I am looking for a CSS selector for the following table:
Peter | male | 34
Susanne | female | 12
Is there any selector to match all TDs containing “male”?
BoltClock
694k159 gold badges1384 silver badges1352 bronze badges
asked Oct 5, 2009 at 14:26
![]()
8
If I read the specification correctly, no.
You can match on an element, the name of an attribute in the element, and the value of a named attribute in an element. I don’t see anything for matching content within an element, though.
answered Oct 5, 2009 at 14:33
Dean JDean J
39.1k16 gold badges67 silver badges93 bronze badges
3
Using jQuery:
$('td:contains("male")')
answered Jan 31, 2012 at 15:04
moettingermoettinger
4,8952 gold badges15 silver badges20 bronze badges
8
You’d have to add a data attribute to the rows called data-gender with a male or female value and use the attribute selector:
HTML:
<td data-gender="male">...</td>
CSS:
td[data-gender="male"] { ... }
answered Oct 5, 2009 at 14:39
Esteban KüberEsteban Küber
36.2k15 gold badges79 silver badges97 bronze badges
4
There is actually a very conceptual basis for why this hasn’t been implemented. It is a combination of basically 3 aspects:
- The text content of an element is effectively a child of that element
- You cannot target the text content directly
- CSS does not allow for ascension with selectors
These 3 together mean that by the time you have the text content you cannot ascend back to the containing element, and you cannot style the present text. This is likely significant as descending only allows for a singular tracking of context and SAX style parsing. Ascending or other selectors involving other axes introduce the need for more complex traversal or similar solutions that would greatly complicate the application of CSS to the DOM.
answered Oct 30, 2012 at 20:44
Matt WhippleMatt Whipple
7,0241 gold badge23 silver badges34 bronze badges
3
You could set content as data attribute and then use attribute selectors, as shown here:
/* Select every cell matching the word "male" */
td[data-content="male"] {
color: red;
}
/* Select every cell starting on "p" case insensitive */
td[data-content^="p" i] {
color: blue;
}
/* Select every cell containing "4" */
td[data-content*="4"] {
color: green;
}<table>
<tr>
<td data-content="Peter">Peter</td>
<td data-content="male">male</td>
<td data-content="34">34</td>
</tr>
<tr>
<td data-content="Susanne">Susanne</td>
<td data-content="female">female</td>
<td data-content="14">14</td>
</tr>
</table>You can also use jQuery to easily set the data-content attributes:
$(function(){
$("td").each(function(){
var $this = $(this);
$this.attr("data-content", $this.text());
});
});
toms
5056 silver badges23 bronze badges
answered Dec 22, 2016 at 10:59
BuksyBuksy
11.4k8 gold badges62 silver badges68 bronze badges
4
As CSS lacks this feature you will have to use JavaScript to style cells by content. For example with XPath’s contains:
var elms = document.evaluate( "//td[contains(., 'male')]", node, null, XPathResult.UNORDERED_NODE_SNAPSHOT_TYPE, null )
Then use the result like so:
for ( var i=0 ; i < elms.snapshotLength; i++ ){
elms.snapshotItem(i).style.background = "pink";
}
https://jsfiddle.net/gaby_de_wilde/o7bka7Ls/9/
![]()
answered May 11, 2016 at 8:21
user40521user40521
1,92720 silver badges7 bronze badges
4
I’m afraid this is not possible, because the content is no attribute nor is it accessible via a pseudo class. The full list of CSS3 selectors can be found in the CSS3 specification.
answered Oct 5, 2009 at 14:33
Edwin V.Edwin V.
1,3078 silver badges11 bronze badges
0
For those who are looking to do Selenium CSS text selections, this script might be of some use.
The trick is to select the parent of the element that you are looking for, and then search for the child that has the text:
public static IWebElement FindByText(this IWebDriver driver, string text)
{
var list = driver.FindElement(By.CssSelector("#RiskAddressList"));
var element = ((IJavaScriptExecutor)driver).ExecuteScript(string.Format(" var x = $(arguments[0]).find(":contains('{0}')"); return x;", text), list);
return ((System.Collections.ObjectModel.ReadOnlyCollection<IWebElement>)element)[0];
}
This will return the first element if there is more than one since it’s always one element, in my case.
the Tin Man
158k41 gold badges214 silver badges302 bronze badges
answered Jan 20, 2015 at 16:21
1
If you don’t create the DOM yourself (e.g. in a userscript) you can do the following with pure JS:
for ( td of document.querySelectorAll('td') ) {
console.debug("text:", td, td.innerText)
td.setAttribute('text', td.innerText)
}
for ( td of document.querySelectorAll('td[text="male"]') )
console.debug("male:", td, td.innerText)<table>
<tr>
<td>Peter</td>
<td>male</td>
<td>34</td>
</tr>
<tr>
<td>Susanne</td>
<td>female</td>
<td>12</td>
</tr>
</table>Console output
text: <td> Peter
text: <td> male
text: <td> 34
text: <td> Susanne
text: <td> female
text: <td> 12
male: <td text="male"> male
answered Dec 15, 2019 at 18:56
![]()
Gerold BroserGerold Broser
13.9k4 gold badges48 silver badges103 bronze badges
Excellent answers all around, but I think I can add something that worked for me in a practical scenario: exploiting the aria-label attribute for CSS.
For the readers that don’t know: aria-label is an attribute that is used in conjunction with other similar attributes to let a screen-reader know what something is, in case someone with a visual impairment is using your website. Many websites add these attributes to elements with images or text in them, as “descriptors”.
This makes it highly website-specific, but in case your element contains this, it’s fairly simple to select that element using the content of the attribute:
HTML:
<td aria-label="male">Male</td>
<td aria-label="female">Female</td>
CSS:
td[aria-label="male"] {
outline: 1px dotted green;
}
This is technically the same thing as using the data-attribute solution, but this will work for you if you are not the author of the website, plus this is not some out-of-the-way solution that is specifically designed to support this use case; it’s fairly common on its own. The one downside of it is that there’s really no guarantee that your intended element will have this attribute present.
answered Jun 3, 2022 at 9:41
![]()
cst1992cst1992
3,7431 gold badge29 silver badges40 bronze badges
1
Most of the answers here try to offer alternative to how to write the HTML code to include more data because at least up to CSS3 you cannot select an element by partial inner text. But it can be done, you just need to add a bit of vanilla JavaScript, notice since female also contains male it will be selected:
cells = document.querySelectorAll('td');
console.log(cells);
[].forEach.call(cells, function (el) {
if(el.innerText.indexOf("male") !== -1){
//el.click(); click or any other option
console.log(el)
}
}); <table>
<tr>
<td>Peter</td>
<td>male</td>
<td>34</td>
</tr>
<tr>
<td>Susanne</td>
<td>female</td>
<td>14</td>
</tr>
</table><table>
<tr>
<td data-content="Peter">Peter</td>
<td data-content="male">male</td>
<td data-content="34">34</td>
</tr>
<tr>
<td data-conten="Susanne">Susanne</td>
<td data-content="female">female</td>
<td data-content="14">14</td>
</tr>
</table>
answered Dec 27, 2017 at 20:11
![]()
Eduard FlorinescuEduard Florinescu
16.5k28 gold badges112 silver badges177 bronze badges
I agree the data attribute (voyager’s answer) is how it should be handled, BUT, CSS rules like:
td.male { color: blue; }
td.female { color: pink; }
can often be much easier to set up, especially with client-side libs like angularjs which could be as simple as:
<td class="{{person.gender}}">
Just make sure that the content is only one word! Or you could even map to different CSS class names with:
<td ng-class="{'masculine': person.isMale(), 'feminine': person.isFemale()}">
For completeness, here’s the data attribute approach:
<td data-gender="{{person.gender}}">
