Excel для Microsoft 365 Excel для Microsoft 365 для Mac Excel для Интернета Excel 2021 Excel 2021 для Mac Excel 2019 Excel 2019 для Mac Excel 2016 Excel 2016 для Mac Excel 2013 Excel 2010 Excel 2007 Excel для Mac 2011 Excel Starter 2010 Еще…Меньше
Оценивает дисперсию по выборке.
Важно: Эта функция была заменена одной или несколькими новыми функциями, которые обеспечивают более высокую точность и имеют имена, лучше отражающие их назначение. Хотя эта функция все еще используется для обеспечения обратной совместимости, она может стать недоступной в последующих версиях Excel, поэтому мы рекомендуем использовать новые функции.
Дополнительные сведения о новом варианте этой функции см. в статье Функция ДИСП.В.
Синтаксис
ДИСП(число1;[число2];…)
Аргументы функции ДИСП описаны ниже.
-
Число1 Обязательный. Первый числовой аргумент, соответствующий выборке из генеральной совокупности.
-
Число2… Необязательный. Числовые аргументы 2—255, соответствующие выборке из генеральной совокупности.
Замечания
-
В функции ДИСП предполагается, что аргументы являются только выборкой из генеральной совокупности. Если данные представляют всю генеральную совокупность, для вычисления дисперсии следует использовать функцию ДИСПР.
-
Аргументы могут быть либо числами, либо содержащими числа именами, массивами или ссылками.
-
Учитываются логические значения и текстовые представления чисел, которые непосредственно введены в список аргументов.
-
Если аргумент является массивом или ссылкой, то учитываются только числа. Пустые ячейки, логические значения, текст и значения ошибок в массиве или ссылке игнорируются.
-
Аргументы, которые представляют собой значения ошибок или текст, не преобразуемый в числа, вызывают ошибку.
-
Чтобы включить логические значения и текстовые представления чисел в ссылку как часть вычисления, используйте функцию ДИСПА.
-
Функция ДИСП вычисляется по следующей формуле:
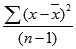
где x — выборочное среднее СРЗНАЧ(число1,число2,…), а n — размер выборки.
Пример
Скопируйте образец данных из следующей таблицы и вставьте их в ячейку A1 нового листа Excel. Чтобы отобразить результаты формул, выделите их и нажмите клавишу F2, а затем — клавишу ВВОД. При необходимости измените ширину столбцов, чтобы видеть все данные.
|
Прочность |
||
|
1345 |
||
|
1301 |
||
|
1368 |
||
|
1322 |
||
|
1310 |
||
|
1370 |
||
|
1318 |
||
|
1350 |
||
|
1303 |
||
|
1299 |
||
|
Формула |
Описание |
Результат |
|
=ДИСП(A2:A11) |
Дисперсия предела прочности для всех протестированных инструментов. |
754,2667 |
Нужна дополнительная помощь?
Нужны дополнительные параметры?
Изучите преимущества подписки, просмотрите учебные курсы, узнайте, как защитить свое устройство и т. д.
В сообществах можно задавать вопросы и отвечать на них, отправлять отзывы и консультироваться с экспертами разных профилей.
Вычислим в
MS
EXCEL
дисперсию и стандартное отклонение выборки. Также вычислим дисперсию случайной величины, если известно ее распределение.
Сначала рассмотрим
дисперсию
, затем
стандартное отклонение
.
Дисперсия выборки
Дисперсия выборки
(
выборочная дисперсия,
sample
variance
) характеризует разброс значений в массиве относительно
среднего
.
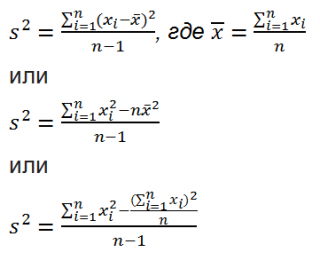
Все 3 формулы математически эквивалентны.
Из первой формулы видно, что
дисперсия выборки
это сумма квадратов отклонений каждого значения в массиве
от среднего
, деленная на размер выборки минус 1.
Для вычисления дисперсии выборки нужно:
- вычислить среднее значение выборки;
-
вычислить “расстояния” от каждого значения до среднего (x
i
-x
ср.
); - возвести “расстояния” в квадрат, чтобы отклонения в разные стороны от среднего не компенсировали друг друга;
- вычислить среднее значение квадратов “расстояний”)
Примечание
: в знаменателе формулы стоит n-1, а не n т.к. дисперсия выборки – это оценка дисперсии случайной величины (вычитаем 1, чтобы оценка была несмещенной).
В MS EXCEL 2007 и более ранних версиях для вычисления
дисперсии
выборки
используется функция
ДИСП()
, англ. название VAR, т.е. VARiance. С версии MS EXCEL 2010 рекомендуется использовать ее аналог
ДИСП.В()
, англ. название VARS, т.е. Sample VARiance. Кроме того, начиная с версии MS EXCEL 2010 присутствует функция
ДИСП.Г(),
англ. название VARP, т.е. Population VARiance, которая вычисляет
дисперсию
для
генеральной совокупности
. Все отличие сводится к знаменателю: вместо n-1 как у
ДИСП.В()
, у
ДИСП.Г()
в знаменателе просто n. До MS EXCEL 2010 для вычисления дисперсии генеральной совокупности использовалась функция
ДИСПР()
.
Дисперсию выборки
можно также вычислить непосредственно по нижеуказанным формулам (см.
файл примера
)
=КВАДРОТКЛ(Выборка)/(СЧЁТ(Выборка)-1)
=(СУММКВ(Выборка)-СЧЁТ(Выборка)*СРЗНАЧ(Выборка)^2)/ (СЧЁТ(Выборка)-1)
– обычная формула
=СУММ((Выборка -СРЗНАЧ(Выборка))^2)/ (СЧЁТ(Выборка)-1
) –
формула массива
Дисперсия выборки
равна 0, только в том случае, если все значения равны между собой и, соответственно, равны
среднему значению
. Обычно, чем больше величина
дисперсии
, тем больше разброс значений в массиве.
Дисперсия выборки
является точечной оценкой
дисперсии
распределения случайной величины, из которой была сделана
выборка
. О построении
доверительных интервалов
при оценке
дисперсии
можно прочитать в статье
Доверительный интервал для оценки дисперсии в MS EXCEL
.
Дисперсия случайной величины
Чтобы вычислить
дисперсию
случайной величины, необходимо знать ее
функцию распределения
.
Для
дисперсии
случайной величины Х часто используют обозначение Var(Х).
