Данный алгоритм можно реализовать рекурсивным и нерекурсивным способом. Рекурсивные решения обычно более понятны, но менее оптимальны. Например, рекурсивная реализация этой задачи почти в два раза короче нерекурсивной, но занимает O(n) пространства, где n — количество элементов связного списка.
При решение данной задачи помните, что можно выбрать значение k так, что при передаче k = 1 мы получим последний элемент, 2 — предпоследний и т.д. Или выбрать k так, чтобы k = 0 соответствовало последнему элементу.
Решение 1. Размер связного списка известен
Если размер связного списка известен, k-й элемент с конца легко вычислить (длина — k). Нужно пройтись по списку и найти этот элемент.
Решение 2. Рекурсивное решение
Такой алгоритм рекурсивно проходит связный список. По достижении последнего элемента алгоритм начинает обратный отсчет, и счетчик сбрасывается в 0. Каждый шаг инкрементирует счетчик на 1. Когда счетчик достигнет k, искомый элемент будет найден.
Реализация этого алгоритма коротка и проста — достаточно передать назад целое значение через стек. К сожалению, оператор return не может вернуть значение узла. Так как же обойти эту трудность?
Подход А: не возвращайте элемент
Можно не возвращать элемент, достаточно вывести его сразу, как только он будет найден. А в операторе return вернуть значение счетчика.
public static int nthToLast(LinkedListNode head, int k) {
if (head == null) {
return 0;
}
int i = nthToLast(head.next, k) + 1;
if (i == k) {
System.out.println(head.data);
}
return i;
}Решение верно, но можно пойти другим путем.
Подход Б: используйте C++
Второй способ — использование С++ и передача значения по ссылке. Такой подход позволяет не только вернуть значение узла, но и обновить счетчик путем передачи указателя на него.
node* nthToLast(node* head, int k, int& i) {
if (head == NULL) {
return NULL;
}
node* nd = nthToLast(head->next, k, i);
i = i + 1;
if (i == k) {
return head;
}
return nd;
}Решение 3. Итерационное решение
Итерационное решение будет более сложным, но и более оптимальным. Можно использовать два указателя — p1 и p2. Сначала оба указателя указывают на начало списка. Затем перемещаем p2 на k узлов вперед. Теперь мы начинаем перемещать оба указателя одновременно. Когда p2 дойдет до конца списка, p1 будет указывать на нужный нам элемент.
LinkedListNode nthToLast(LinkedListNode head, int k) {
if (k <= 0) return 0;
LinkedListNode p1 = head;
LinkedListNode p2 = head;
for (int i = 0; i < k - 1; i++) {
if (p2 == null) return null;
p2 = p2.next;
}
if (p2 == null) return null;
while (p2.next != null) {
p1 = p1.next;
p2 = p2.next;
}
return p1;
}Разбор взят из перевода книги Г. Лакман Макдауэлл и предназначен исключительно для ознакомления.
Если он вам понравился, то рекомендуем купить книгу «Карьера программиста. Как устроиться на работу в Google, Microsoft или другую ведущую IT-компанию».
First of all
As mention in comment, but to be more clear, the question is from:
<Cracking the coding interview 6th>|IX Interview Questions|2. Linked Lists|Question 2.2.
It’s a great book by Gayle Laakmann McDowell, a software engineer from Google, who has interviewed a lot people.
Approaches
(Assuming the linked list doesn’t keep track of length), there are 2 approaches in O(n) time, and O(1) space:
- Find length first, then loop to the (len-k+1) element.
This solution is not mentioned in the book, as I remember. - Loop, via 2 pointer, keep them (k-1) distance.
This solution is from the book, as the same in the question.
Code
Following is the implementation in Java, with unit test, (without using any advanced data structure in JDK itself).
KthToEnd.java
/**
* Find k-th element to end of singly linked list, whose size unknown,
* <p>1-th is the last, 2-th is the one before last,
*
* @author eric
* @date 1/21/19 4:41 PM
*/
public class KthToEnd {
/**
* Find the k-th to end element, by find length first.
*
* @param head
* @param k
* @return
*/
public static Integer kthToEndViaLen(LinkedListNode<Integer> head, int k) {
int len = head.getCount(); // find length,
if (len < k) return null; // not enough element,
return (Integer) head.getKth(len - k).value; // get target element with its position calculated,
}
/**
* Find the k-th to end element, via 2 pinter that has (k-1) distance.
