Кто там? — Идентификация человека по голосу
Время на прочтение
6 мин
Количество просмотров 56K

Здравствуй, дорогой читатель!
Предлагаю твоему вниманию интересную и познавательную статью об отдельно взятом методе распознавания говорящего. Всего каких-то пару месяцев назад я наткнулся на статью о применении мел-кепстральных коэффициентов для распознавании речи. Она не нашла отклика, вероятно, из-за недостаточной структурированости, хотя материал в ней освещен очень интересный. Я возьму на себя ответственность донести этот материал в доступной форме и продолжить тему распознавания речи на Хабре.
Под катом я опишу весь процесс идентификации человека по голосу от записи и обработки звука до непосредственно определения личности говорящего.
Запись звука
Наша история начинается с записи аналогового сигнала с внешнего источника с помощью микрофона. В результате такой операции мы получим набор значений, которые соответствуют изменению амплитуды звука со временем. Такой принцип кодирования называется импульсно-кодовой модуляцией aka PCM (Pulse-code modulation). Как можно догадаться, «сырые» данные, полученные из аудио-потока, пока еще не годятся для наших целей. Первым делом нужно преобразовать непослушные биты в набор осмысленных значений — амплитуд сигнала. [1, с. 31] В качестве входных данных я буду использовать несжатый 16-битный знаковый (PCM-signed) wav-файл с частотой дискретизации 16 кГц.
double[] readAmplitudeValues(bool isBigEndian)
{
int MSB, LSB; // старший и младший байты
byte[] buffer = ReadDataFromExternalSource(); // читаем данные откуда-нибудь
double[] data = new double[buffer.length / 2];
for (int i = 0; i < buffer.length; i += 2)
{
if(isBigEndian) // задает порядок байтов во входном сигнале
{
// первым байтом будет MSB
MSB = buffer[2 * i];
// вторым байтом будет LSB
LSB = buffer[2 * i + 1];
}
else
{
// наоборот
LSB = buffer[2 * i];
MSB = buffer[2 * i + 1];
}
// склеиваем два байта, чтобы получить 16-битное вещественное число
// все значения делятся на максимально возможное - 2^15
data[i] = ((MSB << 8) || LSB) / 32768;
}
return data;
}
Освежить знания про порядок байтов можно на википедии.
Обработка звука
Полученные значения амплитуд могут не совпадать даже для двух одинаковых записей из-за внешнего шума, разных громкостей входного сигнала и других факторов. Для приведения звуков к «общему знаменателю» используется нормализация. Идея пиковой нормализации проста: разделить все значения амплитуд на максимальную (в рамках данного звукового файла). Таким образом мы уравняли образцы речи, записанные с разной громкостью, уложив все в шкалу от -1 до 1. Важно, что после такой трансформации любой звук полностью заполняет заданный промежуток.
Нормализация, на мой взгляд, — самый простой и эффективный алгоритм предварительной обработки звука. Существуют также масса других: «отрезающие» частоты выше или ниже заданной, сглаживающие и др.
Разделяй и властвуй
Даже при работе со звуком с минимально достаточной частотой дискретизации (16 кГц) размер уникальных характеристик для секундного образца звука просто огромен — 16000 значений амплитуд. Производить сколь-нибудь сложные операции над такими объемами данных не представляется возможным. Кроме того, не совсем понятно, как сравнивать объекты с разным количеством уникальных черт.
Для начала снизим вычислительную сложность задачи, разбив ее на меньшие по сложности подзадачи. Этим ходом убиваем сразу двух зайцев, ведь установив фиксированный размер подзадачи и усреднив результаты вычислений по всем задачам, получим наперед заданное количество признаков для классификации.
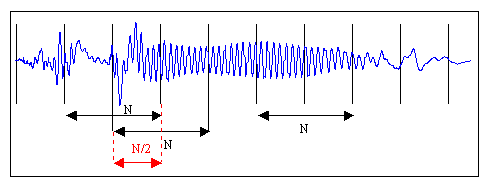
На рисунке изображена «порезка» звукового сигнала на кадры длины N с половинным перекрытием. Необходимость в перекрытии вызвана искажением звука в случае, если бы кадры были расположены рядом. Хотя на практике этим приемом часто принебрегают для экономии вычислительных ресурсов. Следуя рекоммендациям [1, с. 28], выберем длину кадра равной 128 мс, как компромисс между точностью (длинные кадры) и скоростью (короткие кадры). Остаток речи, который не занимает полный кадр, можно заполнить нулями до желаемого размера или просто отбросить.
Для устранения нежелаетльных эффектов при дальнейшей обработке кадров, умножим каждый элемент кадра на особую весовую функцию («окно»). Результатом станет выделение центральной части кадра и плавное затухание амплитуд на его краях. Это необходимо для достижения лучших результатов при прогонке преобразования Фурье, поскольку оно ориентировано на бесконечно повторяющийся сигнал. Соответственно, наш кадр должен стыковаться сам с собой и как можно более плавно. Окон существует великое множество. Мы же будем использовать окно Хэмминга.
