Из этой статьи Вы узнаете, как найти xml элемент по его атрибуту с помощью простого LINQ запроса. И так для начала создадим Windows Forms приложение и поместим на форму: два элемента управления textBox (txtAtrName и txtAtrValue), кнопку и один listBox. Затем добавим в наш проект xml файл, который содержит следующую структуру:
<root> <user id="1" age="20" name="Vasya"/> <user id="2" age="25" name="Ola"/> <user id="3" age="30" name="Petya"/> <user id="4" age="25" name="Vasya"/> </root>
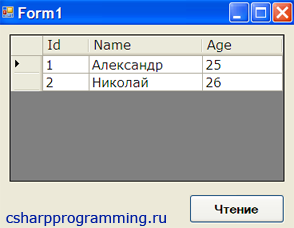
Задача: найти все xml элементы, которые содержат атрибут «age» со значением 25. Надеюсь, Вы уже знаете, что такое XML и как с ним работать, поэтому сразу же переходим к решению задачи.
исходный код
using System.Xml.Linq; //добавить
try
{
XDocument xDoc = XDocument.Load("My.xml");
var elements = from elmts in xDoc.Descendants()
where elmts.Attribute(txtAtrName.Text).Value == txtAtrValue.Text
select elmts;
foreach (var element in elements)
{
listBox1.Items.Add(element);
}
}
catch (Exception ex)
{
MessageBox.Show(ex.Message);
}
Результат

Всё работает, но если Вы сейчас попытаетесь найти XML элемент, у которого атрибут «age» не существует, то в результате Вы получите исключение. Например, не много изменим XML файл и удалим у четвертого элемента атрибут «age».
<root> ... <user id="4" name="Vasya"/> </root>
Выполним выше указанный код, в результате получаем исключение NullReferenceException.
Чтобы этого избежать нужно, добавить в Linq запрос проверку на null. То есть сначала мы должны убедиться, что XML атрибут существует, а только потом получить его значение.
var elements = from elmts in xDoc.Descendants() where elmts.Attribute(txtAtrName.Text) != null && elmts.Attribute(txtAtrName.Text).Value == txtAtrValue.Text select elmts;
Теперь всё в порядке.
Читайте также:
- Основные компоненты .NET Framework (CLR и Framework Class Library)
- Как разархивировать rar файл?
- WebBrowser работа с html атрибутами
In a given XML file, I’m trying to search for the presence of a string using XPath in Java. However, even though the string is there, my output is always coming up as a No. Hoping someone here can point out what I may be doing wrong?
XML File:
<article>
<body>
<section>
<h1>intro1</h1>
<region>introd1</region>
<region>introd2</region>
</section>
<section>
<h1 class="pass">1 task objectives</h1>
<region>object1</region>
<region>object2</region>
</section>
<section>
<h1 class="pass">1 task objectives</h1>
<region>object1</region>
<region>This is the Perfect Word I am looking for</region>
</section>
</body>
</article>
Within Java, I’m trying to check for the presence of the word "perfect" like this:
expr = xpath.compile("//article//body//section//region[contains(.,'perfect')]");
object result = expr.evaluate(doc,XPathConstants.NODESET);
NodeList nodes = (NodeList)result;
if (nodes.getLength() > 0) {
System.out.println("Found");
// do other stuff here
} else {
System.out.println("Not found");
}
When I run this, the output is always "Not Found". Any idea what I am doing wrong?
![]()
asked Jun 17, 2013 at 2:46
I tested this…
expr =xpath.compile("/article/body/section/region[contains(translate(text(), 'ABCDEFGHIJKLMNOPQRSTUVWXYZ', 'abcdefghijklmnopqrstuvwxyz'), 'perfect')]");
Against
<article>
<body>
<section>
<h1>intro1</h1>
<region>perfect</region>
<region>Perfect</region>
</section>
<section>
<h1 class="pass">1 task objectives</h1>
<region>pErFeCt</region>
<region>Not Perfect</region>
</section>
<section>
<h1 class="pass">1 task objectives</h1>
<region>object1</region>
<region>This is the Perfect Word I am looking for</region>
</section>
</body>
</article>
Using…
import java.io.File;
import java.util.logging.Level;
import java.util.logging.Logger;
import javax.xml.parsers.DocumentBuilderFactory;
import javax.xml.xpath.XPath;
import javax.xml.xpath.XPathConstants;
import javax.xml.xpath.XPathExpression;
import javax.xml.xpath.XPathFactory;
import org.w3c.dom.Document;
import org.w3c.dom.Node;
import org.w3c.dom.NodeList;
public class TestXML05 {
public static void main(String[] args) {
try {
DocumentBuilderFactory factory = DocumentBuilderFactory.newInstance();
Document doc = factory.newDocumentBuilder().parse(new File("Sample.xml"));
XPathFactory xFactory = XPathFactory.newInstance();
XPath xPath = xFactory.newXPath();
XPathExpression exp = xPath.compile("/article/body/section/region[contains(translate(text(), 'ABCDEFGHIJKLMNOPQRSTUVWXYZ', 'abcdefghijklmnopqrstuvwxyz'), 'perfect')]");
NodeList nl = (NodeList)exp.evaluate(doc.getFirstChild(), XPathConstants.NODESET);
for (int index = 0; index < nl.getLength(); index++) {
Node node = nl.item(index);
System.out.println(node.getTextContent());
}
} catch (Exception ex) {
Logger.getLogger(TestXML05.class.getName()).log(Level.SEVERE, null, ex);
}
}
}
Which outputted…
perfect
Perfect
pErFeCt
Not Perfect
This is the Perfect Word I am looking for
answered Jun 17, 2013 at 3:05
![]()
MadProgrammerMadProgrammer
342k22 gold badges227 silver badges363 bronze badges
3
XML/XPath are case-sensitive, your XPath should be
//article//body//section//region[contains(., 'Perfect')]
To make case-insensitive, use this
//article//body//section//region[
contains(translate(., 'ABCDEFGHIJKLMNOPQRSTUVWXYZ', 'abcdefghijklmnopqrstuvwxyz'),
'perfect')
]
answered Jun 17, 2013 at 2:50
![]()
Kirill PolishchukKirill Polishchuk
54.5k10 gold badges121 silver badges125 bronze badges
1
Язык разметки XML с самого первого стандарта окружает пользователей компьютеров. Таблицы в Excel, выгрузки из интернет-магазинов, RSS-ленты с новостями — все это основано на XML. Хоть визуальное отображение отличается на устройствах и в программах, но в основе всегда лежит единый формат.