answered Dec 4, 2017 at 9:37
![]()
DJDaveMarkDJDaveMark
2,56720 silver badges35 bronze badges
1
If you’re using Chimp / Webdriver.io, they support a lot more CSS selectors than the CSS spec.
This, for example, will click on the first anchor that contains the words “Bad bear”:
browser.click("a*=Bad Bear");
answered Feb 2, 2018 at 17:26
![]()
Ryan ShillingtonRyan Shillington
22.4k14 gold badges91 silver badges106 bronze badges
@voyager’s answer about using data-* attribute (e.g. data-gender="female|male" is the most effective and standards compliant approach as of 2017:
[data-gender='male'] {background-color: #000; color: #ccc;}
Pretty much most goals can be attained as there are some albeit limited selectors oriented around text. The ::first-letter is a pseudo-element that can apply limited styling to the first letter of an element. There is also a ::first-line pseudo-element besides obviously selecting the first line of an element (such as a paragraph) also implies that it is obvious that CSS could be used to extend this existing capability to style specific aspects of a textNode.
Until such advocacy succeeds and is implemented the next best thing I could suggest when applicable is to explode/split words using a space deliminator, output each individual word inside of a span element and then if the word/styling goal is predictable use in combination with :nth selectors:
$p = explode(' ',$words);
foreach ($p as $key1 => $value1)
{
echo '<span>'.$value1.'</span>;
}
Else if not predictable to, again, use voyager’s answer about using data-* attribute. An example using PHP:
$p = explode(' ',$words);
foreach ($p as $key1 => $value1)
{
echo '<span data-word="'.$value1.'">'.$value1.'</span>;
}
answered Sep 9, 2017 at 10:09
If you want to apply style to the content you want. Easy trick.
td { border: 1px solid black; }
td:empty { background: lime; }
td:empty::after { content: "male"; } <table>
<tr>
<td>Peter</td>
<td><!--male--></td>
<td>34</td>
</tr>
<tr>
<td>Susanne</td>
<td>female</td>
<td>14</td>
</tr>
</table>https://jsfiddle.net/hyda8kqz/
answered Aug 24, 2021 at 6:58
ArsenArsen
1137 bronze badges
1
I find the attribute option to be your best bet if you don’t want to use javascript or jquery.
E.g to style all table cells with the word ready, In HTML do this:
<td status*="ready">Ready</td>
Then in css:
td[status*="ready"] {
color: red;
}
answered Apr 9, 2020 at 13:36
![]()
1
Doing small Filter Widgets like this:
var searchField = document.querySelector('HOWEVER_YOU_MAY_FIND_IT')
var faqEntries = document.querySelectorAll('WRAPPING_ELEMENT .entry')
searchField.addEventListener('keyup', function (evt) {
var testValue = evt.target.value.toLocaleLowerCase();
var regExp = RegExp(testValue);
faqEntries.forEach(function (entry) {
var text = entry.textContent.toLocaleLowerCase();
entry.classList.remove('show', 'hide');
if (regExp.test(text)) {
entry.classList.add('show')
} else {
entry.classList.add('hide')
}
})
})
answered Sep 15, 2018 at 21:36
campino2kcampino2k
1,6101 gold badge14 silver badges25 bronze badges
The syntax of this question looks like Robot Framework syntax.
In this case, although there is no css selector that you can use for contains, there is a SeleniumLibrary keyword that you can use instead.
The Wait Until Element Contains.
Example:
Wait Until Element Contains | ${element} | ${contains}
Wait Until Element Contains | td | male
answered Aug 9, 2019 at 14:26
![]()
I am looking for a CSS selector for the following table:
Peter | male | 34
Susanne | female | 12
Is there any selector to match all TDs containing “male”?
BoltClock
694k159 gold badges1384 silver badges1352 bronze badges
asked Oct 5, 2009 at 14:26
![]()
8
If I read the specification correctly, no.
You can match on an element, the name of an attribute in the element, and the value of a named attribute in an element. I don’t see anything for matching content within an element, though.
answered Oct 5, 2009 at 14:33
Dean JDean J
39.1k16 gold badges67 silver badges93 bronze badges
3
Using jQuery:
$('td:contains("male")')
answered Jan 31, 2012 at 15:04
moettingermoettinger
4,8952 gold badges15 silver badges20 bronze badges
8
You’d have to add a data attribute to the rows called data-gender with a male or female value and use the attribute selector:
HTML:
<td data-gender="male">...</td>
CSS:
td[data-gender="male"] { ... }
answered Oct 5, 2009 at 14:39
Esteban KüberEsteban Küber
36.2k15 gold badges79 silver badges97 bronze badges
4
There is actually a very conceptual basis for why this hasn’t been implemented. It is a combination of basically 3 aspects:
- The text content of an element is effectively a child of that element
- You cannot target the text content directly
- CSS does not allow for ascension with selectors
These 3 together mean that by the time you have the text content you cannot ascend back to the containing element, and you cannot style the present text. This is likely significant as descending only allows for a singular tracking of context and SAX style parsing. Ascending or other selectors involving other axes introduce the need for more complex traversal or similar solutions that would greatly complicate the application of CSS to the DOM.
answered Oct 30, 2012 at 20:44
Matt WhippleMatt Whipple
7,0241 gold badge23 silver badges34 bronze badges
3
You could set content as data attribute and then use attribute selectors, as shown here:
/* Select every cell matching the word "male" */
td[data-content="male"] {
color: red;
}
/* Select every cell starting on "p" case insensitive */
td[data-content^="p" i] {
color: blue;
}
/* Select every cell containing "4" */
td[data-content*="4"] {
color: green;
}<table>
<tr>
<td data-content="Peter">Peter</td>
<td data-content="male">male</td>
<td data-content="34">34</td>
</tr>
<tr>
<td data-content="Susanne">Susanne</td>
<td data-content="female">female</td>
<td data-content="14">14</td>
</tr>
</table>You can also use jQuery to easily set the data-content attributes:
$(function(){
$("td").each(function(){
var $this = $(this);
$this.attr("data-content", $this.text());
});
});
toms
5056 silver badges23 bronze badges
answered Dec 22, 2016 at 10:59
BuksyBuksy
11.4k8 gold badges62 silver badges68 bronze badges
4
As CSS lacks this feature you will have to use JavaScript to style cells by content. For example with XPath’s contains:
var elms = document.evaluate( "//td[contains(., 'male')]", node, null, XPathResult.UNORDERED_NODE_SNAPSHOT_TYPE, null )
Then use the result like so:
for ( var i=0 ; i < elms.snapshotLength; i++ ){
elms.snapshotItem(i).style.background = "pink";
}
https://jsfiddle.net/gaby_de_wilde/o7bka7Ls/9/
![]()
answered May 11, 2016 at 8:21
user40521user40521
1,92720 silver badges7 bronze badges
4
I’m afraid this is not possible, because the content is no attribute nor is it accessible via a pseudo class. The full list of CSS3 selectors can be found in the CSS3 specification.
answered Oct 5, 2009 at 14:33
Edwin V.Edwin V.
1,3078 silver badges11 bronze badges
0
For those who are looking to do Selenium CSS text selections, this script might be of some use.
The trick is to select the parent of the element that you are looking for, and then search for the child that has the text:
public static IWebElement FindByText(this IWebDriver driver, string text)
{
var list = driver.FindElement(By.CssSelector("#RiskAddressList"));
var element = ((IJavaScriptExecutor)driver).ExecuteScript(string.Format(" var x = $(arguments[0]).find(":contains('{0}')"); return x;", text), list);
return ((System.Collections.ObjectModel.ReadOnlyCollection<IWebElement>)element)[0];
}
This will return the first element if there is more than one since it’s always one element, in my case.
the Tin Man
158k41 gold badges214 silver badges302 bronze badges
answered Jan 20, 2015 at 16:21
1
If you don’t create the DOM yourself (e.g. in a userscript) you can do the following with pure JS:
for ( td of document.querySelectorAll('td') ) {
