Рассмотренные в лабораторной работе 2 распределения вероятностей СВ
опираются на знание закона распределения СВ. Для практических задач такое
знание – редкость. Здесь закон распределения обычно неизвестен, или известен с
точностью до некоторых неизвестных параметров. В частности, невозможно
рассчитать точное значение соответствующих вероятностей, так как нельзя
определить количество общих и благоприятных исходов. Поэтому вводится статистическое
определение вероятности. По этому определению вероятность равна отношению
числа испытаний, в которых событие произошло, к общему числу произведенных
испытаний. Такая вероятность называется статистической частотой.
Связь
между эмпирической функцией распределения и функцией распределения
(теоретической функцией распределения) такая же, как связь между частотой события
и его вероятностью.
Для
построения выборочной функции распределения весь диапазон изменения случайной
величины X (выборки)
разбивают на ряд интервалов (карманов) одинаковой ширины. Число интервалов
обычно выбирают не менее 3 и не более 15. Затем определяют число значений
случайной величины X, попавших
в каждый интервал (абсолютная частота, частота интервалов).
Частота интервалов – число, показывающее сколько раз значения,
относящиеся к каждому интервалу группировки, встречаются в выборке. Поделив эти
числа на общее количество наблюдений (n), находят относительную частоту (частость) попадания
случайной величины X в заданные
интервалы.
По
найденным относительным частотам строят гистограммы выборочных функций
распределения. Гистограмма распределения частот – это графическое
представление выборки, где по оси абсцисс (ОХ) отложены величины интервалов, а
по оси ординат (ОУ) – величины частот, попадающих в данный классовый интервал.
При увеличении до бесконечности размера выборки выборочные функции
распределения превращаются в теоретические: гистограмма превращается в график
плотности распределения.
Накопленная частота интервалов – это число, полученное
последовательным суммированием частот в направлении от первого интервала к
последнему, до того интервала
включительно, для которого определяется накопленная частота.
В Excel для построения выборочных функций распределения
используются специальная функция ЧАСТОТА
и процедура Гистограмма из пакета анализа.
Функция ЧАСТОТА (массив_данных,
двоичный_массив) вычисляет частоты появления случайной величины в интервалах
значений и выводит их как массив цифр, где
•
массив_данных
— это массив или ссылка на
множество данных, для которых
вычисляются частоты;
•
двоичный_массив
— это массив интервалов, по
которым группируются значения выборки.
Процедура
Гистограмма из Пакета анализа выводит
результаты выборочного распределения в виде таблицы и графика. Параметры диалогового окна Гистограмма:
•
Входной диапазон – диапазон исследуемых данных
(выборка);
•
Интервал карманов – диапазон ячеек или набор граничных
значений, определяющих выбранные интервалы (карманы). Эти значения должны быть
введены в возрастающем порядке. Если
диапазон карманов не был введен, то набор интервалов, равномерно распределенных между минимальным и
максимальным значениями данных, будет создан
автоматически.
•
выходной диапазон предназначен для ввода ссылки на левую верхнюю ячейку выходного диапазона.
•
переключатель
Интегральный процент позволяет установить режим включения в
гистограмму графика интегральных
процентов.
•
переключатель
Вывод графика позволяет установить режим автоматического создания встроенной диаграммы на листе, содержащем
выходной диапазон.
Пример 1. Построить эмпирическое распределение веса
студентов в килограммах для следующей
выборки: 64, 57, 63, 62, 58, 61, 63, 70, 60, 61, 65, 62, 62, 40, 64, 61, 59, 59, 63, 61.
Решение
1. В ячейку А1 введите слово Наблюдения,
а в диапазон А2:А21 — значения веса
студентов (см. рис. 1).
2.
В
ячейку В1 введите названия интервалов Вес, кг. В диапазон В2:В8 введите
граничные значения интервалов (40, 45,
50, 55, 60, 65, 70).
3.
Введите
заголовки создаваемой таблицы: в ячейки С1 — Абсолютные частоты, в ячейки D1 — Относительные
частоты, в ячейки E1 — Накопленные частоты.(см. рис. 1).
4.
С
помощью функции Частота заполните столбец абсолютных частот, для этого
выделите блок ячеек С2:С8. С
панели инструментов Стандартная
вызовите Мастер функций (кнопка fx). В появившемся диалоговом окне
выберите категорию Статистические и функцию
ЧАСТОТА, после чего нажмите кнопку ОК. Указателем мыши в рабочее поле Массив_данных
введите диапазон данных наблюдений (А2:А8). В рабочее поле Двоичный_массив
мышью введите диапазон интервалов (В2:В8). Слева на клавиатуре последовательно нажмите комбинацию клавиш Ctrl+Shift+Enter. В столбце C должен появиться массив абсолютных частот (см. рис.1).
5.
В
ячейке C9 найдите общее количество
наблюдений. Активизируйте ячейку С9, на
панели инструментов Стандартная нажмите кнопку Автосумма.
Убедитесь, что диапазон суммирования указан правильно и нажмите клавишу Enter.
6.
Заполните столбец относительных частот. В ячейку введите формулу
для вычисления относительной частоты: =C2/$C$9.
Нажмите клавишу Enter. Протягиванием (за правый
нижний угол при нажатой левой кнопке мыши) скопируйте введенную формулу в диапазон и получите массив относительных частот.
7.
Заполните
столбец накопленных частот. В ячейку D2 скопируйте значение относительной
частоты из ячейки E2. В ячейку D3 введите формулу: =E2+D3. Нажмите клавишу Enter. Протягиванием (за правый нижний угол при нажатой левой кнопке мыши) скопируйте введенную формулу
в диапазон D3:D8. Получим массив накопленных
частот.

Рис. 1. Результат вычислений из
примера 1
8.
Постройте диаграмму относительных и накопленных частот. Щелчком указателя
мыши по кнопке на панели инструментов вызовите Мастер диаграмм. В появившемся диалоговом окне выберите закладку Нестандартные
и тип диаграммы График/гистограмма. После
редактирования диаграмма будет иметь такой вид, как на рис. 2.

