Функция ЧАСТОТА используется для определения количества вхождения определенных величин в заданный интервал и возвращает данные в виде массива значений. Используя функцию ЧАСТОТА, мы узнаем, как посчитать частоту в Excel.
Пример использования функции ЧАСТОТА в Excel
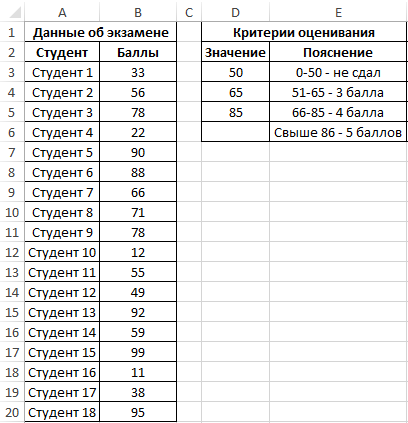
Пример 1. Студенты одной из групп в университете сдали экзамен по физике. При оценке качества сдачи экзамена используется 100-бальная система. Для определения окончательной оценки по 5-бальной системе используют следующие критерии:
- От 0 до 50 баллов – экзамен не сдан.
- От 51 до 65 баллов – оценка 3.
- От 66 до 85 баллов – оценка 4.
- Свыше 86 баллов – оценка 5.
Для статистики необходимо определить, сколько студентов получили 5, 4, 3 баллов и количество тех, кому не удалось сдать экзамен.
Внесем данные в таблицу:
Для решения выделим области из 4 ячеек и введем следующую функцию:
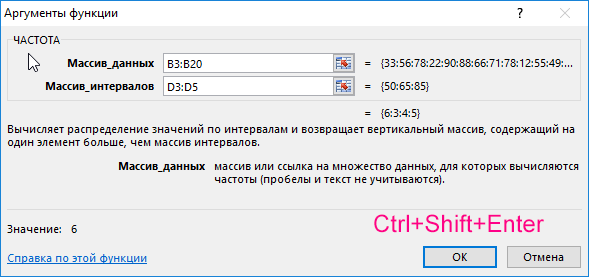
Описание аргументов:
- B3:B20 – массив данных об оценках студентов;
- D3:D5 – массив критериев нахождения частоты вхождений в массиве данных об оценках.
Выделяем диапазон F3:F6 жмем сначала клавишу F2, а потом комбинацию клавиш Ctrl+Shift+Enter, чтобы функция ЧАСТОТА была выполнена в массиве. Подтверждением того что все сделано правильно будут служить фигурные скобки {} в строке формул по краям. Это значит, что формула выполняется в массиве. В результате получим:
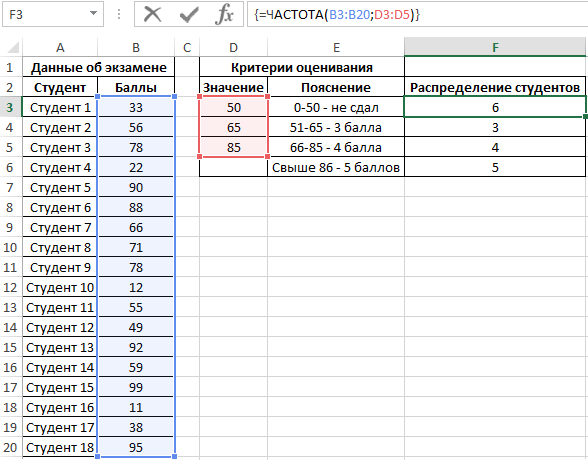
То есть, 6 студентов не сдали экзамен, оценки 3, 4 и 5 получили 3, 4 и 5 студентов соответственно.
Пример определения вероятности используя функцию ЧАСТОТА в Excel
Пример 2. Известно то, что если существует только два возможных варианта развития событий, вероятности первого и второго равны 0,5 соответственно. Например, вероятности выпадения «орла» или «решки» у подброшенной монетки равны ½ и ½ (если пренебречь возможностью падения монетки на ребро). Аналогичное расчетное распределение вероятностей характерно для следующей функции СЛУЧМЕЖДУ(1;2), которая возвращает случайное число в интервале от 1 до 2. Было проведено 20 вычислений с использованием данной функции. Определить фактические вероятности появления чисел 1 и 2 соответственно на основании полученных результатов.
