17 авг. 2022 г.
читать 1 мин
Вы можете использовать функцию Duplicated () для поиска повторяющихся значений в кадре данных pandas.
Эта функция использует следующий базовый синтаксис:
#find duplicate rows across all columns
duplicateRows = df[df.duplicated ()]
#find duplicate rows across specific columns
duplicateRows = df[df.duplicated(['col1', 'col2'])]
В следующих примерах показано, как использовать эту функцию на практике со следующими пандами DataFrame:
import pandas as pd
#create DataFrame
df = pd.DataFrame({'team': ['A', 'A', 'A', 'A', 'B', 'B', 'B', 'B'],
'points': [10, 10, 12, 12, 15, 17, 20, 20],
'assists': [5, 5, 7, 9, 12, 9, 6, 6]})
#view DataFrame
print(df)
team points assists
0 A 10 5
1 A 10 5
2 A 12 7
3 A 12 9
4 B 15 12
5 B 17 9
6 B 20 6
7 B 20 6
Пример 1. Поиск повторяющихся строк во всех столбцах
В следующем коде показано, как найти повторяющиеся строки во всех столбцах DataFrame:
#identify duplicate rows
duplicateRows = df[df.duplicated ()]
#view duplicate rows
duplicateRows
team points assists
1 A 10 5
7 B 20 6
Есть две строки, которые являются точными копиями других строк в DataFrame.
Обратите внимание, что мы также можем использовать аргумент keep=’last’ для отображения первых повторяющихся строк вместо последних:
#identify duplicate rows
duplicateRows = df[df.duplicated (keep='last')]
#view duplicate rows
print(duplicateRows)
team points assists
0 A 10 5
6 B 20 6
Пример 2. Поиск повторяющихся строк в определенных столбцах
В следующем коде показано, как найти повторяющиеся строки только в столбцах «команда» и «точки» в DataFrame:
#identify duplicate rows across 'team' and 'points' columns
duplicateRows = df[df.duplicated(['team', 'points'])]
#view duplicate rows
print(duplicateRows)
team points assists
1 A 10 5
3 A 12 9
7 B 20 6
Есть три строки, в которых значения столбцов «команда» и «очки» являются точными копиями предыдущих строк.
Пример 3. Поиск повторяющихся строк в одном столбце
В следующем коде показано, как найти повторяющиеся строки только в столбце «команда» DataFrame:
#identify duplicate rows in 'team' column
duplicateRows = df[df.duplicated(['team'])]
#view duplicate rows
print(duplicateRows)
team points assists
1 A 10 5
2 A 12 7
3 A 12 9
5 B 17 9
6 B 20 6
7 B 20 6
Всего имеется шесть строк, в которых значения в столбце «команда» являются точными копиями предыдущих строк.
Дополнительные ресурсы
В следующих руководствах объясняется, как выполнять другие распространенные операции в pandas:
Как удалить повторяющиеся строки в Pandas
Как удалить повторяющиеся столбцы в Pandas
Как выбрать столбцы по индексу в Pandas
I have a list of items that likely has some export issues. I would like to get a list of the duplicate items so I can manually compare them. When I try to use pandas duplicated method, it only returns the first duplicate. Is there a a way to get all of the duplicates and not just the first one?