*
* @param head
* @param k
* @return
*/
public static Integer kthToEndVia2Pointer(LinkedListNode<Integer> head, int k) {
LinkedListNode<Integer> p0 = head; // begin at 0-th element,
LinkedListNode<Integer> p1 = head.getKth(k - 1); // begin at (k-1)-th element,
while (p1.next != null) {
p0 = p0.next;
p1 = p1.next;
}
return p0.value;
}
static class LinkedListNode<T> {
private T value;
private LinkedListNode next;
public LinkedListNode(T value) {
this.value = value;
}
/**
* Append a new node to end.
*
* @param value
* @return new node
*/
public LinkedListNode append(T value) {
LinkedListNode end = getEnd();
end.next = new LinkedListNode(value);
return end.next;
}
/**
* Append a range of number, range [start, end).
*
* @param start included,
* @param end excluded,
*/
public void appendRangeNum(Integer start, Integer end) {
KthToEnd.LinkedListNode last = getEnd();
for (int i = start; i < end; i++) {
last = last.append(i);
}
}
/**
* Get end element of the linked list this node belongs to, time complexity: O(n).
*
* @return
*/
public LinkedListNode getEnd() {
LinkedListNode end = this;
while (end != null && end.next != null) {
end = end.next;
}
return end;
}
/**
* Count of element, with this as head of linked list.
*
* @return
*/
public int getCount() {
LinkedListNode end = this;
int count = 0;
while (end != null) {
count++;
end = end.next;
}
return count;
}
/**
* Get k-th element from beginning, k start from 0.
*
* @param k
* @return
*/
public LinkedListNode getKth(int k) {
LinkedListNode<T> target = this;
while (k-- > 0) {
target = target.next;
}
return target;
}
}
}
KthToEndTest.java
(unit test, using TestNG, or you change to JUnit / .., as wish)
import org.testng.Assert;
import org.testng.annotations.BeforeClass;
import org.testng.annotations.Test;
/**
* KthToEnd test.
*
* @author eric
* @date 1/21/19 5:20 PM
*/
public class KthToEndTest {
private int len = 10;
private KthToEnd.LinkedListNode<Integer> head;
@BeforeClass
public void prepare() {
// prepare linked list with value [0, len-1],
head = new KthToEnd.LinkedListNode(0);
head.appendRangeNum(1, len);
}
@Test
public void testKthToEndViaLen() {
// validate
for (int i = 1; i <= len; i++) {
Assert.assertEquals(KthToEnd.kthToEndViaLen(head, i).intValue(), len - i);
}
}
@Test
public void testKthToEndVia2Pointer() {
// validate
for (int i = 1; i <= len; i++) {
Assert.assertEquals(KthToEnd.kthToEndVia2Pointer(head, i).intValue(), len - i);
}
}
}
Tips:
KthToEnd.LinkedListNode
It’s a simple singly linked list node implemented from scratch, it represents a linked list start from itself.
It doesn’t additionally track head / tail / length, though it has methods to do that.
От переводчика:
Данная статья является переводом статьи, опубликованной в блоге javarevisited. Она может быть интересна как новичкам, так и опытным программистам при подготовке к собеседованиям. В дальнейшем, планируется перевод цикла статей об алгоритмах и рецептах решений проблем как типового, так и академического характера. С удовольствием принимаются конструктивные предложения и замечания как по качеству перевода, так и по выбору новых статей
Нахождение 3-го элемента от конца в односвязном списке или n-го узла от хвоста является одним из каверзных и часто задаваемых вопросов по проблемам односвязных списков на собеседованиях. Задача, в данном случае, в том, чтобы решить проблему всего в один проход цикла, т.е., нельзя снова пройтись по связному списку и нельзя идти в обратном направлении, т.к. список односвязный. Если вы когда-нибудь решали проблемы связных списков, например, нахождение длины, вставки или удаления элементов, вы должны уже быть знакомы с вопросом обхода списков. В данной статье мы используем тот же самый алгоритм, который мы использовали для нахождения срединного элемента связного списка в один проход цикла. Этот алгоритм также известен как «алгоритм черепахи и зайца» из-за скорости двух указателей, используемых алгоритмом для обхода односвязного списка.
Если вы помните, алгоритм использует два указателя — быстрый и медленный. Медленный указатель начинает обход, когда быстрый достигает N-ого элемента, например, для нахождения 3-го элемента от конца, второй указатель начнет обход, когда первый указатель достигнет 3-го элемента.
