I tried this but showing “undefined”.
function test() {
var t = document.getElementById('superman').value;
alert(t); }
Is there any way to get the value using simple Javascript no jQuery Please!
asked Apr 29, 2012 at 6:28
![]()
You’ll probably want to try textContent instead of innerHTML.
Given innerHTML will return DOM content as a String and not exclusively the “text” in the div. It’s fine if you know that your div contains only text but not suitable if every use case. For those cases, you’ll probably have to use textContent instead of innerHTML
For example, considering the following markup:
<div id="test">
Some <span class="foo">sample</span> text.
</div>
You’ll get the following result:
var node = document.getElementById('test'),
htmlContent = node.innerHTML,
// htmlContent = "Some <span class="foo">sample</span> text."
textContent = node.textContent;
// textContent = "Some sample text."
See MDN for more details:
- textContent
- innerHTML
![]()
DeBraid
8,4915 gold badges30 silver badges43 bronze badges
answered Apr 29, 2012 at 11:30
![]()
dhardhar
2,6582 gold badges17 silver badges13 bronze badges
5
Because textContent is not supported in IE8 and older, here is a workaround:
var node = document.getElementById('test'),
var text = node.textContent || node.innerText;
alert(text);
innerText does work in IE.
answered Nov 9, 2016 at 15:51
![]()
dev4lifedev4life
10.7k6 gold badges59 silver badges72 bronze badges
You can use innerHTML(then parse text from HTML) or use innerText.
let textContentWithHTMLTags = document.querySelector('div').innerHTML;
let textContent = document.querySelector('div').innerText;
console.log(textContentWithHTMLTags, textContent);
innerHTML and innerText is supported by all browser(except FireFox < 44) including IE6.
answered Dec 7, 2018 at 12:56
![]()
AbdusAbdus
1233 silver badges9 bronze badges
Actually you dont need to call document.getElementById() function to get access to your div.
You can use this object directly by id:
text = test.textContent || test.innerText;
alert(text);
![]()
ℛɑƒæĿᴿᴹᴿ
4,7933 gold badges38 silver badges57 bronze badges
answered Apr 1, 2020 at 12:17
![]()
Последнее обновление Сен 22, 2021
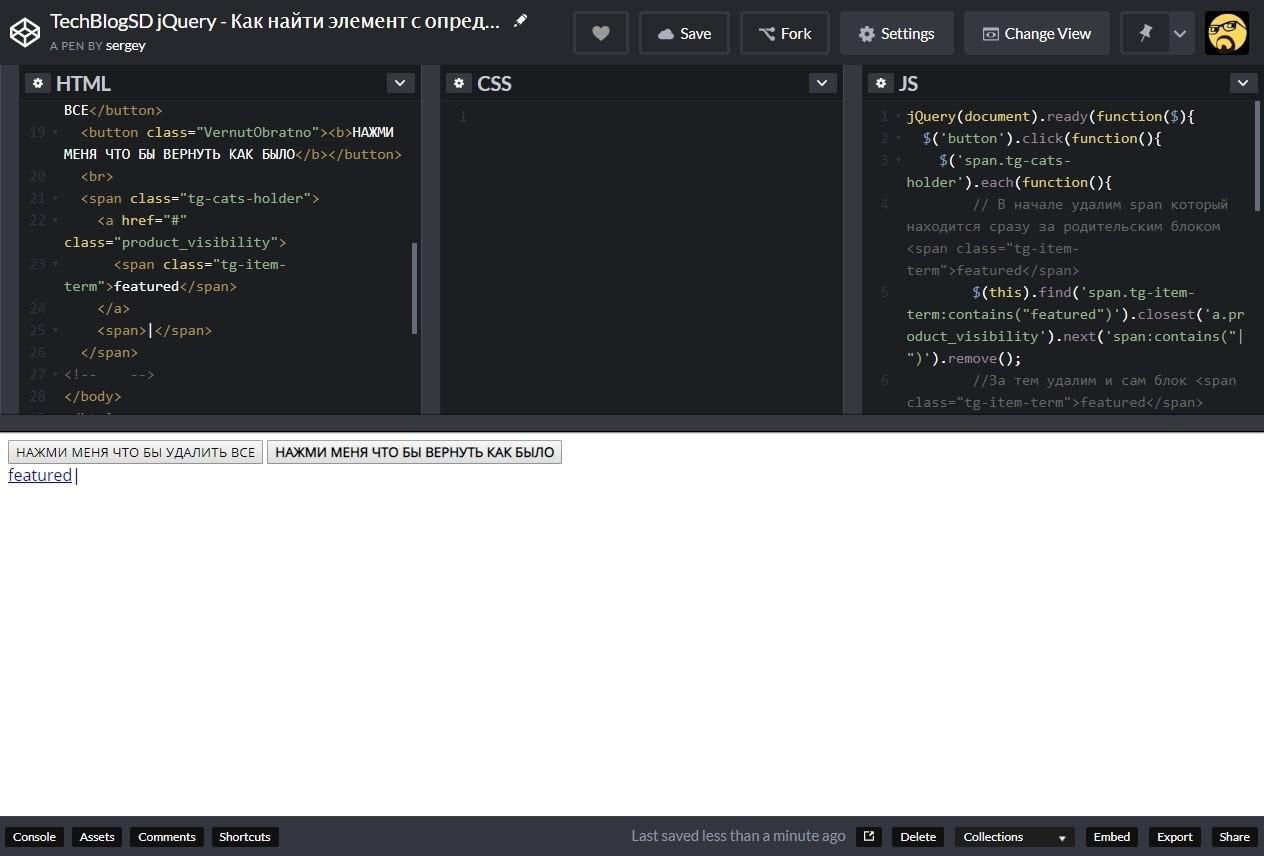
При создании сайтов а именно при написании скриптов веб разработчики часто сталкиваются с необходимостью найти определенный текст, а если быть точнее то найти блок с определенным текстом. В данном примере мы разберем как именно можно найти блок с текстом и произвести с ним определенные манипуляции.