Рис. 2
Диаграмма относительных и накопленных частот из примера 1
Задания для самостоятельной работы
1. Для данных из примера 1 построить выборочные функции распределения, воспользовавшись процедурой Гистограмма из пакета Анализа.
2. Построить выборочные функции распределения
(относительные и накопленные частоты) для роста
в см. 20 студентов: 181, 169, 178, 178, 171, 179, 172, 181, 179, 168, 174, 167, 169, 171, 179, 181, 181,
183, 172, 176.
3. Найдите распределение по абсолютным частотам для
следующих результатов тестирования в
баллах: 79, 85, 78, 85, 83, 81, 95, 88, 97, 85 (используйте границы интервалов 70, 80, 90).
4. Рассмотрим любой из критериев оценки качеств педагога-профессионала,
например, «успешное решение задач обучения и воспитания». Ответ на этот вопрос
анкеты типа «да», «нет» достаточно груб. Чтобы уменьшить относительную ошибку
такого измерения, необходимо увеличить число возможных ответов на конкретный
критериальный вопрос. В табл. 1 представлены возможные варианты ответов.
Обозначим
этот параметр через х. Тогда в процессе ответа на вопрос величина х
примет дискретное значение х, принадлежащее определенному интервалу значений.
Поставим в соответствие каждому из ответов определенное числовое значение
параметра х (см. табл. 1).
Табл. 1 Критериальный вопрос: успешное решение задач обучения и воспитания
|
№ п/п |
Варианты ответов |
Х |
|
1 |
Абсолютно неуспешно |
0,1 |
|
2 |
Неуспешно |
0,2 |
|
3 |
Успешно в очень |
0,3 |
|
4 |
В определенной |
0,4 |
|
5 |
В среднем успешно, |
0,5 |
|
6 |
Успешно с |
0,6 |
|
7 |
Успешно, но |
0,7 |
|
8 |
Достаточно успешно |
0,8 |
|
9 |
Очень успешно |
0,9 |
|
10 |
Абсолютно успешно |
1 |
При проведении анкетирования в каждой отдельной
анкете параметр х принимает случайное значение, но только в пределах числового
интервала от 0,1 до 1.
Тогда в результате измерений мы получаем
неранжированный ряд случайных значений (см. табл. 2).
Таблица 2.
Результаты опроса ста учителей

Сгруппируйте полученную выборку, рассчитайте среднее
значение выборки, стандартное отклонение, абсолютную и относительную частоту
появления параметра, а также постройте график плотности вероятности f(x)=

где
W(x) – относительная частота наступления события;

– стандартное
отклонение;

=3,14.
Постройте график функции f(x) и сравните его с
нормальным распределением Гаусса.
Решение математических задач
средствами Excel: Практикум/ В.Я. Гельман. – СПб.: Питер, 2003 – с. 168-172
Интервальный вариационный ряд и его характеристики
- Построение интервального вариационного ряда по данным эксперимента
- Гистограмма и полигон относительных частот, кумулята и эмпирическая функция распределения
- Выборочная средняя, мода и медиана. Симметрия ряда
- Выборочная дисперсия и СКО
- Исправленная выборочная дисперсия, стандартное отклонение выборки и коэффициент вариации
- Алгоритм исследования интервального вариационного ряда
- Примеры
п.1. Построение интервального вариационного ряда по данным эксперимента
Интервальный вариационный ряд – это ряд распределения, в котором однородные группы составлены по признаку, меняющемуся непрерывно или принимающему слишком много значений.
Общий вид интервального вариационного ряда
| Интервалы, (left.left[a_{i-1},a_iright.right)) | (left.left[a_{0},a_1right.right)) | (left.left[a_{1},a_2right.right)) | … | (left.left[a_{k-1},a_kright.right)) |
| Частоты, (f_i) | (f_1) | (f_2) | … | (f_k) |
Здесь k – число интервалов, на которые разбивается ряд.
Размах вариации – это длина интервала, в пределах которой изменяется исследуемый признак: $$ F=x_{max}-x_{min} $$
Правило Стерджеса
Эмпирическое правило определения оптимального количества интервалов k, на которые следует разбить ряд из N чисел: $$ k=1+lfloorlog_2 Nrfloor $$ или, через десятичный логарифм: $$ k=1+lfloor 3,322cdotlg Nrfloor $$
Скобка (lfloor rfloor) означает целую часть (округление вниз до целого числа).
Шаг интервального ряда – это отношение размаха вариации к количеству интервалов, округленное вверх до определенной точности: $$ h=leftlceilfrac Rkrightrceil $$
Скобка (lceil rceil) означает округление вверх, в данном случае не обязательно до целого числа.
Алгоритм построения интервального ряда
На входе: все значения признака (left{x_jright}, j=overline{1,N})
Шаг 1. Найти размах вариации (R=x_{max}-x_{min})
Шаг 2. Найти оптимальное количество интервалов (k=1+lfloorlog_2 Nrfloor)
Шаг 3. Найти шаг интервального ряда (h=leftlceilfrac{R}{k}rightrceil)
Шаг 4. Найти узлы ряда: $$ a_0=x_{min}, a_i=1_0+ih, i=overline{1,k} $$ Шаг 5. Найти частоты (f_i) – число попаданий значений признака в каждый из интервалов (left.left[a_{i-1},a_iright.right)).
На выходе: интервальный ряд с интервалами (left.left[a_{i-1},a_iright.right)) и частотами (f_i, i=overline{1,k})
Заметим, что поскольку шаг h находится с округлением вверх, последний узел (a_kgeq x_{max}).
Например:
Проведено 100 измерений роста учеников старших классов.
Минимальный рост составляет 142 см, максимальный – 197 см.
Найдем узлы для построения соответствующего интервального ряда.
По условию: (N=100, x_{min}=142 см, x_{max}=197 см).