Внутри XML-файла может находиться огромное количество информации, поэтому и встает вопрос о перемещении и выборке внутри документа. Как это сделать быстро? Какие средства применять, чтобы в интернет-магазине найти нужный товар из десятков тысяч других? Для навигации и поиска внутри XML используется язык запросов XPath.
В этой статье разберем:
- для кого может быть полезен XPath
- базовые конструкции языка для поиска информации в XML
- чем XPath отличается от CSS-селекторов при поиске в HTML
- Синтаксис XPath
- Отличия от CSS-селекторов
- Кому нужен Xpath
- Заключение
Синтаксис XPath
Для начала создадим базовый пример XML, с которым и будем работать весь урок. Например, список курсов по верстке на Хекслете в XML будет выглядеть так:
<?xml version="1.0" encoding="UTF-8"?>
<courses>
<title>Курсы HTML и CSS (верстка)</title>
<description>На курсах по верстке вы познакомитесь с основами HTML и CSS, научитесь верстать адаптивные страницы, работать с препроцессорами. Освоите современные технологии и инструменты, включая Flex, Sass, Bootstrap.</description>
<course>
<name>Основы современной верстки</name>
<tags>HTML5, CSS, DevTools, верстка</tags>
<duration value="9">9 часов</duration>
<url lang="ru">https://ru.hexlet.io/courses/layout-designer-basics</url>
<url lang="en">https://hexlet.io/courses/layout-designer-basics</url>
</course>
<course>
<name>Основы верстки контента</name>
<tags>CSS3, HTML5, Селекторы, Доступность, CSS Columns, CSS Units, Верстка</tags>
<duration value="18">18 часов</duration>
<url lang="ru">https://ru.hexlet.io/courses/css-content</url>
<url lang="en">https://hexlet.io/courses/css-content</url>
</course>
<course>
<name>Bootstrap 5: Основы верстки</name>
<tags>Bootstrap 5, Адаптивность, HTML, CSS3</tags>
<duration value="10">10 часов</duration>
<url lang="ru">https://ru.hexlet.io/courses/bootstrap_basic</url>
<url lang="en">https://hexlet.io/courses/bootstrap_basic</url>
</course>
</courses>
Это учебный пример, но для отработки навыков XPath подойдет и любой другой XML. Принципы XPath сохранятся при любой структуре файла, потому что по стандарту XML можно использовать элементы с произвольными тегами.
Для тестирования результата подойдут такие онлайн-сервисы, как:
- Code Beautify
- XPather
Абсолютные пути
Самый простой запрос состоит из обращения к корневому элементу. Для этого достаточно выполнить запрос /courses. Нам вернется XML в почти таком же виде, что и в примере выше. Обратите внимание на строку <?xml version="1.0" encoding="UTF-8"?>. Она отличается, потому что элемент не внутри <courses>:
<courses>
<title>Курсы HTML и CSS (верстка)</title>
<description>На курсах по верстке вы познакомитесь с основами HTML и CSS, научитесь верстать адаптивные страницы, работать с препроцессорами. Освоите современные технологии и инструменты, включая Flex, Sass, Bootstrap.</description>
<course>
<name>Основы современной верстки</name>
<tags>HTML5, CSS, DevTools, верстка</tags>
<duration value="9">9 часов</duration>
<url lang="ru">https://ru.hexlet.io/courses/layout-designer-basics</url>
<url lang="en">https://hexlet.io/courses/layout-designer-basics</url>
</course>
<course>
<name>Основы верстки контента</name>
<tags>CSS3, HTML5, Селекторы, Доступность, CSS Columns, CSS Units, Верстка</tags>
<duration value="18">18 часов</duration>
<url lang="ru">https://ru.hexlet.io/courses/css-content</url>
<url lang="en">https://hexlet.io/courses/css-content</url>
</course>
<course>
<name>Bootstrap 5: Основы верстки</name>
<tags>Bootstrap 5, Адаптивность, HTML, CSS3</tags>
<duration value="10">10 часов</duration>
<url lang="ru">https://ru.hexlet.io/courses/bootstrap_basic</url>
<url lang="en">https://hexlet.io/courses/bootstrap_basic</url>
</course>
</courses>
В качестве результата XPath возвращает узлы XML-документа.