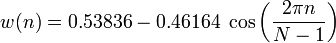
n — порядковый номер элемента в кадре, для которого вычисляется новое значение амплитуды
N — как и ранее, длина кадра (количество значений сигнала, измеренных за период)
Дискретное преобразование Фурье
Следующим шагом будет получение кратковременной спектрограммы каждого кадра в отдельности. Для этих целей используем дискретное преобразование Фурье.

N — как и ранее, длина кадра (количество значений сигнала, измеренных за период)
xn — амплитуда n-го сигнала
Xk — N комплексных амплитуд синусоидальных сигналов, слагающих исходный сигнал
Кроме этого, возведем каждое значение Xk в квадрат для дальнейшего логарифмирования.
Переход к мел-шкале
На сегодняшний день наиболее успешными являются системи распознавания голоса, использующие знания об устройстве слухового аппарата. Несколько слов об этом есть и на Хабре. Если говорить вкратце, то ухо интерпретирует звуки не линейно, а в логарифмическом масштабе. До сих пор все операции мы проделывали над «герцами», теперь перейдем к «мелам». Наглядно представить зависимость поможет рисунок.

Как видно, мел-шкала ведет себя линейно до 1000 Гц, а после проявляет логарифмическую природу. Переход к новой шкале описывается несложной зависимостью.

m — частота в мелах
f — частота в герцах
Получение вектора признаков
Сейчас мы как никогда близко к нашей цели. Вектор признаков будет состоять из тех самых мел-кепстральных коэффициентов. Вычисляем их по формуле [2]
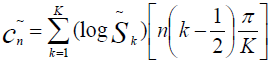
cn — мел-кепстральный коэффициент под номером n
Sk — амплитуда k-го значения в кадре в мелах
K — наперед заданное количество мел-кепстральных коэффициэнтов
n ∈ [1, K]
Как правило, число K выбирают равным 20 и начинают отсчет с 1 из-за того, что коэффициент c0 несет мало информации о говорящем, так как является, по сути, усреднением амплитуд входного сигнала. [2]
Так кто же все-таки говорил?
Последней стадией является классификация говорящего. Классификация производится вычислением меры схожести пробных данных и уже известных. Мера схожести выражается расстоянием от вектора признаков пробного сигнала до вектора признаков уже классифицированного. Нас будет интересовать наиболее простое решение — расстояние городских кварталов.

Такое решение больше подходит для векторов дискретной природы, в отличие от расстояния Евклида.
Внимательный читатель наверняка помнит, что автор в начале статьи упоминал про усреднение признаков речевых кадров. Итак, восполняя этот пробел, завершаю статью описанием алгоритма нахождения усредненного вектора признаков для нескольких кадров и нескольких образцов речи.
Кластеризация
Нахождение вектора признаков для одного образца не составит труда: такой вектор представляется как среднее арифметическое векторов, характеризующих отдельные кадры речи. Для повышения точности распознавания просто необходимо усреднять результаты не только между кадрами, но и учитывать показатели нескольких речевых образцов. Имея несколько записей голоса, разумно не усреднять показатели к одному вектору, а провести кластеризацию, например с помощью метода k-средних.
Итоги
Таким образом, я рассказал о простой но эффективной системе идентификации человека по голосу. Резюмируя, процесс распознавания построен следующим образом:
- Собираем несколько тренировочных образцов речи, чем больше — тем лучше.
- Находим для каждого из них характеристический вектор признаков.
- Для образцов с известным автором проводим кластеризацию с одним центром (усреднение) или несколькими. Приемлемые результаты начинаются уже с использованием 4-х центров для каждого диктора. [2]
- В режиме опознавания находим расстояние от пробного вектора до изученных во время тренировки центров кластеров. К какому кластеру пробная речь окажется ближе — к такому диктору и относим образец.
- Можно экспериментально установить даже некоторый доверительный интервал — максимальное расстояние, на котором может находиться пробный образец от центра кластера. В случае превышения этого значения — классифицировать образец как неизвестный.
Я всегда рад полезным комментариям по поводу улучшения материала. Спасибо за внимание.
Литература:
- Modular Audio Recognition Framework v.0.3.0.6 (0.3.0 final) and its Applications
- Speaker identification using mel frequency cepstral coefficients
Содержание
- Машинный слух. Как работает идентификация человека по его голосу
- Содержание статьи
- Характеристики голоса
- Предобработка звука
- Идентификация с использованием MFCC
- Тестирование метода
- Присоединяйся к сообществу «Xakep.ru»!
- Кто там? — Идентификация человека по голосу
- Запись звука
- Обработка звука
- Разделяй и властвуй
- Дискретное преобразование Фурье
- Переход к мел-шкале
- Получение вектора признаков
- Так кто же все-таки говорил?
- Кластеризация
- Итоги
Машинный слух. Как работает идентификация человека по его голосу
Содержание статьи
Характеристики голоса
В первую очередь голос определяется его высотой. Высота — это основная частота звука, вокруг которой строятся все движения голосовых связок. Эту частоту легко почувствовать на слух: у кого-то голос выше, звонче, а у кого-то ниже, басовитее.
Другой важный параметр голоса — это его сила, количество энергии, которую человек вкладывает в произношение. От силы голоса зависит его громкость, насыщенность.
Еще одна характеристика — то, как голос переходит от одного звука к другому. Этот параметр наиболее сложный для понимания и для восприятия на слух, хотя и самый точный — как и отпечаток пальца.