Дисперсия
равна
математическому ожиданию
квадрата отклонения от среднего E(X): Var(Х)=E[(X-E(X))
2
]
Если случайная величина имеет
дискретное распределение
, то
дисперсия
вычисляется по формуле:
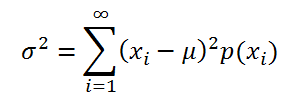
где x
i
– значение, которое может принимать случайная величина, а μ – среднее значение (
математическое ожидание случайной величины
), р(x) – вероятность, что случайная величина примет значение х.
Если случайная величина имеет
непрерывное распределение
, то
дисперсия
вычисляется по формуле:
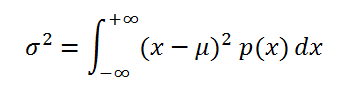
где р(x) –
плотность вероятности
.
Для распределений, представленных в MS EXCEL
,
дисперсию
можно вычислить аналитически, как функцию от параметров распределения. Например, для
Биномиального распределения
дисперсия
равна произведению его параметров: n*p*q.
Примечание
:
Дисперсия,
является
вторым центральным моментом
, обозначается D[X], VAR(х), V(x). Второй центральный момент – числовая характеристика распределения случайной величины, которая является мерой разброса случайной величины относительно
математического ожидания
.
Примечание
: О распределениях в MS EXCEL можно прочитать в статье
Распределения случайной величины в MS EXCEL
.
Размерность
дисперсии
соответствует квадрату единицы измерения исходных значений. Например, если значения в выборке представляют собой измерения веса детали (в кг), то размерность дисперсии будет кг
2
. Это бывает сложно интерпретировать, поэтому для характеристики разброса значений чаще используют величину равную квадратному корню из
дисперсии
–
стандартное отклонение
.
Некоторые свойства
дисперсии
:
Var(Х+a)=Var(Х), где Х – случайная величина, а – константа.
Var(aХ)=a
2
Var(X)
Var(Х)=E[(X-E(X))
2
]=E[X
2
-2*X*E(X)+(E(X))
2
]=E(X
2
)-E(2*X*E(X))+(E(X))
2
=E(X
2
)-2*E(X)*E(X)+(E(X))
2
=E(X
2
)-(E(X))
2
Это свойство дисперсии используется в
статье про линейную регрессию
.
Var(Х+Y)=Var(Х) + Var(Y) + 2*Cov(Х;Y), где Х и Y – случайные величины, Cov(Х;Y) – ковариация этих случайных величин.
Если случайные величины независимы (independent), то их
ковариация
равна 0, и, следовательно, Var(Х+Y)=Var(Х)+Var(Y). Это свойство дисперсии используется при выводе
стандартной ошибки среднего
.
Покажем, что для независимых величин Var(Х-Y)=Var(Х+Y). Действительно, Var(Х-Y)= Var(Х-Y)= Var(Х+(-Y))= Var(Х)+Var(-Y)= Var(Х)+Var(-Y)= Var(Х)+(-1)
2
Var(Y)= Var(Х)+Var(Y)= Var(Х+Y). Это свойство дисперсии используется для построения
доверительного интервала для разницы 2х средних
.
Примечание
: квадратный корень из дисперсии случайной величины называется Среднеквадратическое отклонение (или другие названия – среднее квадратическое отклонение, среднеквадратичное отклонение, квадратичное отклонение, стандартное отклонение, стандартный разброс).
Стандартное отклонение выборки
Стандартное отклонение выборки
– это мера того, насколько широко разбросаны значения в выборке относительно их
среднего
.
По определению,
стандартное отклонение
равно квадратному корню из
дисперсии
:
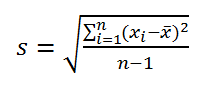
Стандартное отклонение
не учитывает величину значений в
выборке
, а только степень рассеивания значений вокруг их
среднего
. Чтобы проиллюстрировать это приведем пример.
Вычислим стандартное отклонение для 2-х выборок: (1; 5; 9) и (1001; 1005; 1009). В обоих случаях, s=4. Очевидно, что отношение величины стандартного отклонения к значениям массива у выборок существенно отличается. Для таких случаев используется
Коэффициент вариации
(Coefficient of Variation, CV) – отношение
Стандартного отклонения
к среднему
арифметическому
, выраженного в процентах.
В MS EXCEL 2007 и более ранних версиях для вычисления
Стандартного отклонения выборки
используется функция
=СТАНДОТКЛОН()
, англ. название STDEV, т.е. STandard DEViation. С версии MS EXCEL 2010 рекомендуется использовать ее аналог
=СТАНДОТКЛОН.В()
, англ. название STDEV.S, т.е. Sample STandard DEViation.
Кроме того, начиная с версии MS EXCEL 2010 присутствует функция
СТАНДОТКЛОН.Г()
, англ. название STDEV.P, т.е. Population STandard DEViation, которая вычисляет
стандартное отклонение
для
генеральной совокупности
. Все отличие сводится к знаменателю: вместо n-1 как у
СТАНДОТКЛОН.В()
, у
СТАНДОТКЛОН.Г()
в знаменателе просто n.
Стандартное отклонение
можно также вычислить непосредственно по нижеуказанным формулам (см.
файл примера
)
=КОРЕНЬ(КВАДРОТКЛ(Выборка)/(СЧЁТ(Выборка)-1)) =КОРЕНЬ((СУММКВ(Выборка)-СЧЁТ(Выборка)*СРЗНАЧ(Выборка)^2)/(СЧЁТ(Выборка)-1))
Другие меры разброса
Функция
КВАДРОТКЛ()
вычисляет с умму квадратов отклонений значений от их
среднего
. Эта функция вернет тот же результат, что и формула
=ДИСП.Г(
Выборка
)*СЧЁТ(
Выборка
)
, где
Выборка
– ссылка на диапазон, содержащий массив значений выборки (
именованный диапазон
). Вычисления в функции
КВАДРОТКЛ()
производятся по формуле:
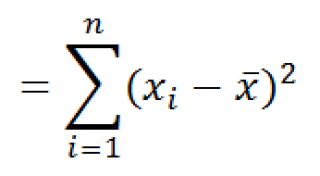
Функция
СРОТКЛ()
является также мерой разброса множества данных. Функция
СРОТКЛ()
вычисляет среднее абсолютных значений отклонений значений от
среднего
. Эта функция вернет тот же результат, что и формула
=СУММПРОИЗВ(ABS(Выборка-СРЗНАЧ(Выборка)))/СЧЁТ(Выборка)
, где
Выборка
– ссылка на диапазон, содержащий массив значений выборки.
