В этой статье мы изучим методы JavaScript для поиска элементов в HTML-документе: querySelector, querySelectorAll, getElementById и другие. Кроме них рассмотрим ещё следующие: matches, contains и closest. Первые два из них могут быть полезны для выполнения различных проверок, а третий использоваться, когда нужно получить родительский элемент по CSS-селектору.
Методы для выбора HTML-элементов
Работа с веб-страницей так или иначе связана с манипулированием HTML-элементами. Но перед тем, как над ними выполнить некоторые действия (например, добавить стили), их сначала нужно получить.
Выбор элементов в основном выполняется с помощью этих методов:
querySelector;querySelectorAll.
Они позволяют выполнить поиск HTML-элементов по CSS-селектору. При этом querySelector выбирает один элемент, а querySelectorAll – все.
Кроме них имеются ещё:
getElementById;getElementsByClassName;getElementsByTagName;getElementsByName.
Но они сейчас применяются довольно редко. В основном используется либо querySelector, либо querySelectorAll.
querySelectorAll
Метод querySelectorAll применяется для выбора всех HTML-элементов, подходящих под указанный CSS-селектор. Он позволяет искать элементы как по всей странице, так и внутри определённого элемента:
// выберем элементы по классу item во всем документе
const items = document.querySelectorAll('.item');
// выберем .btn внутри #slider
const buttons = document.querySelector('#slider').querySelectorAll('.btn');Здесь на первой строчке мы нашли все элементы с классом item. На следующей строчке мы сначала выбрали элемент с id="slider", а затем в нём все HTML-элементы с классом btn.
Метод querySelectorAll как вы уже догадались принимает в качестве аргумента CSS-селектор в формате строки, который соответственно и определяет искомые элементы. В качестве результата querySelectorAll возвращает объект класса NodeList. Он содержит все найденные элементы:

Полученный набор представляет собой статическую коллекцию HTML-элементов. Статической она называется потому, что она не изменяется. Например, вы удалили элемент из HTML-документа, а в ней как был этот элемент, так он и остался. Чтобы обновить набор, querySelectorAll нужно вызвать заново:
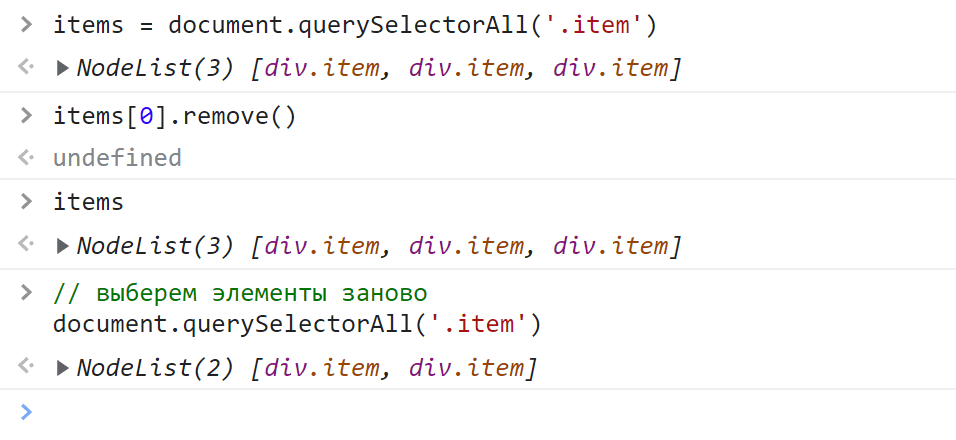
Узнать количество найденных элементов можно с помощью свойства length:
// выберем элементы с атрибутом type="submit"
const submits = document.querySelectorAll('[type="submit"]');
// получим количество найденных элементов
const countSubmits = submits.length;Обращение к определённому HTML-элементу коллекции выполняется также как к элементу массива, то есть по индексу. Индексы начинаются с 0:
// получим первый элемент
const elFirst = submits[0];
// получим второй элемент
const elSecond = submits[1];Здесь в качестве результата мы получаем HTML-элемент или undefined, если элемента с таким индексом в наборе NodeList нет.
Перебор коллекции HTML-элементов
Перебор NodeList обычно осуществляется с помощью forEach:
// получим все <p> на странице
const elsP = document.querySelectorAll('p');
// переберём выбранные элементы
elsP.forEach((el) => {
// установим каждому элементу background-color="yellow"
el.style.backgroundColor = 'yellow';
});Также перебрать набор выбранных элементов можно с помощью цикла for или for...of:
// получим все элементы p на странице
const elsP = document.querySelectorAll('p');
// for
for (let i = 0, length = elsP.length; i < length; i++) {
elsP[i].style.backgroundColor = 'yellow';
}
// for...of
for (let el of elsP) {
el.style.backgroundColor = 'yellow';
}querySelector
Метод querySelector также как и querySelectorAll выполняет поиск по CSS-селектору. Но в отличие от него, он ищет только один HTML-элемент:
// ищем #title во всём документе
const elTitle = document.querySelector('#title');
// ищем footer в <body>
const elFooter = document.body.querySelector('footer');На первой строчке мы выбираем HTML-элемент, имеющий в качестве id значение title. На второй мы ищем в <body> HTML-элемент по тегу footer.
В качестве результата этот метод возвращает найденный HTML-элемент или null, если он не был найден.
querySelector всегда возвращает один HTML-элемент, даже если под указанный CSS-селектор подходят несколько:
<ul id="list">
<li>First</li>
<li>Second</li>
<li>Third</li>
</ul>
<script>
// выберем <li>, расположенный в #list
const elFirst = document.querySelector('#list > li');
elFirst.style.backgroundColor = 'yellow';
</script>Задачу, которую решает querySelector можно выполнить через querySelectorAll:
const elFirst = document.querySelectorAll('#list > li')[0];Но querySelector в отличие от querySelectorAll делает это намного быстрее, да и писать так проще. То есть querySelectorAll не возвращает как querySelector сразу же первый найденный элемент. Он сначала ищет все элементы, и только после того, как он это сделает, мы можем уже обратиться к первому HTML-элементу в этой коллекции.
Обычно перед тем, как выполнить какие-то действия с найденным HTML-элементом необходимо сначала проверить, а действительно ли он был найден:
const elModal = document.querySelector('.modal');
// если элемент .modal найден, то ...
if (elModal) {
// переключим у elModal класс show
elModal.classList.toggle('show');
}Здесь мы сначала проверили существования HTML-элемента, и только потом выполнили над ним некоторые действия.
Методы getElement(s)By* для выбора HTML-элементов
Здесь мы рассмотрим методы, которые сейчас применяются довольно редко для поиска HTML-элементов. Но в некоторых случаях они могут быть очень полезны. Это:
getElementById– получает один элемент поid;getElementsByClassName– позволяет найти все элементы с указанным классом или классами;getElementsByTagName– выбирает элементы по тегу;getElementsByName– получает все элементы с указанным значением атрибутаname.
1. Метод getElementById позволяет найти HTML-элемент на странице по значению id:
<div id="comments">...</div>
...
<script>
// получим HTMLElement и сохраним его в переменную elComments
const elComments = document.getElementById('comments');
</script>В качестве результата getElementById возвращает объект класса HTMLElement или значение null, если элемент не был найден. Этот метод имеется только у объекта document.
Указывать значение id необходимо с учётом регистра. Так например, document.getElementById('aside') и document.getElementById('ASIDE') ищут элементы с разным id.
Обратите внимание, что в соответствии со стандартом в документе не может быть несколько тегов с одинаковым id, так как значение идентификатора на странице должно быть уникальным.
Тем не менее, если вы допустили ошибку и в документе существуют несколько элементов с одинаковым id, то метод getElementById более вероятно вернёт первый элемент, который он встретит в DOM. Но на это полагаться нельзя, так как такое поведение не прописано в стандарте.
То, что делает getElementById можно очень просто решить посредством querySelector:
// получим элемент #title
const elTitle = document.getElementById('title');
// получим элемента #title, используя querySelector
const elTitleSame = document.querySelector('#nav');Кстати, оба этих метода возвращают в качестве результата один и тот же результат. Это либо HTML-элемент (экземпляр класса HTMLElement) или null, если элемент не найден.
2. Метод getElementsByClassName позволяет найти все элементы с заданным классом или классами. Его можно применить для поиска элементов как во всём документе, так и внутри указанного. В первом случае его нужно будет вызывать как метод объекта document, а во втором – как метод соответствующего HTML-элемента:
// найдем элементы с классом control в документе
const elsControl = document.getElementsByClassName('control');
// выберем элементы внутри другого элемента, в данном случае внутри формы с id="myform"
const elsFormControl = document.forms.myform.getElementsByClassName('form-control');В качестве результата он возвращает живую HTML-коллекцию найденных элементов. Чем живая коллекция отличается от статической мы рассмотрим ниже.
Здесь мы сохранили найденные элементы в переменные elsControl и elsFormControl. В первой переменной будет находиться HTMLCollection, содержащая элементы с классом control. Во второй – набор элементов с классом form-control, находящиеся в форме с id="myform". Для получения этой формы мы использовали document.forms.myform.
