Как найти дубли страниц на сайте и что с ними делать: советы от Яндекса

В блоге для вебмастеров команда Яндекса разместила статью по дублям страниц на сайте, где рассказала, что это такое, как их обнаружить и что можно предпринять.
Дубли – это страницы сайта с одинаковым или практически полностью совпадающим контентом. Среди их негативных последствий отмечают замедление индексирования нужных страниц (робот будет посещать каждую страницу отдельно друг от друга), а также трудности в интерпретации данных веб-аналитики.
Страницы-дубли могут появиться на сайте во время автоматической генерации (CMS сайта создает ссылки не только с ЧПУ, но и техническим адресом), некорректных настроек и ссылок с незначащими GET-параметрами или со слешем на конце и без (например, для поисковой системы сайты https://site.ru/page и https://site.ru/pages/ – это разные страницы).
Искать дубли можно вручную или же положиться на систему Яндекса: в разделе «Диагностика» Вебмастера появилось специальное уведомление о таких страницах.
Далее команда Яндекса привела несколько способов взаимодействия со страницами в зависимости от ситуации:

Изображение: webmaster.yandex.ru
Ознакомиться с данными рекомендациями подробнее можно на этой странице или в Справке Яндекса.

Если человек настраивает сервер, это не новость; новость – если сервер настраивает человека.
Новый подкаст от Timeweb
Рекомендуем


Яндекс рассказал, чем вредны дубли страниц и как их обнаружить на сайте.
Дубли — это страницы сайта с одинаковым или практически полностью совпадающим контентом. Дубли приводят к таким последствиям:
- Замедляется индексирование нужных страниц. Если на сайте много дублей, робот будет посещать все дублированные страницы отдельно друг от друга. Это может снизить скорость обхода страниц, ведь потребуется больше времени, чтобы робот дошёл до нужных страниц.
- Затрудненяется интерпретация данных веб-аналитики. Страница из группы дублей выбирается поисковой системой автоматически, и этот выбор может меняться. Это значит, что адрес страницы-дубля в поиске может меняться с обновлениями поисковой базы, что может повлиять на страницу в поиске (например, узнаваемость ссылки пользователями) и затруднит сбор статистики.
Как обнаружить дубли
Автоматически. Найти дубли теперь можно в разделе «Диагностика». Там появилось специальное уведомление, которое отобразит большую долю дублированных страниц сайта.
Уведомление появляется с небольшой задержкой в 2-3 дня. Причина — на сбор данных и их обработку требуется время. Подписываться на оповещения не нужно, уведомление появится автоматически.
Вручную. Если вы хотите найти дубли вручную, перейдите в Вебмастер. Во вкладке «Индексирование» откройте «Страницы в поиске», нажмите на «Исключённые» в правой части страницы. Прокрутите вниз, в правом нижнем углу увидите опцию «Скачать таблицу». Выберите подходящий формат и загрузите архив. Откройте скачанный файл: у страниц-дублей будет статус DUPLICATE.
Как оставить в поиске нужную страницу

В случае с «мусорными» страницами воспользуйтесь одним из способов:
- Добавьте в файл robots.txt директиву Disallow, и страница-дубль не будет индексироваться.
- Запретите их индексирование при помощи мета-тега noindex. Тогда поисковой робот исключит эти страницы из базы по мере их переобхода.
- Настройте HTTP-код ответа 403/404/410. Данный метод менее предпочтителен, так как показатели недоступных страниц не будут учитываться, и если где-то на сайте или в поиске еще есть ссылки на такие страницы, пользователь попадет на недоступную ссылку.
В случае со страницами-дублями воспользуйтесь одним из способов:
- Для дублей с незначащими GET-параметрами добавьте в файл robots.txt межсекционную директиву Clean-param. Она будет обрабатываться в любом месте файла robots.txt. Указывать её для роботов Яндекса при помощи User-Agent: Yandex не требуется. Но если вы хотите указать директивы именно для наших роботов, убедитесь, что для User-Agent: Yandex указаны и все остальные директивы — Disallow и Allow. Если в robots.txt будет указана директива User-Agent: Yandex, наш робот будет следовать указаниям только для этой директивы, а User-Agent: * будет проигнорирован.
- Установите редирект с HTTP-кодом 301 с одной дублирующей страницы на другую. В этом случае в поиске будет участвовать цель установленного редиректа. Укажите предпочитаемый (канонический) адрес страницы, который будет участвовать в поиске.
- Используйте атрибут rel=«canonical». При работе с атрибутом rel=«canonical» учитывайте, что если содержимое дублей имеет некоторые отличия или очень часто обновляется, то такие страницы все равно могут попасть в поиск из-за различий в этом содержимом. В этом случае рекомендуем использовать варианты выше.
Подробнее о работе со страницами-дублями читайте в Справке.
В наших новостях всегда есть немного больше, чем у других. Подпишитесь на канал в Телеграм и читайте интересные новости первыми.
Подписаться
Полное руководство от Яндекса: Поиск и устранение дублей сайта
- 16.03.2018
-
Eye
4 695 -
Chatbubbles
0 -
Categories
SEO, Яндекс

- Причины появления дублей
- Поиск дублей
- Устранение дублей
- Ответы на вопросы
Для начала посмотрим, в чем же заключается опасность дублирующих страниц на сайте, попробуем найти дубли на ресурсе и их устранить для того, чтобы в будущем они не появлялись.
Опасность дублей на сайте
Перед тем как говорить о дублях, хочется дать определение, что же такое дублирующая страница сайта. Под дублями мы понимаем несколько страниц одного ресурса, который содержит в достаточной мере идентичный текстовый контент. Хочу обратить ваше внимание, что речь мы ведем только об одном ресурсе и говорим о текстовом контенте в том плане, что подразумеваем, что робот при определении дублирующих страниц смотрит только на текстовое содержимое страниц вашего сайта. Он не проверяет дизайн, либо изображение на данных страничках, а смотрит только на текст. В большинстве случаев дублирующие страницы – это одна и та же страница сайта, доступная по нескольким адресам.
Причины появления дублей
Причин появления дублей на сайте огромное количество.

Все они связаны с различными ошибками. Например, ошибки в содержимом страниц, когда некорректно указаны относительные ссылки, ошибки, связанные с отсутствием, либо недостаточным количеством текста на страницах, некорректные настройки 404 кода ответа, либо доступность служебных страниц сайта, либо особенности работы CMS, которую вы используете. Это большое количество дублирующих страниц зачастую гнетет вебмастеров, и они откладывают работу над дублями в долгий ящик и не хотят этим заниматься.
Проблемы, к которым приводят дубли
Но на самом деле делать этого не стоит, поскольку наличие дублей может привести к различным проблемам. Их можно разделить на три большие группы:
- Во-первых, это смена релевантной страницы в результатах поиска.
- Во-вторых, обход роботом большого количества дублирующих страниц вместо того, чтобы индексировать нужные странички сайта.
- И, в-третьих, это проблема со сбором статистики на вашем ресурсе.
Давайте рассмотрим более подробно каждую проблему.
Смена релевантной страницы

Я взял сразу пример из практики. На сайте есть страничка с бухгалтерскими услугами, которая доступна по двум адресам. Первый адрес находится в разделе «услуги», а второй адрес – это страничка в корне сайта. Контент данных страничек абсолютно одинаков. Поскольку робот не хранит в своей базе сразу несколько идентичных документов, он выбирает самостоятельно страницу для включения в поисковую выдачу. Кажется, что, по сути, не должно произойти ничего плохого, ведь странички абсолютно похожи между собой. Но вы же опытные вебмастера и знаете, что позиции конкретной страницы по запросам рассчитываются на основании нескольких сотен показателей. Поэтому при смене страницы в поисковой выдаче ее позиции могут измениться.

Как произошло и в нашем случае. По конкретному запросу «услуги бухгалтерского отчета» видно, что в середине июня произошло проседание позиций. Это как раз связано с тем, что сменилась релевантная страница в поисковой выдаче и спустя несколько дней, в районе 19 сентября, позиции восстановились, поскольку в поиск вернулась нужная страница сайта, который участвовал в выдаче до этого. Согласитесь, даже такое небольшое изменение позиций сайта может очень сильно повлиять на трафик, на ваш ресурс.
Обход дублирующих страниц

Вторая причина, по которой необходимо бороться с дублями, связана с тем, что робот начинает посещать большое количество дублирующих страниц. Поскольку количество запросов со стороны индексирующего робота ограничено, например, производительностью вашего сервера или CMS, вами с помощью директивы Crawl-delay, а также роботом, то при большом количестве дублирующих страниц начинает скачивать именно их вместо того, чтобы индексировать нужные вам страницы сайта.

В результате, в поисковой выдаче могут показываться неактуальные данные, и пользователи, переходя на ваш ресурс, не будут видеть информацию, которую вы размещали на сайте.

Тоже пример из практики по обходу дублирующих страниц. Очень большой интернет-магазин, где видно, что до конца мая робот каждый день скачивал чуть меньше 1 миллиона страниц с сайта. После обновления ресурса и внесения изменений на сайт видно, что робот резко увеличил нагрузку на ресурс и начал скачивать несколько миллионов страниц. Огромные цифры.

Если посмотреть, что именно скачивает индексирующий робот, то можно увидеть, что большое количество – этот желтый пласт, несколько десятков миллионов – это как раз дублирующие страницы. Их примеры можно будет посмотреть ниже:

Это страницы с некорректными параметрами, get параметрами в URL-адресе. Такие странички появились из-за некорректного обновления CMS, используемой на сайте.
Затруднение сбора статистики

И третья проблема, к которой могут привести дублирующие страницы – это проблемы со сбором статистики на вашем сайте. Например, в Яндекс. Вебмастере, либо в Яндекс. Метрике.

Если говорить о Яндекс. Вебмастере, то в разделе «Страницы в поиске» вы можете наблюдать такую картину. При каждом обновлении поисковой базы количество страниц в поиске остается практически неизменным, но видно, что робот на верхнем графике при каждом добавлении, добавляет и удаляет примерно одинаковое количество страниц. Происходит процесс, постоянно что-то добавляется/удаляется, но при этом в поиске количество страниц остается неизменным. Странная ситуация.
Смотрим раздел «Статистика обхода»:

Ежедневно робот посещает несколько тысяч новых страниц сайта. Это только новые страницы. При этом данные страницы при поисковой выдаче, как видно на графике ниже, опять-таки не попадают. Это опять же связано с обходом дублирующих страниц, которые потом в поисковую выдачу не включаются.