Задача
Необходимо найти блок с текстом “featured”и удалить span блок который следует за родительским элементом нашего блока (с текстом). Затем удалить сам блок с текстом.
JS готовый скрипт
jQuery(document).ready(function($){
$('span.tg-cats-holder').each(function(){
$(this).find('span.tg-item-term:contains("featured")').closest('a.product_visibility').next('span:contains(",")').remove();
$(this).find('span.tg-item-term:contains("featured")').closest('a.product_visibility').remove();
});
});Описание логики скрипта
Для решения данной задачи перебираем каждый (ну в данном примере я так решил) родительский блок в котором находятся все наши блоки с которыми необходимо произвести все манипуляции – в моем примере это блок “span.tg-cats-holder”. Перебор мы производим при помощи .each.
$('span.tg-cats-holder').each(function(){Далее в функции ищем наш блок с текстом, за содержащийся в блоке текст отвечает:
После того как блок с текстом был найден переходим к родительскому блоку при помощи .closest:
.closest('a.product_visibility')После перехода, находим находящийся рядом с родительским блоком span содержащий “|” и удаляем его:
.next('span:contains("|")').remove();Далее, при помощи .remove() происходит удаление и самого блока.
Пример на CodePen.io
Источник записи:
8 января, 2021 12:14 пп
4 770 views
| Комментариев нет
Development
Эта серия мануалов покажет вам, как создать и настроить веб-сайт с помощью CSS, языка таблиц стилей, используемого для управления внешним видом сайтов. Вы можете выполнить все мануалы по порядку, чтобы создать тестовый веб-сайт и познакомиться с CSS, или вразброс использовать описанные здесь методы для оптимизации других проектов CSS.
Примечание: Найти все мануалы этой серии можно по тегу CSS-practice
Для работы с CSS вам нужно иметь базовые знания по HTML, стандартному языку разметки, который используется для отображения документов в браузере. Если ранее вы не работали с HTML, рекомендуем предварительно изучить первые десять руководств серии Создание веб-сайта с помощью HTML.
Элемент <div> добавляется в HTML-документ при помощи открывающих и закрывающих тегов. Сам по себе этот элемент обычно мало влияет на представление веб-страницы. Если присвоить ему набор CSS правил, вы сможете изменить размер, цвет и другие его свойства.
