Часто в статистике нас интересует измерение параметров населения — чисел, описывающих некоторые характеристики всего населения.
Двумя наиболее распространенными параметрами населения являются:
1. Среднее значение населения: среднее значение некоторой переменной в популяции (например, средний рост мужчин в США).
2. Доля населения: доля некоторой переменной в населении (например, доля жителей округа, которые поддерживают определенный закон).
Хотя мы заинтересованы в измерении этих параметров, обычно слишком дорого и долго собирать данные о каждом человеке в популяции, чтобы вычислить параметр популяции.
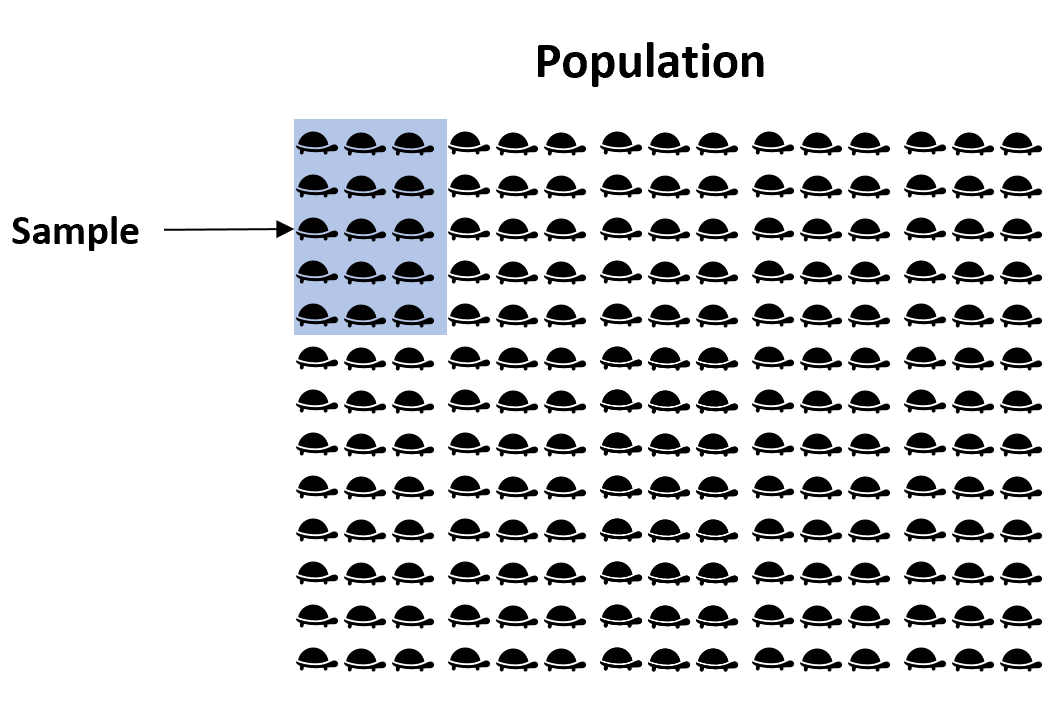
Вместо этого мы обычно берем случайную выборку из общей совокупности и используем данные из выборки для оценки параметра совокупности.
Например, предположим, что мы хотим оценить средний вес определенного вида черепах во Флориде. Поскольку во Флориде тысячи черепах, было бы очень много времени и денег, чтобы обойти и взвесить каждую отдельную черепаху.
Вместо этого мы могли бы взять простую случайную выборку из 50 черепах и использовать средний вес черепах в этой выборке для оценки истинного среднего значения популяции:
Проблема в том, что средний вес черепах в выборке не обязательно точно соответствует среднему весу черепах во всей популяции. Например, мы можем просто случайно выбрать образец, полный черепах с низким весом, или, возможно, образец, полный тяжелых черепах.
Чтобы зафиксировать эту неопределенность, мы можем создать доверительный интервал. Доверительный интервал — это диапазон значений, который может содержать параметр генеральной совокупности с определенным уровнем достоверности. Он рассчитывается по следующей общей формуле:
Доверительный интервал = (точечная оценка) +/- (критическое значение) * (стандартная ошибка)
Эта формула создает интервал с нижней границей и верхней границей, который, вероятно, содержит параметр совокупности с определенным уровнем достоверности.
