Раздел:
Сайтостроение /
JavaScript /
|
|
Что такое JavaScript
Небольшая книга о JavaScript, которая поможет вам в изучении JavaScript. В книге и рассылке сведения для начинающих: что такое JavaScript, как это работает, письма, которые помогут принять решение, надо ли вам это или нет, а также полезные ссылки на обучающие материалы. |

Иногда требуется программно найти определённый HTML-элемент в документе. В некоторых случаях сделать это можно перебором
всех элементов, как это мы уже делали ранее. Однако не всегда это удобно и уместно. Поэтому следует знать и другие способы.
Как всегда напоминаю, что полный обучающий курс по JavaScript можно найти здесь:
>>> JavaScript, jQuery и Ajax с нуля до гуру >>>
Способов поиска элемента с помощью JavaScript существует немало. В этой статье будут рассмотрены лишь некоторые, основанные на использовании следующих методов:
getElementById– поиск элемента по идентификатору IDgetElementsByTagName– поиск элементов по наименованию тегаgetElementsByClassName– поиск элементов по наименованию классаgetElementsByName– поиск элементов по имени
Обратите внимание, что первый метод ищет и возвращает только один элемент, поскольку подразумевается, что в пределах документа все идентификаторы должны быть уникальными.
Остальные методы ищут все элементы с совпадающими наименованиями и возвращают коллекцию (массив) элементов.
Далее разберём примеры использования всех этих методов, чтобы понять, как это можно использовать.
Поиск элемента по ID
Пример исходного кода:
<body>
<h2 id="header1">Заголовок 1</h2>
<h2 id="header2">Заголовок 2</h2>
<script>
<!--
function FindID(name)
{
var e = document.getElementById(name);
//Возвращает соответствующий элемент
return e;
}
var str = FindID('header1');
document.write(str.innerHTML, '<br>');
// -->
</script>
</body>
Браузер выведет следующее:

Метод getElementById находит в документе элемент с указанным
идентификатором и возвращает его. Ну а далее в сценарии мы выводим содержимое найденного элемента,
которое хранится в свойстве элемента innerHTML.
Поиск элементов по имени тега
Пример исходного кода:
<body>
<h2>Заголовок</h2>
<ul>
<liЭлемент списка 1</li>
<li>Элемент списка 2</li>
<li>Элемент списка 3</li>
<li>Элемент списка 4</li>
</ul>
<script>
<!--
function FindTag(name)
{
var r = [];
var e = document.getElementsByTagName(name);
for (var i = 0; i < e.length; i++)
r.push(e[i]);
//Возвращает список соответствующих элементов
return r;
}
var str = FindTag('li');
for (var i = 0; i < str.length; i++)
document.write(str[i].innerHTML, '<br>');
// -->
</script>
</body>
Браузер выведет следующее:

Поиск элементов по имени класса
Пример исходного кода:
<body>
<h2>Заголовок</h2>
<ul>
<li class="test">Элемент списка 1</li>
<li class="my test">Элемент списка 2</li>
<li class="my">Элемент списка 3</li>
<li class="test_4">Элемент списка 4</li>
</ul>
<script>
<!--
function FindClass(name)
{
var r = [];
var e = document.getElementsByClassName(name);
for (var i = 0; i < e.length; i++)
r.push(e[i]);
//Возвращает список соответствующих элементов
return r;
}
var str = FindClass('test');
for (var i = 0; i < str.length; i++)
document.write(str[i].innerHTML, '<br>');
// -->
</script>
</body>
Браузер выведет следующее:

Обратите внимание, что в поиск попадает и класс “my test”, потому что там есть слово test. Но это не страшно, поскольку имена классов обычно состоят из одного слова.
Поиск элементов по имени
Пример исходного кода:
<body>
<h2>Заголовок</h2>
<p name="p">
Первый абзац
</p>
<p name="p">
Второй абзац
</p>
<p name="p3">
Третий абзац
</p>
<script>
<!--
function FindName(name)
{
var r = [];
var e = document.getElementsByName(name);
for (var i = 0; i < e.length; i++)
r.push(e[i]);
//Возвращает список соответствующих элементов
return r;
}
var str = FindName('p');
for (var i = 0; i < str.length; i++)
document.write(str[i].innerHTML, '<br>');
// -->
</script>
</body>

Эта статья – лишь капля в море знаний о JavaScript. Если хотите испить эту чашу до дна, то изучить этот язык, а также jQuery и Ajax можно здесь:
>>> JavaScript, jQuery и Ajax с нуля до гуру >>>
|
|
Программирование на JavaScript
Видеокурс о программировании на JavaScript. Содержит 8 больших разделов от основ до работы с сетевыми запросами. |

|
|
Помощь в технических вопросах
Помощь студентам. Курсовые, дипломы, чертежи (КОМПАС), задачи по программированию: Pascal/Delphi/Lazarus; С/С++; Ассемблер; языки программирования ПЛК; JavaScript; VBScript; Fortran; Python; C# и др. Разработка (доработка) ПО ПЛК (предпочтение – ОВЕН, CoDeSys 2 и 3), а также программирование панелей оператора, программируемых реле и других приборов систем автоматизации. |

Оглавление
- Поиск по словам и фразам через панель «Навигация»
- Расширенный поиск в Ворде
Бывают такие ситуации, когда в огромной статье нужно найти определённый символ или слово. Перечитывать весь текст – не вариант, необходимо воспользоваться быстрым способом – открыть поиск в Ворде. Существует несколько способов, с помощью которых можно легко совершать поиск по документу.
Поиск по словам и фразам через панель «Навигация»
Чтобы найти какую-либо фразу или слово в документе Ворд, надо открыть окно «Навигация». Найти данное окно можно с помощью шагов ниже:
- Откройте в основном меню вкладку «Главная»;
- Нажмите на кнопку «Найти» в области «Редактирования»;

Внимание. Вызвать быстрый поиск можно посредством комбинации клавиш «Ctrl+F». - Теперь в левой части от основной рабочей области появится окно под названием «Навигация» с областью для поиска;

- Кликните по окну поиска и напечатайте искомую фразу или слово;
- Программа автоматически подсветит слово в тексте оранжевым цветом;
- На панели «Навигация» ниже области поиска, появятся фрагменты текста с искомым словом, которое будет выделено жирным. Благодаря данной функции можно с легкостью передвигаться от одной части текста к другой, которые содержат поисковое слово.

