И транскрипция, и трансляция относятся к матричным биосинтезам. Матричным биосинтезом называется синтез
биополимеров (нуклеиновых кислот, белков) на матрице – нуклеиновой кислоте ДНК или РНК. Процессы матричного биосинтеза относятся к пластическому обмену: клетка расходует энергию АТФ.
Матричный синтез можно представить как создание копии исходной информации на несколько другом или новом
“генетическом языке”. Скоро вы все поймете – мы научимся достраивать по одной цепи ДНК другую, переводить РНК в ДНК
и наоборот, синтезировать белок с иРНК на рибосоме. В данной статье вас ждут подробные примеры решения задач, генетический словарик пригодится – перерисуйте его себе 🙂

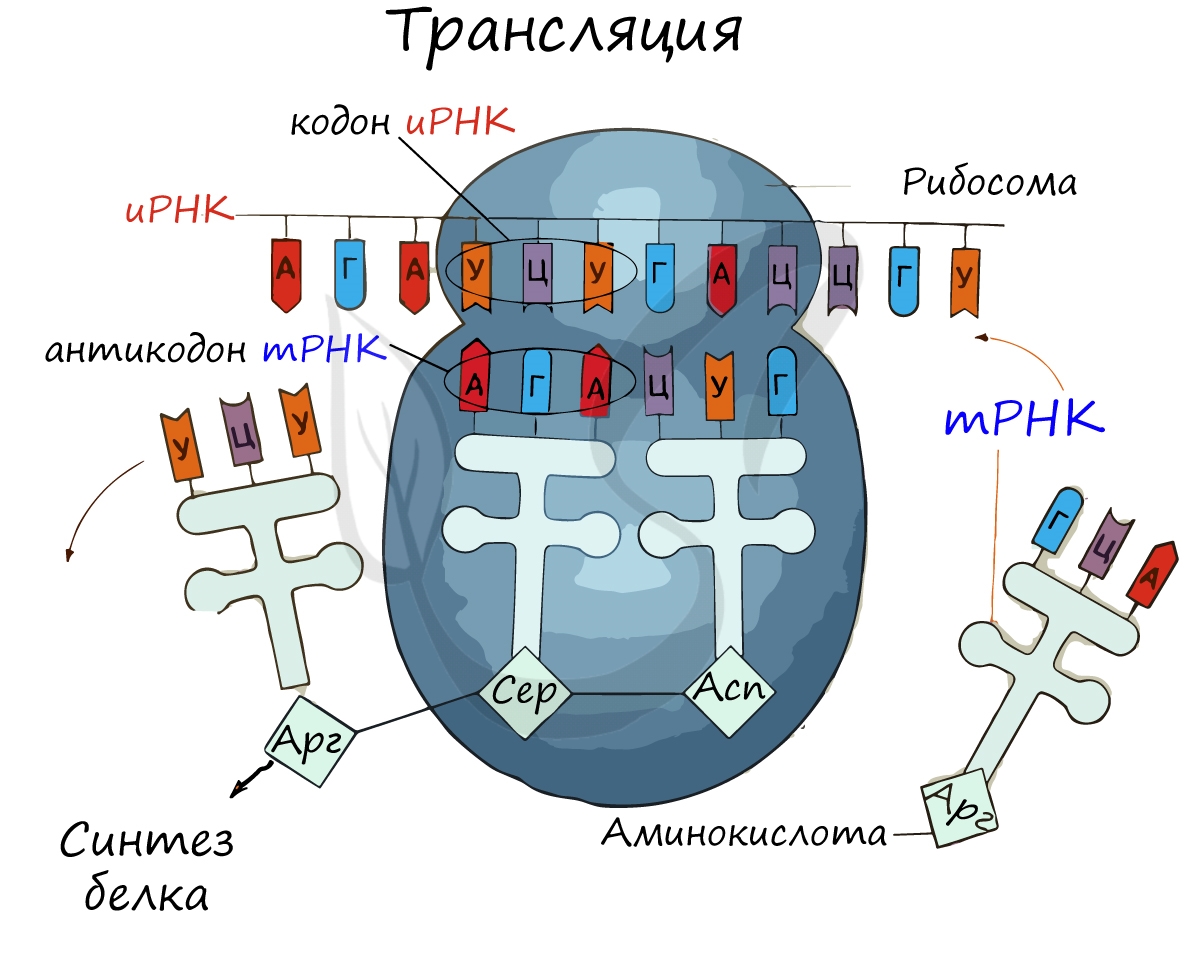
Возьмем 3 абстрактных нуклеотида ДНК (триплет) – АТЦ. На иРНК этим нуклеотидам будут соответствовать – УАГ (кодон иРНК).
тРНК, комплементарная иРНК, будет иметь запись – АУЦ (антикодон тРНК). Три нуклеотида в зависимости от своего расположения
будут называться по-разному: триплет, кодон и антикодон. Обратите на это особое внимание.
Репликация ДНК – удвоение, дупликация (лат. replicatio — возобновление, лат. duplicatio – удвоение)
Процесс синтеза дочерней молекулы ДНК по матрице родительской ДНК. Нуклеотиды достраивает фермент ДНК-полимераза по
принципу комплементарности. Переводя действия данного фермента на наш язык, он следует следующему правилу: А (аденин) переводит в Т (тимин), Г (гуанин) – в Ц (цитозин).
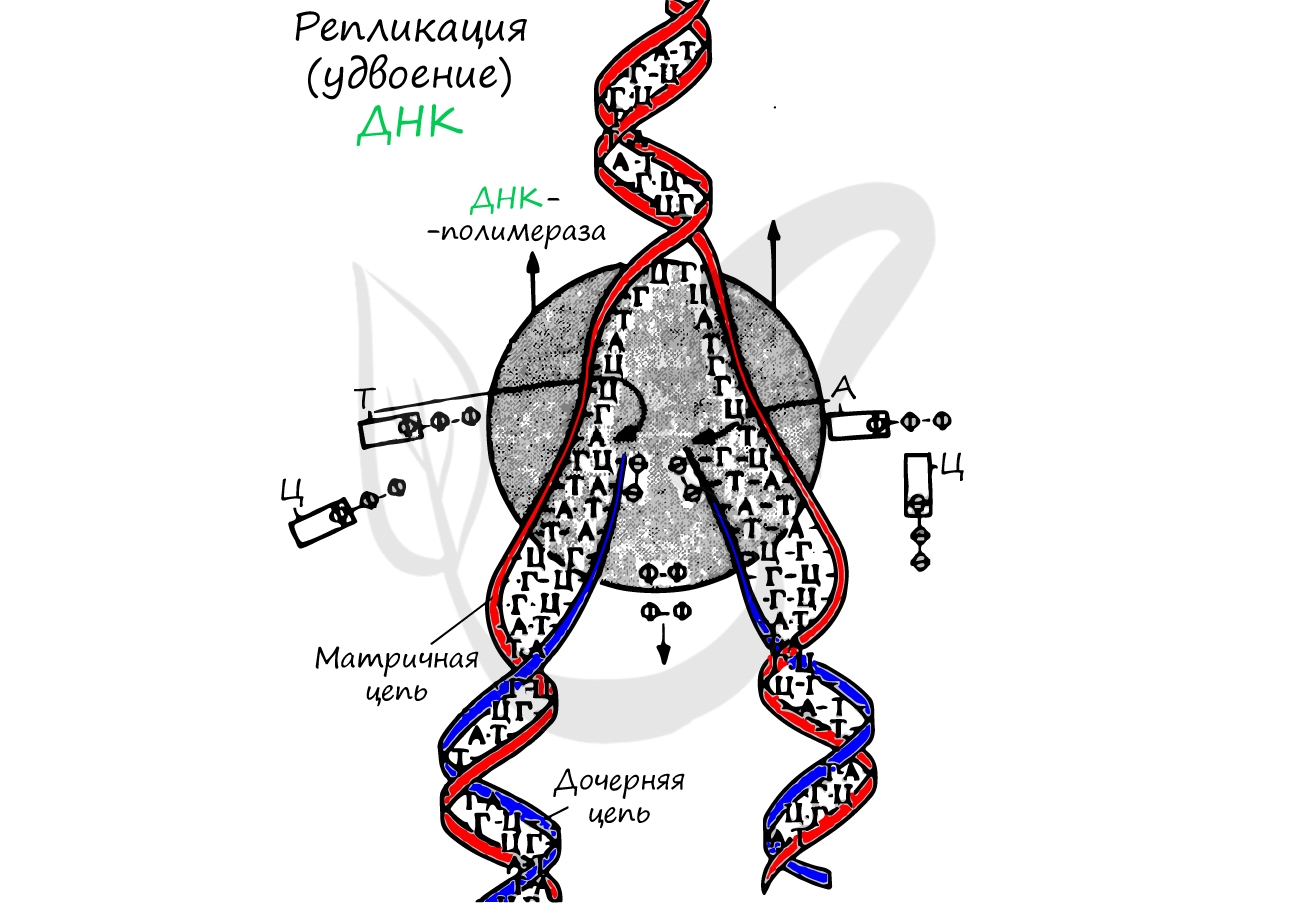
Удвоение ДНК происходит в синтетическом периоде интерфазы. При этом общее число хромосом не меняется, однако каждая из них
содержит к началу деления две молекулы ДНК: это необходимо для равномерного распределения генетического материала между
дочерними клетками.
Транскрипция (лат. transcriptio — переписывание)
Транскрипция представляет собой синтез информационной РНК (иРНК) по матрице ДНК. Несомненно, транскрипция происходит
в соответствии с принципом комплементарности азотистых оснований: А – У, Т – А, Г – Ц, Ц – Г (загляните в “генетический словарик”
выше).
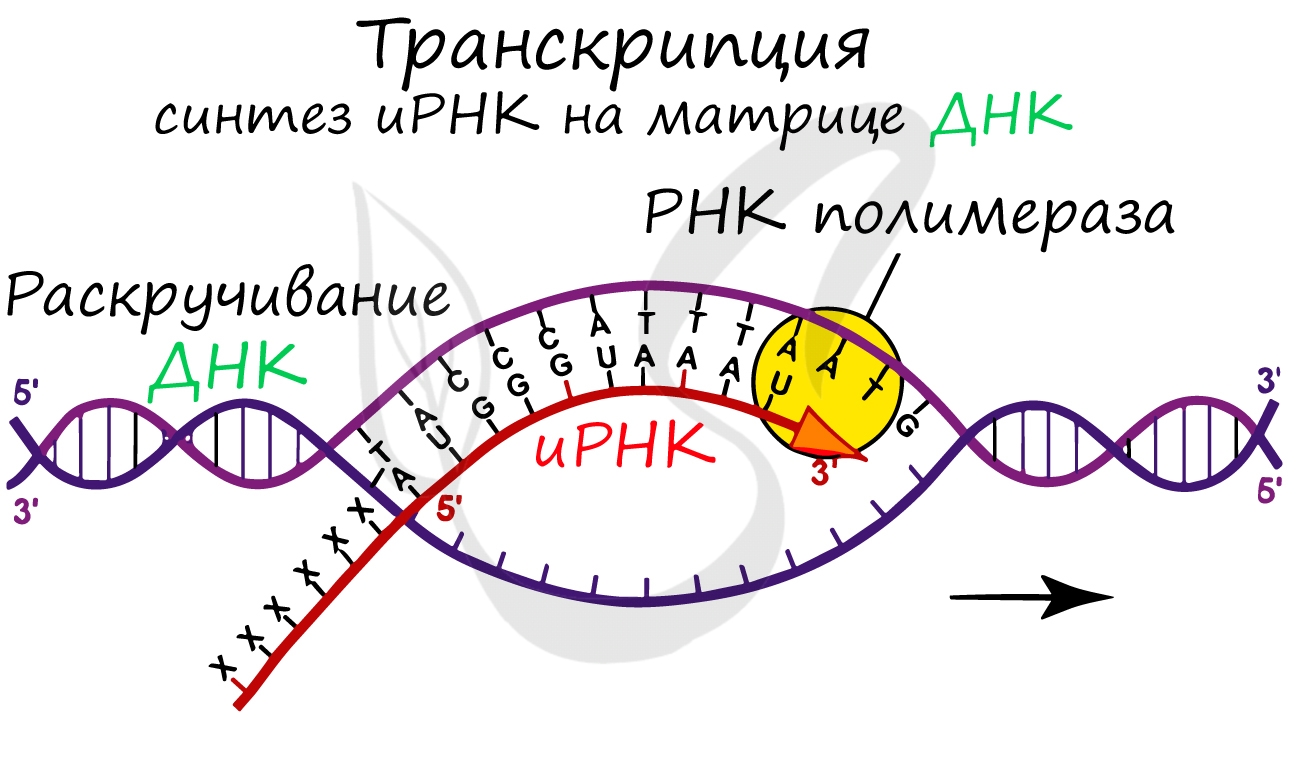
До начала непосредственно транскрипции происходит подготовительный этап: фермент РНК-полимераза узнает особый участок молекулы ДНК – промотор и связывается с ним. После связывания с промотором происходит раскручивание молекулы ДНК, состоящей из двух
цепей: транскрибируемой и смысловой. В процессе транскрипции принимает участие только транскрибируемая цепь ДНК.
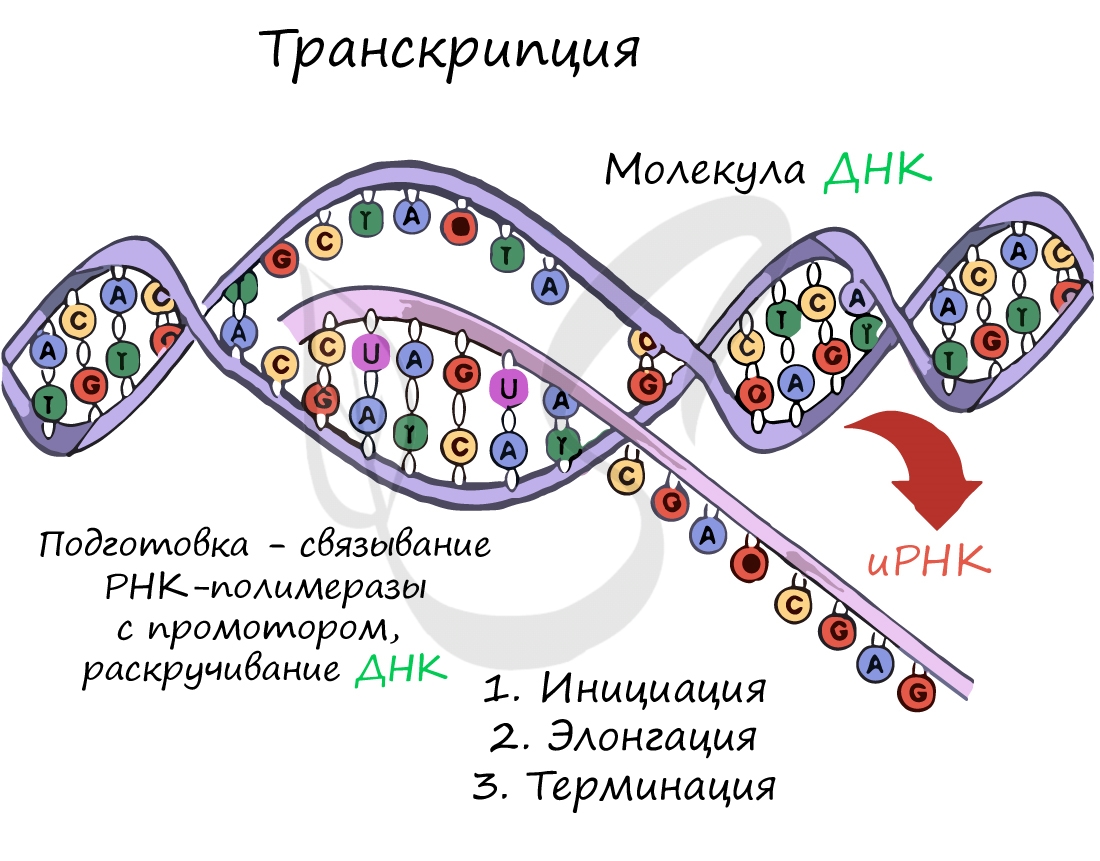
Транскрипция осуществляется в несколько этапов:
- Инициация (лат. injicere — вызывать)
- Элонгация (лат. elongare — удлинять)
- Терминация (лат. terminalis — заключительный)
Образуется несколько начальных кодонов иРНК.