A small subsection of my dataset looks like this:
ID,ENROLLMENT_DATE,TRAINER_MANAGING,TRAINER_OPERATOR,FIRST_VISIT_DATE
1536D,12-Feb-12,"06DA1B3-Lebanon NH",,15-Feb-12
F15D,18-May-12,"06405B2-Lebanon NH",,25-Jul-12
8096,8-Aug-12,"0643D38-Hanover NH","0643D38-Hanover NH",25-Jun-12
A036,1-Apr-12,"06CB8CF-Hanover NH","06CB8CF-Hanover NH",9-Aug-12
8944,19-Feb-12,"06D26AD-Hanover NH",,4-Feb-12
1004E,8-Jun-12,"06388B2-Lebanon NH",,24-Dec-11
11795,3-Jul-12,"0649597-White River VT","0649597-White River VT",30-Mar-12
30D7,11-Nov-12,"06D95A3-Hanover NH","06D95A3-Hanover NH",30-Nov-11
3AE2,21-Feb-12,"06405B2-Lebanon NH",,26-Oct-12
B0FE,17-Feb-12,"06D1B9D-Hartland VT",,16-Feb-12
127A1,11-Dec-11,"064456E-Hanover NH","064456E-Hanover NH",11-Nov-12
161FF,20-Feb-12,"0643D38-Hanover NH","0643D38-Hanover NH",3-Jul-12
A036,30-Nov-11,"063B208-Randolph VT","063B208-Randolph VT",
475B,25-Sep-12,"06D26AD-Hanover NH",,5-Nov-12
151A3,7-Mar-12,"06388B2-Lebanon NH",,16-Nov-12
CA62,3-Jan-12,,,
D31B,18-Dec-11,"06405B2-Lebanon NH",,9-Jan-12
20F5,8-Jul-12,"0669C50-Randolph VT",,3-Feb-12
8096,19-Dec-11,"0649597-White River VT","0649597-White River VT",9-Apr-12
14E48,1-Aug-12,"06D3206-Hanover NH",,
177F8,20-Aug-12,"063B208-Randolph VT","063B208-Randolph VT",5-May-12
553E,11-Oct-12,"06D95A3-Hanover NH","06D95A3-Hanover NH",8-Mar-12
12D5F,18-Jul-12,"0649597-White River VT","0649597-White River VT",2-Nov-12
C6DC,13-Apr-12,"06388B2-Lebanon NH",,
11795,27-Feb-12,"0643D38-Hanover NH","0643D38-Hanover NH",19-Jun-12
17B43,11-Aug-12,,,22-Oct-12
A036,11-Aug-12,"06D3206-Hanover NH",,19-Jun-12
My code looks like this currently:
df_bigdata_duplicates = df_bigdata[df_bigdata.duplicated(cols='ID')]
There area a couple duplicate items. But, when I use the above code, I only get the first item. In the API reference, I see how I can get the last item, but I would like to have all of them so I can visually inspect them to see why I am getting the discrepancy. So, in this example I would like to get all three A036 entries and both 11795 entries and any other duplicated entries, instead of the just first one. Any help is most appreciated.

Рассмотрим задачу выявления и удаления дублирующих значений в массивах информации с библиотекой Pandas. В демонстрационных целях будем использовать набор объявлений о продажах квартир в Республике Северная Осетия-Алания, имеющий следующий вид:
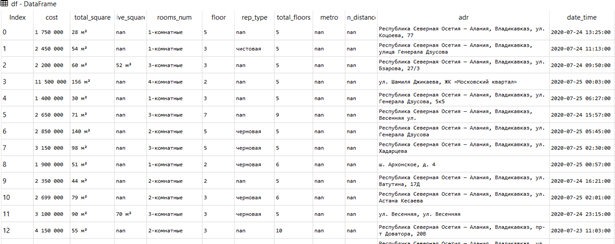
Для определения дублирующих данных можно воспользоваться методом duplicated, в котором при желании задается подмножество столбцов, одинаковые значения в которых являются признаком дубликата (параметр subset, по умолчанию равен None – все столбцы), а также стратегию пометки строк как дубликата (параметр keep, только первое вхождение не помечается как дубликат – по умолчанию, только последнее значение не помечается как дубликат, все повторяющиеся значения помечаются как дубликаты). Продемонстрируем работу метода на заданном наборе столбцов и со стратегией пометки всех дублирующих значений:
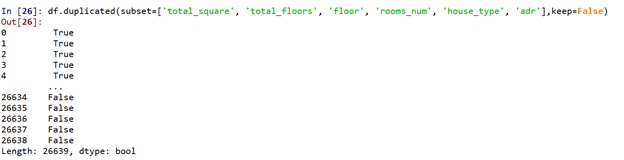
Чтобы получить соответствующие значения столбцов достаточно проиндексировать таблицу объектом Series, полученным на предыдущем шаге:
Для удаления повторяющихся значений в pandas предназначен метод drop_duplicates, который в числе прочих имеет такие же, как и duplicated параметры. Продемонстрируем его применение на практике:
То есть данный метод удалит все строки, которые имеют одинаковые значения в заданных столбцах. Это можно проверить альтернативным способом, получив индексы строк таблицы, для которых duplicated выдает положительное значение, и удалив их из таблицы по номерам:
The function pd.duplicated() gives you a boolean series indicating which rows in a dataframe are duplicated like below:
0 False
1 False
2 False
3 False
4 True
5 False
6 True
7 True
8 True
9 True
10 True
dtype: bool
It however does not tell you which row the duplicates are duplicates of.
Index 4 for example could be a duplicate of 0,1,2,3 or 5.
Is there a clever way of identifying which rows are duplicated and what these rows are duplicates of?
