15 Июня 2011 12:06
15 Июн 2011 12:06
|
Google объявил о нововведениях в своем поисковике на компьютерах и в мобильных устройствах.
Пользователям ноутбуков и настольных ПК стали доступны три новые функции: голосовой поиск (Google Voice Search), поиск по изображению (Search by Image) и функция мгновенной загрузки Instant Pages.
Голосовой поиск и поиск по изображению – функции, изначально появившиеся на мобильных устройствах. Для использования голосового поиска необходимо в веб-браузере Google Chrome 11 или более поздней версии перейти по адресу Google.com (выбрать в настройках поиска родной язык английский). Напротив строки для ввода запроса появится пиктограмма микрофона. Нажатие на кнопку активирует запись с подключенного или встроенного микрофона, далее поисковая система распознает произнесенное выражение.
В Google утверждают, что система учитывает 230 млрд комбинаций слов в различных устойчивых предложениях и способна распознавать не только слова и словосочетания, например, «bolognese sauce», но и стандартные фразы. Более того, благодаря интеграции с сервисом Google Translate система может обрабатывать и запросы на перевод, такие как «translate to spanish where can I buy a hamburger». Правда, функция работает только с английским языком.
На официальном сайте Google в системных требованиях указана только необходимость использования определенной версии Chrome, однако корреспонденту CNews не удалось вызвать пиктограмму микрофона при наличии встроенного микрофона ни в Windows XP, ни в Windows 7. Возможно, данная функция доступна пока только пользователям, территориально расположенным в США.
Для работы функции Voice Search используется интферсейс HTML Speech Input API и собственно технология распознавания. Она встроена в браузер и является закрытой. В компании не сообщили, смогут ли данной технологией воспользоваться разработчики сторонних браузеров. Впервые функция распознавания голоса в Chrome появилась в апреле с выходом одиннацатой версии браузера (с плоским логотипом).
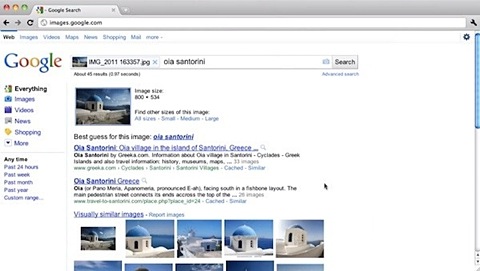
Поиск Google по изображениям позволяет найти даже малоизвестные места
Для того чтобы воспользоваться поиском по изображению, необходимо открыть адрес images.google.com, и здесь уже не имеет значения, какой язык указан, и используется ли Chrome. При переходе по ссылке рядом с поисковой строкой появляется пиктограмма фотоаппарата. Кликнув на нее, пользователь может указать URL к изображению в интернете, по которому он желает выполнить поиск, либо загрузить картинку со своего компьютера. Функция работает в Chrome, Firefox и Safari, но не работает в Opera.
Назван самый надежный способ организации IaaS
Маркет

В Google продемонстрировали, как с помощью Search by Image можно узнать название здания или любой другой достопримечательности. В частности, система смогла не только распознать изображение известной на весь мир «Саграды Фамилии» в Барселоне, но и церковь в малоизвестной деревушке Ойя в Греции (на изображении).
Наконец, функция Instant Pages является продолжением Google Instant («Живой поиск»). Работая в тандеме с существующей технологией, новая функция заранее подгружает страницы, расположенные по адресам наверху результатов мгновенного поиска. Таким образом, страницы открываются с минимальной задержкой – появляется возможность дополнительной экономии времени.
В компании утверждают, что в среднем пользователь вынужден ждать около 5 секунд, пока сайт, который он нашел в Google, загрузится. Поэтому при наличии Instant Pages он экономит это время – в дополнение к тем 2-5 секундам, которые, как утверждают в Google, помогает экономить Google Instant. Чтобы посмотреть, как работает новая функция, необходимо загрузить бета-версию Chrome с технологией пререндеринга.
Помимо нововведений в «настольном» поиске, компания улучшила поиск на устройствах под управлением iOS и Android. В частности, в мобильном приложении Google для указанных платформ появились пиктограммы наиболее популярных для текущего региона категорий запросов. Например, «Рестораны», «Кофейни», «Бары» и так далее. Данное нововведение призвано упростить поиск близлежащих заведений – нажатие на пиктограмму выдает информацию о ресторанах, кофейнях, барах и других местах, расположенных вблизи от текущего местоположения пользователя, а также указывает эти места на карте. Новая функция работает на iOS 4.0 и Android 2.2 и более поздних версиях платформ.