Вычисления в функции
СРОТКЛ
()
производятся по формуле:
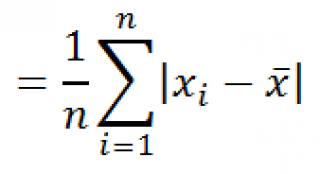
Содержание
- Вычисление дисперсии
- Способ 1: расчет по генеральной совокупности
- Способ 2: расчет по выборке
- Блог о программе Microsoft Excel: приемы, хитрости, секреты, трюки
- Использование метода «сырого счета» (пример с готовкой)
- Расчет дисперсии в Excel
- Дисперсия выборки
- Дисперсия случайной величины
- Стандартное отклонение выборки
- Другие меры разброса

Среди множества показателей, которые применяются в статистике, нужно выделить расчет дисперсии. Следует отметить, что выполнение вручную данного вычисления – довольно утомительное занятие. К счастью, в приложении Excel имеются функции, позволяющие автоматизировать процедуру расчета. Выясним алгоритм работы с этими инструментами.
Вычисление дисперсии
Дисперсия – это показатель вариации, который представляет собой средний квадрат отклонений от математического ожидания. Таким образом, он выражает разброс чисел относительно среднего значения. Вычисление дисперсии может проводиться как по генеральной совокупности, так и по выборочной.
Способ 1: расчет по генеральной совокупности
Для расчета данного показателя в Excel по генеральной совокупности применяется функция ДИСП.Г. Синтаксис этого выражения имеет следующий вид:
Всего может быть применено от 1 до 255 аргументов. В качестве аргументов могут выступать, как числовые значения, так и ссылки на ячейки, в которых они содержатся.
Посмотрим, как вычислить это значение для диапазона с числовыми данными.
- Производим выделение ячейки на листе, в которую будут выводиться итоги вычисления дисперсии. Щелкаем по кнопке «Вставить функцию», размещенную слева от строки формул.
Запускается Мастер функций. В категории «Статистические» или «Полный алфавитный перечень» выполняем поиск аргумента с наименованием «ДИСП.Г». После того, как нашли, выделяем его и щелкаем по кнопке «OK».
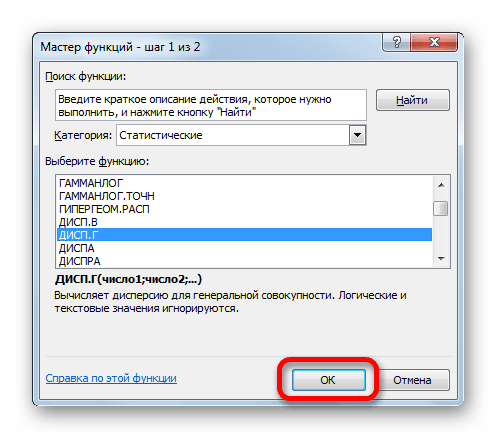
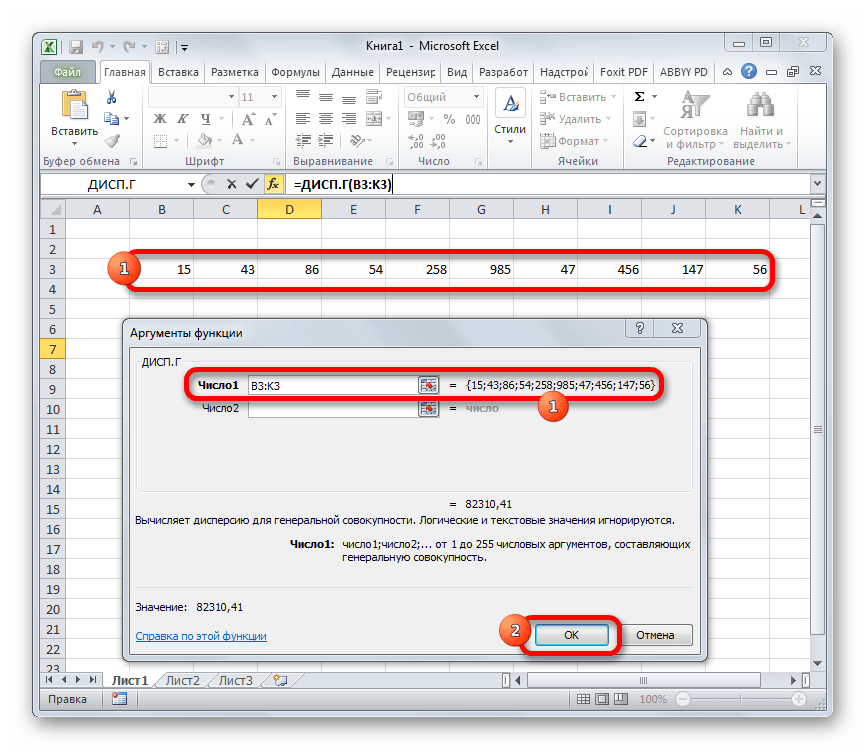
Выполняется запуск окна аргументов функции ДИСП.Г. Устанавливаем курсор в поле «Число1». Выделяем на листе диапазон ячеек, в котором содержится числовой ряд. Если таких диапазонов несколько, то можно также использовать для занесения их координат в окно аргументов поля «Число2», «Число3» и т.д. После того, как все данные внесены, жмем на кнопку «OK».
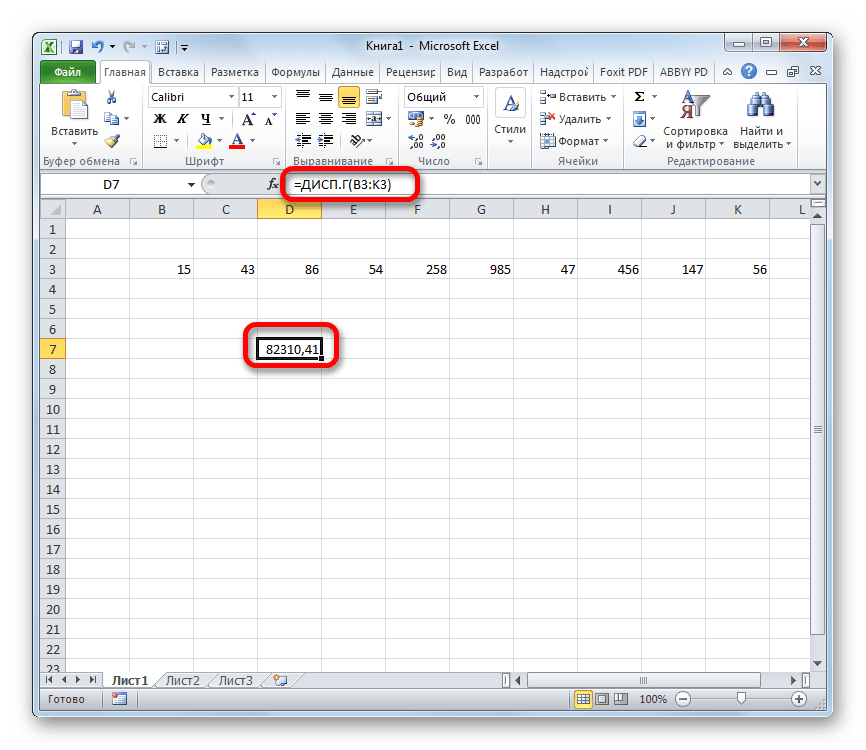
Способ 2: расчет по выборке
В отличие от вычисления значения по генеральной совокупности, в расчете по выборке в знаменателе указывается не общее количество чисел, а на одно меньше. Это делается в целях коррекции погрешности. Эксель учитывает данный нюанс в специальной функции, которая предназначена для данного вида вычисления – ДИСП.В. Её синтаксис представлен следующей формулой:
Количество аргументов, как и в предыдущей функции, тоже может колебаться от 1 до 255.