Заполним исходную таблицу случайными значениями от 1-го до 2-ух:
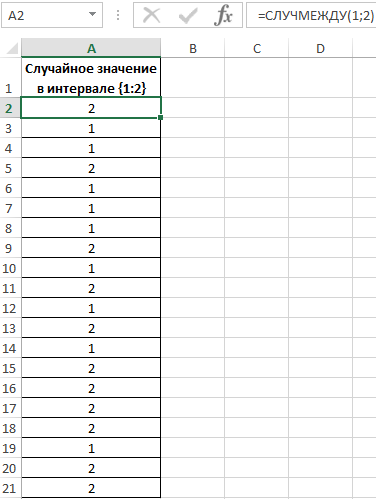
Для определения случайных значений в исходной таблице была использована специальная функция:
=СЛУЧМЕЖДУ(1;2)
Для определения количества сгенерированных 1 и 2 используем функцию:
=ЧАСТОТА(A2:A21;1)
Описание аргументов:
- A2:A21 – массив сгенерированных функцией =СЛУЧМЕЖДУ(1;2) значений;
- 1 – критерий поиска (функция ЧАСТОТА ищет значения от 0 до 1 включительно и значения >1).
В результате получим:
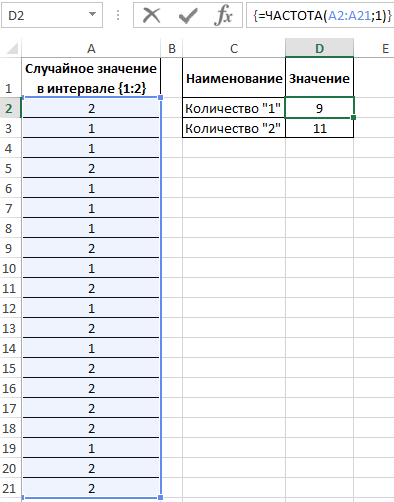
Вычислим вероятности, разделив количество событий каждого типа на общее их число:
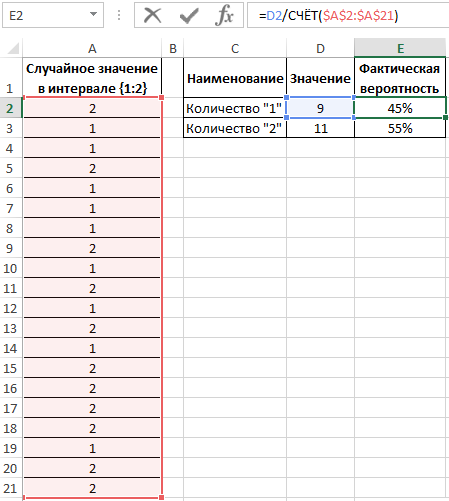
Для подсчета количества событий используем функцию =СЧЁТ($A$2:$A$21). Или можно просто разделить на значение 20. Если заранее не известно количество событий и размер диапазона со случайными значениями, тогда можно использовать в аргументах функции СЧЁТ ссылку на целый столбец: =СЧЁТ(A:A). Таким образом будет автоматически подсчитывается количество чисел в столбце A.
Вероятности выпадения «1» и «2» – 0,45 и 0,55 соответственно. Не забудьте присвоить ячейкам E2:E3 процентный формат для отображения их значений в процентах: 45% и 55%.
