Я расскажу, как быстро найти дубли страниц и обезопасить себя от негативных последствий, к которым они могут привести.
Материал в первую очередь будет полезен как практикующим SEO-специалистам, так и владельцам сайтов. Но для начала давайте совсем быстро пробежимся по теории.
Немного теории
Наверняка многие слышали, что дубли страниц — это плохо. Подробно останавливаться на данном вопросе не буду, так как тема популярная, и качественной информации в интернете, даже появившейся в последнее время, много. Отмечу только неприятности, которые могут появиться у сайта при наличии дублей:
- проблемы с индексацией (особенно актуально для крупных сайтов);
- размытие релевантности и ранжирование нецелевых страниц;
- потеря естественных ссылок, которые могут появляться на страницах дублей;
- общая пессимизация проекта и санкции поисковых систем.
Поэтому в процессе продвижения проектов этому вопросу должно уделяться особое внимание.
Также стоит вкратце остановится на двух разновидностях дублей:
- Полные дубли — это когда один и тот же контент доступен по разным URL. Например: http://www.foxtrot.com.ua/ и https://www.foxtrot.com.ua/.
- Частичные дубли — когда страницы имеют общую семантику, решают одни и те же задачи пользователей и имеют похожий контент, но не являются полными дублями. Да, получилось достаточно запутанно, поэтому предлагаю рассмотреть пример: https://vc.ru/category/телеграм и https://vc.ru/category/telegram.
Обе страницы имеют общую семантику, похожий контент и решают одни и те же задачи пользователей, но при этом не являются полными дублями, так как содержимое страниц разное.
Выявить полные дубли намного проще, да и проблем они могут привести куда больше из-за своей массовости, а вот с неполными дублями нужно работать точечно и избавляться от них при формировании правильной структуры сайта. Далее в этой статье под дублями будут подразумеваться полные дубли.
Итак, мы определились, что проект не должен содержать дубли. Точка. Особенно критично, когда дубли начинают индексироваться поисковыми системами. И чтобы этого не случилось, а также для предотвращения других негативных последствий, их нужно выявлять и устранять. О том, как с ними бороться, можно найти много материалов, но если в комментариях будут просьбы рассказать подробнее, то я обязательно это сделаю в одной из следующих статей.
Чтобы никого не запутать, сейчас опустим момент с формированием нужных дублей (например, страниц с UTM-метками).
Выявление полных дублей
Обычно специалисты проверяют у продвигаемого проекта наличие следующих дублей:
1. Дубли страниц с разными протоколами: http и https.
2. С www и без www.
3. Со слешем на конце URL и без него.
При этом каждая страница содержит canonical на себя.
4. Строчные и прописные буквы во вложенностях URL.
Это пример того, как на разных типах страниц один и тот же принцип формирования дублей обрабатывается по-разному.
5. Добавления в конце URL:
index.php
home.php
index.html
home.html
index.htm
home.htm
Как видно, оба URL проиндексированы в «Яндексе»:
А разве это все возможные дубли?
В своей практике я сталкивался с огромным количеством примеров формирования дублей, и самые популярные, которые встречались не единожды, я укажу ниже:
6. Множественное добавление ////////////////// в конце URL.
7. Множественное добавление ////////////////// между вложенностями.
Очень часто встречающаяся ошибка.
8. Добавление произвольных символов в конец URL, формируя новую вложенность.
9. Добавление произвольных символов в существующую вложенность.
10. Добавление вложенности с произвольными символами.
Не совсем дубль, но страница отдаёт 200-й код ответа сервера, что позволит ей попасть в индекс.
11. Добавление * в конце URL.
12. Замена нижнего подчеркивания на тире и наоборот.
13. Добавление произвольных цифр в конце URL, формируя новую вложенность.
Такие дубли часто формируются со страниц публикаций на WordPress.
14. Замена вложенностей местами.
15. Отсутствие внутренней вложенности.
Пункты 14 и 15 опять же не являются полными дублями, но аналогично пункту 10 отдают 200 код ответа сервера.
16. Копирование первой вложенности и добавление её в конец URL.
17. Дубли .html, .htm или .php для страниц, которые заканчиваются на один из этих расширений.
Например:
- http://sad-i-ogorod.ru/shop/11041.php;
- http://sad-i-ogorod.ru/shop/11041.htm;
- http://sad-i-ogorod.ru/shop/11041.html.
Все приведённые выше типы дублей были выявлены в индексе поисковых систем более чем у нескольких проектов. Хотите ли вы рисковать появлением такого огромного количества дублей? Думаю, нет. Поэтому и важно выявить те дубли, которые формируются и обезопасить себя от попадания их в индекс поисковых систем. А практика показывает, что рано или поздно они находят и индексируют такие страницы, хотя ни внутренних, ни внешних ссылок на данные страницы нет.
Проверять вручную все эти дубли очень долго. К тому же важно проверять каждый тип страниц на наличие дублей. Почему? Да потому, что страницы категории товаров и страница определённого товара могут иметь разные дубли. Пример уже был ранее рассмотрен.
Также в большинстве сайтов могут использоваться разные CMS для разного типа контента. Нормальная практика, когда, например, интернет-магазин на OpenCart подключает блог на WordPress. Соответственно и дубли страниц этих CMS будут кардинально отличаться.
Поэтому мы и разработали сервис, который формирует все возможные страницы дублей и указывает их ответ сервера. В первую очередь сервис делали для своих нужд, ведь он экономит огромное количество времени специалистов, но с радостью готовы с ним поделиться.
Как с ним работать и как читать его результаты — сейчас будем разбираться.
Онлайн-сервис поиска дублей страниц
1. Для начала перейдите по ссылке.
2. Подготовьте разные типы страниц сайта, у которого хотите выявить возможные дубли.
Рекомендуемые к анализу типы страниц и их примеры:
- главная страница: http://www.foxtrot.com.ua/;
- страница категории: http://www.foxtrot.com.ua/ru/shop/noutbuki.html;
- целевая страница: http://www.foxtrot.com.ua/ru/shop/noutbuki_asus.html;
- страница товаров: http://www.foxtrot.com.ua/ru/shop/noutbuki_asus_f541nc-go054t.html;
- служебная страница: http://www.foxtrot.com.ua/ru/stores.
Для новостных и информационных ресурсов это могут быть:
- главная страница: https://www.maximonline.ru/;
- страница раздела: https://www.maximonline.ru/skills/lifehacking/;
- страница публикации или новости: https://www.maximonline.ru/guide/maximir/_article/myi-byili-v-55-sekundah-ot-strashnogo-pozora-ne-o/;
- страница тегов: https://www.maximonline.ru/tags/luchshie-lajfxaki-nedeli/;
- служебная страница: https://www.maximonline.ru/zhurnal/reklamnyj-otdel/_article/reklama-vmaxim/.
3. Вбиваем данные страницы в форму ввода и нажимаем кнопку «Отправить запрос»:
4. Запускается процесс обработки скрипта:
Немного ожидаем и получаем результат его работы по всем внедрённым страницам:
5. Анализируем результаты и подготавливаем рекомендации веб-программисту по устранению дублей.