console.debug("text:", td, td.innerText)
td.setAttribute('text', td.innerText)
}
for ( td of document.querySelectorAll('td[text="male"]') )
console.debug("male:", td, td.innerText)<table>
<tr>
<td>Peter</td>
<td>male</td>
<td>34</td>
</tr>
<tr>
<td>Susanne</td>
<td>female</td>
<td>12</td>
</tr>
</table>Console output
text: <td> Peter
text: <td> male
text: <td> 34
text: <td> Susanne
text: <td> female
text: <td> 12
male: <td text="male"> male
answered Dec 15, 2019 at 18:56
![]()
Gerold BroserGerold Broser
13.9k4 gold badges48 silver badges103 bronze badges
Excellent answers all around, but I think I can add something that worked for me in a practical scenario: exploiting the aria-label attribute for CSS.
For the readers that don’t know: aria-label is an attribute that is used in conjunction with other similar attributes to let a screen-reader know what something is, in case someone with a visual impairment is using your website. Many websites add these attributes to elements with images or text in them, as “descriptors”.
This makes it highly website-specific, but in case your element contains this, it’s fairly simple to select that element using the content of the attribute:
HTML:
<td aria-label="male">Male</td>
<td aria-label="female">Female</td>
CSS:
td[aria-label="male"] {
outline: 1px dotted green;
}
This is technically the same thing as using the data-attribute solution, but this will work for you if you are not the author of the website, plus this is not some out-of-the-way solution that is specifically designed to support this use case; it’s fairly common on its own. The one downside of it is that there’s really no guarantee that your intended element will have this attribute present.
answered Jun 3, 2022 at 9:41
![]()
cst1992cst1992
3,7431 gold badge29 silver badges40 bronze badges
1
Most of the answers here try to offer alternative to how to write the HTML code to include more data because at least up to CSS3 you cannot select an element by partial inner text. But it can be done, you just need to add a bit of vanilla JavaScript, notice since female also contains male it will be selected:
cells = document.querySelectorAll('td');
console.log(cells);
[].forEach.call(cells, function (el) {
if(el.innerText.indexOf("male") !== -1){
//el.click(); click or any other option
console.log(el)
}
}); <table>
<tr>
<td>Peter</td>
<td>male</td>
<td>34</td>
</tr>
<tr>
<td>Susanne</td>
<td>female</td>
<td>14</td>
</tr>
</table><table>
<tr>
<td data-content="Peter">Peter</td>
<td data-content="male">male</td>
<td data-content="34">34</td>
</tr>
<tr>
<td data-conten="Susanne">Susanne</td>
<td data-content="female">female</td>
<td data-content="14">14</td>
</tr>
</table>
answered Dec 27, 2017 at 20:11
![]()
Eduard FlorinescuEduard Florinescu
16.5k28 gold badges112 silver badges177 bronze badges
I agree the data attribute (voyager’s answer) is how it should be handled, BUT, CSS rules like:
td.male { color: blue; }
td.female { color: pink; }
can often be much easier to set up, especially with client-side libs like angularjs which could be as simple as:
<td class="{{person.gender}}">
Just make sure that the content is only one word! Or you could even map to different CSS class names with:
<td ng-class="{'masculine': person.isMale(), 'feminine': person.isFemale()}">
For completeness, here’s the data attribute approach:
<td data-gender="{{person.gender}}">
answered Dec 4, 2017 at 9:37
![]()
DJDaveMarkDJDaveMark
2,56720 silver badges35 bronze badges
1
If you’re using Chimp / Webdriver.io, they support a lot more CSS selectors than the CSS spec.
This, for example, will click on the first anchor that contains the words “Bad bear”:
browser.click("a*=Bad Bear");
answered Feb 2, 2018 at 17:26
![]()
Ryan ShillingtonRyan Shillington
22.4k14 gold badges91 silver badges106 bronze badges
@voyager’s answer about using data-* attribute (e.g. data-gender="female|male" is the most effective and standards compliant approach as of 2017:
[data-gender='male'] {background-color: #000; color: #ccc;}
Pretty much most goals can be attained as there are some albeit limited selectors oriented around text. The ::first-letter is a pseudo-element that can apply limited styling to the first letter of an element. There is also a ::first-line pseudo-element besides obviously selecting the first line of an element (such as a paragraph) also implies that it is obvious that CSS could be used to extend this existing capability to style specific aspects of a textNode.
Until such advocacy succeeds and is implemented the next best thing I could suggest when applicable is to explode/split words using a space deliminator, output each individual word inside of a span element and then if the word/styling goal is predictable use in combination with :nth selectors:
$p = explode(' ',$words);
foreach ($p as $key1 => $value1)
{
echo '<span>'.$value1.'</span>;
}
Else if not predictable to, again, use voyager’s answer about using data-* attribute. An example using PHP:
$p = explode(' ',$words);
foreach ($p as $key1 => $value1)
{
echo '<span data-word="'.$value1.'">'.$value1.'</span>;
}
answered Sep 9, 2017 at 10:09
If you want to apply style to the content you want. Easy trick.
td { border: 1px solid black; }
td:empty { background: lime; }
td:empty::after { content: "male"; } <table>
<tr>
<td>Peter</td>
<td><!--male--></td>
<td>34</td>
</tr>
<tr>
<td>Susanne</td>
<td>female</td>
<td>14</td>
</tr>
</table>https://jsfiddle.net/hyda8kqz/
answered Aug 24, 2021 at 6:58
ArsenArsen
1137 bronze badges
1
I find the attribute option to be your best bet if you don’t want to use javascript or jquery.
E.g to style all table cells with the word ready, In HTML do this:
<td status*="ready">Ready</td>
Then in css:
td[status*="ready"] {
color: red;
}
answered Apr 9, 2020 at 13:36
![]()
1
Doing small Filter Widgets like this:
var searchField = document.querySelector('HOWEVER_YOU_MAY_FIND_IT')
var faqEntries = document.querySelectorAll('WRAPPING_ELEMENT .entry')
searchField.addEventListener('keyup', function (evt) {
var testValue = evt.target.value.toLocaleLowerCase();
var regExp = RegExp(testValue);
faqEntries.forEach(function (entry) {
var text = entry.textContent.toLocaleLowerCase();
entry.classList.remove('show', 'hide');
if (regExp.test(text)) {
entry.classList.add('show')
} else {
entry.classList.add('hide')
}
})
})
answered Sep 15, 2018 at 21:36
campino2kcampino2k
1,6101 gold badge14 silver badges25 bronze badges
The syntax of this question looks like Robot Framework syntax.
In this case, although there is no css selector that you can use for contains, there is a SeleniumLibrary keyword that you can use instead.
The Wait Until Element Contains.
Example:
Wait Until Element Contains | ${element} | ${contains}
Wait Until Element Contains | td | male
answered Aug 9, 2019 at 14:26
![]()
Improve Article
Save Article
Like Article
Improve Article
Save Article
Like Article
In this article, we will learn about CSS selectors for elements containing certain text. Selectors are used to finding the HTML elements you want to style. We can achieve this task by using an attribute-value selector.
CSS [attribute-value] Selector: In the [attribute-value] selector, you can choose any attribute name from the HTML document and the name of the value. After providing the appropriate attribute and value, the parser will find that attribute with that value and accordingly change as per the CSS property or rule.
Syntax:
[attribute~=value] {
// CSS Property
}
Example 1: In the below code, we will make use of the above CSS [attribute-value] selector.
HTML
<!DOCTYPE html>
<html>
<head>
<style>
[title~=gfg1] {
border: 5px solid green;
}
</style>
</head>
<body>
<center>
<h1 style="color:green">GeeksforGeeks</h1>
<h3>A computer science portal for geeks</h3>
<div title="gfg1">GFG1</div>
<div title="gfg2">GFG2</div>
<div title="gfg3">GFG3</div>
</center>
</body>
</html>
Output:

Example 2: In the below code, we will make use of the above CSS [attribute-value] selector.
HTML
<!DOCTYPE html>
<html>
<head>
<style>
[title~=gfg1] {
color: red;
}
</style>
</head>
<body>
<center>
<h1 style="color:green">GeeksforGeeks</h1>
<h3>A computer science portal for geeks</h3>
<h2 title="gfg2">GFG1</h2>
<h2 title="gfg1">GFG2</h2>
<h2 title="gfg3">GFG3</h2>
</center>
</body>
</html>
Output:

Last Updated :
25 Aug, 2022
Like Article
Save Article

Привет! Меня зовут Иван, я руковожу горизонталью автоматизации тестирования в Skyeng. Часть моей работы — обучать ручных тестировщиков ремеслу автоматизации. И тема с поиском локаторов, по моему опыту, самая тяжкая для изучения. Здесь куча нюансов, которые надо учитывать. Но стоит разобраться, и локаторы начинают бросаться в глаза сами. Хороший автоматизатор должен идеально уметь находить читабельные и краткие локаторы на странице. Об этом и пойдет речь ниже.
Наливаем чай-кофе и погнали!
Что такое локатор
Локатор — обычный текст, которой идентифицирует себя как элемент DOM’а страницы. Простым языком: с помощью локатора на странице можно найти элементы. В случае CSS — локатор включает в себя набор уникальных атрибутов элемента, а в случае XPath — это путь по DOM’у к элементу.
Если вы изучали CSS ранее, то в конструкции ниже p будет являться локатором элемента, также и атрибут color: red может являться его локатором. Атрибут элемента это всё, что идёт после тега. Например, в теге <p class=”element” id=”value”> атрибутами являются class и id.
p: {
color: red;
}Сразу оговорка по терминологии, локатор = селектор.
Локатор — это название селектора на русском. Иногда встречаю в интернете, что селектор относится только к CSS, но это не совсем так. XPath-локатор тоже может быть, просто означает он путь к элементу в DOM’е. Давайте похоливарим в комментах, чем же всё-таки локатор отличается от селектора 😉
DOM страницы — это HTML-код, написанный человеком или сгенерированный фреймворком, который преобразуется браузером в DOM. То есть набор объектов, где каждый объект — это HTML-тег.

Есть очень много видов локаторов, но чаще всего в работе применяется лишь часть из них. Их можно искать по следующим видам:
-
имя элемента
-
id
-
классы
-
кастомные атрибуты
-
родители и дети элементов
-
ссылки
-
и так далее.
Полное строение элемента
Элемент состоит из имени, то есть самого HTML-тега. Например, div, span, input, button и другие. Внутри него перечислены атрибуты, которые отвечают за все возможные свойства элемента. Например, цвет, размер, действие, которое будет происходить по клику на элемент.

У элемента может быть родитель и ребёнок. Родитель может быть один, а детей может быть несколько. Если детей несколько, то они являются соседями и каждый из них образует свою ось. 1 ребёнок = 1 ось со своими особенностями и своими вложенными элементами. А — родитель, B D E F W X Y — дети A. У каждого элемента есть свои дети, свои дальнейшие ветки, это и называется оси.

Поиск локаторов в браузере
Для поиска элементов в DOM’е страницы нужны средства разработчиков в браузере. Рассмотрим их на примере Chrome. Они же называются DevTools (F12). Нас интересует вкладка Elements, именно там находятся все элементы. Чтобы найти локатор в поле Elements, нужно нажать Ctrl+F. Внизу появится небольшое поле поиска, с ним мы будем работать всё время.
Давайте попробуем найти элемент по названию HTML-тега. Искать просто: в строке поиска вводим название тега. Скорее всего этот локатор элемента будет не уникальным и по его значению найдутся много элементов. Для тестов важно, чтобы был только один элемент для взаимодействия. Если одному локатору будут соответствовать несколько элементов, то тест или будет взаимодействовать с первым из них, или просто упадёт с ошибкой. Элементы можно искать не только с помощью тегов (p, span, div и т.д.), но и с помощью атрибутов тега. Например, color=”red” и class=”button”. Подробнее об этом чуть ниже.