Теперь воспользуемся более сложной формулой для вычисления максимальной частоты повторов:
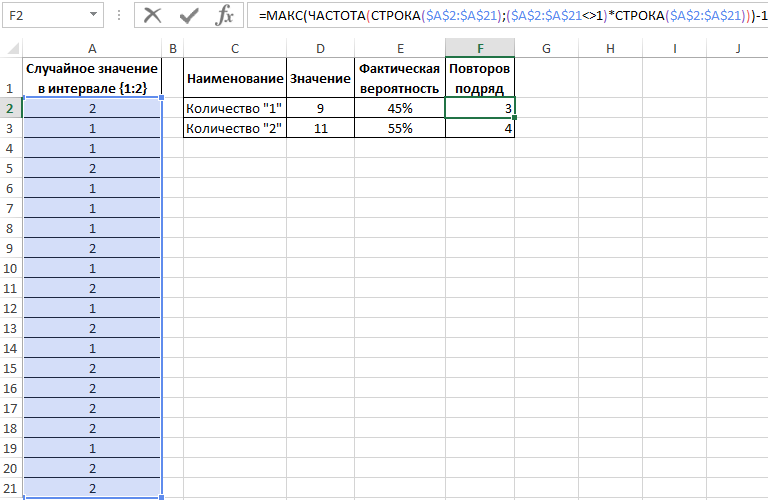
Формулы в ячейках F2 и F3 отличаются только одним лишь числом после оператора сравнения «не равно»: <>1 и <>2.
Интересный факт! С помощью данной формулы можно легко проверить почему не работает стратегия удвоения ставок в рулетке казино. Данную стратегию управления ставками в азартных играх называют еще Мартингейл. Дело в том, что количество случайных повторов подряд может достигать 18-ти раз и более, то есть восемнадцать раз подряд красные или черные. Например, если ставку в 2 доллара 18 раз удваивать – это уже более пол миллиона долларов «просадки». Это уже провал по любым техникам планирования рисков. Так же следует учитывать, что кроме «черные» и «красные» иногда выпадает еще и «зеро», что окончательно уничтожает все шансы. Так же интересно, что сумма всех чисел в рулетке от 0 до 36 равна 666.
Как посчитать неповторяющиеся значения в Excel?
Пример 3. Определить количество уникальных вхождений в массив числовых данных, то есть не повторяющихся значений.
Исходная таблица:
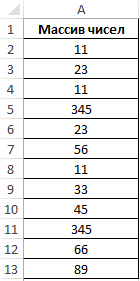
Определим искомую величину с помощью формулы:
В данном случае функция ЧАСТОТА выполняет проверку наличия каждого из элементов массива данных в этом же массиве данных (оба аргумента совпадают). С помощью функции ЕСЛИ задано условие, которое имеет следующий смысл:
- Если искомый элемент содержится в диапазоне значений, вместо фактического количества вхождений будет возвращено 1;
- Если искомого элемента нет – будет возвращен 0 (нуль).
Полученное значение (количество единиц) суммируется.
В результате получим:
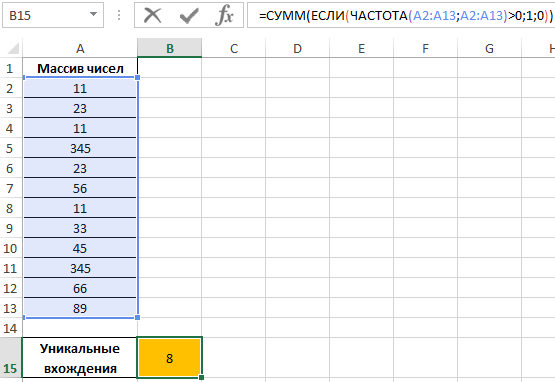
То есть, в указанном массиве содержится 8 уникальных значений.
Скачать пример функции ЧАСТОТА в Excel
Функция ЧАСТОТА в Excel и особенности ее синтаксиса
Данная функция имеет следующую синтаксическую запись:
Описание аргументов функции (оба являются обязательными для заполнения):
- массив_данных – данные в форме массива либо ссылка на диапазон значений, для которых необходимо определить частоты.
- массив_интервалов – данные в формате массива либо ссылка не множество значений, в которые группируются значения первого аргумента данной функции.
Примечания 1:
- Если в качестве аргумента массив_интервалов был передан пустой массив или ссылка на диапазон пустых значений, результатом выполнения функции ЧАСТОТА будет являться число элементов, входящих диапазон данных, которые были переданы в качестве первого аргумента.
- При использовании функции ЧАСТОТА в качестве обычной функции Excel будет возвращено единственное значение, соответствующее первому вхождению в массив_интервалов (то есть, первому критерию поиска частоты вхождения).