- 10 функций Telegram, о которых вы не знали: наводим порядок в чатах
Содержание
- Машинный слух. Как работает идентификация человека по его голосу
- Содержание статьи
- Характеристики голоса
- Предобработка звука
- Идентификация с использованием MFCC
- Тестирование метода
- Присоединяйся к сообществу «Xakep.ru»!
- Кто там? — Идентификация человека по голосу
- Запись звука
- Обработка звука
- Разделяй и властвуй
- Дискретное преобразование Фурье
- Переход к мел-шкале
- Получение вектора признаков
- Так кто же все-таки говорил?
- Кластеризация
- Итоги
Машинный слух. Как работает идентификация человека по его голосу
Содержание статьи
Характеристики голоса
В первую очередь голос определяется его высотой. Высота — это основная частота звука, вокруг которой строятся все движения голосовых связок. Эту частоту легко почувствовать на слух: у кого-то голос выше, звонче, а у кого-то ниже, басовитее.
Другой важный параметр голоса — это его сила, количество энергии, которую человек вкладывает в произношение. От силы голоса зависит его громкость, насыщенность.
Еще одна характеристика — то, как голос переходит от одного звука к другому. Этот параметр наиболее сложный для понимания и для восприятия на слух, хотя и самый точный — как и отпечаток пальца.
Предобработка звука
Человеческий голос — это не одинокая волна, это сумма множества отдельных частот, создаваемых голосовыми связками, а также их гармоники. Из-за этого в обработке сырых данных волны тяжело найти закономерности голоса.
Нам на помощь придет преобразование Фурье — математический способ описать одну сложную звуковую волну спектрограммой, то есть набором множества частот и амплитуд. Эта спектрограмма содержит всю ключевую информацию о звуке: так мы узнаем, какие в исходном голосе содержатся частоты.
Но преобразование Фурье — математическая функция, которая нацелена на идеальный, неменяющийся звуковой сигнал, поэтому она требует практической адаптации. Так что, вместо того чтобы выделять частоты из всей записи сразу, эту запись мы поделим на небольшие отрезки, в течение которых звук не будет меняться. И применим преобразование к каждому из кусочков.
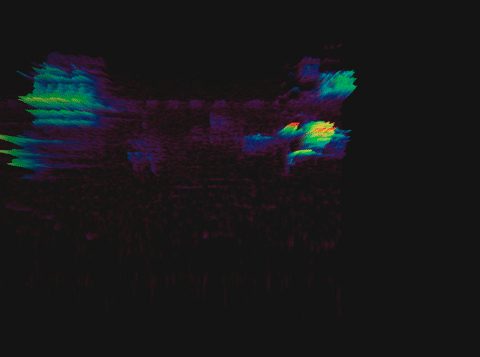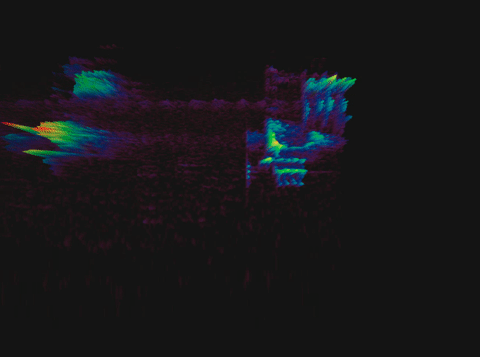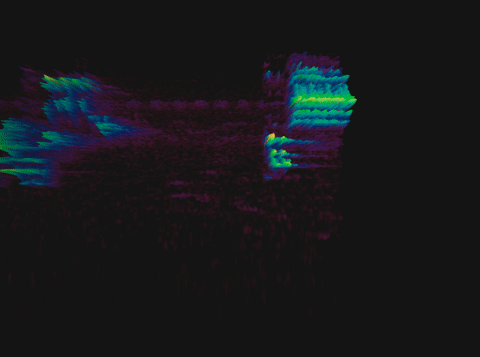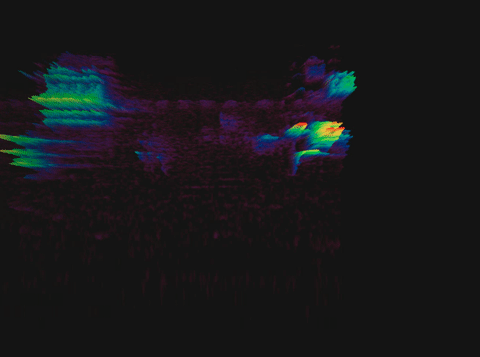 Спектрограмма пения птицы
Спектрограмма пения птицы
Выбрать длительность блока несложно: в среднем один слог человек произносит за 70–80 мс, а интонационно выделенный вдвое дольше — 100–150 мс. Подробнее об этом можно почитать в исследовании.
