Ну, раз обход в глубину нужен, то запускайте от каждой вершины полный перебор и ищите пути назад в эту же вершину.
Для этого вам надо будет помечать вершины при входе, как пройденные, и убирать пометку при выходе. В самом обходе перебирайте все ребра и рекурсивно запускайтесь от пока не обойденных вершин. Если видите ребро в первую вершину – вы нашли цикл, сохраните текущую глубину в ответ, если она лучше пока что найденного.
Для ускорения можно: Не уходить рекурсивно глубже, чем текущий ответ. Помечать вершины не просто пометкой посещена/не посещена, а глубиной рекурсивного вызова. Тогда, если есть ребро в уже обойденную вершину – вы нашли какой-то цикл с какой-то длинной (текущая глубина – глубина второй вершины + 1). Его сразу же можно брать как возможный ответ. Если граф связный, то можно запускаться только от одной вершины, или можно запускаться от одной вершины в каждой компоненте связности.
Но это все равно будет работать за экспоненциальную сложность.
Другая задача – проверить, есть ли в графе любой цикл – решается обходом в глубину за линейную сложность.
From the graph theory we know that:
- if the quantity of vertices of a graph is more than the quantity of edges, therefore, cycles (closed contours) are absent.
- if the quantity of vertices of a graph is equal to the quantity of edges, therefore, a graph has only one cycle.
- if the quantity of vertices of a graph is less than the quantity of edges, therefore, a graph has more than one closed contour.

This problem can be solved, using the algorithm Depth first search:
#include <iostream>
#include <vector>
#include <set>
#include <algorithm>
using namespace std;
const int maximumSize=40;
vector<vector<int>> visited(maximumSize, vector<int>(maximumSize, 0));
vector<int> graph[maximumSize], closedContour, temporary;
int vertices, edges;
set<vector<int>> contours;
void showContentSetVector(set<vector<int>> input)
{
for(auto iterator=input.begin(); iterator!=input.end(); ++iterator)
{
for(auto item : *iterator)
{
cout<<item<<", ";
}
cout<<endl;
}
return;
}
bool compare(int i,int j)
{
return (i<j);
}
void createGraph()
{
cin>>vertices>>edges;
int vertex0, vertex1;
for(int i=1; i<=edges; ++i)
{
cin>>vertex0>>vertex1;
graph[vertex0].push_back(vertex1);
graph[vertex1].push_back(vertex0);
}
return;
}
void depthFirstSearch(int initial, int current, int previous)
{
if(visited[initial][current]==1)
{
for(int i=0; i<temporary.size(); ++i)
{
if(temporary[i]==current)
{
for(int j=i; j<temporary.size(); ++j)
{
closedContour.push_back(temporary[j]);
}
}
}
sort(closedContour.begin(), closedContour.end(), compare);
contours.insert(closedContour);
closedContour.clear();
return;
}
visited[initial][current]=1;
temporary.push_back(current);
for(int next : graph[current])
{
if(next==previous)
{
continue;
}
depthFirstSearch(initial, next, current);
}
temporary.pop_back();
return;
}
void solve()
{
createGraph();
for(int vertex=1; vertex<=vertices; ++vertex)
{
temporary.clear();
depthFirstSearch(vertex, vertex, -1);
}
cout<<"contours <- ";
showContentSetVector(contours);
return;
}
int main()
{
solve();
return 0;
}
Here is the result:
contours <-
1, 2, 3, 4,
6, 7, 8,
Нахождение цикла — алгоритмическая задача поиска цикла в последовательности значений итеративной функции[en].
Для любой функции f, отображающей конечное множество S в себя, и для любого начального значения x0 из S последовательность итеративных значений функции:

должна в конечном счёте использовать одно значение дважды, то есть должна существовать такая пара индексов i и j, что xi = xj. Как только это случится, последовательность будет продолжаться периодически, повторяя ту же самую последовательность значений от xi до xj − 1. Нахождение цикла — это задача поиска индексов i и j при заданной функции f и начальном значении x0.
Известно несколько алгоритмов поиска цикла быстро и при малой памяти. Алгоритм «черепахи и зайца» Флойда передвигает два указателя с различной скоростью через последовательность значений, пока не получит одинаковые значения. Другой алгоритм, алгоритм Брента, основан на идее экспоненциального поиска[en]. Оба алгоритма, Флойда и Брента, используют только фиксированное число ячеек памяти, и число вычислений функции пропорционально расстоянию от стартовой точки до первой точки повторения. Некоторые другие алгоритмы используют большее количество памяти, чтобы получить меньшее число вычислений значений функции.
Задача нахождения цикла используется для проверки качества генераторов псевдослучайных чисел и криптографических хеш-функций, в алгоритмах вычислительной теории чисел[en], для определения бесконечных циклов в компьютерных программах и периодических конфигураций клеточных автоматов, а также для автоматического анализа формы[en] связных списков.
Пример[править | править код]

Функция из множества {0,1,2,3,4,5,6,7,8} в то же множество и соответствующий функциональный граф
Рисунок показывает функцию f, отображающую множество S = {0,1,2,3,4,5,6,7,8} на себя. Если начать с точки x0 = 2 и повторять применение функции f к получаемым значениям, увидим последовательность значений
- 2, 0, 6, 3, 1, 6, 3, 1, 6, 3, 1, ….
Цикл в этой последовательности значений — 6, 3, 1.
Определения[править | править код]
Пусть S — конечное множество, f — некая функция, отображающая S в то же самое множество, а x0 — любой элемент из S. Для любого i > 0 пусть xi = f(xi − 1). Пусть μ — наименьший индекс, для которого значение xμ повторяется бесконечное число раз в последовательности значений xi, и пусть λ (длина цикла) — наименьшее положительное целое число, такое, что xμ = xλ + μ. Задача нахождения цикла — это задача поиска λ и μ[1].
Можно рассматривать эту задачу как задачу теории графов, если построить функциональный граф (то есть ориентированный граф, в котором каждая вершина имеет единственную исходящую дугу), вершины которого являются элементами множества S, а рёбра соответствуют отображению элементов в соответствующие значения функции, как показано на рисунке. Множество вершин, достижимых из стартовой вершины x0 образуют подграф в форме, похожем на греческую букву ро (ρ) — путь длины μ от x0 до цикла из λ вершин[2].
Представление в компьютере[править | править код]
Обычно f не задаётся в виде таблицы значений, как показано на рисунке выше. Скорее алгоритм определения цикла может получить на входе либо последовательность значений xi, либо подпрограмму вычисления f. Задача состоит в нахождении λ и μ с проверкой малого числа значений последовательности, либо с обращением к процедуре вычисления значения как можно меньшее число раз. Обычно важна также ёмкостная сложность[en] алгоритма задачи нахождения цикла: желательно использовать память, значительно меньшую по сравнению с размером последовательности целиком.