Размах вариации: (R=197-142=55) (см)
Оптимальное число интервалов: (k=1+lfloor 3,322cdotlg 100rfloor=1+lfloor 6,644rfloor=1+6=7)
Шаг интервального ряда: (h=lceilfrac{55}{5}rceil=lceil 7,85rceil=8) (см)
Получаем узлы ряда: $$ a_0=x_{min}=142, a_i=142+icdot 8, i=overline{1,7} $$
| (left.left[a_{i-1},a_iright.right)) cм | (left.left[142;150right.right)) | (left.left[150;158right.right)) | (left.left[158;166right.right)) | (left.left[166;174right.right)) | (left.left[174;182right.right)) | (left.left[182;190right.right)) | (left[190;198right]) |
п.2. Гистограмма и полигон относительных частот, кумулята и эмпирическая функция распределения
Относительная частота интервала (left.left[a_{i-1},a_iright.right)) – это отношение частоты (f_i) к общему количеству исходов: $$ w_i=frac{f_i}{N}, i=overline{1,k} $$
Гистограмма относительных частот интервального ряда – это фигура, состоящая из прямоугольников, ширина которых равна шагу ряда, а высота – относительным частотам каждого из интервалов.
Площадь гистограммы равна 1 (с точностью до округлений), и она является эмпирическим законом распределения исследуемого признака.
Полигон относительных частот интервального ряда – это ломаная, соединяющая точки ((x_i,w_i)), где (x_i) – середины интервалов: (x_i=frac{a_{i-1}+a_i}{2}, i=overline{1,k}).
Накопленные относительные частоты – это суммы: $$ S_1=w_1, S_i=S_{i-1}+w_i, i=overline{2,k} $$ Ступенчатая кривая (F(x)), состоящая из прямоугольников, ширина которых равна шагу ряда, а высота – накопленным относительным частотам, является эмпирической функцией распределения исследуемого признака.
Кумулята – это ломаная, которая соединяет точки ((x_i,S_i)), где (x_i) – середины интервалов.
Например:
Продолжим анализ распределения учеников по росту.
Выше мы уже нашли узлы интервалов. Пусть, после распределения всех 100 измерений по этим интервалам, мы получили следующий интервальный ряд:
| i | 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| (left.left[a_{i-1},a_iright.right)) cм | (left.left[142;150right.right)) | (left.left[150;158right.right)) | (left.left[158;166right.right)) | (left.left[166;174right.right)) | (left.left[174;182right.right)) | (left.left[182;190right.right)) | (left[190;198right]) |
| (f_i) | 4 | 7 | 11 | 34 | 33 | 8 | 3 |
Найдем середины интервалов, относительные частоты и накопленные относительные частоты:
| (x_i) | 146 | 154 | 162 | 170 | 178 | 186 | 194 |
| (w_i) | 0,04 | 0,07 | 0,11 | 0,34 | 0,33 | 0,08 | 0,03 |
| (S_i) | 0,04 | 0,11 | 0,22 | 0,56 | 0,89 | 0,97 | 1 |
Построим гистограмму и полигон:

Построим кумуляту и эмпирическую функцию распределения: 

Эмпирическая функция распределения (относительно середин интервалов): $$ F(x)= begin{cases} 0, xleq 146\ 0,04, 146lt xleq 154\ 0,11, 154lt xleq 162\ 0,22, 162lt xleq 170\ 0,56, 170lt xleq 178\ 0,89, 178lt xleq 186\ 0,97, 186lt xleq 194\ 1, xgt 194 end{cases} $$
п.3. Выборочная средняя, мода и медиана. Симметрия ряда
Выборочная средняя интервального вариационного ряда определяется как средняя взвешенная по частотам: $$ X_{cp}=frac{x_1f_1+x_2f_2+…+x_kf_k}{N}=frac1Nsum_{i=1}^k x_if_i $$ где (x_i) – середины интервалов: (x_i=frac{a_{i-1}+a_i}{2}, i=overline{1,k}).
Или, через относительные частоты: $$ X_{cp}=sum_{i=1}^k x_iw_i $$
Модальным интервалом называют интервал с максимальной частотой: $$ f_m=max f_i $$ Мода интервального вариационного ряда определяется по формуле: $$ M_o=x_o+frac{f_m-f_{m-1}}{(f_m-f_{m-1})+(f_m+f_{m+1})}h $$ где
(h) – шаг интервального ряда;
(x_o) – нижняя граница модального интервала;
(f_m,f_{m-1},f_{m+1}) – соответственно, частоты модального интервала, интервала слева от модального и интервала справа.
Медианным интервалом называют первый интервал слева, на котором кумулята превысила значение 0,5. Медиана интервального вариационного ряда определяется по формуле: $$ M_e=x_o+frac{0,5-S_{me-1}}{w_{me}}h $$ где
(h) – шаг интервального ряда;
(x_o) – нижняя граница медианного интервала;
(S_{me-1}) накопленная относительная частота для интервала слева от медианного;
(w_{me}) относительная частота медианного интервала.
Расположение выборочной средней, моды и медианы в зависимости от симметрии ряда аналогично их расположению в дискретном ряду (см. §65 данного справочника).
Например:
Для распределения учеников по росту получаем:
| (x_i) | 146 | 154 | 162 | 170 | 178 | 186 | 194 | ∑ |
| (w_i) | 0,04 | 0,07 | 0,11 | 0,34 | 0,33 | 0,08 | 0,03 | 1 |
| (x_iw_i) | 5,84 | 10,78 | 17,82 | 57,80 | 58,74 | 14,88 | 5,82 | 171,68 |
$$ X_{cp}=sum_{i=1}^k x_iw_i=171,68approx 171,7 text{(см)} $$ На гистограмме (или полигоне) относительных частот максимальная частота приходится на 4й интервал [166;174). Это модальный интервал.
Данные для расчета моды: begin{gather*} x_o=166, f_m=34, f_{m-1}=11, f_{m+1}=33, h=8\ M_o=x_o+frac{f_m-f_{m-1}}{(f_m-f_{m-1})+(f_m+f_{m+1})}h=\ =166+frac{34-11}{(34-11)+(34-33)}cdot 8approx 173,7 text{(см)} end{gather*} На кумуляте значение 0,5 пересекается на 4м интервале. Это – медианный интервал.
