Время на прочтение
5 мин
Количество просмотров 61K
Описание общей потребности в поиске данных и объектов в базе данных
Поиск данных, а также хранимых процедур, таблиц и других объектов в базе данных является достаточно актуальным вопросом в том числе и для C#-разработчиков, а также и для .NET-разработки в целом.
Достаточно часто может возникнуть ситуация, при которой нужно найти:
- объект базы данных (таблицу, представление, хранимую процедуру, функцию и т д)
- данные (значение и в какой таблице располагается)
- фрагмент кода в определениях объектов базы данных
Существует множество готовых решений как платных, так и бесплатных.
Сначала рассмотрим как можно осуществлять поиск данных и объектов в базе данных с помощью встроенных средств самой СУБД, а затем рассмотрим как это сделать с помощью бесплатной утилиты dbForge Search.
Поиск с помощью встроенных средств самой СУБД
Определить есть ли таблица Employee в базе данных можно с помощью следующего скрипта:
Поиск таблицы по имени
select [object_id], [schema_id],
schema_name([schema_id]) as [schema_name],
[name],
[type],
[type_desc],
[create_date],
[modify_date]
from sys.all_objects
where [name]='Employee';
Результат может быть примерно такой:

Здесь выводятся:
- идентификаторы объекта и схемы, где располагается объект
- название этой схемы и название этого объекта
- тип объекта и описание этого типа объекта
- даты и время создания и последней модификации объекта
Чтобы найти все вхождения строки “Project”, то можно использовать следующий скрипт:
Поиск всех объектов по подстроке в имени
select [object_id], [schema_id],
schema_name([schema_id]) as [schema_name],
[name],
[type],
[type_desc],
[create_date],
[modify_date]
from sys.all_objects
where [name] like '%Project%';
Результат может быть примерно такой:

Как видно из результата, здесь подстроку “Project” содержат не только две таблицы Project и ProjectSkill, но и также некоторые первичные и внешние ключи.
Чтобы понять кому именно принадлежат данные ключи, добавим в вывод поле parent_object_id и его имя и схему, в которой он располагается следующим образом:
Поиск всех объектов по подстроке в имени с выводом родительских объектов
select ao.[object_id], ao.[schema_id],
schema_name(ao.[schema_id]) as [schema_name],
ao.parent_object_id,
p.[schema_id] as [parent_schema_id],
schema_name(p.[schema_id]) as [parent_schema_name],
p.[name] as [parent_name],
ao.[name],
ao.[type],
ao.[type_desc],
ao.[create_date],
ao.[modify_date]
from sys.all_objects as ao
left outer join sys.all_objects as p on ao.[parent_object_id]=p.[object_id]
where ao.[name] like '%Project%';
Результатом будет вывод таблицы с детальной информацией о родительских объектах, т е где определены первичные и внешние ключи:

В запросах используются следующие системные объекты:
- таблица sys.all_objects
- скалярная функция schema_name
Итак, разобрали как найти объекты в базе данных с помощью встроенных средств самой СУБД.
Теперь покажем как найти данные в базе данных на примере поиска строк.
Чтобы найти строковое значение по всем таблицам базы данных, можно воспользоваться следующим решением. Упростим данное решение и покажем как можно найти например значение “Ramiro” с помощью следующего скрипта:
Поиск строковых значений по подстроке во всех таблицах базы данных
set nocount on
declare @name varchar(128), @substr nvarchar(4000), @column varchar(128)
set @substr = '%Ramiro%'
declare @sql nvarchar(max);
create table #rslt
(table_name varchar(128), field_name varchar(128), [value] nvarchar(max))
declare s cursor for select table_name as table_name from information_schema.tables where table_type = 'BASE TABLE' order by table_name
open s
fetch next from s into @name
while @@fetch_status = 0
begin
declare c cursor for
select quotename(column_name) as column_name from information_schema.columns
where data_type in ('text', 'ntext', 'varchar', 'char', 'nvarchar', 'char', 'sysname', 'int', 'tinyint') and table_name = @name
set @name = quotename(@name)
open c
fetch next from c into @column
while @@fetch_status = 0
begin
--print 'Processing table - ' + @name + ', column - ' + @column
set @sql='insert into #rslt select ''' + @name + ''' as Table_name, ''' + @column + ''', cast(' + @column +
' as nvarchar(max)) from' + @name + ' where cast(' + @column + ' as nvarchar(max)) like ''' + @substr + '''';
print @sql;
exec(@sql);
fetch next from c into @column;
end
close c
deallocate c
fetch next from s into @name
end
select table_name as [Table Name], field_name as [Field Name], count(*) as [Found Mathes] from #rslt
group by table_name, field_name
order by table_name, field_name
drop table #rslt
close s
deallocate s
Результат выполнения может быть таким:

Здесь выводятся имена таблиц и в каких столбцах хранится значение, содержащие подстроку “Ramiro”. А также количество найденных входов данной подстроки для найденной пары таблица-колонка.
Чтобы найти объекты, в определениях которых есть заданный фрагмент кода, можно воспользоваться следующими системными представлениями:
- sys.sql_modules
- sys.all_sql_modules
- sys.syscomments
Например, используя последнее представление, можно с помощью следующего скрипта найти все объекты, в определениях которых встречается заданный фрагмент кода:
Поиск фрагмента кода в определениях объектов базы данных
select obj.[object_id],
obj.[name],
obj.[type_desc],
sc.[text]
from sys.syscomments as sc
inner join sys.objects obj on sc.[id]=obj.[object_id]
where sc.[text] like '%code snippet%';
Здесь будет выведен идентификатор, название, описание и полное определение объекта.
Поиск с помощью бесплатной утилиты dbForge Search
Однако, более удобно поиск производить с помощью готовых хороших инструментов. Одним из таких инструментов является dbForge Search.
Для вызова этой утилиты в окне SSMS нажмите на кнопку  .
.