В некоторых приложениях, и, в частности, в ро-алгоритме Полларда для факторизации целых чисел, алгоритм имеет очень ограниченный доступ к S и f. В ро-алгоритме Полларда, например, S — это множество сравнимых по неизвестному простому множителю числа, который следует разложить на множители, так что даже размер множества S для алгоритма неизвестен.
Чтобы алгоритм нахождения цикла работал в таких стеснённых условиях, он должен разрабатываться на основе следующих возможностей. Первоначально алгоритм имеет в памяти объект, представляющий указатель на начальное значение x0. На любом шаге алгоритм может осуществлять одну из трёх действий: он может копировать любой указатель в любой другой объект памяти, он может вычислить значение f и заменить любой указатель на указатель на вновь образованный объект из последовательности, или использовать процедуру проверки совпадения значений, на которые указывают два указателя.
Тест проверки равенства может повлечь некоторые нетривиальные вычисления. Например, в ро-алгоритме Полларда этот тест проверяет, не имеет ли разность двух запомненных значений нетривиальный наибольший общий делитель с разлагаемым на множители числом [2]. В этом контексте, по аналогии с моделью вычисления машины указателей[en], алгоритм, использующий только копирование указателей, передвижение в последовательности и тест на равенство, можно назвать алгоритмом указателей.
Алгоритмы[править | править код]
Если вход задан как подпрограмма вычисления f, задачу нахождения цикла можно тривиально решить, сделав только λ + μ вызовов функции просто путём вычисления последовательности значений xi и использования структуры данных такой, как хеш-таблица, для запоминания этих значений и теста, что каждое последующее значение ещё не запомнено. Однако ёмкостная сложность данного алгоритма пропорциональна λ + μ, и эта сложность излишне велика. Кроме того, чтобы использовать этот метод для алгоритма указателей, потребуется использовать тест на равенство для каждой пары значений, что приведёт к квадратичному времени. Таким образом, исследования в этой области преследуют две цели: использовать меньше места, чем этот бесхитростный алгоритм, и найти алгоритм указателей, который использует меньше проверок на равенство.
Черепаха и заяц[править | править код]
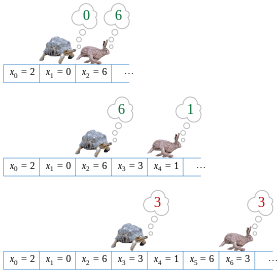
Алгоритм Флойда поиска цикла «черепаха и заяц», применённый у последовательности 2, 0, 6, 3, 1, 6, 3, 1, …
Алгоритм Флойда поиска цикла — это алгоритм указателей, который использует только два указателя, которые передвигаются вдоль последовательности с разными скоростями. Алгоритм называется также алгоритмом «черепахи и зайца» с намёком на басню Эзопа «Черепаха и заяц»[en].
Алгоритм назван именем Роберта Флойда, которому Дональд Кнут приписывает изобретение метода[3][4]. Однако алгоритм не был опубликован в работах Флойда, и, возможно, это ошибка атрибуции: Флойд описывает алгоритмы для перечисления всех простых циклов в ориентированном графе в статье 1967 года[5], но в этой статье не описана задача нахождения цикла в функциональных графах, являющихся объектами рассмотрения статьи. Фактически утверждение Кнута, сделанное в 1969 году и приписывающее алгоритм Флойду без цитирования, является первым известным упоминанием данного алгоритма в печати, и, таким образом, алгоритм может оказаться математическим фольклором[en], не принадлежащим определённой личности[6].
Основная идея алгоритма заключается в том, что для любых целых i ≥ μ и k ≥ 0, xi = xi + kλ, где λ — длина цикла, а μ — индекс первого элемента в цикле. В частности, i = kλ ≥ μ тогда и только тогда, когда xi = x2i.
Таким образом, чтобы найти период ν повторения, который будет кратен λ, алгоритму нужно проверять на повторение лишь значения этого специального вида — одно значение вдвое дальше от начала, чем второе.
Как только период ν будет найден, алгоритм пересматривает последовательность с начальной точки, чтобы найти первое повторяющееся значение xμ в последовательности, используя факт, что λ делит ν, а потому xμ = xμ + v. Наконец, как только значение μ станет известно, легко найти длину λ кратчайшего цикла повторения путём нахождения первой позиции μ + λ, для которой xμ + λ = xμ.
Алгоритм использует два указателя в заданной последовательности: один (черепаха) идёт по значениям xi, а другой (заяц) по значениям x2i. На каждом шаге алгоритма индекс i увеличивается на единицу, передвигая черепаху на один элемент вперёд, а зайца — на два элемента, после чего значения в этих точках сравниваются. Наименьшее значение i > 0, для которого черепаха и заяц будут указывать на одинаковые значения, является искомым значением ν.
Следующая программа на языке Python показывает, каким образом идея может быть реализована.
def floyd(f, x0): # Основная часть алгоритма: находим повторение x_i = x_2i. # Заяц движется вдвое быстрее черепахи, # и расстояние между ними увеличивается на единицу от шага к шагу. # Однажды они окажутся внутри цикла, и тогда расстояние между ними # будет делиться на λ. tortoise = f(x0) # f(x0) является элементом, следующим за x0. hare = f(f(x0)) while tortoise != hare: tortoise = f(tortoise) hare = f(f(hare)) # В этот момент позиция черепахи ν, # которая равна расстоянию между черепахой и зайцем, # делится на период λ. Таким образом, заяц, двигаясь # по кольцу на одну позицию за один раз, # и черепаха, опять начавшая движение со стартовой точки x0 и # приближающаяся к кольцу, встретятся в начале кольца # Находим позицию μ встречи. mu = 0 tortoise = x0 while tortoise != hare: tortoise = f(tortoise) hare = f(hare) # Заяц и черепаха двигаются с одинаковой скоростью mu += 1 # Находим длину кратчайшего цикла, начинающегося с позиции x_μ # Заяц движется на одну позицию вперёд, # в то время как черепаха стоит на месте. lam = 1 hare = f(tortoise) while tortoise != hare: hare = f(hare) lam += 1 return lam, mu
Данный код получает доступ к последовательности лишь запоминанием и копированием указателей, вычислением функции и проверкой равенства. Таким образом, алгоритм является алгоритмом указателей. Алгоритм использует O(λ + μ) операций этих типов и O(1) памяти [7].
Алгоритм Брента[править | править код]
Ричард Брент описал альтернативный алгоритм нахождения цикла, которому, подобно алгоритму черепахи и зайца, требуется лишь два указателя на последовательность [8]. Однако он основан на другом принципе — поиске наименьшей степени 2i числа 2, которая больше как λ, так и μ.
Для i = 0, 1, 2, …, алгоритм сравнивает x2i−1 со значениями последовательности вплоть до следующей степени двух, останавливая процесс, когда найдётся совпадение. Алгоритм имеет два преимущества по сравнению с алгоритмом черепахи и зайца: во-первых, он находит правильную длину λ цикла сразу и не требуется второй шаг для её определения, а во-вторых, на каждом шаге вызов функции f происходит только один раз, а не три раза [9].