Данные для расчета медианы: begin{gather*} x_o=166, w_m=0,34, S_{me-1}=0,22, h=8\ \ M_e=x_o+frac{0,5-S_{me-1}}{w_me}h=166+frac{0,5-0,22}{0,34}cdot 8approx 172,6 text{(см)} end{gather*} begin{gather*} \ X_{cp}=171,7; M_o=173,7; M_e=172,6\ X_{cp}lt M_elt M_o end{gather*} Ряд асимметричный с левосторонней асимметрией.
При этом (frac{|M_o-X_{cp}|}{|M_e-X_{cp}|}=frac{2,0}{0,9}approx 2,2lt 3), т.е. распределение умеренно асимметрично.
п.4. Выборочная дисперсия и СКО
Выборочная дисперсия интервального вариационного ряда определяется как средняя взвешенная для квадрата отклонения от средней: begin{gather*} D=frac1Nsum_{i=1}^k(x_i-X_{cp})^2 f_i=frac1Nsum_{i=1}^k x_i^2 f_i-X_{cp}^2 end{gather*} где (x_i) – середины интервалов: (x_i=frac{a_{i-1}+a_i}{2}, i=overline{1,k}).
Или, через относительные частоты: $$ D=sum_{i=1}^k(x_i-X_{cp})^2 w_i=sum_{i=1}^k x_i^2 w_i-X_{cp}^2 $$
Выборочное среднее квадратичное отклонение (СКО) определяется как корень квадратный из выборочной дисперсии: $$ sigma=sqrt{D} $$
Например:
Для распределения учеников по росту получаем:
| $x_i$ | 146 | 154 | 162 | 170 | 178 | 186 | 194 | ∑ |
| (w_i) | 0,04 | 0,07 | 0,11 | 0,34 | 0,33 | 0,08 | 0,03 | 1 |
| (x_iw_i) | 5,84 | 10,78 | 17,82 | 57,80 | 58,74 | 14,88 | 5,82 | 171,68 |
| (x_i^2w_i) – результат | 852,64 | 1660,12 | 2886,84 | 9826 | 10455,72 | 2767,68 | 1129,08 | 29578,08 |
$$ D=sum_{i=1}^k x_i^2 w_i-X_{cp}^2=29578,08-171,7^2approx 104,1 $$ $$ sigma=sqrt{D}approx 10,2 $$
п.5. Исправленная выборочная дисперсия, стандартное отклонение выборки и коэффициент вариации
Исправленная выборочная дисперсия интервального вариационного ряда определяется как: begin{gather*} S^2=frac{N}{N-1}D end{gather*}
Стандартное отклонение выборки определяется как корень квадратный из исправленной выборочной дисперсии: $$ s=sqrt{S^2} $$
Коэффициент вариации это отношение стандартного отклонения выборки к выборочной средней, выраженное в процентах: $$ V=frac{s}{X_{cp}}cdot 100text{%} $$
Подробней о том, почему и когда нужно «исправлять» дисперсию, и для чего использовать коэффициент вариации – см. §65 данного справочника.
Например:
Для распределения учеников по росту получаем: begin{gather*} S^2=frac{100}{99}cdot 104,1approx 105,1\ sapprox 10,3 end{gather*} Коэффициент вариации: $$ V=frac{10,3}{171,7}cdot 100text{%}approx 6,0text{%}lt 33text{%} $$ Выборка однородна. Найденное значение среднего роста (X_{cp})=171,7 см можно распространить на всю генеральную совокупность (старшеклассников из других школ).
п.6. Алгоритм исследования интервального вариационного ряда
На входе: все значения признака (left{x_jright}, j=overline{1,N})
Шаг 1. Построить интервальный ряд с интервалами (left.right[a_{i-1}, a_ileft.right)) и частотами (f_i, i=overline{1,k}) (см. алгоритм выше).
Шаг 2. Составить расчетную таблицу. Найти (x_i,w_i,S_i,x_iw_i,x_i^2w_i)
Шаг 3. Построить гистограмму (и/или полигон) относительных частот, эмпирическую функцию распределения (и/или кумуляту). Записать эмпирическую функцию распределения.
Шаг 4. Найти выборочную среднюю, моду и медиану. Проанализировать симметрию распределения.
Шаг 5. Найти выборочную дисперсию и СКО.
Шаг 6. Найти исправленную выборочную дисперсию, стандартное отклонение и коэффициент вариации. Сделать вывод об однородности выборки.
п.7. Примеры
Пример 1. При изучении возраста пользователей коворкинга выбрали 30 человек.
Получили следующий набор данных:
18,38,28,29,26,38,34,22,28,30,22,23,35,33,27,24,30,32,28,25,29,26,31,24,29,27,32,24,29,29
Постройте интервальный ряд и исследуйте его.
1) Построим интервальный ряд. В наборе данных: $$ x_{min}=18, x_{max}=38, N=30 $$ Размах вариации: (R=38-18=20)
Оптимальное число интервалов: (k=1+lfloorlog_2 30rfloor=1+4=5)
Шаг интервального ряда: (h=lceilfrac{20}{5}rceil=4)
Получаем узлы ряда: $$ a_0=x_{min}=18, a_i=18+icdot 4, i=overline{1,5} $$
| (left.left[a_{i-1},a_iright.right)) лет | (left.left[18;22right.right)) | (left.left[22;26right.right)) | (left.left[26;30right.right)) | (left.left[30;34right.right)) | (left.left[34;38right.right)) |
Считаем частоты для каждого интервала. Получаем интервальный ряд:
| (left.left[a_{i-1},a_iright.right)) лет | (left.left[18;22right.right)) | (left.left[22;26right.right)) | (left.left[26;30right.right)) | (left.left[30;34right.right)) | (left.left[34;38right.right)) |
| (f_i) | 1 | 7 | 12 | 6 | 4 |
2) Составляем расчетную таблицу:
| (x_i) | 20 | 24 | 28 | 32 | 36 | ∑ |
| (f_i) | 1 | 7 | 12 | 6 | 4 | 30 |
| (w_i) | 0,033 | 0,233 | 0,4 | 0,2 | 0,133 | 1 |
| (S_i) | 0,033 | 0,267 | 0,667 | 0,867 | 1 | – |
| (x_iw_i) | 0,667 | 5,6 | 11,2 | 6,4 | 4,8 | 28,67 |
| (x_i^2w_i) | 13,333 | 134,4 | 313,6 | 204,8 | 172,8 | 838,93 |
3) Строим полигон и кумуляту

Эмпирическая функция распределения: $$ F(x)= begin{cases} 0, xleq 20\ 0,033, 20lt xleq 24\ 0,267, 24lt xleq 28\ 0,667, 28lt xleq 32\ 0,867, 32lt xleq 36\ 1, xgt 36 end{cases} $$ 4) Находим выборочную среднюю, моду и медиану $$ X_{cp}=sum_{i=1}^k x_iw_iapprox 28,7 text{(лет)} $$ На полигоне модальным является 3й интервал (самая высокая точка).