Появится следующее окно поиска:
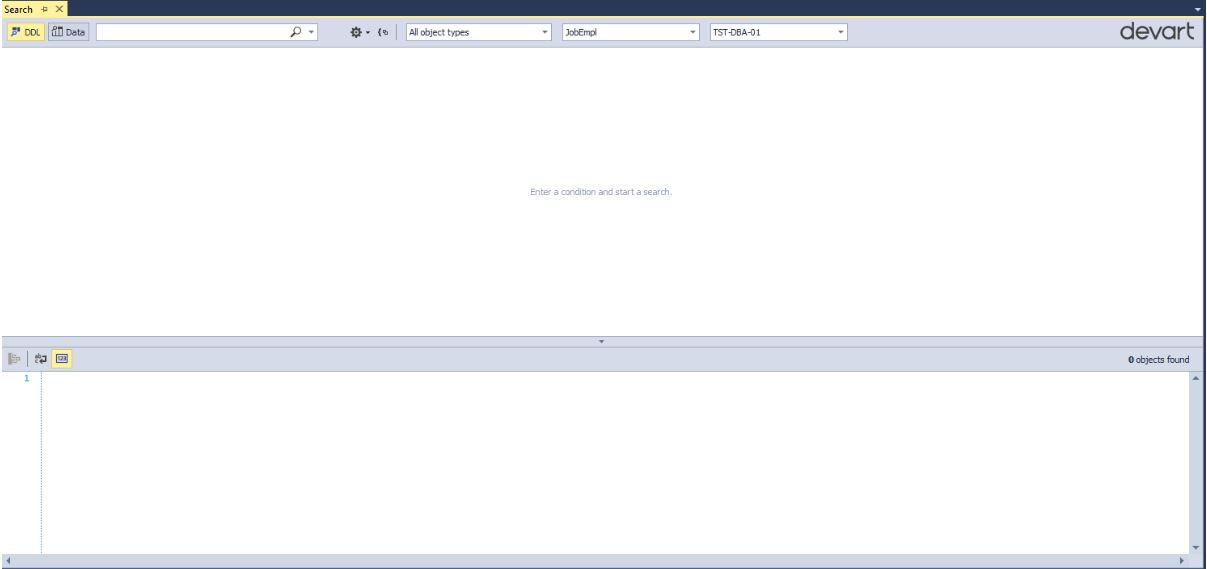
Обратите внимание на верхнюю панель (слева направо):
- можно переключать режим поиска (ищем DDL (объекты) или данные)
- непосредственно что ищем (какую подстроку)
- учитывать ли регистр, искать точное соответствие слову, искать вхождения:

- группировать результат по типам объектов — кнопка
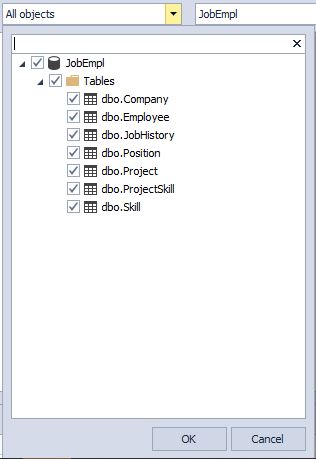
- выбрать нужные типы объектов для поиска:
- также можно задать несколько баз данных для поиска и выбрать экземпляр MS SQL Server
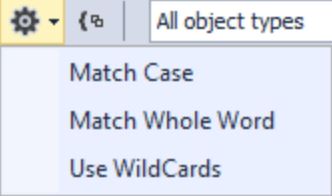

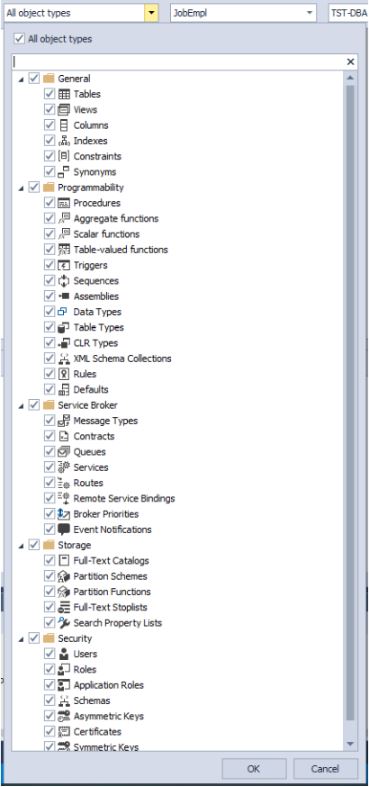
Это все в режиме поиска объектов, т е когда включен DDL:
В режиме поиска данных изменится только выбор типов объектов:
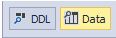
А именно будут доступны для выбора только таблицы, где и хранятся собственно сами данные:
Теперь как и раньше найдем все вхождения подстроки “Project” в названиях объектов:
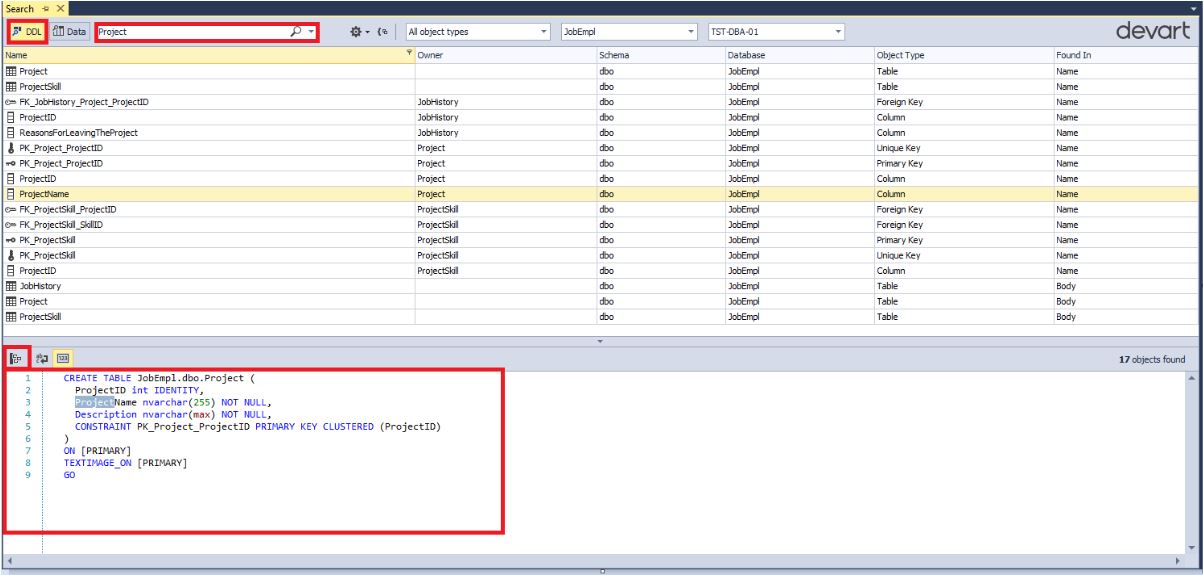
Как видно, был выбран режим поиска по DDL-объектам, заполнено что ищем-строка “Project”, остальное все было по умолчанию.
При выделении найденного объекта внизу отображается код определения данного объекта или всего его родительского объекта.
Также можно переместить навигацию на найденный объект, щелкнув на кнопку  :
:
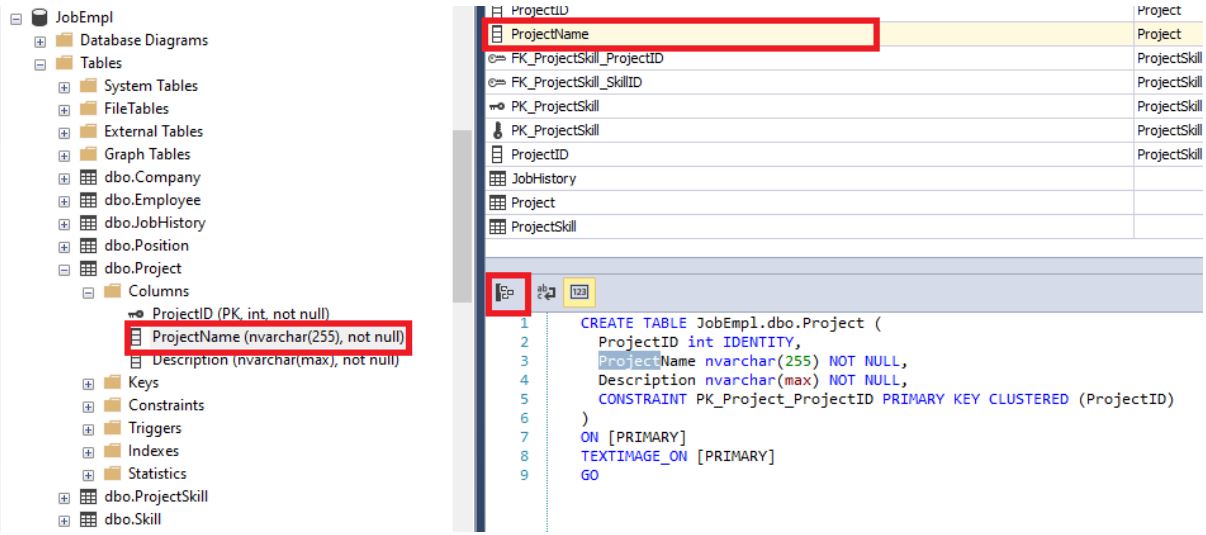
Можно также сгруппировать найденные объекты по их типу:
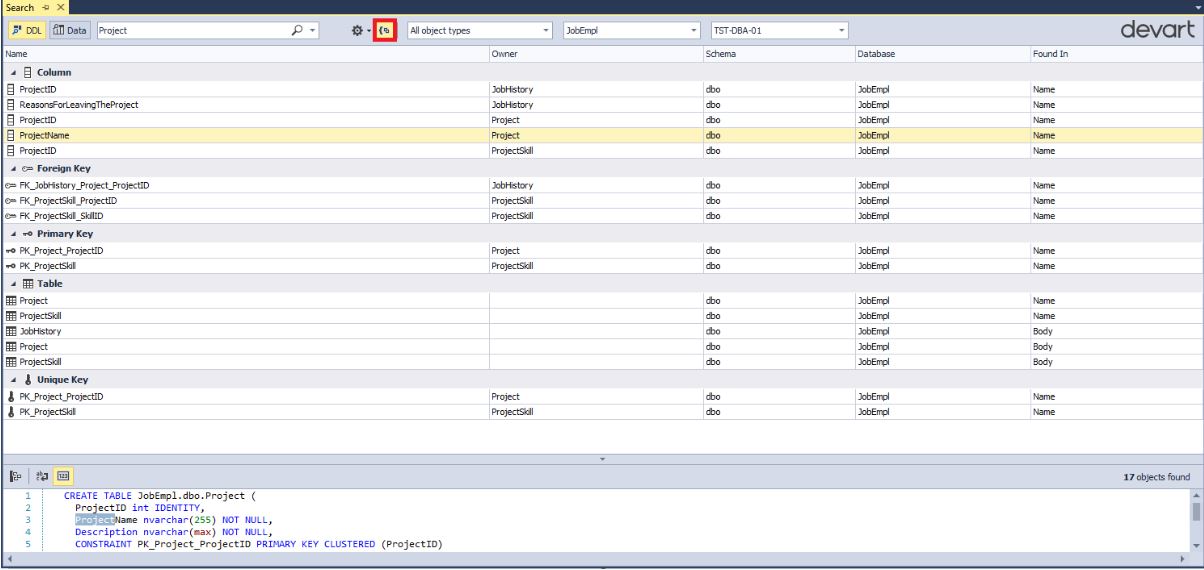
Обратите внимание, что выводятся даже те таблицы, в которых есть поля, в именах которых содержится подстрока “Project”. Однако, напомним, что режим поиска можно менять: искать полное соответствие/частичное/учитывать регистр или нет.