- Массив возвращаемых данной функцией элементов содержит на один элемент больше, чем количество элементов, содержащихся в массив_интервалов. Это происходит потому, что функция ЧАСТОТА вычисляет также количество вхождений величин, значения которых превышают верхнюю границу интервалов. Например, в наборе данных 2,7, 10, 13, 18, 4, 33, 26 необходимо найти количество вхождений величин из диапазонов от 1 до 10, от 11 до 20, от 21 до 30 и более 30. Массив интервалов должен содержать только их граничные значения, то есть 10, 20 и 30. Функция может быть записана в следующем виде: =ЧАСТОТА({2;7;10;13;18;4;33;26};{10;20;30}), а результатом ее выполнения будет столбец из четырех ячеек, которые содержат следующие значения: 4,2, 1, 1. Последнее значение соответствует количеству вхождений чисел > 30 в массив_данных. Такое число действительно является единственным – это 33.
- Если в состав массив_данных входят ячейки, содержащие пустые значения или текст, они будут пропущены функцией ЧАСТОТА в процессе вычислений.
Примечания 2:
- Функция может использоваться для выполнения статистического анализа, например, с целью определения наиболее востребованных для покупателей наименований продукции.
- Данная функция должна быть использована как формула массива, поскольку возвращаемые ей данные имеют форму массива. Для выполнения обычных формул после их ввода необходимо нажать кнопку Enter. В данном случае требуется использовать комбинацию клавиш Ctrl+Shift+Enter.
=ЧАСТОТА(массив_данных;массив_интервалов)
![]()
Загрузить PDF
![]()
Загрузить PDF
С абсолютной частотой все довольно просто: она определяет, сколько раз конкретное число содержится в имеющемся наборе данных (объектов или значений). А вот относительная частота характеризует отношение количества конкретного числа в наборе данных. Другими словами, относительная частота – это отношение количества определенного числа к общему количеству чисел в наборе данных. Имейте в виду, что вычислить относительную частоту достаточно легко.
-

1
Соберите данные. Если вы решаете математическую задачу, в ее условии должен быть дан набор данных (чисел). В противном случае проведите эксперимент или исследование и соберите необходимые данные. Подумайте, в какой форме записать исходные данные.
- Например, нужно собрать данные о возрасте людей, которые посмотрели определенный фильм. Конечно, можно записать точный возраст каждого человека, но в этом случае вы получите довольно большой набор данных с 60-70 числами в пределах от 10 до 70 или 80. Поэтому лучше сгруппировать данные по категориям, таким как «Моложе 20», «20-29», «30-39» «40-49», «50-59» и «Старше 60». Получится упорядоченный набор данных с шестью группами чисел.
- Другой пример: врач собирает данные о температуре пациентов в определенный день. Если записать округленные числа, например, 37, 38, 39, то результат будет не слишком точным, поэтому здесь данные нужно представить в виде десятичных дробей.
-
2
Упорядочьте данные. Когда вы соберете данные, у вас, скорее всего, получится хаотичный набор чисел, например, такой: 1, 2, 5, 4, 6, 4, 3, 7, 1, 5, 6, 5, 3, 4, 5, 1. Такая запись кажется практически бессмысленной и с ней сложно работать. Поэтому упорядочьте числа по возрастанию (от меньшего к большему), например, так: 1,1,1,2,3,3,4,4,4,5,5,5,5,6,6,7.[1]
- Упорядочивая данные, будьте внимательны, чтобы не пропустить ни одного числа. Посчитайте общее количество чисел в наборе данных, чтобы убедиться, что вы записали все числа.
-
3
Создайте таблицу с данными. Собранные данные можно организовать в виде таблицы. Такая таблица будет включать три столбца и использоваться для вычисления относительной частоты. Столбцы обозначьте следующим образом:[2]
Реклама



-
1
Найдите количество чисел в наборе данных. Относительная частота характеризует, сколько раз конкретное число содержится в имеющемся наборе данных по отношению к общему количеству чисел. Чтобы найти относительную частоту, нужно посчитать общее количество чисел в наборе данных. Общее количество чисел станет знаменателем дроби, с помощью которой будет вычислена относительная частота.[3]
- В нашем примере набор данных содержит 16 чисел.