После этого, оба указателя двигаются на один шаг за итерацию, пока первый указатель не будет указывать на null, что говорит о достижении конца связного списка. В этот момент, второй указатель указывает на 3-й или N-й узел от конца. Проблема решена, вы можете либо вывести значение узла, либо вернуть ссылку вызывающей стороне в соответствии с вашими требованиями.
Это одна из многих проблем структур данных и и алгоритмических проблем, с которыми вы столкнетесь на типичном собеседовании (см. Cracking the Coding Interviews). Поскольку связанный список является популярной структурой данных, вопросы по нахождению в цикле и определению длины связанных списков, так же как и освещаемый в данной статье, довольно популярны.
Программа на Java по нахождению N-го узла от хвоста связанного списка
Далее приведен полный листинг программы на Java по нахождению N-го элемента от конца односвязного списка. Данная программа решает задачу в один проход, т.е., обход связного списка производится только один раз. Как вы видите, мы использовали всего один цикл while в методе getLastNode(int n). Данный метод принимает целочисленный параметр и может использоваться для нахождения n-го элемента от конца связного списка, например, для 2-го элемента от хвоста, необходимо 2 шага, а для получения 3-го элемента списка — 3.
Класс SinglyLinkedList представляет собой односвязный список в Java. Это тот же класс, который мы использовали ранее в статьях об односвязных списках, например, о реализации связного списка в Java. Это коллекция класса Node, представляющего собой узел связного списка. Он содержит часть данных и ссылку на следующий узел. Класс SinglyLinkedList также содержит ссылку на голову, т.е. первый узел связного списка.
Далее приведено визуальное объяснение нахождения 2-го элемента от хвоста односвязного списка. Видно, как быстрый и медленный указатели проходят по списку, и когда быстрый указатель указывает на хвост, медленный указывает на n-й узел от конца.
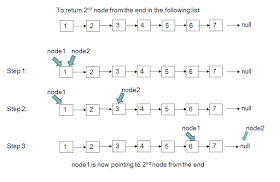
Как программист, вы должны знать основные структуры данных и алгоритмы, например, что такое связный список, ее достоинства и недостатки и когда его использовать, например, он хорош для частого добавления и удаления элементов, но уже не так хорош для поиска, т.к. поиск элемента в связном списке занимает O(n) времени. Вы можете прочесть больше о связных списках в хороших книгах о структурах данных и алгоритмах, как, например, Введение в алгоритмы Томаса Х. Кормена — одной из лучших книг для изучения этой темы.
Поначалу, вам может не понравиться эта книга, так как ее немного трудно понять из-за темы и стиля изложения, но вы должны следовать ей и обращаться к ней время от времени, чтобы понимать ключевые структуры данных, например, массивы, связные списки, деревья и т.д.
N-й узел от конца в односвязном списке
public class Practice {
public static void main(String args[]) {
SinglyLinkedList list = new SinglyLinkedList();
list.append("1");
list.append("2");
list.append("3");
list.append("4");
System.out.println("связный список : " + list);
System.out.println("Первый узел от конца: " + list.getLastNode(1));
System.out.println("Второй узел от конца: " + list.getLastNode(2));
System.out.println("Третий узел от конца: " + list.getLastNode(3));
}
}
/**
* Реализация структуры данных в виде связного списка на Java
*
* @author Javin
*
*/
class SinglyLinkedList {
static class Node {
private Node next;
private String data;
public Node(String data) {
this.data = data;
}
@Override
public String toString() {
return data.toString();
}
}
private Node head; // Голова - это первый узел связного списка
/**
* проверяет, пуст ли список
*
* @возвращает true если связный список пуст, т.е., узлов нет
*/
public boolean isEmpty() {
return length() == 0;
}
/**
* добавляет узел в хвост связного списка
*
* @param data
*/
public void append(String data) {
if (head == null) {
head = new Node(data);
return;
}
tail().next = new Node(data);
}
/**
* возвращает последний узел или хвост данного связного списка
*
* @return последний узел
*/
private Node tail() {
Node tail = head;
// Находит последний элемент связного списка, известный как хвост
while (tail.next != null) {
tail = tail.next;
}
return tail;
}
/**
* метод возвращающий длину связного списка
*
* @return длину, т.е, число узлов в связном списке
*/
public int length() {
int length = 0;
Node current = head;
while (current != null) {
length++;
current = current.next;
}
return length;
}
/**
* получения n-го узла от конца
*