Микро-задание: попробуй открыть DevTools на этой страничке (F12) и найти (Ctrl + F) количество элементов с тегом button.
P.S. поздравляю, ты уже написал свой первый локатор! Дальше — больше 🙂
Уникальные локаторы
Где будем практиковаться? https://eu.battle.net/login/ru/ — простая и понятная форма авторизации.


Рассмотрим поиск на примере формы авторизации и регистрации. В коде страницы есть 2 поля («Почта» и «Пароль») и кнопка «Авторизация». Сравним, по каким атрибутам можно найти локатор и определим уникальные атрибуты.

Подробно разберём, как можно найти локатор поля Почта:

Разберём, как можно найти локатор поля Пароль:

Разберём, как можно найти локатор поля Авторизация:

Начнём с разбора не уникальных локаторов. Если по локатору находятся 2 и более элементов на HTML-странице, такой локатор можно назвать неуникальным. Тест при обнаружении большого количества элементов по данному локатору упадёт или возьмёт первый. Ненадежно, точно не наш бро.
Уникальный, но non-suitable локатор. Если мы в DevTools введем вышеуказанные названия, то найдется элемент. И здесь мы опускаемся до следующего уровня написания локаторов — уровня понятности, читаемости и надёжности локатора.
-
title=”Электронная почта или телефон” — считается плохим паттерном писать локаторы с русским текстом. Тем более в примере текст в title еще и длинный, это визуально громоздко. На текст завязываться можно в крайнем случае, но нужно быть готовым к тому, что тексты часто меняются, любая правка может сломать автотесты.
-
title=”Пароль” — аналогично ^
-
type=”text” — представь, ты открываешь среду разработки и видишь локатор “тип=текст”. Совсем не ясно, к какому элементу относится локатор. Со смысловой точки зрения, это неудачный локатор, потому что он не передаёт смысл локатора.
-
type=”password” — этот атрибут говорит о том, что у поля тип «password» и все символы, которые мы вводим заменяются на звёздочки/точки. При добавлении еще одного поля с type=”password” (например, поле «Подтвердите пароль») локатор сразу станет неактуальным. Стараемся думать наперёд.
Уникальные локаторы. Они найдут только один элемент, они осмысленные, иногда читабельные и краткие. Как раз уникальные атрибуты — это class, id, name и подобные. Они точно наши бро!
Небольшой итог
Хороший локатор — краткий, читабельный и осмысленный. Например, у поля «Пароль» хорошо иметь в локаторе слово password.
Возникает вопрос, почему class=”btn-block btn btn-primary submit-button btn-block” был вынесен в категорию уникальных? Такие локаторы встречаются повсеместно, и именно их мы берём за основу и приводим к красивому виду.
Поиск элементов с помощью CSS
id и class — самые важные атрибуты, с помощью которых мы будем искать бóльшую часть элементов на странице. Есть очень много тонкостей по работе с ними, постараемся рассмотреть все из них.
Кнопка «Авторизация» имеет несколько классов в одном:
-
btn-block
-
btn
-
btn-primary
-
submit-button
-
btn-block
Каждый из этих классов определяет свой визуал кнопки. Например, btn-primary определяет цвет кнопки, submit-button увеличивает её размер (это лишь догадки, основное значение знают только Blizzard). Несколько классов внутри атрибута class разделяются пробелом.
Наличие более одного класса внутри атрибута говорит о том, что он комбинированный. Бывают и комбинированные атрибуты кроме классов. Но классы необязательно будут уникальны для одного элемента. В данном случае у кнопки «Авторизация» такие атрибуты:
class="btn-block btn btn-primary submit-button btn-block"
Но если добавить туда кнопку «Регистрация», то может отличаться лишь один класс. Например, он будет выглядеть следующим образом:
class="btn-block btn btn-primary registration-button btn-block"
Сразу заметно, что отличается всего лишь один класс — submit-button сменился на registration-button. Остальные свойства могут иметь и другие кнопки.
Читабельность локатора
Допустим, мы ищем элемент по полному классу. Это хороший и действенный способ. Почти всегда элемент будет уникальным, но очень нечитабельным и громоздким, как в случае с кнопкой «Авторизация».
class с помощью CSS можно записать следующим образом:
-
.locator (точка — сокращенная запись class’а)
-
или выделяем название и значение класса в квадратные скобочки: [class=”value”]
Полный класс элемента кнопки «Авторизация» состоит из 5 классов: btn-block btn btn-primary submit-button btn-block, а выглядеть полный локатор будет так:
[class=”btn-block btn btn-primary submit-button btn-block”]
Разделение происходит с помощью пробела внутри. Для класса его сокращенной формой является точка, поэтому можно записать локатор так:
btn-block.btn.btn-primary.submit-button.btn-block
Да, стало короче, но всё равно есть смысловая перегрузка. Сокращаем дальше.
Отдельно здесь стоит добавить про поиск по подстроке. Запись [class=”локатор”] ищет только всю строку класса элемента. Если мы напишем [class=”btn-block”] или любой другой класс, то кнопка «Авторизация» не будет найдена. Но если мы запишем локатор полностью [class=”btn-block btn btn-primary submit-button btn-block”], то кнопка найдётся.
Из данной ситуации помогает найти выход символ звёздочки. Он ищет ПОДстроку в строке, то есть часть локатора может найти элемент.
Краткость локатора
Про подстроку
Можно почитать на википедии, там приведён доступный пример для общего понимания поиска по подстроке. Также поиск по подстроке можно сравнить с методом includes из JS
Локатор кнопки«Авторизация» [class=”btn-block btn btn-primary submit-button btn-block”] можно записать следующим образом:
-
[class*=”btn-block”]
-
[class*=”submit-button”]
-
[class*=”btn-block btn”]
-
[class*=”btn btn-primary”]
-
[class*=”primary submit”] (конец одного класса и начала другого, но только в том случае, если они написаны подряд, друг за другом)
-
можно даже сократить название подкласса: не длинное submit-button, а просто submit, например, [class*=”submit”]. Можно даже сократить слово submit — [class*=”sub”].
Важно понимать, это будет работать, если классы идут только последовательно. Если мы укажем [class*=”btn-block submit-button”], то локатор работать не будет, потому что между btn-block и submit-button идут несколько классов: btn и btn-primary. Но это можно обойти, разделив локатор на 2 разных. Например, 2 класса слитно — [class*=”btn-block”][class*=”submit-button”]. Это работает и часто пригождается, когда нужно уточнить, в каком именно элементе мы ищем определенный класс.
Также можно комбинировать краткую запись с помощью точки и тега элемента:
-
.submit-button = [class*=”submit-button”]
