Given two lists with elements and indices, write a Python program to find elements of list 1 at indices present in list 2.
Examples:
Input : lst1 = [10, 20, 30, 40, 50]
lst2 = [0, 2, 4]
Output : [10, 30, 50]
Explanation:
Output elements at indices 0, 2 and 4 i.e 10, 30 and 50 respectively.
Input : lst1 = ['Hello', 'geeks', 'for', 'geeks']
lst2 = [1, 2, 3]
Output : ['geeks', 'for', 'geeks']
Below are some Pythonic approaches to do the above task.
Approach #1 : Naive(List comprehension) The first approach to find the desired elements is to use list comprehension. We traverse through ‘lst2’ and for each ith element, we output lst1[i].
Python3
def findElements(lst1, lst2):
return [lst1[i] for i in lst2]
lst1 = [10, 20, 30, 40, 50]
lst2 = [0, 2, 4]
print(findElements(lst1, lst2))
Time complexity: O(n), where n is the length of lst2
Auxiliary space: O(m), where m is the length of the returned list.
Approach #2 : Using Python map() We can also use Python map() method where we apply lst1.__getitem__ function on lst2 which return lst1[i] for each element ‘i’ of lst2.
Python3
def findElements(lst1, lst2):
return list(map(lst1.__getitem__, lst2))
lst1 = [10, 20, 30, 40, 50]
lst2 = [0, 2, 4]
print(findElements(lst1, lst2))
Time complexity: O(n), where n is the length of lst2.
Auxiliary space: O(m), where m is the length of lst2.
Approach #3 : Using itemgetter()
Python3
from operator import itemgetter
def findElements(lst1, lst2):
return list((itemgetter(*lst2)(lst1)))
lst1 = [10, 20, 30, 40, 50]
lst2 = [0, 2, 4]
print(findElements(lst1, lst2))
Time complexity: O(m), where m is the length of the lst2 list.
Auxiliary space: O(m+k), where k is the length of the returned list.
Approach #4: Using numpy
Python3
import numpy as np
def findElements(lst1, lst2):
return list(np.array(lst1)[lst2])
lst1 = [10, 20, 30, 40, 50]
lst2 = [0, 2, 4]
print(findElements(lst1, lst2))
The time complexity of this program is O(n), where n is the length of lst2.
The space complexity of this program is O(n), where n is the length of lst2.
Approach #6: Using a dictionary
This approach involves creating a dictionary that maps the indices in lst2 to their corresponding elements in lst1. Then, we can uselist comprehension to extract the values from the dictionary.
In this code, we first create a dictionary called index_map that maps the indices of lst1 to their corresponding elements. Then, we use a list comprehension to extract the values from index_map for the indices in lst2. Finally, we return the list of extracted values as the result.
Python3
def findElements(lst1, lst2):
index_map = {index: element for index, element in enumerate(lst1)}
return [index_map[index] for index in lst2]
lst1 = [10, 20, 30, 40, 50]
lst2 = [0, 2, 4]
print(findElements(lst1, lst2))
Time complexity: O(n)
Auxiliary space: O(n)
Method#7: Using Recursive method.
Algorithm:
- Define a function findElements that takes in two lists lst1 and lst2, and an index idx (optional, default=0) and a list res (optional, default=[]).
- If idx is equal to the length of lst2, return res (base case).
- Get the element at the index lst2[idx] in lst1 and append it to res.
- Recursively call findElements with the updated idx (idx+1) and res.
- Return the final value of res after all recursive calls have finished.
Python3
def findElements(lst1, lst2, idx=0, res=[]):
if idx == len(lst2):
return res
res.append(lst1[lst2[idx]])
return findElements(lst1, lst2, idx+1, res)
lst1 = [10, 20, 30, 40, 50]
lst2 = [0, 2, 4]
res = findElements(lst1, lst2)
print(res)
Time Complexity: O(n), where n is the length of lst2. We visit each element of lst2 exactly once, and the time taken to get the element at each index in lst1 is constant time. So the time complexity is proportional to the length of the input list lst2.
Auxiliary Space: O(n), where n is the length of lst2. This is because we need to store the list of elements in res, which can have a maximum length of n if all indices in lst2 are valid. Additionally, the recursive calls use up memory on the call stack, which can go up to a depth of n if all indices in lst2 are valid.
Last Updated :
18 Mar, 2023
Like Article
Save Article
Here’s the Pythonic way to do it:
data = [['a','b'], ['a','c'], ['b','d']]
search = 'c'
any(e[1] == search for e in data)
Or… well, I’m not going to claim this is the “one true Pythonic way” to do it because at some point it becomes a little subjective what is Pythonic and what isn’t, or which method is more Pythonic than another. But using any() is definitely more typical Python style than a for loop as in e.g. RichieHindle’s answer,
Of course there is a hidden loop in the implementation of any, although it breaks out of the loop as soon as it finds a match.
Since I was bored I made a timing script to compare performance of the different suggestions, modifying some of them as necessary to make the API the same. Now, we should bear in mind that fastest is not always best, and being fast is definitely not the same thing as being Pythonic. That being said, the results are… strange. Apparently for loops are very fast, which is not what I expected, so I’d take these with a grain of salt without understanding why they’ve come out the way they do.