Если вы используете Яндекс. Метрику для сбора статистики посещаемости конкретной страницы, то может возникнуть следующая ситуация. Данная страница показывалась ранее по конкретному запросу и на нее были переходы из результатов поиска. Но видно, что в начале мая данные переходы прекратились. Страничка перестала показываться по запросам посетителей, пользователей поисковой системы перестали переходить по ней. Что же произошло на самом деле? В поисковую выдачу включилась дублирующая страница и пользователи поиска переходят именно на нее, а не на нужную страницу, за которой вы наблюдаете с помощью Яндекс. Метрики.
Проблемы, к которым приводят дубли
В результате три больших проблемы, к которым могут привести дублирующие страницы вашего сайта:
- Это смена релевантной страницы.
- Обход дублирующих страниц вместо нужных.
- Проблемы со сбором статистики
Согласитесь, три больших проблемы, которые должны вас как-то мотивировать к работе над дублирующими страницами сайта. Но чтобы что-то предпринять, сначала нужно найти дубли найти. Об этом следующий раздел.
Поиск дублей
Если немножко изменить довольно-таки популярный диалог, получилось бы следующее: «Видишь дублирующие страницы? – Нет. – И я нет, а они есть». Так же на самом деле, практически на каждом ресурсе в Интернете есть дублирующие страницы, осталось их только найти.
Источник для поиска дублей «Страницы в поиске»
Начнем с самого простого способа, будем искать дубли с помощью раздела «Страницы в поиске» в Яндекс. Вебмастере.

Всего 4 клика, с помощью которых можно увидеть все дублирующие страницы на вашем ресурсе. Первый клик – заходим в раздел «Страницы в поиске», переходим на вкладку «Исключенные страницы»:

Выбираем сортировку и нажимаем кнопку «применить»:
В результате чего на нашем экране видны все страницы, которые исключил робот из поисковой выдачи, поскольку посчитал дублирующими.
Согласитесь, очень легко, 4 клика, быстро, понятно и вот все дублирующие страницы с вашего ресурса удалены.
Если таких дублирующих страниц много, как в нашем случае их несколько десятков тысяч, можно полученную таблицу скачать в Excel’евском формате, либо CSV’шном и дальше использовать в своих интересах. Например, собрать какую-то статистику, посмотреть списком все страницы, которые исключил индексирующий робот.
Источник для поиска дублей «Статистика обхода»

Второй способ – это раздел «Статистика обхода». Соседний раздел, переходим в него, смотрим, что посещает индексирующий робот.

Внизу раздела можно включить сортировку по 200 коду и видно, какие страницы доступны для робота и какие страницы посещает робот. В этом разделе можно увидеть не только дублирующие страницы, но и различные служебные страницы сайта, которые так же индексировать не хотелось бы.
Источник для поиска дублей «Ваша фантазия»

Третий способ посложнее и вам нужно будет применить свою фантазию. Берем любую страницу на вашем сайте и добавляем к ней произвольный get-параметр. В данном случае к странице добавили параметр test со значением 123. Используемый инструмент – «проверка ответа сервера», нажимаем кнопку «Проверить» и смотрим код ответа от данной страницы. Если такая страница доступна, как в нашем случае, отвечает кодом ответа 200, это может привести к появлению дублирующих страниц на вашем сайте. Например, если робот найдет такую ссылку где-то в Интернете, он проиндексирует и потенциально страница может стать дублирующей, что не очень хорошо.
Источник для поиска дублей «Проверить статус URL»

И четвертый способ, с которым я надеюсь вы никогда не столкнетесь после сегодняшнего вебинара – это инструмент «Проверить статус URL». В ситуации, если нужная вам страница уже пропала из результатов поиска, вы можете использовать этот инструмент, чтобы посмотреть по каким причинам это произошло. В данном случае видно, что страница была исключена из поисковой выдачи, поскольку дублирует уже представленную в поиске страницу сайта, и вы видите соответствующую рекомендацию.
Источник для поиска дублей

Четыре простых способа, которые может использовать каждый вебмастер, каждый владелец сайта с помощью сервиса Яндекс. Вебмастер. Кажется, все очень легко и просто, я думаю, что никаких проблем у вас не возникнет. Но помимо этих четырех способов вы можете использовать свои способы, например, посмотреть логи вашего сервера, к каким страницам обращается робот и посетители, посмотреть статистику Яндекс. Метрики, а также поисковую выдачу. Возможно, там получится найти дублирующие страницы вашего ресурса.
После того, как мы нашли дубли, с ними нужно что-то делать, каким-то образом работать. Об этом следующий раздел.
Устранение дублей

Все дубли можно разделить на две большие группы:
- Это явные дубли. Это страницы одного сайта, которые содержат абсолютно идентичный контент.
- Это неявные дубли. Это страницы с похожим содержимым одного сайта.
Внутри этих больших групп представлено огромное количество видов конкретных дубей. Сейчас мы с вами обсудим каким образом можно их устранить.
Дубли: со слэшом в конце и без

Самый простой вид дублей – это страницы со слэшом в конце адреса и без слэша, как указано в нашем примере. Самый простой вид дублей и, естественно, простое их решение, устранение этих дублей. Для таких дублирующих страниц мы советуем использовать 301 серверное перенаправление с одного типа адресов на другой тип страниц. Вы спросите, а какие страницы нужно оставить для робота?
Здесь решение принимать только вам. Вы можете посмотреть результаты поиска и увидеть какие именно страницы вашего сайта присутствуют в поисковой выдаче на данный момент. Если сейчас индексируются и участвуют в поиске страницы без слэша, соответственно, со страниц со слэшом можно установить перенаправление на нужные вам. Это прямо укажет роботу на то, какие именно страницы нужно индексировать и включать в поисковую выдачу. Настроить редирект можно разными способами – с помощью служебного файла htaccess, либо в настройках CMS выбрать формат адресов.
Дубли: один товар в двух категориях

Второй вид дублей – это один и тот же товар, который находится в нескольких категориях. В данном случае у нас товар – мяч, он доступен по адресу с категорией, игрушки/мяч и доступен так же в корневой папке вашего сайта. Для робота, поскольку эти страницы абсолютно одинаковые, это как раз дубли. В такой ситуации я советую вам использовать атрибут rel=” canonical” с указанием адреса канонической страницы, ту страницу, которую необходимо включать в поисковую выдачу. Это будет прямое указание для робота, и в поиске будет участвовать именно нужный вам адрес.
Какой адрес выбирать? В такой ситуации стоит подумать о посетителях вашего сайта. Посмотрите, какой формат адресов будет удобен и поможет им лучше ориентироваться на вашем сайте при просмотре адресов, понимать, в какой категории, например, они находятся.
Дубли: версии для печати
Следующий пример дублирующих страниц – это страницы «Версии для печати»:

В качестве примера я взял страницу одного сайта, в котором собраны тексты песен. Видно, что с левой стороны у нас версия для обычных пользователей с дизайном, с фоном, со стилями, а с правой стороны – версия для печати для того, чтобы было удобно распечатать эту страничку на принтере. Поскольку данные страницы доступны по разным адресам, потенциально для робота они тоже дублирующие, потому что текстовое содержимое данных страниц абсолютно похожее.

Для подобных страниц, для того, чтобы дублирование в случае их наличия не возникло, я вам советую использовать запрет в файле robots.txt. Например, как в нашем случае запрет Disallow: /node_print.php* укажет роботу на то, что все страницы по подобным адресам индексировать нельзя. Одно простое правило позволит вам избежать проблем с дублирующими страницами.
Дубли: незначащие параметры
Следующий вид дублей – это страницы с незначащими параметрами.

Незначащие параметры – это те get-параметры в URL-адресе ваших страниц, которые совсем не меняют их содержимое. Посмотрим пример, который я взял. У нас есть страница без параметров – это страничка page, есть вторая страница с utm-метками, например, они используются в рекламных компаниях и есть страничка с параметрами идентификатора сессии, например, если у вас Foon. Поскольку эти параметры абсолютно не меняют контент страницы, для робота это дублирующие страницы сайта.
Для таких ситуаций у нас есть специальная директива Clean-param. Она так же располагается в файле robots.txt и в ней можно перечислить все незначащие параметры, которые используются на вашем сайте. В данном случае у нас два параметра: utm_source и sid. Указали их в директиве Clean-param. Эта директива поможет роботу не только указать на то, что данные параметры являются незначащими, но и укажет роботу на то, что на вашем сайте есть страницы по чистому адресу, без данных get-параметров. Если она была роботу ранее неизвестна, он придет и специально скачает страничку по чистому адресу и включит ее в поисковую выдачу.
Такая сложная логика, но эта логика позволит вам избежать проблем и ситуаций, а нужные вам странички по чистым адресам будут всегда присутствовать в поисковой выдаче. Чего не будет происходить, если вы используете запрет, как указано в примере ниже. В данном случае робот не узнает, что на вашем сайте есть такие страницы по чистым адресам. Поэтому для незначащих параметров используйте директиву Clean-param.
Дубли: страницы действий
Очень близко по смыслу это страницы действий на вашем сайте.

Например, если пользователь на вашем ресурсе добавляет товар в корзину, либо сравнивает его с другими товарами, возможно, перемещается по страницам с комментариями, добавляются дополнительные служебные параметры, которые характеризуют действия на вашем сайте. При этом контент на таких страницах может совсем не меняться, либо может меняться совсем незначительным способом.
Чтобы робот совсем не посещал такие страницы, не добавлял их в свою базу, для данных случаев советую использовать запрет в файле robots.txt. Вы можете перечислить в директиве Disallow по отдельности каждый из параметров, который характеризует действия на сайте, либо, если совсем не хотите, чтобы страницы с параметрами индексировались, используйте правила, которые указаны ниже. Одно такое правило позволит сразу избежать возможных проблем из-за наличия таких страниц действий.
Дубли: некорректные относительные адреса

В случае, если на вашем сайте, как в примере, о котором ранее я говорил, в интернет-магазине появились некорректные относительные адреса, то, примерно, у вас возникнет следующая ситуация. У вас одна и та же страничка, например, как наш мячик, будет находиться в разделе игрушки/мяч, так и станет доступна по большому количеству вложенностей этой категории. В данном случае – несколько раз повторяется категория «игрушки» и потом «мяч». И в конце обычные пользователи, и роботы видят товар, который находится на исходном адресе.
Во-первых, чтобы побороть такие страницы, стоит разобраться с причинами их появления. Просмотреть исходный код страниц вашего сайта и проверить, корректно ли вы используете относительные ссылки на вашем ресурсе. После того, как ошибку нашли, настройте возврат 404 кода на запрос индексирующего робота к таким страницам. Это сразу позволит избежать дублирования информации.
Дубли: похожие товары
Следующий вид дублей, он же относится и к неявным дублирующим страницам – это похожие товары.