Например, из вышеуказанного примера можно сделать следующие выводы:
- наличие дублей страниц с протоколами http и https;
- редирект со страницы без www на www происходит с помощью 302 редиректа (временный редирект);
- наличие дублей с добавление множественных слешей.
Соответственно, необходимо подготовить следующие рекомендации веб-разработчику:
1. Определиться, какой протокол всё же основной, и на страницы с этим протоколом настроить 301 редирект.
2. Изменить 302 редирект на 301 при перенаправлении страниц без www на аналогичные с www.
3. Настроить 301 редирект страниц со множественным добавлением слешей в конце URL на целевые страницы.
Важно понимать, что помимо шаблонных формирований дублей, указанных в данной статье, у вашего проекта могут формироваться уникальные дубли. Поэтому не забывайте мониторить страницы, которые попадают в индекс поисковых систем. Помогут в этом «Яндекс.Вебмастер» и Google Search Console.
Update
Сервис будет дорабатываться и дополняться полезными функциями. Так, выкатили обновление, позволяющее перед публикацией статьи определить изменения URL от исходного значения:
Если материал вам был полезен, прошу оценить его стрелкой вверх.
До скорых встреч и берегите ваши проекты.
Как обнаружить дубли страниц на сайте
Дубли — это страницы сайта с одинаковым или практически полностью совпадающим контентом. Наличие таких страниц может негативно сказаться на взаимодействии сайта с поисковой системой.
Чем вредны дубли?
Негативные последствия от дублей могут быть такими:
- Замедление индексирования нужных страниц. Если на сайте много одинаковых страниц, робот будет посещать их все отдельно друг от друга. Это может повлиять на скорость обхода нужных страниц, ведь потребуется больше времени, чтобы посетить именно нужные страницы.
- Затруднение интерпретации данных веб-аналитики. Страница из группы дублей выбирается поисковой системой автоматически, и этот выбор может меняться. Это значит, что адрес страницы-дубля в поиске может меняться с обновлениями поисковой базы, что может повлиять на страницу в поиске (например, узнаваемость ссылки пользователями) и затруднит сбор статистики.
Если на сайте есть одинаковые страницы, они признаются дублями, и в поиске тогда будет показываться по запросу только одна страница. Но адрес этой страницы в выдаче может меняться по очень большому числу факторов. Данные изменения могут затруднить сбор аналитики и повлиять на поисковую выдачу.
Как могут появиться дубли?
Дубли могут появиться на сайт в результате:
- Автоматической генерации. Например, CMS сайта создает ссылки не только с ЧПУ, но и техническим адресом: https://site.ru/noviy-tovar и https://site.ru/id279382.
- Некорректных настроек. К примеру, при неправильно настроенных относительных ссылках на сайте могут появляться ссылки по адресам, которых физически не существует, и они отдают такой же контент, как и нужные страницы сайта. Или на сайте не настроена отдача HTTP-кода ответа 404 для недоступных страниц — от них приходит «заглушка» с сообщением об ошибке, но они остаются доступными для индексирования.
- Ссылок с незначащими GET-параметрами. Зачастую GET-параметры не добавляют никакого контента на страницу, а используются, к примеру, для подсчета статистики по переходам — из какой-нибудь определенной социальной сети. Такие ссылки тоже могут быть признаны дублями (и недавно мы добавили специальное уведомление для таких ссылок, подробнее посмотреть можно тут).
- Ссылок со слешем на конце и без. Для поисковой системы сайты https://site.ru/page и https://site.ru/pages/ — это разные страницы (исключение составляет только главная страница, между https://site.ru/ и https://site.ru разницы нет).
Как обнаружить дубли
Теперь находить одинаковые страницы стало проще: в разделе «Диагностика» появилось специальное уведомление, которое расскажет про большую долю дублей на вашем сайте. Алерт появляется с небольшой задержкой в 2-3 дня — это обусловлено тем, что на сбор достаточного количества данных и их обработку требуется время. С этим может быть связано появление в нем исправленных страниц. Подписываться на оповещения не нужно, уведомление появится само.
А если вы хотите найти дубли вручную, перейдите в Вебмастер, во вкладке «Индексирование» откройте «Страницы в поиске», нажмите на «Исключённые» в правой части страницы. Прокрутите вниз, в правом нижнем углу вы увидите опцию «Скачать таблицу». Выберите подходящий формат и загрузите архив. Откройте скачанный файл: у страниц-дублей будет статус DUPLICATE.
Обратите внимание, что ссылки на сайте с одинаковым контентом не всегда признаются дублирующими. Это может быть связано с тем, что поисковая система еще не успела проиндексировать дубли, или на момент их индексирования содержимое несколько различалось. Такое бывает, если страницы, к примеру, динамически обновляют часть контента, из-за чего поисковая система каждый раз получает немного разные версии, хотя по факту содержимое очень похоже. Например, когда на странице есть лента похожих товаров, которая постоянно обновляется. Если вы точно знаете, что такие страницы являются дублями, то необходимо оставить в поиске только нужные страницы.
Как оставить в поиске нужную страницу в зависимости от ситуации

В случае с «мусорными» страницами воспользуйтесь одним из способов:
- Добавьте в файл robots.txt директиву Disallow, чтобы запретить индексирование страницы-дубля;
- Если вы не можете ограничить такие ссылки в robots.txt, запретите их индексирование при помощи мета-тега noindex. Тогда поисковой робот сможет исключить страницы из базы по мере их переобхода;
- Если такой возможности нет, можно настроить HTTP-код ответа 403/404/410. Данный метод менее предпочтителен, так как показатели недоступных страниц не будут учитываться, и если где-то на сайте или в поиске еще есть ссылки на такие страницы, пользователь попадет на недоступную ссылку.
В случае со страницами-дублями воспользуйтесь одним из способов:
- Для дублей с незначащими GET-параметрами рекомендуем добавить в файл robots.txt директиву Clean-param. Директива Clean-param — межсекционная. Это означает, что она будет обрабатываться в любом месте файла robots.txt. Указывать ее для роботов Яндекса при помощи User-Agent: Yandex не требуется. Но если вы хотите указать директивы именно для наших роботов, убедитесь, что для User-Agent: Yandex указаны и все остальные директивы — Disallow и Allow. Если в robots.txt будет указана директива User-Agent: Yandex, наш робот будет следовать указаниям только для этой директивы, а User-Agent: * будет проигнорирован;
- Вы можете установить редирект с HTTP-кодом 301 с одной дублирующей страницы на другую. В этом случае в поиске будет участвовать цель установленного редиректа. Укажите предпочитаемый (канонический) адрес страницы, который будет участвовать в поиске;
- Также можно использовать атрибут rel=«canonical». При работе с атрибутом rel=«canonical» стоит учитывать, что если содержимое дублей имеет некоторые отличия или очень часто обновляется, то такие страницы все равно могут попасть в поиск из-за различий в этом содержимом. В этом случае рекомендуем использовать другие предложенные варианты.