Anyway, when I used the list defined in the question with three sublists of two elements each, from fastest to slowest I get these results:
- RichieHindle’s answer with the
forloop, clocking in at 0.22 μs - Terence Honles’ first suggestion which creates a list, at 0.36 μs
- Pierre-Luc Bedard’s answer (last code block), at 0.43 μs
- Essentially tied between Markus’s answer and the
forloop from the original question, at 0.48 μs - Coady’s answer using
operator.itemgetter(), at 0.53 μs - Close enough to count as a tie between Alex Martelli’s answer with
ifilter()and Anon’s answer, at 0.67 μs (Alex’s is consistently about half a microsecond faster) - Another close-enough tie between jojo’s answer, mine, Brandon E Taylor’s (which is identical to mine), and Terence Honles’ second suggestion using
any(), all coming in at 0.81-0.82 μs - And then user27221’s answer using nested list comprehensions, at 0.95 μs
Obviously the actual timings are not meaningful on anyone else’s hardware, but the differences between them should give some idea of how close the different methods are.
When I use a longer list, things change a bit. I started with the list in the question, with three sublists, and appended another 197 sublists, for a total of 200 sublists each of length two. Using this longer list, here are the results:
- RichieHindle’s answer, at the same 0.22 μs as with the shorter list
- Coady’s answer using
operator.itemgetter(), again at 0.53 μs - Terence Honles’ first suggestion which creates a list, at 0.36 μs
- Another virtual tie between Alex Martelli’s answer with
ifilter()and Anon’s answer, at 0.67 μs - Again a close-enough tie between my answer, Brandon E Taylor’s identical method, and Terence Honles’ second suggestion using
any(), all coming in at 0.81-0.82 μs
Those are the ones that keep their original timing when the list is extended. The rest, which don’t, are
- The
forloop from the original question, at 1.24 μs - Terence Honles’ first suggestion which creates a list, at 7.49 μs
- Pierre-Luc Bedard’s answer (last code block), at 8.12 μs
- Markus’s answer, at 10.27 μs
- jojo’s answer, at 19.87 μs
- And finally user27221’s answer using nested list comprehensions, at 60.59 μs
Время чтения 3 мин.
Существует несколько способов проверки наличия элемента в списке в Python:
- Использование метода index() для поиска индекса элемента в списке.
- Использование оператора in для проверки наличия элемента в списке.
- Использование метода count() для подсчета количества вхождений элемента.
- Использование функции any().
- Функция filter() создает новый список элементов на основе условий.
- Применение цикла for.
Содержание
- Способ 1: Использование метода index()
- Способ 2: Использование «оператора in»
- Способ 3: Использование функции count()
- Синтаксис
- Пример
- Способ 4: использование понимания списка с any()
- Способ 5: Использование метода filter()
- Способ 6: Использование цикла for
Способ 1: Использование метода index()
Чтобы найти элемент в списке Python, вы можете использовать метод list index(). Список index() — это встроенный метод, который ищет элемент в списке и возвращает его индекс.
Если один и тот же элемент присутствует более одного раза, метод возвращает индекс первого вхождения элемента.
Индекс в Python начинается с 0, а не с 1. Таким образом, через индекс мы можем найти позицию элемента в списке.
|
streaming = [‘netflix’, ‘hulu’, ‘disney+’, ‘appletv+’] index = streaming.index(‘disney+’) print(‘The index of disney+ is:’, index) |
Выход
|
The index of disney+ is: 2 |
Метод list.index() принимает единственный аргумент, элемент, и возвращает его позицию в списке.
Способ 2: Использование «оператора in»
Используйте оператор in, чтобы проверить, есть ли элемент в списке.
|
main_list = [11, 21, 19, 46] if 19 in main_list: print(“Element is in the list”) else: print(“Element is not in the list”) |
Выход
Вы можете видеть, что элемент «19» находится в списке. Вот почему оператор in возвращает True.
Если вы проверите элемент «50», то оператор in вернет False и выполнит оператор else.
Способ 3: Использование функции count()
Метод list.count() возвращает количество вхождений данного элемента в списке.
Синтаксис
Метод count() принимает единственный элемент аргумента: элемент, который будет подсчитан.
Пример
|
main_list = [11, 21, 19, 46] count = main_list.count(21) if count > 0: print(“Element is in the list”) else: print(“Element is not in the list”) |
Выход
Мы подсчитываем элемент «21», используя список в этой функции example.count(), и если он больше 0, это означает, что элемент существует; в противном случае это не так.
Способ 4: использование понимания списка с any()
Any() — это встроенная функция Python, которая возвращает True, если какой-либо элемент в итерируемом объекте имеет значение True. В противном случае возвращается False.
|
main_list = [11, 21, 19, 46] output = any(item in main_list for item in main_list if item == 22) print(str(bool(output))) |
Выход
Вы можете видеть, что в списке нет «22». Таким образом, нахождение «22» в списке вернет False функцией any(). Если функция any() возвращает True, элемент в списке существует.
Способ 5: Использование метода filter()
Метод filter() перебирает элементы списка, применяя функцию к каждому из них.
Функция filter() возвращает итератор, который перебирает элементы, когда функция возвращает значение True.
|
main_list = [11, 21, 19, 46] filtered = filter(lambda element: element == 19, main_list) print(list(filtered)) |
Выход
В этом примере мы используем функцию filter(), которая принимает функцию и перечисляет ее в качестве аргумента.
Мы использовали лямбда-функцию, чтобы проверить, совпадает ли входной элемент с любым элементом из списка, и если это так, он вернет итератор. Чтобы преобразовать итератор в список в Python, используйте функцию list().
Мы использовали функцию list() для преобразования итератора, возвращаемого функцией filter(), в список.