Следующая программа на языке Python более детально показывает, как эта техника работает.
def brent(f, x0): # Основная фаза: ищем степень двойки power = lam = 1 tortoise = x0 hare = f(x0) # f(x0) — элемент/узел, следующий за x0. while tortoise != hare: if power == lam: # время начать новую степень двойки? tortoise = hare power *= 2 lam = 0 hare = f(hare) lam += 1 # Находим позицию первого повторения длины λ mu = 0 tortoise = hare = x0 for i in range(lam): # range(lam) образует список со значениями 0, 1, ... , lam-1 hare = f(hare) # расстояние между черепахой и зайцем теперь равно λ. # Теперь черепаха и заяц движутся с одинаковой скоростью, пока не встретятся while tortoise != hare: tortoise = f(tortoise) hare = f(hare) mu += 1 return lam, mu
Подобно алгоритму черепахи и зайца, этот алгоритм является алгоритмом указателей, использующим O(λ + μ) проверок и вызовов функций и памяти O(1). Несложно показать, что число вызовов функции никогда не превзойдёт числа вызовов в алгоритме Флойда.
Брент утверждает, что в среднем его алгоритм работает примерно на 36 % быстрее алгоритма Флойда, и что он обгоняет ро-алгоритм Полларда примерно на 24 %. Он осуществил анализ среднего варианта[en] вероятностной версии алгоритма, в котором последовательность индексов, проходимых медленным указателем, не является степенью двойки, а является степенью двойки, умноженной на случайный коэффициент. Хотя основной целью его алгоритма была разложение числа на множители, Брент также обсуждает приложение алгоритма для проверки псевдослучайных генераторов[8].
Время в обмен на память[править | править код]
Много авторов изучали техники для нахождения цикла, использующих большее количество памяти, чем у методов Флойда и Брента, но, зато, работающих быстрее. В общем случае эти методы запоминают некоторые ранее вычисленные значения последовательности и проверяют, не совпадает ли новое значение с одним из запомненных. Чтобы делать это быстро, обычно они используют хеш-таблицы или подобные структуры данных, а потому такие алгоритмы не являются алгоритмами указателей (в частности, обычно их нельзя приспособить к ро-алгоритму Полларда). Чем эти методы отличаются, так это способом определения, какие значения запоминать. Следуя Нивашу[10], мы кратко рассмотрим эти техники.
Брент[8] уже описывал вариации своей техники, в которых индексы запомненных значений последовательности являются степенями числа R, отличного от двух. При выборе R ближе к единице и, запоминая значения последовательности с индексами, близкими к последовательным степеням R, алгоритм нахождения цикла может использовать число вызовов функции, которое не превосходит произвольно малого множителя оптимального значения λ + μ[11][12].
Седжвик, Шиманьский и Яо [13] предложили метод, который использует M ячеек памяти и требует в худшем случае только 
Некоторые авторы описали методы отмеченных точек, которые запоминают в таблице значения функции, опираясь на критерии, использующие значения, а не индексы (как в методе Седжвика и др.). Например, могут запоминаться значения по модулю от некоторого числа d[14][15]. Более просто, Ниваш[10] приписывает Вудруфу предложение запоминать случайно выбранное предыдущее значение, делая подходящий случайный выбор на каждом шаге.
Ниваш[10] описывает алгоритм, который не использует фиксированного количества памяти, но для которого ожидаемое количество используемой памяти (в предположении, что входная функция случайна) логарифмически зависит от длины последовательности. По этой технике элемент записывается в таблицу, если никакой предыдущий элемент не имеет меньшего значения. Как показал Ниваш, элементы в этой технике можно располагать в стеке, и каждое последующее значение нужно сравнивать только с элементом на вершине стека. Алгоритм прекращает работу, когда повторение элемента с меньшим значением найдено. Если использовать несколько стеков и случайную перестановку значений внутри каждого стека, получаем выигрыш в скорости за счёт памяти аналогично предыдущим алгоритмам. Однако даже версия алгоритма с одним стеком не является алгоритмом указателей, поскольку требуется знать, какое из значений меньше.
Любой алгоритм нахождения цикла, запоминающий максимум M значений из входной последовательности, должен сделать по меньшей мере 
Приложения[править | править код]
Нахождение цикла используется во многих приложениях.
Определение длины цикла генератора псевдослучайных чисел является одной из мер его силы. Об этом приложении говорил Кнут при описании метода Флойда[3]. Брент[8] описал результат тестирования линейного конгруэнтного генератора. Период генератора оказался существенно меньше афишированного. Для более сложных генераторов последовательность значений, в которых находят цикл, может не представлять вывод генератора, а лишь его внутреннее состояние.
Некоторые алгоритмы теории чисел опираются на нахождение цикла, включая ро-алгоритм Полларда для факторизации целых чисел[18] и связанный с ним алгоритм «кенгуру» для задачи дискретного логарифмирования[19].
В криптографии возможность найти два различных значения xμ−1 и xλ+μ−1, отображающихся некоторой криптографической функцией ƒ в одно и то же значение xμ, может говорить о слабости ƒ. Например, Кискатр и Делессаилле[15] применили алгоритмы нахождения цикла для поиска сообщения и пары ключей DES, которые отображают это сообщение в одно и то же зашифрованное значение. Калиски, Ривест и Шерман[en][20] также использовали алгоритмы нахождения цикла для атаки на DES. Техника может быть использована для поиска коллизий в криптографической хеш-функции[21].
Нахождение циклов может быть полезно как путь обнаружения бесконечных циклов в некоторых типах компьютерных программ[22].
Периодические конфигурации в моделировании клеточного автомата можно найти, применив алгоритмы нахождения цикла к последовательности состояний автомата[10].
Анализ формы[en] связных списков является техникой проверки корректности алгоритма, использующего эти структуры. Если узел в списке ссылается некорректно на более ранний узел в том же списке, структура образует цикл, который может быть найден с помощью таких алгоритмов[23]. В языке Common Lisp принтер S-выражений при переменной *print-circle* обнаруживает зацикленные списковые структуры и печатает их компактно.
Теске[12] описывает приложение в вычислительной теории групп для вычисления структуры абелевой группы по множеству её генераторов. Криптографические алгоритмы Калиски и др.[20] можно рассматривать также как попытку раскрыть структуру неизвестной группы.
Фич[24] коротко упомянула применение для компьютерного моделирования небесной механики, которое она приписывает Кэхэну. В этом приложении нахождение цикла в фазововом пространстве системы орбит можно использовать для определения, является ли система периодической с точностью модели[16].
Примечания[править | править код]
- ↑ Joux, 2009, p. 223.
- ↑ 1 2 Joux, 2009, p. 224.
- ↑ 1 2 Knuth, 1969, p. 7, ex. 6, 7.
- ↑ Menezes, van Oorschot, Vanstone, 1996, p. 125.