Продолжим цепочку и обратимся к описанию из элемента <description>. Для этого добавим в запрос путь к description: /courses/description. Результатом выполнения станет:
<description>На курсах по верстке вы познакомитесь с основами HTML и CSS, научитесь верстать адаптивные страницы, работать с препроцессорами. Освоите современные технологии и инструменты, включая Flex, Sass, Bootstrap.</description>
Путь, который строится от корневого элемента, называется абсолютным. Используем схему из прошлого запроса и обратимся к любому элементу внутри XML.
Попробуем обратиться к имени курса. В этом случае вернется поле <name> из всех курсов. Запрос /courses/course/name вернет:
<name>Основы современной верстки</name>
<name>Основы верстки контента</name>
<name>Bootstrap 5: Основы верстки</name>
Вот список некоторых базовых запросов и их результат:
| Запрос | Результат |
|---|---|
/courses/course |
Все данные из всех элементов <course></course> |
/courses/course/name |
<name>Основы современной верстки</name><name>Основы верстки контента</name><name>Bootstrap 5: Основы верстки</name> |
/courses/course/duration |
<duration value="9">9 часов</duration><duration value="18">18 часов</duration><duration value="10">10 часов</duration> |
Относительные пути
Прошлые запросы строились с помощью абсолютных путей — то есть мы указывали полный путь до информации. Бывают ситуации, когда полный путь не подходит: например, мы хотим обраться к какому-то уникальному полю или не знаем полный путь. В этом случае можно использовать относительный путь — он произведет поиск по всему XML и вернет узлы, подходящие под запрос.
Чтобы записать относительный путь, нужно использовать конструкцию //. После нее можно написать любое поле и получить результат. Например, //name вернет поля <name> из всего XML:
<name>Основы современной верстки</name>
<name>Основы верстки контента</name>
<name>Bootstrap 5: Основы верстки</name>
Проблема такого подхода — уникальность полей. В документах одни и те же имена полей могут обозначать разные данные в зависимости от расположения. Поэтому используйте относительные пути только там, где уверены в возвращаемых данных. Например, в нашем примере название курса может быть заключено в <title>:
<courses>
<title>Курсы HTML и CSS (верстка)</title>
<!-- ... -->
<course>
<title>Основы современной верстки</title>
<!-- ... -->
</course>
<course>
<title>Основы верстки контента</title>
<!-- ... -->
</course>
<course>
<title>Bootstrap 5: Основы верстки</title>
<!-- ... -->
</course>
</courses>
Запрос //title вернет не только имена курсов, но и узел, который находится в <courses>:
<title>Курсы HTML и CSS (верстка)</title>
<title>Основы современной верстки</title>
<title>Основы верстки контента</title>
<title>Bootstrap 5: Основы верстки</title>
Чтобы сэкономить пару секунд, разработчики опускают корневой элемент и пользуются относительными путями. Например, вместо /courses/course/name они пишут //course/name. Для практики попробуйте прошлые примеры перевести на относительные пути с помощью такого механизма.
Несколько примеров запросов с идентичными ответами, как и в прошлой таблице:
| Запрос | Результат |
|---|---|
//course |
Все данные из всех элементов <course></course> |
//name |
<name>Основы современной верстки</name><name>Основы верстки контента</name><name>Bootstrap 5: Основы верстки</name> |
//course/duration |
<duration value="9">9 часов</duration><duration value="18">18 часов</duration><duration value="10">10 часов</duration> |
Предикаты
В примерах запросов к именам возвращались имена всех найденных курсов. В некоторых ситуациях это может быть избыточно. Что делать, если хочется получить данные только по первому курсу в <courses>? На помощь приходят предикаты — конструкции, с помощью которых можно отфильтровать элементы по заданным условиям.
Выберем ключевые слова первого курса по верстке. Для этого достаточно использовать запрос //course[1]/tags:
<tags>HTML5, CSS, DevTools, верстка</tags>
Обратите внимание на[1]. Это предикат с таким условием: «Взять элемент по индексу 1». Попробуйте сделать запрос ко второму или третьему элементу. Достаточно поменять всего одну цифру!
В XPath индексы элементов начинаются с единицы, а не с нуля, как в принятых стандартах программирования. Если вы уже программируете, это может немного запутать.
Предикаты помогают делать точные выборки. Например, получить ссылки на русскоязычные страницы курсов. Для этого нужно получить элементы <url>, у которых атрибут lang равен ru. Делается это указанием атрибута и значения. Чтобы XPath отличил атрибут от элемента перед атрибутом указывается символ @.
Теперь запрос будет выглядеть так: //course/url[@lang="ru"]
<url lang="ru">https://ru.hexlet.io/courses/layout-designer-basics</url>
<url lang="ru">https://ru.hexlet.io/courses/css-content</url>
<url lang="ru">https://ru.hexlet.io/courses/bootstrap_basic</url>
Иногда полезно выбрать элементы, которые имеют хоть какой-то атрибут. Для этого можно использовать конструкцию //*[@*]:
<duration value="9">9 часов</duration>
<url lang="ru">https://ru.hexlet.io/courses/layout-designer-basics</url>
<url lang="en">https://hexlet.io/courses/layout-designer-basics</url>
<duration value="18">18 часов</duration>
<url lang="ru">https://ru.hexlet.io/courses/css-content</url>
<url lang="en">https://hexlet.io/courses/css-content</url>
<duration value="10">10 часов</duration>
<url lang="ru">https://ru.hexlet.io/courses/bootstrap_basic</url>
<url lang="en">https://hexlet.io/courses/bootstrap_basic</url>
По примеру выше видно, знак * обозначает «все/любой».