Метод getElementsByClassName позволяет искать элементы не только по одному классу, но и сразу по нескольким, которые должны присутствовать у элемента:
// выберем элементы .btn.btn-danger
const elsBtn = document.getElementsByClassName('btn btn-danger');На querySelectorAll этот пример решается так:
const elsBtn = document.querySelectorAll('.btn.btn-danger');3. Метод getElementsByTagName предназначен для получения коллекции элементов по имени тега:
// найдем все <a> в документе
const anchors = document.getElementsByTagName('a');
// найдем все >li> внутри #list
const elsLi = document.getElementById('list').getElementsByTagName('li');На первой строчке мы выбрали все <a> в документе и присвоили полученную HTMLCollection переменной anchors. На второй – мы сначала получили #list, а затем в нём нашли все <li>.
Задачу по выбору элементов внутри другого элемента с помощью querySelectorAll выполняется намного проще:
const elsLi = document.querySelectorAll('#list li');Для выбора всех элементов можно использовать символ *:
// выберем все элементы в <body>
const els = document.body.getElementsByTagName('*');4. В JavaScript getElementsByName можно использовать для выбора элементов, имеющих определенное значение атрибута name:
// получим все элементы с name="phone"
const elsPhone = document.getElementsByName('phone');Через querySelectorAll это выполняется так:
const elsPhone = document.querySelectorAll('[name="phone"]');getElementsBy* и живые HTML-коллекции
В JavaScript getElementsByTagName, getElementsByClassName и getElementsByName в отличие от других методов (например, querySelectorAll) возвращают живую коллекцию HTML-элементов (на английском live HTMLCollection). То есть коллекцию содержимое которой автоматически обновляется при изменении DOM. Для наглядности рассмотрим следующий пример.
Например, на странице изначально имеется два <li>. Выберем их с помощью getElementsByTagName и сохраним полученную HTMLCollection в переменную els. Теперь с помощью els мы можем получить эту коллекцию. Сейчас в ней два <li>. Затем через 5 секунд, используя setTimeout добавим ещё один <li>. Если сейчас мы обратимся к переменной els, то увидим, что в ней уже находятся три <li>:
<ul>
<li>One</li>
<li>Two</li>
</ul>
<script>
// получим живую коллекцию <li>
const els = document.getElementsByTagName('li');
// выведем количество <li> в консоль
console.log(`Количество <li>: ${els.length}`); // 2
// через 5 секунд добавим ещё один <li>
setTimeout(() => {
// вставим на страницу новый <li>
document.querySelector('ul').insertAdjacentHTML('beforeend', '<li>Three</li>');
// выведем количество <li> в консоль
console.log(`Количество <li>: ${els.length}`); // 3
}, 5000);
</script>
Как вы видите, здесь полученная коллекция является живой, то есть она может автоматически измениться. В ней сначала было два <li>. Но после того, как мы на страницу добавили ещё один подходящий элемент, в ней их стало уже три.
Если в коде приведённом выше заменить выбор элементов на querySelectorAll, то мы увидим, что в ней находится статическая (не живая) коллекция элементов:
// получим статическую коллекцию
const els = document.querySelectorAll('li'); <li>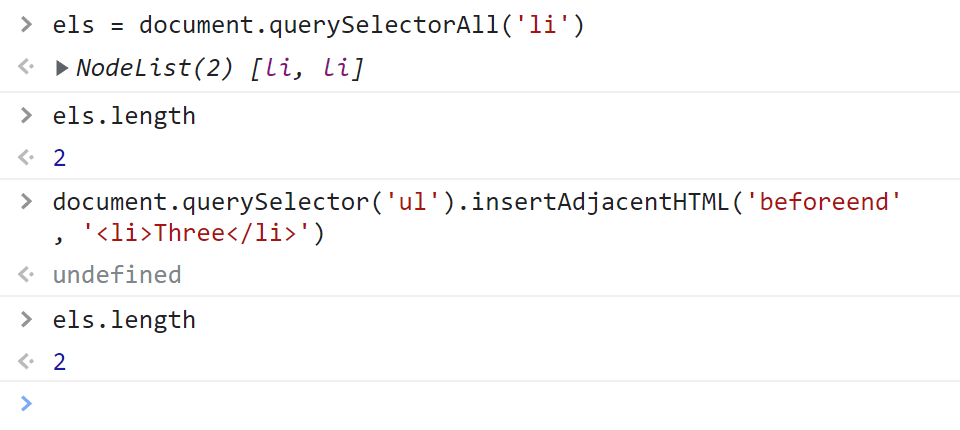
Как вы видите количество элементов в коллекции не изменилось. Чтобы после изменения DOM получить актуальную коллекцию элементов, их нужно просто выбрать заново посредством querySelectorAll:
<ul>
<li>One</li>
<li>Two</li>
</ul>
<script>
// получим статическую коллекцию <li>
let els = document.querySelectorAll('li');
// выведем количество <li> в консоль
console.log(`Количество <li>: ${els.length}`); // 2
// через 5 секунд добавим ещё один <li>
setTimeout(() => {
// вставим на страницу новый <li>
document.querySelector('ul').insertAdjacentHTML('beforeend', '<li>Three</li>');
// получим заново статическую коллекцию <li>
els = document.querySelectorAll('li');
// выведем количество <li> в консоль
console.log(`Количество <li>: ${els.length}`); // 3
}, 5000);
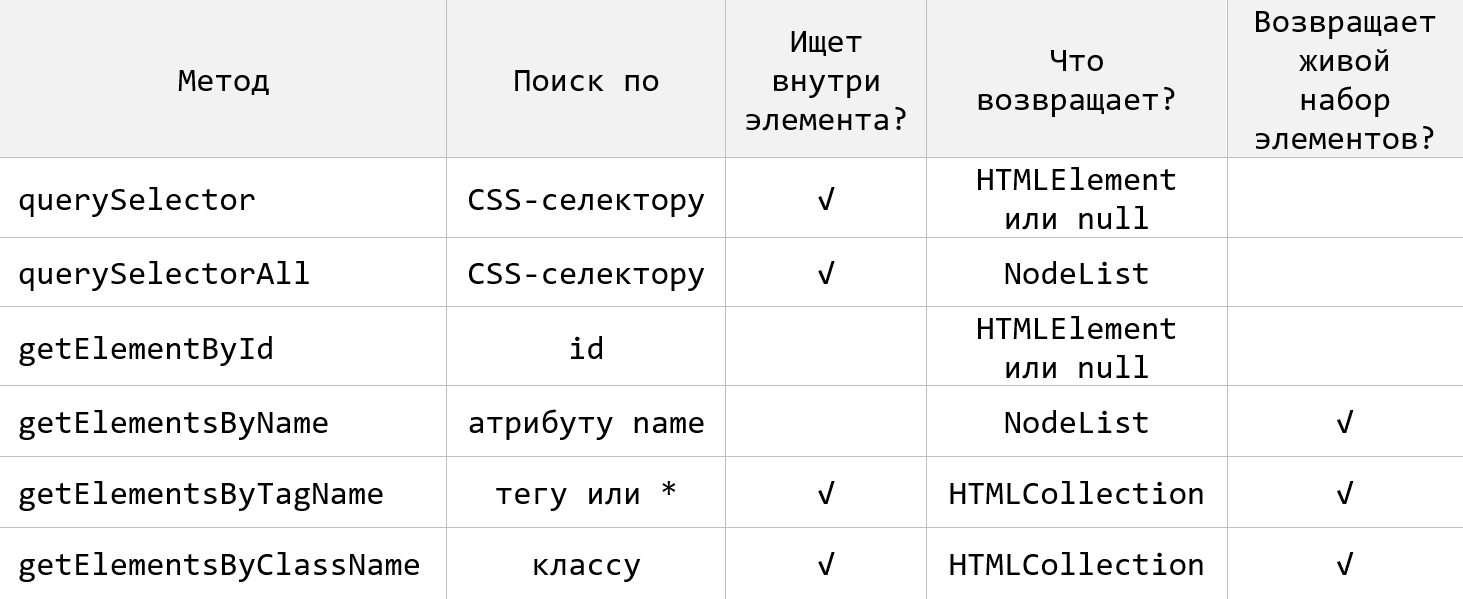
</script>Таким образом в JavaScript насчитывается 6 основных методов для выбора HTML-элементов на странице. По чему они ищут и что они возвращают приведено на следующем рисунке:
Экземпляры класса HTMLCollection не имеют в прототипе метод forEach. Поэтому если вы хотите использовать этот метод для перебора такой коллекции, её необходимо преобразовать в массив:
const items = document.getElementsByClassName('item');
[...items].forEach((el) => {
console.log(el);
});matches, closest и contains
В JavaScript имеются очень полезные методы:
matches– позволяет проверить соответствует ли HTML-элемент указанному CSS-селектору;closest– позволяет найти для HTML-элемента его ближайшего предка, подходящего под указанный CSS-селектор (поиск начинается с самого элемента);contains– позволяет проверить содержит ли данный узел другой в качестве потомка (проверка начинается с самого этого узла).
1. Метод matches ничего не выбирает, но он является очень полезным, так как позволяет проверить HTML-элемент на соответствие CSS-селектору. Он возвращает true, если элемент ему соответствует, иначе false.
