпечаток напетой мелодии с отпечатком оригинала на серверах Google.
Более подробно о том, как работают нейросети и что такое обучение нейросетей, мы рассказывали в отдельной статье.
Алексей, глав. ред. Deep-Review
P.S. Не забудьте подписаться в Telegram на наш научно-популярный сайт о мобильных технологиях, чтобы не пропустить самое интересное!
Краткая история алгоритмической композиции
♦ ♦ ♦
1. Античность
Алгоритмической музыкой (алгоритмической музыкальной композицией) называют процесс создания музыкальных отрывков, последовательностей и композиций с помощью математических моделей, правил и алгоритмов.
Музыка и математика постоянно переплетались, начиная с незапамятных времен. В античности музыка вообще считалась ответвлением математики. Аврелий Кассиодор описывал математику как союз четырех дисциплин: арифметики, музыки, геометрии, и астрономии.
Первый опыт по формализации музыкальных звуков с помощью математических методов принадлежит Пифагору. В области гармоники Пифагором были произведены важные акустические исследования, приведшие к открытию закона, согласно которому первые (то есть самые главные, самые значимые) консонансы определяются простейшими числовыми отношениями 2/1, 3/2, 4/3. Так, половина струны звучит в октаву, 2/3 — в квинту, 3/4 — в кварту с целой струной. «Самая совершенная гармония» задаётся четвёркой простых чисел 6, 8, 9, 12, где крайние числа образуют между собой октаву, числа, взятые через одно — две квинты, а края с соседями — две кварты.
2. Средние Века
Первый известный пример применения алгоритмического подхода к сочинению музыки принадлежит итальянскому теоретику музыки Гвидо д’Ареццо (1026), разработавшему соответствующий метод привязки текста к нотам. Каждая нота была назначена определенной гласной и мелодия варьировалась, исходя из положения гласных в тексте. Стандартная 12-нотная октава была размечена следующим образом:
Г A B C D E F G a b c d e f g
Затем под этой строкой размещались три цикла гласных:
Г A B C D E F G a b c d e f g
a e i o u a e i o u a e i o u
После этого композитору оставалось составить мелодию, пользуясь такой таблицей, опираясь на извлеченные текстовые гласные.
3. Классический период
Следующим примером попытки применения алгоритмических процедур в докомпьютерную эпоху являются музыкальные кости Моцарта. В данном случае использовались музыкальные фрагменты, которые должны были быть объединены исходя из бросков кости.

Музыкальные кости Моцарта для 16-тактного менуэта
Номера сверху обозначают восьмые части вальса, а номера слева – возможные комбинации двух брошенных кубиков. Числа внутри матрицы соответствуют количеству тактов музыкальных фрагментов, которые затем объединяются для создания алгоритмического вальса.
Еще одна математическая модель, использовавшаяся в искусстве на протяжении веков – золотое сечение. Под золотым сечением (обозначающимся греческой буквой  ) подразумевается точка, делящая любой сегмент на такие две части, что соотношение размера более большой части по отношению к маленькой равно соотношению всего сегмента по отношению к большей части.
) подразумевается точка, делящая любой сегмент на такие две части, что соотношение размера более большой части по отношению к маленькой равно соотношению всего сегмента по отношению к большей части.
Золотое сечение неразрывно связано с последовательностью чисел Фибоначчи, открытой Леонардо Пизанским в 13 веке:
1, 1, 2, 3, 5, 8, 13, 21, 34, 55, 89, 144….,
где каждое последующее число является суммой двух предыдущих.
Данная последовательность всегда привлекала различных композиторов, которые использовали ее в качестве структурной схемы. По отношению ко всей длине произведения точка золотого сечения приходится примерно на 61,8 % хронометража. Обычно композиторы оставляют на данный отрезок кульминацию отрывка или драматический момент. Самым ранним примером использования такого подхода можно назвать мотет английского композитора Томаса Таллиса «Положиться на кого-то другого» – в золотой середине этого произведения идет такт полной тишины, за которым следует вступление хора из 40 голосов. Также использование золотого сечения можно встретить в произведениях таких композиторов как Шуберт, Бах, Дебюсси.
4. XX век
Бурное развитие науки и, в частности, математики, начавшееся с середины XIX века, позволило композиторам и ученым воплощать в своих трудах такие идеи, которые ранее казались невозможными. В 20—30х годах двадцатого века, украинский композитор и музыкальный теоретик Иосиф Шиллингер (1985—1943), иммигрировавший в США, развил свою «систему музыкальный композиции Шиллингера» – объемное произведение размером в две тысячи страниц. Данная система покрывала все фундаментальные аспекты музыкальной композиции – контрапункты, ритмы, гармонии и т. д.
Основной принцип работы этой системы заключался в использовании результирующего вектора (система была по сути геометрической) взаимовлияющих периодических колебаний на квадратную область ритмических и структурных пропорций, с последующей проекцией на области нот и аккордов, контрапунктов, гармонических прогрессий, эмоциональных и семантических аспектов.
