Асимптотический анализ алгоритмов
Время на прочтение
7 мин
Количество просмотров 140K
Прежде чем приступать к обзору асимптотического анализа алгоритмов, хочу сказать пару слов о том, в каких случаях написанное здесь будет актуальным. Наверное многие программисты читая эти строки, думают про себя о том, что они всю жизнь прекрасно обходились без всего этого и конечно же в этих словах есть доля правды, но если встанет вопрос о доказательстве эффективности или наоборот неэффективности какого-либо кода, то без формального анализа уже не обойтись, а в серьезных проектах, такая потребность возникает регулярно.
В этой статье я попытаюсь простым и понятным языком объяснить, что же такое сложность алгоритмов и асимптотический анализ, а также возможности применения этого инструмента, для написания собственного эффективного кода. Конечно, в одном коротком посте не возможно охватить полностью такую обширную тему даже на поверхностном уровне, которого я стремился придерживаться, поэтому если то, что здесь написано вам понравится, я с удовольствием продолжу публикации на эту тему.
Итак приступим.
Во многих работах описывающих те или иные алгоритмы, часто можно встретить обозначения типа:
O(g(n)), Ω(g(n)), Θ(g(n)).
Давайте разбермся, что же это такое, но сначала я перечислю основные классы сложности применяемые при анализе:
f(n) = O(1) константа
f(n) = O(log(n)) логарифмический рост
f(n) = O(n) линейный рост
f(n) = O(n*log(n)) квазилинейный рост
f(n) = O(n^m) полиномиальный рост
f(n) = O(2^n) экспоненциальный рост
Если раньше вы не встречались с подобными обозначениями, не переживайте, после прочтения этой статьи, все станет намного понятнее.
А начнем мы с символа O.
O(g(n))
Сначала приведу формальное определение:
(1.1) Запись вида f(n) = O(g(n)) означает, что ф-ия f(n) возрастает медленнее чем ф-ия g(n) при с = с1 и n = N, где c1 и N могут быть сколь угодно большими числами, т.е. При c = c1 и n >= N, c*g(n) >=f(n).
Таким образом O – означает верхнее ограничение сложности алгоритма.
Давайте теперь попробуем применить это знание на практике.
Возьмем известную любому программисту задачу сортировки. Допустим нам необходимо отсортировать массив чисел, размерностью 10 000 000 элементов. Договоримся рассматривать худший случай, при котором для выполнения алгоритма понадобится наибольшее количество итераций. Не долго думая, мы решаем применять сортировку пузырьком как самую простую с точки зрения реализации.
Сортировка пузырьком позволяет отсортировать массив любой размерности без дополнительных выделений памяти. Вроде бы все прекрасно и мы с чистой совестью начинаем писать код (для примеров здесь и далее будет использоваться язык Python).
def bubble_sort(arr):
. . for j in xrange(0, N - 1):
. . . . for i in xrange(0, N - 1):
. . . . . . if(arr[i] > arr[i+1]):
. . . . . . . . tmp = arr[i]
. . . . . . . . arr[i] = arr[i+1]
. . . . . . . . arr[i+1] = tmp
Я намерено не ввожу проверку на наличие хотябы одного обмена (которая кстати не сказывается на O — сложности алгоритма), ради упрощения понимания сути.
Взглянув на код, сразу же обращаем внимание на вложеный цикл. О чем нам это говорит? Я надеюсь, что читатель знаком с основами программирования на любом языке (кроме функциональных, в которых циклы отсутствуют как таковые, а повторения реализуются рекурсией) и наглядно представляет себе, что такое вложеные циклы и как они работают. В данном примере, внешний цикл выполняется ровно n = 10 000 000 (т.к. наш массив состоит из 10 000 000 элементов) и столько же раз выполняется внутренний цикл, из этого очевидно следует, что общее кол-во итераций будет порядка n^2. Т.е. кол-во итераций зависит от размерности входных данных как ф-ия от n^2. Теперь, зная сложность алгоритма, мы можем проверить, насколько хорошо он будет работать в нашем случае. Подставив цифры в формулу n^2 получаем ответ 10 000 000 * 10 000 000 = 10 000 000 000 0000 итераций.
Хммм, впечатляет… В цикле у нас 3 комманды, предположим, что на выполнение каждой из них требуется 5 единиц времени (с1 = 5), тогда общее кол-во времени затраченного на сортировку нашего массива будет равно 5*f(n^2) (синяя кривая на рис.1).

рис.1.
зеленая кривая соответствует графику ф-ии x^2 при c = 1, синия c = 5, красная c = 7
Здесь и далее на всех графиках ось абсцисс будет соответствовать размерности входных данных, а ось ординат кол-ву итераций необходимых для выполнения алгоритма.