Предобработка звука
Человеческий голос — это не одинокая волна, это сумма множества отдельных частот, создаваемых голосовыми связками, а также их гармоники. Из-за этого в обработке сырых данных волны тяжело найти закономерности голоса.
Нам на помощь придет преобразование Фурье — математический способ описать одну сложную звуковую волну спектрограммой, то есть набором множества частот и амплитуд. Эта спектрограмма содержит всю ключевую информацию о звуке: так мы узнаем, какие в исходном голосе содержатся частоты.
Но преобразование Фурье — математическая функция, которая нацелена на идеальный, неменяющийся звуковой сигнал, поэтому она требует практической адаптации. Так что, вместо того чтобы выделять частоты из всей записи сразу, эту запись мы поделим на небольшие отрезки, в течение которых звук не будет меняться. И применим преобразование к каждому из кусочков.
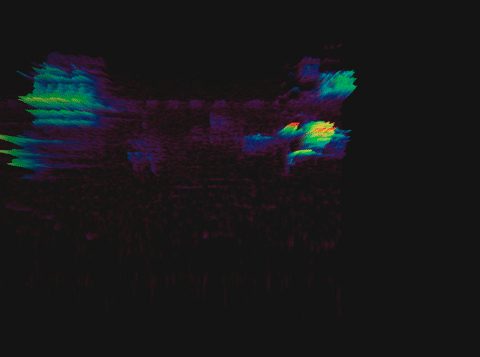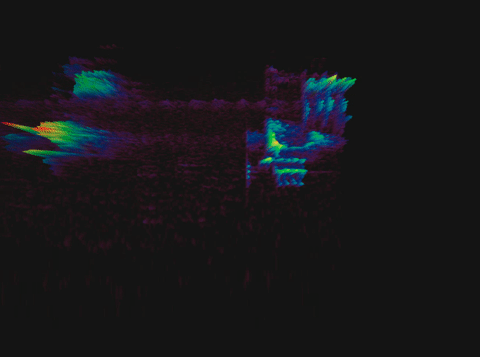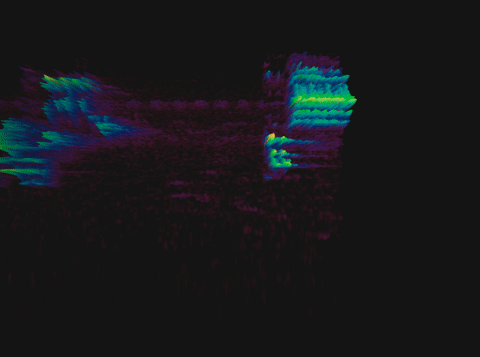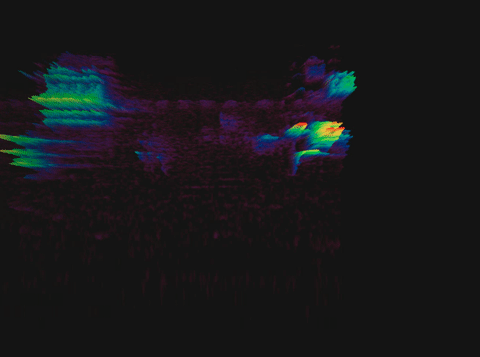 Спектрограмма пения птицы
Спектрограмма пения птицы
Выбрать длительность блока несложно: в среднем один слог человек произносит за 70–80 мс, а интонационно выделенный вдвое дольше — 100–150 мс. Подробнее об этом можно почитать в исследовании.
Следующий шаг — посчитать спектрограмму второго порядка, то есть спектрограмму от спектрограммы. Это нужно сделать, поскольку спектрограмма, помимо основных частот, также содержит гармоники, которые не очень удобны для анализа: они дублируют информацию. Расположены эти гармоники на равном друг от друга расстоянии, единственное их различие — уменьшение амплитуды.
Давай посмотрим, как выглядит спектр монотонного звука. Начнем с волны — синусоиды, которую издает, например, проводной телефон при наборе номера.
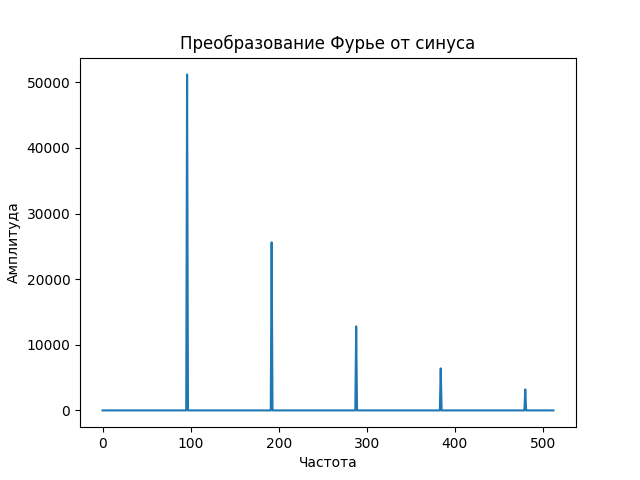
Видно, что, кроме основного пика, на самом деле представляющего сигнал, есть меньшие пики, гармоники, которые полезной информации не несут. Именно поэтому, прежде чем получать спектрограмму второго порядка, первую спектрограмму логарифмируют, чем получают пики схожего размера.
