
В сфере распознавания эмоций голос – второй по важности после лица источник эмоциональных данных. Голос можно охарактеризовать по нескольким параметрам. Высота голоса – одна из основных таких характеристик, однако в сфере акустических технологий корректнее называть этот параметр частотой основного тона.
Частота основного тона имеет непосредственное отношение к тому, что мы называем интонацией. А интонация, например, связана с эмоционально-экспрессивными характеристиками голоса.
Тем не менее, определение частоты основного тона является не совсем тривиальной задачей с интересными нюансами. В этой статье мы обсудим особенности алгоритмов для ее определения и сравним существующие решения на примерах конкретных аудиозаписей.
Введение
Для начала вспомним, чем, по сути, является частота основного тона и в каких задачах она может понадобиться. Частота основного тона, которую еще обозначают как ЧОТ, Fundamental Frequency или F0 – это частота колебания голосовых связок при произнесении тоновых звуков (voiced). При произнесении нетоновых звуков (unvoiced), например говорении шепотом или произнесении шипящих и свистящих звуков, связки не колеблются, а значит эта характеристика для них не релевантна.
* Обратите внимание, что деление на тоновые и не тоновые звуки не эквивалентно делению на гласные и согласные.
Вариабельность частоты основного тона довольно велика, причем она может сильно отличаться не только между людьми (для более низких в среднем мужских голосов частота составляет 70-200 Гц, а для женских может достигать 400 Гц), но и для одного человека, особенно в эмоциональной речи.
Определение частоты основного тона применяется для решения широкого спектра задач:
- Распознавание эмоций, как мы уже сказали выше;
- Определение пола;
- При решении задачи сегментации аудио с несколькими голосами или разделения речи на фразы;
- В медицине для определения патологических характеристик голоса (например, с помощью акустических параметров Jitter and Shimmer). Например, определение признаков заболевания Паркинсона [1]. Jitter and Shimmer также могут быть использованы для распознавания эмоций [2].
Однако при определении F0 существует ряд сложностей. К примеру, часто можно перепутать F0 с гармониками, что может привести к так называемым эффектам pitch doubling/pitch halving [3]. А в аудиозаписи плохого качества F0 вычислить бывает довольно сложно, так как нужный пик на низких частотах практически исчезает.
Кстати, помните историю про Laurel и Yanny? Различия в том, какие слова слышат люди при прослушивании одной и той же аудиозаписи, возникли как раз из-за разницы в восприятии F0, на которую влияют много факторов: возраст слушающего, степень усталости, устройство воспроизведения. Так, при прослушивании записи в колонках с качественным воспроизведением низких частот, вы будете слышать Laurel, а в аудиосистемах, где низкие частоты воспроизводятся плохо, Yanny. Эффект перехода можно заметить и на одном устройстве, например здесь. А в этой статье в качестве слушателя выступает нейросеть. В другой статье можно почитать, как объясняется феномен Yanny/Laurel с позиций речеобразования.
Поскольку подробный разбор всех методов определения F0 был бы чересчур объемным, статья носит обзорный характер и может помочь сориентироваться в теме.
Методы определения F0
Методы определения F0 можно разделить на три категории: основанные на временной динамике сигнала, или time-domain; основанные на частотной структуре, или frequency-domain, а также комбинированные методы. Предлагаем ознакомиться с обзорной статьей по теме, где подробно разбираются обозначенные методы выделения F0.
Отметим, что любой из обсуждаемых алгоритмов состоит из 3 основных шагов:
Препроцессинг (фильтрация сигнала, разделение его на фреймы)
Поиск возможных значений F0 (кандидатов)
Трекинг — выбор наиболее вероятной траектории F0 (поскольку для каждого момента времени мы имеем несколько конкурирующих кандидатов, нам необходимо найти среди них наиболее вероятный трек)
Time-domain
Очертим несколько общих моментов. Перед применением методов time-domain сигнал предварительно фильтруют, оставляя только низкие частоты. Задаются пороги – минимальная и максимальная частоты, например от 75 до 500 Гц. Определение F0 производится только для участков с гармонической речью, поскольку для пауз или шумовых звуков это не только бессмысленно, но и может внести ошибки в соседние фреймы при применении интерполяции и/или сглаживании. Длину фрейма выбирают так, чтобы в ней содержалось как минимум три периода.
Основной метод, на базе которого впоследствии появилось целое семейство алгоритмов – автокорреляционный. Подход достаточно прост — необходимо рассчитать автокорреляционную функцию и взять ее первый максимум. Он и будет отображать самую выраженную частотную компоненту в сигнале. В чем может быть сложность в случае использования автокорреляции и почему далеко не всегда первый максимум будет соответствовать нужной частоте? Даже в близких к идеальным условиям на записях высокого качества метод может ошибаться из-за сложной структуры сигнала. В условиях близких к реальным, где помимо прочего мы можем столкнуться с исчезновением нужного пика на шумных записях или записях изначально низкого качества, число ошибок резко возрастает.
Несмотря на ошибки, автокорреляционный метод довольно удобен и привлекателен своей базовой простотой и логичностью, поэтому именно он взят за основу во многих алгоритмах, в том числе в YIN (Инь). Даже само название алгоритма отсылает нас к балансу между удобством и неточностью метода автокорреляции: “The name YIN from ‘‘yin’’ and ‘‘yang’’ of oriental philosophy alludes to the interplay between autocorrelation and cancellation that it involves.” [4]
Создатели YIN попытались исправить слабые места автокорреляционного подхода. Первое изменение – использование функции Cumulative Mean Normalized Difference, которая должна снизить чувствительность к амплитудным модуляциям, сделать пики более явными:
begin{equation}
d’_t(tau)=
begin{cases}
1, & tau=0 \
d_t(tau) bigg/ bigg[ frac{1}{tau} sumlimits_{j=1}^{tau} d_t(j) bigg], & text{otherwise}
end{cases}
end{equation}
Также YIN пытается избежать ошибок, возникающих в случаях, когда длина оконной функции не делится нацело на период колебания. Для этого используется параболическая интерполяция минимума. На последнем шаге обработки аудиосигнала выполняется функция Best Local Estimate для предотвращения резких скачков значений (хорошо это или плохо – вопрос спорный).
Frequency-domain
Если говорить о частотной области, то на первый план выходит гармоническая структура сигнала, то есть наличие спектральных пиков на частотах, кратных F0. “Свернуть” этот периодический паттерн в явный пик можно при помощи кепстрального анализа. Кепстр — преобразование Фурье от логарифма спектра мощности; кепстральный пик соответствует наиболее периодической компоненте спектра (про него можно почитать здесь и здесь).
Гибридные методы определения F0
Следующий алгоритм, на котором стоит остановиться поподробнее, имеет говорящее название YAAPT — Yet Another Algorithm of Pitch Tracking — и фактически является гибридным, потому что использует как частотную, так и временную информацию. Полное описание есть в статье, здесь мы опишем только основные этапы.

Рисунок 1. Схема алгоритма YAAPTalgo (ссылка).
YAAPT состоит из нескольких основных этапов, первым из которых является препроцессинг. На этом этапе значения изначального сигнала возводят в квадрат, получают вторую версию сигнала. Этот шаг преследует ту же цель, что и Cumulative Mean Normalized Difference Function в YIN – усиление и восстановление “затертых” пиков автокорреляции. Обе версии сигнала фильтруют — обычно берут диапазон 50-1500 Гц, иногда 50-900 Гц.
Затем по спектру преобразованного сигнала рассчитывается базовая траектория F0. Кандидаты на F0 определяются с помощью функции Spectral Harmonics Correlation (SHC).
begin{equation}
SHC(t,f) = sumlimits_{f’=-WL/2}^{WL/2} prodlimits_{r=1}^{NH+1}S(t,rf+f’)
end{equation}
где S(t,f) — магнитудный спектр для фрейма t и частоты f, WL — длина окна в Гц, NH — число гармоник (авторы рекомендуют использовать первые три гармоники). Также по спектральной мощности происходит определение фреймов voiced-unvoiced, после чего ищется наиболее оптимальная траектория, при этом учитывается возможность pitch doubling/pitch halving [3, Section II, C].
Далее, как для изначального сигнала, так и для преобразованного производится определение кандидатов на F0, и вместо автокорреляционной функции здесь используется Normalized Cross Correlation (NCCF).
begin{equation}
NCCF(m) = frac{sumlimits_{n=0}^{N-m-1} x(n)*x(n+m)}{sqrt{sumlimits_{n=0}^{N-m-1} x^2(n) * sumlimits_{n=0}^{N-m-1} x^2(n+m)}}text{,} hspace{0.3cm} 0 < m < M_{0}
end{equation}
Следующий этап — оценка всех возможных кандидатов и вычисление их значимости, или веса (merit). Вес кандидатов, полученных по аудио сигналу, зависит не только от амплитуды пика NCCF, но и от их близости к траектории F0, определенной по спектру. То есть частотный домен считается хоть и грубым в плане точности, но зато устойчивым [3, Section II, D].
Затем для всех пар оставшихся кандидатов рассчитывается матрица Transition Cost — цены перехода, по которой в итоге и находят оптимальную траекторию [3, Section II, E].