-
2
Найдите количество определенного числа. То есть посчитайте, сколько раз конкретное число встречается в наборе данных. Это можно сделать как для одного числа, так и для всех чисел из набора данных.[4]
- Например, в нашем примере число встречается в наборе данных три раза.
- Например, в нашем примере число
-
3
Разделите количество конкретного числа на общее количество чисел. Так вы найдете относительную частоту для определенного числа. Вычисление можно представить в виде дроби или воспользоваться калькулятором или электронной таблицей, чтобы разделить два числа.[5]
Реклама



-
1
Результаты вычислений запишите в созданную ранее таблицу. Она позволит представить результаты в наглядной форме. По мере вычисления относительной частоты результаты записывайте в таблицу напротив соответствующего числа. Как правило, значение относительной частоты можно округлить до второго знака после десятичной запятой, но это на ваше усмотрение (в зависимости от требований задачи или исследования). Помните, что округленный результат не равен точному ответу.[6]
- В нашем примере таблица относительных частот будет выглядеть следующим образом:
- x : n(x) : P(x)
- 1 : 3 : 0,19
- 2 : 1 : 0,06
- 3 : 2 : 0,13
- 4 : 3 : 0,19
- 5 : 4 : 0,25
- 6 : 2 : 0,13
- 7 : 1 : 0,06
- Итого : 16 : 1,01
-
2
Представьте числа (элементы), которых нет в наборе данных. Иногда представление чисел с нулевой частотой так же важно, как и представление чисел с ненулевой частотой. Обратите внимание на собранные данные; если между данными имеются пробелы, их нужно заполнить нулями.
- В нашем примере набор данных включает все числа от 1 до 7. Но предположим, что числа 3 нет в наборе. Возможно, это немаловажный факт, поэтому нужно записать, что относительная частота числа 3 равна 0.
-
3
Выразите результаты в процентах. Иногда результаты вычислений нужно преобразовать из десятичных дробей в проценты. Это общепринятая практика, потому что относительная частота характеризует процент случаев появления определенного числа в наборе данных. Чтобы преобразовать десятичную дробь в проценты, нужно десятичную запятую передвинуть на две позиции вправо и приписать символ процента.
- Например, десятичная дробь 0,13 равна 13%.
- Десятичная дробь 0,06 равна 6% (обратите внимание, что перед 6 стоит 0).
Реклама



Советы
- Относительная частота характеризует наличие или возникновение определенного события в наборе событий.
- Если сложить относительные частоты всех чисел из набора данных, вы получите единицу. Помните, что при сложении округленных результатов сумма не будет равна 1,0.
- Если набор данных слишком большой, чтобы обработать его вручную, воспользуйтесь программой MS Excel или MATLAB; это позволит избежать ошибок в процессе вычисления.
Реклама
Источники
Об этой статье
Эту страницу просматривали 144 126 раз.
Была ли эта статья полезной?
Функция
ЧАСТОТА(
)
, английская версия FREQUENCY()
,
вычисляет частоту попадания значений в заданные пользователем интервалы и возвращает соответствующий массив чисел.
Функцией
ЧАСТОТА()
можно воспользоваться, например, для подсчета количества результатов тестирования, попадающих в определенные интервалы (См.
Файл примера
)
Синтаксис функции
ЧАСТОТА
(
массив_данных
;
массив_интервалов
)
Массив_данных
— массив или ссылка на множество ЧИСЛОвых данных, для которых вычисляются частоты.
Массив_интервалов
— массив или ссылка на множество интервалов, в которые группируются значения аргумента «массив_данных».
Функция
ЧАСТОТА()
вводится как
формула массива
после выделения диапазона смежных ячеек, в которые требуется вернуть полученный массив распределения (частот). Т.е. после ввода формулы необходимо вместо нажатия клавиши
ENTER
нажать сочетание клавиш
CTRL+SHIFT+ENTER
.