Нити ДНК последовательно расплетаются, освобождая место для передвигающейся РНК-полимеразы. Молекула иРНК
быстро растет.
Достигая особого участка цепи ДНК – терминатора, РНК-полимераза получает сигнал к прекращению синтеза иРНК. Транскрипция завершается. Синтезированная иРНК направляется из ядра в цитоплазму.
Трансляция (от лат. translatio — перенос, перемещение)
Куда же отправляется новосинтезированная иРНК в процессе транскрипции? На следующую ступень – в процесс трансляции.
Он заключается в синтезе белка на рибосоме по матрице иРНК. Последовательность кодонов иРНК переводится в последовательность
аминокислот.
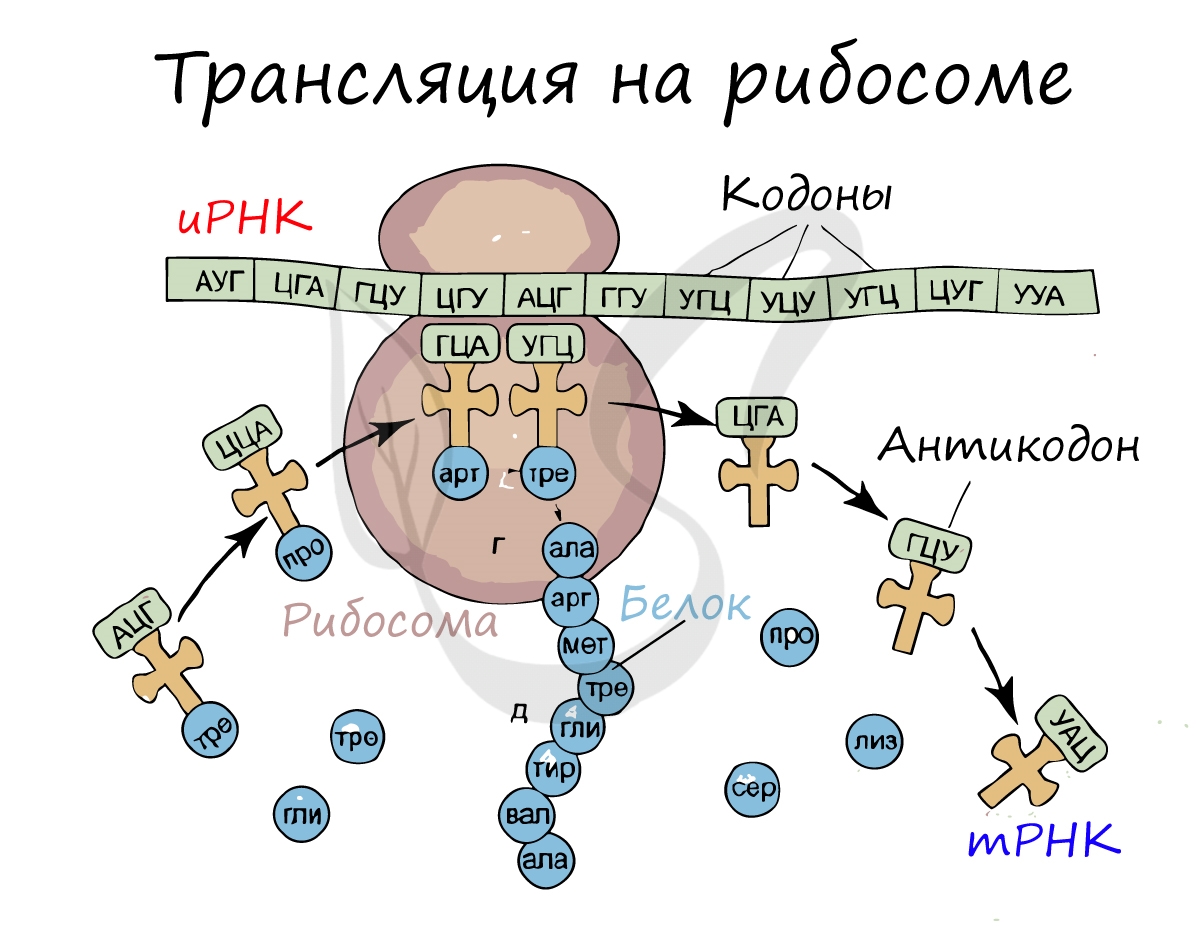
Перед процессом трансляции происходит подготовительный этап, на котором аминокислоты присоединяются к соответствующим молекулам тРНК. Трансляцию можно разделить на несколько стадий:
- Инициация
- Элонгация
- Терминация
Информационная РНК (иРНК, синоним – мРНК (матричная РНК)) присоединяется к рибосоме, состоящей из двух субъединиц.
Замечу, что вне процесса трансляции субъединицы рибосом находятся в разобранном состоянии.
Первый кодон иРНК, старт-кодон, АУГ оказывается в центре рибосомы, после чего тРНК приносит аминокислоту,
соответствующую кодону АУГ – метионин.
Рибосома делает шаг, и иРНК продвигается на один кодон: такое в фазу элонгации происходит десятки тысяч раз.
Молекулы тРНК приносят новые аминокислоты, соответствующие кодонам иРНК. Аминокислоты соединяются друг с другом: между ними образуются пептидные связи, молекула белка растет.
Доставка нужных аминокислот осуществляется благодаря точному соответствию 3 нуклеотидов (кодона) иРНК 3 нуклеотидам (антикодону) тРНК. Язык перевода между иРНК и тРНК выглядит как: А (аденин) – У (урацил), Г (гуанин) – Ц (цитозин).
В основе этого также лежит принцип комплементарности.
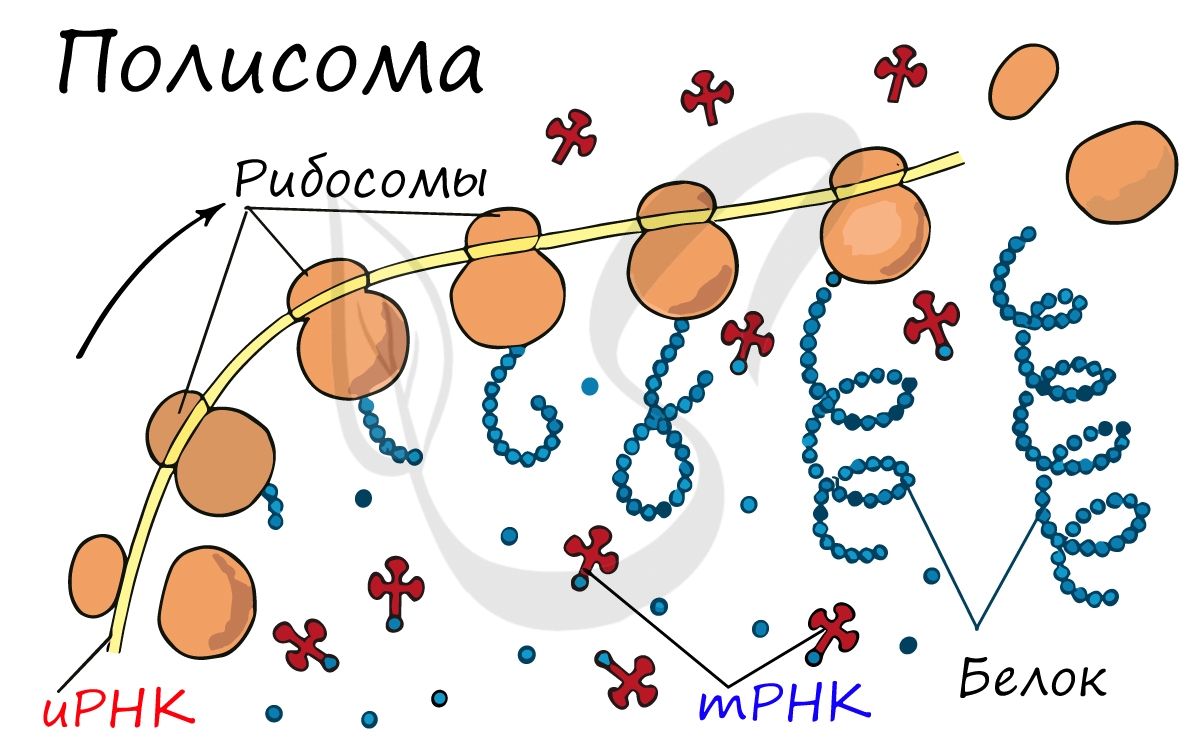
Движение рибосомы вдоль молекулы иРНК называется транслокация. Нередко в клетке множество рибосом садятся на одну молекулу
иРНК одновременно – образующаяся при этом структура называется полирибосома (полисома). В результате происходит одновременный синтез множества одинаковых белков.
Синтез белка – полипептидной цепи из аминокислот – в определенный момент завершатся. Сигналом к этому служит попадание
в центр рибосомы одного из так называемых стоп-кодонов: УАГ, УГА, УАА. Они относятся к нонсенс-кодонам (бессмысленным), которые не кодируют ни одну аминокислоту. Их функция – завершить синтез белка.
Существует специальная таблица для перевода кодонов иРНК в аминокислоты. Пользоваться ей очень просто, если вы запомните, что
кодон состоит из 3 нуклеотидов. Первый нуклеотид берется из левого вертикального столбика, второй – из верхнего горизонтального,
третий – из правого вертикального столбика. На пересечении всех линий, идущих от них, и находится нужная вам аминокислота 🙂
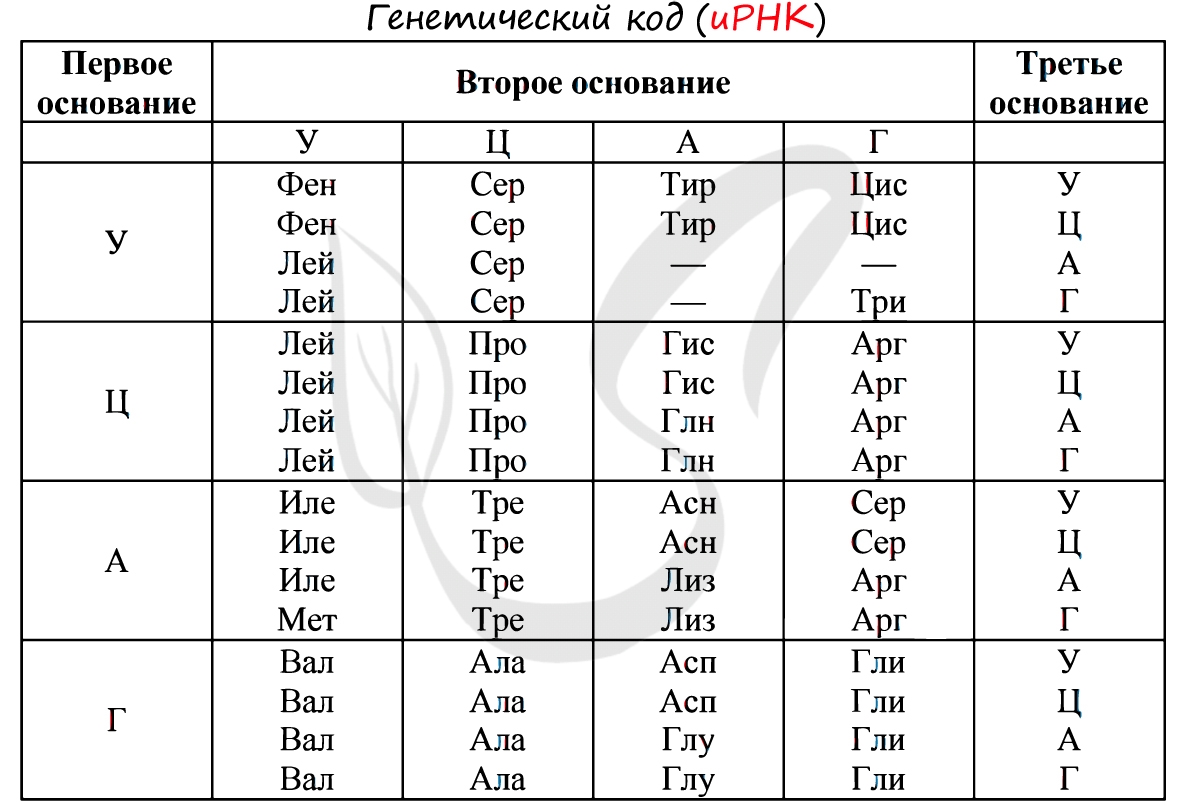
Давайте потренируемся: кодону ЦАЦ соответствует аминокислота Гис, кодону ЦАА – Глн. Попробуйте самостоятельно найти
аминокислоты, которые кодируют кодоны ГЦУ, ААА, УАА.
Кодону ГЦУ соответствует аминокислота – Ала, ААА – Лиз. Напротив кодона УАА в таблице вы должны были обнаружить прочерк:
это один из трех нонсенс-кодонов, завершающих синтез белка.
Примеры решения задачи №1
Без практики теория мертва, так что скорее решим задачи! В первых двух задачах будем пользоваться таблицей генетического кода (по иРНК),
приведенной вверху.
“Фрагмент цепи ДНК имеет следующую последовательность нуклеотидов: ЦГА-ТГГ-ТЦЦ-ГАЦ. Определите последовательность нуклеотидов
во второй цепочке ДНК, последовательность нуклеотидов на иРНК, антикодоны
соответствующих тРНК и аминокислотную последовательность соответствующего фрагмента молекулы белка, используя таблицу генетического кода”

Объяснение:
По принципу комплементарности мы нашли вторую цепочку ДНК: ГЦТ-АЦЦ-АГГ-ЦТГ. Мы использовали следующие правила при нахождении второй нити
ДНК: А-Т, Т-А, Г-Ц, Ц-Г.