* @param n
* @return n-й узел от последнего
*/
public String getLastNode(int n) {
Node fast = head;
Node slow = head;
int start = 1;
while (fast.next != null) {
fast = fast.next;
start++;
if (start > n) {
slow = slow.next;
}
}
return slow.data;
}
@Override
public String toString() {
StringBuilder sb = new StringBuilder();
Node current = head;
while (current != null) {
sb.append(current).append("-->");
current = current.next;
}
if (sb.length() >= 3) {
sb.delete(sb.length() - 3, sb.length());
}
return sb.toString();
}
}
Вывод
связный список: 1–>2–>3–>4
первый узел от конца: 4
второй узел от конца: 3
третий узел от хвоста:
Вот и все о нахождении 3-го элемента с конца связного списка в Java. Мы написали программу, решающую задачу в один проход с использованием подхода с двумя указателями, также известного как алгоритм зайца и черепахи, т.к. один указатель медленней второго. Это один из полезных приемов, т.к. вы можете использовать такой же алгоритм для определения цикла в связном списке, как показано тут. Вы также можете творчески подойти к использованию этого алгоритма при решении других проблем, когда необходим обход по связанному списку и манипулирование узлами одновременно.
Списки, кортежи и словари
Список
Последнее обновление: 29.01.2022
Для работы с наборами данных Python предоставляет такие встроенные типы как списки, кортежи и словари.
Список (list) представляет тип данных, который хранит набор или последовательность элементов. Во многих языках программирования есть аналогичная структура данных, которая называется массив.
Создание списка
Для создания списка применяются квадратные скобки [], внутри которых через запятую перечисляются элементы списка. Например, определим список чисел:
numbers = [1, 2, 3, 4, 5]
Подобным образом можно определять списки с данными других типов, например, определим список строк:
people = ["Tom", "Sam", "Bob"]
Также для создания списка можно использовать функцию-конструктор list():
numbers1 = [] numbers2 = list()
Оба этих определения списка аналогичны – они создают пустой список.
Список необязательно должен содержать только однотипные объекты. Мы можем поместить в один и тот же список одновременно строки, числа, объекты других типов данных:
objects = [1, 2.6, "Hello", True]
Для проверки элементов списка можно использовать стандартную функцию print, которая выводит содержимое списка в удобочитаемом виде:
numbers = [1, 2, 3, 4, 5] people = ["Tom", "Sam", "Bob"] print(numbers) # [1, 2, 3, 4, 5] print(people) # ["Tom", "Sam", "Bob"]
Конструктор list может принимать набор значений, на основе которых создается список:
numbers1 = [1, 2, 3, 4, 5]
numbers2 = list(numbers1)
print(numbers2) # [1, 2, 3, 4, 5]
letters = list("Hello")
print(letters) # ['H', 'e', 'l', 'l', 'o']
Если необходимо создать список, в котором повторяется одно и то же значение несколько раз, то можно использовать символ звездочки *,
то есть фактически применить операцию умножения к уже существующему списку:
numbers = [5] * 6 # 6 раз повторяем 5 print(numbers) # [5, 5, 5, 5, 5, 5] people = ["Tom"] * 3 # 3 раза повторяем "Tom" print(people) # ["Tom", "Tom", "Tom"] students = ["Bob", "Sam"] * 2 # 2 раза повторяем "Bob", "Sam" print(students) # ["Bob", "Sam", "Bob", "Sam"]
Обращение к элементам списка
Для обращения к элементам списка надо использовать индексы, которые представляют номер элемента в списка. Индексы начинаются с нуля.
То есть первый элемент будет иметь индекс 0, второй элемент – индекс 1 и так далее. Для обращения к элементам с конца можно использовать отрицательные индексы, начиная с -1. То есть у последнего элемента
будет индекс -1, у предпоследнего – -2 и так далее.
people = ["Tom", "Sam", "Bob"] # получение элементов с начала списка print(people[0]) # Tom print(people[1]) # Sam print(people[2]) # Bob # получение элементов с конца списка print(people[-2]) # Sam print(people[-1]) # Bob print(people[-3]) # Tom
Для изменения элемента списка достаточно присвоить ему новое значение:
people = ["Tom", "Sam", "Bob"] people[1] = "Mike" # изменение второго элемента print(people[1]) # Mike print(people) # ["Tom", "Mike", "Bob"]
Разложение списка
Python позволяет разложить список на отдельные элементы:
people = ["Tom", "Bob", "Sam"] tom, bob, sam = people print(tom) # Tom print(bob) # Bob print(sam) # Sam
В данном случае переменным tom, bob и sam последовательно присваиваются элементы из списка people. Однако следует учитывать, что количество переменных
должно быть равно числу элементов присваиваемого списка.