EdChum
372k198 gold badges806 silver badges560 bronze badges
asked Mar 26, 2015 at 11:11
Try groupby, size and filter for the ones with size above 1.
>>> df = pd.DataFrame([[1, 1], [1, 2], [1, 1], [2, 2], [2, 2], [1, 3]], columns=["a", "b"])
>>> results = df.groupby(["a", "b"]).size()
>>> results = results[results > 1]
>>> results
a b
1 1 2
2 2 2
dtype: int64
You can also sort in order to get the most duplicated ones (if that interests you)
answered Mar 26, 2015 at 11:27
grechutgrechut
2,8671 gold badge18 silver badges17 bronze badges
You can use .groupby to get the following:
import pandas as pd
df = pd.DataFrame({'a': [1, 2, 3, 3, 2, 0, 4, 5, 6]})
df.groupby('a').groups
# {0: [5], 1: [0], 2: [1, 4], 3: [2, 3], 4: [6], 5: [7], 6: [8]}
Then decide on the values of that dict what you want to do…
answered Mar 26, 2015 at 11:27
![]()
Jon ClementsJon Clements
138k32 gold badges244 silver badges278 bronze badges
2
It however does not tell you which row the duplicates are duplicates of. Index 4 for example could be a duplicate of 0,1,2,3 or 5.
.duplicated(keep=False) discards this information about where the duplicate “groups” reside. I found two ways around this: one is using .unique() in a for loop, the other is s.groupby(s)
s = pd.Series(["A","B","C","A","A","B","D","E"])
# what i want is a string like this
"""
0, 3 and 4: A
1 and 5: B
2: C
6: D
7: E
"""
string = ""
for val in s.unique():
# here, we have access to the grouped values in s[s == val]
string += do_something(s[s == val])
# this is another way
string = s.groupby(s).apply(lambda x: do_something_else(x.index))
![]()
Dharman♦
30.3k22 gold badges84 silver badges132 bronze badges
answered Jan 15, 2021 at 10:06
![]()
Newer versions of pandas have a ‘keep’ option where you can specify which values you would want to mark. In this case, you would mark keep=False (and mark them all)
In [2]: df = pd.DataFrame({'x':[1, 2, 4, 4, 5]})
In [3]: df
Out[3]:
x
0 1
1 2
2 4
3 4
4 5
In [4]: df.duplicated('x', keep=False)
Out[4]:
0 False
1 False
2 True
3 True
4 False
dtype: bool
answered Apr 22, 2016 at 11:10
![]()

Introduction to Pandas Find Duplicates
Dealing with real-world data can be messy and overwhelming at times, as the data is never perfect. It consists of many problems such as outliers, duplicate and missing values, etc. There is a very popular fact in the data science world that data scientists / data analysts spend 80% of their time in data cleaning and preparation for a machine learning algorithm. In this article, we will be covering a very popular problem, that is, how to find and remove duplicate values/records in a pandas dataframe. Pandas module in python provides us with some in-built functions such as dataframe.duplicated() to find duplicate values and dataframe.drop_duplicates() to drop duplicate values. We will be discussing these functions along with others in detail in the subsequent sections.
Syntax and Parameters
The basic syntax for dataframe.duplicated() function is as follows :
dataframe.duplicated(subset = 'column_name', keep = {'last', 'first', 'false')The parameters used in the above mentioned function are as follows :
- Dataframe : Name of the dataframe for which we have to find duplicate values.
- Subset : Name of the specific column or label based on which duplicate values have to be found.
- Keep : While finding duplicate values, which occurrence of the value has to be marked as duplicate. That is, the first value is to be considered duplicated or the subsequent values have to be considered as duplicate or all the values (false) have to be considered duplicate.
The subset argument is optional. Having understood the dataframe.duplicated() function to find duplicate records, let us discuss dataframe.drop_duplicates() to remove duplicate values in the dataframe.
The basic syntax for dataframe.drop_duplicates() function is similar to duplicated() function. It can be written as follows :
dataframe.drop_duplicates(subset = 'column_name', keep = {'last', 'first', 'false'}, inplace = {'True', 'False'})Most of the arguments mentioned in this function have been discussed above in dataframe.duplicated() function. The one which is not discussed is :
Inplace: Inplace ensures if the changes are to be made in the original data frame(True) or not(False).
Examples of Pandas Find Duplicates
Now we have discussed the syntax and arguments used for working with functions used for dealing with duplicate records in pandas. But no learning is complete without some practical examples, ergo let’s try a few examples based on these functions. In order to do that, we have to first create a dataframe with duplicate records. You may use the following data frame for the purpose.
