В свете последних событий в мире много компаний перешли на удаленный режим работы. При этом для сохранения эффективности бизнес-процессов на сетевые периметры были вынесены приложения, которые не предназначены для прямого размещения на периметре, например внутрикорпоративные веб-приложения, на эту тему недавно было наше исследование. Если между службами ИТ и ИБ нет тесной связи, возникают ситуации, когда на сетевом периметре появилось бизнес-приложение, о котором у службы ИБ нет информации.
Решением подобных проблем может быть периодическое исследование периметра организации. Для решения задачи подходят сетевые сканеры, поисковики по интернету вещей, сканеры уязвимостей и услуги по анализу защищенности. Далее в статье рассмотрим виды и параметры сканирования, их преимущества и недостатки, инструменты, которые часто используются, и методы обработки результатов.
Ping-сканирование
Первый рассматриваемый вид сканирования — ping-сканирование. Основная задача — обнаружить «живые» узлы в сети. Под ping-сканированием понимают широковещательную рассылку пакетов ICMP. Сканер рассылает пакеты типа Echo REQUEST по указанным IP-адресам и ожидает в ответ пакеты типа Echo REPLY. Если ответ получен, считается, что узел присутствует в сети по указанному IP-адресу.
Протокол ICMP широко используется администраторами сетей для диагностики, поэтому, чтобы избежать разглашения информации об узлах, важна корректная настройка средств защиты периметра. Для корпоративных сетей такой вид сканирования не релевантен при внешнем сканировании, потому что большинство средств защиты по умолчанию блокируют протокол ICMP либо ответы по этому протоколу. При отсутствии нестандартных задач в корпоративной сети на выход, как правило, разрешены следующие виды ICMP-сообщений: Destination Unreachable, Echo REQUEST, Bad IP header, а на вход разрешены Echo REPLY, Destination Unreachable, Source Quench, Time Exceeded, Bad IP header. В локальных сетях не такая строгая политика безопасности, и злоумышленники могут применять этот способ, когда уже проникли в сеть, однако это легко детектируется.
Сканирование портов
Объединим TCP-сканирование и UDP-сканирование под общим названием — сканирование портов. Сканирование этими методами определяет доступные порты на узлах, а затем на основе полученных данных делается предположение о типе используемой операционной системы или конкретного приложения, запущенного на конечном узле. Под сканированием портов понимают пробные попытки подключения к внешним узлам. Рассмотрим основные методы, реализованные в автоматизированных сетевых сканерах:
- TCP SYN,
- TCP CONNECT,
- UDP scan.
Метод TCP SYN — наиболее популярен, используется в 95% случаев. Его называют сканированием с установкой полуоткрытого соединения, так как соединение не устанавливается до конца. На исследуемый порт посылается сообщение SYN, затем идет ожидание ответа, на основании которого определяется статус порта. Ответы SYN/ACK говорят о том, что порт прослушивается (открыт), а ответ RST говорит о том, что не прослушивается.
Если после нескольких запросов не приходит никакого ответа, то сетевой трафик до порта узла назначения фильтруется средствами межсетевого экранирования (далее будем использовать термин «порт фильтруется»). Также порт помечается как фильтруемый, если в ответ приходит сообщение ICMP с ошибкой достижимости (Destination Unreachable) и определенными кодами и флагами.
Метод TCP CONNECT менее популярен, чем TCP SYN, но все-таки часто встречается на практике. При реализации метода TCP CONNECT производится попытка установить соединение по протоколу TCP к нужному порту с процедурой handshake. Процедура заключается в обмене сообщениями для согласования параметров соединения, то есть служебными сообщениями SYN, SYN/ACK, ACK, между узлами. Соединение устанавливается на уровне операционной системы, поэтому существует шанс, что оно будет заблокировано средством защиты и попадет в журнал событий.
UDP-сканирование медленнее и сложнее, чем TCP-сканирование. Из-за специфики сканирования UDP-портов о них часто забывают, ведь полное время сканирование 65 535 UDP-портов со стандартными параметрами на один узел занимает у большинства автоматизированных сканеров до 18 часов. Это время можно уменьшить за счет распараллеливания процесса сканирования и рядом других способов. Следует уделять внимание поиску UDP-служб, потому что UDP-службы реализуют обмен данными с большим числом инфраструктурных сервисов, которые, как правило, вызывают интерес злоумышленников.
На сетевых периметрах часто встречаются UDP-сервисы DNS (53), NTP (123), SNMP (161), VPN (500, 1194, 4500), RDG (3391). Реже встречаются сервисные службы типа echo (7), discard (9), chargen (19), а также DAYTIME (13), TFTP (69), SIP (5060), сервисы NFS (2049), RPC (111, 137-139, 761 и др.), СУБД (1434).
Для определения статуса порта посылается пустой UDP-заголовок, и если в ответ приходит ошибка достижимости ICMP Destination Unreachable с кодом Destination port unreachable, это значит, что порт закрыт; другие ошибки достижимости ICMP (Destination host unreachable, Destination protocol unreachable, Network administratively prohibited, Host administratively prohibited, Communication administratively prohibited) означают, что порт фильтруется. Если порт отвечает UDP-пакетом, значит, он открыт. Из-за специфики UDP и потери пакетов запросы повторяются несколько раз, обычно три и более. Как правило, если ответ не получен, статус порта определяется в состоянии «открыт» или «фильтруется», поскольку непонятно, что стало причиной — блокировка трафика средством защиты или потеря пакетов.
Для точности определения статуса порта и самой службы, запущенной на UDP-порте, используется специальная полезная нагрузка, наличие которой должно вызвать определенную реакцию у исследуемого приложения.
Редкие методы сканирования
Методы, которые практически не используются:
- TCP ACK,
- TCP NULL, FIN, Xmas,
- «Ленивое сканирование».
Прямое назначение метода ACK-сканирования — выявить правила средств защиты, а также определить фильтруемые порты. В пакете запроса при таком типе сканирования установлен только ACK-флаг. Открытые и закрытые порты вернут RST-пакет, так как порты достижимы для ACK-пакетов, но состояние неизвестно. Порты, которые не отвечают или посылают в ответ ICMP-сообщение Destination Unreachable с определенными кодами считаются фильтруемыми.
Методы TCP NULL, FIN, Xmas заключаются в отправке пакетов с отключенными флагами в заголовке TCP. При NULL-сканировании не устанавливаются никакие биты, при FIN-сканировании устанавливается бит TCP FIN, а в Xmas-сканировании устанавливаются флаги FIN, PSH и URG. Методы основаны на особенности спецификации RFC 793, согласно которой при закрытом порте входящий сегмент, не содержащий RST, повлечет за собой отправку RST в ответ. Когда порт открыт, ответа не будет. Ошибка достижимости ICMP означает, что порт фильтруется. Эти методы считаются более скрытными, чем SYN-сканирование, однако и менее точны, потому что не все системы придерживаются RFC 793.
«Ленивое сканирование» является самым скрытным из методов, поскольку для сканирования используется другой узел сети, который называется зомби-узлом. Метод применяется злоумышленниками для разведки. Преимущество такого сканирования в том, что статус портов определяется для зомби-узла, поэтому, используя разные узлы, можно установить доверительные связи между узлами сети. Полное описание метода доступно по ссылке.
Процесс выявления уязвимостей
Под уязвимостью будем понимать слабое место узла в целом или его отдельных программных компонентов, которое может быть использовано для реализации атаки. В стандартной ситуации наличие уязвимостей объясняется ошибками в программном коде или используемой библиотеке, а также ошибками конфигурации.
Уязвимость регистрируется в MITRE CVE, а подробности публикуются в NVD. Уязвимости присваивается идентификатор CVE, а также общий балл системы оценки уязвимости CVSS, отражающий уровень риска, который уязвимость представляет для конечной системы. Подробно об оценке уязвимостей написано в нашей статье. Централизованный список MITRE CVE — ориентир для сканеров уязвимостей, ведь задача сканирования — обнаружить уязвимое программное обеспечение.
Ошибка конфигурации — тоже уязвимость, но подобные уязвимости нечасто попадают в базу MITRE; впрочем, они все равно попадают в базы знаний сканеров с внутренними идентификаторами. В базы знаний сканеров попадают и другие типы уязвимостей, которых нет в MITRE CVE, поэтому при выборе инструмента для сканирования важно обращать внимание на экспертизу его разработчика. Сканер уязвимостей будет опрашивать узлы и сравнивать собранную информацию с базой данных уязвимостей или списком известных уязвимостей. Чем больше информации у сканера, тем точнее результат.
Рассмотрим параметры сканирования, виды сканирования и принципы обнаружения уязвимостей при помощи сканеров уязвимостей.
Параметры сканирования
За месяц периметр организации может неоднократно поменяться. Проводя сканирование периметра в лоб можно затратить время, за которое результаты станут нерелевантными. При сильном увеличении скорости сканирования сервисы могут «упасть». Надо найти баланс и правильно выбрать параметры сканирования. От выбора зависят потраченное время, точность и релевантность результатов. Всего можно сканировать 65 535 TCP-портов и столько же UDP-портов. По нашему опыту, среднестатистический периметр компании, который попадает в пул сканирования, составляет две полных сети класса «С» с маской 24.
Основные параметры:
- количество портов,
- глубина сканирования,
- скорость сканирования,
- параметры определения уязвимостей.
По количеству портов сканирование можно разделить на три вида — сканирование по всему списку TCP- и UDP-портов, сканирование по всему списку TCP-портов и популярных UDP-портов, сканирование популярных TCP- и UDP-портов. Как определить популярности порта? В утилите nmap на основе статистики, которую собирает разработчик утилиты, тысяча наиболее популярных портов определена в конфигурационном файле. Коммерческие сканеры также имеют преднастроенные профили, включающие до 3500 портов.
Если в сети используются сервисы на нестандартных портах, их также стоит добавить в список сканируемых. Для регулярного сканирования мы рекомендуем использовать средний вариант, при котором сканируются все TCP-порты и популярные UDP-порты. Такой вариант наиболее сбалансирован по времени и точности результатов. При проведении тестирования на проникновение или полного аудита сетевого периметра рекомендуется сканировать все TCP- и UDP-порты.
Важная ремарка: не получится увидеть реальную картину периметра, сканируя из локальной сети, потому что на сканер будут действовать правила межсетевых экранов для трафика из внутренней сети. Сканирование периметра необходимо проводить с одной или нескольких внешних площадок; в использовании разных площадок есть смысл, только если они расположены в разных странах.
Под глубиной сканирования подразумевается количество данных, которые собираются о цели сканирования. Сюда входит операционная система, версии программного обеспечения, информация об используемой криптографии по различным протоколам, информация о веб-приложениях. При этом имеется прямая зависимость: чем больше хотим узнать, тем дольше сканер будет работать и собирать информацию об узлах.
При выборе скорости необходимо руководствоваться пропускной способностью канала, с которого происходит сканирование, пропускной способностью канала, который сканируется, и возможностями сканера. Существуют пороговые значения, превышение которых не позволяет гарантировать точность результатов, сохранение работоспособности сканируемых узлов и отдельных служб. Не забывайте учитывать время, за которое необходимо успеть провести сканирование.
Параметры определения уязвимостей — наиболее обширный раздел параметров сканирования, от которого зависит скорость сканирования и объем уязвимостей, которые могут быть обнаружены. Например, баннерные проверки не займут много времени. Имитации атак будут проведены только для отдельных сервисов и тоже не займут много времени. Самый долгий вид — веб-сканирование.
Полное сканирование сотни веб-приложений может длиться неделями, так как зависит от используемых словарей и количества входных точек приложения, которые необходимо проверить. Важно понимать, что из-за особенностей реализации веб-модулей и веб-сканеров инструментальная проверка веб-уязвимостей не даст стопроцентной точности, но может очень сильно замедлить весь процесс.
Веб-сканирование лучше проводить отдельно от регулярного, тщательно выбирая приложения для проверки. Для глубокого анализа использовать инструменты статического и динамического анализа приложений или услуги тестирования на проникновение. Мы не рекомендуем использовать опасные проверки при проведении регулярного сканирования, поскольку существует риск нарушения работоспособности сервисов. Подробно о проверках см. далее, в разделе про работу сканеров.
Инструментарий
Если вы когда-нибудь изучали журналы безопасности своих узлов, наверняка замечали, что интернет сканирует большое количество исследователей, онлайн-сервисы, ботнеты. Подробно описывать все инструменты нет смысла, перечислим некоторые сканеры и сервисы, которые используются для сканирования сетевых периметров и интернета. Каждый из инструментов сканирования служит своей цели, поэтому при выборе инструмента должно быть понимание, зачем он используется. Иногда правильно применять несколько сканеров для получения полных и точных результатов.
Сетевые сканеры: Masscan, Zmap, nmap. На самом деле утилит для сканирования сети намного больше, однако для сканирования периметра вряд ли вам понадобятся другие. Эти утилиты позволяют решить большинство задач, связанных со сканированием портов и служб.
Поисковики по интернету вещей, или онлайн-сканеры — важные инструменты для сбора информации об интернете в целом. Они предоставляют сводку о принадлежности узлов к организации, сведения о сертификатах, активных службах и иную информацию. С разработчиками этого типа сканеров можно договориться об исключении ваших ресурсов из списка сканирования или о сохранении информации о ресурсах только для корпоративного пользования. Наиболее известные поисковики: Shodan, Censys, Fofa.
Для решения задачи не обязательно применять сложный коммерческий инструмент с большим числом проверок: это излишне для сканирования пары «легких» приложений и сервисов. В таких случаях будет достаточно бесплатных сканеров. Бесплатных веб-сканеров много, и тяжело выделить наиболее эффективные, здесь выбор, скорее, дело вкуса; наиболее известные: Skipfish, Nikto, ZAP, Acunetix, SQLmap.
Для выполнения минимальных задач сканирования и обеспечения «бумажной» безопасности могут подойти бюджетные коммерческие сканеры с постоянно пополняемой базой знаний уязвимостей, а также поддержкой и экспертизой от вендора, сертификатами ФСТЭК. Наиболее известные: XSpider, RedCheck, Сканер-ВС.
При тщательном ручном анализе будут полезны инструменты Burp Suite, Metasploit и OpenVAS. Недавно вышел сканер Tsunami компании Google.