Примечание. Поиск будет выдавать как точный вариант запроса фразы, так и производный. Наглядно можно увидеть на примере ниже.

Внимание. Если выделить определённое слово в тексте и нажать «Ctrl+F», то сработает поиск по данному слову. Причем в области поиска искомое слово уже будет написано.
Если случайно закрыли окно поиска, то нажмите сочетание клавиш «Ctrl+Alt+Y». Ворд повторно начнет искать последнюю искомую фразу.
Расширенный поиск в Ворде
Если понадобилось разыскать какой-то символ в определенном отрывке статьи, к примеру, знак неразрывного пробела или сноску, то в помощь расширенный поиск.
Метод 1: Вкладка «Главная»
Найти расширенный поиск можно нажав по стрелке на кнопке «Найти» во вкладке «Главная».

В новом окне в разделе «Найти» нужно кликнуть по кнопке «Больше». Тогда раскроется полный функционал данного поиска.

В поле «Найти» напишите искомую фразу или перейдите к кнопке «Специальный» и укажите нужный вариант для поиска.

Далее поставьте соответствующий вид документа, нажав по кнопке «Найти в», если нужно совершить поиск по всему документу то «Основной документ».

Когда надо совершить поиск по какому-то фрагменту в статье, изначально нужно его выделить и указать «Текущий фрагмент».

В окне «Найти и заменить» всплывет уведомление сколько элементов найдено Вордом.

Метод 2: Через окно «Навигация»
Открыть расширенный поиск можно через панель «Навигация».

Рядом со значком «Лупа» есть маленький треугольник, нужно нажать по нему и выбрать «Расширенный поиск».

В этой статье мы изучим методы JavaScript для поиска элементов в HTML-документе: querySelector, querySelectorAll, getElementById и другие. Кроме них рассмотрим ещё следующие: matches, contains и closest. Первые два из них могут быть полезны для выполнения различных проверок, а третий использоваться, когда нужно получить родительский элемент по CSS-селектору.
Методы для выбора HTML-элементов
Работа с веб-страницей так или иначе связана с манипулированием HTML-элементами. Но перед тем, как над ними выполнить некоторые действия (например, добавить стили), их сначала нужно получить.
Выбор элементов в основном выполняется с помощью этих методов:
querySelector;querySelectorAll.
Они позволяют выполнить поиск HTML-элементов по CSS-селектору. При этом querySelector выбирает один элемент, а querySelectorAll – все.
Кроме них имеются ещё:
getElementById;getElementsByClassName;getElementsByTagName;getElementsByName.
Но они сейчас применяются довольно редко. В основном используется либо querySelector, либо querySelectorAll.
querySelectorAll
Метод querySelectorAll применяется для выбора всех HTML-элементов, подходящих под указанный CSS-селектор. Он позволяет искать элементы как по всей странице, так и внутри определённого элемента:
// выберем элементы по классу item во всем документе
const items = document.querySelectorAll('.item');
// выберем .btn внутри #slider
const buttons = document.querySelector('#slider').querySelectorAll('.btn');Здесь на первой строчке мы нашли все элементы с классом item. На следующей строчке мы сначала выбрали элемент с id="slider", а затем в нём все HTML-элементы с классом btn.
Метод querySelectorAll как вы уже догадались принимает в качестве аргумента CSS-селектор в формате строки, который соответственно и определяет искомые элементы. В качестве результата querySelectorAll возвращает объект класса NodeList. Он содержит все найденные элементы:

Полученный набор представляет собой статическую коллекцию HTML-элементов. Статической она называется потому, что она не изменяется. Например, вы удалили элемент из HTML-документа, а в ней как был этот элемент, так он и остался. Чтобы обновить набор, querySelectorAll нужно вызвать заново:
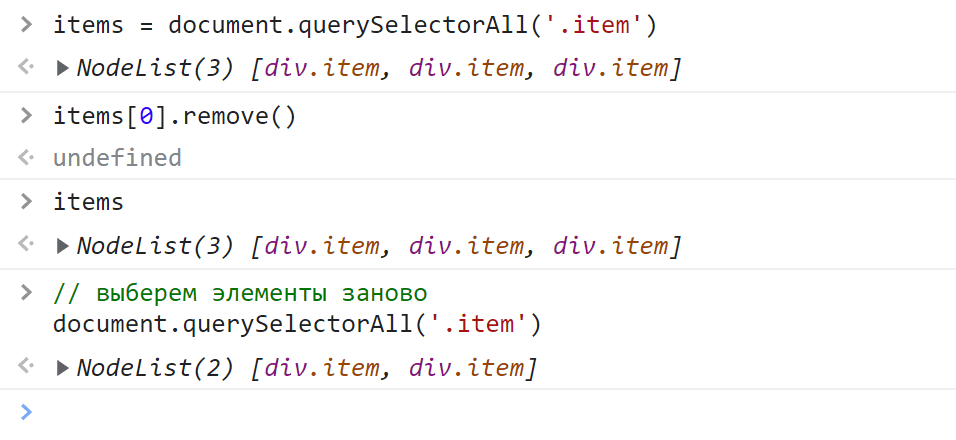
Узнать количество найденных элементов можно с помощью свойства length:
// выберем элементы с атрибутом type="submit"
const submits = document.querySelectorAll('[type="submit"]');
// получим количество найденных элементов
const countSubmits = submits.length;Обращение к определённому HTML-элементу коллекции выполняется также как к элементу массива, то есть по индексу. Индексы начинаются с 0:
// получим первый элемент
const elFirst = submits[0];
// получим второй элемент
const elSecond = submits[1];Здесь в качестве результата мы получаем HTML-элемент или undefined, если элемента с таким индексом в наборе NodeList нет.
Перебор коллекции HTML-элементов
Перебор NodeList обычно осуществляется с помощью forEach:
// получим все <p> на странице
const elsP = document.querySelectorAll('p');
// переберём выбранные элементы
elsP.forEach((el) => {
// установим каждому элементу background-color="yellow"
el.style.backgroundColor = 'yellow';
});Также перебрать набор выбранных элементов можно с помощью цикла for или for...of:
// получим все элементы p на странице
const elsP = document.querySelectorAll('p');
// for
for (let i = 0, length = elsP.length; i < length; i++) {
elsP[i].style.backgroundColor = 'yellow';
}
// for...of
for (let el of elsP) {
el.style.backgroundColor = 'yellow';
}querySelector
Метод querySelector также как и querySelectorAll выполняет поиск по CSS-селектору. Но в отличие от него, он ищет только один HTML-элемент:
// ищем #title во всём документе
const elTitle = document.querySelector('#title');
// ищем footer в <body>
const elFooter = document.body.querySelector('footer');На первой строчке мы выбираем HTML-элемент, имеющий в качестве id значение title. На второй мы ищем в <body> HTML-элемент по тегу footer.
В качестве результата этот метод возвращает найденный HTML-элемент или null, если он не был найден.
querySelector всегда возвращает один HTML-элемент, даже если под указанный CSS-селектор подходят несколько:
<ul id="list">
<li>First</li>
<li>Second</li>
<li>Third</li>
</ul>
<script>
// выберем <li>, расположенный в #list
const elFirst = document.querySelector('#list > li');
elFirst.style.backgroundColor = 'yellow';
</script>Задачу, которую решает querySelector можно выполнить через querySelectorAll:
const elFirst = document.querySelectorAll('#list > li')[0];Но querySelector в отличие от querySelectorAll делает это намного быстрее, да и писать так проще. То есть querySelectorAll не возвращает как querySelector сразу же первый найденный элемент. Он сначала ищет все элементы, и только после того, как он это сделает, мы можем уже обратиться к первому HTML-элементу в этой коллекции.
Обычно перед тем, как выполнить какие-то действия с найденным HTML-элементом необходимо сначала проверить, а действительно ли он был найден:
const elModal = document.querySelector('.modal');
// если элемент .modal найден, то ...
if (elModal) {
// переключим у elModal класс show
elModal.classList.toggle('show');
}Здесь мы сначала проверили существования HTML-элемента, и только потом выполнили над ним некоторые действия.
Методы getElement(s)By* для выбора HTML-элементов
Здесь мы рассмотрим методы, которые сейчас применяются довольно редко для поиска HTML-элементов. Но в некоторых случаях они могут быть очень полезны. Это:
getElementById– получает один элемент поid;getElementsByClassName– позволяет найти все элементы с указанным классом или классами;getElementsByTagName– выбирает элементы по тегу;getElementsByName– получает все элементы с указанным значением атрибутаname.
1. Метод getElementById позволяет найти HTML-элемент на странице по значению id:
<div id="comments">...</div>
...
<script>
// получим HTMLElement и сохраним его в переменную elComments
const elComments = document.getElementById('comments');
</script>В качестве результата getElementById возвращает объект класса HTMLElement или значение null, если элемент не был найден. Этот метод имеется только у объекта document.
Указывать значение id необходимо с учётом регистра. Так например, document.getElementById('aside') и document.getElementById('ASIDE') ищут элементы с разным id.