Теперь найдем значение “Ramiro” по всем таблицам:
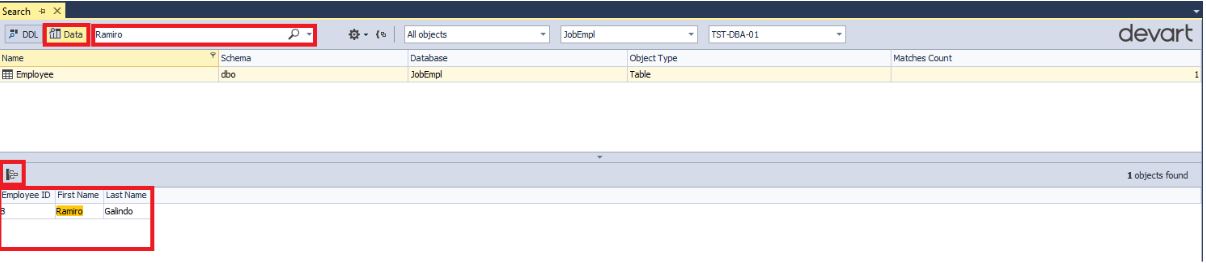
Обратите внимание, что внизу отображаются все строки, в которых содержится подстрока “Ramiro” выбранной таблицы Employee.
Также можно переместить навигацию к найденному объекту, нажав как и ранее на кнопку :
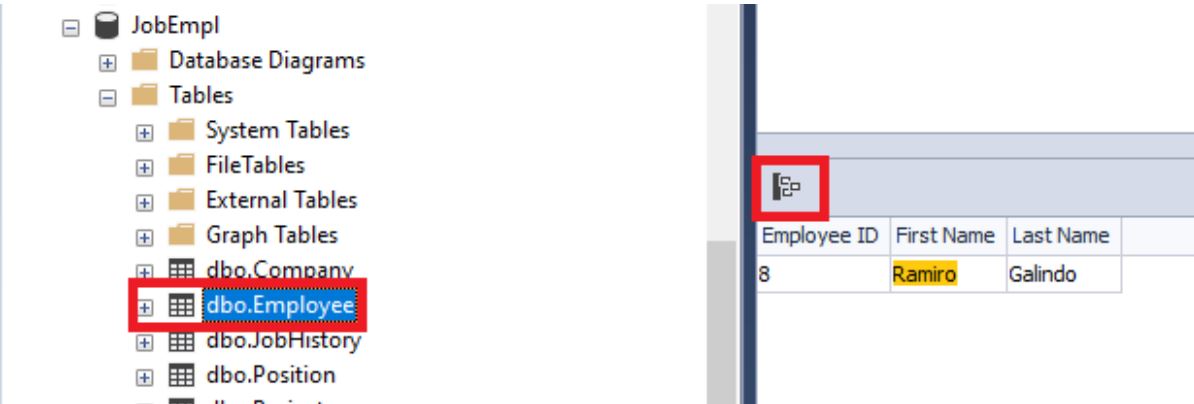
Таким образом мы можем искать нужные объекты и данные в базе данных.
Заключение
Были рассмотрены способы поиска как самих данных, так и объектов в базе данных как с помощью встроенных средств самой СУБД MS SQL Server, так и с помощью бесплатной утилиты dbForge Search.
Также от компании Devart есть и ряд других бесплатных готовых решений, полный список которых можно посмотреть здесь.
Источники
- Search_Script.sql
- SSMS
- dbForge Search
- Документация по Microsoft SQL
- Бесплатные решения от компании Devart
There are lots of workable answers already. Just thought I would add one I came up with that has a lot of optional funcionality.
--=======================================================================
-- MSSQL Unified Search
-- Minimum compatibility level = 130 (SQL Server 2016)
-- NOTE: The minimum compatibility level is required by the built-in STRING_SPLIT() function.
-- However, you can create the STRING_SPLIT() function at the bottom of this script for
-- lower versions of MSSQL Server.
--
-- Usage:
-- Set the parameters below and execute this script.
--
/************************ Enter Parameters Here ************************/
/**/
/**/ DECLARE @SearchString VARCHAR(1000) = 'string to search for'; -- Accepts SQL wilcards
/**/
/**/ DECLARE @IncludeUserTables BIT = 1;
/**/ DECLARE @IncludeViews BIT = 0;
/**/ DECLARE @IncludeStoredProcedures BIT = 0;
/**/ DECLARE @IncludeFunctions BIT = 0;
/**/ DECLARE @IncludeTriggers BIT = 0;
/**/
/**/ DECLARE @DebugMode BIT = 0;
/**/ DECLARE @ExcludeColumnTypes NVARCHAR(500) = 'text, ntext, char, nchar, timestamp, bigint, tinyint, smallint, bit, date, time, smalldatetime, datetime, datetime2, real, money, float, decimal, binary, varbinary, image'; -- Comma delimited list
/**/
/***********************************************************************/
SET NOCOUNT ON;
SET @SearchString = QUOTENAME(@SearchString,'''');
DECLARE @Results TABLE ([ObjectType] NVARCHAR(200), [ObjectName] NVARCHAR(200), [ColumnName] NVARCHAR(400), [Value] NVARCHAR(MAX), [SelectStatement] NVARCHAR(1000));
DECLARE @ExcludeColTypes TABLE (system_type_id INT);
INSERT INTO @ExcludeColTypes ([system_type_id])
SELECT [system_type_id]
FROM sys.types WHERE
[name] IN (
SELECT LTRIM(RTRIM([value])) FROM STRING_SPLIT(@ExcludeColumnTypes,',')
);
DECLARE @ObjectType NVARCHAR(200);
DECLARE @ObjectName NVARCHAR(200);
DECLARE @Value NVARCHAR(MAX);
DECLARE @SelectStatement NVARCHAR(1000);
DECLARE @Query NVARCHAR(4000);
/********************* Table Objects *********************/
IF (@IncludeUserTables = 1)
BEGIN
DECLARE @TableObjectId INT = (SELECT MIN([object_id]) FROM sys.tables);
DECLARE @ColumnId INT;
WHILE @TableObjectId IS NOT NULL
BEGIN
SELECT @ObjectType = 'USER TABLE';
SELECT @ObjectName = '[' + SCHEMA_NAME([schema_id]) + '].[' + OBJECT_NAME(@TableObjectId) + ']' FROM sys.tables WHERE [object_id] = @TableObjectId;
SET @ColumnId = (SELECT MIN([column_id]) FROM sys.columns WHERE [system_type_id] NOT IN (SELECT [system_type_id] FROM @ExcludeColTypes) AND [object_id] = @TableObjectId);
WHILE @ColumnId IS NOT NULL
BEGIN
SELECT @Value = '[' + [name] +']' FROM sys.columns WHERE [object_id] = @TableObjectId AND column_id = @ColumnId;
SET @SelectStatement = 'SELECT * FROM ' + @ObjectName + ' WHERE CAST(' + @Value + ' AS NVARCHAR(4000)) LIKE ' + @SearchString + ';';
SET @Query = 'SELECT '
+ QUOTENAME(@ObjectType, '''')
+ ', ' + QUOTENAME(@ObjectName, '''')
+ ', ' + QUOTENAME(@Value, '''')
+ ', ' + @Value
+ ', ''' + REPLACE(@SelectStatement,'''','''''') + ''''
+ ' FROM ' + @ObjectName
+ ' WHERE CAST(' + @Value + ' AS NVARCHAR(4000)) LIKE ' + @SearchString + ';';
IF @DebugMode = 0
BEGIN
INSERT INTO @Results EXEC(@Query);
END;
ELSE
BEGIN
PRINT 'Select Statement: ' + @SelectStatement;
PRINT 'Query: ' + @Query;
END;
SET @ColumnId = (SELECT MIN([column_id]) FROM sys.columns WHERE [system_type_id] NOT IN (SELECT [system_type_id] FROM @ExcludeColTypes) AND [object_id] = @TableObjectId AND [column_id] > @ColumnId);
END;
SET @TableObjectId = (SELECT MIN([object_id]) FROM sys.tables WHERE [object_id] > @TableObjectId);
END;
END;
/********************* Objects Other than Tables *********************/
SET @Query = 'SELECT ' +
'ObjectType = CASE ' +
'WHEN b.[type] = ''V'' THEN ''VIEW'' ' +
'WHEN b.[type] = ''P'' THEN ''STORED PROCEDURE'' ' +
'WHEN b.[type] = ''FN'' THEN ''SCALAR-VALUED FUNCTION'' ' +
'WHEN b.[type] = ''IF'' THEN ''TABLE-VALUED FUNCTION'' ' +
'WHEN b.[type] = ''TR'' THEN ''TRIGGER'' ' +
'END ' +
',[ObjectName] = ''['' + SCHEMA_NAME(b.[schema_id]) + ''].['' + OBJECT_NAME(a.[object_id]) + '']'' ' +
',[ColumnName] = NULL ' +
',[Value] = a.[definition] ' +
',[SelectStatement] = ''SP_HELPTEXT '' + QUOTENAME(''['' + SCHEMA_NAME(b.[schema_id]) + ''].['' + OBJECT_NAME(a.[object_id]) + '']'','''''''') + '';'' ' +
'FROM [sys].[sql_modules] a ' +
'JOIN [sys].[objects] b ON a.[object_id] = b.[object_id] ' +
'WHERE ' +
'( ' +