Примеры
Теперь применим все вышеописанные алгоритмы к конкретным аудиозаписям. В качестве отправной точки будем использовать Praat — инструмент, который является основным для многих исследователей речи. А затем на Python посмотрим реализацию YIN и YAAPT и сравним полученные результаты.
В качестве аудио-материала можно использовать любые доступные аудио. Мы взяли несколько отрывков из нашей базы RAMAS — мультимодального датасета, созданного при участии актеров ВГИК. Можно также воспользоваться материалом из других открытых баз, например LibriSpeech или RAVDESS.
Для наглядного примера мы взяли отрывки из нескольких записей с мужским и женским голосами, как нейтральными, так и эмоционально-окрашенными, и для наглядности соединили их в одну запись. Посмотрим на наш сигнал, его спектрограмму, интенсивность (оранжевый цвет), и F0 (синий цвет). В Praat это можно сделать при помощи Ctrl+O (Open — Read from file) и затем кнопки View & Edit.

Рисунок 2. Спектрограмма, интенсивность (оранжевый цвет), F0 (синий цвет) в Praat.
На аудио довольно четко видно, что при эмоциональной речи высота голоса повышается как у мужчин, так и у женщин. При этом F0 для эмоциональной мужской речи вполне может сравниться с F0 женского голоса.
Трекинг
Выберем в меню Praat вкладку Analyze periodicity – to Pitch (ac), то есть определение F0 при помощи автокорреляции. Появится окно для задания параметров, в котором есть возможность задать 3 параметра для определения кандидатов на F0 и еще 6 параметров для алгоритма поиска пути (path-finder), который выстраивает наиболее вероятную траекторию F0 среди всех кандидатов.
Много параметров (в Praat их описание есть также по кнопке Help)
- Silence threshold — порог относительной амплитуды сигнала для определения тишины, стандартное значение 0.03.
- Voicing threshold — вес unvoiced candidate, максимальное значение равно 1. Чем выше этот параметр, тем больше фреймов будут определены как unvoiced, то есть не содержащие тоновых звуков. В этих фреймах F0 определяться не будет. Значение этого параметра — пороговое для пиков автокорреляционной функции. Значение по умолчанию — 0.45
- Octave cost — определяет, насколько больший вес имеют высокочастотные кандидаты по отношению к низкочастотным. Чем выше значение, тем большее предпочтение отдается высокочастотным кандидатом. Стандартное значение — 0.01 на октаву.
- Octave-jump cost — при увеличении этого коэффициента уменьшается количество резких скачкообразных переходов между последовательными значениями F0. Значение по умолчанию — 0.35.
- Voiced/Unvoiced cost — при увеличении этого коэффициента уменьшается количество Voiced/Unvoiced переходов. Значение по умолчанию — 0.14.
- Pitch ceiling (Hz) — кандидаты выше этой частоты не рассматриваются. Стандартное значение — 600 Гц.
Подробное описание алгоритма можно найти в статье 1993 года.
Как выглядит результат работы трекера (path-finder) можно посмотреть, нажав ОК и затем просмотрев (View & Edit) получившийся файл Pitch. Видно, что помимо выбранной траектории были еще довольно значимые кандидаты с частотой ниже.
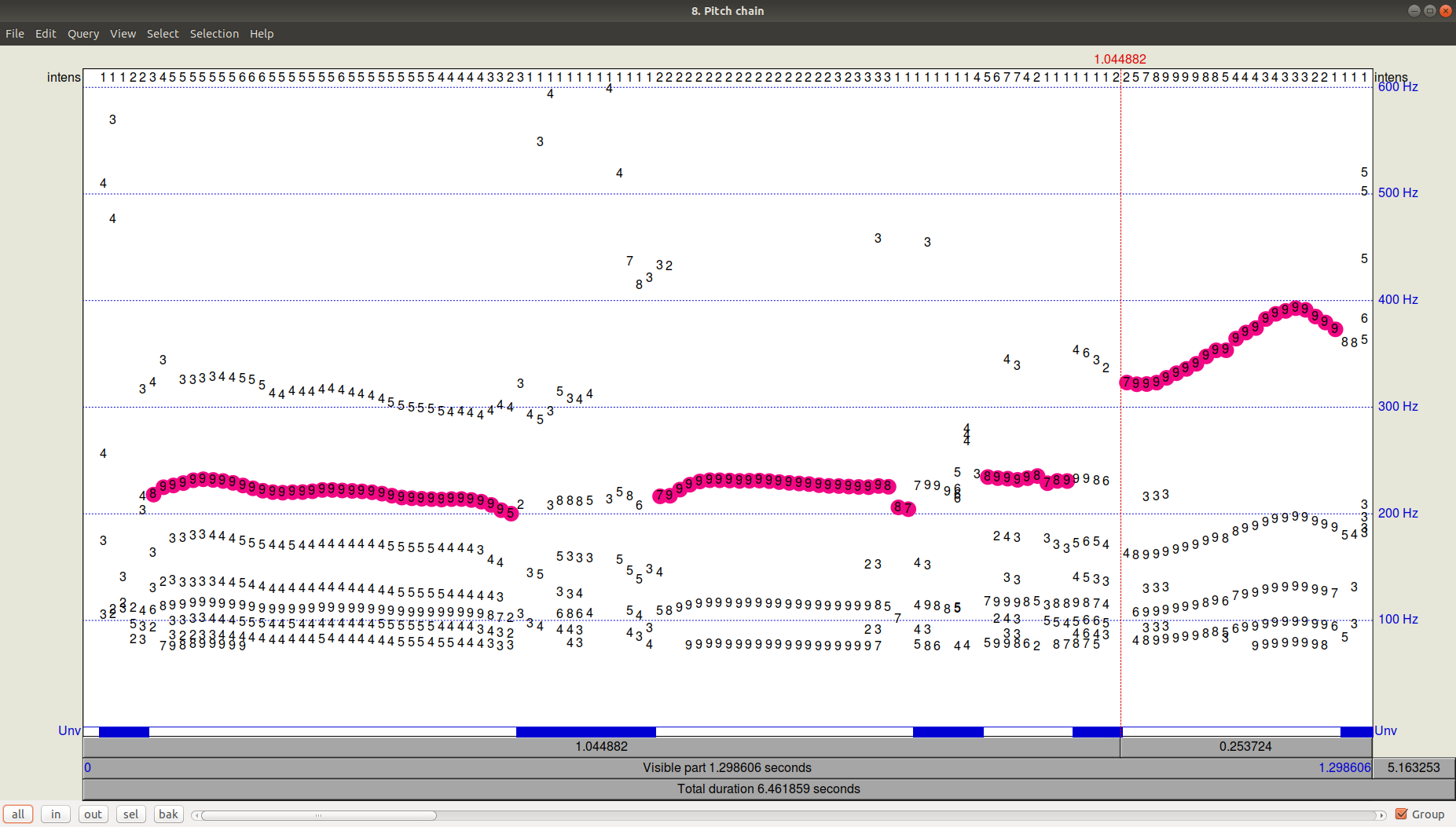
Рисунок 3. PitchPath для первых 1,3 секунд аудиозаписи.
А что же в Python?
Возьмем две библиотеки, предлагающих питч-трекинг – aubio, в которой алгоритмом по умолчанию является YIN, и библиотеку AMFM_decompsition, в которой есть реализация алгоритма YAAPT. В отдельный файл (файл PraatPitch.txt) вставим значения F0 из Praat (это можно сделать вручную: выбрать звуковой файл, нажать View & Edit, выделить весь файл и выбрать в верхнем меню Pitch-Pitch listing).
Теперь сравним результаты по всем трем алгоритмам (YIN, YAAPT, Praat).
Много кода
import amfm_decompy.basic_tools as basic
import amfm_decompy.pYAAPT as pYAAPT
import matplotlib.pyplot as plt
import numpy as np
import sys
from aubio import source, pitch
# load audio
signal = basic.SignalObj('/home/eva/Documents/papers/habr/media/audio.wav')
filename = '/home/eva/Documents/papers/habr/media/audio.wav'
# YAAPT pitches
pitchY = pYAAPT.yaapt(signal, frame_length=40, tda_frame_length=40, f0_min=75, f0_max=600)
# YIN pitches
downsample = 1
samplerate = 0
win_s = 1764 // downsample # fft size
hop_s = 441 // downsample # hop size
s = source(filename, samplerate, hop_s)
samplerate = s.samplerate
tolerance = 0.8
pitch_o = pitch("yin", win_s, hop_s, samplerate)
pitch_o.set_unit("midi")
pitch_o.set_tolerance(tolerance)
pitchesYIN = []
confidences = []
total_frames = 0
while True:
samples, read = s()
pitch = pitch_o(samples)[0]
pitch = int(round(pitch))
confidence = pitch_o.get_confidence()
pitchesYIN += [pitch]
confidences += [confidence]
total_frames += read
if read < hop_s:
break
# load PRAAT pitches
praat = np.genfromtxt('/home/eva/Documents/papers/habr/PraatPitch.txt', filling_values=0)
praat = praat[:,1]
# plot
fig, (ax1,ax2,ax3) = plt.subplots(3, 1, sharex=True, sharey=True, figsize=(12, 8))
ax1.plot(np.asarray(pitchesYIN), label='YIN', color='green')
ax1.legend(loc="upper right")
ax2.plot(pitchY.samp_values, label='YAAPT', color='blue')
ax2.legend(loc="upper right")
ax3.plot(praat, label='Praat', color='red')
ax3.legend(loc="upper right")
plt.show()

Рисунок 4. Сравнение работы алгоритмов YIN, YAAPT и Praat.
