What’s the simplest SQL statement that will return the duplicate values for a given column and the count of their occurrences in an Oracle database table?
For example: I have a JOBS table with the column JOB_NUMBER. How can I find out if I have any duplicate JOB_NUMBERs, and how many times they’re duplicated?
asked Sep 12, 2008 at 15:10
1
Aggregate the column by COUNT, then use a HAVING clause to find values that appear more than once.
SELECT column_name, COUNT(column_name)
FROM table_name
GROUP BY column_name
HAVING COUNT(column_name) > 1;
answered Sep 12, 2008 at 15:13
Bill the LizardBill the Lizard
396k209 gold badges563 silver badges877 bronze badges
5
Another way:
SELECT *
FROM TABLE A
WHERE EXISTS (
SELECT 1 FROM TABLE
WHERE COLUMN_NAME = A.COLUMN_NAME
AND ROWID < A.ROWID
)
Works fine (quick enough) when there is index on column_name. And it’s better way to delete or update duplicate rows.
answered Sep 13, 2008 at 9:35
GrreyGrrey
6711 gold badge6 silver badges4 bronze badges
3
Simplest I can think of:
select job_number, count(*)
from jobs
group by job_number
having count(*) > 1;
answered Sep 12, 2008 at 15:17
![]()
JosephStyonsJosephStyons
56.9k63 gold badges159 silver badges232 bronze badges
4
You don’t need to even have the count in the returned columns if you don’t need to know the actual number of duplicates. e.g.
SELECT column_name
FROM table
GROUP BY column_name
HAVING COUNT(*) > 1
answered Sep 13, 2008 at 14:55
EvanEvan
18.1k8 gold badges41 silver badges48 bronze badges
How about:
SELECT <column>, count(*)
FROM <table>
GROUP BY <column> HAVING COUNT(*) > 1;
To answer the example above, it would look like:
SELECT job_number, count(*)
FROM jobs
GROUP BY job_number HAVING COUNT(*) > 1;
answered Sep 12, 2008 at 15:18
AndrewAndrew
12.9k15 gold badges55 silver badges85 bronze badges
In case where multiple columns identify unique row (e.g relations table ) there you can use following
Use row id
e.g. emp_dept(empid, deptid, startdate, enddate)
suppose empid and deptid are unique and identify row in that case
select oed.empid, count(oed.empid)
from emp_dept oed
where exists ( select *
from emp_dept ied
where oed.rowid <> ied.rowid and
ied.empid = oed.empid and
ied.deptid = oed.deptid )
group by oed.empid having count(oed.empid) > 1 order by count(oed.empid);
and if such table has primary key then use primary key instead of rowid, e.g id is pk then
select oed.empid, count(oed.empid)
from emp_dept oed
where exists ( select *
from emp_dept ied
where oed.id <> ied.id and
ied.empid = oed.empid and
ied.deptid = oed.deptid )
group by oed.empid having count(oed.empid) > 1 order by count(oed.empid);
answered Sep 20, 2012 at 7:25
0
I usually use Oracle Analytic function ROW_NUMBER().
Say you want to check the duplicates you have regarding a unique index or primary key built on columns (c1, c2, c3).
Then you will go this way, bringing up ROWID s of rows where the number of lines brought by ROW_NUMBER() is >1:
Select *
From Table_With_Duplicates
Where Rowid In (Select Rowid
From (Select ROW_NUMBER() Over (
Partition By c1, c2, c3
Order By c1, c2, c3
) nbLines
From Table_With_Duplicates) t2
Where nbLines > 1)
MT0
138k11 gold badges57 silver badges115 bronze badges
answered Oct 24, 2017 at 8:21
![]()
J. ChomelJ. Chomel
8,14215 gold badges41 silver badges68 bronze badges
Doing
select count(j1.job_number), j1.job_number, j1.id, j2.id
from jobs j1 join jobs j2 on (j1.job_numer = j2.job_number)
where j1.id != j2.id
group by j1.job_number
will give you the duplicated rows’ ids.
answered Sep 12, 2008 at 15:24
agnulagnul
12.5k14 gold badges63 silver badges85 bronze badges
SELECT SocialSecurity_Number, Count(*) no_of_rows
FROM SocialSecurity
GROUP BY SocialSecurity_Number
HAVING Count(*) > 1
Order by Count(*) desc
![]()
Simon Adcock
3,5243 gold badges25 silver badges41 bronze badges
answered Apr 5, 2013 at 6:48
I know its an old thread but this may help some one.