' a.[definition] LIKE ' + @SearchString +
') ' +
'AND ' +
'( ' +
' ( ' +
CAST(@IncludeViews AS VARCHAR(1)) + ' = 1 ' +
' AND ' +
' b.[type] IN (''V'') ' +
' ) ' +
' OR ' +
' ( ' +
CAST(@IncludeStoredProcedures AS VARCHAR(1)) + ' = 1 ' +
' AND ' +
' b.[type] IN (''P'') ' +
' ) ' +
' OR ' +
' ( ' +
CAST(@IncludeFunctions AS VARCHAR(1)) + ' = 1 ' +
' AND ' +
' b.[type] IN (''FN'',''IF'') ' +
' ) ' +
' OR ' +
' ( ' +
CAST(@IncludeTriggers AS VARCHAR(1)) + ' = 1 ' +
' AND ' +
' b.[type] IN (''TR'') ' +
' ) ' +
'); ';
IF @DebugMode = 0
BEGIN
INSERT INTO @Results EXEC(@Query);
END;
ELSE
BEGIN
PRINT 'Select Statement: ' + @SelectStatement;
PRINT 'Query: ' + @Query;
END;
IF @DebugMode = 0
BEGIN
SELECT
[ObjectType]
,[ObjectName]
,[ColumnName]
,[Value]
,[Count] = CASE
WHEN [ObjectType] IN ('USER TABLE') THEN COUNT(1)
ELSE NULL
END
,[SelectStatement]
FROM @Results
GROUP BY [ObjectType], [ObjectName], [ColumnName], [Value], [SelectStatement]
ORDER BY [Value];
END;
/********************** STRING_SPLIT() FUNCTION **********************
CREATE FUNCTION STRING_SPLIT (
@Expression nvarchar(4000)
,@Delimiter nvarchar(100)
)
RETURNS @Ret TABLE ([value] NVARCHAR(4000))
AS
BEGIN
DECLARE @Start INT = 0, @End INT, @Length INT;
SELECT @End = CHARINDEX(@Delimiter,@Expression), @Length = @End - @Start;
IF @End <= 0
BEGIN
INSERT INTO @Ret ([value]) VALUES (@Expression);
END
ELSE
BEGIN
WHILE @Length >= 0
BEGIN
INSERT INTO @Ret ([value])
SELECT ltrim(rtrim(substring(@Expression,@Start,@Length)));
SELECT @Start = @End + LEN(@Delimiter)
SELECT @End = CHARINDEX(@Delimiter,@Expression,@Start)
IF @End < 1
SELECT @End = LEN(@Expression) + 1;
SELECT @Length = @End - @Start;
END;
END;
RETURN;
END;
*********************************************************************/
24 июня, 2022 12:23 пп
483 views
| Комментариев нет
mySQL
Structured Query Language, более известный как SQL, обеспечивает большую гибкость с точки зрения вставки данных в таблицы. Например, вы можете вставлять отдельные строки данных с помощью ключевого слова VALUES, копировать целые наборы данных из существующих таблиц с помощью запросов SELECT, а также определять столбцы таким образом, чтобы SQL автоматически вставлял в них данные.
В этом материале вы узнаете, как использовать синтаксис INSERT INTO для добавления данных в таблицы с помощью каждого из перечисленных выше средств.
Требования
Чтобы следовать этому руководству, вам понадобится любая машина с установленной системой управления реляционными базами данных (RDBMS), которая использует SQL. Инструкции и примеры в этом руководстве были выполнены на основе следующей среды:
- Сервер Ubuntu 20.04 + пользователь с правами администратора и брандмауэр UFW (настройка такого сервера описана в этом руководстве).
- Защищенная копия MySQL на сервере (инструкции вы найдете в мануале Установка MySQL в Ubuntu 20.04).
Примечание: Обратите внимание, что многие СУБД используют собственные уникальные реализации SQL. Команды, описанные в этом руководстве, будут работать правильно на большинстве СУБД, однако точный синтаксис или вывод могут отличаться, если вы тестируете их не в MySQL, а в другой системе.
Вам также понадобится база данных и таблица, на которых вы сможете попрактиковаться. Если у вас их нет, вы можете выполнить следующий раздел мануала.
Подключение к MySQL и создание тестовой базы данных
Если ваша БД SQL работает на удаленном сервере, подключитесь к серверу по SSH с локального компьютера:
ssh 8host@your_server_ip
Затем откройте командную строку MySQL, заменив 8host именем вашей учетной записи пользователя MySQL.
mysql -u 8host -p
Создайте базу данных по имени insertDB:
CREATE DATABASE insertDB;
Если база данных была создана успешно, вы получите такой вывод:
Query OK, 1 row affected (0.01 sec)
Чтобы выбрать базу данных insertDB, выполните следующую команду USE:
USE insertDB;
Вы увидите вывод:
Database changed
После выбора базы данных insertDB создайте в ней таблицу. Давайте для примера предположим, что у вас есть фабрика и вы хотите создать таблицу для хранения информации о ваших сотрудниках. Эта таблица будет включать в себя следующие пять столбцов:
- name: имя каждого сотрудника, выраженное при помощи типа данных varchar, не более 30 символов.
- position: в этом столбце будет храниться должность каждого сотрудника, опять же выраженная с помощью типа данных varchar с максимальным количеством символов 30.
- department: отдел, в котором работает каждый сотрудник, выраженный с помощью типа данных varchar, не более 20 символов.
- hourlyWage: столбец для записи почасовой заработной платы каждого сотрудника, в нем используется тип данных decimal, при этом любые значения в этом столбце ограничены до четырех цифр, причем две из этих цифр находятся справа от запятой. Таким образом, диапазон допустимых значений в этом столбце составляет от -99,99 до 99,99.
- startDate: дата приема на работу каждого сотрудника, выраженная с помощью типа данных date. Значения этого типа должны соответствовать формату YYYY-MM-DD.
Создайте таблицу factoryEmployees, которая будет включать эти пять столбцов:
CREATE TABLE factoryEmployees ( name varchar(30), position varchar(30), department varchar(20), hourlyWage decimal(4,2), startDate date );
Теперь можно приступать к выполнению остальной части руководства.