Нас интересует только та часть координатной плоскости, которая соответствует значениям x большим 0, т.к. любой массив, по-определению, не может иметь отрицательный размер, поэтому, для удобства, уберем левые части графиков ф-ий, ограничившись лишь первой четвертью координатной плоскости.

рис.2.
зеленая кривая соответствует графику ф-ии x^2 при c = 1, синия c = 5, красная c = 7
Возьмем c2 = 7. Мы видим, что новая ф-ия растет быстрее предыдущей (красная кривая на рис.2). Из определения (1.1), делаем вывод, что при с2 = 7 и n >= 0, g(n) = 7*n^2 всегда больше или равна ф-ии f(n) = 5*n^2, следовательно наша программа имет сложность O(n^2).
Кто не до конца понял это объяснение, посмотрите на графики ф-ий и заметьте, что ф-ия отмеченная на нем красным, при n >= 0 всегда имеет большее значение по y, чем ф-ия отмеченная синим.
Теперь подумаем, хорошо ли это или плохо в нашем случае и можем ли мы заставить алгоритм работать эффективнее?
Как можно понять из графиков, приведенных на рис. 2, квадратичная ф-ия возрастает довольно быстро и при большом объеме входных данных, сортировка массива таким способом, может занять довольно длительное время, причем увеличение мощности процессора, будет сказываться лишь на коэффициенте c1, но сам алгоритм, по-прежнему будет принадлежать к классу алгоритмов с полиномиальной функцией роста O(n^2) (тут мы опять же используем определение (1.1) и подбираем такие c2 и N при которых с2*n^2 будет возрастать быстрее чем наша ф-ия c1*n^2 начиная с некоторого n >= N) и если в ближайшем будущем изобретут процессор, который будет сортировать наш массив всего за пару секунд, то при немного большем объеме входных данных, этот прирост в производительности будет полностью нивелирован кол-вом необходимых вычислений.
Таким же временным средством является решение реализовать алгоритм на низкоуровневом языке (например ассемблере), так как все, что мы сможем сделать – это, опять же, лишь немного уменьшить коэффициент c1 при этом все-равно оставаясь в классе сложности O(n^2).
А что будет, если вместо одноядерного процессора, мы будем использовать 4-х ядерный? На самом деле, результат изменится не сильно.
Разобьем наш массив на 4 части и каждую часть поручим выполнять отдельному ядру. Что мы получим? На сортировку каждой части понадобится ровно O((n / 4)^2). Так как все части сортируются одновременно, то этот результат и будет конечным временем сортировки четырех подмассивов, размерностью n/4. Возведем получившееся выражение в квадрат, получив таким образом сложность равную O(1/16*n^2 + n), где n — итерации необходимые на сортировку итогового массива полученного конкатенацией четырех готовых подмассивов.
Поскольку анализ у нас асимптотический, то при достаточно больших n, ф-ия n^2 будет вносить гораздо больший вклад в итоговый результат, чем n и поэтому мы спокойно можем им пренебречь, как наиболее медленно возрастающем членом, также за малозначимостью принебрегаем коэффициентом 1/16 (см. (1.1)), что в итоге дает нам все тоже O(n^2).
Мы приходим к неутишительному выводу о том, что увеличением числа процессоров, равно как и повышение их частоты, не дают существенного прироста при данном алгоритме сортировки.
Что же можно сделать в этой ситуации, чтобы радикально ускорить сортировку? Необходимо, чтобы в худшем случае сложность алгоритма была меньше чем O(n^2). Поразмыслив немного, мы решаем, что не плохо бы было, придумать такой алгоритм, сложность которого не превышает O(n), т.е. является линейной. Очевидно, что в случае O(n) скорость работы программы возрастет в N раз, так как вместо N^2 итераций, нам необходимо будет сделать всего лишь N. Прогнозируемый прирост скорости отлично виден на рис.3.

Серой прямой обозначена линейная сложность, а три кривых показывают сложность n^2 при различных коэффициентах c.
Но оказывается, что сделать сортировку со сложностью O(n) в общем случае просто не возможно (док-во)! Так на какую же сложность мы в лучшем случае можем расчитывать? Она равна O(n*log(n)), что является теоретически доказаным минимальным верхнем пределом для любого алгоритма сортировки основанного на сравнении элементов. Это конечно немного не то, чего мы ожидали получить, но все же это уже и не O(n^2). Осталось найти алгоритм сортировки удовлетворяющий нашим требованиям.
Покопавшись в интернете, видим, что им удовлетворяет «пирамидальная сортировка». Я не буду вдаваться в подробности алгоритма, желающие могут прочитать о нем самостоятельно на wiki, скажу только, что его сложность принадлежит классу O(n*log(n)) (т.е. максимально возможная производительность для сортировки), но при этом, он довольно труден в реализации.