- ↑ Floyd, 1967, p. 636—644.
- ↑ Aumasson, Meier, Phan, Henzen, 2015, p. 21, сноска 8.
- ↑ Joux, 2009, p. 225—226, Section 7.1.1, Floyd’s cycle-finding algorithm.
- ↑ 1 2 3 4 Brent, 1980, p. 176—184.
- ↑ Joux, 2009, p. 226—227, Section 7.1.2, Brent’s cycle-finding algorithm.
- ↑ 1 2 3 4 Nivasch, 2004, p. 135—140.
- ↑ Schnorr, Lenstra, 1984, p. 289—311.
- ↑ 1 2 Teske, 1998, p. 1637—1663.
- ↑ Sedgewick, Szymanski, Yao, 1982, p. 376—390.
- ↑ van Oorschot, Wiener, 1999, p. 1—28.
- ↑ 1 2 Quisquater, Delescaille, 1989, p. 429—434.
- ↑ 1 2 Fich, 1981, p. 96—105.
- ↑ Allender, Klawe, 1985, p. 231—237.
- ↑ Pollard, 1975, p. 331—334.
- ↑ Pollard, 1978, p. 918—924.
- ↑ 1 2 Kaliski, Rivest, Sherman, 1988, p. 3—36.
- ↑ Joux, 2009, p. 242—245, Section 7.5, Collisions in hash functions.
- ↑ Van Gelder, 1987, p. 23—31.
- ↑ Auguston, Hon, 1997, p. 37—42.
- ↑ Fich, 1981.
Литература[править | править код]
- Allender, Eric W.; Klawe, Maria M. Improved lower bounds for the cycle detection problem // Theoretical Computer Science. — 1985. — Vol. 36, no. 2–3. — doi:10.1016/0304-3975(85)90044-1. — P. 231—237.
- Auguston, Mikhail; Hon, Miu Har. . Assertions for Dynamic Shape Analysis of List Data Structures // AADEBUG ’97, Proceedings of the Third International Workshop on Automatic Debugging. — Linköping University, 1997. — (Linköping Electronic Articles in Computer and Information Science). — P. 37—42.
- Aumasson, Jean-Philippe; Meier, Willi; Phan, Raphael C.-W.; Henzen, Luca. . The Hash Function BLAKE. — Heidelberg, New York, Dordrecht, London: Springer, 2015. — (Information security and Cryptography). — ISBN 978-3-662-44756-7.
- Brent R. P. An improved Monte Carlo factorization algorithm // BIT Numerical Mathematics. — 1980. — Vol. 20, no. 2. — P. 176—184. — doi:10.1007/BF01933190.
- Fich, Faith Ellen. . Lower bounds for the cycle detection problem // Proc. 13th ACM Symposium on Theory of Computing. — 1981. — doi:10.1145/800076.802462. — P. 96—105.
- Floyd R. W. Non-deterministic Algorithms // Journal of ACM. — 1967. — Vol. 14, no. 4. — P. 636—644. — doi:10.1145/321420.321422.
- Joux, Antoine. . Algorithmic Cryptanalysis. — CRC Press, 2009. — P. 223. — ISBN 9781420070033.
- Kaliski, Burton S. Jr.; Rivest, Ronald L.; Sherman Alan T. Is the Data Encryption Standard a group? (Results of cycling experiments on DES) // Journal of Cryptology. — 1988. — Vol. 1, no. 1. — P. 3—36. — doi:10.1007/BF00206323.
- Knuth, Donald E. . The Art of Computer Programming, vol. II: Seminumerical Algorithms. — Addison-Wesley, 1969. — P. 7, exercises 6 and 7.
- Русский перевод: Кнут Д. Э. . Искусство программирования. 3-е изд. Т. 2. Получисленные алгоритмы. — Вильямс, 2005. — ISBN 5-8459-0081-6.
- Menezes, Alfred J.; van Oorschot, Paul C.; Vanstone, Scott A. . Handbook of Applied Cryptography. — CRC Press, 1996. — ISBN 0-8493-8523-7.
- Nivasch, Gabriel. Cycle detection using a stack // Information Processing Letters. — 2004. — Vol. 90, no. 3. — P. 135—140. — doi:10.1016/j.ipl.2004.01.016.
- Pollard J. M. A Monte Carlo method for factorization // BIT. — 1975. — Vol. 15, no. 3. — P. 331—334. — doi:10.1007/BF01933667.
- Pollard J. M. Monte Carlo methods for index computation (mod p) // Mathematics of Computation. — American Mathematical Society, 1978. — Vol. 32, no. 143. — P. 918—924. — doi:10.2307/2006496. — JSTOR 2006496.
- Quisquater J.-J., Delescaille J.-P. . How easy is collision search? Application to DES // Advances in Cryptology — EUROCRYPT ’89, Workshop on the Theory and Application of Cryptographic Techniques. — Springer-Verlag, 1989. — P. 429—434. — (Lecture Notes in Computer Science, vol. 434). (недоступная ссылка)
- Schnorr, Claus P.; Lenstra, Hendrik W. A Monte Carlo factoring algorithm with linear storage // Mathematics of Computation. — 1984. — Vol. 43, no. 167. — P. 289—311. — doi:10.2307/2007414. — JSTOR 2007414.
- Sedgewick, Robert; Szymanski, Thomas G.; Yao, Andrew C.-C. The complexity of finding cycles in periodic functions // SIAM Journal on Computing. — 1982. — Vol. 11, no. 2. — P. 376—390. — doi:10.1137/0211030.
- Teske, Edlyn. A space-efficient algorithm for group structure computation // Mathematics of Computation. — 1998. — Vol. 67, no. 224. — P. 1637—1663. — doi:10.1090/S0025-5718-98-00968-5.
- Van Gelder, Allen. Efficient loop detection in Prolog using the tortoise-and-hare technique // Journal of Logic Programming. — 1987. — Vol. 4, no. 1. — P. 23—31. — doi:10.1016/0743-1066(87)90020-3.
- van Oorschot, Paul C.; Wiener, Michael J. Parallel collision search with cryptanalytic applications // Journal of Cryptology. — 1999. — Vol. 12, no. 1. — P. 1—28. — doi:10.1007/PL00003816.
Ссылки[править | править код]
- Gabriel Nivasch, Задача нахождения цикла и стековый алгоритм
- Черепаха и заяц, Portland Pattern Repository
- Floyd’s Задача нахождения цикла (Черепаха и заяц)
- Brent’s Задача нахождения цикла (Черепаха и заяц)
Сайт переезжает. Большинство статей уже перенесено на новую версию.
Скоро добавим автоматические переходы, но пока обновленную версию этой статьи можно найти там.
Задача
Дан ориентированный граф (G = (V, E)), а также вершина (s).
Найти длину кратчайшего пути от (s) до каждой из вершин графа. Длина пути — количество рёбер в нём.
BFS
BFS — breadth-first search, или же поиск в ширину.