Система Шиллингера была встречена резкой критикой за псевдонаучность, отсутствие внятных математических обоснований, и слишком сложный, непостоянный и сбивчивый стиль изложения. Однако именно эта работа определила направления многих будущих научных исследований в области алгоритмического сочинения музыки и вернула интерес к сфере, забытой на несколько веков.
Первым же человеком, использовавшим математический подход в музыке не в качестве инструмента, а в качестве принципа ее сочинения, был греческий архитектор и музыкант Яннис Ксенакис (1922—2001). По его словам, «с появлением электронных компьютеров композитор станет чем-то вроде пилота: ему останется нажимать кнопки, вводя координаты, и осуществлять контроль над путешествием корабля в пространстве музыки».
В 50-х последним словом авангардистской мысли был так называемый «сериализм» – сложнейшим образом устроенная музыка, которая воспринималась как акустический пуантилизм – то есть состояла из отдельных звуков, висящих в пустоте. На слух никакой логической связи между этими разнородными звуками обнаружить было невозможно, всё вместе производило впечатление бессистемного, визгливого и довольно разреженного акустического пара. Ксенакис написал статью против сериалистического метода, считая, что параметры отдельных звуков не имеют значения, и, разумеется, настроил против себя весь европейский авангард.
Ксенакис прменил к алгоритмическому сочинению музыки стохастические формулы. Более подробно это можно описать на примере его композиции «Брошенное эхо» для 21 инструмента. Данное сочинение было написано путем генерации сетки из 28 колонок и 7 строк. Каждая строка представляла собой группу инструментов, а каждая колонка – временной период. Ксенакис создавал определенное число музыкальных событий и случайным образом назначал их каждой ячейке. Внутри каждой ячейки он выбирал высоту звука и время смены одного события другим. В частности, он генерировал число событий с помощью распределения Пуассона, время смены отрезков с помощью экспоненциального распределения, высоту тона путем применения равномерного распределения. Скорость Глиссандо же определялась распределением Максвелла-Больцманна.

сетка Ксенакиса, описанная в его книге «Формализованная музыка»
Лежарен Хиллер (1924—1994) – американский композитор, доктор химических наук, и, позднее, магистр музыки, первым применил компьютер для алгоритмическй генерации музыки. Его самое знаменитое детище «Сюита Иллиака для струнного квартета» (Илииак – название компьютера, на котором она была разработана) – первая композиция, «сочиненная» машиной (1955).
Сюита состояла из четырех частей. Первая часть была основана на серии нот, сгенерированных случайно и попарно объединенных в соответствии с правилами полифонии XVI века, описанными Джованни Палестриной (итальянский композитор-полифонист). Данные правила содержали три составляющие: мелодическую (ноты, включенные в октаву; ноты, повторение которых запрещено), гармонические (были разрешены только следующие интервалы – унисон, октава, минорные или мажорные квинты, сексты, терции; увеличенные кварты считались диссонансными), и правила смешивания (запрет на параллелизацию квинт и октав и т. д.). Вторая часть основывалась практически на тех же принципах, только заданными в соответствии со строгими арифметическими операциями. В третьей части были добавлены правила, описывающие ритм и темп. В четвертой же части компьютеру было доверено выбирать подходящие ноты, руководствуясь вероятностными методами Марковских цепей. Случайный процесс был основан на убеждении, что в последовательности событий, выбор нового события (в данном случае, ноты), тесно связан с непосредственно предшествующим событием.
«Сюита Илииака» стала первым примером применения системы, основанной на знаниях в сфере алгоритмического сочинения музыки и первым опытом композиции, удовлетворительно звучащей для человеческого восприятия (особенно ее вторая часть). Произведение пользовалось большой популярностью и неоднократно переиздавалось на аудионосителях.
Первым и единственным ученым, занимавшимся проблемой алгоритмического сочинения музыки в нашей стране был советский музыкант и математик Рудольф Зарипов. В 1960 году на ЭВМ УРАЛ он смоделировал одноголосые марши и вальсы.
В программе УРАЛа каждая нота была обозначена пятизначным числом, в котором первые две цифры обозначали порядковый номер звука, третья цифра – длительность звука, четвертая и пятая – высоту звука. Машина должна была заканчивать мелодию всегда первой ступенью лада и приближаться к концу наиболее короткими интервалами. Были запрещены последовательности из шести нот подряд в одном направлении и парные шаги, превышающие в сумме октаву. Моделирование мелодии производилось с помощью случайного процесса, ограниченного данными правилами.
Эксперимент дал удовлетворительный результат: некоторые мелодии были неприемлемы даже по меркам музыкального авангарда того времени.
5. Современные подходы
Самыми используемыми в последние несколько десятилетий подходами к решению задачи алгоритмической композиции можно назвать несколько техник – Л-системы, клеточные автоматы, генетические алгоритмы, нейронные сети.
Теория хаоса — математический аппарат, описывающий поведение некоторых нелинейных динамических систем, подверженных при определённых условиях явлению, известному, как хаос. К частным случаям теории хаоса можно отнести знаменитый Эффект бабочки, а к повлиявшим на развитие алгоритмического сочинения музыки – теорию Фракталов и Л-системы.