Следующий шаг — посчитать спектрограмму второго порядка, то есть спектрограмму от спектрограммы. Это нужно сделать, поскольку спектрограмма, помимо основных частот, также содержит гармоники, которые не очень удобны для анализа: они дублируют информацию. Расположены эти гармоники на равном друг от друга расстоянии, единственное их различие — уменьшение амплитуды.
Давай посмотрим, как выглядит спектр монотонного звука. Начнем с волны — синусоиды, которую издает, например, проводной телефон при наборе номера.
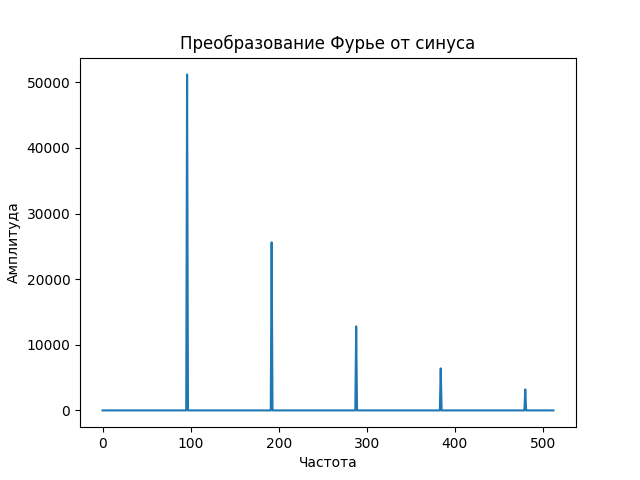
Видно, что, кроме основного пика, на самом деле представляющего сигнал, есть меньшие пики, гармоники, которые полезной информации не несут. Именно поэтому, прежде чем получать спектрограмму второго порядка, первую спектрограмму логарифмируют, чем получают пики схожего размера.
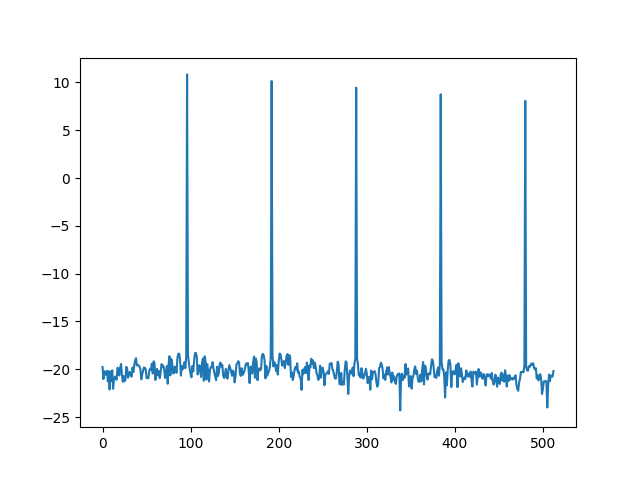 Логарифм спектрограммы синуса
Логарифм спектрограммы синуса
Теперь, если мы будем искать спектрограмму второго порядка, или, как она была названа, «кепстр» (анаграмма слова «спектр»), мы получим во много раз более приличную картинку, которая полностью, одним пиком, отображает нашу изначальную монотонную волну.
Одна из самых полезных особенностей нашего слуха — его нелинейная природа по отношению к восприятию частот. Путем долгих экспериментов ученые выяснили, что эту закономерность можно не только легко вывести, но и легко использовать.
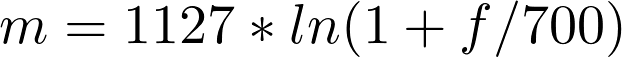 Зависимость мела от герца
Зависимость мела от герца
Эту новую величину назвали мел, и она отлично отражает способность человека распознавать разные частоты — чем выше частота звука, тем сложнее ее различить.
 График перевода герца в мелы
График перевода герца в мелы
Теперь попробуем применить все это на практике.