В данном руководстве мы поговорим о стилизации HTML элемента разделения контента – элемента <div> – с помощью CSS. Элемент <div> можно использовать для структурирования макета и разбиения страницы на отдельные компоненты для создания индивидуального стиля. Сможете понять, как создавать и стилизовать элементы <div>, а также научитесь добавлять и стилизовать другие элементы внутри контейнера <div>. Навык работы с элементом <div> как с инструментом компоновки пригодится вам позже, когда вы начнете создавать свой тестовый сайт.
Требования
Чтобы следовать этому мануалу, нужно подготовит среду по мануалу Подготовка проекта CSS и HTML с помощью Visual Studio Code.
Краткий обзор элемента <div>
Давайте посмотрим на практике, как работает элемент <div>. Сотрите все, что есть в файле styles.css (если вы добавляли в него код из предыдущих мануалов серии). Затем добавьте следующее CSS правило для селектора тега <div>:
div {
background-color: green;
height: 100px;
width: 100px;
}
Сохраните файл styles.css. Затем откройте файл index.html, сотрите все, что там есть (кроме первой строки кода: <link rel=”stylesheet” href=”css/styles.css”>), и добавьте следующий фрагмент:
<div></div>
Обратите внимание, элемент <div> состоит из открывающего и закрывающего тега, но не требует какого-либо контента.
Сохраните файл index.html и перезагрузите его в браузере. Если вы не знаете, как просматривать оффлайн-файл HTML, пожалуйста, обратитесь к нашему мануалу по работе с HTML-элементами (раздел «Просмотр оффлайн HTML-файла в браузере»).
На вашей веб-странице должно появиться зеленое поле шириной 100 пикселей и высотой 100 пикселей, согласно CSS-правилу:
Теперь, когда у вас есть правило стиля для элемента <div>, каждый элемент <div> на вашей странице будет оформлен точно так же. Но чаще всего на элементы <div> должны быть стилизованы по-разному. По этой причине для стилизации элементов <div> разработчики часто используют классы.
Чтобы попрактиковаться в создании классов для <div>, удалите из файла styles.css только что созданное CSS-правило и добавьте следующие три новых набора правил:
.div-1 {
background-color: blue;
height: 50px;
width: 50px;
}
.div-2 {
background-color: red;
height: 100px;
width: 100px;
}
.div-3 {
background-color: yellow;
height: 200px;
width: 200px;
}
В этом фрагменте содержатся правила стиля для трех разных классов: div-1, div-2 и div-3. Обратите внимание, имена селекторов классов начинаются с точки.
Сохраните файл styles.css и перейдите в файл index.html. Сотрите только что созданный элемент <div> и добавьте три новых элемента, применив к каждому из них класс, который соответствует селекторам CSS из файла styles.css:
<div class="div-1"></div>
<div class="div-2"></div>
<div class="div-3"></div>
Обратите внимание, класс добавляется в качестве атрибута к тегу <div>: для этого нужно указать атрибут class и имя класса в открывающем теге <div>. Сохраните файл и перезагрузите его в своем браузере. Вы должны получить такой результат:
На вашей веб-странице будет три элемента <div>, каждый из которых отличается по цвету и размеру в соответствии с присвоенным ему правилом стиля. Обратите внимание, каждый элемент <div> указывается с новой строки, поскольку элементы <div> являются блочными элементами и это их поведение по умолчанию.
Читайте также: Строчные и блочные элементы HTML
Добавление и стилизация текста в контейнере <div>
Вы можете поместить в контейнер <div> текст, вставив его между открывающим и закрывающим тегами <div>. Попробуйте добавить текст в каждый из трех элементов <div> в файле index.html:
<div class="div-1">Blue</div>
<div class="div-2">Red</div>
<div class="div-3">Yellow</div>
Сохраните файл и загрузите его в браузере. Теперь в каждом из контейнеров <div> должен отображаться текст:
Blue
Red
Yellow
В текст внутри элементов <div> можно добавить дополнительные HTML-элементы. Для примера попробуйте добавить к вашему тексту внутри тегов <div> в файле index.html теги заголовков (от <h2> до <h4>):
<div class="div-1"><h2>Blue</h2></div>
<div class="div-2"><h3>Red</h3></div>
<div class="div-3"><h4>Yellow</h4></div>
Сохраните файл и перезагрузите его в браузере. Текст внутри контейнеров <div> теперь будет оформлен в соответствии со свойствами тегов:
Blue
Red
Yellow
Обратите внимание, элементы <div> также немного изменили свои позиции. Это смещение вызвано стандартными свойствами полей для элементов с тегами <h2> по <h4>. Больше о полях вы узнаете в следующем мануале, посвященном блоковой модели CSS (пока что мы проигнорируем эти поля).