Обратите внимание, что в соответствии со стандартом в документе не может быть несколько тегов с одинаковым id, так как значение идентификатора на странице должно быть уникальным.
Тем не менее, если вы допустили ошибку и в документе существуют несколько элементов с одинаковым id, то метод getElementById более вероятно вернёт первый элемент, который он встретит в DOM. Но на это полагаться нельзя, так как такое поведение не прописано в стандарте.
То, что делает getElementById можно очень просто решить посредством querySelector:
// получим элемент #title
const elTitle = document.getElementById('title');
// получим элемента #title, используя querySelector
const elTitleSame = document.querySelector('#nav');Кстати, оба этих метода возвращают в качестве результата один и тот же результат. Это либо HTML-элемент (экземпляр класса HTMLElement) или null, если элемент не найден.
2. Метод getElementsByClassName позволяет найти все элементы с заданным классом или классами. Его можно применить для поиска элементов как во всём документе, так и внутри указанного. В первом случае его нужно будет вызывать как метод объекта document, а во втором – как метод соответствующего HTML-элемента:
// найдем элементы с классом control в документе
const elsControl = document.getElementsByClassName('control');
// выберем элементы внутри другого элемента, в данном случае внутри формы с id="myform"
const elsFormControl = document.forms.myform.getElementsByClassName('form-control');В качестве результата он возвращает живую HTML-коллекцию найденных элементов. Чем живая коллекция отличается от статической мы рассмотрим ниже.
Здесь мы сохранили найденные элементы в переменные elsControl и elsFormControl. В первой переменной будет находиться HTMLCollection, содержащая элементы с классом control. Во второй – набор элементов с классом form-control, находящиеся в форме с id="myform". Для получения этой формы мы использовали document.forms.myform.
Метод getElementsByClassName позволяет искать элементы не только по одному классу, но и сразу по нескольким, которые должны присутствовать у элемента:
// выберем элементы .btn.btn-danger
const elsBtn = document.getElementsByClassName('btn btn-danger');На querySelectorAll этот пример решается так:
const elsBtn = document.querySelectorAll('.btn.btn-danger');3. Метод getElementsByTagName предназначен для получения коллекции элементов по имени тега:
// найдем все <a> в документе
const anchors = document.getElementsByTagName('a');
// найдем все >li> внутри #list
const elsLi = document.getElementById('list').getElementsByTagName('li');На первой строчке мы выбрали все <a> в документе и присвоили полученную HTMLCollection переменной anchors. На второй – мы сначала получили #list, а затем в нём нашли все <li>.
Задачу по выбору элементов внутри другого элемента с помощью querySelectorAll выполняется намного проще:
const elsLi = document.querySelectorAll('#list li');Для выбора всех элементов можно использовать символ *:
// выберем все элементы в <body>
const els = document.body.getElementsByTagName('*');4. В JavaScript getElementsByName можно использовать для выбора элементов, имеющих определенное значение атрибута name:
// получим все элементы с name="phone"
const elsPhone = document.getElementsByName('phone');Через querySelectorAll это выполняется так:
const elsPhone = document.querySelectorAll('[name="phone"]');getElementsBy* и живые HTML-коллекции
В JavaScript getElementsByTagName, getElementsByClassName и getElementsByName в отличие от других методов (например, querySelectorAll) возвращают живую коллекцию HTML-элементов (на английском live HTMLCollection). То есть коллекцию содержимое которой автоматически обновляется при изменении DOM. Для наглядности рассмотрим следующий пример.
Например, на странице изначально имеется два <li>. Выберем их с помощью getElementsByTagName и сохраним полученную HTMLCollection в переменную els. Теперь с помощью els мы можем получить эту коллекцию. Сейчас в ней два <li>. Затем через 5 секунд, используя setTimeout добавим ещё один <li>. Если сейчас мы обратимся к переменной els, то увидим, что в ней уже находятся три <li>:
<ul>
<li>One</li>
<li>Two</li>
</ul>
<script>
// получим живую коллекцию <li>
const els = document.getElementsByTagName('li');
// выведем количество <li> в консоль
console.log(`Количество <li>: ${els.length}`); // 2