Вернемся к первой цепочке, и именно от нее пойдем к иРНК: ГЦУ-АЦЦ-АГГ-ЦУГ. Мы использовали следующие правила при переводе ДНК в иРНК:
А-У, Т-А, Г-Ц, Ц-Г.
Зная последовательность нуклеотидов иРНК, легко найдем тРНК: ЦГА, УГГ, УЦЦ, ГАЦ. Мы использовали следующие правила перевода иРНК в тРНК:
А-У, У-А, Г-Ц, Ц-Г. Обратите внимание, что антикодоны тРНК мы разделяем запятыми, в отличие кодонов иРНК. Это связано с тем, что
тРНК представляют собой отдельные молекулы (в виде клеверного листа), а не линейную структуру (как ДНК, иРНК).
Пример решения задачи №2
“Известно, что все виды РНК синтезируются на ДНК-матрице. Фрагмент цепи ДНК, на которой синтезируется участок центральной петли тРНК, имеет
следующую последовательность нуклеотидов: ТАГ-ЦАА-АЦГ-ГЦТ-АЦЦ. Установите нуклеотидную последовательность участка тРНК, который синтезируется
на данном фрагменте, и аминокислоту, которую будет переносить эта тРНК в процессе биосинтеза белка, если третий триплет соответствует антикодону
тРНК”

Обратите свое пристальное внимание на слова “Известно, что все виды РНК синтезируются на ДНК-матрице. Фрагмент цепи ДНК, на которой
синтезируется участок центральной петли тРНК “. Эта фраза кардинально меняет ход решения задачи: мы получаем право напрямую и сразу
синтезировать с ДНК фрагмент тРНК – другой подход здесь будет считаться ошибкой.
Итак, синтезируем напрямую с ДНК фрагмент молекулы тРНК: АУЦ-ГУУ-УГЦ-ЦГА-УГГ. Это не отдельные молекулы тРНК (как было
в предыдущей задаче), поэтому не следует разделять их запятой – мы записываем их линейно через тире.
Третий триплет ДНК – АЦГ соответствует антикодону тРНК – УГЦ. Однако мы пользуемся таблицей генетического кода по иРНК,
так что переведем антикодон тРНК – УГЦ в кодон иРНК – АЦГ. Теперь очевидно, что аминокислота кодируемая АЦГ – Тре.
Пример решения задачи №3
Длина фрагмента молекулы ДНК составляет 150 нуклеотидов. Найдите число триплетов ДНК, кодонов иРНК, антикодонов тРНК и
аминокислот, соответствующих данному фрагменту. Известно, что аденин составляет 20% в данном фрагменте (двухцепочечной
молекуле ДНК), найдите содержание в процентах остальных нуклеотидов.

Один триплет ДНК состоит из 3 нуклеотидов, следовательно, 150 нуклеотидов составляют 50 триплетов ДНК (150 / 3). Каждый триплет ДНК
соответствует одному кодону иРНК, который в свою очередь соответствует одному антикодону тРНК – так что их тоже по 50.
По правилу Чаргаффа: количество аденина = количеству тимина, цитозина = гуанина. Аденина 20%, значит и тимина также 20%.
100% – (20%+20%) = 60% – столько приходится на оставшиеся цитозин и гуанин. Поскольку их процент содержания равен, то
на каждый приходится по 30%.
Теперь мы украсили теорию практикой. Что может быть лучше при изучении новой темы? 🙂
© Беллевич Юрий Сергеевич 2018-2023
Данная статья написана Беллевичем Юрием Сергеевичем и является его интеллектуальной собственностью. Копирование, распространение
(в том числе путем копирования на другие сайты и ресурсы в Интернете) или любое иное использование информации и объектов
без предварительного согласия правообладателя преследуется по закону. Для получения материалов статьи и разрешения их использования,
обратитесь, пожалуйста, к Беллевичу Юрию.
Темы «Молекулярная биология» и «Генетика» – наиболее интересные и сложные темы в курсе «Общая биология». Эти темы изучаются и в 9-х, и в 11х классах, но времени на отработку умения решать задачи в программе явно недостаточно. Однако умение решать задачи по генетике и молекулярной биологии предусмотрено Стандартом биологического образования, а также такие задачи входят в состав КИМ ЕГЭ.
Для решения задач по молекулярной биологии необходимо владеть следующими биологическими понятиями: виды нуклеиновых кислот,строение ДНК, репликация ДНК , функции ДНК, строение и функции РНК, генетический код, свойства генетического кода,мутация.
Типовые задачи знакомят с основными приемами рассуждений в генетике, а “сюжетные”– полнее раскрывают и иллюстрируют особенности этой науки, делая ее интересной и привлекательной для учащихся. Подобранные задачи характеризуют генетику как точную науку, использующую математические методы анализа. Решение задач в биологии требует умения анализировать фактический материал, логически думать и рассуждать , а также определенной изобретательности при решении особенно трудных и запутанных задач.
Для закрепления теоретического материала по способам и приемам решения задач предлагаются задачи для самостоятельного решения, а также вопросы для самоконтроля.
Примеры решения задач
Необходимые пояснения:
- Один шаг это полный виток спирали ДНК–поворот на 360o
- Один шаг составляют 10 пар нуклеотидов
- Длина одного шага – 3,4 нм
- Расстояние между двумя нуклеотидами – 0,34 нм
- Молекулярная масса одного нуклеотида – 345 г/моль
- Молекулярная масса одной аминокислоты – 120 г/мол
- В молекуле ДНК: А+Г=Т+Ц (Правило Чаргаффа: ∑(А) = ∑(Т), ∑(Г) = ∑(Ц), ∑(А+Г) =∑(Т+Ц)
- Комплементарность нуклеотидов: А=Т; Г=Ц
- Цепи ДНК удерживаются водородными связями, которые образуются между комплементарными азотистыми основаниями: аденин с тимином соединяются 2 водородными связями, а гуанин с цитозином тремя.
- В среднем один белок содержит 400 аминокислот;
- вычисление молекулярной массы белка:
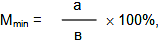
где Мmin – минимальная молекулярная масса белка,
а – атомная или молекулярная масса компонента,
в – процентное содержание компонента.
Задача № 1.Одна из цепочек ДНК имеет последовательность нуклеотидов : АГТ АЦЦ ГАТ АЦТ ЦГА ТТТ АЦГ … Какую последовательность нуклеотидов имеет вторая цепочка ДНК той же молекулы. Для наглядности можно использовать магнитную “азбуку” ДНК (прием автора статьи) .
Решение: по принципу комплементарности достраиваем вторую цепочку (А-Т,Г-Ц) .Она выглядит следующим образом: ТЦА ТГГ ЦТА ТГА ГЦТ ААА ТГЦ.
Задача № 2. Последовательность нуклеотидов в начале гена, хранящего информацию о белке инсулине, начинается так: ААА ЦАЦ ЦТГ ЦТТ ГТА ГАЦ. Напишите последовательности аминокислот, которой начинается цепь инсулина.
Решение: Задание выполняется с помощью таблицы генетического кода, в которой нуклеотиды в иРНК (в скобках – в исходной ДНК) соответствуют аминокислотным остаткам.
Задача № 3. Большая из двух цепей белка инсулина имеет (так называемая цепь В) начинается со следующих аминокислот : фенилаланин-валин-аспарагин-глутаминовая кислота-гистидин-лейцин. Напишите последовательность нуклеотидов в начале участка молекулы ДНК, хранящего информацию об этом белке.
Решение (для удобства используем табличную форму записи решения): т.к. одну аминокислоту могут кодировать несколько триплетов, точную структуру и-РНК и участка ДНКопределить невозможно, структура может варьировать. Используя принцип комплементарности и таблицу генетического кода получаем один из вариантов:
| Цепь белка |
Фен |
Вал |
Асн |
Глу |
Гис |
Лей |
|
|
и-РНК |
УУУ |
ГУУ |
ААУ |
ГАА |
ЦАЦ |
УУА |
|
|
ДНК |
1-я цепь |
ААА |
ЦАА |
ТТА |
ЦТТ |
ГТГ |
ААТ |
|
2-я цепь |
ТТТ |
ГТТ |
ААТ |
ГАА |
ЦАЦ |
ТТА |
Задача № 4. Участок гена имеет следующее строение, состоящее из последовательности нуклеотидов: ЦГГ ЦГЦ ТЦА ААА ТЦГ … Укажите строение соответствующего участка белка, информация о котором содержится в данном гене. Как отразится на строении белка удаление из гена четвертого нуклеотида?
Решение (для удобства используем табличную форму записи решения): Используя принцип комплементарности и таблицу генетического кода получаем:
| Цепь ДНК |
ЦГГ |
ЦГЦ |
ТЦА |
ААА |
ТЦГ |
|
и -РНК |
ГЦЦ |
ГЦГ |
АГУ |
УУУ |
АГЦ |
|
Аминокислоты цепи белка |
Ала-Ала-Сер-Фен-Сер |
При удалении из гена четвертого нуклеотида – Ц произойдут заметные изменения – уменьшится количество и состав аминокислот в белке:
| Цепь ДНК |
ЦГГ |
ГЦТ |
ЦАА |
ААТ |
ЦГ |
|
и -РНК |
ГЦЦ |
ЦГА |
ГУУ |
УУА |
ГЦ |
|
Аминокислоты цепи белка |
Ала-Арг-Вал-Лей- |
Задача № 5. Вирусом табачной мозаики (РНК-содержащий вирус) синтезируется участок белка с аминокислотной последовательностью: Ала – Тре – Сер – Глу – Мет-. Под действием азотистой кислоты (мутагенный фактор) цитозин в результате дезаминирова ния превращается в урацил. Какое строение будет иметь участок белка вируса табачной мозаики, если все цитидиловые нуклеотиды подвергнутся указанному химическому превращению?
Решение (для удобства используем табличную форму записи решения): Используя принцип комплементарности и таблицу генетического кода получаем :
| Аминокислоты цепи белка (исходная) |
Ала – Тре – Сер – Глу – Мет- |
||||
|
и -РНК (исходная) |
ГЦУ |
АЦГ |
АГУ |
ГАГ |
АУГ |
|
и -РНК (дезаминированная) |
ГУУ |
АУГ |
АГУ |
ГАГ |
АУГ |
|
Аминокислоты цепи белка (дезаминированная) |
Вал – Мет – Сер – Глу – Мет- |
Задача № 6. При синдроме Фанкоми (нарушение образования костной ткани) у больного с мочой выделяются аминокислоты , которым соответствуют кодоны в и -РНК : АУА ГУЦ АУГ УЦА УУГ ГУУ АУУ. Определите, выделение каких аминокислот с мочой характерно для синдрома Фанкоми, если у здорового человека в моче содержатся аминокислоты аланин, серин, глутаминовая кислота, глицин.
Решение (для удобства используем табличную форму записи решения): Используя принцип комплементарности и таблицу генетического кода получаем:
| и -РНК |
АУА |
ГУЦ |
АУГ |
УЦА |
УУГ |
ГУУ |
АУУ |
|
Аминокислоты цепи белка (больного человека) |
Изе-Вал-Мет-Сер-Лей-Вал-Иле |
||||||
|
Аминокислоты цепи белка (здорового человека) |
Ала-Сер-Глу-Гли |
Таким образом, в моче больного человека только одна аминокислота (серин) такая же как, у здорового человека, остальные – новые, а три, характерные для здорового человека, отсутствуют.
Задача № 7. Цепь А инсулина быка в 8-м звене содержит аланин, а лошади – треонин, в 9-м звене соответственно серин и глицин. Что можно сказать о происхождении инсулинов?
Решение (для удобства сравнения используем табличную форму записи решения): Посмотрим, какими триплетами в и-РНК кодируются упомянутые в условии задачи аминокислоты.
| Организм |
Бык |
Лошадь |
|
8-е звено |
Ала |
Тре |
|
и- РНК |
ГЦУ |
АЦУ |
|
9-е звено |
Сер |
Гли |
|
и- РНК |
АГУ |
ГГУ |
Т.к. аминокислоты кодируются разными триплетами, взяты триплеты, минимално отличающиеся друг от друга. В данном случае у лошади и быка в 8-м и 9-м звеньях изменены аминокислоты в результате замены первых нуклеотидов в триплетах и -РНК : гуанин заменен на аденин ( или наоборот). В двухцепочечной ДНК это будет равноценно замене пары Ц-Г на Т-А (или наоборот).
Следовательно, отличия цепей А инсулина быка и лошади обусловлены транзициями в участке молекулы ДНК, кодирующей 8-е и 9-е звенья цепи А инсулинов быка и лошади.
Задача № 7 . Исследования показали, что в и- РНК содержится 34% гуанина,18% урацила, 28% цитозина и 20% аденина.Определите процентный состав азотистых оснваний в участке ДНК, являющейся матрицей для данной и-РНК.
Решение (для удобства используем табличную форму записи решения): Процентное соотношение азотистых оснований высчитываем исходя из принципа комплементарности:
| и-РНК |
Г |
У |
Ц |
А |
|
34% |
18% |
28% |
20% |
|
|
ДНК (смысловая цепь, считываемая) |
Г |
А |
Ц |
Т |
|
28% |
18% |
34% |
20% |
|
|
ДНК (антисмысловая цепь) |
Г |
А |
Ц |
Т |
|
34% |
20% |
28% |
18% |
Суммарно А+Т и Г+Ц в смысловой цепи будут составлять: А+Т=18%+20%=38% ; Г+Ц=28%+34%=62%. В антисмысловой (некодируемой) цепи суммарные показатели будут такими же , только процент отдельных оснований будет обратный: А+Т=20%+18%=38% ; Г+Ц=34%+28%=62%. В обеих же цепях в парах комплиментарных оснований будет поровну, т.е аденина и тимина – по 19%, гуанина и цитозина по 31%.
Задача № 8. На фрагменте одной нити ДНК нуклеотиды расположены в последователь ности: А–А–Г–Т–Ц–Т–А–Ц–Г–Т–А–Т. Определите процентное содержание всех нукле отидов в этом фрагменте ДНК и длину гена.
Решение:
1) достраиваем вторую нить (по принципу комплементарности)
2) ∑(А +Т+Ц+Г) = 24,из них ∑(А) = 8 = ∑(Т)
| 24 – 100% |
=> х = 33,4% |
|
8 – х% |
|
24 – 100% |
=> х = 16,6% |
|
4 – х% |
∑(Г) = 4 = ∑(Ц)
3) молекула ДНК двуцепочечная, поэтому длина гена равна длине одной цепи:
12 × 0,34 = 4,08 нм
Задача № 9. В молекуле ДНК на долю цитидиловых нуклеотидов приходится 18%. Определите процентное содержание других нуклеотидов в этой ДНК.
Решение:
1) т.к. Ц = 18%, то и Г = 18%;
2) на долю А+Т приходится 100% – (18% +18%) = 64%, т.е. по 32%
Задача № 10. В молекуле ДНК обнаружено 880 гуанидиловых нуклеотидов, которые составляют 22% от общего числа нуклеотидов в этой ДНК. Определите: а) сколько других нуклеотидов в этой ДНК? б) какова длина этого фрагмента?