Мы видим, что при заданных по умолчанию параметрах YIN довольно сильно выбивается, получая очень плоскую траекторию с заниженными относительно Praat значениями и полностью теряя переходы между мужским и женским голосом, а также между эмоциональной и не эмоциональной речью.
YAAPT зарезал совсем высокий тон при эмоциональной женской речи, но в целом справился явно лучше. За счет каких своих особенностей YAAPT работает лучше — сразу ответить точно, конечно, нельзя, но можно предположить, что роль играет получение кандидатов из трех источников и более скрупулезный расчет их веса, чем в YIN.
Заключение
Поскольку вопрос определения частоты основного тона (F0) в том или ином виде встает почти перед каждым, кто работает со звуком, путей для его решения достаточно много. Вопрос необходимой точности и особенности аудиоматериала в каждом конкретном случае определяют, насколько внимательно необходимо подбирать параметры, или в ином случае можно ограничиться базовым решения наподобие YAAPT. Принимая Praat за эталон алгоритма для обработки речи (все же им пользуется огромное количество исследователей), можно сделать вывод о том, что YAAPT в первом приближении надежнее и точнее, чем YIN, хотя и для него наш пример оказался сложноват.
Автор: Ева Казимирова, научный сотрудник Neurodata Lab, специалист по обработке речи.
Оффтоп: Понравилась статья? На самом деле у нас куча подобных интересных задач по ML, математике и программированию, и нам нужны мозги. Тебе такое интересно? Приходи к нам! E-mail: hr@neurodatalab.com
Ссылки
- Rusz, J., Cmejla, R., Ruzickova, H., Ruzicka, E. Quantitative acoustic measurements for characterization of speech and voice disorders in early untreated Parkinson’s disease. The Journal of the Acoustical Society of America, vol. 129, issue 1 (2011), pp. 350-367. Access
- Farrús, M., Hernando, J., Ejarque, P. Jitter and Shimmer Measurements for Speaker Recognition. Proceedings of the Annual Conference of the International Speech Communication Association, INTERSPEECH, vol. 2 (2007), pp. 1153-1156. Access
- Zahorian, S., Hu, HA. Spectral/temporal method for robust fundamental frequency tracking. The Journal of the Acoustical Society of America, vol. 123, issue 6 (2008), pp. 4559-4571. Access
- De Cheveigné, A., Kawahara, H. YIN, a fundamental frequency estimator for speech and music. The Journal of the Acoustical Society of America, vol. 111, issue 4 (2002), pp. 1917-1930. Access
Длительность. Измерение длительности исследуемого отрезка (звука, слога, слова) производится следующим образом: определяются границы этого отрезка и подсчитывается количество колебаний отметчика времени, укладывающихся в пределах этих границ. Зная частоту отметчика времени, можно определить время, за которое происходит одно колебание, а затем, умножив это время на число колебаний отметчика времени, узнать длительность исследуемого участка. Например, если нам нужно измерить длительность гласного в каком-нибудь слове, отметим сначала его границы; определим, что на этом отрезке умещается п колебаний отметчика времени, определим время, занимаемое одним периодом колебаний отметчика времени: если частота времени 1000 Гц, то одно колебание занимает 0,001 с; тогда длительность гласного п- 0,001 с. Если запись ведется с двумя отметчиками времени, то сначала подсчитывается длительность по более низкому отметчику. Например, если в длительность гласного укладывается 12 целых колебаний отметчика времени с частотой 100 Гц и 3 колебания отметчика времени с частотой 1000 Гц, то длительность гласного складывается из:
0,123 с=123 мс.
Заметим, что осциллограмма дает наглядное представление об относительной длительности звуков без вычисления абсолютной длительности. По рисункам, например, без всяких предварительных подсчетов* можно судить о сравнительной длительности ударного и безударных гласных в пределах одного слова (см. рис. 12).
Рuс. 10. Осциллограммы глухих щелевых согласных в слогах фы, су, ух, шу. Скорость движения пленки — 500 мм/с, отметчик времени — 100 Гц.
Шумовые составляющие самые слабые для губного ф — это хорошо видно при сравнении осциллограмм, приведенных на этом рисунке. Осциллографический рисунок согласного ш характеризуется значительной амплитудой (рассмотрите также и осциллограмму ш в слове Саша на рис. 3 и 4). Осциллографический рисунок заднеязычного х отличается большой амплитудой шумовых составляющих, но сама «щеточка» реже, что связано с более низкой частотой этих составляющих по сравнению с другими щелевыми согласными.

Рис. II. Осциллограммы глухих взрывных и аффрикат в слогах ка, то, ца. Скорость движения кинопленки — 500 мм/с, отметчик времени — 100 Гц.
Различия между глухими взрывными согласными —в интенсивности и длительности шумовых составляющих: на приведенных осциллограммах хорошо видно, что г имеет меньшую длительность шумовой фазы, чем к.
Аффриката ц имеет осциллографический рисунок, близкий к рисунку глухого щелевого с (см. рис. 10), но длительность этого шума гораздо меньше.
Интенсивность. Осциллографическая кривая дает представление об интенсивности частотных составляющих каждого звука. Как мы уже говорили, чем больше интенсивность колебательного движения, тем сильнее отклонение регистрирующего колебание луча от исходного положения, т. е. амплитуда колебания. Так как звук характеризуется большим количеством частотных составляющих, при изучении их интенсивности важно знать, интенсивность каких именно частот определяет с точки зрения восприятия громкость звука. Относительно этого имеется несколько различных предположений.
Если рассматривать интенсивность звуков с точки зрения тех артикуляционных движений, которые ее обеспечивают, то для представления об интенсивности нужно точно знать характеристики источника (голосового, импульсного или турбулентного). Это значит, что нужны специальные преобразования звука, в результате которых подавляются его форуантные характеристики. Однако чаще всего нас интересуют такие характеристики интенсивности звуков, которые связаны с их фонетическими свойствами, т. е. с реальным их звучанием. При этом амплитуда звука определяется совокупностью амплитуд всех частотных составляющих. Осциллографическая кривая в таком случае дает достаточно адекватное представление об интенсивности речевого сигнала.

Рис. 12. Осциллограмма слова краска. Скорость движения кинопленки — 250 мм/с, отметчик времени — 100 Гц.
Интенсивный и длительный взрыв согласного к регистрируется на этой осциллограмме очень четко; далее следует гласноподобный участок дрожащего согласного р, за этим участком — фаза сближения языка с верхними зубами, затем опять раскрытие, образующее гласноподобный звук. Мы уже знаем (см. рис. 7), что провести границу между р и следующим гласным довольно трудно. В данном случае начало гласного определим по величине амплитуды; длительность ударного гласного около НО мс, длительность безударного— около 120. Заметим, кстати, что обычно ударный гласный более значительно превышает по своей длительности безударный, но здесь такая маленькая разница обусловлена фонетически: ударный а находится в окружении групп из двух согласных (кр и ск), а заударный — в абсолютном конце слова. Обратите внимание и на амплитуду звуков. Прежде всего она несимметрична относительно нулевой линии: отклонение «вниз» значительно меньше, чем отклонение «вверх» (понятие «верх» и «низ» существенно только для осциллограммы, но не для записываемого звука!). Интенсивность ударного гласного здесь больше, чем безударного; и максимальное отклонение от нулевой линии здесь сильнее, и такое отклонение наблюдается на большей протяженности гласного.
Однако имеется одно важное обстоятельство, накладывающее определенные ограничения. Вид осциллографической кривой зависит от фазовых соотношений частот: если два колебания, дающие результирующую кривую, находятся в одинаковой фазе, то суммарная амплитуда будет большей, если же эти колебания сдвинуты по фазе относительно друг друга, то суммарная амплитуда, естественно, будет меньшей. Несмотря на то что, по данным психо-акустики, фазовые отношения частотных составляющих звуков речи не имеют никакого значения при восприятии, этот факт должен быть специально рассмотрен. Практически зависимость суммарной амплитуды от фазовых соотношений составляющих частот означает, что два звука, характеризующиеся одинаковой громкостью, могут иметь совершенно различные амплитуды. Нужно, однако, отметить, что практика осциллографического анализа речи показывает, что такие случаи практически не встречаются: как правило, амплитудные характеристики звуков хорошо J соответствуют данным восприятия их громкости.
Измерение амплитуды сигнала по осциллограмме в качестве коррелята интенсивности звука используется во многих экспериментально-фонетических исследованиях.
Осциллограмма дает наглядное представление об изменении силы звука во времени (ослабление или усиление его). При этом видно не только направление изменения, но и его реальное распределение во времени.
Как уже было сказано, для получения достоверной осциллограммы необходимо, чтобы частота записываемого звука была в 3—4 раза ниже собственной частоты вибратора. Это имеет особенное значение при изучении интенсивности, так как при несоблюдении указанного условия в первую очередь ослабляется амплитуда записываемого звука, т. е. нарушаются реальные соотношения, имеющие место в речи.