Посмотрим на графики ниже и сравним скорости возрастания кол-ва вычислений для двух рассмотренных алгоритмов сортировки.

рис.4.
Фиолетовая кривая показывает алгоритм со сложностью n*log(n). Видно, что на больших n, пирамидальная сортировка существенно выигрывает у сортировки пузырьком при любом из трех опробованных нами коэффициентах, однако все-равно уступает гипотетической сортировке линейной сложности (серая прямая на графике).
В любом случае, даже на медленном компьютере она будет работать гораздо быстрее, чем «пузырек» на быстром.
Остается открытым вопрос, целесообразно ли всегда предпочитать пирамидальную сортировку сортировке пузырьком?

рис.5.
Как видно на рис.5, при малых n, различия между двумя алгоритмами достаточно малы и выгода от использования пирамидальной сортировки — совсем незначительна, а учитывая, что «пузырек» реализуется буквально 5-6 строчками кода, то при малых n, он действительно является более предпочтительным с точки зрения умственных и временных затрат на реализацию 🙂
В заключении, чтобы более наглядно продемонстрировать разницу между классами сложности, приведу такой пример:
Допустим у нас етсь ЭВМ 45-ти летней давности. В голове сразу всплывают мысли о больших шкафах, занимающих довольно-таки обширную площадь. Допустим, что каждая команда на такой машине выполняется примерно за 10 миллисек. С такой скоростью вычислений, имея алгоритм сложности O(n^2), на решение поставленой задачи уйдет оооочень много времени и от затеи придется отказаться как от невыполнимой за допустимое время, если же взять алгоритм со сложностью O(n*log(n)), то ситуация в корне изменится и на расчет уйдет не больше месяца.
Посчитаем, сколько именно займет сортировка массива в обоих случаях
сверх-неоптимальный алгоритм (бывает и такое, но редко):
O(2^n) = оооооочень медленно, вселенная умрет, прежде чем мы закончим наш расчет…
пузырек:
O(n^2) = 277777778 часов (классический “пузырек”)
пирамидальная сортировка:
O(n*log(n)) = 647 часов (то чего мы реально можем добиться, применяя пирамидальную сортировку)
фантастически-эффективный алгоритм:
O(n) = 2.7 часов (наш гипотетический алгоритм, сортирующий за линейное время)
и наконец:
O(log(n)) = оооооочень быстро, жаль, что чудес не бывает…
Два последних случая (хоть они и не возможны в реальности при сортировке данных) я привел лишь для того, чтобы читатель ощутил огромную разницу между алгоритмами различных классов сложности.
На последок хочу заметить, что буквой O обычно обозначают минимальный из классов сложности, которому соответствует данный алгоритм. К примеру, я мог бы сказать, что сложность сортировки пузырьком равна O(2^n) и теоретически это было бы абсолютно верным утверждением, однако на практике такая оценка была бы лишена смысла.
Асимптотическая сложность алгоритмов встречается повсеместно. Доступно рассказываем, что это такое, где и как используется.
Если хочешь подтянуть свои знания, загляни на наш курс «Алгоритмы и структуры данных», на котором ты:
- углубишься в решение практических задач;
- узнаешь все про сложные алгоритмы, сортировки, сжатие данных и многое другое.
Ты также будешь на связи с преподавателем и другими студентами.
В итоге будешь браться за сложные проекты и повысишь чек за свою работу 🙂
Интересно, хочу попробовать
Асимптотическая сложность алгоритмов представляет собой время и память, которые понадобятся вашей программе в процессе работы. Одно дело – знать, что существуют линейные или логарифмические алгоритмы, но совсем другое – понимать, что же за всем этим стоит.
С помощью Big O Notation можно математически описать то, как поведет себя программа в условиях наихудшего сценария при большом количестве входных данных. Например, если вы используете сортировку пузырьком, чтобы отсортировать элементы в целочисленном массиве по возрастанию, то худшим сценарием в этом случае будет отсортированный в убывающем порядке массив. При таком раскладе вашему алгоритму понадобится наибольшее количество операций и памяти.
Разобравшись в принципе работы Big O Notation, вы сможете решить проблему оптимизации ваших программ и добиться максимально эффективного кода.
Сложности О(1) и O(n) самые простые для понимания.
О(1) означает, что данной операции требуется константное время. Например, за константное время выполняется поиск элемента в хэш-таблице, так как вы напрямую запрашиваете какой-то элемент, не делая никаких сравнений. То же самое относится к вызову i-того элемента в массиве. Такие операции не зависят от количества входных данных.