Решение:
1) ∑(Г) = ∑(Ц)= 880 (это 22%); На долю других нуклеотидов приходится 100% – (22%+22%)= 56%, т.е. по 28%; Для вычисления количества этих нуклеотидов составляем пропорцию:
22% – 880
28% – х, отсюда х = 1120
2) для определения длины ДНК нужно узнать, сколько всего нуклеотидов содержится в 1 цепи:
(880 + 880 + 1120 + 1120) : 2 = 2000
2000 × 0,34 = 680 (нм)
Задача № 11. Дана молекула ДНК с относительной молекулярной массой 69 000, из них 8625 приходится на долю адениловых нуклеотидов. Найдите количество всех нуклеотидов в этой ДНК. Определите длину этого фрагмента.
Решение:
1) 69 000 : 345 = 200 (нуклеотидов в ДНК), 8625 : 345 = 25 (адениловых нуклеотидов в этой ДНК),∑(Г+Ц) = 200 – (25+25)= 150, т.е. их по 75;
2) 200 нуклеотидов в двух цепях, значит в одной – 100. 100 × 0,34 = 34 (нм)
Задача № 12. Что тяжелее: белок или его ген?
Решение: Пусть х – количество аминокислот в белке, тогда масса этого белка – 120х, количество нуклеотидов в гене, кодирующем этот белок, – 3х, масса этого гена – 345 × 3х. 120х < 345 × 3х, значит ген тяжелее белка.
Задача № 13. Гемоглобин крови человека содержит 0, 34% железа. Вычислите минимальную молекулярную массу гемоглобина.
Решение: Мmin = 56 : 0,34% · 100% = 16471
Задача №14. Альбумин сыворотки крови человека имеет молекулярную массу 68400. Определите количество аминокислотных остатков в молекуле этого белка.
Решение: 68400 : 120 = 570 (аминокислот в молекуле альбумина)
Задача №15. Белок содержит 0,5% глицина. Чему равна минимальная молекулярная масса этого белка, если М глицина = 75,1? Сколько аминокислотных остатков в этом белке?
Решение: Мmin = 75,1 : 0,5% · 100% = 15020 ; 15020 : 120 = 125 (аминокислот в этом белке)
Задачи для самостоятельной работы
- Молекула ДНК распалась на две цепочки. одна из них имеет строение : ТАГ АЦТ ГГТ АЦА ЦГТ ГГТ ГАТ ТЦА … Какое строение будет иметь вторая молекула ДНК ,когда указанная цепочка достроится до полной двухцепочечной молекулы ?
- Полипептидная цепь одного белка животных имеет следующее начало : лизин-глутамин-треонин-аланин-аланин-аланин-лизин-… С какой последовательности нуклеотидов начинается ген, соответствующий этому белку?
- Участок молекулы белка имеет следующую последовательность аминокислот: глутамин-фенилаланин-лейцин-тирозин-аргинин. Определите одну из возможных последовательностей нуклеотидов в молекуле ДНК.
- Участок молекулы белка имеет следующую последовательность аминокислот: глицин-тирозин-аргинин-аланин-цистеин. Определите одну из возможных последовательностей нуклеотидов в молекуле ДНК.
- Одна из цепей рибонуклеазы (фермента поджелудочной железы) состоит из 16 аминокислот: Глу-Гли-асп-Про-Тир-Вал-Про-Вал-Про-Вал-Гис-фен-Фен-Асн-Ала-Сер-Вал. Определите структуру участка ДНК , кодирующего эту часть рибонуклеазы.
- Фрагмент гена ДНК имеет следующую последовательность нуклеотидов ГТЦ ЦТА АЦЦ ГГА ТТТ. Определите последовательность нуклеотидов и-РНК и аминокислот в полипептидной цепи белка.
- Фрагмент гена ДНК имеет следующую последовательность нуклеотидов ТЦГ ГТЦ ААЦ ТТА ГЦТ. Определите последовательность нуклеотидов и-РНК и аминокислот в полипептидной цепи белка.
- Фрагмент гена ДНК имеет следующую последовательность нуклеотидов ТГГ АЦА ГГТ ТТЦ ГТА. Определите последовательность нуклеотидов и-РНК и аминокислот в полипептидной цепи белка.
- Определите порядок следования аминокислот в участке молекулы белка, если известно, что он кодируется такой последовательностью нуклеотидов ДНК: ТГА ТГЦ ГТТ ТАТ ГЦГ ЦЦЦ. Как изменится белок , если химическим путем будут удалены 9-й и 13-й нуклеотиды?
- Кодирующая цепь ДНК имеет последовательность нуклеотидов: ТАГ ЦГТ ТТЦ ТЦГ ГТА. Как изменится структура молекулы белка, если произойдет удвоение шестого нуклеотида в цепи ДНК. Объясните результаты.
- Кодирующая цепь ДНК имеет последовательность нуклеотидов: ТАГ ТТЦ ТЦГ АГА. Как изменится структура молекулы белка, если произойдет удвоение восьмого нуклеотида в цепи ДНК. Объясните результаты.
- Под воздействием мутагенных факторов во фрагменте гена: ЦАТ ТАГ ГТА ЦГТ ТЦГ произошла замена второго триплета на триплет АТА. Объясните, как изменится структура молекулы белка.
- Под воздействием мутагенных факторов во фрагменте гена: АГА ТАГ ГТА ЦГТ ТЦГ произошла замена четвёртого триплета на триплет АЦЦ. Объясните, как изменится структура молекулы белка.
- Фрагмент молекулы и-РНК имеет следующую последовательность нуклеотидов: ГЦА УГУ АГЦ ААГ ЦГЦ. Определите последовательность аминокислот в молекуле белка и её молекулярную массу.
- Фрагмент молекулы и-РНК имеет следующую последовательность нуклеотидов: ГАГ ЦЦА ААУ АЦУ УУА. Определите последовательность аминокислот в молекуле белка и её молекулярную массу.
- Ген ДНК включает 450пар нуклеотидов. Какова длина, молекулярная масса гена и сколько аминокислот закодировано в нём?
- Сколько нуклеотидов содержит ген ДНК, если в нем закодировано 135 аминокислот. Какова молекулярная масса данного гена и его длина?
- Фрагмент одной цепи ДНК имеет следующую структуру: ГГТ АЦГ АТГ ТЦА АГА. Определите первичную структуру белка, закодированного в этой цепи, количество (%) различных видов нуклеотидов в двух цепях фрагмента и его длину.
- Какова молекулярная масса гена и его длина, если в нем закодирован белок с молекулярной массой 1500 г/моль?
- Какова молекулярная масса гена и его длина, если в нем закодирован белок с молекулярной массой 42000 г/моль?
- В состав белковой молекулы входит 125 аминокислот. Определите количество нуклеотидов в и-РНК и гене ДНК, а также количества молекул т-РНК принявших участие в синтезе данного белка.
- В состав белковой молекулы входит 204 аминокислоты. Определите количество нуклеотидов в и-РНК и гене ДНК, а также количества молекул т-РНК принявших участие в синтезе данного белка.
- В синтезе белковой молекулы приняли участие 145 молекул т-РНК. Определите число нуклеотидов в и-РНК, гене ДНК и количество аминокислот в синтезированной молекуле белка.
- В синтезе белковой молекулы приняли участие 128 молекул т-РНК. Определите число нуклеотидов в и-РНК, гене ДНК и количество аминокислот в синтезированной молекуле белка.
- Фрагмент цепи и-РНК имеет следующую последовательность: ГГГ УГГ УАУ ЦЦЦ ААЦ УГУ. Определите, последовательность нуклеотидов на ДНК, антикодоны т-РНК, и последовательность аминокислот соответствующая фрагменту гена ДНК.
- Фрагмент цепи и-РНК имеет следующую последовательность: ГУУ ГАА ЦЦГ УАУ ГЦУ. Определите, последовательность нуклеотидов на ДНК, антикодоны т-РНК, и последовательность аминокислот соответствующая фрагменту гена ДНК.
- В молекуле и-РНК содержится 13% адениловых, 27% гуаниловых и 39% урациловых нуклеотидов. Определите соотношение всех видов нуклеотидов в ДНК, с которой была транскрибирована данная и-РНК.
- В молекуле и-РНК содержится 21% цитидиловых, 17% гуаниловых и 40% урациловых нуклеотидов. Определите соотношение всех видов нуклеотидов в ДНК, с которой была транскрибирована данная и-РНК
- Молекула и-РНК содержит 21% гуаниловых нуклеотидов, сколько цитидиловых нуклеотидов содержится в кодирующей цепи участка ДНК?
- Если в цепи молекулы ДНК, с которой транскрибирована генетическая информация, содержалось 11% адениловых нуклеотидов, сколько урациловых нуклеотидов будет содержаться в соответствующем ему отрезке и-РНК?
Используемая литература.
- Болгова И.В. Сборник задач по общей биологии с решениями для поступающих в вузы–М.: ООО “Издательство Оникс”:”Издательство.”Мир и Образование”, 2008г.
- Воробьев О.В. Уроки биологии с применением информационных технологий .10 класс. Методическое пособие с электронным приложением–М.:Планета,2012г.
- Чередниченко И.П. Биология. Интерактивные дидактические материалы.6-11 класс. Методическое пособие с электронным интерактивным приложением. – М.:Планета,2012г.
- Интернет-ссылки:
- http://ru.convdocs.org/download/docs-8406/8406.doc
- https://bio.1sept.ru/articles/2009/06
Генетический код — это система записи генетической информации о порядке расположения аминокислот в белках в виде последовательности нуклеотидов в ДНК или РНК.
Каждая аминокислота белка закодирована в ДНК триплетом — тремя расположенными подряд нуклеотидами. Каждому триплету нуклеотидов соответствует одна аминокислота в молекуле белка.
Так как ДНК состоит из четырёх видов нуклеотидов, то число возможных сочетаний из (4) по (3) равно
43=64
. Но в состав белков входит всего (20) аминокислот. Установлено, что многие аминокислоты кодируются не одним, а несколькими триплетами (до (6)), т. е. генетический код является вырожденным. Благодаря такому свойству генетического кода хранение и передача наследственной информации оказываются более надёжными.
Пример:
аминокислоту пролин кодируют (4) триплета — ГГА, ГГГ, ГГТ и ГГЦ, которые отличаются только одним нуклеотидом. Если произойдёт ошибка в третьем нуклеотиде, то структура белка не изменится — всё равно это будет кодовый триплет аминокислоты пролин.
Учёные определили, какими триплетами ДНК закодирована каждая из (20) аминокислот, образующих молекулы белков, и составили карту генетического кода.

Рис. (1). Карта генетического кода
Чтобы определить название закодированной триплетом аминокислоты, находим нуклеотиды в таблице: первый нуклеотид — слева, второй — вверху и третий — справа. Проводим от всех нуклеотидов линии, и в месте их пересечения читаем название кислоты. В таблице показан пример определения аминокислоты: триплет ГТГ кодирует аминокислоту гистидин.
Каждая молекула ДНК содержит большое количество генов, поэтому в ней есть триплеты, которые отделяют один ген от другого — стоп-кодоны, или своеобразные «знаки препинания» (АТТ, АТЦ, АЦЦ).
Свойства генетического кода
1. Код триплетен. Каждую аминокислоту кодируют три нуклеотида, расположенные подряд.
2. Код универсален. Все живые организмы (от бактерии до человека) используют единый генетический код.
3. Код вырожден. Одна аминокислота может кодироваться не одним, а несколькими триплетами.
4. Код однозначен. Каждый триплет соответствует только одной аминокислоте.
5. Код не перекрывается. Каждый нуклеотид входит в состав только одного кодового триплета.
Порядок расположения нуклеотидов в цепях ДНК определяет её неповторимость, а также специфичность белков, которые ею кодируются. Для каждого вида и для каждой отдельной особи вида строение ДНК и белков индивидуально.
Источники:
Рис. 1. Карта генетического кода © ЯКласс.
Запросы «DNA» и «ДНК» перенаправляются сюда; см. также другие значения терминов DNA и ДНК.
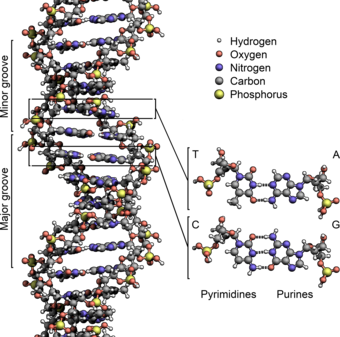
Структура ДНК (двойная спираль). Различные атомы в структуре показаны в разных цветах; детальная структура двух пар оснований показана снизу справа

Дезоксирибонуклеи́новая кислота́ (ДНК) — макромолекула (одна из трёх основных, две другие — РНК и белки), обеспечивающая хранение, передачу из поколения в поколение и реализацию генетической программы развития и функционирования живых организмов.
Молекула ДНК хранит биологическую информацию в виде генетического кода, состоящего из последовательности нуклеотидов[1]. ДНК содержит информацию о структуре различных видов РНК и белков.
В клетках эукариот (животных, растений и грибов) ДНК находится в ядре клетки в составе хромосом, а также в некоторых клеточных органеллах (митохондриях и пластидах). В клетках прокариотических организмов (бактерий и архей) кольцевая или линейная молекула ДНК, так называемый нуклеоид, прикреплена изнутри к клеточной мембране. У прокариот и у низших эукариот (например дрожжей) встречаются также небольшие автономные, преимущественно кольцевые молекулы ДНК, называемые плазмидами. Кроме того, одно- или двухцепочечные молекулы ДНК могут образовывать геном ДНК-содержащих вирусов.
С химической точки зрения ДНК — длинная полимерная молекула, состоящая из повторяющихся блоков — нуклеотидов. Каждый нуклеотид состоит из азотистого основания, сахара (дезоксирибозы) и фосфатной группы. Связи между нуклеотидами в полимерной цепи образуются за счёт дезоксирибозы и фосфатной группы (фосфодиэфирные связи).
В подавляющем большинстве случаев (кроме некоторых вирусов, содержащих одноцепочечную ДНК) макромолекула ДНК состоит из двух нуклеотидных цепей. В нуклеотидах, входящих в состав ДНК, встречаются четыре азотистых основания: аденин (A), гуанин (G), тимин (T) и цитозин (C). Азотистые основания одной цепи соединены с азотистыми основаниями другой цепи водородными связями, обеспечивая таким образом связь двух цепей макромолекулы ДНК друг с другом. Азотистые основания образуют связи поппарно согласно принципу комплементарности: аденин (A) соединяется только с тимином (T), гуанин (G) — только с цитозином (C) [⇨].
Двухцепочечная молекула ДНК закручена по винтовой линии. Структура молекулы ДНК в целом получила традиционное, но ошибочное название «двойной спирали»: на самом деле, она является «двойным винтом». Винтовая линия может быть правой (A- и B-формы ДНК) или левой (Z-форма ДНК)[2].
Последовательность нуклеотидов позволяет «кодировать» информацию о различных типах РНК, наиболее важными из которых являются информационные, или матричные (мРНК), рибосомальные (рРНК) и транспортные (тРНК). Все эти типы РНК синтезируются на матрице ДНК за счёт копирования последовательности ДНК в последовательность РНК, синтезируемой в процессе транскрипции, и далее принимают участие в биосинтезе белков (процессе трансляции). Помимо кодирующих последовательностей, ДНК содержит последовательности, выполняющие в клетках регуляторные и структурные функции. Кроме того, в геноме эукариот часто встречаются участки, принадлежащие «генетическим паразитам», например транспозонам.