Вставка данных вручную
Общий синтаксис для вставки данных в SQL выглядит следующим образом:
INSERT INTO table_name (column1, column2, . . . columnN) VALUES (value1, value2, . . . valueN);
Чтобы протестировать это, запустите следующую команду INSERT INTO, она загрузит таблицу factoryEmployees с одной строкой данных:
INSERT INTO factoryEmployees
(name, position, department, hourlyWage, startDate)
VALUES
('Agnes', 'thingamajig foreman', 'management', 26.50, '2017-05-01');
Вывод выглядит так:
Query OK, 1 row affected (0.00 sec)
Этот оператор начинается с ключевых слов INSERT INTO, за которыми следует имя таблицы, в которую вы хотите вставить данные. За именем таблицы следует список столбцов, в которые оператор добавит данные, заключенные в круглые скобки. После списка столбцов идет ключевое слово VALUES, а затем набор значений, заключенных в круглые скобки и разделенных запятыми.
Порядок, в котором вы перечисляете столбцы, не имеет значения. Важно помнить следующее: порядок значений, которые вы предоставляете, обязательно должен совпадать с порядком столбцов. SQL всегда будет пытаться вставить первое заданное значение в первый столбец списка, второе значение — во второй столбец и так далее. Для иллюстрации введите следующий оператор INSERT. Он добавляет еще одну строку данных, но перечисляет данные в другом порядке:
INSERT INTO factoryEmployees
(department, hourlyWage, startDate, name, position)
VALUES
('production', 15.59, '2018-04-28', 'Jim', 'widget tightener');
Вывод:
Query OK, 1 row affected (0.00 sec)
Если вы неправильно разместите значения, SQL может ввести ваши данные в неправильные столбцы. Кроме того, если какое-либо из значений конфликтует с типом данных столбца, возникнет ошибка, как в этом примере:
INSERT INTO factoryEmployees
(name, hourlyWage, position, startDate, department)
VALUES
('Louise', 'doodad tester', 16.50, '2017-05-01', 'quality assurance');
Ошибка выглядит так:
ERROR 1366 (HY000): Incorrect decimal value: 'doodad tester' for column 'hourlyWage' at row 1
Имейте в виду: вы должны указать значение для каждого созданного вами столбца; однако ведь не все столбцы будут иметь свое значение в каждой строке. Если ни один из пропущенных столбцов не имеет ограничения, которое могло бы вызвать ошибку в этом случае (например, NOT NULL), MySQL добавит NULL вместо любых пропущенных значений:
INSERT INTO factoryEmployees
(name, position, hourlyWage)
VALUES
('Harry', 'whatzit engineer', 26.50);
Вы получите такой вывод:
Query OK, 1 row affected (0.01 sec)
Если строка, которую вы вводите, содержит значения для каждого столбца в таблице, вам вообще не нужно включать имена столбцов. Имейте в виду, что введенные вами значения должны соответствовать порядку, в котором столбцы были определены в самой таблице.
В этом примере перечисленные значения соответствуют порядку, в котором определены столбцы в таблице:
INSERT INTO factoryEmployees
VALUES
('Marie', 'doodad welder', 'production', 27.88, '2018-03-29');
Вывод:
Query OK, 1 row affected (0.00 sec)
Вы также можете добавить сразу несколько записей, разделив все строки запятыми, например:
INSERT INTO factoryEmployees
VALUES
('Giles', 'gizmo inspector', 'quality assurance', 26.50, '2019-08-06'),
('Daphne', 'gizmo presser', 'production', 32.45, '2017-11-12'),
('Joan', 'whatzit analyst', 'quality assurance', 29.00, '2017-04-29');
Вывод:
Query OK, 3 rows affected (0.00 sec) Records: 3 Duplicates: 0 Warnings: 0
Копирование данных с помощью оператора SELECT
Чтобы не указывать данные построчно, вы можете скопировать несколько строк данных из одной таблицы и вставить их в другую с помощью запроса SELECT.
Синтаксис такой операции выглядит следующим образом:
INSERT INTO table_A (col_A1, col_A2, col_A3) SELECT col_B1, col_B2, col_B3 FROM table_B;
Вместо ключевого слова VALUES, которое обычно идет за списком столбцов, в этом примере за ним следует оператор SELECT. Оператор SELECT в этом примере включает только оператор FROM, но он может обработать любой допустимый запрос.
Выполните следующую операцию CREATE TABLE, чтобы создать новую таблицу showroomEmployees. Обратите внимание, что столбцы этой таблицы имеют те же имена и типы данных, что и в таблице factoryEmployees, которую мы создали в предыдущем разделе:
CREATE TABLE showroomEmployees ( name varchar(30), hourlyWage decimal(4,2), startDate date );
Вывод:
Query OK, 0 rows affected (0.02 sec)
Теперь вы можете загрузить в эту новую таблицу некоторые данные из таблицы factoryEmployees, которую создали ранее, включив запрос SELECT в INSERT INTO.
Если запрос SELECT возвращает то же количество столбцов в том же порядке, что и столбцы целевой таблицы, и они имеют совместимые (или совпадающие) типы данных, вы можете опустить список столбцов в операторе INSERT INTO:
INSERT INTO showroomEmployees SELECT factoryEmployees.name, factoryEmployees.hourlyWage, factoryEmployees.startDate FROM factoryEmployees WHERE name = 'Agnes';
Вывод выглядит так:
Query OK, 1 row affected (0.01 sec) Records: 1 Duplicates: 0 Warnings: 0
Примечание: Каждому из столбцов, перечисленных в запросе SELECT этой операции, предшествует имя таблицы factoryEmployees и точка. Когда вы указываете имя таблицы при ссылке на такой столбец, это называется fully qualified column reference. В данном конкретном случае это делать не обязательно. На самом деле следующий оператор INSERT INTO даст тот же результат, что и предыдущий:
INSERT INTO showroomEmployees SELECT name, hourlyWage, startDate FROM factoryEmployees WHERE name = 'Agnes';
В примерах данного раздела для ясности используются полные (fully qualified) ссылки на столбцы, что на практике может стать хорошей и полезной привычкой. Подобные ссылки не только помогут упростить понимание и устранение неполадок в SQL, но и пригодятся в некоторых операциях, которые ссылаются на более чем одну таблицу (это, например, запросы, включающие предложения JOIN).
Оператор SELECT в этой операции включает опцию WHERE, благодаря которой запрос возвращает только строки из таблицы factoryEmployees, чей столбец name содержит значение Agnes. Поскольку в исходной таблице есть только одна такая строка, только именно она будет скопирована в таблицу showroomEmployees.
Выполните следующий проверочный запрос, чтобы извлечь все записи в таблице showroomEmployees:
SELECT * FROM showroomEmployees;
Вы получите такой результат:
+-------+------------+------------+ | name | hourlyWage | startDate | +-------+------------+------------+ | Agnes | 26.50 | 2017-05-01 | +-------+------------+------------+ 1 row in set (0.00 sec)
Вы можете вставить несколько строк данных через любой запрос, который вернет более одной строки из исходной таблицы. Например, следующий запрос вернет каждую запись из БД factoryEmployees, в которой значение в столбце name не начинается с буквы J:
INSERT INTO showroomEmployees SELECT factoryEmployees.name, factoryEmployees.hourlyWage, factoryEmployees.startDate FROM factoryEmployees WHERE name NOT LIKE 'J%';
Вы получите:
Query OK, 5 rows affected (0.01 sec) Records: 5 Duplicates: 0 Warnings: 0
Запустите этот запрос еще раз, чтобы получить все записи в таблице showroomEmployees:
SELECT * FROM showroomEmployees;
Результат выглядит так:
+--------+------------+------------+ | name | hourlyWage | startDate | +--------+------------+------------+ | Agnes | 26.50 | 2017-05-01 | | Agnes | 26.50 | 2017-05-01 | | Harry | 26.50 | NULL | | Marie | 27.88 | 2018-03-29 | | Giles | 26.50 | 2019-08-06 | | Daphne | 32.45 | 2017-11-12 | +--------+------------+------------+ 6 rows in set (0.00 sec)
Обратите внимание на две одинаковые строки со значением Agnes. Каждый раз, когда вы запускаете INSERT INTO вместе с SELECT, SQL обрабатывает результаты запроса как новый набор данных. Если вы не наложите определенные ограничения на свою таблицу или не разработаете более детализированные запросы, при добавлении данных в таблицу они частично будут повторяться.