Чтобы стилизовать текст внутри <div>, вы можете указать значения свойств текста в наборах правил для классов <div>. Попробуйте добавить свойства в свои наборы правил в файле styles.css, как в следующем фрагменте кода:
.div-1 {
background-color: blue;
height: 50px;
width: 50px;
font-size: 10px;
color: white;
}
.div-2 {
background-color: red;
height: 100px;
width: 100px;
font-size: 20px;
color: yellow;
}
.div-3 {
background-color: yellow;
height: 200px;
width: 200px;
font-size:30px;
color: blue;
}
Сохраните файл styles.css и перезагрузите index.html в браузере. Текст внутри контейнеров <div> теперь будет оформлен в соответствии с CSS правилами в файле styles.css:
Blue
Red
Yellow
Заключение
В этом мануале вы узнали, как изменить цвет и размер элемента <div>, а также как добавить и стилизовать текст внутри такого элемента. Позже – когда мы начнем создавать веб-сайт – мы будем использовать элемент <div> для управления макетом страницы. В следующем мануале мы поговорим о блоковой модели CSS и о том, как ее использовать для настройки свойств контента, отступов, границ и полей элементов.
Tags: CSS, CSS-practice, HTML
Вопрос OP – это простой JavaScript, а не jQuery. Хотя есть много ответов, и мне нравится @Pawan Nogariya ответ, пожалуйста, проверьте эту альтернативу.
Вы можете использовать XPATH в JavaScript. Подробнее о статье MDN здесь.
Метод document.evaluate() оценивает запрос/выражение XPATH. Таким образом, вы можете передавать выражения XPATH, переходить в документ HTML и находить нужный элемент.
В XPATH вы можете выбрать элемент, используя текстовый узел, такой как следующий, whch получает div, у которого есть следующий текстовый узел.
//div[text()="Hello World"]
Чтобы получить элемент, содержащий некоторый текст, используйте следующее:
//div[contains(., 'Hello')]
Метод contains() в XPATH принимает узел как первый параметр и текст для поиска в качестве второго параметра.
Проверьте это шлепнуть здесь, это пример использования XPATH в JavaScript
Вот фрагмент кода:
var headings = document.evaluate("//h1[contains(., 'Hello')]", document, null, XPathResult.ANY_TYPE, null );
var thisHeading = headings.iterateNext();
console.log(thisHeading); // Prints the html element in console
console.log(thisHeading.textContent); // prints the text content in console
thisHeading.innerHTML += "<br />Modified contents";
Как вы можете видеть, я могу захватить элемент HTML и изменить его, как мне нравится.
Как я могу найти DIV с определенным текстом? Например:
<div>
SomeText, text continues.
</div>
Попытка использовать что-то вроде этого:
var text = document.querySelector('div[SomeText*]').innerTEXT;
alert(text);
Но, конечно, это не сработает. Как мне это сделать?
2016-05-08 09:41
14
ответов
Решение
Вопрос OP касается простого JavaScript, а не jQuery. Хотя ответов много, и мне нравится ответ @Pawan Nogariya, пожалуйста, ознакомьтесь с этой альтернативой.
Вы можете использовать XPATH в JavaScript. Больше информации о статье MDN здесь.
document.evaluate() Метод оценивает запрос / выражение XPATH. Таким образом, вы можете передать туда выражения XPATH, перейти в HTML-документ и найти нужный элемент.
В XPATH вы можете выбрать элемент с помощью текстового узла, как показано ниже, который получает div который имеет следующий текстовый узел.
//div[text()="Hello World"]
Чтобы получить элемент, содержащий некоторый текст, используйте следующее:
//div[contains(., 'Hello')]
contains() Метод в XPATH принимает узел в качестве первого параметра и текст для поиска в качестве второго параметра.