В случае, если у вас не очень удачная хэш-функция, которая привела к большому количеству коллизий, поиск элемента может занять О(n), где n – это количество объектов в хэш-таблице. В худшем случае Вам понадобится сделать n сравнении, а именно пройтись по всем элементам структуры. Очевидно, что скорость линейных алгоритмов, то есть алгоритмов, работающих в О(n), зависит от количества входных данных. В случае с линейными алгоритмами в худшем случае вам придется провести какую-то операцию с каждый элементом.
Бинарный поиск является одним из классических примеров алгоритмов, работающих за O(log_2(n)). Каждая операция уменьшает количество входных данных вдвое.
Например, если у вас есть отсортированный массив, насчитывающий 8 элементов, в худшем случае вам понадобится сделать Log_2(8)=3 сравнений, чтобы найти нужный элемент.
Рассмотрим отсортированный одномерный массив с 16 элементами:

Допустим, нам нужно найти число 13.
Мы выбираем медиану массива и сравниваем элемент под индексом 7 с числом 13.
Так как наш массив отсортирован, а 16 больше, чем 13, мы можем не рассматривать элементы, которые находятся под индексом 7 и выше. Так мы избавились от половины массива.
Дальше снова выбираем медиану в оставшейся половине массива.

Сравниваем и получаем, что 8 меньше, чем 13. Уменьшаем массив вдвое, выбираем элемент посередине и делаем еще одно сравнение. Повторяем процесс, пока не останется один элемент в массиве. Последнее сравнение возвращает нужный элемент. Лучшее развитие событий – если первая выбранная медиана и есть ваше число. Но в худшем случае вы совершите log_2(n) сравнений.
Сложность O(n*log n) можно представить в виде комбинации O(log n) и O(n). Такую сложность можно получить, если в вашей программе есть один for-цикл, который содержит еще один for-цикл. То есть нестинг циклов, один из которых работает за O(log n), а другой – за O(n).
for(int i = 0; i < n; i++) //выполняется n раз
for(int j = 1; j < n; j = j * 2) // выполняется blogs раз
print “hello"; //константное время
Сложность O(n^2) встречается довольно часто в алгоритмах сортировки. Ее легко можно получить, если в программе имплементировать нестинг двух for-циклов, работающих в O(n).
Например:
for(int i = 0; i < n; i++) // выполняется n раз
for(int j = 0; j < n; j++) //выполняется n раз
print “hello”; // константно
То же самое произойдет, если вам надо будет пройтись по элементам двумерного массива.
Алгоритмы, которые можно описать с помощью нотации O(n^2 + n + 3) или O(n^2-100000), или даже O(n^2 + 100000000) все равно считаются квадратными. При большом количестве входных данных только наибольшая степень n является важной. Константы и коэффициенты обычно не берут во внимание. То же самое касается линейных и логарифмических функций. O( n +1000) и O(1000*n) все равно будут работать в O(n).
Использование алгоритмов, которые работают в O(n^2) и выше (например, экспоненциальная функция 2^n), является плохой практикой. Следует избегать подобных алгоритмов, если хотите, чтобы ваша программа работала за приемлемое время и занимала оптимальное количество памяти.
Почерпнули для себя что-то новое? Делитесь тем, что мы могли упустить 😉
Войти на сайте МЭШ
Войдите с учетной записью ученика или учителя МЭШ,
чтобы получить доступ к личному кабинету.

Расчет асимптотической сложности
Расчет асимптотики – 1
Часто необходимо понимать насколько эффективен написанный код. Для этого обычно оценивают время выполнения и/или затрачиваемую память.
Для выражения этой оценки часто используют асимптотическую сложность (в дальнейшем будем считать, что времени, т.к. по сравнению с памятью значимых отличий нет)
Сложность зависит от переменных входных параметров и выражают ее как функцию, зависящую от размеров этих данных (подробнее в примере в конце теории).
Для оценки сложности нам интересно именно асимптотическое поведение этих функций (отсюда и короткое выражение – “асимптотика кода”), то есть когда входные данные довольно большого размера.
Поэтому используют так называемую О-нотацию. За этим стоит не самая простая математическая теория, в которую углубляться не будем. Желающие могут подробнее ознакомиться на википедии или других интернет-ресурсах.
Однако стоит запомнить, что асимптотику кода почти всегда указывают в этой самой нотации, поэтому стоит самим всегда так делать. На небольшом примере разберемся как примерно это делать.
Как очевидно из названия, функции записываются внутри скобок, обозначенных большой буквой “O”. Например: О(n), O(nm), O(log(c)), где как n, m, c или др. мы обозначаем потенциальные размеры входных данных.
Теперь о том, как саму асимптотику считать.
1) Для начала надо понять от размера каких данных зависит время выполнения программы. Сопоставим размеру этих данных переменные, в контексте которых и будем вычислять асимптотику. Обычно их обозначают буквами n, а затем m.