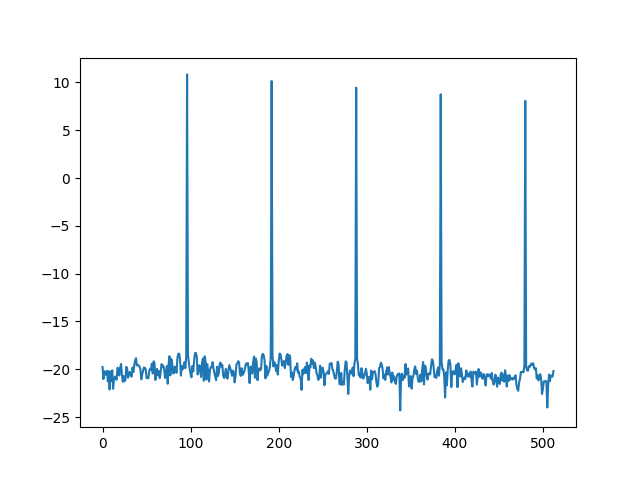 Логарифм спектрограммы синуса
Логарифм спектрограммы синуса
Теперь, если мы будем искать спектрограмму второго порядка, или, как она была названа, «кепстр» (анаграмма слова «спектр»), мы получим во много раз более приличную картинку, которая полностью, одним пиком, отображает нашу изначальную монотонную волну.
Одна из самых полезных особенностей нашего слуха — его нелинейная природа по отношению к восприятию частот. Путем долгих экспериментов ученые выяснили, что эту закономерность можно не только легко вывести, но и легко использовать.
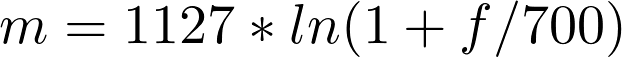 Зависимость мела от герца
Зависимость мела от герца
Эту новую величину назвали мел, и она отлично отражает способность человека распознавать разные частоты — чем выше частота звука, тем сложнее ее различить.
 График перевода герца в мелы
График перевода герца в мелы
Теперь попробуем применить все это на практике.
Идентификация с использованием MFCC
Мы можем взять длительную запись голоса человека, посчитать кепстр для каждого маленького участка и получить уникальный отпечаток голоса в каждый момент времени. Но этот отпечаток слишком большой для хранения и анализа — он зависит от выбранной длины блока и может доходить до двух тысяч чисел на каждые 100 мс. Поэтому из такого многообразия необходимо извлечь определенное количество признаков. С этим нам поможет мел-шкала.
Мы можем выбрать определенные «участки слышимости», на которых просуммируем все сигналы, причем количество этих участков равно количеству необходимых признаков, а длины и границы участков зависят от мел-шкалы.
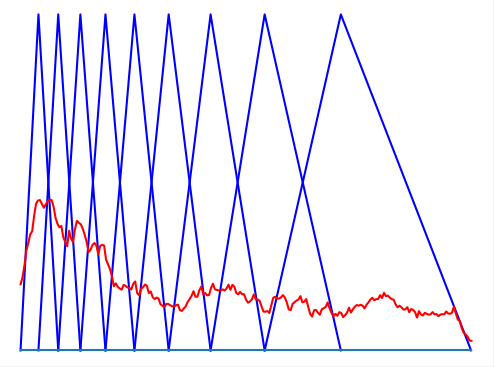 Вычисление мел-частотных кепстральных коэффициентов
Вычисление мел-частотных кепстральных коэффициентов
Вот мы и познакомились с мел-частотными кепстральными коэффициентами (MFCC). Количество признаков может быть произвольным, но чаще всего варьируется от 20 до 40.
Эти коэффициенты отлично отражают каждый «частотный блок» голоса в каждый момент времени, а значит, если обобщить время, просуммировав коэффициенты всех блоков, мы сможем получить голосовой отпечаток человека.
Тестирование метода
Давай скачаем несколько записей видео с YouTube, из которых извлечем голос для наших экспериментов. Нам нужен чистый звук без шумов. Я выбрал канал TED Talks.
Скачаем несколько видеозаписей любым удобным способом, например с помощью утилиты youtube-dl. Она доступна через pip или через официальный репозиторий Ubuntu или Debian. Я скачал три видеозаписи выступлений: двух женщин и одного мужчины.
Затем преобразуем видео в аудио, создаем несколько кусков разной длины без музыки или аплодисментов.
Теперь разберемся с программой на Python 3. Нам понадобятся библиотеки numpy для вычислений и librosa для обработки звука, которые можно установить с помощью pip . Для твоего удобства все сложные вычисления коэффициентов упаковали в одну функцию librosa.feature.mfcc . Загрузим звуковую дорожку и извлечем характеристики голоса.
Присоединяйся к сообществу «Xakep.ru»!
Членство в сообществе в течение указанного срока откроет тебе доступ ко ВСЕМ материалам «Хакера», позволит скачивать выпуски в PDF, отключит рекламу на сайте и увеличит личную накопительную скидку! Подробнее
Источник
Кто там? — Идентификация человека по голосу

Здравствуй, дорогой читатель!