Когда выбраны элементы по атрибутам, можно произвести дополнительную фильтрацию по этим значениям. Например, найдем элементы <duration> со значением атрибута value больше 9. Внутри предикатов используются операторы сравнения, знакомые по языкам программирования:
>— больше<— меньше>=— больше или равно<=— меньше или равно=— равно!=— не равно
Запрос будет выглядеть так: //course/duration[@value > 9]:
<duration value="18">18 часов</duration>
<duration value="10">10 часов</duration>
Мы разобрались, как выбирать одно поле — это интересная, но редкая задача. Чаще разработчики обрабатывают данные по всему файлу или нескольким полям. Попробуем одновременно использовать предикат и обратиться к другим полям. Обратите внимание на два момента:
- Предикат необязательно должен идти в конце запроса
- Внутри предиката могут находиться новые пути, которые нужно проверить
Мы уже знаем, как с помощью предиката отфильтровать данные по полю <duration>. Эту задачу мы выполняли с помощью конструкции duration[@value > 9]. А теперь попробуем сделать эту конструкцию предикатом для <course>. Так мы получим данные о курсах с длительностью больше 9 часов: //course[duration[@value > 9]]:
<course>
<title>Основы верстки контента</title>
<tags>CSS3, HTML5, Селекторы, Доступность, CSS Columns, CSS Units, Верстка</tags>
<duration value="18">18 часов</duration>
<url lang="ru">https://ru.hexlet.io/courses/css-content</url>
<url lang="en">https://hexlet.io/courses/css-content</url>
</course>
<course>
<title>Bootstrap 5: Основы верстки</title>
<tags>Bootstrap 5, Адаптивность, HTML, CSS3</tags>
<duration value="10">10 часов</duration>
<url lang="ru">https://ru.hexlet.io/courses/bootstrap_basic</url>
<url lang="en">https://hexlet.io/courses/bootstrap_basic</url>
</course>
Можно продолжить этот запрос и получить только имена курсов. Тогда предикат будет в середине запроса, а не в его конце: `//course[duration[@value > 9]]/name
<name>Основы верстки контента</name>
<name>Bootstrap 5: Основы верстки</name>
Функции
В прошлых примерах запросы затрагивали теги и атрибуты. Сами данные мы не затрагивали, хотя это огромный пласт информации, по которой можно делать выборки. Для решения этой задачи используются встроенные в XPath функции. Они являются частью предикатов — например, @. Попробуем найти курс с названием «Основы верстки контента».
Для поиска по тексту внутри элемента используется функция text(). Ее задача — получить текстовое значение элемента и сравнить его с условием по необходимости. Вот как будет выглядеть запрос для поиска курса с нужным именем: //course[name[text()="Основы верстки контента"]]
<course>
<name>Основы верстки контента</name>
<tags>CSS3, HTML5, Селекторы, Доступность, CSS Columns, CSS Units, Верстка</tags>
<duration value="18">18 часов</duration>
<url lang="ru">https://ru.hexlet.io/courses/css:content</url>
<url lang="en">https://hexlet.io/courses/css:content</url>
</course>
Но что, если нам известно только часть названия? Для этого существует функция contains(), которая принимает два аргумента:
- Строка, где будет производиться поиск
- Подстрока, которая будет искаться
Для примера найдем курс, у которого в ключевых словах есть слово «Bootstrap». Функция примет текстовое значение элемента tags и найдет там слово «Bootstrap»: //course[tags[contains(text(), "Bootstrap")]]
<course>
<name>Bootstrap 5: Основы верстки</name>
<tags>Bootstrap 5, Адаптивность, HTML, CSS3</tags>
<duration value="10">10 часов</duration>
<url lang="ru">https://ru.hexlet.io/courses/bootstrap_basic</url>
<url lang="en">https://hexlet.io/courses/bootstrap_basic</url>
</course>
В стандарте XPath существует еще несколько функций, но цель статьи — показать принципы работы тех или иных механизмов, а не дать исчерпывающую документацию по всему языку.
Отличия от CSS-селекторов
Если вы писали на JavaScript, то знаете, что элементы можно искать с помощью CSS-селекторов, используя методы querySelector() или querySelectorAll(). Почему же разработчики иногда ищут элементы внутри HTML именно с помощью XPath?
Дело в концепции поиска элементов. Используя CSS, можно идти только в глубину без возможности обратиться к родительским элементам. В отличие от CSS, XPath позволяет в любой момент обращаться и к дочерним, и к родительским элементам.
Если вы хотите подробнее изучить поиск по HTML с помощью XPath, рекомендуем обратиться к статье Introduction to using XPath in JavaScript.
С помощью CSS нельзя найти все элементы div, внутри которых есть ссылки — можно найти сами ссылки, но не их родителей. XPath позволяет это сделать простым сочетанием div[a]. Постепенно ситуация меняется: в CSS появился селектор :has(), но он поддерживается еще не всеми новыми версиями браузеров. Со временем это изменится, но пока реальность именно такая.