2) Далее выразим реальное время работы через эти переменные. Если некоторые части сложно посчитать точно, то оценивают приблизительно и сверху (то есть преувеличивают с запасом), т.к. предположить, что программа тратит больше ресурсов, чем на самом деле, не страшно, а вот обратная ситуация потенциально может приводить к проблемам.
3) После этого среди всех слагаемых возьмем самое “тяжелое”. Их может быть несколько, если их нельзя сравнить (например разные переменные, т.е. размеры разных входов, т.к. мы не знаем заранее что именно программа получит на вход). Далее опускаются константные множители у этих слагаемых (даже если изначально было, например, 100000n или 0.00001n, то остается только n) и после этого результат записывается в О-нотации.
Разберем небольшой пример.
Предположим, что у нас есть программа, которая принимает на вход массив целых чисел и сравнивает количество обменов, необходимых для сортировки пузырьком этого массива и сортировки слиянием.
Здесь время работы программы зависит только от входящего массива. Обозначим за n его размер.
Посчитаем реальное время работы. n итераций на считывание массива, сортировка пузырьком, которая в худшем случае будет использовать n*(n-1)/2 обменов (здесь нам важно учитывать именно худший случай), сортировка слиянием, время которой тяжело оценить точно, но оценим его сверху как 10*n*log(n) (т.к. мы знаем, что она работает за О(n*log(n)), но как уже было сказано, константы опускаются)
Итого примерное время работы: n + n*(n-1)/2 + 10*n*log(n) = n + n^2/2 – n/2 + 10*n*log(n). Довольно понятно, что 1ое и 3ее слагаемые здесь не являются определяющими. Вопрос лишь в том, что “тяжелее”, 2ое или 4ое.
Заметим, что при небольшом n, например, при n=4, 4ое слагаемое имеет на порядок большее значение, чем 2ое (8 против 80). Однако это не имеет никакого значения, как раз потому, что мы проводим асимптотический анализ, то есть предполагая, что входные данные довольно большого размера, например, n=1000000. При таком размере входных данных уже наглядно видно, насколько n^2/2 на самом деле превышает 10*n*log(n).
В итоге мы оставили самое “тяжелое” слагаемое n^2/2 и теперь проигнорируем его константный множитель 1/2. Таким образом, асимптотика данного алгоритма равна О(n^2).
Стоит понимать, что хоть асимптотически константа не играет роли, в реальной жизни это имеет важное значение, поэтому оценивать точное время работы тоже важно, т.к. иногда бывает выгоднее выбрать алгоритм с большей асимптотикой, потому что на реальных данных он может быть всегда быстрее. В этом кроется минус асимптотического анализа: предполагается, что значение переменных стремится к бесконечности, и в итоге одна функция принимает большие значения, чем другая, при таких огромных значениях, что в реальной жизни такого быть не может. Но на практике такие случаи встречаются крайне редко.
Часто бывает полезно оценить, сколько времени работает алгоритм. Конечно, можно его просто реализовать и запустить, но тут возникают проблемы:
- На разных компьютерах время работы всегда будет отличаться.
- Не всегда заранее доступны именно те данные, на которых он в реальности будет запускаться.
- Иногда приходится оценивать алгоритмы, требующие часы или даже дни работы.
- Жизнь коротка, и если есть несколько вариантов алгоритмов, то хочется заранее предсказать, какой из них будет быстрее, чтобы реализовывать только его.
Для этого, в качестве первого приближения, попробуем оценить число операций в алгоритме. Возникает вопрос: какие именно операции считать. Как один из вариантов — учитывать любые элементарные операции:
- арифметические операции с числами:
+, -, *, / - сравнение чисел:
<, >, <=, >=, ==, != - присваивание:
a[0] = 3
При этом важно не просто считать строчки, а ещё учитывать, как реализованы некоторые отдельные вещи в самом языке. Например, в питоне срезы массива (array[3:10]) копируют этот массив, то есть этот срез работает за 7 элементарных действий. А swap, например, можно реализовать за 3 присваивания.
Упражнение. Попробуйте посчитать точное число сравнений и присваиваний в сортировках пузырьком, выбором, вставками и подсчетом в худшем случае. Это должна быть какая-то формула, зависящая от $n$ — длины массива.
Чтобы учесть вообще все элементарные операции, ещё надо посчитать, например, сколько раз прибавилась единичка внутри цикла for. А ещё, например, строчка n = len(array) — это тоже действие. Поэтому даже посчитав их, не сразу очевидно, какой из этих алгоритмов работает быстрее — сравнивать формулы сложно. Хочется придумать способ упростить эти формулы так, чтобы
- не нужно было учитывать информацию, не очень сильно влияющую на итоговое время;
- легко было оценивать время работы разных алгоритмов для больших чисел;
- легко было сравнивать алгоритмы на предмет того, какой из них лучше подходит для тех или иных входных данных.