Для страниц со слешем на конце и без рекомендуем использовать редирект 301. Можно выбрать в качестве доступной как ссылку со слешем, так и без него — для индексирования разницы никакой нет.
В случае с важными контентыми страницами для их индексирования и представления в поиске важно использовать:
- Файлы Sitemap;
- Метрику;
- Установку счётчика;
- Настройку обхода страниц роботами.
Подробные рекомендации о работе со страницами-дублями читайте в Справке.
P. S. Подписывайтесь на наши каналы
Блог Яндекса для Вебмастеров
Канал Яндекса о продвижении сайтов на YouTube
Канал для владельцев сайтов в Яндекс.Дзен
Если страницы сайта доступны по разным адресам, но имеют одинаковое содержимое, робот Яндекса может посчитать их дублями и объединить в группу дублей.
Примечание. Дублями признаются страницы в рамках одного сайта. Например, страницы на региональных поддоменах с одинаковым содержимым не считаются дублями.
Если на сайте есть страницы-дубли:
-
Из результатов поиска может пропасть нужная вам страница, так как робот выбрал другую страницу из группы дублей.
Также в некоторых случаях страницы могут не объединяться в группу и участвовать в поиске как разные документы. Таким образом конкурировать между собой. Это может оказать влияние на сайт в поиске.
-
В зависимости от того, какая страница останется в поиске, адрес документа может измениться. Это может вызвать трудности при просмотре статистики в сервисах веб-аналитики.
-
Индексирующий робот дольше обходит страницы сайта, а значит данные о важных для вас страницах медленнее передаются в поисковую базу. Кроме этого, робот может создать дополнительную нагрузку на сайт.
- Как определить, есть ли страницы-дубли на сайте
- Как избавиться от страниц-дублей
Страницы-дубли появляются по разным причинам:
-
Естественным. Например, если страница с описанием товара интернет-магазина присутствует в нескольких категориях сайта.
-
Связанным с особенностями работы сайта или его CMS (например, версией для печати, UTM-метки для отслеживания рекламы и т. д.)
Чтобы узнать, какие страницы исключены из поиска из-за дублирования:
-
Перейдите в Вебмастер на страницу Страницы в поиске и выберите Исключённые страницы.
-
Нажмите значок
 и выберите статус «Удалено: Дубль».
и выберите статус «Удалено: Дубль».
 и выберите статус
и выберите статус Также вы можете выгрузить архив — внизу страницы выберите формат файла. В файле дублирующая страница имеет статус DUPLICATE. Подробно о статусах
Если дубли появились из-за добавления GET-параметров в URL, об этом появится уведомление в Вебмастере на странице Диагностика.
Примечание. Страницей-дублем может быть как обычная страница сайта, так и ее быстрая версия, например AMP-страница.
Чтобы оставить в поисковой выдаче нужную страницу, укажите роботу Яндекса на нее . Это можно сделать несколькими способами в зависимости от вида адреса страницы.
Контент дублируется на разных URLКонтент главной страницы дублируется на других URLВ URL есть или отсутствует / (слеш) в конце адресаВ URL есть несколько / (слешей)URL различаются значениями GET-параметров, при этом контент одинаковВ URL есть параметры AMP-страницы
Пример для обычного сайта:
http://example.com/page1/ и http://example.com/page2/Пример для сайта с AMP-страницами:
http://example.com/page/ и http://example.com/AMP/page/В этом случае:
-
Установите редирект с HTTP-кодом 301 с одной дублирующей страницы на другую. В этом случае в поиске будет участвовать цель установленного редиректа.
-
Добавьте в файл robots.txt директиву Disallow, чтобы запретить индексирование страницы-дубля.
Если вы не можете ограничить такие ссылки в robots.txt, запретите их индексирование при помощи мета-тега noindex. Тогда поисковой робот сможет исключить страницы из базы по мере их переобхода.
Также вы можете ограничить AMP-страницы, которые дублируют контент страниц другого типа.
Чтобы определить, какая страница должна остаться в поиске, ориентируйтесь на удобство посетителей вашего сайта. Например, если речь идет о разделе с похожими товарами, вы можете выбрать в качестве страницы для поиска корневую или страницу этого каталога — откуда посетитель сможет просмотреть остальные страницы. В случае дублирования обычных HTML и AMP-страниц, рекомендуем оставлять в поиске обычные HTML.
https://example.com и https://example.com/index.phpВ этом случае:
-
Установите редирект с HTTP-кодом 301 с одной дублирующей страницы на другую. В этом случае в поиске будет участвовать цель установленного редиректа.
Рекомендуем устанавливать перенаправление с внутренних страниц на главную. Если вы настроите редирект со страницы https://example.com/ на https://example.com/index.php, контент страницы https://example.com/index.php будет отображаться по адресу https://example.com/ — согласно правилам обработки редиректов.
http://example.com/page/ и http://example.com/pageВ этом случае установите редирект с HTTP-кодом 301 с одной дублирующей страницы на другую. Тогда в поиске будет участвовать цель установленного редиректа.
Не рекомендуем в этом случае использовать атрибут rel=canonical, так как он может игнорироваться. При редиректе пользователи будут попадать сразу на нужный URL страницы.
Если проблема на главной странице, настраивать на ней ничего не нужно. Поисковая система распознает страницы http://example.com и http://example.com/ как одинаковые.
Яндекс индексирует ссылки со слешем на конце и без одинаково. При выборе URL, который останется в поиске, нужно учесть, по какому адресу сейчас индексируются страницы, если редирект еще не был установлен. Например, если в поиске уже участвуют страницы без слеша, стоит настроить перенаправление со страниц со слешем на ссылки без слеша. Это позволит избежать дополнительной смены адреса страниц в поиске.
http://example.com/page////something/В этом случае поисковая система убирает дублирующиеся символы. Страница будет индексироваться по адресу http://example.com/page/something/.
Если в URL есть (например, http://example.com/page/something/\\), поисковая система воспринимает такую страницу как отдельную. Она будет индексироваться по адресу http://example.com/page/something/\\.
В этом случае:
-
Установите редирект с HTTP-кодом 301 с одной страницы на другую. В этом случае в поиске будет участвовать цель установленного редиректа.
-
Укажите предпочитаемый (канонический) адрес страницы, который будет участвовать в поиске.
-
Добавьте в файл robots.txt директиву Disallow, чтобы запретить индексирование страницы.
Если вы не можете ограничить такие ссылки в robots.txt, запретите их индексирование при помощи мета-тега noindex. Тогда поисковой робот сможет исключить страницы из базы по мере их переобхода.
Используйте рекомендации, если различия есть в тех параметрах, которые не влияют на контент. Например, такими параметрами могут быть UTM-метки:
https://example.com/page?utm_source=instagram&utm_medium=cpcВ этом случае добавьте в файл robots.txt директиву Clean-param, чтобы робот не учитывал параметры в URL. Если в Вебмастере отображается уведомление о дублировании страниц из-за GET-параметров, этот способ исправит ошибку. Уведомление пропадет, когда робот узнает об изменениях.