Этот алгоритм позволяет решать следующую задачу.
Алгоритм работает следующим образом.
- Создадим массив (dist) расстояний. Изначально (dist[s] = 0) (поскольку расстояний от вершины до самой себя равно (0)) и (dist[v] = infty) для (v neq s).
- Создадим очередь (q). Изначально в (q) добавим вершину (s).
- Пока очередь (q) непуста, делаем следующее:
- Извлекаем вершину (v) из очереди.
- Рассматриваем все рёбра ((v, u) in E). Для каждого такого ребра пытаемся сделать релаксацию: если (dist[v] + 1 < dist[u]), то мы делаем присвоение (dist[u] = dist[v] + 1) и добавляем вершину (u) в очередь.
Визуализации:
-
https://visualgo.net/mn/dfsbfs
-
https://www.hackerearth.com/practice/algorithms/graphs/breadth-first-search/visualize/
Интуитивное понимание алгоритма
Можно представить, что мы поджигаем вершину (s). Каждый шаг алгоритма — это распространение огня на соседние вершины. Понятно, что огонь доберётся до вершины по кратчайшему пути.
Заметьте, что этот алгоритм очень похож на DFS — достаточно заменить очередь на стек и поиск в ширину станет поиском в глубину. Действительно, оба алгоритма при обработке вершины просто записывают всех непосещенных соседей, в которые из неё есть ребро, в структуру данных, и после этого выбирает следующую вершину для обработки в структуре данных. В DFS это стек (благодаря рекурсии), поэтому мы сначала записываем соседа, идем в обрабатываем его полностью, а потом начинаем обрабатывать следующего соседа. В BFS это очередь, поэтому мы кидаем сразу всех соседей, а потом начинаем обрабатывать вообще другую вершину – ту непосещенную, которую мы положили в очередь раньше всего.
Оба алгоритма позволяют обойти граф целиком – посетить каждую вершину ровно один раз. Поэтому они оба подходят для таких задач как: * поиск компонент связности * проверка графа на двудольность * построение остова
Реализация на C++
n — количество вершин в графе; adj — список смежности
vector<int> bfs(int s) {
// длина любого кратчайшего пути не превосходит n - 1,
// поэтому n - достаточное значение для "бесконечности";
// после работы алгоритма dist[v] = n, если v недостижима из s
vector<int> dist(n, n);
dist[s] = 0;
queue<int> q;
q.push(s);
while (!q.empty()) {
int v = q.front();
q.pop();
for (int u : adj[v]) {
if (dist[u] > dist[v] + 1) {
dist[u] = dist[v] + 1;
q.push(u);
}
}
}
return dist;
}Свойства кратчайших путей
Обозначение: (d(v)) — длина кратчайшего пути от (s) до (v).
Лемма 1. > Пусть ((u, v) in E), тогда (d(v) leq d(u) + 1).
Действительно, существует путь из (s) в (u) длины (d(u)), а также есть ребро ((u, v)), следовательно, существует путь из (s) в (v) длины (d(u) + 1). А значит кратчайший путь из (s) в (v) имеет длину не более (d(u) + 1),
Лемма 2. > Рассмотрим кратчайший путь от (s) до (v). Обозначим его как (u_1, u_2, dots u_k) ((u_1 = s) и (u_k = v), а также (k = d(v) + 1)).
> Тогда (forall (i < k): d(u_i) + 1 = d(u_{i + 1})).
Действительно, пусть для какого-то (i < k) это не так. Тогда, используя лемму 1, имеем: (d(u_i) + 1 > d(u_{i + 1})). Тогда мы можем заменить первые (i + 1) вершин пути на вершины из кратчайшего пути из (s) в (u_{i + 1}). Полученный путь стал короче, но мы рассматривали кратчайший путь — противоречие.
Корректность
Утверждение. > 1. Расстояния до тех вершин, которые были добавлены в очередь, посчитаны корректно. > 2. Вершины лежат в очереди в порядке неубывания расстояния, притом разность между кратчайшими расстояними до вершин в очереди не превосходит (1).
Докажем это по индукции по количеству итераций алгоритма (итерация — извлечение вершины из очереди и дальнейшая релаксация).
База очевидна.
Переход. Сначала докажем первую часть. Предположим, что (dist[v] + 1 < dist[u]), но (dist[v] + 1) — некорректное расстояние до вершины (u), то есть (dist[v] + 1 neq d(u)). Тогда по лемме 1: (d(u) < dist[v] + 1). Рассмотрим предпоследнюю вершину (w) на кратчайшем пути от (s) до (u). Тогда по лемме 2: (d(w) + 1 = d(u)). Следовательно, (d(w) + 1 < dist[v] + 1) и (d(w) < dist[v]). Но тогда по предположению индукции (w) была извлечена раньше (v), следовательно, при релаксации из неё в очередь должна была быть добавлена вершина (u) с уже корректным расстоянием. Противоречие.
Теперь докажем вторую часть. По предположению индукции в очереди лежали некоторые вершины (u_1, u_2, dots u_k), для которых выполнялось следующее: (dist[u_1] leq dist[u_2] leq dots leq dist[u_k]) и (dist[u_k] – dist[u_1] leq 1). Мы извлекли вершину (v = u_1) и могли добавить в конец очереди какие-то вершины с расстоянием (dist[v] + 1). Если (k = 1), то утверждение очевидно. В противном случае имеем (dist[u_k] – dist[u_1] leq 1 leftrightarrow dist[u_k] – dist[v] leq 1 leftrightarrow dist[u_k] leq dist[v] + 1), то есть упорядоченность сохранилась. Осталось показать, что ((dist[v] + 1) – dist[u_2] leq 1), но это равносильно (dist[v] leq dist[u_2]), что, как мы знаем, верно.
Время работы
Из доказанного следует, что каждая достижимая из (s) вершина будет добавлена в очередь ровно (1) раз, недостижимые вершины добавлены не будут. Каждое ребро, соединяющее достижимые вершины, будет рассмотрено ровно (2) раза. Таким образом, алгоритм работает за (O(V+ E)) времени, при условии, что граф хранится в виде списка смежности.
Неориентированные графы
Если дан неориентированный граф, его можно рассматривать как ориентированный граф с двумя обратными друг другу ориентированными рёбрами.
Восстановление пути
Пусть теперь заданы 2 вершины (s) и (t), и необходимо не только найти длину кратчайшего пути из (s) в (t), но и восстановить какой-нибудь из кратчайших путей между ними. Всё ещё можно воспользоваться алгоритмом BFS, но необходимо ещё и поддерживать массив предков (p), в котором для каждой вершины будет храниться предыдущая вершина на кратчайшем пути.
Поддерживать этот массив просто: при релаксации нужно просто запоминать, из какой вершины мы прорелаксировали в данную. Также будем считать, что (p[s] = -1): у стартовой вершины предок — некоторая несуществующая вершина.