Перебор элементов
Для перебора элементов можно использовать как цикл for, так и цикл while.
Перебор с помощью цикла for:
people = ["Tom", "Sam", "Bob"]
for person in people:
print(person)
Здесь будет производиться перебор списка people, и каждый его элемент будет помещаться в переменную person.
Перебор также можно сделать с помощью цикла while:
people = ["Tom", "Sam", "Bob"]
i = 0
while i < len(people):
print(people[i]) # применяем индекс для получения элемента
i += 1
Для перебора с помощью функции len() получаем длину списка. С помощью счетчика i выводит по элементу, пока значение счетчика не станет равно
длине списка.
Сравнение списков
Два списка считаются равными, если они содержат один и тот же набор элементов:
numbers1 = [1, 2, 3, 4, 5]
numbers2 = list([1, 2, 3, 4, 5])
if numbers1 == numbers2:
print("numbers1 equal to numbers2")
else:
print("numbers1 is not equal to numbers2")
В данном случае оба списка будут равны.
Получение части списка
Если необходимо получить какую-то определенную часть списка, то мы можем применять специальный синтаксис, который может принимать следующие формы:
-
list[:end]: через параметр end передается индекс элемента, до которого нужно копировать список -
list[start:end]: параметр start указывает на индекс элемента, начиная с которого надо скопировать элементы -
list[start:end:step]: параметр step указывает на шаг, через который будут копироваться элементы из списка. По умолчанию этот параметр равен 1.
people = ["Tom", "Bob", "Alice", "Sam", "Tim", "Bill"] slice_people1 = people[:3] # с 0 по 3 print(slice_people1) # ["Tom", "Bob", "Alice"] slice_people2 = people[1:3] # с 1 по 3 print(slice_people2) # ["Bob", "Alice"] slice_people3 = people[1:6:2] # с 1 по 6 с шагом 2 print(slice_people3) # ["Bob", "Sam", "Bill"]
Можно использовать отрицательные индексы, тогда отсчет будет идти с конца, например, -1 – предпоследний, -2 – третий сконца и так далее.
people = ["Tom", "Bob", "Alice", "Sam", "Tim", "Bill"] slice_people1 = people[:-1] # с предпоследнего по нулевой print(slice_people1) # ["Tom", "Bob", "Alice", "Sam", "Tim", "Bill"] slice_people2 = people[-3:-1] # с третьего с конца по предпоследний print(slice_people2) # [ "Sam", "Tim"]
Методы и функции по работе со списками
Для управления элементами списки имеют целый ряд методов. Некоторые из них:
-
append(item): добавляет элемент item в конец списка
-
insert(index, item): добавляет элемент item в список по индексу index
-
extend(items): добавляет набор элементов items в конец списка
-
remove(item): удаляет элемент item. Удаляется только первое вхождение элемента. Если элемент не найден, генерирует исключение ValueError
-
clear(): удаление всех элементов из списка
-
index(item): возвращает индекс элемента item. Если элемент не найден, генерирует исключение ValueError
-
pop([index]): удаляет и возвращает элемент по индексу index. Если индекс не передан, то просто удаляет последний элемент.
-
count(item): возвращает количество вхождений элемента item в список
-
sort([key]): сортирует элементы. По умолчанию сортирует по возрастанию. Но с помощью параметра key мы можем передать функцию сортировки.
-
reverse(): расставляет все элементы в списке в обратном порядке
-
copy(): копирует список
Кроме того, Python предоставляет ряд встроенных функций для работы со списками:
-
len(list): возвращает длину списка
-
sorted(list, [key]): возвращает отсортированный список
-
min(list): возвращает наименьший элемент списка
-
max(list): возвращает наибольший элемент списка
Добавление и удаление элементов
Для добавления элемента применяются методы append(), extend и insert, а для удаления – методы remove(),
pop() и clear().