// выберем HTML элемент, имеющий атрибут data-target="slider"
const elSlider = document.querySelector('[data-target="slider"]');
// проверим соответствует ли он CSS селектору 'div'
const result = element.matches('div');Пример, в котором выберем все <li>, расположенные внутри #questions, а затем удалим те из них, которые соответствуют селектору .answered:
// выберем все <li> в #questions
const els = document.querySelectorAll('#questions > li');
// переберём выбранные элементы
els.forEach((el) => {
// если элемент соответствует селектору .answered, то ...
if (el.matches('.answered')) {
// удалим элемент
el.remove();
}
});В этом примере проверим каждый <li> на соответствие селектору active. Выведем в консоль каждый такой элемент:
<ul>
<li>One</li>
<li class="active">Two</li>
<li>Three</li>
</ul>
<script>
document.querySelectorAll('li').forEach((el) => {
if (el.matches('.active')) {
console.log(el);
}
});
// li.active
</script>Ранее, в «старых» браузерах данный метод имел название matchesSelector, а также поддерживался с использованием префиксов. Если вам нужна поддержка таких браузеров, то можно использовать следующий полифилл:
if (!Element.prototype.matches) {
Element.prototype.matches = Element.prototype.matchesSelector || Element.prototype.webkitMatchesSelector || Element.prototype.mozMatchesSelector || Element.prototype.msMatchesSelector;
}2. Метод closest очень часто используется в коде. Он позволяет найти ближайшего предка, подходящего под указанный CSS-селектор. При этом поиск начинается с самого элемента, для которого данный метод вызывается. Если этот элемент будет ему соответствовать, то closest вернёт его.
<div class="level-1">
<div class="level-2">
<div class="level-3"></div>
</div>
</div>
<script>
const el = document.querySelector('.level-3');
const elAncestor = el.closest('.level-1');
console.log(elAncestor);
</script>Здесь мы сначала выбираем HTML-элемент .level-3 и присваиваем его переменной el. Далее мы пытаемся среди предков этого элемента включая его сам найти такой, который отвечает заданному CSS-селектору, в данном случае .level-1.
Начинается поиск всегда с самого этого элемента. В данном случае он не подходит под указанный селектор. Следовательно, этот метод переходит к его родителю. Он тоже не отвечает этому CSS-селектору. Значит, closest переходит дальше, то есть уже к его родителю. Этот элемент подходит под указанный селектор. Поэтому поиск прекращается и этот метод возвращает его в качестве результата.
Метод closest возвращает null, когда он дошёл бы конца иерархии и не нашёл элемент отвечающий указанному селектору. То есть, если такого элемента нет среди предков.
В этом примере найдем с помощью closest для .active его ближайшего родителя, отвечающего CSS-селектору #list > li:
<ul id="list">
<li>One</li>
<li>
Two
<ul>
<li>Four</li>
<li class="active">Five</li>
</ul>
</li>
<li>Three</li>
</ul>
<script>
const elActive = document.querySelector('.active');
const elClosest = elActive.closest('#list > li');
elClosest.style.backgroundColor = 'yellow';
</script>В JavaScript closest очень часто используется в обработчиках событий. Это связано с тем, чтобы события всплывают и нам нужно, например, узнать кликнул ли пользователь в рамках какого-то элемента:
document.addEventListener('click', (e) => {
if (e.closest.matches('.btn__action')) {
// пользователь кликнул внутри .btn__action
}
});3. Метод contains позволяет проверить содержит ли некоторый узел другой в качестве потомка. При этом проверка начинается с самого этого узла, для которого этот метод вызывается. Если узел соответствует тому для которого мы вызываем данный метод или является его потомком, то contains в качестве результата возвращает логическое значение true. В противном случае false:
<div id="div-1">
<div id="div-2">
<div id="div-3">...</div>
</div>
</div>
<div id="div-4">...</div>
<script>
const elDiv1 = document.querySelector('#div-1');
elDiv1.contains(elDiv1); // true
const elDiv3 = document.querySelector('#div-3');
elDiv1.contains(elDiv3); // true
const elDiv4 = document.querySelector('#div-4');
elDiv1.contains(elDiv4); // false
</script>Здесь выражение elDiv1.contains(elDiv1) возвращает true, так как проверка начинается с самого элемента. Это выражение elDiv1.contains(elDiv3) тоже возвращает true, так как elDiv3 находится внутри elDiv1. А вот elDiv1.contains(elDiv4) в качестве результата возвращает false, так как elDiv4 не находится внутри elDiv1.
В этом примере проверим с помощью contains содержит ли <p> другие узлы в качестве потомка:
<h1>Tag b</h1>
<p>This is <b>tag b</b>.</p>
<script>
const elP = document.querySelector('p');
const elB = document.querySelector('b');
const textNode = elB.firstChild;
const elH1 = document.querySelector('h1');
elP.contains(elP); // true
elP.contains(elB); // true
elP.contains(elH1); // false
elP.contains(textNode); // true
</script>Метод contains позволяет проверить является ли потомком не только узел-элемент, но и любой другой узел. Например, узнаем является ли потомком elDiv1 указанный текстовый узел:
const elDiv1 = document.querySelector('#div-1');
const textNode = document.querySelector('#div-3').firstChild;
elDiv1.contains(textNode); // trueЗадачи
1. Узнать количество элементов с атрибутом data-toggle="modal" на странице:
const count = document.querySelectorAll('[data-toggle="modal"]').length;
console.log(count);2. Найти все элементы <a> с классом nav внутри элемента <ul> :
const anchors = document.querySelectorAll('ul.nav a');3. Получить элемент по id, значение которого равно pagetitle:
var pagetitle = document.querySelector('#pagetitle');4. Выполнить поиск элемента по классу nav:
var el = document.querySelector('.nav');5. Найти элемент <h3>, находящийся в теге <div> с классом comments, который в свою очередь расположен в <main>:
var header = document.querySelector('main div.comments h3');6. Имеется страница. В ней следует выбрать:
- последний элемент с классом
article, расположенный в<main>(решение); - все элементы
.section, находящиеся в.asideкроме 2 второго (решение); - элемент
<nav>расположенный после<header>(решение).
Поиск: getElement*, querySelector*
Свойства навигации по DOM хороши, когда элементы расположены рядом. А что, если нет? Как получить произвольный элемент страницы?
Для этого в DOM есть дополнительные методы поиска.
document.getElementById или просто id
Если у элемента есть атрибут id, то мы можем получить его вызовом document.getElementById(id), где бы он ни находился.
Например:
<div id="elem"> <div id="elem-content">Element</div> </div> <script> // получить элемент *!* let elem = document.getElementById('elem'); */!* // сделать его фон красным elem.style.background = 'red'; </script>
Также есть глобальная переменная с именем, указанным в id:
<div id="*!*elem*/!*"> <div id="*!*elem-content*/!*">Элемент</div> </div> <script> // elem - ссылка на элемент с id="elem" elem.style.background = 'red'; // внутри id="elem-content" есть дефис, так что такой id не может служить именем переменной // ...но мы можем обратиться к нему через квадратные скобки: window['elem-content'] </script>
…Но это только если мы не объявили в JavaScript переменную с таким же именем, иначе она будет иметь приоритет:
<div id="elem"></div> <script> let elem = 5; // теперь elem равен 5, а не <div id="elem"> alert(elem); // 5 </script>
Это поведение соответствует [стандарту](https://html.spec.whatwg.org/#dom-window-nameditem), но поддерживается в основном для совместимости, как осколок далёкого прошлого.
Браузер пытается помочь нам, смешивая пространства имён JS и DOM. Это удобно для простых скриптов, которые находятся прямо в HTML, но, вообще говоря, не очень хорошо. Возможны конфликты имён. Кроме того, при чтении JS-кода, не видя HTML, непонятно, откуда берётся переменная.
В этом учебнике мы будем обращаться к элементам по `id` в примерах для краткости, когда очевидно, откуда берётся элемент.
В реальной жизни лучше использовать `document.getElementById`.
“`smart header=”Значение id должно быть уникальным”
Значение `id` должно быть уникальным. В документе может быть только один элемент с данным `id`.
Если в документе есть несколько элементов с одинаковым значением id, то поведение методов поиска непредсказуемо. Браузер может вернуть любой из них случайным образом. Поэтому, пожалуйста, придерживайтесь правила сохранения уникальности id.
```warn header="Только `document.getElementById`, а не `anyElem.getElementById`"
Метод `getElementById` можно вызвать только для объекта `document`. Он осуществляет поиск по `id` по всему документу.
querySelectorAll [#querySelectorAll]
Самый универсальный метод поиска – это elem.querySelectorAll(css), он возвращает все элементы внутри elem, удовлетворяющие данному CSS-селектору.
Следующий запрос получает все элементы <li>, которые являются последними потомками в <ul>:
<ul> <li>Этот</li> <li>тест</li> </ul> <ul> <li>полностью</li> <li>пройден</li> </ul> <script> *!* let elements = document.querySelectorAll('ul > li:last-child'); */!* for (let elem of elements) { alert(elem.innerHTML); // "тест", "пройден" } </script>
Этот метод действительно мощный, потому что можно использовать любой CSS-селектор.