Восстановление пути делается с конца. Мы знаем последнюю вершину пути — это (t). Далее, мы сводим задачу к меньшей, переходя к нахождению пути из (s) в (p[t]).
Реализация BFS с восстановлением пути
// теперь bfs принимает 2 вершины, между которыми ищется пути
// bfs возвращает кратчайший путь из s в t, или же пустой vector, если пути нет
vector<int> bfs(int s, int t) {
vector<int> dist(n, n);
vector<int> p(n, -1);
dist[s] = 0;
queue<int> q;
q.push(s);
while (!q.empty()) {
int v = q.front();
q.pop();
for (int u : adj[v]) {
if (dist[u] > dist[v] + 1) {
p[u] = v;
dist[u] = dist[v] + 1;
q.push(u);
}
}
}
// если пути не существует, возвращаем пустой vector
if (dist[t] == n) {
return {};
}
vector<int> path;
while (t != -1) {
path.push_back(t);
t = p[t];
}
// путь был рассмотрен в обратном порядке, поэтому его нужно перевернуть
reverse(path.begin(), path.end());
return path;
}Проверка принадлежности вершины кратчайшему пути
Дан ориентированный граф (G), найти все вершины, которые принадлежат хотя бы одному кратчайшему пути из (s) в (t).
Запустим из вершины (s) в графе (G) BFS — найдём расстояния (d_1). Построим транспонированный граф (G^T) — граф, в котором каждое ребро заменено на противоположное. Запустим из вершины (t) в графе (G^T) BFS — найдём расстояния (d_2).
Теперь очевидно, что (v) принадлежит хотя бы одному кратчайшему пути из (s) в (t) тогда и только тогда, когда (d_1(v) + d_2(v) = d_1(t)) — это значит, что есть путь из (s) в (v) длины (d_1(v)), а затем есть путь из (v) в (t) длины (d_2(v)), и их суммарная длина совпадает с длиной кратчайшего пути из (s) в (t).
Кратчайший цикл в ориентированном графе
Найти цикл минимальной длины в ориентированном графе.
Попытаемся из каждой вершины найти кратчайший цикл, проходящий через неё, с помощью BFS. Это делается аналогично обычному BFS: мы должны найти расстояний от вершины до самой себя, при этом не считая, что оно равно (0).
Итого, у нас (|V|) запусков BFS, и каждый запуск работает за (O(|V| + |E|)). Тогда общее время работы составляет (O(|V|^2 + |V| |E|)). Если инициализировать массив (dist) единожды, а после каждого запуска BFS возвращать исходные значения только для достижимых вершин, решение будет работать за (O(|V||E|)).
Задача
Дан взвешенный ориентированный граф (G = (V, E)), а также вершина (s). Длина ребра ((u, v)) равна (w(u, v)). Длины всех рёбер неотрицательные.
Найти длину кратчайшего пути от (s) до каждой из вершин графа. Длина пути — сумма длин рёбер в нём.
Алгоритм Дейкстры
Алгоритм Дейкстры решает приведённую выше задачу. Он работает следующим образом.
- Создать массив (dist) расстояний. Изначально (dist[s] = 0) и (dist[v] = infty) для (v neq s).
- Создать булёв массив (used), (used[v] = 0) для всех вершин (v) — в нём мы будем отмечать, совершалась ли релаксация из вершины.
- Пока существует вершина (v) такая, что (used[v] = 0) и (dist[v] neq infty), притом, если таких вершин несколько, то (v) — вершина с минимальным (dist[v]), делать следующее:
- Пометить, что мы совершали релаксацию из вершины (v), то есть присвоить (used[v] = 1).
- Рассматриваем все рёбра ((v, u) in E). Для каждого ребра пытаемся сделать релаксацию: если (dist[v] + w(v, u) < dist[u]), присвоить (dist[u] = dist[v] + w(v, u)).
Иными словами, алгоритм на каждом шаге находит вершину, до которой расстояние сейчас минимально и из которой ещё не была произведена релаксация, и делает её.
Посчитаем, за сколько работает алгоритм. Мы (V) раз ищем вершину минимальным (dist), поиск минимума у нас линейный за (O(V)), отсюда (O(V^2)). Обработка ребер у нас происходит суммарно за (O(E)), потому что на каждое ребро мы тратим (O(1)) действий. Так мы находим финальную асимптотику: (O(V^2 + E)).
Реализация на C++
Рёбра будем хранить как pair<int, int>, где первое число пары — куда оно ведёт; а второе — длина ребра.
// INF - infinity - бесконечность
const long long INF = (long long) 1e18 + 1;
vector<long long> dijkstra(int s) {
vector<long long> dist(n, INF);
dist[s] = 0;
vector<bool> used(n);
while (true) {
// находим вершину, из которой будем релаксировать
int v = -1;
for (int i = 0; i < n; i++) {
if (!used[i] && (v == -1 || dist[i] < dist[v])) {
v = i;
}
}
// если не нашли подходящую вершину, прекращаем работу алгоритма
if (v == -1) {
break;
}
for (auto &e : adj[v]) {
int u = e.first;
int len = e.second;
if (dist[u] > dist[v] + len) {
dist[u] = dist[v] + len;
}
}
}
return dist;
}Восстановление пути
Восстановление пути в алгоритме Дейкстры делается аналогично восстановлению пути в BFS (и любой динамике).
Дейкстра на сете
Искать вершину с минимальным (dist) можно гораздо быстрее, используя такую структуру данных как очередь с приоритетом. Нам нужно хранить пары ((dist, index)) и уметь делать такие операции: * Извлечь минимум (чтобы обработать новую вершину) * Удалить вершину по индексу (чтобы уменьшить (dist) до какого-то соседа) * Добавить новую вершину (чтобы уменьшить (dist) до какого-то соседа)
Для этого используют, например, кучу или сет. Удобно помимо сета хранить сам массив dist, который его дублирует, но хранит элементы по порядку. Тогда, чтобы заменить значение ((dist_1, u)) на ((dist_2, u)), нужно удалить из сета значение ((dist[u], u)), сделать (dist[u] = dist_2;) и добавить в сет ((dist[u], u)).
Данный алгоритм будет работать за (V O(log V)) извлечений минимума и (O(E log V)) операций уменьшения расстояния до вершины (может быть сделано после каждого ребра). Поэтому алгоритм работает за (O(E log V)).
Заметьте, что этот алгоритм не лучше и не хуже, чем без сета, который работает за (O(V^2 + E)). Ведь если (E = O(V^2)) (граф почти полный), то Дейкстра без сета работает быстрее, а если, наример, (E = O(V)), то Дейкстра на сете работает быстрее. Учитывайте это, когда выбираете алгоритм.
Задача¶
Дан ориентированный граф $G = (V, E)$, а также вершина $s$.
Найти длину кратчайшего пути от $s$ до каждой из вершин графа. Длина пути — количество рёбер в нём.
BFS¶
BFS — breadth-first search, или же поиск в ширину.