Как правило, в интернет-магазинах один и тот же товар доступен в нескольких вариантах. Например, разного размера, цвета, мощности, все, что угодно. В большинстве случаев такие товары доступны по отдельным URL-адресам. Что, естественно, затрудняет работы индексирующего робота, поскольку, по сути, эти странички практически ничем не отличаются, поэтому для таких страниц я советую использовать один URL-адрес, по которому сразу можно выбрать варианты исполнения данного товара, размер, либо цвет.
Это позволит не только роботу хорошо ориентироваться на вашем ресурсе и позволит избежать дублирования информации, но и облегчит посетителям переходы по страничкам. Не нужно будет возвращаться обратно в каталог, выбирать нужный вариант, вы можете установить селектор, и ваши пользователи на одной странице смогут сразу выбрать тот вариант, который им нужен.
Если такой возможности нет, нет возможности разместить этот селектор, вы можете добавить на такие страницы, на страницы с вариантами, дополнительное какое-то описание, расписать, почему такая мощность и для каких вариантов она подходит, почему такой цвет лучше, чем другой цвет, может быть, оттенками отличается. Добавить различные отзывы покупателей, которые купили именно тот или иной вариант цвета. Так же вы можете закрыть с помощью тега noindex служебные текстовые части страниц. Это укажет роботу на то, что контентная страница на самом деле отличается и нужно в поисковую выдачу включать оба или несколько вариантов страниц.
Дубли: фото без описания
Очень похожие по смыслу – это страницы с фотографиями без описаний.
Например, если у вас фотогалерея, либо фотобанки. Что делаем для таких страниц? Добавляем либо какое-то текстовое описание, либо различные теги, которые будут характеризовать фотографию, которая размещена на страничке.
Дубли: фильтры и сортировки

Давайте к следующему варианту дублей – это страницы фильтров и сортировки. Например, когда на вашем сайте в каталоге можно отсортировать товары по цене, размеру, материалу. Для начала, при работе над такими страницами нужно подумать, полезны ли они пользователям поисковой системы или нет, в достаточной ли мере хорошо они отвечают на конкретные запросы пользователей.
Например, если у вас есть страница с сортировкой дешевых кондиционеров, а пользователи как раз и ищут дешевые кондиционеры, конечно, такие страницы стоит оставить доступными, они будут полезны пользователям поисковой системы. Если такие странички не нужны, я советую вам их запрещать в файле robots.txt. Как в примере ниже, страницы всей сортировки, размеров и фильтрации запретили с помощью директив Disallow. Это оставит для робота только нужные страницы вашего сайта, что ускорит их индексирование.
Дубли: страницы пагинации

Очень близко по смыслу – это страницы пагинации.
Но рекомендации здесь другие. Если ваш каталог достаточно большой и у вас много различных товаров, вы, скорее всего, используете пагинацию для того, чтобы пользователям было удобнее ориентироваться в каталоге и не видеть сразу все товары, представленные на вашем сайте. В таком случае мы рекомендуем размещать атрибут real=”canonical” с указанием канонической страницы, в данном случае это первая страница каталога, которая будет индексироваться и помазываться в поисковой выдаче. Пользователи, переходя из поиска, так же будут попадать на заглавную стартовую страницу конкретного раздела вашего каталога.
Как работать с дублями