Совет. Директива Clean-Param является межсекционной, поэтому может быть указана в любом месте файла. Если вы указываете другие директивы именно для робота Яндекса, перечислите все предназначенные для него правила в одной секции. При этом строка User-agent: * будет проигнорирована.
- Пример директивы Clean-param
-
#для адресов вида: example.com/page?utm_source=instagram&utm_medium=cpc example.com/page?utm_source=link&utm_medium=cpc&utm_campaign=new #robots.txt будет содержать: User-agent: Yandex Clean-param: utm /page #таким образом указываем роботу, что нужно оставить в поиске адрес https://example.com/page #чтобы директива применялась к параметрам на страницах по любому адресу, не указывайте адрес: User-agent: Yandex Clean-param: utm
Если у вас нет возможности изменить robots.txt, укажите предпочитаемый (канонический) адрес страницы, который будет участвовать в поиске.
http://example.com/page/ и http://example.com/page?AMPВ этом случае добавьте директиву Clean-param в файл robots.txt, чтобы робот не учитывал параметры в URL.
Если AMP-страницы формируются не GET-параметром, а при помощи директории формата /AMP/, их можно рассматривать как обычные контентные дубли.
Робот узнает об изменениях, когда посетит ваш сайт. После посещения страница, которая не должна участвовать в поиске, будет исключена из него в течение трех недель. Если на сайте много страниц, этот процесс может занять больше времени.
Проверить, что изменения вступили в силу, можно в Яндекс Вебмастере на странице Страницы в поиске.
В статье про технический аудит сайта мы упомянули, что среди прочего SEO-специалисту важно проверить, а есть ли дубли страниц на продвигаемом им веб-ресурсе. И если они найдутся, то нужно немедленно устранить проблему. Однако там в рамках большого обзора я не хотел обрушивать на голову читателя кучу разнообразной информации, поэтому о том, что такое дубликаты страниц сайта, как их находить и удалять, мы вместе с вами детальнее рассмотрим здесь.
Почему и как дубли страниц мешают поисковому продвижению
Для начала отвечу на вопрос «Как?». Дубликаты страниц сильно затрудняют SEO, т. к. поисковые системы не могут понять, какую из веб-страниц им нужно показывать в выдаче по релевантным запросам. Поэтому чаще всего, чтобы не путаться, они понижают сайт в ранжировании или даже банят его, если проблема имеет массовый характер. После этого должно быть понятно, насколько важно сразу проверить продвигаемый ресурс на дубликаты.
Теперь давайте посмотрим, почему так получается, что дубли создают проблему? Для этого рассмотрим такой простой пример. Взгляните на следующее изображение и определите, какой из овощей наиболее точно соответствует запросу «спелый помидор»?

Хотя овощи немного отличаются размером, но все три из них подходят под категорию «спелого помидора». Поэтому сделать выбор в пользу одно из них довольно сложно.
Такая же дилемма встает перед поисковыми алгоритмами, когда они видят на сайте несколько одинаковых (полных) или почти одинаковых (частичных) копий одной и той же страницы.
Как наличие дублей сказывается на продвижении:
- Чаще всего падает релевантность основной продвигаемой страницы и, соответственно, снижаются позиции по используемым ключевым словам.
- Также могут «прыгать» позиции по ключам из-за того, что поисковик будет менять страницу для показа в поисковой выдаче.
- Если проблема не ограничивается несколькими урлами, а распространяется на весь сайт, то в таком случае Яндекс и Google могут наказать неприятным фильтром.
Понимая теперь, насколько серьезными могут быть последствия, рассмотрим виды дубликатов.
SEO-шников много, профессионалов — единицы. Научитесь технической и поведенческой оптимизации, создавайте семантические ядра и продвигайте проекты в ТОП!
Получить скидку →

Ежедневные советы от диджитал-наставника Checkroi прямо в твоем телеграме!
Подписывайся на канал
Подписаться
Виды дублей
Выше мы уже выяснили, что дубли бывают идентичными (полными) и частичными. Полным называют такой дубликат, когда одну и ту же веб-страницу поисковик находит по различным адресам.
Когда появляются полные дубли:
- Зачастую это происходит, если забыли указать главное зеркало, и весь сайт может показываться в поиске с www и без него, c http и с https. Чтобы устранить эту проблему, читайте здесь детальнее о том, что такое зеркало сайта.
- Кроме того, бывают ситуации, когда возникают дубли главной страницы ввиду особенностей движка или проведенной веб-разработчиком работы. Тогда, к примеру, главная может быть доступна со слешем «/» в конце и без него, с добавлением слов home, start, index.php и т. п.
- Нередко дубли возникают, когда в индекс попадают страницы с динамичными адресами, появляющиеся обычно при использовании фильтров для сортировки и сравнения товаров.
- Часть движков (WordPress, Joomla, Opencart, ModX) сами по себе генерируют дубли. К примеру, в Joomla по умолчанию часть страниц доступна к отображению с разными урлами: mysite.ru/catalog/17 и mysite.ru/catalog/17-article.html и т. п.
- Если для отслеживания сессий применяют специальные идентификаторы, то они также могут индексироваться и создавать копии.
- Иногда в индекс также попадают страницы по адресам, к которым добавлены utm-метки. Такие метки вставляют, чтобы отслеживать эффективность проводимых рекламных кампаний, и по-хорошему они не должны быть проиндексированы. Однако на практике подобные урлы часто можно видеть в поисковой выдаче.
Когда возникают частичные дубли
Полные дубли легко найти и устранить, а вот с частичными уже придется повозиться. Поэтому на рассмотрении их видов стоит остановиться детальнее.
Пагинация страниц
Используя пагинацию страниц, владельцы сайтов делают навигацию для посетителей более простой, но вместе с тем создают проблему для поискового продвижения. Каждая страница пагинации – это фактически дубль зачастую с теми же мета-данными, СЕО-текстом.
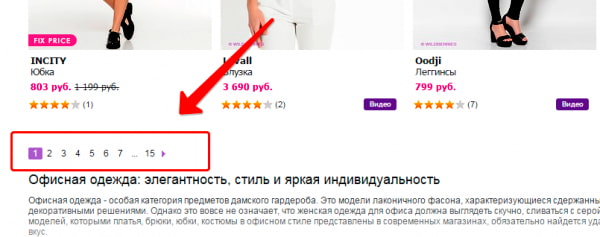
К примеру, основная страница имеет вид https://mysite.ru/women/clothes, а у страницы пагинации адрес будет https://mysite.ru/women/clothes/?page=2. Адреса получаются разные, а содержимое будет почти одинаковым.
Блоки новостей, популярных статей и комментариев
Чтобы удержать пользователя на сайте, ему часто предлагают ознакомиться с наиболее интересными новостями, комментариями и статьями. Название этих объектов с частью содержимого обычно размещают по бокам или снизу от основного материала. Если эти куски будут проиндексированы, то поисковик определит, что на некоторых страницах одинаковый контент, а это очень плохо.