Способ 6: Использование цикла for
Вы можете узнать, находится ли элемент в списке, используя цикл for в Python.
|
main_list = [11, 21, 19, 46] for i in main_list: if(i == 46): print(“Element Exists”) |
Выход
В этом примере мы прошли список элемент за элементом, используя цикл for, и если элемент списка совпадает с входным элементом, он напечатает «Element exists».
На чтение 4 мин Просмотров 4.7к. Опубликовано 03.03.2023
Содержание
- Введение
- Поиск методом count
- Поиск при помощи цикла for
- Поиск с использованием оператора in
- В одну строку
- Поиск с помощью лямбда функции
- Поиск с помощью функции any()
- Заключение
Введение
В ходе статьи рассмотрим 5 способов поиска элемента в списке Python.
Поиск методом count
Метод count() возвращает вхождение указанного элемента в последовательность. Создадим список разных цветов, чтобы в нём производить поиск:
colors = ['black', 'yellow', 'grey', 'brown']Зададим условие, что если в списке colors присутствует элемент ‘yellow’, то в консоль будет выведено сообщение, что элемент присутствует. Если же условие не сработало, то сработает else, и будет выведена надпись, что элемента отсутствует в списке:
colors = ['black', 'yellow', 'grey', 'brown']
if colors.count('yellow'):
print('Элемент присутствует в списке!')
else:
print('Элемент отсутствует в списке!')
# Вывод: Элемент присутствует в списке!Поиск при помощи цикла for
Создадим цикл, в котором будем перебирать элементы из списка colors. Внутри цикла зададим условие, что если во время итерации color приняла значение ‘yellow’, то элемент присутствует:
colors = ['black', 'yellow', 'grey', 'brown']
for color in colors:
if color == 'yellow':
print('Элемент присутствует в списке!')
# Вывод: Элемент присутствует в списке!Поиск с использованием оператора in
Оператор in предназначен для проверки наличия элемента в последовательности, и возвращает либо True, либо False.
Зададим условие, в котором если ‘yellow’ присутствует в списке, то выводится соответствующее сообщение:
colors = ['black', 'yellow', 'grey', 'brown']
if 'yellow' in colors:
print('Элемент присутствует в списке!')
else:
print('Элемент отсутствует в списке!')
# Вывод: Элемент присутствует в списке!В одну строку
Также можно найти элемент в списке при помощи оператора in всего в одну строку:
colors = ['black', 'yellow', 'grey', 'brown']
print('Элемент присутствует в списке!') if 'yellow' in colors else print('Элемент отсутствует в списке!')
# Вывод: Элемент присутствует в списке!Или можно ещё вот так:
colors = ['black', 'yellow', 'grey', 'brown']
if 'yellow' in colors: print('Элемент присутствует в списке!')
# Вывод: Элемент присутствует в списке!Поиск с помощью лямбда функции
В переменную filtering будет сохранён итоговый результат. Обернём результат в список (list()), т.к. метода filter() возвращает объект filter. Отфильтруем все элементы списка, и оставим только искомый, если он конечно присутствует:
colors = ['black', 'yellow', 'grey', 'brown']
filtering = list(filter(lambda x: 'yellow' in x, colors))Итак, если искомый элемент находился в списке, то он сохранился в переменную filtering. Создадим условие, что если переменная filtering не пустая, то выведем сообщение о присутствии элемента в списке. Иначе – отсутствии:
colors = ['black', 'yellow', 'grey', 'brown']
filtering = list(filter(lambda x: 'yellow' in x, colors))
if filtering:
print('Элемент присутствует в списке!')
else:
print('Элемент отсутствует в списке!')
# Вывод: Элемент присутствует в списке!Поиск с помощью функции any()
Функция any принимает в качестве аргумента итерабельный объект, и возвращает True, если хотя бы один элемент равен True, иначе будет возвращено False.
Создадим условие, что если функция any() вернёт True, то элемент присутствует:
colors = ['black', 'yellow', 'grey', 'brown']
if any(color in 'yellow' for color in colors):
print('Элемент присутствует в списке!')
else:
print('Элемент отсутствует в списке!')
# Вывод: Элемент присутствует в списке!Внутри функции any() при помощи цикла производится проверка присутствия элемента в списке.
Заключение
В ходе статьи мы с Вами разобрали целых 5 способов поиска элемента в списке Python. Надеюсь Вам понравилась статья, желаю удачи и успехов! 🙂
#статьи
- 30 ноя 2022
-

0
Рассказали всё самое важное о списках для тех, кто только становится «змееустом».
Иллюстрация: Оля Ежак для Skillbox Media

Любитель научной фантастики и технологического прогресса. Хорошо сочетает в себе заумного технаря и утончённого гуманитария. Пишет про IT и радуется этому.
Сегодня мы подробно поговорим о, пожалуй, самых важных объектах в Python — списках. Разберём, зачем они нужны, как их использовать и какие удобные функции есть для работы с ними.