-
.btn = [class*=”btn”]
-
.btn-block = [class*=”btn-block”]
-
button[class*=”submit-button”] = button.submit-button
-
button[class*=”btn”] = button.btn
-
button[class*=”btn”][class*=“submit-button”] = button.btn.submit-button
-
button[class*=”submit”]
Краткую запись (через точку) предпочтительнее использовать, чем полную (в квадратных скобках).
Лаконичность локатора
Мы можем определить кнопку «Авторизация» по классу submit-button. Это не самый лаконичный локатор, но дословно означает действие отправки данных на сервер с формы авторизации. Но что делать, если у кнопки нет контекста? Например, классы кнопки Авторизации будут выглядеть так: [class=”btn-block btn btn-primary btn-block”]. Если нет контекста из слова submit (отправка), то можно очень быстро потеряться и сразу не ясно, к какому элементу относится этот локатор. В данном случае нам поможет название текущего элемента или его родителя.
Для наглядности рассмотрим весь блок с кнопкой «Авторизация».
Как вариант — к локатору можно добавить сам тег button. Например, button[class*=”btn”] (сократил класс для наглядности). В таком случае можно взять тег или класс родителя за основу, а именно div или [class=”control-group submit no-cancel”]. Если нужно указать родителя, то эта связь пишется через пробел. Через пробел можно обращаться на любой уровень вложенности, например, из form сразу прыгнуть к button. Полный путь будет выглядеть так: form div button.
С полученными знаниями можно расширить пул локаторов:
-
form button
-
form [type=”submit”]
-
#password-form #submit (решётка — сокращённая форма id, точка — сокращённая форма class)
-
и еще много-много локаторов, которые можно найти комбинаторикой, главное, чтобы по итогу локатор выглядел кратко и лаконично, передавал суть элемента
А как с ID
С ID работает всё точно также, только краткая запись ID — это решётка, например, <form id=”password-form”> можно записать как form#password-form, по такому же принципу, как и с классом
Поиск по кастомным атрибутам
Кастомные атрибуты тоже заслуживают упоминания. У элемента могут быть не только классы и айдишники, но и еще бесконечно множество атрибутов. В исключительных случаях можно искать элементы по этим атрибутам, но только в случае их приличного вида. Например, в случае кнопки «Авторизация» указаны несколько необычных атрибутов, которые вряд ли можно использовать за основу для её поиска:
-
data-loading-text
-
tabindex=”0″
Очень хорошей практикой на проекте является обвешивание интерактивных элементов кастомным атрибутом data-qa или data-qa-id. Например, <button id=”css-1232” data-qa=”login-button”>. Если поменяют локатор, то этот атрибут останется и тесты будут стабильными долгое время. Добавлять эти атрибуты могут фронтенд-разработчики или автоматизаторы, если имеют доступ к коду фронтенда и возможность пушить в него правки.
Локаторы можно и нужно комбинировать! Элементы, состоящие из нескольких классов, айди и других атрибутов, можно объединять в один локатор. Например, возьмем элемент формы, который находится выше кнопки «Авторизация»: form#password-form[method=”post”][class*=”username”]
Итоги поиска локаторов с помощью CSS
-
классы и id можно писать сокращенно с помощью точки и решетки
-
<button class=”login”>: .login = [class=”login”] = [class*=”log”] = button.login = button[class=”login”]
-
<button id=”size”>: #size = [id=”size”] = [id*=”ze”] = button#size = button[id=”size”]
-
всё, что не class, и не id в сокращённом виде пишем в [] (квадратных скобках), например, [name=”phone”], [data-qa-id=”regButton”]
-
если тег лежит внутри другого тега, то переходим к нему через пробел (независимо от степени вложенности), например, <span> -> <button> -> <a> = span a = button a = span button a
Поиск элементов с помощью XPath
XPath в корне отличается от CSS как идеей, так и реализацией. XPath — это полноценный язык для поиска элементов в дереве, причём неважно каком, будь это XML или XHTML. Можно использовать XPath в веб-страницах, нативной мобильной вёрстке и других инструментах.
Я изучал XPath больше месяца с нуля. Проблема была в том, что я никак не понимал принцип его работы — мы ходим от элемента к элементу, но не ясно, как это происходит, как писать красивые пути, какие преимущества у такого подхода. Неделями изучал документацию, статьи на блогах (к сожалению, тогда еще не было человекопонятных статей на Хабре) и видео в ютубе. Мне очень помогло одно видео, где автор объяснял базовые принципы XPath, после чего меня осенило и в голове сложилась картинка. Поэтому хочу поделиться с вами этой информацией, чтобы сократить время на изучение тонны материала. Изучение XPath самостоятельно полезно, но я бы с огромным удовольствием потратил полтора месяца на вещи поважнее.
Предположим, у нас есть следующая структура документа:
<div class="popup">
<div id="payment-popup">
<button name="regButton">
<span href="/doReg">Кнопка</span>
</button>
</div>
</div>XPath — это путь от элемента к элементу. Можно представить, что структура тегов — это дерево каталогов, как в любой ОС. Например, в данном случае теги можно представить в виде папок: div -> div -> button -> span. В терминале по ним можно переключаться через команду cd, а именно: cd div/div/button/span
div/div/button/span — это и есть путь к элементу с помощью XPath, только первый элемент ищут по всему дереву элементов, поэтому пишут // в начале строки. В данном случае это будет выглядеть так: //div/div/button/span. 2 слэша можно использовать не только в начале — они обозначают то, что мы ищем элемент где-то внутри. Например, //div//span — элемент будет найден, мы пропустили второй div и button.
Главная отличительная особенность XPath — возможность проходить не только от родителя к детям, но и от детей к родителям. Например, есть структура:
<div class=”popup”>
<div id=”payment-popup”>
<button name=”regButton”>
<span href=”/doReg” />
</button>
<button name=”loginButton”>
<span href=”/doLogin” />
</button>
</div>
</div>
Мы можем перейти от кнопки doLogin в кнопку doReg вот так:
//*[@href=”/doLogin”]/../..//*[@href=”/doReg”]
Чтобы перейти на уровень выше, как и терминале ОС, нужно написать 2 точки, как показано в примере. С помощью 2 точек мы поднимаемся с уровня span сначала до button, а с button до общего div.
Главный вопрос, который может возникнуть, а где это может пригодиться? Практически всюду, где есть одинаковые блоки, которые отличаются по какому-то одному признаку. Возьмем страницу RDR2 в Epic Games. На середине страницы сейчас перечислены 3 издания:

В DevTools отчётливо видно, что блоки идентичные. Отличия только в названии издания, описании и цене.

Есть задача: нажмите на кнопку «Купить сейчас» у издания Red Dead Online. Для этого надо завязаться на текст издания, подняться до первого общего элемента у названия издания и кнопки и опуститься до кнопки «Купить сейчас».
//*[contains(text(), “Red Dead Online”)]/ancestor::*[contains(@data-component, "OfferCard")]//*[contains(@data-component, "Purchase")]
Лайфхак: как найти первый общий элемент у двух элементов?
Нажимаем на любом элементе ПКМ -> Посмотреть код, открывается вкладка Elements. Наводим курсором на текущий элемент и он выделяется синим цветом. Просто тащим курсор наверх, пока визуально не найдём элемент, который объединяет 2 элемента — в нашем случае текст и кнопку «Купить сейчас».

В XPath, как и в CSS, можно искать по элементам и по атрибутам в элементе. Например:
<div class=”popup”>
<div id=”payment-popup”>
<button name=”regButton”>
<span href=”/doReg” />
</button>
<button name=”loginButton”>
<span href=”/doLogin” />
</button>
</div>
</div>Можно найти кнопку регистрации:
-
//*[@href=”/doReg”] или //span[@href=”/doReg”] -
//*[@name=”regButton”] или //button[@name=”regButton”]
Как мы можем заметить — звёздочка заменяет название элемента. Где стоит звёздочка, означает, что элемент может называться как угодно. Главное, чтобы внутри него был заданный атрибут. Если мы хотим указать конкретный элемент, то подставляем его вместо звёздочки. Например, путь //span[@href=”/doReg”] — сразу говорит нам, что в элементе span мы ищем @href=”/doReg”, но если нам не важен элемент, то тогда span заменяем на звёздочку //*[@href=”/doReg”].
Атрибуты всегда пишутся со знаком @ в начале, это тоже особенность языка.
Еще следует упомянуть переходы по смежным осям. В примере выше есть 2 разные оси — 2 button: элементы одинаковые, но отвечают за разные кнопки. Это можно сделать с помощью зарезервированных слов: following-sibling и preceding-sibling.
Например, нам нужно достать кнопку Войти, зная кнопку Регистрация: //*[@name=”regButton”]/following-sibling::*[@name=”loginButton”]. Если нужно найти кнопку Регистрации зная кнопку Войти, то делается это точно также, только ищем в осях, идущих до кнопки Регистрации: //*[@name=”loginButton”]/preceding-sibling::*[@name=”regButton”]. Переходы между осями или дереву (вверх-вниз) всегда происходит через 2 точки, если мы пишем полное название направления, например, following-sibling::, ancestor::
Не всегда есть возможность искать элементы по полному названию класса, так как оно может являться достаточно большим и нечитабельным. В CSS мы это делали с помощью символа звёздочки. Здесь звёздочку заменяет слово contains и работает точно также, как и в CSS. Например, ищем кнопку Войти: //*[contains(@name, “Login”)]. Как мы видим, contains — это что-то вроде функции в XPath. 1 параметр — атрибут, в котором ищем часть текста, 2 — сам текст.
Последней функцией, которую мы рассмотрим, будет text(). Она позволяет искать элемент по тексту, который в нём находится. Например, есть HTML-разметка:
<button>
<span>Кнопка Войти</span>
</button>
<button>
<span>Кнопка Регистрация</span>
</button>Чтобы найти текст по точному совпадению, нужно писать следующий путь: //*[text()=”Кнопка Войти”]. Но если мы захотим искать по 1 слову, то на помощь приходит комбинация со словом contains, а именно: //*[contains(text(), “Войти”)].
Коротко про «Гибкие локаторы»
Термин «гибкий локатор» применяется к поиску локаторов через CSS и с XPath. Называется он гибким, потому что независимо от текста внутри — локатор не изменится. Для примера снова возьмём страничку с игрой RDR2. На ней есть 3 издания. Сами локаторы не меняются, меняется только текст (название, описание, цена). Общий шаблон локатора будет выглядеть так: //*[contains(text(), “Название издания”)]/ancestor::*[contains(@data-component, “OfferCard”)]//*[contains(@data-component, “Purchase”)]. Текст уже можем в него передавать любой, какой захотим. Так вот именно этот локатор будет называться гибким — его тело остаётся неизменным, а меняются лишь параметры внутри него. В автоматизации мы очень часто пользуемся гибкими локаторами.
Выводы
Мы разобрали 2 основных способа поиска элементов на странице, с помощью CSS и XPath. Небольшое сравнение этих методов:
|
Плюсы CSS |
Минусы CSS |
|
– краткий – читабельный – простой для освоения и полностью граничит с изучением базового CSS – что-то вроде мифа — он работает быстрее, то есть быстрее ищет элемент на странице, но на фоне мощности современных процессоров эта разница во времени неощутима и составляет пару миллисекунд |
– может переходить только от родителя к ребёнку, но не наоборот — вверх подниматься нельзя – более ограниченный набор функций для поиска элементов, например, нельзя искать элемент по тексту, который в нём находится – CSS заточен только под веб-страницы |
|
Плюсы XPath |
Минусы XPath |
|
– полноценный язык для поиска элементов не только в вебе, но и в других средах и документах – позволяет перемещаться по дереву вниз и вверх – гибко работает с осями элементов – есть очень много функций, которые помогают в поиске локаторов, например, поиску по тексту в элементе или аналог normalize-space, который убирает пробелы у строки по бокам |
– громоздкий – нечитабельный – сложен в освоении – работает дольше, чем поиск по CSS, хоть и незначительно |
В тестах лучше использовать CSS, но это не всегда реально. Именно поэтому в таких случаях приходит на помощь XPath.
Полезные ссылки
CSS:
-
https://flukeout.github.io/ — практика в поиске локаторов.
-
https://code.tutsplus.com/ru/tutorials/the-30-css-selectors-you-must-memorize–net-16048 — полезно узнать про различные виды селекторов. Мы используем не все, но всегда бывает ситуация, когда раз в жизни придётся использовать тот или иной локатор.
-
https://appletree.or.kr/quick_reference_cards/CSS/CSS%20selectors%20cheatsheet.pdf — локаторы наглядно.
-
https://learn.javascript.ru/css-selectors — оформление в виде документации.
XPath:
-
https://topswagcode.com/xpath/ — практика в поиске локаторов.
-
https://www.w3schools.com/xml/xpath_nodes.asp — подробнее про ноды.
-
https://www.w3schools.com/xml/xpath_syntax.asp — синтаксис.
-