Идентификация с использованием MFCC
Мы можем взять длительную запись голоса человека, посчитать кепстр для каждого маленького участка и получить уникальный отпечаток голоса в каждый момент времени. Но этот отпечаток слишком большой для хранения и анализа — он зависит от выбранной длины блока и может доходить до двух тысяч чисел на каждые 100 мс. Поэтому из такого многообразия необходимо извлечь определенное количество признаков. С этим нам поможет мел-шкала.
Мы можем выбрать определенные «участки слышимости», на которых просуммируем все сигналы, причем количество этих участков равно количеству необходимых признаков, а длины и границы участков зависят от мел-шкалы.
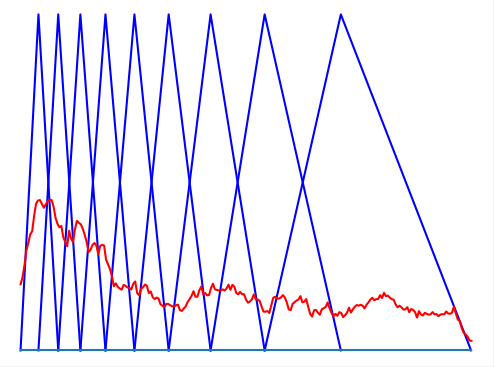 Вычисление мел-частотных кепстральных коэффициентов
Вычисление мел-частотных кепстральных коэффициентов
Вот мы и познакомились с мел-частотными кепстральными коэффициентами (MFCC). Количество признаков может быть произвольным, но чаще всего варьируется от 20 до 40.
Эти коэффициенты отлично отражают каждый «частотный блок» голоса в каждый момент времени, а значит, если обобщить время, просуммировав коэффициенты всех блоков, мы сможем получить голосовой отпечаток человека.
Тестирование метода
Давай скачаем несколько записей видео с YouTube, из которых извлечем голос для наших экспериментов. Нам нужен чистый звук без шумов. Я выбрал канал TED Talks.
Скачаем несколько видеозаписей любым удобным способом, например с помощью утилиты youtube-dl. Она доступна через pip или через официальный репозиторий Ubuntu или Debian. Я скачал три видеозаписи выступлений: двух женщин и одного мужчины.
Затем преобразуем видео в аудио, создаем несколько кусков разной длины без музыки или аплодисментов.
Теперь разберемся с программой на Python 3. Нам понадобятся библиотеки numpy для вычислений и librosa для обработки звука, которые можно установить с помощью pip . Для твоего удобства все сложные вычисления коэффициентов упаковали в одну функцию librosa.feature.mfcc . Загрузим звуковую дорожку и извлечем характеристики голоса.
Присоединяйся к сообществу «Xakep.ru»!
Членство в сообществе в течение указанного срока откроет тебе доступ ко ВСЕМ материалам «Хакера», позволит скачивать выпуски в PDF, отключит рекламу на сайте и увеличит личную накопительную скидку! Подробнее
Источник
Кто там? — Идентификация человека по голосу

Здравствуй, дорогой читатель!
Предлагаю твоему вниманию интересную и познавательную статью об отдельно взятом методе распознавания говорящего. Всего каких-то пару месяцев назад я наткнулся на статью о применении мел-кепстральных коэффициентов для распознавании речи. Она не нашла отклика, вероятно, из-за недостаточной структурированости, хотя материал в ней освещен очень интересный. Я возьму на себя ответственность донести этот материал в доступной форме и продолжить тему распознавания речи на Хабре.
Под катом я опишу весь процесс идентификации человека по голосу от записи и обработки звука до непосредственно определения личности говорящего.
Запись звука
Наша история начинается с записи аналогового сигнала с внешнего источника с помощью микрофона. В результате такой операции мы получим набор значений, которые соответствуют изменению амплитуды звука со временем. Такой принцип кодирования называется импульсно-кодовой модуляцией aka PCM (Pulse-code modulation). Как можно догадаться, «сырые» данные, полученные из аудио-потока, пока еще не годятся для наших целей. Первым делом нужно преобразовать непослушные биты в набор осмысленных значений — амплитуд сигнала. [1, с. 31] В качестве входных данных я буду использовать несжатый 16-битный знаковый (PCM-signed) wav-файл с частотой дискретизации 16 кГц.
Освежить знания про порядок байтов можно на википедии.