Предлагаю твоему вниманию интересную и познавательную статью об отдельно взятом методе распознавания говорящего. Всего каких-то пару месяцев назад я наткнулся на статью о применении мел-кепстральных коэффициентов для распознавании речи. Она не нашла отклика, вероятно, из-за недостаточной структурированости, хотя материал в ней освещен очень интересный. Я возьму на себя ответственность донести этот материал в доступной форме и продолжить тему распознавания речи на Хабре.
Под катом я опишу весь процесс идентификации человека по голосу от записи и обработки звука до непосредственно определения личности говорящего.
Запись звука
Наша история начинается с записи аналогового сигнала с внешнего источника с помощью микрофона. В результате такой операции мы получим набор значений, которые соответствуют изменению амплитуды звука со временем. Такой принцип кодирования называется импульсно-кодовой модуляцией aka PCM (Pulse-code modulation). Как можно догадаться, «сырые» данные, полученные из аудио-потока, пока еще не годятся для наших целей. Первым делом нужно преобразовать непослушные биты в набор осмысленных значений — амплитуд сигнала. [1, с. 31] В качестве входных данных я буду использовать несжатый 16-битный знаковый (PCM-signed) wav-файл с частотой дискретизации 16 кГц.
Освежить знания про порядок байтов можно на википедии.
Обработка звука
Полученные значения амплитуд могут не совпадать даже для двух одинаковых записей из-за внешнего шума, разных громкостей входного сигнала и других факторов. Для приведения звуков к «общему знаменателю» используется нормализация. Идея пиковой нормализации проста: разделить все значения амплитуд на максимальную (в рамках данного звукового файла). Таким образом мы уравняли образцы речи, записанные с разной громкостью, уложив все в шкалу от -1 до 1. Важно, что после такой трансформации любой звук полностью заполняет заданный промежуток.
Нормализация, на мой взгляд, — самый простой и эффективный алгоритм предварительной обработки звука. Существуют также масса других: «отрезающие» частоты выше или ниже заданной, сглаживающие и др.
Разделяй и властвуй
Даже при работе со звуком с минимально достаточной частотой дискретизации (16 кГц) размер уникальных характеристик для секундного образца звука просто огромен — 16000 значений амплитуд. Производить сколь-нибудь сложные операции над такими объемами данных не представляется возможным. Кроме того, не совсем понятно, как сравнивать объекты с разным количеством уникальных черт.
Для начала снизим вычислительную сложность задачи, разбив ее на меньшие по сложности подзадачи. Этим ходом убиваем сразу двух зайцев, ведь установив фиксированный размер подзадачи и усреднив результаты вычислений по всем задачам, получим наперед заданное количество признаков для классификации. 
На рисунке изображена «порезка» звукового сигнала на кадры длины N с половинным перекрытием. Необходимость в перекрытии вызвана искажением звука в случае, если бы кадры были расположены рядом. Хотя на практике этим приемом часто принебрегают для экономии вычислительных ресурсов. Следуя рекоммендациям [1, с. 28], выберем длину кадра равной 128 мс, как компромисс между точностью (длинные кадры) и скоростью (короткие кадры). Остаток речи, который не занимает полный кадр, можно заполнить нулями до желаемого размера или просто отбросить.
Для устранения нежелаетльных эффектов при дальнейшей обработке кадров, умножим каждый элемент кадра на особую весовую функцию («окно»). Результатом станет выделение центральной части кадра и плавное затухание амплитуд на его краях. Это необходимо для достижения лучших результатов при прогонке преобразования Фурье, поскольку оно ориентировано на бесконечно повторяющийся сигнал. Соответственно, наш кадр должен стыковаться сам с собой и как можно более плавно. Окон существует великое множество. Мы же будем использовать окно Хэмминга. 
n — порядковый номер элемента в кадре, для которого вычисляется новое значение амплитуды
N — как и ранее, длина кадра (количество значений сигнала, измеренных за период)
Дискретное преобразование Фурье
Следующим шагом будет получение кратковременной спектрограммы каждого кадра в отдельности. Для этих целей используем дискретное преобразование Фурье. 
N — как и ранее, длина кадра (количество значений сигнала, измеренных за период)
xn — амплитуда n-го сигнала
Xk — N комплексных амплитуд синусоидальных сигналов, слагающих исходный сигнал
Кроме этого, возведем каждое значение Xk в квадрат для дальнейшего логарифмирования.
Переход к мел-шкале
На сегодняшний день наиболее успешными являются системи распознавания голоса, использующие знания об устройстве слухового аппарата. Несколько слов об этом есть и на Хабре. Если говорить вкратце, то ухо интерпретирует звуки не линейно, а в логарифмическом масштабе. До сих пор все операции мы проделывали над «герцами», теперь перейдем к «мелам». Наглядно представить зависимость поможет рисунок. 
Как видно, мел-шкала ведет себя линейно до 1000 Гц, а после проявляет логарифмическую природу. Переход к новой шкале описывается несложной зависимостью. 
m — частота в мелах
f — частота в герцах
Получение вектора признаков
Сейчас мы как никогда близко к нашей цели. Вектор признаков будет состоять из тех самых мел-кепстральных коэффициентов. Вычисляем их по формуле [2] 
cn — мел-кепстральный коэффициент под номером n
Sk — амплитуда k-го значения в кадре в мелах
K — наперед заданное количество мел-кепстральных коэффициэнтов
n ∈ [1, K]
Как правило, число K выбирают равным 20 и начинают отсчет с 1 из-за того, что коэффициент c0 несет мало информации о говорящем, так как является, по сути, усреднением амплитуд входного сигнала. [2]
Так кто же все-таки говорил?