// через 5 секунд добавим ещё один <li>
setTimeout(() => {
// вставим на страницу новый <li>
document.querySelector('ul').insertAdjacentHTML('beforeend', '<li>Three</li>');
// выведем количество <li> в консоль
console.log(`Количество <li>: ${els.length}`); // 3
}, 5000);
</script>
Как вы видите, здесь полученная коллекция является живой, то есть она может автоматически измениться. В ней сначала было два <li>. Но после того, как мы на страницу добавили ещё один подходящий элемент, в ней их стало уже три.
Если в коде приведённом выше заменить выбор элементов на querySelectorAll, то мы увидим, что в ней находится статическая (не живая) коллекция элементов:
// получим статическую коллекцию
const els = document.querySelectorAll('li'); <li>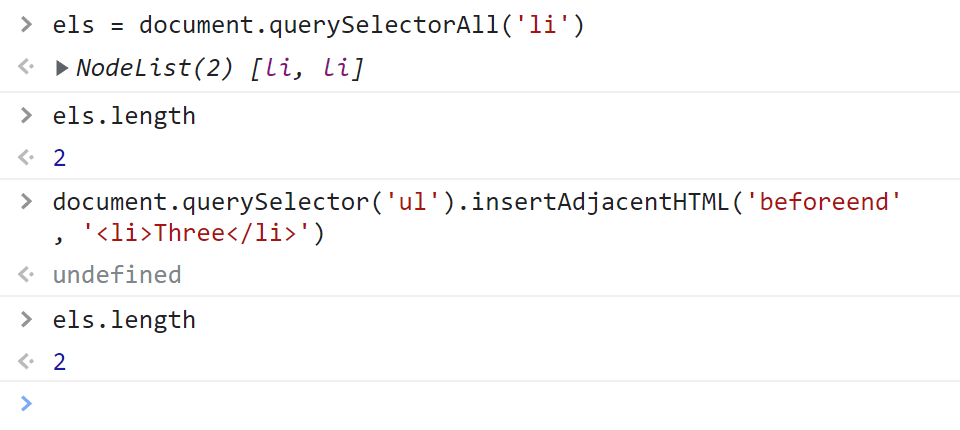
Как вы видите количество элементов в коллекции не изменилось. Чтобы после изменения DOM получить актуальную коллекцию элементов, их нужно просто выбрать заново посредством querySelectorAll:
<ul>
<li>One</li>
<li>Two</li>
</ul>
<script>
// получим статическую коллекцию <li>
let els = document.querySelectorAll('li');
// выведем количество <li> в консоль
console.log(`Количество <li>: ${els.length}`); // 2
// через 5 секунд добавим ещё один <li>
setTimeout(() => {
// вставим на страницу новый <li>
document.querySelector('ul').insertAdjacentHTML('beforeend', '<li>Three</li>');
// получим заново статическую коллекцию <li>
els = document.querySelectorAll('li');
// выведем количество <li> в консоль
console.log(`Количество <li>: ${els.length}`); // 3
}, 5000);
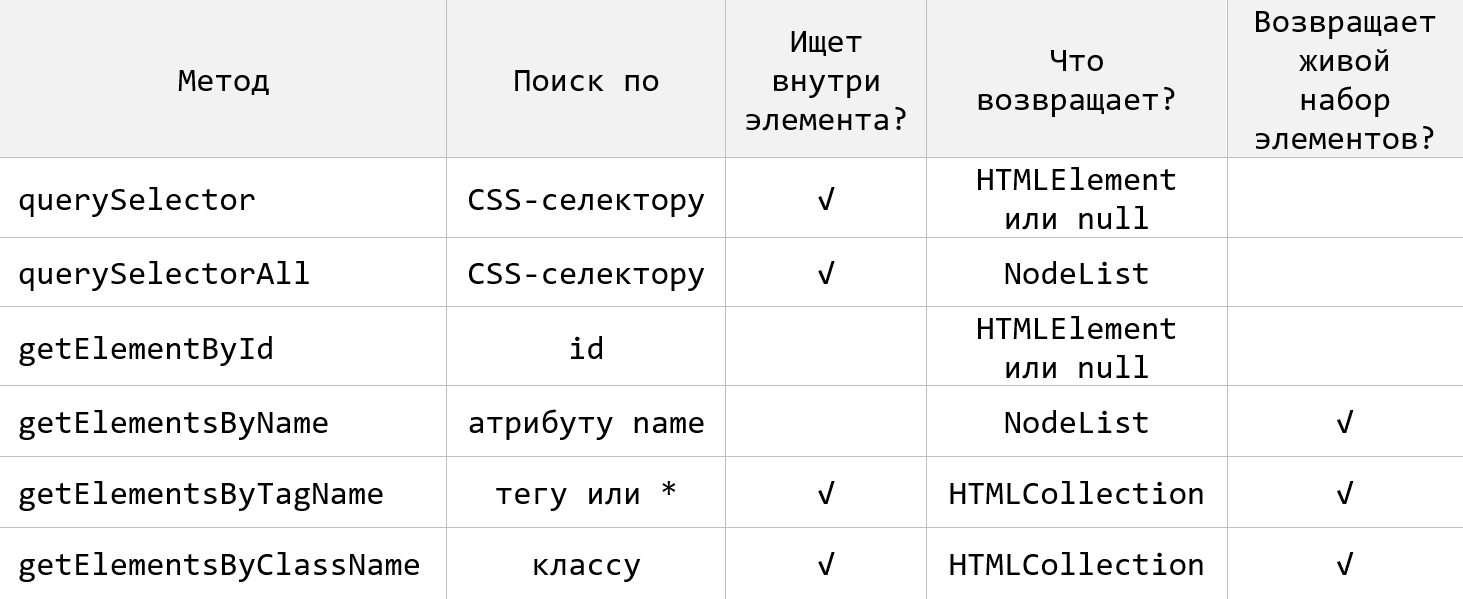
</script>Таким образом в JavaScript насчитывается 6 основных методов для выбора HTML-элементов на странице. По чему они ищут и что они возвращают приведено на следующем рисунке:
Экземпляры класса HTMLCollection не имеют в прототипе метод forEach. Поэтому если вы хотите использовать этот метод для перебора такой коллекции, её необходимо преобразовать в массив:
const items = document.getElementsByClassName('item');
[...items].forEach((el) => {
console.log(el);
});matches, closest и contains
В JavaScript имеются очень полезные методы:
matches– позволяет проверить соответствует ли HTML-элемент указанному CSS-селектору;closest– позволяет найти для HTML-элемента его ближайшего предка, подходящего под указанный CSS-селектор (поиск начинается с самого элемента);contains– позволяет проверить содержит ли данный узел другой в качестве потомка (проверка начинается с самого этого узла).
1. Метод matches ничего не выбирает, но он является очень полезным, так как позволяет проверить HTML-элемент на соответствие CSS-селектору. Он возвращает true, если элемент ему соответствует, иначе false.
// выберем HTML элемент, имеющий атрибут data-target="slider"
const elSlider = document.querySelector('[data-target="slider"]');
// проверим соответствует ли он CSS селектору 'div'
const result = element.matches('div');Пример, в котором выберем все <li>, расположенные внутри #questions, а затем удалим те из них, которые соответствуют селектору .answered:
// выберем все <li> в #questions
const els = document.querySelectorAll('#questions > li');
// переберём выбранные элементы
els.forEach((el) => {
// если элемент соответствует селектору .answered, то ...
if (el.matches('.answered')) {
// удалим элемент
el.remove();
}
});В этом примере проверим каждый <li> на соответствие селектору active. Выведем в консоль каждый такой элемент:
<ul>
<li>One</li>
<li class="active">Two</li>
<li>Three</li>
</ul>
<script>
document.querySelectorAll('li').forEach((el) => {
if (el.matches('.active')) {
console.log(el);
}
});
// li.active
</script>Ранее, в «старых» браузерах данный метод имел название matchesSelector, а также поддерживался с использованием префиксов. Если вам нужна поддержка таких браузеров, то можно использовать следующий полифилл:
if (!Element.prototype.matches) {
Element.prototype.matches = Element.prototype.matchesSelector || Element.prototype.webkitMatchesSelector || Element.prototype.mozMatchesSelector || Element.prototype.msMatchesSelector;
}2. Метод closest очень часто используется в коде. Он позволяет найти ближайшего предка, подходящего под указанный CSS-селектор. При этом поиск начинается с самого элемента, для которого данный метод вызывается. Если этот элемент будет ему соответствовать, то closest вернёт его.
<div class="level-1">
<div class="level-2">