Этот алгоритм позволяет решать следующую задачу.
Алгоритм работает следующим образом.
- Создадим массив $dist$ расстояний. Изначально $dist[s] = 0$ (поскольку расстояний от вершины до самой себя равно $0$) и $dist[v] = infty$ для $v neq s$.
- Создадим очередь $q$. Изначально в $q$ добавим вершину $s$.
- Пока очередь $q$ непуста, делаем следующее:
- Извлекаем вершину $v$ из очереди.
- Рассматриваем все рёбра $(v, u) in E$. Для каждого такого ребра пытаемся сделать релаксацию: если $dist[v] + 1 < dist[u]$, то мы делаем присвоение $dist[u] = dist[v] + 1$ и добавляем вершину $u$ в очередь.
Визуализации:
-
https://visualgo.net/mn/dfsbfs
-
https://www.hackerearth.com/practice/algorithms/graphs/breadth-first-search/visualize/
Интуитивное понимание алгоритма¶
Можно представить, что мы поджигаем вершину $s$. Каждый шаг алгоритма — это распространение огня на соседние вершины. Понятно, что огонь доберётся до вершины по кратчайшему пути.
Заметьте, что этот алгоритм очень похож на DFS — достаточно заменить очередь на стек и поиск в ширину станет поиском в глубину. Действительно, оба алгоритма при обработке вершины просто записывают всех непосещенных соседей, в которые из неё есть ребро, в структуру данных, и после этого выбирает следующую вершину для обработки в структуре данных. В DFS это стек (благодаря рекурсии), поэтому мы сначала записываем соседа, идем в обрабатываем его полностью, а потом начинаем обрабатывать следующего соседа. В BFS это очередь, поэтому мы кидаем сразу всех соседей, а потом начинаем обрабатывать вообще другую вершину – ту непосещенную, которую мы положили в очередь раньше всего.
Оба алгоритма позволяют обойти граф целиком – посетить каждую вершину ровно один раз. Поэтому они оба подходят для таких задач как:
- поиск компонент связности
- проверка графа на двудольность
- построение остова
Реализация на C++¶
n — количество вершин в графе; adj — список смежности
vector<int> bfs(int s) { // длина любого кратчайшего пути не превосходит n - 1, // поэтому n - достаточное значение для "бесконечности"; // после работы алгоритма dist[v] = n, если v недостижима из s vector<int> dist(n, n); dist[s] = 0; queue<int> q; q.push(s); while (!q.empty()) { int v = q.front(); q.pop(); for (int u : adj[v]) { if (dist[u] > dist[v] + 1) { dist[u] = dist[v] + 1; q.push(u); } } } return dist; }
Свойства кратчайших путей¶
Обозначение: $d(v)$ — длина кратчайшего пути от $s$ до $v$.
Лемма 1.
Пусть $(u, v) in E$, тогда $d(v) leq d(u) + 1$.
Действительно, существует путь из $s$ в $u$ длины $d(u)$, а также есть ребро $(u, v)$, следовательно, существует путь из $s$ в $v$ длины $d(u) + 1$. А значит кратчайший путь из $s$ в $v$ имеет длину не более $d(u) + 1$,
Лемма 2.
Рассмотрим кратчайший путь от $s$ до $v$. Обозначим его как $u_1, u_2, dots u_k$ ($u_1 = s$ и $u_k = v$, а также $k = d(v) + 1$).
Тогда $forall (i < k): d(u_i) + 1 = d(u_{i + 1})$.
Действительно, пусть для какого-то $i < k$ это не так. Тогда, используя лемму 1, имеем: $d(u_i) + 1 > d(u_{i + 1})$. Тогда мы можем заменить первые $i + 1$ вершин пути на вершины из кратчайшего пути из $s$ в $u_{i + 1}$. Полученный путь стал короче, но мы рассматривали кратчайший путь — противоречие.
Корректность¶
Утверждение.
- Расстояния до тех вершин, которые были добавлены в очередь, посчитаны корректно.
- Вершины лежат в очереди в порядке неубывания расстояния, притом разность между кратчайшими расстояними до вершин в очереди не превосходит $1$.
Докажем это по индукции по количеству итераций алгоритма (итерация — извлечение вершины из очереди и дальнейшая релаксация).
База очевидна.
Переход. Сначала докажем первую часть. Предположим, что $dist[v] + 1 < dist[u]$, но $dist[v] + 1$ — некорректное расстояние до вершины $u$, то есть $dist[v] + 1 neq d(u)$. Тогда по лемме 1: $d(u) < dist[v] + 1$. Рассмотрим предпоследнюю вершину $w$ на кратчайшем пути от $s$ до $u$. Тогда по лемме 2: $d(w) + 1 = d(u)$. Следовательно, $d(w) + 1 < dist[v] + 1$ и $d(w) < dist[v]$. Но тогда по предположению индукции $w$ была извлечена раньше $v$, следовательно, при релаксации из неё в очередь должна была быть добавлена вершина $u$ с уже корректным расстоянием. Противоречие.
Теперь докажем вторую часть. По предположению индукции в очереди лежали некоторые вершины $u_1, u_2, dots u_k$, для которых выполнялось следующее: $dist[u_1] leq dist[u_2] leq dots leq dist[u_k]$ и $dist[u_k] – dist[u_1] leq 1$. Мы извлекли вершину $v = u_1$ и могли добавить в конец очереди какие-то вершины с расстоянием $dist[v] + 1$. Если $k = 1$, то утверждение очевидно. В противном случае имеем $dist[u_k] – dist[u_1] leq 1 leftrightarrow dist[u_k] – dist[v] leq 1 leftrightarrow dist[u_k] leq dist[v] + 1$, то есть упорядоченность сохранилась. Осталось показать, что $(dist[v] + 1) – dist[u_2] leq 1$, но это равносильно $dist[v] leq dist[u_2]$, что, как мы знаем, верно.
Время работы¶
Из доказанного следует, что каждая достижимая из $s$ вершина будет добавлена в очередь ровно $1$ раз, недостижимые вершины добавлены не будут. Каждое ребро, соединяющее достижимые вершины, будет рассмотрено ровно $2$ раза. Таким образом, алгоритм работает за $O(V+ E)$ времени, при условии, что граф хранится в виде списка смежности.
Неориентированные графы¶
Если дан неориентированный граф, его можно рассматривать как ориентированный граф с двумя обратными друг другу ориентированными рёбрами.
Восстановление пути¶
Пусть теперь заданы 2 вершины $s$ и $t$, и необходимо не только найти длину кратчайшего пути из $s$ в $t$, но и восстановить какой-нибудь из кратчайших путей между ними. Всё ещё можно воспользоваться алгоритмом BFS, но необходимо ещё и поддерживать массив предков $p$, в котором для каждой вершины будет храниться предыдущая вершина на кратчайшем пути.