Сложность изучения силы звуков заключается и в. том, что, во-первых, разные звуки могут иметь разную амплитуду в зависимости от их собственных качественных характеристик. Так, например, известно, что открытые звуки типа а, е, о имеют большую амплитуду, чем закрытые звуки типа и, ы, у. Такое различие, конечно, связано не с тем, что одни «специально» произносятся громче, а други» —тише, а с тем, что в первом случае возникают более благоприятные условия для усиления звука, чем во втором.
Вторая трудность общего характера, возникающая при изучении интенсивности, заключается в том, что реальная громкость звука, которая в конечном счете и воспринимается, зависит не только от амплитуды колебания, т. е. силы звука, но и от его частоты.
Для измерения интенсивности по амплитуде осциллографической кривой имеется несколько возможностей. Прежде всего необходимо выбрать то значение амплитуды, которое будет измеряться. Отклонения кривой вверх и вниз от нулевой линии не одинаковы (не симметричны), поэтому необходимо последовательно измерять всегда одно и то же по знаку отклонение — положительное или отрицательное. Измерение амплитуды производится в миллиметрах, однако существует возможность получить представление о том, какому увеличению интенсивности в децибелах соответствует увеличение амплитуды на ту или иную величину.
Важным является вопрос о том, какие именно амплитудные значения должны измеряться. Так как существует обоснованное данными психоакустики мнение о том, что человек определяет громкость сигнала по наибольшей в данном отрезке интенсивности, можно предположить, что измерение максимальной амплитуды в каждом звуке будет давать удовлетворительное представление о соотношениях интенсивности в данном речевом отрезке. С другой стороны, данные о постоянной времени человеческого слуха говорят о том, что время, за которое в слухе происходит усреднение характеристик звука, зависит от свойств самого звука и колеблется °т 20 до 200 мс. Поэтому естественно предположить, что для фонетической характеристики интенсивности небезразлично, каким образом она изменяется на протяжении звука. Это значит, что для описания интенсивности звука недостаточно указать только максимальное значение амплитуды — нужно еще определить, в каком месте звука (в начале, середине или конце) этот максимум наблюдается, какова длительность звука, характеризующаяся максимальными значениями амплитуды, и каковы соседние значения амплитуд (т. е. какова степень изменения интенсивности на протяжении данного, отрезка звучания) (см. рис. 12).
Частота основного тона. Осциллографическая кривая дает возможность достаточно точно измерить высоту основного тона или частоту колебания голосовых связок. Каждый звук, произнесенный с участием голосового источника, имеет специфическую картину, характеризующуюся определенной повторяемостью рисунка. Это определяется периодичностью колебаний голосовых связок. При определении частоты колебаний первая задача заключается в правильном выделении периода колебаний и в подсчете числа колебаний, характеризующего исследуемый звук.
В зависимости от конкретных потребностей производимого анализа можно производить определение частоты колебаний голосовых связок с разной степенью точности.
Наиболее точным является определение частоты каждого из периодов. Для такого измерения необходимо, чтобы скорость съемки осциллограммы была достаточно велика (порядка 1000 мм/с), а частота отметчика времени была значительно выше частоты колебаний голосовых связок. Если частота отметчика времени — 1000 Гц, то это значит, что мы можем измерять длительность периода с точностью до одной мс. Определение частоты колебания производится по формуле f=1/T, где f — частота, Т — длительность периода.
Однако измерение каждого периода требует больших затрат времени. Поэтому возможен и другой путь измерения частоты основного тона. При этом мы получаем значение средней частоты основного тона или для групп, содержащих определенное число периодов, или для частей звука. В первом случае мы измеряем среднюю частоту группы из трех, четырех или пяти и т. д. периодов (в зависимости от желаемой точности).
Средняя частота определяется по формуле f=(1*n)/T, где п — число периодов, Т — длительность данной группы периодов.
В результате на протяжении анализируемого звука получим столько значений средней частоты основного-тона, сколько групп по п периодов могут уместиться на его длительности.
Другая возможность заключается в том, что звук делят на две, три, четыре и т. д. равных по длительности частей и измеряют среднюю частоту основного тона на каждом из этих участков по той же формуле. Модификацией такого способа является измерение частоты одного периода или группы периодов в начале, середине и конце изучаемого звука.
Все указанные способы дают нам более или менее точное представление об изменении частоты основного тона во времени. Однако в ряде случаев бывает достаточно определить среднее значение частоты основного тона на данном звуке. Для этого подсчитывается число периодов основного тона и длительность гласного. Средняя частота основного тона определяется по известной уже формуле f=(1*n)/T
Определение частоты колебаний голосовых связок диктора (Исследование измерителя основного тона речевого сигнала)
Страницы работы
Содержание работы
2. Лабораторная работа
Определение частоты колебаний голосовых связок диктора
(Исследование измерителя основного тона речевого
сигнала)
Цель
работы. Исследовать точность работы
измерителя основного тона.
Краткие
теоретические сведения
При идентификации личности широко
применяются биометрические методы. В частности, при идентификации личности по
голосу измеряется частота вибраций голосовых связок (частота основного тона
речевого сигнала) при производстве вокализованных звуков (то есть тех звуков, в
создании которых участвуют голосовые связки). Назначение измерителя основного
тона (ИОТ) — классификация сегментов (коротких отрезков) речевых сигналов на
невокализованные и вокализованные, а также определение периода (частоты)
основного тона в последнем случае.
Принцип работы ИОТ основан на анализе
автокорреляционной функции сигнала или связанной с ней функции с целью
определения их периода. В последнее время широко используется кратковременная
функция среднего значения разности – AMDF(AverageMagnitudeDifferenceFunction):
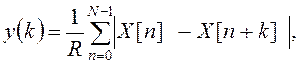
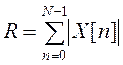 , где R –
, где R –
нормирующий делитель; Х[n] – значение входного
сигнала ИОТ в момент времени nTд; Tд – период дискретизации; N
– число выборок в сегменте сигнала. В общем случае Х[n]
– сумма периодического и случайного компонентов, поэтому данная функция
является случайной. Типичная форма ее математического ожидания для
вокализованных звуков изображена на рис. 2.1 (сплошная линия). Штриховыми
линиями указана зона наиболее вероятных значений y(k).
Период Тот основного
тона определяется расстоянием между двумя минимумами функции. Измерительный
порог rи служит
для фиксации минимумов. Минимальные значения функции определяются лишь для тех
значений k, которые обеспечивают выполнение условия y(k)
≤ rи. Из рис.
2.1. следует, что чем больше разброс значений y(k),
меньших rи, тем
больше разброс значений измеренного периода (Тmin … Тmax), а следовательно, и больше погрешность измерения.
Если шумовая составляющая в сигнале достаточно велика, то принимается решение о
невокализованности звука. При этом наименьшее значение функции превышает
«классификационный» порог rк.
Необходимо отметить, что значения y(k) в точках
локальных минимумов определяются не только периодичностью исследуемого сигнала,
то есть соотношением шумового и детерминированного компонентов в данном случае,
но и уровнем формант (области «всплеска» мощности в спектре сигнала).
 |
Рис. 2.1
Если форманты достаточно мощные, то
появляются дополнительные глубокие «провалы» в функции, которые могут привести
к грубым ошибкам измерения периода основного тона Тот.
Поэтому часто на вход ИОТ подается не сам сегмент сигнала, а его остаток
предсказания на выходе анализирующего фильтра. В остатке предсказания
формантная структура сигнала значительно разрушена при сохранении
периодичности, обусловленной импульсами основного тона.
Так как наиболее вероятные значения
частоты основного тона лежат в пределах (50…500)Гц, то для повышения точности
измерения перед вычислением AMDF сигнал
пропускают через фильтр нижних частот (ФНЧ) с частотой среза 1 кГц.
Схема
обработки сигналов в лабораторной работе
На рис. 2.2 приведена схема обработки
сигналов, проводимой в лабораторной работе. Фильтр нижних частот ФНЧ,
вычислитель AMDF и
измеритель И, где определяется признак вокализованности сегмента «Т/Ш» и
временной интервал между соседними минимумами AMDF,
составляют измеритель основного тона ИОТ. С помощью генераторов: шума – ГШ,
импульсов – ГИ и гармонических колебаний – Г формируется модель сегмента
сигнала на входе ИОТ с различным отношением сигнал – шум. Оно изменяется с
помощью перемножителя П в зависимости от коэффициента усиления G.
По команде «И/С» (импульс – синусоидальный сигнал) ключ подключает либо ГИ –
при этом моделируется ситуация, когда на входе ИОТ присутствует остаток
предсказания, либо Г – при этом моделируется случай анализа вокализованного
сегмента непосредственно.