If you need to print other columns of the table while checking for duplicate use below:
select * from table where column_name in
(select ing.column_name from table ing group by ing.column_name having count(*) > 1)
order by column_name desc;
also can add some additional filters in the where clause if needed.
answered Jul 23, 2018 at 7:57
![]()
Here is an SQL request to do that:
select column_name, count(1)
from table
group by column_name
having count (column_name) > 1;
typedef
1,1491 gold badge6 silver badges11 bronze badges
answered Jan 12, 2018 at 11:02
![]()
1. solution
select * from emp
where rowid not in
(select max(rowid) from emp group by empno);
answered Feb 10, 2016 at 10:08
![]()
DoOrDieDoOrDie
3153 silver badges12 bronze badges
0
Also u can try something like this to list all duplicate values in a table say reqitem
SELECT count(poid)
FROM poitem
WHERE poid = 50
AND rownum < any (SELECT count(*) FROM poitem WHERE poid = 50)
GROUP BY poid
MINUS
SELECT count(poid)
FROM poitem
WHERE poid in (50)
GROUP BY poid
HAVING count(poid) > 1;
Yaron Idan
6,1175 gold badges43 silver badges66 bronze badges
answered Jan 27, 2016 at 14:23
StackerStacker
491 silver badge4 bronze badges
Summary: in this tutorial, you will learn how to find duplicate records in the Oracle Database.
Let’s start by setting up a sample table for the demonstration.
Setting up a sample table
First, the following statement creates a new table named fruits that consists of three columns: fruit id, fruit name, and color:
CREATE TABLE fruits ( fruit_id NUMBER generated BY DEFAULT AS IDENTITY, fruit_name VARCHAR2(100), color VARCHAR2(20) );Code language: SQL (Structured Query Language) (sql)
Second, insert some rows into the fruits table:
Code language: SQL (Structured Query Language) (sql)
INSERT INTO fruits(fruit_name,color) VALUES('Apple','Red'); INSERT INTO fruits(fruit_name,color) VALUES('Apple','Red'); INSERT INTO fruits(fruit_name,color) VALUES('Orange','Orange'); INSERT INTO fruits(fruit_name,color) VALUES('Orange','Orange'); INSERT INTO fruits(fruit_name,color) VALUES('Orange','Orange'); INSERT INTO fruits(fruit_name,color) VALUES('Banana','Yellow'); INSERT INTO fruits(fruit_name,color) VALUES('Banana','Green');
Third, query data from the fruits table:
Code language: SQL (Structured Query Language) (sql)
SELECT * FROM fruits;
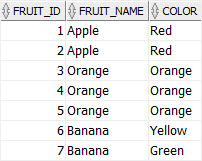
As you can see from the picture above, the fruits table has duplicate records with the same information repeated in both fruit_name and color columns.
Finding duplicate rows using the aggregate function
To find duplicate rows from the fruits table, you first list the fruit name and color columns in both SELECT and GROUP BY clauses. Then you count the number of appearances each combination appears with the COUNT(*) function as shown below:
Code language: SQL (Structured Query Language) (sql)
SELECT fruit_name, color, COUNT(*) FROM fruits GROUP BY fruit_name, color;

The query returned a single row for each combination of fruit name and color. It also included the rows without duplicates.
To return just the duplicate rows whose COUNT(*) is greater than one, you add a HAVING clause as follows:
Code language: SQL (Structured Query Language) (sql)
SELECT fruit_name, color, COUNT(*) FROM fruits GROUP BY fruit_name, color HAVING COUNT(*) > 1;
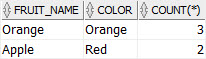
So now we have duplicated record. It shows one row for each copy.
If you want to return all the rows, you need to query the table again as shown below:
Code language: SQL (Structured Query Language) (sql)
SELECT * FROM fruits WHERE (fruit_name, color) IN (SELECT fruit_name, color FROM fruits GROUP BY fruit_name, color HAVING COUNT(*) > 1 ) ORDER BY fruit_name, color;
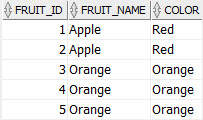
Now, we have all duplicate rows displayed in the result set.