-
Выделяем ячейку и таким же способом, как и в предыдущий раз, запускаем Мастер функций.
В категории «Полный алфавитный перечень» или «Статистические» ищем наименование «ДИСП.В». После того, как формула найдена, выделяем её и делаем клик по кнопке «OK».
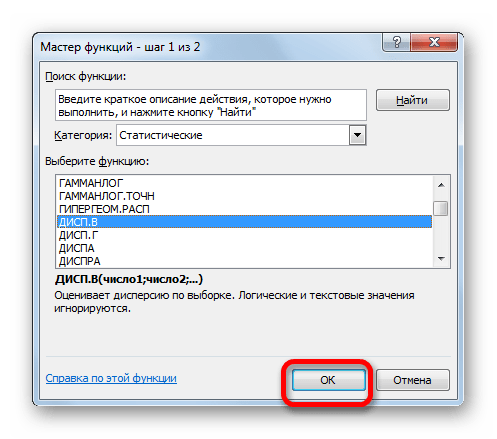
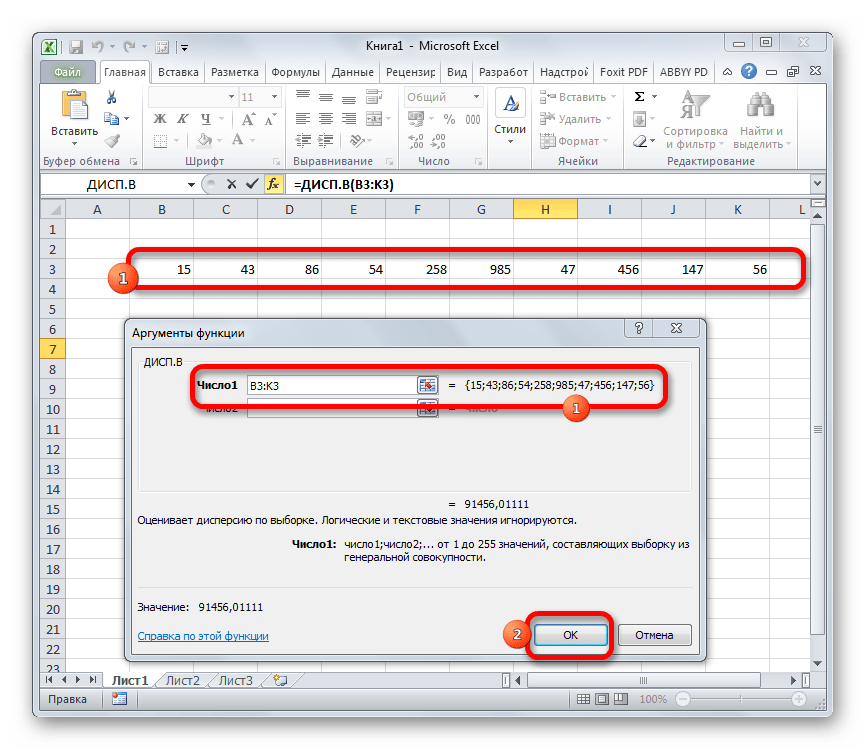
Производится запуск окна аргументов функции. Далее поступаем полностью аналогичным образом, как и при использовании предыдущего оператора: устанавливаем курсор в поле аргумента «Число1» и выделяем область, содержащую числовой ряд, на листе. Затем щелкаем по кнопке «OK».
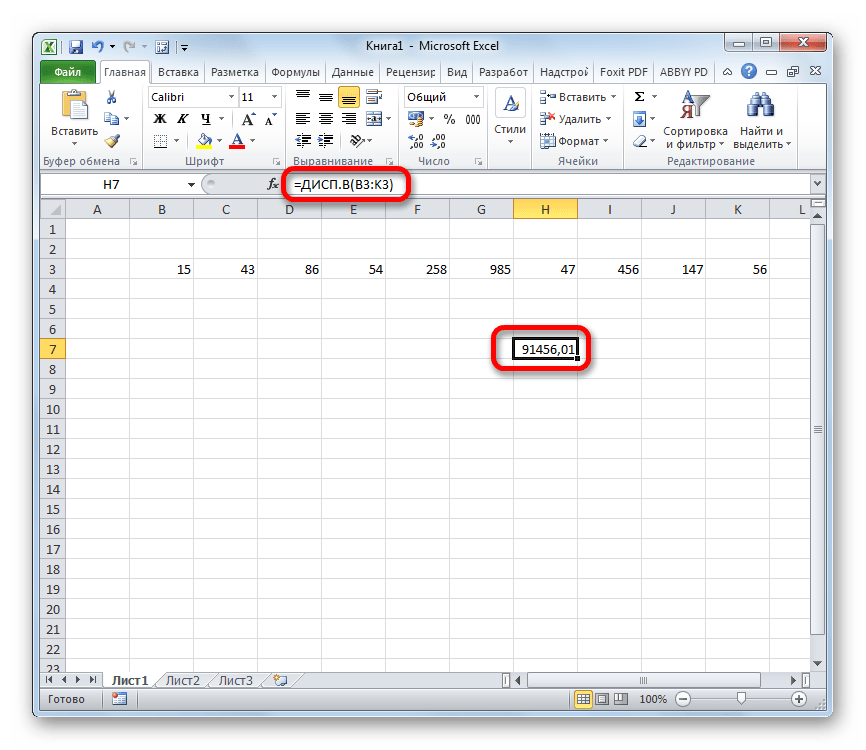
Как видим, программа Эксель способна в значительной мере облегчить расчет дисперсии. Эта статистическая величина может быть рассчитана приложением, как по генеральной совокупности, так и по выборке. При этом все действия пользователя фактически сводятся только к указанию диапазона обрабатываемых чисел, а основную работу Excel делает сам. Безусловно, это сэкономит значительное количество времени пользователей.
Отблагодарите автора, поделитесь статьей в социальных сетях.