Для этого придумали О-нотацию — асимптотическое время работы вместо точного (часто его ещё называют просто асимптотикой).
Определение. Пусть $f(n)$ — это какая-то функция. Говорят, что функция $g(n) = O(f(n))$, если существует такие константы $c$ и $n_0$, что $g(n) < c cdot f(n)$ для всех $n geq n_0$.
Например:
- $frac{n}{3} = O(n)$
- $frac{n(n-1)(n-2)}{6} = O(n^3)$
- $1 + 2 + 3 + ldots + n = O(n^2)$
- $1^2 + 2^2 + 3^2 + ldots + n^2 = O(n^3)$
- $log_2{n} + 3 = O(log n)$
- $179 = O(1)$
- $10^{100} = O(1)$
В контексте анализа алгоритмов, фраза «алгоритм работает за $O(f(n))$ операций» означает, что начиная с какого-то $n$ он делает не более чем за $c cdot f(n)$ операций.
В таких обозначениях можно сказать, что
- сортировка пузырьком работает за $O(n^2)$;
- сортировка выбором работает за $O(n^2)$;
- сортировка вставками работает за $O(n^2)$;
- сортировка подсчетом работает за $O(n + m)$.
Это обозначение удобно тем, что оно короткое и понятное, а также не зависит от умножения на константу или прибавления константы. Например, если алгоритм работает за $O(n^2)$, то это может значить, что он работает за $n^2$, за $n^2 + 3$, за $frac{n(n-1)}{2}$ или даже за $1000 cdot n^2 + 1$ действие. Главное — что функция ведет себя как $n^2$, то есть при увеличении $n$ она увеличивается как некоторая квадратичная функция: если увеличить $n$ в 10 раз, время работы программы увеличится приблизительно в 100 раз.
Основное преимущество О-нотации в том, что все рассуждения про то, сколько операций в swap или считать ли отдельно присваивания, сравнения и циклы — отпадают. Каков бы ни был ответ на эти вопросы, они меняют ответ лишь на константу, а значит асимптотическое время работы алгоритма не меняется.
Первые три сортировки поэтому называют квадратичными — они работают за $O(n^2)$. Сортировка подсчетом может работать намного быстрее — она работает за $O(n + m)$, а если $m leq n$, то это вообще линейная функция $O(n)$.
Асимптотический анализ
В этой статье вы узнаете, что такое асимптотические нотации, познакомитесь с О-нотацией, нотациями Тета и Омега.
Эффективность алгоритма зависит от следующих параметров: время выполнения, объем памяти и других ресурсов, необходимых для его выполнения. Эффективность измеряется с помощью асимптотических нотаций.
Производительность алгоритма может отличаться при работе с различными типами данных. С увеличением количества входных данных она также изменяется.
Асимптотический анализ — метод изучения производительности алгоритмов при различных объемах и типах входных данных.
Асимптотические нотации
Асимптотические нотации — это графики функций. Они служат для описания времени работы алгоритма, когда размер входных данных стремится к определенному значению или пределу.
Возьмем, к примеру, сортировку пузырьком. Когда массив, который мы вводим, уже отсортирован, время выполнения алгоритма линейно — это лучший случай.
Но если массив отсортирован в обратном порядке, то время выполнения будет максимальным (квадратичное). То есть, это худший случай.
Если входной массив не находится в этих двух состояниях, то время выполнения алгоритма среднее. Длительность выполнения алгоритма описывается асимптотическими нотациями.
В основном используются три нотации:
- большое «О»,
- омега-нотация,
- тета-нотация.
Большое «О»
Большое «О» — это верхняя граница скорости выполнения алгоритма. Эта нотация показывает скорость алгоритма в худшем случае.