Другой пример — поиск элементов по тексту внутри них. С этой задачей CSS никогда не справится, так как такой цели у него нет. XPath, как мы изучили, умеет это делать с помощью функции text().
Кому нужен Xpath
Если коротко, Xpath нужен всем, кто работает с XML.
Чтобы разобраться подробнее, изучим несколько примеров:
SEO-специалисты. Специалисты по продвижению часто обрабатывают большие массивы данных и вытаскивают информацию со страниц сайта.
Например, для них критичны мета-теги — дополнительная информация, в которой содержатся иконки сайтов, название страницы, описание и так далее. Эту информацию SEO-специалист может автоматически парсить с помощью запросов в XPath.
Тестировщики. При работе с Front-end тестировщики часто проверяют тот или иной вывод информации на странице — для этого они выбирают отдельные элементы с нужной страницы. Это можно делать через XPath и DevTools, встроенный в браузеры на основе Chromium.
Разработчики. Они часто используют парсеры — это скрипты, которые ищут нужную информацию на страницах одного или нескольких сайтов. Например, мы хотим сравнить стоимость одного и того же товара в разных магазинах. Для такой задачи можно написать скрипт, который пройдется по всем нужным сайтам, сравнит цены и вернет данные. В этом случае для поиска информацию на странице можно использовать XPath.
Это лишь часть сценариев, в которых пригождается язык XPath — на самом деле, их десятки.
Заключение
В этой статье мы рассмотрели, где встречается XML и кому он может пригодиться. Мы научились составлять базовые запросы и изучили часто используемые конструкции XPath:
- Абсолютные и относительные пути
- Предикаты
- Поиск по атрибутам
- Операторы сравнения
- Функции
Также теперь вы знаете, что поиск по HTML с помощью XPath может быть эффективнее поиска с помощью CSS-селекторов.
В этой статье мы постарались дать знания, которые помогут справиться с большинством задач. Но это далеко не все возможности XPath — это более глубокий язык, чем представлено в статье. Как и с другими технологиями, тут важно набить руку. Чем больше вы практикуетесь, тем более точные и полезные запросы пишете.
XML или расширяемый язык разметки, который обычно используется для структурирования, хранения и передачи данных между системами. Хотя он и не так распространен, как раньше, он все еще используется в таких службах, как RSS и SOAP, а также для структурирования файлов, таких как документы Microsoft Office.
Поскольку Python является популярным языком для Интернета и анализа данных, вполне вероятно, что в какой-то момент вам понадобится читать или записывать XML-данные, и в этом случае вам повезло.
В этой статье мы в первую очередь рассмотрим модуль ElementTree для чтения, записи и изменения данных XML в Python.
DOM – это упрощенная реализация объектной модели документа. DOM – это интерфейс прикладного программирования, который рассматривает XML как древовидную структуру, где каждый узел в дереве является объектом. Таким образом, использование этого модуля требует, чтобы мы были знакомы с его функциями.
Модуль ElementTree предоставляет более “питонический” интерфейс для работы с XMl и является хорошим вариантом для тех, кто не знаком с DOM. Это также, вероятно, лучший кандидат для использования большим количеством начинающих программистов из-за его простого интерфейса, который вы увидите в этой статье.
В этой статье модуль ElementTree будет использоваться во всех примерах, тогда как minidom также будет продемонстрирован, но только для подсчета и чтения XML-документов.
Пример файла XML
В приведенных ниже примерах мы будем использовать следующий XML-файл, который мы сохраним как «items.xml»:
<data>
<items>
<item name="item1">item1abc</item>
<item name="item2">item2abc</item>
</items>
</data>
Как видите, это довольно простой пример XML, содержащий всего несколько вложенных объектов и один атрибут. Однако этого должно быть достаточно, чтобы продемонстрировать все операции XML в этой статье.
Чтение документов
Чтобы проанализировать XML-документ с помощью minidom, мы должны сначала импортировать его из модуля xml.dom. Этот модуль использует функцию синтаксического анализа для создания объекта DOM из нашего XML-файла. Функция синтаксического анализа имеет следующий синтаксис:
xml.dom.minidom.parse(filename_or_file[, parser[, bufsize]])
Здесь имя файла может быть строкой, содержащей путь к файлу или объект типа файла. Функция возвращает документ, который можно обрабатывать как тип XML. Таким образом, мы можем использовать функцию getElementByTagName(), чтобы найти конкретный тег.
Поскольку каждый узел можно рассматривать как объект, мы можем получить доступ к атрибутам и тексту элемента, используя свойства объекта. В приведенном ниже примере мы получили доступ к атрибутам и тексту определенного узла и всех узлов вместе.
from xml.dom import minidom
# parse an xml file by name
mydoc = minidom.parse('items.xml')
items = mydoc.getElementsByTagName('item')
# one specific item attribute
print('Item #2 attribute:')
print(items[1].attributes['name'].value)
# all item attributes
print('nAll attributes:')
for elem in items:
print(elem.attributes['name'].value)
# one specific item's data
print('nItem #2 data:')
print(items[1].firstChild.data)
print(items[1].childNodes[0].data)
# all items data
print('nAll item data:')
for elem in items:
print(elem.firstChild.data)
Результат такой:
$ python minidomparser.py Item #2 attribute: item2 All attributes: item1 item2 Item #2 data: item2abc item2abc All item data: item1abc item2abc
Если мы хотим использовать уже открытый файл, мы можем просто передать наш файловый объект для синтаксического анализа следующим образом:
datasource = open('items.xml')
# parse an open file
mydoc = parse(datasource)
Кроме того, если данные XML уже были загружены в виде строки, вместо этого мы могли бы использовать функцию parseString().