Доверительный интервал = [нижняя граница, верхняя граница]
Например, формула для расчета доверительного интервала для среднего значения генеральной совокупности выглядит следующим образом:
Доверительный интервал = x +/- z*(s/ √n )
куда:
- x : выборочное среднее
- z: выбранное значение z
- s: стандартное отклонение выборки
- n: размер выборки
Z-значение, которое вы будете использовать, зависит от выбранного вами уровня достоверности. В следующей таблице показано значение z, которое соответствует популярным вариантам выбора уровня достоверности:
| Уровень достоверности | z-значение | | — | — | | 0,90 | 1,645 | | 0,95 | 1,96 | | 0,99 | 2,58 |
Например, предположим, что мы собираем случайную выборку черепах со следующей информацией:
- Размер выборки n = 25
- Средний вес выборки x = 300
- Стандартное отклонение выборки s = 18,5
Вот как найти вычислить 90% доверительный интервал для истинного среднего веса населения:
90% доверительный интервал: 300 +/- 1,645*(18,5/√25) = [293,91, 306,09]
Мы интерпретируем этот доверительный интервал следующим образом:
Вероятность того, что доверительный интервал [293,91, 306,09] содержит истинный средний вес популяции черепах, составляет 90%.
Другой способ сказать то же самое состоит в том, что существует только 10-процентная вероятность того, что истинное среднее значение генеральной совокупности лежит за пределами 90-процентного доверительного интервала. То есть существует только 10%-ная вероятность того, что истинный средний вес популяции черепах больше 306,09 фунтов или меньше 293,91 фунтов.
Ничего не стоит, что есть два числа, которые могут повлиять на размер доверительного интервала:
1. Размер выборки: чем больше размер выборки, тем уже доверительный интервал.
2. Уровень достоверности: чем выше уровень достоверности, тем шире доверительный интервал.
Типы доверительных интервалов
Существует много типов доверительных интервалов. Вот наиболее часто используемые:
Доверительный интервал для среднего
Доверительный интервал для среднего значения — это диапазон значений, который может содержать среднее значение генеральной совокупности с определенным уровнем достоверности. Формула для расчета этого интервала:
Доверительный интервал = x +/- z*(s/ √n )
куда:
- x : выборочное среднее
- z: выбранное значение z
- s: стандартное отклонение выборки
- n: размер выборки
Ресурсы: Как рассчитать доверительный интервал для среднего
Доверительный интервал для среднего калькулятора
Доверительный интервал для разницы между средними значениями
Доверительный интервал (ДИ) для разницы между средними значениями представляет собой диапазон значений, который, вероятно, содержит истинное различие между двумя средними значениями генеральной совокупности с определенным уровнем достоверности. Формула для расчета этого интервала:
Доверительный интервал = ( x 1 – x 2 ) +/- t * √ ((s p 2 /n 1 ) + (s p 2 /n 2 ))
куда:
- x 1 , x 2 : среднее значение для образца 1, среднее значение для образца 2
- t: t-критическое значение, основанное на доверительном уровне и (n 1 +n 2 -2) степенях свободы
- s p 2 : объединенная дисперсия
- n 1 , n 2 : размер выборки 1, размер выборки 2
куда:
- Объединенная дисперсия рассчитывается как: s p 2 = ((n 1 -1)s 1 2 + (n 2 -1)s 2 2 ) / (n 1 +n 2 -2)
- Критическое значение t можно найти с помощью калькулятора обратного t-распределения .
Ресурсы: Как рассчитать доверительный интервал для разницы между средними
Доверительный интервал для калькулятора разницы между средними значениями
Доверительный интервал для пропорции
Доверительный интервал для доли — это диапазон значений, который может содержать долю населения с определенным уровнем достоверности. Формула для расчета этого интервала:
Доверительный интервал = p +/- z * (√ p (1-p) / n )
куда:
- p: доля выборки
- z: выбранное значение z
- n: размер выборки
Ресурсы: Как рассчитать доверительный интервал для пропорции
Доверительный интервал для калькулятора пропорций
Доверительный интервал для разницы в пропорциях
Доверительный интервал для разницы в пропорциях — это диапазон значений, который может содержать истинную разницу между двумя пропорциями населения с определенным уровнем достоверности. Формула для расчета этого интервала:
Доверительный интервал = (p 1 –p 2 ) +/- z*√(p 1 (1-p 1 )/n 1 + p 2 (1-p 2 )/n 2 )
куда:
- p 1 , p 2 : доля образца 1, доля образца 2
- z: z-критическое значение, основанное на доверительном уровне
- n 1 , n 2 : размер выборки 1, размер выборки 2
Ресурсы: Как рассчитать доверительный интервал для разницы пропорций
Доверительный интервал для калькулятора разницы пропорций
Доверительный интервал для генеральной средней и генеральной доли по большим выборкам
Рассмотрим
большие выборки (порядка сотен наблюдений).