<div class="level-3"></div>
</div>
</div>
<script>
const el = document.querySelector('.level-3');
const elAncestor = el.closest('.level-1');
console.log(elAncestor);
</script>Здесь мы сначала выбираем HTML-элемент .level-3 и присваиваем его переменной el. Далее мы пытаемся среди предков этого элемента включая его сам найти такой, который отвечает заданному CSS-селектору, в данном случае .level-1.
Начинается поиск всегда с самого этого элемента. В данном случае он не подходит под указанный селектор. Следовательно, этот метод переходит к его родителю. Он тоже не отвечает этому CSS-селектору. Значит, closest переходит дальше, то есть уже к его родителю. Этот элемент подходит под указанный селектор. Поэтому поиск прекращается и этот метод возвращает его в качестве результата.
Метод closest возвращает null, когда он дошёл бы конца иерархии и не нашёл элемент отвечающий указанному селектору. То есть, если такого элемента нет среди предков.
В этом примере найдем с помощью closest для .active его ближайшего родителя, отвечающего CSS-селектору #list > li:
<ul id="list">
<li>One</li>
<li>
Two
<ul>
<li>Four</li>
<li class="active">Five</li>
</ul>
</li>
<li>Three</li>
</ul>
<script>
const elActive = document.querySelector('.active');
const elClosest = elActive.closest('#list > li');
elClosest.style.backgroundColor = 'yellow';
</script>В JavaScript closest очень часто используется в обработчиках событий. Это связано с тем, чтобы события всплывают и нам нужно, например, узнать кликнул ли пользователь в рамках какого-то элемента:
document.addEventListener('click', (e) => {
if (e.closest.matches('.btn__action')) {
// пользователь кликнул внутри .btn__action
}
});3. Метод contains позволяет проверить содержит ли некоторый узел другой в качестве потомка. При этом проверка начинается с самого этого узла, для которого этот метод вызывается. Если узел соответствует тому для которого мы вызываем данный метод или является его потомком, то contains в качестве результата возвращает логическое значение true. В противном случае false:
<div id="div-1">
<div id="div-2">
<div id="div-3">...</div>
</div>
</div>
<div id="div-4">...</div>
<script>
const elDiv1 = document.querySelector('#div-1');
elDiv1.contains(elDiv1); // true
const elDiv3 = document.querySelector('#div-3');
elDiv1.contains(elDiv3); // true
const elDiv4 = document.querySelector('#div-4');
elDiv1.contains(elDiv4); // false
</script>Здесь выражение elDiv1.contains(elDiv1) возвращает true, так как проверка начинается с самого элемента. Это выражение elDiv1.contains(elDiv3) тоже возвращает true, так как elDiv3 находится внутри elDiv1. А вот elDiv1.contains(elDiv4) в качестве результата возвращает false, так как elDiv4 не находится внутри elDiv1.
В этом примере проверим с помощью contains содержит ли <p> другие узлы в качестве потомка:
<h1>Tag b</h1>
<p>This is <b>tag b</b>.</p>
<script>
const elP = document.querySelector('p');
const elB = document.querySelector('b');
const textNode = elB.firstChild;
const elH1 = document.querySelector('h1');
elP.contains(elP); // true
elP.contains(elB); // true
elP.contains(elH1); // false
elP.contains(textNode); // true
</script>Метод contains позволяет проверить является ли потомком не только узел-элемент, но и любой другой узел. Например, узнаем является ли потомком elDiv1 указанный текстовый узел:
const elDiv1 = document.querySelector('#div-1');
const textNode = document.querySelector('#div-3').firstChild;
elDiv1.contains(textNode); // trueЗадачи
1. Узнать количество элементов с атрибутом data-toggle="modal" на странице:
const count = document.querySelectorAll('[data-toggle="modal"]').length;
console.log(count);2. Найти все элементы <a> с классом nav внутри элемента <ul> :
const anchors = document.querySelectorAll('ul.nav a');3. Получить элемент по id, значение которого равно pagetitle:
var pagetitle = document.querySelector('#pagetitle');4. Выполнить поиск элемента по классу nav:
var el = document.querySelector('.nav');5. Найти элемент <h3>, находящийся в теге <div> с классом comments, который в свою очередь расположен в <main>:
var header = document.querySelector('main div.comments h3');6. Имеется страница. В ней следует выбрать:
- последний элемент с классом
article, расположенный в<main>(решение); - все элементы
.section, находящиеся в.asideкроме 2 второго (решение); - элемент
<nav>расположенный после<header>(решение).