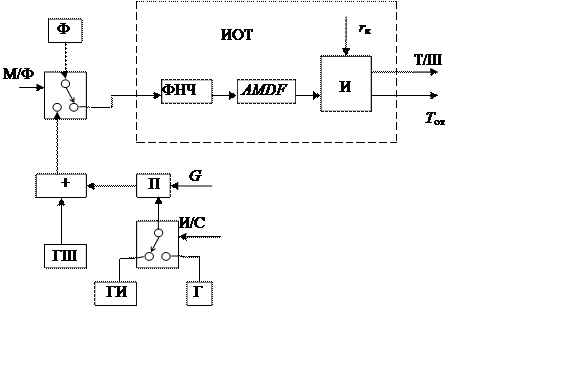 |
Рис. 2.2
В лабораторной работе имеется также
возможность подачи на вход ИОТ сигнала из файла Ф записанного заранее реального
звука. При этом можно оценить качество работы ИОТ с реальными сигналами.
Подключение файла Ф осуществляется по команде «М/Ф» (модель – запись реального
сигнала). Фильтр нижних частот ФНЧ, вычислитель функции AMDF и измеритель
периода основного тона И образуют собственно структуру ИОТ.
В лабораторной работе предусмотрена
возможность наблюдения «осциллограмм» сигналов на входе ИОТ, а также графика AMDF.
Порядок
выполнения работы
1. Для заданной формы входного сигнала определить
зависимость минимального значения AMDF от отношения сигнал – шумymin(c/ш).
Построить график зависимости.
Порядок выполнения данного пункта работы:
-установить значение порога классификации достаточно большим
(примерно 1,5), чтобы результаты последующего анализа AMDF соответствовали
вокализованным звукам;
-значение коэффициента усиления Кус установить
достаточно большим, чтобы минимум AMDF составил примерно 0,1 от
максимума AMDF. Зафиксировать значение минимума AMDF
как результат произведения максимального модуля на относительное значение
минимума AMDF (провести
три замера и найти среднее значение минимума);
-уменьшить Кус и вновь зафиксировать
значение минимума AMDF как результат произведения максимального модуля на
относительное значение минимума AMDF (провести
три замера и найти среднее значение минимума);
-повторить указанные действия, пока минимум AMDF
не увеличится примерно до 0,5 от максимума. Построить требуемый график (получив
7 – 10 точек).
2. Найти такое наибольшее значение Кус,
при котором каждые 5 замеров частоты основного тона из 10 замеров в несколько
раз отличаются от заданного значения частоты основного тона – имеют место сбои
в определении частоты основного тона. Зафиксировать соответствующее значение
минимума AMDF. Эта ситуация соответствует границе разделения звуков
на вокализованные и невокализованные.
3. Установить
порог классификации равным определенному выше значению минимума AMDF.
Зафиксировать «осциллограммы» входного
сигнала ИОТ, выходного сигнала ФНЧ и график AMDF для
данного случая.
4. Найти вокализованные сегменты заданного
звукового файла и сопоставить их с осциллограммами речевого сигнала в звуковом
редакторе COOLEDIT.95. По результатам сравнения скорректировать найденное ранее
значение классификационного порога.
5. Зафиксировать график AMDF и
«осциллограммы» для заданного вокализованного сегмента реального звукового
сигнала. Установив найденный порог классификации, определить частоту основного
тона.
Содержание отчета
1. Структурная схема
процесса обработки сигнала при исследовании измерителя основного тона.
2. Таблицы и графики
определенных зависимостей, «осциллограммы» сигналов.
3. Выводы по работе.
Контрольные
вопросы
1. К чему приведет чрезмерное уменьшение
значения порога классификации?
2. С какой целью при определении
периода основного тона вводится измерительный порог?
3. К чему приведет исключение фильтра
нижних частот из состава измерителя основного тона?
Похожие материалы
- Изучение приемов работы с массивами и файлами, а также средств визуализации результатов работы
- Проектирование радиоприемного устройства. Расчет структурной схемы линейного тракта
- Передаточные функции разомкнутой и замкнутой систем. Дифференциальное уравнение системы
Информация о работе
Тип:
Отчеты по лабораторным работам
Уважаемый посетитель!
Чтобы распечатать файл, скачайте его (в формате Word).
Ссылка на скачивание – внизу страницы.
Текущая версия страницы пока не проверялась опытными участниками и может значительно отличаться от версии, проверенной 11 апреля 2021 года; проверки требует 1 правка.
VF (англ. Voice Frequency — частота голоса) — речевая полоса частот, одна из звуковых частот, использующаяся для передачи голоса.
В телефонии используется полоса частот от 300 Гц до 3400 Гц, из-за того что форманты, определяющие разборчивость речи, расположены в основном в этой полосе частот. Именно по этой причине частоты электромагнитного спектра между 300 и 3400 Гц также называется голосовыми частотами (несмотря на то, что это электромагнитное излучение, а не акустическое). Для передачи одного канала голосовой частоты, включая защитную полосу частот, обычно выделяют полосу пропускания 4 кГц, допускающую частоту дискретизации 8 кГц для использования в импульсно-кодовой модуляции в телефонной сети общего пользования.
Фундаментальная частота[править | править код]
Голос типичного взрослого мужчины имеет фундаментальную частоту (нижнюю) от 85 до 155 Гц, типичной взрослой женщины от 165 до 255 Гц. Таким образом, фундаментальная частота большинства голосов ниже нижнего предела «голосовой частоты», определённой выше, тем не менее обертоны создают впечатление слышимости фундаментального тона.
См. также[править | править код]
- Форманта
- Голос
- Канал тональной частоты
- DS0
Литература[править | править код]
- Вартанян И. А. Звук — слух — мозг. — Л. : Наука, 1981.
Ссылки[править | править код]
- Звук, звуковые явления
Урок 1. Как работает голос. Физика и анатомия извлечения звука
 Чтобы эффективно работать над развитием голоса и речи, необходимо понимать, что такое вообще звук, голос и речь. Поэтому цель данного урока – разобраться, что такое звук, голос и речь с точки зрения физики и анатомии. Чтобы добиться положительного результата, нужно понимать оба аспекта. Знание анатомии поможет научиться управлять голосом, а понимание физических основ звука – визуализировать результат занятий и контролировать правильное звукоизвлечение.
Чтобы эффективно работать над развитием голоса и речи, необходимо понимать, что такое вообще звук, голос и речь. Поэтому цель данного урока – разобраться, что такое звук, голос и речь с точки зрения физики и анатомии. Чтобы добиться положительного результата, нужно понимать оба аспекта. Знание анатомии поможет научиться управлять голосом, а понимание физических основ звука – визуализировать результат занятий и контролировать правильное звукоизвлечение.
В данном уроке мы рассмотрим физику звука, физику и анатомию голоса, а также узнаем, как работает голос и что общего в развитии голоса и речи. Также мы дадим ссылки на полезные сервисы, которые помогут вам провести самостоятельную диагностику возможностей своего голоса, если у вас есть такое желание.
Мы рекомендуем это сделать, чтобы вам было проще и нагляднее увидеть прогресс после того, как вы начнете работать с голосом.
Содержание:
- Что такое звук и голос с точки зрения физики
- Что такое звук и голос с точки зрения анатомии
- Устройство слуха
- Тест на проверку знаний
Итак, план действий на ближайший урок у нас намечен, поэтому приступаем к делу!
Что такое звук и голос с точки зрения физики
Начнем с того, что такое звук и голос с точки зрения физики. Звук – физическое явление, представляющее собой распространение механических волновых колебаний.
С точки зрения физики звук имеет три свойства:
- высота;
- сила;
- звуковой спектр.
Высота зависит от частоты колебаний. Колебания происходят с определенной периодичностью и измеряются в герцах. Герц – это единица частоты периодических процессов в Международной системе единиц, а также в системах единиц СГС и МКГСС.
Сила звука (она же громкость) зависит от амплитуды колебаний. Больше амплитуда – сильнее звук. Единица измерения силы звука – децибел (дБ). Для примера: шелест листьев – около 10 дБ, а громкий разговор – до 90 дБ.
Звуковой спектр – это совокупность добавочных колебаний или обертонов, возникающих вместе с основной частотой. Это особенно четко можно наблюдать в музыке или пении. Обертона повышают основной тон в кратных соотношениях (overtone: оver – над, tone – тон) и придают звуку дополнительную окраску, т.е. тембр.
Звуки с периодическими (одинаковыми и равномерно повторяющимися) волновыми колебаниями называются музыкальными тонами. Звуковые колебания непериодической повторяемости не являются музыкальными тонами. Это, например, скрип, треск и прочие звуки.
О силе звука и звуковых спектрах мы поговорим в следующих уроках, а сейчас вернемся к высоте звука.
Виды звука по высоте:
- Волновые колебания, воспринимаемые человеческим ухом, т.е. в диапазоне 16-20 000 Гц (герц).
- Ультразвук – звуковые волны, имеющие частоты выше воспринимаемых человеческим ухом, т.е. выше 20 000 Гц.
- Инфразвук – звуковые колебания, имеющие частоты ниже воспринимаемых человеческим ухом, т.е. ниже 16 Гц.