Блог о программе Microsoft Excel: приемы, хитрости, секреты, трюки

Дисперсия — это мера рассеяния, описывающая сравнительное отклонение между значениями данных и средней величиной. Является наиболее используемой мерой рассеяния в статистике, вычисляемая путем суммирования, возведенного в квадрат, отклонения каждого значения данных от средней величины. Формула для вычисления дисперсии представлена ниже:
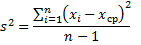
s 2 – дисперсия выборки;
xср — среднее значение выборки;
n — размер выборки (количество значений данных),
(xi – xср) — отклонение от средней величины для каждого значения набора данных.
Для лучшего понимания формулы, разберем пример. Я не очень люблю готовку, поэтому занятием этим занимаюсь крайне редко. Тем не менее, чтобы не умереть с голоду, время от времени мне приходится подходить к плите для реализации замысла по насыщению моего организма белками, жирами и углеводами. Набор данных, редставленный ниже, показывает, сколько раз Ренат готовит пищу каждый месяц:

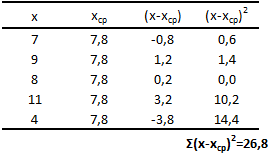
Первым шагом при вычислении дисперсии является определение среднего значения выборки, которое в нашем примере равняется 7,8 раза в месяц. Остальные вычисления можно облегчить с помощью следующей таблицы.
Финальная фаза вычисления дисперсии выглядит так:
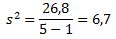
Для тех, кто любит производить все вычисления за один раз, уравнение будет выглядеть следующим образом:
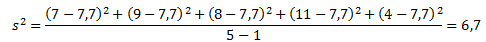
Использование метода «сырого счета» (пример с готовкой)
Существует более эффективный способ вычисления дисперсии, известный как метод «сырого счета». Хотя с первого взгляда уравнение может показаться весьма громоздким, на самом деле оно не такое уж страшное. Можете в этом удостовериться, а потом и решите, какой метод вам больше нравится.
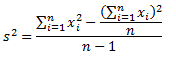
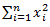 — сумма каждого значения данных после возведения в квадрат,
— сумма каждого значения данных после возведения в квадрат,
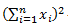 — квадрат суммы всех значений данных.
— квадрат суммы всех значений данных.
Не теряйте рассудок прямо сейчас. Позвольте представить все это в виде таблицы, и тогда вы увидите, что вычислений здесь меньше, чем в предыдущем примере.
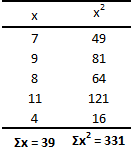
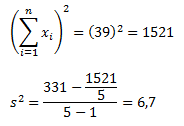
Как видите, результат получился тот же, что и при использовании предыдущего метода. Достоинства данного метода становятся очевидными по мере роста размера выборки (n).
Расчет дисперсии в Excel
Как вы уже, наверное, догадались, в Excel присутствует формула, позволяющая рассчитать дисперсию. Причем, начиная с Excel 2010 можно найти 4 разновидности формулы дисперсии:
1) ДИСП.В – Возвращает дисперсию по выборке. Логические значения и текст игнорируются.
2) ДИСП.Г — Возвращает дисперсию по генеральной совокупности. Логические значения и текст игнорируются.
3) ДИСПА — Возвращает дисперсию по выборке с учетом логических и текстовых значений.
4) ДИСПРА — Возвращает дисперсию по генеральной совокупности с учетом логических и текстовых значений.
Для начала разберемся в разнице между выборкой и генеральной совокупностью. Назначение описательной статистики состоит в том, чтобы суммировать или отображать данные так, чтобы оперативно получать общую картину, так сказать, обзор. Статистический вывод позволяет делать умозаключения о какой-либо совокупности на основе выборки данных из этой совокупности. Совокупность представляет собой все возможные исходы или измерения, представляющие для нас интерес. Выборка — это подмножество совокупности.
Например, нас интересует совокупность группы студентов одного из Российских ВУЗов и нам необходимо определить средний бал группы. Мы можем посчитать среднюю успеваемость студентов, и тогда полученная цифра будет параметром, поскольку в наших расчетах будет задействована целая совокупность. Однако, если мы хотим рассчитать средний бал всех студентов нашей страны, тогда эта группа будет нашей выборкой.
Разница в формуле расчета дисперсии между выборкой и совокупностью заключается в знаменателе. Где для выборки он будет равняться (n-1), а для генеральной совокупности только n.
Теперь разберемся с функциями расчета дисперсии с окончаниями А, в описании которых сказано, что при расчете учитываются текстовые и логические значения. В данном случае при расчете дисперсии определенного массива данных, где встречаются не числовые значения, Excel будет интерпретировать текстовые и ложные логические значения как равными 0, а истинные логические значения как равными 1.
Итак, если у вас есть массив данных, рассчитать его дисперсию ни составит никакого труда, воспользовавшись одной из перечисленных выше функций Excel.
Вычислим в MS EXCEL дисперсию и стандартное отклонение выборки. Также вычислим дисперсию случайной величины, если известно ее распределение.
Сначала рассмотрим дисперсию, затем стандартное отклонение.
Дисперсия выборки
Дисперсия выборки (выборочная дисперсия, sample variance) характеризует разброс значений в массиве относительно среднего.
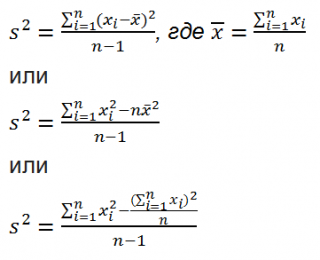
Все 3 формулы математически эквивалентны.
Из первой формулы видно, что дисперсия выборки это сумма квадратов отклонений каждого значения в массиве от среднего, деленная на размер выборки минус 1.
В MS EXCEL 2007 и более ранних версиях для вычисления дисперсии выборки используется функция ДИСП() , англ. название VAR, т.е. VARiance. С версии MS EXCEL 2010 рекомендуется использовать ее аналог ДИСП.В() , англ. название VARS, т.е. Sample VARiance. Кроме того, начиная с версии MS EXCEL 2010 присутствует функция ДИСП.Г(), англ. название VARP, т.е. Population VARiance, которая вычисляет дисперсию для генеральной совокупности. Все отличие сводится к знаменателю: вместо n-1 как у ДИСП.В() , у ДИСП.Г() в знаменателе просто n. До MS EXCEL 2010 для вычисления дисперсии генеральной совокупности использовалась функция ДИСПР() .
Дисперсию выборки можно также вычислить непосредственно по нижеуказанным формулам (см. файл примера )
=КВАДРОТКЛ(Выборка)/(СЧЁТ(Выборка)-1)
=(СУММКВ(Выборка)-СЧЁТ(Выборка)*СРЗНАЧ(Выборка)^2)/ (СЧЁТ(Выборка)-1) – обычная формула
=СУММ((Выборка -СРЗНАЧ(Выборка))^2)/ (СЧЁТ(Выборка)-1 ) – формула массива
Дисперсия выборки равна 0, только в том случае, если все значения равны между собой и, соответственно, равны среднему значению. Обычно, чем больше величина дисперсии, тем больше разброс значений в массиве.