Отдельной строкой стоит упомянуть об онлайн-поисковике уязвимостей Vulners. Это большая база данных контента информационной безопасности, где собирается информация об уязвимостях с большого количества источников, куда, кроме типовых баз, входят вендорские бюллетени безопасности, программы bug bounty и другие тематические ресурсы. Ресурс предоставляет API, через который можно забирать результаты, поэтому можно реализовать баннерные проверки своих систем без фактического сканирования здесь и сейчас. Либо использовать Vulners vulnerability scanner, который будет собирать информацию об операционной системе, установленных пакетах и проверять уязвимости через API Vulners. Часть функций ресурса платные.
Средства анализа защищенности
Все коммерческие системы защиты поддерживают основные режимы сканирования, которые описаны ниже, интеграцию с различными внешними системами, такими как SIEM-системы, patch management systems, CMBD, системы тикетов. Коммерческие системы анализа уязвимостей могут присылать оповещения по разным критериям, а поддерживают различные форматы и типы отчетов. Все разработчики систем используют общие базы уязвимостей, а также собственные базы знаний, которые постоянно обновляются на основе исследований.
Основные различия между коммерческими средствами анализа защищенности — поддерживаемые стандарты, лицензии государственных структур, количество и качество реализованных проверок, а также направленность на тот или иной рынок сбыта, например поддержка сканирования отечественного ПО. Статья не призвана представить качественное сравнение систем анализа уязвимостей. На наш взгляд, у каждой системы есть свои преимущества и недостатки. Для анализа защищенности подходят перечисленные средства, можно использовать их комбинации: Qualys, MaxPatrol 8, Rapid 7 InsightVM, Tenable SecurityCenter.
Как работают системы анализа защищенности
Режимы сканирования реализованы по трем схожим принципам:
- Аудит, или режим белого ящика.
- Комплаенс, или проверка на соответствие техническим стандартам.
- Пентест, или режим черного ящика.
Основной интерес при сканировании периметра представляет режим черного ящика, потому что он моделирует действия внешнего злоумышленника, которому ничего не известно об исследуемых узлах. Ниже представлена краткая справка обо всех режимах.
Аудит — режим белого ящика, который позволяет провести полную инвентаризацию сети, обнаружить все ПО, определить его версии и параметры и на основе этого сделать выводы об уязвимости систем на детальном уровне, а также проверить системы на использование слабых паролей. Процесс сканирования требует определенной степени интеграции с корпоративной сетью, в частности необходимы учетные записи для авторизации на узлах.
Авторизованному пользователю, в роли которого выступает сканер, значительно проще получать детальную информацию об узле, его программном обеспечении и конфигурационных параметрах. При сканировании используются различные механизмы и транспорты операционных систем для сбора данных, зависящие от специфики системы, с которой собираются данные. Список транспортов включает, но не ограничивается WMI, NetBios, LDAP, SSH, Telnet, Oracle, MS SQL, SAP DIAG, SAP RFC, Remote Engine с использованием соответствующих протоколов и портов.
Комплаенс — режим проверки на соответствие каким-либо стандартам, требованиям или политикам безопасности. Режим использует схожие с аудитом механизмы и транспорты. Особенность режима — возможность проверки корпоративных систем на соответствие стандартам, которые заложены в сканеры безопасности. Примерами стандартов являются PCI DSS для платежных систем и процессинга, СТО БР ИББС для российских банков, GDPR для соответствия требованиям Евросоюза. Другой пример — внутренние политики безопасности, которые могут иметь более высокие требования, чем указанные в стандартах. Кроме того, существуют проверки установки обновлений и другие пользовательские проверки.
Пентест — режим черного ящика, в котором у сканера нет никаких данных, кроме адреса цели или доменного имени. Рассмотрим типы проверок, которые используются в режиме:
- баннерные проверки,
- имитация атак,
- веб-проверки,
- проверки конфигураций,
- опасные проверки.
Баннерные проверки основываются на том, что сканер определяет версии используемого программного обеспечения и операционной системы, а затем сверяет эти версии со внутренней базой уязвимостей. Для поиска баннеров и версий используются различные источники, достоверность которых также различается и учитывается внутренней логикой работы сканера. Источниками могут быть баннеры сервиса, журналы, ответы приложений и их параметры и формат. При анализе веб-серверов и приложений проверяется информация со страниц ошибок и запрета доступа, анализируются ответы этих серверов и приложений и другие возможные источники информации. Сканеры помечают уязвимости, обнаруженные баннерной проверкой, как подозрения на уязвимость или как неподтвержденную уязвимость.
Имитация атаки — это безопасная попытка эксплуатации уязвимости на узле. Имитации атаки имеют низкий шанс на ложное срабатывание и тщательно тестируются. Когда сканер обнаруживает на цели сканирования характерный для уязвимости признак, проводится эксплуатация уязвимости. При проверках используют методы, необходимые для обнаружения уязвимости; к примеру, приложению посылается нетипичный запрос, который не вызывает отказа в обслуживании, а наличие уязвимости определяется по ответу, характерному для уязвимого приложения.
Другой метод: при успешной эксплуатации уязвимости, которая позволяет выполнить код, сканер может направить исходящий запрос типа PING либо DNS-запрос от уязвимого узла к себе. Важно понимать, что не всегда уязвимости удается проверить безопасно, поэтому зачастую в режиме пентеста проверки появляются позже, чем других режимах сканирования.
Веб-проверки — наиболее обширный и долгий вид проверок, которым могут быть подвергнуты обнаруженные веб-приложения. На первом этапе происходит сканирование каталогов веб-приложения, обнаруживаются параметры и поля, где потенциально могут быть уязвимости. Скорость такого сканирования зависит от используемого словаря для перебора каталогов и от размера веб-приложения.
На этом же этапе собираются баннеры CMS и плагинов приложения, по которым проводится баннерная проверка на известные уязвимости. Следующий этап — основные веб-проверки: поиск SQL Injection разных видов, поиск недочетов системы аутентификации и хранения сессий, поиск чувствительных данных и незащищенных конфигураций, проверки на XXE Injection, межсайтовый скриптинг, небезопасную десериализацию, загрузку произвольных файлов, удаленное исполнение кода и обход пути. Список может быть шире в зависимости от параметров сканирования и возможностей сканера, обычно при максимальных параметрах проверки проходят по списку OWASP Top Ten.
Проверки конфигураций направлены на выявление ошибок конфигураций ПО. Они выявляют пароли по умолчанию либо перебирают пароли по короткому заданному списку с разными учетными записями. Выявляют административные панели аутентификации и управляющие интерфейсы, доступные принтеры, слабые алгоритмы шифрования, ошибки прав доступа и раскрытие конфиденциальной информации по стандартным путям, доступные для скачивания резервные копии и другие подобные ошибки, допущенные администраторами IT-систем и систем ИБ.
В число опасных проверок попадают те, использование которых потенциально приводит к нарушению целостности или доступности данных. Сюда относят проверки на отказ в обслуживании, варианты SQL Injection с параметрами на удаление данных или внесение изменений. Атаки перебора паролей без ограничений попыток подбора, которые приводят к блокировке учетной записи. Опасные проверки крайне редко используются из-за возможных последствий, однако поддерживаются сканерами безопасности как средство эмуляции действий злоумышленника, который не будет переживать за сохранность данных.
Сканирование и результаты
Мы рассмотрели основные методы сканирования и инструменты, перейдем к вопросу о том, как использовать эти знания на практике. Для начала требуется ответить на вопрос, что и как необходимо сканировать. Для ответа на этот вопрос необходимо собрать информацию о внешних IP-адресах и доменных именах, которые принадлежат организации. По нашему опыту, лучше разделять цели сканирования на инвентаризацию и определение уязвимостей.
Инвентаризационное сканирование можно проводить гораздо чаще, чем сканирование на уязвимости. При инвентаризации хорошей практикой является обогащение результатов информацией об администраторе сервиса, внутреннем IP-адресе сервиса, если используется NAT, а также о важности сервиса и его назначении. Информация в будущем поможет оперативно устранять инциденты, связанные с обнаружением нежелательных или уязвимых сервисов. В идеальном случае в компании есть процесс и политика размещения сервисов на сетевом периметре, в процессе участвуют службы ИТ и ИБ.
Даже при таком подходе присутствует вероятность ошибок по причинам, связанным с человеческим фактором и различными техническими сбоями, которые приводят к появлению нежелательных сервисов на периметре. Простой пример: на сетевом устройстве Check Point написано правило, которое транслирует порт 443 из внутренней сети на периметр. Сервис, который там был, устарел и выведен из эксплуатации. Службе ИТ об этом не сообщили, соответственно правило осталось. В таком случае на периметре может оказаться аутентификация в административную панель устройства Check Point либо другой внутренний сервис, который не планировали там размещать. При этом формально картина периметра не менялась и порт доступен.
Чтобы обнаружить подобные изменения, необходимо сканировать периодически и применять дифференциальное сравнение результатов, тогда будет заметно изменение баннера сервиса, которое привлечет внимание и приведет к разбору инцидента.
Устранение уязвимостей
Первым шагом к правильной технической реализации процесса устранения уязвимостей является грамотное представление результатов сканирования, с которыми придется работать. Если используется несколько разнородных сканеров, правильнее всего будет анализировать и объединять информацию по узлам в одном месте. Для этого рекомендуется использовать аналитические системы, где также будет храниться вся информация об инвентаризации.
Базовым способом для устранения уязвимости является установка обновлений. Можно использовать и другой способ — вывести сервис из состава периметра (при этом все равно необходимо установить обновления безопасности).
Можно применять компенсирующие меры по настройке, то есть исключать использование уязвимого компонента или приложения. Еще вариант — использовать специализированные средства защиты, такие как IPS или application firewall. Конечно, правильнее не допускать появления нежелательных сервисов на сетевом периметре, но такой подход не всегда возможен в силу различных обстоятельств, в особенности требований бизнеса.
Приоритет устранения уязвимостей
Приоритет устранения уязвимостей зависит от внутренних процессов в организации. При работе по устранению уязвимостей для сетевого периметра важно четкое понимание, для чего сервис находится на периметре, кто его администрирует и кто является его владельцем. В первую очередь можно устранять уязвимости на узлах, которые отвечают за критически важные бизнес-функции компании. Естественно, такие сервисы нельзя вывести из состава периметра, однако можно применить компенсирующие меры или дополнительные средства защиты. С менее значимыми сервисами проще: их можно временно вывести из состава периметра, не спеша обновить и вернуть в строй.
Другой способ — приоритет устранения по опасности или количеству уязвимостей на узле. Когда на узле обнаруживается 10–40 подозрений на уязвимость от баннерной проверки — нет смысла проверять, существуют ли они там все, в первую очередь это сигнал о том, что пора обновить программное обеспечение на этом узле. Когда возможности для обновления нет, необходимо прорабатывать компенсирующие меры. Если в организации большое количество узлов, где обнаруживаются уязвимые компоненты ПО, для которых отсутствуют обновления, то пора задуматься о переходе на программного обеспечение, еще находящееся в цикле обновления (поддержки). Возможна ситуация, когда для обновления программного обеспечения сначала требуется обновить операционную систему.
Итоги
Всю информацию о сервисах и службах на вашем сетевом периметре можете получить не только вы, но и любой желающий из интернета. С определенной точностью возможно определить уязвимости систем даже без сканирования. Для снижения рисков возникновения инцидентов информационной безопасности необходимо следить за своим сетевым периметром, вовремя прятать или защищать нежелательные сервисы, а также устанавливать обновления.
Неважно, организован процесс собственными силами или с привлечением сторонних экспертов, оказывающих услуги по контролю периметра или анализу защищенности. Самое главное — обеспечить контроль периметра и устранение уязвимостей на регулярной основе.
Автор: Максим Федотов, старший специалист отдела онлайн-сервисов, PT Expert Security Center, Positive Technologies
Если вы думаете, что кто-то использует вашу сеть Wi-fi, вам нужно уделить внимание безопасности Wi-Fi – хорошо защищенную сеть довольно сложно взломать.
Однако, чтобы подтвердить свои подозрения, вам нужно проверить свою сеть и посмотреть, что там происходит.
Лучший способ сделать это, как правило, получить доступ к панели управления вашего маршрутизатора.
Содержание
- Проверьте веб-интерфейс вашего маршрутизатора
- Более простой вариант: использовать инструмент сетевого сканирования
- Nirsoft Wireless Network Watcher (Windows)
- Who Is on My WiFI/WhoFi (Mac/Windows/Android)
- Advanced IP Scanner (Windows)
- Fing (Android/iOS)
- Angry IP Scanner (Windows/ Mac/ Linux)
- Использование командной строки (Windows)
- Используя Nmap или Nutty (Linux)
Проверьте веб-интерфейс вашего маршрутизатора
Где вы можете изменить имя сети, пароль и другие административные задачи.
Обычно это можно сделать, введя адрес (обычно 192.168.0.1, 192.168.1.1, 192.168.2.1 или 192.168.1.100) в панель браузера.
Поиск на наклейке на роутере, как правило, помогает определить, с каким из них зайти.
После этого вам нужно будет войти в роутер.
(Изменение учетных данных это разумный шаг, так как большинство маршрутизаторов поставляются с настройками по умолчанию, такими как «admin» и «password».)
Когда вы войдете в систему, поищите вариант под названием «Подключенные устройства», «Локальная сеть», «Wi-Fi» или что-то похожее, что может дать вам информацию о вашей сети.
Это зависит от производителя маршрутизатора.
Журналы могут быть скрыты за кнопкой или меню, которое показывает вам информацию о клиентах DHCP.
Вы найдете MAC-адрес, и в зависимости от производителя маршрутизатора вы можете увидеть IP-адрес, имя устройства или другую информацию.
Если вам известны MAC-адреса вашего устройства, которые вы должны подключить к вашей сети, вы можете просто сравнить список с журналами вашего маршрутизатора.
Более простой вариант: использовать инструмент сетевого сканирования
Если доступ к вашему маршрутизатору и сравнение MAC-адресов на самом деле не ваш вриант, существует множество программ, которые помогут вам контролировать вашу сеть.
Обычно они не показывают подробные журналы, как ваш маршрутизатор (если вы не настроите их на автоматическое сканирование и сбор данных каждые несколько минут), но они могут рассказать вам, что происходит в вашей сети в любой момент времени, и некоторые из них может сделать гораздо больше.