При работе над дублями обязательно:
- Не недооцениваете риски, к которым могут привести дублирующие страницы на вашем сайте.
- Нашли дубли в Яндекс. Вебмастере, применили к ним различные изменения на вашем ресурсе, чтобы дубли в последующем не появлялись в поисковой выдаче.
- Следить за дублирующими страницами вы так же можете в разделе «Страницы в поиске», а с помощью инструмента «Важные страницы» можно смотреть за статусом наиболее востребованных страниц вашего сайта, что тоже очень полезно для того, чтобы моментально отреагировать на появление дублирующих страниц.
Полезное:
- Настройка индексирования сайта в Яндексе: от теории к практике
- Как поиск находит страницу сайта? Описание процесса индексации страниц сайта
Ответы на вопросы
«Если для пагинации задействовать real canonical, то как узнает робот о товарах на страницах далее первой?».
Неканонические страницы посещаются индексирующим роботом. Он же действительно должен узнать о товарах на таких страничках. Поэтому не переживайте, на индексирование товаров, которые размещены на второй, третьей и далее страницах пагинации, робот обязательно узнает, проиндексирует.
«У нас на сайте есть раздел с пресс-релизами. После публикации пресс-релиза на нашем сайте, мы размещаем тот же пресс-релиз на других ресурсах в Интернете. В результате страницы с пресс-релизом на нашем сайте получают статус недостаточно качественных, а пресс-релиз на спец. ресурсах нормально появляется в выдаче. Как сделать, чтобы текст нашего пресс-релиза был в поиске с нашего сайта и со специального сайта агрегатора?».
Во-первых, под дублями мы понимаем две странички одного и того же ресурса. В вашем случае речь идет о страницах абсолютно разных сайтов. Посмотрите, насколько ваша страница удобна для пользователей поисковых систем. Действительно текстовое содержимое агрегатора и вашего сайта может быть абсолютно одинаковым, но посмотрите, чем отличается навигация. Возможно, вам стоит пересмотреть навигацию, либо добавить более полезный и интересный материал для ваших пользователей: смежные темы, разделы, какую-то дополнительную информацию. Возможно, пользователи выбирают агрегатор по той причине, что на нем можно сразу увидеть смежные категории или смежную информацию.
«У какого параметра выше приоритет – Clean-param или у Disallow? Если присоединить Disallow, а потом Clean-param, что будет работать?»
Будет работать Disallow, потому что он запрещает индексировать роботу конкретные страницы. Он даже не будет совсем к ним обращаться. В зависимости от того, какой у вас дубль или какие служебные параметры вы используете. Выбирайте либо первый, либо второй вариант.
«Является ли дублем страница с одинаковым набором get-параметров, но расположенных в разном порядке?».
Да, для робота такие страницы могут быть дублирующими.
«У меня интернет-магазин, в котором около пяти миллионов страниц, в поиске примерно 500 тысяч и 1,5 миллиона дублей. Дубли в нашем случае появляются из-за использования get параметров и огромного количества utm меток. Я закрываю их в robots.txt, уходит из индекса, но опять появляется. А бывает и так, что очень многие не уходят из индекса, хотя в robots.txt были запрещены. Как часто робот обходит файл robots.txt, почему такие задержки и неучтенные директивы Disallow?».
Давайте начнем с конца вопроса. Файлик robots.txt индексирующий робот обновляет примерно два раза в сутки, поэтому о внесенных вами правилах он узнает достаточно быстро. В поисковой выдаче те изменения, которые вы внесли, применяются в течение недели-полутора, в зависимости от частоты обновления поисковой базы. Если даже по прошествии этого времени робот все равно включает запрещенные страницы в поисковую выдачу, проверьте, а действительно ли запрет установлен корректно. В Яндекс. Вебмастер есть инструмент «Анализ робота robots.txt», укажите в нем адрес вашего сайта и проверьте, а действительно ли запрет установлен корректно.
«Что делать, если за дубль страниц робот принимает схожие товары. Отличия title и заголовков, но схожее описание. Неужели нужно уникализировать каждый товар? Что делать, если их тысячи?».
Как раз это примеры, которые я вам говорил во время презентации. Посмотрите, если вам сложно уникализировать товар всю тысячу вариантов или вариаций, начните с того, какие товары у вас лучше продаются на сайте, которые будут полезнее вам в поисковой выдаче. Например, наиболее распространенный вариант товара или какая-то позиция, которая лучше всего продается. Начните писать уникальные описания для таких страниц, продолжите постепенно по уменьшению популярности. Возможно, вам не нужны все тысячи страниц в результатах поиска, возможно, их никто не ищет и вам нужно написать всего несколько десятков хороших описаний для товаров. Так же, как вариант, вы можете запретить общие фрагменты на странице с помощью тега noindex, чтобы робот увидел, что их текстовый контент действительно отличается.
«Есть ли разница для поискового робота, когда проблема дублей решается с помощью 301 редиректа или rel canonical? Что лучше?».
Как я говорил, в зависимости от ситуации лучше тот или второй вариант.
«Повторите, пожалуйста, для чего нужен clean-param в случае незначащих параметров».
Clean-param нужен в случае незначащих параметров. В чем его отличительная особенность? Индексирующий робот, если сталкивается со страницами с незначащими параметрами и видит директиву Clean-param, идет в свою внутреннюю базу и проверяет наличие страницы по чистому адресу, без данных параметров в адресе. Если такая страница не проиндексирована по каким-то причинам, он старается ее проиндексировать и в случае успеха включает именно ее в поисковую выдачу. Страницы с незначащими параметрами в поиск не попадают
«Что посоветуете по настройке индексации форумов? Что стоит запретить, разрешить? По моим наблюдениям, робот активно индексирует одну-две страницы форума и не особо индексирует последующие. Так ли это?».
На самом деле для робота это совсем разные странички, страницы пагинации на форуме. Для форума такие страницы стоит оставить, потому что их содержимое отличается, разные сообщения на первой и второй странице пагинации. По поводу запретов, на одном из предыдущих вебинаров я рассказывал, что именно стоит запрещать к индексированию на этих сайтах. Это так же применимо и к форумам – все служебные страницы, страницы фильтров, сортировки.
«После исправления дублей как быстро обновиться информация у вебмастера на странице в поиске?».
Обычно изменения начинают происходить в течении недели после внесения изменений на ваш сайт. Робот начинает отслеживать эти изменения, в поиске они проявляются в течении недели.
«Подскажите, пожалуйста, изначально не могли определиться с тем, как описать URL-адреса – транслитом или кириллицей. В итоге была выбрана кириллица и все URL были на ней. В итоге поняли, что для нас будет лучше перейти на транслит и переделали все URL-адреса на транслит. В поисковых запросах выделяются страницы с кириллицей в URL и с транслитом. URL кириллицы определяется, как 404 и перекидывает на главную страницу сайта. Являются ли эти страницы дублями и удалит ли их робот из поисковых запросов?».
Поскольку контент таких страниц отличается, по одним адресам у вас страницы 404 может быть. С содержимым главной страницы, а по другим – действительно нужные странички вашего сайта, то такие страницы не будут считаться дублирующими страницами. Немножко отойдя от темы, я советую вам в будущем, при смене формата адресов страниц на сайте, использовать 301 серверный редирект со старых страниц на новые страницы.
«Насколько плохо, если страница имеет глубину вложенности 6?».
На самом деле ничего плохого в этом нет. Но нужно понимать, что, в случае, если на вашем сайте нет файла Sitemap, а роботу для того, чтобы узнать о наличии этой странички с 6 уровнем вложенности нужно будет скачать 5 других страниц вашего сайта, чтобы узнать о ее наличии. Поэтому в принципе ничего плохого нет, но смотрите за тем, чтобы файлик Sitemap с такой страницей был у вас и робот знал об этом файле.
«Одна и та же статья в основном домене и поддомене рассматривается как дубли?».
Нет, дублирования в данном случае нет.
«Якоря дублями не считаются, так как поддержка мне отписывала когда-то, что они не учитывают такие параметры».
Да, если вы используете именно анкоры в url-адресах, они дублирующими считаться не будут. Для робота это один и тот же адрес страницы.
Источник (видео): Поисковая оптимизация сайта: ищем дубли страниц
Материал адресован предпринимателям и маркетологам, которые хотят сами контролировать состояние сайта, а также проверять работу SEO-подрядчика. Далеко не всегда нужно знать HTML, чтобы успешно склеивать и удалять дубли страниц. Понимание того, как работает система, позволяет сформулировать грамотное техзадание программисту.
Дубли — это страницы сайта, контент которых полностью или частично совпадает. По сути, дубли — это полные или частичные копии страниц, доступные по уникальным URL-адресам.
Дублированный контент — массовая проблема. Считается, что до трети всех сайтов содержит дубли.
Какие бывают дубли страниц на сайте
Дубли бывают полными, когда по разным URL-адресам доступны абсолютно идентичные страницы, и частичными. Во втором случае контент страниц совпадает на 80% и более. Поисковые системы расценивают такие страницы как неуникальные и объединяют их в так называемый дублирующий кластер.
Пожалуй, нет предпринимателей, маркетологов, SEO-специалистов и вебмастеров, которые бы не сталкивались со следующими типами полных дубликатов:
Одна и та же страница по адресу с «WWW» и без «WWW»:
https://site.ru
https://www.site.ru
Дубли страниц с протоколами HTTP и HTTPS:
http//site.ru
https//site.ru
Дубли со слешем (слешами) на конце или в середине URL и без:
https//site.ru/page
https//site.ru/page/
https//site.ru/page//
https//site.ru///page
Дубли главной страницы с различными приписками на конце URL:
https://site.ru/index
https://site.ru/index.php
https://site.ru/index.html
https://site.ru/home.html
https://site.ru/index.htm
https://site.ru/home.htm
https://site.ru/default.asp
https://site.ru/default.aspx
Страница доступна по URL-адресам в верхнем и нижнем регистрах:
https//site.ru/page
https//site.ru/PAGE
https//site.ru/Page
Дубли с нарушениями в иерархии URL-адресов. К примеру, товар доступен по нескольким разным URL:
https://site.ru/category/tovar
https://site.ru/tovar
https://site.ru/category/dir/tovar
https://site.ru/dir/tovar
Дубли с добавлением произвольных вложенностей или символов в URL-адрес:
https://site.ru/page/blablabla
https://site.ru/blablabla/page
https://site.ru/pageblablabla
На месте blablabla может стоять случайный набор цифр и латинских символов.
Дубли с добавлением «звездочки» в конце URL:
https://site.ru/page/
https://site.ru/page/*
Дубли с заменой дефиса на нижнее подчеркивание или наоборот:
https://site.ru/category/tovar-001
https://site.ru/category/tovar_001
Дубли, возникающие из-за добавления в URL-адрес дополнительных параметров и меток:
URL-адреса с GET-параметрами. С помощью GET-параметров вебмастер адаптирует контент страницы под конкретного пользователя. Область применения: интернет-магазины, форумы, отзовики. GET-параметры в адресе расположены после символа «?» и разделяются символом «&». Например, в адресе https://site.ru/?top=1 GET-параметр top имеет значение 1. Если GET-параметр влияет на содержание страницы — это не дубль. А если GET-параметр не меняет контент страницы, то этот параметр называют незначащим, и страницу стоит скрыть от поиска. Примеры адресов с незначащими GET-параметрами:
https://site.ru/index.php?example=15&product=40
https://site.ru/index.php?example=40&cat=15
URL-адреса с UTM-метками. UTM-метки могут иметь вид https://www.site.ru/?utm_source=yandex&utm_medium=cpc Они помогают системам аналитики отслеживать параметры трафика. Несмотря на то, что страницы с UTM не должны индексироваться поисковыми машинами, нередко в выдаче встречается полный дубль страницы с UTM-меткой.
URL-адреса с метками GCLID (Google Click Identifier). Метки позволяют сервису Google Analytics отследить действия посетителей, которые перешли на сайт по рекламному объявлению. Адрес перехода может выглядеть так: https://site.ru/?gclid=blablabla, где blablabla — определенный набор символов.
URL-адреса с метками YCLID. Метки отслеживают эффективность рекламных кампаний в Яндекс Метрике. Адрес перехода может выглядеть так: https://site.ru/?yclid=blablabla (набор цифр)
URL-адреса с метками OPENSTAT. Это универсальные метки, которые применяют для анализа эффективности рекламы, посещаемости и поведения пользователей на сайте. Пример, как может выглядеть ссылка: https://site.ru/?_openstat=blablabla
Дубли, сгенерированные реферальной ссылкой. С помощью реферальных ссылок сайты распознают, от кого пришел новый посетитель. Вид ссылки может быть такой: https://site.ru/register/?refid=blablabla Когда пользователь переходит по URL с параметром «?ref=…», должно происходить перенаправление на URL-адрес без параметра, но разработчики часто забывают сделать эту настройку.
Распространенные типы частичных дублей:
Карточки (страницы) похожих товаров. Актуально для интернет-магазинов и маркетплейсов, где товары отличаются только определенными характеристиками (цветом, размерами, материалом). В итоге карточки имеют практически одинаковый контент. Решением будет объединить близкие товары на одной странице и добавить селектор для выбора характеристик. Либо — уникализировать описания товаров на их карточках.
Страницы результатов поиска по сайту. Этот тип страниц опасен тем, что пользователи могут сгенерировать большое количество подобных страниц за короткий промежуток времени.
Дубли, возникающие при пагинации, сортировке, фильтрации контента. Содержимое таких страниц, включая заголовок и описание, может оставаться неизменным, меняется только порядок размещения элементов:
https://site.ru/category/ (целевая страница)
https://site.ru/category/?price=low (страница-дубль с сортировкой по убыванию цены)
https://site.ru/category/?price=high (страница-дубль с сортировкой по возрастанию цены)
Региональные версии страниц. При выборе региона на странице изменяются адрес, номер телефона, название города, заголовок, но основной контент не меняется, и такие страницы поисковики могут расценить как дубли.
Версии для печати или скачивания в PDF, например:
https://site.ru/category/tovar1
https://site.ru/category/tovar1/print
https://site.ru/category/tovar1/pdf
Страницы отзывов и комментариев, когда при выборе соответствующей вкладки на странице товара, происходит добавление параметра в URL-адрес, но сам контент фактически не меняется, а просто открывается новый таб.
Встречается комбинирование в URL-адресах описанных выше вариантов.
Откуда берутся дубли страниц
Полные и частичные дубликаты страниц часто возникают из-за особенностей работы CMS. Дубли могут автоматически генерироваться при добавлении в адрес GET-параметров и меток.
Человеческие ошибки также приводят к копированию страниц на сайте, например:
- контент-менеджер один и тот же товар поместил в несколько категорий, и теперь карточка товара доступна по разным URL-адресам;
- вебмастер изменил структуру сайта — существующим страницам присвоил новые URL, но они остались доступны и по старым адресам;
- вебмастер допустил ошибку в директивах robots.txt, в настройке 301 редиректов или страницы 404.
Отдельный случай — смысловые дубли, когда разные страницы сайта конкурируют за одни и те же поисковые запросы. Эта ошибка возникает из-за неправильной кластеризации семантики.
Чем опасно дублирование страниц на сайте
Коварство дублей в том, что пользователю они не мешают получить нужную информацию. Зато с точки зрения SEO дубли страниц представляют серьезную опасность.
Прежде всего — поисковые машины могут неправильно идентифицировать релевантную страницу.
Посмотрите на картинку и скажите, какой из трех плодов более релевантен запросу «зеленое яблоко».

Согласитесь, ответить не просто. Все объекты — яблоки, и они зеленые. Они одинаково релевантны запросу, а выбрать нас просят один.
В таком же затруднительном положении оказывается поисковая машина, когда ей нужно выбрать из двух, трех или более копий одну страницу и показать ее в результатах поиска. Не удивительно, что поисковик «колеблется», «меняет мнение» — дубли скачут в выдаче.
Трафик разделяется. В итоге ни одна из конкурирующих страниц не накапливает достаточно метрик для закрепления в топе. Лишь со временем одна страница станет ранжироваться, а другие будут размечены как дубли.
Другой негативный эффект — посадочные страницы недополучают ссылочную массу. Посетители, встречая в результатах поиска не оригинальную страницу, а дубликат, начинают ссылаться на него. Результат — посадочная страница теряет естественную ссылочную массу.
Страдает скорость обхода и индексирования. Когда на сайте много дублей, роботы тратят больше времени на их обход, вместо того, чтобы сканировать ценный контент. А значит, посадочные страницы сайта будут медленнее попадать в поиск.
Сами по себе дубли страниц не являются причиной пессимизации сайта — но лишь до тех пор, пока поисковые алгоритмы не посчитают, что вебмастер намеренно создает дубли с целью манипулировать выдачей.
Даже если дело не доходит до бана, множество страниц с одинаковым контентом размывают качество сайта в глазах поисковиков. Значительная доля страниц-дублей сигнализирует поисковым системам, что сайт не достоин быть в топе выдачи.
Наконец, если устранение дублей откладывать в долгий ящик, их может накопиться столько, что специалисту физически будет сложно обработать отчеты, систематизировать причины дублирования и внести исправления. Дубли страниц подобны баобабам в сказке о Маленьком принце: если их не выпалывать, они корнями разорвут планету.

В интересах SEO-специалиста находить и устранять дубли регулярно.
Как обнаружить дубли страниц?
Поиск дублей страниц можно вести разными способами. Чтобы найти все дубли и ничего не упустить, лучше использовать поочередно несколько сервисов и способов. Для поиска основных дубликатов достаточно какого-то одного инструмента — вебмастер волен выбрать тот, который ему ближе.
Парсинг сайта в специализированной программе или онлайн-сервисе
Для поиска дубликатов подходит программа Screaming Frog SEO Spider. До 500 адресов инструмент позволяет протестировать бесплатно.
Screaming Frog находит как полные дубли страниц, так и частичные. Оба вида дублей отображаются на вкладке Content под фильтрами Exact Duplicates и Near Duplicates.