Использование ElementTree
ElementTree представляет нам очень простой способ обработки файлов XML. Как всегда, чтобы использовать его, мы должны сначала импортировать модуль. В нашем коде мы используем команду import с ключевым словом as, что позволяет нам использовать упрощенное имя (в данном случае ET) для модуля в коде.
После импорта мы создаем древовидную структуру с функцией синтаксического анализа и получаем ее корневой элемент. Получив доступ к корневому узлу, мы можем легко перемещаться по Tree.
Используя ElementTree и аналогично предыдущему примеру кода, мы получаем атрибуты узла и текст, используя объекты, связанные с каждым узлом.
Код выглядит следующим образом:
import xml.etree.ElementTree as ET
tree = ET.parse('items.xml')
root = tree.getroot()
# one specific item attribute
print('Item #2 attribute:')
print(root[0][1].attrib)
# all item attributes
print('nAll attributes:')
for elem in root:
for subelem in elem:
print(subelem.attrib)
# one specific item's data
print('nItem #2 data:')
print(root[0][1].text)
# all items data
print('nAll item data:')
for elem in root:
for subelem in elem:
print(subelem.text)
Результат будет следующим:
$ python treeparser.py Item #2 attribute: item2 All attributes: item1 item2 Item #2 data: item2abc All item data: item1abc item2abc
Как видите, это очень похоже на пример минидома. Одно из основных отличий заключается в том, что объект attrib – это просто объект словаря, что делает его немного более совместимым с другим кодом Python. Нам также не нужно использовать значение для доступа к значению атрибута элемента, как мы это делали раньше.
Возможно, вы заметили, что доступ к объектам и атрибутам с помощью ElementTree немного больше похож на Pythonic, как мы упоминали ранее. Это связано с тем, что данные XML анализируются как простые списки и словари, в отличие от minidom, где элементы анализируются как пользовательские xml.dom.minidom.Attr и «узлы DOM Text».
Подсчет элементов
Как и в предыдущем случае, минидом нужно импортировать из модуля dom. Этот модуль предоставляет функцию getElementsByTagName, которую мы будем использовать для поиска элемента тега. После получения мы используем встроенный метод len() для получения количества подэлементов, подключенных к узлу. Результат, полученный из приведенного ниже кода, показан на рисунке 3.
from xml.dom import minidom
# parse an xml file by name
mydoc = minidom.parse('items.xml')
items = mydoc.getElementsByTagName('item')
# total amount of items
print(len(items))
$ python counterxmldom.py 2
Имейте в виду, что при этом будет подсчитано только количество дочерних элементов под заметкой, для которой вы выполняете len(), которая в данном случае является корневым узлом. Если вы хотите найти все подэлементы в гораздо большем дереве, вам нужно будет пройти по всем элементам и подсчитать каждого из их дочерних элементов.
Точно так же модуль ElementTree позволяет нам вычислить количество узлов, подключенных к узлу.
Пример кода:
import xml.etree.ElementTree as ET
tree = ET.parse('items.xml')
root = tree.getroot()
# total amount of items
print(len(root[0]))
Результат такой:
$ python counterxml.py 2
Запись
ElementTree также отлично подходит для записи данных в файлы XML. В приведенном ниже коде показано, как создать XML-файл с той же структурой, что и файл, который мы использовали в предыдущих примерах.
Шаги следующие:
- Создайте элемент, который будет работать как наш корневой элемент. В нашем случае тег для этого элемента – «данные».
- Когда у нас есть корневой элемент, мы можем создавать подэлементы с помощью функции SubElement. Эта функция имеет синтаксис:
Подэлемент (родительский, тег, attrib = {}, ** дополнительный).
Здесь parent – это родительский узел, к которому нужно подключиться, attrib – это словарь, содержащий атрибуты элемента, а extra – дополнительные аргументы ключевого слова. Эта функция возвращает нам элемент, который можно использовать для присоединения других подэлементов, как мы это делаем в следующих строках, передавая элементы в конструктор SubElement.
3. Хотя мы можем добавлять наши атрибуты с помощью функции SubElement, мы также можем использовать функцию set(), как мы это делаем в следующем коде. Текст элемента создается с помощью свойства text объекта Element.
4. В последних трех строках приведенного ниже кода мы создаем строку из XML-дерева и записываем эти данные в файл, который мы открываем.
Пример кода:
import xml.etree.ElementTree as ET
# create the file structure
data = ET.Element('data')
items = ET.SubElement(data, 'items')
item1 = ET.SubElement(items, 'item')
item2 = ET.SubElement(items, 'item')
item1.set('name','item1')
item2.set('name','item2')
item1.text = 'item1abc'
item2.text = 'item2abc'
# create a new XML file with the results
mydata = ET.tostring(data)
myfile = open("items2.xml", "w")
myfile.write(mydata)
Выполнение этого кода приведет к созданию нового файла «items2.xml», который должен быть эквивалентен исходному файлу «items.xml», по крайней мере, с точки зрения структуры данных XML. Вы, вероятно, заметите, что результирующая строка представляет собой только одну строку и не содержит отступов.