Псевдоклассы в CSS-селекторе, в частности `:hover` и `:active`, также поддерживаются. Например, `document.querySelectorAll(':hover')` вернёт коллекцию (в порядке вложенности: от внешнего к внутреннему) из текущих элементов под курсором мыши.
querySelector [#querySelector]
Метод elem.querySelector(css) возвращает первый элемент, соответствующий данному CSS-селектору.
Иначе говоря, результат такой же, как при вызове elem.querySelectorAll(css)[0], но он сначала найдёт все элементы, а потом возьмёт первый, в то время как elem.querySelector найдёт только первый и остановится. Это быстрее, кроме того, его короче писать.
matches
Предыдущие методы искали по DOM.
Метод elem.matches(css) ничего не ищет, а проверяет, удовлетворяет ли elem CSS-селектору, и возвращает true или false.
Этот метод удобен, когда мы перебираем элементы (например, в массиве или в чём-то подобном) и пытаемся выбрать те из них, которые нас интересуют.
Например:
<a href="http://example.com/file.zip">...</a> <a href="http://ya.ru">...</a> <script> // может быть любая коллекция вместо document.body.children for (let elem of document.body.children) { *!* if (elem.matches('a[href$="zip"]')) { */!* alert("Ссылка на архив: " + elem.href ); } } </script>
closest
Предки элемента – родитель, родитель родителя, его родитель и так далее. Вместе они образуют цепочку иерархии от элемента до вершины.
Метод elem.closest(css) ищет ближайшего предка, который соответствует CSS-селектору. Сам элемент также включается в поиск.
Другими словами, метод closest поднимается вверх от элемента и проверяет каждого из родителей. Если он соответствует селектору, поиск прекращается. Метод возвращает либо предка, либо null, если такой элемент не найден.
Например:
<h1>Содержание</h1> <div class="contents"> <ul class="book"> <li class="chapter">Глава 1</li> <li class="chapter">Глава 2</li> </ul> </div> <script> let chapter = document.querySelector('.chapter'); // LI alert(chapter.closest('.book')); // UL alert(chapter.closest('.contents')); // DIV alert(chapter.closest('h1')); // null (потому что h1 - не предок) </script>
getElementsBy*
Существуют также другие методы поиска элементов по тегу, классу и так далее.
На данный момент, они скорее исторические, так как querySelector более чем эффективен.
Здесь мы рассмотрим их для полноты картины, также вы можете встретить их в старом коде.
elem.getElementsByTagName(tag)ищет элементы с данным тегом и возвращает их коллекцию. Передав"*"вместо тега, можно получить всех потомков.elem.getElementsByClassName(className)возвращает элементы, которые имеют данный CSS-класс.document.getElementsByName(name)возвращает элементы с заданным атрибутомname. Очень редко используется.
Например:
// получить все элементы div в документе let divs = document.getElementsByTagName('div');
Давайте найдём все input в таблице:
<table id="table"> <tr> <td>Ваш возраст:</td> <td> <label> <input type="radio" name="age" value="young" checked> младше 18 </label> <label> <input type="radio" name="age" value="mature"> от 18 до 50 </label> <label> <input type="radio" name="age" value="senior"> старше 60 </label> </td> </tr> </table> <script> *!* let inputs = table.getElementsByTagName('input'); */!* for (let input of inputs) { alert( input.value + ': ' + input.checked ); } </script>
“`warn header=”Не забываем про букву "s"!”
Одна из самых частых ошибок начинающих разработчиков (впрочем, иногда и не только) – это забыть букву `”s”`. То есть пробовать вызывать метод `getElementByTagName` вместо getElementsByTagName.
Буква "s" отсутствует в названии метода getElementById, так как в данном случае возвращает один элемент. Но getElementsByTagName вернёт список элементов, поэтому "s" обязательна.
````warn header="Возвращает коллекцию, а не элемент!"
Другая распространённая ошибка - написать:
```js
// не работает
document.getElementsByTagName('input').value = 5;
Попытка присвоить значение коллекции, а не элементам внутри неё, не сработает.
Нужно перебрать коллекцию в цикле или получить элемент по номеру и уже ему присваивать значение, например, так:
// работает (если есть input) document.getElementsByTagName('input')[0].value = 5;
Ищем элементы с классом `.article`:
```html run height=50
<form name="my-form">
<div class="article">Article</div>
<div class="long article">Long article</div>
</form>
<script>
// ищем по имени атрибута
let form = document.getElementsByName('my-form')[0];
// ищем по классу внутри form
let articles = form.getElementsByClassName('article');
alert(articles.length); // 2, находим два элемента с классом article
</script>
```
## Живые коллекции
Все методы `"getElementsBy*"` возвращают *живую* коллекцию. Такие коллекции всегда отражают текущее состояние документа и автоматически обновляются при его изменении.
В приведённом ниже примере есть два скрипта.
1. Первый создаёт ссылку на коллекцию `<div>`. На этот момент её длина равна `1`.
2. Второй скрипт запускается после того, как браузер встречает ещё один `<div>`, теперь её длина - `2`.
```html run
<div>First div</div>
<script>
let divs = document.getElementsByTagName('div');
alert(divs.length); // 1
</script>
<div>Second div</div>
<script>
*!*
alert(divs.length); // 2
*/!*
</script>
```
Напротив, `querySelectorAll` возвращает *статическую* коллекцию. Это похоже на фиксированный массив элементов.
Если мы будем использовать его в примере выше, то оба скрипта вернут длину коллекции, равную `1`:
```html run
<div>First div</div>
<script>
let divs = document.querySelectorAll('div');
alert(divs.length); // 1
</script>
<div>Second div</div>
<script>
*!*
alert(divs.length); // 1
*/!*
</script>
```
Теперь мы легко видим разницу. Длина статической коллекции не изменилась после появления нового `div` в документе.
## Итого
Есть 6 основных методов поиска элементов в DOM:
<table>
<thead>
<tr>
<td>Метод</td>
<td>Ищет по...</td>
<td>Ищет внутри элемента?</td>
<td>Возвращает живую коллекцию?</td>
</tr>
</thead>
<tbody>
<tr>
<td><code>querySelector</code></td>
<td>CSS-selector</td>
<td>✔</td>
<td>-</td>
</tr>
<tr>
<td><code>querySelectorAll</code></td>
<td>CSS-selector</td>
<td>✔</td>
<td>-</td>
</tr>
<tr>
<td><code>getElementById</code></td>
<td><code>id</code></td>
<td>-</td>
<td>-</td>
</tr>
<tr>
<td><code>getElementsByName</code></td>
<td><code>name</code></td>
<td>-</td>
<td>✔</td>
</tr>
<tr>
<td><code>getElementsByTagName</code></td>
<td>tag or <code>'*'</code></td>
<td>✔</td>
<td>✔</td>
</tr>
<tr>
<td><code>getElementsByClassName</code></td>
<td>class</td>
<td>✔</td>
<td>✔</td>
</tr>
</tbody>
</table>
Безусловно, наиболее часто используемыми в настоящее время являются методы `querySelector` и `querySelectorAll`, но и методы `getElement(s)By*` могут быть полезны в отдельных случаях, а также встречаются в старом коде.
Кроме того:
- Есть метод `elem.matches(css)`, который проверяет, удовлетворяет ли элемент CSS-селектору.
- Метод `elem.closest(css)` ищет ближайшего по иерархии предка, соответствующему данному CSS-селектору. Сам элемент также включён в поиск.
И, напоследок, давайте упомянем ещё один метод, который проверяет наличие отношений между предком и потомком:
- `elemA.contains(elemB)` вернёт `true`, если `elemB` находится внутри `elemA` (`elemB` потомок `elemA`) или когда `elemA==elemB`.
На этом занятии
рассмотрим методы поиска произвольных элементов в HTML-документе. Рассмотренные
свойства на предыдущем занятии по навигации DOM-дереву хороши
если элементы расположены рядом. Но что делать, если требуемый объект может
находиться в самых разных местах. Как его искать? Вот об этом и пойдет сейчас
речь.
В самом простом
случае мы можем у любого тега HTML-документа прописать атрибут id с некоторым уникальным
значением. Например:
<!DOCTYPE html> <html> <head> <title>Уроки по JavaScript</title> </head> <body> <div id="div_id"> <p>Текст внутри блока div </div> <script> </script> </body> </html>
Здесь у нас тег div имеет атрибут id со значением div_id. Мы это
значение придумываем сами, главное, чтобы оно было уникальным в пределах HTML-страницы.
Теперь можно получить этот элемент div по этому id, где бы он ни
находился в DOM-дереве. Для
этого используется метод getElementById объекта document:
let divElem = document.getElementById('div_id'); console.log( divElem );
Мы в методе getElementById в качестве
аргумента указываем строку со значением атрибута id и на выходе
получаем ссылку на этот элемент.
Или же можем
получить доступ к этому элементу напрямую через глобальную переменную div_id, которая
автоматически создается браузером при формировании DOM-дерева:
Но этот второй
способ имеет одну уязвимость: если мы создадим в скрипте переменную с таким же
именем, то прежнее значение div_id будет затерто:
let div_id = "не тег div";
так что этот
подход следует применять с большой осторожностью, лучше использовать метод getElementById.
В стандарте ES6+ появился
новый метод поиска элементов querySelectorAll, который возвращает список
элементов, удовлетворяющих CSS-селектору, который мы в нем указываем.