Последней стадией является классификация говорящего. Классификация производится вычислением меры схожести пробных данных и уже известных. Мера схожести выражается расстоянием от вектора признаков пробного сигнала до вектора признаков уже классифицированного. Нас будет интересовать наиболее простое решение — расстояние городских кварталов. 
Такое решение больше подходит для векторов дискретной природы, в отличие от расстояния Евклида.
Внимательный читатель наверняка помнит, что автор в начале статьи упоминал про усреднение признаков речевых кадров. Итак, восполняя этот пробел, завершаю статью описанием алгоритма нахождения усредненного вектора признаков для нескольких кадров и нескольких образцов речи.
Кластеризация
Нахождение вектора признаков для одного образца не составит труда: такой вектор представляется как среднее арифметическое векторов, характеризующих отдельные кадры речи. Для повышения точности распознавания просто необходимо усреднять результаты не только между кадрами, но и учитывать показатели нескольких речевых образцов. Имея несколько записей голоса, разумно не усреднять показатели к одному вектору, а провести кластеризацию, например с помощью метода k-средних.
Итоги
Таким образом, я рассказал о простой но эффективной системе идентификации человека по голосу. Резюмируя, процесс распознавания построен следующим образом:
- Собираем несколько тренировочных образцов речи, чем больше — тем лучше.
- Находим для каждого из них характеристический вектор признаков.
- Для образцов с известным автором проводим кластеризацию с одним центром (усреднение) или несколькими. Приемлемые результаты начинаются уже с использованием 4-х центров для каждого диктора. [2]
- В режиме опознавания находим расстояние от пробного вектора до изученных во время тренировки центров кластеров. К какому кластеру пробная речь окажется ближе — к такому диктору и относим образец.
- Можно экспериментально установить даже некоторый доверительный интервал — максимальное расстояние, на котором может находиться пробный образец от центра кластера. В случае превышения этого значения — классифицировать образец как неизвестный.
Я всегда рад полезным комментариям по поводу улучшения материала. Спасибо за внимание.
Источник
15 Июня 2011 12:06
15 Июн 2011 12:06
|
Google объявил о нововведениях в своем поисковике на компьютерах и в мобильных устройствах.
Пользователям ноутбуков и настольных ПК стали доступны три новые функции: голосовой поиск (Google Voice Search), поиск по изображению (Search by Image) и функция мгновенной загрузки Instant Pages.
Голосовой поиск и поиск по изображению – функции, изначально появившиеся на мобильных устройствах. Для использования голосового поиска необходимо в веб-браузере Google Chrome 11 или более поздней версии перейти по адресу Google.com (выбрать в настройках поиска родной язык английский). Напротив строки для ввода запроса появится пиктограмма микрофона. Нажатие на кнопку активирует запись с подключенного или встроенного микрофона, далее поисковая система распознает произнесенное выражение.
В Google утверждают, что система учитывает 230 млрд комбинаций слов в различных устойчивых предложениях и способна распознавать не только слова и словосочетания, например, «bolognese sauce», но и стандартные фразы. Более того, благодаря интеграции с сервисом Google Translate система может обрабатывать и запросы на перевод, такие как «translate to spanish where can I buy a hamburger». Правда, функция работает только с английским языком.
На официальном сайте Google в системных требованиях указана только необходимость использования определенной версии Chrome, однако корреспонденту CNews не удалось вызвать пиктограмму микрофона при наличии встроенного микрофона ни в Windows XP, ни в Windows 7. Возможно, данная функция доступна пока только пользователям, территориально расположенным в США.
Для работы функции Voice Search используется интферсейс HTML Speech Input API и собственно технология распознавания. Она встроена в браузер и является закрытой. В компании не сообщили, смогут ли данной технологией воспользоваться разработчики сторонних браузеров. Впервые функция распознавания голоса в Chrome появилась в апреле с выходом одиннацатой версии браузера (с плоским логотипом).
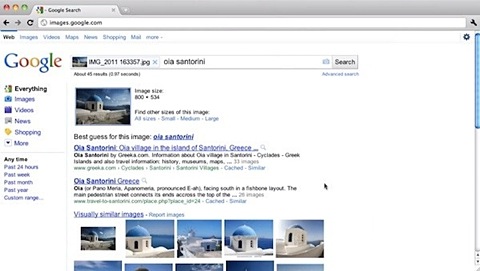
Поиск Google по изображениям позволяет найти даже малоизвестные места
Для того чтобы воспользоваться поиском по изображению, необходимо открыть адрес images.google.com, и здесь уже не имеет значения, какой язык указан, и используется ли Chrome. При переходе по ссылке рядом с поисковой строкой появляется пиктограмма фотоаппарата. Кликнув на нее, пользователь может указать URL к изображению в интернете, по которому он желает выполнить поиск, либо загрузить картинку со своего компьютера. Функция работает в Chrome, Firefox и Safari, но не работает в Opera.