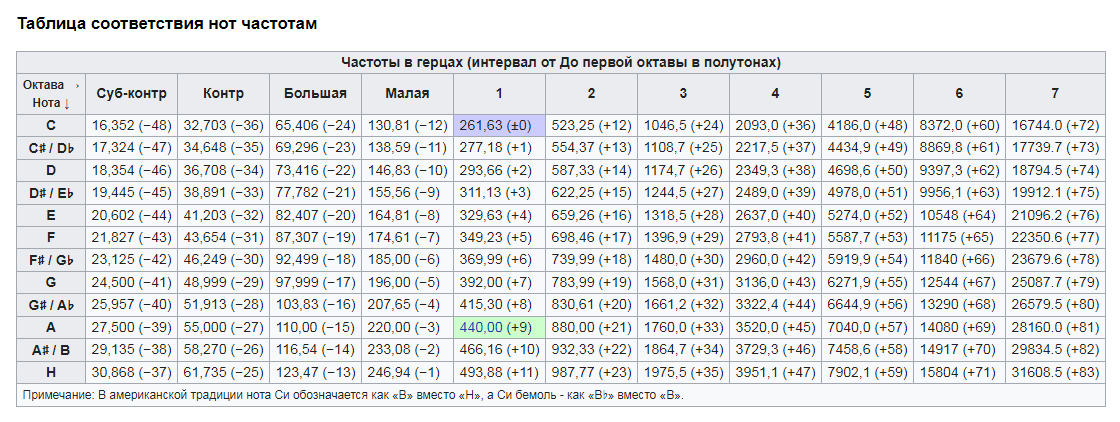
Таким образом, чем больше частота колебаний, тем выше звук. В контексте нашего курса по развитию голоса нас интересует слышимый диапазон, т.е. 16-20 000 Гц. В нижней части диапазона звук субъективно воспринимается как более глухой и басистый, в верхней части – как более тонкий и звонкий. Весь слышимый диапазон звуков распределен по так называемой нотно-октавной шкале (см. рис.1а), построенной на основе двоичной системы.
Дело в том, что звуки, частота которых различается в 2 раза (в 2 раза выше или ниже), воспринимаются на слух как сходные. Музыкантам эта таблица хорошо знакома, а всем остальным она представлена для осмысления, насколько велики возможности человеческого слуха и, соответственно, голоса. В обозначения нот и октав можно пока не вникать. Эту тему мы затронем, когда будем говорить о развитии певческого голоса.
Итак, мы подошли к тому, что такое голос, и чем он отличается от звука. Звук – это более широкое понятие. В контексте нашего курса звук – это абсолютно все, что мы можем услышать. Это пение птиц, шелест травы, плеск воды, рокот мотора, жужжание принтера, звон бокалов и, конечно, человеческий голос.
Голос – это результат работы голосового аппарата и органов звукоизвлечения (об их строении с точки зрения анатомии мы поговорим позже). Возможности голоса несколько меньше, чем возможности человеческого уха, в том плане, что даже рекордсмены не могут охватить голосом всю гамму звуков в диапазоне 16-20 000 Гц. Правда, некоторые из них могут выйти за пределы слышимого диапазона.
Голоса-рекордсмены из Книги рекордов Гиннеса:
- Самую высокую вокальную ноту среди мужчин «фа диез» 5-й октавы (5 989 Гц) взял Амирхоссейн Молаи в Тегеране (Иран) 31 июля 2019 года [Guinness World Records, 2019].
- Самую высокую ноту среди женщин «соль» 7-й октавы (25 087 Гц) взяла бразильская певица Джорджия Браун в 2004 году. Технически эта нота не является музыкальной. Также Джорджии Браун принадлежит мировой рекорд на самый широкий вокальный диапазон среди женщин. Ее диапазон простирается от «соль» большой октавы (98 Гц) до «соль» 7-й октавы (итого 8 октав) [Guinness World Records, 2004].
- Самая низкая вокальная нота среди женщины составила 57,9 Гц, что чуть выше, чем нота «ля» контроктавы. Ее взяла Марьяна Павлова (Великобритания) в Валлингтоне, Большой Лондон, Великобритания, 3 июня 2019 года [Guinness World Records, 2019].
- Самая низкая вокальная нота, воспроизводимая мужчиной, – G-7 (0,189 Гц), была достигнута певцом и композитором Тимом Стормсом (США) в студии Citywalk Studios в Брэнсоне, штат Миссури, США, 30 марта 2012 года. Частотный выход голоса Тимоти был измерен с помощью оборудования Bruel & Kjaer (низкочастотный микрофон, прецизионный анализатор звука и ноутбук для постанализа) [Guinness World Records, 2012].
К слову, в музыке принято использовать далеко не весь слышимый диапазон. В этом легко убедиться, взглянув на клавиши фортепиано. Все 88 клавиш (36 черных и 52 белых) охватывают диапазон от «ля» субконтроктавы (27,5 Гц) до ноты «до» 5-й октавы (4 186 Гц). Этого полностью достаточно, чтобы воспроизвести любое музыкальное произведение, комфортное для человеческого уха и того, как мы слышим звуки.
Возможности собственного голоса вы можете проверить, скачав Pano Tuner и разрешив приложению доступ к микрофону. Попробуйте взять самую высокую и самую низкую доступную вам сейчас ноту, но не делайте более трех попыток подряд, т.к. это может привести к перенапряжению голосового аппарата. Зафиксируйте результат и повторите опыт после прохождения нашего курса. Если вы ранее никогда не занимались тренировкой голоса и не работали над расширением диапазона, возможно, у вас это получится сейчас, когда вы изучите анатомию голоса и приемы, помогающие звукоизвлечению.
Есть варианты, доступные онлайн без предварительного скачивания приложений. Например, сервис Vocal Max. Для старта нажмите на кнопку «Начать», выберите ноту, с которой вам удобнее стартовать, и возьмите ее. Как только вы в нее попадете, она поменяет цвет, а следующий шаг будет возможен только на любую из соседних нот как вверх, так и вниз. Если вы пока не разбираетесь в нотах, попробуйте взять ноту «до» 1-й октавы – она есть в диапазоне практически каждого человека. Изучив предыдущую иллюстрацию, вы ее легко найдете самостоятельно.
По мере того, как вы будете брать каждую из последующих нот, они также будут менять цвет. Когда вы исчерпаете свой диапазон, нажмите «Закончить» и сохраните результат, допустим, в виде скриншота. Скорее всего, через 1-2 месяца тренировок ваш диапазон станет шире.
И, наконец, речь. Речь – это совместный результат работы голосового аппарата и мышления. Если для того чтобы издавать просто звуки (крик, плач, стон и другие), нам достаточно задействовать голосовой аппарат, для речи нужно предварительное осмысление того, что вы хотите сказать. Для речи используется меньший диапазон голоса, чем для разного рода звуков – крика, плача, стона и других.
Различают внутреннюю и внешнюю речь, но в контексте нашего курса нас интересует, в первую очередь, развитие внешней речи, где задействуются органы звукоизвлечения. В то же время красивая внешняя речь невозможна без развития внутренней речи, т.е. планирования и контроля «в уме» речевых действий, внутреннего проговаривания запланированных фраз.
Кстати, в нашем курсе вы узнаете, что звукоизвлечение тоже можно планировать! «В уме» можно репетировать не только текст будущего сообщения, но также его эмоциональную насыщенность, громкость, высоту. А поможет в этом осмысленный подход к звукоизвлечению, знание анатомии голоса и понимание, как те или иные движения и положения органов звукоизвлечения влияют на ваш голос и вашу речь.
Что такое звук и голос с точки зрения анатомии
Голос – это звук, возникающий с помощью выдыхаемого воздуха, колебания голосовых связок и резонирования. При этом голосовые складки (или связки – мы будем использовать оба термина) участвуют лишь в тонком управлении голосом, а основную работу выполняет воздушный поток и резонанс.
Для понимания, как работает голос и как формируется речь, нам необходимо изучить устройство звукового аппарата человека. Разделим задачу на две составляющие: как устроен голосовой аппарат и как устроен слух. Начнем с голоса.
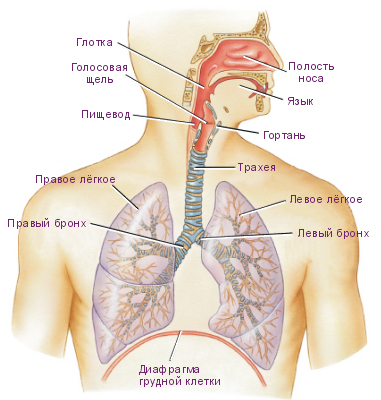
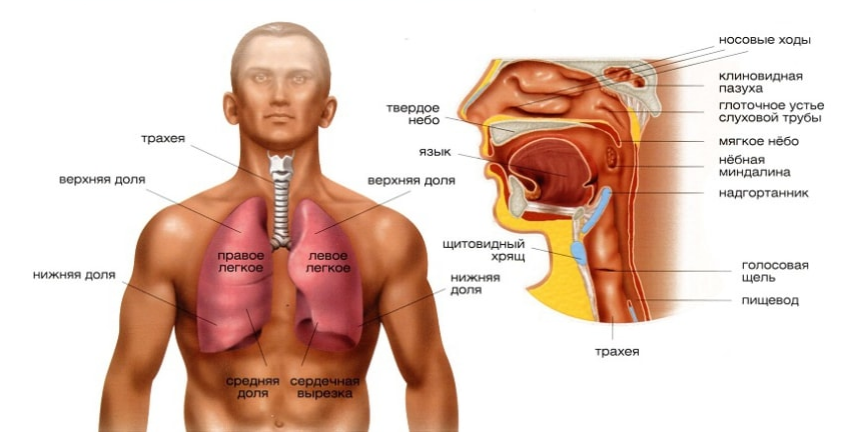
Общее устройство дыхательной системы и голосового аппарата:
| 1 | легкие; |
| 2 | грудная клетка; |
| 3 | диафрагма; |
| 4 | брюшной пресс; |
| 5 | бронхи; |
| 6 | трахея; |
| 7 | гортань; |
| 8 | голосовые связки (находятся внутри гортани); |
| 9 | глотка; |
| 10 | полость рта; |
| 11 | полость носа с придаточными полостями; |
| 12 | элементы нервной системы, проводящие и передающие сигналы, соединяющие органы голосообразования с мозговыми центрами. |
Мы рассматриваем дыхательную систему и голосовой аппарат как единое целое, потому что звукоизвлечение происходит за счет выдыхаемого воздуха. Настоятельно рекомендуем сначала изучить строение дыхательной системы и голосового аппарата в самом общем схематичном виде, а уже потом перейти к подробному изучению, анализируя иллюстрации со все большим количеством элементов и подробностей.
