Часто в статистике нас интересует измерение параметров населения — чисел, описывающих некоторые характеристики всего населения.
Двумя наиболее распространенными параметрами населения являются:
1. Среднее значение населения: среднее значение некоторой переменной в популяции (например, средний рост мужчин в США).
2. Доля населения: доля некоторой переменной в населении (например, доля жителей округа, которые поддерживают определенный закон).
Хотя мы заинтересованы в измерении этих параметров, обычно слишком дорого и долго собирать данные о каждом человеке в популяции, чтобы вычислить параметр популяции.
Вместо этого мы обычно берем случайную выборку из общей совокупности и используем данные из выборки для оценки параметра совокупности.
Например, предположим, что мы хотим оценить средний вес определенного вида черепах во Флориде. Поскольку во Флориде тысячи черепах, было бы очень много времени и денег, чтобы обойти и взвесить каждую отдельную черепаху.
Вместо этого мы могли бы взять простую случайную выборку из 50 черепах и использовать средний вес черепах в этой выборке для оценки истинного среднего значения популяции:
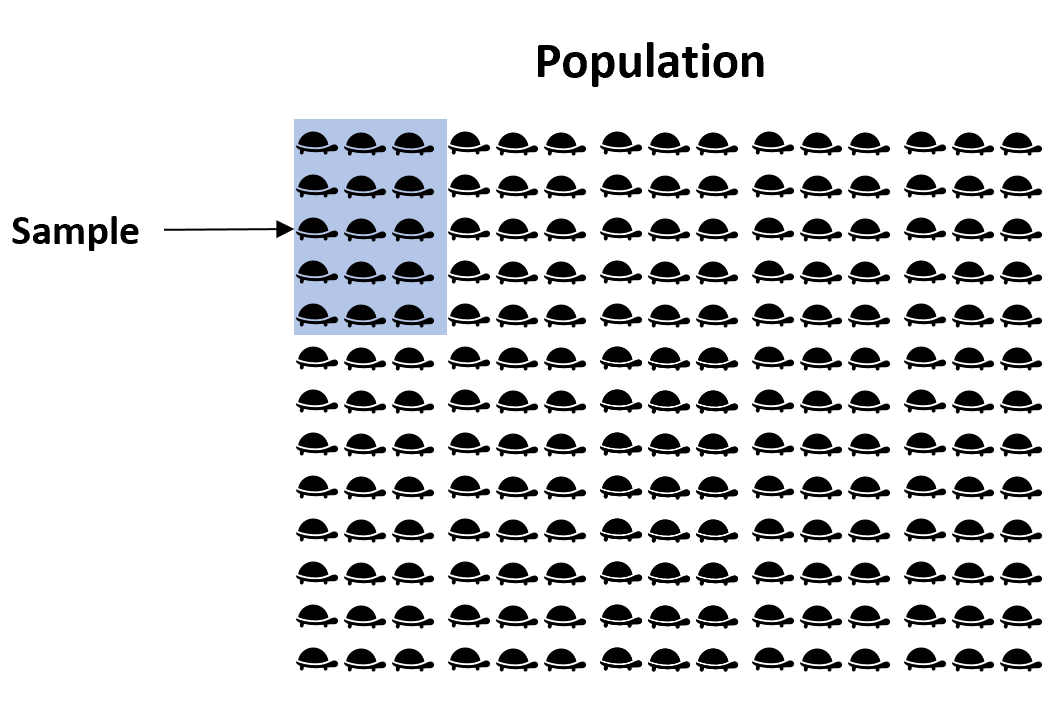
Проблема в том, что средний вес черепах в выборке не обязательно точно соответствует среднему весу черепах во всей популяции. Например, мы можем просто случайно выбрать образец, полный черепах с низким весом, или, возможно, образец, полный тяжелых черепах.
Чтобы зафиксировать эту неопределенность, мы можем создать доверительный интервал. Доверительный интервал — это диапазон значений, который может содержать параметр генеральной совокупности с определенным уровнем достоверности. Он рассчитывается по следующей общей формуле:
Доверительный интервал = (точечная оценка) +/- (критическое значение) * (стандартная ошибка)
Эта формула создает интервал с нижней границей и верхней границей, который, вероятно, содержит параметр совокупности с определенным уровнем достоверности.
Доверительный интервал = [нижняя граница, верхняя граница]
Например, формула для расчета доверительного интервала для среднего значения генеральной совокупности выглядит следующим образом:
Доверительный интервал = x +/- z*(s/ √n )
куда:
- x : выборочное среднее
- z: выбранное значение z
- s: стандартное отклонение выборки
- n: размер выборки
Z-значение, которое вы будете использовать, зависит от выбранного вами уровня достоверности. В следующей таблице показано значение z, которое соответствует популярным вариантам выбора уровня достоверности:
| Уровень достоверности | z-значение | | — | — | | 0,90 | 1,645 | | 0,95 | 1,96 | | 0,99 | 2,58 |
Например, предположим, что мы собираем случайную выборку черепах со следующей информацией:
- Размер выборки n = 25
- Средний вес выборки x = 300
- Стандартное отклонение выборки s = 18,5
Вот как найти вычислить 90% доверительный интервал для истинного среднего веса населения:
90% доверительный интервал: 300 +/- 1,645*(18,5/√25) = [293,91, 306,09]
Мы интерпретируем этот доверительный интервал следующим образом:
Вероятность того, что доверительный интервал [293,91, 306,09] содержит истинный средний вес популяции черепах, составляет 90%.
Другой способ сказать то же самое состоит в том, что существует только 10-процентная вероятность того, что истинное среднее значение генеральной совокупности лежит за пределами 90-процентного доверительного интервала. То есть существует только 10%-ная вероятность того, что истинный средний вес популяции черепах больше 306,09 фунтов или меньше 293,91 фунтов.
Ничего не стоит, что есть два числа, которые могут повлиять на размер доверительного интервала:
1. Размер выборки: чем больше размер выборки, тем уже доверительный интервал.
2. Уровень достоверности: чем выше уровень достоверности, тем шире доверительный интервал.
Типы доверительных интервалов
Существует много типов доверительных интервалов. Вот наиболее часто используемые:
Доверительный интервал для среднего
Доверительный интервал для среднего значения — это диапазон значений, который может содержать среднее значение генеральной совокупности с определенным уровнем достоверности. Формула для расчета этого интервала:
Доверительный интервал = x +/- z*(s/ √n )
куда:
- x : выборочное среднее
- z: выбранное значение z
- s: стандартное отклонение выборки
- n: размер выборки
Ресурсы: Как рассчитать доверительный интервал для среднего
Доверительный интервал для среднего калькулятора
Доверительный интервал для разницы между средними значениями
Доверительный интервал (ДИ) для разницы между средними значениями представляет собой диапазон значений, который, вероятно, содержит истинное различие между двумя средними значениями генеральной совокупности с определенным уровнем достоверности. Формула для расчета этого интервала:
Доверительный интервал = ( x 1 – x 2 ) +/- t * √ ((s p 2 /n 1 ) + (s p 2 /n 2 ))
куда:
- x 1 , x 2 : среднее значение для образца 1, среднее значение для образца 2
- t: t-критическое значение, основанное на доверительном уровне и (n 1 +n 2 -2) степенях свободы
- s p 2 : объединенная дисперсия
- n 1 , n 2 : размер выборки 1, размер выборки 2
куда:
- Объединенная дисперсия рассчитывается как: s p 2 = ((n 1 -1)s 1 2 + (n 2 -1)s 2 2 ) / (n 1 +n 2 -2)
- Критическое значение t можно найти с помощью калькулятора обратного t-распределения .
Ресурсы: Как рассчитать доверительный интервал для разницы между средними
Доверительный интервал для калькулятора разницы между средними значениями
Доверительный интервал для пропорции
Доверительный интервал для доли — это диапазон значений, который может содержать долю населения с определенным уровнем достоверности. Формула для расчета этого интервала:
Доверительный интервал = p +/- z * (√ p (1-p) / n )
куда:
- p: доля выборки
- z: выбранное значение z
- n: размер выборки
Ресурсы: Как рассчитать доверительный интервал для пропорции
Доверительный интервал для калькулятора пропорций
Доверительный интервал для разницы в пропорциях
Доверительный интервал для разницы в пропорциях — это диапазон значений, который может содержать истинную разницу между двумя пропорциями населения с определенным уровнем достоверности. Формула для расчета этого интервала:
Доверительный интервал = (p 1 –p 2 ) +/- z*√(p 1 (1-p 1 )/n 1 + p 2 (1-p 2 )/n 2 )
куда:
- p 1 , p 2 : доля образца 1, доля образца 2
- z: z-критическое значение, основанное на доверительном уровне
- n 1 , n 2 : размер выборки 1, размер выборки 2
Ресурсы: Как рассчитать доверительный интервал для разницы пропорций
Доверительный интервал для калькулятора разницы пропорций
![]()
Загрузить PDF
![]()
Загрузить PDF
Доверительный интервал является показателем точности измерений. Это также показатель того, насколько стабильна полученная величина, то есть насколько близкую величину (к первоначальной величине) вы получите при повторении измерений (эксперимента). Выполните следующие действия, чтобы вычислить доверительный интервал для нужных величин.
Шаги
-