Автоматическая вставка данных
Создавая таблицу, вы можете применить к столбцам определенные атрибуты, которые заставят СУБД автоматически заполнить их данными.
Чтобы проиллюстрировать это, запустите следующую команду. Она создаст таблицу interns, которая включает в себя три столбца. Первый столбец, internID, содержит данные типа int. Однако обратите внимание, что он также включает атрибут AUTO_INCREMENT. С его помощью SQL будет автоматически генерировать уникальное числовое значение для каждой новой строки, начиная с 1 (по умолчанию) и увеличивая его на 1 с каждой последующей записью.
Второй столбец, department, включает ключевое слово DEFAULT. С его помощью СУРБД автоматически вставит значение по умолчанию — в этом примере мы используем ‘production’ — если вы не укажете department в списке столбцов оператора INSERT INTO:
CREATE TABLE interns ( internID int AUTO_INCREMENT PRIMARY KEY, department varchar(20) DEFAULT 'production', name varchar(30) );
Примечание: Атрибут AUTO_INCREMENT — это специфичная функция MySQL, многие другие СУБД имеют собственный метод увеличения целых чисел. Чтобы лучше понять, как ваша СУБД управляет автоматическим счетом, рекомендуем обратиться к ее официальной документации.
Здесь мы собрали для вас список документаций нескольких популярных БД с открытым исходным кодом:
- Документация MySQL по атрибуту AUTO_INCREMENT
- Документация PostgreSQL по последовательным типам данных
- Документация SQLite по Autoincrement
Чтобы продемонстрировать работу этих функций, мы заполним таблицу interns некоторыми данными, выполнив следующую команду INSERT INTO. Эта операция задает значения только для столбца name:
INSERT INTO interns (name) VALUES ('Pierre'), ('Sheila'), ('Francois');
Вы получите такой вывод:
Query OK, 3 rows affected (0.01 sec) Records: 3 Duplicates: 0 Warnings: 0
Затем запустите этот запрос, чтобы вернуть каждую запись из таблицы:
SELECT * FROM interns;
Вы получите такой результат:
+----------+------------+----------+ | internID | department | name | +----------+------------+----------+ | 1 | production | Pierre | | 2 | production | Sheila | | 3 | production | Francois | +----------+------------+----------+ 3 rows in set (0.00 sec)
Результат показывает, что из-за определений столбцов предыдущая команда INSERT INTO добавила значения как в internID, так и в department, хотя мы не указывали их.
Чтобы добавить в столбец department нестандартное значение, вам нужно будет указать его в операторе INSERT INTO, например, так:
INSERT INTO interns (name, department)
VALUES
('Jacques', 'management'),
('Max', 'quality assurance'),
('Edith', 'management'),
('Daniel', DEFAULT);
Результат выглядит так:
Query OK, 4 rows affected (0.00 sec) Records: 4 Duplicates: 0 Warnings: 0
Обратите внимание, последняя строка значений в этом примере вместо строкового значения включает ключевое слово DEFAULT. Благодаря этому БД вставит значение по умолчанию (‘production’):
SELECT * FROM interns;
Результат выглядит так:
+----------+-------------------+----------+ | internID | department | name | +----------+-------------------+----------+ | 1 | production | Pierre | | 2 | production | Sheila | | 3 | production | Francois | | 4 | management | Jacques | | 5 | quality assurance | Max | | 6 | management | Edith | | 7 | production | Daniel | +----------+-------------------+----------+ 7 rows in set (0.00 sec)
Итоги
Прочитав это руководство, вы узнали о нескольких различных способах вставки данных в таблицу: это определение отдельных строк данных с помощью ключевого слова VALUES, копирование целых наборов данных с помощью запросов SELECT и определение столбцов, в которые SQL будет автоматически вставлять данные.
Описанные здесь команды будут работать в любой СУБД на основе SQL. Однако имейте в виду, что каждая база данных SQL использует свою собственную уникальную реализацию языка, поэтому для получения более полного описания оператора INSERT INTO и его параметров вам следует обратиться к официальной документации вашей СУБД.
Читайте также: Как работать с ограничениями в SQL
Tags: MySQL, SQL, Ubuntu 20.04
Очень часто разработчики и администраторы БД сталкиваются с задачей поиска в базе данных всех упоминаний какого-либо объекта, столбца, переменной или поиск всех таблиц, где встречается искомое значение. Если вам приходилось решать подобную проблему, то вы знаете, что это ни самая тривиальная задача и Ctrl+F здесь не поможет.
Готового решения нет ни в SQL Server Management Studio ни в Visual Studio, вот несколько сценариев, которые вы можете использовать:
Поиск данных в таблицах и представлениях
Есть много реализаций на T-SQL поиска данных по всем таблицам с просмотром всех столбцов и это не самая оптимальная реализация, так как везде используется перебор в курсоре системных представлений.
DECLARE @SearchText varchar(200), @Table varchar(100), @TableID int, @ColumnName varchar(100), @String varchar(1000); SET @SearchText = 'John'; DECLARE CursorSearch CURSOR FOR SELECT name, object_id FROM sys.objects WHERE type = 'U'; OPEN CursorSearch; FETCH NEXT FROM CursorSearch INTO @Table, @TableID; WHILE @@FETCH_STATUS = 0 BEGIN DECLARE CursorColumns CURSOR FOR SELECT name FROM sys.columns WHERE object_id = @TableID AND system_type_id IN(167, 175, 231, 239); OPEN CursorColumns; FETCH NEXT FROM CursorColumns INTO @ColumnName; WHILE @@FETCH_STATUS = 0 BEGIN SET @String = 'IF EXISTS (SELECT * FROM ' + @Table + ' WHERE ' + @ColumnName + ' LIKE ''%' + @SearchText + '%'') PRINT ''' + @Table + ', ' + @ColumnName + ''''; EXECUTE (@String); FETCH NEXT FROM CursorColumns INTO @ColumnName; END; CLOSE CursorColumns; DEALLOCATE CursorColumns; FETCH NEXT FROM CursorSearch INTO @Table, @TableID; END; CLOSE CursorSearch; DEALLOCATE CursorSearch;
У этого решения есть много недостатков:
- Использование курсоров, а это, как правило неэффективный код
- Сложный запрос, который медленно работает даже на небольших базах данных
- Поиск работает только по текстовым данным, поэтому для поиска, например, даты потребуется доработка
Поиск объектов
Поиск объектов в БД по имени или их упоминание в других объектах немного проще, чем поиск определённого текста. Есть так же несколько разных сценариев поиска, но все их объединяет одно: обращение к системным объектам.
Во всех следующих сценариях осуществляется поиск переменной @StartProductID в хранимых процедурах. Но скрипты можно использовать и для поиска в других объектах – в триггерах, функциях, столбцах и т.д.
INFORMATION_SCHEMA.ROUTINES
Системное представление INFORMATION_SCHEMA.ROUTINES позволяет найти любой параметр, встречающийся в процедурах или функциях. Колонка ROUTINE_DEFINITION содержит полный текст объекта, который был указан при его создании.
SELECT ROUTINE_NAME, ROUTINE_DEFINITION FROM INFORMATION_SCHEMA.ROUTINES WHERE ROUTINE_DEFINITION LIKE '%@StartproductID%' AND ROUTINE_TYPE='PROCEDURE'
Результат работы запроса:

Не используйте представления INFORMATION_SCHEMA, чтобы определить схему объекта. Единственный надежный способ найти схему объекта — выполнить запрос к представлению каталога sys.objects.
Представление sys.syscomments
Содержит записи для всех представлений, правил, значений по умолчанию, триггеров, ограничений CHECK и DEFAULT, а также для всех хранимых процедур в базе данных. Столбец text содержит инструкции исходных определений SQL.
SELECT OBJECT_NAME( id ) FROM SYSCOMMENTS WHERE text LIKE '%@StartProductID%' AND OBJECTPROPERTY(id , 'IsProcedure') = 1 GROUP BY OBJECT_NAME( id );
Результат:
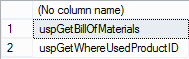
Этот метод не желательно использовать, так как в будущих версиях SQL Server представление sys.syscomments будет удалено.