Дисперсия выборки является точечной оценкой дисперсии распределения случайной величины, из которой была сделана выборка. О построении доверительных интервалов при оценке дисперсии можно прочитать в статье Доверительный интервал для оценки дисперсии в MS EXCEL.
Дисперсия случайной величины
Чтобы вычислить дисперсию случайной величины, необходимо знать ее функцию распределения.
Для дисперсии случайной величины Х часто используют обозначение Var(Х). Дисперсия равна математическому ожиданию квадрата отклонения от среднего E(X): Var(Х)=E[(X-E(X)) 2 ]
Если случайная величина имеет дискретное распределение, то дисперсия вычисляется по формуле:
где xi – значение, которое может принимать случайная величина, а μ – среднее значение (математическое ожидание случайной величины), р(x) – вероятность, что случайная величина примет значение х.
Если случайная величина имеет непрерывное распределение, то дисперсия вычисляется по формуле:
Для распределений, представленных в MS EXCEL, дисперсию можно вычислить аналитически, как функцию от параметров распределения. Например, для Биномиального распределения дисперсия равна произведению его параметров: n*p*q.
Примечание: Дисперсия, является вторым центральным моментом, обозначается D[X], VAR(х), V(x). Второй центральный момент — числовая характеристика распределения случайной величины, которая является мерой разброса случайной величины относительно математического ожидания.
Примечание: О распределениях в MS EXCEL можно прочитать в статье Распределения случайной величины в MS EXCEL.
Размерность дисперсии соответствует квадрату единицы измерения исходных значений. Например, если значения в выборке представляют собой измерения веса детали (в кг), то размерность дисперсии будет кг 2 . Это бывает сложно интерпретировать, поэтому для характеристики разброса значений чаще используют величину равную квадратному корню из дисперсии – стандартное отклонение.
Некоторые свойства дисперсии:
Var(Х+a)=Var(Х), где Х — случайная величина, а — константа.
Var(Х)=E[(X-E(X)) 2 ]=E[X 2 -2*X*E(X)+(E(X)) 2 ]=E(X 2 )-E(2*X*E(X))+(E(X)) 2 =E(X 2 )-2*E(X)*E(X)+(E(X)) 2 =E(X 2 )-(E(X)) 2
Это свойство дисперсии используется в статье про линейную регрессию .
Var(Х+Y)=Var(Х) + Var(Y) + 2*Cov(Х;Y), где Х и Y — случайные величины, Cov(Х;Y) — ковариация этих случайных величин.
Если случайные величины независимы (independent), то их ковариация равна 0, и, следовательно, Var(Х+Y)=Var(Х)+Var(Y). Это свойство дисперсии используется при выводе стандартной ошибки среднего.
Покажем, что для независимых величин Var(Х-Y)=Var(Х+Y). Действительно, Var(Х-Y)= Var(Х-Y)= Var(Х+(-Y))= Var(Х)+Var(-Y)= Var(Х)+Var(-Y)= Var(Х)+(-1) 2 Var(Y)= Var(Х)+Var(Y)= Var(Х+Y). Это свойство дисперсии используется для построения доверительного интервала для разницы 2х средних.
Стандартное отклонение выборки
Стандартное отклонение выборки — это мера того, насколько широко разбросаны значения в выборке относительно их среднего.
По определению, стандартное отклонение равно квадратному корню из дисперсии:
Стандартное отклонение не учитывает величину значений в выборке, а только степень рассеивания значений вокруг их среднего. Чтобы проиллюстрировать это приведем пример.
Вычислим стандартное отклонение для 2-х выборок: (1; 5; 9) и (1001; 1005; 1009). В обоих случаях, s=4. Очевидно, что отношение величины стандартного отклонения к значениям массива у выборок существенно отличается. Для таких случаев используется Коэффициент вариации (Coefficient of Variation, CV) — отношение Стандартного отклонения к среднему арифметическому, выраженного в процентах.
В MS EXCEL 2007 и более ранних версиях для вычисления Стандартного отклонения выборки используется функция =СТАНДОТКЛОН() , англ. название STDEV, т.е. STandard DEViation. С версии MS EXCEL 2010 рекомендуется использовать ее аналог =СТАНДОТКЛОН.В() , англ. название STDEV.S, т.е. Sample STandard DEViation.
Кроме того, начиная с версии MS EXCEL 2010 присутствует функция СТАНДОТКЛОН.Г() , англ. название STDEV.P, т.е. Population STandard DEViation, которая вычисляет стандартное отклонение для генеральной совокупности. Все отличие сводится к знаменателю: вместо n-1 как у СТАНДОТКЛОН.В() , у СТАНДОТКЛОН.Г() в знаменателе просто n.
Стандартное отклонение можно также вычислить непосредственно по нижеуказанным формулам (см. файл примера )
=КОРЕНЬ(КВАДРОТКЛ(Выборка)/(СЧЁТ(Выборка)-1))
=КОРЕНЬ((СУММКВ(Выборка)-СЧЁТ(Выборка)*СРЗНАЧ(Выборка)^2)/(СЧЁТ(Выборка)-1))
Другие меры разброса
Функция КВАДРОТКЛ() вычисляет с умму квадратов отклонений значений от их среднего. Эта функция вернет тот же результат, что и формула =ДИСП.Г( Выборка )*СЧЁТ( Выборка ) , где Выборка — ссылка на диапазон, содержащий массив значений выборки (именованный диапазон). Вычисления в функции КВАДРОТКЛ() производятся по формуле:
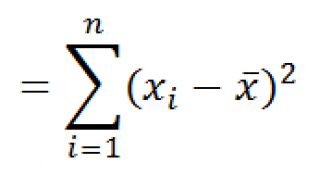
Функция СРОТКЛ() является также мерой разброса множества данных. Функция СРОТКЛ() вычисляет среднее абсолютных значений отклонений значений от среднего. Эта функция вернет тот же результат, что и формула =СУММПРОИЗВ(ABS(Выборка-СРЗНАЧ(Выборка)))/СЧЁТ(Выборка) , где Выборка — ссылка на диапазон, содержащий массив значений выборки.
Вычисления в функции СРОТКЛ () производятся по формуле:

Дисперсия — это мера рассеяния, описывающая сравнительное отклонение между значениями данных и средней величиной. Является наиболее используемой мерой рассеяния в статистике, вычисляемая путем суммирования, возведенного в квадрат, отклонения каждого значения данных от средней величины. Формула для вычисления дисперсии представлена ниже:
![]()
где:
s2 – дисперсия выборки;
xср — среднее значение выборки;
n — размер выборки (количество значений данных),
(xi – xср) — отклонение от средней величины для каждого значения набора данных.