Проверьте этот план здесь, это пример использования XPATH в JavaScript
Вот фрагмент кода:
var headings = document.evaluate("//h1[contains(., 'Hello')]", document, null, XPathResult.ANY_TYPE, null );
var thisHeading = headings.iterateNext();
console.log(thisHeading); // Prints the html element in console
console.log(thisHeading.textContent); // prints the text content in console
thisHeading.innerHTML += "<br />Modified contents";
Как видите, я могу взять элемент HTML и изменить его так, как мне нравится.
2016-05-08 10:10
Вы можете использовать это довольно простое решение:
Array.from(document.querySelectorAll('div'))
.find(el => el.textContent === 'SomeText, text continues.');
-
Array.fromпреобразует NodeList в массив (есть несколько способов сделать это, например, оператор распространения или срез) -
Теперь результат в виде массива позволяет использовать
Array.findметод, вы можете затем вставить любой предикат. Вы также можете проверить textContent с помощью регулярных выражений или что угодно.
Обратите внимание, что Array.from а также Array.find Особенности ES2015. Быть совместимым со старыми браузерами, такими как IE10, без транспилятора:
Array.prototype.slice.call(document.querySelectorAll('div'))
.filter(function (el) {
return el.textContent === 'SomeText, text continues.'
})[0];
2017-08-24 19:57
Так как вы спросили об этом в JavaScript, чтобы вы могли иметь что-то вроде этого
function contains(selector, text) {
var elements = document.querySelectorAll(selector);
return Array.prototype.filter.call(elements, function(element){
return RegExp(text).test(element.textContent);
});
}
А потом назови это так
contains('div', 'sometext'); // find "div" that contain "sometext"
contains('div', /^sometext/); // find "div" that start with "sometext"
contains('div', /sometext$/i); // find "div" that end with "sometext", case-insensitive
2016-05-08 09:52
Это решение делает следующее:
-
Использует оператор распространения ES6 для преобразования NodeList всех
divс массивом. -
Обеспечивает вывод, если
divсодержит строку запроса, а не только в том случае, если она точно равна строке запроса (что происходит для некоторых других ответов). Например, он должен обеспечивать вывод не только для SomeText, но и для SomeText, текст продолжается. -
Выводит весь
divсодержимое, а не только строка запроса. Например, для “SomeText, текст продолжается” следует выводить всю эту строку, а не только “SomeText”. -
Позволяет для нескольких
divs, чтобы содержать строку, а не только одинdiv,
[...document.querySelectorAll('div')] // get all the divs in an array
.map(div => div.innerHTML) // get their contents
.filter(txt => txt.includes('SomeText')) // keep only those containing the query
.forEach(txt => console.log(txt)); // output the entire contents of those<div>SomeText, text continues.</div>
<div>Not in this div.</div>
<div>Here is more SomeText.</div>2018-04-12 03:32
Столкнувшись с этим в 2021 году, я обнаружил, что использование XPATH слишком сложно (нужно научиться чему-то еще) для чего-то, что должно быть довольно простым.
Придумал это:
function querySelectorIncludesText (selector, text){
return Array.from(document.querySelectorAll(selector))
.find(el => el.textContent.includes(text));
}
Применение:
querySelectorIncludesText('button', 'Send')
Обратите внимание, что я решил использовать
includes и не строгое сравнение, потому что это то, что мне действительно нужно, не стесняйтесь адаптироваться.
Эти полифилы могут понадобиться, если вы хотите поддерживать все браузеры:
/**
* String.prototype.includes() polyfill
* https://developer.mozilla.org/en-US/docs/Web/JavaScript/Reference/Global_Objects/String/includes#Polyfill
* @see https://vanillajstoolkit.com/polyfills/stringincludes/
*/
if (!String.prototype.includes) {
String.prototype.includes = function (search, start) {
'use strict';
if (search instanceof RegExp) {
throw TypeError('first argument must not be a RegExp');
}
if (start === undefined) {
start = 0;
}
return this.indexOf(search, start) !== -1;
};
}
2021-05-05 12:46
Лучше всего посмотреть, есть ли у вас родительский элемент div, к которому вы обращаетесь. Если это так, получите родительский элемент и выполните element.querySelectorAll("div"), Как только вы получите nodeList применить фильтр к нему над innerText имущество. Предположим, что родительский элемент div, к которому мы обращаемся, имеет id из container, Обычно вы можете получить доступ к контейнеру напрямую из идентификатора, но давайте сделаем это правильно.
var conty = document.getElementById("container"),
divs = conty.querySelectorAll("div"),
myDiv = [...divs].filter(e => e.innerText == "SomeText");
Итак, это все.