Представление sys.sql_modules
Содержит по одной строке для каждого объекта, являющегося модулем, определенным на языке SQL в SQL Server.
SELECT OBJECT_NAME( object_id ) FROM sys.sql_modules WHERE OBJECTPROPERTY(object_id , 'IsProcedure') = 1 AND definition LIKE '%@StartProductID%';
Результат такой же, как в предыдущем способе:
Другие представления информационной схемы
Запрос к представлениям sys.syscomments, sys.schemas и sys.objects. Представление sys.schemas содержит информацию обо всех схемах внутри базы данных. В представление sys.objects содержится информация обо всех объектах базы данных. Обратите внимание, что для поиска информации о триггерах необходимо просматривать отдельное представление sys.triggers.
DECLARE @searchString nvarchar( 50 ); SET@searchString = '@StartProductID'; SELECT DISTINCT s.name AS Schema_Name , O.name AS Object_Name , C.text AS Object_Definition FROM syscomments C INNER JOIN sys.objects O ON C.id = O.object_id INNER JOIN sys.schemas S ON O.schema_id = S.schema_id WHERE C.text LIKE '%' + @searchString + '%' OR O.name LIKE '%' + @searchString + '%' ORDER BY Schema_name , Object_name;
Полученный результат:

Основным недостатком данных методов поиска является то, что для поиска каждого нового типа объектов необходимо вносить в скрипты изменения. Чтобы сделать это вы должны хорошо понимать внутреннюю организацию и структуру системных объектов SQL Server. Кроме того, нужно позаботиться об обработке различных ошибок и исключений, например, связанных с поиском строк, содержащих экранирующие символы.
Если вы не являетесь опытным разработчиком, не знакомы с внутренним устройством хранения DDL информации объектов БД или предпочитаете использовать проверенное и безошибочное решение, то начните использовать ApexSQL Search.
ApexSQL Search – это надстройка (ADD-IN) для SSMS и Visual Studio, которая позволяет искать любой текст в объектах базы данных (в том числе имена объектов), данные, хранящиеся в таблицах и представлениях (даже если они зашифрованы), осуществлять повторные поиски по истории в один клик.
Для поиска данных в таблицах и представлениях:
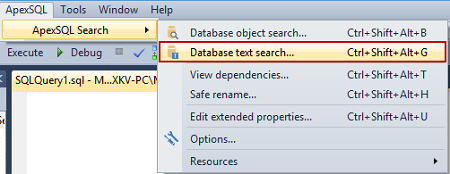
- В меню SQL Server Management Studio или Visual Studio найдите ApexSQL Search
-
Выберите вариант Database text search…:
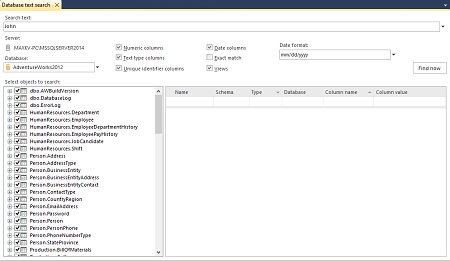
- В текстовом поле поиска Search text укажите искомый текст.
- В раскрывающемся меню Database выберите базу данных для поиска
- В дереве поиска Select objects to search укажите таблицы и представления для поиска или оставьте их все выделенными
- С помощью флажков укажите в каких типах данных необходимо осуществить поиск (numeric, text type, uniqueidentifier, date columns), искать ли в представлениях, необходимо ли строгое совпадение и, при поиске даты, укажите её формат.
-
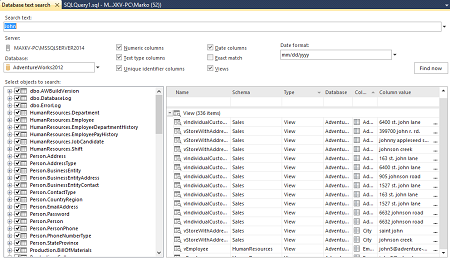
После нажатия кнопки Find now, вы получите сводную таблицу со списком таблиц и представлений, которые содержат искомое значение:
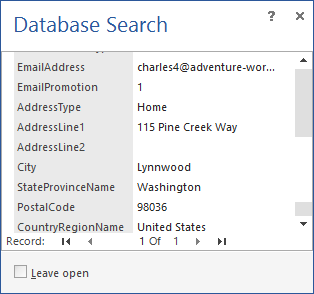
- Нажмите кнопку с многоточием в колонке Column value, чтобы получить детали:
Для поиска объектов:
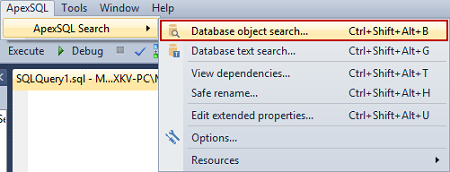
- В меню SQL Server Management Studio или Visual Studio найдите ApexSQL Search
-
Выберите вариант Database object search…:
- В поле поиска Search text укажите искомый объект, например, имя переменной.
- В раскрывающемся меню Database выберите базу данных для поиска
- В дереве поиска Objects укажите типы объектов для поиска или оставьте их все выделенными
- Флажками укажите детали поиска: искать ли в именах объектов, колонок, индексов или только в самих описания объектов. Просматривать ли системные объекты, нужно ли точное совпадение, а также можно указать экранирующий символ.
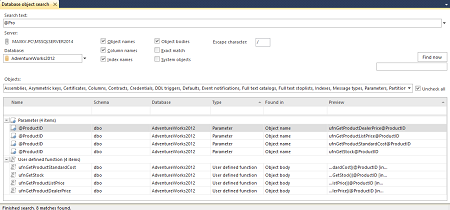
- После этого начинаем поиск Find now:
В таблице будет полный список объектов, которые содержат искомое значение.
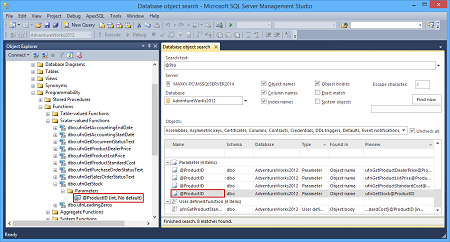
- При двойном щелчке по объекту в таблице Database object search, можно увидеть его ссылку в Object Explorer
SQL Server Management Studio и Visual Studio не имеют встроенной возможности поиска объектов и данных в БД. Запросы, которые решают эту задачу неэффективны, медленные в работе и требуют глубоких знаний системных объектов SQL Server. Но зато с этой задачей прекрасно справляется ApexSQL Search
Переводчик: Алексей Князев
November 20, 2015
Поиск данных и объектов в базе данных MS SQL Server с помощью бесплатной утилиты dbForge Search
Описание общей потребности в поиске данных и объектов в базе данных
Поиск данных, а также хранимых процедур, таблиц и других объектов в базе данных является достаточно актуальным вопросом в том числе и для C#-разработчиков, а также и для .NET-разработки в целом.
Достаточно часто может возникнуть ситуация, при которой нужно найти:
- объект базы данных (таблицу, представление, хранимую процедуру, функцию и т д)
- данные (значение и в какой таблице располагается)
- фрагмент кода в определениях объектов базы данных
Сначала рассмотрим как можно осуществлять поиск данных и объектов в базе данных с помощью встроенных средств самой СУБД, а затем рассмотрим как это сделать с помощью бесплатной утилиты dbForge Search.
Поиск с помощью встроенных средств самой СУБД
Определить есть ли таблица Employee в базе данных можно с помощью следующего скрипта:
Результат может быть примерно такой:
- идентификаторы объекта и схемы, где располагается объект
- название этой схемы и название этого объекта
- тип объекта и описание этого типа объекта
- даты и время создания и последней модификации объекта
Результат может быть примерно такой:
Как видно из результата, здесь подстроку “Project” содержат не только две таблицы Project и ProjectSkill, но и также некоторые первичные и внешние ключи.
Чтобы понять кому именно принадлежат данные ключи, добавим в вывод поле parent_object_id и его имя и схему, в которой он располагается следующим образом:
Результатом будет вывод таблицы с детальной информацией о родительских объектах, т е где определены первичные и внешние ключи:
В запросах используются следующие системные объекты:
- таблица sys.all_objects
- скалярная функция schema_name
Чтобы найти строковое значение по всем таблицам базы данных, можно воспользоваться следующим решением. Упростим данное решение и покажем как можно найти например значение “Ramiro” с помощью следующего скрипта:
Результат выполнения может быть таким:
Здесь выводятся имена таблиц и в каких столбцах хранится значение, содержащие подстроку “Ramiro”. А также количество найденных входов данной подстроки для найденной пары таблица-колонка.