Обработка звука
Полученные значения амплитуд могут не совпадать даже для двух одинаковых записей из-за внешнего шума, разных громкостей входного сигнала и других факторов. Для приведения звуков к «общему знаменателю» используется нормализация. Идея пиковой нормализации проста: разделить все значения амплитуд на максимальную (в рамках данного звукового файла). Таким образом мы уравняли образцы речи, записанные с разной громкостью, уложив все в шкалу от -1 до 1. Важно, что после такой трансформации любой звук полностью заполняет заданный промежуток.
Нормализация, на мой взгляд, — самый простой и эффективный алгоритм предварительной обработки звука. Существуют также масса других: «отрезающие» частоты выше или ниже заданной, сглаживающие и др.
Разделяй и властвуй
Даже при работе со звуком с минимально достаточной частотой дискретизации (16 кГц) размер уникальных характеристик для секундного образца звука просто огромен — 16000 значений амплитуд. Производить сколь-нибудь сложные операции над такими объемами данных не представляется возможным. Кроме того, не совсем понятно, как сравнивать объекты с разным количеством уникальных черт.
Для начала снизим вычислительную сложность задачи, разбив ее на меньшие по сложности подзадачи. Этим ходом убиваем сразу двух зайцев, ведь установив фиксированный размер подзадачи и усреднив результаты вычислений по всем задачам, получим наперед заданное количество признаков для классификации. 
На рисунке изображена «порезка» звукового сигнала на кадры длины N с половинным перекрытием. Необходимость в перекрытии вызвана искажением звука в случае, если бы кадры были расположены рядом. Хотя на практике этим приемом часто принебрегают для экономии вычислительных ресурсов. Следуя рекоммендациям [1, с. 28], выберем длину кадра равной 128 мс, как компромисс между точностью (длинные кадры) и скоростью (короткие кадры). Остаток речи, который не занимает полный кадр, можно заполнить нулями до желаемого размера или просто отбросить.
Для устранения нежелаетльных эффектов при дальнейшей обработке кадров, умножим каждый элемент кадра на особую весовую функцию («окно»). Результатом станет выделение центральной части кадра и плавное затухание амплитуд на его краях. Это необходимо для достижения лучших результатов при прогонке преобразования Фурье, поскольку оно ориентировано на бесконечно повторяющийся сигнал. Соответственно, наш кадр должен стыковаться сам с собой и как можно более плавно. Окон существует великое множество. Мы же будем использовать окно Хэмминга. 
n — порядковый номер элемента в кадре, для которого вычисляется новое значение амплитуды
N — как и ранее, длина кадра (количество значений сигнала, измеренных за период)
Дискретное преобразование Фурье
Следующим шагом будет получение кратковременной спектрограммы каждого кадра в отдельности. Для этих целей используем дискретное преобразование Фурье. 
N — как и ранее, длина кадра (количество значений сигнала, измеренных за период)
xn — амплитуда n-го сигнала
Xk — N комплексных амплитуд синусоидальных сигналов, слагающих исходный сигнал
Кроме этого, возведем каждое значение Xk в квадрат для дальнейшего логарифмирования.
Переход к мел-шкале
На сегодняшний день наиболее успешными являются системи распознавания голоса, использующие знания об устройстве слухового аппарата. Несколько слов об этом есть и на Хабре. Если говорить вкратце, то ухо интерпретирует звуки не линейно, а в логарифмическом масштабе. До сих пор все операции мы проделывали над «герцами», теперь перейдем к «мелам». Наглядно представить зависимость поможет рисунок. 
Как видно, мел-шкала ведет себя линейно до 1000 Гц, а после проявляет логарифмическую природу. Переход к новой шкале описывается несложной зависимостью. 
m — частота в мелах
f — частота в герцах
Получение вектора признаков
Сейчас мы как никогда близко к нашей цели. Вектор признаков будет состоять из тех самых мел-кепстральных коэффициентов. Вычисляем их по формуле [2] 
cn — мел-кепстральный коэффициент под номером n
Sk — амплитуда k-го значения в кадре в мелах
K — наперед заданное количество мел-кепстральных коэффициэнтов
n ∈ [1, K]
Как правило, число K выбирают равным 20 и начинают отсчет с 1 из-за того, что коэффициент c0 несет мало информации о говорящем, так как является, по сути, усреднением амплитуд входного сигнала. [2]
Так кто же все-таки говорил?