1
Запишите задачу. Например: средний вес студента мужского пола в университете АВС составляет 90 кг. Вы будете тестировать точность предсказания веса студентов мужского пола в университете АВС в пределах данного доверительного интервала.
-
2
Составьте подходящую выборку. Вы будете использовать ее для сбора данных для тестирования гипотезы. Допустим, вы уже случайно выбрали 1000 студентов мужского пола.
-
3
Рассчитайте среднее значение и стандартное отклонение этой выборки. Выберите статистические величины (например, среднее значение и стандартное отклонение), которые вы хотите использовать для анализа вашей выборки. Вот как вычислить среднее значение и стандартное отклонение:
- Для расчета среднего значения выборки сложите значения весов 1000 выбранных мужчин и разделите результат на 1000 (число мужчин). Допустим, получили средний вес, равный 93 кг.
- Для расчета стандартного отклонения выборки необходимо найти среднее значение. Затем нужно вычислить дисперсию данных или среднее значение квадратов разностей от среднего. Найдя это число, просто возьмите квадратный корень из него. Допустим, в нашем примере стандартное отклонение равно 15 кг (заметим, что иногда эта информация может быть дана вместе с условием статистической задачи).
-
4
Выберите нужный доверительный уровень. Наиболее часто используемые доверительные уровни: 90 %, 95 % и 99 %. Он также может быть дан вместе с условием задачи. Допустим, вы выбрали 95 %.
-
5
Рассчитайте предел погрешности. Вы можете найти предел погрешности с помощью следующей формулы: Za/2 * σ/√(n). Za/2 = коэффициент доверия (где а = доверительный уровень), σ = стандартное отклонение, а n = размер выборки. Это формула показывает, что вы должны умножить критическое значение на стандартную ошибку. Вот как вы можете решить эту формулу, разбив ее на части:
- Вычислите критическое значение или Za/2. Доверительный уровень равен 95 %. Преобразуйте проценты в десятичную дробь: 0,95 и разделите ее на 2, чтобы получить 0,475. Затем посмотрите в таблицу Z-оценок, чтобы найти соответствующее значение для 0,475. Вы найдете значение 1,96 (на пересечении строки 1,9 и столбца 0,06).
- Возьмите стандартную ошибку (стандартное отклонение): 15 и разделите ее на квадратный корень из размера выборки: 1000. Вы получите: 15/31,6 или 0,47 кг.
- Умножьте 1,96 на 0,47 (критическое значение на стандартную ошибку), чтобы получить 0,92 — предел погрешности.
-
6
Запишите доверительный интервал. Чтобы сформулировать доверительный интервал, просто запишите среднее значение (93) ± погрешность. Ответ: 93 ± 0,92. Вы можете найти верхнюю и нижнюю границы доверительного интервала, прибавляя и вычитая погрешность к/от средней величины. Итак, нижняя граница составляет 93 – 0,92 или 92,08, а верхняя граница составляет 93 + 0,92 или 93,92.
- Вы можете использовать следующую формулу для вычисления доверительного интервала: x̅ ± Za/2 * σ/√(n), где x̅ — среднее значение.
Реклама