Чтобы найти объекты, в определениях которых есть заданный фрагмент кода, можно воспользоваться следующими системными представлениями:
Здесь будет выведен идентификатор, название, описание и полное определение объекта.
Поиск с помощью бесплатной утилиты dbForge Search
Однако, более удобно поиск производить с помощью готовых хороших инструментов. Одним из таких инструментов является dbForge Search.
Для вызова этой утилиты в окне SSMS нажмите на кнопку .
Появится следующее окно поиска:
Обратите внимание на верхнюю панель (слева направо):
- можно переключать режим поиска (ищем DDL (объекты) или данные)
- непосредственно что ищем (какую подстроку)
- учитывать ли регистр, искать точное соответствие слову, искать вхождения:
В режиме поиска данных изменится только выбор типов объектов:
А именно будут доступны для выбора только таблицы, где и хранятся собственно сами данные:
Теперь как и раньше найдем все вхождения подстроки “Project” в названиях объектов:
Как видно, был выбран режим поиска по DDL-объектам, заполнено что ищем-строка “Project”, остальное все было по умолчанию.
При выделении найденного объекта внизу отображается код определения данного объекта или всего его родительского объекта.
Также можно переместить навигацию на найденный объект, щелкнув на кнопку :
Можно также сгруппировать найденные объекты по их типу:
Обратите внимание, что выводятся даже те таблицы, в которых есть поля, в именах которых содержится подстрока “Project”. Однако, напомним, что режим поиска можно менять: искать полное соответствие/частичное/учитывать регистр или нет.
Теперь найдем значение “Ramiro” по всем таблицам:
Обратите внимание, что внизу отображаются все строки, в которых содержится подстрока “Ramiro” выбранной таблицы Employee.
Также можно переместить навигацию к найденному объекту, нажав как и ранее на кнопку :
Таким образом мы можем искать нужные объекты и данные в базе данных.
Заключение
Были рассмотрены способы поиска как самих данных, так и объектов в базе данных как с помощью встроенных средств самой СУБД MS SQL Server, так и с помощью бесплатной утилиты dbForge Search.
Также от компании Devart есть и ряд других бесплатных готовых решений, полный список которых можно посмотреть здесь.

Где-то месяц назад ко мне обратился коллега с просьбой помочь составить комплексный запрос (если это можно так назвать), который можно было бы скопировать и вставить в phpMyAdmin, для выборки всех данных из таблиц плагина, оставшихся после удаления сайта/сайтов из сети WordPress.
Что? Объясняю. Допустим, у нас есть сеть на WordPress, в которой имеется N число сайтов. Установлен сетевой плагин, который для каждого сайта создает собственную таблицу в базе данных. Таблицы имеют следующие имена: wp_table для первого сайта и wp_N_table для N-го сайта (например, wp_10_table для десятого сайта в сети). В нашем случае, сайт X, Y и Z были удалены, но таблицы остались. Задача: одним запросом получить данные из этих таблиц для дальнейшего анализа.
Я не считаю себя огромным специалистом SQL и мне данная задача изначально показалась если не невыполнимой, то уж точно не той, которую я мог бы решить за пару минут. Пришлось покопаться в сети и найти как такое решают другие. Ниже представлено мое видение потенциального решения данной проблемы. Не беру на себя ответственность утверждать, что это самое оптимальное решение, но оно позволило мне поближе познакомиться с процедурным расширением SQL.
Итак, приступим. Изначально я разбил задачу на несколько этапов:
- Получить список всех таблиц от плагина
- Найти «таблицы-сироты»
- Получить данные из найденных таблиц
Чтобы всего этого добиться, мы будем использовать хранимые процедуры в SQL.
Хранимая процедура — объект базы данных, представляющий собой набор SQL-инструкций, который компилируется один раз и хранится на сервере. Хранимые процедуры очень похожи на обыкновенные процедуры языков высокого уровня, у них могут быть входные и выходные параметры и локальные переменные, в них могут производиться числовые вычисления и операции над символьными данными, результаты которых могут присваиваться переменным и параметрам. В хранимых процедурах могут выполняться стандартные операции с базами данных (как DDL, так и DML). Кроме того, в хранимых процедурах возможны циклы и ветвления, то есть в них могут использоваться инструкции управления процессом исполнения.
Базовый синтаксис для них следующий:
С помощью DELIMITER $$ мы задаем последовательность символов, которая будет завершать хранимую процедуру, без этого при наборе первой же строчки SQL будет исполнять набранный код. Данная последовательность может быть произвольной. В конце $$ укажет на завершение процедуры.
Создаем процедуру GetAllTables() с помощью CREATE PROCEDURE , она будет иметь начало BEGIN и конец END .
CALL GetAllTables(); — это выполнение всей процедуры.
В теле GetAllTables() мы объявляем переменные с помощью инструкции DECLARE , задаем тип и значение по умолчанию:
В переменной v_finished мы будем хранить статус обработки, в v_table — текущую таблицу.
Далее мы будем использовать курсор, чтобы осуществить построчную обработку нашего запроса. Задаем курсор table_cursor, который будет получать название таблиц из базы данных, соответствующих определенной маске.
Указываем что мы будем делать, когда не найдем больше результатов. Обработчик ошибок объявляется следующим образом:
Здесь action может принимать значение CONTINUE или EXIT , которые указывают на то что нужно продолжить или прекратить исполнение кода при достижении определенных условий. В нашем случае условием является NOT FOUND (результатов больше нет), при достижении которого мы задаем значение переменной v_finished равной 1.
Теперь мы отобразим все таблицы, которые были найдены в базе данных по заданной маске. Для этого лишь надо выполнить SQL запрос:
Наверное, повторение одного запроса здесь и выше, когда мы задавали курсор, является не самым оптимальным решением, но зато оно понятно для начинающих и не требует каких-то углубленных знаний SQL.
Далее мы откроем установленный раннее курсор и задаем цикл get_data , где будем последовательно присваивать переменной v_table результаты нашего запроса.
Проверяем закончилась ли выборка и есть ли еще результаты. Напоминаю, что если результатов нет, то переменная v_finished будет равна 1. Это мы задавали выше. Если больше результатов нет, то мы выходим из цикла.
Здесь у меня возникла небольшая проблема: таблицы-то я нахожу, но как определить что именно данная таблица — это оставшаяся таблица от удаленного сайта. Как я писал выше, все таблицы в базе данных имеют вид wp_N_table. Нам лишь нужно получить значение N, присвоить его переменной v_id и посмотреть есть ли сайт с данным индексом в таблице wp_blogs. Но есть одно условие — у первого сайта в сети не будет индекса N, таблица будет иметь вид wp_table. Но, в то же время, сайт с индексом 1 все равно будет присутствовать в таблице wp_blogs. Чтобы избежать ошибок, мы сделаем небольшую проверку и установим v_id = 1 , если N не будет задана в названии таблицы:
Теперь осталось самое простое — для всех таблиц, индекс которых мы не нашли в wp_blogs, нужно выполнить запрос выборки данных и отобразить все это пользователю:
Чтобы подставить значение v_table в запрос, необходимо использовать команду concat, результат которой мы присваиваем переменной sql_query . Кстати, переменные в коде задаются с символом @ перед именем.
Как найти таблицу в sql по имени
 Сортировка колонки звездность (убывание), а если звездность одинаковая, то по названию (возрастание)
Сортировка колонки звездность (убывание), а если звездность одинаковая, то по названию (возрастание)
Фраймворк Grails. Данный код формирует страницу результатов поиска в виде таблицы. Каким образом.
Заполнение строки таблицы по названию в столбце
Помогите пожалуйста. Есть таблица "Таблица1".При появлении в ячейке "A10" значения из столбца .
Поиск файла по названию
Я задумал (возможно самую тупую (весомую) идею. ) добавление музыки. Я подумал что не всем.
Поиск файлов по названию
Нужно найти txt файлы которые длиннее 3 символов. т.е my.txt не должно находить, а mymy.txt должно