Количество элементов в возвращаемом массиве на единицу больше числа элементов в массиве «
массив_интервалов
». Дополнительный элемент в возвращаемом массиве содержит количество значений, превышающих верхнюю границу интервала, содержащего наибольшие значения (см. пример ниже).
Пример
Пусть в диапазоне
А2:А101
имеется исходный массив чисел от 1 до 100.
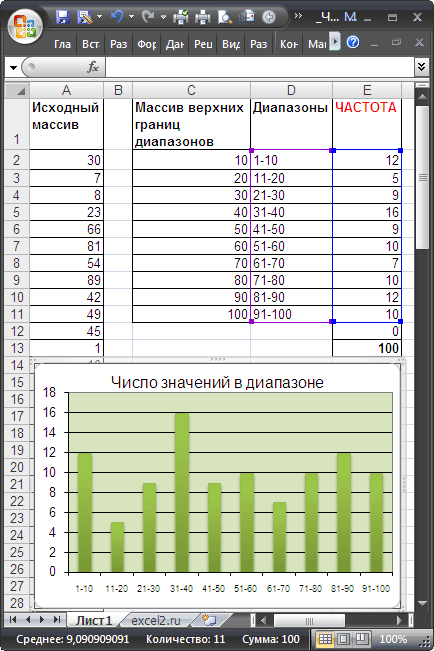
Подсчитаем количество чисел, попадающих в интервалы 1-10; 11-20; …91-100.
Сформируем столбце
С
массив верхних границ диапазонов (интервалов). Для наглядности в столбце
D
сформируем текстовые значения соответствующие границам интервалов (1-10; 11-20; …91-100).
Для ввода формулы выделим диапазон
Е2:Е12
, состоящий из 11 ячеек (на 1 больше, чем число верхних границ интервалов). В
Строке формул
введем
=ЧАСТОТА($A$2:$A$101;$C$2:$C$11)
. После ввода формулы необходимо нажать сочетание клавиш
CTRL+SHIFT+ENTER
. Диапазон
Е2:Е12
заполнится значениями:
-
в
Е2
– будет содержаться количество значений из
А2:А101
, которые меньше или равны 10; -
в
Е3
– количество значений из
А2:А101
, которые меньше или равны 20, но больше 10; -
в
Е11
– количество значений из
А2:А101
, которые меньше или равны 100, но больше 90; -
в
Е12
– количество значений из
А2:А101
, которые больше 100 (таких нет, т.к. исходный массив содержит числа от 1 до 100).
Примечание
. Функцию
ЧАСТОТА()
можно заменить формулой =
СУММПРОИЗВ(($A$5:$A$104>C5)*($A$5:$A$104<=C6))
(См.
Файл примера
)
При анализе данных периодически возникает задача подсчитать количество значений, попадающих в заданные интервалы “от и до” (в статистике их называют “карманы”). Например, подсчитать количество звонков определенной длительности при разборе статистики по мобильной связи, чтобы понимать какой тариф для нас выгоднее:
")
Для решения подобной задачи можно воспользоваться функцией ЧАСТОТА (FREQUENCY). Ее синтаксис прост:
=ЧАСТОТА(Данные; Карманы)
где
- Карманы – диапазон с границами интервалов, попадание в которые нас интересует
- Данные – диапазон с исходными числовыми значениями, которые мы анализируем
Обратите внимание, что эта функция игнорирует пустые ячейки и ячейки с текстом, т.е. работает только с числами.
Для использования функции ЧАСТОТА нужно:
- заранее подготовить ячейки с интересующими нас интервалами-карманами (желтые F2:F5 в нашем примере)
- выделить пустой диапазон ячеек (G2:G6) по размеру на одну ячейку больший, чем диапазон карманов (F2:F5)
- ввести функцию ЧАСТОТА и нажать в конце сочетание Ctrl+Shift+Enter, т.е. ввести ее как формулу массива
Во всех предварительно выделенных ячейках посчитается количество попаданий в заданные интервалы. Само-собой, для реализации подобной задачи можно использовать и другие способы (функцию СЧЁТЕСЛИ, сводные таблицы и т.д.), но этот вариант весьма хорош.