Список (list) — это упорядоченный набор элементов, каждый из которых имеет свой номер, или индекс, позволяющий быстро получить к нему доступ. Нумерация элементов в списке начинается с 0: почему-то так сложилось в C, а C — это база. Теорий на этот счёт много — на «Хабре» даже вышло большое расследование 🙂
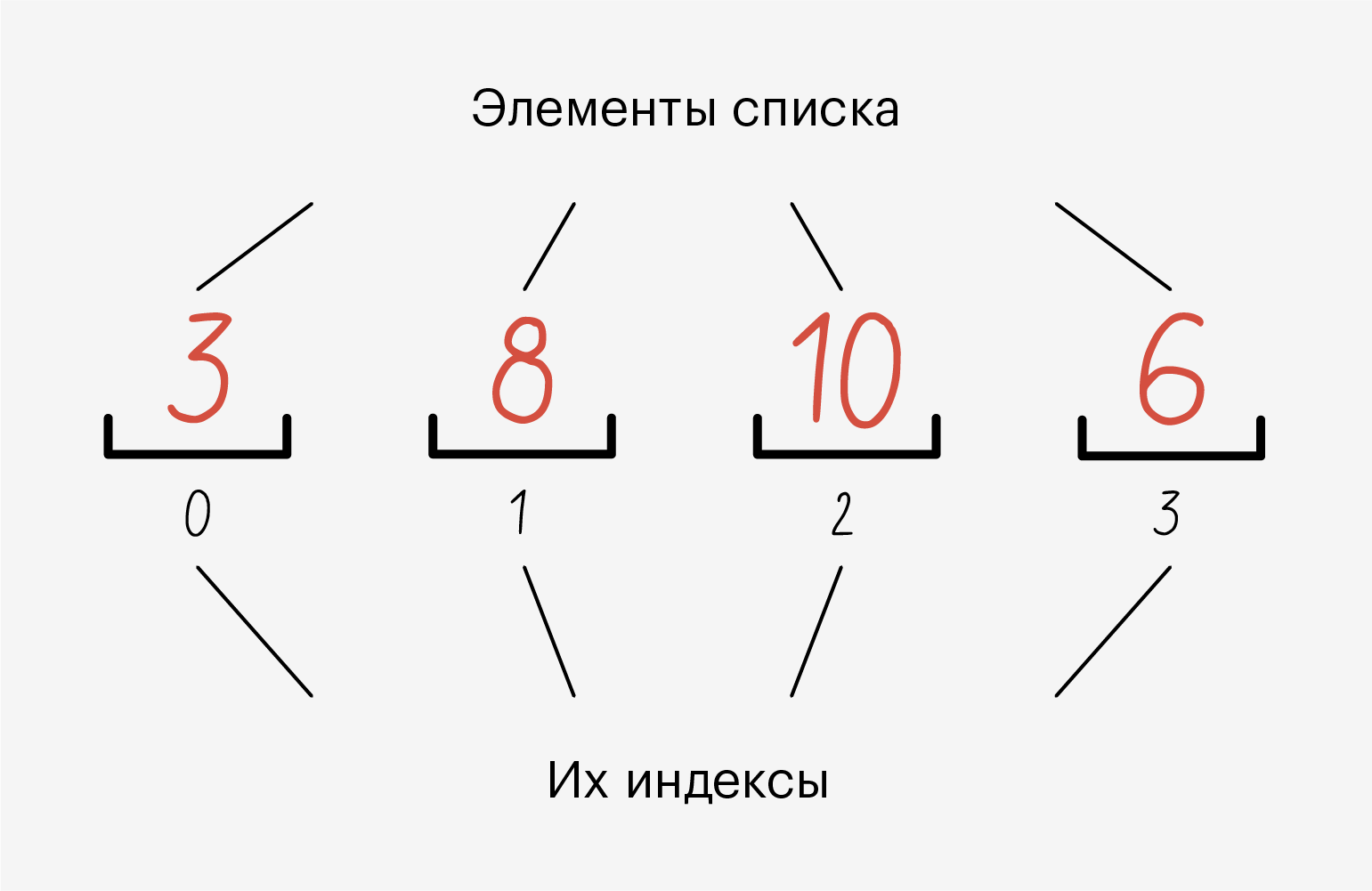
Иллюстрация: Оля Ежак для Skillbox Media
В одном списке одновременно могут лежать данные разных типов — например, и строки, и числа. А ещё в один список можно положить другой и ничего не сломается:
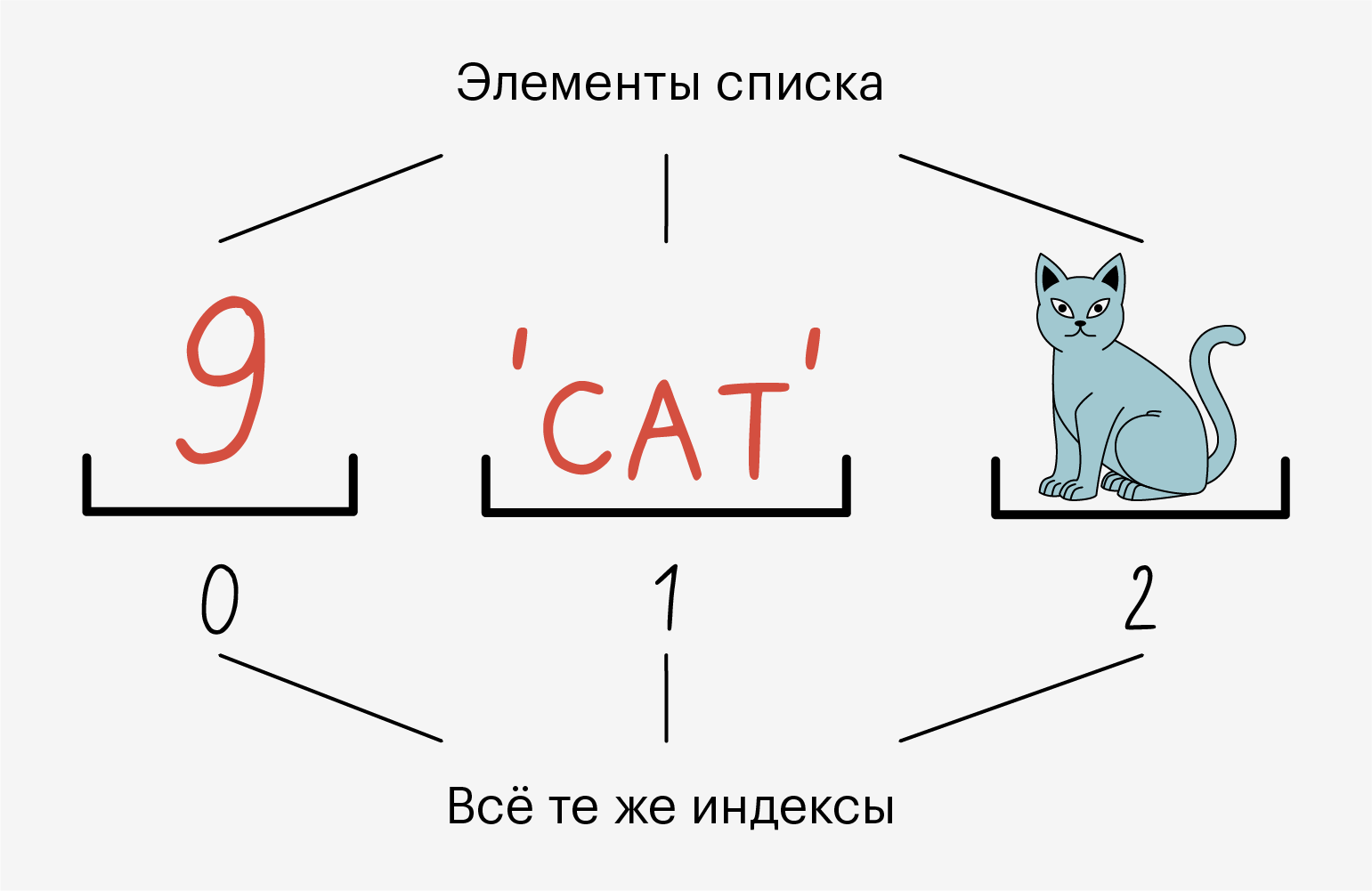
Иллюстрация: Оля Ежак для Skillbox Media