2016-05-08 09:53
Если вы не хотите использовать jquery или что-то подобное, вы можете попробовать это:
function findByText(rootElement, text){
var filter = {
acceptNode: function(node){
// look for nodes that are text_nodes and include the following string.
if(node.nodeType === document.TEXT_NODE && node.nodeValue.includes(text)){
return NodeFilter.FILTER_ACCEPT;
}
return NodeFilter.FILTER_REJECT;
}
}
var nodes = [];
var walker = document.createTreeWalker(rootElement, NodeFilter.SHOW_TEXT, filter, false);
while(walker.nextNode()){
//give me the element containing the node
nodes.push(walker.currentNode.parentNode);
}
return nodes;
}
//call it like
var nodes = findByText(document.body,'SomeText');
//then do what you will with nodes[];
for(var i = 0; i < nodes.length; i++){
//do something with nodes[i]
}
Когда у вас есть узлы в массиве, которые содержат текст, вы можете что-то с ними сделать. Как предупреждение каждого или распечатать на консоль. Одно предостережение в том, что это может не обязательно захватывать div как таковые, это будет захватывать родителя текстового узла, в котором находится текст, который вы ищете.
2016-05-08 10:28
Для Google это лучший результат для тех, кому нужно найти узел с определенным текстом. В порядке обновления, список узлов теперь итеративен в современных браузерах без необходимости преобразования его в массив.
Решение может использовать forEach, как так.
var elList = document.querySelectorAll(".some .selector");
elList.forEach(function(el) {
if (el.innerHTML.indexOf("needle") !== -1) {
// Do what you like with el
// The needle is case sensitive
}
});
Это сработало для меня, чтобы найти / заменить текст внутри списка узлов, когда обычный селектор не мог выбрать только один узел, поэтому мне пришлось фильтровать каждый узел один за другим, чтобы проверить его на предмет стрелки.
2017-11-06 22:59
Используйте XPath и document.evaluate (), и убедитесь, что используете text(), а не. для аргумента contains (), иначе у вас будет весь HTML или самый внешний элемент div.
var headings = document.evaluate("//h1[contains(text(), 'Hello')]", document, null, XPathResult.ANY_TYPE, null );
или игнорировать начальные и конечные пробелы
var headings = document.evaluate("//h1[contains(normalize-space(text()), 'Hello')]", document, null, XPathResult.ANY_TYPE, null );
или соответствовать всем типам тегов (div, h1, p и т. д.)
var headings = document.evaluate("//*[contains(text(), 'Hello')]", document, null, XPathResult.ANY_TYPE, null );
Затем итерации
let thisHeading;
while(thisHeading = headings.iterateNext()){
// thisHeading contains matched node
}
2017-12-11 15:54
Поскольку нет ограничений на длину текста в атрибуте данных, используйте атрибуты данных! И затем вы можете использовать обычные селекторы css для выбора ваших элементов, как того хочет OP.
for (const element of document.querySelectorAll("*")) {
element.dataset.myInnerText = element.innerText;
}
document.querySelector("*[data-my-inner-text='Different text.']").style.color="blue";<div>SomeText, text continues.</div>
<div>Different text.</div>В идеале вы выполняете часть настройки атрибутов данных при загрузке документа и немного сужаете селектор querySelectorAll для повышения производительности.
2020-02-26 01:58
Здесь уже есть много отличных решений. Однако, чтобы предоставить более оптимизированное решение и еще одно, соответствующее идее поведения и синтаксиса querySelector, я выбрал решение, которое расширяет Object парой функций-прототипов. Обе эти функции используют регулярные выражения для сопоставления текста, однако строка может быть предоставлена как свободный параметр поиска.