Данные для расчета моды: begin{gather*} x_0=26, f_m=12, f_{m-1}=7, f_{m+1}=6, h=4\ M_o=x_o+frac{f_m-f_{m-1}}{(f_m-f_{m-1})+(f_m+f_{m+1})}h=\ =26+frac{12-7}{(12-7)+(12-6)}cdot 4approx 27,8 text{(лет)} end{gather*}
На кумуляте медианным является 3й интервал (преодолевает уровень 0,5).
Данные для расчета медианы: begin{gather*} x_0=26, w_m=0,4, S_{me-1}=0,267, h=4\ M_e=x_o+frac{0,5-S_{me-1}}{w_{me}}h=26+frac{0,5-0,4}{0,267}cdot 4approx 28,3 text{(лет)} end{gather*} Получаем: begin{gather*} X_{cp}=28,7; M_o=27,8; M_e=28,6\ X_{cp}gt M_egt M_0 end{gather*} Ряд асимметричный с правосторонней асимметрией.
При этом (frac{|M_o-X_{cp}|}{|M_e-X_{cp}|} =frac{0,9}{0,1}=9gt 3), т.е. распределение сильно асимметрично.
5) Находим выборочную дисперсию и СКО: begin{gather*} D=sum_{i=1}^k x_i^2w_i-X_{cp}^2=838,93-28,7^2approx 17,2\ sigma=sqrt{D}approx 4,1 end{gather*}
6) Исправленная выборочная дисперсия: $$ S^2=frac{N}{N-1}D=frac{30}{29}cdot 17,2approx 17,7 $$ Стандартное отклонение (s=sqrt{S^2}approx 4,2)
Коэффициент вариации: (V=frac{4,2}{28,7}cdot 100text{%}approx 14,7text{%}lt 33text{%})
Выборка однородна. Найденное значение среднего возраста (X_{cp}=28,7) лет можно распространить на всю генеральную совокупность (пользователей коворкинга).
Шкала интервалов и частота попадания в интервал
|
Номер интервала |
Границы интервалов, тыс. |
Середины интервалов тыс. |
Частота |
г) по данным табл.
2.2 строится гистограмма fn(l)
(рис. 2.1). Для ее построения в прямоугольной
системе координат по оси абсцисс
откладывают отрезки, изображающие
интервал варьирования, и на этих отрезках,
как на основании, строят прямоугольники
с высотами, равными частотам
соответствующего интервала. В результате
получают ступенчатую фигуру, состоящую
из прямоугольников, которую и называют
гистограммой.
-
Определить
параметры и характеристики закона
распределения. Для нормального закона
распределения плотность вероятности
имеет вид
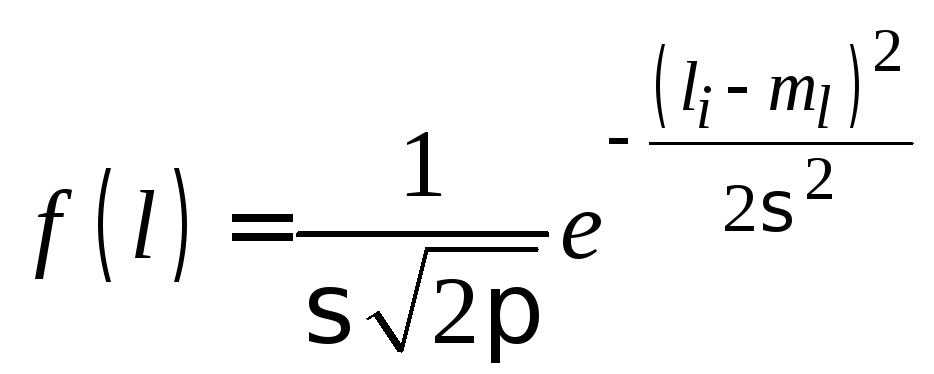 .
.
Статистические
характеристики теоретического
распределения
оцениваются
по результатам испытаний:
– математическое
ожидание (для интервального вариационного
ряда, табл. 2.2)
![]() ,
,
где
![]() –
–
середины интервалов,r
– количество интервалов;
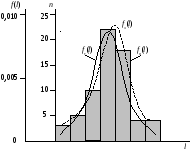
Рис. 2.1
–
среднеквадратическое
отклонение (для интервального вариаци-
онного
ряда, табл. 2.2)
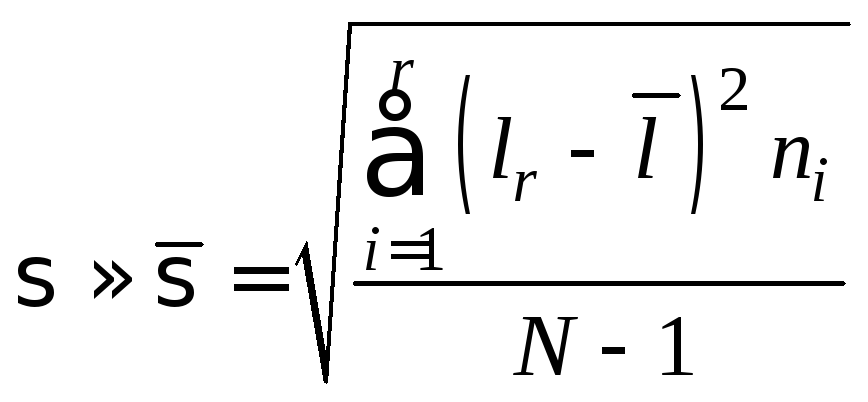 ;
;
– значения
эмпирической плотности распределения
вероятностей
![]() по интервалам
по интервалам
наработки (табл. 2.3)
![]() ;
;
–
нормированные и
центрированные отклонения середины
интер-
валов
![]() (табл. 2.3)
(табл. 2.3)
![]() ;
;
– значения
теоретической плотности распределения
вероятностей
(табл.