Все элементы в списке пронумерованы. Мы можем без проблем узнать индекс элемента и обратиться по нему.
Списки называют динамическими структурами данных, потому что их можно менять на ходу: удалить один или несколько элементов, заменить или добавить новые.
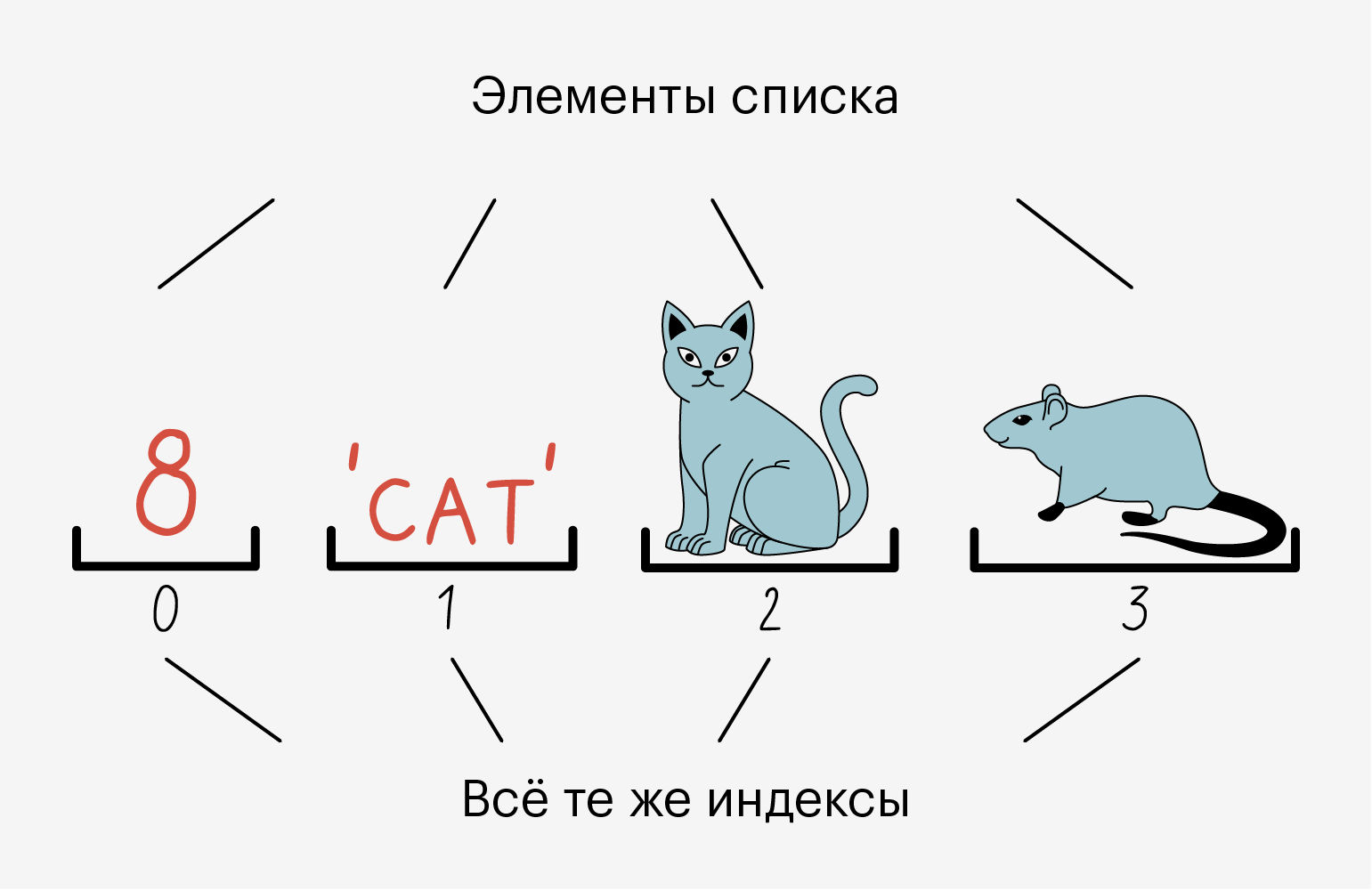
Иллюстрация: Оля Ежак для Skillbox Media
Когда мы создаём объект list, в памяти компьютера под него резервируется место. Нам не нужно переживать о том, сколько выделяется места и когда оно освобождается — Python всё сделает сам. Например, когда мы добавляем новые элементы, он выделяет память, а когда удаляем старые — освобождает.