Для лучшего понимания формулы, разберем пример. Я не очень люблю готовку, поэтому занятием этим занимаюсь крайне редко. Тем не менее, чтобы не умереть с голоду, время от времени мне приходится подходить к плите для реализации замысла по насыщению моего организма белками, жирами и углеводами. Набор данных, редставленный ниже, показывает, сколько раз Ренат готовит пищу каждый месяц:
![]()
Первым шагом при вычислении дисперсии является определение среднего значения выборки, которое в нашем примере равняется 7,8 раза в месяц. Остальные вычисления можно облегчить с помощью следующей таблицы.

Финальная фаза вычисления дисперсии выглядит так:
![]()
Для тех, кто любит производить все вычисления за один раз, уравнение будет выглядеть следующим образом:
![]()
Использование метода «сырого счета» (пример с готовкой)
Существует более эффективный способ вычисления дисперсии, известный как метод «сырого счета». Хотя с первого взгляда уравнение может показаться весьма громоздким, на самом деле оно не такое уж страшное. Можете в этом удостовериться, а потом и решите, какой метод вам больше нравится.
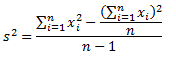
где:
![]() — сумма каждого значения данных после возведения в квадрат,
— сумма каждого значения данных после возведения в квадрат,
![]() — квадрат суммы всех значений данных.
— квадрат суммы всех значений данных.
Не теряйте рассудок прямо сейчас. Позвольте представить все это в виде таблицы, и тогда вы увидите, что вычислений здесь меньше, чем в предыдущем примере.
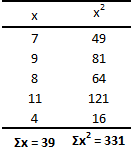
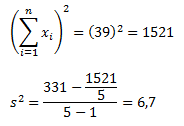
Как видите, результат получился тот же, что и при использовании предыдущего метода. Достоинства данного метода становятся очевидными по мере роста размера выборки (n).
Как вы уже, наверное, догадались, в Excel присутствует формула, позволяющая рассчитать дисперсию. Причем, начиная с Excel 2010 можно найти 4 разновидности формулы дисперсии:
1) ДИСП.В – Возвращает дисперсию по выборке. Логические значения и текст игнорируются.
2) ДИСП.Г — Возвращает дисперсию по генеральной совокупности. Логические значения и текст игнорируются.
3) ДИСПА — Возвращает дисперсию по выборке с учетом логических и текстовых значений.
4) ДИСПРА — Возвращает дисперсию по генеральной совокупности с учетом логических и текстовых значений.
Для начала разберемся в разнице между выборкой и генеральной совокупностью. Назначение описательной статистики состоит в том, чтобы суммировать или отображать данные так, чтобы оперативно получать общую картину, так сказать, обзор. Статистический вывод позволяет делать умозаключения о какой-либо совокупности на основе выборки данных из этой совокупности. Совокупность представляет собой все возможные исходы или измерения, представляющие для нас интерес. Выборка — это подмножество совокупности.
Например, нас интересует совокупность группы студентов одного из Российских ВУЗов и нам необходимо определить средний бал группы. Мы можем посчитать среднюю успеваемость студентов, и тогда полученная цифра будет параметром, поскольку в наших расчетах будет задействована целая совокупность. Однако, если мы хотим рассчитать средний бал всех студентов нашей страны, тогда эта группа будет нашей выборкой.
Разница в формуле расчета дисперсии между выборкой и совокупностью заключается в знаменателе. Где для выборки он будет равняться (n-1), а для генеральной совокупности только n.
Теперь разберемся с функциями расчета дисперсии с окончаниями А, в описании которых сказано, что при расчете учитываются текстовые и логические значения. В данном случае при расчете дисперсии определенного массива данных, где встречаются не числовые значения, Excel будет интерпретировать текстовые и ложные логические значения как равными 0, а истинные логические значения как равными 1.
Итак, если у вас есть массив данных, рассчитать его дисперсию ни составит никакого труда, воспользовавшись одной из перечисленных выше функций Excel.
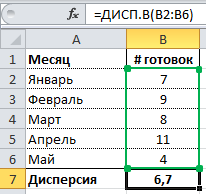
Microsoft Excel предоставляет широкий набор инструментов и функций для анализа данных и статистической оценки. Одной из распространенных функций является дисперсия, которую можно рассчитать с помощью VAR.P и VAR.S-команды, в зависимости от типа данных, которые вы измеряете.
Применяя формулы дисперсии в Excel, важно использовать правильную формулу как для выборки, так и для всей совокупности. В этой статье мы обсудим, что представляет собой дисперсия в статистике, какие общие функции вы можете использовать в Excel и как рассчитать дисперсию в Excel с примерами, которые вам помогут.
Что представляет собой дисперсия в статистике?
Дисперсия – это мера вариации в статистике, которая показывает, насколько далеко друг от друга находится каждая точка в наборе данных. Измерение дисперсии также может сказать вам, как далеко значения данных находятся от среднего значения, которое представляет собой среднее значение для описания определенного параметра выборки или популяции. В математике вы возводите в квадрат разность значений данных и среднего значения и берете среднее арифметическое этих возведенных в квадрат разностей, чтобы получить дисперсию.
Виды отклонений
Вы можете измерить дисперсию для всей совокупности или для выборки из совокупности, и для каждого типа метрики дисперсии используется своя функция в Excel:
-
Популяционная дисперсия: Популяционная дисперсия измеряет всю совокупность и использует командную функцию VAR.P() в Excel для расчета дисперсии при игнорировании текстовых и логических данных.
-
Дисперсия выборки: Дисперсия выборки – это вариация выборки из популяции, для этого используется командная функция VAR.S() в Excel для расчета дисперсии без учета текстовых и логических данных.
-
Меры дисперсии для логических и текстовых входов: Вы можете измерить дисперсию выборки и дисперсию для совокупности, когда вы хотите оценить текстовые и логические аргументы. Excel использует VARA() для выборочной дисперсии и VARPA() для дисперсии популяции, когда у вас есть логические и текстовые входные данные, такие как Истина=1, Ложь=0 или ввод = ноль.
Как рассчитать дисперсию в Excel для совокупности
Приведенные ниже шаги показывают, как рассчитать дисперсию в Excel при оценке всей совокупности:
1. Введите и упорядочьте данные
Импортируйте данные в чистый лист Excel и организуйте их в соответствии с потребностями оценки.