Расшифровка структуры ДНК (1953 год) стала одним из поворотных моментов в истории биологии. За выдающийся вклад в это открытие Фрэнсису Крику, Джеймсу Уотсону и Морису Уилкинсу была присуждена Нобелевская премия по физиологии или медицине 1962 года. Розалинд Франклин, получившая рентгенограммы, без которых Уотсон и Крик не имели бы возможность сделать выводы о структуре ДНК, умерла в 1958 году от рака (Нобелевскую премию не дают посмертно)[3].
История изучения[править | править код]



ДНК как химическое вещество была выделена Иоганном Фридрихом Мишером в 1869 году из остатков клеток, содержащихся в гное. Он выделил вещество, в состав которого входят азот и фосфор. Вначале новое вещество получило название нуклеин, а позже, когда Мишер определил, что это вещество обладает кислотными свойствами, вещество получило название нуклеиновая кислота[4]. Биологическая функция новооткрытого вещества была неясна, и долгое время ДНК считалась запасником фосфора в организме. Более того, даже в начале XX века многие биологи считали, что ДНК не имеет никакого отношения к передаче информации, поскольку строение молекулы, по их мнению, было слишком однообразным и не могло содержать закодированную информацию.
До 1930-х годов считалось, что ДНК содержится только в животных клетках, а в растительных — РНК. В 1934 году в журнале «Hoppe-Seyler’s Zeitschrift fur physiologishe Chemie»[5], затем в 1935 году в «Ученых записках МГУ»[6] вышли статьи советских биохимиков А. Н. Белозерского и А. Р. Кизеля, в которых доказывалось присутствие ДНК в растительных клетках. В 1936 году группой Белозерского ДНК была выделена из семян и тканей бобовых, злаковых и других растений[7]. Результатом исследований этой же группы советских учёных в 1939 — 1947 годах стала первая в мировой научной литературе информация о содержании нуклеиновых кислот у различных видов бактерий.
Постепенно было доказано, что именно ДНК, а не белки, как считалось раньше, является носителем генетической информации. Одно из первых решающих доказательств принесли эксперименты Освальда Эвери, Колина Маклауда и Маклина Маккарти (1944 г.) по трансформации бактерий. Им удалось показать, что за так называемую трансформацию (приобретение болезнетворных свойств безвредной культурой в результате добавления в неё мёртвых болезнетворных бактерий) отвечает выделенная из пневмококков ДНК. Эксперимент американских учёных Алфреда Херши и Марты Чейз (эксперимент Херши — Чейз, 1952 г.) с помеченными радиоактивными изотопами белками и ДНК бактериофагов показали, что в заражённую клетку передаётся только нуклеиновая кислота фага, а новое поколение фага содержит такие же белки и нуклеиновую кислоту, как исходный фаг[8].
Вплоть до 50-х годов XX века точное строение ДНК, как и способ передачи наследственной информации, оставалось неизвестным. Хотя и было доподлинно известно, что ДНК состоит из нескольких цепочек, состоящих из нуклеотидов, никто не знал точно, сколько этих цепочек и как они соединены.
В результате работы группы биохимика Эрвина Чаргаффа в 1949—1951 гг. были сформулированы так называемые правила Чаргаффа. Чаргаффу и сотрудникам удалось разделить нуклеотиды ДНК при помощи бумажной хроматографии и определить точные количественные соотношения нуклеотидов разных типов. Соотношение, выявленное для аденина (А), тимина (Т), гуанина (Г) и цитозина (Ц), оказалось следующим: количество аденина равно количеству тимина, а гуанина — цитозину: А=Т, Г=Ц[9][10]. Эти правила, наряду с данными рентгеноструктурного анализа, сыграли решающую роль в расшифровке структуры ДНК.
Структура двойной спирали ДНК была предложена Френсисом Криком и Джеймсом Уотсоном в 1953 году на основании рентгеноструктурных данных, полученных Морисом Уилкинсом и Розалинд Франклин, и правил Чаргаффа[11]. Позже предложенная Уотсоном и Криком модель строения ДНК была доказана, а их работа отмечена Нобелевской премией по физиологии или медицине 1962 г. Среди лауреатов не было скончавшейся к тому времени от рака Розалинд Франклин, так как премия не присуждается посмертно[12].
Интересно, что в 1957 году американцы Александер Рич, Гэри Фелзенфелд и Дэйвид Дэйвис описали нуклеиновую кислоту, составленную тремя спиралями[13]. А в 1985—1986 годах Максим Давидович Франк-Каменецкий в Москве показал, как двухспиральная ДНК складывается в так называемую H-форму, составленную уже не двумя, а тремя нитями ДНК[14][15].
Структура молекулы[править | править код]
Нуклеотиды[править | править код]
Структуры оснований в составе ДНК
Дезоксирибонуклеиновая кислота (ДНК) представляет собой биополимер (полианион), мономером которого является нуклеотид[16][17].
Каждый нуклеотид состоит из остатка фосфорной кислоты, присоединённого по 5′-положению к сахару дезоксирибозе, к которому также через гликозидную связь (C—N) по 1′-положению присоединено одно из четырёх азотистых оснований.
Именно наличие характерного сахара и составляет одно из главных различий между ДНК и РНК, зафиксированное в названиях этих нуклеиновых кислот (в состав РНК входит сахар рибоза)[18]. Пример нуклеотида — аденозинмонофосфат, у которого основанием, присоединённым к фосфату и рибозе, является аденин (A) (показан на рисунке).
Исходя из структуры молекул, основания, входящие в состав нуклеотидов, разделяют на две группы: пурины (аденин [A] и гуанин [G]) образованы соединёнными пяти- и шестичленным гетероциклами; пиримидины (цитозин [C] и тимин [T]) — шестичленным гетероциклом[19].
В виде исключения, например, у бактериофага PBS1, в ДНК встречается пятый тип оснований — урацил ([U]), пиримидиновое основание, отличающееся от тимина отсутствием метильной группы на кольце, обычно заменяющее тимин в РНК[20].
Тимин (T) и урацил (U) не так строго приурочены к ДНК и РНК соответственно, как это считалось ранее. Так, после синтеза некоторых молекул РНК значительное число урацилов в этих молекулах метилируется с помощью специальных ферментов, превращаясь в тимин. Это происходит в транспортных и рибосомальных РНК[21].
Двойная спираль[править | править код]

В зависимости от концентрации ионов и нуклеотидного состава молекулы двойная спираль ДНК в живых организмах существует в разных формах. На рисунке представлены формы A, B и Z (слева направо)
Полимер ДНК обладает довольно сложной структурой. Нуклеотиды соединены между собой ковалентно в длинные полинуклеотидные цепи. Эти цепи в подавляющем большинстве случаев (кроме некоторых вирусов, обладающих одноцепочечными ДНК-геномами) попарно объединяются при помощи водородных связей во вторичную структуру, получившую название двойной спирали[11][18].
Остов каждой из цепей состоит из чередующихся фосфатов и сахаров[22]. Внутри одной цепи ДНК соседние нуклеотиды соединены фосфодиэфирными связями, которые формируются в результате взаимодействия между 3′-гидроксильной (3’—ОН) группой молекулы дезоксирибозы одного нуклеотида и 5′-фосфатной группой (5’—РО3) другого. Асимметричные концы цепи ДНК называются 3′ (три прайм) и 5′ (пять прайм). Полярность цепи играет важную роль при синтезе ДНК (удлинение цепи возможно только путём присоединения новых нуклеотидов к свободному 3′-концу).
Как уже было сказано выше, у подавляющего большинства живых организмов ДНК состоит не из одной, а из двух полинуклеотидных цепей. Эти две длинные цепи закручены одна вокруг другой в виде двойной спирали, стабилизированной водородными связями, образующимися между обращёнными друг к другу азотистыми основаниями входящих в неё цепей. В природе эта спираль, чаще всего, правозакрученная. Направления от 3′-конца к 5′-концу в двух цепях, из которых состоит молекула ДНК, противоположны (цепи «антипараллельны» друг другу).
Ширина двойной спирали составляет от 22 до 24 Å, или 2,2—2,4 нм, длина каждого нуклеотида — 3,3 Å (0,33 нм)[23]. Подобно тому, как в винтовой лестнице сбоку можно увидеть ступеньки, на двойной спирали ДНК в промежутках между фосфатным остовом молекулы можно видеть рёбра оснований, кольца которых расположены в плоскости, перпендикулярной по отношению к продольной оси макромолекулы.
В двойной спирали различают малую (12 Å) и большую (22 Å) бороздки[24]. Белки, например, факторы транскрипции, которые присоединяются к определённым последовательностям в двухцепочечной ДНК, обычно взаимодействуют с краями оснований в большой бороздке, где те более доступны[25].
Образование связей между основаниями[править | править код]
Каждое основание на одной из цепей связывается с одним определённым основанием на второй цепи. Такое специфическое связывание называется комплементарным. Пурины комплементарны пиримидинам (то есть способны к образованию водородных связей с ними): аденин образует связи только с тимином, а цитозин — с гуанином. В двойной спирали цепочки также связаны с помощью гидрофобных взаимодействий и стэкинга, которые не зависят от последовательности оснований ДНК[26].
Комплементарность двойной спирали означает, что информация, содержащаяся в одной цепи, содержится и в другой цепи. Обратимость и специфичность взаимодействий между комплементарными парами оснований важна для репликации ДНК и всех остальных функций ДНК в живых организмах.
Так как водородные связи нековалентны, они легко разрываются и восстанавливаются. Цепочки двойной спирали могут расходиться как замок-молния под действием ферментов (хеликазы) или при высокой температуре[27]. Разные пары оснований образуют разное количество водородных связей. АТ связаны двумя, ГЦ — тремя водородными связями, поэтому на разрыв ГЦ требуется больше энергии. Процент ГЦ-пар и длина молекулы ДНК определяют количество энергии, необходимой для диссоциации цепей: длинные молекулы ДНК с большим содержанием ГЦ более тугоплавки[28]. Температура плавления нуклеиновых кислот зависит от ионного окружения, рост ионной силы стабилизирует ДНК по отношению к денатурированию. При добавлении к ДНК хлорида натрия существует линейная зависимость между температурой плавления и логарифмом ионной силы раствора. Предполагается, что добавление электролита ведет к экранированию зарядов в цепях ДНК и этим уменьшает силы электростатического отталкивания между заряженными фосфатными группами, способствуя жёсткости структуры. Аналогично температуру плавления ДНК повышают ионы марганца, кобальта, цинка и никеля, но ионы меди, кадмия и свинца, напротив, понижают её[29].
Части молекул ДНК, которые из-за их функций должны быть легко разделяемы, например, ТАТА последовательность в бактериальных промоторах, обычно содержат большое количество А и Т.
Химические модификации азотистых оснований[править | править код]
Структура цитозина, 5-метилцитозина и тимина. Тимин может возникать путём деаминирования 5-метилцитозина
Азотистые основания в составе ДНК могут быть ковалентно модифицированы, что используется при регуляции экспрессии генов. Например, в клетках позвоночных метилирование цитозина с образованием 5-метилцитозина используется соматическими клетками для передачи профиля генной экспрессии дочерним клеткам. Метилирование цитозина не влияет на спаривание оснований в двойной спирали ДНК. У позвоночных метилирование ДНК в соматических клетках ограничивается метилированием цитозина в последовательности ЦГ[30]. Средний уровень метилирования отличается у разных организмов, так, у нематоды Caenorhabditis elegans метилирование цитозина не наблюдается, а у позвоночных обнаружен высокий уровень метилирования — до 1 %[31]. Другие модификации оснований включают метилирование аденина у бактерий и гликозилирование урацила с образованием «J-основания» в кинетопластах[32].
Метилирование цитозина с образованием 5-метилцитозина в промоторной части гена коррелирует с его неактивным состоянием[33]. Метилирование цитозина важно также для инактивации Х-хромосомы у млекопитающих[34]. Метилирование ДНК используется в геномном импринтинге[35]. Значительные нарушения профиля метилирования ДНК происходят при канцерогенезе[36].
Несмотря на биологическую роль, 5-метилцитозин может спонтанно утрачивать аминную группу (деаминироваться), превращаясь в тимин, поэтому метилированные цитозины являются источником повышенного числа мутаций[37].
Повреждения ДНК[править | править код]

Интеркалированное химическое соединение, которое находится в середине спирали — бензопирен, основной мутаген табачного дыма[38]
ДНК может повреждаться разнообразными мутагенами, к которым относятся окисляющие и алкилирующие вещества, а также высокоэнергетическая электромагнитная радиация — ультрафиолетовое и рентгеновское излучение. Тип повреждения ДНК зависит от типа мутагена. Например, ультрафиолет повреждает ДНК путём образования в ней димеров тимина, которые возникают при образовании ковалентных связей между соседними основаниями[39].
Оксиданты, такие как свободные радикалы или пероксид водорода, приводят к нескольким типам повреждения ДНК, включая модификации оснований, в особенности гуанозина, а также двухцепочечные разрывы в ДНК[40]. По некоторым оценкам, в каждой клетке человека окисляющими соединениями ежедневно повреждается порядка 500 оснований[41][42]. Среди разных типов повреждений наиболее опасные — это двухцепочечные разрывы, потому что они трудно репарируются и могут привести к потерям участков хромосом (делециям) и транслокациям.
Многие молекулы мутагенов вставляются (интеркалируют) между двумя соседними парами оснований. Большинство этих соединений, например: бромистый этидий, даунорубицин, доксорубицин и талидомид, имеет ароматическую структуру. Для того чтобы интеркалирующее соединение могло поместиться между основаниями, они должны разойтись, расплетая и нарушая структуру двойной спирали. Эти изменения в структуре ДНК мешают репликации, вызывая мутации, и транскрипции. Поэтому интеркалирующие соединения часто являются канцерогенами, наиболее известные из которых — бензопирен, акридины, афлатоксин и бромистый этидий[43][44][45]. Несмотря на эти негативные свойства, в силу их способности подавлять транскрипцию и репликацию ДНК, интеркалирующие соединения используются в химиотерапии для подавления быстро растущих клеток рака[46].
Некоторые вещества (цисплатин[47], митомицин C[48], псорален[49]) образуют поперечные сшивки между нитями ДНК и подавляют синтез ДНК, благодаря чему используются в химиотерапии некоторых видов рака (см. Химиотерапия злокачественных новообразований).
Суперскрученность[править | править код]
Если взяться за концы верёвки и начать скручивать их в разные стороны, она становится короче и на верёвке образуются «супервитки». Так же может быть суперскручена и ДНК. В обычном состоянии цепочка ДНК делает один оборот на каждые 10,4 пар оснований, но в суперскрученном состоянии спираль может быть свёрнута туже или расплетена[50]. Выделяют два типа суперскручивания: положительное — в направлении нормальных витков, при котором основания расположены ближе друг к другу; и отрицательное — в противоположном направлении. В природе молекулы ДНК обычно находятся в отрицательном суперскручивании, которое вносится ферментами — топоизомеразами[51]. Эти ферменты удаляют дополнительное скручивание, возникающее в ДНК в результате транскрипции и репликации[52].