Среди других инструментов технического аудита сайтов отметим следующие, доступные в России осенью 2022 года:
- SE Ranking
- Site Analyzer
- PromoPult
- Xenu Link Sleuth
- BatchUniqueChecker
- Siteliner
- Copyscape
- Comparser
- СайтРепорт
Поиск дублей с помощью вебмастеров поисковых систем
Раздел «Яндекс Вебмастер/Диагностика» уведомит вебмастера о проблеме, если дубли составят значительную долю страниц на сайте.
В разделе «Яндекс Вебмастер/Индексирование/Страницы в поиске» под фильтром «Исключенные» отображается диаграмма и список исключенных из индекса страниц:

На скриншоте — произвольный сайт-пример. Видно, что Яндекс удалил из индекса 182 неканонические (дублирующие) страницы.
Прокрутив вниз, в правом нижнем углу находим опцию «Скачать таблицу». В скачанном файле у страниц-дублей будет статус DUPLICATE.
Функционал для определения дублей имеется в разделе «Яндекс Вебмастер/Индексирование/Заголовки и описания». Когда сайт свободен от дублей, здесь выводится сообщение: «Всё в порядке. На сайте не найдено большого количества одинаковых Title и Description».
В Google Search Console состояние дел с индексацией страниц отображается на диаграмме:

Кроме того, сервис раскрывает причины, почему часть страниц оказалась вне индекса:

Зная причину дублирования, вебмастер быстрее исправит ошибку.
Поиск дублей через операторы
Поисковый оператор «site:» ограничивает результаты поиска только страницами заданного сайта, например:

Просмотрев выдачу, можем обнаружить страницы-дубликаты, а также «мусорные» страницы, которые нужно удалить из индекса.
Если перед оператором «site:» поместить уникальный фрагмент текста со страницы, то поисковик покажет в выдаче только эту страницу:

Одна страница в результатах поиска значит, что у нее нет дублей. Если же в выдаче несколько страниц, возможно, это и есть дубли, от которых необходимо избавиться.
Этот прием сужает поиск до наиболее важных, посадочных страниц, дублирование которых недопустимо.
Один из явных признаков дублей — повторяющиеся Title. Найти копии метатегов Title на сайте помогают операторы «site:» и «intitle:» — см. скриншот:

Мониторинг дублей, которые возникают на страницах сортировок, фильтров и поиска, можно вести с помощью операторов «site:» и «inurl:».
Запросы будут выглядеть так:
- site:https://site.ru inurl:sort
- site:https://site.ru inurl:filter
- site:https://site.ru inurl:search
Операторы, в основном, одинаково работают в Google и Яндексе.
Поиск дублей с помощью операторов может быть полезен владельцам небольших сайтов, например, бизнесам в сфере услуг.
Задача: избавиться от дублей
Для нового и старого сайтов решения проблемы с дублями — разные. На новом следует предупредить проблему — провести первичную настройку сайта. А на старом уже нужно лечение.
Большинство дублей страниц устраняется с помощью правильной настройки CMS. Иными словами, эффективное избавление от дублей сводится к составлению техзадания вебмастеру или программисту и проверки его реализации.
Для «выкорчевывания» дублей, засоряющих выдачу, существует несколько способов, и применяются они в зависимости от ситуации или типа дублей:
- физическое удаление;
- перенаправление;
- назначение канонической страницы;
- запрет на индексирование.
Рассмотрим основные способы устранения дублей страниц на сайте.
Физическое удаление дублей
Нет страницы — нет проблемы. Физическое устранение — хорошее решение для статических дублей. Одновременно удаляются ссылки на страницу во внутренней перелинковке сайта.
Метод работает со страницами, которые «не жалко», то есть без ссылочного веса и трафика. В противном случае трафик со страницы лучше перенаправить на основную посадочную посредством 301 редиректа.
Склейка дублей через 301 редирект
301 редирект сообщает роботам поисковых систем, что по данному URL страница больше недоступна и перенесена на другой адрес навсегда. Посетители автоматически перенаправляются со старого адреса на актуальный. Как правило, в течение двух недель страница-копия выпадает из поиска.
Главные преимущества 301 редиректа — передача показателей авторитетности и ссылочного веса страницы-копии, а также однозначное указание роботам на склейку доменов/страниц.
301 редирект — самый надежный способ избавления от дублей, но при этом самый требовательный к профессиональным навыкам вебмастера или программиста.
Если сайт использует сервер Apache, то редирект настраивают путем создания или редактирования служебного файла .htaccess Место этого файла — в корневом каталоге сайта (там же, где и файла robots.txt, о котором речь ниже). Доступ к корневому каталогу — по FTP.
Самый простой 301 редирект — со страницы на страницу:
Redirect 301 /page-1/ https://site.ru/page-2/
Один из обязательных технических редиректов, без которого не обходится ни один сайт, — перенаправление трафика с главной страницы с префиксом WWW на главную страницу без WWW. Или наоборот. Процедура называется «выбор главного зеркала сайта».
Два адреса одного сайта — с WWW и без — возникают автоматически в ходе присвоения сайту домена.
Редирект с субдомена WWW на вариант без WWW в файле .htaccess происходит по правилу:
RewriteCond %{HTTP_HOST} ^www.site.ru$ [NC]
RewriteRule ^(.*)$ https://site.ru/$1 [R=301,L]
Выбор в пользу домена с WWW выглядит так:
RewriteCond %{HTTP_HOST} ^site.ru$ [NC]
RewriteRule ^(.*)$ https://www.site.ru/$1 [R=301,L]
Для новых сайтов чаще выбирают домен без WWW, то есть перенаправляют трафик с адреса вида https://www.site.ru на https://site.ru Но если сайт уже получает трафик, лучше выбрать в качестве главного зеркала более посещаемый вариант домена.
Для SEO подавляющего большинства сайтов нет никакой разницы, какое зеркало главное. Только для высоконагруженных проектов, например, сайтов маркетплейсов и социальных сетей всегда выбирают адрес с WWW. Это нужно, в частности, для настройки сети доставки контента (CDN).
Другой обязательный ныне редирект — перенаправление трафика с простого протокола HTTP на защищенный протокол передачи данных HTTPS:
RewriteCond %{HTTPS} !=on
RewriteRule^(.*)$ https://%{HTTP_HOST}/$1 [R=301,L]
Редактируя .htaccess, вебмастера настраивают другие типы 301 редиректов для случаев:
- лишние слеши в URL;
- нарушена иерархия URL;
- URL в разных регистрах;
- URL с параметрами;
- и других.
В этой работе важно следить за корректностью новой части кода: если в ней будут ошибки, исчезнут не только дублирующие страницы, но и весь сайт.
Если сайт размещен на сервере Nginx, то 301 редирект настраивается по-иному.
Большинство CMS упрощает вебмастерам и владельцам сайтов настройку рабочего зеркала сайта. Редактирование файла .htaccess доступно через плагины.
Современные конструкторы сайтов имеют панель, где выбор рабочего зеркала совершается простым выбором опций. К примеру, в Tilda панель выглядит так:

Подобный интерфейс предусмотрен в Яндекс Вебмастере, где склейка доменов производится в разделе «Индексирование/Переезд сайта». В панели убираем (или ставим) галочку напротив WWW, ставим галочку напротив HTTPS и сохраняем изменения.

В течение полутора-двух недель Яндекс склеит зеркала, переиндексирует страницы, и в поиске появятся только URL-адреса страниц сайта в соответствии с нашим выбором.
В Google Search Console главным зеркалом всегда автоматически назначается адрес с HTTPS. Выбор зеркала с WWW или без делается либо с помощью 301 редиректа, либо через указание канонический страницы.
Проверить корректность настройки 301 редиректа можно плагином Redirect Path или другими. А также посмотреть динамику показателей в Google Search Console и Яндекс Вебмастере. Когда после склейки показы и клики на доменах-копиях равны нулю — значит, все настроено правильно.
Если владелец не счел нужным выбрать основной домен, то поисковая система сама назначит один из сайтов на роль основного зеркала. Однако не всегда это решение будет оптимальным с точки зрения продвижения.
301 редирект — мощный инструмент, он работает во всех поисковиках, но имеет ту особенность, что дублирующая страница полностью выпадает из индекса. В ряде случаев это нежелательно.
В таких ситуациях вебмастера оставляют дубли в индексе, но сообщают поисковикам, какая страница является основной или канонической. Именно она появляется в результатах поиска.
Назначение канонической страницы
Альтернативой 301 редиректу является метатег с атрибутом rel=«canonical». Этот атрибут указывает на каноническую, приоритетную для индексации страницу. При этом дубликаты размечаются поисковым роботом как второстепенные документы и не попадают в индекс, но остаются доступны пользователям.
Самый популярный способ указать на приоритетную страницу — в коде между тегами <head> и </head> страницы-дубля добавить метатег Link с атрибутом rel=«canonical»:
<link rel=«canonical» href=«ссылка на каноническую страницу» />
Такую ссылку следует добавить в код всех страниц-дублей. Процедура доступна владельцам сайтов и маркетологам даже с минимальным знанием HTML. Кроме того, тут нечего бояться — настройкой canonical сложно что-либо сломать на сайте.
Другой способ — добавить в код страницы-дубля HTTP-заголовок вида:
Link: <ссылка на каноническую страницу>; rel=«canonical»
Этот способ подходит как для обычных HTML-страниц, так и для электронных документов (PDF, DOC, XLS и т.д.).
Рекомендуем проверить корректность файла sitemap.xml . В карте сайта все страницы по умолчанию считаются каноническими. Однако канонический адрес в sitemap.xml является менее значимым сигналом, чем атрибут rel=«canonical». Лучше не делать ставку на этот метод. Главное, чтобы в карту сайта не попадали дубли страниц, иначе поисковые боты будут путаться в выборе канонического адреса.
Канониклы можно прописывать вручную, но это займет много времени, поэтому есть смысл использовать плагины. Например, в WordPress — это Yoast SEO или All in One SEO.
Конструктор Tilda по умолчанию проставляет каноникал сам на себя — Google такое допускает и даже приветствует. Пример — ниже:

Что выбрать для искоренения дублей — каноникал или 301 редирект?
В ситуации, если вебмастер не хочет показывать пользователю запрашиваемую страницу (ее больше не существует или она переехала), нужно применять 301 редирект.
В том случае, когда пользователь должен увидеть запрашиваемую страницу, даже если они неканоническая, — настраиваем canonical. Среди таких полезных дублей могут быть страницы фильтров, сортировок, пагинации, с UTM-метками, мобильные версии сайтов, AMP- и Turbo-страницы.
301 редирект — это прямой запрет индексации. Атрибут canonical — мягкая рекомендация, которой поисковые системы могут и не последовать. Google анализирует более 20 сигналов, чтобы решить, какую страницу выбрать в качестве канонической из дублирующего кластера, и rel=«canonical» лишь один из них.
Узнать, есть ли у страницы каноническая версия, отличная от указанной вебмастером, можно в «Яндекс Вебмастер/Индексирование/Страницы в поиске/Последние изменения/Статус и URL», а также в «Google Search Console/Проверка URL». Нередко лучшим решением будет довериться алгоритмам в выборе канонической страницы.
Яндекс и Google рекомендуют прописывать в метатеге Link абсолютный, а не относительный адрес канонической страницы. Размещать в коде два и более указания на каноникал бессмысленно — поисковики проигнорируют их все.
Запрет на индексацию дублей
Сканирование и индексацию дублей можно запретить или, по меньшей мере, постараться предотвратить. Делается это с помощью файла robots.txt или метатега.
Текстовый файл robots.txt размещается в корне сайта и управляет доступом к его содержимому. Файл robots.txt сообщает поисковым ботам, какие страницы или файлы сайта не следует сканировать.
Для этого используется директива Disallow, которая запрещает поисковым ботам заходить на ненужные страницы:
User-agent: *
Disallow: /page-duplicate
Специалисты используют блокировку через robots.txt в случаях, когда полностью уверены, что поисковые роботы не должны видеть дубли и служебные страницы. Чаще всего — это страницы с результатами поиска, страницы для печати и скачивания и другие, загрязняющие выдачу.
Способ практически не требует навыков программиста, но он не подходит, если дублей много: на изменение robots.txt каждого дубля уйдет значительное время.
Проверить корректность файла robots.txt позволяет Яндекс Вебмастер…

…и Google Search Console:

На скриншотах в файле robots.txt нет никаких запретов на сканирование и индексацию страниц сайта.
С блокировкой индексации есть две проблемы — маленькая и большая.
Малая проблема состоит в том, что инструкции файла robots.txt носят рекомендательный характер для поисковых ботов. Они не гарантируют удаление дубликатов из выдачи, если они были проиндексированы ранее или на дубли страниц ведут ссылки — роботы могут перейти по ним, и дубликат попадет в индекс.
Более надежный способ запретить индексацию дублей — использовать метатег robots следующих видов:
<meta name=«robots» content=«noindex, nofollow»> (не индексировать документ и не переходить по ссылкам)
<meta name=«robots» content=«noindex, follow»> (не индексировать документ, но при этом переходить по ссылкам)
В отличие от robots.txt, этот метатег — прямая команда, и она не будет игнорироваться поисковыми роботами.
Основная проблема, точнее, особенность, о которой нужно знать, связана с политикой поисковых систем. В настоящее время Google и Яндекс не рекомендует блокировать поисковым роботам доступ к идентичному контенту с помощью файла robots.txt или иными способами.
Не имея возможности сканировать страницы-дубликаты, поисковики не смогут определять, что по разным URL размещены одинаковые материалы, и будут обращаться с этими страницами как с уникальными.
Лучше разрешить сканирование таких URL, но при этом пометить их как копии при помощи тега <link> с атрибутом rel=«canonical» или настроить 301 редирект. Эти инструкции, в отличие от блокировки, передают вес дубликата целевой странице.
Яндекс (только Яндекс!) для блокировки индексации страниц с незначащими GET-параметрами рекомендует использовать директиву Clean-Param.
Пример для адреса с UTM-метками:
Clean-Param: utm_source&utm_medium&utm_campaign
Робот Яндекса, видя эту директиву в файле robots.txt, не будет много раз обходить повторяющийся контент. Как следствие, эффективность обхода повысится.
Завершающий этап — обновление карты сайта
Карта сайта sitemap.xml — служебный файл, который содержит систематизированный перечень страниц, рекомендованных для приоритетной поисковой индексации. При каждом обходе робот смотрит, какие изменения вносились в этот файл, и быстро освежает информацию о сайте в индексе.
Включать в файл sitemap.xml нужно только канонические, открытые для сканирования и индексации страницы, отдающие код ответа 200. И, напротив, следить, чтобы в карту сайта не попадали дубли страниц.
Все URL в карте сайта должны быть открыты в robots.txt для сканирования, индексации и не должны содержать метатег «noindex».
Сайтмап должна автоматически регулярно обновляться при добавлении/удалении, закрытии/открытии для индексации заданных страниц.
Карту сайта следует рассматривать в качестве подсказки роботам, какие страницы владелец сайта, маркетолог, вебмастер считает наиболее качественными. Но это только подсказка, а не руководство к действию.
Пагинация страниц сайта: как избежать дублирования
Пагинация на сайте — это разделение массива данных на части и вывод их на отдельных страницах. Так достигается высокая скорость загрузки страниц, улучшаются поведенческие факторы. Это удобно пользователям десктопов.
Адреса страниц пагинации могут быть как статическими, так и динамическими:
https://site.ru/catalog/page-2/ (статический URL)
https://site.ru/catalog?page=2 (динамический URL)
Множество однотипных страниц пагинации поисковики могут расценить как дубли. Решения проблемы следующие.
Запрет на индексацию в файле robots.txt. Disallow прописывается на всех страницах пагинации, кроме первой. Минус: поисковой системе будет сложнее отыскать все товары или новости категории.
Запрет на индексацию в метатеге robots. На всех страницах пагинации, кроме первой, прописывается инструкция <meta name=«robots» content=«noindex, follow» />. Минус тот же, см. выше.
Назначение первой страницы канонической. На всех остальных страницах пагинации проставляется rel=«canonical» со ссылкой на первую страницу.
Первая страница — это всегда начальная страница категории, поэтому https://site.ru/catalog/ и https://site.ru/catalog/page-1/ будут одной и той же страницей — дубликатами. Важно настроить 301 редирект с https://site.ru/catalog/page-1/ на https://site.ru/catalog/.
Создание страницы «View all» («Показать все») со всеми товарами всех страниц пагинации. На эту страницу настраиваются ссылки-канониклы со страниц пагинации. Роботам достаточно обработать один этот URL, чтобы весь контент попал в индекс. Подходит для небольших категорий с 3-4 страницами пагинации, иначе — слишком долгая загрузка.
Назначение всех страниц пагинации в качестве канонических. Простановка атрибута rel=«canonical» каждой страницы на саму себя. Метод увеличивает число документов коммерческой направленности в индексе, демонстрирует поисковику полный ассортимент продукции в категории, улучшает коммерческие факторы. Подход популярен в англоязычном SEO.
Уникализация каждой страницы пагинации подстановкой номера страницы, топонима, характеристики (НЧ-запроса). Title каждой страницы пагинации отличается от Title первой страницы и образуется по шаблону с подстановкой переменных, например:
- Наименование категории + {номер страницы}
- Купить {наименование товара} + в {название города} + по цене от {минимальная стоимость}
- {Характеристика товара (тип, цвет и т.д.)} + купить в интернет-магазине «название»
Description страниц пагинации образуется по такому же принципу:
- Заказывайте {наименование товара} + в интернет-магазине «название». Скидка 10% на первый заказ, бесплатная доставка курьером.
- Купить {наименование товара} — доставка по России, гарантия 1 год, наложенный платеж. Более 300 моделей в интернет-магазине «название». Выбирайте {наименование категории} от производителя.
- {Наименование товара} + по цене от {минимальная стоимость} — характеристики, фото, реальные отзывы покупателей. Заходите на сайт «название» или звоните +7 (xxx) xxx-xx-xx.
Оптимизированный текст должен быть размещен только на первой странице и не повторяться на остальных страницах пагинации.
Связывание страниц пагинации атрибутами rel=«prev»/«next». Для первой страницы в head вставляем строку: <link rel=«next» href=«https://site.ru/page2.html»>. Для каждой последующей страницы указываем ссылку на следующую и предыдущую страницу. Для второй страницы пагинации в разделе head должно быть прописано:
<link rel=«prev» href=«https://site.ru/page1.html»>
<link rel=«next» href=«https://site.ru/page3.html»>
И так далее. Правда, Google уже несколько лет не использует эту разметку, а Яндекс ее не считывает. На поиске присутствие/отсутствие такой цепочки никак не отражается.
Бесконечная прокрутка, или Single Page Content. Содержимое категории подгружается динамически, как только посетитель ресурса прокручивает скролл до самого низа или нажимает на кнопку «Показать еще». Бесконечные ленты приняты в социальных сетях, мобильных версиях маркетплейсов и онлайн-СМИ. Прием способен надолго задержать посетителя на ресурсе. Настраивается прокрутка при помощи AJAX-подгрузок в JavaScript. При этом URL не меняется, просто по запросу пользователя подгружаются новые порции контента. Google находит у этого современного способа представления контента ощутимые преимущества.