Code:
#importing pandas
import pandas as pd
#input data
data = {'Country': ['India','India','USA','USA','UK','Germany','India','Germany', 'USA', 'China', 'Japan'],
'Personality': ['Sachin Tendulkar','Sania Mirza','Serena Williams','Venus Willians',
'Morgan Freeman','Michael Schumacher','Priyanka Chopra','Michael Schumacher',
'Serena Williams','Jack Ma','Sakamoto Ryoma']
}
#create a dataframe from the data
df = pd.DataFrame(data, columns = ['Country','Personality'])
#print dataframe
dfThe output of the given code snippet would be a data frame called ‘df’ as shown below :
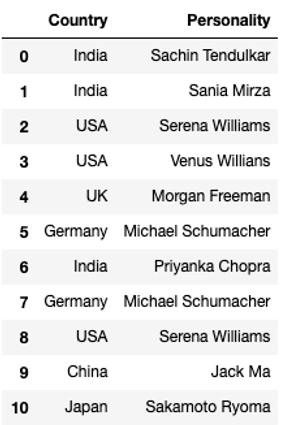
Duplicate Values of Data Frame
We can clearly see that there are a few duplicate values in the data frame.
1. Finding Duplicate Values in the Entire Dataset
In order to find duplicate values in pandas, we use df.duplicated() function. The function returns a series of boolean values depicting if a record is duplicate or not.
df.duplicated()
By default, it considers the entire record as input, and values are marked as a duplicate based on their subsequent occurrence, i.e. the first value is not marked as duplicate but other values after that are marked as duplicate.
2. Finding in a Specific Column
In the previous example, we have used the duplicated() function without any arguments. Here, we have used the function with a subset argument to find duplicate values in the countries column.
df.duplicated(subset = 'Country')
3. Finding in a Specific Column and Marking Last Occurrence as Not Duplicate
df.duplicated(subset = 'Country', keep = 'last')
4. Finding the Count of Duplicate Records in the Entire Dataset
In order to find the total number of values, we can perform a sum operation on the results obtained from the duplicated() function, as shown below.
df.duplicated().sum()![]()
5. Finding the Count of Duplicate Values in a Specific Column
df.duplicated(subset='Country').sum()![]()
6. Removing Duplicate Records in the Dataset.
df.drop_duplicates(keep = 'first')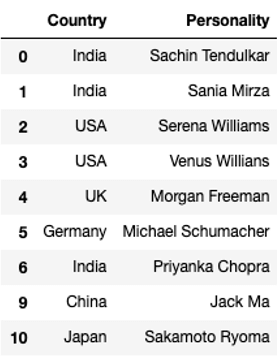
The function has successfully removed record no. 7 and 8 as they were duplicated. We should note that the drop_duplicates() function does not make inplace changes by default. That is the records would not be removed from the original dataframe. As can be seen from the image below.
df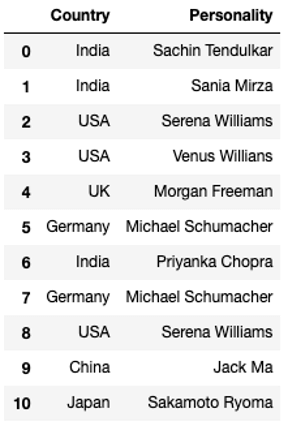
The original data frame is still the same with duplicate records. In order to save changes to the original dataframe, we have to use an inplace argument as shown in the next example.
7. Removing Duplicate Records in the Dataset Inplace.
df.drop_duplicates(keep = 'first', inplace = True)
df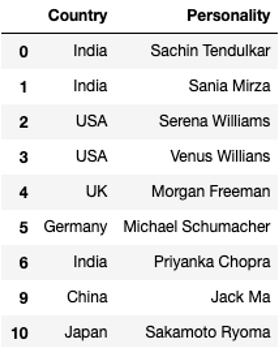
Conclusion
Finding and removing duplicate values can seem like a daunting task for large datasets. But pandas has made it easy, by providing us with some in-built functions such as dataframe.duplicated() to find duplicate values and dataframe.drop_duplicates() to remove duplicate values.
Recommended Articles
We hope that this EDUCBA information on “Pandas Find Duplicates” was beneficial to you. You can view EDUCBA’s recommended articles for more information.
- Pandas DataFrame.merge()
- Pandas Transform
- Pandas Aggregate()
- Pandas DataFrame.fillna()