2.3)
![]() ,
,
где
![]() – плотность вероятности нормального
– плотность вероятности нормального
распределения
(табл. П2 Приложения).
Результаты расчета
представляются в табл. 2.3.
Т
а б л и ц а 2.3
Параметры распределения
|
|
|
|
|
|
По результатам
табл. 2.3 строятся графики
![]() и
и![]() ,
,
которые
совмещаются с построенной ранее
гистограммой
(рис. 2.1).
-
Проверить согласие
между эмпирическим и теоретическим
(нор-
мальным)
распределениями по критерию
![]() Пирсона
Пирсона
![]() ,
,
где
![]() – эмпирические и теоретические частоты
– эмпирические и теоретические частоты
попадания случайной величины вi-й
интервал соответственно; n
= N
.
Правило применения
критерия 2
сводится к следующему. Рассчитав значение
2
и выбрав уровень значимости критерия
![]() ,
,
по
таблицам2-распределения
(табл. П3 Приложения) определяют
![]() ,
,
где![]() –
–
число степеней свободы,r
– количество интервалов, s
– количество параметров распределения
(для нормального распределения s
= 2). Если
![]() >
>![]() ,
,
то проверяемую гипотезу отвергают; если![]()
![]()
![]() ,
,
то гипотезу принимают.
Необходимым
условием применения критерия Пирсона
является наличие в каждом из интервалов
не менее пяти наблюдений. Если количество
наблюдений в отдельных интервалах
меньше пяти, интервалы объединяются.
Вероятность
![]() определяется следующим образом.
определяется следующим образом.
Вероятностьр1
выражает вероятность того, что случайная
величина Х,
имеющая нормальный закон распределения,
принимает значение, принадлежащее
интервалу (l1
– l2),
т.е.
![]()
![]() ,
,
где
![]()
– функция
Лапласа (табл. П4 Приложения). Аналогично
вычисляются остальные рi.
Для
нахождения статистики 2
составляется табл. 2.4. Далее делается
заключение о согласии эмпирического и
теоретического законов распределения.
Т а б л и ц а 2.4
Соседние файлы в предмете [НЕСОРТИРОВАННОЕ]
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
Функция ЧАСТОТА используется для определения количества вхождения определенных величин в заданный интервал и возвращает данные в виде массива значений. Используя функцию ЧАСТОТА, мы узнаем, как посчитать частоту в Excel.
Пример использования функции ЧАСТОТА в Excel
Пример 1. Студенты одной из групп в университете сдали экзамен по физике. При оценке качества сдачи экзамена используется 100-бальная система. Для определения окончательной оценки по 5-бальной системе используют следующие критерии:
- От 0 до 50 баллов – экзамен не сдан.
- От 51 до 65 баллов – оценка 3.
- От 66 до 85 баллов – оценка 4.
- Свыше 86 баллов – оценка 5.
Для статистики необходимо определить, сколько студентов получили 5, 4, 3 баллов и количество тех, кому не удалось сдать экзамен.
Внесем данные в таблицу:
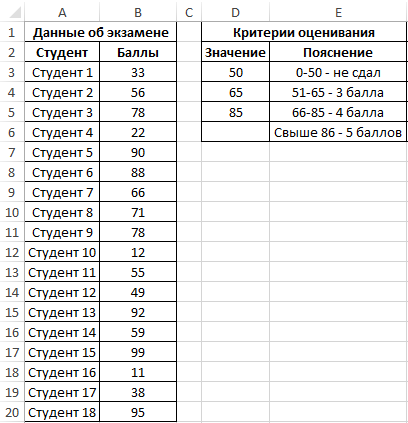
Для решения выделим области из 4 ячеек и введем следующую функцию:
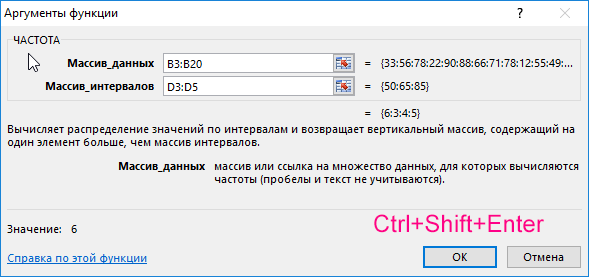
Описание аргументов:
- B3:B20 – массив данных об оценках студентов;
- D3:D5 – массив критериев нахождения частоты вхождений в массиве данных об оценках.
Выделяем диапазон F3:F6 жмем сначала клавишу F2, а потом комбинацию клавиш Ctrl+Shift+Enter, чтобы функция ЧАСТОТА была выполнена в массиве. Подтверждением того что все сделано правильно будут служить фигурные скобки {} в строке формул по краям. Это значит, что формула выполняется в массиве. В результате получим:
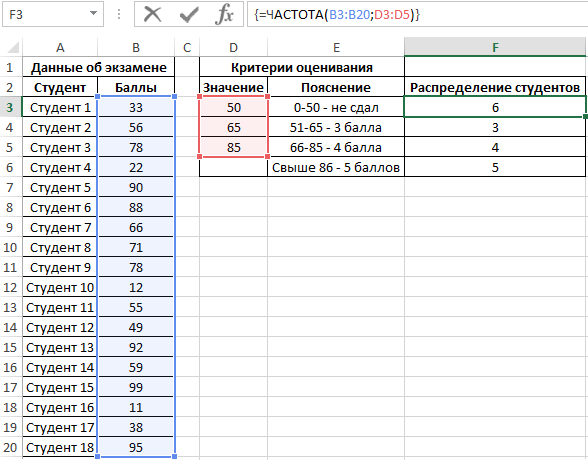
То есть, 6 студентов не сдали экзамен, оценки 3, 4 и 5 получили 3, 4 и 5 студентов соответственно.