Использование методов:
people = ["Tom", "Bob"]
# добавляем в конец списка
people.append("Alice") # ["Tom", "Bob", "Alice"]
# добавляем на вторую позицию
people.insert(1, "Bill") # ["Tom", "Bill", "Bob", "Alice"]
# добавляем набор элементов ["Mike", "Sam"]
people.extend(["Mike", "Sam"]) # ["Tom", "Bill", "Bob", "Alice", "Mike", "Sam"]
# получаем индекс элемента
index_of_tom = people.index("Tom")
# удаляем по этому индексу
removed_item = people.pop(index_of_tom) # ["Bill", "Bob", "Alice", "Mike", "Sam"]
# удаляем последний элемент
last_item = people.pop() # ["Bill", "Bob", "Alice", "Mike"]
# удаляем элемент "Alice"
people.remove("Alice") # ["Bill", "Bob", "Mike"]
print(people) # ["Bill", "Bob", "Mike"]
# удаляем все элементы
people.clear()
print(people) # []
Проверка наличия элемента
Если определенный элемент не найден, то методы remove и index генерируют исключение. Чтобы избежать подобной ситуации, перед операцией с
элементом можно проверять его наличие с помощью ключевого слова in:
people = ["Tom", "Bob", "Alice", "Sam"]
if "Alice" in people:
people.remove("Alice")
print(people) # ["Tom", "Bob", "Sam"]
Выражение if "Alice" in people возвращает True, если элемент “Alice” имеется в списке people. Поэтому конструкция if "Alice" in people
может выполнить последующий блок инструкций в зависимости от наличия элемента в списке.
Удаление с помощью del
Python также поддерживает еще один способ удаления элементов списка – с помощью оператора del. В качестве параметра этому оператору передается удаляемый элемент
или набор элементов:
people = ["Tom", "Bob", "Alice", "Sam", "Bill", "Kate", "Mike"] del people[1] # удаляем второй элемент print(people) # ["Tom", "Alice", "Sam", "Bill", "Kate", "Mike"] del people[:3] # удаляем по четвертый элемент не включая print(people) # ["Bill", "Kate", "Mike"] del people[1:] # удаляем со второго элемента print(people) # ["Bill"]
Подсчет вхождений
Если необходимо узнать, сколько раз в списке присутствует тот или иной элемент, то можно применить метод count():
people = ["Tom", "Bob", "Alice", "Tom", "Bill", "Tom"]
people_count = people.count("Tom")
print(people_count) # 3
Сортировка
Для сортировки по возрастанию применяется метод sort():
people = ["Tom", "Bob", "Alice", "Sam", "Bill"] people.sort() print(people) # ["Alice", "Bill", "Bob", "Sam", "Tom"]
Если необходимо отсортировать данные в обратном порядке, то мы можем после сортировки применить метод reverse():
people = ["Tom", "Bob", "Alice", "Sam", "Bill"] people.sort() people.reverse() print(people) # ["Tom", "Sam", "Bob", "Bill", "Alice"]
При сортировке фактически сравниваются два объекта, и который из них “меньше”, ставится перед тем, который “больше”. Понятия “больше” и “меньше”
довольно условны. И если для чисел все просто – числа расставляются в порядке возрастания, то для строк и других объектов ситуация сложнее. В частности, строки
оцениваются по первым символам. Если первые символы равны, оцениваются вторые символы и так далее. При чем цифровой символ считается “меньше”,
чем алфавитный заглавный символ, а заглавный символ считается меньше, чем строчный.
Таким образом, если в списке сочетаются строки с верхним и нижним регистром, то мы можем получить не совсем корректные результаты, так как для нас строка
“bob” должна стоять до строки “Tom”. И чтобы изменить стандартное поведение сортировки, мы можем передать в метод sort() в качестве параметра функцию:
people = ["Tom", "bob", "alice", "Sam", "Bill"] people.sort() # стандартная сортировка print(people) # ["Bill", "Sam", "Tom", "alice", "bob"] people.sort(key=str.lower) # сортировка без учета регистра print(people) # ["alice", "Bill", "bob", "Sam", "Tom"]
Кроме метода sort мы можем использовать встроенную функцию sorted, которая имеет две формы:
-
sorted(list): сортирует список list -
sorted(list, key): сортирует список list, применяя к элементам функцию key
people = ["Tom", "bob", "alice", "Sam", "Bill"] sorted_people = sorted(people, key=str.lower) print(sorted_people) # ["alice", "Bill", "bob", "Sam", "Tom"]
При использовании этой функции следует учитывать, что эта функция не изменяет сортируемый список, а все отсортированные элементы она помещает в новый список,
который возвращается в качестве результата.