Л-системы были впервые описаны в 1968 году венгерским ботаником Аристидом Линденмайером как инструмент для изучения развития простых многоклеточных организмов. Поздее базис Л-систем был расширен для моделирования сложных ветвящихся структур — разнообразных деревьев и цветов. Первым для решения задач автоматической генерации музыки их применил в своей диссертации 1996 года американский программист и композитор Люк Дюбуа. Работа Л-системы начинается с определения трех наборов параметров – алфавита (список символов, которыми будет оперировать система, как на входе, так и на выходе, в нашем случае, например, ноты), набора правил (например, классических законов гармонии) и аксиомы (символ или строка символов для начального ввода).
Л-системы относятся к экспертным системам, основанным на знаниях и заданном наборе правил. К таким системам также можно отнести уже упоминавшиеся Марковские цепи, в которых вероятность перехода от одной ноты к другой вычисляется на основе матрицы вероятностных переходов, исходя из заранее определенных статистических правил.
Другой современный подход – использование Клеточных автоматов, изобретенных американским математиком Джоном фон Нейманом в 1966 году. Клеточный автомат может мыслиться как стилизованный мир. Пространство представлено равномерной сеткой, каждая ячейка или клетка которой содержит несколько битов данных; время идет вперед дискретными шагами, а законы мира выражаются единственным набором правил, скажем, небольшой справочной таблицей, по которой любая клетка на каждом шаге вычисляет свое новое состояние по состояниям ее близких соседей. Таким образом, законы системы являются локальными и повсюду одинаковыми.
Первым клеточные автоматы в алгоритмической музыке применил бразильский композитор, получивший позднее степень доктора математических наук в Великобритании, Эдуардо Рек Миранда. Его интерактивная система CAMUS генерировала мелодию на основе двух клеточных автоматов: игры в «жизнь» Джона Неймана, и Demon Cyclic Space Больцмана. Игра в «жизнь», описанная Джоном Конвеем и популяризованная Мартином Гарднером, использует следующие правила: если клетка имеет двух “живых” соседей, она остаётся в прежнем состоянии. Если клетка имеет трёх “живых” соседей, она переходит в “живое” состояние. В остальных случаях клетка “умирает”. Несмотря на свою простоту, система проявляет огромное разнообразие поведения, колеблясь между очевидным хаосом и порядком.
Первый клеточный автомат отвечает за выбор нот. Каждая клетка соответствует триаде: первая нота дана заранее определенной из последовательности из 12 нот, а две другие – определены координатами клетки в музыкальном пространстве. Demon Cyclic Space же отвечает за оркестровку, он определяет, какой из инструментов будет подыгрывать основной мелодии.
Генетический алгоритм — это эвристический алгоритм поиска, используемый для решения задач оптимизации и моделирования путём случайного подбора, комбинирования и вариации искомых параметров с использованием механизмов, напоминающих биологическую эволюцию.
Первопроходцем в применении генетических алгоритмов в алгоритмический музыке считается Джон Бильс – профессор Рочестерского института технологий (Нью-Йорк, США), использовавший его для генерации джазовой соло-импровизации в своей программе GenJam.
Работа генетического алгоритма начинается с применения эквивалента биологического образования новых генов на пространство случайно распределенных решений для нахождения в итоге оптимального набора. Решения представлены хромосомами, а строки аллель – строками чисел, и задача рекомбинации генов сводится к созданию новых аллелей из аллель, взятых от родительских хромосом путем применения генетических операторов, в большинстве случаев, мутации и скрещивания. Перебирание хромосом продолжается до достижения определенного условия прерывания. Генетические алгоритмы в задаче автоматического музицирования разделяются по виду использованной фитнесс-функции – степень приспособленности хромосом может быть оценена исходя из заранее заданных четких условий, либо может быть определена непосредственно человеком при прослушивании и субъективной оценке.
Под обучающимися системами понимают системы, в которых не задано априорных правил, а система сама обучается чертам на примерах. Чаще всего, под такими системами подразумеваются искусственные нейронные сети, имитирующие работу нейронов мозга человека и способные обучаться на основе предоставленных примеров. Обычно такие системы используются в другой отрасли музыкальной математики – распознавании музыкальных отрывков, например, для решения задач реставрации испорченных аудиоданных или составления автоматических партитур. Существует несколько систем, использующих нейронные сети, например, HARMONET или CONCERT. HARMONET используется для оркестровки мелодий на основе обучении правилам гармонии И. Баха. Первым человеком, применившим нейронные сети в решении задач алгоритмической композиции, был Питер Тодд, профессор психологии и информатики из Калифорнии.
Также, одно из самых последних направлений в сфере алгоритмической композиции – моделирование эмоциональной нагрузки произведений для устранения проблемы сухого математического расчета и привнесения в машинную музыку элементов настроений и смысла, вкладываемых человеком в сочиняемые композиции.
.