Пример определения вероятности используя функцию ЧАСТОТА в Excel
Пример 2. Известно то, что если существует только два возможных варианта развития событий, вероятности первого и второго равны 0,5 соответственно. Например, вероятности выпадения «орла» или «решки» у подброшенной монетки равны ½ и ½ (если пренебречь возможностью падения монетки на ребро). Аналогичное расчетное распределение вероятностей характерно для следующей функции СЛУЧМЕЖДУ(1;2), которая возвращает случайное число в интервале от 1 до 2. Было проведено 20 вычислений с использованием данной функции. Определить фактические вероятности появления чисел 1 и 2 соответственно на основании полученных результатов.
Заполним исходную таблицу случайными значениями от 1-го до 2-ух:
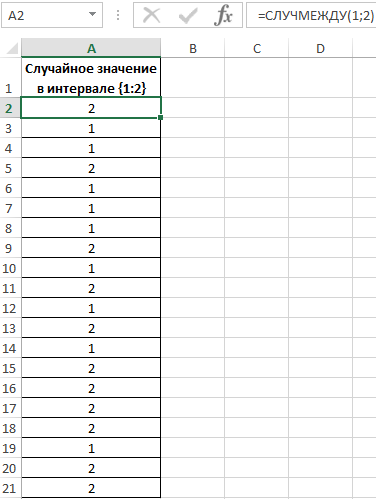
Для определения случайных значений в исходной таблице была использована специальная функция:
=СЛУЧМЕЖДУ(1;2)
Для определения количества сгенерированных 1 и 2 используем функцию:
=ЧАСТОТА(A2:A21;1)
Описание аргументов:
- A2:A21 – массив сгенерированных функцией =СЛУЧМЕЖДУ(1;2) значений;
- 1 – критерий поиска (функция ЧАСТОТА ищет значения от 0 до 1 включительно и значения >1).
В результате получим:
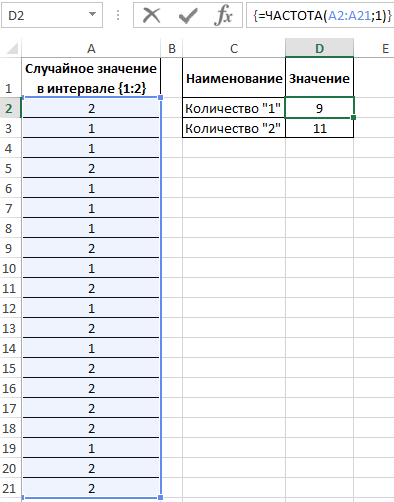
Вычислим вероятности, разделив количество событий каждого типа на общее их число:
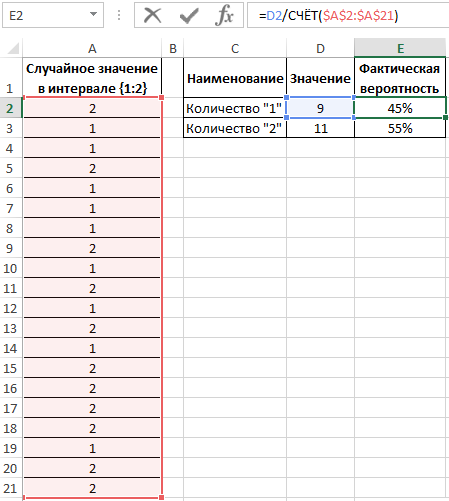
Для подсчета количества событий используем функцию =СЧЁТ($A$2:$A$21). Или можно просто разделить на значение 20. Если заранее не известно количество событий и размер диапазона со случайными значениями, тогда можно использовать в аргументах функции СЧЁТ ссылку на целый столбец: =СЧЁТ(A:A). Таким образом будет автоматически подсчитывается количество чисел в столбце A.
Вероятности выпадения «1» и «2» – 0,45 и 0,55 соответственно. Не забудьте присвоить ячейкам E2:E3 процентный формат для отображения их значений в процентах: 45% и 55%.
Теперь воспользуемся более сложной формулой для вычисления максимальной частоты повторов:
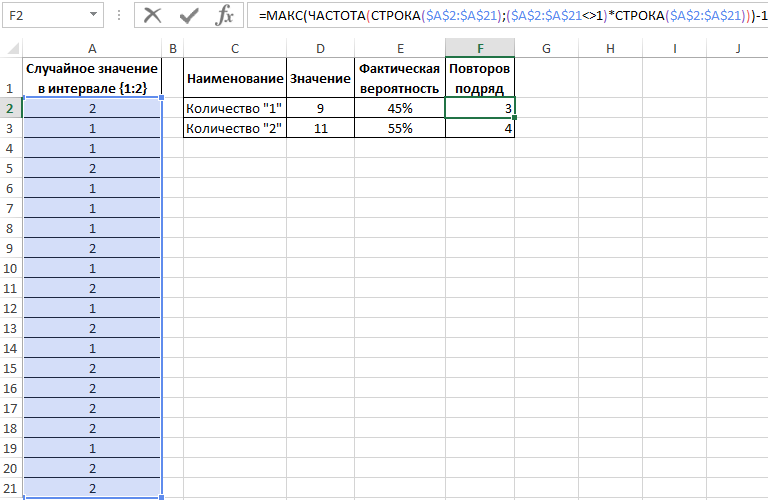
Формулы в ячейках F2 и F3 отличаются только одним лишь числом после оператора сравнения «не равно»: <>1 и <>2.