Кроме того, с помощью функции ЧАСТОТА можно легко подсчитывать количество уникальных чисел в наборе с помощью простой формулы массива:

Ссылки по теме
- Как подсчитать количество уникальных элементов в списке
- Как сделать список без повторений
- Частотный анализ данных с помощью сводных таблиц и формул
-
Пользуясь формулой, вычисляем накопленные частоты интервалов. В частности,
![]() ;
;
![]() ;
;
![]() ;
;
![]() .
.
-
Вычисляем частости
интервалов. Например,
![]() ;
;
![]() ;
;
![]() .
.
-
Вычисляем
накопленные частости интервалов. -
Данные вычислений
заносим в табл. 2
Таблица 2
|
№ интервала |
Границы |
Частота |
Накопленная |
Частость |
Накопленная |
|
1 |
5 |
3 |
3 |
0,06 |
0,06 |
|
2 |
7 |
9 |
12 |
0,18 |
0,24 |
|
3 |
9 |
17 |
29 |
0,34 |
0,58 |
|
4 |
11 |
10 |
39 |
0,20 |
0,78 |
|
5 |
13 |
7 |
46 |
0,14 |
0,92 |
|
6 |
15 |
4 |
50 |
0,08 |
1 |
Распределение
типа сведенного в табл. 2 представляет
собой интервальный
вариационный ряд.
Анализ вариационных
рядов упрощается при их графическом
представлении. Наряду с гистограммой
и полигоном частот можно построить
полигон
накопленных частостей (кумулята)
График получается
при соединении точек прямыми отрезками.
Координаты точек соответствуют верхним
границам интервалов и
накопленным частотам. Если по оси ординат
откладывать накопленные частости, то
полученный график называется полигоном
накопленных частостей.
Если ряд не интервальный, то по оси
![]()
откладывают значения измеряемого
признака, а по оси
![]()
соответствующие накопленные частоты
или частости. На рис.2 изображен полигон
накопленных частостей для примера 3.

На
практике соседние точки чаще всего
соединяют кривыми линиями (рис. 3).
1 .3. Статистические характеристики вариационного ряда
Для
полноты картины анализа выборки
рассматривают статистические
характеристики
вариационного ряда. С этой целью оценивают
следующие качества ряда:
-
центральную
тенденцию выборки; -
вариацию.
Центральную
тенденцию выборки оценивают такими
статистическими характеристиками, как
-
мода;
-
медиана;
-
среднее
арифметическое значение.
К
характеристикам вариации относят:
-
размах;
-
дисперсию;
-
среднее
квадратическое отклонение; -
коэффициент
вариации; -
ошибку
выборочного среднего.
Модой
называется значение признака, наиболее
часто встречающееся в выборке. Мода
обозначается
![]() .
.
Если значения выборки сгруппированы в
интервальный вариационный ряд, то
выбирается модальный
интервал с
наибольшей частотой.
Медиана
это такое значение признака, при котором
одна половина значений признака меньше
ее, а другая половина
больше (медиана делит вариационный ряд
пополам). Медиана обозначается
![]() .
.
Для отыскания медианы выборку ранжируют,
то есть значения признака располагают
в порядке возрастания или убывания. В
ранжированной выборке ранг (порядковый
номер в выборке)
![]()
медианы определяют по формуле:
![]()
, где
![]()
объем выборки.
При
![]()
нечетном ранг
![]()
целое число, и медианой считают следующее
значение:
![]() .
.
При
![]()
четном ранг
![]()
число не целое, представимое в виде
![]() ,
,
где
![]()
целое. В таком случае медианой считают
значение
![]() .
.
Среднее
арифметическое неупорядоченной
выборки вычисляют по формуле:
 .
.
В случае интервального
вариационного ряда формула приобретает
вид:
 ,
,
где
![]()
частота
![]() -го
-го
интервала,
![]()
среднее арифметическое значение этого
интервала.
Размах вариации
– это разность
между максимальным и минимальным
значениями выборки:
![]() .
.
Дисперсией
называется
средний квадрат отклонений значений
признака от среднего арифметического
и вычисляется по формуле:
![]() .
.