Структура теломер. Зелёным цветом показан ион металла, хелатированный в центре структуры[53]
Структуры на концах хромосом[править | править код]
На концах линейных хромосом находятся специализированные структуры ДНК, называемые теломерами. Основная функция этих участков — поддержание целостности концов хромосом[54]. Теломеры также защищают концы ДНК от деградации экзонуклеазами и предотвращают активацию системы репарации[55]. Поскольку обычные ДНК-полимеразы не могут реплицировать 3′ концы хромосом, это делает специальный фермент — теломераза.
В клетках человека теломеры часто представлены одноцепочечной ДНК и состоят из нескольких тысяч повторяющихся единиц последовательности ТТАГГГ[56]. Эти последовательности с высоким содержанием гуанина стабилизируют концы хромосом, формируя очень необычные структуры, называемые G-квадруплексами и состоящие из четырёх, а не двух взаимодействующих оснований. Четыре гуаниновых основания, все атомы которых находятся в одной плоскости, образуют пластинку, стабилизированную водородными связями между основаниями и хелатированием в центре неё иона металла (чаще всего калия). Эти пластинки располагаются стопкой друг над другом[57].
На концах хромосом могут образовываться и другие структуры: основания могут быть расположены в одной цепочке или в разных параллельных цепочках. Кроме этих «стопочных» структур теломеры формируют большие петлеобразные структуры, называемые Т-петли или теломерные петли. В них одноцепочечная ДНК располагается в виде широкого кольца, стабилизированного теломерными белками[58]. В конце Т-петли одноцепочечная теломерная ДНК присоединяется к двухцепочечной ДНК, нарушая спаривание цепочек в этой молекуле и образуя связи с одной из цепей. Это трёхцепочечное образование называется Д-петля (от англ. displacement loop)[57].
Биологические функции[править | править код]
ДНК является носителем генетической информации, записанной в виде последовательности нуклеотидов с помощью генетического кода. С молекулами ДНК связаны два основополагающих свойства живых организмов — наследственность и изменчивость. В ходе процесса, называемого репликацией ДНК, образуются две копии исходной цепочки, наследуемые дочерними клетками при делении, отсюда следует, что образовавшиеся клетки оказываются генетически идентичны исходной.
Генетическая информация реализуется при экспрессии генов в процессах транскрипции (синтеза молекул РНК на матрице ДНК) и трансляции (синтеза белков на матрице РНК).
Последовательность нуклеотидов «кодирует» информацию о различных типах РНК: информационных, или матричных (мРНК), рибосомальных (рРНК) и транспортных (тРНК). Все эти типы РНК синтезируются на основе ДНК в процессе транскрипции. Роль их в биосинтезе белков (процессе трансляции) различна. Информационная РНК содержит информацию о последовательности аминокислот в белке, рибосомальные РНК служат основой для рибосом (сложных нуклеопротеиновых комплексов, основная функция которых — сборка белка из отдельных аминокислот на основе иРНК), транспортные РНК доставляют аминокислоты к месту сборки белков — в активный центр рибосомы, «ползущей» по иРНК.
Структура генома[править | править код]

ДНК генома бактериофага: фотография под просвечивающим электронным микроскопом
Большинство природных ДНК имеет двухцепочечную структуру, линейную (эукариоты, некоторые вирусы и отдельные роды бактерий) или кольцевую (прокариоты, хлоропласты и митохондрии). Линейную одноцепочечную ДНК содержат некоторые вирусы и бактериофаги.
Молекулы ДНК находятся in vivo в плотно упакованном, конденсированном состоянии[59]. В клетках эукариот ДНК располагается главным образом в ядре и на стадии профазы, метафазы или анафазы митоза доступны для наблюдения с помощью светового микроскопа в виде набора хромосом. Бактериальная (прокариоты) ДНК обычно представлена одной кольцевой молекулой ДНК, расположенной в неправильной формы образовании в цитоплазме, называемым нуклеоидом[60]. Генетическая информация генома состоит из генов. Ген — единица передачи наследственной информации и участок ДНК, который влияет на определённую характеристику организма. Ген содержит открытую рамку считывания, которая транскрибируется, а также регуляторные последовательности (англ.) (рус., например промотор и энхансер, которые контролируют экспрессию открытых рамок считывания.
У многих видов только малая часть общей последовательности генома кодирует белки. Так, только около 1,5 % генома человека состоит из кодирующих белок экзонов, а больше 50 % ДНК человека состоит из некодирующих повторяющихся последовательностей ДНК[61]. Причины наличия такого большого количества некодирующей ДНК в эукариотических геномах и огромная разница в размерах геномов (С-значение) — одна из неразрешённых научных загадок[62]; исследования в этой области также указывают на большое количество фрагментов реликтовых вирусов в этой части ДНК.
Последовательности генома, не кодирующие белок[править | править код]
В настоящее время накапливается всё больше данных, противоречащих идее о некодирующих последовательностях как «мусорной ДНК» (англ. junk DNA).
Теломеры и центромеры содержат малое число генов, но они важны для функционирования и стабильности хромосом[55][63]. Часто встречающаяся форма некодирующих последовательностей человека — псевдогены, копии генов, инактивированные в результате мутаций[64]. Эти последовательности нечто вроде молекулярных ископаемых, хотя иногда они могут служить исходным материалом для дупликации и последующей дивергенции генов[65].
Другой источник разнообразия белков в организме — это использование интронов в качестве «линий разреза и склеивания» в альтернативном сплайсинге[66].
Наконец, не кодирующие белок последовательности могут кодировать вспомогательные клеточные РНК, например мяРНК[67]. Недавнее исследование транскрипции генома человека показало, что 10 % генома даёт начало полиаденилированным РНК[68], а исследование генома мыши показало, что 62 % его транскрибируется[69].
Транскрипция и трансляция[править | править код]
Генетическая информация, закодированная в ДНК, должна быть прочитана и в конечном итоге выражена в синтезе различных биополимеров, из которых состоят клетки. Последовательность оснований в цепочке ДНК напрямую определяет последовательность оснований в РНК, на которую она «переписывается» в процессе, называемом транскрипцией. В случае мРНК эта последовательность определяет аминокислоты белка. Соотношение между нуклеотидной последовательностью мРНК и аминокислотной последовательностью определяется правилами трансляции, которые называются генетическим кодом. Генетический код состоит из трёхбуквенных «слов», называемых кодонами, состоящих из трёх нуклеотидов (то есть ACT, CAG, TTT и т. п.).
Во время транскрипции нуклеотиды гена копируются на синтезируемую РНК РНК-полимеразой. Эта копия в случае мРНК декодируется рибосомой, которая «читает» последовательность мРНК, осуществляя спаривание матричной РНК с транспортными РНК, которые присоединены к аминокислотам. Поскольку в трёхбуквенных комбинациях используются 4 основания, всего возможны 64 кодона (4³ комбинации). Кодоны кодируют 20 стандартных аминокислот, каждой из которых соответствует в большинстве случаев более одного кодона. Один из трёх кодонов, которые располагаются в конце мРНК, не означает аминокислоту и определяет конец белка, это «стоп» или «нонсенс» кодоны — TAA, TGA, TAG.
Репликация[править | править код]
Деление клеток необходимо для размножения одноклеточного и роста многоклеточного организма, но до деления клетка должна удвоить геном, чтобы дочерние клетки содержали ту же генетическую информацию, что и исходная клетка. Из нескольких теоретически возможных механизмов удвоения (репликации) ДНК реализуется полуконсервативный. Две цепочки разделяются, а затем каждая недостающая комплементарная последовательность ДНК воспроизводится ферментом ДНК-полимеразой. Этот фермент синтезирует полинуклеотидную цепь, находя правильный нуклеотид через комплементарное спаривание оснований и присоединяя его к растущей цепочке. ДНК-полимераза не может начинать новую цепь, а может лишь наращивать уже существующую, поэтому она нуждается в короткой цепочке нуклеотидов — (праймере), синтезируемом праймазой. Так как ДНК-полимеразы могут синтезировать цепочку только в направлении 5′ –> 3′, антипараллельные цепи ДНК копируются по-разному: одна цепь синтезируется непрерывно, а вторая прерывчато[70].
Взаимодействие с белками[править | править код]
Все функции ДНК зависят от её взаимодействия с белками. Взаимодействия могут быть неспецифическими, когда белок присоединяется к любой молекуле ДНК, или зависеть от наличия особой последовательности. Ферменты также могут взаимодействовать с ДНК, из них наиболее важные — это РНК-полимеразы, которые копируют последовательность оснований ДНК на РНК в транскрипции или при синтезе новой цепи ДНК — репликации.
Структурные и регуляторные белки[править | править код]
Хорошо изученными примерами взаимодействия белков и ДНК, не зависящего от нуклеотидной последовательности ДНК, является взаимодействие со структурными белками. В клетке ДНК связана с этими белками, образуя компактную структуру, которая называется хроматин. У эукариот хроматин образован при присоединении к ДНК небольших щелочных белков — гистонов, менее упорядоченный хроматин прокариот содержит гистон-подобные белки[71][72]. Гистоны формируют дискообразную белковую структуру — нуклеосому, вокруг каждой из которых вмещается два оборота спирали ДНК. Неспецифические связи между гистонами и ДНК образуются за счёт ионных связей щелочных аминокислот гистонов и кислотных остатков сахарофосфатного остова ДНК[73]. Химические модификации этих аминокислот включают метилирование, фосфорилирование и ацетилирование[74]. Эти химические модификации изменяют силу взаимодействия между ДНК и гистонами, влияя на доступность специфических последовательностей для факторов транскрипции и изменяя скорость транскрипции[75]. Другие белки в составе хроматина, которые присоединяются к неспецифическим последовательностям — белки с высокой подвижностью в гелях, которые ассоциируют большей частью с согнутой ДНК[76]. Эти белки важны для образования в хроматине структур более высокого порядка[77].
Особая группа белков, присоединяющихся к ДНК — это белки, которые ассоциируют с одноцепочечной ДНК. Наиболее хорошо охарактеризованный белок этой группы у человека — репликационный белок А, без которого невозможно протекание большинства процессов, где расплетается двойная спираль, включая репликацию, рекомбинацию и репарацию. Белки этой группы стабилизируют одноцепочечную ДНК и предотвращают формирование стеблей-петель или деградации нуклеазами[78].
В то же время другие белки узнают и присоединяются к специфическим последовательностям. Наиболее изученная группа таких белков — различные классы факторов транскрипции, то есть белки, регулирующие транскрипцию. Каждый из этих белков узнаёт свою последовательность, часто в промоторе, и активирует или подавляет транскрипцию гена. Это происходит при ассоциации факторов транскрипции с РНК-полимеразой либо напрямую, либо через белки-посредники. Полимераза ассоциирует сначала с белками, а потом начинает транскрипцию[79]. В других случаях факторы транскрипции могут присоединяться к ферментам, которые модифицируют находящиеся на промоторах гистоны, что изменяет доступность ДНК для полимераз[80].
Так как специфические последовательности встречаются во многих местах генома, изменения в активности одного типа фактора транскрипции могут изменить активность тысяч генов[81]. Соответственно, эти белки часто регулируются в процессах ответа на изменения в окружающей среде, развития организма и дифференцировки клеток. Специфичность взаимодействия факторов транскрипции с ДНК обеспечивается многочисленными контактами между аминокислотами и основаниями ДНК, что позволяет им «читать» последовательность ДНК. Большинство контактов с основаниями происходит в главной бороздке, где основания более доступны[25].
Ферменты, модифицирующие ДНК[править | править код]
Топоизомеразы и хеликазы[править | править код]
В клетке ДНК находится в компактном, т. н. суперскрученном состоянии, иначе она не смогла бы в ней уместиться. Для протекания жизненно важных процессов ДНК должна быть раскручена, что производится двумя группами белков — топоизомеразами и хеликазами.
Топоизомеразы — ферменты, которые имеют и нуклеазную, и лигазную активности. Они изменяют степень суперскрученности в ДНК. Некоторые из этих ферментов разрезают спираль ДНК и позволяют вращаться одной из цепей, тем самым уменьшая уровень суперскрученности, после чего фермент заделывает разрыв[51]. Другие ферменты могут разрезать одну из цепей и проводить вторую цепь через разрыв, а потом лигировать разрыв в первой цепи[82]. Топоизомеразы необходимы во многих процессах, связанных с ДНК, таких как репликация и транскрипция[52].
Хеликазы — белки, которые являются одним из молекулярных моторов. Они используют химическую энергию нуклеозидтрифосфатов, чаще всего АТФ, для разрыва водородных связей между основаниями, раскручивая двойную спираль на отдельные цепочки[83]. Эти ферменты важны для большинства процессов, где белкам необходим доступ к основаниям ДНК.
Нуклеазы и лигазы[править | править код]
В различных процессах, происходящих в клетке, например рекомбинации и репарации, участвуют ферменты, способные разрезать и восстанавливать целостность нитей ДНК. Ферменты, разрезающие ДНК, носят название нуклеаз. Нуклеазы, которые гидролизуют нуклеотиды на концах молекулы ДНК, называются экзонуклеазами, а эндонуклеазы разрезают ДНК внутри цепи. Наиболее часто используемые в молекулярной биологии и генетической инженерии нуклеазы — это эндонуклеазы рестрикции (рестриктазы), которые разрезают ДНК около специфических последовательностей. Например, фермент EcoRV (рестрикционный фермент № 5 из ‘E. coli’) узнаёт шестинуклеотидную последовательность 5′-GAT|ATC-3′ и разрезает ДНК в месте, указанном вертикальной линией. В природе эти ферменты защищают бактерии от заражения бактериофагами, разрезая ДНК фага, когда она вводится в бактериальную клетку. В этом случае нуклеазы — часть системы модификации-рестрикции[84]. ДНК-лигазы «сшивают» концы фрагментов ДНК между собой, катализируя формирование фосфодиэфирной связи с использованием энергии АТФ.
Рестрикционные нуклеазы и лигазы используются в клонировании и фингерпринтинге.

ДНК-лигаза I (кольцеобразная структура, состоящая из нескольких одинаковых молекул белка, показанных разными цветами), лигирующая повреждённую цепь ДНК
Полимеразы[править | править код]
Существует также важная для метаболизма ДНК группа ферментов, которые синтезируют цепи полинуклеотидов из нуклеозидтрифосфатов — ДНК-полимеразы. Они добавляют нуклеотиды к 3′-гидроксильной группе предыдущего нуклеотида в цепи ДНК, поэтому все полимеразы работают в направлении 5′–> 3′[85]. В активном центре этих ферментов субстрат — нуклеозидтрифосфат — спаривается с комплементарным основанием в составе одноцепочечной полинуклеотидной цепочки — матрицы.