Интересный факт! С помощью данной формулы можно легко проверить почему не работает стратегия удвоения ставок в рулетке казино. Данную стратегию управления ставками в азартных играх называют еще Мартингейл. Дело в том, что количество случайных повторов подряд может достигать 18-ти раз и более, то есть восемнадцать раз подряд красные или черные. Например, если ставку в 2 доллара 18 раз удваивать – это уже более пол миллиона долларов «просадки». Это уже провал по любым техникам планирования рисков. Так же следует учитывать, что кроме «черные» и «красные» иногда выпадает еще и «зеро», что окончательно уничтожает все шансы. Так же интересно, что сумма всех чисел в рулетке от 0 до 36 равна 666.
Как посчитать неповторяющиеся значения в Excel?
Пример 3. Определить количество уникальных вхождений в массив числовых данных, то есть не повторяющихся значений.
Исходная таблица:
Определим искомую величину с помощью формулы:
В данном случае функция ЧАСТОТА выполняет проверку наличия каждого из элементов массива данных в этом же массиве данных (оба аргумента совпадают). С помощью функции ЕСЛИ задано условие, которое имеет следующий смысл:
- Если искомый элемент содержится в диапазоне значений, вместо фактического количества вхождений будет возвращено 1;
- Если искомого элемента нет – будет возвращен 0 (нуль).
Полученное значение (количество единиц) суммируется.
В результате получим:
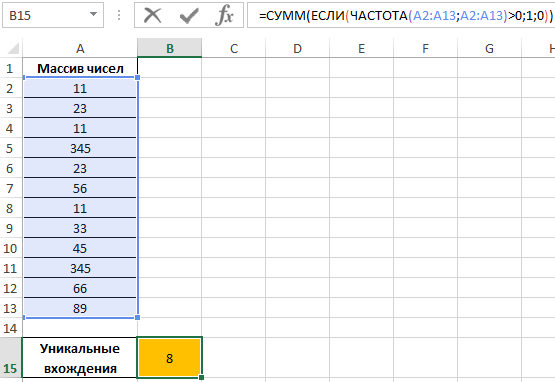
То есть, в указанном массиве содержится 8 уникальных значений.
Скачать пример функции ЧАСТОТА в Excel
Функция ЧАСТОТА в Excel и особенности ее синтаксиса
Данная функция имеет следующую синтаксическую запись:
Описание аргументов функции (оба являются обязательными для заполнения):
- массив_данных – данные в форме массива либо ссылка на диапазон значений, для которых необходимо определить частоты.
- массив_интервалов – данные в формате массива либо ссылка не множество значений, в которые группируются значения первого аргумента данной функции.
Примечания 1:
- Если в качестве аргумента массив_интервалов был передан пустой массив или ссылка на диапазон пустых значений, результатом выполнения функции ЧАСТОТА будет являться число элементов, входящих диапазон данных, которые были переданы в качестве первого аргумента.
- При использовании функции ЧАСТОТА в качестве обычной функции Excel будет возвращено единственное значение, соответствующее первому вхождению в массив_интервалов (то есть, первому критерию поиска частоты вхождения).
- Массив возвращаемых данной функцией элементов содержит на один элемент больше, чем количество элементов, содержащихся в массив_интервалов. Это происходит потому, что функция ЧАСТОТА вычисляет также количество вхождений величин, значения которых превышают верхнюю границу интервалов. Например, в наборе данных 2,7, 10, 13, 18, 4, 33, 26 необходимо найти количество вхождений величин из диапазонов от 1 до 10, от 11 до 20, от 21 до 30 и более 30. Массив интервалов должен содержать только их граничные значения, то есть 10, 20 и 30. Функция может быть записана в следующем виде: =ЧАСТОТА({2;7;10;13;18;4;33;26};{10;20;30}), а результатом ее выполнения будет столбец из четырех ячеек, которые содержат следующие значения: 4,2, 1, 1. Последнее значение соответствует количеству вхождений чисел > 30 в массив_данных. Такое число действительно является единственным – это 33.
- Если в состав массив_данных входят ячейки, содержащие пустые значения или текст, они будут пропущены функцией ЧАСТОТА в процессе вычислений.
Примечания 2:
- Функция может использоваться для выполнения статистического анализа, например, с целью определения наиболее востребованных для покупателей наименований продукции.
- Данная функция должна быть использована как формула массива, поскольку возвращаемые ей данные имеют форму массива. Для выполнения обычных формул после их ввода необходимо нажать кнопку Enter. В данном случае требуется использовать комбинацию клавиш Ctrl+Shift+Enter.
=ЧАСТОТА(массив_данных;массив_интервалов)
При анализе данных периодически возникает задача подсчитать количество значений, попадающих в заданные интервалы “от и до” (в статистике их называют “карманы”). Например, подсчитать количество звонков определенной длительности при разборе статистики по мобильной связи, чтобы понимать какой тариф для нас выгоднее:
")
Для решения подобной задачи можно воспользоваться функцией ЧАСТОТА (FREQUENCY). Ее синтаксис прост:
=ЧАСТОТА(Данные; Карманы)
где
- Карманы – диапазон с границами интервалов, попадание в которые нас интересует
- Данные – диапазон с исходными числовыми значениями, которые мы анализируем
Обратите внимание, что эта функция игнорирует пустые ячейки и ячейки с текстом, т.е. работает только с числами.
Для использования функции ЧАСТОТА нужно:
- заранее подготовить ячейки с интересующими нас интервалами-карманами (желтые F2:F5 в нашем примере)
- выделить пустой диапазон ячеек (G2:G6) по размеру на одну ячейку больший, чем диапазон карманов (F2:F5)
- ввести функцию ЧАСТОТА и нажать в конце сочетание Ctrl+Shift+Enter, т.е. ввести ее как формулу массива
Во всех предварительно выделенных ячейках посчитается количество попаданий в заданные интервалы. Само-собой, для реализации подобной задачи можно использовать и другие способы (функцию СЧЁТЕСЛИ, сводные таблицы и т.д.), но этот вариант весьма хорош.
Кроме того, с помощью функции ЧАСТОТА можно легко подсчитывать количество уникальных чисел в наборе с помощью простой формулы массива:

Ссылки по теме
- Как подсчитать количество уникальных элементов в списке
- Как сделать список без повторений
- Частотный анализ данных с помощью сводных таблиц и формул