Средним
квадратическим отклонением называется
положительный квадратный корень из
дисперсии:
 ,
,
Среднее квадратическое
отклонение имеет ту же единицу измерения,
что и варьирующий признак. Оно характеризует
степень отклонения значений признака
от его среднего арифметического значения
в абсолютных единицах.
Для
сравнения варьируемости двух или
нескольких выборок, имеющих разные
единицы измерения, используют коэффициент
вариации. Коэффициент
вариации
это относительный показатель, равный
отношению среднего квадратического
отклонения к среднему арифметическому
значению:
![]() .
.
Принято
считать, что если
![]() ,
,
то варьируемость малая,
![]()
средняя,
![]()
большая.
Отклонения
выборочных коэффициентов от параметров
в генеральной совокупности называются
ошибками
параметров. Эти ошибки возникают в силу
того, что выборочная совокупность
представляет генеральную совокупность
только приближенно. Если взять несколько
вариантов выборок объемом
![]()
из одной и той же генеральной совокупности
и вычислить для каждой из них среднее
арифметическое, то окажется, что средние
арифметические выборок варьируют вокруг
среднего арифметического для генеральной
совокупности
![]()
в
![]()
раз меньше, чем отдельные варианты. На
этом основании в качестве стандартной
ошибки выборочного среднего
принимают величину
![]() .
.
Чтобы
подчеркнуть точность оценки среднего
выборочного, его чаще всего записывают
в виде: ![]() .
.
Пример 4.
В качестве оценки силовой подготовки
учащихся 5 класса произведен тест на
количество подтягиваний на перекладине.
Данные теста
следующие: 9, 9, 10, 11, 8, 7, 10, 7, 9, 11, 7, 8, 9, 8, 9.
Требуется вычислить
моду, медиану, среднее арифметическое
значение, размах вариации, дисперсию,
среднее квадратическое отклонение,
коэффициент вариации и ошибку выборочного
среднего данной выборки.
Решение.
Непосредственным подсчетом убеждаемся,
что значение
![]()
встречается в выборке чаще других (5
раз), следовательно,
![]() .
.
Для
вычисления медианы производим ранжировку
заданной выборки:
7, 7, 7, 8, 8, 8, 9, 9, 9, 9,
9, 10, 10, 11, 11
Объем выборки
![]()
число нечетное, поэтому ранг медианы
вычисляем по формуле:
![]() ,
,
то есть медианой
является 8-е значение выборки),
![]() .
.
Среднее арифметическое
значение выборки находим, пользуясь
формулой:

Крайние значения
ряда) определяют минимальное и максимальное
значения выборки
![]() ,
,
![]() .
.
Согласно определению, размах вариации
равен:
![]() .
.
Для удобства
вычисления дисперсии составляем таблицу.
Пользуясь суммой значений последней
колонки и формулой, находим: ![]() .
.
|
|
|
|
|
|
1 |
9 |
0,2 |
0,04 |
|
2 |
9 |
0,2 |
0,04 |
|
3 |
10 |
1,2 |
1,44 |
|
4 |
11 |
2,2 |
4,84 |
|
5 |
8 |
-0,8 |
0,64 |
|
6 |
7 |
-1,8 |
3,24 |
|
7 |
10 |
1,2 |
1,44 |
|
8 |
7 |
-1,8 |
3,24 |
|
9 |
9 |
0,2 |
0,44 |
|
10 |
11 |
2,2 |
4,24 |
|
11 |
7 |
-1,8 |
3,24 |
|
12 |
8 |
-0,8 |
0,64 |
|
13 |
9 |
0,2 |
0,04 |
|
14 |
8 |
-0,8 |
0,64 |
|
15 |
9 |
0,2 |
0,04 |
|
|
132 |
24,4 |
Вычислим среднее
квадратическое отклонение:
![]() .
.
Коэффициент
вариации:
![]() ,
,
откуда делаем вывод
результаты тестирования имеют средний
коэффициент вариации.
Ошибку выборочного
среднего арифметического находим:
![]() .
.
Наконец, записываем:
![]() .
.
Соседние файлы в предмете [НЕСОРТИРОВАННОЕ]
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