Последней стадией является классификация говорящего. Классификация производится вычислением меры схожести пробных данных и уже известных. Мера схожести выражается расстоянием от вектора признаков пробного сигнала до вектора признаков уже классифицированного. Нас будет интересовать наиболее простое решение — расстояние городских кварталов. 
Такое решение больше подходит для векторов дискретной природы, в отличие от расстояния Евклида.
Внимательный читатель наверняка помнит, что автор в начале статьи упоминал про усреднение признаков речевых кадров. Итак, восполняя этот пробел, завершаю статью описанием алгоритма нахождения усредненного вектора признаков для нескольких кадров и нескольких образцов речи.
Кластеризация
Нахождение вектора признаков для одного образца не составит труда: такой вектор представляется как среднее арифметическое векторов, характеризующих отдельные кадры речи. Для повышения точности распознавания просто необходимо усреднять результаты не только между кадрами, но и учитывать показатели нескольких речевых образцов. Имея несколько записей голоса, разумно не усреднять показатели к одному вектору, а провести кластеризацию, например с помощью метода k-средних.
Итоги
Таким образом, я рассказал о простой но эффективной системе идентификации человека по голосу. Резюмируя, процесс распознавания построен следующим образом:
- Собираем несколько тренировочных образцов речи, чем больше — тем лучше.
- Находим для каждого из них характеристический вектор признаков.
- Для образцов с известным автором проводим кластеризацию с одним центром (усреднение) или несколькими. Приемлемые результаты начинаются уже с использованием 4-х центров для каждого диктора. [2]
- В режиме опознавания находим расстояние от пробного вектора до изученных во время тренировки центров кластеров. К какому кластеру пробная речь окажется ближе — к такому диктору и относим образец.
- Можно экспериментально установить даже некоторый доверительный интервал — максимальное расстояние, на котором может находиться пробный образец от центра кластера. В случае превышения этого значения — классифицировать образец как неизвестный.
Я всегда рад полезным комментариям по поводу улучшения материала. Спасибо за внимание.
Источник
Голосовой помощник «Алиса» научился распознавать владельца по голосу. Для этого пользователю необходимо повторить за помощником пять фраз, чтобы алгоритм смог составить модель голоса. Пока что это позволяет «Алисе» учитывать музыкальные предпочтения только одного пользователя, сообщается на сайте Яндекса.
Современные голосовые помощники умеют не только рассказывать о погоде или отвечать на поисковые запросы, но и выполнять более важные функции. Например, они могут зачитывать мероприятия из календаря или последние личные сообщения, а также активировать подключенные устройства, такие как кондиционер или лампа. Это потенциально способно облегчить жизнь пользователей, но также представляет собой опасность, потому что доступ к такому инструменту могут получить посторонние люди.
Для защиты от неправомерного доступа многие популярные голосовые помощники, такие как Google Assistant, Siri и Alexa, оснащены функцией распознавания голоса. Теперь эту функцию получил и голосовой помощник «Алиса» от Яндекса. Для настройки функции умной колонке необходимо сказать «Алиса, запомни мой голос». После этого помощник сначала спрашивает имя пользователя, а затем просит его повторить пять фраз, на основе которых алгоритмы создают модель голоса для последующего распознавания.
Пока функция распознавания голоса в «Алисе» имеет несколько ограничений. Во-первых, она работает только с музыкой и позволяет не учитывать в будущем музыкальные предпочтения других людей, когда они просят колонку поставить те или иные песни или жанры. Во-вторых, сервис умеет запоминать только одного пользователя. В-третьих, если у пользователя есть несколько колонок разных моделей, процедуру запоминания голоса необходимо пройти на каждой из них. Кроме того, оказалось, что попросить Алису забыть голос может любой пользователь, даже если голосовой помощник запомнил не его.
От редактора
После публикации заметки пресс-служба Яндекса заявила, что пока функция находится в стадии тестирования, хотя и доступна всем желающим. Разработчики заявили, что планируют исправить ошибку, из-за которой Алиса не проверяет личность человека, произносящего команду «Алиса, забудь мой голос».
Неизвестно, планирует ли Яндекс распространить эту функцию на другие персонализированные или критические запросы. К примеру, в мае компания представила новую версию автомобильной мультимедийной системы «Яндекс.Авто», позволяющей управлять некоторыми функциями автомобиля с помощью голосовых команд: «Алису» в автомобиле можно попросить открыть окно или даже включить по дороге прибор, подключенный к системе умного дома.