Вот простая иллюстрация:
А вот более сложная:
Такой подход позволит вам не запутаться, изучая звукоизвлечение и голосообразование, и соблюсти постепенный переход от простого к сложному.
Простая иллюстрация:
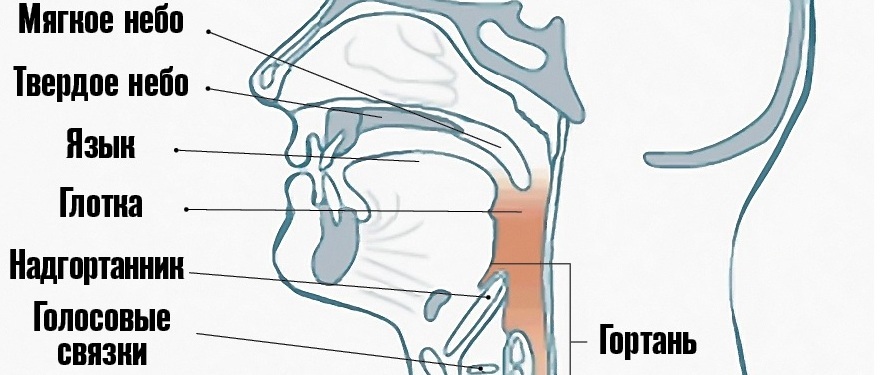
И более сложная:
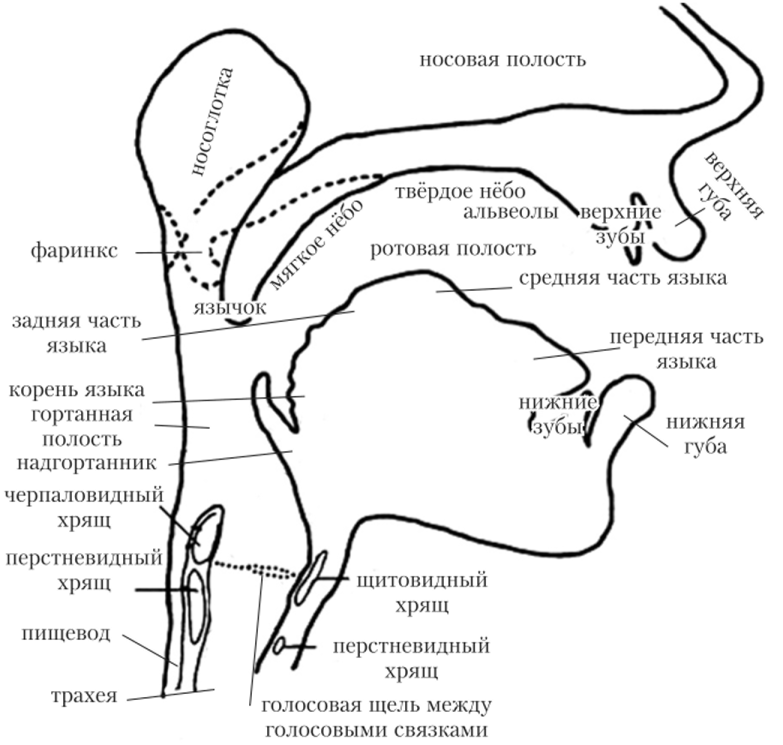
Теперь перейдем к тому, как именно происходит звукоизвлечение. Рассмотрим процесс поэтапно.
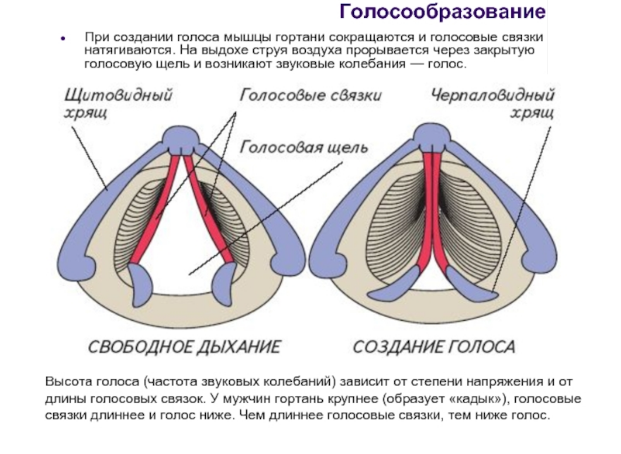
Звукоизвлечение – как происходит:
- Звук образуется за счет потока воздуха, выдыхаемого из легких.
- Струя воздуха приводит в движение голосовые складки.
- Высота голоса предопределяется длиной и натяжением связок. Чем сильнее натяжение, тем выше голос. Чем длиннее голосовые связки, тем ниже голос.
- Сила голоса предопределяется плотностью смыкания связок и давлением воздуха.
- Степень натяжения голосовых связок меняется при сокращении внутренних мышц гортани.
- Голосовые связки прикреплены к черпаловидным хрящам и к щитовидным хрящам, смещение которых предопределяет положение связок.
- При помощи языка, губ, мягкого и твердого неба создается та или иная форма ротовой полости, которая предопределяет получение того или иного звука.
Так образуется голос:
А так – речь:
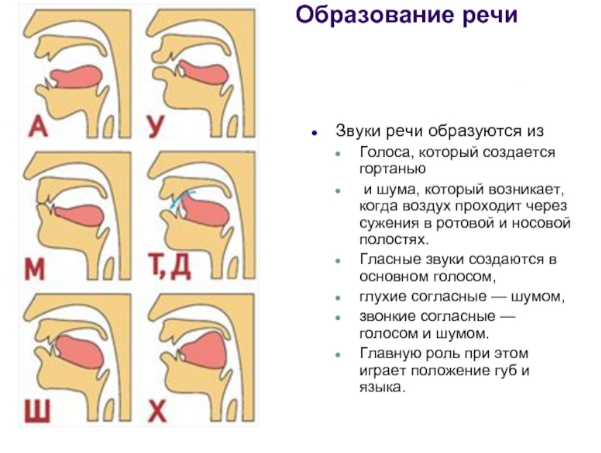
Остановимся подробнее на зависимости высоты голоса от связок. Высота голоса, т.е. частота звуковых колебаний, зависит как от напряжения, так и от длины голосовых связок.
Коротким связкам колебаться легче, поэтому они могут совершать большее число колебаний в единицу времени. Чем больше колебаний, тем выше голос. Длинные связки «раскачать» тяжелее, поэтому они способны совершать меньшее число колебаний в единицу времени. Чем меньше колебаний, тем ниже голос.
Это явление можно образно сравнить с размахом крыльев у птиц. Так, скорость взмаха крыльев миниатюрной колибри составляет от 50 до 80, а у некоторых видов до 200 взмахов за секунду. А такая заметно более крупная птица как аист, совершает всего 2 (два!) взмаха крыльями в секунду.
Проиллюстрируем сказанное:
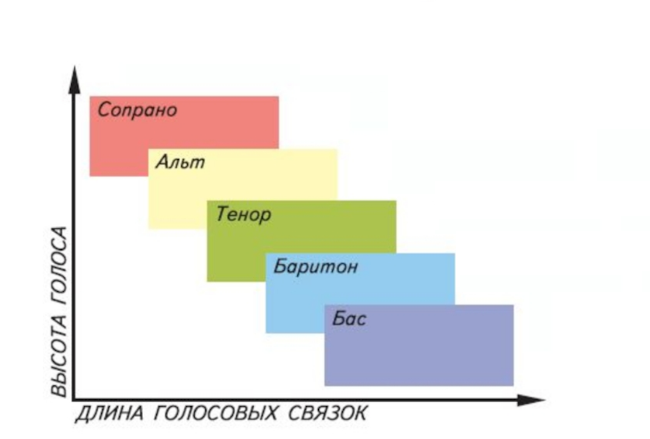
Посмотрев на диаграмму зависимости высоты голоса от длины голосовых связок, можно условно сказать, что басы – это наши аисты, а сопрано – это колибри. Это деление, принятое в академической опере, весьма условно. Есть люди, чей голосовой диапазон выходит далеко за рамки какого-то одного типа голоса.