Никак не работать с пагинацией. Этот путь не такой глупый, как может показаться. Расчет на то, что современные поисковики сами способны разобраться со структурой представления товаров/новостей, как бы ни была реализована пагинация. Главная задача вебмастера — обеспечить индексацию страниц пагинации.
Пожалуй, одного универсального решения касательно дублирования страниц при пагинации не существует. Выбор стратегии зависит от обстоятельств: объема ассортимента, типа сайта, CMS, приоритетной поисковой системы и других.
«Холивары», которые ведутся по этому вопросу в SEO-среде, имеют своим истоком абсолютизацию положительного опыта, полученного в конкретных обстоятельствах. Не факт, что этот опыт хорошо себя покажет в другом контексте.
Тем не менее, выделим тренды в SEO страниц пагинации, которые нам представляются актуальными:
- не закрывать контент от индексации;
- уникализировать страницы пагинации;
- настраивать канониклы на страницу «View all»;
- настраивать канониклы на самих на себя;
- смелее использовать бесконечную прокрутку.
Поясним последний пункт. В 2022 году смартфоны — это около 80% всего интернет-трафика. Экраны размером с ладонь сформировали UX, где нет мест пагинации.
На смартфонах удобно:
- прокручивать вертикально;
- смахивать горизонтально;
- просматривать (сортировать, фильтровать) карточки, которых может быть много;
- кликать по карточкам — загружать не только одноэкранное изображение или вертикальное видео, но и пространный материал (статью, rich-контент в маркетплейсе).
Смартфоны диктуют иные способы структуризации и представления многостраничного контента, отличные от традиционной пагинации. Какие именно способы и как теперь быть с дублями — тема отдельной статьи.
Добавим сюда отложенную загрузку изображений Lazy Load, распределенные сети доставки контента CDN, стандарты связи LTE и 5G, другие технологии, которые кардинально ускоряют загрузку даже тяжелого контента. Все это снимает одну из главных задач пагинации — ускорение загрузки контента.
В 2022 году пагинация — это бензиновый двигатель. Пока еще широко распространен, но будущего нет. Актуальны вопросы организации и представления контента в мобайле, включая устранение дублей.
Не согласны? Возразите нам в комментариях к статье!
Заключение
Одни и те же дубли страниц на сайте можно закрыть от индексации разными способами. На практике работают и канонизация страниц, и редирект, и директивы robots.txt, и метатег robots.
Каждый поисковик дает свои рекомендации. Google не приветствует закрытие дублей с помощью robots.txt или метатега robots с атрибутами «noindex, nofollow», а предлагает использовать rel=«canonical» и 301 редирект.
А вот Яндекс более лоялен к robots.txt — здесь даже есть своя директива Clean-Param, которая помогает устранять дубли с GET-параметрами.
Задача оптимизатора – подобрать способы, которые будут оптимальны для конкретного кейса. К примеру, если ресурс ориентирован на зарeбежную аудиторию, лучше взять за основу рекомендации Google. Для России лучше придерживаться рекомендаций Яндекса.
Выбирайте способ, исходя из технических предпосылок и собственных навыков программирования. Ну, а если нет времени на то, чтобы разобраться с дублями, закажите бесплатный аудит сайта в impulse.guru
Помимо рекомендаций по работе с дублями вы получите массу полезной информации о своем ресурсе: наличии ошибок в HTML-коде, заголовках, метатегах, структуре, внутренней перелинковке, юзабилити, оптимизации контента. В итоге у вас на руках будет готовая SEO-стратегия продвижения ресурса в интересах вашего бизнеса.
В статье про технический аудит сайта мы упомянули, что среди прочего SEO-специалисту важно проверить, а есть ли дубли страниц на продвигаемом им веб-ресурсе. И если они найдутся, то нужно немедленно устранить проблему. Однако там в рамках большого обзора я не хотел обрушивать на голову читателя кучу разнообразной информации, поэтому о том, что такое дубликаты страниц сайта, как их находить и удалять, мы вместе с вами детальнее рассмотрим здесь.
Почему и как дубли страниц мешают поисковому продвижению
Для начала отвечу на вопрос «Как?». Дубликаты страниц сильно затрудняют SEO, т. к. поисковые системы не могут понять, какую из веб-страниц им нужно показывать в выдаче по релевантным запросам. Поэтому чаще всего, чтобы не путаться, они понижают сайт в ранжировании или даже банят его, если проблема имеет массовый характер. После этого должно быть понятно, насколько важно сразу проверить продвигаемый ресурс на дубликаты.
Теперь давайте посмотрим, почему так получается, что дубли создают проблему? Для этого рассмотрим такой простой пример. Взгляните на следующее изображение и определите, какой из овощей наиболее точно соответствует запросу «спелый помидор»?

Хотя овощи немного отличаются размером, но все три из них подходят под категорию «спелого помидора». Поэтому сделать выбор в пользу одно из них довольно сложно.
Такая же дилемма встает перед поисковыми алгоритмами, когда они видят на сайте несколько одинаковых (полных) или почти одинаковых (частичных) копий одной и той же страницы.
Как наличие дублей сказывается на продвижении:
- Чаще всего падает релевантность основной продвигаемой страницы и, соответственно, снижаются позиции по используемым ключевым словам.
- Также могут «прыгать» позиции по ключам из-за того, что поисковик будет менять страницу для показа в поисковой выдаче.
- Если проблема не ограничивается несколькими урлами, а распространяется на весь сайт, то в таком случае Яндекс и Google могут наказать неприятным фильтром.
Понимая теперь, насколько серьезными могут быть последствия, рассмотрим виды дубликатов.
SEO-шников много, профессионалов — единицы. Научитесь технической и поведенческой оптимизации, создавайте семантические ядра и продвигайте проекты в ТОП!
Получить скидку →