Григорий Копиев
Агентство национальной безопасности США с середины 2000-х активно использует системы распознавания речи для слежки — и способно с высокой точностью установить личность человека, обладая только записью голоса. Издание The Intercept, основанное автором нескольких расследований о системах слежки в АНБ Гленном Гринвальдом, рассказывает, как устроена система распознавания голоса у американских спецслужб — и она куда более совершенная, чем коммерческие разработки.
Голос — самый надежный способ идентифицировать человека. Его трудно подделать, образец, в отличие от ДНК и отпечатков пальцев, легко получить незаметно, голос нельзя так легко изменить, как внешность или паспортные данные. Вокруг любого человека постоянно есть микрофоны, взять хотя бы мобильный телефон.
Для того, чтобы опознать человека по голосу, иногда достаточно нескольких слов. Чем больше база образцов голоса, тем быстрее и надежнее работает распознавание. Вместе с системами идентификации по голосу в АНБ разработали также так называемый «Google для голоса», автоматически переводящий разговорную речь в текст. По этой базе данных можно осуществлять поиск, существует и возможность следить за конкретными ключевыми словами в речи.
Агентство национальной безопасности с 1996 года финансирует исследования в области разработки технологий распознавания речи. Впервые их стали масштабно применять во время войны в Ираке, был даже создан голосовой профиль Саддама Хусейна; также система применялась для поиска укрытия Осамы бен Ладена и во многих других контртеррористических операциях.
«Правительство практически не обсуждает эту технологию, потому что к ней есть много вопросов, на которые оно не хотело бы отвечать. Это самое важное, что случилось с нами и нашими правами со времени терактов 11 сентября 2001 года. Чтобы эта технология работала, нужно только открывать рот», — рассказывает The Intercept бывший сотрудник американских спецслужб на условиях анонимности.
О том, как работает система сбора данных о переписке пользователей в интернете, созданная в АНБ, мы знаем с 2013 года благодаря Эдварду Сноудену. Как следует из материалов, которые он передал журналистам, американские спецслужбы создали масштабную систему сбора метаданных о переписке, которая позволяет узнать многое о человеке — и по решению суда, которое не предается огласке, читать и саму переписку. Для создания этой системы АНБ совместно с британскими спецслужбами организовали масштабную сеть перехвата интернет-трафика при содействии крупнейших онлайн-компаний.
В перехват попадались и аудиофайлы, в том числе телефонные разговоры. Уже как минимум с 2006 года автоматические системы перехвата аудиоданных умели определять, на каком языке и диалекте говорит человек, его пол, а также сравнивать образец голоса с тем, что уже есть в базе данных. Уже в 2010-м система распознавала речь на 25 языках. В 2007-м во время визита президента Ирана Махмуда Ахмадинежада в США спецслужбы получили образцы голосов всех 143 членов делегации; система посылала уведомления, если они говорили о чем-то потенциально важном.
С годами технология развивалась и совершенствовалась. К примеру, уже к 2010 году АНБ научилось выявлять случаи, когда люди говорят по телефону с помощью фильтров, маскирующих голос для конспирации. В Йемене было найдено 80 таких случаев на один миллион проверенных аудиозаписей. Такой анализ позволил спецслужбам выявить несколько человек, которые скрывались от американских агентов. Развернутая в том же году система анализа переговоров в Мехико научилась вычленять из обычных записей слово «бомба» и уведомлять об этом.
АНБ применяет систему распознавания речи не только для поиска террористов за рубежом, но и для выявления потенциальных предателей внутри спецслужбы, пишет The Intercept. Как именно она использовалась и помогла ли найти людей, планировавших утечки секретных документов, достоверно неизвестно, но, судя по всему, в спецслужбе создали базу данных из образцов голосов сотрудников.
Американские законы запрещают сбор данных о гражданах страны без разрешения суда, но при массовой слежке за онлайн-перепиской информация неизбежно попадает в базы данных и анализируется. Пока, по данным издания, нет сведений, что АНБ начало собирать образцы речи американцев. Если же спецслужба сможет доказать, что по закону имеет на это право, то получит мощный инструмент для установления личности любого человека, который по каким-либо причинам этого не хочет — анонимного источника журналистов, самих журналистов, преступников или активистов и многих других.
Ситуация осложняется распространением домашних голосовых помощников типа Amazon Echo, которые постоянно анализируют все разговоры в квартире на случай, если владелец к ним обратится. АНБ уже доказало, что может получать доступ к трафику крупнейших компаний и анализировать его по своему усмотрению.