Большинство из них довольно просты в использовании – просто скачайте, запустите и просканируйте свою сеть
Nirsoft Wireless Network Watcher (Windows)
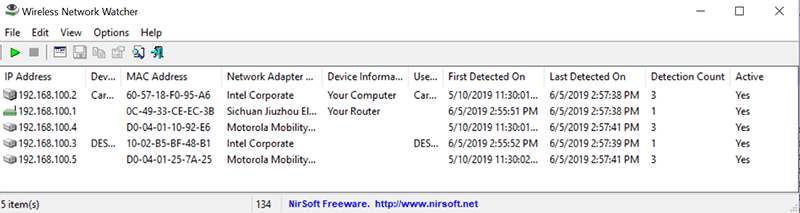
Эта программа проста, бесплатна и эффективна.
Она сканирует вашу сеть, сообщает адреса и подробную информацию о подключенных устройствах и даже сколько раз она обнаруживала эти устройства, возможно, позволяя вам обнаруживать подозрительную активность при регулярном сканировании.
Who Is on My WiFI/WhoFi (Mac/Windows/Android)
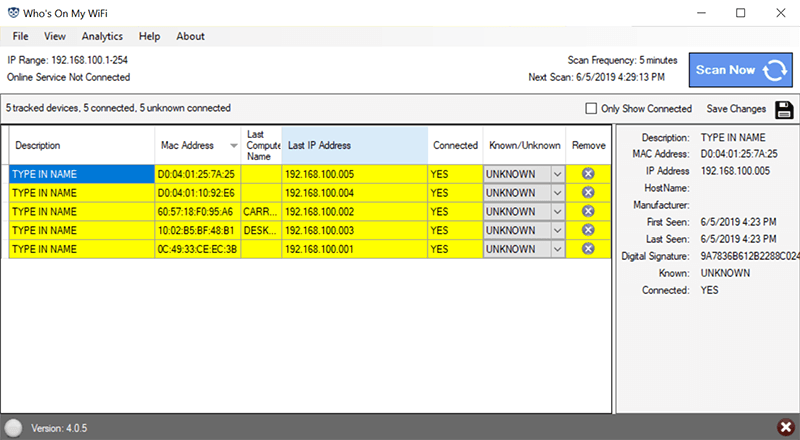
Предназначенная для использования с более масштабным пакетом анализа и оптимизации сети, эта программа также может использоваться в качестве персонального сетевого сканера.
Она должна показывать вам наиболее важную информацию об устройствах в вашей сети и даже позволяет автоматически сканировать ее.
Advanced IP Scanner (Windows)
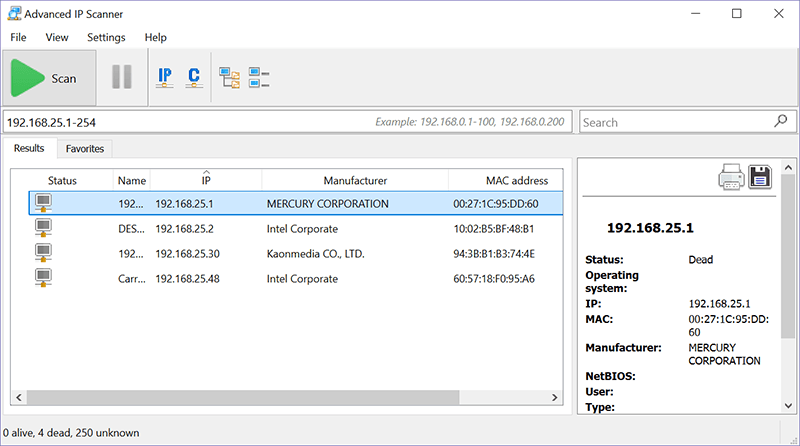
Advanced IP Scanner расскажет вам все о том, кто находится в вашей сети, ничего нового, но очень полезно.
См. подробнее:
- ?️ Как просканировать сеть на предмет поиска расшаренных папок, принтеров и т.д.
- 8 лучших инструментов сканеров IP для управления сетью
Fing (Android/iOS)
Он дает вам быстрые, четкие результаты и предоставляет некоторые аналитические инструменты, если вам интересно – отличный способ сделать быструю проверку сети.
Angry IP Scanner (Windows/ Mac/ Linux)
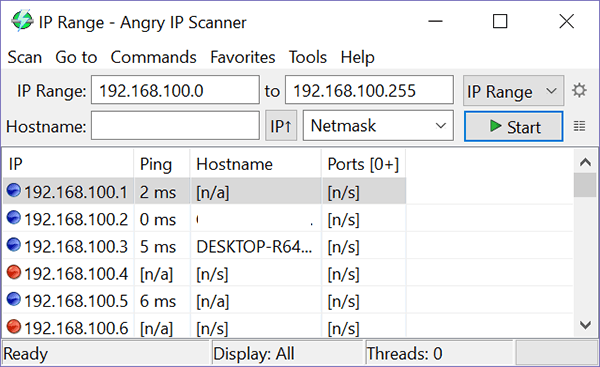
Несмотря на название, пользуясь этой программой, вы не очень злитесь, если вы продвинутый пользователь.
Интерфейс немного менее прост для людей, которые могут быть не знакомы с сетью.
Как установить Angry IP Scanner на ubuntu 16.04
Использование командной строки (Windows)
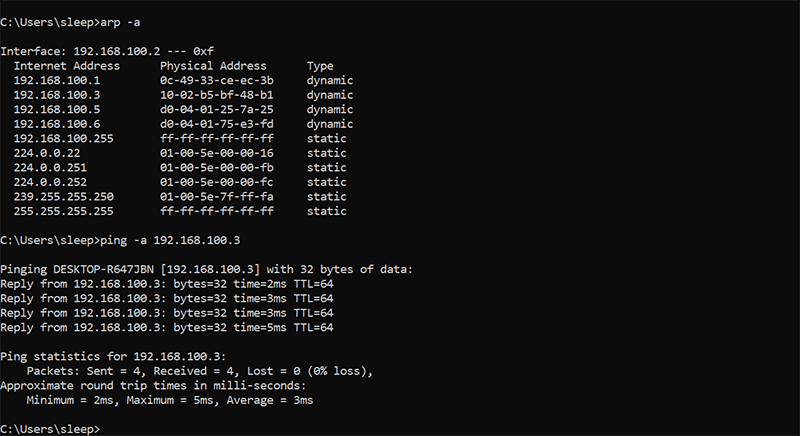
Другой способ проверить устройства, которые в настоящее время находятся в вашей сети, – быстрый, но в тоже время этот метод немного менее прост и не дает вам много информации.
Просто откройте cmd и введите arp -a.
Это отобразит список IP и MAC-адресов.
Чтобы узнать имя устройства, связанного с IP-адресом, введите ping -a <Вставьте IP-адрес>.
ping -a <IP>.
Используя Nmap или Nutty (Linux)
Если вы пользователь Linux, вы можете использовать популярный инструмент сетевого анализа в вашей сети.
Кроме того, вы можете попробовать Nutty, который в настоящее время доступен в Elementary OS и Ubuntu.
- Как сканировать удаленный хост на открытые порты с помощью портативного сканера nmap
- Как перечислить каталоги веб-серверов с помощью Nmap на Kali Linux
- Как установить NMAP в Windows с примерами использования в реальном времени
- Отключение портов 135 и 445 / Сканирование на уязвимость Nmap
- ? 5 Утилит Linux для проверки сетевого подключения
- Зачем об этом беспокоиться?
Если вы не пытаетесь оптимизировать и управлять большой сетью, вам, вероятно, это не понадобится на регулярной основе.
Тем не менее, это быстро и легко, если вам интересно узнать о вашей сети или вы подозреваете несанкционированное использование.
Это может помочь вам выяснить, какие устройства вызывают проблемы.
Также может быть, что вы просто ленивый и хотите узнать MAC-адрес этой машины по всей комнате, не вставая и не проверяя.
Если вы думаете, что кто-то использует ваш Wi-Fi без разрешения, вам, вероятно, нужно действовать. О безопасности Wi-Fi Ваш – тяжело для любого Кто-то взломал сеть Вполне безопасно. Чтобы подтвердить свои подозрения, вам нужно проверить свою сеть и посмотреть, что там происходит, в поисках устройств, мешающих вашей пропускной способности.
Лучший способ сделать это обычно – получить доступ к панели администратора вашего роутера. Если у вас нет доступа к веб-интерфейсу маршрутизатора, возможно, из-за того, что вы сканируете общедоступную сеть или, возможно, небрежно проверяете Airbnb на наличие скрытых камер (не гарантия, потому что умный шпион поместит их в скрытую сеть или использует вашу память card), лучше всего иметь программу или приложение, которое сканирует сеть для вас.
Проверьте веб-интерфейс управления маршрутизатором.
Чтобы получить более подробную информацию об устройствах в вашей сети, вам нужно будет зайти в веб-интерфейс маршрутизатора – то же самое место, где вы можете изменить свое сетевое имя и пароль и выполнить другие административные задачи. Обычно это можно сделать, набрав адрес (обычно 192.168.0.1, 192.168.1.1, 192.168.2.1 или 192.168.1.100) в строке браузера. Вы должны изучить марку своего маршрутизатора или посмотреть на устройство, поскольку оно обычно помогает понять, какое из них выбрать.
Затем вам нужно будет войти в маршрутизатор, используя информацию по умолчанию, напечатанную на устройстве, или то, на что вы ее изменили. (Процесс изменения – умный ход, потому что большинство маршрутизаторов поставляются с настройками по умолчанию, такими как «admin» и «password».)
Войдя внутрь, поищите опцию «Подключенные устройства», «ЛВС», «Беспроводная локальная сеть» или что-нибудь, что может дать вам информацию о вашей сети. Это зависит от производителя маршрутизатора. Журналы также могут быть скрыты за кнопкой или меню, которое показывает вам информацию о DHCP-клиентах.
Вы узнаете, что нашли нужное место, когда увидите список подключенных в данный момент устройств, который может дать вам возможность увидеть Журналы предыдущей активности также. Вы всегда будете видеть MAC-адрес, и в зависимости от производителя вашего маршрутизатора вы также можете увидеть IP-адрес, имя устройства или другую информацию. Если вы знаете MAC-адреса каждого устройства, которое должно быть подключено к вашей сети, вы можете просто сравнить список с журналами маршрутизатора (если они доступны), чтобы увидеть, что происходит.
Более простой вариант: использовать инструмент сетевого сканирования
Если подключение к маршрутизатору и сравнение MAC-адресов – не ваша чашка чая, существует множество программ, которые могут вам помочь. Контролируйте свою сеть. Он обычно не показывает вам подробные журналы, как ваш маршрутизатор (если вы не настроите его на автоматическое сканирование и сбор данных каждые несколько минут), но он может сказать вам, что происходит в вашей сети в любой момент времени, а некоторые могут это сделать. гораздо больше, чем это. Обычно они предоставляют вам информацию о производителе устройства, позволяя легко узнать, что вы смотрите, поскольку большинство из них очень просты в использовании – просто загрузите инструмент, запустите его и запустите процесс. Проверка сети.
Nirsoft Wireless Network Watcher (Windows)
эта программа Просто, бесплатно и эффективно. вставать проверьте свою сеть , сообщает вам адреса и сведения о подключенных устройствах и отслеживает, как часто он обнаруживает эти устройства, позволяя отслеживать подозрительные действия с помощью регулярного сканирования.
Кто есть в моем WiFI / WhoFi (Mac / Windows / Android)
Разработано эта программа Для использования с пакетом крупномасштабного сетевого анализа и оптимизации, его также можно использовать бесплатно в качестве личного инструмента сканирования сети. Он должен показать вам самую важную информацию об устройствах в вашей сети и даже позволить вам настроить его на Автоматическое сканирование вашей сети через определенные промежутки времени и собирать данные об устройствах на нем.
Расширенный IP-сканер (Windows)
Говорит тебе Расширенный IP-сканер Со всеми основами О том, кто в вашей сети В этом нет ничего нового, но это очень полезно, если вы ищете инструменты, которые помогут вам получить доступ к устройствам в вашей локальной сети и управлять ими удаленно.
Финг (Android/iOS)
Если вам нужен красивый и плавный мобильный опыт, это сложно превзойти Fing. Он дает быстрые и видимые результаты и предлагает некоторые Инструменты анализа, если вам интересно – Отличный способ сделать Быстрое сканирование сети.
Злой IP-сканер (Windows/Mac/Linux)
Несмотря на название, использование эта программа Это вряд ли вас сильно рассердит, если вы продвинутый пользователь. Интерфейс немного менее понятен для людей, которые, возможно, не знакомы с сетью, но он предлагает много расширенные функции Если это то, что вам нужно.
Использование командной строки (Windows)
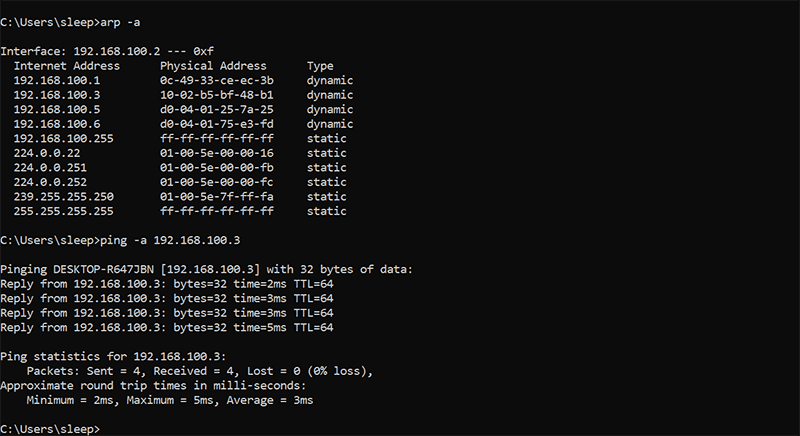
Другой способ проверить устройства, которые в настоящее время находятся в вашей сети, – это использовать командную строку, хотя этот метод менее очевиден и не дает много информации. Просто откройте командную строку и введите arp -a. Это отобразит список IP- и MAC-адресов. Чтобы увидеть имена связанных устройств айпи адрес , записывать пинг -a.