https://www.w3schools.com/xml/xpath_axes.asp — оси.
-
https://soltau.ru/index.php/themes/dev/item/413-kratkoe-rukovodstvo-po-xpath — более подробная информация с примерами на русском.
Что такое CSS-селектор?
Селекторы CSS – это шаблоны, используемые для выделения элемента(ов), с которыми вы хотите взаимодействовать.
Они могут быть использованы в ваших CSS-файлах, в вашем JavaScript-коде или в ваших автоматических тестах.
Аналогия ресторана
Использование CSS-селектора для выбора элемента – это все равно, что рассказать кому-то, как добраться до вашего любимого ресторана.
Если ваш любимый ресторан имеет уникальное название, это действительно легко.
Но если его нет, необходимо предоставить более подробную информацию.
Вы можете предоставить инструкции о том, как добраться туда, или другие детали о ресторане.
Указание направлений обычно работает, если только этот ресторан не является грузовиком с едой, который передвигается.
Легкий путь
Вы можете получить CSS Селектор для элемента непосредственно из Chrome Developer Tools: 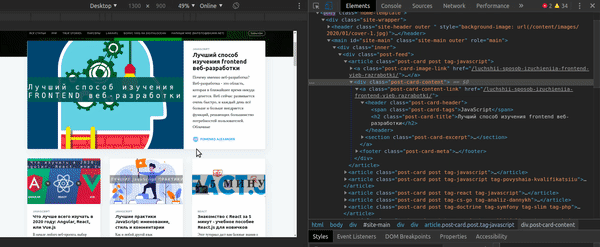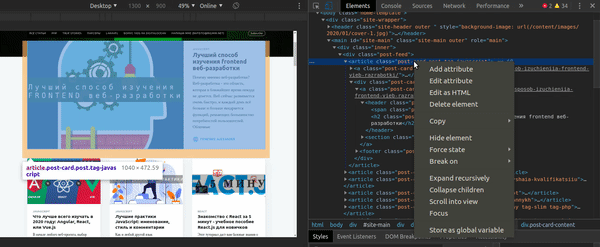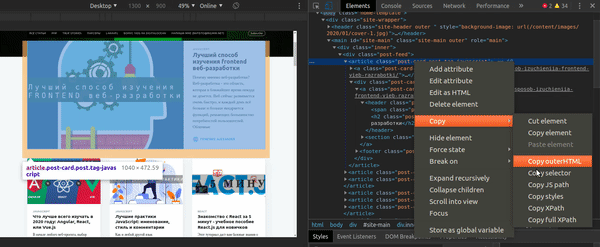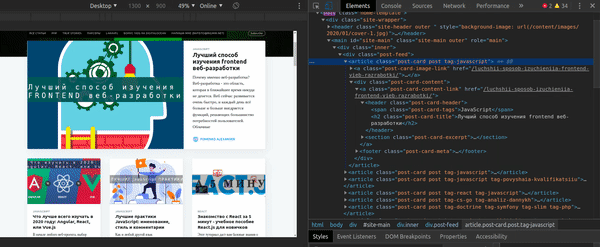
Но этот CSS Selector может быть недостаточно хорош для ваших конкретных потребностей.
И иногда вам будет просто необходимо написать свой собственный CSS Selector. Потому что знания CSS-селекторов сейчас не сводится к багажу знаний для верстальщика. Их нужно знать и бекенд разработчику (при написании парсеров, интеграции вёрстки, работы с JavaScript, например). Так же, они являются важным оружием СЕО-шников, которые настраивают аналитику, работу с событиями и целями, действиями пользователей с DOM-деревом страницы. Потому, когда меня спрашивают, кому нужно знать CSS-селекторы? Я отвечаю – всем и каждому, без исключения :).
1. Пишем CSS селектор, используя идентификатор ID.
Это самый простой пример селектора CSS.
Допустим, у вас есть элемент div с ID boss:
<div id="boss">I'm the boss.</div>Ваш селектор CSS будет выглядеть так:
#bossВы можете использовать эту опцию, только если идентификатор этого элемента не является динамическим.
2. Пишем CSS-селектор, используя имя класса.
Что, если у вашего элемента класс называется boss?
<div class="boss">I'm the boss.</div>Ваш селектор CSS будет выглядеть так:
.bossСтоит знать, что названия классов обычно используется несколькими элементами.
Общая ошибка заключается в том, что можно увидеть несколько имен классов и подумать, что это всего лишь одно имя класса с пробелами.
Имена классов не могут иметь пробелов.
Если вы видите пробел в значении атрибута класса, это просто означает, что у вас более одного имени класса.
<div class="boss champion expert">I'm the boss.</div>Ваш CSS селектор будет выглядеть так:
.bossИли вот так:
.championИли вот так:
.expert3. Пишем CSS селектор, используя атрибут Name.
Современные фреймворки, такие как React и Ember.js, имеют тенденцию делать идентификаторы динамическими, что делает их ненадежными при использовании в CSS Selector.
В таких случаях можно обратиться к элементу по атрибуту Name.
<div name="boss">I'm the boss.</div>И CSS селектор будет выглядеть так:
div[name="boss"]В основном, атрибут name приписывается для полей формы. Потому, больше частый случай обращений по нему, именно в контексте форм и её полей.
4. Напишем CSS-селектор, используя любой атрибут.
Вы можете использовать шаблон из предыдущего примера для написания CSS Селектора, используя любой атрибут, а не только Name.
tag_name[attribute="attribute_value"]Вы даже можете пропустить имя тега:
[attribute="attribute_value"]Или просто используйте звездочку вместо имени тега:
*[attribute="attribute_value"]Допустим, у нас есть файловый инпут с динамическим идентификатором:
<input type="file" id ="upload3388">Так как мы не можем использовать ID, мы можем просто написать CSS селектор, который выполнит поиск по атрибуту type:
input[type="file"]5. Напишем CSS-селектор, используя несколько атрибутов.
<input type="text" placeholder="Full Name">
<input type="text" placeholder="Email">
<input type="text" placeholder="Telephone">Нам просто нужно прописать эти атрибуты:
tag_name[attribute1="attribute1_value"][attribute2="attribute_2_value"]Или, если мы хотим конкретизировать, выбрав первый элемент, CSS селектор инпута будет выглядеть:
input[type="text"][placeholder="Full Name"]6. Напишем CSS селектор, используя часть атрибута.
Вы можете столкнуться с ситуацией, когда все ваши атрибуты являются динамическими, как в таком случае прописать CSS-селектор?
<div id="boss5693">I'm the boss.</div>
<div id="champ4435">I'm the champ.</div>
<div id="expert9811">I'm the expert.</div>.Наш CSS Selector может описать следующим шаблоном:
tag_name[attribute^="part_of_attribute_value"]Итак, CSS-селектор для первого элемента div будет выглядеть так:
div[id^="boss"]7. Напишем CSS-селектор, используя родителей элемента.
Давайте рассмотрим этот пример:
<html>
<body>
<div class="login-form">
<input id="mat-input-6" type="text" placeholder="Email">
<input id="mat-input-9" type="password" placeholder="Password">
</div>
</body>
</html>
Мы легко можем заметить, что идентификаторы динамические, поэтому мы должны избегать их.
Мы можем написать CSS селектор для поля ввода Email, используя его родителей:
body > div > input[type=text]:nth-child(1)Очевидно, было бы проще написать это с помощью атрибута, однако вариант выше вам тоже однажды понадобится:
input[placeholder="Email"]8. Напишем CSS-селектор, используя текст внутри элемента.
<html>
<body>
<ul class="items">
<li class="item">Apple</li>
<li class="item">Orange</li>
<li class="item">Banana</li>
</ul>
</body>
</html>
Попробуем написать CSS Selector для элемента списка Orange.
Однако, к сожалению, мы не можем.
У CSS Selector-а нет возможности поиска элемента по тексту, но у XPaths есть.
XPath для элемента Orange будет:
//li[contains(text(),'Orange')]Резюме
В этой статье я привёл различные виды селекторов css с примерами. Были рассмотрены как примеры селектора поиска по атрибуту, вложенные селекторы, или xpath. После прочтения этой статьы вы точно поймёте, как написать css selector, скопировать готовый, используя браузер, или написать неточный поиск css * селектора.