Например, певец Димаш имеет диапазон в 6 октав + 5 полутонов от «ля» контроктавы до ноты «ре» 5-й октавы. Таким образом, его голос полностью вмещает диапазон, в котором поет баритон, тенор, альт и сопрано, а также захватывает верхнюю часть басового регистра и часть так называемого «свисткового регистра», который выходит за пределы верхних нот сопрано. Посмотрев выступление Димаша, можно услышать, как филигранно он тянет ноты мелодии композиции (не путать с текстом песни!) в свистковом регистре:
Тут мы подошли вплотную к разнице между образованием голоса и образованием речи. Из первой части нашего урока вы уже знаете, что голос – это более широкое понятие, чем речь. Голос без речи возможен – например, крик, стон, плач, а вот речь без голоса невозможна никак.
В образовании речи большую роль играет положение языка, губ, мягкого и твердого неба. С их помощью мы создаем ту или иную форму ротовой полости. Та или иная форма ротовой полости позволяет направить поток воздуха в ту или иную сторону, чем и предопределяется разница звуков, получаемых при разном положении языка, губ, мягкого и твердого неба.
Теперь пару слов о том, куда направлять поток воздуха. По умолчанию поток воздуха направляется в резонаторы – полости внутри организма, отражаясь внутри которых, он превращается в звук. Основными резонаторами для человеческого голоса являются глотка, ротовая и носовая полости и трахея. Также резонировать способны придаточные пазухи, теменная кость, прочие полости внутри черепа.
Этим, кстати, объясняется, почему мы слышим собственный голос иначе, чем слушающие нас люди. Мы воспринимаем волновые колебания от черепа и прочих резонирующих полостей, которые проходят через наш организм. Таким образом, мы воспринимаем голос, который издаем, не только посредством слуха. А все наши слушатели воспринимают наш голос исключительно через свой слух. Поэтому, если мы хотим узнать, как слышат наш голос окружающие, нужно сделать аудиозапись – например, на диктофон в смартфоне.
Ввиду того, что наш курс носит прикладной характер, тут будет уместным уточнить пару моментов. В большинстве курсов, обучающих ораторскому мастерству, вокалу, технике речи, вам встретится такое понятие как «грудной резонатор». Это некоторая условность, связанная с тем, что среднестатистическому человеку сложно представить, где у него находится трахея, однако очень легко ощутить вибрации внутри грудной клетки.
Поэтому, если вы захотите расширить нижнюю часть голосового диапазона, поработать над красивым звучанием низких нот своего голоса, следует быть готовыми к тому, что вам будут встречаться формулировки наподобие «работа грудного резонатора», «упражнения для развития грудного резонатора» и т.д.
Забегая вперед, скажем, что в уроке №2 мы затронем тему раскрытия резонаторов, в том числе грудного, и подробнее объясним термины, чтобы в дальнейшем вы могли самостоятельно пользоваться любыми книгами и онлайн-ресурсами по углубленному обучению технике речи и/или вокалу.
Чтобы понять, что такое резонанс, нужно вспомнить молодость – примерно старшую или среднюю группу детского садика – когда мы дули на листок бумаги и получали самый настоящий свист. Или когда делали «телефон» из стаканчиков и веревочки. Смысл в том, что нить должна быть натянута, и только тогда по ней можно передать звук. К слову, вы можете воспроизвести этот эксперимент и сейчас. Заодно познакомите с основами физики своих детей или племянников. Видеоинструкция прилагается:
К слову, обратите внимание, что на 01:25 в кадр попадает акустическая гитара. Звучание гитары – это тоже пример резонанса. Волновые колебания идут через отверстие деки внутрь корпуса и преобразуются в звуки, высота которых зависит от того, какую струну и на каком ладу вы зажали. В данном случае струны являются аналогом голосовых связок. У электрогитары с цельной декой тоже есть внутри резонирующие полости, просто они не видны снаружи. Электрическая часть лишь усиливает механические волновые колебания, воспринимаемые человеческим слухом. И вот теперь мы вплотную подошли к устройству слуха.
Устройство слуха
Слух, голос и речь тесно взаимосвязаны. Если, например, потеря слуха произошла в доречевом периоде, человек так и не научится говорить. При остаточном слухе человек может получить речевые навыки с помощью слухового аппарата, усиливающего звук настолько, чтобы его можно было услышать.
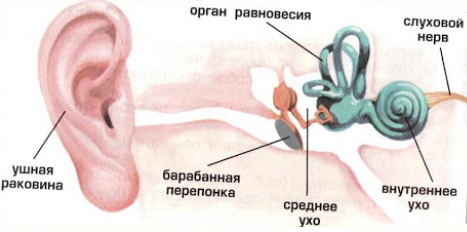
Как устроен слух:
- Наружное ухо.
- Среднее ухо.
- Барабанная перепонка между наружным и средним ухом.
- Внутреннее ухо.
- Слуховые проводящие пути.
Вот простая иллюстрация:
А теперь более сложная:
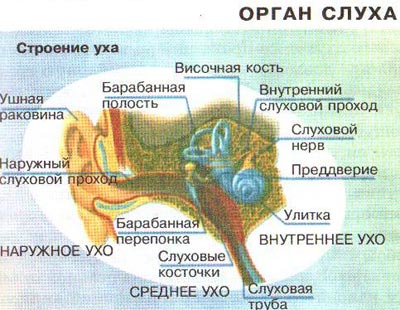
Улавливаемые наружным ухом звуковые волны, ударяют в барабанную перепонку и заставляют ее вибрировать. Колебания передаются в среднее ухо. В свою очередь, внутреннее ухо состоит из двух компонентов. Первый компонент – это преддверия и полукружные каналы, которые отвечают за чувство равновесия и положения тела в пространстве, из-за чего данный элемент часто обозначают как «орган равновесия».
Второй компонент внутреннего уха – это так называемая улитка, заполненная жидкостью, которая вибрирует под воздействием волновых колебаний. Внутри улитки находится специальный орган (кортиев орган), который непосредственно отвечает за слух. Он содержит около 30 тысяч клеток, улавливающих звуковые колебания и передающих сигнал к слуховой зоне коры головного мозга. Каждая клетка настроена на определенную частоту, и, если часть из них погибнет, человек перестанет слышать звуки на той частоте, за которую отвечали погибшие клетки.
Также стоит подробнее рассказать про слуховые проводящие пути. Это группа нервных волокон, отвечающих за передачу нервных импульсов от улитки к слуховым центрам, расположенным в височных долях головного мозга. В головном мозге происходит обработка и анализ комплексных звуков (речь, мелодия, песня). Скорость передачи аудиосигнала от наружного уха к центрам мозга происходит за 10 миллисекунд.
Представление о том, как устроен слух, как мы слышим звуки позволяет лучше понять, что такое музыкальный слух и как его развить. Большинство из нас слышали выражение, что «неработающие органы атрофируются». Это в полной мере относится и к элементам устройства человеческого слуха.
Чем большее количество клеток из тех 30 тысяч, улавливающих звуковые колебания и передающих сигнал к слуховой зоне коры головного мозга, вы заставите работать, тем более тренированным будет ваш слух. Если вы будете слушать звуки на разной частоте, со временем вы потренируете каждую клеточку кортиева органа. Они начнут быстрее реагировать на «свою» частоту.
Соответственно, нервные волокна, которые отвечают за передачу нервных импульсов от улитки к слуховым центрам, будут быстрее передавать максимально точную информацию к слуховым центрам, расположенным в височных долях головного мозга. А обработка и анализ комплексных звуков с каждым разом будут все детальнее и эффективнее.
Всем заинтересовавшимся рекомендуем прочитать статью на нашем сайте «Музыкальный слух: что это такое и как его развить». Если вы профессиональный музыкант, значительная часть информации вам будет известна. А вот если вы не знакомы с музыкальной грамотой, но планируете карьеру лектора, оратора, трибуна, педагога, психолога, вам стоит ознакомиться со статьей и взять некоторые элементы развития музыкального слуха на вооружение, т.к. это поможет вам в дальнейшем развитии голоса и речи уже после окончания нашего курса.
А сейчас подведем итоги урока. Сегодня вы изучили физику звука, физику и анатомию голоса, а также узнали, как работает голос и что общего в развитии голоса и речи. Вы узнали, что основными физическими характеристиками звука являются высота, сила и звуковой спектр, а также познакомились с устройством голосового аппарата, органов слуха и поняли, как происходит звукоизвлечение и голосообразование.
Закрепите полученные знания при помощи теста, после чего мы ждем вас на следующем уроке!
Тест на усвоение материала урока
Если вы хотите проверить свои знания по теме данного урока, можете пройти небольшой тест, состоящий из нескольких вопросов. В каждом вопросе правильным может быть только 1 вариант. После выбора вами одного из вариантов, система автоматически переходит к следующему вопросу. На получаемые вами баллы влияет правильность ваших ответов и затраченное на прохождение время. Обратите внимание, что вопросы каждый раз разные, а варианты перемешиваются.
А теперь переходим к разбору голосовых характеристик.