Finding duplicate records using analytic function
See the following query:
Code language: SQL (Structured Query Language) (sql)
SELECT f.*, COUNT(*) OVER (PARTITION BY fruit_name, color) c FROM fruits f;
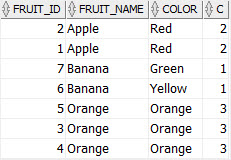
In this query, we added an OVER() clause after the COUNT(*) and placed a list of columns, which we checked for duplicate values, after a partition by clause. The partition by clause split rows into groups.
Different from using the GROUP BY above, the analytic function preserves the result set, therefore, you still can see all the rows in the table once.
Because you can use the analytic function in the WHERE or HAVING clause, you need to use the WITH clause:
Code language: SQL (Structured Query Language) (sql)
WITH fruit_counts AS ( SELECT f.*, COUNT(*) OVER (PARTITION BY fruit_name, color) c FROM fruits f ) SELECT * FROM fruit_counts WHERE c > 1 ;
Or you need to use an inline view:
Code language: SQL (Structured Query Language) (sql)
SELECT * FROM (SELECT f.*, COUNT(*) OVER (PARTITION BY fruit_name, color) c FROM fruits f ) WHERE c > 1;
Now, you should know how to how to find duplicate records in Oracle Database. It’s time to clean up your data by removing the duplicate records.
Was this tutorial helpful?
The following examples return duplicate rows from an Oracle Database table.
Sample Data
Suppose we have a table with the following data:
SELECT * FROM Pets;Result:
PetId PetName PetType ----- ------- ------- 1 Wag Dog 1 Wag Dog 2 Scratch Cat 3 Tweet Bird 4 Bark Dog 4 Bark Dog 4 Bark Dog
The first two rows are duplicates, as are the last three rows. In this case the duplicate rows contain duplicate values across all columns, including the ID column.
Option 1
We can use the following query to see how many rows are duplicates:
SELECT
PetId,
PetName,
PetType,
COUNT(*) AS "Count"
FROM Pets
GROUP BY
PetId,
PetName,
PetType
ORDER BY PetId;Result:
PETID PETNAME PETTYPE Count 1 Wag Dog 2 2 Scratch Cat 1 3 Tweet Bird 1 4 Bark Dog 3
We grouped the rows by all columns, and returned the row count of each group. Any row with a count greater than 1 is a duplicate.
We can order it by count in descending order, so that the rows with the most duplicates appear first:
SELECT
PetId,
PetName,
PetType,
COUNT(*) AS "Count"
FROM Pets
GROUP BY
PetId,
PetName,
PetType
ORDER BY Count(*) DESC;Result:
PETID PETNAME PETTYPE Count 4 Bark Dog 3 1 Wag Dog 2 2 Scratch Cat 1 3 Tweet Bird 1
Option 2
If we only want the duplicate rows listed, we can use the the HAVING clause to return only rows with a count of greater than 1:
SELECT
PetId,
PetName,
PetType,
COUNT(*) AS "Count"
FROM Pets
GROUP BY
PetId,
PetName,
PetType
HAVING COUNT(*) > 1
ORDER BY COUNT(*) DESC;Result:
PETID PETNAME PETTYPE Count 4 Bark Dog 3 1 Wag Dog 2
Option 3
Another option is to use the ROW_NUMBER() window function:
SELECT
PetId,
PetName,
PetType,
ROW_NUMBER() OVER (
PARTITION BY PetId, PetName, PetType
ORDER BY PetId, PetName, PetType
) AS rn
FROM Pets;Result:
PETID PETNAME PETTYPE RN 1 Wag Dog 1 1 Wag Dog 2 2 Scratch Cat 1 3 Tweet Bird 1 4 Bark Dog 1 4 Bark Dog 2 4 Bark Dog 3
The PARTITION BY clause divides the result set produced by the FROM clause into partitions to which the function is applied. When we specify partitions for the result set, each partition causes the numbering to start over again (i.e. the numbering will start at 1 for the first row in each partition).