Например, предположим, что преподаватель вводит оценки класса для задания. Класс представляет собой целую совокупность, и профессор организует столбец A для имен студентов и столбец B для оценок. Специалист по исследованию данных, изучающий алгоритмы машинного обучения, может использовать различные входные и организационные методы для анализа дисперсии, поскольку их совокупность данных может быть большой.
В обоих примерах формула VAR.Функция P необходима, поскольку она вычисляет дисперсию для всей популяции.
2. Создайте отдельную ячейку для формулы
Используйте отдельный столбец и ячейку для ввода команды функции. В примере с экзаменационными оценками профессора можно использовать ячейку в столбце C или D для вычисления дисперсии. После выбора ячейки, которую вы хотите использовать для командной функции, пометьте столбец для вашего расчета, Дисперсия, для пояснения.
3. Введите VAR.Функция P
В обозначенном столбце Дисперсия, выберите ячейку и введите командную функцию для дисперсии совокупности. Введите имена ячеек, используя синтаксис =VAR.P(ячейка:ячейка).
В качестве примера предположим, что оценки за предыдущие экзамены находятся в ячейках с B2 по B207. Если профессор вводит формулу в ячейку C2, синтаксис приводит к =VAR.P(B2:B207).
4. Оценить результаты
В зависимости от типа проводимого вами анализа данных, оценка дисперсии совокупности может указывать на несколько факторов. Если дисперсия больше, это означает, что данные удалены от среднего значения. Меньшее значение указывает на то, что данные ближе к среднему значению. Дисперсия, равная нулю, показывает, что точки данных имеют равное значение среднего.
Как рассчитать выборочную дисперсию в Excel
Используйте следующие шаги для расчета выборочной дисперсии в Excel:
1. Выберите выборку населения
Использование VAR.Функция S требует меньшей выборки из популяции.
Например, в средней школе с 1 500 учениками выпускного класса учитель может выбрать случайную выборку из 150 экзаменационных оценок, чтобы оценить тенденции в тестировании. При выборе группы выборки введите данные в новый лист Excel.
2. Упорядочите данные в своей электронной таблице
Отсортируйте данные выборки в электронной таблице, используя соответствующие столбцы, ячейки и метки. Используя предыдущий пример, преподаватели могут расположить 150 выборочных оценок, используя только один столбец для анонимности или два столбца для перечисления имен учащихся и соответствующих им оценок. Вы можете расположить данные в порядке возрастания или убывания с помощью функций сортировки Excel.
3. Выделите отдельную ячейку для формулы
В новом столбце выделите ячейку для командной функции.
В выборке из 150 оценок преподаватели выбирают ячейку в столбце D, чтобы ввести формулу. Пометить новый столбец Вариация чтобы выделить функцию из остальных данных.
4. Введите VAR.Функция S
Используя синтаксис =VAR.S(cell:cell), введите командную функцию для ячеек, которые вы оцениваете.
Например, предположим, что вы отслеживаете ежедневные температуры в течение одного года и хотите взять дисперсию для двух конкретных месяцев. Если данные одного из месяцев находятся в ячейках с B2 по B32, а данные другого месяца – в ячейках с C2 по C33, вы введете командную формулу в виде =VAR.S(B2:B32;C2:C33).
5. Оцените дисперсию выборки
Выборочная дисперсия является неотъемлемой частью при изучении очень больших совокупностей, поскольку она дает оценку параметров, которые могут быть справедливы для всей совокупности. Поэтому оценка выборочной дисперсии может дать вам подробное представление о закономерностях и поведении переменных, которые вы изучаете в популяции.
Как и в случае с дисперсией совокупности, меньшая дисперсия говорит о том, что данные выборки ближе к среднему значению выборки, а большая дисперсия говорит о том, что данные выборки дальше от среднего значения выборки. Дисперсия, равная нулю, по-прежнему показывает значения данных, равные среднему выборочному значению.
Важность вычисления дисперсии
Дисперсия является важным статистическим измерением, поскольку она предоставляет информацию для различных тем анализа данных и полезна, когда:
-
Измерение коэффициентов ошибок: Вариация необходима для понимания уровня ошибки при оценке статистических данных. Коэффициент ошибки показывает, насколько вероятно, что нулевая гипотеза неверна.
-
Выявление причин вариации: Вычисление вариации также важно для понимания того, что вызывает большие различия в наборе данных. Например, определение того, что такие факторы, как возраст и пол, влияют на рост взрослого человека, может помочь организовать выборочные данные для дополнительного анализа.
-
Вычисление коэффициента вариации: Дисперсия дает вам результат, который вы можете использовать для определения коэффициента вариации. Эта метрика важна для понимания взаимосвязи между переменными в различных наборах данных.
-
Оценка различий между переменными: Расчеты дисперсии также могут иметь решающее значение для понимания различий между разными популяциями. Многие аналитики используют дисперсию для понимания различий в финансовых показателях, показателях продаж и операционной производительности в бизнес-среде.
-
Установление однородности для параметрической оценки: Вариация – это измерение, которое применяется в инференциальной статистике, поэтому для ее установления не требуются параметры. Хотя дисперсия является непараметрическим расчетом, вы можете использовать ее для установления критериев для проведения параметрических оценок в различных группах.
Примеры
Рассмотрим следующие примеры расчета дисперсии с помощью VAR.P и VAR.Команды функции S:
Пример дисперсии популяции
Учительница хочет вычислить дисперсию экзаменационных оценок своего класса. Класс представляет собой целую популяцию, поэтому учитель использует VAR.Функция P в электронной таблице Excel. Введя имена студентов в колонку A, 9 баллов в колонку B и формулу в колонку C, она вычисляет дисперсию как:
A B C
| Студент 1 | 95 | = VAR.P(B2:B10) = 58.09876543 |
| Студент 2 | 88 | |
| Студент 3 | 73 | |
| Студент 4 | 79 | |
| Студент 5 | 84 | |
| Студент 6 | 98 | |
| Студент 7 | 92 | |
| Студент 8 | 86 | |
| Студент 9 | 80 |
Пример дисперсии
Ученый-эколог хочет оценить изменения pH воды за последние шесть месяцев. Поскольку в совокупности данных имеется примерно 182 дня значений pH, ученый берет выборку одного значения за каждый из месяцев, в течение которых он отслеживал качество воды.
Ученый вводит свои данные в электронную таблицу и использует VAR.S-функция для вычисления дисперсии выборочных данных. С месяцами в столбце A, данными pH в столбце B и дисперсионной функцией в столбце C, расчет дает результат:
Образец Месяц Дисперсия pH
| Март | 5.5 | =VAR.S(B2:B7) = 0.224 |
| Апрель | 6.1 | |
| Май | 6.8 | |
| Июнь | 6.6 | |
| Июль | 5.9 | |
| Август | 6.3 |
Обратите внимание, что ни одна из компаний, упомянутых в этой статье, не связана с Indeed.