Теорема.
Вероятность того, что отклонение
выборочной средней (или доли) от
генеральной средней (или доли) не
превзойдёт по абсолютной величине число
![]() ,
,
равна:
![]() ,
,
![]() ;
;
![]() ,
,
![]() . –
. –
формулы
доверительной вероятности для средней
и доли.
Где
![]() – функция Лапласа,
– функция Лапласа,![]() и
и![]() – среднеквадратические отклонения
– среднеквадратические отклонения
выборочной средней и выборочной доли
или среднеквадратические ошибки выборки
(собственно случайная повторная выборка).
Если выборка бесповторная, то
среднеквадратические отклонения
выборочной средней и выборочной доли
–![]() и
и![]() .
.
|
Повторная |
Бесповторная |
|
|
Средняя |
|
|
|
Доля |
|
|
Формулы для
нахождения среднеквадратических ошибок
выборки запишем в таблицу.
При малом объеме
выборки
![]() величина
величина![]()
![]() ,
,
поэтому значения для среднеквадратических
ошибок при повторной и бесповторной
выборке приблизительно равны между
собой.
Следствия теоремы:
-
при
заданной доверительной вероятности
 предельная ошибка выборки
предельная ошибка выборки
![]() ,
,
![]() ,
,
где
![]() .
.
-
доверительные
интервалы для генеральной средней и
генеральной доли могут быть найдены
по формулам
![]() ,
,
![]() .
.
Пример 9.1. Для
определения средней урожайности пшеницы
на площади 10000 Га определена урожайность
на 1000 Га. Результаты выборки приведены
в таблице:
|
Урожайность, ц/Га |
11-13 |
13-15 |
15-17 |
17-19 |
|
Количество, Га |
150 |
200 |
450 |
200 |
Найти:
1) вероятность того,
что средняя урожайность пшеницы на всём
массиве отличается от средней выборочной
не более чем на 0,1 ц, если выборка:
а) повторная;
б) бесповторная;
2) границы, в которых
с вероятностью 0,9973 заключена средняя
урожайность на всём массиве.
Решение. Вычислим
выборочную среднюю и выборочную
дисперсию.
Середины интервалов
равны:
![]() .
.
![]()
![]() ц.
ц.
![]() ,
,
![]()
Исправленная
дисперсия
![]() .
.
-
Запишем
формулу доверительной вероятности для
выборочной средней
![]() .
.
а)
Если выборка повторная, то
![]() ,
,
где![]() ,
,![]() .
.
Найдем
![]() .
.
Т.о.
![]() ,
,
а доверительная вероятность
![]() .
.
б)
Если выборка бесповторная, то
![]() ,
,
где![]() .
.
Найдем
![]() .
.
Т.о.
![]() ,
,
а доверительная вероятность
![]() .
.
-
Средняя
урожайность на всём массиве заключена
в границах:
![]() .
.
По условию
![]()
![]()
![]()
Предельная ошибка
выборки:
![]()
![]() ц. – выборка повторная,
ц. – выборка повторная,
![]()
![]() ц. – выборка
ц. – выборка
бесповторная.
Таким образом с
вероятностью 0,9973 средняя урожайность
на всём массиве заключена в границах:
![]() ,
,
т.е.![]() – выборка повторная,
– выборка повторная,
![]() ,
,
т.е.
![]() – выборка бесповторная.
– выборка бесповторная.
-
Объём выборки
Для проведения
выборочного наблюдения важно правильно
установить объём выборки
![]() при заданных величинах надёжности
при заданных величинах надёжности
оценки![]() и точности оценки
и точности оценки![]() .
.
Объём выборки находится из формул
предельной ошибки выборки:![]() – при оценке генеральной средней или
– при оценке генеральной средней или![]() – при оценке генеральной доли.
– при оценке генеральной доли.
Формулы для нахождения
объема выборки представлены в таблице.
|
Повторная |
Бесповторная |
|
|
Средняя |
|
|
|
Доля |
|
|
Если найден объём
повторной выборки
![]() ,
,
то объём бесповторной выборки![]() можно определить по формуле
можно определить по формуле
![]() .
.
Так как
![]() ,
,
то![]() .
.
Пример 9.2.По
условию примера 9.1. определить объём
выборки, при котором с вероятностью
0,9973 отклонение средней урожайности в
выборке от средней урожайности на всей
площади посева не превзойдет 0,5 ц (по
абсолютной величине).