Советы
- И t-оценки и z-оценки можно рассчитать вручную, а также с помощью графического калькулятора или статистических таблиц, которые часто встречаются в учебниках по статистике. Также доступны онлайн-инструменты.
- Критическое значение, используемое для расчета погрешности, является постоянным и выражается либо через t-оценку, либо через z-оценку. T-оценка обычно более предпочтительна в условиях, когда стандартное отклонение выборки неизвестно или когда используется маленькая выборка.
- Ваша выборка должна быть достаточной (по размеру) для того, чтобы вычислить правильный доверительный интервал.
- Доверительный интервал не указывает на вероятность получения того или иного результата. Например, если вы на 95 % уверены, что среднее значение вашей выборки лежит между 75 и 100, то доверительный интервал в 95 % не означает, что среднее значение попадает в ваш диапазон.
- Есть много методов, таких как простая случайная выборка, систематический отбор и стратифицированная выборка, с помощью которых вы можете собрать репрезентативную выборку для тестирования.
Реклама
Что вам понадобится
- Выборка
- Компьютер
- Доступ в интернет
- Учебник статистики
- Графический калькулятор
Об этой статье
Эту страницу просматривали 263 889 раз.
Была ли эта статья полезной?
Способы расчета доверительного интервала

21 апреля 2016
Часто оценщику приходится анализировать рынок недвижимости того сегмента, в котором располагается объект оценки. Если рынок развит, проанализировать всю совокупность представленных объектов бывает сложно, поэтому для анализа используется выборка объектов. Не всегда эта выборка получается однородной, иногда требуется очистить ее от экстремумов – слишком высоких или слишком низких предложений рынка. Для этой цели применяется доверительный интервал. Цель данного исследования – провести сравнительный анализ двух способов расчета доверительного интервала и выбрать оптимальный вариант расчета при работе с разными выборками в системе estimatica.pro.
Способы расчета доверительного интервала
Доверительный интервал – вычисленный на основе выборки интервал значений признака, который с известной вероятностью содержит оцениваемый параметр генеральной совокупности.
Смысл вычисления доверительного интервала заключается в построении по данным выборки такого интервала, чтобы можно было утверждать с заданной вероятностью, что значение оцениваемого параметра находится в этом интервале. Другими словами, доверительный интервал с определенной вероятностью содержит неизвестное значение оцениваемой величины. Чем шире интервал, тем выше неточность.
Существуют разные методы определения доверительного интервала. В этой статье рассмотрим 2 способа:
- через медиану и среднеквадратическое отклонение;
- через критическое значение t-статистики (коэффициент Стьюдента).
Этапы сравнительного анализа разных способов расчета ДИ:
1. формируем выборку данных;
2. обрабатываем ее статистическими методами: рассчитываем среднее значение, медиану, дисперсию и т.д.;
3. рассчитываем доверительный интервал двумя способами;
4. анализируем очищенные выборки и полученные доверительные интервалы.
Этап 1. Выборка данных
Выборка сформирована с помощью системы estimatica.pro. В выборку вошло 91 предложение о продаже 1 комнатных квартир в 3-ем ценовом поясе с типом планировки «Хрущевка».
Таблица 1. Исходная выборка
|
№ |
Цена 1 кв.м., д.е. |
|
1 |
50943 |
|
2 |
35000 |
|
3 |
51613 |
|
4 |
50645 |
|
5 |
49841 |
|
… |
… |
|
86 |
58772 |
|
87 |
70714 |
|
88 |
53393 |
|
89 |
54876 |
|
90 |
52542 |
|
91 |
56140 |
Рис.1. Исходная выборка

Этап 2. Обработка исходной выборки
Обработка выборки методами статистики требует вычисления следующих значений:
1. Среднее арифметическое значение

2. Медиана – число, характеризующее выборку: ровно половина элементов выборки больше медианы, другая половина меньше медианы
![]() (для выборки, имеющей нечетное число значений)
(для выборки, имеющей нечетное число значений)
3. Размах – разница между максимальным и минимальным значениями в выборке

4. Дисперсия – используется для более точного оценивания вариации данных

5. Среднеквадратическое отклонение по выборке (далее – СКО) – наиболее распространённый показатель рассеивания значений корректировок вокруг среднего арифметического значения.

6. Коэффициент вариации – отражает степень разбросанности значений корректировок

7. коэффициент осцилляции – отражает относительное колебание крайних значений цен в выборке вокруг средней

Таблица 2. Статистические показатели исходной выборки
|
Показатель |
Значение |
|
Ср. значение |
54970 |
|
Медиана |
53934 |
|
Размах |
39194 |
|
Дисперсия |
45126821 |
|
СКО |
6755 |
|
Коэф. вариации |
12,29% |
|
Коэф. осциляции |
71,30% |
Коэффициент вариации, который характеризует однородность данных, составляет 12,29%, однако коэффициент осцилляции слишком велик. Таким образом, мы можем утверждать, что исходная выборка не является однородной, поэтому перейдем к расчету доверительного интервала.
Этап 3. Расчёт доверительного интервала
Способ 1. Расчёт через медиану и среднеквадратическое отклонение.
Доверительный интервал определяется следующим образом: минимальное значение – из медианы вычитается СКО; максимальное значение – к медиане прибавляется СКО.
Формула доверительного интервала:

Таким образом, доверительный интервал (47179 д.е.; 60689 д.е.)
Значения, содержащиеся в исходной выборке и не попадающие в доверительный интервал, удаляем. Удалено 20 объектов, что составило 22% выборки.
Рис. 2. Значения, попавшие в доверительный интервал 1.

Способ 2. Построение доверительного интервала через критическое значение t-статистики (коэффициент Стьюдента)
С.В. Грибовский в книге «Математические методы оценки стоимости имущества» описывает способ вычисления доверительного интервала через коэффициент Стьюдента. При расчете этим методом оценщик должен сам задать уровень значимости ∝, определяющий вероятность, с которой будет построен доверительный интервал. Обычно используются уровни значимости 0,1; 0,05 и 0,01. Им соответствуют доверительные вероятности 0,9; 0,95 и 0,99. При таком методе полагают истинные значения математического ожидания и дисперсии практически неизвестными (что почти всегда верно при решении практических задач оценки).
Формула доверительного интервала:

n – объем выборки;
![]() – критическое значение t- статистики (распределения Стьюдента) с уровнем значимости ∝,числом степеней свободы n-1,которое определяется по специальным статистическим таблицам либо с помощью MS Excel (
– критическое значение t- статистики (распределения Стьюдента) с уровнем значимости ∝,числом степеней свободы n-1,которое определяется по специальным статистическим таблицам либо с помощью MS Excel (![]() →”Статистические”→ СТЬЮДРАСПОБР);
→”Статистические”→ СТЬЮДРАСПОБР);
∝ – уровень значимости, принимаем ∝=0,01.