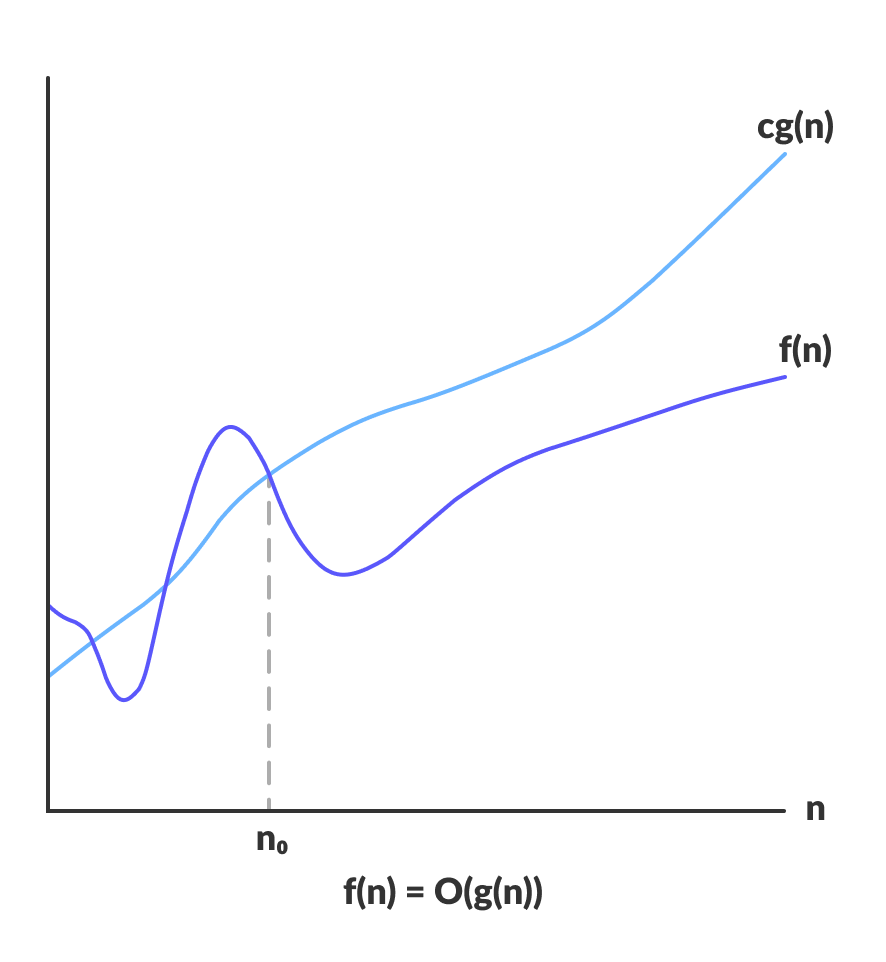
O(g(n)) = { f(n): существуют такие константы c и n0,
что 0 ≤ f(n) ≤ cg(n) для любых n ≥ n0 }
Это выражение — описание функции f(n). Она принадлежит множеству O(g(n)), если существует положительная константа c, при которой f(n) лежит в промежутке от 0 до cg(n) при достаточно больших n.
Для любого n функция времени выполнения алгоритма не пересечет функцию O(g(n)).
Так как эта нотация дает нам представления о худшей скорости выполнения алгоритма, то ее анализ обязателен — нам всегда интересна эта характеристика.
Омега нотация (Ω-нотация)
Омега нотация — противоположность большому «О». Она показывает нижнюю границу скорости выполнения алгоритма. Она описывает лучший случай выполнения алгоритма.
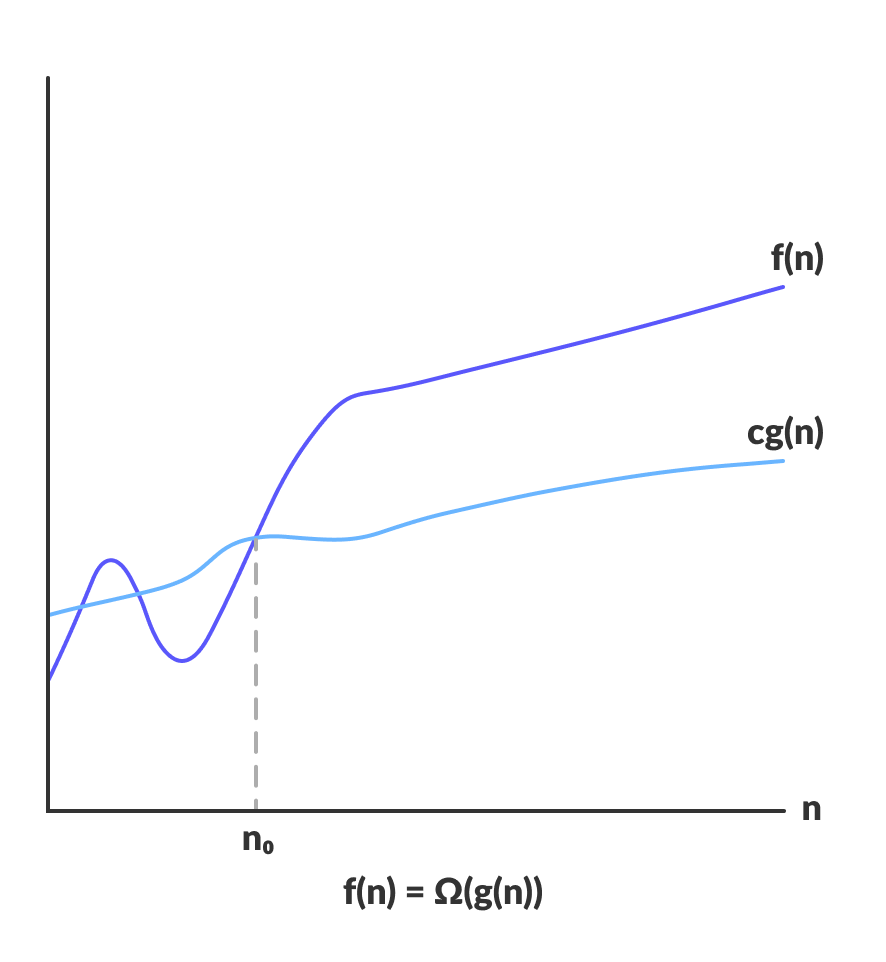
Ω(g(n)) = { f(n): существуют такие положительные константы c и n0,
что 0 ≤ cg(n) ≤ f(n) для всех n ≥ n0 }
Это выражение — описание функции f(n). Она лежит в множестве Ω(g(n)), если существует такая положительная константа c, при которой f(n) лежит выше cg(n) при достаточно больших n.