Под капотом списков в Python лежит структура данных под названием «массив». У массива есть два важных свойства: под каждый элемент он резервирует одинаковое количество памяти, а все элементы следуют друг за другом, без «пробелов».
Однако в списках Python можно хранить объекты разного размера и типа. Более того, размер массива ограничен, а размер списка в Python — нет. Но всё равно мы знаем, сколько у нас элементов, а значит, можем обратиться к любому из них с помощью индексов.
И тут есть небольшой трюк: списки в Python представляют собой массив ссылок. Да-да, решение очень элегантное — каждый элемент такого массива хранит не сами данные, а ссылку на их расположение в памяти компьютера!
Чтобы создать объект list, в Python используют квадратные скобки — []. Внутри них перечисляют элементы через запятую:
a = [1, 2, 3]
Мы создали список a и поместили в него три числа, которые разделили запятыми. Давайте выведем его с помощью функции print():
print(a) >>> [1, 2, 3]
Python выводит элементы в квадратных скобках, чтобы показать, что это list, а также ставит запятые между элементами.
Мы уже говорили, что списки могут хранить данные любого типа. В примере ниже объект b хранит: строку — cat, число — 123 и булево значение — True:
b = ['cat', 123, True] print(b) >>> ['cat', 123, True]
Также в Python можно создавать вложенные списки:
c = [1, 2, [3, 4]] print(c) >>> [1, 2, [3, 4]]
Мы получили объект, состоящий из двух чисел — 1 и 2, и вложенного list с двумя элементами — [3, 4].
Если просто хранить данные в списках, то от них будет мало толку. Поэтому давайте рассмотрим, какие операции они позволяют выполнить.
Доступ к элементам списка получают по индексам, через квадратные скобки []:
a = [1, 2, 3] print(a[1]) >>> 2
Мы обратились ко второму элементу и вывели его с помощью print().
Здесь важно помнить две вещи:
- у каждого элемента есть свой индекс;
- индексы начинаются с 0.
Давайте ещё поиграем с индексами:
a = [1, 2, 3, 4] a[0] # Обратится к 1 a[2] # Обратится к 3 a[3] # Обратится к 4 a[4] # Выведет ошибку
В последней строке мы обратились к несуществующему индексу, поэтому Python выдал ошибку.
Кроме того, Python поддерживает обращение к нескольким элементам сразу — через интервал. Делается это с помощью двоеточия — :.
a = [1, 2, 3, 4] a[0:2] # Получим [1, 2]
Двоеточие позволяет получить срез списка. Полная форма оператора выглядит так: начальный_индекс:конечный_индекс:шаг.
Здесь мы указываем, с какого индекса начинается «срез», на каком заканчивается и с каким шагом берутся элементы — по умолчанию 1. Единственный нюанс с конечным индексом: хоть мы и можем подумать, что закончим именно на нём, на самом деле Python остановится на элементе с индексом конечный_индекс — 1. Почему создатели языка решили так сделать? Кто их знает.
В примере выше мы начали с индекса 0, а закончили на 1, потому что последний индекс не включается. Наш шаг был 1, то есть мы прошлись по каждому элементу.
Усложним пример:
a = [1, 2, 3, 4, 5] a[1:6:2] # Получим [2, 4]
Здесь мы шли по элементам с шагом 2. Начали с индекса 1 — это первое число внутри скобок, а закончили на индексе 6, не включая его. Двигались с шагом 2, то есть через один элемент, и получили — [2, 4].
Протестируйте этот тип индексации сами, чтобы лучше понять, как работают срезы в Python.
Списки — это динамическая структура данных. А значит, мы можем менять их уже после создания.
Например, можно заменить один элемент на другой:
a = [1, 2, 3] a[1] = 4 print(a) >>> [1, 4, 3]
Мы обратились к элементу по индексу и заменили его на число 4. Всё прошло успешно, список изменился.