Использование Nmap или Nutty (Linux)
Если вы пользователь Linux, вы можете использовать популярный инструмент сетевого анализа. Nmap Чтобы определить Устройства в вашей сети , следуя инструкциям на главном веб-сайте инструмента. В качестве альтернативы вы можете попробовать увлекающийся , в настоящее время доступно в операционной системе Элементарная ОС и Ubuntu.
Почему меня это волнует?
Если вы не пытаетесь оптимизировать большую сеть и управлять ею, вам может не понадобиться делать это на регулярной основе. Однако это быстро и легко, если вы обеспокоены своей сетью или подозреваете несанкционированное использование и хотите найти устройства, которые мешают вашей пропускной способности. Это может помочь, если вы хотите знать, какие устройства вызывают проблемы. Это также может быть связано с тем, что вы ленивы и хотите знать MAC-адреса всех устройств в комнате, не вставая и не проверяя. Работайте умнее, а не усерднее, правда? В худшем случае, если вы найдете кого-то, кто использует вашу сеть, пора читать дальше Безопасность Wi-Fi.
УДК 004.415.532
С. В. Бредихин В. И. Костин 2, Н. Г. Щербакова 3
Институт вычислительной математики и математической геофизики СО РАН пр. Акад. Лаврентьева, 6, Новосибирск, 630090, Россия E-mail: 1 bred@nsc.ru; 2 v_kostin@ngs.ru; 3 nata@nsc.ru
ОБНАРУЖЕНИЕ СКАНЕРОВ В IP-СЕТЯХ МЕТОДОМ ПОСЛЕДОВАТЕЛЬНОГО СТАТИСТИЧЕСКОГО АНАЛИЗА
Рассматриваются подходы к обнаружению сканирования в IP-сетях. Приведен обзор методов, применяемых в системах обнаружения вторжения Snort и Bro и статистических моделей выявления аномального трафика. Особое внимание уделяется методу последовательного анализа и моделям, использующим этот метод для выявления сканеров. Представлен алгоритм для выявления сканеров в IP-сетях, который базируется на методе последовательного анализа А. Вальда. Приведены результаты апробирования алгоритма на трафике сети Интернет СО РАН. Даны оценки эффективности алгоритма и исследованы его возможности в зависимости от выбора параметров.
Ключевые слова: сети на базе стека протоколов IP, сканирование адресов и портов, базовые системы Snort и Bro, вероятностные подходы, метод последовательного анализа А. Вальда, модели TRW и TAPS, алгоритм обнаружения сканеров.
Введение
Известно, что сети, построенные на Ш-протоколах, регулярно подвергаются различным процедурам зондирования с целью определения текущего состояния сетевых устройств. В результате выполнения этих процедур определяются адреса устройств, доступных в изучаемой зоне, протоколы или сервисы, которые они поддерживают. Зондирование проводится с разными целями. Например: поисковые системы изучают информационные серверы с целью обнаружения нового контента; p2p-клиенты находят своих коллег; системные администраторы проводят ревизию сети с целью своевременного обнаружения уязвимых компьютеров и принятия превентивных мер защиты.
Ничего предосудительного в этих исследованиях нет до тех пор, пока информация, полученная в результате зондирования, не попадает к злоумышленникам. Они ищут незащищенные компьютеры для несанкционированного размещения на них своих, как правило, вредоносных, программ. Для поиска подходящих компьютеров используется «сетевая разведка», в результате проведения которой можно получить неафишируемую информацию о составе сетевых устройств и текущие характеристики их настроек. В связи с возможной угрозой, системным администраторам желательно знать, как действуют сканеры и каковы их сильные и слабые места, чтобы если не предотвратить, то зафиксировать попытки сканирования и, возможно, вторжение. Последствия вторжения могут быть весьма неприятными, например, заражение компьютера и приведение его в состояние «зомби» или атака сетевого устройства путем организации непрерывного потока запросов, что может блокировать его работоспособность. Одним из видов сетевой разведки является сканирование доступных Ш-ад-ресов и / или tcp / udp-портов. Информация о методах и средствах сканирования приведена в [1].
В настоящей работе под сканированием гр-адресов мы понимаем проверку достижимости сетевых устройств, способности отвечать и / или выяснение, какие Ш-протоколы на них поддерживаются. Под сканированием ^р / пйр-портов – деятельность, направленную на проверку того, какие tcp / udp-порты открыты для доступа у сетевых устройств. Эти порты являются уязвимым точками сети, поскольку, как правило, через них осуществляется неконтролируемый доступ – вторжение. Под сканером будем понимать сетевой компьютер (хост), на кото-
ISSN 1818-7900. Вестник НГУ. Серия: Информационные технологии. 2009. Том 7, выпуск 4 © С. В. Бредихин, В. И. Костин, Н. Г. Щербакова, 2009
ром функционирует какая-либо программа сканирования. Вопрос о том, как корректно отличить нормальное поведение активного хоста от хоста, осуществляющего вторжение, является фундаментальной проблемой любой системы обнаружения сетевых аномалий.
На этапе проектирования алгоритма для обнаружения процесса сканирования возникает ряд трудностей. Во-первых, нет четкого определения активности. Например, считать ли сканером активное устройство, делающее попытки установить top-соединения с небольшим количеством сетевых устройств, если известно, что часть попыток неуспешна. Во-вторых, не определено, какая степень детализации объекта сканирования требуется. Например, это множество портов одного локального адреса или это один порт множества смежных адресов. В-третьих, априори неясно, сколько времени требуется наблюдать за работой хоста, прежде чем принять решение, является ли он сканером. И, наконец, что считать враждебным сканированием. В конечном счете, считать ли процесс сканирования безопасным или нет, решать сетевым администраторам.
Системы NIDS и nt-метод
В состав системы защиты сети от несанкционированного доступа (NIDS – аббревиатура от Network Intrusion Detection System), как правило, входят подсистемы, выявляющие процедуры враждебного сканирования. Программы этих подсистем, анализируют поступающий в сеть трафик. Методы, заложенные в основу алгоритмов анализа поведения сетевых устройств, можно условно разделить на две основные группы. Первая группа использует метод, суть которого состоит в вычислении метрики, определяющей соотношение N подозрительных событий за время наблюдения T, далее будем называть его nt-метод. Вторая группа использует методы теории вероятностей и математической статистики.
Среди общедоступных систем NIDS категории Open Source Software лидируют две: Snort (M. Roesch, 1998) и Bro (V. Paxson, 1998). В состав обеих входят подсистемы обнаружения сканеров. Исследуемым материалом является «сырой» трафик, собираемый с помощью функций библиотеки libpcap. Далее будем использовать следующие обозначения: протокол -protocol; IP-адрес источника – srcip; IP-адрес получателя – dstip; порт источника – src_port; порт получателя – dst_port.
Система Snort 1 может в реальном времени производить анализ трафика, чтобы предотвратить атаки различных типов. Предварительно в Snort закладывают информацию об активных устройствах исследуемой сети, т. е. заранее формируется множество адресов сетевых устройств, являющихся легальными, активными источниками и получателями данных. Например, такими устройствами являются dns-, proxy- и web-серверы. Эта информация позволяет ускорить работу системы и сократить число ложных результатов. Snort использует специальный язык, определяющий набор правил для анализа трафика.
В основу подсистемы выявления сканирования заложено предположение, что сканер не имеет информации о хостах сканируемой сети, поэтому большинство его обращений к устройствам сети будет неуспешным. Далее мы рассматриваем только сканирование с использованием протоколов tcp и udp. Выявление сканеров производится на уровне выделенных модулей системы Snort – препроцессоров. Препроцессор flow, получая сырой трафик, собираемый с помощью функций библиотеки libpcap (Unix), отслеживает неправильно сформированные пакеты, используемые при так называемом «скрытом сканировании», и формирует потоки записей на основе пяти полей IP-пакетов {protocol, srcip, src_port, dstip, dst_port}. Препроцессор следующего уровня анализирует потоки на предмет выявления сканирования и вырабатывает сигналы тревоги. В первых версиях системы препроцессор portscan посылал сигнал тревоги, если:
• хост с адресом src ip совершал N попыток установить соединение с хостами защищаемой сети, используя при этом P различных портов за T секунд в случае использования tcp-протокола;
1 См.: http://www.snort.org/
• хост с адресом scr ip совершил N попыток контактировать с хостами защищаемой сети, используя при этом P различных портов за T секунд в случае использования uap-протокола.
В обоих случаях это могут быть попытки типа: один src_ip ^ одному dstip или один srcip ^ многим dstips. Пороги N, P и T являются конфигурируемыми параметрами. В более поздних версиях системы (текущая версия 2.8.2) для обнаружения сканирования на втором этапе используется препроцессор sfportscan. Следует заметить, что в Snort заложена возможность исключать штатные и включать пользовательские препроцессоры.
Препроцессор sfportscan определяет следующие типы tcp / udp-сканирования:
• portscan one ^ one – хост с адресом srcip активно обращается к разным портам хоста dstip;
• decoy one ^ one – один хост активно обращается к разным портам хоста dstjp, используя при этом в качестве адреса источника собственный адрес src_ip и вымышленный (spoofed);
• distributed portscan – хосты с разными адресами srcips обращаются к разным портам одного хоста с адресом dst ip;
• portsweep – хост с адресом srcip обращается к разным хостам с адресами dst ips, используя один и тот же порт назначения.
Пользователь может задать один из уровней защиты: low, medium и high. Если выбран уровень low, то для src_ip рассматриваются только неудачные попытки (N) контактировать с хостами защищаемой сети за определенный интервал T. По окончанию интервала T посылается сообщение, и счетчик сбрасывается. Этот уровень почти не дает ложных результатов. Если выбран уровень medium, то рассматриваются все попытки контактировать с хостами защищаемой сети за время T. По прошествии интервала T также посылается сообщение, и счетчик сбрасывается. Если выбран уровень high, то счетчики ведутся непрерывно, а сообщения посылаются по таймеру. Таким способом выявляется медленное сканирование.
Во время работы препроцессор ведет счетчики, значения которых приводятся в сообщениях. Priority Count – сколько плохих ответов (отказ или нет ответа) получено данным src_ip. ConnectionCount – счетчик активных соединений для данного хоста, ведется для адресов источников и адресов назначения. Эта мера информативна для tcp-соединений. IPCount -счетчик числа хостов с адресами src ips, которые пытались контактировать с данным dst ip. Значение этого счетчика может быть небольшим для сканирования типа one ^ one и может быть большим для активных хостов и распределенного сканирования. Port_Count – счетчик портов dst_ports, по которым производились попытки контактировать с хостом dst ip. Этот счетчик, совместно с IPCount, используется для различения сканирования one->one и decoy one ^ one. Scanned / Scanner IP Range – в случае сканирования типа portsweep (один к многим) сохраняется диапазон сканируемых адресов, в случае portscan (один к одному) диапазон адресов сканеров.
Пользователи имеют возможность настроить механизм обнаружения сканеров применительно к своей сети (сетям) следующим образом.
1. Определять множество адресов, за которыми следить; множество адресов, которые не считать сканерами; множество адресов, которые не считать сканируемыми. Это можно сделать как априори, так и в результате наблюдения за сигналами тревоги.
2. Следить за соотношениями Connection Count / IP Count, Port Count / IP Count, Connection Count / Port Count для выявления ложных сигналов тревоги. Соотношение Connection Count / IP Count должно быть как можно более высоким для сканирования типа portscan и низким для сканирования типа portsweep. Соотношение Port Count / IP Count должно быть высоким для portscan и низким для portsweep. Соотношение Connection Count / Port Count должно быть низким для portscan и высоким для portsweep. Большое значение счетчика Priority Count является хорошим показателем как для portscan, так и для portsweep, если только не используется экранирование.
3. Если это не помогает, снизить уровень защиты.
Таким образом, метод выявления сканирования, используемый системой Snort, относится к базовому типу. При создании анализатора сканирования авторы ориентировались на выяв-
ление всех вариантов сканирования, определенных в классической утилите сканирования Nmap [1].
Система Bro 2 – это открытая автономная система пассивного мониторинга, предназначенная для выявления подозрительной активности. Данные о трафике собираются с помощью функций библиотеки libpcap. Концептуально Bro делится на два уровня.
На первом уровне, например, происходит фильтрация плохо сформированных пакетов, определение, для каких протоколов прикладного уровня передавать все пакеты на следующий уровень для проведения тщательного анализа, а для каких собирать только информацию о tep/udp-сессиях. Обработка tcp/udp-пакетов происходит следующим образом. Если встречается запрос на установление top-соединения, то, если по прошествии таймера T не было получено ответа, соединение будет иметь статус connectionattempt. Если в ответ получено подтверждение, то статус будет connectionestablished, который может измениться на connection finished, если сессия закончится в рассматриваемый период. Если получен отказ, то статус будет connectionrejected. Сохраняются времена начала и конца сессии, количество переданных и полученных байтов. В случае udp, если хост с адресом srcip посылает запрос устройству с адресом dst_ip, используя при этом порт источника src_port и порт назначения dst_port, то считается, что устанавливается псевдосоединение, которое будет иметь статус udp_reply, если от dstip будет получен соответствующий ответ, иначе – статус udp_request. Результаты работы первого уровня передаются на следующий уровень, в который закладывается политика обеспечения безопасности. Мы не будем останавливаться на способах взаимодействия уровней и языке задания правил безопасности.
Подсистема выявления сканирования, Scan Analyzer, функционирует на втором уровне. В подсистему, так же как и в случае Snort, может закладываться информация о легально активных хостах и адресах назначения, к которым происходит многочисленные обращения. Система Bro различает два типа сканирования: сканирование адресов и сканирование портов. Для каждого типа сканирования определяется свой набор порогов активности, и, если величина активности превышает один из этих порогов, система генерирует соответствующее этой величине сообщение, например, предупреждение или сигнал тревоги. Scan Analyzer выявляет, кроме того, попытки взломать сервер с помощью подбора имени пользователя и пароля, на которых мы не будем останавливаться.