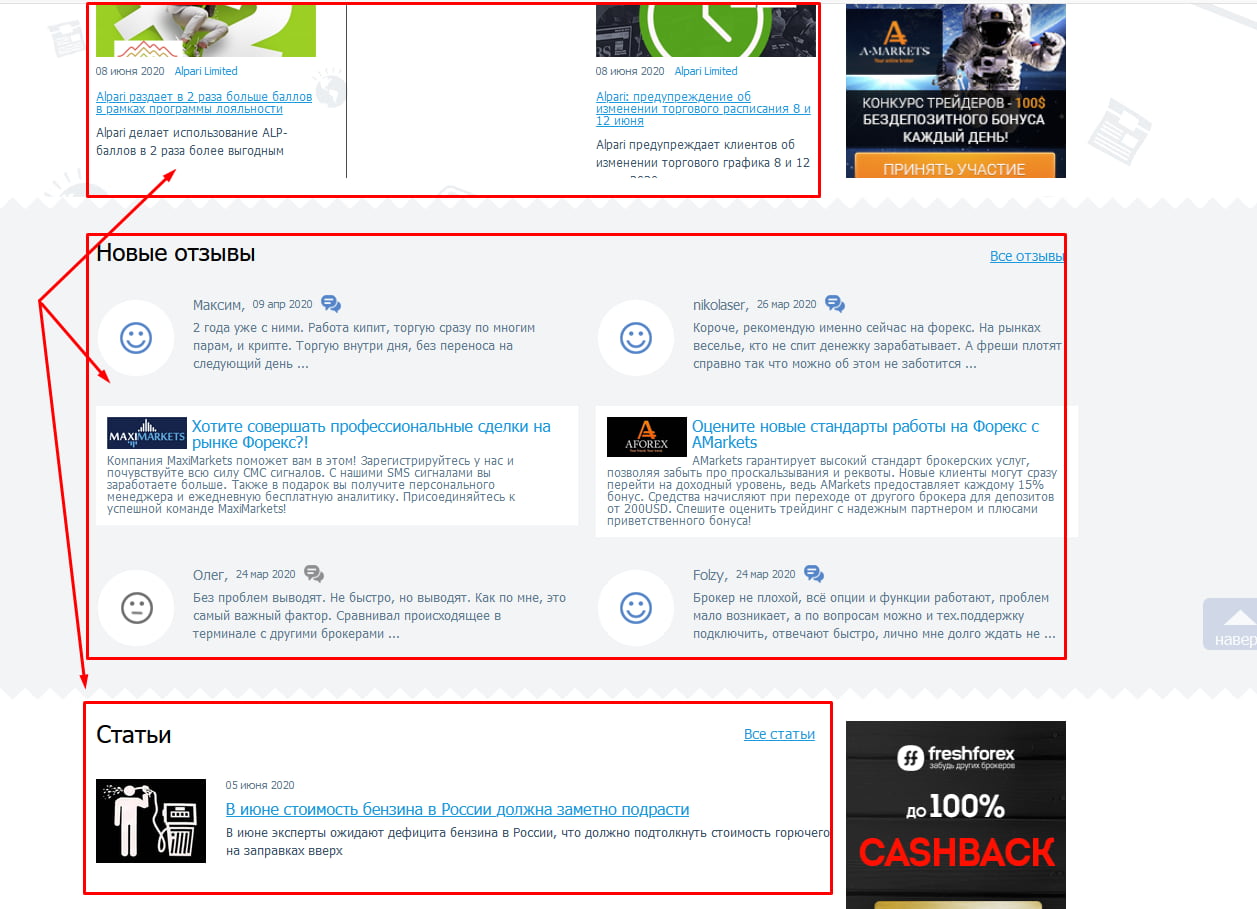
На скриншоте видно, как внизу главной страницы сайта размещаются три блока с последними статьями, новостями и отзывами. То есть текстовое содержимое есть в соответствующих разделах сайта, и здесь на главной оно повторяется, создавая частичные дубли.
Версии страниц для печати
Некоторые веб-страницы сайта доступны в обычном варианте и в версии для печати, которая отличается от основной адресом и отсутствием значительной части строк кода, т. к. для печатаемой страницы не нужна значительная часть функционала.
Обычная страница может открываться, например, по адресу https://my-site.ru/page, а у варианта для печати адрес немного изменится и будет похож на такой: https://my-site.ru/page?print.
Сайты с технологией AJAX
На некоторых сайтах, применяемых технологию AJAX, возникают так называемые html-слепки. Сами по себе они не опасны, если нет ошибок в имплантации способа индексирования AJAX-страниц, когда поисковых ботов направляют не на основную страницу, а на html-слепок, где робот индексирует одну и ту же страницу по двум адресам:
- основному;
- адресу html-слепка.
Для нахождения таких html-слепков стоит в основном адресе заменить часть «!#» на такой код: «?_escaped_fragment_=».
Частичные дубли опасны тем, что они не вызывают значительного снижения позиций в один момент, а понемногу портят картину, усугубляя ситуацию день за днем.
Как происходит поиск дублей страниц на сайте
Существует несколько основных способов, позволяющих понять, как найти дубли страниц оптимизатору на сайте:
Вручную
Уже зная, где стоит искать дубликаты, SEO-специалист без особого труда может найти значительную часть копий, попробовав различные варианты урлов.
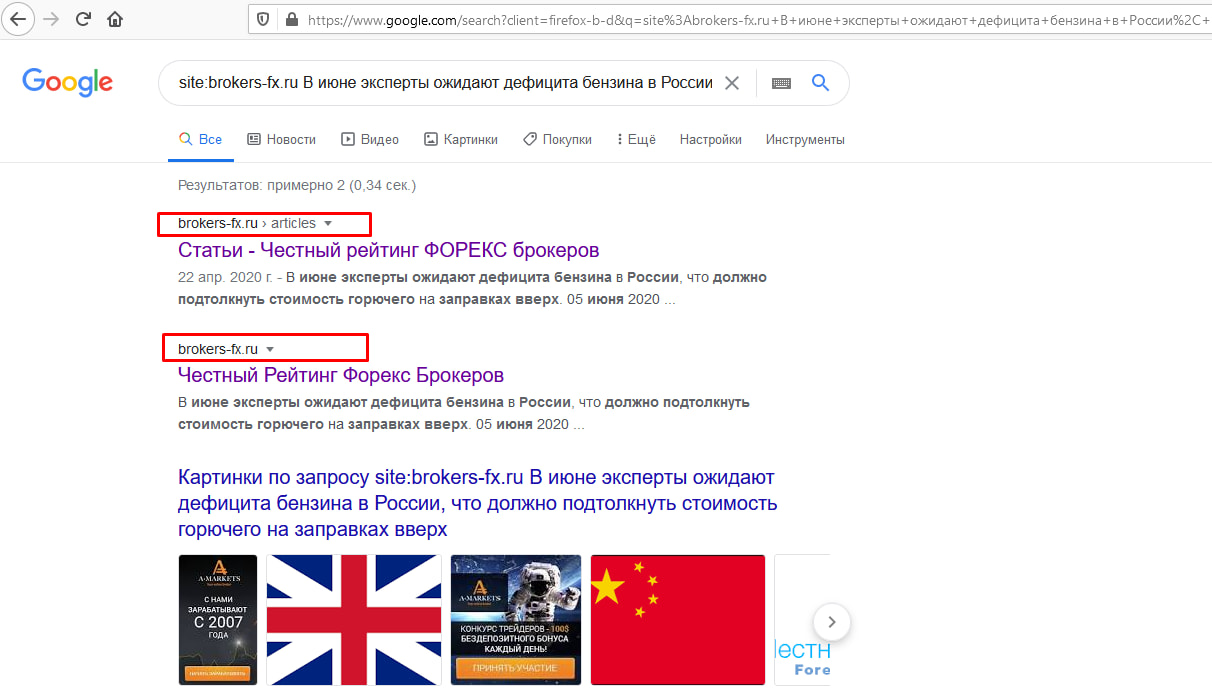
С применением команды site
Вставляем в адресную строку команду «site:», вводим после нее домен и часть текстового содержания, после чего Google сам выдаст все найденные варианты. На скриншоте ниже видно, что мы ввели первое предложение свежей статьи после команды «site:», и Google показывает, что у основной страницы с материалом есть частичный дубль на главной.