Решение. Если выборка
повторная, то ее объем
![]() .
.
В качестве
![]() берём состоятельную оценку
берём состоятельную оценку![]() ;
;
так как
![]()
![]() по таблице
по таблице![]() .
.
Таким образом![]() .
.
Объем бесповторной
выборки
![]()
![]() .
.
Соседние файлы в предмете [НЕСОРТИРОВАННОЕ]
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
Оценки параметров генеральной совокупности. Доверительные интервалы
- Переход от выборки к генеральной совокупности
- Способы, виды и методы отбора
- Распространение результатов выборки на генеральную совокупность при изучении альтернативного признака
- Алгоритм построения доверительного интервала для оценки генеральной доли
- Для каких величин строят доверительные интервалы?
- Примеры
п.1. Переход от выборки к генеральной совокупности
В статистическом исследовании при изучении некоторого признака (или набора признаков) проводят конечное число наблюдений (x_1,x_2,…,x_k).
Реально полученная совокупность наблюдений (left{x_iright}) называется выборкой (sample).
Как правило, при этом существует более обширная генеральная совокупность (population), на которую результаты анализа выборки планируется распространить. Например:
Выборка
Генеральная совокупность
50 посетителей магазина, заполнившие анкеты
Все будущие посетители магазина
100 опрошенных школьников
Все школьники города/области/страны
10 опытов с определением периода математического маятника
Все математические маятники
Репрезентативность выборки – способность выборки представлять исследуемый признак достаточно полно с точки зрения его свойств в генеральной совокупности.
Насколько большой должна быть выборка, чтобы надежно представлять генеральную совокупность? К концу параграфа мы получим ответ на этот вопрос для определенного класса задач.
Попутно заметим, что малой называют выборку, если при исследовании одного признака её объем (nlt 30), а при исследовании k признаков (frac{n}{k}lt 10).
п.2. Способы, виды и методы отбора
| Простой случайный | Объекты случайно извлекаются из генеральной совокупности, например, с помощью генератора случайных чисел. |
| Простой механический | Объекты извлекаются по тегу, например, при поиске по дате, номеру, букве алфавита и т.д. |
| Стратифицированный (типический) |
Объекты извлекаются по признаку, например, по возрасту, району проживания, профессии и т.д. |
| Серийный | Простым случайным или простым механическим способом отбирается группа (серия) объектов, а затем они все изучаются (сплошное исследование). Например, выбор дома и опрос всех его жильцов; или выбор партии товара и проверка каждого изделия в партии. |
| Комбинированный | Сочетание нескольких предыдущих способов. |
| Индивидуальный | Отбираются отдельные единицы генеральной совокупности |
| Групповой | Отбираются однородные по некоторому признаку группы |
| Комбинированный | Сочетание индивидуального и группового |
| Повторная выборка | Единицу генеральной совокупности отбирают, показания регистрируют, а затем возвращают обратно (т.е. могут опять выбрать). |
| Бесповторная выборка | Единицу генеральной совокупности отбирают, показания регистрируют, и обратно не возвращают. |
п.3. Распространение результатов выборки на генеральную совокупность при изучении альтернативного признака
Альтернативным называют признак, который имеет только два варианта значений.
Например:
1) орел или решка;
2) 0 или 1;
3) качественный или бракованный и т.п.
Мы уже знаем, что конечное число экспериментов с таким признаком описывается биномиальным распределением (см. §40 справочника для 9 класса), а при (nrightarrow infty) биномиальное распределение приближается к нормальному (см. §64 данного справочника).
При исследовании альтернативного признака x генеральной совокупности с помощью выборки будем использовать следующие обозначения:
| Генеральная совокупность |
Выборка | |
| Объем | $$ N $$ | $$ n $$ |
| Число единиц с признаком x | $$ N_x $$ | $$ n_x $$ |
| Доля единиц с признаком x | $$ p=frac{N_x}{N} $$ | $$ w=frac{n_x}{n} $$ |
| Дисперсия | $$ sigma^2=p(1-p) $$ | $$ sigma^2=w(1-w) $$ |
| CKO | $$ sigma=sqrt{p(1-p)} $$ | $$ sigma=sqrt{w(1-w)} $$ |
Например:
Из партии товара в 1000 изделий было случайным образом выбрано 100 изделий, и среди них обнаружено 8 бракованных. Для этой выборки можем записать: begin{gather*} N=1000, n=100, n_x=8, w=frac{8}{100}=0,08\ sigma^2=w(1-w)=frac{8}{100}cdotfrac{92}{100}=frac{736}{10000}=0,0736; sigma=sqrt{frac{736}{10000}}approx 0,2713 end{gather*}
Средняя ошибка выборки равна среднему квадратичному отклонению выборочной средней от математического ожидания генеральной совокупности: $$ m=frac{sigma}{sqrt{n}} $$ Для альтернативного признака с бесповторной выборкой: $$ m=sqrt{frac{w(1-w)}{n}left(1-frac nNright)} $$ Для альтернативного признака с повторной выборкой: $$ m=sqrt{frac{w(1-w)}{n}} $$
В партии товара из предыдущего примера (w=0,005) – доля брака.