Команда Найти и заменить в программе Word довольно полезная функция, особенно, если необходимо быстро выполнить поиск или замену одних слов, символов или форматов другими словами, символами или форматами. Но не всем известно, что можно с помощью замены убрать лишние пробелы, исправить стиль абзацев, добавить или удалить переносы, специальные символы и многое другое. Как пользоваться навигацией в программе ворд и чем она полезна?
Подписывайтесь на мой канал и читайте полезные статьи-инструкции:
Быстрая навигация и поиск по документу Word
Чтобы в документе быстро найти нужное слово, часть слова, символ, Заголовок и т.д. используем функцию Навигация. Ранее я уже писала об Области навигации по стилям и заголовкам в документе и читайте об этом в статье Область навигации или Схема документа: дополнительный помощник в больших документах Word. Включить область навигации в документе можно с помощью горячих клавиш Ctrl+F. В поле Навигации вписываем нужное слово для поиска и выбираем подходящий вариант отображения: Заголовки, Страницы, Результаты.
Чтобы переключаться (совершать переходы) от одного найденного слова к другому, щелкайте мышью по результатам в навигации и в документе будет отображаться подсвеченное желтым “найденное слово”.
О поиске и переходах в Области навигации в Заголовках есть отдельная статья.
Как использовать поиск по документу?
Чтобы в документе найти нужное слово, часть слова, символ и т.д. используем функцию поиска «Найти».
1 способ:
1. В окне открытого документа используем сочетание клавиш Ctrl+H или команду Главная – Найти – Расширенный поиск.
2. В окне «Найти и заменить» на вкладке «Найти» в графе «Найти» набираем слово или символ, который надо отыскать в документе.
3. Если в поиске нуждается специальный символ (символы разметки и т.д.), щелкаем по кнопке «Больше».
4. В группе «Параметры поиска» задаем:
– «Учитывать регистр» – для поиска слов с учетом прописных и строчных букв;
– «Только слово целиком» – для поиска только полных заданных слов, без учета неполных совпадений;
– «Только слово целиком» – для поиска только полных заданных слов, без учета неполных совпадений;
– «Постановочные знаки» – для поиска слов с помощью специальных подстановочных знаков. При этом если этот пункт не включать, то знаки, введенные в окно поиска, будут считаться обычным текстом;
– «Произноситься как» – для поиска слов, имеющих одинаковое произношение со словом, набранным в графе «Найти», но различных по написанию;
– «Все словоформы» – для поиска всех форм слова. При этом формы слов должны быть одинаковыми частями речи — например существительными или глаголами. Эта настройка не работает при включении поиска со знаками подстановки и поиска по одинаковому произношению;
– «Учитывать префикс» – для поиска слов с учетом изменений префикса;
– «Учитывать суффикс» – для поиска слов с учетом изменений суффикса;
– «Не учитывать знаки препинания» – для поиска слов без учета знаков препинания;
– «Не учитывать пробелы» – для поиска слов без учета знаков с пробела.
5. В графе «Направление» задаем направление поиска – везде, вперед или назад. Обычно используется значение «Везде».
6. Для поиска текста с учетом форматирования щелкаем по кнопке «Формат».
7. В меню «Формат» выбираем дополнительные свойства искомого текста или символов – в окнах форматов абзаца, шрифта, рамки, табуляции и т.д.
8. Для поиска специальных символов и знаков щелкаем по кнопке «Специальный».
9. В меню «Специальный» выбираем в списке знаки и символы, которых нет на клавиатуре, – разрывы строки, раздела, строк и т.д.
10. Для поиска слов или символов только в тексте или же только в колонтитулах документа щелкаем по кнопке «Найти в» и в меню выбираем нужное место для просмотра.
11. Если необходимо искать во всем документе без исключения, после выбора всех параметров поиска щелкаем по кнопке «Найти далее».
12. Слова или символы, автоматически отвечающие параметрам поиска, будут выделяться в тексте по ходу их просмотра.
13. Достигнув конца документа, если просмотр не был начат с первой страницы документа, программа предложит просмотреть первые страницы. Щелкаем по кнопке «Да» или «Нет» в окне запроса.
14. По окончанию просмотра всего документа выйдет сообщение.
2 способ:
1. В окне открытого документа переходим к вкладке «Главная».
2. В группе «Редактирование» щелкаем по кнопке «Найти».
3. В окне «Найти и заменить» действуем так же, как и в первой инструкции.
Как использовать в документе замену?
Чтобы в документе быстро найти и заменить нужное слово, часть слова, символ и т.д., используем функцию поиска и замены «Найти и заменить».
1 способ:
1. В окне открытого документа используем сочетание клавиш Ctrl+H.
2. В окне «Найти и заменить» на вкладке «Заменить» в графе «Найти» набираем слово или символ, который надо отыскать в документе.
3. Задаем при необходимости все его параметры и форматирования так же, как описано в предыдущей инструкции по поиску.
4. Затем в графе «Заменить на:» вводим слово, часть слова, символ и т.д., которым заменится найденное слово.
Примечание. При этом используем те же принципы выбора параметров, что и при поиске.
5. Для пошагового поиска и замены щелкаем по кнопке «Заменить».
6. Для полного поиска и полной замены во всем тексте документа щелкаем по кнопке «Заменить все».
2 способ:
1. В окне открытого документа переходим к вкладке «Главная».
2. В группе «Редактирование» щелкаем по кнопке «Заменить».
3. В окне «Найти и заменить» действуем так же, как и в первой инструкции.
Пример использования поиска и замены
Если в документе большое количество лишних пробелов, выполните следующие действия:
1. В окне открытого документа активируйте функции «Заменить» или сочетание клавиш Ctrl+H (и переключаемся на вкладку Найти)
2. В графе «Найти» поставьте курсор ввода текста и наберите два пробела подряд.
3. В графе «Заменить на:» поставьте курсор ввода текста и наберите один пробел.
4. Щелкните по кнопке «Заменить все». В окошке выйдет сообщение о количестве осуществленных замен.
5. Повторно щелкайте по кнопке «Заменить все» до тех пор, пока в окошке не будет сообщение, что осуществлено 0 замен.
Оставайтесь на канале Изучаем Word, подписывайтесь и узнаете больше об этой программе вместе со мной:) Лайк за мои труды!
Подписывайтесь на канал “Изучаем Word: шаг за шагом”, делитесь статьей в социальных сетях.
Работая с текстом, особенно с большими объемами, зачастую необходимо найти слово или кусок текста. Для этого можно воспользоваться поиском по тексту в Ворде. Существует несколько вариантов поиска в Word:
- Простой поиска, через кнопку «Найти» (открывается панель Навигация);
- Расширенный поиск, через кнопку «Заменить», там есть вкладка «Найти».
Самый простой поиск в ворде – это через кнопку «Найти». Эта кнопка расположена во вкладке «Главная» в самом правом углу.