Option 4
We can use the above query as a common table expression:
WITH cte AS
(
SELECT
PetId,
PetName,
PetType,
ROW_NUMBER() OVER (
PARTITION BY PetId, PetName, PetType
ORDER BY PetId, PetName, PetType
) AS Row_Number
FROM Pets
)
SELECT * FROM cte WHERE Row_Number <> 1;Result:
PETID PETNAME PETTYPE ROW_NUMBER 1 Wag Dog 2 4 Bark Dog 2 4 Bark Dog 3
This returns just the excess rows from the matching duplicates. So if there are two identical rows, it returns one of them. If there are three identical rows, it returns two, and so on.
Option 5
Given our table doesn’t contain a primary key column we can take advantage of Oracle’s rowid pseudocolumn:
SELECT * FROM Pets
WHERE EXISTS (
SELECT 1 FROM Pets p2
WHERE Pets.PetName = p2.PetName
AND Pets.PetType = p2.PetType
AND Pets.rowid > p2.rowid
);Result:
PETID PETNAME PETTYPE 1 Wag Dog 4 Bark Dog 4 Bark Dog
The way this works is, each row in an Oracle database has a rowid pseudocolumn that returns the address of the row. The rowid is a unique identifier for rows in the table, and usually its value uniquely identifies a row in the database. However, it’s important to note that rows in different tables that are stored together in the same cluster can have the same rowid.
One benefit of the above example is that we can replace SELECT * with DELETE in order to de-dupe the table.
Option 6
And finally, here’a another option that uses the rowid pseudocolumn:
SELECT * FROM Pets
WHERE rowid > (
SELECT MIN(rowid) FROM Pets p2
WHERE Pets.PetName = p2.PetName
AND Pets.PetType = p2.PetType
);Result:
PETID PETNAME PETTYPE 1 Wag Dog 4 Bark Dog 4 Bark Dog
Same result as the previous example.
As with the previous example, we can replace SELECT * with DELETE in order to remove duplicate rows from the table.
SELECT *
FROM (
SELECT t.*, ROW_NUMBER() OVER (PARTITION BY station_id, obs_year ORDER BY entity_id) AS rn
FROM mytable t
)
WHERE rn > 1
by Quassnoi is the most efficient for large tables.
I had this analysis of cost :
SELECT a.dist_code, a.book_date, a.book_no
FROM trn_refil_book a
WHERE EXISTS (SELECT 1 from trn_refil_book b Where
a.dist_code = b.dist_code and a.book_date = b.book_date and a.book_no = b.book_no
AND a.RowId <> b.RowId)
;
gave a cost of 1322341
SELECT a.dist_code, a.book_date, a.book_no
FROM trn_refil_book a
INNER JOIN (
SELECT b.dist_code, b.book_date, b.book_no FROM trn_refil_book b
GROUP BY b.dist_code, b.book_date, b.book_no HAVING COUNT(*) > 1) c
ON
a.dist_code = c.dist_code and a.book_date = c.book_date and a.book_no = c.book_no
;
gave a cost of 1271699
while
SELECT dist_code, book_date, book_no
FROM (
SELECT t.dist_code, t.book_date, t.book_no, ROW_NUMBER() OVER (PARTITION BY t.book_date, t.book_no
ORDER BY t.dist_code) AS rn
FROM trn_refil_book t
) p
WHERE p.rn > 1
;
gave a cost of 1021984
The table was not indexed….
В случае, когда несколько столбцов идентифицируют уникальную строку (например, таблицу отношений), вы можете использовать следующие
Использовать идентификатор строки например emp_dept (empid, deptid, startdate, enddate) предположим, что empid и deptid уникальны и идентифицируют строку в этом случае
select oed.empid, count(oed.empid)
from emp_dept oed
where exists ( select *
from emp_dept ied
where oed.rowid <> ied.rowid and
ied.empid = oed.empid and
ied.deptid = oed.deptid )
group by oed.empid having count(oed.empid) > 1 order by count(oed.empid);
и если в такой таблице есть первичный ключ, используйте первичный ключ вместо rowid, например id – pk, затем
select oed.empid, count(oed.empid)
from emp_dept oed
where exists ( select *
from emp_dept ied
where oed.id <> ied.id and
ied.empid = oed.empid and
ied.deptid = oed.deptid )
group by oed.empid having count(oed.empid) > 1 order by count(oed.empid);