Средняя ошибка при определении доли брака в генеральной совокупности зависит от способа отбора партии. Пусть выборка бесповторная (при выборе 100 изделий из 1000 мы откладывали их в сторону).
Тогда: begin{gather*} m=sqrt{frac{w(1-w)}{n}left(1-frac nNright)}=sqrt{frac{0,0736}{1000}left(1-frac{100}{1000}right)}approx 0,0257 end{gather*}
Предельная ошибка выборки при изучении альтернативного признака равна произведению средней ошибки выборки на Z-коэффициент, который зависит от заданного уровня значимости α: $$ triangle=Z_alpha m $$
Доверительным интервалом оценки неизвестного параметра генеральной совокупности называют вычисленный на основе данных выборки интервал, в котором генеральный параметр содержится с известной вероятностью.
Доверительный интервал для оценки среднего значения доли в генеральной совокупности: $$ p=wpmtriangle text{или} w-triangleleq pleq 2+triangle $$
(Z_alpha) – это квантиль нормального распределения, который появляется потому, что генеральная совокупность считается нормально распределенной.
Величина (P=1-alpha) называется уровнем доверия (доверительной вероятностью), это вероятность того, что при измерении доли в генеральной совокупности её значение попадет в заданный интервал.
Соответственно (alpha) – уровень значимости – это вероятность промаха.
Существуют таблицы со значениями (Z_alpha).
Для расчета также можно пользоваться MS Excel функцией НОРМСТОБР(1-α/2).
Например:
Найдем (Z_alpha) для доверительной вероятности 95%.
(P=0,95Rightarrowalpha=1-P=0,05) 
Теперь найдем предельную ошибку выборки для нашего примера с точностью до тысячных: $$ triangle =1,9600cdot 0,0257approx 0,050 $$ Заметим, что расчеты в данном случае ведутся в Excel, и мы просто записываем результаты округлений, в то время как в сам Excel хранит результаты и выполняет вычисления точностью до 15 значащих цифр.
Если вы ведете расчеты на калькуляторе с промежуточными округлениями, то для того, чтобы получить результат с точностью до тысячных, нужно иметь «про запас» еще одну цифру после запятой (т.е. до 4х знаков).
95% доверительный интервал имеет вид: begin{gather*} 0,08-0,050leq pleq 0,08+0,050\ 0,030leq pleq 0,130 end{gather*} Вывод: с вероятностью 95% можно утверждать, что доля брака в генеральной совокупности (всей партии) составляет от 3,0% до 13,0%.
п.4. Минимальный объем выборки
Минимальный необходимый объем выборки для построения доверительного интервала для среднего значения с заданной точностью (triangle) и уровнем значимости α равен:
– для повторной выборки (n_{мин}=left(frac{Z_alpha sigma}{triangle}right)^2)
– для бесповторной выборки (n_{мин}=frac{1}{left(frac{triangle}{Z_alpha sigma}right)^2+frac1N})
Например:
Пусть «целевая» предельная ошибка выборки равна (triangle =0,01), доверительная вероятность равна 95%.
Для нашего примера с партией товара получаем (бесповторная выборка): $$ n_{мин}=frac{1}{left(frac{0,01}{1,96cdot 0,271}right)^2+frac{1}{1000}}approx 738,7approx uparrow 739 $$ Нам необходимо проверить не менее 739 изделий из 1000, чтобы записать для средней доли в генеральной совокупности (p=wpm 0,01).