С использованием программ и онлайн-сервисов
Для поиска дублей часто применяют три популярные программы на ПК:
- Xenu – бесплатная;
- NetPeak – от $15 в месяц, но есть 14-дневный trial;
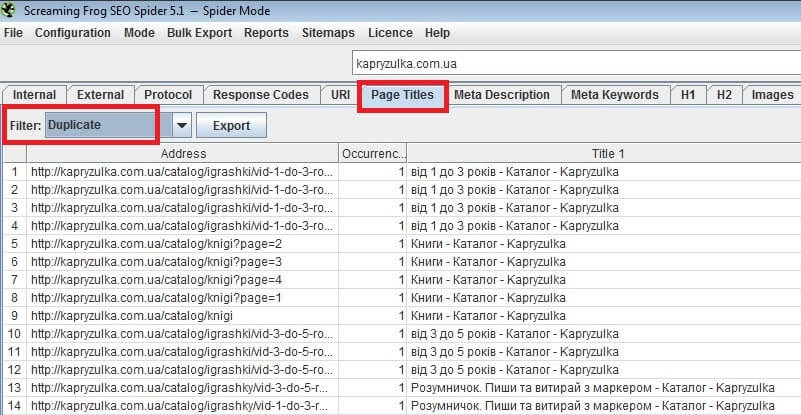
- Screaming Frog – платная (149 фунтов за год), но есть ограниченная бесплатная версия, которой хватает для большинства нужд.
Вот пример того, как ищет дубликаты программа Screaming Frog:
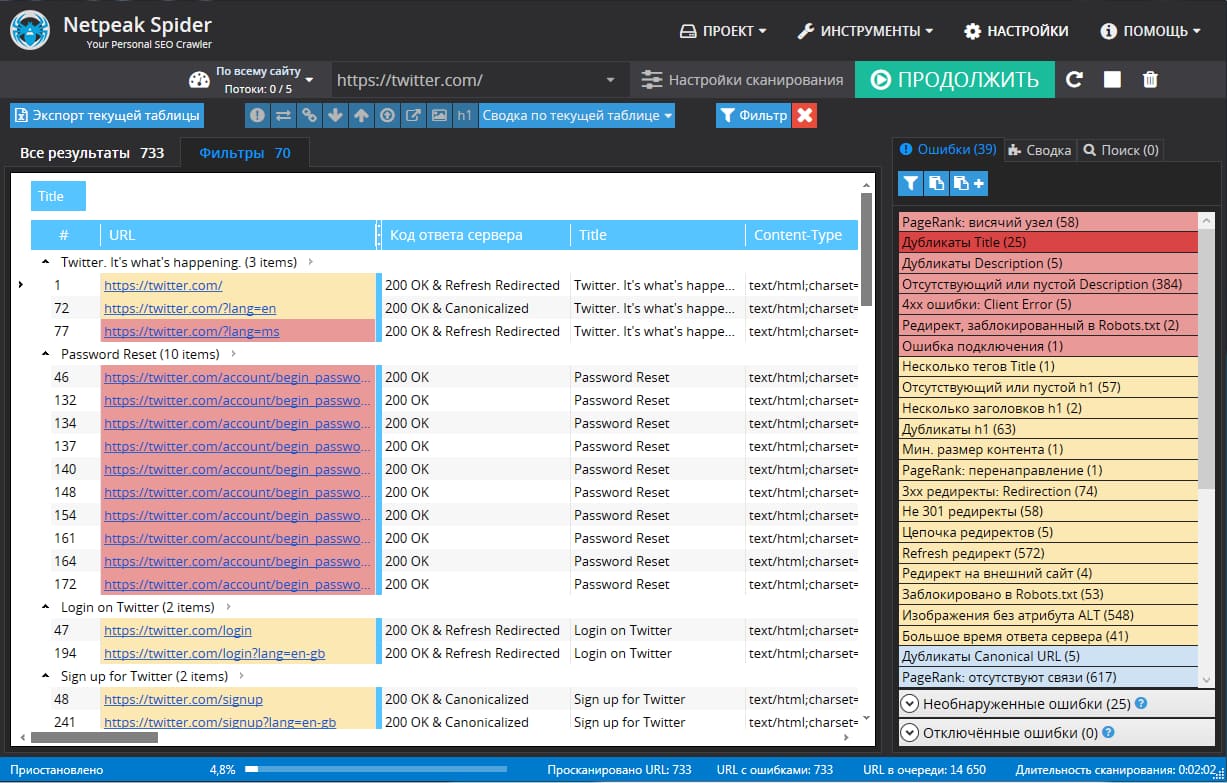
А вот как можно проверить дубли страниц в NetPeak:
Для онлайн-поиска дублей страниц можно использовать специальные веб-сервисы наподобие Serpstat.
Использование Google Search Console и Яндекс Вебмастер
В обновленной версии Google Search Console для поиска дублей смотрим «Предупреждения» и «Покрытие». Там поисковая система сама сообщает о проблемных, на ее взгляд, страницах, которым нужно уделить внимание.