Значения, содержащиеся в исходной выборке и не попадающие в доверительный интервал, удаляем. Удалено 62 объекта, что составило 68% выборки.
Рис. 2. Значения, попавшие в доверительный интервал 2.

Этап 4. Анализ разных способов расчета доверительного интервала
Два способа расчета доверительного интервала – через медиану и коэффициент Стьюдента – привели к разным значениям интервалов. Соответственно, получилось две различные очищенные выборки.
Таблица 3. Статистические показатели по трем выборкам.
|
Показатель |
Исходная выборка |
1 вариант |
2 вариант |
|
Среднее значение |
54970 |
53593 |
54750 |
|
Медиана |
53934 |
53425 |
54688 |
|
Размах |
39194 |
12888 |
3677 |
|
Дисперсия |
45126821 |
8919645 |
1228707 |
|
СКО |
6755 |
3008 |
1128 |
|
Коэф. вариации |
12,29% |
5,61% |
2,06% |
|
Коэф. осциляции |
71,30% |
24,05% |
6,72% |
|
Количество выбывших объектов, шт. |
20 |
62 |
На основании выполненных расчетов можно сказать, что полученные разными методами значения доверительных интервалов пересекаются, поэтому можно использовать любой из способов расчета на усмотрение оценщика.
Однако мы считаем, что при работе в системе estimatica.pro целесообразно выбирать метод расчета доверительного интервала в зависимости от степени развитости рынка:
- если рынок неразвит, применять метод расчета через медиану и среднеквадратическое отклонение, так как количество выбывших объектов в этом случае невелико;
- если рынок развит, применять расчет через критическое значение t-статистики (коэффициент Стьюдента), так как есть возможность сформировать большую исходную выборку.
При подготовке статьи были использованы:
1. Грибовский С.В., Сивец С.А., Левыкина И.А. Математические методы оценки стоимости имущества. Москва, 2014 г.
2. Данные системы estimatica.pro
Читайте также:
Расчет корректировок методом парных продаж
Статью подготовили: Наталья Ничкова и Михаил Филимонов
-
Расчет доверительных интервалов
Доверительный
интервал – термин, используемый в
математической статистике при интервальной
оценке статистических параметров, что
предпочтительнее при небольшом объёме
выборки.
Доверительный интервал для математического ожидания
Найдем
доверительный интервал для математического
ожидания при условии, что дисперсия
генеральной величины неизвестна, а
доверительная вероятность равна 1 – α.
Для
расчета доверительного интервала
применим формулу:

x
– среднее значение величины
 –квантиль
–квантиль
распределения Стьюдента с
 степенью свободы
степенью свободы
 –несмещенное
–несмещенное
выборочное стандартное отклонение
 –объем
–объем
выборки
-
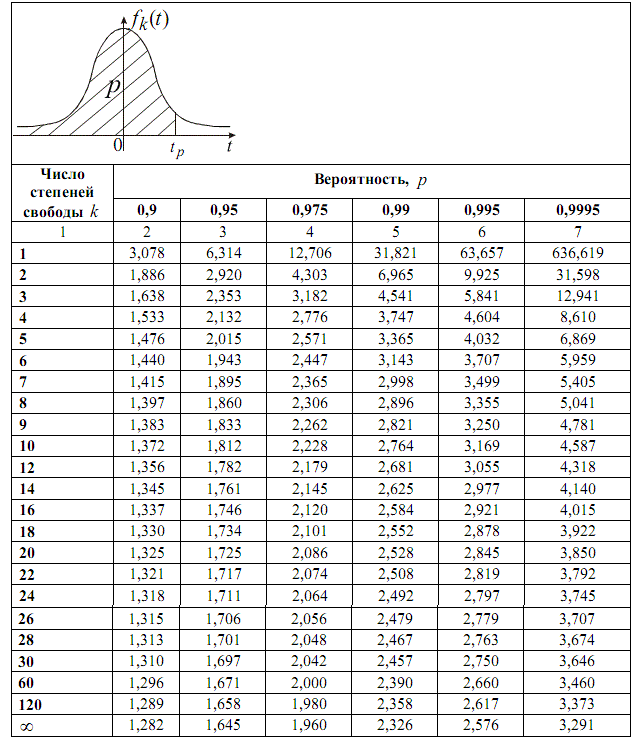
Определим
квантиль распределения Стьюдента, для
этого воспользуемся стандартной
таблицей:
 возьмем
возьмем
равным 0,05.
Выберем
значение
 = 2,571
= 2,571
-
Найдем
S:
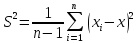
 10.15
10.15
 2.94
2.94
-
Подставим
все известные значения в формулу из
пункта 1):
Для
M[X]:


Для
M[Y]:


Доверительный интервал для дисперсии
Найдем
доверительный интервал для дисперсии
при условии, что среднее значение
величины неизвестно, а доверительная
вероятность равна 1 – α.
Для
расчета доверительного интервала
применим формулу:
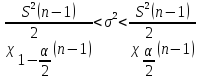
 –дисперсия
–дисперсия
 –несмещенное
–несмещенное
выборочная дисперсия
 –квантиль
–квантиль
распределения
 со степенями свободы
со степенями свободы .
.
-
Определим
квантиль распределения
,
для этого воспользуемся специальной
таблицей:
 ,
,

![]()

 12,8325
12,8325
 0,8312
0,8312
-
Подставим
найденные значения в формулу из пункта
1):
Для
Х:


Для
У:


Доверительный интервал для корреляции
Найдем
доверительный интервал для корреляции
при условии, что выборка получена из
генеральной совокупности, r
– выборочный коэффициент корреляции.
Для
расчета доверительного интервала
применим формулу:

-
Рассчитаем
:
 :
:
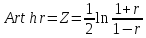
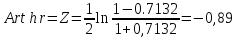
-
возьмем
из таблицы квантилей нормального
распределения:
 возьмем
возьмем

-
Подставим
все в формулы:


-
Найдем
с помощью таблицы гиперболических
тангенсов:
 с помощью таблицы гиперболических
с помощью таблицы гиперболических

-
Проверка гипотез
Таким
образом было установлено, что между
заработной платой сотрудников ДПС и
количеством оштрафованных существует
связь. Искомая
корреляция равна -0.7132. Это
высокая степень взаимосвязи – значения
коэффициента корреляции находится в
пределах от 0,7 до 0,99. Нам удалось выявить
зависимость, и результаты в данном
случае оказались вполне ожидаемы. Чем
выше средняя заработная плата по субъекту
РФ, тем меньше оштрафованных. Почему
получились такие результаты, нам остается
только гадать. Да и не было нашей целью
объяснять почему именно так. Мы должны
были, ради личного интереса, посмотреть
есть ли связь.
-
Регрессия
Любая
нелинейная регрессия, в которой уравнение
регрессии для изменений в одной переменной
(у) как функции t изменений в другой (х)
является квадратичным, кубическим или
уравнение более высокого порядка. Хотя
математически всегда возможно получить
уравнение регрессии, которое будет
соответствовать каждой “загогулине”
кривой, большинство этих пертурбаций
возникает в результате ошибок в
составлении выборки или измерении, и
такое “совершенное” соответствие
ничего не дает. Не всегда легко определить,
соответствует ли криволинейная регрессия
набору данных, хотя существуют
статистические тесты для определения
того, значительно ли увеличивает каждая
более высокая степень уравнения степ
совпадения этого набора данных.
Теперь,
будем считать, что выборочная криволинейная
регрессия определяется уравнением:


Коэффициенты
называются выборочными коэффициентами
регрессии.
Из
ранее изученных пунктов, нам известны
следующие параметры:
х
= 20,35
у
= 9,47
 =
=
85,79
 =
=
7,21
 =
=
-0.71
Теперь
мы можем подставить все значения в
уравнение:
Соседние файлы в папке МДЗ
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
Когда нам нужно получить одно число в качестве оценки параметра совокупности, мы используем точечную оценку. Тем не менее, из-за ошибки выборки, точечная оценка не будет в точности равняться параметру совокупности при любом размере данной выборки.
Часто, вместо точечной оценки, более полезным подходом будет найти диапазон значений, в рамках которого, как мы ожидаем, может находится значение искомого параметра с заданным уровнем вероятности.
Этот подход называется интервальной оценкой параметра (англ. ‘interval estimate of parameter’), а доверительный интервал выполняет роль этого диапазона значений.
Определение доверительного интервала.
Доверительный интервал (англ. ‘confidence interval’) представляет собой диапазон, для которого можно утверждать, с заданной вероятностью (1 – alpha ), называемой степенью доверия (или степенью уверенности, англ. ‘degree of confidence’), что он будет содержать оцениваемый параметр.
Этот интервал часто упоминается как (100 (1 – alpha)% ) доверительный интервал для параметра.
Конечные значения доверительного интервала называются нижним и верхним доверительными пределами (или доверительными границами или предельной погрешностью, англ. ‘lower/upper confidence limits’).
В этом чтении, мы имеем дело только с двусторонними доверительными интервалами – доверительные интервалами, для которых мы вычисляем и нижние и верхние пределы.
Кроме того, можно определить два типа односторонних доверительных интервалов для параметра совокупности.
Нижний односторонний доверительный интервал устанавливает только нижний предел. Это означает допущение, что с определенной степенью доверия параметр совокупности равен или превышает нижний предел.
Верхний односторонний доверительный интервал устанавливает только верхний предел. Это означает допущение, что с определенной степенью доверия параметр совокупности меньше или равен верхнему пределу.
Инвестиционные аналитики редко используют односторонние доверительные интервалы.
Доверительные интервалы часто дают либо вероятностную интерпретацию, либо практическую интерпретацию.
При вероятностной интерпретации, мы интерпретируем 95%-ный доверительный интервал для среднего значения совокупности следующим образом.
При повторяющейся выборке, 95% таких доверительных интервалов будут, в конечном счете, включать в себя среднее значение совокупности.
Например, предположим, что мы делаем выборку из совокупности 1000 раз, и на основании каждой выборки мы построим 95%-ный доверительный интервал, используя вычисленное выборочное среднее.
Из-за случайного характера выборок, эти доверительные интервалы отличаются друг от друга, но мы ожидаем, что 95% (или 950) этих интервалов включают неизвестное значение среднего по совокупности.
На практике мы обычно не делаем такие повторяющиеся выборки. Поэтому в практической интерпретации, мы утверждаем, что мы 95% уверены в том, что один 95%-ный доверительный интервал содержит среднее по совокупности.
Мы вправе сделать это заявление, потому что мы знаем, что 95% всех возможных доверительных интервалов, построенных аналогичным образом, будут содержать среднее по совокупности.
Доверительные интервалы, которые мы обсудим в этом чтении, имеют структуры, подобные описанной ниже базовой структуре.
Построение доверительных интервалов.
Доверительный интервал (100 (1 – alpha)% ) для параметра имеет следующую структуру.
Точечная оценка (pm) Фактор надежности (times) Стандартная ошибка
где
- Точечная оценка = точечная оценка параметра (значение выборочной статистики).
- Фактор надежности (англ. ‘reliability factor’) = коэффициент, основанный на предполагаемом распределении точечной оценки и степени доверия ((1 – alpha)) для доверительного интервала.
- Стандартная ошибка = стандартная ошибка выборочной статистики, значение которой получено с помощью точечной оценки.
Величину (Фактор надежности) (times) (Cтандартная ошибка) иногда называют точностью оценки (англ. ‘precision of estimator’). Большие значения этой величины подразумевают более низкую точность оценки параметра совокупности.
Самый базовый доверительный интервал для среднего значения по совокупности появляется тогда, когда мы делаем выборку из нормального распределения с известной дисперсией. Фактор надежности в данном случае на основан стандартном нормальном распределении, которое имеет среднее значение, равное 0 и дисперсию 1.
Стандартная нормальная случайная величина обычно обозначается как (Z). Обозначение (z_alpha ) обозначает такую точку стандартного нормального распределения, в которой (alpha) вероятности остается в правом хвосте.
Например, 0.05 или 5% возможных значений стандартной нормальной случайной величины больше, чем ( z_{0.05} = 1.65 ).
Предположим, что мы хотим построить 95%-ный доверительный интервал для среднего по совокупности, и для этой цели, мы сделали выборку размером 100 из нормально распределенной совокупности с известной дисперсией (sigma^2) = 400 (значит, (sigma) = 20).
Мы рассчитываем выборочное среднее как ( overline X = 25 ). Наша точечная оценка среднего по совокупности, таким образом, 25.
Если мы перемещаем 1.96 стандартных отклонений выше среднего значения нормального распределения, то 0.025 или 2.5% вероятности остается в правом хвосте. В силу симметрии нормального распределения, если мы перемещаем 1.96 стандартных отклонений ниже среднего, то 0.025 или 2.5% вероятности остается в левом хвосте.
В общей сложности, 0.05 или 5% вероятности лежит в двух хвостах и 0.95 или 95% вероятности лежит между ними.
Таким образом, ( z_{0.025} = 1.96) является фактором надежности для этого 95%-ного доверительного интервала. Обратите внимание на связь (100 (1 – alpha)% ) для доверительного интервала и (z_{alpha/2}) для фактора надежности.
Стандартная ошибка среднего значения выборки, заданная Формулой 1, равна:
( sigma_{overline X} = 20 Big / sqrt{100} = 2 )
Доверительный интервал, таким образом, имеет нижний предел:
( overline X – 1.96 sigma_{overline X} ) = 25 – 1.96(2) = 25 – 3.92 = 21.08.
Верхний предел доверительного интервала равен:
( overline X + 1.96sigma_{overline X} ) = 25 + 1.96(2) = 25 + 3.92 = 28.92
95%-ный доверительный интервал для среднего по совокупности охватывает значения от 21.08 до 28.92.
Доверительные интервалы для среднего по совокупности (нормально распределенная совокупность с известной дисперсией).
Доверительный интервал (100 (1 – alpha)% ) для среднего по совокупности ( mu ), когда мы делаем выборку из нормального распределения с известной дисперсией ( sigma^2 ) задается формулой:
( Large dst overline X pm z_{alpha /2}{sigma over sqrt n} ) (Формула 4)
Факторы надежности для наиболее часто используемых доверительных интервалов приведены ниже.
Факторы надежности для доверительных интервалов на основе стандартного нормального распределения.
Мы используем следующие факторы надежности при построении доверительных интервалов на основе стандартного нормального распределения:
- 90%-ные доверительные интервалы: используется (z_{0.05}) = 1.65
- 95%-ные доверительные интервалы: используется (z_{0.025}) = 1.96
- 99%-ные доверительные интервалы: используется (z_{0.005}) = 2.58
На практике, большинство финансовых аналитиков используют значения для (z_{0.05}) и (z_{0.005}), округленные до двух знаков после запятой.
Для справки, более точными значениями для (z_{0.05}) и (z_{0.005}) являются 1.645 и 2.575, соответственно.
Для быстрого расчета 95%-ного доверительного интервала (z_{0.025}) иногда округляют 1.96 до 2.
Эти факторы надежности подчеркивают важный факт о всех доверительных интервалах. По мере того, как мы повышаем степень доверия, доверительный интервал становится все шире и дает нам менее точную информацию о величине, которую мы хотим оценить.
«Чем уверенней мы хотим быть, тем меньше мы должны быть уверены»
см. Freund и Williams (1977), стр. 266.
На практике, допущение о том, что выборочное распределение выборочного среднего, по меньшей мере, приблизительно нормальное, часто является обоснованным, либо потому, что исходное распределение приблизительно нормальное, либо потому что мы имеем большую выборку и поэтому к ней применима центральная предельная теорема.
Однако, на практике, мы редко знаем дисперсию совокупности. Когда дисперсия генеральной совокупности неизвестна, но выборочное среднее, по меньшей мере, приблизительно нормально распределено, у нас есть два приемлемых пути чтобы вычислить доверительные интервалы для среднего значения совокупности.
Вскоре мы обсудим более консервативный подход, который основан на t-распределении Стьюдента (t-распределение, для краткости).
Распределение статистики (t) называется t-распределением Стьюдента (англ. “Student’s t-distribution”) из-за псевдонима «Студент» (Student), использованного британским математиком Уильямом Сили Госсеттом, который опубликовал свою работу в 1908 году.
В финансовой литературе, это наиболее часто используемый подход для статистической оценки и проверки статистических гипотез, касающихся среднего значения, когда дисперсия генеральной совокупности не известна, как для малого, так и для большого размер выборки.
Второй подход к доверительным интервалам для среднего по совокупности, основанного на стандартном нормальном распределении, – это z-альтернатива (англ. ‘z-alternative’). Он может быть использован только тогда, когда размер выборки является большим (в общем случае, размер выборки 30 или больше, можно считать большим).
В отличии от доверительного интервала, приведенного в Формуле 4, этот доверительный интервал использует стандартное отклонение выборки (s) при вычислении стандартной ошибки выборочного среднего (по Формуле 2).
Доверительные интервалы для среднего по совокупности – z-альтернатива (большая выборка, дисперсия совокупности неизвестна).
Доверительный интервал (100 (1 – alpha)% ) для среднего по совокупности ( mu ) при выборке из любого распределения с неизвестной дисперсией, когда размер выборки большой, задается формулой:
( Large dst overline X pm z_{alpha /2}{s over sqrt n} ) (Формула 5)
Поскольку этот тип доверительного интервала применяется довольно часто, мы проиллюстрируем его вычисление в Примере 4.
Пример (4) расчета доверительного интервала для среднего по совокупности коэффициентов Шарпа с использованием z-статистики.
Предположим, что инвестиционный аналитик делает случайную выборку акций взаимных фондов США и рассчитывает средний коэффициент Шарпа.
[см. также: CFA – Коэффициент Шарпа]
Размер выборки равен 100, а средний коэффициент Шарпа составляет 0.45. Выборка имеет стандартное отклонение 0.30.
Рассчитайте и интерпретируйте 90-процентный доверительный интервал для среднего по совокупности всех акций взаимных фондов США с использованием фактора надежности на основе стандартного нормального распределения.
Фактор надежности для 90-процентного доверительного интервала, как указано ранее, составляет ( z_{0.05} = 1.65 ).
Доверительный интервал будет равен:
( begin{aligned} & overline X pm z_{0.05}{s over sqrt n } \ &= 0.45 pm 1.65{0.30 over sqrt {100}} \ &= 0.45 pm 1.65(0.03) = 0.45 pm 0.0495 end{aligned} )
Доверительный интервал охватывает значения 0.4005 до 0.4995, или от 0.40 до 0.50, с округлением до двух знаков после запятой. Аналитик может сказать с 90-процентной уверенностью, что интервал включает среднее по совокупности.
В этом примере аналитик не делает никаких конкретных предположений о распределении вероятностей, характеризующем совокупность. Скорее всего, аналитик опирается на центральную предельную теорему для получения приближенного нормального распределения для выборочного среднего.
Как показывает Пример 4, даже если мы не уверены в характере распределения совокупности, мы все еще можем построить доверительные интервалы для среднего по совокупности, если размер выборки достаточно большой, поскольку можем применить центральную предельную теорему.
Концепция степеней свободы.
Обратимся теперь к консервативной альтернативе и используем t-распределение Стьюдента, чтобы построить доверительные интервалы для среднего по совокупности, когда дисперсия генеральной совокупности не известна.
Для доверительных интервалов на основе выборок из нормально распределенных совокупностей с неизвестной дисперсией, теоретически правильный фактор надежности основан на t-распределении. Использование фактора надежности, основанного на t-распределении, имеет важное значение для выборок небольшого размера.
Применение фактора надежности (t) уместно, когда дисперсия генеральной совокупности неизвестна, даже если у нас есть большая выборка и мы можем использовать центральную предельную теорему для обоснования использования фактора надежности (z). В этом случае большой выборки, t-распределение обеспечивает более консервативные (широкие) доверительные интервалы.
t-распределение является симметричным распределением вероятностей и определяется одним параметром, известным как степени свободы (DF, от англ. ‘degrees of freedom’). Каждое значение для числа степеней свободы определяет одно распределение в этом семействе распределений.
Далее мы сравним t-распределения со стандартным нормальным распределением, но сначала мы должны понять концепцию степеней свободы. Мы можем сделать это путем изучения расчета выборочной дисперсии.