Как оптимизировать внутреннюю логистику предприятия?
ПО

В Google продемонстрировали, как с помощью Search by Image можно узнать название здания или любой другой достопримечательности. В частности, система смогла не только распознать изображение известной на весь мир «Саграды Фамилии» в Барселоне, но и церковь в малоизвестной деревушке Ойя в Греции (на изображении).
Наконец, функция Instant Pages является продолжением Google Instant («Живой поиск»). Работая в тандеме с существующей технологией, новая функция заранее подгружает страницы, расположенные по адресам наверху результатов мгновенного поиска. Таким образом, страницы открываются с минимальной задержкой – появляется возможность дополнительной экономии времени.
В компании утверждают, что в среднем пользователь вынужден ждать около 5 секунд, пока сайт, который он нашел в Google, загрузится. Поэтому при наличии Instant Pages он экономит это время – в дополнение к тем 2-5 секундам, которые, как утверждают в Google, помогает экономить Google Instant. Чтобы посмотреть, как работает новая функция, необходимо загрузить бета-версию Chrome с технологией пререндеринга.
Помимо нововведений в «настольном» поиске, компания улучшила поиск на устройствах под управлением iOS и Android. В частности, в мобильном приложении Google для указанных платформ появились пиктограммы наиболее популярных для текущего региона категорий запросов. Например, «Рестораны», «Кофейни», «Бары» и так далее. Данное нововведение призвано упростить поиск близлежащих заведений – нажатие на пиктограмму выдает информацию о ресторанах, кофейнях, барах и других местах, расположенных вблизи от текущего местоположения пользователя, а также указывает эти места на карте. Новая функция работает на iOS 4.0 и Android 2.2 и более поздних версиях платформ.
- ИТ-маркетплейс Market.CNews: выбрать лучший из тысячи тариф на облачную инфраструктуру IaaS среди десятков поставщиков
В современном мире все больший интерес проявляется к биометрическим технологиям и биометрическим системам идентификации личности, и этот интерес вполне понятен.
Биометрическая идентификация основана на принципе распознавания и сравнения уникальных характеристик человеческого организма. Основными источниками биометрической характеристики человека являются отпечатки пальцев, радужная оболочка и сетчатка глаз, голос, лицо, подпись, походка и др. Эти биометрические идентификаторы принадлежат человеку и являются его неотъемлемой частью. Их нельзя где-то забыть, оставить, потерять.
Для биометрической идентификации можно применять различные характеристики и черты человека. В данной статье дается краткий обзор, как работают биометрические технологии на примере системы распознавания личности по голосу.
Ценность голосовых технологий для биометрики была неоднократно доказана. Однако только высокое качество реализации автоматических систем распознавания диктора способно реально внедрить такие технологии в практику. Подобные системы уже существуют. Они находят применение в системах безопасности, в банковских технологиях, электронной коммерции, правоохранительной практике.
Использование систем распознавания диктора является наиболее естественным и экономичным способом решения проблем неавторизованного доступа к компьютеру или системам передачи информации, а также проблем многоуровневого контроля доступа к сетевым или информационным ресурсам.
Системы распознавания диктора могут решать две задачи: определять личность из заданного, ограниченного списка людей (идентификация личности) или подтверждать личность говорящего (верификация личности). Идентификация и верификация личности по голосу являются направлениями развития технологии обработки речи.

Рис. 1 – Распознавание диктора
Речь – это сигнал, возникающий в результате преобразований, происходящих на нескольких различных уровнях: семантическом, лингвистическом, артикуляционном и акустическом. Как известно, источником речевого сигнала служит речевой тракт, который возбуждает звуковые волны в упругой воздушной среде. Под речевым трактом обычно подразумевается орган речеобразования, расположенный над голосовыми связками. Как видно из рисунка 2 речевой тракт состоит из гортаноглотки, ротоглотки, ротовой полости, носоглотки и носовой полости.

Рис. 2 – Строение речевого тракта человека
Голос человека возникает при прохождении воздуха из легких через трахею в гортань, мимо голосовых связок, и, далее в глотку и рот и носовую полость. Когда звуковая волна проходит через речевой тракт, ее частотный спектр изменяется под действием колебаний речевого тракта. Колебания речевого тракта называются формантами. Системы верификации диктора обычно распознают отличительные признаки речевого сигнала, которые отражают индивидуальную особенность мышечной активности речевого тракта личности.
Рассмотрим более подробно систему верификации диктора. Верификация личности по голосу – это определение, является ли говорящий тем, кем он представляется. Пользователь, ранее зарегистрированный в системе, произносит свой идентификатор, который представляет собой регистрационный номер, парольное слово или фразу. При текстозависимом распознавании парольное слово известно системе, и она «просит» пользователя произнести его. Парольное слово отображается на экране, и человек произносит его в микрофон. При текстонезависимом распознавании произносимое пользователем парольное слово не совпадает с эталонным, т.е. в качестве пароля пользователь может произносить произвольное слово или фразу. Система верификации принимает речевой сигнал, обрабатывает его и решает, принять или отклонить предъявляемый пользователем идентификатор. Система может сообщить пользователю о недостаточной степени совпадения его голоса с имеющимся эталоном и попросить произнести дополнительную информацию, чтобы принять окончательное решение.