В процессе репликации ДНК ДНК-зависимая ДНК-полимераза синтезирует копию исходной последовательности ДНК. Точность очень важна в этом процессе, так как ошибки в полимеризации приведут к мутациям, поэтому многие полимеразы обладают способностью к «редактированию» — исправлению ошибок. Полимераза узнаёт ошибки в синтезе по отсутствию спаривания между неправильными нуклеотидами. После определения отсутствия спаривания активируется 3′–> 5′ экзонуклеазная активность полимеразы, и неправильное основание удаляется[86]. В большинстве организмов ДНК-полимеразы работают в виде большого комплекса, называемого реплисомой, которая содержит многочисленные дополнительные субъединицы, например хеликазы[87].
РНК-зависимые ДНК-полимеразы — специализированный тип полимераз, которые копируют последовательность РНК на ДНК. К этому типу относятся обратная транскриптаза, которая содержится в ретровирусах и используется при инфекции клеток, а также теломераза, необходимая для репликации теломер[88]. Теломераза — необычный фермент, потому что она содержит собственную матричную РНК[55].
Транскрипция осуществляется ДНК-зависимой РНК-полимеразой, которая копирует последовательность ДНК одной цепочки на мРНК. В начале транскрипции гена РНК-полимераза присоединяется к последовательности в начале гена, называемой промотором, и расплетает спираль ДНК. Потом она копирует последовательность гена на матричную РНК до тех пор, пока не дойдёт до участка ДНК в конце гена — терминатора, где она останавливается и отсоединяется от ДНК. Также как ДНК-зависимая ДНК-полимераза человека, РНК-полимераза II, которая транскрибирует большую часть генов в геноме человека, работает в составе большого белкового комплекса, содержащего регуляторные и дополнительные единицы[89].
Генетическая рекомбинация[править | править код]
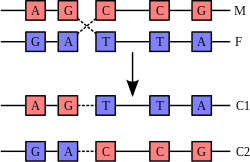
Рекомбинация происходит в результате физического разрыва в хромосомах (М) и (F) и их последующего соединения с образованием двух новых хромосом (C1 и C2)
Двойная спираль ДНК обычно не взаимодействует с другими сегментами ДНК, и в человеческих клетках разные хромосомы пространственно разделены в ядре[90]. Это расстояние между разными хромосомами важно для способности ДНК действовать в качестве стабильного носителя информации. В процессе рекомбинации с помощью ферментов две спирали ДНК разрываются, обмениваются участками, после чего непрерывность спиралей восстанавливается, поэтому обмен участками негомологичных хромосом может привести к повреждению целостности генетического материала.
Рекомбинация позволяет хромосомам обмениваться генетической информацией, в результате этого образуются новые комбинации генов, что увеличивает эффективность естественного отбора и важно для быстрой эволюции новых белков[91]. Генетическая рекомбинация также играет роль в репарации, особенно в ответе клетки на разрыв обеих цепей ДНК[92].
Самая распространённая форма кроссинговера — это гомологичная рекомбинация, когда принимающие участие в рекомбинации хромосомы имеют очень похожие последовательности. Иногда в качестве участков гомологии выступают транспозоны. Негомологичная рекомбинация может привести к повреждению клетки, поскольку в результате такой рекомбинации возникают транслокации. Реакция рекомбинации катализируется ферментами, которые называются рекомбиназы, например, Cre. На первом этапе реакции рекомбиназа делает разрыв в одной из цепей ДНК, позволяя этой цепи отделиться от комплементарной цепи и присоединиться к одной из цепей второй хроматиды. Второй разрыв в цепи второй хроматиды позволяет ей также отделиться и присоединиться к оставшейся без пары цепи из первой хроматиды, формируя структуру Холлидея. Структура Холлидея может передвигаться вдоль соединённой пары хромосом, меняя цепи местами. Реакция рекомбинации завершается, когда фермент разрезает соединение, а две цепи лигируются[93].
Эволюция метаболизма, основанного на ДНК[править | править код]
ДНК содержит генетическую информацию, которая делает возможной жизнедеятельность, рост, развитие и размножение всех современных организмов. Однако как долго в течение четырёх миллиардов лет истории жизни на Земле ДНК была главным носителем генетической информации, неизвестно. Существуют гипотезы, что РНК играла центральную роль в обмене веществ, поскольку она может и переносить генетическую информацию, и осуществлять катализ с помощью рибозимов[94][95][96]. Кроме того, РНК — один из основных компонентов «фабрик белка» — рибосом. Древний РНК-мир, где нуклеиновая кислота была использована и для катализа, и для переноса информации, мог послужить источником современного генетического кода, состоящего из четырёх оснований. Это могло произойти в результате того, что число оснований в организме было компромиссом между небольшим числом оснований, увеличивавшим точность репликации, и большим числом оснований, увеличивающим каталитическую активность рибозимов[97].
К сожалению, древние генетические системы не дошли до наших дней. ДНК в окружающей среде в среднем сохраняется в течение 1 миллиона лет, постепенно деградируя до коротких фрагментов. Извлечение ДНК из бактериальных спор, заключённых в кристаллах соли 250 млн лет назад, и определение последовательности генов 16S рРНК[98], служит темой оживлённой дискуссии в научной среде[99][100].
См. также[править | править код]
- Вектор (биология)
- Геном человека
- Действие излучений на структуру и функции ДНК
- Методы секвенирования нового поколения
- Мобильные элементы генома
- Нуклеопротеиды
- Спиртовая преципитация
- Футпринтинг ДНК
- Центральная догма молекулярной биологии
- Цис-элемент
- ДНК-компьютер
- Трёхцепочечная ДНК
Примечания[править | править код]
- ↑ Александр Панчин. Сумма биотехнологии [1]. — АСТ, 2015. — С. 13. — 432 с. — ISBN 978-5-17-093602-1.
- ↑ Bustamante C., Bryant Z., Smith S. B. Ten years of tension: single-molecule DNA mechanics (англ.) // Nature. — 2003. — Vol. 421, no. 6921. — P. 423—427.
- ↑ Erica Westly. No Nobel for You: Top 10 Nobel Snubs. Rosalind Franklin–her work on the structure of DNA never received a Nobel (англ.). Scientific American (6 октября 2008). Дата обращения: 18 ноября 2013. Архивировано 8 января 2014 года.
- ↑ Dahm R. Friedrich Miescher and the discovery of DNA (англ.) // Dev Biol (англ.) (рус. : journal. — 2005. — Vol. 278, no. 2. — P. 274—288. — PMID 15680349.
- ↑ Kiesel A., Beloserskii A. Hoppe-Seyler’s Zeitschrift fur physiologishe Chemie, 229, 160—166. 1934.
- ↑ Белозерский А. Н. Ученые записки МГУ, вып.4, 209—215, 1935.
- ↑ Белозерский А. Н., Чигирев С. Д. Биохимия, 1, 136—146, 1936.
- ↑ Hershey A., Chase M. Independent functions of viral protein and nucleic acid in growth of bacteriophage (англ.) // The Journal of General Physiology (англ.) (рус. : journal. — Rockefeller University Press (англ.) (рус., 1952. — Vol. 36, no. 1. — P. 39—56. — PMID 12981234.
- ↑ Elson D., Chargaff E. On the deoxyribonucleic acid content of sea urchin gametes (англ.) // Experientia : journal. — 1952. — Vol. 8, no. 4. — P. 143—145. — doi:10.1007/BF02170221. — PMID 14945441.
- ↑ Chargaff E., Lipshitz R., Green C. Composition of the deoxypentose nucleic acids of four genera of sea-urchin (англ.) // J Biol Chem : journal. — 1952. — Vol. 195, no. 1. — P. 155—160. — PMID 14938364.
- ↑ 1 2 Watson J., Crick F. Molecular structure of nucleic acids; a structure for deoxyribose nucleic acid (рум.) // Nature. — 1953. — Т. 171, nr. 4356. — P. 737—8.
- ↑ The Nobel Prize in Physiology or Medicine 1962 Архивная копия от 4 января 2007 на Wayback Machine Nobelprize .org Accessed 22 Dec 06
- ↑ Н. Домрина В России есть кому делать науку — если будет на что // Журнал «Наука и жизнь», № 2, 2002. Дата обращения: 21 апреля 2013. Архивировано 3 октября 2013 года.
- ↑ Maxim Frank-Kamenetskii DNA structure: A simple solution to the stability of the double helix? // Журнал Nature № 324, 305 (27 November 1986). Дата обращения: 21 апреля 2013. Архивировано 16 ноября 2005 года.
- ↑ Maxim Frank-Kamenetskii H-form DNA and the hairpin-triplex model // Журнал Nature № 333, 214 (19 May 1988)
- ↑ Alberts, Bruce; Alexander Johnson, Julian Lewis, Martin Raff, Keith Roberts, and Peter Walters. Molecular Biology of the Cell; Fourth Edition (англ.). — New York and London: Garland Science (англ.) (рус., 2002.
- ↑ Butler, John M. (2001) Forensic DNA Typing «Elsevier». pp. 14 — 15. ISBN 978-0-12-147951-0
- ↑ 1 2 Berg J., Tymoczko J. and Stryer L. (2002) Biochemistry. W. H. Freeman and Company ISBN 0-7167-4955-6
- ↑ Abbreviations and Symbols for Nucleic Acids, Polynucleotides and their Constituents Архивная копия от 5 февраля 2007 на Wayback Machine IUPAC-IUB Commission on Biochemical Nomenclature (CBN) Accessed 03 Jan 2006
- ↑ Takahashi I., Marmur J. Replacement of thymidylic acid by deoxyuridylic acid in the deoxyribonucleic acid of a transducing phage for Bacillus subtilis (англ.) // Nature : journal. — 1963. — Vol. 197. — P. 794—5.
- ↑ Agris P. Decoding the genome: a modified view (англ.) // Nucleic Acids Res (англ.) (рус. : journal. — 2004. — Vol. 32, no. 1. — P. 223—38. — PMID 14715921.
- ↑ Ghosh A., Bansal M. A glossary of DNA structures from A to Z (англ.) // Acta Crystallogr D Biol Crystallogr (англ.) (рус. : journal. — International Union of Crystallography, 2003. — Vol. 59, no. Pt 4. — P. 620—6.
- ↑ Mandelkern M., Elias J., Eden D., Crothers D. The dimensions of DNA in solution (англ.) // J Mol Biol (англ.) (рус. : journal. — 1981. — Vol. 152, no. 1. — P. 153—61.
- ↑ Wing R., Drew H., Takano T., Broka C., Tanaka S., Itakura K., Dickerson R. Crystal structure analysis of a complete turn of B-DNA (англ.) // Nature : journal. — 1980. — Vol. 287, no. 5784. — P. 755—8.
- ↑ 1 2 Pabo C., Sauer R. Protein-DNA recognition (англ.) // Annu Rev Biochem (англ.) (рус. : journal. — Vol. 53. — P. 293—321.
- ↑ Ponnuswamy P., Gromiha M. On the conformational stability of oligonucleotide duplexes and tRNA molecules (англ.) // J Theor Biol (англ.) (рус. : journal. — 1994. — Vol. 169, no. 4. — P. 419—432. — PMID 7526075.
- ↑ Clausen-Schaumann H., Rief M., Tolksdorf C., Gaub H. Mechanical stability of single DNA molecules (англ.) // Biophys J (англ.) (рус. : journal. — 2000. — Vol. 78, no. 4. — P. 1997—2007. — PMID 10733978.
- ↑ Chalikian T., Völker J., Plum G., Breslauer K. A more unified picture for the thermodynamics of nucleic acid duplex melting: a characterization by calorimetric and volumetric techniques (англ.) // Proceedings of the National Academy of Sciences of the United States of America : journal. — 1999. — Vol. 96, no. 14. — P. 7853—7858. — PMID 10393911.
- ↑ Е.Е.Крисс, К.Б.Яцимирский. Взаимодействие нуклеиновых кислот с металлами..
- ↑ Молекулярная биология клетки: в 3-х томах / Б. Альбертс, А. Джонсон, Д. Льюис и др. — М.-Ижевск: НИЦ «Регулярная и хаотическая динамика», Институт компьютерных исследований, 2013. — Т. I. — С. 719—733. — 808 с. — ISBN 978-5-4344-0112-8.
- ↑ Bird A. DNA methylation patterns and epigenetic memory (англ.) // Genes Dev : journal. — 2002. — Vol. 16, no. 1. — P. 6—21.
- ↑ Gommers-Ampt J., Van Leeuwen F., de Beer A., Vliegenthart J., Dizdaroglu M., Kowalak J., Crain P., Borst P. beta-D-glucosyl-hydroxymethyluracil: a novel modified base present in the DNA of the parasitic protozoan T. brucei (англ.) // Cell : journal. — Cell Press, 1993. — Vol. 75, no. 6. — P. 1129—36.
- ↑ Jones P. A. Functions of DNA methylation: islands, start sites, gene bodies and beyond // Nature Reviews Genetics. — 2012. — Т. 13, № 7. — С. 484—492.
- ↑ Klose R., Bird A. Genomic DNA methylation: the mark and its mediators (англ.) // Trends Biochem Sci (англ.) (рус. : journal. — 2006. — Vol. 31, no. 2. — P. 89—97.
- ↑ Li E., Beard C., Jaenisch R. Role for DNA methylation in genomic imprinting //Nature. — 1993. — Т. 366. — №. 6453. — С. 362—365
- ↑ Ehrlich M. DNA methylation in cancer: too much, but also too little //Oncogene. — 2002. — Т. 21. — №. 35. — С. 5400-5413
- ↑ Walsh C., Xu G. Cytosine methylation and DNA repair (неопр.) // Curr Top Microbiol Immunol. — Т. 301. — С. 283—315.
- ↑ Created from PDB 1JDG Архивная копия от 22 сентября 2008 на Wayback Machine
- ↑ Douki T., Reynaud-Angelin A., Cadet J., Sage E. Bipyrimidine photoproducts rather than oxidative lesions are the main type of DNA damage involved in the genotoxic effect of solar UVA radiation (англ.) // Biochemistry : journal. — 2003. — Vol. 42, no. 30. — P. 9221—6.
- ↑ Cadet J., Delatour T., Douki T., Gasparutto D., Pouget J., Ravanat J., Sauvaigo S. Hydroxyl radicals and DNA base damage (неопр.) // Mutation Research (англ.) (рус.. — Elsevier, 1999. — Т. 424, № 1—2. — С. 9—21.
- ↑ Shigenaga M., Gimeno C., Ames B. Urinary 8-hydroxy-2′-deoxyguanosine as a biological marker of in vivo oxidative DNA damage (англ.) // Proceedings of the National Academy of Sciences of the United States of America : journal. — 1989. — Vol. 86, no. 24. — P. 9697—701.
- ↑ Cathcart R., Schwiers E., Saul R., Ames B. Thymine glycol and thymidine glycol in human and rat urine: a possible assay for oxidative DNA damage (англ.) // Proceedings of the National Academy of Sciences of the United States of America : journal. — 1984. — Vol. 81, no. 18. — P. 5633—7.
- ↑ Ferguson L., Denny W. The genetic toxicology of acridines (неопр.) // Mutation Research (англ.) (рус.. — Elsevier, 1991. — Т. 258, № 2. — С. 123—60.
- ↑ Jeffrey A. DNA modification by chemical carcinogens (англ.) // Pharmacol Ther : journal. — 1985. — Vol. 28, no. 2. — P. 237—72.