Просто реализуйте следующие функции:
// find all elements with inner text matching a given regular expression
// args:
// selector: string query selector to use for identifying elements on which we
// should check innerText
// regex: A regular expression for matching innerText; if a string is provided,
// a case-insensitive search is performed for any element containing the string.
Object.prototype.queryInnerTextAll = function(selector, regex) {
if (typeof(regex) === 'string') regex = new RegExp(regex, 'i');
const elements = [...this.querySelectorAll(selector)];
const rtn = elements.filter((e)=>{
return e.innerText.match(regex);
});
return rtn.length === 0 ? null : rtn
}
// find the first element with inner text matching a given regular expression
// args:
// selector: string query selector to use for identifying elements on which we
// should check innerText
// regex: A regular expression for matching innerText; if a string is provided,
// a case-insensitive search is performed for any element containing the string.
Object.prototype.queryInnerText = function(selector, text){
return this.queryInnerTextAll(selector, text)[0];
}
После реализации этих функций вы можете выполнять следующие вызовы:
document.queryInnerTextAll('div.link', 'go');
Это найдет все дивы, содержащие ссылку класс со словом идти в InnerText (например. Налево или идти вниз или идти прямо или это Go О.Д.)document.queryInnerText('div.link', 'go');
Это будет работать точно так же, как в приведенном выше примере, за исключением того, что вернет только первый соответствующий элемент.document.queryInnerTextAll('a', /^Next$/);
Найдите все ссылки с точным текстом Далее (с учетом регистра). Это исключит ссылки, содержащие слово Next вместе с другим текстом.document.queryInnerText('a', /next/i);
Найдите первую ссылку, содержащую слово ” следующий”, независимо от регистра (например, ” Следующая страница” или ” Перейти к следующему”).e = document.querySelector('#page');e.queryInnerText('button', /Continue/);
Это выполняет поиск в элементе контейнера кнопки, содержащей текст ” Продолжить” (с учетом регистра). (например, ” Продолжить” или ” Перейти к следующему”, но не продолжить)
2020-07-31 21:40
Вот подход XPath, но с минимумом жаргона XPath.
Обычный выбор на основе значений атрибутов элемента (для сравнения):
// for matching <element class="foo bar baz">...</element> by 'bar'
var things = document.querySelectorAll('[class*="bar"]');
for (var i = 0; i < things.length; i++) {
things[i].style.outline = '1px solid red';
}
Выбор XPath на основе текста внутри элемента.
// for matching <element>foo bar baz</element> by 'bar'
var things = document.evaluate('//*[contains(text(),"bar")]',document,null,XPathResult.ORDERED_NODE_SNAPSHOT_TYPE,null);
for (var i = 0; i < things.snapshotLength; i++) {
things.snapshotItem(i).style.outline = '1px solid red';
}
А вот и нечувствительность к регистру, поскольку текст более изменчив:
// for matching <element>foo bar baz</element> by 'bar' case-insensitively
var things = document.evaluate('//*[contains(translate(text(),"ABCDEFGHIJKLMNOPQRSTUVWXYZ","abcdefghijklmnopqrstuvwxyz"),"bar")]',document,null,XPathResult.ORDERED_NODE_SNAPSHOT_TYPE,null);
for (var i = 0; i < things.snapshotLength; i++) {
things.snapshotItem(i).style.outline = '1px solid red';
}
2019-08-23 01:34
Я искал способ сделать что-то подобное с помощью Regex и решил создать что-то свое, чем хотел бы поделиться, если другие ищут подобное решение.
function getElementsByTextContent(tag, regex) {
const results = Array.from(document.querySelectorAll(tag))
.reduce((acc, el) => {
if (el.textContent && el.textContent.match(regex) !== null) {
acc.push(el);
}
return acc;
}, []);
return results;
}
2021-06-06 20:47
У меня была аналогичная проблема.
Функция, возвращающая все элементы, включающие текст из аргумента.
Это работает для меня:
function getElementsByText(document, str, tag = '*') {
return [...document.querySelectorAll(tag)]
.filter(
el => (el.text && el.text.includes(str))
|| (el.children.length === 0 && el.outerText && el.outerText.includes(str)))
}
2019-10-28 00:00