Сканирование адресов: удаленный хост с адресом src ip пытается установить tcp-соединения с определенным количеством адресов назначения или, в случае udp протокола, пытается контактировать с определенным количеством адресов назначения. В общем случае не прослеживается, чем закончилась попытка установить соединение; для выделенных протоколов, таких как ftp и telnet, определенных на первом уровне, внимание уделяется неудачным попыткам. Для выявления сканирования ip-адресов ведутся две таблицы: distinct_peers [src ip, dst ip], где сохраняется информация о всех различных парах взаимодействующих адресов, если появилась новая пара, то увеличивается счетчик в таблице addr_count[src_ip], где ведется учет, со сколькими различными адресами взаимодействовало устройство с данным src_ip. Если это количество превысило один из заданных порогов, посылается уведомление. По умолчанию используется шкала порогов {100, 1 000, 10 000}, т. е. уведомление посылается по превышению 100, затем по превышению 1 000 и т. д. Информация собирается и для сканирования, инициированного локальными устройствами. Для них определяется своя шкала порогов, по умолчанию {1 000, 1 0000}.
Сканирование портов: для каждого src_ip ведется таблица distinct_ports[src_ip, dst_port], где сохраняется информация о том, по каким портам назначения dst_port контактировал src ip. Вторая таблица port_count[src_ip] хранит информацию о количестве портов назначения для данного src ip. Если это количество превысило один из заданных порогов, посылается уведомление. По умолчанию порог равен 25. Заметим, что информация собирается безотносительно к адресу назначения. Если порог превышен, Scan Analyzer начинает собирать информацию, к какому адресу назначения относится порт. Эта информация позволяет уменьшить количество устройств, ложно принятых за сканеры, однако это дорогостоящая мера.
2 См.: http://www.bro-ids.org/
В подсистеме выявления сканирования намеренно не учитывается фактор времени, чтобы не пропустить «тонкие» сканеры, например такие, которые в течение короткого промежутка времени работают интенсивно, а затем подолгу не проявляют активность.
Заметим, что на текущий момент Scan Analyzer не способен выявлять распределенное сканирование. Пороги, адреса назначения и адреса источников, которые следует игнорировать при выявлении сканирования, задаются при настройке Scan Analyzer с помощью инициализации переменных, scan variables. Scan functions определяют, что следует предпринять, если обнаружено сканирование со стороны srcjp. Например, если при настройке указано, что можно прерывать коннективность и src_ip не попал в число тех, с кем нельзя ее прерывать никогда, то она будет прервана. Система Bro позволяет принимать кардинальные меры борьбы с злоумышленниками. Хотя Bro выявляет не все виды сканирования, является ресурсоемким и основывается на статических порогах, наличие шкалы порогов и отсутствие временных рамок делает ее достаточно привлекательной.
Вероятностные подходы и развитие nt-метода
NT-метод показывает хорошие результаты в случае массированного, методичного сканирования. Однако правильный выбор порога является камнем преткновения. Выявление сканеров, которые посылают запросы в случайном темпе или используют большие временные задержки в своей работе, также является проблемой, поскольку такое поведение невозможно выявить с помощью N/T метрики. Возникает необходимость в более изощренных методах выявления аномального поведения сетевых устройств.
Далее предполагается, что известно «нормальное» состояние сети, т. е. распределение вероятностей обращений к активным сетевым устройствам и сервисам. Например, вероятности обращений к адресу P(dstip), порту P(dst_port) или совместная вероятность P(dst_ip, dst_port). Тогда если устройство с адресом src ip обращается к какому-либо устройству с адресом dst ip и использует в качестве порта назначения dst_port, а P(dst_ip, dst_port) мала, то устройство попадает в число подозреваемых. Основная трудность состоит в том, какие именно вероятности, условные вероятности и совместные вероятности хранить, тем более что нужно собирать информацию в течение длительного периода времени. Рассмотрим работы, в которых предлагаются различные подходы к решению этой задачи.
Авторы [2] особое внимание уделяют изучению медленных сканеров, к которым не применимы nt-методы. Вводится основополагающее понятие footprint – количество различных комбинаций dst_ip/dst_port, т. е. след, который оставляет источник. Здесь и далее пара-метр/параметр2 означает, что параметр2 фиксирован, а параметр меняется. Авторы предполагают, что сканер ищет конкретные сервисы, предоставляемые хостами данной сети, т. е. сканируется большое количество адресов по небольшому количеству портов. Самый простой подход (первая мера) состоит в подсчете числа различных комбинаций, используемых источником.
Однако сканеры зачастую интересуются портами, открытыми на определенных хостах, по этим данным они, например, идентифицируют операционную систему исследуемого хоста. Поэтому необходимо следить и за комбинациями dsp_port/dst_ip (вторая мера), т. е. иметь полную информацию об активности источника. В качестве третьей меры авторы предлагают рассматривать количество обращений к закрытым портам, т. е. рассматривать комбинации dsp_port/dst_ip, где порты не поддерживаются на dst ip или недоступны для src ip. И, наконец, рассматривается метрика, которая обобщает идею наблюдения за закрытыми портами.
Предполагается, что априори известно распределение нормального трафика защищаемой сети по хостам и портам, т. е. если в пакете встречается данная комбинация dst_port/dst_ip, обозначим ее х, то известна вероятность ее появления P(x). Определим индекс аномальности пакета (или события), содержащего пару х через отрицательный логарифм правдоподобия:
A(x) = -log(P(x)).
Индекс аномальности множества X = xb x2, … определим как
А(Х) = ZxgXA(x).
Таким образом, чем больше необычных комбинаций использует сканер, тем быстрее он будет обнаружен. Заметим, что здесь игнорируется тот факт, что распределение вероятностей зависит от времени суток. Поэтому для сканеров, функционирующих в разное время, индекс аномальности рассчитывается, по существу, относительно разных распределений.
Понятие индекса аномальности события используется в модели Spice [2], состоящей из двух компонент: сенсора и коррелятора. В задачу сенсора входит определение индекса аномальности наблюдаемых событий. События с высоким значением этого индекса передаются коррелятору, который группирует их и генерирует отчеты об обнаруженных аномалиях.
Индекс аномальности события определяется на основе таблиц вероятности отдельных элементов, условных и совместных вероятностей. Например, для каждой четверки (dst_port, dst_ip, src_port, srcip) вычисляется вероятность ее появления и сохраняется в таблице. Однако такая таблица будет слишком объемной, кроме того, если процент нормального трафика высок, то будет много ложных тревог. Поэтому можно рассматривать вероятности различных комбинаций этих параметров, например, P(dst_port), P(src_port, dst_port), P(dst_ip, src_ip, src_port). Для определения независимости между случайными величинами предлагается использовать графическую модель – Байесовскую сеть [3].
Коррелятор объединяет события в группы. Функция, определяющая, насколько связаны между собой события e1 и e2, имеет вид
f(eu e2) = c1h1(e1, e2) + c2h2(eb e2) + … + ch(eb e2),
где cb …, ck- константы, а hi, …, hk – эвристические функции, отражающие, каким образом события объединяются между собой при сканировании, они строятся на основании знаний о поведении сканеров. Например, проверяется, используется ли один и тот же адрес источника, порт назначения, сеть назначения; как соотносятся времена событий, адреса назначения, порты назначения; как соотносятся ближайшие события; как растет значение порта источника по сравнению с ростом адреса назначения и т. д. Сильно связанные между собой события (значение функции f() превосходит заданный порог) объединяются в подгруппы. Слабо связанные между собой группы не рассматриваются.
Работу коррелятора можно представить как построение графа, в вершинах которого находятся события, а ребра отображают связи между ними. Для того чтобы добавить новое событие (вершину) к графу, требуется просчитать, насколько связано это событие с каждым из уже имеющихся узлов. Поскольку число узлов может оказаться большим, то для выполнения этой операции используется метод «имитации отжига» [4]. Индекс аномальности группы событий – это сумма индексов событий. Если сумма превысила некоторый порог, то посылается отчет о группе аномальных событий.
Таким образом, сенсор принимает решение на уровне пакетов, а коррелятор объединяет пакеты в группы. Частично это можно сделать с помощью генерации потоков (netflow), в которых пакеты агрегируются в группы на основе содержимого полей пакета. Однако не все связи между событиями можно определить с помощью потоков, например, распределенное сканирование.
Модель Spice [2] была частично реализована в системе SPADE (Statistical Packet Anomaly Detection Engine). Рассматривались только tcp-пакеты с флагом SYN, как считающиеся наиболее информативными. Препроцессор flow, входящий в Snort и включенный в эту систему, преобразует сырой трафик и формирует структуры данных, содержащие нужные поля. SPADE обеспечивает возможность выбора, на основании каких данных будет определяться аномальность пакетов. Это либо одна из совместных вероятностей P(src_ip, src_port, dst_ip, dst_port), P(src_ip, dstip, dst_port), P(dst_ip, dst_port), либо Байесовская сеть, определяющая, как связаны между собой параметры src ip, src_port, dst ip, dst_port. Поскольку выбор порога является узким местом методики, SPADE предоставляет возможность регулирования порога в зависимости от нагрузки сети. Кроме того, отчеты об аномальности могут поступать как на основе периодичности, так и на основе некоторых статистических характеристик.
Для определения качества используемой методики введены две метрики: производительность (efficiency) и эффективность (effectiveness). Производительность – это отношение количества выявленных эталонных сканеров (true positives) к количеству адресов источников, определенных алгоритмом как сканеры (all positives). Эффективность – отношение количества
выявленных эталонных сканеров (true positives) к количеству эталонных сканеров (trues). Отметим, что определенные здесь метрики качества алгоритма используются в работах других авторов, например, в [5].
Для проверки работы SPADE использовался специально подготовленный блок данных трафика, в котором были выявлены эталонные сканеры. Затем результаты SPADE были проанализированы с использованием различных значений параметров: порогов и вероятностных мер. Было выявлено, что между производительностью и эффективностью существует обратная связь: если повышается эффективность, то понижается производительность. Результаты показали, что методика дает хорошие результаты при правильно выбранных параметрах. Следует заметить, что низкая производительность приемлема для SPADE при условии, что пакеты будут переданы на следующий уровень, который выявит часть ложных тревог.
Использование двухступенчатой структуры в модели Spice представляется интересным подходом, позволяющим производить тщательный анализ данных. Однако Spice предполагает достаточно большой объем предварительной работы по объединению событий в группы.
В работе [6] предлагается совместить возможности nt-метода и метода определения аномальности, предложенного в [2]. Для выявления сканирования учитывается весь трафик, инициированный устройством с адресом src_ip за определенный период времени, а аномальность определяется на основе обращения к редко используемым комбинациям dst_ip / dst_port. Однако если сканер действительно использует редкие пары, то обратное неверно. В результате, во-первых, небольшое количество обращений к редко используемой паре приводит к тому, что источник определяется как сканер, во-вторых, обращение к часто используемой паре будет иметь большую степень правдоподобия, и сканер будет пропущен.
Рассматриваются две новых характеристики, отличающие поведение сканера от поведения обычного хоста. Во-первых, если рассмотреть взаимодействие сканера с устройством с адресом dst ip и использованием порта назначения dst_port, то для сканеров, в отличие от обычных хостов, при этом зачастую не используется более трех пакетов, так как сканеры либо запрашивают неактивный сервис, либо в случае активного намеренно не завершают процедуру установления соединения. Поэтому предлагается рассматривать только входящие потоки, содержащие менее 4 пакетов. Во-вторых, большинство сканеров последовательно перебирает адреса одной и той же подсети, в отличие от нормальных хостов, обычно использующих случайный набор адресов назначения при поиске. Поэтому можно рассматривать сканирование не отдельных адресов, а подсетей. Предлагается вести счетчик для адреса источника src_ip использующего комбинацию dst_ip / dst_port в рамках подсети (сканирование подсетей).
Кроме использования эвристических предположений, предлагается использование так называемой usage based схемы, подобной используемой в [2]. Отслеживается история контактов для адреса источника src_ip в рамках временного интервала, но оценивается каждое взаимодействие с уникальным адресом dst_ip по порту dst_port по-разному. Для устройства с адресом src_ip рассматриваем число обращений к некоторому порту dst_port. Если устройство с адресом src_ip впервые контактирует с устройством с адресом назначения dst_ip с использованием данного порта назначения, то к индексу аномальности ScanScoresrc_ip прибавляется не единица, как в базовом методе, а 1/(1+g(countdstjp/dst_port)), где count – число различных источников, обращавшихся к этой паре. Таким образом, учитывается, часто ли используется такая пара, например, обращение к веб-сайтам, которые используются многими, будет иметь меньший вес, чем редко используемая случайная комбинация. Кроме того, в данном методе, наряду с понятием time window (время, в течение которого ведется наблюдение), используется понятие connection window, т. е. сохраняется информация об N контактах для каждого источника, это позволяет правильно оценивать сканеры с низкой скоростью сканирования. Хост с адресом src ip объявляется сканером, если суммарный индекс аномальности ScanScoresrc ip за время time window или connection window превосходит заданный порог. Проведенные авторами [6] эксперименты показали, что предлагаемые методы позволяют значительно снизить количество ложных тревог по сравнению с nt-методом.
В работе [7] для выявления сканирования рассматривается поток пакетов между защищаемой сетью и внешним миром. В процессе анализа трафика строятся две таблицы. В одной таблице собираются все пары (src ip, dst ip), в другой – все пары (src ip, dst_port). Эти таб-
лицы используются для определения необычности распределения использования адресов или портов назначения. С вероятностной точки зрения ставится цель выявить, у какого источника распределение значительно отличается от для всех источников.
Аналогично, распределение _рог^гс_1р) отличается от общей вероятности P(dst_роМ).
Пусть В – множество адресов назначения защищаемой сети, с которыми был контакт извне, а Д е /) – множество адресов, с которыми контактировал нгс //;,. Соответственно рассматриваются все множество портов Р и множество портов Рь используемых Пусть – количество источников, которые контактировали с dst_ipj в рассматриваемой выборке. Определим априорную вероятность нормального контакта с dst_ipj :
здесь суммирование производится по всем адресам назначения, с которыми был контакт. В противоположность этому для атакующего устройства, которое с равной вероятностью может обращаться к любому адресу назначения, определяем вероятность:
Раи^Щ) = ID.
Аналогично определяются вероятности Pnorm(dst_рог^) и Patt(dst_рог^).