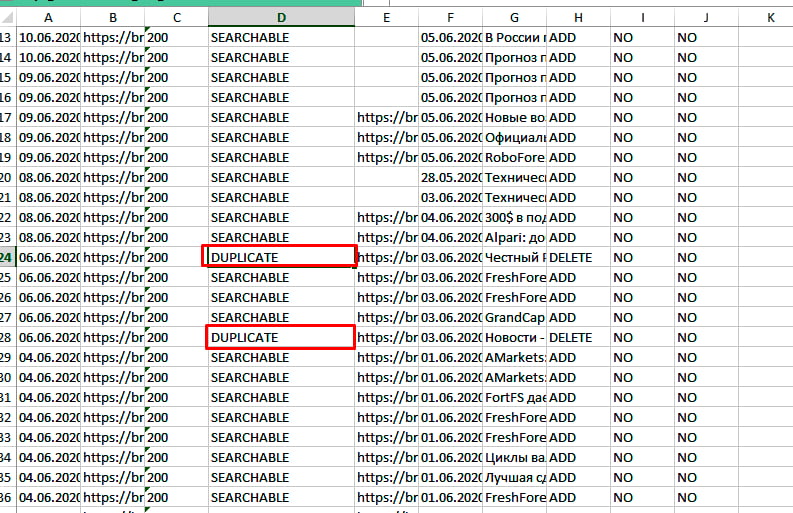
Что касается Yandex, то здесь все намного удобнее. Для поиска дублей заходим в Яндекс Вебмастер, открыв раздел «Индексирование» – «Страницы в поиске». Опускаемся в самый низ, выбираем справа удобный формат файла – XLS или CSV, скачиваем его и открываем. В этом документе все дубликаты в строке «Статус» будут иметь обозначение DUPLICATE.
Как убрать дубли?
Чтобы удалить дубли страниц на сайте, можно использовать разные приемы в зависимости от ситуации. Давайте же с ними познакомимся:
При помощи noindex и nofollow
Самый простой способ – закрыть от индексации, используя метатег <meta name=”robots” content=”noindex,nofollow”/>, который помещают в шапку между открывающим тегом <head> и закрывающим </head>. Попав на страницу с таким метатегом, поисковые алгоритмы не станут ее индексировать и учитывать ссылки, находящиеся здесь.
При добавлении метатега «noindex,nofollow» на страницу, крайне важно, чтобы для нее не была запрещена индексация через файл robots.txt.
При помощи robots.txt
Индексирование отдельных дублей можно запретить в файле robots.txt, используя директиву Disallow. В таком случае примерный вид кода, добавляемого в robots.txt, будет таким:
User-agent: *
Disallow: /dublictate.html
Host: mysite.ru
Через robots.txt удобно запрещать индексацию служебных страниц. Выглядит это следующим образом:

Этот вариант зачастую применяют, если невозможно использовать предыдущий.
При помощи canonical
Еще один удобный способ – применить метатег canonical, который говорит поисковым роботам, что они попали на страницу-дубликат, а заодно указывает, где находится основная страница. Этот метатег помещают в шапку между открывающим тегом <head> и закрывающим </head>, и выглядит он так:
<link rel=”canonical” href=”адрес основной страницы” />
Как убрать дубликаты на страницах с пагинацией
В случае присутствия на сайте многостраничного каталога, на второй и последующих страницах могут возникать частичные дубли. Смотрим, как это может быть:
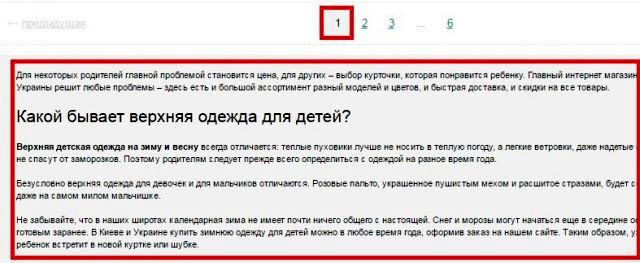
Выше на скрине 1-я страница каталога, а вот вторая:
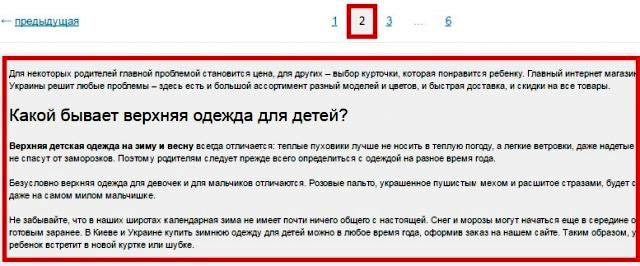 То есть на каждой странице дублируется текст и теги: Title и Description.
То есть на каждой странице дублируется текст и теги: Title и Description.
В таких случаях SEO-специалисту нужно добиться, чтобы:
- текст отображался только на 1-й странице;
- Title и Description были уникальными для каждой страницы, хотя их можно сделать шаблонными с минимальными отличиями;
- в адресах страниц пагинации должны отсутствовать динамические параметры.
Понимая теперь, что такое дубликаты страниц сайта, и как бороться с дублями, вы сможете не допустить попадания в индекс копий, которые будут препятствовать продвижению в поисковых системах. Если после прочтения статьи у вас остались вопросы, или вы хотите дополнить материал своими ценными замечаниями, то обязательно сделайте это в комментариях ниже.
- Почему дубли страниц — это плохо?
- Как найти дубли страниц?
- Как убрать дубли страниц на сайте?
Почему дубли страниц — это плохо?
Дубли — это страницы с одинаковым содержимым, т.е. они дублируют друг друга.
Причины, по которым страницы дублируются, могут быть разными:
- автоматическая генерация;
- ошибки в структуре сайта;
- некорректная разбивка одного кластера на две страницы и другие.
Дубли страниц — это плохо для продвижения и раскрутки сайта, даже несмотря на то, что они могут появляться по естественным причинам. Дело в том, что поисковые роботы хуже ранжируют страницы, контент которых мало чем отличается от других страниц. И чем больше таких страниц, тем больше сигналов поисковым ботам, что это сайт не достоин быть в топе выдачи.
Что происходит с сайтом, у которого есть дубликаты страниц?
- Снижается его релевантность. Обе страницы с одинаковым контентом пессимизируются в выдаче, теряют позиции и трафик.
- Снижается процент уникальности текстового контента. Из-за этого понизится уникальность всего сайта.
- Снижается вес URL-адресов сайта. По каждому запросу в выдачу поиска попадает только одна страница, а если таких одинаковых страниц несколько, все теряют в весе.
- Увеличивается время на индексацию. Чем больше страниц, тем больше времени нужно боту, чтобы индексировать ваш сайт. Для крупных сайтов проблемы с индексацией могут сильно сказаться на трафике из поиска.
- Бан от поисковых систем. Можно вообще вылететь из выдачи на неопределенный срок.
В общем, становится понятно, что дубли никому не нужны. Давайте разбираться, как найти и обезвредить дублирующиеся страницы на сайте.
Как найти дубли страниц?

Кирилл Бузаков,
SEO-оптимизатор компании SEO.RU:
«Когда мы получаем в работу сайт, мы проверяем его на наличие дублей страниц, отдающих код 200. Разберем, какие это могут быть дубли.
Возможные типы дублей страниц на сайте
-
Дубли страниц с протоколами http и https.
Например: https://site.ru и http://site.ru
-
Дубли с www и без.
Например: https://site.ru и https://www.site.ru
-
Дубли со слешем на конце URL и без.
Например: https://site.ru/example/ и https://site.ru/example
-
Дубли с множественными слешами в середине либо в конце URL.