! Для ускорения работы, для поиска в Ворде воспользуйтесь комбинацией клавишей: CRL+F
После нажатия кнопки или сочетания клавишей откроется окно Навигации, где можно будет вводить слова для поиска.

! Это самый простой и быстрый способ поиска по документу Word.
Для обычного пользователя большего и не нужно. Но если ваша деятельность, вынуждает Вас искать более сложные фрагменты текста (например, нужно найти текст с синим цветом), то необходимо воспользоваться расширенной формой поиска.
Расширенный поиск в Ворде
Часто возникает необходимость поиска слов в Ворде, которое отличается по формату. Например, все слова, выделенные жирным. В этом как рас и поможет расширенный поиск.
Существует 3 варианта вызова расширенного поиска:
- В панели навигация, после обычного поиска

- На кнопке «Найти» нужно нажать на стрелочку вниз

- Нужно нажать на кнопку «Заменить» , там выйдет диалоговое окно. В окне перейти на вкладку «Найти»

В любом случае все 3 варианта ведут к одной форме – «Расширенному поиску».
Как в Word найти слово в тексте – Расширенный поиск
После открытия отдельного диалогового окна, нужно нажать на кнопку «Больше»

После нажатия кнопки диалоговое окно увеличится

Перед нами высветилось большое количество настроек. Рассмотрим самые важные:
Направление поиска
В настройках можно задать Направление поиска. Рекомендовано оставлять пункт «Везде». Так найти слово в тексте будет более реально, потому что поиск пройдет по всему файлу. Еще существуют режимы «Назад» и «Вперед». В этом режиме поиск начинается от курсора и идет вперед по документу или назад (Вверх или вниз)

Поиск с учетом регистра
Поиск с учетом регистра позволяет искать слова с заданным регистром. Например, города пишутся с большой буквы, но журналист где-то мог неосознанно написать название города с маленькой буквы. Что бы облегчить поиск и проверку, необходимо воспользоваться этой конфигурацией:

Поиск по целым словам
Если нажать на вторую галочку, «Только слово целиком», то поиск будет искать не по символам, а по целым словам. Т.е. если вбить в поиск только часть слова, то он его не найдет. Напимер, необходимо найти слово Ворд, при обычном поиске будут найдены все слова с разными окончаниями (Ворде, Ворду), но при нажатой галочке «Только слова целиком» этого не произойдет.

Подстановочные знаки
Более тяжелый элемент, это подстановочные знаки. Например, нам нужно найти все слова, которые начинаются с буквы м и заканчиваются буквой к. Для этого в диалоговом окне поиска нажимаем галочку «Подстановочные знаки», и нажимаем на кнопку «Специальный», в открывающемся списке выбираем нужный знак:

В результате Word найдет вот такое значение:

Поиск омофонов
Microsoft Word реализовал поиск омофонов, но только на английском языке, для этого необходимо выбрать пункт «Произносится как». Вообще, омофоны — это слова, которые произносятся одинаково, но пишутся и имеют значение разное. Для такого поиска необходимо нажать «Произносится как». Например, английское слово cell (клетка) произносится так же, как слово sell (продавать).

! из-за не поддержания русского языка, эффективность от данной опции на нуле
Поиск по тексту без учета знаков препинания
Очень полезная опция «Не учитывать знаки препинания». Она позволяет проводить поиск без учета знаков препинания, особенно хорошо, когда нужно найти словосочетание в тексте.

Поиск слов без учета пробелов
Включенная галочка «Не учитывать пробелы» позволяет находить словосочетания, в которых есть пробел, но алгоритм поиска Word как бы проглатывает его.

Поиск текста по формату
Очень удобный функционал, когда нужно найти текст с определенным форматированием. Для поиска необходимо нажать кнопку Формат, потом у Вас откроется большой выбор форматов:

Для примера в тексте я выделил Жирным текст «как найти слово в тексте Word». Весть текст выделен полужирным, а кусок текста «слово в тексте Word» сделал подчернутым.
В формате я выбрал полужирный, подчеркивание, и русский язык. В итоге Ворд наше только фрагмент «слово в тексте». Только он был и жирным и подчеркнутым и на русском языке.

После проделанных манипуляция не забудьте нажать кнопку «Снять форматирование». Кнопка находится правее от кнопки «Формат».
Специальный поиск от Ворд
Правее от кнопки формат есть кнопка «Специальный». Там существует огромное количество элементов для поиска
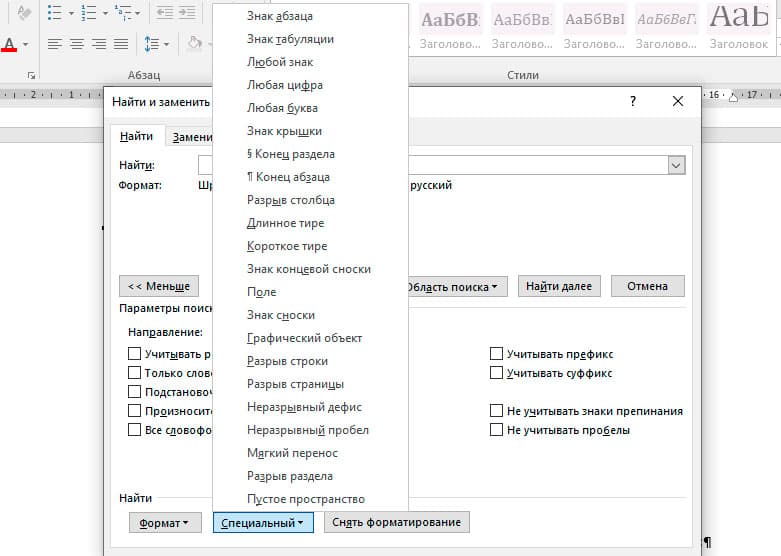
Через этот элемент можно искать:
- Только цифры;
- Графические элементы;
- Неразрывные пробелы или дефисы;
- Длинное и короткое тире;
- Разрывы разделов, страниц, строк;
- Пустое пространство (особенно важно при написании курсовых и дипломных работ);
- И много других элементов.
Опции, которые не приносят пользы
!Это мое субъективное мнение, если у вас есть другие взгляды, то можете писать в комментариях.
- Опция «произносится как». Не поддержание русского языка, делает эту опцию бессмысленной;
- Опция «все словоформы», опция полезная при замене. А если нужно только найти словоформы, то с этим справляется обычный поиск по тексту;
- Опция «Учитывать префикс» и «Учитывать суффикс» – поиск слов, с определенными суффиксами и префиксами. Этот пункт так же полезен будет при замене текста, но не при поиске. С этой функцией справляется обычный поиск.