В предположении, что достижение каждого адреса является независимым событием, определяются вероятности контакта с множеством адресов назначения Di для нормального хоста и атакующего Рж,гт(Р^ и Рай^) В общем виде формулы выглядят так:
Р(Д) = P(Di = dst_ip2, …}) * Р(Щ)-
Здесь вероятность контактировать с конкретным множеством адресов умножается на вероятность P(Di) контактировать с множеством адресов данной мощности. Это делается для того, чтобы внести дополнительную характеристику, предполагая, что атакующий обращается к большому количеству адресов I портов в отличие от нормального хоста. В свою очередь, P(Di = {dst_ip, dst_ip2, …}) определяется через произведение вероятностей контакта с каждым отдельным адресом. Мы не рассматриваем вопрос, насколько достоверны априорные вероятности, и не будем приводить точные формулы.
Если для некоторого адреса источника src_ip зафиксировано множество адресов назначения Di, такое что Paй(Di) > Рпогт(РЬ, адрес объявляется сканером. На практике вычисляются отрицательные логарифмы правдоподобия:
КогтФ)) = -1и(РпогтФг)); Ь^О) = – Ь(Ра«(Д)).
И, если для src_ip верно неравенство Ь^тфг) – Ь^^) > 0, то устройство с адресом src_ip объявляется сканером.
В предложенном методе учитывается как нестандартное использование адресов или портов, так и обращения к большому числу адресов и портов. Остается невыясненным, как определять вероятность доступа к устройствам, к которым еще никто не обращался. Более того, нет оценки, достаточно ли различаются, например, вероятности контакта с множеством адресов назначения для нормального и атакующего хостов, чтобы на их основании сделать предположение о том, является ли хост сканером.
8Л-метод
Модели, о которых пойдет речь ниже, основаны на «Последовательном анализе» (далее -8а-метод) А. Вальда (1902-1950) [8] – способе проверки статистических гипотез, при котором необходимое число наблюдений не фиксируется заранее, а определяется в процессе самой проверки. 8Л-метод позволяет ограничиться значительно меньшим числом наблюдений, чем при способах, в которых число наблюдений фиксировано заранее. Одно из главных утверждений [Там же] состоит в том, что процедура проверки в случае двух простых альтернативных гипотез и наличии однородной независимой выборки оптимальна по числу шагов.
Оставляя в силе вышесказанное предположение, сформулируем суть 8а-метода. Пусть Х -случайная величина, а х1,…, хп, … – последовательность независимых и одинаково распре-
деленных наблюдений за Х. Допустим, что относительно этого распределения имеется два предположения. Гипотеза H0 – наблюдения распределены с плотностью р0(х), а гипотеза H1 -наблюдения распределены с плотностью Pi(x). После каждого наблюдения предоставляется выбор из трех возможных решений: принять H0 и закончить наблюдения, принять H1 и закончить наблюдения, не принимать ни одну из гипотез и продолжить наблюдения.
Решающая процедура 8 определяется следующим образом. Фиксируются два порога: верхний A и нижний B, такие что 0 < B < A. Пусть выполнено n наблюдений (n = 1, 2, …). Обозначим через Ln(Xj,…, хп) отношение правдоподобия:
1=1 Poxi)
Процедура S на шаге п такова: если Ln(x],…,xn) > А. то принимается гипотеза Я, и процесс наблюдения заканчивается; если Ln{xl,…, хп) <В, то принимается гипотеза Я„ и процесс наблюдения заканчивается; если В <Ln{xl,…, хп) < А, то выполняется еще одно наблюдение, вычисляется новое отношение правдоподобия Ln+l{xl,…, хя+1), для которого вновь применяется S .
Эта процедура характеризуется вероятностями ошибок и средними числами наблюдений:
а = а (А, В) – Р{ принята Я, / верна Н0} – ошибка первого рода;
Р = Р(А, В) = Р{ принята Н0 / верна Я, [ ошибка второго рода;
п0=п0(А,В)=Е(п/Н0), и, =п1(А,В)=Е(п/Н1), где n – число наблюдений (случайная величина) до принятия окончательного решения, а E -математическое ожидание. Зададим желаемые вероятности ошибок первого и второго рода а0 и Р0, и воспользуемся тремя результатами из [8].
Во-первых, фактом, что среди всех решающих правил 8 ‘, обладающих свойством
а(5′) < а0, Р(5′)<Э0,
последовательный критерий отношения вероятностей 8 имеет минимальные средние числа наблюдений:
Й0(8*)<Й0(8′), И1(8*)<И1(8′).
Во-вторых, вместо An В можно использовать приближенные значения:
а 1-ос
В-третьих, формулами для вычисления среднего числа наблюдений, которые зависят от параметровр0(х),р1(х), а и р.
Таким образом, задав параметры а, Р,/>о и р можно построить алгоритм принятия той или иной гипотезы за конечное число шагов.
iНе можете найти то, что вам нужно? Попробуйте сервис подбора литературы.
Модели на базе sa-метода
Известно несколько моделей (и алгоритмов на их основе), базирующихся на sa-методе для выявления сканеров в IP-сетях [5; 9]. Исходными данными является информация о трафике, зафиксированная в точках наблюдения. На основании анализа этих данных необходимо определить множество IP-адресов сетевых устройств, которые предположительно являются сканерами. Поскольку единой модели поведения сканеров не существует, в каждом случае исследуется своя модель поведения.
Наше внимание привлек подход, представленный в работе [5]. Рассматриваемая в ней модель и алгоритм TRW не только использует эвристические предположения по поводу поведения сканеров, но и применяет метод проверки предположений на основе оптимального метода последовательного анализа [8], связывающего пороги с ошибками первого и второго рода.
Модель TRW. В основе модели TRW (Threshold Random Walk) [5] лежит предположение о том, что сканеры чаще, чем не сканеры, предпринимают попытки установить tcp-соединения
с несуществующими сетевыми устройствами (ip-адрес назначения не используется) или попытки запросить несуществующие сервисы (tcp-порт назначения не используется).
Рассматривается фрагмент сети; ip-адреса устройств, входящих во фрагмент, считаются локальными адресами. Исследуются tcp-соединения, проходящие через контрольные точки, отделяющие изучаемый сетевой фрагмент от глобальной сети. При проверке работы соответствующего алгоритма исходными данными являлась предварительно собранная информация
0 tcp-сессиях, полученная с помощью системы Bro в контрольных точках. Если рассматривать трафик в реальном времени, то при поступлении первого пакета на установление tcp-соединения нельзя сразу определить, будет ли соединение успешным. Однако в случае небольшого размера исследуемого фрагмента сети можно хранить данные о том, какие сетевые устройства активны и какие сервисы они обслуживают.
Будем считать, что произошло событие, если удаленный хост c адресом srcip произвел первую c начала времени наблюдения попытку установить tcp-соединение с локальным хостом с адресом dstip. Попытка считается успешной, если соединение установлено, и неуспешной, если получен отказ или не было получено ответа.
Для каждого удаленного адреса srcip рассматривается последовательность наблюдений за событиями. Результат наблюдения на шаге i характеризует случайная величина Yi, определяемая следующим образом: Yi = 0, если попытка соединения успешна, и Yi = 1, если попытка соединения неуспешна. Итак, для каждого src ip строится последовательность наблюдений Y1, Y2, …
Определяются две гипотезы: гипотеза H1 состоит в том, что устройство с адресом src_ip является сканером, а гипотеза H0 – что устройство с адресом src ip не является сканером.
Анализируя последовательность наблюдений Y1, Y2, …, необходимо за конечное число шагов сделать заключение, какая из гипотез верна для устройства с адресом src_ip.
Предположим, что если гипотеза Hj верна, то случайные величины Y IH ■, sa-метод
1 = 1, 2, …, j = 0, 1, независимы и одинаково распределены. Обозначим через PYi |Hj] условную вероятность случайной величины Y при верности гипотезы Hj. Выразим распределение Бернулли для Y :
p[Y=o|#0] = e0,P[Y=i|#0]=i-eo, P[Y, = o|^] = e15 P[Y=i|^]=i-e1.
Из предположения о том, что попытка установить соединение более успешна для не сканеров, чем для сканеров, ясно, что 90 > 9j.
Следуя sa-методу, определим отношение правдоподобия для вектора событий Y = (Yi, …, Y„):
w уPY|H0]
Механизм принятия решения основан на пошаговом обновлении значения Л(У) и сравнении полученного значения Л (У) с верхним и нижним порогами гц и т|0 соответственно. Если Л(7) >r¡j, то принимается гипотеза Н. Если Л (У) < П., • т° принимается гипотеза Н0. Если г|0 < Л(У) < r|j, то продолжаем наблюдение, т. е. переходим к рассмотрению следующего события. Величина Л(У) осуществляет так называемое случайное блуждание между величинами Г|0 и Т|1 .
В работе [5] в означает вероятность обнаружения сканера:
в = Р{ принята Hi / Hi}.
Соответственно вероятность ошибки второго рода Р{принята H0 / H1} – 1 – в. Тогда неравенства для порогов выглядят следующим образом:
Р 1-Р
а 1-а
Приблизительную оценку для числа наблюдений N, требуемых для принятия решения, можно выразить в виде формул
E[NH0] =
E[NH,] = –
i Р л м !”Р a In — + (1-а) In-—
а_1-а
Зо1п^ + (1-0о)1пЬ®1 и0 1-W0
а_1-а
), In — + (1 – 0,) In
1 е0 ^ i-e0
(2)
Видно, что число шагов зависит от четырех параметров: а, в, 90, 9i. Таким образом, определив эти параметры и провeдя пошаговое вычисление отношения правдоподобия для каждого удаленного srcip за конечное число шагов, можно принять решение, какая из гипотез справедлива.
В [5] приведены результаты исследования, позволяющие рационально задать значения а, в, 90, 91. В тестируемом блоке данных предварительно было выделено множество эталонных сканеров, обозначим его TRUESCAN. Это множество IP-адресов сканеров, которые желательно выявить с помощью предлагаемого алгоритма. Для оценки алгоритма используются приведенные выше характеристики: производительность и эффективность. Сформулируем их в терминах гипотез.
Производительность P – отношение количества IP-адресов, правильно распознанных как сканеры (принадлежат множеству TRUESCAN), к общему количеству IP-адресов, которые алгоритм определил как сканеры:
принята гипотеза Их / верна гипотеза Их принята гипотеза И1
Эффективность E – отношение количества IP-адресов, правильно распознанных как сканеры (принадлежат множеству TRUESCAN), к общему количеству эталонных сканеров:
принята гипотеза Их / верна гипотеза Их
| TRUESCAN | ‘
По этим параметрам алгоритм сравнивается с Bro и Snort. Выясняется, что TRW показывает наивысшую эффективность при производительности выше, чем 0,96.
Модель TRWSYN [9] является модификацией модели TRW и предназначена для обнаружения сканеров в опорной сети – сетевой инфраструктуре, связывающей между собой различные участки сети и предоставляющей возможность обмена информацией между фрагментами. Опорная сеть характеризуется не только высокой производительностью, но и широким диапазоном IP-адресов, отсутствием информации об оконечном оборудовании и нередко асимметричной маршрутизацией. Для работы TRWSYN, во-первых, не требуется априорных знаний о реакции хостов на запрос на установление tcp-соединения; во-вторых, он пригоден для сети с асимметричной маршрутизацией.
В данной модели, так же как и в TRW, рассматриваются попытки устройства с адресом src_ip установить tcp-соединение с устройством с адресом dst ip. Но статус tcp-соединения определяется не на основе одного пакета с флагом SYN, а на основе последовательности пакетов.
В качестве исходных данных рассматривается последовательность потоков. Сырые данные группируются в потоки (flows) на основании следующих правил: пакет принадлежит потоку, если поля его tcp / ip заголовка соответствуют фиксированной пятерке {src ip, dst_ip, src_port, dst_port, protocol}; время, в которое появился первый пакет, соответствующий пятерке, считается временем начала потока; поток считается завершенным, если истек установленный таймер; временем завершения потока является время появления последнего пакета. Заметим, что при проверке работы алгоритма исходные данные, так же как и в случае TRW,
были собраны предварительно. Это делалось намеренно, для того, чтобы иметь возможность определить множество «реальных» сканеров, с которым можно сравнивать результаты работы алгоритма.
Обозначим через flow.srcip, flow.dstip, flow.pkts и flow.flag адреса источника и назначения, количество пакетов в потоке и tcp-флаги соответственно. В модели TRWSYN считается, что произошло событие для потока flow.srcip, если поток закончился. Если flow.srcip содержит один tcp-пакет с флагом SYN, то соединение считается неуспешным (Yi = 1). Если flow.scrip содержит несколько пакетов или один пакет без флага SYN, то соединение считается успешным (Yi = 0). На самом деле, реальное соединение может быть и неуспешным, но без этой погрешности алгоритм не применим к опорной сети.
В алгоритме TRWSYN основной цикл для вычисления значения Л (У) для каждого flow.src ip выглядит следующим образом:
если (flow.pkts > 1) или (flow.pkts == 1 и flow.flag != SYN)),
I’ll. ” »J
иначе, если (flow.pkts == 1) и (flow.flag == SYN),
тоЛ(У) = л<П*-ЫЫЩ ‘ I’ll. I »J
Механизм принятия решения относительно каждого scr ip выглядит так: если Л(У) > r|j, то хост с данным scr ip считается сканером, а если Л(У) < г|0, то хост с данным scr ip не считается сканером.
Модель TAPS. В основе модели TAPS (Time-based Access Pattern Sequential Hypothesis Testing) [9] лежит предположение о том, что сканеры имеют большую пропорцию соотношения IP-адресов к портам или, наоборот, портов к IP-адресам в сравнении с не сканерами. В качестве механизма порождения событий используются временные интервалы. Мотивация выбора истечения заданного интервала времени как события базируется на наблюдении, что атакующим устройствам необходимо поддерживать определенную скорость сканирования.
Задаются два параметра T – временной интервал, и k – параметр соотношения. В качестве исходных данных рассматривается последовательность потоков. Каждые T секунд происходит событие. Рассмотрим некоторый srcip и все flows, попавшие в интервал, для которых flow.src ip = src ip. Подсчитываем количество различных адресов назначения, flow.dst ip, обозначим его # ip , и количество различных портов назначения, flow.dst_port, обозначим его # port.
# ip # port
Если- > k или- > k, то событие успешное (Yi = 1); (3)
# port # ip ( )
#7p , # port T7
если-< к и-< к , то событие неуспешное (У = 0). /¿п
#port #ip
На основании полученных данных вычисляется отношение правдоподобия (1) и сравнивается с выбранными верхним и нижним порогами r)j и г)0.