Поддерживать этот массив просто: при релаксации нужно просто запоминать, из какой вершины мы прорелаксировали в данную. Также будем считать, что $p[s] = -1$: у стартовой вершины предок — некоторая несуществующая вершина.
Восстановление пути делается с конца. Мы знаем последнюю вершину пути — это $t$. Далее, мы сводим задачу к меньшей, переходя к нахождению пути из $s$ в $p[t]$.
Реализация BFS с восстановлением пути¶
// теперь bfs принимает 2 вершины, между которыми ищется пути // bfs возвращает кратчайший путь из s в t, или же пустой vector, если пути нет vector<int> bfs(int s, int t) { vector<int> dist(n, n); vector<int> p(n, -1); dist[s] = 0; queue<int> q; q.push(s); while (!q.empty()) { int v = q.front(); q.pop(); for (int u : adj[v]) { if (dist[u] > dist[v] + 1) { p[u] = v; dist[u] = dist[v] + 1; q.push(u); } } } // если пути не существует, возвращаем пустой vector if (dist[t] == n) { return {}; } vector<int> path; while (t != -1) { path.push_back(t); t = p[t]; } // путь был рассмотрен в обратном порядке, поэтому его нужно перевернуть reverse(path.begin(), path.end()); return path; }
Проверка принадлежности вершины кратчайшему пути¶
Дан ориентированный граф $G$, найти все вершины, которые принадлежат хотя бы одному кратчайшему пути из $s$ в $t$.
Запустим из вершины $s$ в графе $G$ BFS — найдём расстояния $d_1$. Построим транспонированный граф $G^T$ — граф, в котором каждое ребро заменено на противоположное. Запустим из вершины $t$ в графе $G^T$ BFS — найдём расстояния $d_2$.
Теперь очевидно, что $v$ принадлежит хотя бы одному кратчайшему пути из $s$ в $t$ тогда и только тогда, когда $d_1(v) + d_2(v) = d_1(t)$ — это значит, что есть путь из $s$ в $v$ длины $d_1(v)$, а затем есть путь из $v$ в $t$ длины $d_2(v)$, и их суммарная длина совпадает с длиной кратчайшего пути из $s$ в $t$.
Кратчайший цикл в ориентированном графе¶
Найти цикл минимальной длины в ориентированном графе.
Попытаемся из каждой вершины найти кратчайший цикл, проходящий через неё, с помощью BFS. Это делается аналогично обычному BFS: мы должны найти расстояний от вершины до самой себя, при этом не считая, что оно равно $0$.
Итого, у нас $|V|$ запусков BFS, и каждый запуск работает за $O(|V| + |E|)$. Тогда общее время работы составляет $O(|V|^2 + |V| |E|)$. Если инициализировать массив $dist$ единожды, а после каждого запуска BFS возвращать исходные значения только для достижимых вершин, решение будет работать за $O(|V||E|)$.
Задача¶
Дан взвешенный ориентированный граф $G = (V, E)$, а также вершина $s$. Длина ребра $(u, v)$ равна $w(u, v)$. Длины всех рёбер неотрицательные.
Найти длину кратчайшего пути от $s$ до каждой из вершин графа. Длина пути — сумма длин рёбер в нём.
Алгоритм Дейкстры¶
Алгоритм Дейкстры решает приведённую выше задачу. Он работает следующим образом.
- Создать массив $dist$ расстояний. Изначально $dist[s] = 0$ и $dist[v] = infty$ для $v neq s$.
- Создать булёв массив $used$, $used[v] = 0$ для всех вершин $v$ — в нём мы будем отмечать, совершалась ли релаксация из вершины.
- Пока существует вершина $v$ такая, что $used[v] = 0$ и $dist[v] neq infty$, притом, если таких вершин несколько, то $v$ — вершина с минимальным $dist[v]$, делать следующее:
- Пометить, что мы совершали релаксацию из вершины $v$, то есть присвоить $used[v] = 1$.
- Рассматриваем все рёбра $(v, u) in E$. Для каждого ребра пытаемся сделать релаксацию: если $dist[v] + w(v, u) < dist[u]$, присвоить $dist[u] = dist[v] + w(v, u)$.
Иными словами, алгоритм на каждом шаге находит вершину, до которой расстояние сейчас минимально и из которой ещё не была произведена релаксация, и делает её.
Посчитаем, за сколько работает алгоритм. Мы $V$ раз ищем вершину минимальным $dist$, поиск минимума у нас линейный за $O(V)$, отсюда $O(V^2)$. Обработка ребер у нас происходит суммарно за $O(E)$, потому что на каждое ребро мы тратим $O(1)$ действий. Так мы находим финальную асимптотику: $O(V^2 + E)$.
Реализация на C++¶
Рёбра будем хранить как pair<int, int>, где первое число пары — куда оно ведёт; а второе — длина ребра.
// INF - infinity - бесконечность const long long INF = (long long) 1e18 + 1; vector<long long> dijkstra(int s) { vector<long long> dist(n, INF); dist[s] = 0; vector<bool> used(n); while (true) { // находим вершину, из которой будем релаксировать int v = -1; for (int i = 0; i < n; i++) { if (!used[i] && (v == -1 || dist[i] < dist[v])) { v = i; } } // если не нашли подходящую вершину, прекращаем работу алгоритма if (v == -1) { break; } for (auto &e : adj[v]) { int u = e.first; int len = e.second; if (dist[u] > dist[v] + len) { dist[u] = dist[v] + len; } } } return dist; }
Восстановление пути¶
Восстановление пути в алгоритме Дейкстры делается аналогично восстановлению пути в BFS (и любой динамике).
Дейкстра на сете¶
Искать вершину с минимальным $dist$ можно гораздо быстрее, используя такую структуру данных как очередь с приоритетом. Нам нужно хранить пары $(dist, index)$ и уметь делать такие операции:
- Извлечь минимум (чтобы обработать новую вершину)
- Удалить вершину по индексу (чтобы уменьшить $dist$ до какого-то соседа)
- Добавить новую вершину (чтобы уменьшить $dist$ до какого-то соседа)
Для этого используют, например, кучу или сет. Удобно помимо сета хранить сам массив dist, который его дублирует, но хранит элементы по порядку. Тогда, чтобы заменить значение $(dist_1, u)$ на $(dist_2, u)$, нужно удалить из сета значение $(dist[u], u)$, сделать $dist[u] = dist_2;$ и добавить в сет $(dist[u], u)$.
Данный алгоритм будет работать за $V O(log V)$ извлечений минимума и $O(E log V)$ операций уменьшения расстояния до вершины (может быть сделано после каждого ребра). Поэтому алгоритм работает за $O(E log V)$.
Заметьте, что этот алгоритм не лучше и не хуже, чем без сета, который работает за $O(V^2 + E)$. Ведь если $E = O(V^2)$ (граф почти полный), то Дейкстра без сета работает быстрее, а если, наример, $E = O(V)$, то Дейкстра на сете работает быстрее. Учитывайте это, когда выбираете алгоритм.