Минимальное и максимальное значения
Встроенный функции Python min() и max() позволяют найти минимальное и максимальное значения соответственно:
numbers = [9, 21, 12, 1, 3, 15, 18] print(min(numbers)) # 1 print(max(numbers)) # 21
Копирование списков
При копировании списков следует учитывать, что списки представляют изменяемый (mutable) тип, поэтому если обе переменных будут указывать на один и тот же список, то изменение
одной переменной, затронет и другую переменную:
people1 = ["Tom", "Bob", "Alice"]
people2 = people1
people2.append("Sam") # добавляем элемент во второй список
# people1 и people2 указывают на один и тот же список
print(people1) # ["Tom", "Bob", "Alice", "Sam"]
print(people2) # ["Tom", "Bob", "Alice", "Sam"]
Это так называемое “поверхностное копирование” (shallow copy). И, как правило, такое поведение нежелательное. И чтобы происходило копирование элементов, но при этом
переменные указывали на разные списки, необходимо выполнить глубокое копирование (deep copy). Для этого можно использовать метод copy():
people1 = ["Tom", "Bob", "Alice"]
people2 = people1.copy() # копируем элементы из people1 в people2
people2.append("Sam") # добавляем элемент ТОЛЬКО во второй список
# people1 и people2 указывают на разные списки
print(people1) # ["Tom", "Bob", "Alice"]
print(people2) # ["Tom", "Bob", "Alice", "Sam"]
Соединение списков
Для объединения списков применяется операция сложения (+):
people1 = ["Tom", "Bob", "Alice"] people2 = ["Tom", "Sam", "Tim", "Bill"] people3 = people1 + people2 print(people3) # ["Tom", "Bob", "Alice", "Tom", "Sam", "Tim", "Bill"]
Списки списков
Списки кроме стандартных данных типа строк, чисел, также могут содержать другие списки. Подобные списки можно ассоциировать с таблицами, где вложенные списки
выполняют роль строк. Например:
people = [
["Tom", 29],
["Alice", 33],
["Bob", 27]
]
print(people[0]) # ["Tom", 29]
print(people[0][0]) # Tom
print(people[0][1]) # 29
Чтобы обратиться к элементу вложенного списка, необходимо использовать пару индексов: people[0][1] – обращение ко второму элементу первого вложенного списка.
Добавление, удаление и изменение общего списка, а также вложенных списков аналогично тому, как это делается с обычными (одномерными) списками:
people = [
["Tom", 29],
["Alice", 33],
["Bob", 27]
]
# создание вложенного списка
person = list()
person.append("Bill")
person.append(41)
# добавление вложенного списка
people.append(person)
print(people[-1]) # ["Bill", 41]
# добавление во вложенный список
people[-1].append("+79876543210")
print(people[-1]) # ["Bill", 41, "+79876543210"]
# удаление последнего элемента из вложенного списка
people[-1].pop()
print(people[-1]) # ["Bill", 41]
# удаление всего последнего вложенного списка
people.pop(-1)
# изменение первого элемента
people[0] = ["Sam", 18]
print(people) # [ ["Sam", 18], ["Alice", 33], ["Bob", 27]]
Перебор вложенных списков:
people = [
["Tom", 29],
["Alice", 33],
["Bob", 27]
]
for person in people:
for item in person:
print(item, end=" | ")
Консольный вывод:
Tom | 29 | Alice | 33 | Bob | 27 |
Ученик
(129),
на голосовании
5 лет назад
Голосование за лучший ответ
noname
Мастер
(2098)
5 лет назад
я правильно понял – нужно найти индекс последнего элемента списка?
ДунканУченик (129)
5 лет назад
не совсем так. индекс последнего max элемента (если их несколько, например).
ДунканУченик (129)
5 лет назад
пример ввода: 1 2 3 3
вывод: 3 3
мой код такие случаи обрабатывает, но падает, например, при вводе 3 2 1
ValueError: 3 is not in list
Слава ЛевшанковМастер (1314)
5 лет назад
len(lst) это и есть индекс последнего а нужно найти индекс последнего максимального элемента
s = list(map(int, input().split()))
max_el = max(s)
print([i for i,x in enumerate(s) if x == max_el][-1])