Рис. 3 – Взаимодействие человека с системой
Схема взаимодействия человека с системой верификации личности по голосу изображена на рисунке 3. Пользователь произносит в микрофон предлагаемый ему системой номер для того, чтобы система проверила, соответствует ли его голос эталону, хранящемуся в базе данных системы. Как правило, существует компромисс между точностью распознавания голоса и размером речевого образца, т.е. чем длиннее речевой образец, тем выше точность распознавания. Помимо голоса в микрофон могут попадать эхо и посторонние шумы.
Существует ряд факторов, которые могут способствовать возникновению ошибок верификации и идентификации, например:
- неправильное произнесение или прочтение парольного слова или фразы;
- эмоциональное состояние диктора (стресс, произнесение парольной фразы под принуждением и пр.);
- сложная акустическая обстановка (шум, помехи, радиоволны и пр.);
- разные каналы связи (использование разных микрофонов во время регистрации диктора и верификации);
- простудные заболевания;
- естественные изменения голоса.
Некоторые из них могут быть устранены, например, путем использования более качественных микрофонов.
Процесс верификации личности по голосу состоит из 5 этапов: прием речевого сигнала, параметризация, или выделение отличительных признаков голоса, сравнение полученного образца голоса с ранее установленным эталоном, принятие решения «допуск/отказ», обучение, или обновление эталонной модели. Схема верификации представлена на рисунке 4.

Рис. 4 – Схема верификации
Во время регистрации новый пользователь вводит свой идентификатор, а затем произносит несколько раз ключевое слово или фразу, таким образом создаются эталоны. Число повторов ключевой фразы может варьироваться для каждого пользователя, а может быть постоянным для всех.
Для того чтобы компьютер мог обработать речевой сигнал, звуковая волна преобразовывается в аналоговый, а затем в цифровой сигнал.
На этапе выделения признаков голоса речевой сигнал разбивается на отдельные звуковые кадры, которые впоследствии преобразуются в цифровую модель. Эти модели называют «голосовыми отпечатками». Вновь полученный «голосовой отпечаток» сравнивается с ранее установленным эталоном. Для распознавания личности говорящего самыми важными являются наиболее яркие отличительные признаки голоса, которые позволили бы системе с высокой точностью распознавать голос каждого конкретного пользователя.
Наконец, система принимает решение допустить или отказать пользователю в допуске в зависимости от совпадения или несовпадения его голоса с установленным эталоном. Если система неверно сопоставила предъявленный ей голос с эталоном, то возникает ошибка «ложный допуск» (FA). Если же система не опознала биометрический признак, который соответствует имеющемуся в ней эталону, то говорят об ошибке «ложный отказ» (FR). Ошибка ложного допуска создает брешь в системе безопасности, а ошибка ложного отказа приводит к уменьшению удобства пользования системой, которая иногда не распознаёт человека с первого раза. Попытка снизить вероятность возникновения одной ошибки приводит к более частому возникновению другой, поэтому в зависимости от требований к системе выбирается определённый компромисс, т.е. устанавливается порог принятия решения.
Заключение
Методы голосовой идентификации применяют и на практике. Технология идентификации по голосу Voice Key компании «Речевые Технологии» позволяет организовать регламентированный доступ пользователей по заданной парольной фразе к ресурсам предприятия, телефонным и WEB-сервисам. Использование технологии Voice Key позволяет существенно повысить защищенность систем и, в то же время, упростить процесс идентификации пользователя. Технология Voice Key обеспечит высокую надежность и стабильность работы системы, а также поможет повысить качество обслуживания клиентов.
Все материалы, размещенные на даннном сайте, разрешены к публикации и печати на других ресурсах и печатных издания только при наличии письменного разрешения компании ООО “Речевые Технологии”
Можно ли вычислить человека по голосу в интернете ?
Феликс Меркушев
Знаток
(342),
закрыт
3 года назад
Раньше слышал, как школьники угрожают по голосу вычислить по IP.это вообще возможно? вычислить по голосу всю информацию о человеке ?
Лучший ответ
Николай Миклухо-Маклай
Мыслитель
(8001)
3 года назад
Только Баскова и Киркорова)), а Феликса по усам и хвосту!)))
Остальные ответы
Luar Zero
Оракул
(60513)
3 года назад
Нет. Во-первых по IP вычисляется только название провайдера и город. Во-вторых по голосу вообще ничего не вычисляется, голос и голос.
одиннадцатый май
Просветленный
(42572)
3 года назад
фонограмма голоса принимается судвми как идентификатор личности, более надёжный чем отпечатки пальцев .
kva
Искусственный Интеллект
(200603)
3 года назад
Вычислить можно, если есть база голосов или хотя бы круг подозреваемых. Иначе бесполезняк.
Нет
Просветленный
(28394)
3 года назад
Можно всё. Однако такое специальное оборудование, программное обеспечение доступно лишь органам правопорядка. Поэтому определение IP по голосу есть школьные фантазии.
eqAKZwyd MLgTJIXh
Ученик
(129)
8 месяцев назад
Невозможно, даже по айпи. Если лох конечно, то вычислят, но другим способом.