Например,
добавим в HTML-документ вот
такой маркированный список:
<ul> <li>Солнце <li>Меркурий <li>Венера <li>Земля <li>Марс </ul>
и вот такой
нумерованный список:
<p>Звезды: <ol> <li>Сириус <li>Альдебаран <li>Капелла <li>Ригель </ol>
И теперь хотим
выбрать все теги <li>, но только у маркированного списка.
Для этого запишем метод querySelectorAll с таким CSS-селектором:
let list = document.querySelectorAll("ul > li"); for(let val of list) console.log(val);
Как видите, у
нас были выбраны элементы только маркированного списка. Мало того, в методе querySelectorAll
можно использовать псевдоклассы для указания более сложных CSS-селекторов,
например, так:
let list = document.querySelectorAll("ul > li:first-child");
тогда мы увидим
только первый элемент списка. И так далее. С помощью querySelectorAll можно довольно
просто выбрать нужные элементы и далее производить с ними необходимые действия.
Если же нам
нужно по определенному CSS-селектору найти только первый
подходящий элемент, то для этого применяется другой метод querySelector:
let element = document.querySelector("ol > li"); console.log(element);
Здесь мы из
нумерованного списка выбрали первый тег <li>. Конечно,
здесь можно было бы использовать и предыдущий метод querySelectorAll, а затем,
взять из списка только первый:
let element = document.querySelectorAll("ol > li")[0];
но это будет
работать медленнее, так как все равно сначала будут находиться все подходящие
элементы, а затем, браться первый. Поэтому, если нужно найти только первый
подходящий, то следует использовать querySelector.
Следующий метод matches
позволяет определить: подходит ли данный элемент под указанный CSS-селектор или
нет. Если подходит, то возвращает true, иначе – false. Например,
создадим такое оглавление:
<h1>О звездах</h1> <div class="content-table"> <ul class="stars-list"> <li class="star">О сириусе</li> <li class="star">Об альдебаране</li> <li class="contact">Обратная связь</li> </ul> </div>
И мы, перебирая
список пунктов меню, хотим выбрать только те элементы, у которых class равен star. Это можно сделать так:
let list = document.querySelectorAll("ul.stars-list > li"); for(let item of list) { if(item.matches("li.star")) console.log(item); }
Обратите
внимание, что метод matches относится к объекту DOM, а не к document. Что, в
общем-то логично, так как нам нужно проверить конкретный элемент на
соответствие CSS-селектора. В
результате, в консоле мы увидим первые два элемента:
<li class="star">О сириусе</li> <li class="star">Об альдебаране</li>
Следующий метод
elem.closest(css) ищет ближайшего предка, который соответствует CSS-селектору.
Сам элемент также включается в поиск. Метод возвращает либо предка, либо null,
если такой элемент не найден. Например:
let li = document.querySelector("li.star"); console.log(li.closest('.stars-list')); console.log(li.closest('.content-table')); console.log(li.closest('h1')); // null
Сначала мы
выбираем первый элемент li пункта меню.
Затем, с помощью метода closest ищем ближайшего родителя с
классом stars-list. Находится
список ul. Далее, ищем
родителя с классом content-table. Находим блок div. Наконец,
пытаемся найти родителя с тегом h1. Но его нет, так как h1 в документе не
является родителем для объекта li. Получаем значение null.
В старых версиях
языка JavaScript (стандарта ES5-) существуют
следующие методы для поиска элементов:
-
elem.getElementsByTagName(tag)
ищет элементы с указанным тегом и возвращает их коллекцию. Указав “*”
вместо тега, можно получить всех потомков. -
elem.getElementsByClassName(className)
возвращает элементы, которые имеют указанный CSS-класс. -
document.getElementsByName(name)
возвращает элементы с заданным атрибутом name. (Используется очень редко).
Применение этих
методов очевидно и я привел их здесь лишь для полноты картины, так как вы
можете их встретить в старых скриптах. Вместо всех этих методов теперь
используются методы querySelector и querySelectorAll. Они дают
гораздо больше возможностей, чем старые методы.
Однако, между методами
getElementsBy* и querySelector, querySelectorAll есть одно важное
отличие: методы getElementsBy* возвращают, так называемую, «живую»
коллекцию, то есть, они всегда отражают текущее состояние документа и автоматически
обновляются при его изменении. Например, при загрузке и отображении такого HTML-документа:
<!DOCTYPE html> <html> <head> <title>Уроки по JavaScript</title> </head> <body> <h1>О звездах</h1> <h2>Об альдебаране</h2> <script> let list = document.getElementsByTagName("h2"); </script> <h2>О ригеле</h2> <script> for(let item of list) console.log(item); </script> </body> </html>
Мы в консоле
увидим список из двух тегов h2, хотя когда этот список формировался в
HTML-документе был
всего один тег h2. Второй добавился позже, автоматически. Но, если
мы будем получать список этих элементов с помощью метода querySelectorAll:
let list = document.querySelectorAll("h2");
то увидим только
один тег h2. Так как здесь
делается как бы снимок коллекции на текущий момент состояния HTML-документа и
после этого никак не меняется. Вот этот момент при работе с этими методами
следует иметь в виду.
Ну и в
заключение этого занятия отметим еще один полезный метод
который
возвращает значение true, если elemB является дочерним по отношению к elemA.
И false в противном
случае. Например, вот в этом документе:
<div class="content-table"> <ul class="stars-list"> <li class="star">О сириусе</li> <li class="star">Об альдебаране</li> <li class="contact">Обратная связь</li> </ul> </div>
Можно проверить:
имеется ли список внутри тега div:
let div = document.querySelector("div.content-table"); let ul = document.querySelector("ul.stars-list"); if(div.contains(ul)) console.log("ul внутри div");
Вот такие
основные методы поиска элементов в DOM-дереве есть в JavaScript.
Видео по теме
Основные источники
- DOM Living Standart
- HTML Living Standart
- Document Object Model (DOM) Level 3 Core Specification
- DOM Parsing and Serialization
Введение
JavaScript предоставляет множество методов для работы с Document Object Model или сокращенно DOM (объектной моделью документа): одни из них являются более полезными, чем другие; одни используются часто, другие почти никогда; одни являются относительно новыми, другие признаны устаревшими.
Я постараюсь дать вам исчерпывающее представление об этих методах, а также покажу парочку полезных приемов, которые сделают вашу жизнь веб-разработчика немного легче.
Размышляя над подачей материала, я пришел к выводу, что оптимальным будет следование спецификациям с промежуточными и заключительными выводами, сопряженными с небольшими лирическими отступлениями.
Сильно погружаться в теорию мы не будем. Вместо этого, мы сосредоточимся на практической составляющей.
Для того, чтобы получить максимальную пользу от данной шпаргалки, пишите код вместе со мной и внимательно следите за тем, что происходит в консоли инструментов разработчика и на странице.
Вот как будет выглядеть наша начальная разметка:
<ul id="list" class="list">
<li id="item1" class="item">1</li>
<li id="item2" class="item">2</li>
<li id="item3" class="item">3</li>
</ul>У нас есть список (ul) с тремя элементами (li). Список и каждый элемент имеют идентификатор (id) и CSS-класс (class). id и class — это атрибуты элемента. Существует множество других атрибутов: одни из них являются глобальными, т.е. могут добавляться к любому элементу, другие — локальными, т.е. могут добавляться только к определенным элементам.
Мы часто будем выводить данные в консоль, поэтому создадим такую “утилиту”:
const log = console.logМиксин NonElementParentNode
Данный миксин предназначен для обработки (браузером) родительских узлов, которые не являются элементами.
В чем разница между узлами (nodes) и элементами (elements)? Если кратко, то “узлы” — это более общее понятие, чем “элементы”. Узел может быть представлен элементом, текстом, комментарием и т.д. Элемент — это узел, представленный разметкой (HTML-тегами (открывающим и закрывающим) или, соответственно, одним тегом).
У рассматриваемого миксина есть метод, наследуемый от объекта Document, с которого удобно начать разговор.
Небольшая оговорка: разумеется, мы могли бы создать список и элементы программным способом.
Для создания элементов используется метод createElement(tag) объекта Document:
const listEl = document.createElement('ul')Такой способ создания элементов называется императивным. Он является не очень удобным и слишком многословным: создаем родительский элемент, добавляет к нему атрибуты по одному, внедряем его в DOM, создаем первый дочерний элемент и т.д. Следует отметить, что существует и другой, более изысканный способ создания элементов — шаблонные или строковые литералы (template literals), но о них мы поговорим позже.
Одним из основных способов получения элемента (точнее, ссылки на элемент) является метод getElementById(id) объекта Document:
// получаем ссылку на наш список
const listEl = document.getElementById('list')
log(listEl)
// ul#list.list - такая запись означает "элемент `ul` с `id === list`" и таким же `class`Почему идентификаторы должны быть уникальными в пределах приложения (страницы)? Потому что элемент с id становится значением одноименного свойства глобального объекта window:
log(listEl === window.list) // trueКак мы знаем, при обращении к свойствам и методам window, слово window можно опускать, например, вместо window.localStorage можно писать просто localStorage. Следовательно, для доступа к элементу с id достаточно обратиться к соответствующему свойству window:
log(list) // ul#list.listОбратите внимание, что это не работает в React и других фреймворках, абстрагирующих работу с DOM, например, с помощью Virtual DOM. Более того, там иногда невозможно обратиться к нативным свойствам и методам window без window.