- ↑ Stephens T., Bunde C., Fillmore B. Mechanism of action in thalidomide teratogenesis (англ.) // Biochem Pharmacol (англ.) (рус. : journal. — 2000. — Vol. 59, no. 12. — P. 1489—99.
- ↑ Braña M., Cacho M., Gradillas A., de Pascual-Teresa B., Ramos A. Intercalators as anticancer drugs (англ.) // Curr Pharm Des (англ.) (рус. : journal. — 2001. — Vol. 7, no. 17. — P. 1745—80.
- ↑ Trzaska, Stephen. Cisplatin (англ.) // Chemical & Engineering News (англ.) (рус. : journal. — 2005. — 20 June (vol. 83, no. 25).
- ↑ Tomasz, Maria. Mitomycin C: small, fast and deadly (but very selective) (англ.) // Chemistry and Biology (англ.) (рус. : journal. — 1995. — September (vol. 2, no. 9). — P. 575—579. — doi:10.1016/1074-5521(95)90120-5. — PMID 9383461.
- ↑ Wu Q., Christensen L. A., Legerski R. J., Vasquez K. M. Mismatch repair participates in error-free processing of DNA interstrand crosslinks in human cells (англ.) // EMBO Rep. (англ.) (рус. : journal. — 2005. — June (vol. 6, no. 6). — P. 551—557. — doi:10.1038/sj.embor.7400418. — PMID 15891767. — PMC 1369090.
- ↑ Benham C., Mielke S. DNA mechanics (неопр.) // Annu Rev Biomed Eng (англ.) (рус.. — 2005. — Т. 7. — С. 21—53. — PMID 16004565.
- ↑ 1 2 Champoux J. DNA topoisomerases: structure, function, and mechanism (англ.) // Annu Rev Biochem (англ.) (рус. : journal. — 2001. — Vol. 70. — P. 369—413. — PMID 11395412.
- ↑ 1 2 Wang J. Cellular roles of DNA topoisomerases: a molecular perspective (англ.) // Nat Rev Mol Cell Biol : journal. — 2002. — Vol. 3, no. 6. — P. 430—440. — PMID 12042765.
- ↑ Created from NDB UD0017 Архивировано 7 июня 2013 года.
- ↑ Greider C., Blackburn E. Identification of a specific telomere terminal transferase activity in Tetrahymena extracts (англ.) // Cell : journal. — Cell Press, 1985. — Vol. 43, no. 2 Pt 1. — P. 405—413. — PMID 3907856.
- ↑ 1 2 3 Nugent C., Lundblad V. The telomerase reverse transcriptase: components and regulation (англ.) // Genes Dev : journal. — 1998. — Vol. 12, no. 8. — P. 1073—1085. — PMID 9553037.
- ↑ Wright W., Tesmer V., Huffman K., Levene S., Shay J. Normal human chromosomes have long G-rich telomeric overhangs at one end (англ.) // Genes Dev : journal. — 1997. — Vol. 11, no. 21. — P. 2801—2809. — PMID 9353250.
- ↑ 1 2 Burge S., Parkinson G., Hazel P., Todd A., Neidle S. Quadruplex DNA: sequence, topology and structure (англ.) // Nucleic Acids Res (англ.) (рус. : journal. — 2006. — Vol. 34, no. 19. — P. 5402—5415. — PMID 17012276.
- ↑ Griffith J., Comeau L., Rosenfield S., Stansel R., Bianchi A., Moss H., de Lange T. Mammalian telomeres end in a large duplex loop (англ.) // Cell. — Cell Press, 1999. — Vol. 97, no. 4. — P. 503—514. — PMID 10338214.
- ↑ Teif V.B. and Bohinc K. Condensed DNA: condensing the concepts (неопр.) // Progress in Biophysics and Molecular Biology. — 2010. — doi:10.1016/j.pbiomolbio.2010.07.002.
- ↑ Thanbichler M., Wang S., Shapiro L. The bacterial nucleoid: a highly organized and dynamic structure (англ.) // J Cell Biochem (англ.) (рус. : journal. — 2005. — Vol. 96, no. 3. — P. 506—21.
- ↑ Wolfsberg T., McEntyre J., Schuler G. Guide to the draft human genome (англ.) // Nature. — 2001. — Vol. 409, no. 6822. — P. 824—6.
- ↑ Gregory T. The C-value enigma in plants and animals: a review of parallels and an appeal for partnership (англ.) // Ann Bot (Lond) : journal. — 2005. — Vol. 95, no. 1. — P. 133—46.
- ↑ Pidoux A., Allshire R. The role of heterochromatin in centromere function (англ.) // Philos Trans R Soc Lond B Biol Sci : journal. — 2005. — Vol. 360, no. 1455. — P. 569—79. (недоступная ссылка)
- ↑ Harrison P., Hegyi H., Balasubramanian S., Luscombe N., Bertone P., Echols N., Johnson T., Gerstein M. Molecular fossils in the human genome: identification and analysis of the pseudogenes in chromosomes 21 and 22 (англ.) // Genome Res (англ.) (рус. : journal. — 2002. — Vol. 12, no. 2. — P. 272—80.
- ↑ Harrison P., Gerstein M. Studying genomes through the aeons: protein families, pseudogenes and proteome evolution (англ.) // J Mol Biol (англ.) (рус. : journal. — 2002. — Vol. 318, no. 5. — P. 1155—74.
- ↑ Soller M. Molecular fossils in the human genome: identification and analysis of the pseudogenes in chromosomes 21 and 22 (англ.) // Cell Mol Life Sci : journal. — 2006. — Vol. 63, no. 7—9. — P. 796—819. (недоступная ссылка)
- ↑ Michalak P. RNA world – the dark matter of evolutionary genomics (англ.) : journal. — 2006. — Vol. 19, no. 6. — P. 1768—74. [ Архивировано] 28 января 2019 года.
- ↑ Cheng J., Kapranov P., Drenkow J., Dike S., Brubaker S et al. RNA world – the dark matter of evolutionary genomics (англ.) : journal. — 2005. — Vol. 308. — P. 1149—54.
- ↑ Mattick J. S. RNA regulation: a new genetics? (англ.) // Nat Rev Genet : journal. — 2004. — Vol. 5. — P. 316—323.
- ↑ Albà M. Replicative DNA polymerases (англ.) // Genome Biol (англ.) (рус. : journal. — 2001. — Vol. 2, no. 1. — P. REVIEWS3002.
- ↑ Sandman K., Pereira S., Reeve J. Diversity of prokaryotic chromosomal proteins and the origin of the nucleosome (англ.) // Cell Mol Life Sci : journal. — 1998. — Vol. 54, no. 12. — P. 1350—64.
- ↑ Dame R. T. The role of nucleoid-associated proteins in the organization and compaction of bacterial chromatin (англ.) // Microbiology (англ.) (рус. : journal. — Microbiology Society (англ.) (рус., 2005. — Vol. 56, no. 4. — P. 858—870. — PMID 15853876.
- ↑ Luger K., Mäder A., Richmond R., Sargent D., Richmond T. Crystal structure of the nucleosome core particle at 2.8 A resolution (англ.) // Nature : journal. — 1997. — Vol. 389, no. 6648. — P. 251—60.
- ↑ Jenuwein T., Allis C. Translating the histone code (англ.) // Science. — 2001. — Vol. 293, no. 5532. — P. 1074—80.
- ↑ Ito T. Nucleosome assembly and remodelling (неопр.) // Curr Top Microbiol Immunol. — Т. 274. — С. 1—22.
- ↑ Thomas J. HMG1 and 2: architectural DNA-binding proteins (англ.) // Biochem Soc Trans (англ.) (рус. : journal. — 2001. — Vol. 29, no. Pt 4. — P. 395—401.
- ↑ Grosschedl R., Giese K., Pagel J. HMG domain proteins: architectural elements in the assembly of nucleoprotein structures (англ.) // Trends Genet (англ.) (рус. : journal. — 1994. — Vol. 10, no. 3. — P. 94—100.
- ↑ Iftode C., Daniely Y., Borowiec J. Replication protein A (RPA): the eukaryotic SSB (англ.) // Crit Rev Biochem Mol Biol (англ.) (рус. : journal. — 1999. — Vol. 34, no. 3. — P. 141—80.
- ↑ Myers L., Kornberg R. Mediator of transcriptional regulation (англ.) // Annu Rev Biochem (англ.) (рус. : journal. — Vol. 69. — P. 729—49.
- ↑ Spiegelman B., Heinrich R. Biological control through regulated transcriptional coactivators (англ.) // Cell : journal. — Cell Press, 2004. — Vol. 119, no. 2. — P. 157—167.
- ↑ Li Z., Van Calcar S., Qu C., Cavenee W., Zhang M., Ren B. A global transcriptional regulatory role for c-Myc in Burkitt’s lymphoma cells (англ.) // Proceedings of the National Academy of Sciences of the United States of America : journal. — 2003. — Vol. 100, no. 14. — P. 8164—9.
- ↑ Schoeffler A., Berger J. Recent advances in understanding structure-function relationships in the type II topoisomerase mechanism (англ.) // Biochem Soc Trans (англ.) (рус. : journal. — 2005. — Vol. 33, no. Pt 6. — P. 1465—70.
- ↑ Tuteja N., Tuteja R. Unraveling DNA helicases. Motif, structure, mechanism and function (англ.) // Eur J Biochem (англ.) (рус. : journal. — 2004. — Vol. 271, no. 10. — P. 1849—1863.
- ↑ Bickle T., Krüger D. Biology of DNA restriction (англ.) // Microbiology and Molecular Biology Reviews (англ.) (рус. : journal. — American Society for Microbiology (англ.) (рус., 1993. — Vol. 57, no. 2. — P. 434—50.
- ↑ Joyce C., Steitz T. Polymerase structures and function: variations on a theme? (англ.) // American Society for Microbiology (англ.) (рус. : journal. — 1995. — Vol. 177, no. 22. — P. 6321—9.
- ↑ Hubscher U., Maga G., Spadari S. Eukaryotic DNA polymerases (англ.) // Annu Rev Biochem (англ.) (рус. : journal. — Vol. 71. — P. 133—63.
- ↑ Johnson A., O’Donnell M. Cellular DNA replicases: components and dynamics at the replication fork (англ.) // Annu Rev Biochem (англ.) (рус. : journal. — Vol. 74. — P. 283—315.
- ↑ Tarrago-Litvak L., Andréola M., Nevinsky G., Sarih-Cottin L., Litvak S. The reverse transcriptase of HIV-1: from enzymology to therapeutic intervention (англ.) // The FASEB Journal (англ.) (рус. : journal. — Federation of American Societies for Experimental Biology (англ.) (рус., 1994. — Vol. 8, no. 8. — P. 497—503.
- ↑ Martinez E. Multi-protein complexes in eukaryotic gene transcription (неопр.) // Plant Mol Biol. — 2002. — Т. 50, № 6. — С. 925—47.
- ↑ Cremer T., Cremer C. Chromosome territories, nuclear architecture and gene regulation in mammalian cells (англ.) // Nat Rev Genet : journal. — 2001. — Vol. 2, no. 4. — P. 292—301.
- ↑ Pál C., Papp B., Lercher M. An integrated view of protein evolution (англ.) // Nat Rev Genet : journal. — 2006. — Vol. 7, no. 5. — P. 337—48.
- ↑ O’Driscoll M., Jeggo P. The role of double-strand break repair – insights from human genetics (англ.) // Nat Rev Genet : journal. — 2006. — Vol. 7, no. 1. — P. 45—54.
- ↑ Dickman M., Ingleston S., Sedelnikova S., Rafferty J., Lloyd R., Grasby J., Hornby D. The RuvABC resolvasome (англ.) // Eur J Biochem (англ.) (рус. : journal. — 2002. — Vol. 269, no. 22. — P. 5492—501.
- ↑ Joyce G. The antiquity of RNA-based evolution (англ.) // Nature. — 2002. — Vol. 418, no. 6894. — P. 214—21.
- ↑ Orgel L. Prebiotic chemistry and the origin of the RNA world (англ.) // Crit Rev Biochem Mol Biol (англ.) (рус. : journal. — Vol. 39, no. 2. — P. 99—123. Архивировано 28 июня 2007 года.
- ↑ Davenport R. Ribozymes. Making copies in the RNA world (англ.) // Science. — 2001. — Vol. 292, no. 5520. — P. 1278. — PMID 11360970.
- ↑ Szathmáry E. What is the optimum size for the genetic alphabet? (англ.) // Proceedings of the National Academy of Sciences of the United States of America : journal. — 1992. — Vol. 89, no. 7. — P. 2614—8. — PMID 1372984.
- ↑ Vreeland R., Rosenzweig W., Powers D. Isolation of a 250 million-year-old halotolerant bacterium from a primary salt crystal (англ.) // Nature : journal. — 2000. — Vol. 407, no. 6806. — P. 897—900.
- ↑ Hebsgaard M., Phillips M., Willerslev E. Geologically ancient DNA: fact or artefact? (англ.) // Trends Microbiol (англ.) (рус. : journal. — 2005. — Vol. 13, no. 5. — P. 212—20.
- ↑ Nickle D., Learn G., Rain M., Mullins J., Mittler J. Curiously modern DNA for a “250 million-year-old” bacterium (англ.) // J Mol Evol (англ.) (рус. : journal. — 2002. — Vol. 54, no. 1. — P. 134—7.
Литература[править | править код]
- Альбертс Б., Брей Д., Льюис Дж. и др. Молекулярная биология клетки в 3-х томах. — М.: Мир, 1994. — 1558 с. — ISBN 5-03-001986-3.
- Докинз Р. Эгоистичный ген. — М.: Мир, 1993. — 318 с. — ISBN 5-03-002531-6.
- История биологии с начала XX века до наших дней. — М.: Наука, 1975. — 660 с.
- Льюин Б. Гены. — М.: Мир, 1987. — 544 с.
- Пташне М. Переключение генов. Регуляция генной активности и фаг лямбда. — М.: Мир, 1989. — 160 с. Все форумы > Книга «переключение генов» М. Пташне Архивная копия от 30 октября 2007 на Wayback Machine.
- Уотсон Дж. Д. Двойная спираль: воспоминания об открытии структуры ДНК. Архивная копия от 18 января 2012 на Wayback Machine — М.: Мир, 1969. — 152 с.
- Франк-Каменецкий, М. Самая главная молекула: От структуры ДНК до биомедицины XXI века. — 2-е изд. — М.: Альпина нон-фикшн, 2018. — 336 с. — ISBN 978-5-00139-038-1.
Ссылки[править | править код]
- Методы Архивная копия от 8 июня 2007 на Wayback Machine выделения и исследования ДНК.
- Веб-адреса молекулярно-биологических журналов Архивная копия от 15 августа 2007 на Wayback Machine.
- Международная база данных Архивная копия от 21 марта 2010 на Wayback Machine — последовательности ДНК из разных организмов (англ.).
- Веб-сайт Сэнгеровского Института Архивная копия от 8 января 2021 на Wayback Machine одного из мировых лидеров в области определения последовательностей ДНК и их анализа (англ.).