Ежедневные советы от диджитал-наставника Checkroi прямо в твоем телеграме!
Подписывайся на канал
Подписаться
Виды дублей
Выше мы уже выяснили, что дубли бывают идентичными (полными) и частичными. Полным называют такой дубликат, когда одну и ту же веб-страницу поисковик находит по различным адресам.
Когда появляются полные дубли:
- Зачастую это происходит, если забыли указать главное зеркало, и весь сайт может показываться в поиске с www и без него, c http и с https. Чтобы устранить эту проблему, читайте здесь детальнее о том, что такое зеркало сайта.
- Кроме того, бывают ситуации, когда возникают дубли главной страницы ввиду особенностей движка или проведенной веб-разработчиком работы. Тогда, к примеру, главная может быть доступна со слешем «/» в конце и без него, с добавлением слов home, start, index.php и т. п.
- Нередко дубли возникают, когда в индекс попадают страницы с динамичными адресами, появляющиеся обычно при использовании фильтров для сортировки и сравнения товаров.
- Часть движков (WordPress, Joomla, Opencart, ModX) сами по себе генерируют дубли. К примеру, в Joomla по умолчанию часть страниц доступна к отображению с разными урлами: mysite.ru/catalog/17 и mysite.ru/catalog/17-article.html и т. п.
- Если для отслеживания сессий применяют специальные идентификаторы, то они также могут индексироваться и создавать копии.
- Иногда в индекс также попадают страницы по адресам, к которым добавлены utm-метки. Такие метки вставляют, чтобы отслеживать эффективность проводимых рекламных кампаний, и по-хорошему они не должны быть проиндексированы. Однако на практике подобные урлы часто можно видеть в поисковой выдаче.
Когда возникают частичные дубли
Полные дубли легко найти и устранить, а вот с частичными уже придется повозиться. Поэтому на рассмотрении их видов стоит остановиться детальнее.
Пагинация страниц
Используя пагинацию страниц, владельцы сайтов делают навигацию для посетителей более простой, но вместе с тем создают проблему для поискового продвижения. Каждая страница пагинации – это фактически дубль зачастую с теми же мета-данными, СЕО-текстом.
К примеру, основная страница имеет вид https://mysite.ru/women/clothes, а у страницы пагинации адрес будет https://mysite.ru/women/clothes/?page=2. Адреса получаются разные, а содержимое будет почти одинаковым.
Блоки новостей, популярных статей и комментариев
Чтобы удержать пользователя на сайте, ему часто предлагают ознакомиться с наиболее интересными новостями, комментариями и статьями. Название этих объектов с частью содержимого обычно размещают по бокам или снизу от основного материала. Если эти куски будут проиндексированы, то поисковик определит, что на некоторых страницах одинаковый контент, а это очень плохо.
На скриншоте видно, как внизу главной страницы сайта размещаются три блока с последними статьями, новостями и отзывами. То есть текстовое содержимое есть в соответствующих разделах сайта, и здесь на главной оно повторяется, создавая частичные дубли.
Версии страниц для печати
Некоторые веб-страницы сайта доступны в обычном варианте и в версии для печати, которая отличается от основной адресом и отсутствием значительной части строк кода, т. к. для печатаемой страницы не нужна значительная часть функционала.
Обычная страница может открываться, например, по адресу https://my-site.ru/page, а у варианта для печати адрес немного изменится и будет похож на такой: https://my-site.ru/page?print.
Сайты с технологией AJAX
На некоторых сайтах, применяемых технологию AJAX, возникают так называемые html-слепки. Сами по себе они не опасны, если нет ошибок в имплантации способа индексирования AJAX-страниц, когда поисковых ботов направляют не на основную страницу, а на html-слепок, где робот индексирует одну и ту же страницу по двум адресам:
- основному;
- адресу html-слепка.
Для нахождения таких html-слепков стоит в основном адресе заменить часть «!#» на такой код: «?_escaped_fragment_=».
Частичные дубли опасны тем, что они не вызывают значительного снижения позиций в один момент, а понемногу портят картину, усугубляя ситуацию день за днем.
Как происходит поиск дублей страниц на сайте
Существует несколько основных способов, позволяющих понять, как найти дубли страниц оптимизатору на сайте:
Вручную
Уже зная, где стоит искать дубликаты, SEO-специалист без особого труда может найти значительную часть копий, попробовав различные варианты урлов.
С применением команды site
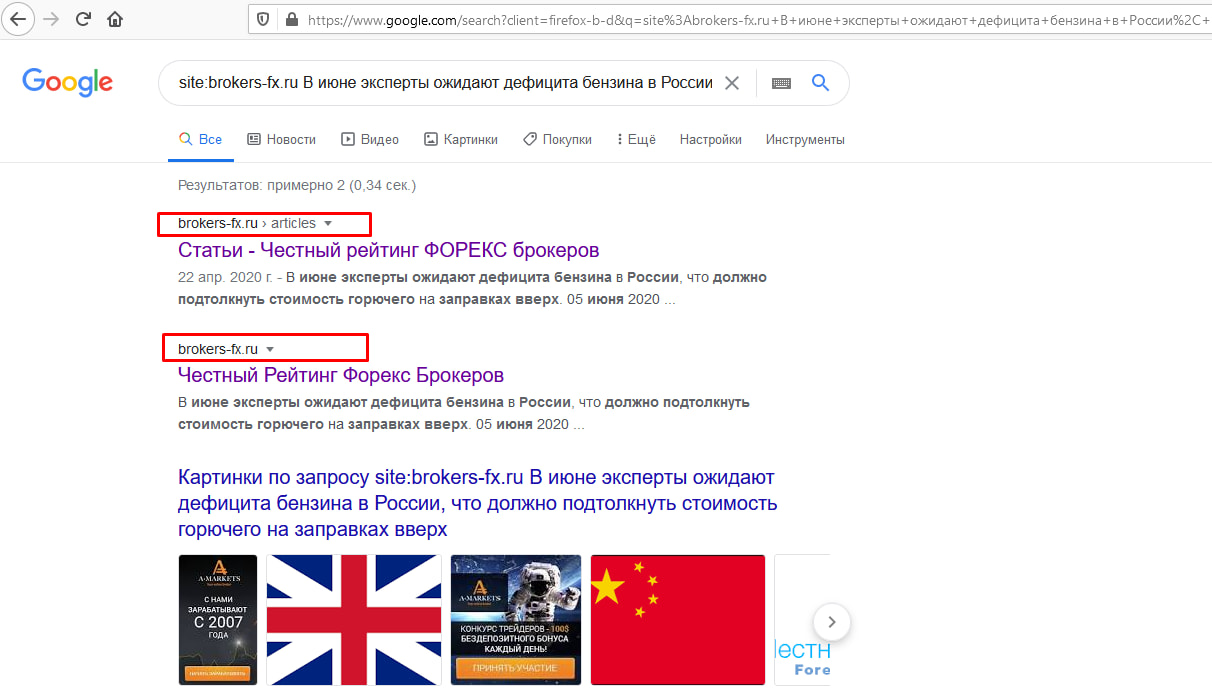
Вставляем в адресную строку команду «site:», вводим после нее домен и часть текстового содержания, после чего Google сам выдаст все найденные варианты. На скриншоте ниже видно, что мы ввели первое предложение свежей статьи после команды «site:», и Google показывает, что у основной страницы с материалом есть частичный дубль на главной.
С использованием программ и онлайн-сервисов
Для поиска дублей часто применяют три популярные программы на ПК:
- Xenu – бесплатная;
- NetPeak – от $15 в месяц, но есть 14-дневный trial;
- Screaming Frog – платная (149 фунтов за год), но есть ограниченная бесплатная версия, которой хватает для большинства нужд.
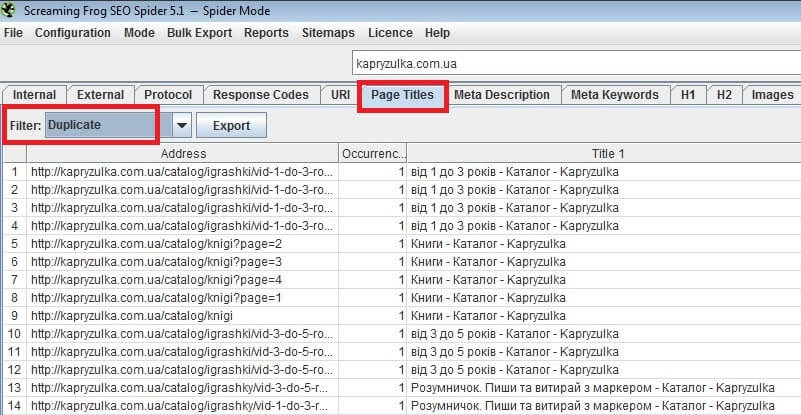
Вот пример того, как ищет дубликаты программа Screaming Frog:
А вот как можно проверить дубли страниц в NetPeak:
Для онлайн-поиска дублей страниц можно использовать специальные веб-сервисы наподобие Serpstat.
Использование Google Search Console и Яндекс Вебмастер
В обновленной версии Google Search Console для поиска дублей смотрим «Предупреждения» и «Покрытие». Там поисковая система сама сообщает о проблемных, на ее взгляд, страницах, которым нужно уделить внимание.
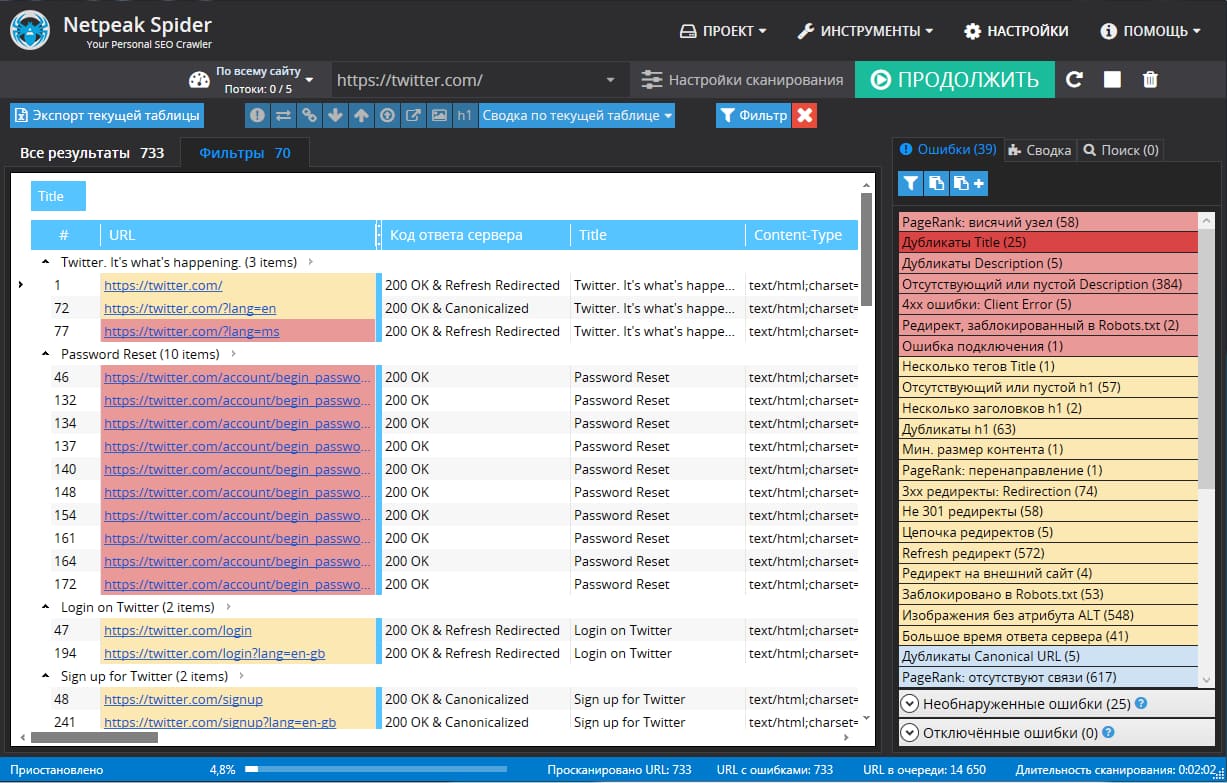
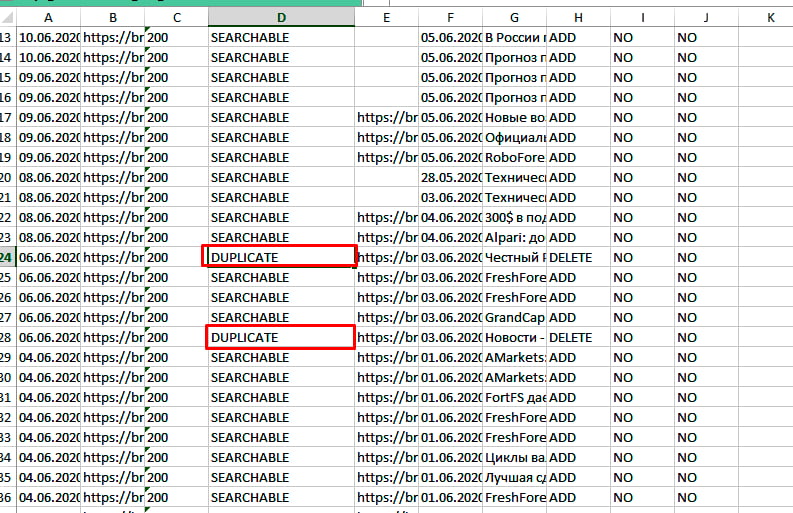
Что касается Yandex, то здесь все намного удобнее. Для поиска дублей заходим в Яндекс Вебмастер, открыв раздел «Индексирование» – «Страницы в поиске». Опускаемся в самый низ, выбираем справа удобный формат файла – XLS или CSV, скачиваем его и открываем. В этом документе все дубликаты в строке «Статус» будут иметь обозначение DUPLICATE.
Как убрать дубли?
Чтобы удалить дубли страниц на сайте, можно использовать разные приемы в зависимости от ситуации. Давайте же с ними познакомимся:
При помощи noindex и nofollow
Самый простой способ – закрыть от индексации, используя метатег <meta name=”robots” content=”noindex,nofollow”/>, который помещают в шапку между открывающим тегом <head> и закрывающим </head>. Попав на страницу с таким метатегом, поисковые алгоритмы не станут ее индексировать и учитывать ссылки, находящиеся здесь.
При добавлении метатега «noindex,nofollow» на страницу, крайне важно, чтобы для нее не была запрещена индексация через файл robots.txt.
При помощи robots.txt
Индексирование отдельных дублей можно запретить в файле robots.txt, используя директиву Disallow. В таком случае примерный вид кода, добавляемого в robots.txt, будет таким:
User-agent: *
Disallow: /dublictate.html
Host: mysite.ru
Через robots.txt удобно запрещать индексацию служебных страниц. Выглядит это следующим образом:

Этот вариант зачастую применяют, если невозможно использовать предыдущий.
При помощи canonical
Еще один удобный способ – применить метатег canonical, который говорит поисковым роботам, что они попали на страницу-дубликат, а заодно указывает, где находится основная страница. Этот метатег помещают в шапку между открывающим тегом <head> и закрывающим </head>, и выглядит он так:
<link rel=”canonical” href=”адрес основной страницы” />
Как убрать дубликаты на страницах с пагинацией
В случае присутствия на сайте многостраничного каталога, на второй и последующих страницах могут возникать частичные дубли. Смотрим, как это может быть:
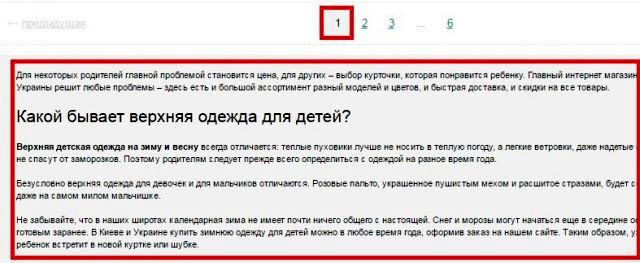
Выше на скрине 1-я страница каталога, а вот вторая:
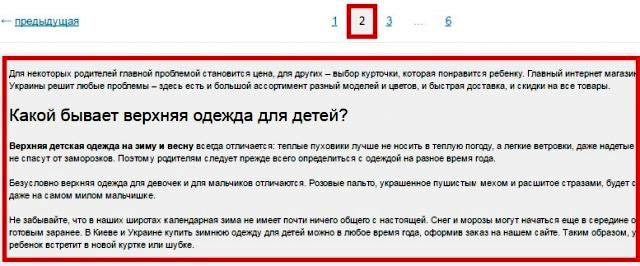 То есть на каждой странице дублируется текст и теги: Title и Description.
То есть на каждой странице дублируется текст и теги: Title и Description.
В таких случаях SEO-специалисту нужно добиться, чтобы:
- текст отображался только на 1-й странице;
- Title и Description были уникальными для каждой страницы, хотя их можно сделать шаблонными с минимальными отличиями;
- в адресах страниц пагинации должны отсутствовать динамические параметры.
Понимая теперь, что такое дубликаты страниц сайта, и как бороться с дублями, вы сможете не допустить попадания в индекс копий, которые будут препятствовать продвижению в поисковых системах. Если после прочтения статьи у вас остались вопросы, или вы хотите дополнить материал своими ценными замечаниями, то обязательно сделайте это в комментариях ниже.