Но нужно быть осторожными, потому что может случиться такое:
a = [1, 2] b = a a[0] = 5 print(a) print(b) >> [5, 2] >> [5, 2]
Сначала мы создали список a с двумя элементами — 1 и 2. Затем объявили переменную b и присвоили ей содержимое a. Потом заменили первый элемент в a и… удивились, что он заменился и в b.
Проблема в том, что a — это ссылка на область в памяти компьютера, где хранится первый элемент списка, а также на следующий его элемент. Вот как всё это устроено в памяти компьютера:
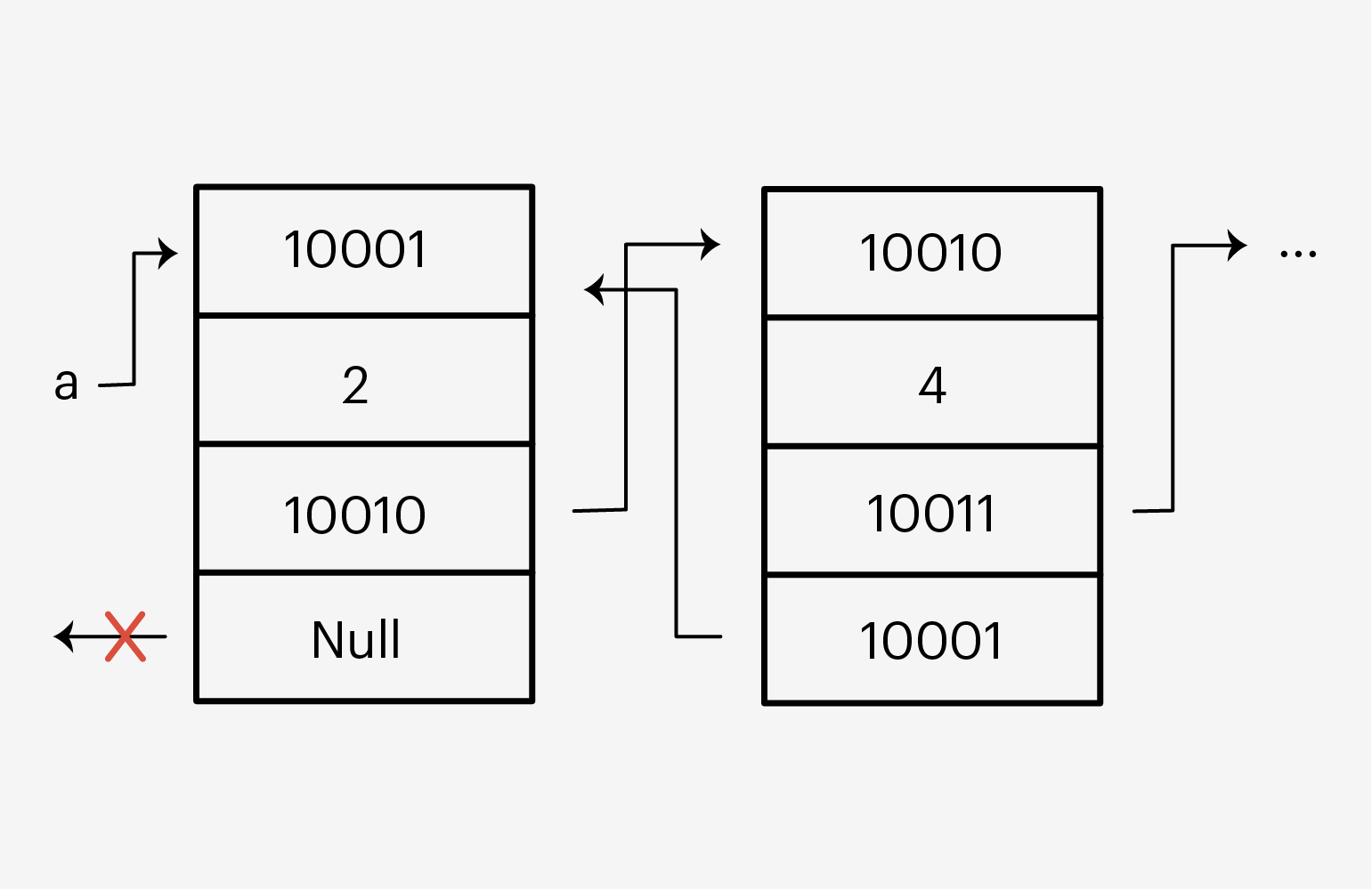
Иллюстрация: Оля Ежак для Skillbox Media
Каждый элемент списка имеет четыре секции: свой адрес, данные, адрес следующего элемента и адрес предыдущего. Если мы получили доступ к какому-то элементу, мы без проблем можем двигаться вперёд-назад по этому списку и менять его данные.
Поэтому, когда мы присвоили списку b список a, то на самом деле присвоили ему ссылку на первый элемент — по сути, сделав их одним списком.
Иногда полезно объединить два списка. Чтобы это сделать, используют оператор +:
a = [1, 2] b = [3, 4] с = a + b print(с) >>> [1, 2, 3, 4]
Мы создали два списка — a и b. Затем переприсвоили a новым списком, который стал объединением старого a и b.
Элементы списка можно присвоить отдельным переменным:
a = [1, 2, 3] d1, d2, d3 = a print(d1) print(d2) print(d3) >>> 1 >>> 2 >>> 3
Здесь из списка a поочерёдно достаются элементы, начиная с индекса 0, и присваиваются переменным. И в отличие от присвоения одного списка другому, в этом случае Python создаст три отдельных целых числа, которые никак не будут связаны с элементами списка, и присвоит их трём переменным. Поэтому, если мы изменим, например, переменную d2, со списком a ничего не случится.