Например: https://site.ru/////////, https://site.ru/////////example/
-
Прописные и строчные буквы на различных уровнях вложенности в URL.
Например: https://site.ru/example/ и https://site.ru/EXAMPLE/
-
Дубли с добавлением на конце URL:
- index.php;
- home.php;
- index.html;
- home.html;
- index.htm;
- home.htm.
Например: https://site.ru/example/ и https://site.ru/example/index.html
-
Дубли с добавлением произвольных символов либо в качестве нового уровня вложенности (в конце или середине URL), либо в существующие уровни вложенности.
Например: https://site.ru/example/saf3qA/, https://site.ru/saf3qA/example/ и https://site.ru/examplesaf3qA/
-
Добавление произвольных цифр в конце URL в качестве нового уровня вложенности.
Например: https://site.ru/example/ и https://site.ru/example/32425/
-
Дубли с добавлением «звездочки» в конце URL.
Например: https://site.ru/example/ и https://site.ru/example/*
-
Дубли с заменой дефиса на нижнее подчеркивание или наоборот.
Например: https://site.ru/defis-ili-nizhnee-podchyorkivanie/ и https://site.ru/defis_ili_nizhnee_podchyorkivanie/
-
Дубли с некорректно указанными уровнями вложенности.
Например: https://site.ru/category/example/ и https://site.ru/example/category/
-
Дубли с отсутствующими уровнями вложенности.
Например: https://site.ru/category/example/ и https://site.ru/example/
Как обнаружить дубли страниц?
Поиск дублей страниц можно произвести разными способами. Если вы хотите собрать все-все дубли и ничего не упустить, лучше использовать все нижеперечисленные сервисы совместно. Но для поиска основных достаточно какого-то одного инструмента, выбирайте, какой вам ближе и удобнее.
-
Парсинг сайта в специализированной программе
Для поиска дубликатов подходит программа Screaming Frog SEO Spider. Запускаем сканирование, а после него проверяем дубли в директории URL → Duplicate:
Кроме того, в директории Protocol → HTTP проверяем страницы с протоколом http — есть ли среди них те, у которых Status Code равен 200:
-
Онлайн-сервисы.
Первый, подходящий нашим целям сервис, — это ApollonGuru.
- Выбираем 5-7 типовых страниц сайта. Например, набор может быть таким: главная, разводящая, карточка товара/страница услуги, статья в блоге, а также другие важные страницы в зависимости от типа сайта.
- Вносим их в поле «Поиск дублей страниц» и нажимаем кнопку «Отправить»:
- Дубли с 200 кодом ответа сервера (смотрим столбец «Код ответа сервера») берем в работу:
Кроме того, необходимо проверять, что с дублей настроены прямые 301 редиректы на основные версии этих же страниц.




Также проверка дублей сайта возможна онлайн-сервисом Check Your Redirects and Statuscode, но он подходит только в том случае, если нужно проанализировать один URL-адрес:

-
Панели веб-мастеров Яндекса и Google.
Найти дублирующиеся страницы можно с помощью собственных инструментов поисковиков — Яндекс.Вебмастера и Google Search Console.
В Яндекс.Вебмастере анализируем раздел «Индексирование», далее — «Страницы в поиске»:
Там можно увидеть текущую индексацию сайта и искомые дубли страниц:
В Search Console анализируем раздел «Покрытие», а именно пункт с исключенными из индекса страницами:



Собираем все дубли в одну таблицу или документ. Затем отправляем их в работу программисту:

Старайтесь подробнее объяснить программисту задачу, так как адресов может быть много».
Как убрать дубли страниц на сайте?

Евгений Костырев,
веб-программист компании SEO.RU:
«С дублирующимися страницами бороться можно разными способами. Если есть возможность, стоит использовать ручной метод. Но такая возможность есть не всегда, потому что здесь нужны серьезные навыки программирования: как минимум, нужно хорошо разбираться в особенностях CMS своего сайта.
Другие же методы не требуют специализированных знаний и тоже могут дать хороший результат. Давайте разберем их.
301 редирект
301 редирект — это самый надежный способ избавления от дублей, но при этом самый требовательный к профессиональным навыкам программиста.
Как это работает: если сайт использует сервер Apache, то нужные правила в файле .htaccess с помощью регулярных выражений.
Самый простой вариант 301 редиректа с одной страницы на другую:
Redirect 301 /test-1/ http://site.ru/test-2/
Устанавливаем 301 редирект со страницы с www на страницу без www (главное зеркало — домен без www):
RewriteCond %{HTTP_HOST} ^www.(.*)$
RewriteRule^(.*)$ http://%1/$1 [L,R=301]
Организуем редирект с протокола http на https:
RewriteCond %{HTTPS} !=on
RewriteRule^(.*)$ https://%{HTTP_HOST}/$1 [R=301,L]
Прописываем 301 редирект для index.php, index.html или index.htm (например, в Joomla), массовая склейка:
RewriteCond %{THE_REQUEST} ^[A-Z]{3,9} /index.(php|html|htm) HTTP/
RewriteRule^(.*)index.(php|html|htm)$ http://site.ru/$1 [R=301,L]
Если же сайт использует Nginx, то правила прописываются в файле nginx.conf. Для перенаправления также нужно прописывать правила с помощью регулярных выражений, например:
location = /index.html {
return 301 https://site.com
}
Вместо index.html можно указать любой другой URL-адрес страницы вашего сайта, с которого нужно сделать редирект.
На этом этапе важно следить за корректностью новой части кода: если в ней будут ошибки, исчезнут не только дубли, но и вообще весь сайт из всего интернета.
Создание канонической страницы
Использование canonical указывает поисковому пауку на ту единственную страницу, которая является оригинальной и должна быть в поисковой выдаче.
Чтобы выделить такую страницу, нужно на всех URL дублей прописать код с адресом оригинальной страницы:
<link rel= “canonical” href= “http://www.site.ru/original-page.html”>
Можно прописывать их вручную, но это займет много времени, поэтому есть смысл использовать плагины. Например, в WordPress это YoastSEO или AllinOneSEOPack.
В 1С-Битрикс это делается с помощью языка программирования PHP в соответствующих файлах. Такая же история и с CMS Joomla: без вмешательства программиста или собственных навыков программирования здесь не обойтись.
Директива Disallow в robots.txt
В файле robots.txt содержатся инструкции для поисковых краулеров, как именно индексировать сайт.
Читать по теме: Как правильно заполнить файл robots.txt: критически важные моменты
Если на сайте есть дубли, можно запретить краулеру их индексировать с помощью директивы:
User-agent: *
Disallow: site.ru/contacts.php?work=225&s=1
Такой способ практически не требует навыков программиста, однако он не подходит, если дублей много: очень много времени уйдет на изменение robots.txt каждого дубля».
Выбирайте способ, исходя из собственных навыков программирования и личных предпочтений, и не давайте поисковикам повод сомневаться в релевантности и качестве вашего сайта.