Алгоритмы TAPS и Snort зависят от скорости канала передачи данных. Этот фактор учитывается с помощью коэффициентов k/T (#ip / #port за T секунд) для TAPS и N/T (#ip за T секунд) для Snort. Для высокоскоростных каналов фактор выше, чем для низкоскоростных. Для Snort приходится выбирать разные коэффициенты в зависимости от скорости канала, чтобы получить хорошие результаты. В случае TAPS, в основе которого лежит метод последовательного анализа, эта зависимость гораздо ниже. Фактически можно пользоваться одной и той же величиной k/T для каналов с разными скоростями передачи.
Для оценки алгоритма определяются три характеристики:
• коэффициент успеха Rs – отношение количества обнаруженных реальных сканеров к общему количеству реальных сканеров (то же, что эффективность E);
• коэффициент ложного обнаружения R+ – отношение количества не сканеров, объявленных как сканеры, к общему количеству реальных сканеров;
• коэффициент потерь Rf— отношение количества пропущенных сканеров к общему количеству реальных сканеров.
По этим коэффициентам сравниваются алгоритмы, реализующие модели Snort, TRWSYN и TAPS. Выясняется, что TAPS имеет наивысший коэффициент Rs при самых низких значениях Rf+ и Rjr. Далее следует TRWSYN, Snort оказался самым неэффективным. Следует заметить, что рассматривалась ранняя версия Snort, где для выявления сканирования вычислялось только соотношение N/T.
Модификация алгоритма TAPS
Для обнаружения сканирующих устройств мы предлагаем модификацию алгоритма, предложенного в модели TAPS [9], который интересен по трем причинам. Во-первых, он не предполагает априорных знаний об исследуемом участке сети. Во-вторых, он расширяет базовый подход, делая выбор метрики N/T не столь критичным. В-третьих, мы обладаем опытом использования такой метрики для выявления «зомбированных» (инфицированных) локальных хостов [10]. Помимо сканеров, обнаруживаемых алгоритмом TAPS, наш алгоритм выявляет «тонкие» сканеры, те, которые интенсивно работают в коротком временном интервале, затем делают значительный перерыв и вновь возобновляют сканирование.
Постановка задачи. Формат исследуемых данных соответствует понятию flow, предложенном в Cisco IOS NetFlow 3. Данные о трафике непрерывно поступают от маршрутизаторов и накапливаются на рабочей станции в виде блоков значительного объема. В роли коллектора потоков выступает рабочая станция, оснащенная пакетом утилит flow-tools 4 для работы с потоками формата и дополнительными утилитами. Коллектор настроен на агрегирование информации за фиксированный интервал времени M. Результатом работы коллектора являются файлы, состоящие из записей, содержащих нужные для работы алгоритма поля.
Анализируя множество таких записей (блок данных), накопленных за время Mi, необходимо определить адреса устройств, которые ведут себя «неадекватно». Время для проведения анализа ограничено, не более M, т. е. до получения следующего блока данных, в противном случае результаты устаревают и теряют значимость. Рассматривается только tcp/udp-трафик.
Алгоритм. Наш алгоритм базируется на методе последовательного анализа [8]. Аналогично TAPS, событием является истечение временного интервала T, где T < M. Для каждого IP-адреса источника, проявившего активность во время текущего интервала, проверяются соотношения (3) и (4) и пересчитывается отношение правдоподобия (1). В пошаговой нотации наш алгоритм выглядит следующим образом.
Входные данные: Блок данных со статистикой, полученной за интервал M. При работе алгоритма анализируются следующие поля записей:
{t1, protocol, src ip, src_port, dstip, dst_port}, где t1 – время начала сбора потока.
Шаг 0. Упорядочиваем блок данных по полю ti в порядке неубывания.
Шаг 1. Инициализируем S – множество подозреваемых IP-адресов источников, STEMP -множество IP-адресов источников, встретившихся за промежуток времени T, множество сканеров SCAN (верна гипотеза H1) и множество не сканеров – NOTSCAN (верна гипотеза H0). Задаем значения параметров алгоритма T, к, п0, п,1 90, 9ь
Шаг 2. Рассматриваем первую строку блока данных. Она содержит следующие поля: ti_1, src_ip_1, dst ip i, dst_port_1. Задаем значение начальной временной отметки T0 := til. Зафиксируем src ip l. Помещаем src_ip_1 в множество S и в множество S TEMP.
3 См.: http://www.cisco.com/univercd/cc/td/doc/cisintwk/intsolns/netflsol/nfwhite.pdf
4 См.: http://www.splintered.net/sw/flow-tools/
Инициализируем Da1 – множество различных значений поля dst_ip, встречающихся в записях, где адресом источника выступает src_ip_1, и Dp1 – множество различных значений поля dst_port, встречающихся в записях, где адресом источника выступает src_ip_1. Каждому адресу источника src_ ip_ j будем ставить в соответствие множества Daj. и Dp, при этом V/, / (src_ ip_ j = src_ ip_ i <=> i = / ).
Помещаем dst_ip_1 в множество Da1, а dst_port_1 в множество Dp1.
Шаг 3. Если файл закончился – остановка, иначе – рассматриваем очередную строку j.
Если src_ip_j е SCAN или src_ipJ е NOTSCAN, то перейти на Шаг 8 – пропускаем строку, иначе:
если src_ip_j £ S. то помещаем srcjpj в множество S и в множество S TEMP и инициализируем соответствующее отношение правдоподобия Д/ := 1.
Если dstip__/ <t Da j, то помещаем dst _ip _j в множество Daj.
Если dst port _j £ Dp j, то помещаем dst port__/ в множество Dpj.
Шаг 4. Проверяем, истек ли таймер T. Таймер считается истекшим, если выполняется неравенство: (t1_ – T) > T . Если таймер истек, то обновляем значение T0, T0 := t1_, и переходим на Шаг 5, иначе переходим на Шаг 3.
Шаг 5. V srcjpj е S TEMP (7 = 1,… S_TEMP) производим следующие действия.
1. Вычисляем мощность соответствующих множеств Dat и Dp,. Обозначим Da, = #ip, Dpi = #port.
2. Обновляем отношение правдоподобия Ai (1), соответствующее адресу srcjpj, следующим образом:
#ip , #port , . -вх
если- > к или- > к, то Аг := Аг–(событие успешно)
#port #ip 1
иначе,
#ip , # port 0X
если-< к и-< к , то Аг := Аг–(событие неуспешно)
#port #ip в{)
3. Сохраняем текущее значение Лг .
Шаг 6. V srcjpj е S TEMP сверяем соответствующее значение Лг с установленными порогами. Если Лг > г|15 то добавляем src jp j в множество сканеров SCAN, исключаем его из множества S и переходим на Шаг 7. Если Лг < г|,,. то добавляем src jp j в множество
NOTSCAN, исключаем его из множества S и переходим на Шаг 7. Иначе переходим на Шаг 7, не производя никаких действий.
iНе можете найти то, что вам нужно? Попробуйте сервис подбора литературы.
Шаг 7. Vi (src ip i&S TEMP) инициализируем множества Dpi’,— 0, Daj’=0. Инициализируем множество адресов источников, исследованных за текущий период, S TEMP := 0.
Шаг 8. Переходим на Шаг 3.
После завершения чтения всех записей блока данных, накопленных за интервал времени Mi, программа, реализующая алгоритм, приостанавливает работу до получения следующего блока Mi+1. В результате работы программы над блоком Mt из множества всех адресов источников выделяются два основных множества SCAN и NOTSCAN. Множество SCAN, представ-
ляющее основной интерес, содержит IP-адреса сканеров. Для каждого такого IP-адреса доступна дополнительная информация, например, число шагов, затраченных до принятия решения, и тип сканирования (порты / адреса).
Особенности алгоритма. В отличие от алгоритма TAPS, анализирующего потоки, построенные в ходе работы, в нашем случае формат исследуемых данных заранее фиксирован и определяется идеологией, предложенной в Cisco IOS NetFlow. Так же как и TAPS, разработанный алгоритм использует механизм временных интервалов, т. е. производит обновление отношения правдоподобия каждые T секунд. При этом в алгоритме TAPS прекращение сетевой активности наблюдаемого устройства с адресом src ip в рассматриваемый период является показателем того, что устройство ведет себя как безопасный хост, т. е. отношение правдоподобия пересчитывается с Yi = 0. В предлагаемом алгоритме отношение правдоподобия для IP-адресов, не проявляющих активность за данный промежуток времени, не обновляется. Это позволяет отследить сканеры, которые действуют интенсивно в течение короткого промежутка времени, и делают большие перерывы между попытками сканирования. Однако, в свою очередь, это может увеличить количество адресов, для которых вообще не принято решение.
Заметим, что ip-адреса, попавшие в множество не сканеров, NOTSCAN, исключаются из рассмотрения до конца рассматриваемого блока данных. Это создает опасность того, что могут быть пропущены устройства, которые сначала не проявляют аномальной активности, а затем начинают интенсивно сканировать. Поначалу кажется целесообразным не формировать множество NOTSCAN, то есть фактически перейти к рассмотрению алгоритма с одной гипотезой H – «сканер». Однако, как показала практика, применение классического варианта предпочтительнее. Рассмотрение лишь одной гипотезы увеличивает количество шагов и количество ложных сканеров, но практически не расширяет множество обнаруживаемых сканеров. Кроме того, для анализа очередного блока статистики программа перезапускается с пустым множеством NOTSCAN, т. е. IP-адреса, попавшие в это множество, исключаются из рассмотрения на небольшой промежуток времени, поэтому риск пропустить активный сканер очень мал.
Эксперимент и оценки
Формат данных. Рассмотрим формат анализируемых данных. Поток (network flow) – это однонаправленная последовательность пакетов между определенным источником и получателем. Подробнее, каждый пакет, проходящий через сетевое устройство, исследуется на наличие ip-атрибутов. Традиционно Cisco IOS NetFlow исследует следующие атрибуты: IP-адрес источника, IP-адрес назначения, порт источника, порт назначения, протокол следующего за IP-протоколом уровня, тип обслуживания (TOS), входной интерфейс устройства, с которого поступают пакеты потока и др.
Правила сбора и отсылки потоков для используемой версии 5 Cisco IOS NetFlow таковы. Потоки собираются устройством и считаются завершенными, когда произойдет одно из следующих событий: транспортный протокол указывает на завершение взаимодействия (флаг TCP FIN); трафик неактивен в течение 15 секунд; для потоков, остающихся постоянно активными, поток принудительно завершается через 30 минут. Потоки, генерируемые сетевыми устройствами, инкапсулируются в UDP-дейтаграммы. Пакеты посылаются на рабочую станцию, задающуюся в конфигурации экспортера, либо когда количество потоков превзойдет определенный максимум, либо каждую секунду (выбирается то событие, которое произошло первым).
В нашем случае коллектор настроен на агрегирование информации в течение 30 минут. Результатом работы коллектора являются файлы, состоящие из записей следующего формата:
|t1|t2|src_7p|dst_7p|src_org|dst_org|src_int|dst_int|src _portdst_portprotocolpacketsoctetsTCP-flags, где
ti – время начала потока (время появления первого пакета, мс);
t2 – время окончания потока (время появления последнего пакета, мс); srcip – IP-адрес источника; dstip – IP-адрес назначения;
srcorg – индекс организации из некоторого фиксированного множества организаций, к которой принадлежит хост с IP-адресом источника (0 – организация неизвестна); dstorg – индекс организации – получателя (0 – организация неизвестна); src_int – SNMP-индекс интерфейса сетевого устройства, по которому поступил поток данных от источника;
dstint – SNMP-индекс интерфейса сетевого устройства, на который отправляется поток данных;
src _port – tcp/udp-порт источника; dst_port – tcp/udp-порт назначения; protocol – протокол (поле protocol IP-пакета). packets – количество пакетов в потоке; octets – количество байтов в потоке;
flags – аккумулированные флаги (FIN, SYN и RST) tcp-пакетов потока. Если установленных флагов нет или протокол отличен от tcp, в поле flags стоит 0.
Эксперимент и оценка эффективности работы алгоритма. Для того чтобы оценить работу алгоритма, была создана программа на языке Perl, реализующая этот алгоритм. Анализировался «эталонный» блок данных, собранных за 30 минут наблюдения и содержащий 4,6 * 106 записей. Этому блоку соответствует 29 650 Мб реального трафика сети Интернет СО РАН [11].
В отсутствие оракула, способного определить правильность принятия той или иной гипотезы, записи были предварительно исследованы, в результате чего было создано эталонное множество сканеров TRUESCAN. В него мы поместили те и только те IP-адреса устройств, которые проявили себя как сканеры. Множество TRUESCAN строилось в два этапа. Исследовались IP-адреса источников. Пусть #port – количество портов назначения, #ip – количество IP-адресов назначения, зафиксированное в блоке для некоторого src_ip. Если выполня-
#ip # port
ется одно из неравенств -> к1 или -> к1 (при этом ki выбирается достаточно
# port #ip
большим, например, к1 =100), то помещаем этот IP-адрес в TRUESCAN. Затем, после дополнительного анализа, оставляем только те IP-адреса, которые мы признали сканерами. На втором этапе анализируется список IP-адресов сканеров, который получен в результате работы программы, реализующей алгоритм. Те IP-адреса, которые не вошли в эталонное множество на первом этапе, но были признаны сканерами после анализа, добавляются к TRUESCAN. В исследуемом блоке содержалось 267 044 различных адресов источников, из них 79 принадлежало множеству TRUESCAN. Следует заметить, что процесс построения эталонного множества требует внимания и значительных временных затрат.
Поскольку не существует общего подхода к определению характеристик алгоритмов распознавания сканирования, были рассмотрены две меры, оценивающие работу алгоритма: эффективность Е и производительность Р, предложенные в [2].
При параметрах к = 10, Т = 10 секунд, а = 0,01, р = 0,01, 9о=0,9 и 0j=O,l за время работы программы, равное ~ 4,5 минутам, был получен следующий результат. Выявлено 40 сканеров (|SCAN|), из них 38 входят в TRUESCAN. Устройства, входящие в SCAN, создали 43 Мб трафика, что составляет 0,15 % от общего трафика блока. Сканеры не генерируют большие объемы трафика, так как в их задачу входит разведка, а не обмен данными. Безопасными были признаны (|N0TSCAN|) 72 303 адреса. Для остальных адресов не было принято решение, так как соответствующие устройства не проявили достаточную активность. Количество пересчетов отношения правдоподобия для src_ip до принятия одной из гипотез в среднем выполнялось за три итерации основного цикла алгоритма.