В ответ на список вопросов The Intercept в АНБ отправили сообщение: «В соответствии с давно установленными правилами, АНБ не подтверждает и не опровергает достоверность сведений о государственных программах, упомянутых в статье» (англ. яз.).
Многие люди разочаровываются в приложениях для знакомств и уходят, так и не повстречав своего человека. Это грустно! К счастью, эта индустрия развивается стремительно и технологии не стоят на месте. В статье расскажу о принципиально новом подходе к знакомствам — через голос. А также о том, на что обратить внимание, чтобы поиск второй половинки увенчался успехом.

Приветствую, друзья!
Меня зовут Елена, я практикующий психолог.
Среди своих знакомых, а также в комментариях я часто сталкиваюсь с подобным: «Да на этих сайтах знакомств вообще не пойми кто сидит. Там точно нет моего человека! Только время потратишь…» Чем дольше человек обитает на сайте, тем быстрее свайпает влево, даже не рассмотрев фото и описание кандидата.
На мой взгляд, основная сложность здесь заключается в том, что люди сравнивают анкету претендента на знакомство с некоторым своим идеалом. Понятно, что совпадение будет в лучшем случае одно на тысячу. И получается, что не поняв толком что-то про человека, мы сразу отправляем его в черный список, тем самым сокращая свои шансы на знакомство с интересным и подходящим партнером.
Один мой знакомый встретил свою нынешнюю жену на сайте знакомств. Он случайно поставил лайк ее пустой анкете (там не было ни фото, ни описания) и это оказалось взаимно. Завязалась переписка и вот результат — счастливы вместе 🙂 Это еще раз подтверждает гипотезу о том, что наши суждения по анкете часто ошибочны. За ничем непримечательным с виду человеком на фото, может скрываться уверенный в себе и любящий мужчина. А за фитоняшкой из спортзала — заботливая домохозяйка, мечтающая о большой семье. Первое впечатление в этом смысле обманчиво.
А как вам идея знакомиться с человеком, не видя фото, а только слыша его голос? Когда я узнала о такой возможности в приложении Vox, то пришла в дикий восторг! Сейчас объясню почему.
Голос, в отличие от фото, говорит о своем владельце гораздо больше. Слыша интонацию, тембр, скорость речи, формулировки, мы тут же составляем свое представление о человеке и, как показывают последние исследования, оно получается достаточно точным. По голосу мы определяем возраст, характер, темперамент, физическую форму и даже приблизительно внешность человека.
Таким образом обходим ловушку нашего мозга, который отвергает якобы неподходящих претендентов по фото, и получаем шанс встретить человека, близкого нам по характеру, ценностям и культурному уровню.
На что обратить внимание при общении только голосом?
Важно понимать, что голос формирует наш образ также, как прическа, одежда и аксессуары. Исследования показали, что низкий голос располагает к доверию. Его обладателей воспринимают как умных, уверенных в себе, авторитетных людей. А если к этому добавляются еще глубина, четкая дикция и средняя скорость речи, то собеседник сдается без боя 🙂
А вот высокие голоса, напротив, часто настораживают и вызывают некоторое беспокойство.
Если же голос слишком тихий, то собеседник воспринимается, как человек нерешительный и неуверенный в себе.
Если вы хотите сделать свой голос более привлекательным в глазах потенциального партнера, можете воспользоваться следующими рекомендациями:
– Перед тем, как начать говорить — улыбнитесь. Улыбка придаст вашему голосу теплоту и дружелюбность.
– Чтобы сделать свой голос более глубоким, позевайте немного перед разговором. Так вы расслабите связки и мышцы горла. Также важно следить за осанкой и держать спину ровно.
– Чтобы голос от волнения не становился выше, можно замедлить дыхание, сделав несколько глубоких вдохов и выдохов.
Как работает приложение и где его скачать?
Если вас заинтересовала тема голосовых знакомств, то скачать приложение Vox можно здесь.
При регистрации нужно будет указать свои данные и загрузить фото. Ну, а потом записать небольшое аудио приветствие. Далее, по уже знакомому принципу, выбираете партнера: слушаете аудио визитки и если понравилось — лайк, если не понравилось — крестик. При взаимности вам открывается фото собеседника и возможность общения в чате.
Мне кажется, эта идея стоит того, чтобы ее попробовать 😉 А вы что думаете, друзья? Поделитесь в комментариях.