п.4. Алгоритм построения доверительного интервала для оценки генеральной доли
На входе: объем выборки n, число повторений признака (n_x), доверительная вероятность (P)
Шаг 1. Найти выборочную долю (w=frac{n_x}{n}), дисперсию (sigma=sqrt{w(1-w)})
Шаг 2. Найти среднюю ошибку выборки (m=frac{sigma}{sqrt{n}})
Шаг 3. Найти уровень значимости (alpha=1-P), рассчитать (Z_alpha) (если в Excel, то НОРМСТОБР(1-α/2))
Шаг 4. Найти предельную ошибку выборки (triangle =Z_alpha m)
На выходе: интервал для генеральной доли (p=wpmtriangle)
Бесповторная выборка
На входе: объем генеральной совокупности N, объем выборки n, число повторений признака (n_x), доверительная вероятность (P)
Шаг 1. Найти выборочную долю (w=frac{n_x}{n}), дисперсию (sigma=sqrt{w(1-w)})
Шаг 2. Найти среднюю ошибку выборки (m=frac{sigma}{sqrt{n}}sqrt{1-frac nN})
Шаг 3. Найти уровень значимости (alpha=1-P), рассчитать (Z_alpha) (если в Excel, то НОРМСТОБР(1-α/2))
Шаг 4. Найти предельную ошибку выборки (triangle =Z_alpha m)
На выходе: интервал для генеральной доли (p=wpmtriangle)
п.5. Для каких величин строят доверительные интервалы?
В этом параграфе мы научились строить доверительный интервал для оценки биномиальной доли в генеральной совокупности.
На практике в статистических исследованиях доверительные интервалы строят для:
– оценки математического ожидания в генеральной совокупности, если выборка образует вариационный ряд (дискретный или непрерывный). Здесь разделяют два случая: а) генеральная дисперсия известна или б) она неизвестна;
– оценки дисперсии генеральной совокупности, если выборка образует вариационный ряд (дискретный или непрерывный). Здесь также разделяют два случая: а) генеральная средняя известна или б) она неизвестна.
Алгоритмы для поиска доверительных интервалов отличаются использованием различных распределений (Z-распределения, t-распределения Стьюдента, χ2-распределения), но, если обобщить, то логика такова: опираясь на результаты выборки и гипотезу о распределении средней или дисперсии, получаем оценку для соответствующей генеральной величины.
Подробней о построении различных доверительных интервалов вы можете узнать из вузовских курсов теории вероятностей и статистики.
п.6. Примеры
Пример 1. Перед выборами мера в городе был проведен опрос 1000 человек (2% бесповторная выборка). В результате опроса оказалось, что за кандидата Y готовы проголосовать 423 человека из опрошенных. Определите с уровнем значимости 3% долю сторонников кандидата Y в городе.
По условию: $$ n=1000; frac nN=2text{%}=0,02; n_x=423; alpha=3text{%}=0,03 $$ Находим выборочную долю и дисперсию: begin{gather*} w=frac{n_x}{n}=frac{423}{1000}=0,423\ sigma^2=w(1-w)=0,423cdot 0,577approx 0,2441 end{gather*} Средняя ошибка выборки: $$ m=sqrt{frac{sigma^2}{n}left(1-frac nNright)}=sqrt{frac{0,2441}{1000}cdot (1-0,02)}approx 0,0155 $$ Находим (Z_alpha)
Предельная ошибка выборки с точностью до тысячных: $$ triangle=Z_alpha m=2,1701cdot 0,0155approx 0,034 $$ 97% доверительный интервал имеет вид: begin{gather*} 0,423-0,034leq pleq 0,423+0,034\ 0,389leq pleq 0,457 end{gather*}
Вывод: с вероятностью 97% (уровнем значимости 3%) можно утверждать, что доля сторонников кандидата Y в городе составляет от 38,9% до 45,7%.
Пример 2. Какое минимальное число людей нужно опросить в городе из предыдущего примера, чтобы можно было с уровнем значимости 3% получить предельную ошибку для генеральной доли (triangle=)1%. Выборка бесповторная.
По условию предыдущего примера общее число жителей в городе: (N=frac{n}{0,02}=50000).
Оценка минимального объема бесповторной выборки: $$ n_{мин}=frac{1}{left(frac{triangle}{Z_alpha sigma}right)^2+frac1N} $$ Нужно подставить: begin{gather*} triangle=1text{%}=0,01; Z_alpha=2,170; sigma=sqrt{0,2441}; N=50000 end{gather*} Получаем: $$ n_{мин}=frac{1}{left(frac{0,01}{2,170cdotsqrt{0,2441}}right)^2+frac{1}{50000}} $$ Таким образом, чтобы снизить предельную ошибку определения генеральной доли до 1%, нужно опросить не менее 9346 человек или почти что каждого пятого жителя города.