Миксин ParentNode
Данный миксин предназначен для обработки родительских элементов (предков), т.е. элементов, содержащих одного и более потомка (дочерних элементов).
children— потомки элемента
const { children } = list // list.children
log(children)
/*
HTMLCollection(3)
0: li#item1.item
1: li#item2.item
2: li#item3.item
length: 3
*/Такая структура называется коллекцией HTML и представляет собой массивоподобный объект (псевдомассив). Существует еще одна похожая структура — список узлов (NodeList).
Массивоподобные объекты имеют свойство length с количеством потомков, метод forEach() (NodeList), позволяющий перебирать узлы (делать по ним итерацию). Такие объекты позволяют получать элементы по индексу, по названию (HTMLCollection) и т.д. Однако, у них отсутствуют методы настоящих массивов, такие как map(), filter(), reduce() и др., что делает работу с ними не очень удобной. Поэтому массивоподобные объекты рекомендуется преобразовывать в массивы с помощью метода Array.from() или spread-оператора:
const children = Array.from(list.children)
// или
const children = [...list.children]
log(children) // [li#item1.item, li#item2.item, li#item3.item] - обычный массивfirstElementChild— первый потомок — элементlastElementChild— последний потомок — элемент
log(list.firstElementChild) // li#item1.item
log(list.lastElementChild) // li#item2.itemДля дальнейших манипуляций нам потребуется периодически создавать новые элементы, поэтому создадим еще одну утилиту:
const createEl = (id, text, tag = 'li', _class = 'item') => {
const el = document.createElement(tag)
el.id = id
el.className = _class
el.textContent = text
return el
}Наша утилита принимает 4 аргумента: идентификатор, текст, название тега и CSS-класс. 2 аргумента (тег и класс) имеют значения по умолчанию. Функция возвращает готовый к работе элемент. Впоследствии, мы реализуем более универсальный вариант данной утилиты.
prepend(newNode)— добавляет элемент в начало спискаappend(newNode)— добавляет элемент в конец списка
// создаем новый элемент
const newItem = createEl('item0', 0)
// и добавляем его в начало списка
list.prepend(newItem)
// создаем еще один элемент
const newItem2 = createEl('item4', 4)
// и добавляем его в конец списка
list.append(newItem2)
log(children)
/*
HTMLCollection(5)
0: li#item0.item
1: li#item1.item
2: li#item2.item
3: li#item3.item
4: li#item4.item
*/Одной из интересных особенностей HTMLCollection является то, что она является “живой”, т.е. элементы, возвращаемые по ссылке, и их количество обновляются автоматически. Однако, эту особенность нельзя использовать, например, для автоматического добавления обработчиков событий.
replaceChildren(nodes)— заменяет потомков новыми элементами
const newItems = [newItem, newItem2]
// заменяем потомков новыми элементами
list.replaceChildren(...newItems) // list.replaceChildren(newItem, newItem2)
log(children) // 2Наиболее универсальными способами получения ссылок на элементы являются методы querySelector(selector) и querySelectorAll(selector). Причем, в отличие от getElementById(), они могут вызываться на любом родительском элементе, а не только на document. В качестве аргумента названным методам передается любой валидный CSS-селектор (id, class, tag и т.д.):
// получаем элемент `li` с `id === item0`
const itemWithId0 = list.querySelector('#item0')
log(itemWithId0) // li#item0.item
// получаем все элементы `li` с `class === item`
const allItems = list.querySelectorAll('.item')
log(allItems) // массивоподобный объект
/*
NodeList(2)
0: li#item0.item
1: li#item4.item
length: 2
*/Создадим универсальную утилиту для получения элементов:
const getEl = (selector, parent = document, single = true) => single ? parent.querySelector(selector) : [...parent.querySelectorAll(selector)]Наша утилита принимает 3 аргумента: CSS-селектор, родительский элемент и индикатор количества элементов (один или все). 2 аргумента (предок и индикатор) имеют значения по умолчанию. Функция возвращает либо один, либо все элементы (в виде обычного массива), совпадающие с селектором, в зависимости от значения индикатора:
const itemWithId0 = getEl('#item0', list)
log(itemWithId0) // li#item0.item
const allItems = getEl('.item', list, false)
log(allItems) // [li#item0.item, li#item4.item]Миксин NonDocumentTypeChildNode
Данный миксин предназначен для обработки дочерних узлов, которые не являются документом, т.е. всех узлов, кроме document.
previousElementSibling— предыдущий элементnextElementSibling— следующий элемент
log(itemWithId0.previousElementSibling) // null
log(itemWithId0.nextElementSibling) // #item4Миксин ChildNode
Данный миксин предназначен для обработки дочерних элементов, т.е. элементов, являющихся потомками других элементов.
before(newNode)— вставляет новый элемент перед текущимafter(newNode)— вставляет новый элемент после текущего
// получаем `li` с `id === item4`
const itemWithId4 = getEl('#item4', list)
// создаем новый элемент
const newItem3 = createEl('item3', 3)
// и вставляем его перед `itemWithId4`
itemWithId4.before(newItem3)
// создаем еще один элемент
const newItem4 = createEl('item2', 2)
// и вставляем его после `itemWithId0`
itemWithId0.after(newItem4)replaceWith(newNode)— заменяет текущий элемент новым
// создаем новый элемент
const newItem5 = createEl('item1', 1)
// и заменяем им `itemWithId0`
itemWithId0.replaceWith(newItem5)remove()— удаляет текущий элемент
itemWithId4.remove()Интерфейс Node
Данный интерфейс предназначен для обработки узлов.
nodeType— тип узла
log(list.nodeType) // 1
// другие варианты
/*
1 -> ELEMENT_NODE (элемент)
3 -> TEXT_NODE (текст)
8 -> COMMENT_NODE (комментарий)
9 -> DOCUMENT_NODE (document)
10 -> DOCUMENT_TYPE_NODE (doctype)
11 -> DOCUMENT_FRAGMENT_NODE (фрагмент) и т.д.
*/nodeName— название узла
log(list.nodeName) // UL
// другие варианты
/*
- квалифицированное название HTML-элемента прописными (заглавными) буквами
- квалифицированное название атрибута
- #text
- #comment
- #document
- название doctype
- #document-fragment
*/baseURI— основной путь
log(list.baseURI) // .../dom/index.htmlparentNode— родительский узелparentElement— родительский элемент
const itemWithId1 = getEl('#item1', list)
log(itemWithId1.parentNode) // #list
log(itemWithId1.parentElement) // #listhasChildNodes()— возвращаетtrue, если элемент имеет хотя бы одного потомкаchildNodes— дочерние узлы
log(list.hasChildNodes()) // true
log(list.childNodes)
/*
NodeList(3)
0: li#item1.item
1: li#item2.item
2: li#item3.item
*/firstChild— первый потомок — узелlastChild— последний потомок — узел
log(list.firstChild) // #item1
log(list.lastChild) // #item3nextSibling— следующий узелpreviousSibling— предыдущий узел
log(itemWithId1.nextSibling) // #item2
log(itemWithId1.previousSibling) // nulltextContent— геттер/сеттер для извлечения/записи текста
// получаем текст
log(itemWithId1.textContent) // 1
// меняем текст
itemWithId1.textContent = 'item1'
log(itemWithId1.textContent) // item1
// получаем текстовое содержимое всех потомков
log(list.textContent) // item123Для извлечения/записи текста существует еще один (устаревший) геттер/сеттер — innerText.
cloneNode(deep)— копирует узел. Принимает логическое значение, определяющее характер копирования: поверхностное — копируется только сам узел, глубокое — копируется сам узел и все его потомки
// создаем новый список посредством копирования существующего
const newList = list.cloneNode(false)
// удаляем у него `id` во избежание коллизий
newList.removeAttribute('id')
// меняем его текстовое содержимое
newList.textContent = 'new list'
// и вставляем его после существующего списка
list.after(newList)
// создаем еще один список
const newList2 = newList.cloneNode(true)
newList.after(newList2)isEqualNode(node)— сравнивает узлыisSameNode(node)— определяет идентичность узлов
log(newList.isEqualNode(newList2)) // true
log(newList.isSameNode(newList2)) // falsecontains(node)— возвращаетtrue, если элемент содержит указанный узел
log(list.contains(itemWithId1)) // trueinsertBefore(newNode, existingNode)— добавляет новый узел (newNode) перед существующим (existingNode)
// создаем новый элемент
const itemWithIdA = createEl('#item_a', 'a')
// и вставляем его перед `itemWithId1`
list.insertBefore(itemWithIdA, itemWithId1)appendChild(node)— добавляет узел в конец списка
// создаем новый элемент
const itemWithIdC = createEl('#item_c', 'c')
// и добавляем его в конец списка
list.appendChild(itemWithIdC)replaceChild(newNode, existingNode)— заменяет существующий узел (existingNode) новым (newNode):
// создаем новый элемент
const itemWithIdB = createEl('item_b', 'b')
// и заменяем им `itemWithId1`
list.replaceChild(itemWithIdB, itemWithId1)removeChild(node)— удаляет указанный дочерний узел
// получаем `li` с `id === item2`
const itemWithId2 = getEl('#item2', list)
// и удаляем его
list.removeChild(itemWithId2)Интерфейс Document
Данный интерфейс предназначен для обработки объекта Document.