Для любого n минимальное время выполнения алгоритма задается как Ω(g(n)).
Тета-нотация (Θ-нотация)
Тета-нотация объединяет в себе сразу две функции — верхнюю и нижнюю. Эта нотация отражает и верхнюю, и нижнюю границу скорости выполнения алгоритма. Именно поэтому она используется для анализа средней скорости выполнения алгоритма.
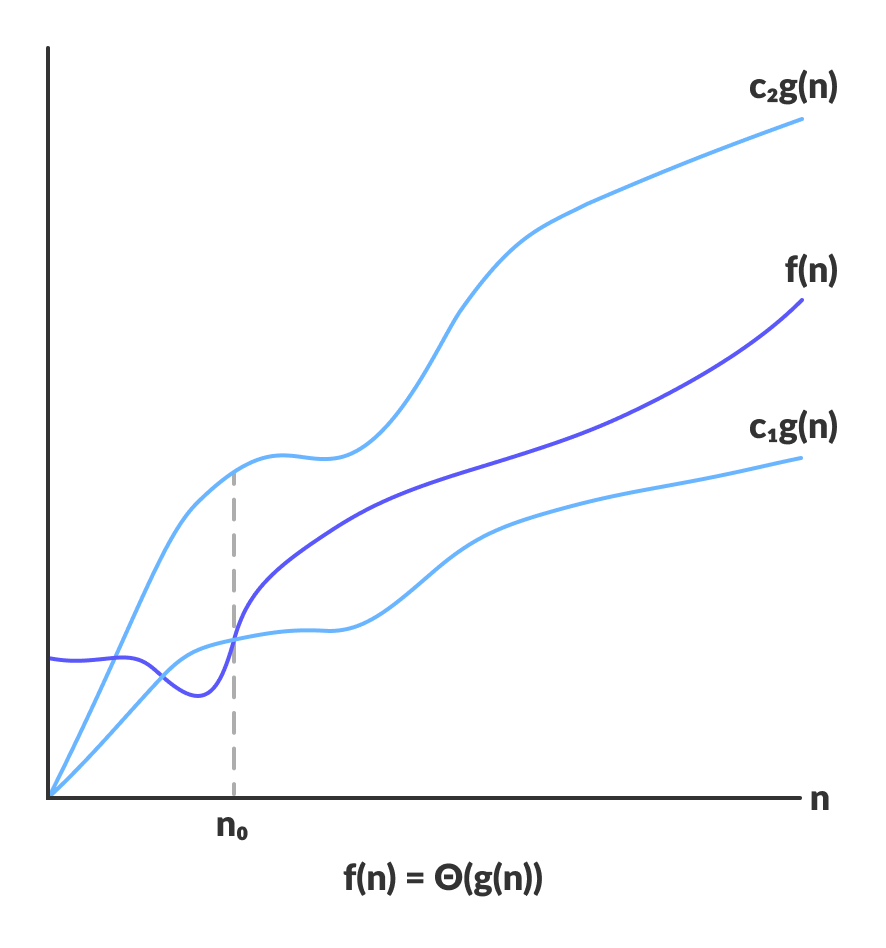
Для функции g(n) Θ(g(n)) задается следующим образом:
Θ(g(n)) = { f(n): существуют такие положительные константы c1, c2 и n0,
что 0 ≤ c1g(n) ≤ f(n) ≤ c2g(n) для любых n ≥ n0 }
Это выражение — описание функции f(n). Она принадлежит множеству Θ(g(n)), если существуют положительные константы с1 и с2 такие, что f(n) лежит между c1g(n) и c2g(n) при достаточно больших n.