Полученные характеристики алгоритма, P = 0,95, E = 0,48, свидетельствуют о том, что производительность алгоритма (отношение числа выявленных сканеров к |SCAN|) достаточно высока, т. е. количество ложных тревог невелико. Невысокая эффективность (отношение
числа выявленных сканеров к TRUESCAN) вызвана тем, что среди невыявленных сканеров основной процент составляют сканеры, которые за короткий промежуток времени сканируют большое количество адресов, а затем не проявляют активность в течение всего рассматриваемого периода. В [2] было замечено, что между производительностью и эффективностью существует обратная связь. Если рассматривать задачу выявления локальных инфицированных хостов, то предпочтение следует отдать высокой производительности. Небольшое время работы алгоритма на блоке данных, собранных за 30 минут, позволяет встроить его в систему анализа «сетевой погоды» [12], функционирующую в режиме реального времени.
Графическое представление результатов. В этом разделе представлена графическая интерпретация результатов работы программы, реализующей наш алгоритм, при различных значениях параметров.
Рис. 1 отображает зависимость коэффициента ложного обнаружения Rf+ (см. модель TAPS) от выбора параметра к при различных значениях параметров 90 и 9t. Таймер во всех случаях выбирался равным 10 секундам (Т = 10). Приводятся два графика: для 90 =0,9; 9j =0,1 и для 90 =0,8; 9j = 0,2 . По оси абсцисс откладывается значение к, по оси ординат – Rf+.
Из рис. 1 видно, что Rf+, при значениях 90 =0,9 и 9j = ОД ниже, чем при значениях 90 = 0,8 и 9j = 9,2 . Для обоих случаев оптимальное значение параметра к « 19 . Рис. 2 отражает зависимость эффективности работы алгоритма Е от выбора параметра к при различных значениях 90 и 0,. Приводятся два графика: для 90 = 0,9; 9t = ОД и для 90 = 0,8 ; 9t = 9,2. По оси абсцисс откладывается значение к, по оси ординат – Е. Видно, что при значениях 90 = 0,9 и 9j = ОД эффективность выше, чем при значениях 90 = 0,8 и 9j = 9,2.
RK
0.4 -0,35 -0.3 -0.26 ■■ 0.2 ■■ 0,15 -0,1 •■ 0.05 ■■
Рис. 1. Зависимость R+ от выбора параметра к
Рис. 2. Зависимость эффективности алгоритма E от выбора параметра к
На рис. 3 отражена зависимость количества распознанных эталонных сканеров от выбора параметра к при различных 90 и 91. Приводятся два графика: для 90 =0,9; 0, – 0.1 и для
90 = 0,8 ; 91 = 0,2. По оси абсцисс откладывается значение к, по оси ординат – количество распознанных эталонных сканеров, Бс.
Видно, что количество распознанных сканеров при 90 = 0,9 и 91 = 0,1 выше, чем при
90 = 0,8 и 91 = 0,2. Таким образом, можно сделать вывод, что значения параметров 90 =0,9 и 91 = 0,1 предпочтительнее, чем 90 = 0,8 и 91 = 0,2 . Это можно интерпретировать так: чем
больше различаются между собой гипотезы, тем лучше результаты работы алгоритма.
Рассмотрим некоторый 1Р-адрес, принадлежащий множеству ТНиЕХСАЫ, для которого проводится процедура принятия решения при различных значениях параметров 90, 91, а, |3. На рис. 4 приведено графическое представление процедуры принятия решения при 90 =0,9,
91 =0,1, ошибка первого рода а = 0,01, ошибка второго рода (3 = 0,91. По оси абсцисс от-
п
кладывается количество шагов алгоритма п, по оси ординат О ^ У1 .
г= 1
Увеличим значения ошибок первого и второго рода и посмотрим, как изменится процедура принятия решения. На рис. 5 приведено графическое представление процедуры принятия решения при 90 = 0,9, 91 = 0,1, ошибка первого рода а = 0,05 , ошибка второго рода р = 9,95 . По оси абсцисс откладывается количество шагов алгоритма – п, по оси ординат – О.
л
Бс
Рис 3. Зависимость количества распознанных сканеров Sc от выбора параметра к
°1 6 5 4 3 2 1 -Гипотеза #0 ^—Гипотеза Нх
-1 -2 2 4 е 8 п
Рис. 4. Процедура принятия решения для данного 1Р-адреса при ошибках первого и второго рода, равных 0,01
при ошибках первого и второго рода, равных 0,05
Сравнив рис. 4 и 5, можно сделать вывод, что при увеличении значений ошибок первого и второго рода расстояние между прямым Н0 и Н1 уменьшается, что логично, так как уменьшается точность алгоритма, это может привести к принятию неверной гипотезы, как видно из
рис. 5.
Теперь посмотрим, что происходит при других значениях 90 и 9t. Пусть 90 = 0,8, 9j = 9,2, а = 0,01, ß = 9,91. Для принятия решения при значениях 90 = 0,8 и 9j = 9,2 требуется большее число шагов, чем при значениях 90 = 0,9 и 9t = 0,1. Иначе говоря, уменьшение 90 и увеличение 9t ведет к росту числа шагов. Аналогичные выводы можно сделать, проанализировав формулы (2), оценивающие среднее число шагов.
Заключение
Безусловно, метод определения сканеров, предложенный в модели TRW [7], является перспективным, поскольку он базируется на математической теории, позволяющей определить ожидаемую эффективность соответствующего алгоритма, и не требует длительного первоначального изучения трафика. Подтверждением этого является появление моделей TRWSYN -TAPS [9] и модифицированной модели TAPS, в которые заложены эвристические предположения, отличные от [5].
Существуют пути улучшения характеристик модели TRW. Можно расширить эвристические предположения о поведении сканеров. Во-первых, определять параметры более консервативно для некоторых сервисов, например, http, так как http-сканер трудно отличить от http-proxy. Во-вторых, делать различие между попытками соединения, на которые получен отказ, и попытками, оставшимися без ответа, так как последние больше похожи на «выстрел в темноте». В-третьих, внести компоненты корреляции: считать две последовательных неудачных попытки соединения более подозрительным поведением, чем перемежающиеся попытки. Однако это приведет к усложнению алгоритма и может поставить под сомнение его эффективность.
Главным ограничением, заложенным в рассматриваемую методику, является предположение о независимости наблюдений. Например, количество устройств, ложно принятых за сканеры, было бы меньше, если учитывать факт, что сканеры чаще всего последовательно перебирают адреса подсетей, в отличие от активных хостов. В случае распределенного сканирования также нужно учитывать совместное распределение, что также значительно усложняет алгоритм.
В ряде работ предлагается решать задачу выявления сканеров с применением технологии Data Mining. Например, в [13] утверждается, что известные алгоритмы, в том числе и TRW,
который имеет статус state-of-the-art, страдают от большого числа ложных тревог, так как не отличают от сканирования p2p-трафик, трафик веб-поисковиков, а также backscatter traffic, когда, например, атакуемый сервер отвечает на DoS атаки по вымышленным адресам. Предлагается использовать классификатор для разделения потоков данных на четыре категории: SCAN, P2P, NORMAL, NOISE. Разделение делается на основании информации, полученной во время достаточно длительного наблюдения за трафиком, и ряда экспертных правил. Достоинства этой методики оцениваются с помощью метрик, эквивалентных производительности и эффективности. Например, в [13] сообщается, что характеристики алгоритма на базе Data Mining выше, чем у TRW.
Существуют подходы к созданию систем IDS, основанные на моделировании сетевого поведения, например, с помощью нейронных сетей. Примером может служить работа [14], где предлагаются методы обучения сети для выявления атак типа зондирование, DoS, u2r (user to root), r2l (remote to local). Применяются также и генетические алгоритмы. В работе [15] рассматривается применение такого алгоритма для дифференциации нормального и аномального сетевого соединения. Этот алгоритм использует предварительную информацию для построения множества правил, учитывающих различные сетевые параметры и применяемых системой обнаружения вторжения. Для защиты компьютерной системы используются также средства, имитирующие поведение биологической иммунной системы, так называемые иммунные алгоритмы, например [16].
Следует заметить, проблема интерпретации полученного ответа (адресов устройств из множества TRUESCAN) остается открытой. Можно блокировать эти адреса, например, как в системе Bro. Это применимо для небольших сетей, и в Bro имеется возможность указать, какие адреса никогда не следует блокировать. Отметим, что значительная часть этих адресов может оказаться фальшивой. Существует методика определения фальшивых адресов с помощью «ловушки» Honeypot 5, которая в ответ на попытку соединения предлагает источнику осуществить полную процедуру handshake, которая обычно не заканчивается, если адреса фальшивые. С помощью этой методики можно выявить неиспользуемые IP-адреса, однако это приводит к дополнительной нагрузке и, следовательно, к значительному увеличению времени работы алгоритма, что ставит под сомнение возможность его работы в режиме online. Видимо, следует классифицировать сканеры по степени их опасности и определить множество соответствующих порогов, о преодолении которых сообщать системному администратору сети, от которого зависят дальнейшие действия в рамках принятой политики сетевой безопасности.
Список литературы
1. Gordon L. NMAP Network Scanning: The Official NMAP Project Guide to Network Discovery and Security Scanning. 2009. P. 468.
2. Stamford S., Hoagland J. A., McAlerney J. M. Practical Automated Detection of Stealthy Portscans // Journal of Computer Security. 2002. Vol. 10, is. 1-2. P. 105-136.
3. Niedermayer D. An Introduction to Bayesian Networks and their Contemporary Application. URL: http://www.niedermayer.ca/papers/bayesian/bayes.html/
4. Kirkpatrick S., Gelatt C. D., Vecchi M. P. Optimization by Simulated Annealing // Science. 1983. Vol. 220. No. 4598. P. 671-680.
5. Jung J., Paxson V., Berger A. W., Balakrishnan H. Fast Portscan Detection Using Sequential Hypothesis Testing // Proceedings IEEE Symposium on Security and Privacy. 2004. P. 211-225.
6. Ertoz L., Eilertson E., Dokas P., Kumar V., Long K. Scan Detection – Revisited // Technical report AHPCRC 127, University of Minnesota – Twin Cities, 2004. P. 127.
7. Lekie C., Kotagiri R. A Probabilistic Approach to Detecting Network Scans // IEEE/IFIP Network Operations and Management Symposium (NOMS). 2002. P. 359-372.
8. Вальд А. Последовательный анализ. М., 1960. C. 328.
5 См.: http://www.dmoz.org/Computers/Security/Honeypots_and_Honeynets/
9. Sridharan A., Ye T., Bhattacharyya S. Connectionless Port Scan Detection on the Backbone // IEEE International Performance, Computing and Communications Conference (IPCCC). 2006. P.10-20.
10. Бредихин С. В., Щербакова Н. Г. Две компоненты анализа сетевого трафика // Вестн. Новосиб. гос. ун-та. Серия: Информационные технологии. 2008. Т. 6, вып. 1. C. 10-14.
11. СПД СО РАН. Сеть передачи данных Сибирского отделения РАН // Информационные материалы научно-координационного совета целевой программы «Информационно-телекоммуникационные ресурсы СО РАН». Новосибирск, 2005. C. 79.
12. Бредихин С. В., Ляпунов В. М., Щербакова Н. Г. Анализатор «сетевой погоды» // Вестн. Новосиб. гос. ун-та. Серия: Информационные технологии. 2005. Т. 2, вып. 1. C. 62-67.
13. Simon G. J., Hui Xiong, Eilerton E., Kumar V. Scan Detection: A Data Mining Approach // Sixth SIAM International Conference on Data Mining. 2006. P. 118-129.
14. Ray-I Chang, Liang-Bin Lai , Wen-De Su, Jen-Chieh Wang, Jen-Shiang Kouh. Intrusion Detection by Backpropagation Neural Networks with Sample-Query and Attribute-Query // International Journal of Computational Intelligence Research. 2007. Vol. 3. No. 1. P. 6-10.
15. Wei Li. Using Genetic Algorithm for Network Intrusion Detection // Proceedings of the United States Department of Energy Cyber Security Group 2004 Training Conference, Kansas City, Kansas, May 24-27, 2004.
16. Visconti A., Fusi N, Tahayori H. Intrusion Detection via Artificial Immune System: A Performance-based Approach // IFIP International Federation for Information Processing. 2008. Vol. 268. P. 125-135.
Материал поступил в редколлегию 28.10.2009
S. V. Bredikhin, V. I Kostin, N. G. Scherbakova SCAN DETECTION IN IP NETWORKS USING SEQUENTIAL HYPOTHESIS TESTING
The approaches to scan detection in IP networks are considered in the first part of the article. The information on the base methods used in the known intrusion detection systems Snort and Bro, and also applying of statistical models for anomalous traffic diagnostic is introduced. The special attention is given to a method of the sequential analysis and to models that use this method for scan detection. The algorithm for scan detection in IP networks is introduced in the second part of the article. The algorithm is based on the method of sequential hypothesis testing by A. Wald. The results of algorithm approbation in the Internet SB RAS environement are given. The performance evaluations are presented and algorithm capabilities depending on the parameters values are investigated.
Keywords: IP-based networks, address / port scanning, base systems Snort and Bro, statistical methods, sequential hypothesis testing by A. Wald, models TRW and TAPS, algorithm.
0
1
Может, в каком-то логе? Кстати, нашел нашего задрота-хакера Джулиана Ассанджа, создателя Викиликс, в холе славы сетевых сканеров.
Цитата
До возникновения идеи о создании программы Nmap были исследованы возможности многих сканеров, таких, как strobe (автор - Julian Assange), netcat (Hobbit), stcp (Uriel Maimon), pscan (Pulvius) ident-scan (Dave Goldsmith) и Satan (Wietse Venema)
Пруф
Кстати, миряне, сканирование – это противоправное деяние или нет?
Не понятно
- Ссылка
Вы не можете добавлять комментарии в эту тему. Тема перемещена в архив.