URLиdocumentURI— адрес документа
log(document.URL) // .../dom/index.html
log(document.documentURI) // ^documentElement:
log(document.documentElement) // htmlgetElementsByTagName(tag)— возвращает все элементы с указанным тегом
const itemsByTagName = document.getElementsByTagName('li')
log(itemsByTagName)
/*
HTMLCollection(4)
0: li##item_a.item
1: li#item_b.item
2: li#item3.item
3: li##item_c.item
*/getElementsByClassName(className)— возвращает все элементы с указанным CSS-классом
const itemsByClassName = list.getElementsByClassName('item')
log(itemsByClassName) // ^createDocumentFragment()— возвращает фрагмент документа:
// создаем фрагмент
const fragment = document.createDocumentFragment()
// создаем новый элемент
const itemWithIdD = createEl('item_d', 'd')
// добавляем элемент во фрагмент
fragment.append(itemWithIdD)
// добавляем фрагмент в список
list.append(fragment)Фрагменты позволяют избежать создания лишних элементов. Они часто используются при работе с разметкой, скрытой от пользователя с помощью тега template (метод cloneNode() возвращает DocumentFragment).
-
createTextNode(data)— создает текст -
createComment(data)— создает комментарий -
importNode(existingNode, deep)— создает новый узел на основе существующего
// создаем новый список на основе существующего
const newList3 = document.importNode(list, true)
// вставляем его перед существующим списком
list.before(newList3)
// и удаляем во избежание коллизий
newList3.remove()createAttribute(attr)— создает указанный атрибут
Интерфейсы NodeIterator и TreeWalker
Интерфейсы NodeIterator и TreeWalker предназначены для обхода (traverse) деревьев узлов. Я не сталкивался с примерами их практического использования, поэтому ограничусь парочкой примеров:
// createNodeIterator(root, referenceNode, pointerBeforeReferenceNode, whatToShow, filter)
const iterator = document.createNodeIterator(list)
log(iterator)
log(iterator.nextNode()) // #list
log(iterator.nextNode()) // #item_a
log(iterator.previousNode()) // #item_a
log(iterator.previousNode()) // #list
log(iterator.previousNode()) // null
// createTreeWalker(root, whatToShow, filter)
// применяем фильтры - https://dom.spec.whatwg.org/#interface-nodefilter
const walker = document.createTreeWalker(list, '0x1', { acceptNode: () => 1 })
log(walker)
log(walker.parentNode()) // null
log(walker.firstChild()) // #item_a
log(walker.lastChild()) // null
log(walker.previousSibling()) // null
log(walker.nextSibling()) // #item_b
log(walker.nextNode()) // #item3
log(walker.previousNode()) // #item_bИнтерфейс Element
Данный интерфейс предназначен для обработки элементов.
localNameиtagName— название тега
log(list.localName) // ul
log(list.tagName) // ULid— геттер/сеттер для идентификатораclassName— геттер/сеттер для CSS-класса
log(list.id) // list
list.id = 'LIST'
log(LIST.className) // listclassList— все CSS-классы элемента (объектDOMTokenList)
const button = createEl('button', 'Click me', 'my_button', 'btn btn-primary')
log(button.classList)
/*
DOMTokenList(2)
0: "btn"
1: "btn-primary"
length: 2
value: "btn btn-primary"
*/Работа с classList
classList.add(newClass)— добавляет новый класс к существующимclassList.remove(existingClass)— удаляет указанный классclassList.toggle(className, force?)— удаляет существующий класс или добавляет новый. Если опциональный аргументforceимеет значениеtrue, данный метод только добавляет новый класс при отсутствии, но не удаляет существующий класс (в этом случаеtoggle() === add()). Еслиforceимеет значениеfalse, данный метод только удаляет существующий класс при наличии, но не добавляет отсутствующий класс (в этом случаеtoggle() === remove())classList.replace(existingClass, newClass)— заменяет существующий класс (existingClass) на новый (newClass)classList.contains(className)— возвращаетtrue, если указанный класс обнаружен в списке классов элемента (данный метод идентиченclassName.includes(className))
// добавляем к кнопке новый класс
button.classList.add('btn-lg')
// удаляем существующий класс
button.classList.remove('btn-primary')
// у кнопки есть класс `btn-lg`, поэтому он удаляется
button.classList.toggle('btn-lg')
// заменяем существующий класс на новый
button.classList.replace('btn', 'btn-success')
log(button.className) // btn-success
log(button.classList.contains('btn')) // false
log(button.className.includes('btn-success')) // trueРабота с атрибутами
hasAttributes()— возвращаетtrue, если у элемента имеются какие-либо атрибутыgetAttributesNames()— возвращает названия атрибутов элементаgetAttribute(attrName)— возвращает значение указанного атрибутаsetAttribute(name, value)— добавляет указанные атрибут и его значение к элементуremoveAttribute(attrName)— удаляет указанный атрибутhasAttribute(attrName)— возвращаетtrueпри наличии у элемента указанного атрибутаtoggleAttribute(name, force)— добавляет новый атрибут при отсутствии или удаляет существующий атрибут. Аргументforceаналогичен одноименному атрибутуclassList.toggle()
log(button.hasAttributes()) // true
log(button.getAttributeNames()) // ['id', 'class']
log(button.getAttribute('id')) // button
button.setAttribute('type', 'button')
button.removeAttribute('class')
log(button.hasAttribute('class')) // falseВ использовании перечисленных методов для работы с атрибутами нет особой необходимости, поскольку многие атрибуты являются геттерами/сеттерами, т.е. позволяют извлекать/записывать значения напрямую. Единственным исключением является метод removeAttribute(), поскольку существуют атрибуты без значений: например, если кнопка имеет атрибут disabled, установка значения данного атрибута в false не приведет к снятию блокировки — для этого нужно полностью удалить атрибут disabled с помощью removeAttribute().
Отдельного упоминания заслуживает атрибут data-*, где символ * означает любую строку. Он предназначен для определения пользовательских атрибутов. Например, в нашей начальной разметке для уникальной идентификации элементов используется атрибут id. Однако, это приводит к загрязнению глобального пространства имен, что чревато коллизиями между нашими переменными и, например, переменными используемой нами библиотеки — когда какой-либо объект библиотеки пытается записаться в свойство window, которое уже занято нашим id.
Вместо этого, мы могли бы использовать атрибут data-id и получать ссылки на элементы с помощью getEl('[data-id="id"]').
Название data-атрибута после символа - становится одноименным свойством объекта dataset. Например, значение атрибута data-id можно получить через свойство dataset.id.
closest(selectors)— возвращает первый родительский элемент, совпавший с селекторами
LIST.append(button)
log(button.closest('#LIST', 'document.body')) // #LISTmatches(selectors)— возвращаетtrue, если элемент совпадает хотя бы с одним селектором
log(button.matches('.btn', '[type="button"]'))
// у кнопки нет класса `btn`, но есть атрибут `type` со значением `button`,
// поэтому возвращается `true`-
insertAdjacentElement(where, newElement)— универсальный метод для вставки новых элементов перед/в начало/в конец/после текущего элемента. Аргументwhereопределяет место вставки. Возможные значения:beforebegin— перед открывающим тегомafterbegin— после открывающего тегаbeforeend— перед закрывающим тегомafterend— после закрывающего тега
-
insertAdjacentText(where, data)— универсальный метод для вставки текста -
Text— конструктор для создания текста -
Comment— конструктор для создания комментария
const text = new Text('JavaScript')
log(text) // "JavaScript"
const part = text.splitText(4)
log(part) // "Script"
log(part.wholeText()) // Script
const comment = new Comment('TODO')
log(comment) // <!--TODO-->Объект Document
location— объект с информацией о текущей локации документа
log(document.location)Свойства объекта location:
hash— хэш-часть URL (символ#и все, что следует за ним), например,#tophost— название хоста и порт, например,localhost:3000hostname— название хоста, например,localhosthref— полный путьorigin—protocol+hostpathname— путь без протоколаport— порт, например,3000protocol— протокол, например,httpssearch— строка запроса (символ?и все, что следует за ним), например,?name=John&age=30
Методы location:
-
reload()— перезагружает текущую локацию -
replace()— заменяет текущую локацию на новую -
title— заголовок документа
log(document.title) // DOM-
head— метаданные документа -
body— тело документа -
images— псевдомассив (HTMLCollection), содержащий все изображения, имеющиеся в документе
const image = document.createElement('img')
image.className = 'my_image'
image.src = 'https://miro.medium.com/max/875/1*ZIH_wjqDfZn6NRKsDi9mvA.png'
image.alt = "V8's compiler pipeline"
image.width = 480
document.body.append(image)
log(document.images[0]) // .my_imagelinks— псевдомассив, содержащий все ссылки, имеющиеся в документе
const link = document.createElement('a')
link.className = 'my_link'
link.href = 'https://github.com/azat-io/you-dont-know-js-ru'
link.target = '_blank'
link.rel = 'noopener noreferrer'
link.textContent = 'Вы не знаете JS'
document.body.append(link)
log(document.links[0]) // .my_linkforms— псевдомассив, содержащий все формы, имеющиеся в документе
const form = document.createElement('form')
form.className = 'my_form'
document.body.append(form)
log(document.forms[0]) // .my_formСледующие методы и свойство считаются устаревшими:
open()— открывает документ для записи. При этом документ полностью очищаетсяclose()— закрывает документ для записиwrite()— записывает данные (текст, разметку) в документwriteln()— записывает данные в документ с переносом на новую строкуdesignMode— управление режимом редактирования документа. Возможные значения:onиoff. Наберитеdocument.designMode = 'on'в консолиDevToolsи нажмитеEnter. Вуаля, страница стала редактируемой: можно удалять/добавлять текст, перетаскивать изображения и т.д.execCommand()— выполняет переданные команды. Со списоком доступных команд можно ознакомиться здесь. Раньше этот метод активно использовался для записи/извлечения данных из буфера обмена (командыcopyиpaste). Сейчас для этого используются методыnavigator.clipboard.writeText(),navigator.clipboard.readText()и др.