Мы можем перебирать элементы списка с помощью циклов for и while.
Так выглядит перебор через for:
animals = ['cat', 'dog', 'bat'] for animal in animals: print(animal) >>> cat >>> dog >>> bat
Здесь мы перебираем каждый элемент списка и выводим их с помощью функции print().
А вот так выглядит перебор через цикл while:
animals = ['cat', 'dog', 'bat'] i = 0 while i < len(animals): print(animals[i]) i += 1 >>> cat >>> dog >>> bat
Этот перебор чуть сложнее, потому что мы используем дополнительную переменную i, чтобы обращаться к элементам списка. Также мы использовали встроенную функцию len(), чтобы узнать размер нашего списка. А ещё в условии цикла while мы указали знак «меньше» (<), потому что индексация элементов идёт до значения количество элементов списка — 1. Как и в прошлом примере, все элементы по очереди выводятся с помощью функции print().
Python поддерживает сравнение списков. Два списка считаются равными, если они содержат одинаковые элементы. Функция возвращает булево значение — True или False:
a = [1, 2, 3] b = [1, 2, 3] print(a == b) >>> True
Получили, что списки равны.
В некоторых языках равенство ещё проверяется и по тому, ссылаются ли переменные на один и тот же объект. Обычно это делается через оператор ===. В Python это можно сделать через оператор is, который проверяет, имеют ли две переменные один и тот же адрес в памяти:
a = [1, 2, 3] b = a print(a is b) >>> True
Получили, что две переменные ссылаются на один и тот же адрес в памяти.
В Python есть четыре функции, которые позволяют узнавать длину списка, сортировать его и возвращать максимальное и минимальное значение.
Возвращает длину списка:
a = [5, 3, 1] len(a) # 3
Возвращает отсортированный список:
a = [8, 1, 3, 2] sorted(a) # [1, 2, 3, 8]
Возвращают наименьший и наибольший элемент списка:
a = [1, 9, -2, 3] min(a) # -2 max(a) # 9
Чтобы проще управлять элементами списка, в стандартной библиотеке Python есть набор популярных методов для списков. Разберём основные из них.
Добавляет новый элемент в конец списка:
a = [1, 2, 3] a.append(4) print(a) >>> [1, 2, 3, 4]
Добавляет новый элемент по индексу:
a = [1, 2, 3] a.insert(0, 4) print(a) >>> [4, 1, 2, 3]
Сначала мы передаём индекс, по которому хотим вставить новый элемент, а затем сам элемент.
Добавляет набор элементов в конец списка:
a = [1, 2, 3] a.extend([4, 5]) print(a) >>> [1, 2, 3, 4, 5]
Внутрь метода extend() нужно передать итерируемый объект — например, другой list или строку.
Вот так метод extend() добавит строку:
a = ['cat', 'dog', 'bat'] a.extend('mouse') print(a) >>> ['cat', 'dog', 'bat', 'm', 'o', 'u', 's', 'e']
Заметьте, что строка добавилась посимвольно.
Удаляет элемент из списка:
a = [1, 2, 3, 1] a.remove(1) print(a) >>> [2, 3, 1]
Метод удаляет только первое вхождение элемента. Остальные остаются нетронутыми.
Если элемента нет в списке, Python вернёт ошибку и программа прервётся:
a = [1, 2, 3, 1] a.remove(5) Traceback (most recent call last): File "<stdin>", line 1, in <module> ValueError: list.remove(x): x not in list
Ошибка говорит, что элемента нет в списке.
Удаляет все элементы из списка и делает его пустым:
a = [1, 2, 3] a.clear() print(a) >>> []
Возвращает индекс элемента списка в Python:
a = [1, 2, 3] print(a.index(2)) >>> 1
Если элемента нет в списке, выведется ошибка:
a = [1, 2, 3] print(a.index(4)) Traceback (most recent call last): File "<stdin>", line 1, in <module> ValueError: 4 is not in list
Удаляет элемент по индексу и возвращает его как результат:
a = [1, 2, 3] print(a.pop()) print(a) >>> 3 >>> [1, 2]
Мы не передали индекс в метод, поэтому он удалил последний элемент списка. Если передать индекс, то получится так:
a = [1, 2, 3] print(a.pop(1)) print(a) >>> 2 >>> [1, 3]
Считает, сколько раз элемент повторяется в списке:
a = [1, 1, 1, 2] print(a.count(1)) >>> 3
Сортирует список:
a = [4, 1, 5, 2] a.sort() # [1, 2, 4, 5]
Если нам нужно отсортировать в обратном порядке — от большего к меньшему, — в методе есть дополнительный параметр reverse:
a = [4, 1, 5, 2] a.sort(reverse=True) # [5, 4, 2, 1]
Переставляет элементы в обратном порядке:
a = [1, 3, 2, 4] a.reverse() # [4, 2, 3, 1]
Копирует список:
a = [1, 2, 3] b = a.copy() print(b) >>> [1, 2, 3]
Лучше не учить это всё, а применять на практике. А ещё лучше — попытаться написать каждый метод самостоятельно, не используя никакие встроенные функции.
Сколько бы вы ни писали код на Python, всё равно придётся подсматривать в документацию и понимать, какой метод что делает. И для этого есть разные удобные сайты — например, полный список методов можно посмотреть на W3Schools.

Научитесь: Профессия Python-разработчик
Узнать больше