Поиск элементов
Модуль ElementTree предлагает функцию findall(), которая помогает нам находить определенные элементы в дереве. Он возвращает все элементы с указанным условием. Кроме того, в модуле есть функция find(), которая возвращает только первый подэлемент, соответствующий указанным критериям. Синтаксис для обеих этих функций выглядит следующим образом:
findall(match, namespaces=None)
find(match, namespaces=None)
Для обеих этих функций параметром соответствия может быть имя XML-тега или путь. Функция findall() возвращает список элементов, а функция find возвращает один объект типа Element.
Кроме того, существует еще одна вспомогательная функция, которая возвращает текст первого узла, соответствующего заданному критерию:
findtext(match, default=None, namespaces=None)
Вот пример кода, который покажет вам, как именно работают эти функции:
import xml.etree.ElementTree as ET
tree = ET.parse('items.xml')
root = tree.getroot()
# find the first 'item' object
for elem in root:
print(elem.find('item').get('name'))
# find all "item" objects and print their "name" attribute
for elem in root:
for subelem in elem.findall('item'):
# if we don't need to know the name of the attribute(s), get the dict
print(subelem.attrib)
# if we know the name of the attribute, access it directly
print(subelem.get('name'))
И вот повторное использование этого кода:
$ python findtree.py
item1
{'name': 'item1'}
item1
{'name': 'item2'}
item2
Изменение
В ElementTree модуле представлены несколько инструментов для изменения существующих XML-документов. В приведенном ниже примере показано, как изменить имя узла, изменить имя атрибута и изменить его значение, а также как добавить дополнительный атрибут к элементу.
Текст узла можно изменить, указав новое значение в текстовом поле объекта узла. Имя атрибута можно переопределить с помощью set(name, value) функции. Функция set не просто работать на существующем атрибуту, он также может быть использован для определения нового атрибута.
В приведенном ниже коде показано, как выполнять эти операции:
import xml.etree.ElementTree as ET
tree = ET.parse('items.xml')
root = tree.getroot()
# changing a field text
for elem in root.iter('item'):
elem.text = 'new text'
# modifying an attribute
for elem in root.iter('item'):
elem.set('name', 'newitem')
# adding an attribute
for elem in root.iter('item'):
elem.set('name2', 'newitem2')
tree.write('newitems.xml')
После выполнения кода результирующий XML-файл newitems.xml будет иметь XML-дерево со следующими данными:
<data>
<items>
<item name="newitem" name2="newitem2">new text</item>
<item name="newitem" name2="newitem2">new text</item>
</items>
</data>
Как мы можем видеть при сравнении с исходным XML-файлом, имена элементов item изменились на «newitem», текст на «новый текст», а атрибут «name2» был добавлен к обоим узлам.
Вы также можете заметить, что запись XML-данных таким способом (вызов tree.write с именем файла) добавляет к XML-дереву дополнительное форматирование, поэтому оно содержит символы новой строки и отступы.
Создание подэлементов
У модуля ElementTree есть несколько способов добавить новый элемент. Первый способ, который мы рассмотрим, – это использовать функцию makeelement(), которая имеет имя узла и словарь с его атрибутами в качестве параметров.
Второй способ – через SubElement() класс, который принимает в качестве входных данных родительский элемент и словарь атрибутов.
В нашем примере ниже мы показываем оба метода. В первом случае у узла нет атрибутов, поэтому мы создали пустой словарь (attrib = {}). Во втором случае мы используем заполненный словарь для создания атрибутов.
import xml.etree.ElementTree as ET
tree = ET.parse('items.xml')
root = tree.getroot()
# adding an element to the root node
attrib = {}
element = root.makeelement('seconditems', attrib)
root.append(element)
# adding an element to the seconditem node
attrib = {'name2': 'secondname2'}
subelement = root[0][1].makeelement('seconditem', attrib)
ET.SubElement(root[1], 'seconditem', attrib)
root[1][0].text = 'seconditemabc'
# create a new XML file with the new element
tree.write('newitems2.xml')
После запуска этого кода результирующий XML-файл будет выглядеть так:
<data>
<items>
<item name="item1">item1abc</item>
<item name="item2">item2abc</item>
</items>
<seconditems>
<seconditem name2="secondname2">seconditemabc</seconditem>
</seconditems>
</data>
Как мы видим при сравнении с исходным файлом, были добавлены элемент «seconditems» и его подэлемент «seconditem». Кроме того, узел «seconditem» имеет атрибут «name2», а его текст – «seconditemabc», как и ожидалось.
Удаление
Как и следовало ожидать, модуль ElementTree имеет необходимые функции для удаления атрибутов и подэлементов узла.
Удаление атрибута
В приведенном ниже коде показано, как удалить атрибут узла с помощью функции pop(). Функция применяется к параметру объекта attrib. Он определяет имя атрибута и устанавливает для него значение «Нет».
import xml.etree.ElementTree as ET
tree = ET.parse('items.xml')
root = tree.getroot()
# removing an attribute
root[0][0].attrib.pop('name', None)
# create a new XML file with the results
tree.write('newitems3.xml')
Результатом будет следующий XML-файл:
<data>
<items>
<item>item1abc</item>
<item name="item2">item2abc</item>
</items>
</data>
Как видно из XML-кода выше, первый элемент не имеет атрибута «name».