Миксин InnerHTML
Геттер/сеттер innerHTML позволяет извлекать/записывать разметку в элемент. Для подготовки разметки удобно пользоваться шаблонными литералами:
const itemsTemplate = `
<li data-id="item1" class="item">1</li>
<li data-id="item2" class="item">2</li>
<li data-id="item3" class="item">3</li>
`
LIST.innerHTML = itemsTemplate
log(LIST.innerHTML)
/*
<li data-id="item1" class="item">1</li>
<li data-id="item2" class="item">2</li>
<li data-id="item3" class="item">3</li>
*/Расширения интерфейса Element
outerHTML— геттер/сеттер для извлечения/записи внешней разметки элемента: то, что возвращаетinnerHTML+ разметка самого элемента
log(LIST.outerHTML)
/*
<ul id="LIST" class="list">
<li data-id="item1" class="item">1</li>
<li data-id="item2" class="item">2</li>
<li data-id="item3" class="item">3</li>
</ul>
*/insertAdjacentHTML(where, string)— универсальный метод для вставки разметки в виде строки. Аргументwhereаналогичен одноименному аргументу методаinsertAdjacentElement()
Метод insertAdjacentHTML() в сочетании с шаблонными литералами и их продвинутой версией — тегированными шаблонными литералами (tagged template literals) предоставляет много интересных возможностей по манипулированию разметкой документа. По сути, данный метод представляет собой движок шаблонов (template engine) на стороне клиента, похожий на Pug, Handlebars и др. серверные движки. С его помощью (при участии History API) можно, например, реализовать полноценное одностраничное приложение (Single Page Application или сокращенно SPA). Разумеется, для этого придется написать чуть больше кода, чем при использовании какого-либо фронтенд-фреймворка.
Вот несколько полезных ссылок, с которых можно начать изучение этих замечательных инструментов:
- Element.insertAdjacentHTML() — MDN
- Изменение документа — JSR
- Шаблонные строки — MDN
- Template Literals — ECMAScript 2022
Иногда требуется создать элемент на основе шаблонной строки. Как это можно сделать? Вот соответствующая утилита:
const createElFromStr = (str) => {
// создаем временный элемент
const el = document.createElement('div')
// записываем в него переданную строку - разметку
el.innerHTML = str
// извлекаем наш элемент
// если мы используем здесь метод `firstChild()`, может вернуться `#text`
// одна из проблем шаблонных строк заключается в большом количестве лишних пробелов
const child = el.fisrtElementChild
// удаляем временный элемент
el.remove()
// и возвращаем наш элемент
return child
}
// шаблон списка
const listTemplate = `
<ul id="list">
<li data-id="item1" class="item">1</li>
<li data-id="item2" class="item">2</li>
<li data-id="item3" class="item">3</li>
</ul>
`
// создаем список на основе шаблона
const listEl = createElFromStr(listTemplate)
// и вставляем его в тело документа
document.body.append(listEl)Существует более экзотический способ создания элемента на основе шаблонной строки. Он предполагает использование конструктора DOMParser():
const createElFromStr = (str) => {
// создаем новый парсер
const parser = new DOMParser()
// парсер возвращает новый документ
const {
body: { children }
} = parser.parseFromString(str, 'text/html')
// нас интересует первый дочерний элемент тела нового документа
return children[0]
}
const listTemplate = `
<ul id="list">
<li data-id="item1" class="item">1</li>
<li data-id="item2" class="item">2</li>
<li data-id="item3" class="item">3</li>
</ul>
`
const listEl = createElFromStr(listTemplate)
document.body.append(listEl)
Еще более экзотический, но при этом самый короткий способ предполагает использование расширения для объекта Range — метода createContextualFragment():
const createElFromStr = (str) => {
// создаем новый диапазон
const range = new Range()
// создаем фрагмент
const fragment = range.createContextualFragment(str)
// и возвращаем его
return fragment
}
// или в одну строку
const createFragment = (str) => new Range().createContextualFragment(str)
const listTemplate = `
<ul id="list">
<li data-id="item1" class="item">1</li>
<li data-id="item2" class="item">2</li>
<li data-id="item3" class="item">3</li>
</ul>
`
document.body.append(createFragment(listTemplate))В завершение, как и обещал, универсальная утилита для создания элементов:
// функция принимает название тега и объект с настройками
const createEl = (tag, opts) => {
const el = document.createElement(tag)
// перебираем ключи объекта и записывает соответствующие свойства в элемент
for (const key in opts) {
el[key] = opts[key]
}
// возвращаем готовый элемент
return el
}
const button = createEl('button', {
// настройками могут быть атрибуты
id: 'my_button',
className: 'btn btn-primary',
textContent: 'Click me',
title: 'My button',
autofocus: true,
// стили
style: 'color: red; cursor: pointer;',
// обработчики и т.д.
onmouseenter: function () {
this.style.color = 'green'
},
onmouseout: function () {
this.style.color = 'blue'
},
onclick: () => alert('Привет!')
})
document.body.append(button)Заключение
Современный JS предоставляет богатый арсенал методов для работы с DOM. Данных методов вполне достаточно для решения всего спектра задач, возникающих при разработке веб-приложений. Хорошее знание этих методов, а также умение их правильно применять гарантируют не только высокое качество (чистоту) кода, но также избавляют от необходимости использовать DOM-библиотеки (такие как jQuery), что в совокупности обусловливает производительность приложения, его поддерживаемость и масштабируемость.
Разумеется, шпаргалка — это всего лишь карманный справочник, памятка для быстрого восстановления забытого материала, предполагающая наличие определенного багажа знаний.
VDS от Маклауд быстрые и безопасные.
Зарегистрируйтесь по ссылке выше или кликнув на баннер и получите 10% скидку на первый месяц аренды сервера любой конфигурации!

В этой главе рассказывается, как найти и получить доступ к HTML элементам на HTML странице.
Поиск HTML элементов
Часто в JavaScript необходимо проводить определенные манипуляции с HTML элементами.
Чтобы это сделать, сначала нужно найти требуемый элемент. Найти HTML элемент можно несколькими способами:
- по идентификатору id
- по имени тега
- по имени класса
- по селекторам CSS
- по наборам объектов HTML
Поиск HTML элемента по идентификатору
Самый простой способ найти HTML элемент в DOM — это использовать его идентификатор id.
В следующем примере мы ищем элемент с id=”intro”:
var myElement = document.getElementById("intro");
Если элемент будет найден, то он будет возвращен в виде объекта (в переменную myElement).
Если элемент не будет найден, то в переменная myElement будет содержать значение null.
Поиск HTML элемента по имени тега
В следующем примере мы ищем все элементы <p>:
var x = document.getElementsByTagName("p");
В следующем примере сначала происходит поиск элемента с id=”main”, а затем всех элементов <p> внутри “main”:
var x = document.getElementById("main");
var y = x.getElementsByTagName("p");
Поиск HTML элемента по имени класса
Если нужно найти все HTML элементы с одним и тем же именем класса, то используют метод getElementsByClassName().
В следующем примере возвращается список всех элементов с атрибутом class=”intro”:
var x = document.getElementsByClassName("intro");
Внимание! Поиск элементов по имени класса не работает в Internet Explorer 8 и более ранних версиях.
Поиск HTML элемента по CSS селекторам
Если нужно найти все HTML элементы, подходящие по заданному CSS селектору (id, имена классов, типы, атрибуты, значения атрибутов и т.п.), используется метод querySelectorAll().
В следующем примере возвращается список всех элементов <p> с атрибутом class=”intro”:
var x = document.querySelectorAll("p.intro");
Внимание! Метод querySelectorAll() не работает в Internet Explorer 8 и более ранних версиях.
Поиск HTML элемента по наборам HTML объектов
В следующем примере производится поиск элемента формы с атрибутом id=”frm1″ в наборе объектов forms, и отображаются все значения элементов:
var x = document.forms["frm1"];
var text = "";
var i;
for (i = 0; i < x.length; i++) {
text += x.elements[i].value + "<br>";
}
document.getElementById("demo").innerHTML = text;
Также доступны следующие HTML объекты (и наборы объектов):
- document.anchors
- document.body
- document.documentElement
- document.embeds
- document.forms
- document.head
- document.images
- document.links
- document.scripts
- document.title