Формула 3 дает несмещенную оценку выборочной дисперсии, которую мы используем. Выражение в знаменателе, ( n – 1 ), означающее размер выборки минус 1, это число степеней свободы при расчете дисперсии совокупности с использованием Формулы 3.
Мы также используем ( n – 1 ) как число степеней свободы для определения факторов надежности на основе распределения Стьюдента. Термин «степени свободы» используются, так как мы предполагаем, что в случайной выборке наблюдения отобраны независимо друг от друга. Числитель выборочной дисперсии, однако, использует выборочное среднее.
Каким образом использование выборочного среднего влияет на количество наблюдений, отобранных независимо, для формулы выборочной дисперсии?
При выборке размера 10 и среднем значении в 10%, к примеру, мы можем свободно отобрать только 9 наблюдений. Независимо от отобранных 9 наблюдений, мы всегда можем найти значение для 10-го наблюдения, которое дает среднее значение, равное 10%. С точки зрения формулы выборочной дисперсии, здесь есть 9 степеней свободы.
Учитывая, что мы должны сначала вычислить выборочное среднее от общего числа (n) независимых наблюдений, только (n – 1) наблюдений могут быть отобраны независимо друг от друга для расчета выборочной дисперсии.
Концепция степеней свободы часто применяется в финансовой статистике, и вы встретите ее в последующих чтениях.
t-распределение Стьюдента.
Предположим, что мы делаем выборку из нормального распределения.
Коэффициент (z = (overline X – mu) Big / (sigma big / sqrt n) ) нормально распределен со средним значением 0 и стандартным отклонением 1, однако, коэффициент (t = (overline X – mu) Big / (s big / sqrt n) ) следует t-распределению со средним 0 и (n – 1) степеней свободы.
Коэффициент (t) не является нормальным, поскольку представляет собой отношение двух случайных величин, выборочного среднего и стандартного отклонения выборки.
Определение стандартной нормальной случайной величины включает в себя только одну случайную величину, выборочное среднее. По мере увеличения степеней свободы, однако, t-распределение приближается к стандартному нормальному распределению.
На Рисунке 1 показано стандартное нормальное распределение и два t-распределения, одно с DF = 2 и одно с DF = 8.
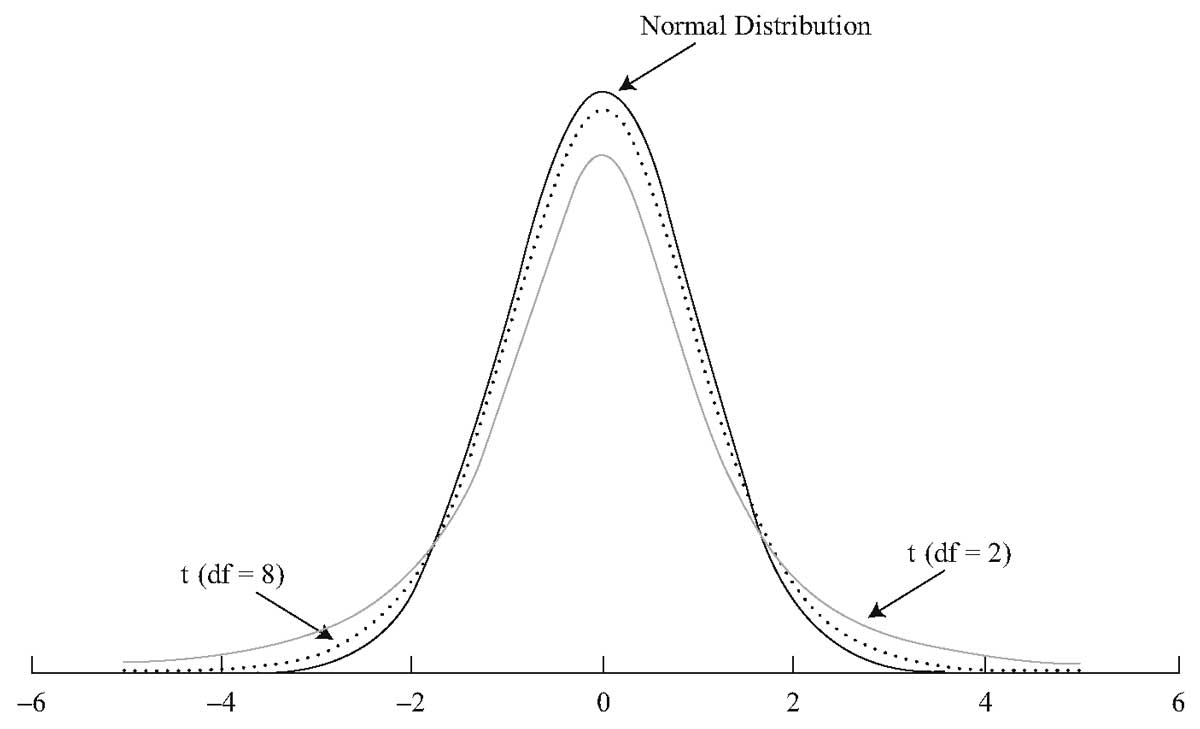 Рисунок (1) t-распределение Стьюдента по сравнению со стандартным нормальным распределением.
Рисунок (1) t-распределение Стьюдента по сравнению со стандартным нормальным распределением.
Из трех распределений, показанных на Рисунке 1, стандартное нормальное распределение имеет хвосты, которые стремятся к нулю быстрее, чем хвосты двух t-распределений. t-распределение симметрично распределено вокруг среднего нулевого значения, так же как и нормальное распределение.
По мере увеличения степеней свободы, t-распределение приближается к стандартному нормальному распределению. t-распределение с DF = 8 ближе к стандартному нормальному, чем t-распределение с DF = 2.
Помимо области плюс и минус четырех стандартных отклонений от среднего значения, остальная область под стандартным нормальным распределением, как представляется, близка к 0. Однако, оба t-распределения содержать некоторую площадь под каждой кривой за пределом четырех стандартных отклонений.
t-распределения имеют более толстые хвосты, но хвосты t-распределения Стьюдента с DF = 8 сильнее напоминают хвосты нормального распределения. По мере увеличения степеней свободы, хвосты распределения Стьюдента становятся менее толстыми.
Для часто используемых значений распределения Стьюдента составлены таблицы. Например, для каждой степени свободы (t_{0.10}), (t_{0.05}), (t_{0.025}), (t_{0.01}) и (t_{0.005}) значения будут такими, что соответственно, 0.10, 0.05, 0.025, 0.01 и 0.005 вероятности останется в правом хвосте для заданного числа степеней свободы.
Значения (t_{0.10}), (t_{0.05}), (t_{0.025}), (t_{0.01}) и (t_{0.005}) также называют односторонними критическими значениями t на значимых уровнях 0.10, 0.05, 0.025, 0.01 и 0.005, для указанного числа степеней свободы.
Например,
для DF = 30,
(t_{0.10}) = 1.310,
(t_{0.05}) = 1.697,
(t_{0.025}) = 2.042,
(t_{0.01}) = 2.457,
(t_{0.005}) = 2.750.
Приведем форму доверительных интервалов для среднего по совокупности, используя распределение Стьюдента.
Доверительные интервалы для среднего по совокупности (дисперсия совокупности неизвестна) – t-распределение.
Если мы делаем выборку из генеральной совокупности с неизвестной дисперсией и соблюдается одно из перечисленных ниже условий:
- выборка является большой, или
- выборка небольшая, но совокупность имеет нормальное распределение, или приблизительно нормально распределена,
то доверительный интервал (100 (1 – alpha)% ) для среднего совокупности ( mu ) задается формулой:
( Large dst overline X pm t_{alpha /2}{s over sqrt n} ) (Формула 6)
где число степеней свободы для ( t_{alpha /2}) равно ( n-1 ), а ( n ) – это размер выборки.
Пример 5 использует данные Примера 4, но применяет t-статистику, а не z-статистику, чтобы рассчитать доверительный интервал для среднего значения совокупности коэффициентов Шарпа.
Пример (5) расчета доверительного интервала для среднего по совокупности коэффициентов Шарпа с использованием t-статистики.
Как и в Примере 4, инвестиционный аналитик стремится вычислить 90-процентный доверительный интервал для среднего по совокупности коэффициентов Шарпа, основанных на случайной выборке из 100 взаимных фондов США.
Выборочное среднее коэффициентов Шарпа составляет 0.45, а выборочное стандартное отклонение – 0.30.
Теперь, признав, что дисперсия генеральной совокупности распределения коэффициентов Шарпа неизвестна, аналитик решает вычислить доверительный интервал, используя теоретически правильную t-статистику.
Поскольку размер выборки равен 100, DF = 99. Используя таблицу степеней свободы, мы находим, что (t_{0.05}) = 1.66.
Этот фактор надежности немного больше, чем фактор надежности (z_{0.05}) = 1.65, который был использован в Примере 4.
Доверительный интервал будет:
( begin{aligned} & overline X pm t_{0.05}{s over sqrt n } \ &= 0.45 pm 1.66{0.30 over sqrt {100}} \ &= 0.45 pm 1.66(0.03) = 0.45 pm 0.0498 end{aligned} )
Доверительный интервал охватывает значения 0.4002 до 0.4998, или 0.40 до 0.50, с двумя знаками после запятой. При округлении до двух знаков после запятой, доверительный интервал не изменился по сравнению с Примером 4.
В Таблице 3 приведены различные факторы надежности, которые мы использовали.
|
Выборка из: |
Статистика для выборки малого размера |
Статистика для выборки большого размера |
|---|---|---|
|
Нормальное распределение с известной дисперсией |
(z) |
(z) |
|
Нормальное распределение с неизвестной дисперсией |
(t) |
(t)* |
|
Ненормальное распределение с известной дисперсией |
недоступно |
(z) |
|
Ненормальное распределение с неизвестной дисперсией |
недоступно |
(t)* |
* Использование (z) также приемлемо.