Удаление одного подэлемента
Один конкретный подэлемент можно удалить с помощью remove функции. Эта функция должна указать узел, который мы хотим удалить.
В следующем примере показано, как его использовать:
import xml.etree.ElementTree as ET
tree = ET.parse('items.xml')
root = tree.getroot()
# removing one sub-element
root[0].remove(root[0][0])
# create a new XML file with the results
tree.write('newitems4.xml')
Результатом будет следующий XML-файл:
<data>
<items>
<item name="item2">item2abc</item>
</items>
</data>
Как видно из приведенного выше XML-кода, теперь есть только один узел «элемент». Второй был удален из исходного дерева.
Удаление всех подэлементов
В ElementTree модуле представляет нам с clear() функцией, которая может быть использована для удаления всех вложенных элементов данного элемента.
В приведенном ниже примере показано, как использовать clear():
import xml.etree.ElementTree as ET
tree = ET.parse('items.xml')
root = tree.getroot()
# removing all sub-elements of an element
root[0].clear()
# create a new XML file with the results
tree.write('newitems5.xml')
Результатом будет следующий XML-файл:
<data>
<items />
</data>
Как видно из приведенного выше XML-кода, все подэлементы элемента «items» были удалены из дерева.
Заключение
Python предлагает несколько вариантов обработки файлов XML. В этой статье мы рассмотрели ElementTree модуль и использовали его для анализа, создания, изменения и удаления файлов XML. Мы также использовали minidom модель для анализа файлов XML. Лично я бы рекомендовал использовать этот ElementTree модуль, так как с ним намного проще работать и он является более современным модулем из двух.
После того, как вы использовали конструктор etree.ElementTree для создания XML-документа, вы можете использовать эти методы в этом экземпляре.
8.1. ElementTree.find()¶
ET.find(path[, namespaces=D])
Этот метод используется для поиска конкретного элемента в документе. Это по существу эквивалентно вызову метода .find() в корневом элементе документа; см. раздел 9.5, «Element.find(): найдите соответствующий подэлемент».
Например, если doc является экземпляром ElementTree, этот вызов:
эквивалентно:
8.2. ElementTree.findall(): поиск соответствующих элементов¶
Учитывая некоторый экземпляр ElementTree, этот метод вернет последовательность из нуля или более элементов, которые соответствуют шаблону, указанному аргументом path.
ET.findall(path[, namespaces=N])
Этот метод работает точно так же, как вызов метода .findall() в корневом элементе документа. См. Раздел 9.6, «Element.findall(): найти все соответствующие подэлементы».
8.3. ElementTree.findtext(): получение текстового содержимого из элемента¶
Чтобы извлечь текст из некоторого элемента, используйте этот метод для экземпляра ElementTree например ET:
ET.findtext(path[, default=None][, namespaces=N])
Этот метод по существу такой же, как вызов метода .findtext() в корневом элементе документа; см. раздел 9.7, «Element.findtext(): Извлечь текстовый контент».
8.4. ElementTree.getiterator(): создать итератор¶
Во многих приложениях вы захотите посетить каждый элемент документа или, возможно, получить информацию из всех тегов определенного типа. Этот метод, на некоторых экземплярах ElementTree ET, вернет итератор, который посещает все соответствующие теги.
Если вы опустите аргумент, вы получите итератор, который генерирует каждый элемент в дереве в порядке документа.
Если вы хотите посетить только теги с определенным именем, передайте это имя в качестве аргумента.
Вот несколько примеров. В этих примерах предположим, что page – это экземпляр ElementTree, содержащий страницу XHTML. В первом примере будет напечатано каждое имя тега на странице в порядке документа.
for elt in page.getiterator(): print elt.tag
Второй пример будет рассматривать каждый элемент div на странице, а для тех, у кого есть атрибут class, он печатает эти атрибуты.
for elt in page.getiterator('div'): if elt.attrib.has_key('class'): print elt.get('class')
8.5. ElementTree.getroot(): найдите корневой элемент¶
Возвращаемое значение обычно будет экземпляром корневого элемента. Однако, если вы создали свой экземпляр ElementTree без указания корневого элемента или входного файла, этот метод вернет None.
8.6. ElementTree.xpath(): оценить выражение XPath¶
Для экземпляра ElementTree ET используйте этот вызов метода для оценки выражения XPath s, используя корневой элемент дерева как узел контекста.
Эти методы возвращают результат выражения XPath. Общие обсуждения XPath см. В разделе 10 «Обработка XPath».
8.7. ElementTree.write(): Записать обратно в XML¶
Чтобы сериализовать (конвертировать в XML) содержимое документа, содержащегося в некотором экземпляре ElementTree, применяйте этот метод:
ET.write(file, pretty_print=False)
Вы должны указать записываемый файловый объект или имя файла, который нужно записать. Если вы установите аргумент pretty_print = True, метод попытается свернуть длинные строки и отступы XML для удобочитаемости.
Например, если у вас есть экземпляр ElementTree на странице переменных, содержащей страницу XHTML, и вы хотите записать ее в стандартный выходной поток, это заявление будет делать это:
import sys page.write(sys.stdout)
